GPUs Rayco González Sicilia Microprocesadores para Comunicaciones 5º ETSIT.
Upload
universidad-militar-nueva-granadaCategory
view
208download
6
BOARD, ALIMENTACIÓN, PUERTOS, BUSES, OVERCLOKING, GPUS Y ALGO MÁS
Msc. Ing. Jairo E. Márquez D.
Introducción
Conocer el sistema operativo de cualquier equipo parte de conocer el hardware que debe gestionar y/o administrar. Es por ello, que es importante identificar los elementos fundamentales que conforma un computador, las últimas tecnologías asociadas a cada elemento y análisis sobre su funcionamiento, es clave para cualquier ingeniero de sistemas, redes, informática y/o ciencias de la computación.
Placa base1
Llamada también como placa madre, tarjeta madre o board (motherboard, mainboard), es una tarjeta de circuito impreso a la que se conectan las partes o componentes de un computador. Tiene instalados una serie de circuitos integrados, entre los que se encuentra el chipset, que sirve como centro de conexión entre la CPU, la memoria RAM, los buses de expansión y otros dispositivos.
Va instalada dentro de una caja que por lo general está hecha de chapa y tiene un panel para conectar dispositivos externos y muchos conectores internos y zócalos para instalar componentes dentro de la caja.
La placa base, incluye un software (firmware) llamado BIOS, que le permite realizar las funcionalidades básicas, tales como pruebas de los dispositivos, vídeo y manejo del teclado, reconocimiento de dispositivos y carga del SO en la RAM. Esto implica que existe más de una BIOS para tareas específicas, por ejemplo BIOS de arranque situado en el disco duro y la placa base.
La BIOS en sí, es un software básico escrito en assembler instalado en la board que permite que esta cumpla su cometido, proporcionando la comunicación de bajo nivel, el funcionamiento y configuración del hardware del sistema que como mínimo, maneja el teclado, y proporciona la salida básica durante el arranque, en la 1 Fuente primaria de consulta. Wikipedia.
que en ocasiones emite pitidos normalizados por el altavoz de la computadora si se producen fallos. Estos mensajes de error son utilizados para encontrar soluciones al momento de armar o reparar un equipo.
También, la BIOS posee un componente de hardware y otro de software. A nivel de hardware, es totalmente configurable y es donde se controlan los procesos del flujo de información en el bus del ordenador, entre el SO y los demás periféricos. A nivel de software, brinda una interfaz generalmente de texto que permite configurar varias opciones del hardware instalado en el PC, como por ejemplo el reloj, o desde qué dispositivos de almacenamiento iniciará el SO (Windows, GNU/Linux, Mac OS X, etc.).
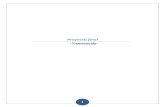
Componentes de la placa base (Diagrama de una placa base típica).

Una placa base típica admite los siguientes componentes:
• Uno o varios conectores de alimentación: por estos conectores, una alimentación eléctrica proporciona a la placa base los diferentes voltajes e intensidades necesarios para su funcionamiento.
• El zócalo de CPU (del inglés socket): es un receptáculo que recibe el micro-procesador y lo conecta con el resto de componentes a través de la placa base.
• Las ranuras de memoria RAM (en inglés memory slot), en número de 2 a 6 en las placas base comunes.
• Las ranuras de expansión: se trata de receptáculos que pueden acoger tarjetas de expansión (estas tarjetas se utilizan para agregar características o aumentar el rendimiento de un ordenador; por ejemplo, una tarjeta gráfica se puede añadir a un ordenador para mejorar el rendimiento 3D). Estos puertos pueden ser puertos ISA (interfaz antigua), PCI (Peripheral Component Interconnect) y, los más recientes, PCI Express.
• El chipset: Es un conjunto de circuitos electrónicos que se encargan de gestionar las transferencias de datos entre los diferentes componentes del computador (CPU, memoria, tarjeta gráfica, unidad de almacenamiento secundario, etc.).
• Un reloj: regula la velocidad de ejecución de las instrucciones del microprocesador y de los periféricos internos.
• La pila de la CMOS: proporciona la electricidad necesaria para operar el circuito constantemente y que éste último no se apague perdiendo la serie de configuraciones guardadas.
• La BIOS (Basic Input-Output System): Es un programa registrado en una memoria no volátil (memorias flash). Este programa es específico de la placa base y se encarga de la interfaz de bajo nivel entre el microprocesador y algunos periféricos. Recupera, y después ejecuta, las instrucciones del MBR (Master Boot Record), registradas en el DD, cuando arranca el sistema operativo.
• El bus: conecta el microprocesador al chipset, está cayendo en desuso frente a HyperTransport y Quickpath.
• El bus de memoria conecta el chipset a la memoria temporal. • El bus de expansión o bus I/O: une el microprocesador a los conectores
entrada/salida y a las ranuras de expansión. • Los conectores de entrada/salida que cumplen normalmente con la
norma PC 99: estos conectores incluyen:
o Los puertos PS2 para conectar el teclado o el ratón, estas interfaces tienden a desaparecer a favor del USB
o Los puertos serie, por ejemplo para conectar dispositivos antiguos. o Los puertos paralelos, por ejemplo para la conexión de antiguas
impresoras. o Los puertos USB (en inglés Universal Serial Bus), por ejemplo para
conectar periféricos recientes. o Los conectores RJ45, para conectarse a una red informática.

o Los conectores VGA, DVI, HDMI o Displayport para la conexión del monitor de la computadora.
o Los conectores IDE o Serial ATA, para conectar dispositivos de almacenamiento, tales como discos duros, unidades de estado sólido y unidades de disco óptico.
o Los conectores de audio, para conectar dispositivos de audio, tales como altavoces o micrófonos.
Con la evolución de las computadoras, más y más características se han integrado en la placa base, tales como circuitos electrónicos para la gestión del vídeo IGP (Integrated Graphic Processor), de sonido o de redes (10/100 Mbps/1 Gbps), evitando así la adición de tarjetas de expansión. Es importante establecer tal como se hizo en clase, que la placa base entorno al chipset, se divide en dos secciones:
− El puente norte (northbridge): gestiona la interconexión entre el microprocesador, la memoria RAM y la unidad de procesamiento gráfico o GPU. − − El puente sur (southbridge): gestiona los periféricos y los dispositivos de almacenamiento, como los DD o las unidades de disco óptico. Las nuevas líneas de procesadores de escritorio tienden
a integrar el propio controlador de memoria en el interior del procesador. Unos conceptos adicionales a tener en cuenta en la motherboard son: Almacenamiento: Son las conexiones que permiten instalar DD y discos SSD de última generación. Cada vez es más importante la velocidad en la lectura y escritura de estos discos que son más económicos. En las tres últimas generaciones (Z97, X99 y Z170) existen las conexiones SATA III, Sata Express y la conexión M.2 que obtiene unas tasas de transferencia en MBps, evitando los cables de almacenamiento y de datos. Lanes: Son los carriles que llevan la información del procesador al resto de piezas “rápidas” como una tarjeta gráfica o disco SSD. Es un factor a tener en cuenta para la configuración de un PC. Por ejemplo, si se desea un PC Gamer con 2 tarjetas gráficas, la serie Z170 puede ser ideal, pero si lo que se quiere son tres tarjetas gráficas, se debe optar

por la plataforma X99 con 28 y 40 LANES o comprar una placa base Z170/Z97 con un chip PLX. Memoria RAM: Muy a tener en cuenta porque no es lo mismo una placa base con módulos DDR3 o con una memoria RAM DDR4. Se puede aprovechar la RAM del anterior PC o nos interesa tener mayor velocidad, voltaje y latencia. Conexiones traseras: En la actualidad se requiere que el equipo disponga de conexiones HDMI, Displayport, DVI, USB 3.0, USB 3.1 Type-C o el necesario PS/2 para teclados mecánicos gaming. Fabricantes de placas base Varios fabricantes se reparten el mercado de placas base, tales como Abit, Albatron, Aopen, ASUS, ASRock, Biostar, Chaintech, Dell, DFI, ECS EliteGroup, Epox, Foxconn, Gigabyte Technology, Intel, MSI, QDI, Sapphire Technology, Soltek, Super Micro, Tyan, Via, XFX, Pc Chips. Algunos diseñan y fabrican uno o más componentes de la placa base, mientras que otros ensamblan los componentes que terceros han diseñado y fabricado.
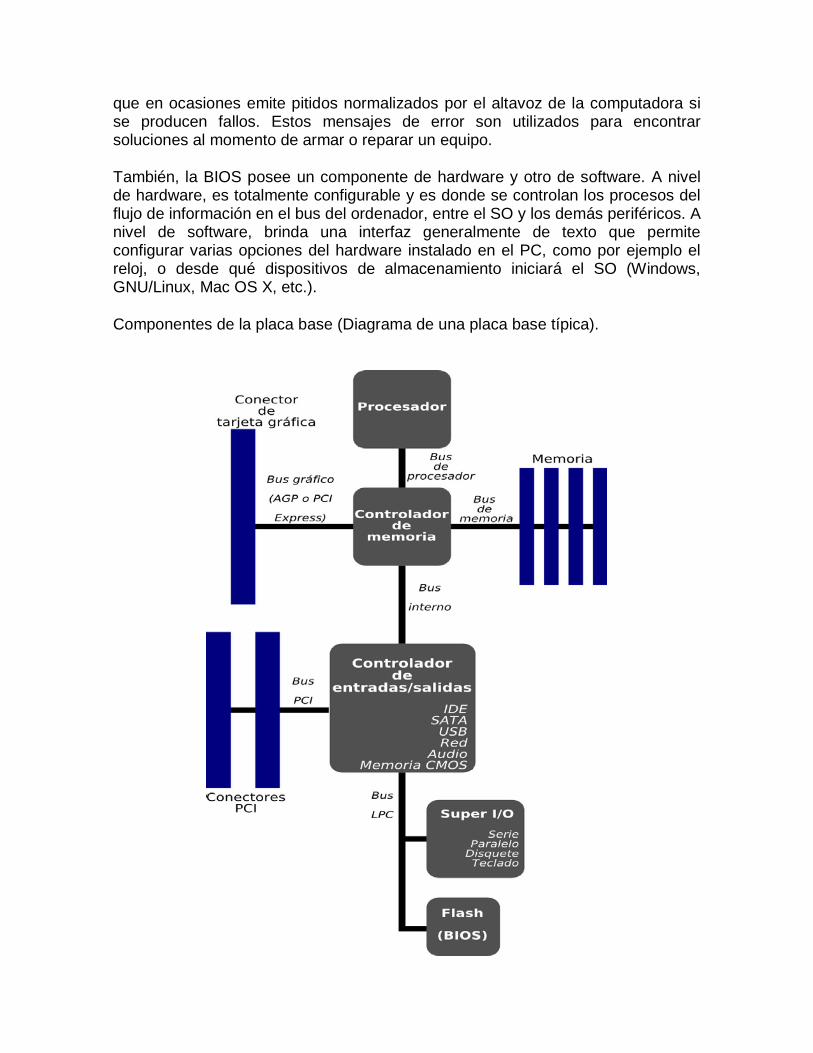
Tipos de placas base
Gigabyte Placa Base Ga-z87x-oc. 2016-2017. Tomado de http://www.pcexpansion.es/gigabyte_placa_base_ga-z87x-oc.php

La mayoría de las placas de PC vendidas después de 2001 se pueden clasificar en dos grupos:
• Las placas base para procesadores AMD
o Slot A Duron, Athlon o Socket A Duron, Athlon, Athlon XP, Sempron o Socket 754 Athlon 64, Mobile Athlon 64, Sempron, Turion o Socket 939 Athlon 64, Athlon FX , Athlon X2, Sempron, Opteron o Socket 940 Opteron y Athlon 64 FX o Socket AM2 Athlon 64, Athlon FX, Athlon X2, Sempron, Phenom o Socket F Opteron o Socket AM2 + Athlon 64, Athlon FX, Athlon X2, Sempron, Phenom o Socket AM3 Phenom II X2/X3/X4. o Socket AM4 Phenom III X3/X4/X5
• Las placas base para procesadores Intel
o Socket 7: Pentium I, Pentium MMX o Slot 1: Pentium II, Pentium III, Celeron o Socket 370: Pentium III, Celeron o Socket 423: Pentium 4 o Socket 478: Pentium 4, Celeron o Socket 775: Pentium 4, Celeron, Pentium D (doble núcleo), Core 2
Duo, Core 2 Quad Core 2 Extreme, Xeon o Socket 603 Xeon o Socket 604 Xeon o Socket 771 Xeon o LGA1366 Intel Core i7, Xeon (Nehalem) o LGA1156 Intel Core i3, Intel Core i5, Intel Core i7 (Nehalem) o LGA 2011 Intel Core i7 (Sandy Bridge) o LGA 1155 Intel Core i7, Intel Core i5 y Intel Core i3 (Sandy Bridge)

Las mejores placas bases AMD recomendadas para el 2016-2017 son:
− Gigabyte 970A-DS3P | AM3+ | 65 euros − MSI 970A SLI Krait Edition cn USB 3.1 | AM3+ | 95 euros − MSI 970 Gaming | AM3+ | 105 euros − Gigabyte GA-990XA-UD3 | AM3+ | 104 euros − Gigabyte F2A88XN – Wifi | FM2 | 110 euros − Asus A88XM Plus | FM2 | 75 euros − MSI AM1 | AM1 | 32 euros − ASRock AM1H-ITX | 64 euros
Mejores placas bases Intel LGA1151 (B150/H170/Z170)
− Gigabyte GA-B150M-D3H | DDR3 | 89 euros − Asrock H170M Pro4 | 104 euros − Asus B150 PRO Gaming/Aura | 134 euros − Gigabyte GA-Z170M-D3H | 125 euros − MSI Z170 Krait Gaming | 135 euros − Gigabyte GA-Z170X-Gaming 3 | 148 euros − MSI Z170A GAming Pro | 152 euros − Asus Maximus VIII Ranger | 186 euros − Asus Maximus VIII Hero | 230 euros − MSI Z170A Gaming M7 | 230 euros − Gigabyte Z170X Gaming 7 | 255 euros − MSI Z170A Xpower Gaming Titanium | 305 euros − Asus Maximus VIII Extreme | 453 euros
Mejores placas bases Intel LGA 2011-3 (X99)
− MSI X99A SLI Plus | 230 euros − MSI X99A SLI Krait Edition | 265 euros − Asus X99-A − Asus X99-PRO USB 3.1 − Asus X99 Deluxe − Asus X99 Rampage V Extreme − MSI X99A GodLike Gaming
Qué placa base comprar en 2017.
Estas placas son lo más actual que podrás conseguir este año, están actualizadas con las últimas novedades tecnológicas y disponen de la suficiente solidez como para recomendarlas. La mayoría cuenta con la última tecnología en protección contra factores de riesgo como la humedad o las variaciones de electricidad, causas comunes de roturas y que gracias a esto podrás evitar.

Para comprar una placa base, la elección dependerá del tipo de ordenador que quiera montar, por ejemplo, para algo básico y no tanto, el modelo Gigabyte GA-H110M-S2H es bueno, ya que cuenta con soporte para los últimos procesadores y memorias. Para juegos y overcloking, se puede emplear un ASUS Z170-P, que incluso cuenta con soporte para USB-C y Crossfire o SLi, tecnologías de alta velocidad que permiten utilizar el equipo al máximo.
Paca base AMD o Intel.
En la actualidad se dispone de 6 u 8 núcleos de la serie FX (AM3+) a buen precio y los cuatros núcleos de la serie mainstrame de Intel (LGA 1150 y LGA 1151). ¿Qué es mejor? Se ha demostrado por activa y por pasiva que Intel ofrece un mejor rendimiento (IPC) pero su precio es más elevado. ¿Merece la pena la inversión? Sí, siempre y cuando sea para jugar, virtualizar y trabajar con equipos Workstation de diseño gráfico y vídeo.
Si lo que se quiere es un pc de bajo costo, AMD es la mejor opción. Actualmente ofrecen sus APU y configuraciones de PC con socket AM1. Son buenos, tienen buena tarjeta gráfica integrada (iGP) y sus placas bases de gama media son baratas.

Board gigabyte

Actual.
Un ejemplo de placa base con todos sus aditamentos para un pc ideal-2016-2017
Motherboard para PC gaming 2016. Fuente http://www.gadgetreview.com/how-to-build-your-next-gaming-pc

RAM DDR4

Debemos tener en cuenta varios conceptos a la hora de elegir a una placa base. Por ejemplo, para el caso de un Asus: Componentes: Comprar una buena placa debe implicar la elección de buenos componentes. Asus tiene su tecnología Digi+, Gigabyte la Ultra Durable y MSI la Military Class. Todas ellas tienen excelentes componentes, pero quién a día de hoy monta las mejores fases de alimentación y CHOKES es Gigabyte. Refrigeración: Se debe elegir entre refrigeración pasiva (sin ventiladores), con ventilador o kit con combo con refrigeración líquida (Por ejemplo, la Gigabyte Z170X SOC Force). Normalmente la refrigeración pasiva es la opción más inteligente, porque no incorpora el pequeño y molesto ventilador que finalmente acaba averiándose. ¿Qué componentes se suelen refrigerar? Básicamente los chips con más calor: fases de alimentación y chipset principal. Chipset: Es el encargado de la interconexión entre el procesador y el resto de elementos, controladoras y memorias de configuración. Cuanto más avanzada, tendrá soporte nativo a conexiones USB 3.1, permitirá conectar más tarjetas gráficas, PCI Express 3.0 o versiones superiores, etc. Puertos de expansión: estos son muy útiles para conectar tarjetas gráficas, controladoras externas de televisión, tarjeta de sonido… Existen muchos tipos: PCI clásicos, PCI Express o las antiguas AGP (ya desfasadas).
Fuente: http://www.digit.in/slideshows/building-a-gaming-pc-tower-under-rs-50-000-1.html

Placa multiprocesador Este tipo de placa base puede acoger a varios procesadores (generalmente de 2, 4, 8 o más). Estas placas base multiprocesador tienen varios zócalos de micro-procesador (socket), lo que les permite conectar varios micro-procesadores físicamente distintos (a diferencia de los de procesador de doble núcleo).
Cuando hay dos procesadores en una placa base, hay dos formas de manejarlos:
• El modo asimétrico, donde a cada procesador se le asigna una tarea diferente. Este método no acelera el tratamiento, pero puede asignar una tarea a una CPU, mientras que la otra lleva a cabo a una tarea diferente.
• El modo simétrico, llamado PSM (Symmetric MultiProcessing), donde cada tarea se distribuye de forma simétrica entre los dos procesadores.
Algunos fabricantes proveen placas base que pueden acoger hasta 8 procesadores (en el caso de socket 939 para procesadores AMD Opteron y sobre socket 604 para procesadores Intel Xeon).
Linux fue el primer sistema operativo en gestionar la arquitectura de doble procesador enx86. Sin embargo, la gestión de varios procesadores existía ya antes en otras plataformas y otros sistemas operativos. Linux 2.6.x maneja multiprocesadores simétricos, y las arquitecturas de memoria no uniformemente distribuida
Algunos fabricantes proveen placas base que pueden acoger hasta 8 procesadores (en el caso de socket 939 para procesadores AMD Opteron y sobre socket 604 para procesadores Intel Xeon).
Z170 ATX motherboard for 6th Gen. Intel processors with CrossChill EK Hybrid air/liquid cooling, full ROG armor and metal fortifying backplate.Tomado de: https://rog.asus.com/19652016/featured/ces-2016-latest-rog-maximus-asus-pro-gaming-motherboards-with-aura-lighting/

