
01 Análisis de Outliers
33
Análisis de Outliers
-
Upload
carlos-carmona -
Category
Documents
-
view
228 -
download
0
description
01 Análisis de Outliers
Transcript of 01 Análisis de Outliers

Análisis de Outliers

1. Introducción
• “Un outlier es una observación la cual se desvía mucho de otras observaciones como para despertar sospechas que esta fue generada por un mecanismo diferente”
• Conocidos como anormalidades, discordansas y desviaciones
• Cuando un proceso se comporta de manera insual este resulta en la creación de outliers
2

1. IntroducciónUtilidad de la detección de outliers• Sistemas de detección de intrusión
• Fraude en tarjetas de crédito
• Eventos de sensado de interés
• Diagnostico medico
• Aplicación de la ley
• Ciencias de la tierra
3

1. Introducción
• Anomalías colectivas: Pueden ser solo inferidas colectivamente desde un conjunto o secuencias de puntos de datos
• Salida de los algoritmos de detección de outliers• Ranking de “outlierness”
• Una etiqueta indicando si un punto de datos en un outlier o no
• Desviaciones significativas de interés
4
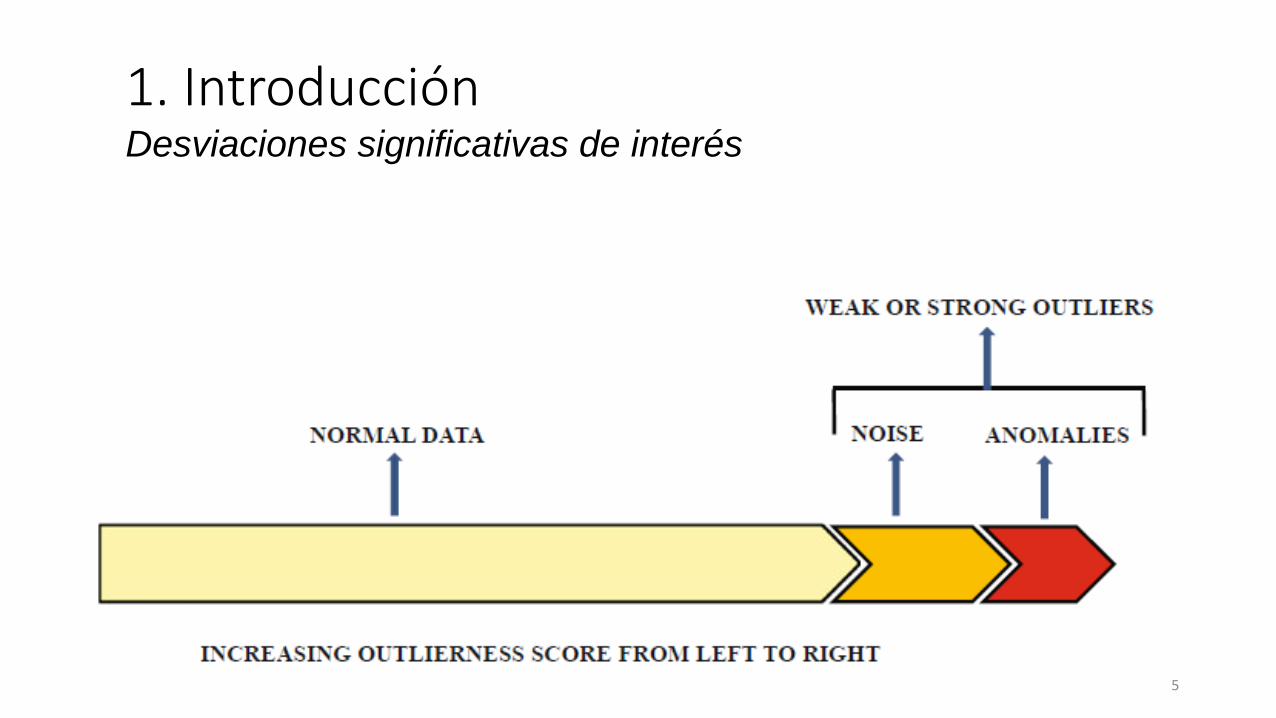
1. IntroducciónDesviaciones significativas de interés
5
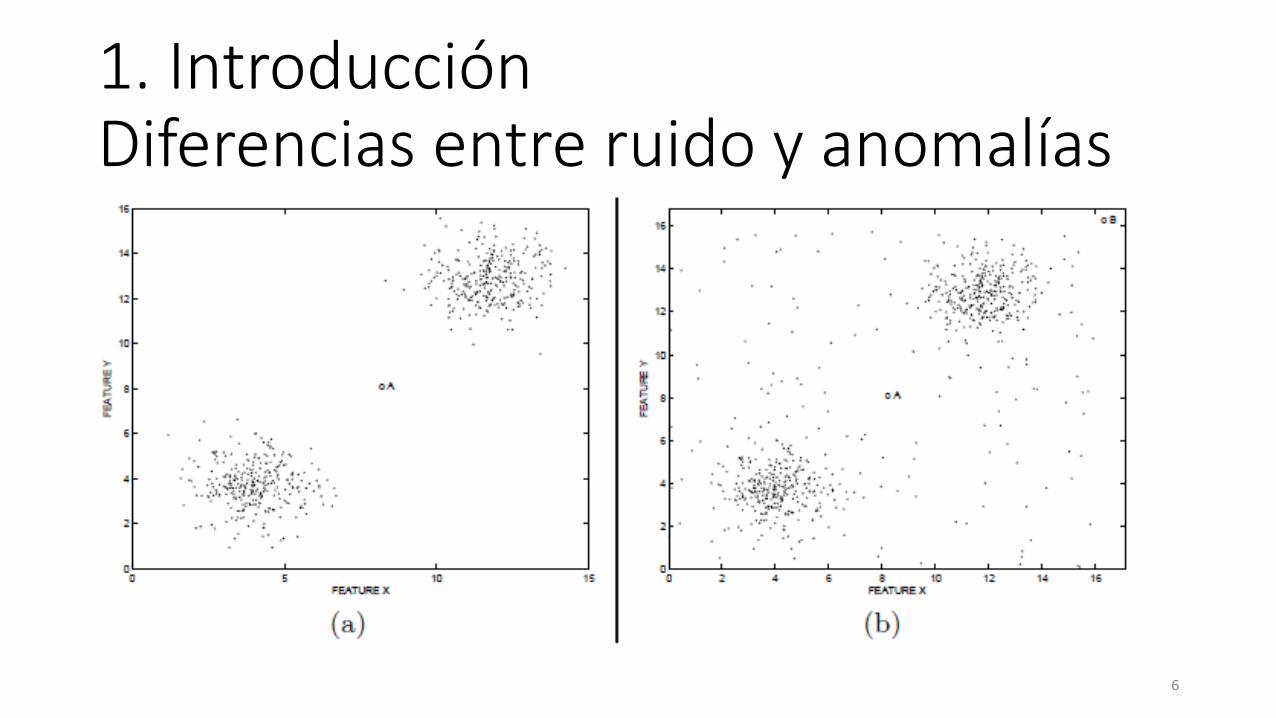
1. IntroducciónDiferencias entre ruido y anomalías
6

