Benemérita Universidad Autónoma de Puebla Facultad … · incorporan los objetos de aprendizaje...
129
1 Benemérita Universidad Autónoma de Puebla Facultad de Ciencias de la Computación Objetos de Aprendizaje para la Enseñanza de Bases de Datos, Ver./012 Academia del Área de Bases de Datos e Ing. de Software de la Facultad de Ciencias de la Computación, BUAP. Editor María del Rocío Boone Rojas ISBN: 978-607-487-524-9 Verano 2012
Transcript of Benemérita Universidad Autónoma de Puebla Facultad … · incorporan los objetos de aprendizaje...

1
Benemérita Universidad Autónoma de Puebla
Facultad de Ciencias de la Computación
Objetos de Aprendizaje para la Enseñanza de
Bases de Datos, Ver./012
Academia del Área de Bases de Datos e Ing. de Software de la
Facultad de Ciencias de la Computación, BUAP.
Editor
María del Rocío Boone Rojas
ISBN: 978-607-487-524-9 Verano 2012

2
Página Legal
Autoridades.
Dr. Enrique Agüera Ibañez Rector de la Benemérita Universidad Autónoma de Puebla Mtro. José Jaime Vázquez López Vicerrector de Docencia Dr. Pedro Hugo Hernández Tejeda Vicerrector de Investigación y Estudios de Posgrado M.C. Marcos González Flores Director de la Facultad de Ciencias de la Computación Dr. Luis Carlos Altamirano Robles Secretario De investigación y de Estudios de Posgrado M.C. Yalú Galicia Hernández Secretaria Académica Dr. Roberto Contreras Juárez Secretario Administrativo Edición: 1ra, Diciembre 2012
ISBN: 978-607-487-524-9
Benemérita Universidad Autónoma de Puebla
Dirección de Fomento Editorial
4 sur 104 Puebla, Pue. México.
Teléfono y fax 0122229-55-00

3
Autores:
M.C. Alma Delia Ambrosio Vázquez.
Dra. Etelvina Archundia Sierra.
M.C. María del Rocío Boone Rojas
M.E. María del Carmen Cerón Garnica.
Dra. Maya Carrillo Ruiz.
Dr. Juan Manuel González Calleros
Dra. Josefina Guerrero García
M.C. María del Consuelo Molina García.
Ing. José Miguel Ángel Ochoa Rodríguez
Dra. María de la Concepción Pérez de Celis Herrero.
Dr. Joaquín Pérez Ortega
Dra. María Josefa Somodevilla García.
M.C. Marco Antonio Soriano Ulloa.
Coordinador:
M.C. María del Rocío Boone Rojas

4
Comité Revisor
Dra. Ofelia Cervantes Villagómez
Dr. Miguel Ángel León Chávez
Prof. José Luis Luna Govea.
Dr. David Pinto Avendaño
M.C. Marco Antonio Soriano Ulloa
Dra. Darnes Vilariño Ayala

5
Presentación
Como parte de los trabajos de la academia del área de Bases de Datos e Ing. de Software de la Facultad de Ciencias de la Computación de la BUAP y como resultado de las experiencias previas así como de la capacitación recibida y los requerimientos de los lineamientos institucionales actuales, en el presente periodo se ha planteado incursionar en el desarrollo de objetos de aprendizaje para la enseñanza de las diversas asignaturas a cargo del área. Por medio de los cuales, se espera retomar las experiencias adquiridas y tomar ventaja de las características propias de los objetos de aprendizaje, tales como, la reutilización, modularidad, flexibilidad, portabilidad e interoperabilidad, entre otros. Así mismo, pretendemos hacer un uso eficiente de las plataformas institucionales disponibles para la administración de los repositorios que se desarrollen, entre las que destacan Blackboard y WebCT.
Relacionado con el proceso de evaluación del aprendizaje, pretendemos que por medio de las citadas plataformas, se realice una “Evaluación Colegiada del Aprendizaje” (anteriormente inmersa en el concepto institucional de “Exámenes Departamentales”) y a través de las “Actividades de Evaluación” contenidas en los objetos de aprendizaje desarrollados, en las que se atienden los lineamientos institucionales correspondientes a dicha evaluación.
De tal forma que a mediano plazo, pretendemos conformar un repositorio de objetos de aprendizaje para cada una de las asignaturas correspondientes al área y para los diversos programas educativos que se ofrecen en la Facultad, los cuales, se actualizarán de forma permanente. A largo plazo, pretendemos formar parte de la comunidad del país que desarrollan objetos de aprendizaje para la enseñanza de las asignaturas de las áreas relacionadas con las Bases de Datos.
En el presente primer trabajo relacionado con el desarrollo de objetos de aprendizaje para el área de B.D e Ing. de Software, se incluyen un par de capítulos relacionados con los términos y aspectos fundamentales de los “objetos de aprendizaje” y sobre elementos para el desarrollo de sus “actividades de evaluación”. Así mismo se incorporan capítulos con temas propios del área de Bases de Datos e Ing. de Software, relacionados con la Ingeniería de Sistemas, en particular, el diseño de Sistemas de Información y el diseño de uno de sus elementos fundamentales: la Base de Datos. En capítulos subsecuentes, se incluyen los objetos de aprendizaje para la enseñanza de la principal contribución teórica en el desarrollo de las Bases de Datos, el Modelo Relacional de Codd.
Para cada uno de los capítulos correspondientes a los objetos de aprendizaje desarrollados, se ha adoptado una estructura que se corresponde con los elementos

6
básicos de un objeto de este tipo: contenidos, actividades de aprendizaje y actividades de evaluación.
Específicamente, la presente publicación consta de 9 capítulos. El capítulo 1 aborda los conceptos y términos fundamentales de los objetos de aprendizaje. El concepto de objeto de aprendizaje y la importancia de las plataformas y administradores de aprendizaje, se menciona la incidencia del diseño de los Objetos de Aprendizaje (OA) para la educación superior en el área de Base de Datos e Ingeniería de Software. La presentación de los objetos de aprendizaje desarrollados, se inicia en el capítulo 2, en el cual se incluyen los conceptos del modelado de datos mediante el modelo Entidad-Relación y su representación gráfica a través de varias notaciones. Relacionado con el capítulo anterior, en el capítulo 3 se describe el proceso de normalización. Los capítulos subsecuentes, incorporan los objetos de aprendizaje correspondientes a los componentes del modelo relacional, el capítulo 4, se describe el componente estructural, la relación, en el capítulo 5, se proporcionan los conceptos del componente de integridad, y las reglas de entidad y de integridad referencial, en el capítulo 6 se desarrolla el componente de manipulación mediante el Álgebra Relacional. Relacionado con este último capítulo, en el capítulo 7 se incorpora el objeto de aprendizaje para la enseñanza del lenguaje estandarizado para bases de datos relacionales, el lenguaje SQL. Como parte de uno de los temas que involucran como uno de sus componentes a una Base de Datos, en el capítulo 8, se presenta una metodología para el diseño de Sistemas de Información basada en los procesos de negocio de una organización. Finalmente en el capítulo 9, se incorporan algunos elementos para la elaboración de reactivos que se pueden considerar como una referencia para la especificación de las “actividades de evaluación” y que atienden recomendaciones contempladas en los lineamientos institucionales para la “Evaluación Colegiada del Aprendizaje”. Específicamente se describen entre otros, formatos para la elaboración de reactivos y el contenido de la tabla de especificaciones.
Expreso mi reconocimiento y agradecimiento a cada uno de los profesores participantes en estos trabajos, sin duda alguna, sus valiosas experiencias en el ejercicio docente y profesional, reflejadas en este documento, establecen ya un precedente y referencia para la organización y mejora de la calidad de los trabajos académicos en nuestra Facultad.
Así mismo, de manera especial, agradezco las contribuciones de los profesores que conforman el comité revisor de la presente publicación.
Resalto también el valioso apoyo de las autoridades administrativas tanto a nivel institucional como de la Facultad que hacen posible la divulgación y oficialización de los resultados de estos trabajos. A cada uno ellos, expreso mi agradecimiento.
A mi pequeña familia, Marquito y Leo, les agradezco su tolerancia, por los espacios de tiempo fugitivos.

7
M.C. María del Rocío Boone Rojas.
Coordinadora del área de Bases de Datos e Ingeniería de Software
Facultad de Ciencias de la Computación.
Verano 2012

8
Contenido
Portada 1 Página Legal 2 Autores 3 Comité Revisor 4 Presentación 5 Capítulo 1 Estructura de un Objeto de Aprendizaje (OA) 11 Etelvina Archundia Sierra, María del Carmen Cerón Garnica, Josefina Guerrero García María del Rocío Boone Rojas 1.Objetos de Aprendizaje (OA). 12 1.1Estructura de un Objeto de Aprendizaje (OA) 13 1.2La Importancia de la Evaluación 15 1.3Corrientes de Aprendizaje Esenciales en los OA 15 2.Importancia de las Plataformas y Administradores de Aprendizaje (LMS) 16 3. Referencias Capítulo 1. 18 Capítulo 2 El Modelo Entidad Relación (MER) 19 María de la Concepción Pérez de Celis Herrero, María Josefa Somodevilla García 2.1 Objetivo Educativo. 19 2.2 Contenido Informativo. 19 2.2.1 Introducción: Modelos de datos 20 2.2.2 Historia del Modelo Entidad-Relación 20 2.2.3 Componentes Básicos del MER 21 2.2.4 Semántica de las Asociaciones (Relaciones) 28 2.2.5 Resumen. 28 2.3 Actividades de Aprendizaje. 29 2.4 Actividades de Evaluación de Adquisición del Conocimiento. 31 2.5 Referencias del Capítulo 2. 32 Capítulo 3 El Proceso de Normalización. 33 Alma Delia Ambrosio Vázquez, José Miguel Ángel Ochoa Rodríguez 3.1 Objetivo Educativo 34 3.2 Contenido Informativo 34 3.2.1 Bases De Datos y Normalización 34 3.2.2 Normalización. 35 3.2.2.1 Dependencia funcional. 35

9
3.2.2.2 Primera Forma Normal (1FN). 37 3.2.2.3 Segunda Forma Normal (2FN). 41 3.2.2.4 Tercera Forma Normal (3FN). 43 3.2.2.5 Cuarta Forma Normal (4FN). 50 3.3 Actividades de Aprendizaje 54 3.4 Actividades de Evaluación de Adquisición del Conocimiento 55 Referencias del Capítulo 3. 55 Capítulo 4 El Componente Estructural del Modelo Relacional. 56 María del Rocío Boone Rojas, Etelvina Archundia Sierra, Marco Antonio Soriano Ulloa. 4.1 Objetivo Educativo. 56 4.2 Contenido Informativo. 57 4.2.1 Antecedentes del Modelo y los Sistemas Relacionales. 57 4.2.2 Los conceptos de Dominio y Relación. 59 4.2.3 Propiedades de las Relaciones. 61 4.2.4 Tipos de Relaciones. 62 4.3 Actividades de Aprendizaje. 62 4.4 Actividades de Evaluación de Adquisición del Conocimiento. 63 4.5 Referencias Capítulo 4. 64 Capítulo 5 El Componente de Integridad del Modelo Relacional. 65 María del Rocío Boone Rojas, Joaquín Pérez Ortega, María del Carmen Cerón Garnica. 5.1 Objetivo Educativo. 65 5.2 Contenido Informativo. 66 5.2.1 El Concepto de Integridad. 66 5.2.2Control de Integridad 69 5.2.3El Componente de Integridad en el Modelo Relacional. 70 5.2.3.1 Regla de Integridad de Entidades. 70 5.2.3.2 Regla de Integridad Referencial. 71 5.2.4 Control de Integridad a nivel de la Aplicación. 72 5.2.5 Caso de Estudio, Disparadores en MySQL. 73 5.3 Actividades de Aprendizaje. 74 5.4 Actividades de Evaluación de Adquisición del Conocimiento. 75 5.5 Referencias Capítulo 4. 75 Capítulo 6 Álgebra Relacional. El Componente de Manipulación del Modelo Relacional.
76
María Josefa Somodevilla García, María de la Concepción Pérez de Celis Herrero 6.1 Objetivo Educativo 76 6.2 Contenido Informativo. 77 6.2.1 Consulta Relacional 77 6.2.2 Lenguaje de Consulta Relacional 77 6.2.3 Operaciones del Álgebra Relacional 78 6.2.4 Formulación de Consultas en Álgebra Relacional 85

10
6.2.5 Resumen 87 6.3 Actividades de Aprendizaje. 87 6.4 Actividades de Evaluación de Adquisición del Conocimiento. 87 6.5 Referencias Capítulo 6. 91 Capítulo 7 El lenguaje SQL. 92 Maya Carrillo Ruiz, María del Rocío Boone Rojas. 7.1 Objetivo Educativo 92 7.2 Contenido Informativo. 93 7.2.1 Introducción 93 7.2.2 Lenguaje de Definición de Datos 93 7.2.3 Lenguaje de Manipulación de Datos 97 7.2.4 Lenguaje de Control de Datos 101 7.3 Actividades de Aprendizaje. 102 7.4 Actividades de Evaluación de Adquisición del Conocimiento. 103 7.5 Referencias Capítulo 7. 103 Capítulo 8 La Identificación de Tareas de Usuario para el Diseño de Sistemas de Información Basados en Workflow.
105
Josefina Guerrero García, Juan Manuel González Calleros 8.1 Objetivo Educativo 105 8.2 Contenido Informativo. 105 8.2.1 Los Sistemas de información en el contexto organizacional 105 8.2.2 La identificación de tareas de usuario para el diseño de sistemas de información 107 8.2.3 Conclusiones 111 8.3 Actividades de Aprendizaje y de Evaluación del Conocimiento. 111 8.4 Referencias Capítulo 8. 114 Capítulo 9 Elaboración de Reactivos para las asignaturas de Bases de Datos e Ingeniería de Software.
116
María del Consuelo Molina García. 9.1 Objetivo Educativo. 116 9.2 Contenido Informativo. 117 9.2.1 Introducción 117 9.2.2 Instrumentos de medición educativa 118 9.2.3 Reactivos de opción múltiple 119 9.2.4 Normas para la construcción de reactivos 121 9.2.5 Normas para los reactivos de opción múltiple 121 9.2.6 Constitución de los reactivos 122 9.2.7 Formato para redactar los reactivos 123 9.2.8 Taxonomías de aprendizaje 124 9.2.9 Tabla de Especificaciones 125 9.2.10 Clasificación de reactivos 127 9.3 Referencias del Capítulo 9 128

11
Capítulo 1
Estructura de un Objeto de Aprendizaje
Etelvina Archundia Sierra María del Carmen Cerón Garnica
Josefina Guerrero García María del Rocío Boone Rojas
En el presente capítulo, se describe brevemente el concepto de Objetos de Aprendizaje, la estructura que contemplan, el saber y saber hacer, los cuales se enriquecen con aspectos de actitudes y reflexión del aprendizaje del alumno. Se considera fundamental en el OA la evaluación del propósito de aprendizaje en su diseño. Para que el alumno relacione los OA es necesario tener habilidades cognitivas semánticas para comprender el todo en sus partes. En las perspectivas se plantea la necesidad de crear objetos de aprendizaje en el b-learning, para la educación semiescolarizada, la cual tendría espacios presenciales y Blackboard, como herramienta de apoyo para la educación media superior y superior, cuidando la planeación de soporte y capacitación tanto a alumnos como docentes en esta modalidad. Se aborda la importancia de las plataformas y administradores de aprendizaje, mencionando la incidencia del diseño de los Objetos de Aprendizaje (OA) para la educación superior en el área de Base de Datos e Ingeniería de Software. Se incorporan teorías del proceso de enseñanza aprendizaje como elemento pedagógico.

12
1. Objetos de Aprendizaje (OA). La aplicación del e-Learning y la transferencia del aprendizaje mediante el Web han interesado a los estudiosos y formulado el concepto de Objeto de Aprendizaje (OA) introducido en 1997, el cual se refiere a aquellos recursos digitales que apoyan la educación y pueden reutilizarse constantemente (SCORM1 Sharable Content Object Reference Model).
Fuente: Horton, W. E-Learning by desing. Pfeiffer, 2nd Edition. (2012).
Se dice que un OA es la mínima estructura independiente que contiene un objetivo, una actividad de aprendizaje y un mecanismo de evaluación. Dada esta definición de L’Allier, en algún momento los ha comparado con átomos, ya que parten de la filosofía de reducir un concepto, a su mínima expresión, sin dejar por ello de estar completos. De esta manera, así como al unir diferentes átomos obtenemos moléculas, al unir diversos objetos de aprendizaje, generamos lecciones, unidades, temas e inclusive cursos [3]. Un OA está constituido por al menos tres componentes internos: contenidos, actividades de aprendizaje, elementos de contextualización y evaluación, además el OA debe tener una estructura (véase fig. 1) de información externa (metadatos) que facilite su almacenamiento, identificación y recuperación [4].
Fig. 1 Elementos operativos para los objetos de aprendizaje Fuente: Elaborada por las autoras
1 http://www.adlnet.org/
Crear los objetos de
aprendizaje con un
propósito educativo.
Utilizar un repositorio
para los objetos de
aprendizaje.

1.1 Estructura de un Objeto de
Citado por Fernández y cols. (2003)transformación (véase figura 2)creativo que permita a través de las técnicas didácticalos OA. Los factores elementalesproducción de los OA siendo: El contenido de la información los cuales se podrán representar mediante el sonirequieren de equipo de cómputo, dispositivos para la captura de audio y video, servidores, documentación etc. Otro factor corresponde a proceso requiere de los factores dede los OA [7].
Fig. 2
La creación de un OA debe de contener el objetivo de aprendizaje, el contenidoinformativo, las actividades de aprendizaje y la evaluación. Si la estructura de OA y los contenidos que lo conforman son precisoaprendizaje desde el nivel básico hasta educación media y superior.
A continuación se describen lode aprendizaje, contenidos informfigura 3).
a) Objetivo de aprendizaje. Es importante identificar una necesidad de aprendizaje (resolver un problema, mejorar, innovar), con base en esto se tiene claro qudatos generales del OA, y se obtiene el material didáctico necesario para real
b) Contenido informativo.
Entradas
• Creatividad
• Técnicas didpacticas
• Técnicas de
desarrollo de
software
Estructura de un Objeto de Aprendizaje (OA)
Citado por Fernández y cols. (2003) la estructura de OA, se considera como un proceso de (véase figura 2) identificando los siguientes elementos de entrada:
que permita a través de las técnicas didácticas y de programación el desarrollo de factores elementales necesarios para la transformación en el proceso de
producción de los OA siendo: El contenido de la información los cuales se podrán nido, video, texto y gráficas. Las acciones a implementar
requieren de equipo de cómputo, dispositivos para la captura de audio y video, servidores, documentación etc. Otro factor corresponde a la investigación de los OA. La salida del
factores de la evaluación y retroalimentación para medir
Fig. 2 Proceso de transformación de un OA Fuente: Elaborada por las autoras
a creación de un OA debe de contener el objetivo de aprendizaje, el contenidoactividades de aprendizaje y la evaluación. Si la estructura de OA y los
contenidos que lo conforman son precisos se podrá aplicar en el proceso de enseñanza aprendizaje desde el nivel básico hasta educación media y superior.
ontinuación se describen los elementos de la estructura de los OA siendo los objetivos de aprendizaje, contenidos informativos, actividades de aprendizaje y la evaluación
s importante identificar una necesidad de aprendizaje (resolver un problema, mejorar,
esto se tiene claro qué es lo que se va a enseñar, se identifican los datos generales del OA, y se obtiene el material didáctico necesario para real
Elementos del Proceso
de transformación para
OA.
• Texto
• Video
• Animación
• Audio
• Simuladores
• Gráficos
• Comunicación
síncona y asíncorna
Salida
• Servicios
• Retroalimentación
• Evaluación
13
la estructura de OA, se considera como un proceso de identificando los siguientes elementos de entrada: El factor
s y de programación el desarrollo de necesarios para la transformación en el proceso de
producción de los OA siendo: El contenido de la información los cuales se podrán as acciones a implementar
requieren de equipo de cómputo, dispositivos para la captura de audio y video, servidores, . La salida del
para medir la calidad
a creación de un OA debe de contener el objetivo de aprendizaje, el contenido actividades de aprendizaje y la evaluación. Si la estructura de OA y los
se podrá aplicar en el proceso de enseñanza
elementos de la estructura de los OA siendo los objetivos , actividades de aprendizaje y la evaluación (véase
s importante identificar una necesidad de aprendizaje (resolver un problema, mejorar, a enseñar, se identifican los
datos generales del OA, y se obtiene el material didáctico necesario para realizarlo.
Retroalimentación

Conceptos
Actividades de
aprendizaje
Actitudinales
Evaluación
Es recomendable hacer uso de múltiples recurimágenes, vídeos y animacioneorganizados de una forma adecuada para captaraprendizaje por parte del mismo.
c) Actividades de aprendizaje. Entendidas como un conjunto de pasos y etapas queobjetivo de promover y facilitar su proceso de aprendizaje.actividades con: Lecturas, resúmenes, realización deactividades de aprendizaje propuestas están aprendizaje.
d) Evaluación.
Uno de los objetivos del los OA, es asegurar alcanzar el obplanteado, es importante implementar actividades que evalúen los conocimientos. Esto se puede implementar mediante pruebas en línea, al finalizar la prueba se debe presentar el puntaje alcanzado por el alumno.
En la estructura del los OA se debe de tomar en cuenta el estándar ISO 9126 donde el aspecto pedagógico, la Interfaz humano computadora y el contenido ocupan un lugar importante en los estudios de Abud Figueroa (2005) [8].
•Lecturas específicas
•Ligas
•Videos
Actividades de
•Ejercicios.
•Técnicas y estrategias cognitivas.
•Aprendizaje Basado en problemas.
•Aprendizaje basado en Proyectos.
•Valores
•Reflexiones
•El ser humano
•Sumativa
•Formativa
•Diagnóstica
Es recomendable hacer uso de múltiples recursos digitales como por ejemplo textos, animaciones (digitalizados en la etapa a). Estos rma adecuada para captar la atención del alumno y se facilite el
aprendizaje por parte del mismo.
Actividades de aprendizaje.
Entendidas como un conjunto de pasos y etapas que el estudiante aplicará con el objetivo de promover y facilitar su proceso de aprendizaje. Algunos ejemp
: Lecturas, resúmenes, realización de ejercicios, simulaciones, etc. actividades de aprendizaje propuestas están relacionadas con su objetivo de
Uno de los objetivos del los OA, es asegurar alcanzar el objetivo de aprendizaje planteado, es importante implementar actividades que evalúen los conocimientos. Esto se puede implementar mediante pruebas en línea, al finalizar la prueba se debe
alcanzado por el alumno.
OA se debe de tomar en cuenta el estándar ISO 9126 donde el aspecto pedagógico, la Interfaz humano computadora y el contenido ocupan un lugar importante en los estudios de Abud Figueroa (2005) [8].
Fig. 3 Elementos didácticos en el OA Fuente: Elaborada por las autoras
14
sos digitales como por ejemplo textos, s (digitalizados en la etapa a). Estos deben ser
la atención del alumno y se facilite el
el estudiante aplicará con el unos ejemplos de
imulaciones, etc. Las relacionadas con su objetivo de
jetivo de aprendizaje planteado, es importante implementar actividades que evalúen los conocimientos. Esto se puede implementar mediante pruebas en línea, al finalizar la prueba se debe
OA se debe de tomar en cuenta el estándar ISO 9126 donde el aspecto pedagógico, la Interfaz humano computadora y el contenido ocupan un lugar

15
1.2 La Importancia de la Evaluación La evaluación de los OA se debe de realizar a partir de la creación del propio OA estableciendo criterios desde referencias: didácticas, de usabilidad y la evaluación de los contenidos acordes al propósito del OA. Si un curso o tema se aborda a través de las plataformas tecnológicas se requiere de una planeación, organización y vialidad que permita la relación de los OA para comprender, aprender y emprender a los usuarios que dispondrán de los materiales didácticos basados en OA. Un ejemplo de la aplicación se dio en la llamada Enciclomedia que intentó ser implantada por la SEP en las escuelas públicas, y que presentó el problema de la perspectiva de la media poblacional, debido a que tanto profesores, alumnos y padres de familia esperabas que el sistema hiciera todo el trabajo, nunca se planteó la necesidad de ofrecer a los profesores capacitación especializada en multimedia para que el uso de esta herramienta fuera correcta. Aunque el e-learning es usado por múltiples empresas y existe una amplia bibliografía para su aplicación, en Estados Unidos y Europa se está implementado un concepto diferente: el aprendizaje mixto blended learning. El aprendizaje mixto usa cursos como e-learning pero con la variante de que los alumnos asistan a un número reducido de horas clase en una instalación física. Esto se asemeja a la educación semipresencial o conocido más comúnmente como el sistema de educación libre en México, que es aplicado al nivel medio superior y superior principalmente [9].
1.3 Corrientes de Aprendizaje Esenciales en los OA Las corrientes teóricas didácticas para el diseño de los OA son indispensables por parte del docente en el proceso de enseñanza aprendizaje a través de la tecnología, el cual requiere de la profesionalización en TIC´s para atender los retos de la educación hoy en día, por lo que el docente universitario debe de ser competente en el dominio de los contenidos de enseñanza del currículo y en la capacidad de transmitir el aprendizaje en los alumnos universitarios. Para el proceso de enseñanza aprendizaje el docente debe de estudiar la forma en la cual planea, el cómo imparte y evalúa sus actividades de aprendizaje en el aula. El docente debe relacionar el conocimiento disciplinar con los beneficios de las corrientes pedagógicas a través de los estudiosos citado por Boone, Archundia y Cerón (2011), como los son: Jean Piaget, Bruner, Lev Vigotsky y Gagne; además del uso de recursos de vanguardia como lo son las Tecnologías de Información TIC´s [5]. La teoría del aprendizaje Constructivista es un reto para desarrollarla e implantar en los entornos de ambientes virtuales basados en OA y finalmente utilizadas en los sistema b-learning, estos modelos se centran en la combinación de estrategias pedagógicas, propias y específicas, de los modelos presenciales y estrategias de los modelos formativos sustentados en las tecnologías Web. Dentro de los modelos constructivistas nace la técnica didáctica del Aprendizaje Basado en Problemas (ABP), que tienden a enfatizar el aprendizaje a través de realizar problemas, explorar posibles respuestas y desarrollar productos y presentaciones [6].

16
2. Importancia de las Plataformas y Administradores de Aprendizaje (LMS)
El uso de la tecnología en los servicios de comunicación mediante el internet ha impactado en los diferentes sectores sociales, productivos y laborales, tales como el comercio electrónico (e-Commerce), los centros de contacto (call centers) y la administración de la relación con el cliente (CRM, customer relationship management);, la tecnología ha cobrado auge en el tiempo actual en el aspecto educativo (e-Learning). En la actualidad se mencionan distintas plataformas y administradores del aprendizaje Learning Management System (LMS) a través de e-learning cono lo son: Moodle, Blackboard y WebCT.
Ahora las plataformas y administradores de aprendizaje se basan en crear ambientes que incluyan los contenidos de los cursos, seguimiento del desempeño del alumno, bibliotecas digitales, estadísticas e información de los cursos y registros de los alumnos.
Al desarrollar los materiales educativos en las plataformas de aprendizaje se facilita la utilización del audio, vídeo, red satelital, televisión interactiva, libros electrónicos, vínculos para enriquecer el aprendizaje a través de la multimedia.
Las plataformas de aprendizaje permiten el ahorro en tiempo de traslado para el usuario, entrega oportuna de las actividades de aprendizaje, dedicación de tiempo flexible y ruta de aprendizaje. Si bien las teorías y estilos de aprendizaje han fortalecido la enseñanza utilizando la tecnología, por lo tanto ¿Cómo aplicar las teorías de enseñanza aprendizaje utilizando el e-Learning en los cursos?, ¿Cuáles son los elementos necesarios para la creación de los materiales didácticos del cuso? y ¿Cómo evaluar el aprendizaje? Para el uso y aplicación de las plataformas de aprendizaje se requiere de la capacitación docente para la creación de los materiales a través de la tecnología y las teorías del proceso de enseñanza aprendizaje.
La Universidad Autónoma de Aguascalientes (AGG) cuenta con la plataforma MOODLE para estudiantes inscritos en los programas de licenciatura y posgrado, cuentan con un repositorio de objetos de aprendizaje (REDOUAA) [1] que permite a los usuarios la visualización y almacenamiento de OA y ofrece también servicio en línea para facilitar la colaboración entre usuarios como pueden ser foros, chats, wikis y editores colaborativos. En 2007 el repositorio contaba con 150 objetos de aprendizaje bajo el estándar SCORM (www.adlnet.gov). Uno de los principales principios que se tiene en el repositorio REDOUAA es el compartir información promoviendo la colaboración entre distintos grupos interesados en el paradigma de objetos de aprendizaje, como es el caso del grupo de trabajo en objetos de aprendizaje de la Escuela Superior Politécnica del Litoral (ESPOL), quienes actualmente representan el centro de desarrollo del repositorio europeo ARIADNE [2]. El proyecto LA FLOR (Latin American Federation of LearningObjectRepositories) busca la creación de un Repositorio Latinoamericano de Objetos de Aprendizaje que aglutine e

17
intercomunique a través de estándares internacionales a los repositorios ya existentes, tiene como objetivos la arquitectura y prototipo operable de repositorio latinoamericano así como fortalecer la Comunidad Latinoamericana de Objetos de Aprendizaje (LACLO). La federación tiene como participantes a ESPOL (Ecuador), UAA (Aguascalientes), UPA (Aguascalientes), BIOE (Brasil), REDCOA (Colombia), UDG (Jalisco).

18
3. Referencias del Capítulo 1
[1] Jaime Muñoz Arteaga, Xavier Ochoa, Edgar Alan Calvillo Moreno y Gonzalo Parra, Integración de REDOUAA a la Federación Latinoamericana de Repositorios de Objetos de Aprendizaje, LACLO 2007, Santiago de Chile , Chile. [2] Ariadne repository, http://www.ariadne-eu.org [3] Enríquez L., LCMS Y OBJETOS DE APRENDIZAJE, 10 de noviembre 2004 • Volumen 5 Número 10 • ISSN: 1067-6079, disponible en: http://www.revista.unam.mx/vol.5/num10/art66/nov_art66.pdf
[4] Ministerio de Educación Nacional Colombiano MEN (2006). Objetos Virtuales de Aprendizaje e Informativos. Consultado junio 6 de 2009, en Portal Colombia Aprende http://www.colombiaaprende.edu.co/html/directivos/1598/article-172369.html.
[5] Boone, Archundia, Cerón, (2011) Tópicos Selectos para la Enseñanza de la Ingeniería de Software: Introducción a la Ingeniería de Software. BUAP, Cap1. México. Disponible en: http://www.cs.buap.mx/libros/libroingsoftoto2011.pdf [6] Carlos Solaya Alape (director de edición). Aprendizaje basado en problemas: de la teoría a la práctica. México, Trillas. ITESM, 2005. [7] FERNÁNDEZ Quiroz Silvia Leticia, Polivirtual: Modelo de producción para recursos digitales de apoyo al bachillerato a distancia disponible en: http://bdistancia.ecoesad.org.mx/contenido/numeros/numero5/experiencias_09.html [8] ABUD Figueroa (2005), MECSE: Conjunto de métricas para evaluar software educativo, Revista educativa UPIICSA XII, V, 39, disponible en: http://www.revistaupiicsa.20m.com/Emilia/RevSepDic05/Antonieta.pdf
[9] Hernández Y, León M., Sistema de Aprendizaje Móvil AAM. Tesis Maestría. Ciencias de la Computación. Benemérita Universidad Autónoma de Puebla. Agosto 2011.

