
Desercion de Medio Periodo - Analisis Descriptivo Costa Rica
Upload
arielmontenegroCategory
view
250download
1description

Unidad 7: Análisis descriptivo de los datos y relación entre variables
A- Descripción Univariada Etapas iniciales: la selección del software y armado de la base de datos Para comenzar el análisis de datos, se suele tomar la decisión básica relacionada con qué software estadístico usar. Esto es crucial en la actualidad donde no se realiza ningún tipo de procesamiento estadístico sin este tipo de herramientas. Como decisión complementaria inicial, debe estructurarse la base de datos a generar. Excel
La tarea siguiente consiste en especificar las denominaciones y características de cada variable que se incluirá en la base de datos, y posteriormente, proceder a la carga (data entry) de la información capturada en las encuestas y/o planillas que se desee sistematizar digitalmente.
Veamos algunas opciones para seleccionar el software que se utilizará para procesar la base de datos. Existen diversas opciones en el mercado. Entre las herramientas más difundidas se encuentra el SPSS (Statistical Package for the Social Sciences). Además, otras herramientas disponibles corresponden a los paquetes básicos de planillas de cálculo o bases de datos, pero no son opciones especialziadas ni que faciliten el uso de las herramientas estadísticas que describiremos en este capítulo.
Algo de historia del programa SPSS: El programa fue creado en 1968 por Norman H. Nie, C. Hadlai (Tex) Hull y Dale H. Bent. Entre 1969 y 1975 la Universidad de Chicago por medio de su National Opinión Research Center estuvo a cargo del desarrollo, distribución y venta del programa. A partir de 1975 corresponde a SPSS Inc.
En 1984 sale la primera versión para computadores personales.
Fichero de datos de SPSS Los ficheros de datos en formato SPSS tienen en Windows la extensión. SAV. Al abrir un fichero de datos con el SPSS, vemos la vista de datos, una tabla en la que las filas indican los casos y las columnas las variables. Cada celda corresponde al valor que una determinada variable adopta en un cierto caso.
7.1 Análisis univariado: Distribuciones de frecuencias Recordemos en primer lugar que las variables pueden ser diferente tipo según el nivel de medición. En tal sentido distinguimos cuatro tipos de variables:
- Las variables nominales cumplen dos requisitos deseables: exhaustividad y exclusividad. El primero indica que las diferentes categorías o valores que asumen cubren la totalidad de posibilidades que pueden surgir. La exclusividad señala que la variable sólo puede asumir uno de los valores posibles. Todas las variables que hacen referencia a un atributo de un objeto. Por ejemplo: la variable es estado de actividad (los valores posibles de la variable son: ocupado, desocupado e inactivo). - Las variables ordinales tienen implícita la jerarquía, lo cual significa que son ordenables. Ejemplos de este tipo de variable lo constituyen: nivel educativo alcanzado; estrato socioeconómico. - Las variables de intervalo diferencian adecuadamente la distancia entre valores de la variable, ya que están expresadas en alguna medida física. Por ejemplo, cantidad de hijos tenidos o temperatura. - Las variables de razón son un tipo especial dentro de las de intervalo, para las cuales el valor 0

tiene un significado claro: indica que no hay presencia de la variable medida. Por ejemplo, edad o ingreso son variables de esta característica.
“12 de los 210 encuestados, tiene estado conyugal viudo”
valor de 1, en indica el 100% de casos“el 40,5% de los encuestados es soltero.

Cuando trabajamos con información recién obtenida, o con errores o problemas durante el trabajo de campo, la revisión de las frecuencias permite analizar la magnitud de ciertos problemas, como por ejemplo el de falta de respuesta.
Análisis univariado: gráficos
a) Diagrama de barras Sirven para representar frecuencias absolutas y relativas. La altura de cada barra indica la cantidad de casos (o la proporción de casos) correspondientes a cada valor de la variable estudiada.

El observar la barra más elevada se identifica el valor que más se repite del conjunto de valores posibles de la variable.
b) Histograma Sirven para representar frecuencias absolutas y relativas. La altura de cada barra indica la cantidad de casos (o la proporción de casos) correspondientes a cada valor de la variable

estudiada. La diferencia principal es que estos últimos se asocian principalmente con variables de intervalo o razón.