Las tarjetas madre necesitan tener dimensiones compatibles con las cajas que las contienen, de manera que desde los primeros computadores personales se han establecido características mecánicas, llamadas factor de forma, que definen la distribución de diversos componentes y las dimensiones físicas, como por ejemplo el largo y ancho de la tarjeta, la posición de agujeros de sujeción y las características de los conectores.
Factor de forma de la placa madre El término factor de forma (en inglés <em>form factor</em>) normalmente se utiliza para hacer referencia a la geometría, las dimensiones, la disposición y los requisitos eléctricos de la placa madre. Para fabricar placas madres que se puedan utilizar en diferentes carcasas de marcas diversas, se han desarrollado algunos estándares:
• AT miniatura/AT tamaño completo es un formato que utilizaban los primeros ordenadores con procesadores 386 y 486. Este formato fue reemplazado por el formato ATX, cuya forma favorecía una mejor circulación de aire y facilitaba a la vez el acceso a los componentes.
• ATX: El formato ATX es una actualización del AT miniatura. Estaba diseñado para mejorar la facilidad de uso. La unidad de conexión de las placas madre ATX está diseñada para facilitar la conexión de periféricos

(por ejemplo, los conectores IDE están ubicados cerca de los discos). De esta manera, los componentes de la placa madre están dispuestos en paralelo. Esta disposición garantiza una mejor refrigeración.
• ATX estándar: Tradicionalmente, el formato del estándar ATX es de 305 x 244 mm. Incluye un conector AGP y 6 conectores PCI. Normalmente sus medidas son 30,5 cm x 24,4 cm y es compatible con el 100% de cajas de PC del mercado (Mid Tower o Semi-Torre). Es el formato recomendado en configuraciones Gamer o para equipos Workstation.
• XL-ATX y E-ATX: Estos son formatos especiales e implican la adquisición de una torre de gran tamaño con 10 o más slots de expansión. Son ideales para el montaje de refrigeración líquidas completas, varias tarjetas gráficas y muchas unidades de almacenamiento.
• micro-ATX: Este formato resulta una actualización de ATX, que posee las mismas ventajas en un formato más pequeño (244 x 244 mm), a un menor costo. El Micro-ATX incluye un conector AGP y 3 conectores PCI. Es un formato muy al uso pero con la llegada de placas bases más pequeñas se ha quedado un poco deshuso. Ideal para equipos de salón.
• Flex-ATX: FlexATX es una expansión del microATX, que ofrece a su vez una mayor flexibilidad para los fabricantes a la hora de diseñar sus ordenadores. Incluye un conector AGP y 2 conectores PCI.
• mini-ATX: El miniATX surge como una alternativa compacta al formato microATX (284 x 208 mm) e incluye a su vez, un conector AGP y 4 conectoresPCI en lugar de los 3 del microATX. Fue diseñado principalmente para mini-PC (ordenadores barebone).
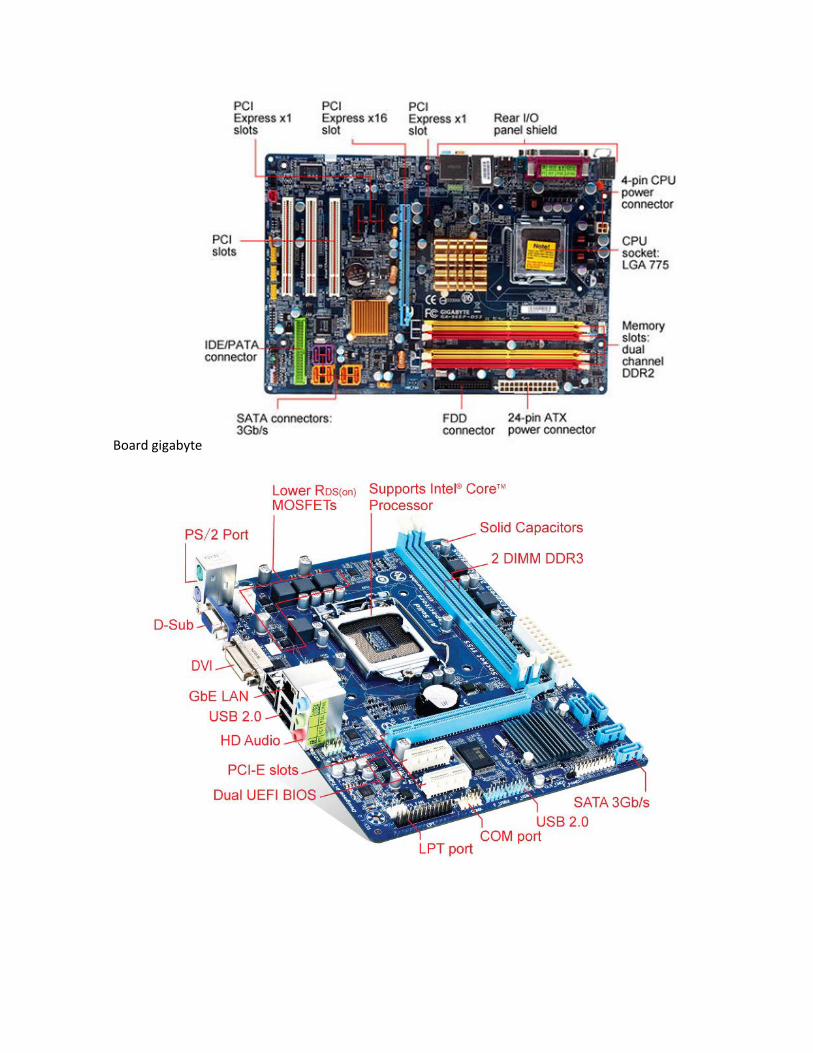
• BTX: El formato BTX (Tecnología Balanceada Extendida), respaldado por la marca Intel, es un formato diseñado para mejorar tanto la disposición de componentes como la circulación de aire, la acústica y la disipación del calor. Los distintos conectores (ranuras de memoria, ranuras de expansión) se hallan distribuidos en paralelo, en el sentido de la circulación del aire. De esta manera, el microprocesador está ubicado al final de la carcasa, cerca de la entrada de aeración, donde el aire resulta más fresco. El cable de alimentación del BTX es el mismo que el de la fuente de alimentación del ATX. El estándar BTX define tres formatos: - BTX estándar, con dimensiones estándar de 325 x 267 mm. - micro-BTX, con dimensiones reducidas (264 x 267 mm).
- pico-BTX, con dimensiones extremadamente reducidas (203 x 267 mm).
- ITX: El formato ITX (Tecnología de Información Extendida), es muy
compacto, diseñado para configuraciones en miniatura como lo son las mini-PC. Su llegada ha revolucionado el mundo de las placas bases y equipos gaming con dimensiones pequeñas y capaz de mover resoluciones 2560 x 1440p (2K) y 3840 x 2160p (4K). Existen dos tipos de formatos ITX principales. a. mini-ITX, con dimensiones pequeñas (170 x 170 mm) y una ranura PCI.
b. nano-ITX, con dimensiones muy pequeñas (120 x 120 mm) y una ranura
miniPCI. Por esta razón, la elección de la placa madre y su factor de forma dependen de la elección de la carcasa. La tabla que se muestra a continuación resume las características de los distintos factores de forma.
Factor de forma Dimensiones Ranuras
ATX 305 x 244 mm AGP/6 PCI
microATX 305 x 244 mm AGP/3 PCI
FlexATX 229 x 191 mm AGP/2 PCI
Mini ATX 284 x 208 mm AGP/4 PCI
Mini ITX 170 x 244 mm 1 PCI
Nano ITX 120 x 244 mm 1 MiniPCI
BTX 325 x 267 mm 7
microBTX 264 x 267 mm 4
picoBTX 203 x 267 mm 1

STANDARD ATX (Advanced Technology Extended)
Se desarrollo como una evolución del factor de forma de Baby-AT2, para mejorar la funcionalidad de los actuales E/S y reducir el costo total del sistema. Este fue creado por Intel en 1995. Fue el primer cambio importante en muchos años en el que las especificaciones técnicas fueron publicadas por Intel en 1995 y actualizadas varias veces desde esa época, la versión más reciente es la 2.2 publicada en 2004.
Una placa ATX tiene un tamaño de 305 mm x 244 mm (12" x 9.6"). Esto permite que en algunas cajas ATX quepan también placas microATX (µATX y a veces referido como mATX). La microATX, es un factor de forma pequeño y estándar para placas base de ordenadores. El tamaño máximo de una placa microATX es de 244mm × 244 mm (9.6 pulgadas × 9.6 pulgadas), siendo así el estándar ATX un 25% más grande con unas dimensiones de 305 mm × 244 mm, es decir, que una de sus principales innovaciones lo constituye la relación de forma, lo que permitiría la instalación de más componentes de cara a ampliar las posibilidades de los equipos, permitiendo incluso una doble capa de puertos de expansión si fuera necesario.
2 Revisar documento en el link http://www.formfactors.org/developer%5Cspecs%5Catx2_2.pdf. http://www.formfactors.org/developer%5Cspecs%5Catx2_1.pdf y http://www.formfactors.org/developer%5Cspecs%5CATX_Spec_V1_0.pdf

El formato ATX se ha pensado (al igual que el Baby-AT) para que los conectores de expansión se sitúen sobre la propia placa, con lo que los equipos seguirán teniendo un tamaño similar al de los actuales, aunque para discos más compactos también se ha definido una versión más reducida denominada mini-ATX (de unos 280 por 204 milímetros).
Eso en cualquiera de ambos se permite la utilización de hasta 7 ranuras de expansión de tipo ISA o PCI, localizadas en la parte izquierda de la placa, mientras que el zócalo del procesador se ha desplazado a la parte posterior derecha junto a la fuente de alimentación (que también se ha visto renovada). De esta forma los elementos de refrigeración dejan de ser un obstáculo, mismo tiempo que el micro se beneficia del flujo de aire adicional que representa el ventilador de la fuente.
El nuevo formato también permite que elementos como los zócalos de memoria queden ahora más accesibles, al tiempo que reduce la cantidad de cables presentes en interior del equipo, al situar los conectores de las controladoras de disco justo debajo de las unidades de almacenamiento. Esto tiene la ventaja añadida de eliminar el peligro de interferencias, algo que será más probable a medida que aumenten las frecuencias de funcionamiento de los nuevos micros.
Uno de los cambios más visibles en el diseño ATX es el cambio de dos conectores de alimentación por uno, influenciado por el nuevo diseño de las fuentes de alimentación.

Las partes generales de la placa ATX son:
A - Conector de entrada telefónica B - Conector Wave Table C - Conector de CD-Audio D - 256kB Pipe Line Burst nivel 2 E - Puerto audio y joystick F - Conector VGA G - Ratón y teclado PS/2 H - Puerto serie I - Zócalo para Pentium J- Zócalo VRM K - 82437FX Controlador de sistema (TSC) L - Conector de alimentacion primario M - 82438FX Data Path (TDP) N - Bancos de memoria SIMM O - Regulador de voltaje CPU 3.3v P - Interface PCI - IDE Q - Regulador de voltaje R - Conector Floppy
S - Conector E/S T- Conector de video U - Controlador gráfico S3 Trío PCI V - Banco de memoria de vídeo W - Jumper de configuración X - Controlador National PC87306 I/O Y - Controlador ventilador auxiliar Z - Pila del reloj AA - Acelerador 82371FB PCI ISA/IDE (PIIX) BB - 4 slots PCI CC - 3 slots ISA DD - Crystal CS4232 audio, OPL3 synthesizer
Ejemplos de ATX de última generación se tiene:

Placa AM3 M4A89TD PRO de Asus, basada en el procesador Phenom II X6 y el chipset 890FX, que es compatible con los nuevos procesadores de 6 núcleos, la M4A89TD PRO. Se trata de un modelo AM3 en formato ATX que viene equipado con un sistema de alimentación de 6+2 fases, 4 slots para memoria DDR3 de doble canal, 2 ranuras PCI-Express x16 con soporte CrossfireX, 6 puertos SATA 6Gbps, Gigabit Ethernet, 2 conexiones USB 3.0 y audio de 8 canales. Además la placa incorpora las últimas tecnologías Turbo Unlocker y Core Unlocker de Asus, que permite utilizar un modo Turbo más agresivo (y compatible con CPUs anteriores a los nuevos Phenom II X6) y desbloquear núcleos de forma sencilla en los procesadores que así lo permitan.
La nueva Asus M4A89TD PRO viene acompañada de varios extras más como el software TurboV para facilitar el overclock, el sistema Express Gate de arranque inmediato con SO embebido y el sistema EPU de ahorro de energía.

L a placa Intel® DX58SO para equipos de sobremesa se ha diseñado para liberar la potencia del procesador Intel Core™ i7 Extreme Edition de 32nm con seis núcleos y compatible hasta con doce hilos con pura capacidad de proceso de CPU, memoria DDR3 de triple canal y compatibilidad total con la tecnología ATI CrossfireX* y NVIDIA SLI*. Posee la última tecnología de chipset Intel X58 Express, que es compatible con la familia de procesadores Intel Core i7 de 45nm a velocidades de 6,4GT/seg. y 4,8 GT/seg. Gracias a la tecnología Intel QuickPath Interconnect (Intel QPI). Además, este chipset es compatible con las tarjetas gráficas dual x16 o quad x8 PCI Express* 2.0 así como con unidades de disco Intel de estado sólido de alto rendimiento en SKUs de consumidor ICH10 y ICH10R. 3Las placas base microATX disponibles actualmente son compatibles con procesadores de Intel o de AMD, pero por ahora no existe ninguna para cualquier otra arquitectura que no sea x864 o x86-645.
3 Pueden consultar en http://www.intel.com/Assets/PDF/prodbrief/x58-product-brief.pdf 4 Es la denominación genérica dada a ciertos microprocesadores de la familia Intel, sus compatibles y la arquitectura básica a la que estos procesadores pertenecen, por la terminación de sus nombres numéricos: 8086, 80286, 80386, 80486, etc.
5 Es una arquitectura basada en la extensión del conjunto de instrucciones x86 para manejar direcciones de 64 bits. Duplica el número y el tamaño de los registros de uso general y de instrucciones SSE (Streaming SIMD Extensions). Las instrucciones SSE son especialmente adecuadas para decodificación de MPEG2, que es el códec utilizado normalmente en los DVD, procesamiento de gráficos tridimensionales y software de

El estándar microATX fue explícitamente diseñado para ser compatible con ATX, por lo que los puntos de anclaje de las placas microATX son un subconjunto de los usados en las placas ATX y el panel de I/O es idéntico. Por lo tanto, las placas microATX pueden ser instaladas en cajas inicialmente diseñadas para placas ATX. Además, generalmente la mayoría de las placas microATX usan los mismos conectores de alimentación que las placas ATX, por lo que pueden ser usadas con fuentes de alimentación concebidas para placas ATX. También válidas para conexión para PS3.
La mayoría de las placas ATX modernas tienen cinco o más puertos de expansión PCI o PCI-Express, mientras que las placas microATX sólo suelen tener tres puertos de expansión, siendo cuatro el número máximo permitido por la especificación. Para evitar en la medida de lo posible la ocupación de puertos y para ahorrar espacio en la caja, las placas microATX de muchos fabricantes vienen con algunos componentes (como por ejemplo la tarjeta gráfica) integrados en la misma placa, lo que facilita su utilización en equipos de reducido tamaño como los centros multimedia.
Por ejemplo, la placa Asus A8N-VM CSM (ver imagen siguiente página) integra un procesador gráfico GeForce6, audio AC97 y gigabit Ethernet, quedando libres por lo tanto los puertos de expansión que habrían sido usados para instalar una tarjeta gráfica, una tarjeta de sonido y una tarjeta Ethernet.
Otra de las características de las placas ATX son el tipo de conector a la fuente de alimentación, el cual es de 24 (20+4) contactos que permiten una única forma de
reconocimiento de voz. Se trata de una arquitectura desarrollada por AMD e implementada bajo el nombre de AMD64, para el caso de Intel se llama Intel 64 (antes EM64T).

conexión y evitan errores como con las fuentes AT y otro conector adicional llamado P4, de 4 contactos. También poseen un sistema de desconexión por software.
ASRock y MSI presentan sus tarjetas madre Mini-ITX para Trinity6
Nuevas tarjetas madre Mini-ITX de ASRock y MSI basadas en el chipset AMD A75. Los APU AMD A-5000 Series “Trinity” para equipos de escritorio socket FM2 fueron lanzados hace poco y junto a ellos llegaron una gran variedad de tarjetas madre socket FM2 de diversos fabricantes.
ASRock y MSI amplían la oferta de modelos disponibles con sus nuevas tarjetas madre en formato Mini-ITX ASRock FMSA75M-ITX y MSI FM2-A75IA-E53; ambas basadas en el chipset AMD A75 y compatibles con los microprocesadores AMD A-5000 Series y Athlon X4 700 Series para socket FM2, y que además cuentan con soporte de hasta 16GB de memoria DDR3 (dos ranuras), puertos USB 3.0, SATA 6Gbps, audio 7.1, Wi-Fi y Bluetooth.
Los APU AMD A-5000 Series para socket FM2 están basados en una fusión entre la micro-arquitectura x86 Piledriver y la arquitectura gráfica VLIW4, la usada en los GPUs AMD Radeon HD 6900 Series, pero con hasta 384 shader processors, cuyo nombre código es Devastator; además toma prestada la unidad de encoding de videos acelerada por hardware VCE (Video Codec Engine) presente en los GPUs AMD Radeon HD 7000 Series. 6 ASRock y MSI presentan sus tarjetas madre Mini-ITX para Trinity: Consultado el 1 de septiembre de 2013. http://www.chw.net/2012/10/asrock-y-msi-presentan-sus-tarjetas-madre-mini-itx-para-trinity/