19
Capítulo 2
El Modelo Entidad-Relación (MER)
María de la Concepción Pérez de Celis Herrero María Josefa Somodevilla García
En este capítulo se introducen los fundamentos del modelado conceptual de datos utilizando el modelo Entidad Relación.
2.1 Objetivo Educativo.
– Presentar los conceptos del modelo entidad-relación (MER) y mostrar cómo representarlos gráficamente a través de varias notaciones.
– Describir algunos de los conceptos de modelado básicos que ofrece. – Abordar algunas de las extensiones propuestas para el MER que permiten el
modelado de requisitos de datos más complejos. 2.2 Contenido Informativo. 2.2.1 Introducción: Modelos de datos 2.2.2 Historia del Modelo Entidad-Relación 2.2.3 Componentes Básicos del MER 2.2.4 Semántica de las Asociaciones (Relaciones) 2.2.5 Resumen.

20
2.2.1 Introducción: Modelos de Datos Un modelo de datos (MD) puede describirse como un conjunto de conceptos y reglas que permiten representar las propiedades estáticas y dinámicas del mundo real objeto de estudio. Un MD es por tanto una colección de conceptos bien definidos matemáticamente que ayudan a expresar básicamente tres tipos de propiedades:
• Propiedades estáticas: Describen la estructura del problema mediante entidades (u objetos), propiedades (o atributos) de esas entidades, y relaciones entre esas entidades.
• Propiedades dinámicas: operaciones sobre entidades, sobre propiedades o relaciones entre operaciones.
• Reglas de integridad sobre las entidades y las operaciones (por ejemplo, transacciones).
El resultado de un modelado de datos es una representación que tiene dos componentes: las propiedades estáticas que se definen en un esquema y las propiedades dinámicas que se definen como especificaciones de transacciones, consultas e informes. Un esquema consiste en una definición de todos los tipos de objetos de la aplicación, incluyendo sus atributos, relaciones y restricciones estáticas. Correspondientemente, existirá un repositorio de información, la base de datos, que es una instancia del esquema. Un determinado tipo de procesos sólo necesita acceder a un subconjunto predeterminado de entidades definidas en un esquema, por lo que este tipo de procesos puede requerir sólo un subconjunto de las propiedades estáticas del esquema general. A este subconjunto de propiedades estáticas se le denomina subesquema. Una transacción consiste en diversas operaciones o acciones sobre las entidades de esquema o subesquema. Una consulta se puede expresar como una expresión lógica sobre los objetos y relaciones definidos en el esquema; una consulta identifica un subconjunto de la base de datos. Las herramientas que se usan para realizar las operaciones de definición de las propiedades estáticas y dinámicas de la base de datos son los lenguajes de definición y manipulación de datos (DDL, DML). Los modelos de datos clásicos (Jerárquico, Redes y Relacional) carecen de un componente semántico que permita interpretar mejor el mundo real, razón por la cual surgen los modelos de datos conceptuales, que son más ricos semánticamente. Entre estos modelos de datos semánticos, el modelo Entidad-Relación es posiblemente el más utilizado 2.2.2 Historia del Modelo Entidad Relación En 1976 Peter Chen publicó el Modelo Entidad Relación (MER) original que proveía un enfoque visual fácil de usar en el diseño conceptual de las bases de datos (Chen, 1976). El modelo ER elude las complicaciones de almacenamiento y consideraciones de eficiencia, las cuales son reservadas para el diseño físico de la base de datos. A partir de su publicación, muchos diseñadores de bases de datos han adoptado el modelo original y lo han usado con pequeños cambios. Además, algunos autores han extendido el modelo incrementando sus capacidades, entre las extensiones hechas se encuentran íconos dinámicos así como una adaptación al modelado de bases de datos orientadas a objetos. A raíz de las numerosas aportaciones que se han hecho al modelo original desde 1976 por numerosos autores podemos afirmar que el MER no es un modelo sino una familia de modelos conceptuales. El Modelo Entidad Relación (MER) se caracteriza principalmente por desarrollar el diseño de las bases de datos en un esquema de alto nivel conceptual sin considerar los problemas de bajo nivel como la eficiencia, el modelo implícito del administrador de base de datos o las estructuras físicas de los datos. El enfoque MER simplifica proceso de diseño introduciendo diseños intermedios llamados vistas de negocio o esquemas de negocio. El esquema de negocio, que se expresa como un diagrama entidad

21
relación, es un diseño conceptual de la base de datos y es una representación pura del mundo real y además como ya se mencionó en los párrafos precedentes, es independiente del almacenamiento y las consideraciones de eficiencia. Este esquema de negocio al ser independiente de implementación, puede más tarde ser trasladado hacia un esquema de usuario específico de un SGBD. Estas dos fases simplifican el proceso y lo hacen más organizado. El esquema de negocio es fácil de diseñar, y, en caso de una transición desde un tipo de SGBD a otro puede ser re-mapeado a un esquema de usuario adecuado al nuevo SGBD. El MER es actualmente extensamente usado durante el análisis de requerimientos y para el modelado conceptual de la base de datos y es soportado por herramientas software de diseño (CASE). Debido a su simplicidad, es también más fácil de entender por individuos no técnicos. Pruebas en el ambiente de un mundo real han mostrado que es una efectiva herramienta de comunicación entre diseñadores de base de datos y usuarios finales. 2.2.3. Componentes Básicos del MER Los componentes básicos de este modelo son: las entidades, los atributos y las asociaciones. Entidad Es una persona, lugar o cosa, concepto o suceso tangible o intangible, real o abstracto de interés, en el universo del discurso del problema (ANSI, 1977). Es un objeto del cual queremos almacenar información en la base de datos. Se denomina tipo de entidad, a la estructura genérica y ocurrencia de la entidad, a cada una de las realizaciones concretas de este tipo de entidad. Su representación gráfica es mediante un rectángulo como se muestra en la Figura 1.
Figura 1. Representación gráfica de un tipo de entidad Un tipo de entidad, define un conjunto de entidades que poseen las mismas características (atributos) por ejemplo:
– PELICULA: titulo, genero, nacionalidad, añoestreno, numcopias – EMPLEADO: CURP, RFC, nombre, fechanac, direccion, telefono, altura, nacionalidad,
edad y una instancia o ocurrencia de una entidad, está entonces descrita por el valor de sus atributos, de este modo sin perder generalidad podemos decir que los objetos que comparten el mimos tipo de características o atributos2, definen un tipo de entidad como es el caso de la entidad PELICULA, donde toda película puede describirse por su titulo, género, nacionalidad, año de estreno y número de copias. Cuando hablamos de una ocurrencia como es el caso de la instancia p1, nos referimos a un ejemplar del tipo de datos PELICULA, en este caso a la película El alquimista impaciente, estrenada en 2002 de nacionalidad Española y que es un Thriller.
2 Las características que describen un objeto pueden variar dependiendo de los requerimientos del usuario y sus intereses dependiendo del contexto de la aplicación
NOMBRE DELTIPO DE ENTIDAD

22
En las secciones subsecuentes profundizaremos en los tipos de atributos que pueden poseer las entidades y como veremos más tarde también las asociaciones. Existen dos tipos de entidades:
� Regular o Fuerte: Las ocurrencias de un tipo de entidad regular se caracterizan por tener existencia propia. A este tipo de entidad se representa por un rectángulo como el mostrado anteriormente.
� Débil: En este tipo de entidad las ocurrencias dependen para su existencia de la existencia de una ocurrencia de algún tipo de entidad regular. De esta forma si se elimina la ocurrencia de la entidad regular de la que dependen se eliminan también con ella todas las ocurrencias de las entidades débiles dependientes. Las entidades débiles se representan por dos rectángulos concéntricos como se muestra en la Figura 2.
Figura 2. Representación gráfica de un tipo de entidad débil
Un ejemplo de estos tipos de entidades es el caso de los dependientes económicos de un empleado cuya existencia no tiene sentido si no existe una ocurrencia de empleado a la cual están asociados. Asociación (Llamada comúnmente Relación) Denotan las interacciones posibles entre entidades 3 . Se denomina Tipo de Asociación a la estructura genérica del conjunto de asociaciones que pueden existir entre dos o más entidades. Se define la Ocurrencia de una Asociación a la vinculación que existe entre las ocurrencias concretas de cada uno de las entidades que participan en la asociación. Una asociación se representa gráficamente por un rombo el cual es etiquetado con el nombre de la asociación y se une mediante arcos a las entidades que relaciona. Cabe mencionar que comúnmente a las asociaciones se les denomina relaciones sin embargo estas difieren completamente de la estructura de relación del Modelo Relacional de Codd, hecha esta mención en adelante, en este capítulo, nos referiremos indistintamente a un tipo de asociación como una relación. En la Figura 3., se muestra la representación gráfica de una asociación entre dos entidades vía la relación HA_RODADO.
3 En los sucesivo hablaremos de entidades simplemente para hacer referencia a tipo de entidad
NOMBRE DELTIPO DE ENTIDAD DÉBIL
Asociación, vínculo o correspondencia entre instancias de entidades relacionadas de alguna manera en el “mundo real”
– El director “Alejandro Amenábar” ha rodado la película “Mar adentro” – El empleado 87654321 trabaja en el local de videoclub “principal” – La película “El imperio contraataca” es una continuación de la película “La
guerra de las galaxias”

Una relación se caracteriza por: � Nombre: Permite identificar de manera única a la relación y además nos da información
semántica sobre la razón por la cual dos entidades pueden estar
Figura 3.
� Grado: Es el número de entidades que participan en una misma relación (Figura 4). Pueden
ser binarias (de grado dos), unarias (de grado uno, en este caso es la asociación ocurrencia de entidad con otras ocurrencias de entidad del mismo tipo), ternarias (grado tres, es decir están asociadas tres entidades) o en general nnúmero de entidades participantes).
Figura 4. Representación gráfica del grado de una relación (a) binaria,
Todo tipo de entidad que participa en un la relación. Los nombres de rol se deben usar, sobre todo, en los tipos reflexivos, para evitar ambigüedadayudan a explicar el significado de la relación.
Figura 5
� Restricciones Estructuralespueden participar en las relacionesen que se pueden vincular dos o más entidades y son modela, por ejemplo: - “Una película debe haber sido dirigida por- “Un director ha dirigido
Grado: Número de – Binaria: grado– Ternaria: grado– Reflexiva
: Permite identificar de manera única a la relación y además nos da información
semántica sobre la razón por la cual dos entidades pueden estar asociadas.
Figura 3. Representación gráfica de una relación entre dos entidades
: Es el número de entidades que participan en una misma relación (Figura 4). Pueden ser binarias (de grado dos), unarias (de grado uno, en este caso es la asociación ocurrencia de entidad con otras ocurrencias de entidad del mismo tipo), ternarias (grado tres, es decir están asociadas tres entidades) o en general n-arias (grado n, donde n denota el número de entidades participantes).
(a)
(c)
. Representación gráfica del grado de una relación (a) binaria, (b) unaria o reflexiva, (c) ternaria
que participa en un tipo de relación juega un papel específico (Rol) en la relación. Los nombres de rol se deben usar, sobre todo, en los tipos de relación reflexivos, para evitar ambigüedad como se muestra en la figura 5. Los nombres de rol
r el significado de la relación.
Figura 5. Relación reflexiva con etiquetado de nombre de Rol
Restricciones Estructurales: Limitan las posibles combinaciones de las pueden participar en las relaciones. Las relaciones estructurales representan las condiciones en que se pueden vincular dos o más entidades y son extraídas de la situación
Una película debe haber sido dirigida por uno y sólo un director” ha dirigido al menos una película y puede haber dirigido muchas
Número de tipos de entidad que participan en el tipo de relacióngrado 2 (el más frecuente)
grado 3 (o recursiva): grado 1
23
: Permite identificar de manera única a la relación y además nos da información
Representación gráfica de una relación entre dos entidades
: Es el número de entidades que participan en una misma relación (Figura 4). Pueden ser binarias (de grado dos), unarias (de grado uno, en este caso es la asociación entre una ocurrencia de entidad con otras ocurrencias de entidad del mismo tipo), ternarias (grado
arias (grado n, donde n denota el
(b)
(b) unaria o reflexiva,
juega un papel específico (Rol) en relación
Los nombres de rol
. Relación reflexiva con etiquetado de nombre de Rol
las entidades que . Las relaciones estructurales representan las condiciones
la situación real que se
muchas”
relación

Podemos distinguir dos c 1) Razón de correspondencia 2) Razón de participación Razón de correspondencia: que pueden intervenir por cada ocurrencia del otro tipo de entidad asociado a la relación. Existen diferentes tipos de cardinalidad o tipos de correspondencias. - Correspondencia 1:1.
ocurrencia de un tipo de entidad relacionada con una ocurrencia del otro tipo de entidad.
- Correspondencia 1:N. relacionar con un número indefinido de ocurrenentidad que participa en la relación.
- Correspondencia N:M. pero, para ambos tipos de entidad.
Para representar la correspondencia gráficamente se agrega una etiqueta como se muestra en la figura 6. Existen numerosas notaciones para el modelo MER, entre las que podemos mencionar la de Piattini y 2011)4, por su aceptación y uso en diferentes textos y artículos del tema.
Figura 6.
Razón de Participación: participan en un tipo de en existencia de un tipo siguientes Clases de Participación: - Participación total
significa que una instancia de esa entidad sólo puede existir si participa en una instancia
4 En este capítulo la notación usada será esta última, por ser muy similar a la original
Podemos distinguir dos clases de restricciones estructurales: de correspondencia
Razón de participación.
ón de correspondencia: Es el número máximo de ocurrencias de un tipo de entidad que pueden intervenir por cada ocurrencia del otro tipo de entidad asociado a la relación.
Existen diferentes tipos de cardinalidad o tipos de correspondencias.
Correspondencia 1:1. Cuando en la relación sólo pueden aparecer, como máximo una ocurrencia de un tipo de entidad relacionada con una ocurrencia del otro tipo de
Correspondencia 1:N. Cuando una ocurrencia de un tipo de entidad se puede relacionar con un número indefinido de ocurrencias (mayor que uno) del otro tipo de entidad que participa en la relación. Correspondencia N:M. Cuando ocurre lo anteriormente descrito para el caso 1:N pero, para ambos tipos de entidad.
Para representar la correspondencia gráficamente se agrega una etiqueta como se muestra en la figura 6. Existen numerosas notaciones para el modelo MER, entre las que podemos
Piattini y Marcos (MPM 1999) y la de Elmasri y Navathe (por su aceptación y uso en diferentes textos y artículos del tema.
Figura 6. Representación gráfica de la Razón de Correspondencia
Razón de Participación: Especifica si todas las instancias (extensión) de un tipo de un tipo de relación, o sólo parte de ellas. Indica también si hay de un tipo de entidad respecto de un tipo de relación. Se distinguen las
articipación:
total (dependencia en existencia): La dependencia en existencia significa que una instancia de esa entidad sólo puede existir si participa en una instancia
En este capítulo la notación usada será esta última, por ser muy similar a la original definida por Chen en 1976
24
Es el número máximo de ocurrencias de un tipo de entidad que pueden intervenir por cada ocurrencia del otro tipo de entidad asociado a la relación.
elación sólo pueden aparecer, como máximo una ocurrencia de un tipo de entidad relacionada con una ocurrencia del otro tipo de
Cuando una ocurrencia de un tipo de entidad se puede cias (mayor que uno) del otro tipo de
Cuando ocurre lo anteriormente descrito para el caso 1:N
Para representar la correspondencia gráficamente se agrega una etiqueta como se muestra en la figura 6. Existen numerosas notaciones para el modelo MER, entre las que podemos
Elmasri y Navathe (EN 2002,
Representación gráfica de la Razón de Correspondencia
de un tipo de entidad hay dependencia Se distinguen las
dependencia en existencia significa que una instancia de esa entidad sólo puede existir si participa en una instancia
definida por Chen en 1976.

de la relación. Cabe señalar que tipo de relación. No tiene el mismo significado (MPM,1999), puesto que se debe entender como que no tiene sentido que exista una entidad que no participe en la relación.de participación total
- Participación parcialparticipan en la relación no están asociadas con ninguna otra instancia de alguna de las otras entidades participantes en la relación. Un ejemplo de este tipo de participación se muestra en la figura 7, donde algunas entidades de EMPLEADO no participan (ninguna relación de DIRIGE y otras si (no todos los empleados son directores de departamento).
Figura 7 Generalmente los conceptos estructurales de participación y correspondencia se conocen como la Cardinalidad del tipo de entidad en la relación (figura 8,9).
Figura 8. Cardinalidad del tipo de entidad. de relación en las que puede intervenir una
EMPLEADO
Cardinalidad: Este concepto proporciona más información acerca de la relación.(min,max) en cada participación dela entidad debe participar al menos en
• si min=1, toda instancia instancia del tipo de relación, es decir: relación
• si min = 0, algunas instancias tipo relación:
Cabe señalar que la dependencia del tipo de entidad es . No tiene el mismo significado que la dependencia en existencia de
1999), puesto que se debe entender como que no tiene sentido que exista una entidad que no participe en la relación. Una entidad débil siempre tiene una de participación total en la relación que la une a su entidad propietaria.
parcial : Aquí algunas instancias de alguna o de todas las entidades que participan en la relación no están asociadas con ninguna otra instancia de alguna de las otras entidades participantes en la relación. Un ejemplo de este tipo de participación se
ra 7, donde algunas entidades de EMPLEADO no participan (ninguna relación de DIRIGE y otras si (no todos los empleados son directores de
(0, ) (1, )
Figura 7. Visualización gráfica del tipo de participación parcial
Generalmente los conceptos estructurales de participación y correspondencia se conocen como la del tipo de entidad en la relación (figura 8,9).
Cardinalidad del tipo de entidad. Números mínimo y máximo de instanciasen las que puede intervenir una instancia del tipo de entidad. Notación
en la línea que une.
DIRIGE
EEEEDEPARTAMENTO
Este concepto proporciona más información acerca de la relación.participación del tipo de entidad en el tipo de relación. Una instancia
debe participar al menos en min y como mucho en max instancias de toda instancia del tipo de entidad debe participar al menos en una
l tipo de relación, es decir: participación total de la entidad
= 0, algunas instancias del tipo de entidad pueden no participar en el : participación parcial de la entidad en la relación.
25
la dependencia del tipo de entidad es con respecto al que la dependencia en existencia de
1999), puesto que se debe entender como que no tiene sentido que exista una tiene una restricción
algunas instancias de alguna o de todas las entidades que participan en la relación no están asociadas con ninguna otra instancia de alguna de las otras entidades participantes en la relación. Un ejemplo de este tipo de participación se
ra 7, donde algunas entidades de EMPLEADO no participan (0) en ninguna relación de DIRIGE y otras si (no todos los empleados son directores de
. Visualización gráfica del tipo de participación parcial
Generalmente los conceptos estructurales de participación y correspondencia se conocen como la
instancias del tipo Notación: (min, max)
DEPARTAMENTO
Este concepto proporciona más información acerca de la relación. Se asocia Una instancia de
la relación debe participar al menos en una
la entidad en la
no participar en el

Figura 9.
La semántica del concepto Cardinalidad de la figura 8., se interpreta considerando las ocurrencias de la relación como se ve en la figura 9., toda instancia de PERSONA está ligada a una instancia de EDIFICIO en la relación USA y puede estar ligada a más de un EDIFICIO. Por otra parte una instancia dada de EDIFICIO puede no estar ligada a ninguna instancia de PERSONA en la relación USA (como es el caso de la instancia e4, esto puede interpretarse como que el edificconstrucción o vacio). La semántica de POSEE es análoga aquí resulta claro que no toda instancia de PERSONA, es dueña de un EDIFICIO, pero también es cierto que una instancia de PERSONA puede estar vinculada con una o más Instancias de EDIFICIO.EDIFICIO en la relación POSEE es (1,1) ya que todo edificio tiene un dueño y solo uno. Atributo Se denomina así a cada una de las propiedades características que tiene un tipo de entidad o una asociación. Existen los siguientes tipos de atríbutos:
- Obligatorios: Son aquellos que deben tener un valor para cada una de las instancias de un tipo de entidad o de un tipo de asociación (relación). Es decir no se permite que una instancia no tenga un valor determinado para ese at
- Opcionales: Aquellos atributos que pueden tener valor o no tenerlo. En el caso de no tener valor el valor que se le asigna es NULO que significa no existe, no se conoce, no aplica. Por ejemplo
- Monovaluados: Aquellos atributos que pueden tener un único valor. Fecha de Nacimiento
- Multievaluados: Los atributos que pueden tener al mismo tiempo más de un valor. ejemplo Nacionalidad
- Simples: Atributos atómicos no divisibles. - Compuestos: Pueden dividirse en otros atributos con significado propio. En este caso
el valor del atributo compuesto se obtiene por la concatenación de los atributos componentes. Por ejemplo
- Derivados: Son atributos cuyo valor se obtienen a partir dexistente (atributos, entidades relacionadas)
- Almacenados: A este tipo pertenecen la mayoría de los atributos y es a partir de estos que se obtienen los atributos derivados.
En la figura 10., se presenta un ejemplo de la notación utilizada para cada uno de los tipos de atributos antes presentados.
Figura 9. Instancias de las relaciones USA y POSEE
La semántica del concepto Cardinalidad de la figura 8., se interpreta considerando las ocurrencias de la relación como se ve en la figura 9., toda instancia de PERSONA está ligada a una instancia de
a relación USA y puede estar ligada a más de un EDIFICIO. Por otra parte una instancia dada de EDIFICIO puede no estar ligada a ninguna instancia de PERSONA en la relación USA (como es el caso de la instancia e4, esto puede interpretarse como que el edificconstrucción o vacio). La semántica de POSEE es análoga aquí resulta claro que no toda instancia de PERSONA, es dueña de un EDIFICIO, pero también es cierto que una instancia de PERSONA puede estar vinculada con una o más Instancias de EDIFICIO. Por otra parte la cardinalidad de EDIFICIO en la relación POSEE es (1,1) ya que todo edificio tiene un dueño y solo uno.
Se denomina así a cada una de las propiedades características que tiene un tipo de entidad o una guientes tipos de atríbutos: Son aquellos que deben tener un valor para cada una de las instancias de
un tipo de entidad o de un tipo de asociación (relación). Es decir no se permite que una instancia no tenga un valor determinado para ese atributo. Por ejemplo RFC
Aquellos atributos que pueden tener valor o no tenerlo. En el caso de no tener valor el valor que se le asigna es NULO que significa no existe, no se conoce, no
Por ejemplo Teléfono Aquellos atributos que pueden tener un único valor.
Fecha de Nacimiento Los atributos que pueden tener al mismo tiempo más de un valor.
Nacionalidad Atributos atómicos no divisibles. Por ejemplo Género
Pueden dividirse en otros atributos con significado propio. En este caso el valor del atributo compuesto se obtiene por la concatenación de los atributos
Por ejemplo Dirección Son atributos cuyo valor se obtienen a partir de otra información ya
existente (atributos, entidades relacionadas). Por ejemplo Edad A este tipo pertenecen la mayoría de los atributos y es a partir de estos
que se obtienen los atributos derivados. Por ejemplo Fecha de Nacimiento
figura 10., se presenta un ejemplo de la notación utilizada para cada uno de los tipos de
26
La semántica del concepto Cardinalidad de la figura 8., se interpreta considerando las ocurrencias de la relación como se ve en la figura 9., toda instancia de PERSONA está ligada a una instancia de
a relación USA y puede estar ligada a más de un EDIFICIO. Por otra parte una instancia dada de EDIFICIO puede no estar ligada a ninguna instancia de PERSONA en la relación USA (como es el caso de la instancia e4, esto puede interpretarse como que el edificio está en construcción o vacio). La semántica de POSEE es análoga aquí resulta claro que no toda instancia de PERSONA, es dueña de un EDIFICIO, pero también es cierto que una instancia de PERSONA
Por otra parte la cardinalidad de EDIFICIO en la relación POSEE es (1,1) ya que todo edificio tiene un dueño y solo uno.
Se denomina así a cada una de las propiedades características que tiene un tipo de entidad o una
Son aquellos que deben tener un valor para cada una de las instancias de un tipo de entidad o de un tipo de asociación (relación). Es decir no se permite que una
RFC Aquellos atributos que pueden tener valor o no tenerlo. En el caso de no
tener valor el valor que se le asigna es NULO que significa no existe, no se conoce, no
Aquellos atributos que pueden tener un único valor. Por ejemplo
Los atributos que pueden tener al mismo tiempo más de un valor. Por
Pueden dividirse en otros atributos con significado propio. En este caso el valor del atributo compuesto se obtiene por la concatenación de los atributos
otra información ya
A este tipo pertenecen la mayoría de los atributos y es a partir de estos Fecha de Nacimiento
figura 10., se presenta un ejemplo de la notación utilizada para cada uno de los tipos de

27
Figura 10. Notación para los diferentes tipos de atributos.
En el caso de los atributos multi-evaluados como es el caso de nacionalidad se denota entre ( ), el número de valores mínimos y máximos que el atributo puede tener. De este modo tenemos que teléfono es un atributo multi-evaluado opcional ya que su valor mínimo es cero pero puede tener si existe hasta tres valores. Denominamos Dominio (Nevado 2010) al conjunto de posibles valores que puede tomar un atributo. Cada dominio tiene un nombre y una existencia propia con independencia de cualquier entidad o atributo. Como un dominio restringe los valores del atributo, puede considerarse como un tipo. Por ejemplo el dominio Nacionalidades tiene como valores {Mexicana, Española, Inglesa, Colombiana}, el atributo nacionalidad de EMPLEADO debe estar definido sobre este dominio. La existencia del tipo de atributo nacionalidad está unido a la existencia del tipo de entidad PERSONA, mientras que el dominio Nacionalidades existe por si mismo independiente de la existencia de cualquier tipo de entidad. Los tipos de asociación o relaciones pueden al igual que los tipos de entidad poseer atributos. Conceptualmente en el caso de relaciones M:N los atributos deben pertenecer a la relación, porque su valor está determinado por la combinación de las instancias participantes, y no por una sola de ellas. En el caso 1:N, sólo se puede llevar a la entidad que está en el lado N de la relación (la que participa una vez, que condiciona el valor del (atributo). En la figura 11., mostramos la notación utilizada para denotar los atributos de las relaciones.
. (a) (b) Figura 11. Presenta dos notaciones para los atributos de una relación (a) es la notación de la de
Piattini y Marcos (MPM 1999) y (b) la de Elmasri y Navathe (EN 2002, 2011). Se denomina atributo identificador principal, al atributo elegido entre todos los atributos de un tipo de entidad que permite identificar unívoca y mínimamente cada una de las ocurrencias de este tipo de entidad. Si existe más de un atributo que cumpla esa condición, a esos atributos los denominaremos atributo identificador candidato, de los cuales se elige uno como principal y los

otros son alternativos (atributos identificadores alternativos). notación para indicar cuál de los atributos es el identificador principal ocandidatos. Cabe señalar que simultáneamente el mismo valor para el atribclave.
Figura 12. Notación para los atributos que son identificador principal o clave 2.2.4. Semántica de las Asociaciones (Relaciones) Los tipos de asociación se clasifican de acuerdo al tipo de las entidades que vinculen, y pueden ser de dos tipos:
- Regulares: cuando relaciona solamente tipos de entidades regulares.- Débiles: cuando relaciona un tipo de entidad débil con una entidad regular. Dentro de este
tipo de relación podemos distinguir dos clases de Existencia , b) Dependencia en Identificación.
Dependencia en existencia (entre entidadesSi desaparece una instancia del tipo de entidad regularentidad débil que dependen de ella Dependencia en identificación Además de la dependencia en existenciaidentificar por sí misma. Su clave es en el tipo de relación débil.
Figura 13. Notación para el tipo de relación débil por existencia y por identificación
2.2.5 Resumen En este capítulo se han introducido los fundamentos del modelado conceptual de datos utilizando el modelo Entidad Relación. Se definió el concepto general de un modelo de datos y se describió una
atributos identificadores alternativos). En la figura 12 se muestra la notación para indicar cuál de los atributos es el identificador principal o clave y cuales son candidatos. Cabe señalar que la restricción de unicidad prohíbe que dos entidades tengan simultáneamente el mismo valor para el atributo clave y que las relaciones, no tienen atributos
Notación para los atributos que son identificador principal o clave
2.2.4. Semántica de las Asociaciones (Relaciones)
Los tipos de asociación se clasifican de acuerdo al tipo de las entidades que vinculen, y pueden ser
relaciona solamente tipos de entidades regulares. Débiles: cuando relaciona un tipo de entidad débil con una entidad regular. Dentro de este tipo de relación podemos distinguir dos clases de dependencia. a) Dependencia en
b) Dependencia en Identificación.
entre entidades) instancia del tipo de entidad regular deben desaparecer las instancias de la
que dependen de ella. Se etiqueta “E” en el tipo de relación débil
de la dependencia en existencia, una instancia del tipo de entidad débil
Su clave es (clave_entidad_regular, clave_parcial). Se
Notación para el tipo de relación débil por existencia y por identificación
En este capítulo se han introducido los fundamentos del modelado conceptual de datos utilizando el modelo Entidad Relación. Se definió el concepto general de un modelo de datos y se describió una
28
En la figura 12 se muestra la clave y cuales son
la restricción de unicidad prohíbe que dos entidades tengan uto clave y que las relaciones, no tienen atributos
Notación para los atributos que son identificador principal o clave
Los tipos de asociación se clasifican de acuerdo al tipo de las entidades que vinculen, y pueden ser
Débiles: cuando relaciona un tipo de entidad débil con una entidad regular. Dentro de este a) Dependencia en
las instancias de la
instancia del tipo de entidad débil no se puede . Se etiqueta “ID”
Notación para el tipo de relación débil por existencia y por identificación
En este capítulo se han introducido los fundamentos del modelado conceptual de datos utilizando el modelo Entidad Relación. Se definió el concepto general de un modelo de datos y se describió una

29
metodología de modelado. La palabra modelo se usa a menudo en niveles diferentes como una metodología para diseñar el esquema conceptual, como un esquema lógico de la base de datos que define los tipos de datos que se deben tener e una aplicación particular y como una base de datos implementada, que contienen hechos específicos del esquema físico. El modelo de datos ER es básicamente un modelo conceptual y es también semántico ya que captura el significado de las cosas en el mundo real. Los modelos de datos conceptuales consisten en general de conjuntos de objetos e interrelaciones, atributos, indicadores de cardinalidad y claves. Los conjuntos de objetos conceptuales representan entidades que son tipos de cosas y las interrelaciones establecen conexiones entre instancias de dos o más conjuntos de objetos. El modelo ER es un estándar para el análisis y diseño de esquemas conceptuales. Existen algoritmos de mapeo entre este modelo y el modelo relacional así como herramientas case que auxilian en el proceso de diseño conceptual y el proceso de mapeo entre modelos de datos.
2.3 Actividades de Aprendizaje En esta sección incluimos algunos ejemplos resueltos de modelado conceptual utilizando el modelo ER (Gut2004). Problema 1: Artículos y pedidos Una base de datos para una pequeña empresa debe contener información acerca de clientes, artículos y pedidos. Hasta el momento se registran los siguientes datos en documentos varios:
• Para cada cliente: Número de cliente (único), Direcciones5 de envío (varias por cliente), Saldo, Límite de crédito (depende del cliente, pero en ningún caso debe superar los $3,000,000), Descuento.
• Para cada artículo: Número de artículo (único), Fábricas que lo distribuyen, Existencias de ese artículo en cada fábrica, Descripción del artículo.
• Para cada pedido: Cada pedido tiene una cabecera y el cuerpo del pedido. La cabecera está formada por el número de cliente, dirección de envío y fecha del pedido. El cuerpo del pedido son varias líneas, en cada línea se especifican el número del artículo pedido y la cantidad.
Además, se ha determinado que se debe almacenar la información de las fábricas. Sin embargo, dado el uso de distribuidores, se usará: Número de la fábrica (único) y Teléfono de contacto. Y se desea saber cuántos artículos (en total) provee la fábrica. También, por información estratégica, se podría incluir información de fábricas alternativas respecto de las que ya fabrican artículos para esta empresa. El diagrama ER que representa la descripción textual es el siguiente:
5 Una dirección se entenderá como Calle, Número, Cp. y Ciudad. Una fecha incluye hora.