1. IntroducciónDiferencias entre ruido y anomalías• En el escenario no supervisado, el ruido representa el limite
semántico entre los datos normales y las verdaderas anomalías
• Generalmente modelado como outliers débiles
• Algunas medidas de outlierness• Esparcimiento de la región subyacente
• KNN basado en distancia
• Ajuste a la distribución de datos subyacente
7

1. IntroducciónDiferencias entre ruido y anomalías• Necesaria una definición entre anomalías y ruido
• Weak outliers y strong outliers
• El mejor camino para distinguir entre outliers y ruido es la retroalimentación con ejemplos de interés
• En escenarios semi-supervisados solo ejemplos de datos normales o anormales están disponibles
8

1. Introducción
• Contextual outliers: cuando la naturaleza de los atributos y sus relaciones provee un criterio de rankin de outlierness
9

1.2 Modelado de los datos
• Procedimiento de un algoritmo de detección de outliers
1. Crear un modelo de patrones normales en los datos
2. Calcular el outlier score
3. Obtener los puntos de datos en base a esos patrones
• Ejemplos de modelos• Gasianos mixtos • Basados en regresión • Basados en proximidadLa elección del modelo es a menudo hecha por el entendimiento de los tipos de desviaciones relaciones relevantes de la aplicación
10
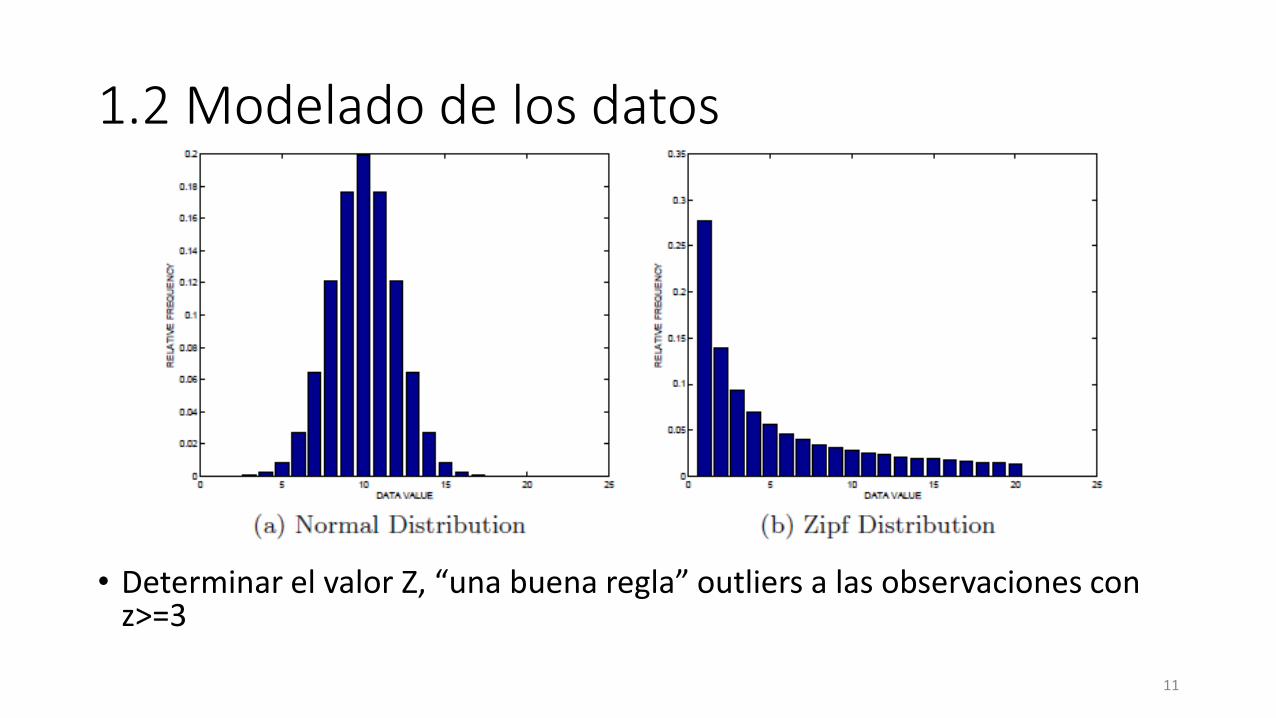
1.2 Modelado de los datos
• Determinar el valor Z, “una buena regla” outliers a las observaciones con z>=3
11

1.3 Modelos básicos de outliers
• La interpretabilidad es deseable para determinar porque un punto en particular es un outlier en términos de su comportamiento relativo con respecto al resto de los datos.
• Esto es también conocido como conocimiento intencional sobre los outliers
Muchas transformaciones Menor interpretabilidad
Menos transformaciones Mayor interpretabilidad
12

1.3.1 Análisis de valores extremos
• 1 dimensión, asume que los valores mas grandes o mas pequeños son outliers
• Para los tipos especiales de outliers es de gran importancia en escenarios específicos
• Es clave determinar colas estadísticas de la distribución de datos subyacente
• Esta definición es diferente a la proporcionada por Hawkins• Ejemplo {1,2,2,50,98,98,99} Outliers: 1, 99
• 50 no-outliers, para modelos de valores extremos (media)
• 50 outlier, modelos probabilísticos y basados en profundidad
13

1.3.1 Análisis de valores extremos
• Usan probabilidad para determinar que un punto sea un valor extremo
• Originalmente diseñado para naturaleza unidimensional
• Es posible generalizar a multidimensional (distancias, profunfdidad)
• El modelado de valores extremos juegan un rol muy importante en los algoritmos de detección de outliers, porque la mayoría de los algoritmos cuantifica las desviaciones de los puntos de datos desde los patrones normales en forma de un record numérico
• Útil para salidas de rankin
14