Estos nuevos APUs usan el socket FM2 y son compatibles con al menos tres generaciones de APUs: Trinity, Kaveri y con los APU basados en la micro-arquitectura Excavator.
HILO DE EJECUCIÓN
En los SO, un hilo de ejecución, hebra o subproceso es la unidad de procesamiento más pequeña que puede ser planificada por un sistema operativo. La creación de un nuevo hilo es una característica que permite a una aplicación realizar varias tareas a la vez (concurrentemente). Los distintos hilos de ejecución comparten una serie de recursos tales como el espacio de memoria, los archivos abiertos, situación de autenticación, etc. Esta técnica permite simplificar el diseño de una aplicación que debe llevar a cabo distintas funciones simultáneamente.
Un hilo es básicamente una tarea que puede ser ejecutada en paralelo con otra tarea.
Los hilos de ejecución que comparten los mismos recursos, sumados a estos recursos, son en conjunto conocidos como un proceso. El hecho de que los hilos de ejecución de un mismo proceso compartan los recursos hace que cualquiera de estos hilos pueda modificar éstos. Cuando un hilo modifica un dato en la memoria, los otros hilos acceden a ese dato modificado inmediatamente. Lo que es propio de cada hilo es el contador de programa7, la pila de ejecución y el estado de la CPU (incluyendo el valor de los registros).
7 El contador de programa (Program Counter o PC), o Puntero de instrucciones (Instruction Pointer), es la parte del secuenciador de instrucciones en algunos computadores, es un registro del procesador de un
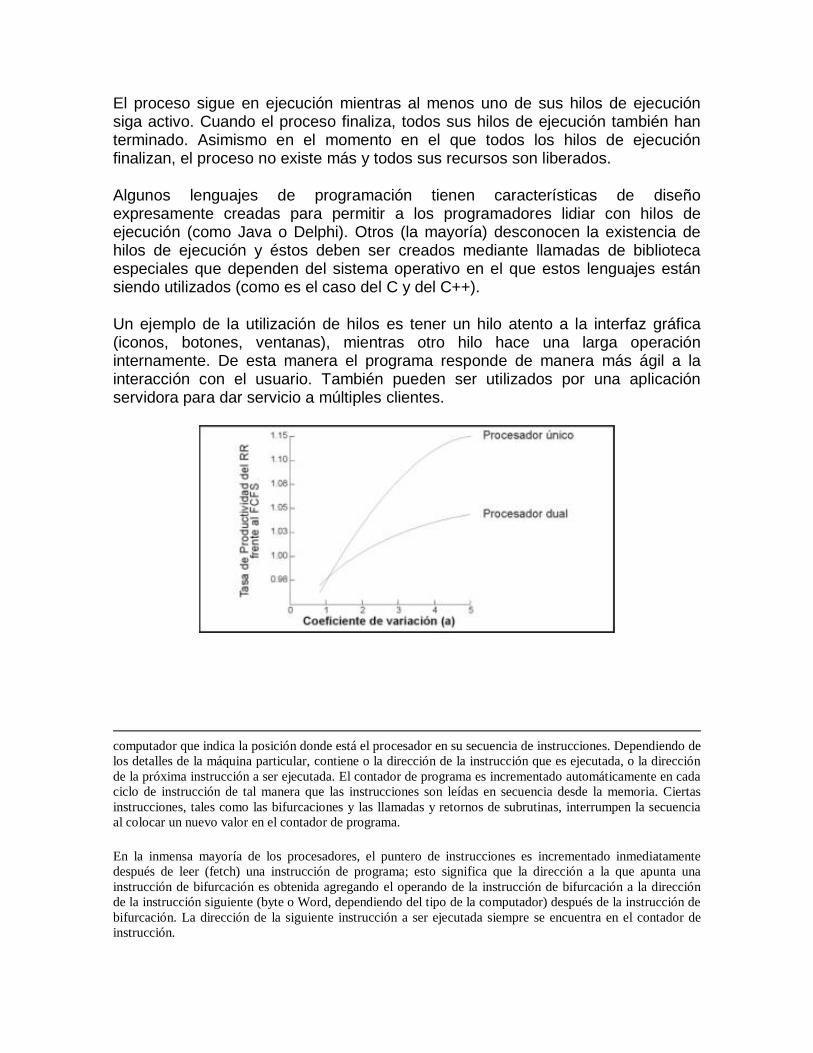
El proceso sigue en ejecución mientras al menos uno de sus hilos de ejecución siga activo. Cuando el proceso finaliza, todos sus hilos de ejecución también han terminado. Asimismo en el momento en el que todos los hilos de ejecución finalizan, el proceso no existe más y todos sus recursos son liberados.
Algunos lenguajes de programación tienen características de diseño expresamente creadas para permitir a los programadores lidiar con hilos de ejecución (como Java o Delphi). Otros (la mayoría) desconocen la existencia de hilos de ejecución y éstos deben ser creados mediante llamadas de biblioteca especiales que dependen del sistema operativo en el que estos lenguajes están siendo utilizados (como es el caso del C y del C++).
Un ejemplo de la utilización de hilos es tener un hilo atento a la interfaz gráfica (iconos, botones, ventanas), mientras otro hilo hace una larga operación internamente. De esta manera el programa responde de manera más ágil a la interacción con el usuario. También pueden ser utilizados por una aplicación servidora para dar servicio a múltiples clientes.
computador que indica la posición donde está el procesador en su secuencia de instrucciones. Dependiendo de los detalles de la máquina particular, contiene o la dirección de la instrucción que es ejecutada, o la dirección de la próxima instrucción a ser ejecutada. El contador de programa es incrementado automáticamente en cada ciclo de instrucción de tal manera que las instrucciones son leídas en secuencia desde la memoria. Ciertas instrucciones, tales como las bifurcaciones y las llamadas y retornos de subrutinas, interrumpen la secuencia al colocar un nuevo valor en el contador de programa.
En la inmensa mayoría de los procesadores, el puntero de instrucciones es incrementado inmediatamente después de leer (fetch) una instrucción de programa; esto significa que la dirección a la que apunta una instrucción de bifurcación es obtenida agregando el operando de la instrucción de bifurcación a la dirección de la instrucción siguiente (byte o Word, dependiendo del tipo de la computador) después de la instrucción de bifurcación. La dirección de la siguiente instrucción a ser ejecutada siempre se encuentra en el contador de instrucción.
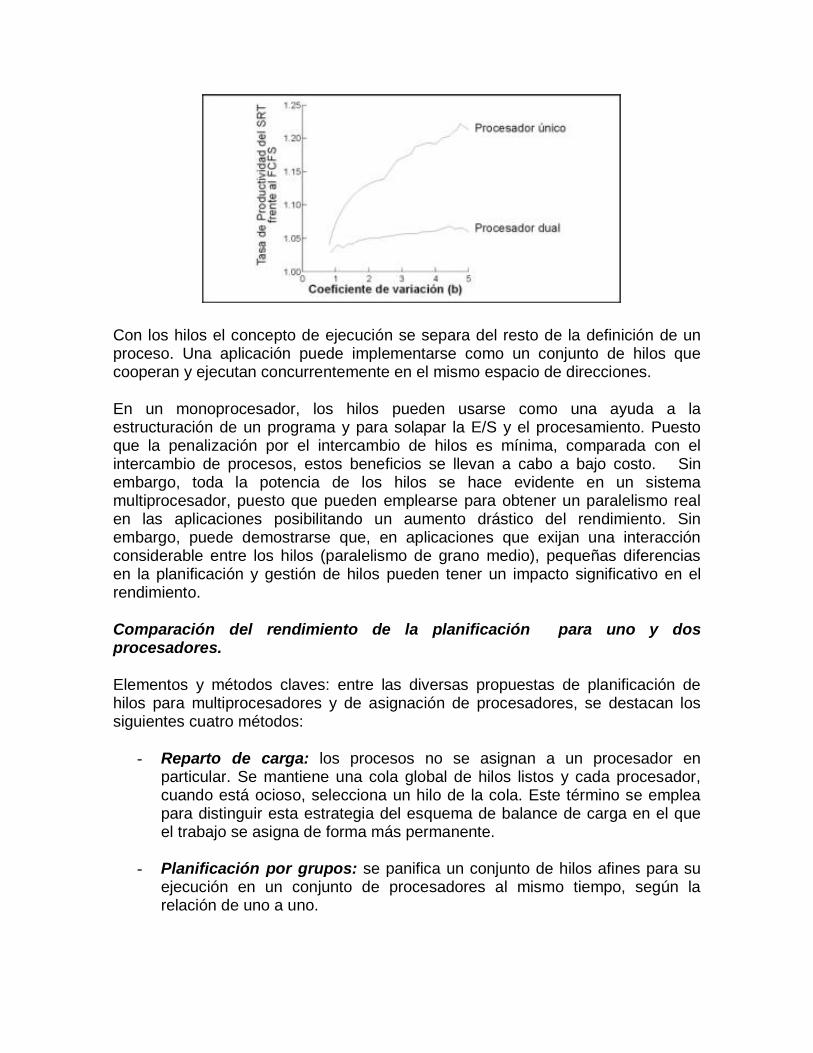
Con los hilos el concepto de ejecución se separa del resto de la definición de un proceso. Una aplicación puede implementarse como un conjunto de hilos que cooperan y ejecutan concurrentemente en el mismo espacio de direcciones.
En un monoprocesador, los hilos pueden usarse como una ayuda a la estructuración de un programa y para solapar la E/S y el procesamiento. Puesto que la penalización por el intercambio de hilos es mínima, comparada con el intercambio de procesos, estos beneficios se llevan a cabo a bajo costo. Sin embargo, toda la potencia de los hilos se hace evidente en un sistema multiprocesador, puesto que pueden emplearse para obtener un paralelismo real en las aplicaciones posibilitando un aumento drástico del rendimiento. Sin embargo, puede demostrarse que, en aplicaciones que exijan una interacción considerable entre los hilos (paralelismo de grano medio), pequeñas diferencias en la planificación y gestión de hilos pueden tener un impacto significativo en el rendimiento.
Comparación del rendimiento de la planificación para uno y dos procesadores.
Elementos y métodos claves: entre las diversas propuestas de planificación de hilos para multiprocesadores y de asignación de procesadores, se destacan los siguientes cuatro métodos:
- Reparto de carga: los procesos no se asignan a un procesador en particular. Se mantiene una cola global de hilos listos y cada procesador, cuando está ocioso, selecciona un hilo de la cola. Este término se emplea para distinguir esta estrategia del esquema de balance de carga en el que el trabajo se asigna de forma más permanente.
- Planificación por grupos: se panifica un conjunto de hilos afines para su ejecución en un conjunto de procesadores al mismo tiempo, según la relación de uno a uno.

- Asignación dedicada de procesadores: es el enfoque opuesto al reparto de carga y ofrece una planificación implícita definida por la asignación de hilos a los procesadores. Mientras un programa se ejecuta, se le asigna un número de procesadores igual al número de hilos que posea. Cuando el programa finaliza, los procesadores retornan a la reserva general para posibles asignaciones a otros programas.
- Planificación dinámica: el número de hilos en un programa se puede cambiar en el curso de la ejecución.
Hyper-Threading: dos por uno.
En lugar de aumentar las frecuencias de reloj, los procesadores de ordenadores actuales contienen más núcleos (físicos), lo cual mejora de forma sostenida el rendimiento al poder ejecutar diversos programas o hilos (threads) en paralelo. Con la tecnología Intel Hyper-Threading se puede llegar a doblar el número de hilos, incorporando lo que se ha dado en llamar “núcleos lógicos”. A continuación se explica su funcionamiento.
La tecnología Hyper-Threading (HT), introducida por primera vez con el procesador Intel Pentium 4, se encuentra en todos los procesadores Intel Core™. Consiste en permitir la ejecución en paralelo de diversos hilos en un procesador, incrementando la velocidad de proceso de las aplicaciones que contengan varios hilos. Desde el punto de vista del software, un procesador con hyper-threading funciona como un sistema multiprocesador simétrico: por cada núcleo (físico) disponible hay dos núcleos lógicos, que en la jerga técnica se denominan Siblings (hermanos). P. Ej. Un procesador de cuatro núcleos con HT se usa como procesador de ocho núcleos. Si el SO es capaz de gestionar múltiples procesadores, no será necesario realizar ajuste alguno para beneficiarse de las ventajas del hyper-threading.
A través de varios conjuntos de registros y un complejo mecanismo de control, diversas instrucciones y flujos de datos paralelos se asignan a etapas internas paralelas del pipeline. En este punto se cubren posibles "huecos" en la línea de

ejecución del procesador, preferentemente con instrucciones de otra aplicación o hilo. Los huecos se producen, por ejemplo, cuando un hilo debe esperar a la memoria principal debido a un fallo de caché. La tecnología Hyper-Threading permite, por lo tanto, el procesado paralelo y simultáneo de diversos hilos (Simultaneous Multi-Threading o SMT).
Después de que el Hyper-Threading fuera desarrollado para procesadores de un solo núcleo, desapareció con la introducción de los procesadores multinúcleo. La tecnología volvió con la arquitectura “Nehalem”, pero solo en los modelos de la gama alta de procesadores Intel Core™ i7. Con la 2ª 3 y 4 generación de procesadores, la tecnología Hyper-Threading se encuentra ya disponible en muchos modelos de esta nueva generación. Con los procesadores Intel Core™ i3, incluso los ordenadores más asequibles se benefician ya de la tecnología Hyper-Threading.
En cierto modo, y a diferencia de la tecnología Hyper-Threading, las últimas generaciones de procesadores Intel Core™ incluye mejoras adicionales para la gestión de los diferentes núcleos: si una aplicación no se ha optimizado para trabajar con varios núcleos, la tecnología Intel Turbo Boost permite revertir la situación. En vez de duplicar el número de núcleos, usará uno solo a una velocidad superior mientras los demás descansan y liberan recursos.
IMC: Controlador de Memoria Integrado de Triple Canal DDR3

A diferencia de las generaciones anteriores de procesadores Intel y adoptando una de las características más aplaudidas de los procesadores AMD, en Nehalem se sacó el controlador de memoria del chipset y se le introdujo dentro del CPU, reduciendo con ello la latencia y aumentando el ancho de banda del que dispone la memoria.
Este nuevo controlador permite manejar hasta 3 canales de memoria DDR3 (lo usual antes de esto era usar controladores de memoria de doble canal) con un ancho de banda máximo de 192bits (a diferencia de los 128bit que nos dan los dos canales tradicionales). Los núcleos Bloomfield lo soportan, pero ni Lynnfield ni Havendale (que son de cuatro y dos núcleos
respectivamente) soportarán esta característica, funcionando solamente con doble canal DDR3. Caché L3: Memoria Caché L3 Compartida Intel integra la memoria cache de tercer nivel compartida para todos los núcleos. El cache L1 se mantiene igual que la arquitectura anterior (64KB por núcleo), el L2 (uno de los fuertes de los Core 2 Duo / Quad) bajó desde 6MB compartidos a 256KB dedicados por cada núcleo y con una menor latencia (11 ciclos). Este cambio se compensó con la adición de la cache L3 de 8MB. Turbo: Intel Turbo Boost Con el fin de darnos más velocidad, Intel incluye la tecnología Turbo Boost. Esto consiste en darle prioridad al núcleo utilizado apagando los otros para no consumir más energía de forma innecesaria. Para “compensar” el reposo de los otros núcleos esta tecnología aumenta la frecuencia (vía aumento del multiplicador) del núcleo utilizado en forma dinámica de acuerdo al nivel de carga solicitado, lo que significa que en aplicaciones que no trabajen con todos los núcleos podremos acceder a una mayor velocidad de proceso de manera estable y sin arriesgarnos a que la temperatura ni el consumo eléctrico se disparen.

Intel incorpora transistores Tri-Gate en nuevos chips de 22 nanómetros
Intel luego de mucho tiempo en investigaciones desarrollo un transistor Tri-Gate 3D que está incluido en los nuevos chips de 22nm. Son más rápidos, más pequeños y tienen una mejor performance. Estos transistores disminuyen en un 50% el consumo energético y aumenta en un 37% la eficiencia sin un coste de producción mucho mayor (entre 2 y 3%).
En los transistores 3-D Tri-Gate la tradicional puerta “plana” de dos dimensiones se sustituye por una “aleta” de silicio tridimensional muy delgada, que se eleva verticalmente desde el sustrato de silicio, por lo que la estructura 3D ofrece una

manera de manejar la densidad. Dado que estas aletas son verticales por su propia naturaleza, los transistores también se pueden empaquetar más próximos, un componente crítico para obtener los beneficios tecnológicos y económicos de la Ley de Moore.
Los nuevos transistores están incluidos en chips orientados a todo tipo de equipos, incluidos equipos móviles.
A continuación un video explicativo de la tecnología Tri-Gate de 22 nanómetros
http://www.paisdigital.org/?p=5119
Board avanzadas
AMD hace poco sacó la board los Opteron 6000 en los cuales la principal virtud era encontrar procesadores de 8 y 12 núcleos. Para el caso de Intel ha sacado Intel Xeon 7500, con hasta 8 núcleos por procesador.
La gran ventaja de los Xeon 7500 es que, al igual que la muchos de los últimos micros de Intel, implementan la tecnología hyperthreading mediante la cual el sistema operativo ve el procesador como su tuviese dos hilos de ejecución por núcleos, o lo que es lo mismo hasta 16 hilos. Por supuesto, se trata de una solución que va incluso más allá de las workstations, estando enfocada a su uso en grandes servidores y racks, en los que Intel ha confirmado que se pueden montar hasta 256 procesadores por servidor, unos 2048 núcleos o 4096 hilos de ejecución. Los precios del Intel Xeon X7560 de 8 núcleos se sitúan en 3.692 dólares, con otros modelos de menor potencia lógicamente más accesibles. La diferencia respecto a los micros Opteron de 8 y 12 núcleos tanto en precio (Opteron 6176 SE de 12 núcleos por 1386 dólares, cerca de ser tres veces más barato) como en potencia y rendimiento bruto, Intel siempre está un poco por encima de AMD. Tipos y dimensiones ATX8
• ATX - • Mini-ATX - 28.4cm x 20.8cm.. • Micro-ATX - 24.4cm x 24.4cm. • Flex-ATX - 22.9cm x 19.1cm. • E-ATX-Format - 30.5cm x 33cm
8 Fuente de consulta. http://es.wikipedia.org/wiki/ATX

Placa base9 microATX Asus A8N-VM CSM.
Ventajas de ATX
• Integración de los puertos E/S en la propia placa base. • La rotación de 90º de los formatos anteriores. • El procesador esta en paralelo con los slots de memoria. • Los slots AGP, PCI, PCI-e, están situados horizontalmente con el
procesador. • Tiene mejor refrigeración.
9 La "placa base" (mainboard), o "placa madre" (motherboard), es el elemento principal de todo ordenador, en el que se encuentran o al que se conectan todos los demás aparatos y dispositivos.

Molex de 24pines (placa base).
A nivel general, todas las placas Standar ATX y las Micro ATX mostradas, presentan la misma configuración para los soportes.
FUENTE DE ALIMENTACIÓN
La fuente de alimentación es la encargada de suministrar la energía al computador, en la que se precisa que ésta sea en todo momento estable y dentro de unos márgenes de tolerancia que en algunos elementos son mínimos.