30
Problema 2: Sistema de Ventas Le contratan para hacer una BD que permita apoyar la gestión de un sistema de ventas. La empresa necesita llevar un control de proveedores, clientes, productos y ventas. Un proveedor tiene un RUT, nombre, dirección, teléfono y página web. Un cliente también tiene RUT, nombre, dirección, pero puede tener varios teléfonos de contacto. La dirección se entiende por calle, número, comuna y ciudad. Un producto tiene un id único, nombre, precio actual, stock y nombre del proveedor. Además se organizan en categorías, y cada producto va sólo en una categoría. Una categoría tiene id, nombre y descripción. Por razones de contabilidad, se debe registrar la información de cada venta con un id, fecha, cliente, descuento y monto final. Además se debe guardar el precio al momento de la venta, la cantidad vendida y el monto total por el producto. La solución propuesta se muestra a continuación

31
2.4 Actividades de Evaluación de Adquisición del Conocimiento. Los siguientes ejercicios sugeridos, pueden también utilizarse para evaluar el tema en el examen departamental correspondiente: 2.2.1 Definir cada uno de los siguientes términos
a. Tipo de entidad b. Conjunto de entidades c. Intensión de una entidad d. Extensión de una entidad e. Atributo f. Dominio de un atributo g. Tipo de relación h. Conjunto de relaciones i. Grado de una relación j. Cardinalidad de una relación

32
k. Dependencia en existencia l. Entidad débil
2.2.2 Considere el tipo de entidad Empleado con atributos: EmpId, RFC, EmNombre, TituloPuesto y Salario. Suponga que en la misma empresa existe un tipo de entidad llamado Proyecto con atributos ProyNombre, FechaInicio, FechaFin y Presup. a. Realice el diagrama ER del enunciado anterior y suponga que quiere representar el número
de horas que se asignan a un empleado por trabajar en un proyecto y muéstrelo en el diagrama.
b. Haga las suposiciones necesarias, enúncielas y tome una decisión sobre la cardinalidad y las restricciones de participación y cardinalidad de la relación y agregue los símbolos adecuados al diagrama ER.
c. Suponga que debe agregar otra entidad llamada Departamento. Cada Empleado trabaja sólo para un departamento. Los proyectos no los patrocina directamente un departamento. Elabore los atributos necesarios y agregue esta entidad y las relaciones adecuadas al diagrama.
2.2.3 El consultorio de un dentista necesita conservar información acerca de pacientes, el número de visitas que hacen al consultorio, el trabajo que se debe realizar, los procedimientos realizados durante las visitas, los cargos y pagos por el tratamiento y los suministros de laboratorio y servicios. Suponga que sólo hay un dentista, de modo que no hay necesidad de almacenar información acerca del dentista en la base de datos. Existen muchos cientos de pacientes. Los pacientes pueden hacer muchas visitas y la base de datos debe almacenar información acerca de los servicios realizados durante cada visita, y los cargos para cada uno de los servicios. Existe una lista estándar de cargos que se mantiene fuera de la base de datos. El consultorio usa tres laboratorios dentales que proporcionan suministros y servicios, como fabricación de dentaduras. Dibuje el diagrama ER completo para este ejemplo.
2.5 Referencias del Capítulo 2 P. Chen, The entity-relationship model:Towards a unified view of data, ACM Trans. Sistemas de bases de datos 1 (1) (1976) 9-36 The ANSI/X3/SPARC DBMS Framework. Report on the Study Group on Database Management Systems. D. Tsichiritzis y A. Klug (eds). Montvalle, N.J.: AFIP Press, 1977. ANSI = American National Standards Institute, <http://www.ansi.org/> Instituto de estándares Americano De Miguel, A.; Piattini, M.; Marcos, E.(1999), Diseño de bases de datos relacionales. Ra-Ma. Ramez Elmasri, Shamkant B. Navathe.(2002, 2011). Fundamentals of Database Systems (6th Edition) [Kindle Edition].Addison Wesley María Victoria Nevado Cabello, (2010), Introducción a las Bases de Datos Relacionales, Editorial Visión Libros, España. Claudio Gutiérrez, Gonzalo Navarro (2004), http://users.dcc.uchile.cl/~mnmonsal/BD/ , CC42A – BASES DE DATOS.

33
Capítulo 3
El Proceso de Normalización.
Alma Delia Ambrosio Vázquez José Miguel Ángel Ochoa Rodríguez
Todo lo que se quiere expresar en este texto, muestra tal como los fundamentos teórico-metodológicos aconsejan que se deben hacer las cosas. En la práctica el objetivo es realizar software con calidad: Esto es garantizar que el producto final cumpla exactamente con las características planteadas en la ingeniería de requerimientos, donde por supuesto la Base de Datos es la estructura que soporta este software. Específicamente en el diseño de Base de Datos, un procedimiento para lograr esta calidad en el software se llama Normalización. La teoría de la normalización es una ayuda que proporciona un procedimiento riguroso para que el diseño de una base de datos, no sea redundante y esté libre de inconsistencias. Una base de datos mal diseñada puede funcionar inicialmente pero puede mostrar anomalías en el almacenamiento debidas al agrupamiento indiscriminado de los campos cuando se efectúan en los archivos las operaciones de inserción, actualización o eliminación. Para reflexionar, pregunto, lo siguiente: ¿Qué pasaría, si el ingeniero civil o el arquitecto construye una casa o un edificio sin hacer sus planos, proyectos o maquetas?, ¿Permitirías que tu propio cirujano te interviniera sin hacer los estudios respectivos para obtener las evidencias del problema de salud que te aqueja? Entonces, ¿por qué los ingenieros en software a veces cedemos a la falta de tiempo y construimos software sin el análisis y diseño expresado en un proyecto? ¿Dónde quedó la ética profesional?... [1].

34
3.1 Objetivo Educativo Objetivos generales:
• Adquirir conocimientos y habilidades de abstracción para analizar requerimientos de reglas de negocio.
• Aplicar los principios del proceso de normalización. Objetivos específicos:
• Definir el concepto de normalización • Explicar los beneficios de la Normalización • Desarrollar el Proceso de Normalización hasta la 4FN
3.2 Contenido Informativo Contenido: 3.2.1 Bases De Datos y Normalización 3.2.2 Normalización. 3.2.2.1 Dependencia funcional. 3.2.2.2 Primera Forma Normal (1FN). Derivación y anomalías en relaciones 1FN. Normalización y verificación de la relación 1FN 3.2.2.3 Segunda Forma Normal (2FN). Anomalías de relaciones 2FN. Normalización y verificación de una relación 2FN. 3.2.2.4 Tercera Forma Normal (3FN). Anomalías debidas a la dependencia de valores Múltiples. Tratamiento de la dependencia de valores Múltiples. 3.2.2.5 Cuarta Forma Normal (4FN). 3.2.1Bases de Datos y Normalización. Una base de datos consiste en una colección de datos relacionados entre sí, que contiene información acerca de una empresa determinada. Toda base de datos se diseña, se construye y se prueba con datos para un propósito específico, está dirigida a un grupo de usuarios y tiene ciertas aplicaciones preconcebidas que interesan a dichos usuarios. [6] Las ventajas de utilizar un sistema de bases de datos, es que una base de datos es compacta, rápida, menos laboriosa y actual. Sin embargo sacar beneficio de estas bondades y lograr un procesamiento eficiente de las peticiones de los usuarios de información, depende de las bases teóricas, métodos, técnicas y herramientas que sean usados en el proceso de diseño de una Base de Datos. Existen dos métodos convencionales que son de relevante importancia para el diseño de bases de datos: el modelo entidad-relación (visto en capítulo anterior) y la normalización. Cuando se crea un modelo E-R, tal vez encuentres que algunos de los atributos son opcionales porque no es necesaria la información para un tipo de instancia en particular. Por ejemplo, únicamente necesitas información para las compañías que abastecen copias de videos.

35
3.2.2 Normalización [8] Para el experto diseñador de bases de datos, derivar entidades o registros de tipo conceptual de un grupo de datos se puede hacer intuitivamente. Sin embargo, tal intuición no siempre surge espontáneamente en los principiantes, especialmente cuando el diseño es muy complejo. La teoría de la normalización es una ayuda que proporciona un procedimiento riguroso para el diseño de bases de datos. Una base de datos mal diseñada puede funcionar inicialmente pero puede mostrar anomalías en el almacenamiento debidas al agrupamiento indiscriminado de los campos cuando se efectúan en los archivos las operaciones de inserción, actualización o eliminación. La teoría de la normalización ayuda a reconocer las cualidades no deseadas en un archivo y la forma de corregirlas. Con el procedimiento de normalización, un archivo conceptual se representa como una tabla de dos dimensiones llamada relación: La forma más simple para representar datos mediante una tabla. El método basado en la normalización supone que el análisis de sistemas produce una lista de los campos de datos de la aplicación y las relaciones entre ellas para que posteriormente sea el proceso de normalización el que separe los campos que identifican identidades de aquellos que sólo las describen. Una relación no-normalizada es una relación que contiene varias ocurrencias de algunos valores en cualquiera de sus campos. Por otro lado, una relación normalizada sólo permite una ocurrencia de un valor en cada campo. Las relaciones normalizadas se agrupan en cuatro categorías llamadas formas normales FN siendo cada nivel una descomposición más completa de una relación que la del nivel anterior. La meta final del proceso de normalización es la agrupación de todos los atributos (o campos) de una base de datos en relaciones adecuadas para que la base se pueda almacenar con el mínimo de datos redundantes. El propósito de este proceso es quitar las cualidades indeseables de una relación que puedan causar anomalías en el almacenamiento cuando se efectúen operaciones de actualización en la base de datos. El proceso de normalización empieza con la combinación de todos los datos de la base en una relación, la que a su vez se descompone en dos o más relaciones más pequeñas. Se efectúan descomposiciones sucesivas de las relaciones intermedias hasta que todas las relaciones obtenidas pertenecen a la cuarta forma normal (4FN). Antes de describir el proceso de la normalización, se debe descubrir la manera de determinar la forma normal de una relación a partir de su relación de atributos conocida como “dependencia funcional”. 3.2.2.1 Dependencia Funcional El análisis de una relación de dependencia funcional entre los campos de una relación permite clasificar la relación en una de las cuatro formas normales. El concepto de dependencia funcional (DF), se tomó de las matemáticas elementales. Se dice que Y es función de X, Y = f(X), si el valor de Y está siempre determinado por el valor de X. Si se aplica la misma terminología a una relación, la dependencia funcional entre los atributos A y B en una relación se define como sigue: El atributo A es funcionalmente dependiente del atributo B si el valor de A esta determinado por el valor de B. Tal dependencia se simboliza: B ---� A Considere la relación CUSTOMER de la figura 3.1. Consta de tres atributos CUST-NO, CUST-NAME y CUST-CITY. Para un valor dado de CUST-NO, digamos C1, sólo puede haber una ciudad CUST-CITY (OTTAWA). Así, el atributo CUST-CITY es funcionalmente dependiente del atributo CUST-NO. La dependencia funcional de CUST-CITY en CUST-NO se denota por:

36
CUST-NO -� CUST-CITY En otras palabras, CUST-NO determina a CUST-CITY. Se dice que CUST-NO es un determinante de CUST-CITY. El atributo CUST-NAME es funcionalmente dependiente del atributo CUST-NO, porque para un valor dado de CUST-NO puede haber sólo un CUST-NAME. Sin embargo, no se puede decir que CUST-NO es funcionalmente dependiente de CUST-NAME porque más de un CUST-NO se puede asociar con un CUST-NAME si dos o más clientes tienen el mismo nombre.
Relación CUSTOMER
Figura 3.1 Dependencia funcional entre atributos en una relación.
Los atributos CUST-NAME y CUST-CITY son funcionalmente dependientes de CUST-NO, porque sólo puede haber un CUST-NAME y un CUST-CITY para un CUST-NO dado. Los atributos CUST-NAME y CUST-CITY de la relación CUSTOMER son funcionalmente dependientes de su clave principal, CUST-NO. Esta relación se representa por el siguiente diagrama de dependencia funcional: CUST-NAME CUST-NO CUST-CITY Se simplificará el diagrama colocando atributos con el mismo determinante en la misma línea.
CUST-NO � CUST-NAME, CUST-CITY Esta representación más simple es útil cuando el diagrama de dependencia funcional contiene una gran cantidad de atributos. La clave primaria de una relación puede ser una clave compuesta (o concatenada) que consta de más de un campo. Por lo tanto, un atributo puede ser funcionalmente dependiente de un grupo de atributos. Un campo en una clave principal compuesta se llama atributo principal. Cualquier campo que no forme parte de la clave principal se llama no-clave. La figura 3.2

37
ilustra diversos tipos de dependencias funcionales. La relación CUSTOMER-ORDER contiene órdenes de compra del catálogo de clientes de diferentes ciudades. Para este ejemplo se supone: A cada artículo ordenado por un cliente se le incluye el precio de manejo y entrega. Esta cantidad está determinada por la ciudad donde el cliente reside. Un cliente puede hacer varios pedidos distintos en la misma fecha. Sin embargo, las órdenes de la misma pieza hechas por un solo cliente en la misma fecha, se combinan y las cantidades se suman. Entonces, la clave principal de la relación es combinación de INV-NO, CUST-NO y DATE y su contenido representa de manera única a cada registro de la tabla. En la práctica, se genera un número único de orden para cada pedido para que las distintas órdenes de un cliente por el mismo artículo y la misma fecha puedan entrar con distintos números de orden. Sin embargo, por la simplicidad del ejemplo, se supondrá que no se generan números de orden y que la combinación de los atributos principales CUST-NO, INV-NO y DATE identifican de manera única cada registro de la relación CUSTOMER-ORDER de la figura 3.2 a). La figura 3.2 b) muestra dos relaciones equivalentes del diagrama DF para la relación CUSTOMER-ORDER en a). El atributo QTY es funcionalmente dependiente de la clave principal compuesta, CUST-NO, INV-NO y DATE. El término dependencia funcional total se refiere al tipo de dependencia donde un atributo es funcionalmente dependiente de todos los campos de la clave primaria. El atributo QTY es totalmente dependiente de la clave primaria porque el valor QTY está determinado por la combinación de los tres atributos principales de esta clave. Sin embargo, la dependencia funcional de UNIT-PRICE en la clave primaria no es total; depende sólo de un subconjunto de esta clave INV-NO. Análogamente, CUST-NAME, CUST-CITY y UNIT-DELIVERY-FEE no son totalmente dependientes de la clave principal porque dependen solamente de CUST-NO. La figura 3.2 b) muestra además que un atributo no-clave puede ser dependiente de otro atributo no-clave. Por ejemplo, UNIT-DELIVERY-FEE es funcionalmente dependiente de CUST-CITY, que es a su vez no-clave, como lo indica la flecha entre los dos no-clave. El propósito de establecer un diagrama de dependencia funcional para una relación es usar un método gráfico para determinar la forma normal de la relación. En las secciones siguientes, se verán ejemplos de las cuatro formas normales y técnicas para normalizar relaciones que previenen anomalías del almacenamiento causadas por relaciones indeseables entre los atributos. 3.2.2.2 Primera Forma Normal (1FN) Una relación está en la primera forma normal (o 1FN) si todos los campos en cada registro contienen un solo valor tomado de sus dominios respectivos. El dominio de un campo es el rango de valores permitidos para el campo. Por ejemplo, si los valores del campo QTY son enteros positivos entre 1 y 99, el dominio QTY es el conjunto de enteros 1, 2,..., 99. Para ilustrar, la relación de la figura 3.3 no es 1FN porque hay más de un valor contenido en los campos QTY y DATE. Por ejemplo, el campo DATE para la ocurrencia C1 contiene dos valores 6/5 y 10/12 y su campo QTY también contiene varios valores 1 y 2. Por lo tanto, la relación no está normalizada y no es un archivo plano. Una relación donde solo un valor está contenido en cada campo se llama archivo plano.

38
Figura 3.2 Dependencia Funcional entre Atributos. -Derivación y anomalías en relaciones 1FN Una relación sin normalizar se puede normalizar con la creación de un registro nuevo para cada uno de los distintos valores en un campo. Por ejemplo la figura 3.3 muestra una manera típica con sentido común de guardar la información de los clientes en forma tabular y sin datos duplicados. Pero para que una base de datos funcione, se deben crear nuevos registros para que reemplacen los espacios que no contienen algún valor en los campos CUST-NO, CUST-NAME, CUST-CITY, UNIT-DELIVERY-FEE, UNIT-PRICE y INV-NO, con los valores apropiados como muestra la figura 3.2 a). Esta última relación está en primera forma normal porque cada campo en un registro contiene un solo valor. En los párrafos siguientes se verá cómo las operaciones de inserción, eliminación o actualización pueden causar efectos adversos (o anomalías de almacenamiento) en la relación 1FN, y por qué una relación 1FN debe ser objeto de normalizaciones posteriores.
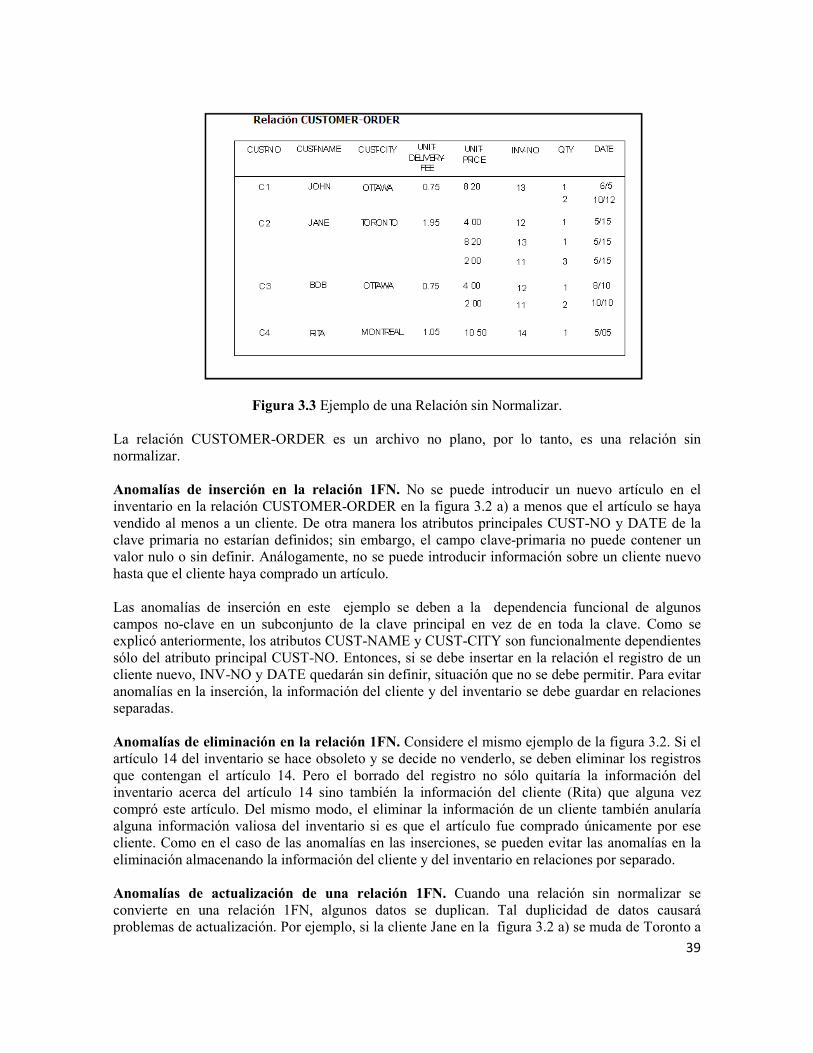
39
Figura 3.3 Ejemplo de una Relación sin Normalizar. La relación CUSTOMER-ORDER es un archivo no plano, por lo tanto, es una relación sin normalizar. Anomalías de inserción en la relación 1FN. No se puede introducir un nuevo artículo en el inventario en la relación CUSTOMER-ORDER en la figura 3.2 a) a menos que el artículo se haya vendido al menos a un cliente. De otra manera los atributos principales CUST-NO y DATE de la clave primaria no estarían definidos; sin embargo, el campo clave-primaria no puede contener un valor nulo o sin definir. Análogamente, no se puede introducir información sobre un cliente nuevo hasta que el cliente haya comprado un artículo. Las anomalías de inserción en este ejemplo se deben a la dependencia funcional de algunos campos no-clave en un subconjunto de la clave principal en vez de en toda la clave. Como se explicó anteriormente, los atributos CUST-NAME y CUST-CITY son funcionalmente dependientes sólo del atributo principal CUST-NO. Entonces, si se debe insertar en la relación el registro de un cliente nuevo, INV-NO y DATE quedarán sin definir, situación que no se debe permitir. Para evitar anomalías en la inserción, la información del cliente y del inventario se debe guardar en relaciones separadas. Anomalías de eliminación en la relación 1FN. Considere el mismo ejemplo de la figura 3.2. Si el artículo 14 del inventario se hace obsoleto y se decide no venderlo, se deben eliminar los registros que contengan el artículo 14. Pero el borrado del registro no sólo quitaría la información del inventario acerca del artículo 14 sino también la información del cliente (Rita) que alguna vez compró este artículo. Del mismo modo, el eliminar la información de un cliente también anularía alguna información valiosa del inventario si es que el artículo fue comprado únicamente por ese cliente. Como en el caso de las anomalías en las inserciones, se pueden evitar las anomalías en la eliminación almacenando la información del cliente y del inventario en relaciones por separado. Anomalías de actualización de una relación 1FN. Cuando una relación sin normalizar se convierte en una relación 1FN, algunos datos se duplican. Tal duplicidad de datos causará problemas de actualización. Por ejemplo, si la cliente Jane en la figura 3.2 a) se muda de Toronto a

40
Ottawa, se tendrá que modificar cada registro que contenga a Jane; de otra manera se registrarán datos inconsistentes. Es evidente que se necesita un método para eliminar las anomalías de almacenamiento separando la relación 1FN en relaciones más pequeñas. -Normalización y verificación de la relación 1FN Como se describió anteriormente, las anomalías de almacenamiento se pueden atribuir a la presencia de uno o más campos no-clave que no son total y funcionalmente dependientes de la clave principal. Afortunadamente, las anomalías de almacenamiento de la relación 1FN se pueden eliminar con el siguiente procedimiento: Quitar de la relación 1FN todos los campos no-clave que no sean totalmente dependientes de la clave primaria. Guardar los campos no-clave que fueron quitados en relaciones nuevas y adecuadas. La figura 3.4 muestra la forma en que se identifican y segregan de la relación 1FN CUSTOMER-ORDER, los campos no-clave que causaban problemas, figura 3.2. Primero, hubo que construir un diagrama de dependencia funcional para la relación CUSTOMER-ORDER y así determinar cuáles campos no-clave no son funcionalmente dependientes de la clave principal. Después se separaron estos campos no-clave en nuevas relaciones apropiadas. El procedimiento de la división de una relación en dos o más relaciones más pequeñas en base a las relaciones de atributos se llama proceso de normalización. Los detalles son: Paso 1 Escoger una clave primaria que pueda representar de manera única cada registro en la relación: CUSTOMER-ORDER (CUST-NO, INV-NO, DATE, CUST-NAME, CUST-CITY, UNIT-DELIVERY-FEE, UNIT-PRICE, QTY) La clave primaria aparece subrayada. Consta de CUST-NO, INV-NO y DATE. Paso 2 Construir un diagrama de dependencia funcional describiendo las relaciones entre los atributos: el diagrama para la relación CUSTOMER-ORDER que se muestra en la figura 3.4 a) indica que sólo QTY es funcionalmente dependiente de una combinación de CUST-NO, INV-NO y DATE. Los atributos CUST-NAME, CUST-CITY y UNIT-DELIVERY-FEE son funcionalmente dependientes de CUST-NO, mientras que UNIT-PRICE es total y funcionalmente dependiente de INV-NO, en vez de serlo de toda la clave principal. Paso 3 Dividir la relación 1FN de tal manera que todos los campos no-clave en cada relación dividida sean total y funcionalmente dependientes de la clave primaria. La relación CUSTOMER-ORDER se descompone en las tres relaciones siguientes. CUSTOMER (CUST-NO, CUST-NAME, CUST-CITY, UNIT-DELIVERY-FEE) INVENTORY (INV-NO, UNIT-PRICE) ORDER (CUST-NO, INV-NO, DATE, QTY) El contenido de las relaciones anteriores aparece en la figura 3.4 b). Pruebas para la eliminación de anomalías en 1FN. Las anomalías de inserción, eliminación y actualización asociadas con la relación 1FN se eliminan después de normalizar la relación 1FN. Como muestra la figura 3.4 b), la información acerca de una nueva pieza en el inventario ahora se

41
puede insertar en la relación INVENTORY. También se puede eliminar información sobre los clientes en la relación CUSTOMER sin necesidad de borrar algún dato del inventario. Por último, sólo se debe actualizar un registro, en vez de toda la relación si es que un cliente se cambia de una ciudad a otra. Una vez que la relación CUSTOMER-ORDER se ha normalizado, el proceso de normalización debe continuar; examinando cada una de las relaciones derivadas (figura 3.4 a)) para buscar otras anomalías. Nuevamente, se construye un diagrama de dependencia funcional para cada relación para determinar a qué forma normal pertenece la relación y decidir si es necesaria una mayor descomposición de las relaciones derivadas. 3.2.2.3 Segunda Forma Normal (2FN). Una relación es ó pertenece a la segunda forma normal si es 1FN y cada atributo no-clave de la relación es total y funcionalmente dependiente de su clave principal. Las relaciones derivadas, figura 3.4, son de la segunda forma normal porque todos sus atributos no-clave ya son total y funcionalmente dependientes de sus claves primarias. De cualquier manera, aun cuando las anomalías de almacenamiento 1FN quedan eliminadas cuando se alcanza la 2FN, pueden surgir otro tipo de anomalías de almacenamiento. -Anomalías de relaciones 2FN. Una relación 2FN puede presentar anomalías de almacenamiento si cualquiera de sus no-claves depende transitivamente de la clave-primaria. Se dice que una no-clave depende transitivamente de la clave primaria si es funcionalmente dependiente de otra no-clave, es decir, depende indirectamente de la clave principal. En la figura 1.4 a), el campo UNIT-DELIVERY-FEE de la relación CUSTOMER es funcionalmente dependiente de CUST-CITY en la misma relación. Sin embargo, CUST-CITY a su vez es dependiente de CUST-NO. Los ejemplos siguientes muestran como esta situación conduce a anomalías de almacenamiento. Anomalías de inserción en la relación 2FN. El precio de entrega UNIT-DELIVERY-FEE para una ciudad en particular no se puede registrar en la relación CUSTOMER hasta que haya al menos un cliente que resida en esa ciudad. De otra manera, la clave principal CUST-NO quedará sin definir. Esta anomalía se debe a la dependencia funcional del atributo no-clave UNIT-DELIVERY-FEE de otro atributo no-clave CUST-CITY en la misma relación. Se pueden evitar tales anomalías si el atributo UNIT-DELIVERY-FEE se registra en otra relación. Anomalías de eliminación en la relación 2FN. Suponga que el cliente Rita cierra su cuenta y se elimina el registro correspondiente de la relación CUSTOMER (figura 3.4). Como Rita es la única cliente de Montreal, la eliminación del registro también causará que se quite la información UNIT-DELIVERY-FEE de $1.50 para la Ciudad de Montreal. Esta anomalía en el borrado se puede atribuir nuevamente a la dependencia funcional del atributo no-clave UNIT-DELIVERY-FEE con respecto a CUST-CITY. Anomalías de actualización en la relación 2FN. En la misma relación 2FN CUSTOMER, figura 3.4 b), John y Bob son de Ottawa. Si se cambia el precio de entrega UNIT-DELIVERY-FEE para Ottawa de $0.75 a $1.00, entonces el precio UNIT-DELIVERY-FEE se debe actualizar dos veces en vez de sólo una.

42
-Normalización y verificación de una relación 2FN. Las anomalías de almacenamiento en una relación 2FN son causadas por la dependencia transitiva de no-claves en su clave primaria. Por tanto, una de las soluciones al problema es eliminar la dependencia transitiva de la relación 2FN almacenando las no-claves que son transitivamente dependientes de la clave primaria en una relación nueva y adecuada. La relación 2FN CUSTOMER, se puede normalizar como muestra la figura 3.5. PASO 1 Examinar cada atributo no-clave de la relación CUSTOMER para determinar si es funcionalmente dependiente de otra no-clave. El diagrama de dependencia funcional mostrado en la figura 3.5 a) indica que el precio UNIT-DELIVERY-FEE es directamente dependiente de CUST-CITY, pero sólo transitivamente dependiente de CUST-NO. PASO 2 Crear una nueva relación para almacenar la no-clave transitivamente dependiente UNIT-DELIVERY-FEE, y su determinante CUST-CITY. La relación 2FN CUSTOMER se divide en dos relaciones, DELIVERY-FEE y CUST. El atributo CUST-CITY debe aparecer en ambas relaciones para que sirva como campo de conexión para ligar las relaciones DELIVERY-FEE y CUST. De la figura 3.5 b) se puede determinar que el precio UNIT-DELIVERY-FEE para el cliente, digamos JOHN, es $0.75 al asociar el valor OTTAWA del campo CUST-CITY, que es común a ambas relaciones. Pruebas para la eliminación de las anomalías 2FN. Una vez que desaparece la dependencia transitiva de una relación se eliminarán las anomalías de la relación 2FN. Se examinarán ahora las dos relaciones derivadas, en la figura 3.5. Se puede introducir el precio UNIT-DELIVERY-FEE para una ciudad aun cuando no haya ningún cliente en la misma. Cuando un cliente desaparece, se puede borrar el registro del cliente sin necesidad de borrar el precio de entrega para la ciudad donde el cliente vive, aún si la persona es el único cliente de esa ciudad. Como el precio UNIT-DELIVERY-FEE, para cualquier ciudad se almacena sólo una vez, se evita el riesgo de inconsistencia en los datos como resultado de una actualización incompleta de los datos redundantes. Hasta ahora se ha visto la manera de eliminar anomalías de almacenamiento de relaciones 1FN y 2FN por medio de la normalización, la relación se divide para remover cierto tipo de dependencias funcionales. Si alguna de las nuevas relaciones derivadas contiene alguna relación indeseable entre sus atributos, continúan las separaciones posteriores hasta que no existan relaciones indeseables en ninguna de las relaciones derivadas. La figura 3.6 resume los pasos del procedimiento de normalización de la relación CUSTOMER-ORDER, figura 3.2. El primer paso involucra una descomposición de la relación 1FN CUSTOMER-ORDER para eliminar aquellas no-claves que no son total y funcionalmente dependientes de la clave primaria. Se derivan tres relaciones: ORDER, INVENTORY y CUSTOMER. En el segundo paso, la relación intermedia 2FN CUSTOMER se divide aún más para quitar la dependencia transitiva; se obtienen las relaciones CUST y DELIVERY-FEE. Las relaciones ORDER e INVENTORY obtenidas del paso uno no contienen dependencias transitivas, y por eso, no se les hace ningún cambio. Como resultado se derivan cuatro relaciones: ORDER, INVENTORY, CUST y DELIVERY-FEE.