También en este caso la barra más elevada da cuenta de la categoría de la variable que tiene más cantidad de repeticiones.
c) Polígono de frecuencias Se trata de un gráfico de líneas que se traza desde los puntos medios de cada intervalo a la altura proporcional a su frecuencia. También sirve para representar tanto frecuencias absolutas como relativas
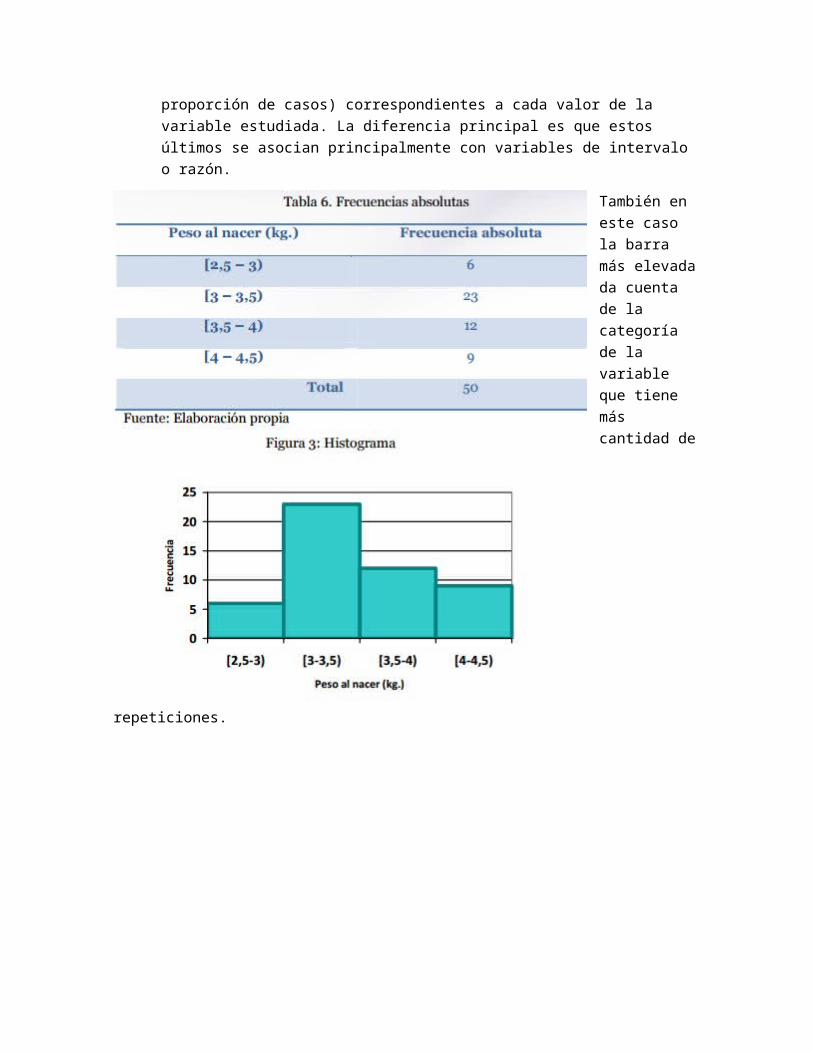
d) Ojiva Es un polígono de frecuencias acumuladas. Permite identificar qué porcentaje o número de casos tiene un valor de a lo sumo el indicado para la variable de estudio en el eje de las absisas.