Como en todo, dentro de las fuentes de alimentación hay un gran surtido de modelos y sobre todo de calidades. Al respecto hay que señalar que la calidad de las fuentes de alimentación que suelen traer las cajas es (salvo algunas excepciones) normal tirando a baja. Cuanto más barata sea la caja peor será la fuente de alimentación que traiga.
La calidad de una fuente de alimentación nos ahorra muchos problemas y, a la larga, dinero.
Cada vez son más los fabricantes de cajas de calidad que no incorporan este elemento, por lo que se debe comprar aparte.
Si se conecta directamente al formato de la antigua AT, el interruptor de entrada de la fuente de alimentación que está conectado a la placa base ATX. Esto hace que se pueda apagar el equipo mediante el software en sí. Sin embargo lo que significa es que la placa base sigue siendo alimentada por una tensión de espera, que puede ser transmitida a las tarjetas de expansión. Esto permite funciones tales como Wake on LAN o Wake on Modem "encendido-apagado", donde el propio ordenador vuelve a encenderse cuando se utiliza la LAN con un paquete de reactivación o el módem recibe una llamada. La desventaja es el consumo de energía en modo de espera y el riesgo de daños causados por picos de voltaje de la red eléctrica, incluso si el equipo no está funcionando.

Para iniciar una fuente de alimentación ATX, es necesario el PS-ON (PowerSupplyOn) Pin 14 y 15. Sin embargo, la fuente de alimentación nunca tiene una carga fija para poder ser activada, ya que puede ser dañada. Debido a la evolución de los procesadores y tarjetas gráficas ha sido necesario añadir al molex de 20pin cuatro pines más, es decir el conector utilizado actualmente en la placa base ATX es de 24 pines que disponen de un conducto de +12 V, +5 V, 3,3 V y tierra.
Molex de 24 pines (fuente alimentación).

Las fuentes para cumplir la norma también tienen que respetar los límites de ruido y oscilación en sus salidas de voltaje, estos límites son 120mV para 12+, 50mV para 5V+ y 3,3V+ estos valores son pico a pico.
Cabe agregar que el conector de alimentación de 20 pines, presenta la siguiente distribución geométrica y eléctrica, para su correcto funcionamiento.
Conector Molex 39-29-9202 de 20 pines en el motherboard
Conector Molex 39-01-2200 de 20 pines en el cable
La distribución se las entradas y salidas de voltaje aparecen en la siguiente gráfica.
Pin Señal Color 1 3.3V 2 3.3V 3 Ground 4 5V 5 Ground 6 5V 7 Ground 8 PW-OK 9 5VSB 10 12V 11 3.3V 12 -12V 13 Ground 14 PS-ON 15 Ground 16 Ground 17 Ground 18 -5V 19 5V 20 5V

Placa ATX con la misma gráfica integrada (ATI HD3200)
Para probar una fuente de alimentación ATX
Para probar la fuente de alimentación ATX, se hacer un puente en el conector que va a la placa entre el cable verde y uno de los negros que tienen al lado (tierra).

Debe tener cuidado y no equivocarse al hacer el puente o puede estropear la fuente.
Nos fijaremos en el cable verde, que es el que enciende la fuente de alimentación cuando está conectado a masa.
Se coloca un cable entre el cable verde y cualquiera de los cables negros, que es la masa. De esta manera se enciende una fuente de alimentación ATX.
Se pueden encontrar fuentes en potencias de 300 a 700W. Sin embargo, esto no significa ni que la fuente consuma siempre esa energía, ni siquiera que sea capaz de suministrarla. Hay que tomar el valor de potencia como un valor de referencia proporcionado por el fabricante. Para saber con exactitud cuanta potencia puede suministrar en cada referencia de tensión los fabricantes proporcionan una tabla con la máxima intensidad disponible en cada nivel.

El conector más grande es el conector ATX, que se conecta y alimenta a la placa base. Este conector tenía antiguamente 20 pines y posteriormente pasó a 24. Por otro lado, muchas fuentes ponen los 4 pines adicionales en un cable adicional que puede ser separado (como se muestra en la imagen) para poder dar servicio a ordenadores antiguos.
Cada cable se encuentra codificado por colores, de forma que dos cables con el mismo color tendrán la misma función. Se debe elegir qué cables nos interesan de todos los que están disponibles. Por ejemplo:
1. Conductor de encendido: Verde (PS-ON). 2. Salidas de voltaje: Amarillo (+3V), Rojo (+5V), Morado (+5V SB) y Amarillo
(+12V). 3. Tierra: Negro (GROUND).
El conductor de +5V SB (donde significa Stand By) es una salida algo especial. Esta salida permanece en tensión aunque la fuente se encuentre apagada. Esto permite, en un futuro, alimentar pequeños sistemas sensores que enciendan la propia fuente ante un evento. Además del conector ATX, la fuente dispone de otros muchos conectores. Se puede aprovechar estos cables para conectar clavijas o tomas rápidas para dispositivos que se empleen habitualmente (por ejemplo, un conector para placa Arduino, un conector micro USB, etc.). El código de colores en los cables es el mismo que el explicado para el conector ATX. No obstante la siguiente figura muestra los esquemas de los conectores más habituales.

No hay que confundir el cable de pines de 12V2 con la extensión de cable (fíjese en el color de los cables). Por otro lado, los cables de conectores molex de IDe y SATA son iguales, únicamente cambia el propio conector. Las averías en la fuente de alimentación pueden ser de dos tipos:
- La fuente deja de funcionar. Con ello el computador deja de funcionar ya que no prende.
- Deja de suministrar las tensiones correctas. Es más difícil de detectar y
sobre todo peligroso, ya que no solo se avería la fuente, si no también puede dañar componentes clave del computador, tales como la board, la memoria y los periféricos (disco duro, unidades ópticas y lectores de medios).

Se puede detectar estas averías por una serie de problemas que empieza a darnos, como errores de lectura, bloqueos sin motivo aparente, dispositivos que fallan estando en perfecto estado, problemas de encendido, etc. Este tipo de avería, son muy peligrosas, por lo que si se tiene indicios que pueden estar ocurriendo, se debe llevar lo antes posible la fuente a que la comprueben o bien cambiarla por otra.
Hay programas de testeo, como Everest y otros similares, que indican los voltajes exactos que le están entrando a la placa base. Es conveniente que de vez en cuando le invierta unos minutos observando si las tensiones suministradas son correctas y, sobre todo, estables. Se debe tener en cuenta que la fuente de alimentación es la primera barrera que tiene el computador para defenderse de problemas relacionados con sobretensiones, por lo que es el primer elemento en caer y afortunadamente el único en la mayoría de los casos) cuando esta sobretensión se produce. PUERTOS10 En la informática, un puerto es una forma genérica de denominar a una interfaz a través de la cual los diferentes tipos de datos se pueden enviar y recibir. Dicha interfaz puede ser de tipo físico, o puede ser a nivel de software (por ejemplo, los puertos que permiten la transmisión de datos entre diferentes ordenadores), en cuyo caso se usa frecuentemente el término puerto lógico. Un puerto físico, es aquella interfaz, o conexión entre dispositivos, que permite conectar físicamente distintos tipos de dispositivos como monitores, impresoras, escáneres, discos duros externos, cámaras digitales, memorias pendrive, etc... Estas conexiones tienen denominaciones particulares como, por ejemplo, los puertos "serie" y "paralelo" de un ordenador.
10 Puertos. Recuperado el 2 de enero de 2013. http://conexionentredoscomputadoras.wikispaces.com/Puertos

En el ámbito de Internet, un puerto es el valor que se usa, en el modelo de la capa de transporte, para distinguir entre las múltiples aplicaciones que se pueden conectar al mismo host, o puesto de trabajo. “Aunque muchos de los puertos se asignan de manera arbitraria, ciertos puertos se asignan, por convenio, a ciertas aplicaciones particulares o servicios de carácter universal. De hecho, la IANA (Internet Assigned Numbers Authority) determina las asignaciones de todos los puertos comprendidos entre los valores [0, 1023] (hasta hace poco, la IANA sólo controlaba los valores desde el 0 al 255). Por ejemplo, el servicio de conexión remota telnet, usado en Internet se asocia al puerto 23. Por tanto, existe una tabla de puertos asignados en este rango de valores y que son los servicios y las aplicaciones que se encuentran en el listado denominado Selected Port Assignments. De manera análoga, los puertos numerados en el intervalo [1024, 65535] se pueden registrar con el consenso de la IANA, vendedores de software y otras organizaciones. Por ejemplo, el puerto 1352 se asigna a Lotus Notes. El puerto serie por excelencia es el RS-232 que utiliza cableado simple desde 3 hilos hasta 25 y que conecta ordenadores o microcontroladores a todo tipo de periféricos, desde terminales a impresoras y módems pasando por ratones. La interfaz entre el RS-232 y el microprocesador generalmente se realiza mediante el integrado 82C50. El RS-232 original tenía un conector tipo D de 25 pines, sin embargo, la mayoría de dichos pines no se utilizaban por lo que IBM incorporó desde su PS/2 un conector más pequeño de solamente 6 pines, que es el que actualmente se utiliza.

En Europa la norma RS-422, de origen alemán, es también un estándar muy usado en el ámbito industrial. Uno de los defectos de los puertos serie iniciales era su lentitud en comparación con los puertos paralelos, sin embargo, con el paso del tiempo, han ido apareciendo multitud de puertos serie con una alta velocidad que los hace muy interesantes ya que tienen la ventaja de un menor cableado y solucionan el problema de la velocidad con un mayor apantallamiento. Son más baratos ya que usan la técnica del par trenzado; por ello, el puerto RS-232 e incluso multitud de puertos paralelos están siendo reemplazados por nuevos puertos serie como el USB, el Firewire o el Serial ATA.
Los puertos serie sirven para comunicar al ordenador con la impresora, el ratón o el módem, sin embargo, el puerto USB sirve para todo tipo de periféricos, desde ratones a discos duros externos, pasando por conexiones bluetooth. Los puertos sATA (Serial ATA): tienen la misma función que los IDE, (a éstos se conecta, la disquetera, el disco duro,
lector/grabador de CD y DVD) pero los sATA cuentan con una mayor velocidad de transferencia de datos. Un puerto de red puede ser puerto serie o puerto paralelo.”11 PCI (Peripheral Component Interconnect)12 Puertos PCI son ranuras de expansión de la placa madre de un ordenador en las que se pueden conectar tarjetas de sonido, de vídeo, de red, etc... El slot PCI se sigue usando hoy en día y podemos encontrar bastantes componentes (la mayoría) en el formato PCI. Dentro de los slots PCI está el PCI-Express. Los componentes que suelen estar disponibles en este tipo de slot son:
• Capturadoras de televisión • Controladoras RAID • Tarjetas de red, inalámbricas, o no • Tarjetas de sonido
11 Puerto. Recuperado el 2 de enero de 2013. http://es.wikipedia.org/wiki/Puerto_(inform%C3%A1tica) 12 ExtremeTech. 09-08-2007. Consultado el 05-09-2007. http://www.extremetech.com/article2/0,1697,2169018,00.asp
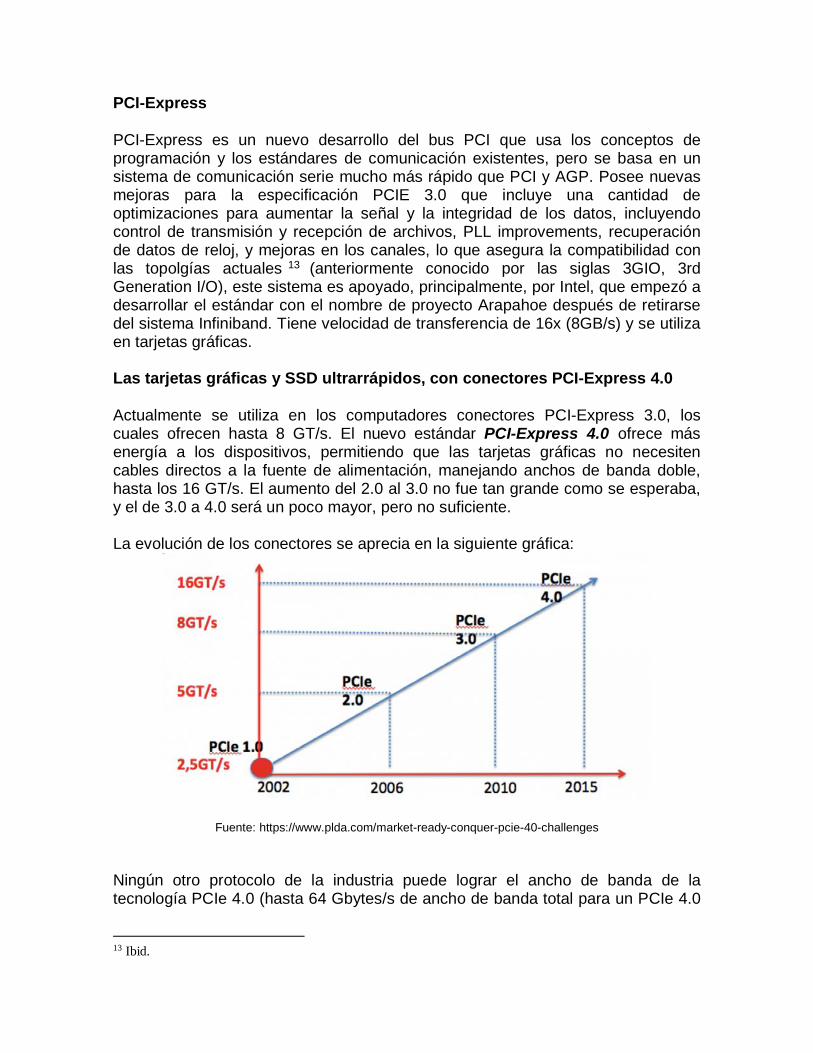
PCI-Express PCI-Express es un nuevo desarrollo del bus PCI que usa los conceptos de programación y los estándares de comunicación existentes, pero se basa en un sistema de comunicación serie mucho más rápido que PCI y AGP. Posee nuevas mejoras para la especificación PCIE 3.0 que incluye una cantidad de optimizaciones para aumentar la señal y la integridad de los datos, incluyendo control de transmisión y recepción de archivos, PLL improvements, recuperación de datos de reloj, y mejoras en los canales, lo que asegura la compatibilidad con las topolgías actuales 13 (anteriormente conocido por las siglas 3GIO, 3rd Generation I/O), este sistema es apoyado, principalmente, por Intel, que empezó a desarrollar el estándar con el nombre de proyecto Arapahoe después de retirarse del sistema Infiniband. Tiene velocidad de transferencia de 16x (8GB/s) y se utiliza en tarjetas gráficas. Las tarjetas gráficas y SSD ultrarrápidos, con conectores PCI-Express 4.0 Actualmente se utiliza en los computadores conectores PCI-Express 3.0, los cuales ofrecen hasta 8 GT/s. El nuevo estándar PCI-Express 4.0 ofrece más energía a los dispositivos, permitiendo que las tarjetas gráficas no necesiten cables directos a la fuente de alimentación, manejando anchos de banda doble, hasta los 16 GT/s. El aumento del 2.0 al 3.0 no fue tan grande como se esperaba, y el de 3.0 a 4.0 será un poco mayor, pero no suficiente. La evolución de los conectores se aprecia en la siguiente gráfica:
Fuente: https://www.plda.com/market-ready-conquer-pcie-40-challenges Ningún otro protocolo de la industria puede lograr el ancho de banda de la tecnología PCIe 4.0 (hasta 64 Gbytes/s de ancho de banda total para un PCIe 4.0
13 Ibid.

x16). Las nuevas interfaces emergentes, tales como: Ethernet 40G / 100G, InfiniBand, unidades de estado sólido (SSD) y la memoria flash están exigiendo tuberías más grandes. Esto hace que la arquitectura PCIe sea la única solución tecnológica que permita lograr este nivel de rendimiento con las nuevas actualizaciones de software mínimos.
Obsérvese los tipos de PCIe. Fuente. https://videocardz.com/29790/pci-express-4-0-to-double-bandwidth-of-
pci-e-3-0
La flexibilidad de las configuraciones de tuberías compatibles con PCIe 4.0 se resumen así:14
a. Tubo de 16 bits es compatible en x1, x2, x4, x8 y x16 con el reloj de 500 MHz tubería a 8 Gbps (ASIC)
b. Tubo de 32 bits es compatible en x1, x2, x4, x8 con el reloj de 500 MHz tubería a 16 Gbps (ASIC)
c. Tubo de 64 bits será apoyado en x1, x2 y x4 con el reloj de 250 MHz tubería a 16 Gbps (ASIC / FPGA)
La flexibilidad de la configuración del núcleo para satisfacer las evoluciones de especificaciones. Cabe mencionar que ya Intel y AMD han dispuesto sus nuevos desarrollos hacia la PCIe 4.0, tal como se aprecia en la figura.
14 Es el mercado Listo para conquistar PCIe 4.0 Retos? (consultado el 10 de marzo de 2017). Recuperado de; https://www.plda.com/market-ready-conquer-pcie-40-challenges

De cara a tener un cambio significativo, PCI-SIG está trabajando en PCI-Express 5.0, que ofrece entre 25 y 32 GT/s, aunque no se verá por lo menos hasta el 2020 como mínimo. Puertos de memoria A estos puertos se conectan las tarjetas de memoria RAM. Los puertos de memoria son aquellos puertos, o bahías, donde se pueden insertar nuevas tarjetas de memoria, con la finalidad de extender la capacidad de la misma. Existen bahías que permiten diversas capacidades de almacenamiento que van desde los 256MB (megabytes) hasta 4GB (gigabytes). Conviene recordar que en la memoria RAM es de tipo volátil, es decir, si se apaga repentinamente el ordenador los datos almacenados en la misma se pierden. Dicha memoria está conectada con la CPU a través de buses de muy alta velocidad. De esta manera, los datos ahí almacenados se intercambian con el procesador a una velocidad unas 1000 veces más rápida que con el disco duro. Puertos inalámbricos
Las conexiones en este tipo de puertos se hacen sin necesidad de cables, a través de la conexión entre un emisor y un receptor, utilizando ondas electromagnéticas. Si la frecuencia de la onda, usada en la conexión, se encuentra en el espectro de infrarrojos se denomina puerto infrarrojo. Si la frecuencia usada en la conexión es la usual en las radio frecuencias entonces sería un puerto Bluetooth.
La ventaja de esta última conexión es que el emisor y el receptor no tienen por qué estar orientados el uno con respecto al otro para que se establezca la

conexión. Esto no ocurre con el puerto de infrarrojos. En este caso los dispositivos tienen que "verse" mutuamente, y no se debe interponer ningún objeto entre ambos ya que se interrumpiría la conexión. Puerto USB15 Un puerto USB permite conectar hasta 127 dispositivos y ya es un estándar en los ordenadores de última generación, que incluyen al menos cuatro puertos USB 3.0 en los más modernos, y algún USB 1.1 en los más anticuados.
Pero ¿qué otras ventajas ofrece este puerto? Es totalmente Plug and play, es decir, con sólo conectar el dispositivo (con el ordenador ya encendido), el dispositivo es reconocido e instalado de manera inmediata. Sólo es necesario que el Sistema Operativo lleve incluido el correspondiente controlador o driver. Presenta una alta velocidad de transferencia en comparación con otro tipo de puertos. USB 1.1 alcanza los 12
Mb/s y hasta los 480 Mb/s (60 MB/s) para USB 2.0, mientras un puerto serie o paralelo tiene una velocidad de transferencia inferior a 1 Mb/s. El puerto USB 2.0 es compatible con los dispositivos USB 1.1 A través del cable USB no sólo se transfieren datos; además es posible alimentar dispositivos externos. El consumo máximo de este controlador es de 2.5 Watts. Los dispositivos se pueden dividir en dispositivos de bajo consumo (hasta 100 mA) y dispositivos de alto consumo (hasta 500 mA). Para dispositivos que necesiten más de 500 mA será necesaria alimentación externa. Hay que tener en cuenta, además, que si se utiliza un concentrador y éste está alimentado, no será necesario realizar consumo del bus. Una de las limitaciones de este tipo de conexiones es que la longitud del cable no debe superar los 5 m y que éste debe cumplir las especificaciones del Standard USB iguales para la 1.1 y la 2.0. Diferentes puertos USB que se han fabricado en sus diferentes modelos y configuraciones, conectores machos y hembras de conectores USB y los puertos USB del tipo A y del tipo B:
15 USB Implementers Forum, Inc.. Consultado el 04-11-2009.