43
Figura 3.4 Normalización de una Relación 1FN.
3.2.2.4 Tercera Forma Normal (3FN) Una relación es 3FN, si es 2FN y ningún atributo no-clave en la relación es funcionalmente dependiente de algún otro atributo no-clave. La relación CUSTOMER de la figura 3.4 a) no es 3FN porque UNIT-DELIVERY-FEE es funcionalmente dependiente de un atributo no-clave CUST-CITY. Las cuatro relaciones derivadas (figura 3.6 ORDER, INVENTORY, CUST, DELIVERY-FEE) son 3FN. En la mayoría de los casos el proceso de normalización queda completo cuando todas las relaciones derivadas son 3FN.

44
Codd dio la definición original de 3FN en 1972. Se le corrigió posteriormente y la definición revisada 3FN se conoce como la forma normal Boyce/Codd (BFCN), una relación es BFCN si cada determinante en la relación es una clave aspirante. Como se mencionó anteriormente, si existe algún atributo que resulte ser total y funcionalmente dependiente de otro, se le llama determinante. Una clave aspirante (candidate key) es un atributo o un grupo de atributos cuyo contenido puede representar de manera única a cada registro de una relación. Cuando en una relación hay más de una clave aspirante, una de las claves aspirantes se designa como la clave primaria. En la mayoría de los casos, cuando una relación es 3FN también es BFCN. Por ejemplo, las cuatro relaciones derivadas (ORDER, INVENTORY, CUST y DELIVERY-FEE) de la figura 3.6, son 3FN y también BFCN. Considere la relación CUST. Esta relación es 3FN porque ninguna no-clave depende transitivamente de otra clave. También es BFCN ya que cada determinante es clave aspirante. (De hecho hay un solo determinante CUST-NO, que también es clave aspirante). Sin embargo, la definición BFCN es más restrictiva que la 3FN. En otras palabras, cuando una relación es 3FN, no es necesariamente BFCN. La situación ocurre cuando dos claves aspirantes sobrepuestas están contenidas en una relación. Se considerará la relación PROJ-PC-PROG de la figura 3.7. La relación contiene dos claves aspirantes sobrepuestas (PROJECT-NO, PC) y (PROJECT-NO, PROGRAMMER), de acuerdo con las siguientes reglas semánticas: Para cada proyecto, una PC dada es usada por sólo un programador, aun cuando el programador trabaje en más de un proyecto. Un proyecto puede usar distintos tipos de PC. Un programador se especializa sólo en un tipo de PC, pero una PC se puede compartir entre distintos programadores para distintos proyectos. Si se designa una de las claves aspirantes, digamos PROJECT-NO, PC, como la clave principal, el diagrama de dependencia funcional de la figura 3.7 a) resume las reglas semánticas anteriores. El diagrama muestra un tipo especial de dependencia cuando el atributo principal PC es dependiente de la no-clave PROGRAMMER. La relación PROJ-PC-PROG es 3FN porque ninguna no-clave es transitivamente dependiente de otras no-claves y la no-clave es totalmente dependiente de la clave primaria. Sin embargo, la relación no es BCFN ya que PROGRAMMER, que no es clave aspirante, es un determinante de PC. Como resultado, la relación sufre de ciertas anomalías de almacenamiento. Por ejemplo, si se contrata un nuevo programador para trabajar con la APPLE, no es posible insertar el registro en la relación PROJ-PC-PROG, figura 3.7 b), hasta que se dé un proyecto al programador. La dificultad aquí es que el atributo principal PROJECT-NO no puede quedar sin definir. Otro ejemplo de anomalía de almacenamiento sucede cuando se desea eliminar la información sobre el proyecto P15. Tal operación también quitaría la información que Don es especialista de ATARI porque P15 es el único proyecto en que trabaja Don.

45
Figura 3.5 Normalización de una Relación 2FN.
La relación 1FN CUSTOMER-ORDER, mediante el proceso de normalización, se convierte en cuatro relaciones 3FN: ORDER, INVENTORY, CUST y DELIVERY-FEE. Las anomalías 3FN suceden cuando hay dos claves sobrepuestas y cuando uno de los atributos principales depende funcionalmente de una no-clave. El problema puede superarse proyectando la relación en dos relaciones BFCN, como se muestra en la figura 3.7 a). La parte b) muestra el contenido de las relaciones en a), donde puede comprobarse si las relaciones derivadas BFCN (PROG-PC y PROJ-PROG) eliminan las anomalías de almacenamiento de la relación 3FN, PROJ-PC-PROG. Del ejemplo anterior se puede ver que la definición de 3FN no es una guía suficiente para la normalización cuando una relación contiene un atributo principal dependiente de una no-clave. Sin embargo, la definición de 3FN es adecuada para la mayoría de los casos. En los ejemplos siguientes una relación 3FN revisada (por ejemplo, BCFN) queda implícita cuando una relación queda clasificada como 3FN.

-Anomalías debidas a la dependencia de valores múltiples. Generalmente, un proceso de normalización termina cuando todas las relaciones derivadpertenecen a la tercera forma normal. Sin embargo, si una relación contiene dependencias de valores múltiples, es necesaria una normalización posterior. Dada una relación, el atributo A de esta relación se dice ser dependiente de multivalores (DMV) del un rango específico de valores del atributo A está determinado por un valor particular.
Figura 3.6
Anomalías debidas a la dependencia de valores múltiples.
Generalmente, un proceso de normalización termina cuando todas las relaciones derivadpertenecen a la tercera forma normal. Sin embargo, si una relación contiene dependencias de valores múltiples, es necesaria una normalización posterior. Dada una relación, el atributo A de esta relación se dice ser dependiente de multivalores (DMV) del un rango específico de valores del atributo A está determinado por un valor particular.
Figura 3.6 Pasos del Proceso de Normalización.
46
Generalmente, un proceso de normalización termina cuando todas las relaciones derivadas pertenecen a la tercera forma normal. Sin embargo, si una relación contiene dependencias de valores múltiples, es necesaria una normalización posterior. Dada una relación, el atributo A de esta relación se dice ser dependiente de multivalores (DMV) del atributo B si un rango específico de valores del atributo A está determinado por un valor particular.

47
Figura 3.7 Relaciones BCFN Obtenidas de una Relación 3FN.

48
Figura 3.8 Dependencia multivalor. Se dispone de cada artículo del inventario en distintos colores y tallas. La clave principal de la relación anterior es INV-NO, COLOR y SIZE. La dependencia multivalores es un caso especial de la dependencia funcional. La DMV de A en B se expresa: B � A La flecha doble indica que B define valores múltiples en A. Considérese la relación INVENTORY de la figura 3.8 b). Para cada artículo del inventario hay una selección de distintos colores y tallas. Los atributos COLOR y SIZE (talla) son dependientes multivalores de INV-NO. En otras palabras cualquier valor de INV-NO determina un rango de valores en los campos SIZE y COLOR. El precio unitario UNIT-PRICE es total y funcionalmente dependiente de INV-NO, para artículos con el mismo número INV-NO, el precio unitario permanece constante sin importar el color o la talla. Si el precio variara para ciertas tallas, se deberían de asignar distintos números de inventario. Por ejemplo, los zapatos tallas uno a cuatro pueden tener el mismo precio bajo un solo número INV-NO, mientras que los zapatos tallas cinco a ocho pueden tener un precio distinto y estar clasificados bajo otro número INV-NO.

49
La clave principal para la relación INVENTORY en la figura 3.8 a) consta de INV-NO, COLOR y SIZE. El atributo INV-NO no puede identificar de manera única a cada registro, porque bajo un número dado de INV-NO existen diversos artículos con diferentes colores y tallas. Por lo tanto, los atributos dependientes multivalores COLOR y SIZE deben pertenecer a la clave principal. El problema evidente con la dependencia multivalores es la redundancia de datos. Como muestra la figura 3.8 b), el artículo del inventario 11 se repite ocho veces ya que viene en cuatro tallas y dos colores. Esta redundancia se agrava cuando la mayoría de las piezas están disponibles en varias tallas y colores. Tratamiento de la dependencia de valores múltiples La redundancia de los datos causada por la dependencia multivalores se puede eliminar siguiendo uno de los dos siguientes métodos. Crear una nueva relación para cada atributo DMV. Reemplazar un atributo DMV con atributos funcionalmente dependientes (DF). Cada método se ilustra con un ejemplo: i) Creación de una relación para cada atributo DMV. Cuando el número de valores repetidos en un DMV es muy grande, se puede crear una nueva relación para el atributo DMV y su clave principal. Considerando el ejemplo de la figura 3.9, si suponemos que el número de tallas para un artículo del inventario es muy grande o indefinido (esto es pueden agregarse tallas nuevas en el futuro), entonces se puede crear una nueva relación SIZE, como se muestra en la figura 3.9 b). La relación contiene todas las tallas disponibles para cada INV-NO. ii) Reemplazando un atributo DMV con varios atributos DF. Si la cantidad de valores distintos en un atributo DMV es un número específico y pequeño, entonces cada uno de los valores del atributo DMV se puede representar por un atributo dentro del mismo registro. Por ejemplo, si la cantidad de colores para cualquier INV-NO dado no excede de tres, el atributo COLOR se puede representar por COLOR1, COLOR2, COLOR3 como se muestra en la figura 3.9 b). Cuando un artículo del inventario está disponible sólo en dos colores, se le puede asignar a COLOR3 un valor nulo o indefinido. La diferencia básica entre los dos tratamientos está en la manera en que se almacenan los distintos valores para un atributo DMV. Con el primer método se crea una nueva relación para un atributo DMV, y los distintos valores que ocurren en un campo DMV se agregan verticalmente –como registros- a la nueva relación. En el segundo método, los distintos valores ocurrentes se agregan horizontalmente en un número fijo de campos, por ejemplo, el atributo multivalor COLOR se representa por medio de tres campos. La limitante de este método es que no se reserva espacio para un número indefinido de colores. Por otro lado, el primer método permite la futura expansión de nuevos valores insertándolos como nuevos registros. El precio de conseguir flexibilidad para acomodar nuevos valores del atributo se pagó con la creación de una nueva relación y el almacenamiento redundante del campo de conexión, por ejemplo INV-NO en la relación SIZE.

50
3.2.2.5 Cuarta Forma Normal (4FN) Una relación esa 4FN (cuarta forma normal) si es BFCN y no contiene dependencias multivalores. Una manera de entender una DMV no trivial consiste en explicar primero qué es una DMV trivial. Sea R una relación con campos A, B, C. La relación se llama trivial si una combinación de valores A y B determina los valores de C. La DMV se expresa: (A,B) -�-� C En otras palabras, una combinación de A y B multidetermina a C. Usando la misma relación R(A,B,C), ocurre una dependencia multivalor de A, y C también es dependiente multivalor de A:
Así, una relación debe contener una clave compuesta que consiste al menos en tres campos subclave antes que pueda ocurrir una DMV no trivial. Por tanto, una relación 3FN con clave primaria con menos de tres atributos principales es automáticamente 4FN. Una dependencia multivalor no trivial también es llamada dependencia unión-binaria no trivial. Considere nuevamente la relación INVENTORY, figura 3.8. Esa relación es 4FN, porque tiene una dependencia multivalor no trivial (o DMV unión-binaria no trivial).
Como se muestra ahí, el problema evidente con DMV no triviales es la excesiva duplicidad de datos. La figura 3.10 a) muestra esquemáticamente la forma de eliminar los DMV no triviales: La relación R se descompone en R1(A,B) y R2(A,C). La figura 3.10 b) regresa al ejemplo concreto de eliminar una relación MVD no trivial de la relación INVENTORY. Cada uno de los dos atributos MVD se separa para crear las nuevas relaciones COLOR y SIZE. El resultado del proceso de normalización obtenido de este ejemplo difiere de la figura 3.8 porque se supuso que el atributo DMV COLOR en este ejemplo también contiene una cantidad ilimitada de valores anidados que se repiten. Por lo tanto, en este ejemplo se creó una nueva relación COLOR en vez de usar COLOR1, COLOR2 y COLOR3 para reemplazar el atributo DMV COLOR. Se puede ver del ejemplo en la figura 3.10 que el tratamiento de una DMV no trivial es equivalente al tratamiento de dos DMV individuales.
A
B
C
INV-NO
COLOR
SIZE

51
Figura 3.9 Tratamiento de los Atributos Dependientes Multivalores. En circunstancias normales no se requiere más normalización después de 3FN, porque ya se han tomado en cuenta los atributos DMV durante la etapa inicial de la normalización para derivar un archivo plano 1FN. La figura 3.11 resume las etapas del proceso de normalización. La normalización es una técnica que puede ser aplicada a partir de diferentes momentos, durante la recopilación de requerimientos, modelado o diseño de la base de datos. Puedes usar esta técnica para verificar la calidad de tu modelo Entidad-Relación después de haber sido creado. Otras metodologías usan la normalización para crear un modelo inicialmente. La técnica de normalización te permite crear un conjunto completo de datos relevantes de la semántica contextual y luego usar un conjunto de reglas para eliminar la redundancia, aplicando las formas normales ya descritas. Cuando se aplica esta técnica es fácil dejarse llevar por la mecánica del mismo y olvidar el propósito, podríamos decir que el objetivo general es una comprensión completa y precisa de las necesidades de datos que soportan la funcionalidad del problema a resolver, digamos que uno de los más grandes beneficios de la Normalización es a través del conocimiento de las necesidades reales,

52
es esencial entender los datos cuando se empiezan a normalizar [7] y establecer entonces la solución estructural que tendrá la Base de Datos aplicando las formas normales.
Figura 3.10 Derivación de relaciones 4FN eliminando
Dependencias multivalores no triviales.

53
Veamos el proceso de normalización en otro ejemplo [7]: No. Emp Nombre
Emp No. dep
Nombre Dep
No ger Nombre Ger
No Proy
Nombre Proy
Fecha Inicial
Horas Facturadas
100200 Alberto 100 Rec.Hum. 100201 Jorge 15 Embarques Ago 2010
100
35 Pruebas Oct 2011
100
45 Análisis Oct 2011
150
100201 Jorge 201 Refacciones 100209 Laura 15 Embarques Ago 2011
200
25 Factibilidad Ago 2010
250
45 Análisis Oct 2011
200
100203 Alberto 302 Rec.Hum. 100402 Arturo 25 Factibilidad May 2012
150
Figura 3.12 Relación no normalizada.
Primero deberemos estudiar el comportamiento de los datos y luego se identifica el conjunto de dependencias funcionales que representan la semántica de la tabla de la figura 3.12, identificamos campos llave con ‘#’ #No.Emp,NombreEmp, No.dep, NombreDep,NoGer, NombreGer, No Proy, NombreProy, FechaInicial, Horasfacturadas Aplicando 1FN la relación se separa en dos nuevas relaciones: #No.Emp, NombreEmp, No.dep, NombreDep, NoGer, NombreGer #No.Emp (FK), No Proy, NombreProy, FechaInicial, Horasfacturadas Aplicando 2FN obtenemos: #No.Emp, NombreEmp, No.dep, NombreDep, NoGer, NombreGer #No.Emp FK),, No Proy (FK), FechaInicial, Horasfacturadas # No Proy, NombreProy Aplicando 3FN obtenemos: #No.Emp, NombreEmp, No.dep FK), NoGer (FK) #No.dep, NombreDep,

54
#NoGer, NombreGer #No.Emp FK), No Proy FK), FechaInicial, Horasfacturadas # No Proy, NombreProy Optimizamos nuestro diseño: #No.Emp, NombreEmp, No.dep FK), NoGer FK) #No.dep, NombreDep, #No.Emp (FK), No Proy(FK), FechaInicial, Horasfacturadas # No Proy, NombreProy
Figura 3.11 Niveles de Normalización. 3.3 Actividades de Aprendizaje A1) El alumno realizará ejercicios de abstracción durante la ingeniería de requerimientos. A2) Realización de ejercicios prácticos, el alumno deberá obtener diagramas E-R normalizados. A3) El alumno realizará diagramas E-R a partir de reglas de negocio planteadas. A4) El alumno obtendrá las reglas de negocio a partir de un diagrama E-R. A5) El alumno obtendrá diagramas E-R a partir de diseño lógico (no normalizado) para normalizarlas. A6) El alumno identificará dependencias funcionales a partir de su análisis de requerimientos. A7) Establecerá nuevas formas de diseñar una Base de Datos, a través de las distintas fases de desarrollo de las Bases de Datos. A8) El alumno desarrollará e implementará software, a partir de su diseño de base de datos normalizado.

55
3.4 Actividades de Evaluación de Adquisición del Conocimiento E1)Ejemplo de reactivos. El alumno deberá ser capaz de resolver situaciones reales, mediante la aplicación de ejercicios prácticos. Desarrolle dos diagramas E-R para representar la siguiente situación. Desarrolle uno como estructura jerárquica y uno como estructura recursiva [7]. “Nuestra compañía vende productos en el país. Así que tenemos dividido en cuatro grandes regiones : Norte , Sur, Este y Oeste. Cada región de venta tiene un código de región único. Cada región de venta está dividida en distritos de venta. Cada distrito tiene un código de distrito único. Cada distrito está formado de territorios de venta. Cada territorio tiene un código de territorio único. Entonces los territorios de venta están divididos en áreas de ventas. Cada área de venta tiene un código de área de venta único. Tenemos un número de agentes de ventas que son responsables de una o más áreas de venta y cada uno tiene una cuota de venta específica. También tenemos gerentes de ventas que son responsables de uno o más distritos de ventas. Los directores de ventas son responsables de una o mas regiones de ventas. Cada gerente de ventas es responsable de los territorios dentro de su distrito. No traslapamos las responsabilidades de nuestros empleados. Un área de venta es siempre responsabilidad de un solo personal de venta y las responsabilidades de nuestros gerentes y directores no se traslapan. Algunas veces nuestro personal de venta, gerentes y directores dejarán el puesto o tendrán un asignamiento especial y no tendrán responsabilidades de ventas. Identificamos todo nuestro personal de ventas por un ID”. 3.5 Referencias del Capítulo 3 [1] Zavala R. 2000. Diseño de un Sistema de Información Geográfica sobre internet. Tesis de Maestría en Ciencias de la Computación. Universidad Autónoma Metropolitana-Azcapotzalco. México, D.F. En prensa. [2] Lara Martínez zuleyka. Base de Datos Multimedia de Daños en inmuebles de la Zona Monumental de la Cd. De Puebla por el sismo del 15 de junio de 1999. [3] Greiff W. R. Paradigma vs Metodología; El Caso de la POO (Parte II). Soluciones Avanzadas. Ene-Feb 1994. pp. 31-39. [4] Lewis G. 1994. "What is Software Engineering?" DataPro (4015). Feb 1994. pp. 1-10. [5] Código de Etica del Ingeniero en Software y de la Práctica Profesional en el site de la Association for Computing Machinery http://www.acm.org/serving/ethics.html. [6] Abraham Silbershatz, Henry F. Korth y S. Sudarshan. “Fundamentos de Bases de Datos”. Tercera Edición, Editorial Mc Graw Hill, 1999. [7] Annette Scott. “Oracle Data Modeling and Relational Database Design”, Student Guide. Edición 1.0. [8] Referencias: Date, C.J., An Introduction to Database Systems, Vol. 1. Addison-Wesley, 1981. Hawryszkiewycz, I.T., Database Analysis and Design, SRA Inc., 1984. Kroenke, D.M., Database Processing: Fundamentals, Design, Implementation. SRA Inc., 1983. “Diseño e implantación de Bases de Datos”, Capitulo 10. Diseño de bases de datos: formas normales de relaciones. [9] María Mercedes Marqués Andrés 2001-02-12 http://www3.uji.es/~mmarques/f47/apun/node87.html [10] Data Modeling and Relational Database Design-Student Guide1.0 Oracle Corporation 1992,1996 Annete Scout, Don Griffin, Carol Brown, Shena Deuchars

56
Capítulo 4
El Modelo Relacional:
El Componente Estructural.
María del Rocío Boone Rojas
Etelvina Archundia Sierra Marco Antonio Soriano Ulloa
En el presente capítulo, se proporciona una introducción al modelo relacional y a los sistemas relacionales, se incluyen sus antecedentes, su estructura y se describe su componente estructural: La relación y los conceptos de dominio, propiedades de las relaciones y los tipos de relaciones. Así mismo, se proponen algunas actividades de aprendizaje y de evaluación del conocimiento.
4.1 Objetivo Educativo.
Que el alumno conozca los antecedentes del modelo relacional e identifique y aplique los términos y conceptos de su componente estructural.

57
4.2 Contenido Informativo.
Contenido:
3.2.1 Antecedentes del Modelo y los Sistemas Relacionales. 3.2.2 Los conceptos de Dominio y Relación. 3.2.3 Propiedades de las Relaciones. 3.2.4 Tipos de Relaciones.
4.2.1Antecedentes del Modelo y los Sistemas Relacionales.
Fig. 3.1 Edgar F.Cood 1923 – 2003
- Hasta fines del decenio de 1970, las B.D. se basaban en estructuras de datos inflexibles, difíciles de navegar. No permitían la independencia de datos.
- En 1970, Edgar T. Codd, de IBM, publica [1], lo cual cambia todo lo anterior.
- IBM genera el primer prototipo de una b.d. relacional, System R, lo cual llevó en su momento a la creación de SQL y de DB2. Paralelamente en 1979, surge la primera versión de Oracle de L. Ellison.
- El "modelo relacional" constituye en si mismo el avance más importante en toda la historia del campo de la bases de datos.
- El enfoque relacional representa la tendencia dominante en el mercado actual.
-Modelo basado en la lógica de predicados y la teoría de conjuntos.
El modelo relacional se ocupa de tres aspectos de los datos:

58
� Su Estructura, El Componente Estructural. � Su Integridad, El Componente de Integridad. � Su Manipulación, El Componente de Manipulación.
Los Sistemas Relacionales.
En la práctica, el modelo relacional se implementa por medio de los DBMS relacionales.
Se puede establecer que un sistema relacional es aquel en el cual:
- El usuario percibe los datos en forma de tablas (y sólo como tablas), y
- los operadores al alcance del usuario (por ejemplo, para recuperación de datos) generan tablas nuevas a partir de las existentes. Así, existirá un operador para extraer un subconjunto de las filas de una tabla determinada, y otro para extraer un subconjunto de las columnas (que pueden considerarse a su vez como tablas ellas mismas).
Ejemplo. De [3] La Base de datos de proveedores y partes.
S SP
S# SNOMBRE SITUACIÓN CIUDAD S# P# CANT S1 Salazar 20 Londres S1 P1 300 S2 Jaimes 10 París S1 P2 200 S3 Bernal 30 París S1 P3 400 S4 Corona 20 Londres S1 P4 200 S5 Aldana 30 Atenas S1 P5 100 S1 P6 100 P S2 P1 300 S2 P2 400 P# PNOMBRE COLOR PESO CIUDAD S3 P3 200 P1 Tuerca Rojo 12 Londres S4 P2 200 P2 Perno Verde 17 París S4 P4 300 P3 Birlo Azul 17 Roma S4 P5 400 P4 Birlo Rojo 14 Londres P5 Leva Azul 12 París P6 Engrane Rojo 19 Londres
La base de datos se compone de tres tablas, cuyos nombres son S, P y SP.
La tabla S representa proveedores. Cada uno tiene un número de proveedor (S#) único; un nombre de proveedor (SNOMBRE); un valor de calificación o situación (SITUACION); y una localidad (CIUDAD).

59
La tabla P representa tipos de parte. Cada tipo de parte tiene un número de parte (P#), el cual es único; un nombre de parte (PNOMBRE); un color (COLOR); un peso (PESO); y una localidad donde se almacenan partes de ese tipo (CIUDAD).
La tabla SP representa envíos. Sirve en cierto sentido para enlazar entre sí las otras dos tablas.
Cada envío tiene un número de proveedor (S#), un número de parte (P#), y una cantidad (CANT).
En este caso.
-Las tablas proveedores y partes se pueden considerar como entidades y un envío se puede considerar como una interrelación ("relación"). En el modelo relacional las entidades y las interrelaciones se representan de la misma manera, esto es, mediante tablas.
-El término de "llave primaria", se le considera como un identificador único para los registros de una tabla. En el ejemplo son: S# en S, P# en P y el campo compuesto (S#,P#) para la tabla SP.
-En los sistemas relacionales los valores de los datos en las tablas son atómicos. Es decir, en cada intersección de fila y columna de cada tabla hay siempre un solo valor, nunca un conjunto de valores.
-Todo el contenido de información en la b.d. se representa como valores explícitos de los datos. En particular las interrelaciones entre tablas se representa mediante valores explícitos de datos, por ejemplo, la interrelación entre la fila S1 de la tabla S y la fila P1 de la tabla P, se representa mediante la existencia de una fila en la tabla SP en la cual el valor de S# es S1 y el valor de P# es P1.
4.2.2 Los Conceptos de Dominio y Relación.
Dominios.
Se supone que el valor de un dato individual es la menor unidad semántica de información en una b.d., el cual es llamado un escalar. Los valores escalares representan la menor unidad semántica de información en el sentido de que son atómicos; no poseen estructura interna (es decir no se pueden descomponer desde el punto de vista del modelo).
Se define un DOMINIO como un conjunto de valores de escalares, todos del mismo tipo.
Los dominios son los fondos de valores, de los cuales se extraen los valores reales que aparecen en los atributos.
Los dominios de valores escalares también son llamados dominios simples.
Se consideran dominios compuestos a aquellos que son combinación de dominios simples. Por ejemplo, considere un tipo llamado "fecha":
Mes/Dia/Año

60
Que se define sobre el producto cartesiano de los dominios:
Mes --- Ene... Dic Dia --- 1 ... 31 Año --- 0 ... 109999
Tabla. 3.1 Terminologia de la Estructura de Datos Relacional
Término Relacional Formal Relación tupla cardinalidad atributo grado llave primaria dominio
Equivalentes Informales tabla fila o registro número de filas columna o campo número de columnas identificador único fondos de valores permitidos.
Los atributos a su vez son simples o compuestos dependiendo de la naturaleza del dominio sobre el cual se definen.
La importancia fundamental de los dominios es que los dominios restringen las comparaciones.
Por ejemplo, considere las sigs. consultaas que involucran comparaciones.
SELECT P.*, SP.* SELECT P.*, SP.* FROM P, SP FROM P, SP WHERE P.P# = SP.P# WHERE P.PESO = SP.CANT;
Un dominio se puede identificar con el término de tipo de datos, tal y como se entiende en los lenguajes de programación.
Relaciones.
Una RELACION (digamos R) sobre un conjunto de dominios D1, D2, ... Dn (no necesariamente todos distintos), se compone de dos partes, una cabecera y un cuerpo.
La Cabecera está formada por un conjunto fijo de atributos, o, en términos más precisos, de pares atributo-dominio, {(A1:D1),(A2:D2),...,(An:Dn)} tales que cada atributo Aj corresponde a uno y sólo uno de los dominios subyacentes Dj (j = 1,2,...,n).
El Cuerpo está formado por un conjunto de tuplas, el cual varía con el tiempo. Cada tupla a su vez está formada por un conjunto de pares atributo-valor {(A1:vi1),(A2:vi2),...,(An:vin)} (i = 1,2, ..., m, donde m es el número de tuplas del conjunto). En cada una de estas tuplas hay uno de estos pares atributo-valor (Aj:vij) para cada atributo Aj de la cabecera. Para cada par atributo-valor (Aj:vij), vij es un valor del dominio único Dj asociado al atributo Aj.

61
Los valores m y n se llaman Cardinalidad y Grado , respectivamente, de la relación R. La cardinalidad varía con el tiempo, pero el grado no.
El número de atributos en una relación o en forma equivalente el número de dominios subyacentes se le llama grado. Una relación de grado uno se llama Unaria; una relación de grado dos, binaria; una relación de grado tres, ternaria; ..., y una relación de grado n, n-aria. En la b.d. de proveedores y partes, los grados de las relaciones S, P y SP son 4,5 y 3 respectivamente.
El número de tuplas en una relación se le llama cardinalidad. En el ejemplo de la b.d. de proveedores y partes, las cardinalidades de las relaciones S, P y SP son 5, 6 y 12 respectivamente.
Fig. 3.2 Ejemplo de una Relación.
4.2.3 Propiedades de las Relaciones.
Las relaciones poseen cuatro propiedades importantes:
1. No existen tuplas duplicadas.
Ya que el cuerpo de una relación es un conjunto, los cuales por definición no tienen elementos duplicados.
*Corolario: Siempre existe una llave primaria.
2. Las tuplas no están ordenadas (de arriba hacia abajo).

62
Ya que el cuerpo de una relación es un conjunto. Los conjuntos no tienen orden.
3. Los atributos no están ordenados (de izquierda a derecha).
La cabecera de una relación se define como un conjunto ( es decir, un conjunto de atributos o, dicho en forma más precisa, de pares atributo-dominio). Como se mencionó en el caso anterior, los conjuntos no tienen orden.
4. Todos los valores de los atributos simples son atómicos.
Todos los dominios subyacentes son a su vez simples; es decir, contienen sólo valores atómicos.
Esta propiedad se puede expresar de una forma muy informal como: en cada posición de fila y columna dentro de una tabla, siempre existe un solo valor, nunca una lista de valores.
Si una relación satisface esta condición, se dice que está Normalizada.
Lo anterior implica que todas las relaciones están normalizadas, en lo concerniente al modelo relacional.
Se le llama normalización al proceso de llevar una relación que no está normalizada a una relación normalizada.
"Una base de datos relacional es una base de datos percibida por el usuario como una colección de relaciones normalizadas de diversos grados que varía con el tiempo."
Una relación puede percibirse como un archivo pero con las siguientes restricciones:
- Cada "archivo" contiene sólo un tipo de registros.
- Los campos no tienen un orden específico, de izquierda a derecha.
- Los registros no tienen un orden específico, de arriba hacia abajo.
- Cada campo tiene un solo valor.
- Los registros poseen un campo identificador único (o combinación de campos) llamado llave primaria.
4.2.4 Tipos de Relaciones.
-Instantáneas, Vistas, Temporales.
4.3 Actividades de Aprendizaje.
A1)Considere la B.D. de su proyecto de curso. Seleccione tres tablas / relaciones. Identifique o en su caso establezca:
A1.1)Encabezado y cuerpo de cada relación.

63
A1.2)Grado y cardinalidad de cada relación.
A1.3)Tres tuplas de cada relación.
A1.4)Para cada relación, un dominio adecuado para cada uno de los atributos.
A1.5)Llave primaria de cada relación.
A1.6)Interrelaciones/vínculos existentes.
A2)Proporcione un análisis e interpretación de cada una de las propiedades de las relaciones.
A3)Proponga tres vistas de las relaciones de su B.D. que puedan ser de interés para el usuario final. Justifique sus propuestas.
A4)Desarrolla la Práctica 3 del “Manual de Prácticas de Laboratorio” del curso. (Crear la B.D. experimental de curso, mediante un DBMS relacional).
4.4 Actividades de Evaluación de Adquisición del Conocimiento.
E1)Ejemplo de reactivos.
R1) La propiedad “No existen tuplas duplicadas”, implica la existencia de:
a)relaciones b)llaves primarias c)llaves ajenas d)dominios
R2)No es un concepto asociado con las propiedades de las relaciones.
a)conjunto b)dominio compuesto c)valores atómicos d)normalización
R3)En los sistemas relacionales las relaciones se representan mediante.
a)apuntadores b)transacciones c)valores explícitos d)registros
R4)No es un concepto de la estructura de datos relacional.
a)dominio b)select c)grado d)cardinalidad
R5)En el cuerpo de una relación, las tuplas no están ordenadas, por.
a)su integridad b)su dominio c)ser un conjunto d)la normalización
R6)Considera la siguiente relación, de la B.D. Películas_Artistas:
Película(ClaveP,Título,Año,Duración,TipoP,Compañía,EstrellaPrincipal)
Proponga datos para seis tuplas.