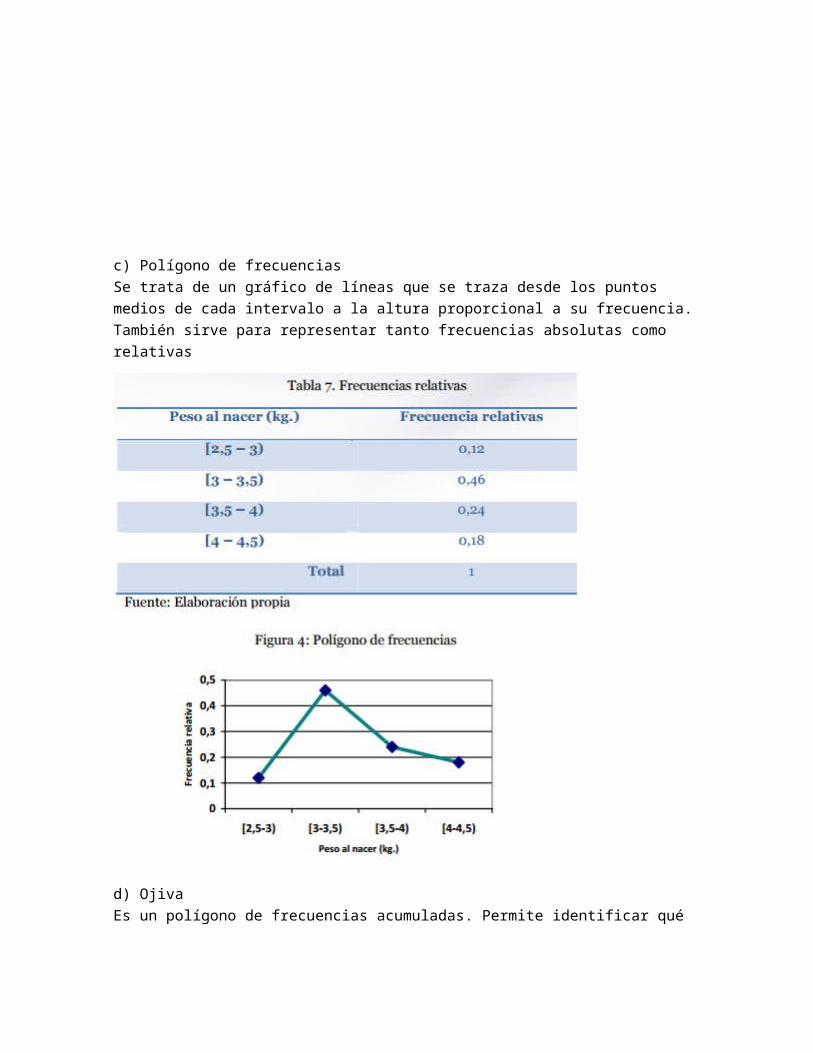
e) Gráfico de sectores Es la representación en un círculo de la participación de los distintos valores de la variable en el total. Consiste en asignar proporcionalmente la superficie, tomando como referencia los 360° que componen la correspondiente circunferencia.
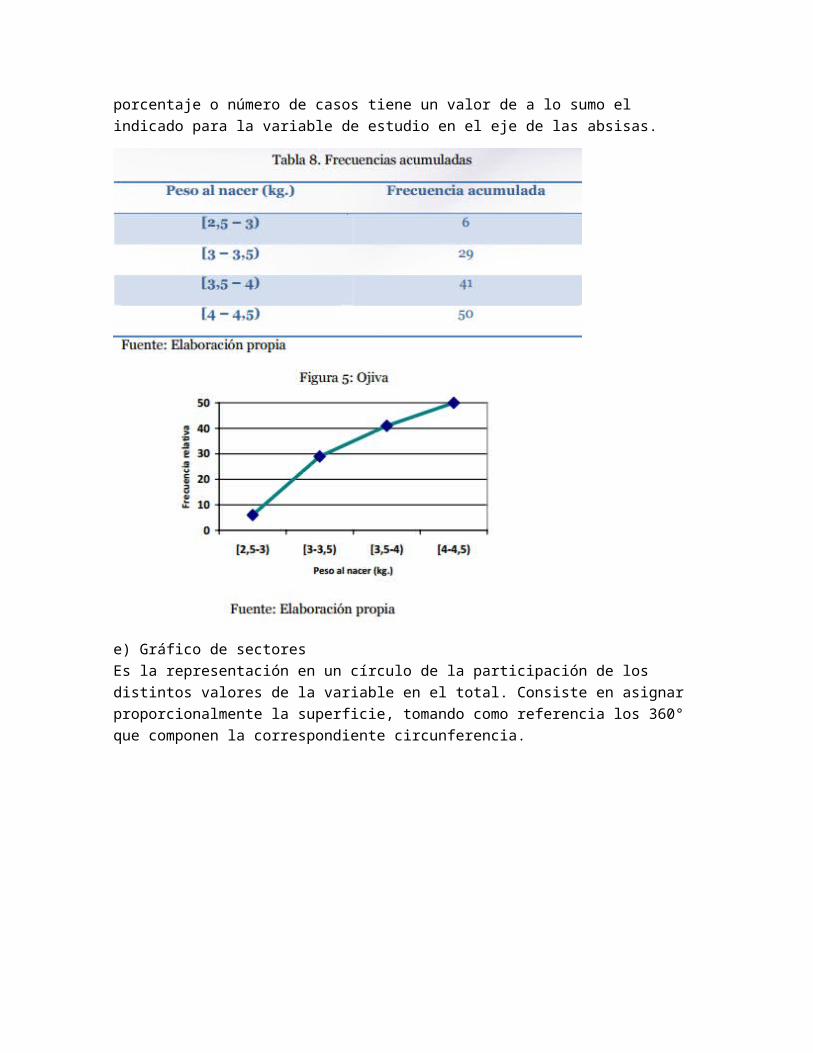
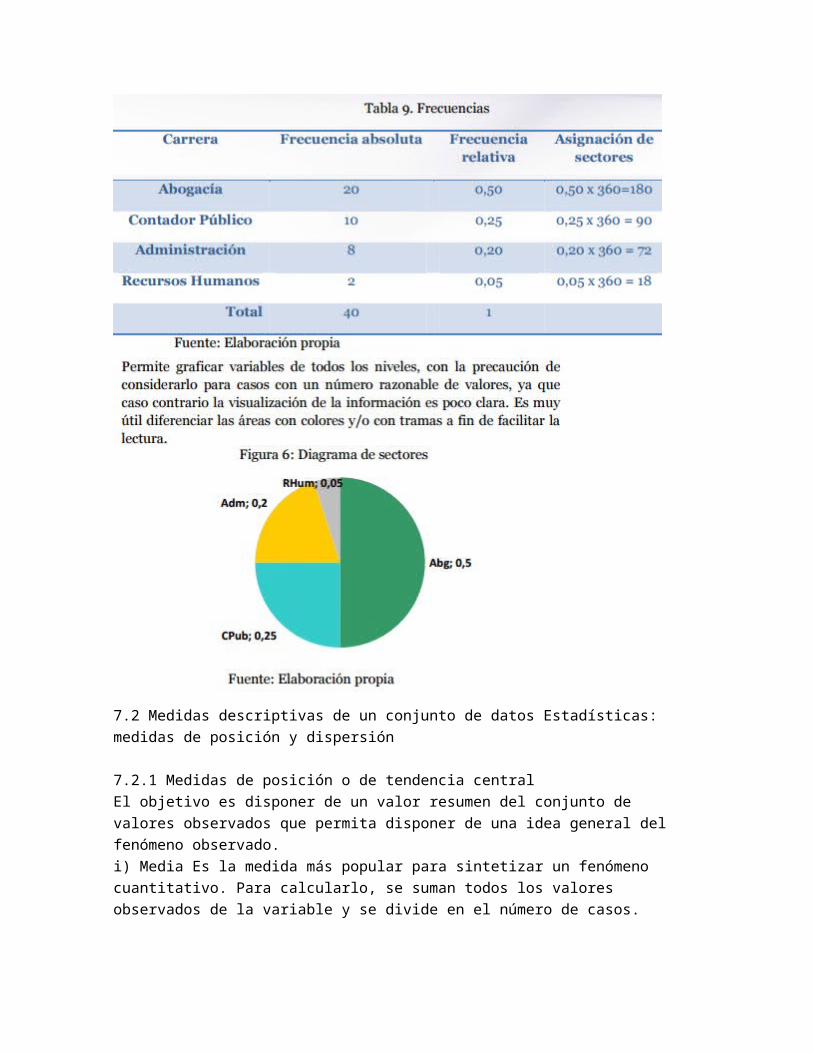
7.2 Medidas descriptivas de un conjunto de datos Estadísticas: medidas de posición y dispersión
7.2.1 Medidas de posición o de tendencia central El objetivo es disponer de un valor resumen del conjunto de valores observados que permita disponer de una idea general del fenómeno observado. i) Media Es la medida más popular para sintetizar un fenómeno cuantitativo. Para calcularlo, se suman todos los valores observados de la variable y se divide en el número de casos. Datos Variable de estudio: Edad de la mujer al tener su primer hijo (años)
La media no es un buen indicador para sintetizar el problema si los valores presentan mucha discrepancia (o variabilidad) entre sí.