Puerto serie Un puerto serie es una interfaz física de comunicación en serie a través de la cual se transfiere información mandando o recibiendo un bit. A lo largo de la mayor parte de la historia de las computadoras, la transferencia de datos a través de los puertos de serie ha sido generalizada. Se ha usado y sigue usándose para conectar las computadoras a dispositivos como terminales o módems. Los mouses, teclados, y otros periféricos también se conectaban de esta forma. Mientras que otras interfaces como Ethernet, FireWire, y USB mandaban datos como un flujo en serie, el término "puerto serie" normalmente identifica el hardware más o menos conforme al estándar RS-232, diseñado para interactuar con un módem o con un dispositivo de comunicación similar. Actualmente en la mayoría de los periféricos serie, la interfaz USB ha reemplazado al puerto serie puesto que es más rápida. La mayor parte de las computadoras están conectadas a dispositivos externos a través de USB y, a menudo, ni siquiera llegan a tener un puerto serie. El puerto serie se elimina para reducir los costes y se considera que es un puerto heredado y obsoleto. Sin embargo, los puertos serie todavía se encuentran en sistemas de automatización industrial y algunos productos industriales y de consumo.

Los dispositivos de redes, como los enrutadores y conmutadores, a menudo tienen puertos serie para modificar su configuración. Los puertos serie se usan frecuentemente en estas áreas porque son sencillos, baratos y permiten la interoperabilidad entre dispositivos. La desventaja es que la configuración de las conexiones serie requiere, en la mayoría de los casos, un conocimiento avanzado por parte del usuario y el uso de comandos complejos si la implementación no es adecuada. PUERTO PARALELO Este puerto envía datos simultáneos por varios canales. Su velocidad en una comunicación entre dos PCs varía desde 1Mb/s hasta los 2,5 Mb/s. Requisitos: Un cable paralelo y dos PCs. Un puerto paralelo es una interfaz entre una computadora y un periférico, cuya principal característica es que los bits de datos viajan juntos, enviando un paquete de byte a la vez. Es decir, se implementa un cable o una vía física para cada bit de datos formando un bus. Mediante el puerto paralelo podemos controlar también periféricos como focos, motores entre otros dispositivos, adecuados para automatización. El cable paralelo es el conector físico entre el puerto paralelo y el dispositivo periférico. En un puerto paralelo habrá una serie de bits de control en vías aparte que irá en ambos sentidos por caminos distintos.

En contraposición al puerto paralelo está el puerto serie, que envía los datos bit a bit por el mismo hilo. El puerto paralelo más conocido en el mundo de los puertos es el puerto de impresora (que cumplen más o menos la norma IEEE 1284, también denominados tipo Centronics) que destaca por su sencillez y que transmite 98 bits. Se ha utilizado principalmente para conectar impresoras, pero también ha sido usado para programadores EPROM, escáneres, interfaces de red Ethernet a 10 Mb, unidades ZIP, SuperDisk y para comunicación entre dos PC (MS-DOS trajo en las versiones 5.0 ROM a 6.22 un programa para soportar esas transferencias). El puerto paralelo de las computadoras, de acuerdo a la norma Centronics, está compuesto por un bus de comunicación bidireccional de 8 bits de datos, además de un conjunto de líneas de protocolo. Las líneas de comunicación cuentan con un retenedor que mantiene el último valor que les fue escrito hasta que se escribe un nuevo dato, las características eléctricas son:
− Tensión de nivel alto: 3,3 o 5 V. − Tensión de nivel bajo: 0 V. − Intensidad de salida máxima: 2,6 mA. − Intensidad de entrada máxima: 24 mA.

Los sistemas operativos basados en DOS y compatibles gestionan las interfaces de puerto paralelo con los nombres LPT1, LPT2 y así sucesivamente, Unix en cambio los nombra como /dev/lp0, /dev/lp1, y demás. Las direcciones base de los dos primeros puertos son: LPT1 = 0x378 LPT2 = 0x278 La estructura consta de tres registros: de control, de estado y de datos. El registro de control es un bidireccional de 4 bits, con un bit de configuración que no tiene conexión al exterior, su dirección en el LPT1 es 0x37A. El registro de estado, se trata de un registro de entrada de información de 5 bits, su dirección en el LPT1 es 0x379. El registro de datos, se compone de 8 bits, es bidireccional. Su dirección en el LPT1 es 0x378. Pines Los pines del puerto paralelo con conector DB25 son:

Las líneas invertidas toman valor verdadero cuando el nivel lógico es bajo. Si no están invertidas, entonces el nivel lógico alto is el valor verdadero.
El pin 25 en el conector DB25 podría no estar conectado a la tierra en computadoras modernas.
Nota: Comunicaciones seriales en Lenguaje C.
En lenguaje C, existe una instrucción especial para manejar las comunicaciones seriales. Esta instrucción posee la siguiente sintaxis:
int bioscom (int cmd, char abyte, int port);
En realidad, esta instrucción acude a la interrupción 14H para permitir la comunicación serial sobre un puerto. Para este caso, cada uno de los parámetros tiene el siguiente significado:
cmd Especifica la operación a realizar

abyte es un caracter que se enviará por el puerto serial
port es la identificación del puerto serial (desde 0 para COM1 hasta 3 para COM4)
El parámetro cmd puede tener los siguientes valores y significados:
0 Inicializa el puerto port con los valores dados por abyte 1 Envía el caracter abyte por el puerto port 2 Lee el caracter recibido por el puerto port 3 Retorna el estado del puerto port
Para la inicialización del puerto, el caracter abyte tiene las interpretaciones que se muestran en la siguiente Tabla.
0x02 0x03
7 bits de datos 8 bits de datos
0x00 0x04
1 bits de parada 2 bits de parada
0x00 0x08 0x18
Sin paridad Paridad impar Paridad par
0x00 0x20 0x40 0x60 0x80 0xA0 0xC0 0xE0
110 baudios 150 baudios 300 baudios 600 baudios 1200 baudios 2400 baudios 4800 baudios 9600 baudios
Para configurar el puerto con algunos parámetros, bastará con realizar una operación OR con los deseados, por ejemplo, para 1200 baudios, sin bit de paridad, sin bit de parada y 8 bits, bastará con seleccïonar la palabra dada por:
abyte = 0x80 | 0x00 | 0x00 | 0x03 o lo que es equivalente,

abyte = 0x83 Para la lectura de un carácter que se haya recibido o del estado del puerto, se deben utilizar variables en las cuales se almacenarán los valores de retorno; en ambos caso se obtienen valores de 16 bits. Para la lectura de un dato recibido, los 8 bits menos significativos corresponden al dato y los 8 más significativos al estado del puerto; si alguno de estos últimos está en "1 ", un error ocurrió; si todos están en "0", el dato fue recibido sin error.
Cuando el comando es 2 o 3 (leer el carácter o el estado del puerto), el argumento a byte no se tiene en cuenta. Para configurar el puerto COM1 con los parámetros del ejemplo dado anteriormente, bastará con la instrucción:
bioscom (0,0x83,0); /*(inicializar, parámetros, COM1)*/ La utilización de los comandos y las instrucciones para la configuración de los puertos aquí expuestos sólo tendrán sentido en la medida en que utilicemos el puerto serial para establecer una comunicación bien con otros computadores o bien con dispositivos electrónicos como microcontroladores.
Comunicación con el puerto paralelo en Lenguaje C.
El lenguaje C permite tanto la lectura como la escritura de los puertos paralelo. Para leer el puerto existen las instrucciones inport e inportb, mientras que para escribir están las instrucciones outport y outportb. La sintaxis de estas instrucciones es la siguiente:
unsigned inport (unsigned portid); unsigned char inportb (unsigned portid); void outport (unsigned portid, unsigned value); void outportb (unsigned portid, unsigned char value);
Ejemplo:
Palabra = inport(puerto); outport (puerto,Palabra); Byte = inportb (puerto); outportb (puerto,Byte);
Las instrucciones que terminan en b ese refieren a la lectura o escritura de un byte, mientras que las que no terminan en esta letra se refieren a una palabra (dos byte). La variable puerto debe contener la dirección de memoria del puerto paralelo, este valor puede ser 378h, 3BCh ó 278h. Por ultimo no hay que olvidar

colocar la siguiente directiva del preprocesador que le indica al C que se usarán las funciones inport, outport, inportb u outportb, declaradas en el archivo dos.h.
#include <dos.h> El siguiente programa consulta la dirección del primer puerto paralelo disponible:
#include <conio.h> #include <dos.h> void main(void) { int puerto; clrscr(); puerto=peekb(0x40,0x8); printf("Dirección: %Xh",puerto); getch(); }
Como verán la utilización del puerto paralelo es mucho más sencillo que el serial.
PCI (Peripheral Component Interconnect, Interconexión de Componentes
Periféricos)
Consiste en un bus de ordenador estándar para conectar dispositivos periféricos directamente a su placa base. Estos dispositivos pueden ser circuitos integrados ajustados en ésta (los llamados "dispositivos planares" en la especificación PCI) o tarjetas de expansión que se ajustan en conectores. Es común en PC, donde ha desplazado al ISA como bus estándar, pero también se emplea en otro tipo de ordenadores.
A diferencia de los buses ISA, el bus PCI permite configuración dinámica de un dispositivo periférico. En el tiempo de arranque del sistema, las tarjetas PCI y el BIOS interactúan y negocian los recursos solicitados por la tarjeta PCI. Esto permite asignación de IRQs (Interrupción o corrupción del hardware o petición de interrupción) 16 y direcciones del puerto por medio de un proceso dinámico diferente del bus ISA, donde las IRQs tienen que ser configuradas manualmente usando jumpers externos.
16 Es una señal recibida por la CPU, indicando que debe "interrumpir" el curso de ejecución actual y pasar a ejecutar código específico para tratar esta situación. La interrupción supone la ejecución temporal de un programa, para pasar a ejecutar una "subrutina de servicio de interrupción", que pertenece al BIOS (Basic Input Output System). Sobre este tema. Ver al final del documento.

Las últimas revisiones de ISA y el bus MCA de IBM ya incorporaron tecnologías que automatizaban todo el proceso de configuración de las tarjetas, pero el bus PCI demostró una mayor eficacia en tecnología "plug and play". Aparte de esto, el bus PCI proporciona una descripción detallada de todos los dispositivos PCI conectados a través del espacio de configuración PCI.
El bus MCA (Micro Channel Architecture) es un bus creado por IBM con la intención de superar las limitaciones que presentaba el bus ISA.
Tarjeta PCI de 32 bits. En este caso, una controladora SCSI de Adaptec.
El gran problema de este bus es que no era compatible con los anteriores y necesitaba de tarjetas de expansión especialmente diseñadas para su estructura. Así, la especificación PCI cubre el tamaño físico del bus, características eléctricas, cronómetro del bus y sus protocolos. El grupo de interés especial de PCI (PCI Special Interest Group) comercializa copias de la especificación en http://www.pcisig.com

Tarjeta de expansión PCI-X Gigabit Ethernet
Variantes convencionales de PCI
• Cardbus es un formato PCMCIA de 32 bits, 33 MHz PCI. • Compact PCI, utiliza módulos de tamaño Eurocard conectado en una placa
hija PCI. • PCI 2.2 funciona a 66 MHz (requiere 3.3 voltios en las señales) (índice de
transferencia máximo de 503 MiB/s (533MB/s) • PCI 2.3 permite el uso de 3.3V y señalizador universal, pero no soporta los
5 voltios en las tarjetas. • PCI 3.0 es el estándar final oficial del bus, con el soporte de 5 voltios
completamente removido. • PCI-X cambia el protocolo levemente y aumenta la transferencia de datos a
133 MHz (índice de transferencia máximo de 1014 MiB/s). • PCI-X 2.0 especifica un ratio de 266 MHz (índice de transferencia máximo
de 2035 MiB/s) y también de 533 MHz, expande el espacio de configuración a 4096 bytes, añade una variante de bus de 16 bits y utiliza señales de 1.5 voltios.
• Mini PCI es un nuevo formato de PCI 2.2 para utilizarlo internamente en los portátiles.
• PC/104-Plus es un bus industrial que utiliza las señales PCI con diferentes conectores.
• Advanced Telecommunications Computing Architecture (ATCA o AdvancedTCA) es la siguiente generación de buses para la industria de las telecomunicaciones.

PCI-Express (PCI-E o PCIE) PCI Express (3GIO, "Entradas/Salidas de Tercera Generación", en inglés: 3rd Generation I/O) es un nuevo desarrollo del bus PCI que usa los conceptos de programación y los estándares de comunicación existentes, pero se basa en un sistema de comunicación serie mucho más rápido. Es una evolución de PCI, en la que se consigue aumentar el ancho de banda mediante el incremento de la frecuencia, llegando a ser 32 veces más rápido que el PCI 2.1. Su velocidad es mayor que PCI-Express, pero presenta el inconveniente de que al instalar más de un dispositivo la frecuencia base se reduce y pierde velocidad de transmisión.
Este bus está estructurado como enlaces punto a punto, full-duplex, trabajando en serie. En PCIE 1.1 (el más común en 2007) cada enlace transporta 250 MB/s en cada dirección. PCIE 2.0 dobla esta tasa y PCIE 3.0 la dobla de nuevo.
Cada slot de expansión lleva uno, dos, cuatro, ocho, dieciséis o treinta y dos enlaces de datos entre la placa base y las tarjetas conectadas. El número de enlaces se escribe con una x de prefijo (x1 para un enlace simple y x16 para una tarjeta con dieciséis enlaces. Treinta y dos enlaces de 250MB/s dan el máximo ancho de banda, 8 GB/s (250 MB/s x 32) en cada dirección para PCIE 1.1. En el uso más común (x16) proporcionan un ancho de banda de 4 GB/s (250 MB/s x 16) en cada dirección.
Ranura PCI-Express 1x.
En comparación con otros buses, un enlace simple es aproximadamente el doble de rápido que el PCI normal; un slot de cuatro enlaces, tiene un ancho de banda comparable a la versión más rápida de PCI-X 1.0, y ocho enlaces tienen un ancho de banda comparable a la versión más rápida de AGP (Accelerated Graphics Port, puerto de gráficos acelerado).
PCI Express está pensado para ser usado sólo como bus local, aunque existen extensores capaces de conectar múltiples placas base mediante cables de cobre o incluso fibra óptica. Debido a que se basa en el bus PCI, las tarjetas actuales pueden ser reconvertidas a PCI Express cambiando solamente la capa física. La velocidad superior del PCI Express permitirá reemplazar casi todos los demás

buses, AGP y PCI incluidos. La idea de Intel es tener un solo controlador PCI Express comunicándose con todos los dispositivos, en vez de con el actual sistema de puente norte y puente sur.
PCI Express no es todavía suficientemente rápido para ser usado como bus de memoria. Esto es una desventaja que no tiene el sistema similar HyperTransport, que también puede tener este uso. Además no ofrece la flexibilidad del sistema InfiniBand, que tiene rendimiento similar, y además puede ser usado como bus interno externo.
Este conector es usado mayormente para conectar tarjetas gráficas. PCI Express en 2006 es percibido como un estándar de las placas base para PC, especialmente en tarjetas gráficas. Marcas como Advanced Micro Devices y nVIDIA entre otras tienen tarjetas gráficas en PCI Express. También ha sido utilizado como puesto para la transferencia de unidades de estado sólido de alto rendimiento, con tasas superiores al Gigabyte por segundo
La AGP, es un puerto desarrollado como solución a los cuellos de botella que se producían en las tarjetas gráficas que usaban el bus PCI. El puerto AGP es de 32 bits como PCI pero cuenta con 8 canales más adicionales para acceso a la RAM. Además puede acceder directamente a esta a través del puente norte pudiendo emular así memoria de vídeo en la RAM. La velocidad del bus es de 66MHz.
El bus AGP cuenta con diferentes modos de funcionamiento.
• AGP 1X: velocidad 66 MHz con una tasa de transferencia de 266 MB/s y funcionando a un voltaje de 3,3V.
• AGP 2X: velocidad 133 MHz con una tasa de transferencia de 532 MB/s y funcionando a un voltaje de 3,3V.
• AGP 4X: velocidad 266 MHz con una tasa de transferencia de 1 GB/s y funcionando a un voltaje de 3,3 o 1,5V para adaptarse a los diseños de las tarjetas gráficas.
• AGP 8X: velocidad 533 MHz con una tasa de transferencia de 2 GB/s y funcionando a un voltaje de 0,7V o 1,5V.
Las tasas de transferencias se consiguen aprovechando los ciclos de reloj del bus mediante un multiplicador pero sin modificarlos físicamente.
El puerto AGP se utiliza exclusivamente para conectar tarjetas gráficas, y debido a su arquitectura sólo puede haber una ranura. Dicha ranura mide unos 8 cm y se encuentra a un lado de las ranuras PCI. Este puerto ha ido disminuyendo con la aparición de la PCI-Express, que proporciona mayores prestaciones en cuanto a frecuencia y ancho de banda. Así, los principales fabricantes de tarjetas gráficas,

como ATI y NVIDIA han ido presentando cada vez menos productos para este puerto.
Slots PCI Express (de arriba a abajo: x4, x16, x1 y x16), comparado con uno tradicional PCI de 32 bits, tal como se ven en la placa DFI LanParty nF4 Ultra-D.
Está pensado para ser usado sólo como bus local, aunque existen extensores capaces de conectar múltiples placas base mediante cables de cobre o incluso fibra óptica. Debido a que se basa en el bus PCI, las tarjetas actuales pueden ser reconvertidas a PCI-Express cambiando solamente la capa física. La velocidad superior del PCI-Express permitirá reemplazar casi todos los demás buses, AGP y PCI incluidos. La idea de Intel es tener un solo controlador PCI-Express comunicándose con todos los dispositivos, en vez de con el actual sistema de puente norte y puente sur. Este conector es usado mayormente para conectar tarjetas gráficas.
No es todavía suficientemente rápido para ser usado como bus de memoria. Esto es una desventaja que no tiene el sistema similar HyperTransport (ver más adelante), que también puede tener este uso. Además no ofrece la flexibilidad del sistema InfiniBand (Ver más adelante), que tiene rendimiento similar, y además puede ser usado como bus interno externo.