64
ClaveP Título Año Duración TipoP Compañia EstrellaPrin
Identifica o en su caso establece:
Grado: ______
Cardinalidad: ______
Llave primaria. _________
Dominio para cada atributo:
ClaveP: _________________________________________________
Título: _________________________________________________
Año: _________________________________________________
Duración: _________________________________________________
TipoP: _________________________________________________
Compañía: _________________________________________________
EstrellaPrincipal: __________________________________________
E2)Evaluar desarrollo y documentación de la Práctica 3, del “Manual de Prácticas de Laboratorio del curso de B.D.”
4.5 Referencias del Capítulo 4.
[1]Codd E.F. A Relational Model of Data for Large Shared Database. Communications of the ACM. 377-387, 1970. [2] Coronel C., Steven Morris & Peter Rob. Bases de Datos, Diseño, Implementación y Administración. Cengage Learning Editores, S.A., Mex. D.F. 2011. [3] Elmasri R. & S. Navathe. Fundamentos de Sistemas de Bases de Datos. Pearson Educación S.A. Madrid, 2007. [4] Date, C.J. Introducción a los Sistemas de Bases de Datos, Addison-Wesley. [5] Ullman, J.D. Principles of Database and Knowledge Base System (vol.1), Computer Science Press, 1988.

65
Capítulo 5
El Modelo Relacional:
El Componente de Integridad.
María del Rocío Boone Rojas Joaquín Pérez Ortega
María del Carmen Cerón Garnica
En el presente capítulo, se describe el componente de integridad del modelo relacional. Se incluye el concepto de integridad y su tratamiento a nivel del DBMS y a nivel de la aplicación. Se establecen los conceptos de llaves primarias y de llaves ajenas, las correspondientes reglas de integridad de entidad y referencial. Así mismo, se proponen algunas actividades de aprendizaje y de evaluación del conocimiento.
5.1 Objetivo Educativo
Que el alumno identifique los conceptos de integridad, llave primaria, llave ajena, las reglas de integridad del modelo relacional y sea capaz de tratar la integridad de una base de datos a nivel de declaración en el DBMS y a nivel de la aplicación.

66
5.2 Contenido Informativo
5.2.1 El Concepto de Integridad. 5.2.2Control de Integridad 5.2.3El Componente de Integridad en el Modelo Relacional. 5.2.3.1 Regla de Integridad de Entidades. 5.2.3.2 Regla de Integridad Referencial. 5.2.4 Control de Integridad a nivel de la Aplicación. 5.2.5 Caso de Estudio, Disparadores en MySQL.
5.2.1 El Concepto de Integridad
El término integridad se refiere a la exactitud o corrección de los datos en la base de datos, o a la calidad de los datos, para ello es necesario incluir ciertas reglas de integridad, cuyo propósito es informar al DBMS de ciertas restricciones del mundo real (como la restricción de que los pesos de ciertos artículos no pueden ser negativos) para que pueda impedir la ocurrencia de tales configuraciones imposibles de valores.
Garantizar un buen soporte de integridad para las aplicaciones de bases de datos, es fundamental para su buen funcionamiento, ya que si no se realiza la verificación adecuada de las restricciones de integridad establecidas para una cierta base de datos, nos puede llevar a estados de inconsistencia en los datos y a un comportamiento impredecible de nuestras aplicaciones.
Clasificación
Existen diferentes clasificaciones de las restricciones de integridad, entre las que se pueden citar las siguientes.
Ullman[4], establece una clasificación general de las restricciones de uso común:
a) Las llaves son atributos o conjuntos de atributos que proporcionan la identificación única de un objeto dentro de su clase o de una entidad dentro de su conjunto entidad.
b) Las restricciones de valor único son requisitos de que el valor de un papel determinado sea único.
c) Las restricciones de integridad referencial son requisitos de que el valor referenciado por algún objeto exista realmente en la base de datos.
d) Las restricciones de dominio requieren que el valor de un atributo sea extraído de un conjunto específico de valores o bien que se encuentre dentro de un intervalo determinado.
e) Las restricciones generales son afirmaciones arbitrarias que deben cumplirse en la base de datos.

67
En [3] se propone un esquema de clasificación en cuatro grandes categorías:
• Restricción de Tipo. Una restricción de tipo es una sola enumeración de los valores validos del tipo. En otras
palabras, una especificación de los valores que conforman el tipo en cuestión. Un ejemplo sencillo seria la restricción de tipo PESO:
TYPE PESO POSSREP ( RATIONAL ) CONSTRAINT THE_PESO ( PESO ) > 0.0;
Por convención es posible que una restricción de tipo haga uso del nombre del tipo aplicable para denotar un valor cualquiera del tipo en cuestión, en el ejemplo, los pesos los limita para que puedan ser representados por un numero racional mayor a cero.
Conceptualmente, las restricciones de tipo son verificadas durante la ejecución de
alguna invocación a cierto sector(PESO) y de inmediato, así ninguna relación puede adquirir nunca un valor para ningún atributo de cualquier tupla si este no es del tipo apropiado. Este tipo de restricción también puede considerarse de Dominio.
• Restricción de atributo.
Una restricción de atributo es básicamente una declaración para que un atributo
especificado sea de un tipo en particular. En otras palabras las restricciones de atributo son parte de la definición del atributo en cuestión y pueden ser identificadas por medio del nombre de atributo correspondiente.
• Restricción de relación.
Una restricción de relación es la que es impuesta a una relación individual, en el caso
especifico de proveedores y partes los proveedores en Londres deben tener un status de 20, las partes rojas deben almacenarse en Londres, etc.
• Restricción de Bases de Datos.
Una restricción de Base de Datos es aquella que relaciona dos o más relaciones
distintas. Cómo ejemplo se puede mencionar ¿Cuáles son las operaciones de actualización que el DBMS debe realizar o monitorear para hacer cumplir la restricción ‘todo numero de proveedor en la relación de envíos existe también en la relación de proveedores’? El primer monitoreo a realizar es que todo numero de proveedor en la relación de envíos exista también en la relación de proveedores (restricción referencial), y la segunda es que toda parte debe tener por lo menos un envió.
Adoración de Miguel y Mario Piattini proponen otra clasificación en dos grandes categorías:

68
• Restricciones Inherentes. Son restricciones que impone en este caso el modelo relacional, el cual no permite
ciertas estructuras. Como la estructura básica del modelo relacional es la relación (tabla), entonces serian las derivadas a relación, que son las características propias de ellas ya mencionadas en el capítulo 1. La Regla Integridad de Entidades es considerada una restricción inherente.
• Restricciones de Usuario ó Semánticas.
Dentro del contexto relacional son las facilidades que el modelo ofrece a los usuarios a
fin de que éstos puedan reflejar en el esquema la semántica del mundo real. Por ello algunos productos añaden ciertas facilidades que permiten programarlas1 (ORACLE ofrece la posibilidad de incluir en el SQL/FORMS la definición de claves ajenas de forma declarativa, lo que resulta muy útil especialmente cuando no estaba incluida en el núcleo del DBMS la integridad referencial).
Las restricciones semánticas del modelo relacional basado en el estándar de SQL son
las siguientes:
� Clave Primaria: Permite declarar un atributo o un conjunto de atributos como clave primaria de una relación, por lo que los valores no se podrán repetir ni se admitirán los nulos. La obligatoriedad de la clave primaria es una restricción inherente del modelo relacional; pero la declaración de un atributo como clave primaria de una relación es una restricción semántica.
� Unicidad. (Unique). Mediante la cual se indica que los valores de un conjunto de
atributos no pueden repetirse en una relación. Esta definición permite la declaración de llaves alternativas.
� Obligatoriedad (NOT NULL), de uno o más atributos, con lo que se indica que el
conjunto de atributos no admite valores nulos.
� Integridad Referencial (FOREIGN KEY). Si una relación R2 tiene un descriptor que es una clave candidata de la relación R1, todo valor de dicho descriptor debe concordar con un valor de la clave candidata referenciada de R1 o bien ser nulo. Cabe destacar que la clave ajena puede ser también parte de la clave primaria de R2.
� Restricciones de Rechazo. Verificación (CHECK) y Aserción(ASSERTION). El
usuario formula una condición mediante un predicado definido sobre un conjunto de atributos, tuplas o dominios, que debe ser verificado en toda operación de actualización para que el nuevo estado constituya una ocurrencia valida del esquema, en SQL92 existen dos clases:

69
- Verificación (CHECK): Comprueba, en toda operación de actualización, si el predicado es cierto o falso y, en el segundo caso, rechaza la operación. La restricción de verificación se define sobre un único elemento (dentro de un CREATE TABLE) y puede o no tener nombre.
- Aserción (ASSERTION): Actúa de forma idéntica a la anterior, pero se diferencia de ella en que puede afectar a varios elementos (por ejemplo, a dos tablas distintas). Por tanto, su definición no va unida a la de un determinado elemento del esquema y siempre ha de tener un nombre.
� Disparador.(trigger) Restricción en la que el usuario pueda especificar libremente la
respuesta (acción) ante una determinada condición. Así como las anteriores reglas de integridad son declarativas, los disparadores son procedimentales, siendo preciso que el usuario escriba el procedimiento que ha de aplicarse en caso de que se cumpla la condición.
5.2.2 Control de Integridad.
De acuerdo a [6] Existen dos formas de incorporar el tratamiento de restricciones de integridad en el sistema:
-Las aplicaciones que actualizan la BD pueden incorporar código adicional que verifique y asegure que no se violan las restricciones.
-El diseñador de la BD puede declarar restricciones como parte del esquema. El DBMS debe de verificar automáticamente las restricciones cada vez que se actualicen los datos.
De acuerdo a [6] Como principio general, la especificación de restricciones debería de ser excluída de las aplicaciones para reducir los costos de programación y para asegurar la calidad de los datos y en su uso.
Incluir las restricciones de integridad en la BD, es decir, que el DBA las especifique y el DBMS las asegure, trae consigo las siguientes ventajas:
Reduce los costos de desarrollo de software debido a que las restricciones de integridad son codificadas sólo una vez y compartidas por todos los usuarios.
El control de las restricciones de integridad es más confiable por ser centralizado y uniforme.
Hace más fácil el mantenimiento. El DBA es el único encargado de definir y modificar las restricciones de integridad.

5.2.3 El Componente de Integridad en el
El modelo relacional incluye dos reglas generales de integridad, las cuales se refieren respectivamente a las llaves primarias y a las llaves ajenas,
Llave Primaria.
En términos informales, la llave primaria de una relación es sólo un para esa relación.
Es posible tener una relación con más de un identificador único. En un caso así, se dirá que la relación tiene varias llaves ccandidatas como llave primaria, y las demás las llamaremos entonces
De una forma más precisa en [3] se define el término "llave candidata" de la forma siguiente:
El atributo K (posiblemente compuesto) de la relación R es una solo si satisface las siguientes dos propiedades, independientes del tiempo:
1. Unicidad:
En cualquier momento dado, no existen dos tuplas en R con el mismo valor de K.
2. Minimalidad:
Si K es compuesto, no será posible eliminar ningún componente de K sin destruir la propiedad de unicidad.
Del conjunto de llaves candidatas de una relación dada, se elige una y sólo una como LLAVE PRIMARIA de esas relación; las demás si existen, se llamarán Así una llave alterna es una llave candidata que no es la llave primaria.
5.2.3.1 La Regla de Integridad de las Entidades:
"Ningún componente de la llave primaria de una relación base puede aceptar valores nulos."
Con "nulos" se quiere decir información faltante por alguna razón, por ejemplo, si la propiedad no es aplicable o si el valor se desconoce (etc.).
La regla de integridad de las entidades se justifica si se considera que las llaves primarias identifican de una forma única
.2.3 El Componente de Integridad en el Modelo Relacional.
El modelo relacional incluye dos reglas generales de integridad, las cuales se refieren respectivamente a las llaves primarias y a las llaves ajenas,
En términos informales, la llave primaria de una relación es sólo un identificador único
Es posible tener una relación con más de un identificador único. En un caso así, se dirá que candidatas; nosotros escogeríamos entonces una de esas llaves
candidatas como llave primaria, y las demás las llamaremos entonces llaves alternativas
De una forma más precisa en [3] se define el término "llave candidata" de la forma
emente compuesto) de la relación R es una llave candidatasolo si satisface las siguientes dos propiedades, independientes del tiempo:
En cualquier momento dado, no existen dos tuplas en R con el mismo valor de K.
K es compuesto, no será posible eliminar ningún componente de K sin destruir la
Del conjunto de llaves candidatas de una relación dada, se elige una y sólo una como de esas relación; las demás si existen, se llamarán llaves alternativas. es una llave candidata que no es la llave primaria.
La Regla de Integridad de las Entidades:
"Ningún componente de la llave primaria de una relación base puede aceptar valores
quiere decir información faltante por alguna razón, por ejemplo, si la propiedad no es aplicable o si el valor se desconoce (etc.).
La regla de integridad de las entidades se justifica si se considera que las llaves primarias identifican de una forma única a las entidades dentro de la b.d.
70
El modelo relacional incluye dos reglas generales de integridad, las cuales
identificador único
Es posible tener una relación con más de un identificador único. En un caso así, se dirá que ; nosotros escogeríamos entonces una de esas llaves
lternativas.
De una forma más precisa en [3] se define el término "llave candidata" de la forma
lave candidata de R si y
En cualquier momento dado, no existen dos tuplas en R con el mismo valor de K.
K es compuesto, no será posible eliminar ningún componente de K sin destruir la
Del conjunto de llaves candidatas de una relación dada, se elige una y sólo una como llaves alternativas.
"Ningún componente de la llave primaria de una relación base puede aceptar valores
quiere decir información faltante por alguna razón, por ejemplo, si la
La regla de integridad de las entidades se justifica si se considera que las llaves primarias

71
"En una base de datos relacional nunca registraremos información acerca de algo que no podamos identificar."
5.2.3.2 Regla de Integridad Referencial.
Llaves Ajenas.
En la b.d. de proveedores (S) y partes (P), los atributos S# y P# de la relación SP son ejemplos de lo que se conoce como llaves Ajenas. De modo informal se puede definir que una llave ajena es un atributo (quizá compuesto) de una relación R2 cuyos valores deben concordar con los de la llave primaria de alguna relación R1 (donde R1 y R2 no necesariamente son distintos, como veremos más adelante.)
Un valor de llave ajena representa una Referencia a la tupla donde se encuentra el valor correspondiente de la llave primaria (la tupla referida o tupla objetivo). Por tanto, el problema de garantizar que la b.d. no incluya valores no válidos de una llave ajena se conoce como el problema de la integridad referencial.
La restricción según la cual los valores de una llave ajena deben concordar con los valores de la llave primaria correspondiente se conoce como restricción referencial. La relación que contiene a la llave ajena se conoce como relación referencial y la relación que contiene a la llave primaria correspondiente se denomina relación referida o relación objetivo.
Se puede definir el término llave ajena de una forma más precisa:
El atributo LF (quizá compuesto) de la relación base R2 es una llave ajena si y sólo si satisface las siguientes propiedades independientes del tiempo:
1. Cada valor de LF es nulo del todo o bien no nulo del todo (con "nulo del todo" o "no nulo del todo" queremos decir que, si LF es compuesto, todos sus componentes son nulos o bien todos sus componentes son no nulos, no una combinación.)
2. Existe una relación base R1 con llave primaria LP tal que cada valor no nulo de LF es idéntico al valor de LP en alguna tupla de R1.
La Regla de Integridad Referencial:
"La base de datos no debe contener valores de llave ajena sin concordancia."
Con el término "valores de llave ajena sin concordancia" queremos decir aquí un valor no nulo de llave ajena para el cual no existe un valor concordante de la llave primaria en la relación objetivo pertinente.
La justificación de esta regla es la siguiente. Así como los valores de la llave primaria representan identificadores de entidades, así los valores de la llave ajena representan Referencias a entidades (a menos que sean nulos, desde luego). La regla de integridad referencial tan sólo dice que si B hace referencia a A, entonces A debe existir.

72
Caso de Estudio.
Sintaxis declarativa para llave ajena, según Date[3]:
FOREIGN KEY (clave ajena) REFERENCES objetivo
NULLS [NOT] ALLOWED
DELETE OF objetivo efecto
UPDATE OF clave-primaria-del-objetivo efecto
En donde efecto:
RESTRICTED
CASCADES
NULLIFIES
O bien opcionalmente se pudiera establecer una regla de integridad particular.
[Reg_Int_ Part.]
5.2.4 Control de Integridad a Nivel de la Aplicación.
El control de integridad se puede realizar a nivel de las aplicaciones por medio de procedimientos activados o disparadores (“triggers”). De acuerdo a [3] y [5] un procedimiento activado es un programa que se ejecuta de forma automática cuando una tabla dada se actualiza, ya sea por una inserción, una modificación o un borrado. El procedimiento se activa en cuanto el evento o tipo de modificación (insert, update, delete) le ocurre a la tabla en cuestión. No importa cuál usuario o programa efectúe la modificación. Si un procedimiento ha sido definido para esa modificación, entonces será activado. Por ello se señala que es importante el asegurar el uso de los procedimientos activados para aquellas situaciones en las que se tenga la certeza de que se requiere su ejecución como respuesta a la modificación.
Como un ejemplo ilustrativo, podemos suponer que nuestro manejador no soporte el tratamiento de la regla de integridad con un efecto restringido. En [5] se presenta el caso en el que para una cierta

73
base de datos deseamos evitar que sea borrado un departamento que tiene empleados asignados (clave ajena coddepto en la tabla empleado, que referencia a la clave primaria de la tabla departamento) en una de las primeras versiones de SQL Server tendríamos que escribir un procedimiento activado de la forma siguiente:
create trigger borrar_depto on departamento for delete as if (select count(*) from tdeleted, empleado where empleado.coddepto = deleted.coddepto) > 0 begin rollback transaction print “No se puede borrar departamento porque tiene empleados” end en donde tdeleted, es una tabla temporal que utiliza Sql Sever para almacenar las tuplas que las va a borrar una sentencia delete antes de que la transacción correspondiente sea confirmada.
Los procedimientos activados también son muy útiles para hacer cumplir las restricciones de integridad específicas y de acuerdo a las necesidades de las aplicaciones.
Como ejemplos de reglas de integridad particulares para B.D. convencionales podemos citar:
(Curso.Requisito == C23) && (NumDetpo == D40)
Digamos que para que un trabajador se pueda inscribir a un curso, deberá de tener como requisito el curso C23 y que su número de Departamento sea D40.
(Especialidades.NEsp == E15) && (Eval >= 8)
Un trabajador debe tener una Especialidad E15 y una evaluación mayor o igual a 8.
5.2.5 Caso de estudio los disparadores en MySQL.
Como un caso ilustrativo, considere la siguiente sintaxis para crear un disparador “trigger” en MySQL [7].
CREATE TRIGGER nombre_disp momento_disp evento_disp
ON nombre_tabla FOR EACH ROW sentencia_disp

74
Un disparador es un objeto con nombre en una base de datos que se asocia con una tabla, y se activa cuando ocurre un evento en particular para esa tabla.
El disparador queda asociado a la tabla nombre_tabla. Esta debe ser una tabla permanente, no puede ser una tabla TEMPORARY ni una vista. momento_disp es el momento en que el disparador entra en acción. Puede ser BEFORE (antes) o AFTER(despues), para indicar que el disparador se ejecute antes o después que la sentencia que lo activa. evento_disp indica la clase de sentencia que activa al disparador. Puede ser INSERT, UPDATE, o DELETE. Por ejemplo, un disparador BEFORE para sentencias INSERT podría utilizarse para validar los valores a insertar. No puede haber dos disparadores en una misma tabla que correspondan al mismo momento y sentencia. Por ejemplo, no se pueden tener dos disparadores BEFORE UPDATE. Pero sí es posible tener los disparadores BEFORE UPDATE y BEFORE INSERT o BEFORE UPDATE y AFTER UPDATE. sentencia_disp es la sentencia que se ejecuta cuando se activa el disparador. Si se desean ejecutar múltiples sentencias, deben colocarse entre BEGIN ... END, el constructor de sentencias compuestas. Esto además posibilita emplear las mismas sentencias permitidas en rutinas almacenadas.
5.3 Actividades de Aprendizaje
1)Considera la sig. Relación:
Empleado(Nemp,CurpEmp,NumSegSocs,NombreEmp,EdaddEmp,DirEmp,TelEmp,NDepto)
-Identifica posibles llaves candidatas.
-Establece la llave primaria y las llaves alternas.
-Identifica una llave ajena.
-Enuncia la regla de integridad de entidad.
2)Analiza. ¿Es posible que algún alumno dentro de la BUAP, tenga matrícula NULA ?.
3)Analiza. ¿Es posible que en una empresa existan dos facturas que tengan asignados el mismo número de factura.?
4)Indica tres casos en los que a nivel de una aplicación podría ser de utilidad validar la regla de integridad de entidades.
5)Enuncia la regla de integridad referencial.
6)Analiza. En una tabla de empleados , ¿es posible hacer referencia a un departamento que no existe?. Qué pasa si es el caso.
7)Analiza. ¿Qué pasa si la tabla de departamentos se eliminara un Departamento que tiene empleados?

75
8)Indica tres casos en los que a nivel de una aplicación podría ser de utilidad validar la regla de integridad referencial.
9)Seleccione un DBMS relacional que sea de su interés. Elabore un reporte en donde incluya la descripción, sintaxis y un ejemplo para cada una de las facilidades que ofrece el DBMS para el control de integridad a nivel declarativo. Por ejemplo, podrían ser: Unique, Primary Key, Foreign Key, Unique, Check, Assertion, entre otras.
10)Seleccione un DBMS relacional que sea de su interés. Elabore un reporte en donde incluya la descripción, sintaxis y un ejemplo de cada una de las facilidades que ofrece el DBMS para el control de integridad a nivel de la aplicación. Por ejemplo, se pueden ofrecer el tipo de disparadores que se describen en la Sec.5. 3.1 para el caso de MySQL.:
5.4 Evaluación de Adquisición del Conocimiento.
E1)Ejemplo de reactivos.
R1)No es una “llave candidata” para la tabla “Alumnos”
a)NumSegSocs b)Nombre c)curp d)NumMatrícula
R2)No es un posible efecto de la regla de integridad referencial.
a)Restricted b)Cascades c)Unique d)Nullfies
R3)Es una posible llave primaria para la tabla “Empleados”.
a)Nombre b)Edad c)NumEmp d)NumDepto.
E2)Implementa un ejemplo de cada una de las facilidades para el control de integridad a nivel declarativo que ofrece el DBMS que hayas investigado.
E3)Implementa ejemplos de tres tipos de disparadores en el DBMS que hayas investigado y documentado.
5.5 Referencias del Capítulo 5.
[1]Codd E.F. A Relational Model of Data for Large Shared Database. Communications of the ACM. 377-387, 1970. [2] Coronel C., Steven Morris & Peter Rob. Bases de Datos, Diseño, Implementación y Administración. Cengage Learning Editores, S.A., Mex. D.F. 2011. [3] Date, C.J. Introducción a los Sistemas de Bases de Datos, Addison-Wesley. [4] Elmasri R. & S. Navathe. Fundamentos de Sistemas de Bases de Datos. Pearson Educación S.A. Madrid, 2007. [5] Pastor L.O. & P.Blesa P. Gestión de Bases de Datos. Universidad Politécnica de Valencia., Valencia, 2000. [6] Ullman, J.D. Principles of Database and Knowledge Base System (vol.1), Computer Science Press, 1988. [7]www.mysql.com

76
Capítulo 6
El Modelo Relacional:
El Componente de Manipulación,
Álgebra Relacional.
María Josefa Somodevilla García María de la Concepción Pérez de Celis Herrero
En el presente capítulo se describe el componente de manipulación del modelo relacional mediante el Álgebra Relacional.
6.1 Objetivo Educativo
Que el alumno aprenda el componente de manipulación del modelo relacional a partir del conocimiento de un conjunto de operaciones algebraicas que describen paso a paso como computar una respuesta sobre las relaciones y que se usan como una representación de una consulta a una base de datos.

77
6.2 Contenido Informativo.
Contenido:
6.2.1 Consulta Relacional
6.2.2 Lenguaje de Consulta Relacional
6.2.3 Operaciones del Álgebra Relacional
6.2.4 Formulación de Consultas en Álgebra Relacional
6.2.5 Resumen
6.2.1 Consulta Relacional
El modelo de datos relacional provee de medios para imponer estructura y restricciones a la base de datos
Nombre Salario Dirección Departamento
Suárez 50k Puebla Ventas
Dávila 40k Atlixco Ventas
Juárez 60k San Martín Ventas
Tapia 65k Tehuacán Contabilidad
Herrera 78k Amozoc Contabilidad
Un modelo de datos también tiene que suministrar operaciones para manipular los datos, por ejemplo:
• Encontrar los nombres y departamentos de los empleados que ganan mas de 55K • Incrementar el salario de todos los Empleados del departamento de Ventas en un 10% • ¿Cuál es la dirección del empleado Juárez?
6.2.2 Lenguaje de Consulta Relacional
Las Consultas relacionales son formuladas en lenguajes de consulta relacionales, siendo los siguientes los más representativos:
� Álgebra Relacional (AR)
– Lenguaje de consulta formal para BDR

78
� Structured Query Language (SQL)
– Lenguaje de consulta comprensivo, comercial ampliamente aceptado como estandar internacional
� Query by Example (QBE)
– Lenguaje de consulta comercial, gráfico con sintaxis mínima.
Comparación entre SQL y AR
SQL AR � Lenguaje Declarativo
– Usuarios especifican qué es el resultado de la consulta, DBMS decide las operaciones y el orden de ejecución
� Operaciones – Provee comandos para crear y modificar la estructura y restricciones de la BD (DDL) – Provee comandos para insertar, borrar, modificar y recuperar (DML)
� Lenguaje Procedural –Expresiones algebraicas que especifican un orden de operaciones, ¿cómo la consulta será procesada?
� Operaciones – Provee operadores, que permiten al usuario especificar peticiones de recuperación únicamente
6.2.3 Operaciones del Álgebra Relacional
� Las operaciones de AR son aplicadas sobre relaciones. � Los resultados de operaciones de AR son también relaciones. � Una secuencia de operaciones de AR forma una expresión, cuyo resultado será también una
relación. La siguiente tabla muestra los tipos de operaciones de AR así como su notación.
Operaciones de Conjunto Operaciones específicas para BDR
Intersection ∩ Select σ Union ∪ Project Π Difference — Join ⋈
Cartesian Product × Division ÷
Para los ejemplos resueltos que se presentan en este capítulo se utilizará la base de datos COMPANY (Elmasri&Navathe2011) la cual está compuesta por seis tablas cuyos esquemas básicos se presentan a continuación:
1. EMPLOYEE [Ssn, Fname, Mit, Lname, Dob, Address, Sex, Salary, Dno, SuperSSN] 2. DEPARTMENT [Dnumber, Dname, MGRSSN,MgrStart] 3. PROJECT [Pno, PName, Plocation, DNum]

79
4. DEPENDENT [ESSN,DepName, Sex, DOB, Relationship] 5. WORKS_ON [ESSN, PNo, Hours] 6. DEPT_LOCS [DNumber, DLocation] Operaciones específicas para BDR
Select σ
σ < condición de selección > ( < nombre de la relación > )
Selecciona aquellas tuplas que satisfacen una condición dada. Esta operación es también llamada “restricción”.
Ejemplos:
EMPLOYEE [Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno]
1. Listar todos los detalles de los empleados que trabajan en el departamento 4.
σ Dno = 4 (EMPLOYEE)
2. Listar todos los detalles de los empleados que trabajan en el departamento 4 y que ganan más de $25000, o que trabajan en el departamento 5 y ganan más de $30000.
σ (Dno = 4 ∧∧∧∧ Salary > 25000) ∨∨∨∨ (Dno = 5 ∧∧∧∧ Salary > 30000) (EMPLOYEE)
Project Π
Π< lista de atributos> ( < nombre de la relación> )
Selecciona aquellos atributos especificados en la lista.
Ejemplos:
EMPLOYEE [Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno]
3. Para cada empleado, listar su nombre, fecha de nacimiento y salario.
Π Ename,Bdate,Salary (EMPLOYEE)
4. Listar los salarios pagados a los empleados en cada departamento, así como su número de departamento.
Π Dno, Salary (EMPLOYEE)
Tratamiento de Consultas Complejas
La formulación de consultas complejas podría requerir de varias operaciones de álgebra relacional, una a continuación de la otra.