ii)Moda Indica cuál es el valor de la variable que más veces se repite en los datos obtenidos. Sirve como indicador para varaibles medidas en cualquier nivel de medición. Hay distribuciones unimodales (tienen una moda), bimodales (dos modas) o multimodales (más de dos modas). Como principal limitación se destaca que no intervienen en su cálculo todos los datos
disponibles. Para el conjunto de datos anterior, correspondiente a la Edad de la mujer al tener su primer hijo, la moda es 30, ya que indica el valor de la variable estudiada que se repite más veces.
iii) Mediana Hace referencia al valor tal que si los datos están ordenados de menor a mayor, divide en dos partes
con la misma cantidad de casos, a los valores que están por debajo de este valor, o que están por encima de este valor. El cálculo de la mediana puede realizarse para variables medidas al menos en el nivel ordinal (por supuesto también las de intervalo o de razón). Se presentan dos situaciones para su cálculo: - Cuando la cantidad de casos analizados es impar. En este caso, el valor central es la mediana:
- Cuando la cantidad de casos analizados es par. En este caso, se toma un promedio de los dos valores centrales de la distribución:
7.2.2 Medidas de dispersión Este tipo de indicadores hacer referencia a la variabilidad o heterogeneidad de los valores recogidos entre sí.
i) Rango o recorrido Indica la diferencia entre el mayor valor obtenido y el menor. Tiene como principal debilidad el hecho de no incluir todos los valores recogidos, y concentrarse justamente en valores muy extremos de la distribución. Para el ejemplo anterior sobre la muestra de Edad de la mujer al tener su primer hijo, el rango corresponde a:
ii) Desviación estándar o típica Esta medida es la más utilizada entre las de dispersión. La desviación estándar corresponde al promedio de la desviación de los casos con relación a la media.


iii) Varianza Corresponde al cuadrado de la desviación estándar. Se trata de otra medida de dispersión muy utilizada, aunque su interpretación, ya que la unidad de medida queda elevada al cuadrado es bastante más compleja. Para el caso anterior, tendremos, dado que se trata de una muestra: Var = (5,37) ² = 28,83 años²
iv) Coeficiente de variación Combina la desviación estándar y la media, de modo de tener un indicador de la variabilidad relativa de la distribución. Es de gran utilidad en la comparación de distribuciones, ya sea de dos o más variables, o de dos o más subgrupos o poblaciones para una misma variable
Medidas de forma: asimetría y curtosis a. Asimetría Indica cómo están agrupados los datos. Cuando el valor es 0, la curva es simétrica (los valores están distribuidos por igual por encima o por debajo de la media, y además, coinciden la media, la mediana y la moda.
Coeficiente de asimetría = 0 Si el valor del coeficiente de asimetría es un valor positivo, la distribución es asimétrica derecha o de sesgo positivo (los casos se agrupan a la izquierda de la curva y pocos valores, no representativos, en el lado derecho de la distribución).