Otros tipos de buses
Es importante anotar, que los buses son espacios físicos que permiten el transporte de información y energía entre dos puntos de la computadora. Los Buses Generales son los siguientes:
• Bus de datos: son las líneas de comunicación por donde circulan los datos externos e internos del microprocesador.
• Bus de dirección: línea de comunicación por donde viaja la información específica sobre la localización de la dirección de memoria del dato o dispositivo al que se hace referencia.
• Bus de control: línea de comunicación por donde se controla el intercambio de información con un módulo de la unidad central y los periféricos.
• Bus de expansión: conjunto de líneas de comunicación encargado de llevar el bus de datos, el bus de dirección y el de control a la tarjeta de interfaz (entrada, salida) que se agrega a la tarjeta principal.
• Bus del sistema: todos los componentes de la CPU se vinculan a través del bus de sistema, mediante distintos tipos de datos el microprocesador y la memoria principal, que también involucra a la memoria caché de nivel 2. La velocidad de trasferencia del bus de sistema está determinada por la frecuencia del bus y el ancho del mínimo.
Extended Industry Standard Architecture (Arquitectura Estándar Industrial Extendida) Abreviado EISA, es una arquitectura de bus para computadoras compatibles con el IBM PC. Fue anunciado en 1988 y desarrollado por el "Grupo de los Nueve" (AST, Compaq, Epson, Hewlett-Packard, NEC Corporation, Olivetti, tANDY, Wyse y Zenith Data Systems), vendedores de computadores clónicos como respuesta al uso por parte de IBM de su arquitectura propietaria MicroChannel (MCA) en su serie PS/2. Tuvo un uso limitado en computadores personales 386 y 486 hasta mediados de los años 1990, cuando fue reemplazado por los buses locales tales como el bus local VESA y el PCI.

EISA amplía la arquitectura de bus ISA a 32 bits y permite que más de una CPU comparta el bus. El soporte de bus mastering también se mejora para permitir acceso hasta a 4GB de memoria. A diferencia de MCA, EISA es compatible de forma descendente con ISA, por lo que puede aceptar tarjetas antiguas XT e ISA, siendo conexiones y las ranuras una ampliación de las del bus ISA.
A pesar de ser en cierto modo inferior a MCA, el estándar EISA fue muy favorecido por los fabricantes debido a la naturaleza propietaria de MCA, e incluso IBM fabricó algunas máquinas que lo soportaban. Pero en el momento en el que hubo una fuerte demanda de un bus de estas velocidades y prestaciones, el bus local VESA y posteriormente el PCI llenaron este nicho y el EISA desapareció en la oscuridad.
EISA introduce las siguientes mejoras sobre ISA:
• Direcciones de memoria de 32 bits para CPU, DMA, y dispositivos de bus master.
• Protocolo de transmisión síncrona para transferencias de alta velocidad. • Traducción automática de ciclos de bus entre maestros y esclavos EISA e
ISA. • Soporte de controladores de periféricos maestros inteligentes. • 33MBps de velocidad de transferencia para buses maestros y dispositivos
DMA. • Interrupciones compartidas • Configuración automática del sistema y las tarjetas de expansión
Bus mastering Es una característica soportada por muchas arquitecturas de bus que permite a un dispositivo conectado al bus para iniciar operaciones. También llamada "First-party DMA"(Primera Parte del DMA), para contrastar con Third-party DMA, en realidad la situación es que el sistema controlador DMA hace la transferencia.
Algunos tipos de buses permiten a un sólo dispositivo (normalmente la CPU, o su proxy) iniciar las operaciones. La mayoría de las arquitecturas bus, incluyendo PCI, permiten múltiples dispositivos de bus master, ya que mejora considerablemente el rendimiento del objetivo general de los sistemas operativos. Algunos SOs de tiempo real prohíben

que los periféricos se conviertan en bus master, porque el programador ya no puede arbitrar para el bus y, por tanto, no puede proporcionar determinadas latencias.
Mientras que bus mastering en teoría permite que un dispositivo periférico pueda comunicarse directamente con otro, en la práctica casi todos los periféricos dominar el bus exclusivamente para realizar la memoria principal del DMA.
Si múltiples dispositivos están habilitados para dominar el bus, tiene que haber un sistema de arbitraje para evitar que múltiples dispositivos intenten manejar el bus de manera simultánea. Un número de esquemas diferentes son usados para esto; por ejemplo SCSI ha fijado una prioridad para cada SCSI ID. PCI no especifico el algoritmo a utilizar, dejando establecidas prioridades para la aplicación.
El acceso directo a memoria (DMA, Direct Memory Access) permite a cierto tipo de componentes de ordenador acceder a la memoria del sistema para leer o escribir independientemente de la CPU principal. Muchos sistemas hardware utilizan DMA, incluyendo controladores de unidades de disco, tarjetas gráficas y tarjetas de sonido. DMA es una característica esencial en todos los ordenadores modernos, ya que permite a dispositivos de diferentes velocidades comunicarse sin someter a la CPU a una carga masiva de interrupciones.17
La DMA puede llevar a problemas de coherencia de caché. Imagine una CPU equipada con una memoria caché y una memoria externa que se pueda acceder directamente por los dispositivos que utilizan DMA. Cuando la CPU accede a X lugar en la memoria, el valor actual se almacena en la caché. Si se realizan operaciones posteriores en X, se actualizará la copia en caché de X, pero no la versión de memoria externa de X. Si la caché no se vacía en la memoria antes de que otro dispositivo intente acceder a X, el dispositivo recibirá un valor caducado de X. Del mismo modo, si la copia en caché de X no es inválida cuando un dispositivo escribe un nuevo valor en la memoria, entonces la CPU funcionará con un valor caducado de X.
Este problema puede ser abordado en una de las dos formas en el diseño del sistema:
• Los sistemas de caché coherente implementan un método en el hardware externo mediante el cual se escribe una señal en el controlador de caché, la cual realiza una invalidación de la caché para escritura de DMA o caché de descarga para lectura de DMA.
• Los sistemas no-coherente dejan este software, donde el sistema operativo debe asegurarse de que las líneas de caché se vacían antes de que una transferencia de salida de DMA sea iniciada y anulada antes de
17 DMA. Recuperado el 25 de mayo de 2012. http://es.wikipedia.org/wiki/DMA

que una parte de la memoria sea afectada por una transferencia entrante de DMA que se haya requerido. El sistema operativo debe asegurarse de que esa parte de memoria no es accedida por cualquier subproceso que se ejecute en ese instante. Este último enfoque introduce cierta sobrecarga a la operación de DMA, ya que la mayoría de hardware requiere un bucle para invalidar cada línea de caché de forma individual.
Los híbridos también existen, donde en la caché secundaria L2 es coherente, mientras que en la caché L1 (generalmente la CPU) es gestionado por el software.
Bus VESA (Video Electronics Standards Association)
Es un tipo de bus de datos para ordenadores personales, utilizado sobre todo en equipos diseñados para el procesador Intel 80486. Permite conectar directamente la tarjeta gráfica al procesador.
Este bus es compatible con el bus ISA mejorando la respuesta gráfica, solucionando el problema de la insuficiencia de flujo de datos de su predecesor. Para ello su estructura consistía en una extensión del ISA de 16 bits. Las tarjetas de expansión de este tipo eran enormes lo que, junto a la aparición del bus PCI, mucho más rápido en velocidad de reloj, y con menor longitud y mayor versatilidad, hizo desaparecer al VESA, aunque sigue existiendo en algunos equipos antiguos.
Bus VLB
En 1992, el bus local de VESA (VLB) fue desarrollado por VESA (Asociación para estándares electrónicos y de video patrocinado por la compañía NEC) para ofrecer un bus local dedicado a sistemas gráficos. El VLB es un conector ISA de 16 bits con un conector de 16 bits agregado:
El bus VLB es un bus de 32 bits inicialmente diseñado para permitir un ancho de banda de 33 MHz (el ancho de banda del primer PC 486 en aquel momento). El

bus local VESA se utilizó en los siguientes 486 modelos (40 y 50 MHz respectivamente) así como en los primeros procesadores Pentium, pero fue reemplazado rápidamente por el bus PCI. Bus ISA18 La versión original del bus ISA (Arquitectura estándar de la industria) que apareció en 1981 con PC XT fue un bus de 8 bits con una velocidad de reloj de 4,77MHz.
En 1984, con la aparición de PC AT (el procesador Intel 286), el bit se expandió a un bus de 16 bits y la velocidad de reloj pasó de 6 a 8 MHz y finalmente a 8,33 MHz, ofreciendo una velocidad de transferencia máxima de 16 Mb/s (en la práctica solamente 8 Mb/s porque un ciclo de cada dos se utilizó para direccionar).
El bus ISA admitió el bus maestro, es decir, permitió que los controladores conectados directamente al bus se comunicaran directamente con los otros periféricos sin tener que pasar por el procesador. Una de las consecuencias del bus maestro es sin dudas el acceso directo a memoria (DMA). Sin embargo, el bus ISA únicamente permite que el hardware direccione los primeros 16 megabytes de RAM.
Hasta fines de la década de 1990, casi todos los equipos contaban con el bus ISA, pero fue progresivamente reemplazado por el bus PCI, que ofrecía un mejor rendimiento.
• Conector ISA de 8 bits:
• Conector ISA de 16 bits:
18 Bus ISA. Recuperado el 30 de mayo de 2013. http://es.kioskea.net/contents/pc/isa-mca-vlb.php3

Tres ranuras ISA.
Bus AGP (Puerto de gráficos acelerado, Accelerated Graphics Port)
La interfaz AGP se ha creado con el único propósito de conectarle una tarjeta de video. Funciona al seleccionar en la tarjeta gráfica un canal de acceso directo a la memoria (DMA, Direct Memory Access), evitado así el uso del controlador de entradas/salidas. En teoría, las tarjetas que utilizan este bus de gráficos necesitan menos memoria integrada ya que poseen acceso directo a la información gráfica (como por ejemplo las texturas) almacenadas en la memoria central.
Su costo es aparentemente inferior.
La versión 1.0 del bus AGP, que funciona con 3.3 voltios, posee un modo 1X que envía 8 bytes cada dos ciclos y un modo 2X que permite transferir 8 bytes por ciclo.
En 1998, la versión 2.0 del bus AGP presenta el AGP 4X que permite el envío de 16 bytes por ciclo. La versión 2.0 del bus AGP funciona con una tensión de 1.5 voltios y con conectores AGP 2.0 "universales" que pueden funcionar con cualquiera de los dos voltajes.
La versión 3.0 del bus AGP apareció en 2002 y permite duplicar la velocidad del AGP 2.0 proponiendo un modo AGP 8X.
El puerto AGP 1X funciona a una frecuencia de 66 MHz, a diferencia de los 33 MHZ del Bus PCI, lo que le provee una tasa máxima de transferencia de 264 MB/s (en contraposición a los 132 MB/s que comparten las diferentes tarjetas para el bus PCI). Esto le proporciona al bus AGP un mejor rendimiento, en especial cuando se muestran gráficos en 3D de alta complejidad.

Con la aparición del puerto AGP 4X, su tasa de transferencia alcanzó los 1 GB/s. Esta generación de AGP presentó un consumo de 25 vatios. La generación siguiente se llamó AGP Pro y consumía 50 vatios.
El AGP Pro 8x ofrece una tasa de transferencia de 2 GB/s.
Las tasas de transferencia para los diferentes estándares AGP son las siguientes:
• AGP 1X : 66,66 MHz x 1(coef.) x 32 bits /8 = 266,67 MB/s • AGP 2X : 66,66 MHz x 2(coef.) x 32 bits /8 = 533,33 MB/s • AGP 4X : 66,66 MHz x 4(coef.) x 32 bits /8 = 1,06 GB/s • AGP 8X : 66,66 MHz x 8(coef.) x 32 bits /8 = 2,11 GB/s
Se debe tener en cuenta que las diferentes normas AGP son compatibles con la versión anterior, lo que significa que las tarjetas AGP 4X o AGP 2X pueden insertarse en una ranura para AGP 8X.
Conectores AGP
Las placas madre más recientes poseen un conector AGP general incorporado identificable por su color marrón. Existen tres tipos de conectores:
• Conector AGP de 1,5 voltios:
• Conector AGP de 3,3 voltios:
• Conector AGP universal:
Esta tabla resume las especificaciones técnicas de cada versión y modo AGP:
AGP Voltaje Modo
AGP 1.0 3,3 voltios 1x, 2x
AGP 2.0 1,5 voltios 1x, 2x, 4x
AGP 2.0 1,5 v y 3,3 v 1x, 2x, 4x

Universal
AGP 3.0 1,5 voltios 4x, 8x
HyperTransport19 También conocido como Lightning Data Transport (LDT), es una tecnología de comunicaciones bidireccional, que funciona tanto en serie como en paralelo, y que ofrece un gran ancho de banda en conexiones punto a punto de baja latencia. Por consiguiente, todos los procesadores poseen un bus principal o de sistema por el cual se envían y reciben todos los datos, instrucciones y direcciones desde los integrados del chipset o desde el resto de los dispositivos. Como puente de conexión entre el procesador y el resto del sistema, este bus define mucho del rendimiento del sistema, su velocidad se mide en bytes por segundo.
Esta tecnología se aplica en la comunicación entre chips de un circuito integrado ofreciendo un enlace (ó bus) avanzado de alta velocidad y alto desempeño; es una conexión universal que está diseñada para reducir el número de buses dentro de un sistema, suministrando un enlace de alto rendimiento a las aplicaciones incorporadas y facilitando sistemas de multiprocesamiento altamente escalables. Este bus puede implementarse de distintas maneras, con el uso de buses seriales o paralelos y con distintos tipos de señales eléctricas. La forma más antigua es el bus paralelo en el cual se definen líneas especializadas en datos, direcciones y para control. En la arquitectura tradicional de Intel (usada 19 HyperTrasport. Recuperado el 30 de noviembre de 2011. http://es.wikipedia.org/wiki/HyperTransport

hasta modelos recientes), ese bus se llama el FSB (Front Side Bus) y es de tipo paralelo con 64 líneas de datos, 32 de direcciones, además de múltiples líneas de control que permiten la transmisión de datos entre el procesador y el resto del sistema. Este esquema se ha utilizado desde el primer procesador de la historia, con mejoras en la señalización que le permite funcionar con relojes de 333Mhz haciendo 4 transferencias por ciclo (1333 MHz como frecuencia nominal).
Existen tres versiones de HyperTransport -- 1.0, 2.0 y 3.0 -- que puede funcionar desde los 200MHz hasta 2.6GHz (mientras el bus PCI corre a 33 o 66 MHz). También soporta tecnología DDR (o Double Data Rate), lo cual permite alcanzar un máximo de 5200 MT/s20 (2600MHz hacia cada dirección: entrada y salida) funcionando a su máxima velocidad (2.6GHz).
Soporta conexiones auto-negociadas para determinar la velocidad. Su velocidad de transferencia máxima, utilizando líneas de 32 bits, tiene por cada uno de sus 2 buses un total de 20.8 GB/s (2.6GHz * (32bits / 8)), lo que supone la suma de 41.6 GB/s en ambas direcciones, superando con creces cualquier otro estándar. Se pueden mezclar también enlaces de varios anchos en una sola aplicación (por ejemplo 2x8 en vez de 1x16). Esto permite una velocidad de interconexión mayor entre la memoria principal y la CPU y una menor entre los periféricos que lo precisen. Además esta tecnología tiene mucho menos latencia que otras soluciones.
En algunos procesadores de AMD e Intel Core i7 (Nehalem) se han usado distintos tipos de buses pero más bien seriales como bus principal. Entre estos se encuentra el bus HyperTransport que maneja los datos en forma de paquetes usando una cantidad menor de líneas de comunicación, permitiendo frecuencias de funcionamiento más altas, para los micros de AMD. Estas tecnologías seriales surgen por la necesidad de resolver el cuello de botella que genera el sistema FSB para los micros modernos, pues éstos deben esperar uno o más ciclos de reloj hasta que los datos se traigan de la memoria, el FSB siempre fue criticado por AMD. HyperTransport en su versión más reciente 3.1 logra frecuencias de 3,2GHz, con un canal máximo de 32 bits logra tasas de transferencias en cada dirección de 25,6 GB/s. Los microprocesadores de última generación de Intel y muchos de AMD poseen además un controlador de memoria DDR en el interior del encapsulado lo que hace necesario la implementación de buses de memoria del procesador hacia los módulos. Ese bus esta de acuerdo a los estándares DDR de JEDEC y consisten en líneas de bus paralelo, para datos, direcciones y control. Dependiendo de la cantidad de canales pueden existir de 1 a 3 buses de memoria.
HyperTransport está basada en paquetes. Cada uno de ellos consiste en un conjunto de palabras de 32 bits independientemente del ancho físico de la 20 Millones de transferencias por segundo.

conexión. La primera palabra de un paquete es siempre una palabra de comando. Si un paquete contiene una dirección los últimos 8 bits de la palabra de comando estarán enlazados con la siguiente palabra de 32 bits para formar una dirección de 40 bits. Además se permite anteponer otra palabra de control de 32 bits cuando se necesite una dirección de 64 bits. Las restantes palabras de 32 bits en un paquete formarán la información útil. Las transferencias, independientemente de su longitud actual, estarán formadas siempre por múltiplos de 32 bits.
Los paquetes de HyperTransport entran en segmentos conocidos como tiempos bit. El número de tiempos bit necesarios depende del ancho de la interconexión. HyperTransport puede usarse para generar mensajes de gestión de sistemas, señales de interrupciones, expedir sondas a dispositivos adyacentes o procesadores y E/S en general y hacer transacciones de datos. Normalmente se pueden usar dos tipos diferentes de comandos de escritura: avisados y no-avisados. Las escrituras avisadas no precisan una respuesta del destino. Son usadas primordialmente para dispositivos con un gran ancho de banda como tráfico a Uniform Memory Access (UMA)21 o transferencias de Acceso directo a memoria (DMA). Las escrituras no-avisadas precisan una respuesta del tipo
21 Es una arquitectura de memoria compartida utilizada en computación paralela, en la que cada procesador puede utilizar una caché privada. Existe un modo para compartir también dispositivos periféricos. El modelo UMA es más adecuado para aplicaciones de propósito general o para aplicaciones multi-usuario. Puede ser utilizado para aumentar el speed up programas largos y tediosos, consiguiendo que varias máquinas ejecuten el mismo programa en menos tiempo y a ser posible con los mismos resultados.