1.3.2 Modelos probabilísticos y estadísticos
• Modelado cercano a la distribución de probabilidad
• Parámetros aprendidos
• Basado en la probabilidad de membresía del dato a k-clusterstomando a cuenta el ajuste de densidad
• Valores con bajo ajuste son outliers
• Diversidad en tipos de datos
• Prueban el ajuste a una distribución la cual puede no ser apropiada
• El numero de parametritos incrementa el ajuste
• Dificiles de interpretar
15

1.3.3 Modelos lineales
• Modelan datos en bajas dimensiones usando correlaciones lineales
• Típicamente mínimos cuadrados para determinar el óptimo ajuste
• Trazan una línea recta que modela la distribución de los datos
• Residuos y valores extremos pueden usarse para determinación de outliers
• PCA puede derivarse en regresión múltiple tales que proyecten los datos en sub-espacios y minimizar los errores mínimos cuadrados
• PCA puede ser usado para reducción de ruido
• Modelos espectrales, generalmente usados en secuencias temporales
16

1.3.4 Modelos basados en proximidad
• Modelan los outliers como puntos aislados del resto de los datos• Análisis de clusters
• Análisis basado en densidad
• Análisis del vecino mas cercano
• Clusters y métodos de densidad: Las regiones mas densas son encontradas y los outliers corresponden a puntos fuera de esas regiones
• Métodos basados en clusters Segmentan los puntos
• Métodos basados en densidad Segmentan el espacio
17

1.3.4 Modelos basados en proximidad
• Métodos en KNN La distancia de cada dato a sus k-ésimos vecinos mas cercanos son determinadas
• Pequeños grupos de puntos los cuales están juntos pero lejos del resto de los datos son tratados como outliers
• Computacionalmente caro, por la determinación de los k-ésimosvecinos para cada punto de datos en el conjunto de datos.
1. Determinar las regiones de densidad del conjunto de datos
2. Determinar una medida de ajuste de los puntos de datos a los diferentes clusters para calcular un outlier score
• Algunos algoritmos asumen determinadas formas en los grupos
18

1.3.5 Modelos basados en la teoría de la información• Se basan en el incremento mínimo del código que describe el conjunto de
datos
• Ejemplo1. ABABABABABABABABABABABABABABABABAB2. ABABACABABABABABABABABABABABABABAB
• La segunda cadena es igual de longitud que la primera, solo es diferente enun símbolo “C”
• La primer cadena puede ser descrita como: “AB 17 veces”
• En la segunda cadena se puede ver “C”, por lo que no puede ser descritaconsistentemente. Es decir incremente la longitud de descripción mínima
• “C” es un outlier
19

1.3.5 Modelos basados en la teoría de la información• Son similares a otros modelos porque describen concisamente un
conjunto de datos
• Probabilísticos Modelos generativos por parámetros
• Cluster o basados en densidad clúster de descripción, histogramas
• PCA o espectral Sub-espacios de baja dimensión de proyección
20

1.3.6 Detección de outliers en altas dimensiones• Datos mas esparcidos
• Pares de datos mas equidistantes
• Los verdaderos outliers pueden ser descubiertos examinando la distribución de datos en bajas dimensiones• Comportándose de manera, pero este comportamiento es enmascarado por
el análisis dimensional completo
• Trabajo computacional altamente costoso
• Típicamente heurísticas evolucionarias
21

1.4 Meta-algoritmos para análisis de outliers
• Ensambles secuenciales: un algoritmo o un conjunto de algoritmos seaplican secuencialmente, hasta que las futuras aplicaciones de losalgoritmos se ven afectados por las aplicaciones anteriores, ya sea entérminos de modificaciones de los datos originales para el análisis oen términos de las opciones específicas de los algoritmos
• Ensambles independientes: diferentes algoritmos, para diferentesinstanciaciones del mismo algoritmo son aplicados, ya sea a unaporción de datos o al conjunto completo.
22

1.5 Los tipos de datos básicos para análisis
• Categóricos, texto y atributos mezclados• Categóricos: valores discretos sin ordenar ej.: genero, código postal
• Regresión puede ser usado de manera limitada con atributos categóricos discretos
• Regresión puede ser extendido para aplicarse a atributos binarios
• Indexado de semántica latente es usado para eliminación de ruido en texto
• Otros: clustering, basados en proximidad, probabilidades etc
23