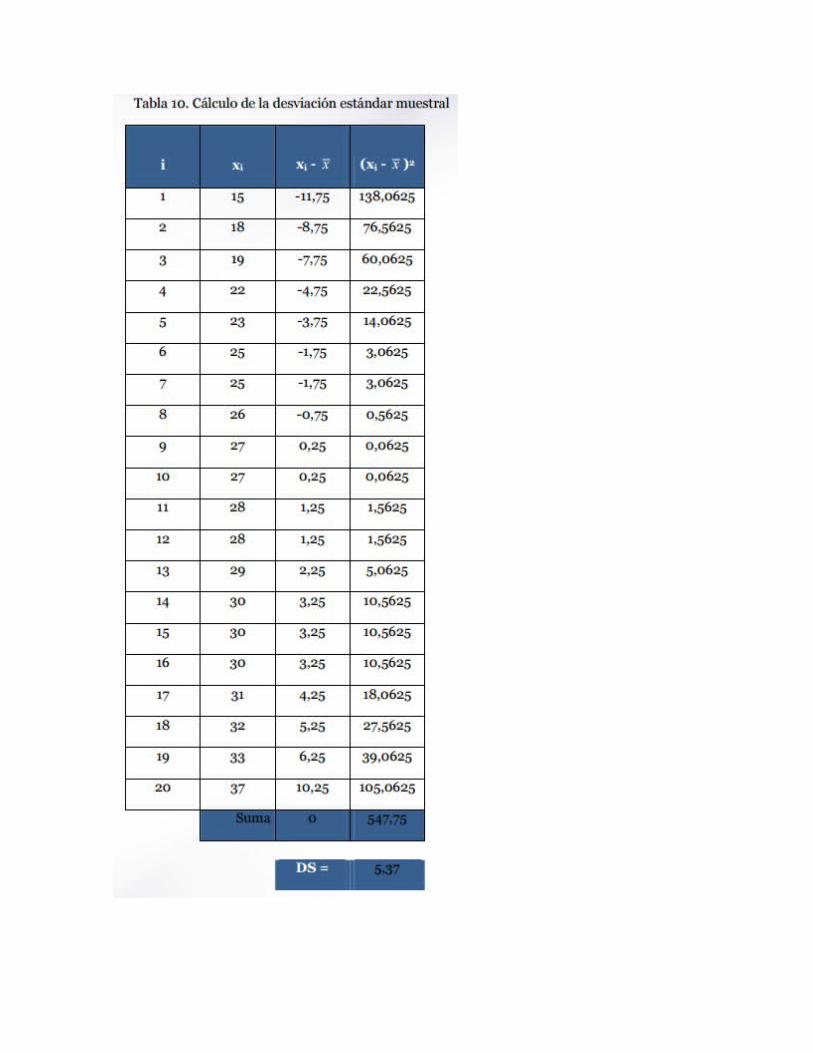
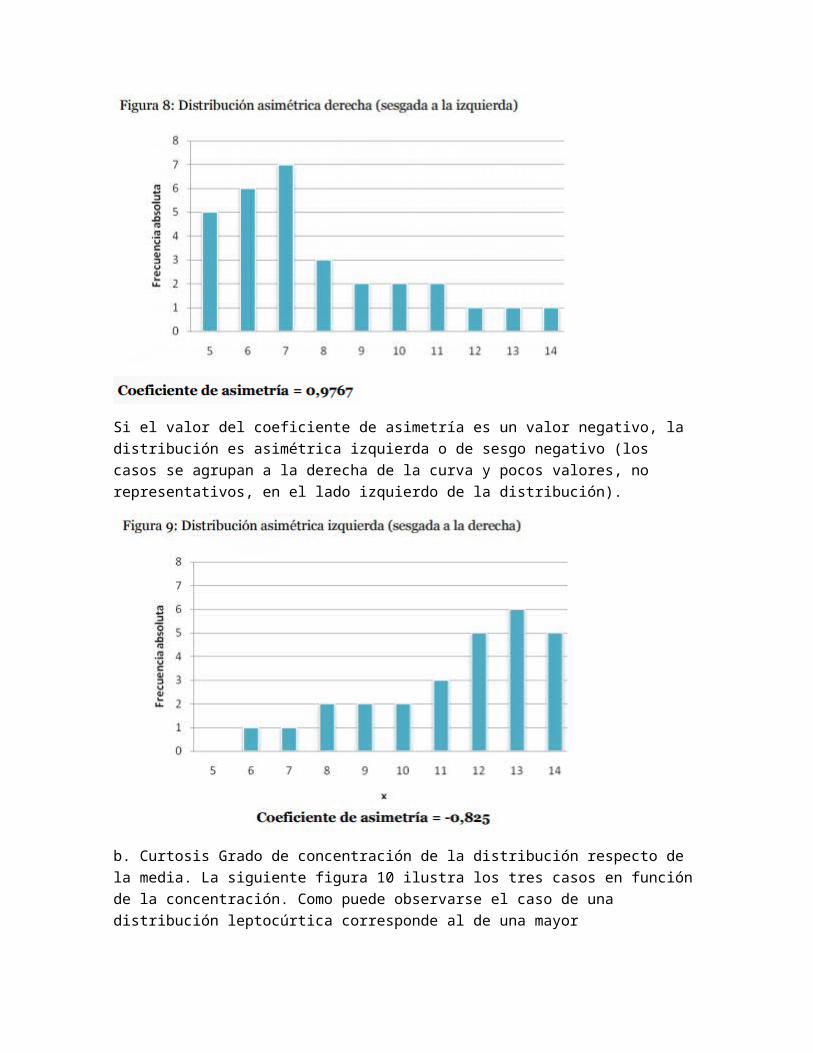
Si el valor del coeficiente de asimetría es un valor negativo, la distribución es asimétrica izquierda o de sesgo negativo (los casos se agrupan a la derecha de la curva y pocos valores, no representativos, en el lado izquierdo de la distribución).