"destino hecho". La lectura también puede provocar que el receptor genere una respuesta. InfiniBand
Es un bus de comunicaciones serie de alta velocidad, diseñado tanto para conexiones internas como externas. Emplea un bus serie bidireccional de tal manera que evita los problemas asociados a buses paralelos en largas distancias (habitación o edificio). A pesar de ser una conexión serie, es muy rápido, ofreciendo una velocidad bruta de unos 2.5Gbps en cada dirección por enlace. Infiniband también soporta doble e incluso cuádruples tasas de transferencia de datos,
llegando a ofrecer 5Gbps y 10Gbps respectivamente. Se usa una codificación 8B/10B, con lo que, de cada 10 bits enviados solamente 8 son de datos, de tal manera que la tasa de transmisión útil es 4/5 de la media. Teniendo esto en cuenta, los anchos de banda ofrecidos por el modo simple, doble y cuádruple son de 2, 4 y 8Gbps respectivamente. Los enlaces pueden añadirse en grupos de 4 o 12, llamados 4X o 12X. Un enlace 12X a cuádruple ritmo tiene un caudal bruto de 120Gpbs, y 96Gbps de caudal eficaz. Actualmente, la mayoría de los sistemas usan una configuración 4X con ritmo simple, aunque los primeros productos soportando doble ritmo ya están penetrando en el mercado. Los sistemas más grandes, con enlaces 12X se usan típicamente en lugares con gran exigencia de ancho de banda, como clústeres de computadores, interconexión en superordenadores y para interconexión de redes.

La latencia teórica de estos sistemas es de unos 160ns. Las reales están en torno a los 6µs, dependiendo bastante del software y el firmware. Infiniband usa una topología conmutada de forma que varios dispositivos pueden compartir la red al mismo tiempo (en oposición a la topología en bus). Los datos se transmiten en paquetes de hasta 4 kB que se agrupan para formar mensajes. Un mensaje puede ser una operación de acceso directo a memoria de lectura o escritura sobre un nodo remoto, un envío o recepción por el canal, una operación de transacción reversible o una transmisión multicast22.
Al igual que en el modelo de canal usado en la mayoría de los mainframes23, todas las transmisiones empiezan o terminan con un adaptador de canal. Cada procesador contiene un host channel adapter (HCA) y cada periférico un target channel adapter (TCA). Estos adaptadores también pueden intercambiar información relativa a la seguridad o a la calidad de servicio del enlace.
OVERCLOCKING Literalmente significa sobre el reloj, es decir, aumentar la frecuencia de reloj de la CPU. La práctica conocida como overclocking (antiguamente conocido como undertiming) pretende alcanzar una mayor velocidad de reloj para un componente electrónico (por encima de las especificaciones del fabricante). La idea es conseguir un rendimiento más alto gratuitamente, o superar las cuotas actuales de rendimiento, aunque esto pueda suponer una pérdida de estabilidad o acortar la vida útil del componente. Esta práctica perdió popularidad en los últimos tiempos, ya que no merecía la pena perder el componente por ganar unos pocos megahertzios. El overclocking ya está más avanzado y permite forzar los componentes aún más (muchas veces cerca del doble) sin que pase nada, siempre que tengan una buena refrigeración.
22 Es el envío de la información en una red a múltiples destinos simultáneamente, usando la estrategia más eficiente para el envío de los mensajes sobre cada enlace de la red sólo una vez y creando copias cuando los enlaces en los destinos se dividen. En oposición a multicast, los envíos de un punto a otro en una red se denominan unidifusión (unicast), y los envíos a todos los nodos en una red se denominan difusión amplia (broadcast). 23 Es una computadora grande, potente y costosa usada principalmente por una gran compañía para el procesamiento de una gran cantidad de datos; por ejemplo, para el procesamiento de transacciones bancarias. Ojo no es un supercomputador.

Este aumento de velocidad produce un mayor gasto energético, y por tanto, una mayor producción de calor residual en el componente electrónico. El calor puede producir fallos en el funcionamiento del componente, y se debe combatir con diversos sistemas de refrigeración (por aire con ventiladores, por agua o con una célula Peltier24 unida a un ventilador). A veces, los fallos producidos por esta práctica, pueden dañar de forma definitiva el componente, otras veces, pueden producir un reinicio que conlleva la pérdida de datos de las aplicaciones abiertas, o en algún caso, la pérdida del sistema de archivos entero.
Tomado de. http://blog.gamemela.com/all-about-overclocking/
Esta práctica está muy extendida entre los usuarios de informática más exigentes, que tratan de llevar al máximo el rendimiento de sus máquinas. Los consumidores menos atrevidos suelen comprar componentes informáticos de bajo coste, forzándolos posteriormente y alcanzando así el rendimiento esperado por los componentes de gama más alta. Por otro lado, los consumidores más fanáticos pueden llegar a adquirir componentes que permiten forzar su funcionamiento, y
24 El efecto Peltier hace referencia a la creación de una diferencia de temperatura debida a un voltaje eléctrico. Sucede cuando una corriente se hace pasar por dos metales o semiconductores conectados por dos “junturas de Peltier”. La corriente propicia una transferencia de calor de una juntura a la otra: una se enfría en tanto que otra se calienta.
Una manera para entender cómo es que este efecto enfría una juntura es notar que cuando los electrones fluyen de una región de alta densidad a una de baja densidad, se expanden (de la manera a lo que hace un gas ideal) y se enfría la región.

conseguir así pruebas de rendimiento inalcanzables para cualquier equipo de consumo. Por este motivo, la mayoría de los fabricantes decide no incluir en la garantía de su hardware los daños producidos por hacerles overclocking.
Hoy en día fabricantes de hardware producen sus productos desbloqueados para permitirles a los usuarios realizar overclock sobre los mismos. Por ejemplo, GPU (unidad de procesamiento gráfico, graphics processing unit), la CPU, etc.25
Es importante anotar, que para la familia del Phenom II, es la primera en eliminar el “defecto del frío” (cold bug), que es un fenómeno físico que hace que los anteriores microprocesadores fabricados por esa empresa dejasen de funcionar cuando eran expuestos a temperaturas anormalmente bajas. Este bug evitaba que los overclockers puedan usar métodos de refrigeración “extremos”, como hielo seco o nitrógeno líquido. Se espera que la eventual eliminación de ese bug permita realizar más overclocking con estas CPUs que con cualquiera otras que haya fabricado AMD en los últimos tiempos.
25 Si quieren sacarle el jugo a su tarjeta de video, pueden consultar este link de NVIDIA, y descargar el documento. http://www.nvidia.com/docs/CP/45121/nforce_680i_sli_overclocking.pdf

Hoy en día los fabricantes de hardware venden algunos de sus productos desbloqueados para permitir a los usuarios realizar overclock sobre los mismos; es el caso de, por ejemplo, GPU, CPU, etc.
Dispositivos refrigerantes
Se tiene el conjunto de disipador y ventilador; los cuales se encargan de eliminar el calor excesivo de la tarjeta. Se distinguen dos tipos:
Disipador: dispositivo pasivo (sin partes móviles y, por tanto, silencioso); compuesto de un metal conductor del calor, extrae este de la tarjeta. Su eficiencia va en función de la estructura y la superficie total, por lo que a mayor demanda de refrigeración, mayor debe ser la superficie del disipador.
Ventilador: dispositivo activo (con partes móviles); aleja el calor emanado de la tarjeta al mover el aire cercano. Es menos eficiente que un disipador, siempre que nos refiramos al ventilador sólo, y produce ruido al tener partes móviles.
Ambos tipos de dispositivo son compatibles entre sí y suelen ser montados juntos en las tarjetas gráficas; un disipador sobre la GPU (el componente que más calor genera en la tarjeta, y en muchas ocasiones, de todo el PC) extrae el calor, y un ventilador sobre él aleja el aire caliente del conjunto.
Ventiladores (disipadores) refrigerantes de CPU y de la tarjeta gráfica.

Disipador de calor Hyper Z600, presenta un alto grado de traspaso térmico. Tiene una base de cobre y seis heatpipes de 6 mm que cruzan un arsenal de aletas de aluminio que pueden perfectamente trabajar en modo pasivo con procesadores con un TDP de hasta 89W. Presenta unas dimensiones de 127.28 x 127.28 x 160 milímetros y un peso de 1045gr, con compatibilidad para socket LGA775 Intel y socket 940/AM2/AM2 de AMD, y también puede ser equipado con dos ventiladores de 120mm para aumentar su rendimiento. La segunda imagen muestra el “Thermaltake V1 AX CPU cooler”, es un disipador y ventilador con dimensiones de 147 (L) x 92 (W) x 143 (H) mm y un peso de 420gr, con base de cobre. El ventilador está compuesto por cuatro heatpipes de 6mm y dos alerones compuesto por aletas de aluminio que son disipadas en el centro por un ventilador de 110mm con una vida útil de 50.000 horas, el ventilador gira en dos velocidades: 1300 y 2000rpm. El ventilador es multi-sockets, por lo que soporta tanto procesadores Intel LGA775 y procesadores AMD de socket AM2/AM2+, Socket 939, 940 y 754.
MÉTODOS PARA ENFRIAR LOS COMPONENTES DE UN COMPUTADOR26
Variadas técnicas son usadas en la actualidad para refrigerar componentes electrónicos, como lo son los microprocesadores, que fácilmente pueden alcanzar temperaturas tan altas que provoquen daño permanente si no son mantenidos a una temperatura adecuada de forma apropiada.
Refrigeración por Aire
La refrigeración pasiva es probablemente el método más antiguo y común para enfriar no sólo componentes electrónicos sino cualquier cosa. La idea es que ocurra intercambio de calor entre el aire a temperatura ambiente y el elemento a enfriar, a temperatura mayor.
26 Fuente. Distintos tipos de refrigeración. Consultado el 1 de septiembre de 2013. http://www.chw.net/2007/03/distintos-tipos-de-refrigeracion/

Las técnicas para enfriar componentes electrónicos, se basa en incrementar la superficie de contacto con el aire para maximizar el calor que éste es capaz de retirar. Justamente con el objeto de maximizar la superficie de contacto, los disipadores o en inglés heatsinks consisten en cientos de aletas delgadas. Mientras más aletas, más disipación. Mientras más delgadas, mejor todavía.
Refrigeración Pasiva por Aire
Las principales ventajas de la disipación pasiva son su inherente simplicidad (es básicamente de un trozo de metal), su durabilidad (carece de piezas móviles) y su bajo costo. Además de lo anterior, no producen ruido. La mayor desventaja de la disipación pasiva es su habilidad limitada para dispersar grandes cantidades de calor rápidamente. Los disipadores (heatsinks) modernos son incapaces de refrigerar efectivamente CPUs de gama alta, sin mencionar GPUs de la misma categoría sin ayuda de un ventilador.
Los disipadores (heatsinks) modernos son usualmente fabricados en cobre o aluminio, materiales que son excelentes conductores de calor y que son relativamente baratos de producir. En particular, el cobre es bastante más caro que el aluminio por lo que los disipadores de cobre se consideran el formato premium mientras que los de aluminio son lo estándar. Sin embargo, si de verdad quisiéramos conductores premium podríamos usar plata para este fin, puesto que su conductividad térmica es mayor todavía. Por eso, aunque el cobre es sustancialmente más caro que el aluminio, es válido decir que ambos son materiales baratos.

Refrigeración Activa por Aire
La refrigeración activa por aire consiste en tomar un sistema pasivo y adicionar un elemento que acelere el flujo de aire a través de las aletas del heatsink. Este elemento es usualmente un ventilador aunque se han visto variantes en las que se utiliza una especie de turbina.
En la refrigeración pasiva tiende a suceder que el aire que rodea al disipador se calienta, y su capacidad de evacuar calor del disipador disminuye. Aunque por convección natural este aire caliente se mueve, es mucho más eficiente incorporar un mecanismo para forzar un flujo de aire fresco a través de las aletas del disipador, y es exactamente lo que se logra con la refrigeración activa.
Aunque la refrigeración activa por aire no es mucho más cara que la pasiva, la solución tiene desventajas significativas. Por ejemplo, al tener partes móviles es susceptible de averiarse, pudiendo ocasionar daños irreparables en el sistema si es que esta avería no se detecta a tiempo (en otras palabras, si un sistema pensado para ser enfriado activamente queda en estado pasivo por mucho tiempo). En segundo lugar, aunque este aspecto ha mejorado mucho todos los ventiladores hacen ruido. Algunos son más silenciosos que otros, pero siempre serán más ruidosos que los cero decibeles que produce una solución pasiva.
Lectura Opcional... ¿Por qué son útiles los disipadores?
Entre más superficie tenga un heatsink mejor será su disipación, pero también es cierto que en cualquier ciclo todo intermediario, por perfecto que sea, es un estorbo. Entonces, ¿cuál es el beneficio de usar un disipador? Por qué no sería mejor dejar que el componente electrónico se entendiera directamente con el aire Esto es porque además de la superficie en este fenómeno interviene una propiedad llamada conductividad térmica, la capacidad de un material de canalizar el calor.

Sea el siguiente ejercicio. Supongamos que tenemos un CPU cuyo núcleo está a la intemperie y tiene una superficie de 1 cm2 (0.0001 m2) y por otro lado tenemos un disipador de cobre que en su base tiene una superficie de 1 cm2 y que gracias al uso de cientos de aletas minúsculas ofrece al aire una superficie de contacto de 1000 cm2 (0.1 m2).
La Ley de Fourier indica que el flujo de calor es directamente proporcional a la superficie de contacto y a la constante de conductividad térmica, por lo que si hacemos un "coeficiente conjunto" definido como el producto de superficie por conductividad, tendremos un indicador comparativo de la capacidad de transferir calor.
Considerando que la conductividad térmica del aire es de aproximadamente 0.02W/m2°K y la del cobre es de 380 W/m2°K, la capacidad del CPU "Nornal" de transmitir calor al aire tiene un coeficiente conjunto de
0.0001 m2 x 0.02 W/ m2·°K = 0.000002 W/°K
Mientras que la capacidad de transmitir calor del CPU al disipador es de:
0.0001 m2 x 380 W/ m2·°K = 0.038 W/°K
A su vez, la capacidad del disipador de transmitir calor al aire es de:
0.1 m2 x 0.02 W/ m2 ·°K = 0.002 W/°K
Evidentemente, el cuello de botella está en la interfaz cobre-aire y no en el contacto CPU-cobre, pero lo importante es que, aunque el paso de calor del CPU al disipador no es perfecto por ejemplo porque el contacto entre las superficies es irregular, y aunque en la segunda mitad de la cadena el cobre igual tendrá que lidiar con la baja conductividad del aire, la capacidad de evacuar calor usando al disipador como intermediario es 1000 veces mayor que la del CPU normal. En

otras palabras, no importa tanto que un disipador no sea el conductor perfecto: es la mejor manera de aumentar la superficie de intercambio de calor.
Refrigeración líquida (Watercooling)
Un método más complejo y menos común es la refrigeración por agua. El agua tiene un calor específico más alto y una mejor conductividad térmica que el aire, gracias a lo cual puede transferir calor más eficientemente y a mayores distancias que el gas.
Bombeando agua alrededor de un procesador es posible remover grandes cantidades de calor de éste en poco tiempo, para luego ser disipado por un radiador ubicado en algún lugar dentro (o fuera) del computador. La principal ventaja de la refrigeración líquida, es su habilidad para enfriar incluso los componentes más calientes de un computador.
Todo lo bueno del watercooling tiene, sin embargo, un precio; la refrigeración por agua es cara, compleja e incluso peligrosa en manos sin experiencia (Puesto que el agua y los componentes electrónicos no son buena pareja). Aunque usualmente menos ruidosos que los basados en refrigeración por aire, los sistemas de refrigeración por agua tienen partes móviles y en consecuencia se sabe eventualmente pueden sufrir problemas de confiabilidad. Sin embargo, una avería en un sistema de Watercooling (por ejemplo, si deja de funcionar la bomba) no es tan grave como en el caso de la refrigeración por aire, puesto que la inercia térmica del fluido es bastante alta e incluso encontrándose estático no será fácil para el CPU calentarlo a niveles peligrosos.
Refrigeración Líquida por Inmersión
Consiste en que un computador es totalmente sumergido en un líquido de conductividad eléctrica muy baja, como el aceite mineral. El computador se mantiene enfriado por el intercambio de calor entre sus partes, el líquido refrigerante y el aire del ambiente. Este método no es práctico para la mayoría de los usuarios por razones obvias.

Pese a que este método tiene un enfoque bastante simple (llene un acuario de aceite mineral y luego ponga su PC adentro) también tiene sus desventajas. Para empezar, debe ser bastante desagradable el intercambio de piezas para upgrade.
Refrigeración por Metal Líquido
Se trata de un invento mostrado por nanoCoolers, compañía basada en Austin, Texas, que hace algunos años desarrolló un sistema de enfriamiento basado en un metal líquido con una conductividad térmica mayor que la del agua, constituido principalmente por Galio e indio.
A diferencia del agua, este compuesto puede ser bombeado electromagnéticamente, eliminando la necesidad de una bomba mecánica. A

pesar de su naturaleza innovadora, el metal líquido de nanoCoolers nunca alcanzó una etapa comercial.
Una explicación bastante extensa y en español puede encontrarse en Hardcore Modding.
Refrigeración Termoeléctrica (TEC)
(Explicación tomada del Review "Amanda TEC Cooler")
En 1834 un frances llamado Juan Peltier descubrió que aplicando una diferencia eléctrica en dos metales o semiconductores (de tipo p y n) unida entre sí, se generaba una diferencia de temperaturas entre las uniones de estos. Las uniones p-n tienden a calentarse y las n-p a enfriarse.
El concepto rudimentario de Peltier fue paulatinamente perfeccionado para que fuera un solo bloque con las uniones semiconductoras, (que generalmente son en base a Seleniuro de Antimonio y Telururo de bismuto) conectadas por pistas de cobre y dispuestas de tal manera, que transportara el calor desde una de sus caras hacia la otra, haciendo del mecanismo una "bomba de calor" ya que es capaz de extraer el calor de una determinada superficie y llevarlo hacia su otra cara para disiparlo.
Estos sistemas son bastante versátiles, basta con invertir la polaridad para invertir el efecto (cambiar el lado que se calienta por el frío y viceversa), la potencia con que enfría es fácilmente modificable dependiendo del voltaje que se le aplique y es bastante amable con el medio ambiente ya que no necesita de gases nocivos como los usados en los refrigeradores industriales para realizar su labor.