1.5.2 Cuando los valores de los datos tienen dependencia• Relacionados unos con otros Manera espacial, temporal o enlaces
explícitos en redes
• Elemento es anómalo debido a sus relaciones contextual outliers o outliers condicionales
• Conjunto de datos son declarados anómalos como un grupo de puntos anomalía colectiva
24

1.5.2.1 Series de tiempo y flujo de datos
• Series de tiempo: Conjunto de valores por medidas continuas sobre el tiempo
• Estampas tiempo consecutivas pequeños cambios outliers
• Ejemplo• 3, 2, 3, 2, 3, 87, 86, 85 87, 89, 86, 3, 84, 91, 86, 91, 88
• Altamente relacionado con el problema de detección de cambios
25

1.5.2.2 Secuencias discretas
• Se obtiene solo unos puntos representativos de toda la secuencia• Ejemplo
• Secuencias biológicas
1.5.2.3 Datos espaciales
• Datos asociados a la ubicación geográfica
• Ejemplo
• Datos relacionados con el clima
26
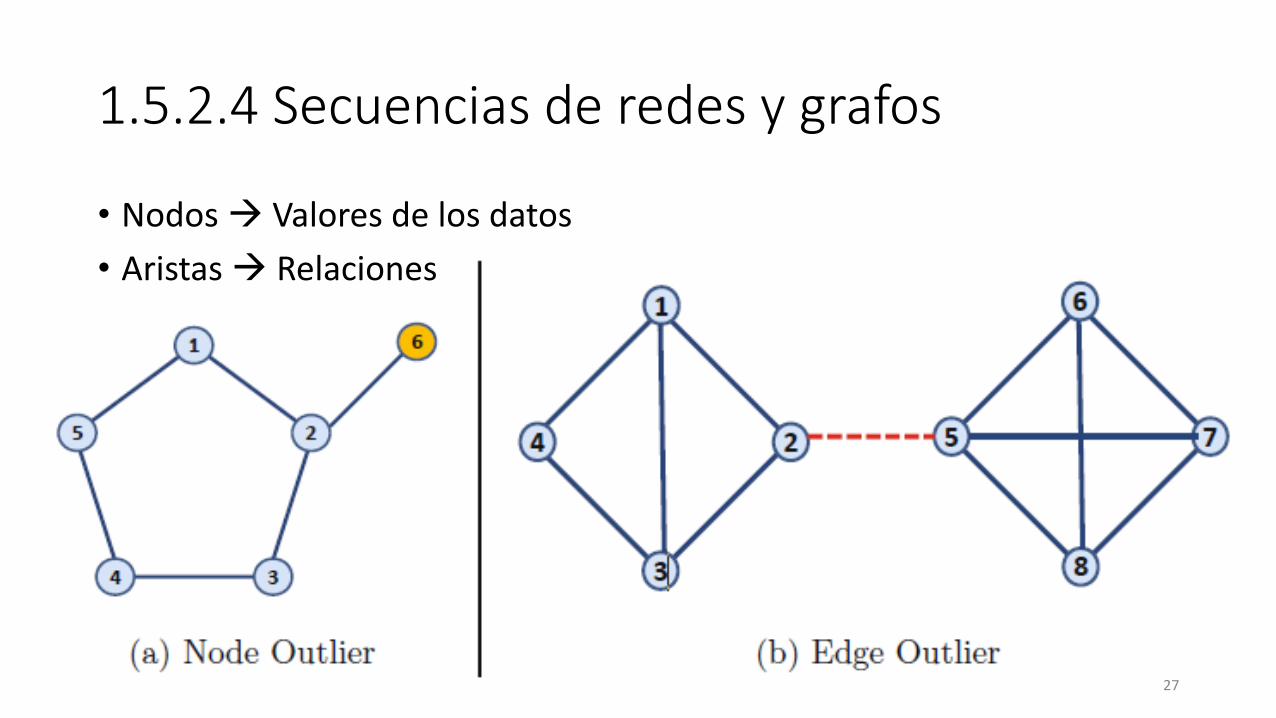
1.5.2.4 Secuencias de redes y grafos
• Nodos Valores de los datos
• Aristas Relaciones
27

1.6 Métodos de detección supervisados
• Escenarios en las que etiquetas previas están disponibles
• Objetivo Entrenar el modelo
• Etiquetas Representan lo que se quiere encontrar
• Aplicaciones• Detección de fraude
• Detección de intrusión
• Fallas
• Diagnósticos deseables
• Caso especial de clasificación
28