b. Curtosis Grado de concentración de la distribución respecto de la media. La siguiente figura 10 ilustra los tres casos en función de la concentración. Como puede observarse el caso de una distribución leptocúrtica corresponde al de una mayor concentración, en tanto el extremo opuesto corresponde a la situación de una distribución platicúrtica.

Las distribuciones mesocúrticas tienen un coeficiente de curtosis igual a 0. En el caso de una distribución Leptocúrtica, el coeficiente de curtosis es positivo, en tanto que el coeficiente es negativo para las distribuciones Platicúrticas.
Algunas consideraciones acerca de la aplicación del análisis univariado en la etapa de análisis de datos - Tras la revisión descriptiva inicial, el investigador debe tomar ciertas decisiones acerca de los datos disponibles, para facilitar los análisis posteriores, teniendo en cuenta los objetivos de la investigación. - En algunos casos, convendrá agrupar valores, por ejemplo, estableciendo intervalos de valores (para variables cuantitativas) o categorías integradoras (para variables cualitativas). Para ello considerará si algunos valores presentan muy bajo nivel de aparición y son asimilables con otras categorías similares. - En el caso de las medidas descriptivas (de tendencia central y dispersión), permiten decidir cuál de ellas refleja mejor el fenómeno, y en qué casos no debe presentarse únicamente la media (dispersión muy elevada y datos sesgados). - La aplicación de técnicas estadísticas más sofisticadas en general exige verificar el cumplimiento de ciertas condiciones (supuestos) acerca de las medidas de tendencia central, de dispersión y de la propia distribución de datos, entre otras, que deben ser verificadas en esta etapa. - Deben tomarse decisiones acerca de las variables con niveles demasiado elevados de no respuesta.
7.3 Relación entre variables: clasificación en referencia al tiempo, a la dirección y a la intensidad. El los siguientes apartados, se han incluido una serie de herramientas de análisis que permiten el análisis conjunto de dos o más variables.
B. Análisis bivariado 1. Tablas de contingencia
Cuando se consideran dos variables al explicar un fenómeno se suele proceder a cruzar ambas en tablas de contingencia. Si se presupone cierta relación causal entre ellas, lo convencional es situar la variable dependiente en las filas y la variable independiente en las columnas.
Cada casillero de la tabla corresponde al cruce de un atributo de una variable con un atributo de la otra variable.
La información extraída de la tabla se limita al análisis de los porcentajes extraídos de la misma (porcentajes del total de casos, porcentajes del total de la fila o porcentajes del total de la columna).
Los totales de las filas y de las columnas reciben un nombre particular: valores marginales, justamente por ubicarse en los márgenes de la tabla.
procedimientos inferenciales:
Si se analizan variables nominales, el grado de asociación entre variables puede ser medido por los siguientes estadísticos: � Phi Cuadrado � C de Pearson � V de Cramer � Q de Yule � Lambda � Tau-Y de Goodman y Kruskal � Coeficiente d (diferencia de proporciones)
Si se analizan variables ordinales, el grado de asociación entre variables puede ser medido por los siguientes estadísticos: � Rho de Spearman � Tau-A, Tau-B y Tau-C de Kendall � Gamma de Goodman y Kruskal � D de Sommer
Si se analizan variables de intervalo o de razón, el grado de asociación entre variables puede ser medido, además, el coeficiente de correlación de Pearson.