– Las operaciones se pueden escribir como expresiones a través de anoperaciones. – Las operaciones pueden ser aplicadas una a la vez creando relaciones intermedias, los cuales tienen que ser asignados a relaciones temporales que tienen que ser nombradas. Ejemplo:
5. Crear una nueva relación llamada RESULTnacimiento. Etiquete las columnas resultantes como ‘Employee’ y ‘DOB’.
RESULT(Employee,DOB )
6. Listar los nombres y salarios de los empleados quienes trabajan en el departamento 5.
Π Ename,Salary ( σ Dno = 5 (EMPLOYEE ) ) EMPS - DEP5 ← σ Dno = 5 (EMPLOYEE )intermedias RESULT ← Π Ename,Salary (EMPS_ DEP5)
Operaciones Básicas de Conjuntos
Una Relación es un conjuntoentonces a las relaciones (tablas). Las operaciones de conjunto se muestran en la siguiente figura:
Para aplicar las operaciones de unión, intersección y diferencia entre dos tablas éstas deben ser compatibles para la unión. Dos relaciones R(A1, A2, ..., An) y S(B1, B2,..., Bn) son compatible para la unión si y sólo sí:
– Tienen el mismo grado n, (n – Sus columnas tienen dominios correspondientes: dom(Ai) = dom(Bi) for 1 Aunque los dominios necesitan ser correspondientes ellos no tienen que tener el mismo nombre, por ejemplo considere las dos tablas siguientes:
WORKS_ON [ESSN, Pno, Hours]WORKED_ON [Employee, Project, Duration]donde
Las operaciones se pueden escribir como expresiones a través de an
Las operaciones pueden ser aplicadas una a la vez creando relaciones intermedias, los cuales tienen que ser asignados a relaciones temporales que tienen que ser nombradas.
5. Crear una nueva relación llamada RESULT, conteniendo a cada empleado y su fecha de nacimiento. Etiquete las columnas resultantes como ‘Employee’ y ‘DOB’.
RESULT(Employee,DOB ) ← Π Ename,Bdate (EMPLOYEE)
6. Listar los nombres y salarios de los empleados quienes trabajan en el departamento 5.
(EMPLOYEE ) ) Consulta con expresión(EMPLOYEE ) Consulta con relaciones
(EMPS_ DEP5)
Operaciones Básicas de Conjuntos
Una Relación es un conjunto de tuplas (no duplicadas). La Teoría de Conjuntos se aplica entonces a las relaciones (tablas). Las operaciones de conjunto se muestran en la siguiente
Para aplicar las operaciones de unión, intersección y diferencia entre dos tablas éstas deben ser compatibles para la unión. Dos relaciones R(A1, A2, ..., An) y S(B1, B2,..., Bn) son compatible para la unión si y sólo sí:
Tienen el mismo grado n, (número de columnas) Sus columnas tienen dominios correspondientes: dom(Ai) = dom(Bi) for 1 ≤ i ≤ n
Aunque los dominios necesitan ser correspondientes ellos no tienen que tener el mismo nombre, por ejemplo considere las dos tablas siguientes:
_ON [ESSN, Pno, Hours] WORKED_ON [Employee, Project, Duration]
80
Las operaciones se pueden escribir como expresiones a través de anidación de
Las operaciones pueden ser aplicadas una a la vez creando relaciones intermedias, los cuales tienen que ser asignados a relaciones temporales que tienen que ser nombradas.
, conteniendo a cada empleado y su fecha de
6. Listar los nombres y salarios de los empleados quienes trabajan en el departamento 5.
Consulta con expresión Consulta con relaciones
Teoría de Conjuntos se aplica entonces a las relaciones (tablas). Las operaciones de conjunto se muestran en la siguiente
Para aplicar las operaciones de unión, intersección y diferencia entre dos tablas éstas deben ser compatibles para la unión. Dos relaciones R(A1, A2, ..., An) y S(B1, B2,..., Bn) son
Aunque los dominios necesitan ser correspondientes ellos no tienen que tener el mismo nombre,

81
dom (ESSN) = dom (Employee) dom (Pno) = dom (Project) dom (Hours) = dom (Duration) Entonces las tablas WORKS_ON y WORKED_ON son compatibles para la unión porque ambas tienen grado 3 y sus atributos correspondientes tienen el mismo dominio.
R1 ∪∪∪∪ R2
Produce una relación que incluye todas las tuplas que aparecen solo en R1, sólo en R2, o en ambas R1 y R2. Las tuplas duplicadas son eliminadas. R1 y R2 tienen que ser compatibles para la unión.
Ejemplo:
7. Listar los ESSN’s de los empleados quienes tienen dependientes o trabajan en proyectos.
Para efectuar la operación solicitada se necesitan que las tablas sean compatibles para la unión pero como no cumplen la condición, entonces se realiza la proyección del atributo ESSN en ambas tablas, como se muestra a continuación:
WORKS_ON [ESSN, PNo, Hours] DEPENDENT [ESSN, Dep_Name, Sex, DOB, Relationship] Π ESSN ( DEPENDENT ) ∪∪∪∪ Π ESSN (WORKS_ON )
R1 ∩ R2
Produce una relación que incluye las tuplas que aparecen en ámbas R1 y R2. R1 y R2 tienen que ser compatibles para la unión.
Ejemplo:
8. Listar los ESSN’s de los empleados quienes tienen dependientes y son managers.
DEPENDENT [ESSN, Dep_Name, Sex, DOB, Relationship] DEPARTMENT [DName, DNumber, MgrSSN, MgrStart] Π ESSN ( DEPENDENT ) ∩ Π MGRSSN (DEPARTMENT )
R1 - R2
Produce una relación que incluye todas las tuplas que aparecen en R1, pero no en R2. R1 y R2 tienen que ser compatibles para la unión. Ejemplo: 9. Listar los ESSN’s de los empleados quienes tienen dependientes pero no trabajan en proyectos. WORKS_ON [ESSN, PNo, Hours] DEPENDENT [ESSN, Dep_Name, Sex, DOB, Relationship]

Π ESSN ( DEPENDENT )
Propiedades de los operadores
� Operadores Commutativos y Asociativos
A ∪∪∪∪ B Commutativa
Asociativa
A∩ B Commutativa
Asociativa
A — B not Commutativa
not Commutativa
� Precedencia entre operadores en expresiones de AR
Los operadores se ejecutan de izquierda a derecha en la expresión. Los ( ) pueden ser usados para alterar la precedencia de los operadores indicando la más alta prioridad.
Ejemplo:
10. Listar todos los empleados quienes son hombres, y ganan más de departamento 5.
EMPLOYEE [Ename, SSN
Π Ename (σ (Sex = ‘M’ and (Salary < 40000 or Dnum = 5))
• Leyes de De Morgan’s¬ ( p ∧ q ) ≡ ¬ p ∨ ¬ q
¬ ( p ∨ q ) ≡ ¬ p ∧ ¬ q
donde p y q son predicados, ejemplo: Salary >40000 and Dept=Research, las siguientes dos expresiones son equivalentes:
( DEPENDENT ) — Π ESSN (WORKS_ON )
adores
Operadores Commutativos y Asociativos
A ∪ B = B ∪ A
(A ∪ B) ∪ C = A ∪ ( B ∪ C )
A ∩ B = B ∩ A
(A ∩ B) ∩ C = A ∩ ( B ∩ C )
not Commutativa A — B ≠ B — A
not Commutativa (A — B) — C ≠ A — (B — C )
Precedencia entre operadores en expresiones de AR
=, ≠, <, >, ≤, ≥ not and or σ, Π ∩, ∪∪∪∪, —, ×, +, ⋈⋈⋈⋈
Los operadores se ejecutan de izquierda a derecha en la expresión. Los ( ) pueden ser usados para alterar la precedencia de los operadores indicando la más alta prioridad.
10. Listar todos los empleados quienes son hombres, y ganan más de $40000 o trabajan en el
SSN, DOB, Address, Sex, Salary, SuperSSN, Dnum]
(Sex = ‘M’ and (Salary < 40000 or Dnum = 5)) (EMPLOYEE ))
Leyes de De Morgan’s
donde p y q son predicados, ejemplo: Salary >40000 and Dept=Research, las siguientes dos expresiones son equivalentes:
82
Los operadores se ejecutan de izquierda a derecha en la expresión. Los ( ) pueden ser usados
$40000 o trabajan en el
, DOB, Address, Sex, Salary, SuperSSN, Dnum]
donde p y q son predicados, ejemplo: Salary >40000 and Dept=Research, las siguientes dos

83
¬ ((Salary > 40000) ∧ (Dept = Research) ) ≡ ¬ (Salary > 40000) ∨ ¬ (Dept = Research) Producto Cartesiano
R1 × R2
� También es conocido como producto cruz. R1 y R2 no necesitan ser compatibles para la unión.
� El resultado de R1 (A1, A2,… An) x R2 (B1, B2, … Bm) s una relación Q con n + m atributos Q (A1, A2, … An, B1, B2, … Bm) en ese orden.
� Q tiene una tupla para cada combinación de tuplas de R1 y R2, entonces si R1 tiene r tuplas y R2 tiene t tuplas, entonces Q tendrá r * t tuplas , ver siguiente ejemplo
Materia CS114 CS115 CS180
*
Estudiante
Carrera
Ana Ingeniería Alfredo Licenciatura
=
Materia Estudiant
e Carrera
CS114 Ana Ingeniería CS114 Alfredo Licenciatura CS115 Ana Ingeniería CS115 Alfredo Licenciatura CS180 Ana Ingeniería CS180 Alfredo Licenciatura
Ejemplo: 11. Para cada empleado mujer, listar su nombre.
EMPLOYEE [Ename,SSN,DOB,Address,Sex,Salary,SuperSSN, Dno]
DEPENDENT [ESSN, DepName, Sex, DOB, Relationship]
FEMALE_EMPS ← σ Sex = ‘F’ (EMPLOYEE) EMP_NAMES ← Π Ename, SSN (FEMALE_EMPS) EMP_DEPEND ← EMP_NAMES × DEPENDENT ACTUAL_DEPEND ← σ SSN = ESSN (EMP_DEPEND) RESULT ← Π Ename, DepName (ACTUAL_DEPEND) Operaciones de Reunión (Join)
La operación Join es similar al Producto Cartesiano, pero sólo pares de tuplas seleccionadas estarán en el resultado. Join es usada para combinar tuplas relacionadas de dos relaciones en una simple tupla de una nueva relación. Esto es necesario cuando la información que se necesita recuperar se encuentra en más de una relación.
Tipos de Operaciones Join:

84
• Theta-Join
R1 ⋈⋈⋈⋈ < condición de join> R2 Una condición(es) de join es de la forma A θ B, donde A ∈ R1 y B ∈ R2, y θ es uno de los siguientes operadores de relación {=, <, ≤, >, ≥} Ejemplo: 12. Para cada empleado, listar todos los empleados quienes ganaron más que el primer empleado. EMPLOYEE [Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] A ← EMPLOYEE B ← EMPLOYEE RESULT ← Π A.Ename, B.Ename (A⋈ A.Salary < B.Salary B) • Equi-Join
R1 ⋈⋈⋈⋈ < condición de join > R2 Especialización de Join donde la condición de join tiene solamente comparaciones de igualdad. Ejemplo: 13. Listar los nombres de los managers de cada departamento. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] DEPARTMENT [ DName, DNumber, MgrSSN, MgrStart] DEPT_MGR ← DEPARTMENT ⋈ MGRSSN = SSN EMPLOYEE RESULT ← Π Ename (DEPT_MGR)jemplo:
• Join Natural R1 * R2 Similar al equi-join excepto que los atributos que son usados en el join son aquellos que tienen el mismo nombre en cada relación. Consecuentemente, ellos no son explícitamente especificados y las columnas duplicadas son eliminadas del resultado, ver siguiente ejemplo:
Materia Estudiante CS114 Ana CS115 Alfredo CS180 Ana CS214 Roberto
*
Estudiante
Carrera
Ana Ingeniería Ana Administración Alfredo Licenciatura
=
Materia Estudiant
e Carrera
CS114 Ana Ingeniería CS114 Ana Administración CS115 Alfredo Licenciatura CS180 Ana Ingeniería CS180 Ana Administración
Ejemplo: 14. Encontrar todos los datos de los empleados quiénes son managers, así como los datos de sus respectivos departamentos. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno ] DEPARTMENT [ DName, DNumber, MgrSSN, MgrStart ] EMPLOYEE * DEPARTMENT no puede ser ejecutado directamente porque en las tablas EMPLOYEE y DEPARTMENT no existen atributos con el mismo dominio y que sean además igualmente nombrados. Entonces se requiere renombrar los atributos de join SSN y Dno de EMPLOYEE, para que tomen los mismos nombres que estos tienen en la tabla

85
DEPARTMENT. Después de la operación de renombrado y asignación entonces el join natural EMP * DEPARTMENT puede ser llevado a cabo, como se muestra a continuación: EMP(MgrSSN ,Dnumber) ← Π SSN,Dno (EMPLOYEE) RESULT ← EMP * DEPARTMENT Operación de División R1 ÷ R2
La relación resultante contiene columnas en R1, pero no en R2. Las relaciones R1 y R2 tienen que ser división compatibles, esto es, las últimas n columnas de R1 tienen que ser idénticamente nombradas a las columnas en R2, donde n es el grado de R2. La relación resultante contiene tuplas t, tal que un valor en t aparece en R1, en combinación con cada tupla en R2, ver siguiente ejemplo:
Estudiante Carrera Materia Ana Ingeniería CS114 Ana Ingeniería CS115 Ana Ingeniería CS180 Alfredo Licenciatura CS114 Alfredo Licenciatura CS180
÷
Materia CS114 CS115
= Estudiante Carrera Ana Ingeniería
Ejemplo: 15. Recuperar los nombres de los empleados quienes trabajan en todos los proyectos donde John Smith trabaja. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] WORKS_ON [ ESSN, Pno, Hours ] SMITH ← σ Ename=‘John Smith’ (EMPLOYEE) SMITH_PNOS ← Π Pno (WORKS_ON ⋈ ESSN=SSN SMITH) SSN_PNOS ← Π ESSN, Pno (WORKS_ON) SSNS(SSN) ← SSN_PNOS ÷ SMITH_PNOS RESULT ← Π Ename (SSNS * EMPLOYEE)
4.2.4 Formulación de Consultas en Álgebra Relacional
� Conocer esquema y estado(s) de la BD. � Interpretación de la consulta en lenguaje natural. � Identificar cuales relaciones, tuplas (SELECT), y atributos (PROJECT) que serán
requeridos por la consulta. � Identificar las interrelaciones entre las relaciones requeridas y de acuerdo a estas cuales
operadores binarios pueden ser usados. (JOIN, PRODUCT, UNION, DIVISION …)
� Formular la consulta teniendo en mente las propiedades de los operadores (Commutativo/Asociativo, Precedencia, y las Leyes de De Morgan)
¿Cuál operador usar?
� Use operadores unarios SELECT / PROJECT cuando seleccionamos tuplas/atributos respectivamente de una sola relación.

86
� Use operadores binarios UNION, INTERSECCION, DIFFERENCE, CARTESIAN PRODUCT, JOIN, DIVISION cuando queremos relacionar 2 ó más relaciones.
Ha sido probado que {σ, Π, U, —, ×} es un conjunto completo de operadores de Álgebra Relacional. Los operadores restantes de AR pueden ser expresados como una secuencia de operaciones del conjunto anterior. Los operadores restantes han sido definidos primariamente por conveniencia.
Expresión de otros operadores en términos de los operadores primarios.
� Intersection R ∩ S ≡ ( R ∪ S ) – (( R — S ) ∪ ( S — R )) � (Thieta/Equi) Join R <condition> S ≡ σ <condition> ( R × S) � Natural Join S(B1,B2, B3, … Bm) R1 (B1, A2, A3, . . . An) ← Π (A1, A2, A3, . . . An) R R * S ≡ Π (B1, A2, A3, ... An, B2, ... Bm) σ <R.B1 = S.B1>( R1×S) � Division
T1 ← Π Y ( R ) T2 ← Π Y ( ( S × T1 ) — R ) R ÷ S ≡ T1 — T2
Funciones y Operaciones de Agregación � La función de Agregación toma una colección de valores y devuelve un único valor como
resultado:
avg: valor promedio min: valor mínimo max: valor máximo sum: suma de valores count: cantidad de valores
� Operación de Agregar en álgebra relacional G1, G2, …, Gn g F1( A1), F2( A2),…, Fn( An) (E)
� E es cualquier expresión en álgebra relacional � G1, G2 …, Gn es una lista de atributos en los cuales agrupar (puede estar vacía) � Cada Fi es una función de agregación
Cada Ai es un nombre de atributo

87
Ejemplo: CUENTAS
Sucursal No.Cuenta Balance Bancomer A-102 400 Bancomer A-201 900 Santander A-217 750 Santander A-215 750 Scotiabank A-222 700
sucursal G sum (balance) (CUENTAS) Sucursal Balance Bancomer 1300 Santander 1500 Scotiabank 700
El resultado de la agregación no tiene un nombre. Puede utilizarse la operación de renombrar (rename) as para denominarla. Por conveniencia, se permite renombrar como parte de la operación de agregación. 6.2.5 Resumen
� El Álgebra Relacional provee los fundamentos teóricos para los lenguajes de consulta relacionales.
– AR opera en relaciones enteras y produce resultados los cuales también son relaciones. – Las expresiones de AR, consisten de una secuencia de operadores de AR, los cuales especifican un procedimiento de alto nivel para alcanzar el resultado de una consulta.
� Sin embargo, la formulación de consultas algebraicas relacionales es procedural, y por lo tanto se enfoca en como el resultado de una consulta puede ser alcanzado.
� Lenguajes de consulta declarativos como SQL, permiten al usuario especificar qué información el usuario quiere, en vez de como el resultado va a ser obtenido.
6.3 Actividades de Aprendizaje. 5.3.1 Exposición de temas
5.3.2 Ejemplos resueltos en Algebra Relacional
(Elmasri&Navathe2011) [1]
Ejercicios de Join
16. Recuperar el nombre y dirección de todos los empleados quienes trabajan en el departamento de “Research”.

88
EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno ] DEPARTMENT [ Dname, Dnumber, MgrSSN, MgrStart ] RESEARCH_DEPT ← σ Dname=‘Research’ (DEPARTMENT) RESEARCH_DEPT_EMPS ← (RESEARCH_DEPT ⋈ EMPLOYEE) Dnumber=Dno RESULT ← Π Ename,Address (RESEARCH_DEPT_EMPS) 17. Para cada proyecto localizado en Houston, listar el número de proyecto, el número del departamento que controla el proyecto, y el nombre, dirección y fecha de nacimiento del manager del departamento.
EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] DEPARTMENT [ Dname, Dnumber, MgrSSN, MgrStart] PROJECT [ PName, Pnumber, Plocation, Dnum] HOUSTON_PROJS ← σ Plocation=‘houston’ (PROJECT) CONTR_DEPT ← (HOUSTON_PROJS ⋈ Dnum=Dnumber DEPARTMENT) PROJ_DEPT_MGR ← (CONTR_DEPT⋈ MgrSSN=SSN EMPLOYEE) RESULT ← Π Pnumber,Dnum,Ename,Address,Bdate (PROJ_DEPT_MGR) Ejercicio de División 18. Encontrar los nombres de los empleados que trabajan en todos los proyectos controlados por el departamento 5. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] PROJECT [ PName, Pnumber, Plocation, Dnum] WORKS_ON [ ESSN, Pno, Hours] DEPT5_PROJS(Pno) ← Π Pnumber (σ Dnum=5 (PROJECT)) EMP_PROJ(SSN,Pno) ← Π ESSN,Pno (WORKS_ON) RESULT_EMP_SSNS ← EMP_PROJ ÷ DEPT5_PROJS RESULT ← Π Ename (RESULT_EMP_SSNS * EMPLOYEE ) Ejercicio de Unión 19. Listar los números de proyectos para aquellos proyectos que involucran al empleado “Smith”, en los roles de trabajador o como manager del departamento que controla el proyecto. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] PROJECT [ PName, Pnumber, Plocation, Dnum] DEPARTMENT [ Dname, Dnumber, MgrSSN, MgrStart] WORKS_ON [ ESSN, Pno, Hours] SMITHS(ESSN) ← Π SSN (σ Ename=‘Smith’ (EMPLOYEE)) SMITH_WORKER_PROJS ← Π Pno (WORKS_ON * SMITHS)

89
MGRS ← Π Ename,Dnumber (EMPLOYEE ⋈ SSN=MgrSSN DEPARTMENT) SMITH_MGRS ← σ Ename=‘Smith’ (MGRS) SMITH_MANAGED_DEPTS(Dnum) ← Π Dnumber (SMITH_MGRS) SMITH_MGR_PROJS(Pno) ← Π Pnumber (SMITH_MANAGED_DEPTS * PROJECT) RESULT ← SMITH_WORKER_PROJS ∪ SMITH_MGR_PROJS Ejercicio de Diferencia 20. Recuperar los nombres de los empleados quienes no tengan dependientes. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] DEPENDENT [ ESSN, Dep_Name, Sex, DOB, Relationship] ALL_EMPS ← Π SSN (EMPLOYEE) EMPS_WITH_DEPS(SSN) ← Π ESSN (DEPENDENT) EMPS_WITHOUT_DEPS ← ( ALL_EMPS — EMPS_WITH_DEPS) RESULT ← Π Ename (EMPS_WITHOUT_DEPS * EMPLOYEE ) Ejercicio de Intersección 21. Listar los nombres de los managers quienes tengan al menos un dependiente. EMPLOYEE [ Ename, SSN, DOB, Address, Sex, Salary, SuperSSN, Dno] DEPARTMENT [ Dname, Dnumber, MgrSSN, MgrStart] DEPENDENT [ ESSN, Dep_Name, Sex, DOB, Relationship] MGR(SSN) ← Π MgrSSN (DEPARTMENT) EMPS_WITH_DEPS(SSN) ← Π ESSN (DEPENDENT) MGRS_WITH_DEPS ← (MGRS ∩ EMPS_WITH_DEPS) RESULT ← Π Ename (MGRS_WITH_DEPS * EMPLOYEE)
6.4 Actividades de Evaluación de Adquisición del Conocimiento.
6.4.1 Ejercicios propuestos para su resolución individual y en equipos
Desarrolle las siguientes consultas en Algebra Relacional la base de datos COMPANY (Elmasri&Navathe2011) [1].
1. Recuperar los nombres de los empleados en el departamento 5 quienes trabajan más de 10 horas a la semana en el proyecto ’ProductX’.
2. Listar los nombres de los empleados quienes tienen un dependiente con su mismo primer nombre.
3. Encontrar los nombres de los empleados que son directamente supervisados por ‘Frankiln Wong’.

90
4. Por cada proyecto, listar el nombre del proyecto y el número total de horas por semana (para todos los empleados) trabajadas en ese proyecto.
5. Recuperar los nombres de los empleados quienes trabajan en todos los proyectos. 6. Recuperar los nombres de os empleados quienes no trabajan en ningún proyecto. 7. Por cada departamento, recuperar el nombre del departamento, y el salario promedio de los
empleados trabajando en ese departamento. 8. Recuperar el salario promedio de todos los empleados del sexo femenino. 9. Encontrar los nombres y direcciones de empleados quienes trabajan en al menos un
proyecto localizado en Houston pero cuyo departamento no esté localizado en Houston. 10. Listar los nombres de los managers de los departamentos quienes no tengan dependientes.
6.4.2 Ejercicios de examen parcial
Considere el siguiente Esquema Relacional: Paciente (No_Paciente, Nombre_Paciente, Edad, Fecha_Ing, No_Exped) Área (No_Area, Nombre_Area, No_Emp_JefeArea) Médico (No_Emp_Med, Nombre_Medico, No_Area) Médico_Atiende_Paciente (No_Emp_Med, No_Paciente, Fecha_Cita) Formule en términos de operaciones del Álgebra Relacional las siguientes consultas: 1. Mostrar los nombres de los pacientes que ingresaron el “24-11-2010”.
PAC_2411 � π Nombre_Paciente ( σ Fecha_Ing=’24-11-2010’(PACIENTE))
2. Recuperar los nombres de los médicos del área de “Pediatría”.
AREA_PEDIATRIA � σ Nombre_Area= ‘Pediatría’ (AREA) MEDICOS_PEDIATRIA � Π Nombre_Medico (AREA_PEDIATRIA * MEDICO) 3. Mostrar el No_Paciente y Nombre_Paciente de los pacientes que tuvieron cita el “23-02-2011” con el médico con No_Emp = “M235”. CITA2311 �σ Fecha_Cita=’23-02-2011’AND No_emp=‘M235’ (MEDICO_ATIENDE_PACIENTE)
PACIENTE2311� π No_Paciente, Nnombre_Paciente (CITA2311 * PACIENTE)

91
6.5 Referencias del Capítulo 6. [1] Elmasri-Navathe. Sistemas de Bases De Datos Conceptos Fundamentales. (2011) . Addison-Wesley Iberoamericana, Sexta Edición, capítulo 6. [2] García-Molina, H., Ullman, J.D. y Widom, J. (2009). Database Systems: The complete book. Prentice Hall. [3] Silberschatz, A., Korth, H.F. y Sudarshan, S. (2011). Database system concepts. McGraw-Hill.

92
Capítulo 7
El Lenguaje de Consulta
Estructurado, SQL
Maya Carrillo Ruiz María del Rocío Boone Rojas
El presente capítulo constituye una introducción básica al lenguaje de consulta estructurado SQL, se presentan el lenguaje de definición de datos, el lenguaje de manipulación de datos y el lenguaje de control de datos. Únicamente se incluyen las clausulas principales, operadores lógicos y de comparación y los tipos de datos convencionales. Así mismo se proponen algunas actividades de aprendizaje y de evaluación del conocimiento.
7.1 Objetivo Educativo.
Que el alumno conozca las principales proposiciones de SQL y las aplique para definir bases de datos y extraer información de las mismas.

93
7.2 Contenido Informativo.
Contenido:
7.2.1 Introducción 7.2.2 Lenguaje de Definición de Datos 7.2.3 Lenguaje de Manipulación de Datos 7.2.4 Lenguaje de Control de Datos 7.2.1 Introducción
El SQL (Sructured Query Language) es un lenguaje utilizado para bases de datos desarrollado entre 1974 y 1975 en IBM Research. Su nombre en ese entonces fue SEQUEL (Structured English Query Language) y servía de interfaz con el SYSTEM R. SQL se introduce por primera vez en una base de datos comercial en 1979 por Oracle. Posteriormente se convierte en un estándar ANSI e ISO dando origen a SQL86 o SQL 1, después a SQL2 y así sucesivamente hasta SQL 4 en el 2004. Precisamente por ser un estándar, lo encontraremos en cualquier manejador de base de datos relacional de los que existen en la actualidad, por ejemplo: ORACLE, SYBASES, SQL SERVER por mencionar algunos.
Un método común para categorizar las instrucciones de SQL es dividirlas por la función que realizan. Con base en este método SQL se divide en tres conjuntos de instrucciones:
• Lenguaje de definición de datos (DDL, Data Definition Language). • Lenguaje de manipulación de datos (DML, Data Management Language). • Lenguaje de control de datos (DCL, Data Control Language).
7.2.2 Lenguaje de Definición de Datos
Este grupo de sentencias de SQL se utilizan para definir los objetos de la base de datos. Objetos tales como la misma base de datos (DATABASE), las tablas (TABLES), las vistas (VIEW), los índices (INDEX), los procedimientos almacenados, los disparadores (TRIGGER). Aquí encontramos las sentencias: CREATE, ALTER y DROP.
La sentencia CREATE se utiliza para crear base de datos, tablas e índices. Para crear una base de datos seguimos la siguiente sintaxis:
CREATE database nombre ON PRIMARY ( name = nombre_basedatos_data, filename:c:\BD.mdf’, -- Directorio donde se crea size = 3MB, --Tamaño de la base de datos maxsize = 7MB, -- Tamaño máximo de base de datos filegrowth = 2MB --crecimiento de la base de datos ) log on name = nombre_basedatos_log, --archivo de transacciones

94
filename:’c:\BD.ldf’, size = 3MB, maxsize = 7MB ) Al crear una base de datos, se generan tres tipos de archivos: .mdf es el archivo de datos principal, .ndf el archivo de datos secundario y .ldf archivo de registro de transacciones. En las sentencias anteriores hemos creado una base de datos de tamaño 3MG que crece hasta 7 MG en incrementos de 2 MB.
Crear una tabla
Ahora bien para crea tablas utilizamos la siguiente sintaxis:
CREATE TABLE <nombre tabla> ( <nombre columna> <tipo de dato>
[NOT NULL] [UNIQUE] [CONSTRAINT <nombre restricción>] [PRIMARY KEY] [REFERENCES] [DEFAULT] [CHECK]
| [PRIMARY KEY (<lista columnas>)] | [FOREIGN KEY (<lista columnas>) REFERENCES (nombretabla)] | [UNIQUE (<lista columnas>)] [CONSTRAINT <nombre restricción>],[,...] ) | [CHECK (condición de búsqueda)]
Tipos de Datos
Datos numéricos INTEGER Entero binario de palabra completa. SMALLINT Entero binario de media palabra. DECIMAL(p,q) Número decimal empacado, p dígitos y signo,
con q dígitos a la derecha del punto decimal. FLOAT(p) Número de punto flotante, con precisión de p
dígitos binarios. Datos de cadena CHARACTER(n) Cadena de longitud fija con exactamente n
caracteres de 8 bits. VARCHAR(n) Cadena de longitud variable con hasta n
caracteres de 8 bits. GRAPHIC(n) Cadena de longitud fija con exactamente n
caracteres de 16 bits. VARGRAPHIC(n) Cadena de longitud variable con hasta n
caracteres de 16 bits. Datos de fecha/hora DATE fecha(aaaammdd) TIME hora(hhmmss) TIMESTAMP "marca de tiempo" (combinación de fecha y
hora, con una precisión de microsegundos) Restricciones de columnas
NOT NULL La columna no permitirá valores nulos.

95
CONSTRAINT Permite asociar un nombre a una restricción. DEFAULT Valor. La columna tendrá un valor por defecto.
El SGBD utiliza este valor cuando no se especifica un valor para dicha columna.
PRIMARY KEY. Permite indicar que esta columna es la clave primaria.
REFERENCES. Es la manera de indicar que este campo, es clave ajena y hace referencia a una clave candidata de otra tabla. Esta foreign key es sólo una columna.
UNIQUE.
Obliga a que los valores de una columna tomen valores únicos (no puede haber dos filas con igual valor). Se implementa creando un índice para dicha(s) columna(s).
CHECK (condición).
Permite indicar una condición que debe de cumplir esa columna.
Restricciones de tablas
PRIMARY KEY (columna1, columna2...). Permite indicar las columnas que forman la clave primaria.
FOREIGN KEY (columna1, columna2....) REFERENCES NombreTabla.
Indica las columnas que son clave ajena referenciando a una clave candidata de otra tabla
UNIQUE (columna1, columna2...). El valor combinado de una o varias columnas es único.
CHECK (condición). Permite indicar una condición que deben cumplir las filas de la tabla. Puede afectar a varias columnas.
La cláusula Foreign Key tiene unas opciones optativas que se explican a continuación:
• Tratamiento de nulos: Cómo debe tratar el SGBD un valor NULL en una o más columnas de la clave ajena, cuando lo compare con las filas de la tabla padre
• Modo de borrado: Para determinar la acción que se debe realizar cuando se elimina una fila referenciada, se debe utilizar una regla de supresión opcional para la relación (CASCADE, SET NULL, SET DEFAULT, NO ACTION).
• Modo de modificación: Una regla de actualización para la relación, que determina la acción que se debe realizar cuando se modifica la clave candidata de la fila referenciada (CASCADE, SET NULL, SET DEFAULT, NO ACTION).
Ejemplo:
CREATE TABLE Clientes (No_ Cliente Integer not null Nombre char(30) not null, Apellido char(30) not null, Dirección char(50) not null, Ciudad char(50) not null,

96
País char(25) not null, Primary key(No_Cliente), Foreign key(No_Departamento) REFERENCES Departamentos ON DELETE SET NULL ON UPDATE CASCADE); )
Para los índices tenemos:
CREATE INDEX "NOMBRE_ÍNDICE" ON "NOMBRE_TABLA" (NOMBRE_COLUMNA)
Ejemplo:
CREATE INDEX IDX_cliente_localidad on Clientes (Ciudad, Pais)
En una base de datos podemos borrar objetos utilizando la sentencia DROP.
Borrar una tabla
Para borra una tabla, utilizamos:
DROP TABLE <nombre tabla> [CASCADE, RESTRICT]
Ejemplos:
DROP TABLE Clientes CASCADE ; -- La tabla se borra, así como las posibles restricciones relativas a esta tabla
DROP TABLE Clientes RESTRICT; -- La tabla se borra sólo si no se hace referencia a ella en ninguna restricción, p.e. en la definición de claves ajenas
Modificar una tabla La sentencia ALTER sirve para agregar o eliminar columnas de una tabla. Dentro de la tabla podemos Add (añadir) o Drop (borrar) columnas y restricciones (PRIMARY KEY, FOREING KEY, UNIQUE, CHECK, CONSTRAINT).
ALTER TABLE <nombre tabla> ADD <nombre columna nueva> <tipo de dato> [NOT NULL] MODIFY <nombre columna> [DEFAULT | DROP DEFAULT] valor DROP <nombre columna> [CASCADE | RESTRICT] ADD [PRIMARY KEY (nombre columna) | FOREIGN KEY (nombre columna) REFERENCES nombre_tabla | UNIQUE (nombre columna) | CHECK (condición) DROP CONSTRAINT nombre-restricción [CASCADE| RESTRICT]
Ejemplos:
ALTER table Clientes add Genero char(1); -- Agrega la columna de Genero a la tabla Clientes.
ALTER table Clientes MODIFY Nombre char(50); -- Cambia la el tamaño del nombre de 30 a 50 caracteres

97
7.2.3 Lenguaje de Manipulación de Datos
Las instrucciones de DML se usan para recuperar, agregar, modificar o borrar datos almacenados en los objetos de una base de datos. Aquí, las instrucciones más frecuentes son: SELECT, INSERT, UPDATE y DELETE empleadas para recuperar, insertar. Modificar y eliminar información almacenada en la base de datos.
La sentencia SELECT que es quizá el corazón del SQL ya que mediante ella se pueden realizar todas las operaciones del algebra relacional, podemos hacer consultas de cualquier tipo a la base de datos en forma no procedural. Esta sentencias permite seleccionar una o varias filas o columnas de una o varias tablas. Su sintaxis es:
SELECT nombre de las columnas
FROM tablas1, tabla2… tablan
WHERE condición de búsqueda
GROUP BY nombre de las columnas por las cuales agrupar --especifica consulta sumaria
HAVING condición de búsqueda para GROUP BY -- Especifica qué grupos incluir de los producidos por GROUP BY
ORDER BY nombre de columnas [ASC|DESC] -- Ordena los resultados de acuerdo a las columnas
--especificadas
Ejemplos:
SELECT Nombre, Apellido, Ciudad, Pais FROM Clientes ORDER BY Pais; -- Genera una lista con el nombre, apellido, ciudad y país de todos los clientes ordenados alfabéticamente por país.
Existen ciertas palabras reservadas que nos permiten hacer selecciones de datos específicos, a continuación una lista de las principales:
DISTINCT: permite seleccionar los valores distintos de la columna especificada SELECT DISTINCT "nombre_columna" FROM "nombre_tabla"
WHERE: Establece la condición que cumplen los datos seleccionados SELECT "nombre_columna" FROM "nombre_tabla" WHERE "condition"
AND/OR: Permite establecer múltiples condiciones SELECT "nombre_columna" FROM "nombre_tabla" WHERE "condición simple" {[AND|OR] "condición simple"}