1.6 Métodos de detección supervisados
• Problema principal Generalmente etiquetas desbalanceadas
• Mas problemas• Ejemplos de outliers muy esparcidos (rare class detection)
• Diferentes niveles de supervisión1. Numero limitado de instancias de clase positiva (outliers) están disponibles
vs una proporción desconocida de ejemplos normales• Positive-Unlabeled Classification (PUC)
2. Solo un subconjunto de instancias de datos normales y anómalos están clasificados
3. Cercano al aprendizaje activo (Active Learning)
29

1.7 Técnicas de evaluación de outliers
• ¿Cómo debemos evaluar una técnica de detección de outlies?
• Esta tarea es mas difícil en el escenario no supervisado• Distancias, correlaciones, medidas de teoría de información
• En escenarios supervisados tenemos las medidas como:
Prescisión=100 ∗|S(t) ∩ G|
|S(t)|
Recall = 100∗|S(t) ∩ G|
|G|
30
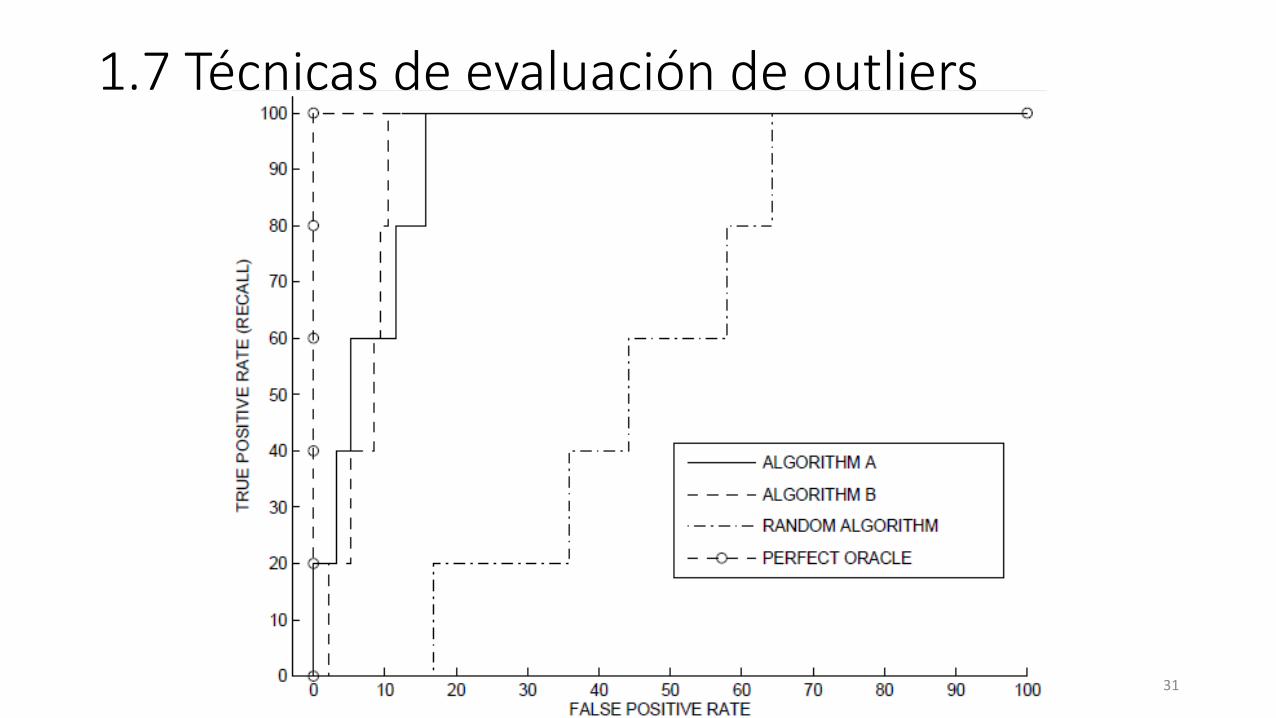
1.7 Técnicas de evaluación de outliers
31

Matriz de confusión
32

Matriz de confusión
33





![[01] Análisis de Problemas - ACR](https://static.fdocumento.com/doc/165x107/55cf9743550346d0339098b9/01-analisis-de-problemas-acr.jpg)