En general, para las tablas de contingencia se utiliza el test X2 (Chi Cuadrado), que permite comparar las frecuencias observadas (los datos obtenidos correspondientes a cada casilla) con las esperadas bajo condiciones de total independencia entre las variables estudiadas. Con este test puede desecharse (si corresponde) la hipótesis de independencia entre las variables y así concluir que existe una asociación entre ellas.
2. Regresión simple Cuando se estudia la relación de tipo lineal entre dos variables, se emplea el análisis de regresión lineal simple. La variable dependiente o explicada debe ser cuantitativa o métrica. La variable independiente puede ser cuantitativa o cualitativa. El objetivo en este caso es predecir el valor de la variable dependiente a partir del valor de la variable independiente.
El modelo se expresa de la siguiente manera: Y = a + b X +e
Y = variable dependiente X = variable independiente a = intercepto u ordenada al origen (valor donde la recta corta el eje Y) b = pendiente de la recta (variación de Y cuando X cambia en una unidad) e = error de estimación
El método utilizado para su estimación es el de Mínimos Cuadrados.

Así, con los datos del ejemplo, podríamos predecir el valor del rendimiento escolar de un niño, conociendo sólo la cantidad de años de escolaridad que tuvo su madre (simplemente reemplazamos en la fórmula indicada el valor de x correspondiente a los años de escolaridad de la madre, y realizamos el cálculo indicado).
3. Análisis multivariado Para el caso de fenómenos complejos, es muy poco frecuente que el análisis bivariado sea suficiente para dar cuenta de las relaciones entre variables. En tales casos, se apela a procedimientos estadísticos más complejos. El siguiente cuadro, sintetiza los principales análisis multivariados que podrían desarrollarse. Nuevamente, para su profundización, dado que escapan a los objetivos de la materia, se recomienda la consulta de un manual de Estadística para ciencias sociales.
Presentación de resultados La tarea de investigación se plasma en informes o reportes de investigación, a ser presentados ante las personas o instituciones que encargaron, avalaron y/o financiaron el desarrollo del proyecto de investigación. La finalidad de este reporte es informar sobre la manera en que se desarrolló la tarea de investigación, y dar cuenta de los principales hallazgos y conclusiones a las cuales se pudo arribar. En general, el informe cuanta con los siguientes elementos constitutivos elementales: 1. Datos de identificación del informe 2. Introducción 3. Aspectos metodológicos 4. Resultados 5. Discusión o desarrollo 6. Conclusión 7. Referencias bibliográficas 8. Anexos (si son necesarios)
Entre los datos de Identificación del informe deben figurar: 1. Título 2. Autor 3. Institución de pertenencia del o los investigadores 4. Fecha de presentación 5. Motivo de la presentación 6. Institución o entidad que avaló, financió y/o encargó el estudio La
Introducción resume el problema y su relevancia, los objetivos perseguidos por la investigación, las principales hipótesis de trabajo y la organización general del informe. En esta sección se indican las principales referencias a los autores consultados. En la descripción de los Aspectos metodológicos, se realiza un raconto de los elementos del diseño de la investigación desarrollada. El método empleado y su vinculación con el problema, la forma de recolección de datos, la estrategia muestral empleada, los formularios de captura de datos (si los hubiera), el desarrollo de prueba pilto (si la hubo) la cantidad de casos que se analizaron, así como las técnicas de análisis de datos que se aplicaron. En el caso de resultar muy extensa, puede incluirse un Anexo metodológico al final del informe.
Los Resultados exponen los hallazgos principales en relación con los objetivos planteados del estudio. Deben ser claros y precisos.
La Discusión presenta la justificación a partir de los datos así como la comparación con resultados de otros estudios, así como las limitaciones que se detectan.
La Conclusión incluye los aspectos más significativos del estudio, que resultan las claves de haber resuelto la investigación.

La reseña de las Referencias Bibliográficas debe incluir todos (y solamente) los textos citados de manera breve durante el informe, con todos los datos básicos que permiten ubicar la obra o trabajo de investigación.
Los Anexos sirven para incluir material que resulta de lectura más pesada o de consulta, pero que pueden obviarse en una recorrida del material. Pueden incluirse tablas o gráficos, formularios de captura de datos, etc.


