98
IN: Selecciona las filas cuyo valor de la columna especificado esta en una la lista de valores SELECT "nombre_columna" FROM "nombre_tabla" WHERE "nombre_columna" IN ('valor1', 'valor2', ...)
BETWEEN: selecciona valores dentro de un rango SELECT "nombre_columna" FROM "nombre_tabla" WHERE "nombre_columna" BETWEEN 'valor1' AND 'valor2'
LIKE: seleciona valores similares al patrón especificado SELECT "nombre_columna" FROM "nombre_tabla" WHERE "nombre_columna" LIKE {patrón}
ORDER BY: ordena las filas de acuerdo a las columnas especificadas SELECT "nombre_columna" FROM "nombre_tabla" [WHERE "condición"] ORDER BY "nombre_columna" [ASC, DESC]
COUNT: cuenta el número de valores de la columna especificada SELECT COUNT("nombre_columna") FROM "nombre_tabla"
SUM: suma los valores de la columna SELECT SUM("nombre_columna") FROM "nombre_tabla"
AVG: calcula el valor promedio de los valores de una columna SELECT AVG("nombre_columna") FROM "nombre_tabla"
MIN: selecciona el valor mínimo de una columna SELECT MIN("nombre_columna") FROM "nombre_tabla"
MAX: selecciona el valor máximo de una columna SELECT MAX("nombre_columna") FROM "nombre_tabla"
GROUP BY: forma grupos de acuerdo a los valores de la columna establecida SELECT "nombre_columna 1", SUM("nombre_columna 2") FROM "nombre_tabla" GROUP BY "nombre_columna 1"
HAVING: elije que grupos de los generados por Group by mostrar. SELECT "nombre_columna 1", SUM("nombre_columna 2") FROM "nombre_tabla"

99
GROUP BY "nombre_columna 1" HAVING (condición)
Ejemplos:
Dadas las siguientes tablas:
1. Obtener los apellidos de los empleados sin repetición
SELECT DISTINCT Apellidos FROM EMPLEADOS
2. Obtener todos los datos de los empleados que trabajan para el departamento 37 y 77
SELECT * FROM EMPLEADOS
WHERE Departamento in (37,77)
3. Obtener el presupuesto total de todos los departamentos
SELECT SUM(Presupuesto) FROM DEPARTAMENTOS
4. Obtener el número de empleados por cada departamento
SELECT Departamento, COUNT(*)
FROM EMPLEADOS
GROUP BY Departamento
5. Reasignar a los empleados del departamento de investigación (código 77) al departamento de informática (código 14)
UPDATE EMPLEADOS
SET Departamento = 14
WHERE Departamento = 77

100
También se pueden hacer consultas de múltiples tablas, para ello las tablas deben tener columnas con valores de dominio común. Generalmente la columna de conexión es la llave primeria de una tabla y la foránea de otras. Existen dos formas para la sintaxis de este tipo de consultas una utilizando join y la otra sin utilizarlo:
Forma 1:
SELECT a1, a2, b1, b2
FROM taba1, tabla2
WHERE tabla1. a1 = tabla2.b1
Forma 2:
SELECT a1, a2, b1, b2
FROM taba1 INNER JOIN tabla2
ON tabla1. a1 = tabla2.b1
Existen otras sentencias útiles para agregar datos a las tablas, para modificar sus valores y eliminar datos de las mismas, estas sentencias son INSERT, UPDATE y DELETE a continuación su sintaxis:
INSERT INTO "nombre_tabla" ("columna1", "columna2", ...) VALUES ("valor1", "valor2", ...)
Ejemplo:
INSERT INTO Clientes (Nombre, Apellido, Dirección, Ciudad, País)
VALUES ('Juan’, ‘Perez', 3 Oriente 512, 'Puebla',’Mexico’)
La sintaxis de UPDATE es:
UPDATE "nombre_tabla" SET "columna_1" = [nuevo valor] WHERE {condición}
Ejemplo:
UPDATE Cliente SET Pais = ´Mexico’ WHERE Ciudad = "Pueblas"
La sintaxis de DELETE es:
DELETE FROM "nombre_tabla" WHERE {condición}

101
Ejemplo:
DELETE FROM Clientes WHERE Ciudad = "Puebla"
7.2.3 Lenguaje de Control de Datos
Una base de datos en un entorno multiusuario requiere tareas de control y gestión que son llevadas a cabo por el administrador de la base de datos o DBA (Data Base Administrator) para lo cual se utiliza un conjunto de sentencias de SQL que forman el lenguaje de control de datos o DCL (Data Control Language). Un importante papel del DBA es la gestión de los usuarios de la base de datos (altas, bajas, etc) y la concesión de ciertos permisos o privilegios de sistema a los usuarios para que éstos puedan realizar determinadas operaciones sobre la base de datos. La concesión de permisos y privilegios se realiza utilizando la sentencia GRANT y la cancelación de los mismos mediante la sentencia REVOKE.
Por defecto un usuario solo tiene acceso a las tablas que él mismo haya creado y no dispone de ningún permiso sobre las tablas de los otros usuarios. Los permisos asociados a las tablas y que pueden ser concedidos y retirados por el creador son los siguientes:
SELECT Consulta de tuplas
INSERT Introducción de tuplas
UPDATE Modificación de tuplas
DELETE Borrado de tuplas
ALTER Modificación de la estructura
ALL Todos los permisos
Los permisos pueden otorgarse con la opción WITH GRANT OPTION que indica que el usuario que recibe dicho permiso puede a su vez otorgarlo a otros usuarios a su voluntad y naturalmente retirarlo si así lo desea. La sintaxis del GRANT es:
GRANT nombre_privilegio ON nombre_del_objeto TO {user_name |PUBLIC |role_name} [WITH GRANT OPTION];
Ejemplos:
GRANT SELECT ON Clientes TO PUBLIC; -- da acceso de select a todos los usuarios sobre la tabla Clientes

102
GRANT DELETE ON Clientes TO PersonalAdmon WITH GRANT OPTION; -- da acceso de borrado al usuario PersonalAdmon, mismo que puede otorgarlo a más usuarios.
Los privilegios se retiran con REVOKE cuya sintaxis es:
REVOKE nombre_del_privilegio ON nombre_objeto FROM {user_name |PUBLIC |role_name} Ejemplo: REVOKE SELECT ON Clientes FROM user1; Quita el privilegio de SELET al usuario1 sobre la rabla Clientes
7.3 Actividades de Aprendizaje.
Considerando dos tablas de una tienda que vende artículos producidos por diferentes fabricantes de acuerdo al siguiente modelo, realiza las consultas que se solicitan:
1. Obtén los nombres de los productos vendidos en a tienda 2. Obtén los nombres y los precios de los productos de la tienda 3. Obtén el nombre de los productos cuyo precio sea menor a 200 pesos 4. Obtén todos los datos de los artículos cuyo precio esté entre 60 y 120 pesos 5. Obtén el nombre y precio en dólares de los artículos de la tienda 6. Selecciona el precio promedio de los artículos 7. Obtén el precio promedio de los artículos cuyo código de fabricante sea 2 8. Obtén el número de artículos cuyo precio sea mayor o igual a 180 pesos 9. Obtén el nombre y precio de los artículos cuyo precio sea mayor o igual a 180 pesos y
ordénalos descendientemente por precio y luego ascendentemente por nombre 10. Obtén un listado completo de artículos, incluyendo por cada artículo los daos del artículo y
de su fabricante 11. Obtén un listado de artículos, incluyendo el nombre del artículo, su precio y el nombre del
fabricante 12. Obtén el precio promedio de los productos de cada fabricante, mostrando sólo los códigos
de fabricante 13. Obtén el precio promedio de los productos de cada fabricante, mostrando el nombre del
fabricante 14. Obtén los nombres de los fabricantes que ofrezcan productos cuyo precio medio sea mayor
o igual a 150 pesos 15. Obtén el nombre y precio del artículo más barato

103
16. Obtén una lista con el nombre y precio de los artículos más caros de cada proveedor (incluyendo el nombre del proveedor)
17. Añadir un nuevo producto. Altavoces, 170 pesos del fabricante 2 18. Cambia el nombre del producto 8 a “Impresora Laser” 19. Aplicar un descuento del 10% a todos los productos 20. Aplicar un descuento de 10 pesos a todos los productos cuyo precio sea mayor o igual a 120
pesos. 21. Otorga al Usuario: SIRS privilegios de borrado sobre la tabla de FABRICANTES
7.4 Actividades de Evaluación de Adquisición del Conocimiento.
E1) Ejemplo de reactivos.
R1) Es el lenguaje de SQL que se utiliza para definir objetos:
a)DDL b)DML c)DCL d)DLL
R2) No es una sentencia válidad del DML
a) SELECT b)INSERT c)UPDATE d)GRANT
R3) Sentencia que permite contar el número de elementos de una columna
a) COUNT b)SUM c)AVG d)DISTINCT
R4) La extensión del archivo de transacciones cuando se crea una base de datos es:
a).mdf b).ndf c).ldf d).tdf
R5) Sentencias de SQL que se utiliza para eliminar una tabla
a)DELETE b)ERASE c)DROP d)ALTER
R6) HAVING es la condición de selección para grupos, cuál de las siguientes sentencias es para la selección de renglones:
a)UPDATE b)WHERE c)DISTINCT d)ORDER BY
7.5 Referencias del Capítulo 7.
[1] Forrest Houlette, Fundamentos de SQL, McGrawHill, 2001 [2] Kevin Kline, Daniel Kline, SQL in a Nutshell, 2001 [3] Andy Oppel, Robert Sheldon, SQL, Tercera Edición, 2009 [4] Alvaro E. García Manual práctico de SQL : http://www.cepeu.edu.py/LIBROS_ELECTRONICOS_4/ManualPracticoSQL.pdf [5] Tutorial de SQL: http://sql.1keydata.com/es/ [6] Borja Sotomayor, Ejercicios resueltos: http://superalumnos.net/files/EjerciciosSQL.pdf

104
Capítulo 8
La Identificación de Tareas de Usuario
para el Diseño de Sistemas de Información
Basados en Workflow.
Josefina Guerrero García Juan Manuel González Calleros
A pesar de que los Sistemas de Información (SI) se consideran vitales en cualquier organización, estos no tienen necesariamente el impacto esperado en la realización de tareas interactivas y no interactivas de estas organizaciones. Muchas causas pueden explicar esta falta de explotación: anteriormente las tareas se planeaban con la suposición implícita de que todo se llevaría a cabo por personas, la estructura organizacional se crea asumiendo que determinadas tareas se asignan a determinados grupos o individuos. En un segundo plano, se considera el uso de la tecnología - o más bien, los SI -que podrían apoyar parcialmente, o incluso tomar el control, del trabajo. Este enfoque no considera las oportunidades que ofrecen los sistemas de información. "Hemos llegado a un punto de inflexión: primero diseñamos los procesos de negocio de una manera más abstracta sin tener en cuenta la aplicación, y luego diseñamos los sistemas de información y la

105
organización juntos. De hecho, decidimos si cada tarea en un proceso debe ser realizado por un sistema de información o una persona"[15]. En este contexto, el SI puede no satisfacer las necesidades de la organización. Profesionales de la tecnología de la información entienden que hay una división entre la organización, con los requisitos de negocio, y el apoyo que se presta para hacer frente a estas exigencias. Buscando maneras de salvar esta brecha, el workflow (flujo del trabajo) podría ser considerado como un medio apropiado para hacer frente a esta necesidad (Figura 8.1).
Figura 8.1 Apoyo a los procesos de negocio a través de los sistemas de workflow
8.1 Objetivo Educativo
Que el alumno pueda ser capaz de entender la transformación de los problemas de negocios en sistemas de información.
8.2 Contenido Informativo
8.2.1. Los Sistemas de información en el contexto organizacional
8.2.2. La identificación de tareas de usuario para el diseño de sistemas de información
8.2.3. Conclusiones
8.2.1 Los Sistemas de Información en el Contexto Organizacional.
Un Sistema de Información (SI) puede definirse como "un conjunto de componentes interrelacionados que recolectan (o recuperan), procesan, almacenan y distribuyen la información" [11]. Un SI es un requisito previo necesario para muchas organizaciones para mantener su competitividad; por ello es muy importante tener éxito en la concepción de un SI, al menos por dos razones: 1) para que un SI sea comprensible en unaorganización donde se va a usar, es necesario tener en cuenta las prácticas actuales de trabajo, 2) un SI determina, en cierto grado, qué trabajo se puede hacer y cómo puede llevarse a cabo, entonces, debe ser diseñado de acuerdo a los objetivos y metas de las organizaciones [15].

106
Desde una perspectiva empresarial, los SI constituyen un importante instrumento para crear valor para la empresa. Permiten incrementar sus ingresos o reducir sus costos al proporcionar información que ayuda a los gerentes a tomar mejores decisiones o que mejora la realización de los procesos de negocios.El valor de un SI para una empresa, así como la decisión de invertir en cualquier nuevo SI, lo determina en gran parte el grado en que el sistema conducirá a la empresa a mejores decisiones administrativas, procesos de negocios más eficientes y una rentabilidad más alta. Los profesionales de la tecnología de la información entendemos que hay una división entre la parte empresarial, con los requisitos de sus negocios, y el apoyo que se presta para hacer frente a estos requisitos. Para lograr recudir esta brecha se considera el modelado de la automatización de los flujos de trabajo a través de modelos de workflow.El workflow es el estudio de los aspectos operacionales de una actividad de trabajo: cómo se estructuran las tareas, cómo se realizan, cuál es su orden correlativo, cómo se sincronizan, cómo fluye la información que soporta las tareas y cómo se le hace seguimiento al cumplimiento de las tareas [15].Un Sistema de Gestión de Workflow (WFMS) es un sistema informático que gestiona y define una serie de tareas dentro de una organización para producir un resultado final. Los WFMS permiten al usuario definir los flujos de trabajo diferentes para diferentes tipos de trabajos o procesos. Por ejemplo, en un entorno de fabricación, un documento de diseño puede ser automáticamente enrutado a partir de diseñador pasando a un director técnico hasta llegar al ingeniero de producción. En cada etapa del flujo de trabajo, un individuo o un grupo es responsable de una tarea específica. Una vez que la tarea se ha completado, el WFMS asegura que los responsables de la tarea siguiente son notificados y reciben los datos que necesitan para realizar su etapa del proceso. Los WFMS también automatizan tareas repetitivas, garantizan que las tareas incompletas son objeto de seguimiento y refleja las dependencias necesarias para la realización de cada tarea. Ha habido un creciente interés en los sistemas de gestión de workflow y el apoyo de flujo de trabajo flexible. Sin embargo, cuando se define un flujo de trabajo, el software no suele apoyar a los diseñadores en la creación de sistemas de informaciónque automaticen los procesos de negocio, es decir, sistemas que permiten a los usuarios finales realizar su trabajo de forma interactiva. Un workflow se refiera a las actividades relacionadas con la ejecución coordinada de las múltiples tareas realizadas por los diferentes recursos en una organización para lograr un objetivo comercial común. Una tarea define un trabajo por hacer por una persona, por un sistema de software o por ambos. El término Sistemas de Información de Workflow (WFIS),introducido en [2] para definir el uso de los conceptos de workflow para apoyar el diseño de sistemas de información, propone una metodología donde el flujo de trabajo se descompone en procesos que a su vez se descomponen en tareas, incluye la descripción de aquellos atributos de las tareas (y los recursos que las ejecutan) que son relevantes para controlar y coordinar su ejecución, así como las relaciones entre las propias tareas; sin olvidar los criterios para asignar la tarea a los recursos (i.e. patrones de asignación [13]). Desarrollar WFIS presenta muchos desafíos debido a la interacción del usuario que se lleva a cabo en dos niveles lógicos diferentes pero sincronizados. En el nivel superior, el workflow del administrador requiere un SI para controlar la ejecución del workflow y la asignación del trabajo a los recursos disponibles. En el nivel inferior, el workflow de los usuarios(empleados de la empresa encargados de ejecutar las tareas de un proceso de negocios) que realizan tareas interactivas asignadas a ellos y que usan un SI para ejecutarlas. Existe una cierta dependencia en estas dos categorías: cualquier cambio del estado del SI de los usuariosdebe ser reflejadoen el SI del administrador del workflow (i.e. el WFMS). En el otro sentido, cuando se requiere un recurso para ejecutar una tarea, estos son notificados a través de su SI mediante el uso de agendas o “WorkList” [14]. La capacidad de distribuir tareas y la información entre los participantes es una característica importante que puede funcionar a una variedadde niveles (grupo de trabajo o entre organizaciones) según el alcance de los flujos de trabajo, ya que puede utilizar una variedad

107
de mecanismos subyacentes de comunicaciones (email, messenger, etc.). Una alternativa de la arquitectura de workflow que hace hincapié en este aspecto de la distribución se muestra en la Figura 8.2. En las siguientes secciones se abordan los diferentes niveles de modelado de un WFIS y se presentan ejemplos de su uso.
Figura 8.2 Distribución en el servicio de workflow. Fuente [16]
8.2.2 La Identificación de Tareas de Usuario para el Diseño de Sistemas de Información Basados en Workflow.
La propuesta para especificar un sistema de información tomando en cuenta los conceptos delworkflow [2,4,12] considera dar respuesta a las cinco preguntas clave para cada parte de un proceso de negocio: ¿qué se quiere hacer?, ¿cómo se va a hacer?, ¿quién lo va a hacer?, ¿con qué se va a hacer?, ¿dónde se va a hacer? La metodologíaestá compuesta de los siguientes pasos principales:
• Identificación de requerimientos del WFIS. Mediante el uso de diferentes medios, tales como: entrevistas, observación directa, consulta de documentos, entre otros; se recopila la información que servirá como insumo para identificar los elementos del proceso de negocio a automatizar, es decir, workflow. Este paso corresponde a los requisitos del problema.
• Diseño del WFIS. Este paso incluye el modelado de procesos y tareas, así como la identificación de la estructura organizacional.
• Implementación del WFIS. Se considera el desarrollo del sistema tomando en cuenta las diferentes interfaces de usuario, las listas de trabajo “Worklist”. Aunque no se define explícitamente se tiene que considerar que la implementación de un gestor de workflow es posible basado en el workflow diseñado en el paso anterior.
El diseño de un WFIS (detallado en la ) es una actividad que puede comenzar a realizarse usando diferentes niveles de abstracción. El diseño del workflow permite a los diseñadores identificar conceptos libremente y empezar los detalles basados en sus preferencias. Por ejemplo, un diseñador puede preferirdescribir los detalles del problema, modelando las tareas de usuario y después describir el modelado de procesos, donde

108
se describen las tareas de alto nivel y su interrelación.Otro diseñador tal vez tiene mejor comprensión del problema con el modelo del workflow (una vista más abstracta del problema) y entonces, empezar a refinar agregando los procesos y finalizar con un modelado de tareas. No hay una restricción para elegir el inicio del modelado, sin embargo se conserva la trazabilidad de los conceptos de los diferentes modelos (el modelado de tareas es la parte del proceso y un modelo de procesos es la parte de un modelo workflow). En la Figura 8.3 las flechas hacia adelante y hacia atrás denotan la propagación de la información de un modelo a otro. Por ejemplo, si se agrega a una especificación un nuevo modelado de tareas, esta nueva tarea debe estar a disposición del modelado de procesos, y viceversa, esto es conocido como diseño evolutivo y se pueden encontrar más detalles al respecto en [10].
Figura 8.3 Metodología para el desarrollo de WFIS
El proceso es iterativo; una vez que se realiza la implementación está puede ser refinada y reiniciar desde los requerimientos del diseño. El modelado de las actividades también es iterativo. Identificación de tareas dentro del escenario. Durante esta etapa se realiza la recolección de los requisitos del sistema. La descripción del modelo tiene como objetivo identificar los escenarios de trabajo y traducirlos a elementos textuales que pueden ser procesados. Para lograr mayor certeza en la información recolectada es necesario

109
identificar al actor encargado de ejecutar el trabajo. Esto facilita la comprensión del trabajo, cuando es llevado fuera de la organización. Requiere reuniones constantes con el usuario final para que el diseñador pueda comprender sus tareas en sus contextos (entorno y recursos disponibles). Con base a la descripción textual que se obtiene del proceso de negocio, el diseñador de workflow identifica qué tareas se llevan a cabo, cómo se realizan, quién las realiza, dónde se realizan;después, se produce una clasificación de estos conceptos, que será validado por el experto del dominio (el usuario final, administrador del Workflow, y el supervisor). El principal elemento a identificar en un escenario es la tarea. Identificar tareas requiere de criterios [9,10] que permitan su selección en un conjunto de datos. Nos fijamos en cuatro dimensiones en el entorno a la ejecución de la tarea: el tiempo, el espacio, los recursos y lanaturaleza de la tarea. Cualquier variación de cualquiera de estas cuatro dimensiones, por si solo o combinado, se genera una nuevatarea. Por ejemplo:
1.Cambio de espacio (o cambio de ubicación): cuando el escenario indica un cambio de ubicación de las operaciones, un cambio de tareas se produce. Por lo tanto, cualquier fragmento de escenario como: “en la sede del trabajador hace…”, indica un cambio de espacio, por lo tanto unanueva tarea. 2. Cambio de los recursos: cuando el escenario sugiere que recursos nuevos o diferentes son explotados, un cambio de tarea se produce. 3. Cambio de hora: cuando el escenario indica un período de tiempo diferente en el que se lleva a cabo la tarea. 4. Cambio de la naturaleza de la tarea: cuando el escenario representa un cambio de tipo de tarea. "En primer lugar la secretaria escribe los datos personales del cliente en la computadora (interactiva), después se imprime la solicitud de queja en la impresora (automático) y, finalmente, el director firma la solicitud de queja (manual)".
Una vez identificadas las diferentes tareas, se procede a elaborar una tabla con los diferentes criterios de identificación utilizados [Tabla 8.1].
Tabla 8.1 Presentación estándar de las tareas
Número Nombre de la tarea No. Pred. Descripción Justificación
Donde: Número= número de la tarea en la aplicación Nombre de la tarea = nombre de la tarea, verbo objeto afectado por la acción N°Pred = número predecesor de la tarea Descripción = descripción detallada de la tarea Justificación = lista de criterios de identificación de la tarea Ejemplo« Tratamiento de ordenes del cliente »
Considere la siguiente descripción de un problema: El proceso de tratamiento de ordenes de un cliente comienza con la apertura de los sobres con los documentos asociados a la compre, enseguida se verifica la orden de compra que esté debidamente firmada y contenga la información necesaria para identificar al cliente. El operador de registros debe, vía una terminal de trabajo,codificar los datos de la orden. Una vez hecho esto el sistema actualiza el inventario de productos asociados a la orden. Algunas cosas de la solicitud dan origen a solicitud de compras, cuando no hay productos en existencia, el resto es separado y será enviado en uno o más envíos. De manera automática cuando nsolicitudes han sido generadas, se procede con la preparación de los envíos de manera que se optimizan los recursos. Cada envío lo prepara un empleado que cruza la bodega recolectando los

110
productos. Al final de la recolección de cosas, se colocan en una máquina que empaqueta los productos. Ahí mismo se envía a imprimir el recibo, factura y los documentos que van con el envío.El paquete y los documentos de acompañamiento (o prueba de no entrega) son enviados al cliente.Cuando llega mercancía, entregas retrasadas,los productos son separados. Cada vez que el producto se ha terminado y no hay forma de enviarlo una notificación se hace al cliente. A continuación se listan las tareas de un escenario de procesamiento de compras de clientes en una empresa y la justificación para separar las tareas. N° Nombre de la
Tarea
N°
Pred
Descripción Justificación
1 Preparación de la orden
-- Abrir sobres, verificar la orden de compra que esté debidamente firmada y contenga la información necesaria para identificar al cliente
--
2 Registro de la Orden 1 El operador de registros debe, vía una terminal de trabajo, codificar los datos de la orden.
-Punto de espera -Punto de decisión -Cambio de recurso
3 Actualiza el inventario
2 Actualiza el inventario de productos asocia a la orden. Algunas cosas de la solicitud dan origen a solicitud de compras, el resto es guardado y será enviado en uno o más envíos.
-Punto de decisión -Cambio de recurso
4 Preparación de la entrega
3 Cuando n solicitudes han sido generadas, se procede con la preparación de los envíos de manera que se optimizan los recursos
- Punto de espera
5 Tratamiento del pedido
4 Cruzar la bodega recolectando los productos
-Cambio de recurso -Cambio de lugar
6 Elaboración del paquete
5 Al final de la recolección de cosas se colocan en una máquina que empaqueta, ahí mismo se envía a imprimir el recibo, factura y los documentos de envío
-Cambio de recurso
7 Envío de mercancía 6 El paquete y los docs. de acompañamiento (o prueba de “no entrega”) son enviados al cliente.
-Cambio de recurso
8 Selección de ordenes retrasadas
7 Cuando llega mercancía, entregas retrasadas de estos productos son seleccionadas
-Diferencia de periodicidad
9 Notificación de no reservas
8 Cada vez que el producto se ha terminado una notificación se hace al cliente
-Diferencia de periodicidad

111
8.2.3 Conclusiones
Desde una perspectiva empresarial, los SI constituyen un importante instrumento para crear valor para la empresa. Permiten incrementar sus ingresos o reducir sus costos al proporcionar información que ayuda a los gerentes a tomar mejores decisiones o que mejora la realización de los procesos de negocios. Los sistemas de workflow son herramientas que permiten la implementación técnica de procesos de negocio. Permiten dar soporte y agilizar el proceso de negocio ganando tiempo. Permite a la gente involucrada llevar a cabo procesos de negocio complejos independientemente del tiempo y el lugar. Un workflow está compuesto de procesos, que a su vez están formados por tareas; una tareas es una unidad de ejecución espacio-temporal en una unidad organizacional usando el mismo conjunto de recursos. Identificando las tareas de usuarios en una organización, se pueden generar árboles de tareas, dando paso al modelado de tareas. Los modelos de tareas describen las actividades del usuario para alcanzar sus metas. Conocer las tareas necesarias para la consecución de objetivos es fundamental para el proceso de diseño (sobre todo si pensamos en sistemas de información como solución).Modelos de tareas representan la intersección entre el diseño de la interfaz de usuario y enfoques más sistemáticos por dar a los diseñadores un medio de representación y manipulación de una abstracción de las actividades que debe realizar para alcanzar los objetivos del usuario. En algunos casos el modelo de tarea de un sistema existente se crea con el fin de entender mejor el diseño subyacente y analizar sus posibles limitaciones y cómo superarlas. El modelado de tareas presenta una solución que es independiente de cualquier posible solución, incluso, computacional. Entonces, modelando las tareas de usuario, es posible generar interfaces de usuario para los sistemas de información [1, 3, 4, 8].
8.4 Actividades de Aprendizaje y Evaluación.
Actividad 8.1) Considere el siguiente escenario:
Cuando un cliente llega a la agencia inmobiliaria, ingresa su solicitud a la secretaria de solicitudes. Indica el tipo de bien que desea rentar o comprar, sus restricciones de presupuesto así como las principales características de los bienes que le podrían interesar. El empleado registra su solicitud, es decir, asocia el perfil del cliente con las variable estándar de comprar de bienes, en caso de ser nuevo cliente se da de alta su perfil en el sistema. La conclusión del registro de una solicitud lanza de manera automática, para cada variante del perfil del cliente, la impresión de bienes que pudieran ser de su interés y que aún estén disponibles (esta lista describe la ubicación del bien, el precio solicitado y la información de la superficie). El cliente examina las listas y elimina lo que no le interesa. Si quedan cosas de su interés entonces se le dirige al servicio de visitas. Para cada bien que le interesa al cliente, se le proporcionan más amplios detalles, mientras otro empleado busca fotografías del bien. Gracias a los detalles extras y las fotos, el cliente puede tener una opinión más amplia del bien. El empleado registra si el cliente está o no de acuerdo y procede a la visita física del inmueble. Se pide: elaborar una tabla de tareas (como la Tabla 8.1) con la ayuda de los criterios de identificación de tareas.
Actividad 8.2) Considere el siguiente escenario:

112
La persona que tiene interés en abrir una cuenta bancaria se dirige con un ejecutivo quien le proporciona información sobre las ventajas, características y la diferencia entre una cuenta de ahorro y cuenta corriente (cuenta de cheques), así como los montos de apertura de cada una, el saldo mínimo mensual que debe mantener en la cuenta y las comisiones de manejo de cuenta. También le indica al cliente los documentos requeridos (credencial de elector, comprobante de domicilio). Una vez que la persona elige el tipo de cuenta a abrir, el ejecutivo entra al sistema del banco e ingresar la información personal del cliente, posteriormente selecciona y captura el número de cuenta que será asignado al cliente, a partir de un conjunto de cuentas asignadas a la sucursal (dicho conjunto de cuentas es un paquete físico de sobres que contienen la tarjeta de debito y en su caso una chequera provisional). Posteriormente, el ejecutivo solicita al cliente introducir su código PIN no mayor a 4 dígitos. Una vez que el ejecutivo termina de capturar toda la información, pide al cliente pase a cajas a depositar el dinero para activar la cuenta mientras el ejecutivo imprime el contrato bancario; después de hacer el depósito el cliente regresa con el ejecutivo para firmar el contrato y la tarjeta de debito. Una vez que el cliente firmo el contrato, el ejecutivo separa una hoja de firmas para enviarla al departamento de digitalización vía correo interno bancario, una vez que es recibida la hoja en el departamento de digitalización se procede a su captura y almacenamiento en la base de datos para que pueda ser consultada en el sistema bancario desde cualquier sucursal. En caso de que haya decidido abrir una cuenta corriente, el ejecutivo debe entregar personalmente en casa del cliente la chequera temporal al día siguiente para verificar la existencia real del domicilio, la chequera personalizada (con nombre del cliente) estará lista en tres días, por lo que el cliente puede recogerla en la misma sucursal. El departamento de chequeras recibe la notificación de la asignación de una cuenta corriente a un nuevo cliente, obtiene el nombre y procede a la impresión de la misma cotejando en sus archivos que números de serie de cheques le corresponden al cliente según el número de cuenta, posteriormente envía la chequera a la sucursal del banco donde el cliente abrió su cuenta. Una vez que el cliente recoge la chequera personalizada, el ejecutivo activa en el sistema la chequera, el cliente debe revisar y firmar electrónicamente en conformidad. El documento firmado es almacenado por el sistema y la agencia encargada de emitir las chequeras es notificada para procesar el cierre en el sistema. Se pide: elaborar una tabla de tareas (como la Tabla 8.1) con la ayuda de los criterios de identificación de tareas.
Ejemplo de posible solución
N° Nombre de la
Tarea
N°
Pred
Descripción Justificación
1 Solicitar información de cuenta bancaria
La persona se dirige con el ejecutivo del banco para abrir una cuenta bancaria.
Recurso(info)
2 Dar información sobre los tipos de cuenta manejadas
1 El ejecutivo del banco le proporciona toda la información referente a abrir una cuenta, ya sea de ahorro, corriente, comisiones, etc.
Recurso(info)
3 Indicar documentos requeridos
El ejecutivo indica al cliente los documentos requeridos para poder abrir la cuenta (credencia de elector, comprobante de domicilio).
Recurso(info)
4 Seleccionar tipo de 3 El cliente decide qué tipo Recurso(info)

113
cuenta de cuenta va a abrir en el banco
5 Entrar al sistema El ejecutivo entra al sistema del banco utilizando sunombre deusuario y contraseña para acceder a él.
Cambio de lugar
5.1 Ingresar información del cliente
5 El ejecutivo proporciona al sistema todos los datos personales necesarios para registrar una nueva cuenta (nombre completo, dirección, teléfono, fecha de nacimiento, referencias personales, etc.)
Recurso(info)
5.2 Dar número de cuenta
5.1 El sistema proporciona al ejecutivo el número de cuenta generado.
Recurso(info)
5.3 Introducir NIP 5.2 El cliente proporciona al sistema el NIP con el que realizará las transacciones en el cajero automático. Un código de 4 dígitos (número del 0-9).
Cambio de lugar
6 Depositar a cuenta 5.2 El cliente deposita dinero a su nueva cuenta para activarla.
Cambio de lugar
7 Imprimir contrato 5.2 El ejecutivo imprime el contrato y sus respectivas copias para ser firmadas por el cliente.
Cambio de lugar
8 Firmar contrato y tarjeta
7 El cliente firma el contrato y su tarjeta
Cambio de lugar
9 Enviar copias de contrato
8 El ejecutivo manda a recursos humanos del banco las copias de los contratos firmados por el cliente, para llevar un mejor registro de la cuenta.
Recurso(info)
10 Entregar chequera 5.1 El ejecutivo entrega directamente en la casa del cliente la chequera de la cuenta recién dada de alta.
Cambio de lugar
11 Recoger chequera 5.1 El cliente recoge directamente en la sucursal del banco la chequera de su cuenta.
Cambio de lugar
12 Cotejar información 10,11 El ejecutivo coteja la información proporcionada por el cliente y valida la entrega de la chequera.
Recurso(info)

114
8.4 Referencias del Capítulo 8
1. Guerrero Garcia, J. Conceptual Modeling of User Interfaces toWorkflowInformationSystems, DEA thesis, UniversitéCatholique de Louvain, Belgique. September 2006
2. Guerrero, J., Vanderdonckt, J., Gonzalez Calleros, J.M., FlowiXML: a Step towards Designing Workflow Management Systems, Journal of Web Engineering, Vol. 4, No. 2, 2008, pp. 163-182.
3. Guerrero, J., Vanderdonckt, J., Gonzalez, J.M., Winckler, M. Modeling User Interfaces to Workflow Information Systems, Proc. of 4th International Conference on Autonomic and Autonomous Systems ICAS’2008 (Gosier, 16-21 March 2008), IEEE Computer Society Press, Los Alamitos, 2008.
4. Guerrero, J., Vanderdonckt, J., Lemaigre, Ch.,GonzálezCalleros, J.M.How to Describe Workflow Information Systems to Support Business Process, Proc. of 10th IEEE Joint Conference on E-Commerce Technology and Enterprise Computing, E-Commerce and E-Services CEC’2008 (Washington D.C., July 21, 2008), IEEE Computer Society Press, Los Alamitos, 2008, pp. 404-411
5. Guerrero García, J., Lemaigre, Ch.,Vanderdonckt, J.,GonzálezCalleros, J.M.Model-Driven Engineering of Workflow User Interfaces, Proc. of 7th Int. Conf. on Computer-Aided Design of User Interfaces CADUI’2008 (Albacete, 11-13 June 2008), Springer, Berlin, 2008
6. Guerrero, J., Vanderdonckt, J., González Calleros, J.M.,Winckler, M.,Towards a Library of Workflow User Interface Patterns, Proc. of 15th Int. Workshop on Design, Specification, and Verification of Interactive Systems DSV-IS’2008 (Kingston, July 16-18, 2008), Lecture Notes in Computer Sciences, Vol. 5136, Springer, Berlin, 2008, pp. 96-101
7. Guerrero, J., Lemaigre, Ch., Gonzalez Calleros, J.M., Vanderdonckt, J., Towards a Model-Based User Interface Development for Workflow Information Systems, International Journal of Universal Computer Science, Vol. 14, No. 19, 2008, pp. 3236-3249
8. Guerrero Garcia, J., Vanderdonckt, J., González Calleros, J.M., Developing user interfaces for community-oriented workflow information systems, Chapter 16, in D. Akoumianakis (ed.), “Virtual Communities of Practice and Social Interactive Technologies: Lifecycle and Workflow Analysis”, IGI Global Inc., Hershey, 2009, pp. 307-329
9. Guerrero Garcia, J. Methodology for DevelopingUser Interfaces to Workflow Information Systems, Ph.D. Thesis, UniversitéCatholique de Louvain, Belgique. February 2010.
10. Guerrero-Garcia, J., Gonzalez-Calleros, J., Vanderdonckt, J., Evolutionary Design of Graphical User Interfaces. InProcs.of the Software Support for User Interface Description Language - Interact'2011 Workshop (UIDL´2011), Lisbon, Portugal, pp. 53-62, ISBN: 978-2-9536757-1-9.
11. Laudon, K., &Laudon, J. (2006). Management information systems: managing the digital firm.UpperSadle River (United States): Pearson Prentice Hall.
12. Lemaigre, Ch., Guerrero, J., Vanderdonckt, J., Interface Model Elicitation from Textual Scenarios, Proc. of 1st IFIP TC 13 Human-Computer Interaction Symposium HCIS’2008

115
(Milan, 8-9 September 2008), P. Forbrig, F. Paterno, A.M. Pejtersen (eds.), International Federation of Information Processing, Vol. 272, Springer, Boston, 2008, pp. 53-66.
13. Russell N., van der Aalst, W.M.P., terHofstede, A.H.M. & Edmond, D. (2005) Workflow Resource Patterns. In the 17th Conference on Advanced Information Systems Egineering (CAISE’05). Porto, Portugal. 13-17 June.
14. SujathaSundaram. WorkList Handler for the WorkTrak Workflow Management System. Available on: http://pooh.east.asu.edu/Lindquist/WorkTral/worktrak.html
15. vander Aalst, W. & van Hee, K., Workflow Management: Models, Methods, and Systems. THE MIT Press, Cambridge. 2002.
16. WfMC. The Workflow Reference Model. Workflow Management Coalition. Document Number TC00-1003. Document Status – Issue 1.1. 19-Jan-1995.

116
Capítulo 9
Elaboración de Reactivos para
las Asignaturas de Bases de Datos
e Ingeniería de Software
María del Consuelo Molina García
En el presente capítulo, se proporciona una guía para realizar reactivos así como contar con elementos que sirvan de apoyo en los procesos de planeación y evaluación y determinar cuáles son las necesidades de las áreas de conocimiento e integrar elementos de evaluación que puedan servir como parámetro de calidad en el proceso educativo.
9. 1 Objetivo Educativo.
Evaluar los conocimientos y habilidades indispensables para el ejercicio profesional eficaz y eficiente de los alumnos de las materias de Bases de Datos e Ingeniería de Software.

117
Objetivos Específicos.
4.1.1. Comprender y definir los lineamientos de reactivos de opción múltiple mediante ejemplos y contraejemplos.
4.1.2. Conocer los niveles de conocimiento de acuerdo a la taxonomía de objetivos de aprendizaje de la Taxonomía de Benjamín Bloom.
4.1.3. Identificar los diferentes niveles de conocimiento en reactivos. 4.1.4. Enriquecer el nivel académico de los alumnos de las materias de Ingeniería de
Software y Bases de datos, cuyos conocimientos sean pertinentes y suficientes.
9.2 Contenido Informativo.
9.2.1. Introducción 9.2.2. Instrumentos de medición educativa 9.2.3. Reactivos de opción múltiple 9.2.3.1 Características de un buen reactivo 9.2.9. Normas para la construcción de reactivos 9.2.5. Normas para los reactivos de opción múltiple 9.2.6. Constitución de los reactivos 9.2.7. Formato para redactar los reactivos 9.2.8. Taxonomías de aprendizaje 9.2.8.1 Taxonomía de Bloom 9.2.9. Tabla de Especificaciones 9.2.10. Clasificación de reactivos 9.3 Referencias del Capitulo 9
9.2.1 Introducción
Es importante mencionar que dentro de toda actividad educativa la evaluación educativa es uno de los elementos fundamentales, misma que a su vez nos permite tomar decisiones acerca de nuestra labor en el aula. ¿Está aprendiendo bien nuestro alumno?, ¿somos buenos enseñando?, ¿evaluamos lo que queremos evaluar?, ¿nuestros exámenes miden lo que realmente esperamos?, etc. Muchas son las tareas que debemos realizar para mejorar el proceso de la enseñanza y el aprendizaje, desde que planeamos nuestras clases, las herramientas didácticas que utilizamos, la forma de enseñar, hasta cómo evaluar a nuestros alumnos. Entre los elementos fundamentales que nos permiten recoger evidencias de lo que se ha logrado en nuestros estudiantes, sobresalen sin duda los instrumentos de medición, pues a través de estos nos evaluamos nosotros mismos como profesores. Ciertamente los exámenes no son el único elemento que nos ayuda a la toma de decisiones, pero si nos proporcionan pautas de acción para mejorar nuestra labor de enseñanza. Al respecto, cabe hacernos la pregunta si nuestros instrumentos de medición son realmente claros para el entendimiento de nuestros alumnos. Es decir, si al hacer nuestras preguntas el alumno sabe lo que le estamos pidiendo, independientemente de si saben o no la respuesta. O bien, al redactar nuestra pregunta tenemos que los alumnos contestan otra cosa diferente de lo que esperábamos. En

118
consecuencia, lo primero que planteamos es que el alumno no sabe, sin darnos cuenta de que nuestra pregunta podría estar mal estructurada, es decir confusa, ambigua o incluso mal redactada. En el caso de los reactivos de opción múltiple se cometen muchos errores de este tipo, no solo en la pregunta en si misma, sino también en las opciones que le presentamos al alumno para que elija la respuesta correcta. Por ejemplo, se puede dar el caso de que al hacer un reactivo de tres o más opciones, resulta que hay dos opciones correctas porque usamos un sinónimo. Puede darse el caso también de que hayamos puesto una opción que esta fuera de contexto de lo que se le preguntaba, y por tanto, el alumno de inmediato la elimina por absurda. Entonces en lugar de que el alumno llegue a la respuesta con base a un análisis, sin darnos cuenta le estamos dando la respuesta correcta. De esta forma y a fin de evitar una serie de errores en nuestros reactivos de opción múltiple, es que se requiere elaborarlos de acuerdo a una normatividad. Es por eso, que el presente capitulo tiene como propósito orientar al docente para elaborar reactivos de calidad con base a una metodología sencilla y práctica. Siguiendo una serie de reglas y normas que se pueden aplicar, sin dejar de lado por supuesto la práctica constante. De esta forma podemos mejorar el diseño de nuestros instrumentos de medición educativa 9.2.2 Instrumentos de Medición Educativa
En términos muy generales entendemos que evaluación es: el enjuiciamiento sistemático de la valía o mérito de un sujeto, de un objeto o de un fenómeno, mientras que la medición es: la asignación de valores numéricos para cuantificar los atributos de hechos, fenómenos, objetos o sujetos, de acuerdo con unidades prestablecidas. En el caso de la medición educativa, la información que se recoge a través de los instrumentos de medición se concibe como parte fundamental que constituye un insumo básico para sustentar juicios valorativos acerca del objeto de estudio. Entonces al aplicar los instrumentos de medición educativa estos tienen el propósito de:
1. Incrementar la calidad y eficacia de los procesos de enseñanza-aprendizaje a través de su continua revisión. 2. Obtener información sobre los resultados de la metodología empleada en la enseñanza que permita establecer correcciones pertinentes. 3. Centrar la atención del alumno hacia aquellos aspectos más relevantes del programa educativo. 4, Servir de retroalimentación, afianzando los aciertos y corrigiendo los errores, orientando tanto al alumno como al profesor.
Cualquiera que sea la estructura del instrumento que apliquemos a los alumnos, estos deben cumplir con dos características fundamentales: la validez y la confiabilidad, es decir, un instrumento de medida debe medir aquello que se propone medir (validez) y además medirlo con precisión (fiabilidad). Para la elaboración de los instrumentos de medición, se debe realizar varios pasos, sin embargo, en este manual nos concentraremos en la parte de la construcción de los reactivos que queremos en nuestro instrumento de medición y en particular, los reactivos de opción múltiple.

119
Antes de continuar, es importante señalar que para la elaboración de nuestro instrumento de medición, este debe estar respaldado por ciertas especificaciones. Estas especificaciones va ser nuestro documento que sustente la elaboración del instrumento y su propósito consiste en presentar los contenidos que se evaluarán, la cantidad de preguntas que corresponde a cada uno, así como el nivel de complejidad de cada pregunta. La complejidad que vamos a utilizar será acorde a la taxonomía propuesta por Benjamín Bloom y colaboradores. Para la construcción de nuestros reactivos utilizaremos las siguientes categorías: Conocimientos, Comprensión, Aplicación y Análisis que se describen más adelante.
9.2.3 Reactivos de Opción Múltiple
Para construir los reactivos de opción múltiple, se tienen que cumplir una serie de normas, las que se refieren tanto al contenido como a la estructura, entendiéndose por contenido todo lo relativo al campo de estudio que trata un área o disciplina determinada; y, por estructura, lo relativo al procedimiento para elaborar reactivos de opción múltiple.
• Definición Se entiende por construcción de reactivos el proceso mediante el cual un especialista elabora preguntas basadas en el contenido de diferentes fuentes documentales, con el fin de detectar el grado de dominio que los sustentantes poseen de dicho contenido.
• Objetivos: 1. Normar la construcción de reactivos de opción múltiple. 2. Orientar a los constructores para la elaboración de reactivos de opción múltiple. 3. Constituir un marco de referencia para la revisión y aceptación de los reactivos. • Clasificación de errores El incumplimiento de las normas para la construcción de reactivos genera tres tipos de errores:
o Errores menores. Son aquellos que no afectan la efectividad del reactivo. o Errores mayores. Son aquellos que, sin invalidar el reactivo, tienen grandes
probabilidades de reducir su efectividad. o Errores críticos. Son aquellos que impiden la efectividad del reactivo,
invalidándolo. Para una mejor representación sobre la elaboración de reactivos de opción múltiple, se considera que éstos tienen la siguiente estructura genérica figura 1:

120
Figura 1. Estructura Genérica
• BASE: Debe plantear un problema, redactado de manera clara y precisa. • OPCIONES: Su contenido debe estar asociado con el problema. Su redacción debe ser
clara y precisa. Entre éstas debe existir sólo una respuesta correcta. • RESPUESTA CORRECTA (clave): Su contenido debe solucionar totalmente el problema
planteado. • DISTRACTORES: Su contenido debe plantear errores de razonamiento o de información.
Estos deben representar: o El error más frecuente que cometen los alumnos. o Términos que pueden confundirse/mezclarse en caso de que el aprendizaje no
haya sido suficiente. 9.2.3.1 Características de un Buen Reactivo
La base y las opciones DEBEN: 1. Estar redactadas con claridad y precisión. 2. Evitar emplear generalizaciones tales como: siempre, nunca, ninguno, todos.
Especialmente cuando éste influye en la respuesta. La pregunta o aseveración:
a) No contiene claves de la respuesta correcta. b) Cuando se requiere distinguir el contraejemplo o la negación de una
característica utiliza la palabra EXCEPTO (en mayúscula y al final de la aseveración) en lugar de “no”.
c) Incluye todas las palabras que puedan repetirse en las diferentes opciones de respuesta.
Las opciones: 1. La extensión y estructura debe ser similar. 2. Son homogéneas, pertenecen al mismo campo semántico. 3. Evitar utilizar sinónimos. 4. Cuidar las consistencias de género y/o número en las opciones de respuesta
Ejemplo:
La propiedad “No existen tuplas duplicadas”, implica la existencia de:

121
a)Relaciones b)Llaves primarias c)Llaves ajenas d)Dominios
9.2.4 Normas para la Construcción de Reactivos
• Generales
1. Los reactivos deben corresponder al contenido y nivel taxonómico asignados en la tabla de referencia. 2. Los reactivos deben apegarse a la información fuente, así como a la ciencia o disciplina científica de que se trate. 3. Los reactivos deben presentar un problema bien definido, es decir, incluir todos los elementos necesarios y suficientes para la solución del mismo. 4. Los reactivos deben incluir estrictamente los elementos necesarios para comprender adecuadamente el problema planteado. 5. Los reactivos deben tener coherencia gramatical. 6. Los reactivos deben ser independientes entre sí, para evitar que unos ayuden a contestar otros. 7. Las respuestas de los reactivos no deben ser condición para resolver el (los) siguiente(s) reactivo(s). 8. Deben redactarse en términos sencillos, claros y precisos, considerando el lenguaje empleado en las fuentes de información y/o el lenguaje propio del nivel y grado educativos. 9. En el caso concreto de matemáticas, el constructor debe presentar los datos para resolver el reactivo de manera que no propicie que el sustentante llegue a la respuesta acertada mediante procedimientos incorrectos. 10. En caso de incluirse dibujos, éstos deben ser claros y congruentes con la construcción total del reactivo. 11. No deben formularse con la misma redacción utilizada en las fuentes de información, excepto cuando se trate de leyes y definiciones, los cuales deben entrecomillarse. Cuando en una prueba se incluya textualmente un escrito, se debe anexar la fuente para verificar que se ha respetado fielmente el original. 12. Si el texto proporcionara pocos elementos para construir un reactivo, es conveniente usar sinónimos comunes. 13. Deben plantearse en forma afirmativa. 19. No deben incluirse marcas de productos y/o circunstancias que fomenten el consumismo y los vicios. 15. No debe incluir nombres de personajes ficticios empleados en los medios masivos de comunicación. 16. No deben involucrar, de manera irónica, nombres de funcionarios e instituciones públicas. 17. La respuesta de cada reactivo debe anotarse en la plantilla de claves o en el cuadro de respuestas y en la tarjeta de reactivos.
9.2.5 Normas para los Reactivos de Opción Múltiple
1. La base debe presentar un problema bien definido, de tal manera que sin leer las opciones tenga sentido propio. 2. Debe existir correspondencia gramatical entre la base y las opciones en cuanto a sintaxis, género, número, persona, tiempo y modo.

122
3. La base incluirá lo estrictamente necesario (palabras y/o elementos gráficos) para comprender el correcto sentido de la respuesta. 4. El reactivo debe incluir una respuesta correcta. 5. La respuesta correcta debe resolver completamente el problema. 6. Sólo una de las opciones debe ser la respuesta correcta. 7. Los distractores no deben ser parcialmente correctos, excepto cuando la base interrogue por la opción más correcta. Cuando la base pregunte por la opción más correcta, deberá subrayarse la expresión que señala la condición para la respuesta. 8. Las opciones deben guardar entre sí un equilibrio coherente en su aspecto gramatical en cuanto a sintaxis, género, número, persona, tiempo y modo, excepto cuando se pregunte precisamente por estos aspectos. 9. Las opciones deben guardar entre sí un equilibrio coherente en cuanto a su longitud. 10. Cuando se utilice una declaración negativa en alguna opción es necesario incluir por lo menos otra opción con declaración negativa. 11. Cuando en las opciones se utilicen cifras numéricas, éstas deben ordenarse en forma ascendente o descendente, de acuerdo a su valor. 12. Las cifras deben alinearse con referencia al punto decimal, ya sea que esté implícito o explícito, excepto cuando se trate de expresiones algebraicas. 13. Cuando los reactivos incluyan dibujos, éstos deberán ser claros y congruentes con la construcción total del reactivo. 19. Los dibujos, figuras o gráficas deben cumplir con las convenciones establecidas para cada caso, teniendo cuidado de no dar por válidos algunos supuestos. 15. Hay que evitar la repetición y/o sinonimia de términos o vocablos entre la base y la respuesta correcta o algún distractor. En caso de que la repetición de estos términos sea necesaria, deben incluirse también en el resto de las opciones. 16. No se deben usar opciones sinónimas (que se expresen en lenguaje diferente, pero tienen el mismo significado). 17. No hay que utilizar, a manera de opciones, frases como “todas éstas”, “ninguna de éstas”, “todas las anteriores”, “ninguna de las anteriores”, “no lo dice el texto” o expresiones similares. 18. Los distractores deben ofrecer una virtual solución al problema planteado, de manera que no se les rechace por absurdos. 19. La letra que designa la respuesta del reactivo debe anotarse correctamente en la plantilla de claves y en la tarjeta del reactivo. 20. La respuesta correcta debe ubicarse en un porcentaje de veces aproximadamente igual en cada una de las opciones. 21. No se debe utilizar las mismas opciones para otros reactivos.
9.2.6 Constituciòn de los Reactivos
• Reactivo Independiente
I. Para plantear el problema no se requiere presentar ninguna información, sea en forma de texto, datos o gráficos. Ejemplo En los sistemas relacionales las relaciones se representan mediante:
a)Apuntadores b) Transacciones c)Valores explícitos d)Registros

123
• Reactivo dependiente
I. Para plantear el problema es indispensable presentar información, sea en forma de texto, datos o gráficos. Ejemplo: Considera la siguiente relación, de la B.D. Películas_Artistas: Película(ClaveP,Título,Año,Duración,TipoP,Compañía,EstrellaPrincipal) Proponga datos para seis tuplas.
ClaveP Título Año Duración TipoP Compañia EstrellaPrin Identifica o en su caso establece: Grado: ______ Cardinalidad: ______ Llave primaria. _________ Dominio para cada atributo: ClaveP: _________________________________________________ Título: _________________________________________________ Año: _________________________________________________ Duración: _________________________________________________ TipoP: _________________________________________________
9.2.7 Formato para Redactar los Reactivos
ASIGNATURA:
NIVEL:
UNIDAD:
TEMA: SUBTEMA:
CONTENIDO:
ESPECIFICACION:
REACTIVO:

124
JUSTIFICACION: AUTOR:
NIVEL TAXONOMICO
REFERENCIA BIBLIOGRAFICA:
9.2.8 Taxonomías de Aprendizaje
Objetivos de aprendizaje y niveles de conocimiento
Cuando se diseña un curso, lo primero que debemos definir es qué queremos que los alumnos sean capaces de hacer. Sabemos su relación con los contenidos… pero hay diferencias sustantivas entre:
• Conocer las causas, • Comprender las causas e • Identificar causas similares en otros contextos, • Aplicar fórmulas, • Resolver ejercicios.
Cada una de ellas implica diferentes niveles de procesamiento y se ilustra en las taxonomías, el camino entre los niveles de aprendizaje humano.
Taxonomías de objetivos de aprendizaje.
Surgen por la necesidad de hacer clases y catalogar el tipo de respuesta esperada por parte del alumno.
9.2.8.1 Taxonomía de Bloom
Procesos básicos
• Conocimiento.- Implica conocimiento de hechos específicos, formas y medios de tratar con los mismos, conocimientos de lo universal y de las abstracciones específicas de un determinado campo del saber. Son de modo general, elementos que deben memorizarse.
• Comprensión: .- Concierne al aspecto más simple del entendimiento que consiste en captar el sentido directo de una comunicación o de un fenómeno, como la comprensión de una orden escrita u oral, o la percepción de lo que ocurrió en cualquier hecho particular.

125
• Aplicación.- Concierne a la interrelación de principios y generalizaciones con casos particulares o prácticos Procesos superiores
• Análisis.- Implica la división de un todo en sus partes y la percepción del significado de las mismas en relación con el conjunto. Comprende el análisis de elementos, de relaciones, etc.
• Síntesis.- Se refiere a la comprobación de la unión de los elementos que forman un todo. Puede consistir en la producción de una comunicación, un plan de operaciones o la derivación de una serie de relaciones abstractas.
• Evaluación.- Este tipo de conocimiento comprende una actitud crítica ante los hechos. Se asocia con juicios relativos a la evidencia interna y externa. Objetivos de evaluación Los objetivos de la evaluación consisten en definir lo que se espera medir; estos objetivos van necesariamente ligados a nuestros propósitos y metas en la experiencia educativa. Antes de seleccionar la metodología y las técnicas para una evaluación, se requiere que exista un programa del curso planeado en su totalidad, con objetivos generales, específicos, actividades y recursos didácticos a utilizar. Estos objetivos nos permiten tener una idea clara de nuestra intención, tanto al enseñar como al evaluar lo aprendido. Es muy importante que exista congruencia entre lo que se enseña y lo que se evalúa. Una vez elaborados estos objetivos podremos elaborar reactivos de exámenes adecuados a la enseñanza
9.2.9 Tabla de Especificaciones
La tabla de especificaciones es una matriz de doble entrada que sirve para obtener una guía del contenido que se deberá cubrir en el examen. Indica cómo deben quedar representadas las distintas áreas proporcionalmente en relación al número total de reactivos.
A continuación se presenta un formato de una tabla de especificaciones para llenar con los contenidos a evaluar, los niveles conductuales, los pesos relativos a asignar y el número de reactivos correspondiente.
TABLA DE ESPECIFICACIONES ÁREA A EVALUAR ________________________ PLAN _______
SUB-AREA (TEMAS)
PESO %
OBJETIVO ESPECIFICO
DE EVALUACIÓN
PESO % CANTIDAD
DE REACTIVOS
TIPO DE REACTIVO
NIVEL COGNITIVO
NUMERO DEL
REACTIVO
30% DEFINIR… 30% 2 O.M. 2 1,2 ANALIZAR…
DE ACUERDO A….
70% 3 F-V 3 3,4,5
COMPRENDER
TOTAL 100% TOTAL DE REACTIVOS

126
Existen diversas metodologías para elaborar la tabla de especificaciones. Por ejemplo, se pueden asignar los contenidos y los pesos relativos tomando en cuenta el tiempo que se dedica a cada unidad, el énfasis que se da a cada contenido, la influencia que tiene un contenido específico sobre otras materias, etc. La tabla de especificaciones debe de ir bien detallada para que los redactores no tengan duda sobre el tipo de reactivos que elaborarán y en qué áreas del conocimiento.
La metodología que se presenta facilita asignar los pesos relativos para cada tópico. Los pasos a seguir para elaborar esta tabla son los siguientes:
Elaborar una matriz de relaciones de los contenidos que contempla el programa analítico. La matriz permitirá saber con objetividad qué se debe evaluar.
A continuación aparece un ejemplo de una matriz de incidencias y dependencias.
1.1 1.2 1.3 2.1 2.2 2.3 2.4 3.1 3.2 3.3 Incidencias 1.1 √ √ √ √ 4 1.2 √ √ √ 3 1.3 √ √ √ 3 2.1 √ √ 2 2.2 √ 1 2.3 √ √ 2 2.4 √ √ 2 3.1 √ 1 3.2 √ 1 3.3 0
Dependencias 19
• Llenar la matriz marcando las incidencias de la siguiente manera: • Incidencias: si el contenido tiene influencia sobre otros. • En la columna total, sumar el número de incidencias hacia la derecha. • Hacer la sumatoria de la columna de totales. • Definir las áreas a evaluar sumando las incidencias de los contenidos que corresponden
a dichas áreas. • Asignar los pesos relativos a las áreas que comprenderá el examen. Estos pesos se
obtienen mediante la siguiente fórmula:
� ���� �� ��� ���� � �100�
����� � ��� ���
• Asignar el número de reactivos a las áreas que comprenderá el examen. Estos valores se
obtienen mediante la siguiente fórmula:
� �� �� ���. � �� ������
100

127
Incidencia Formula para
peso %
Formula para reactivos
No. De Reactivos
1.1 4 9(100)/19 20% 20(25)/100 5 1.2 3 3(100)/19 15.7% 16% 16(25)/100 4 1.3 3 3(100)/19 15.7% 16% 16(25)/100 4 2.1 2 2(100)/19 10.5% 11% 11(25)/100 3 2.2 1 1(100)/19 5.2% 5% 5(25)/100 1 2.3 2 2(100)/19 10.5% 11% 11(25)/100 3 2.4 2 2(100)/19 10.5% 11% 11(25)/100 3 3.1 1 1(100)/19 5.2% 5% 5(25)/100 1 3.2 1 1(100)/19 5.2% 5% 5(25)/100 1 3.3 0 0(100)/19 0% 0% 0(25)/100 0 T.I=19 100% 25
• Asignar el nivel cognitivo de los reactivos que se elaborarán posteriormente. El nivel
cognitivo dará el nivel de dificultad (1 al 6) de los reactivos. Para esto, es necesario conocer los objetivos de enseñanza-aprendizaje.
9.2.10 Clasificacion de Reactivos
Los reactivos del examen están clasificados, de acuerdo con el nivel cognoscitivo que evalúan, de la manera siguiente:
• Recordar: implica la recreación de un hecho, concepto, principio o procedimiento presentado en clase o encontrado en un material impreso (conocimiento).
• Evaluar: requiere que el sustentante seleccione uno o varios criterios, o identifique las consecuencias de una situación dada. Se pueden evaluar hechos, conceptos, principios y procedimientos.
• Resolver problemas: comprende la aplicación de conocimientos, ideas generales, reglas de procedimiento
Bloom y sus colegas desarrollaron una taxonomía acorde a las áreas factibles de aprendizaje personal:
• Cognitivo (intelectual) • Actitudinal (afectivo)
Psicomotor (competencia).
El diseño de cursos y reactivos toma como base la taxonomía del dominio intelectual
Procesos Básicos
• Conocimiento: Implica conocimiento de hechos específicos, formas y medios de tratar con los mismos, conocimientos de lo universal y de las abstracciones específicas de un

128
determinado campo del saber. Son de modo general, elementos que deben memorizarse.
• Comprensión: Concierne al aspecto más simple del entendimiento que consiste en captar el sentido directo de una comunicación o de un fenómeno, como la comprensión de una orden escrita u oral, o la percepción de lo que ocurrió en cualquier hecho particular.
• Aplicación: Concierne a la interrelación de principios y generalizaciones con casos particulares o prácticos
Procesos Superiores
• Análisis: Implica la división de un todo en sus partes y la percepción del significado de las mismas en relación con el conjunto. Comprende el análisis de elementos, de relaciones, etc.
• Síntesis: Se refiere a la comprobación de la unión de los elementos que forman un todo. Puede consistir en la producción de una comunicación, un plan de operaciones o la derivación de una serie de relaciones abstractas.
• Evaluación: Este tipo de conocimiento comprende una actitud crítica ante los hechos. Se asocia con juicios relativos a la evidencia interna y externa.
9.3 Referencias del Capítulo 9
[1]Carreño, H. (1985). Enfoques y principios teóricos de la evaluación. México: Trillas. [2]Martínez Arias, R. (1985). Psicometría. Teoría de los Exámenes Psicológicos y Educativos. Madrid: Síntesis. [3]Monedero J. (1998). Bases teóricas de la evaluación educativa. Granada: Aljibe. [4]Padilla, M. (2002). Técnicas e instrumentos para el diagnóstico y la evaluación educativa. Madrid: CCS. [5]Peralta F. y Sánchez Roda M. (1998). El plan de evaluación: instrumentos. Madrid: Escuela Española. [6]Tenbrink, T. (1999). Evaluación. Guía práctica para profesores. Madrid: Narcea. [7] de la Torre S., Roberto y Caracheo G., Francisco (1993) Redacción de reactivos.

129
Colofón
Objetos de Aprendizaje para la Enseñanza de Bases de Datos, Ver./012
Libro publicado electrónicamente, 2.15 MB, almacenado en un CD en formato PDF. Se terminó de reproducir el 14 de Noviembre de 2012,
en el Laboratorio de Bases de Datos de la Facultad de Ciencias de la Computación, ubicado en la 14 Sur y la Avenida San Claudio, Ciudad Universitaria, Puebla, Pue. Mex.
Teléfono 01-222-229 55 00 Ext. 7208. Responsable de la Publicación, M.C. María del Rocío Boone Rojas.
Tiraje 50 ejemplares. No. De Páginas 129.