El uso de refrigeración termoeléctrica por lo general se circunscribe al ámbito industrial, pero tanto los fanáticos como algunos fabricantes han desarrollado productos que incorporan el elemento Peltier como método para enfriar el procesador de un PC. Estas soluciones, que de por sí involucran un fuerte aumento del consumo eléctrico (toda vez que un peltier es bastante demandante de potencia) no pueden operar por sí solas, pues se hace necesario un sistema que sea capaz de retirar calor de la cara caliente.
Este sistema complementario suele ser de enfriamiento por aire o por agua. En el primero de los casos el concepto se denomina Air Chiller y hay productos comerciales como el Titan Amanda que lo implementan. El segundo caso se denomina Water Chiller, es bastante más efectivo (por la mejor capacidad del agua de retirar calor de la cara caliente) y también hay productos, como el Coolit Freezone, que implementan el sistema.
Refrigeración por Heatpipes
Un heatpipe es una máquina térmica que funciona mediante un fenómeno llamado "convección natural". Este fenómeno, derivado de la expansión volumétrica de los fluidos, causa que al calentarse estos tiendan a hacerse menos densos, y viceversa. En un mismo recipiente, el calentamiento de la base producirá la subida del fluido caliente de abajo y la bajada del fluido aún frío de la parte superior, produciéndose una circulación.
El sistema de heatpipes que se utiliza en los coolers de CPU es un ciclo cerrado en donde un fluido similar al que recorre los refrigeradores se calienta en la base, en contacto con el CPU, se evapora, sube por una tubería hasta el disipador, se condensa y baja como líquido a la base nuevamente.
El transporte de calor que se logra mediante el uso de heatpipes es muy superior al que alcanza un disipador de metal tradicional, por delgadas o numerosas que sean sus aletas. Sin embargo, sería poco ambicioso dejar que los heatpipes hicieran todo el trabajo, por lo que los productos comerciales que han incorporado

el elemento heatpipe complementan su alta capacidad de transporte de calor con voluminosos panales de aluminio o cobre (en buenas cuentas, un heatsink) y ventiladores que mueven bastante caudal de aire.
Cambio de Fase
Los sistemas de enfriamiento por cambio de fase se basan en la misma máquina térmica que opera en todo refrigerador, en la que se utiliza a nuestro favor la ley de los gases perfectos y las propiedades termodinámicas de un gas para instigarlo a tomar o ceder calor del o al medio ambiente en distintos puntos del ciclo.
El cambio de fase es el método de enfriamiento preferido en refrigeradores comerciales y algunos sistemas de aire acondicionado, pero en el campo de la computación se ve muy poco. En un primer acercamiento algunos técnicos en refrigeración aficionados al overclock implementaron máquinas artesanales para aplicar refrigeración por cambio de fase al PC, pero en los últimos años se viene viendo de forma cada vez más frecuente la aparición de sistemas
comerciales, más compactos, estilizados y caros.

Los overclockeros extremos no miran con muy buenos ojos estas soluciones comerciales principalmente por dos razones. Primero, las necesidades de enfriamiento de cada plataforma son distintas, y aunque es improbable que el PC vaya a calentarse utilizando un sistema de cambio de fase, sí puede darse que la solución comercial sea insuficiente para llegar a temperaturas extremadamente bajas. En segundo lugar, hoy por hoy el ciclo clásico que se ilustra en el esquema ha sido refinado y paulatinamente reemplazado por circuitos en cascada, en donde hay varios ciclos de refrigeración por cambio de fase y cada uno enfría al siguiente.
Cambio de fase por vibración
El Vibration Induced Droplet Atomization (VIDA) es un sistema experimental que probablemente nunca se utilizará comercialmente pero por lo ingenioso que resulta vale la pena mencionarlo. En rigor, el fenómeno físico mediante el cual se retira calor es en buenas cuentas un cambio de fase.
El VIDA opera de la siguiente manera: atomizando un fluido que puede ser simplemente agua, y sometiéndolo a una intensa vibración, se logra que éste pase al estado gaseoso a temperatura ambiente. Al evaporarse, el agua (o el líquido que se utilice) toma una gran cantidad de calor del medio circundante. En otras palabras, una gota de agua lo suficientemente pequeña y convenientemente

tratada mediante vibraciones se convertirá en vapor espontáneamente, y si logra que ello ocurra en contacto con la superficie deseada, el agua retirará de ella una gran cantidad de calor.
Criogenia
Se utiliza nitrógeno líquido o hielo seco (dióxido de carbono sólido). Estos materiales son usados a temperaturas extremadamente bajas (el nitrógeno líquido ebulle a los -196ºC y el hielo seco lo hace a -78ºC) directamente sobre el procesador para mantenerlo frío. Sin embargo, después que el líquido refrigerante se haya evaporado por completo debe ser reemplazado. Con el paso del tiempo, el daño al procesador es inevitable, debido a los frecuentes cambios de temperatura, por lo cual la criogenia sólo es utilizada en casos extremos de overclocking y sólo por cortos periodos de tiempo.
En experimentos como el legendario Proyecto Kill Pi o en el campeonato nacional de Overclock se utilizó el método del hielo seco con excelentes resultados.
Claramente cada método de refrigeración tiene ventajas y desventajas. Algunos son caros y bulliciosos, otros no lo suficientemente poderosos, algunos requieren de instalaciones complejas e incluso existen aquellos que pueden dañar el procesador. Buscando crear un disipador (cooler) barato, silencioso y altamente confiable capaz de disipar efectivamente el calor de incluso los procesadores más demandantes de gama alta, Tecnologías Avanzadas Kronos (Kronos Advanced Technologies) dominó un principio físico antiguo conocido como el efecto de descarga corona.

Propulsión de aire electrostático y el efecto de descarga corona
Un nuevo tipo de tecnología de refrigeración ultra-delgada y silenciosa para procesadores está siendo desarrollada por Tecnologías Avanzadas Kronos en colaboración con Intel y la Universidad de Washington. En dos años, esta nueva tecnología podría reemplazar las actuales técnicas de enfriamiento por ventiladores en notebooks y otros dispositivos portátiles, volviéndolos más confiables y mucho más silenciosos.
La tecnología de refrigeración que está siendo desarrollada por Kronos emplea un dispositivo llamado "bomba de viento iónico" (ionic wind pump), un acelerador de fluidos electrostáticos cuyo principio básico de operación es la descarga por efecto corona. Este fenómeno ocurre cuando el potencial de un conductor cargado alcanza una magnitud tal que sobrepasa la rigidez dieléctrica del fluido que lo rodea (por ejemplo aire) este aire, que en otras circunstancias es un excelente aislante, se ioniza y los iones son atraídos y repelidos por el conductor a gran velocidad, produciéndose una descarga eléctrica que exhibe penachos o chispas azules o púrpura, y que a su vez moviliza el fluido.
La descarga por efecto corona es similar a lo que ocurre con la caída de un rayo, salvo porque en ese caso no hay un conductor propiamente tal, la diferencia de potencial eléctrico es tan enorme que los rayos son capaces de atravesar fácilmente 5 kilómetros de aire, que por lo general es uno de los mejores aislantes que existen.

El principio de la propulsión de aire iónico con partículas cargadas por el efecto corona se conoce casi desde el momento en que se descubrió la electricidad. La descarga corona se utiliza de variadas maneras y se aplica en la industria de la fotocopia, en algunos sistemas de aire acondicionado, en lásers de nitrógeno y más notoriamente en ionizadores de aire. Kronos, que desarrolla filtros de aire de alta eficiencia basados en el efecto corona, intentó adaptar la tecnología a la refrigeración de microprocesadores. Con la ayuda de N. E. Jewell-Larsen, C.P. Hsu y A. V. Mamishev del Departamento de Ingeniería Eléctrica (Department of Electrical Engineering) en la Universidad de Washington (Washington University) e Intel, crearon varios prototipos funcionales de un disipador (cooler) de CPU basado en el efecto corona, que puede enfriar efectiva y silenciosamente una CPU moderna.
El disipador de efecto corona desarrollado por Kronos trabaja de la siguiente manera: Un campo eléctrico de gran magnitud es creado en la punta del cátodo, que se coloca en un lado de la CPU. El alto potencial de energía causa que las moléculas de oxígeno y nitrógeno en el aire se ionicen (con carga positiva) y creen una corona (un halo de partículas cargadas). Al colocar un ánodo unido a tierra en el lado opuesto de la CPU se hace que los iones cargados en la corona aceleren hacia el ánodo, chocando con moléculas neutras de aire en el camino. Durante estas colisiones, se transfiere momentum desde el gas ionizado a las moléculas de gas neutras, resultando en un movimiento de aire hacia el ánodo.
Las ventajas de los disipadores (coolers) basados en el efecto de descarga corona son obvias: no tienen partes móviles, lo que elimina ciertos problemas de confiabilidad, puede refrigerar efectivamente incluso los procesadores más

avanzados y demandantes y opera con un nivel de ruido de prácticamente cero con un consumo moderado de energía.
Para aprender más acerca de la tecnología de enfriamiento de Kronos, el sitio The Future of Things entrevistó al profesor Alexander Mamishev y al estudiante de doctorado Nels Jewell-Larsen de la Universidad de Washington (Washington University) y al Dr. Igor Krichtafovitch, Oficial en Jefe de Tecnología (Chief Technology Officer) de Tecnologías Avanzadas Kronos (Kronos Advanced Technologies).
¿Cómo se les ocurrió la idea de utilizar el efecto de descarga corona para enfriar chips de computador?
La idea de refrigerar con viento iónico no fue una revolución en sí misma. Nosotros siempre hemos creído que podríamos proyectar la tecnología de Kronos miniaturizándola para la aplicación en enfriamiento de componentes electrónicos. El verdadero desafío ha sido determinar si es posible generar un flujo de aire eficiente debido a barreras fundamentales que parecían imposibles de superar en una escala tan pequeña: barreras que Kronos ha podido superar en aplicaciones más grandes de su tecnología de efecto corona como lo son la purificación de aire para la industria de la salud y aplicaciones de sonido para el mercado de cancelación de ruidos.
Como pasa usualmente, los intentos iniciales no funcionaron. Tomó más tiempo entender y varios años más para desarrollar un modelo funcional antes que tuviéramos otro momento Eureka con la tecnología de Kronos. Parte de este último momento fue el resultado directo de la colaboración con nuestros colaboradores en el proyecto como la Universidad de Washington e Intel.

Principio de descarga corona
En su forma más básica, la descarga corona convierte descargas eléctricas en iones densos direccionales haciendo que un fluido fluya (en otras palabras, hacer circular aire sin necesidad de un ventilador).
¿Cómo es utilizado el efecto corona para refrigerar la superficie de un microchip en su dispositivo?
El "viento iónico" es generado en la vecindad de la superficie a ser enfriada y es apuntado a esta superficie, resultando en la eliminación de la "capa caliente superficial". Esta "capa" es como una sábana de aire aún caliente que cubre la superficie, mientras de la cual se siga removiendo reduciendo la temperatura del chip.
¿Será el disipador (cooler) corona capaz de enfriar un procesador por sí mismo (en otras palabras, sin ningún ventilador o disipador (heatsink) adicional?
Sí, es posible realizar toda la refrigeración sin ningún ventilador adicional. Hasta ahora hemos probado que podemos generar suficiente flujo de aire para mantener frescos chips relativamente calientes con a dispositivo de tamaños diminuto basado en el efecto corona. También es posible que se utilice esta tecnología con otras soluciones de manejo térmico.
¿Libera su dispositivo alguna cantidad de calor o ruido? (que podría contribuir a la temperatura de todo el sistema).

Como ocurre con otros dispositivos de Kronos, este sistema de refrigeración en miniatura es prácticamente inaudible y genera mínimas cantidades de calor por sí mismo.
¿Qué voltaje se utiliza para crear los iones cargados?
El voltaje de operación depende del diseño y de la aplicación; sin embargo, los prototipos actuales usan valores en el orden de un kilovoltio (1 kV a 8 kV).
¿Aproximadamente cuánto poder consumirá el disipador (cooler) basado en el efecto corona?
El consumo de poder de esta tecnología depende del diseño y de la aplicación específica. Dicho eso, tenemos actualmente prototipos que están diseñados para refrigerar áreas de aproximadamente 1cm2 que consumen aproximadamente 0,1W.
¿Cuánto calor será capaz de dispersar el disipador (cooler) corona? ¿Será posible efectuar Overclock usando el dispositivo?
Actualmente estamos enfocados en las aplicaciones de refrigeración en el sector móvil/ ultra móvil, pues ellos tienen grandes requerimientos respecto a limitaciones en espacio, consumo eléctrico y ruido que pueden generar que la mayoría de las tecnologías convencionales de refrigeración no pueden cumplir adecuadamente. Además, este segmento del mercado es el de más rápido crecimiento en la actualidad y probablemente en los próximos años mantendrá esta tendencia. Eso dicho, no hay razón para que esta tecnología no pueda ser usada en una solución térmica para la plataforma desktop o de servidores con mayores requerimientos en sus Diseños Térmicos de Poder (TPD por sus siglas en inglés). Respecto a lo del overclock? no he realizado los cálculos, pero parece posible.
¿Qué tan pequeño puede ser el disipador (cooler) corona potencialmente?
Los prototipos actuales tienen una región activa de varios milímetros cúbicos, y estamos trabajando en reducir ese número. Sin embargo, el tamaño del dispositivo estará relacionado con los requerimientos de disipación de calor y el tamaño de la fuente de calor. En algunas aplicaciones es posible que el dispositivo tenga la misma área de contacto que el chip a ser enfriado y una altura de sólo unos milímetros.
¿Cuáles son los obstáculos actuales que enfrenta la comercialización de un disipador (cooler) corona para CPU?
Nuestro foco actual es la optimización de esta tecnología en torno a una aplicación específica y la estructura del paquete, maximizando la vida útil del dispositivo, identificando los materiales ideales y el proceso de fabricación tanto para el

desempeño del producto como para su fabricación a gran escala, y por supuesto continuar con la inversión para conducir investigación en esta dirección.
¿En qué punto está su trabajo en este momento, tiene algún prototipo funcional? ¿Requiere de auspicio?
Sí, tenemos varios prototipos funcionales que están siendo usados como "prueba del concepto" (prueba de que el concepto funciona).
Actualmente fondos y recursos limitados no están siendo otorgados por el Centro de Tecnología de Washington (Washington Technology Center, WTC), Tecnologías de Aire Kronos (Kronos Air Technologies) e Intel. Más fondos serán necesarios para acelerar este proyecto.
Dado el auspicio apropiado, ¿Qué tan pronto estará disponible un producto comercial basado en su tecnología y a qué precio?
Sólo podemos dar un estimado. Con el auspicio actual, probablemente tomará hasta dos años para tener el primer producto comercial listo. El precio es difícil de estimar pues podría estar incorporado en muchos niveles distintos de una solución térmica, pero nuestra meta es hacerlo competitivo con otras soluciones de refrigeración de desempeño similar. Cómo hacer overclocking El overclocking puede darle a la computadora un incremento significativo en el rendimiento bajo el riesgo potencial de dañar el propio hardware. Lograr un equilibrio durante el overclocking es más una forma de arte que una ciencia, ya

que cada pieza de hardware reacciona de manera diferente. Lea los pasos a continuación para comenzar a hacerlo en tu propia computadora.27 1. Comprender los aspectos básicos del overclocking. Repasemos, que el
overclocking es el proceso que consiste en aumentar la velocidad del reloj y el voltaje del computador para mejorar su rendimiento. Es una excelente forma de darle una mejora extra a una máquina antigua o extraer un poco más de potencia de una computadora económica. Para los entusiastas, el overclocking es esencial para conseguir hasta el máximo índice de fotogramas de los programas intensivos. El overclocking puede dañar los componentes de la computadora, especialmente si el hardware no está diseñado para ello o si aumenta demasiado el voltaje. Solo debe realizarlo si no tiene problemas con la posibilidad de destruir el hardware.
Tomado de: http://escreveassim.com.br/2013/06/20/voce-realmente-sabe-como-fazer-overclock/
No existen dos sistemas que den los mismos resultados con un overclocking, incluso si tienen exactamente el mismo hardware. Esto se debe a que el overclocking se ve enormemente afectado por las variaciones pequeñas en el proceso de fabricación. No base sus expectativas únicamente en los resultados que lea en Internet para el hardware que tiene. Si busca aumentar el rendimiento en los videojuegos, quizás realizar el overclocking en la tarjeta gráfica es lo mejor. Las laptops no son muy buenas candidatas para este procedimiento, pues sus capacidades de refrigeración son limitadas. Obtendrá un rendimiento mucho
27 Fuente de consulta http://es.wikihow.com/hacer-overclocking

mayor en un computador de escritorio donde tiene un mejor control de las temperaturas.
2. Descargue las herramientas necesarias. Necesitará algunos programas de benchmarking y herramientas para probar la resistencia con la finalidad de probar adecuadamente los resultados del overclocking. Estos programas prueban el rendimiento del procesador así como la capacidad para mantener dicho rendimiento a lo largo del tiempo.
CPU-Z: este es un programa de monitorización simple que permite ver rápidamente la velocidad de reloj y el voltaje en Windows. No realiza ninguna acción, pero es un programa de control fácil de usar que ayuda a garantizar que todo funcione correctamente. https://cpu-z.uptodown.com/windows
Prime95: este es un programa de benchmarking ampliamente utilizado para probar la resistencia. Está diseñado para ejecutarse por periodos largos de tiempo. http://es.ccm.net/download/descargar-15299-prime95

LinX: este es otro programa para medir la resistencia. Es más ligero que el Prime95 y es bueno para realizar pruebas entre cada cambio. http://linx.en.lo4d.com/
3. Verificar la placa madre y el procesador. Cuando se trata del overclocking, diferentes placas madres y procesadores tendrán capacidades distintas. También hay ligeras diferencias cuando se trata de realizar un overclocking en un chipset AMD e Intel, pero el proceso general es el mismo. Lo más importante que deberá buscar es si el multiplicador está desbloqueado o no. Si el multiplicador está bloqueado, solo podrá ajustar la velocidad del reloj, lo que generalmente produce menos resultados.
Tomado de: https://www.profesionalreview.com/2016/02/08/mejores-placas-bases-del-mercado/
Muchas placas madres están diseñadas para el overclocking y deberán dar un acceso completo a los controles del overclocking. Revise la documentación del computador para determinar las capacidades de la placa madre.

Algunos procesadores están más adaptados para soportar un overclocking que otros. Por ejemplo, la línea “K” de los Intel i7 está diseñada específicamente para el overclocking (por ejemplo, Intel i7-2700K).
4. Ejecutar una prueba de resistencia estándar. Antes de empezar con el proceso de overclocking, ejecute una prueba de resistencia utilizando la configuración estándar. Esto dará un punto de referencia que comparar mientras comienza con el overclocking y también mostrará si hay algún problema con la base en la configuración que necesita solucionar antes que el overclocking lo empeore.
Tomado de: http://www.fixitcomputer.org.ve/img/
Asegúrese de revisar la temperatura durante la prueba de resistencia. Si es mayor a los 70 °C (158 °F), probablemente no pueda aprovechar mucho el overclocking antes que la temperatura se vuelva peligrosa. Quizás necesite aplicar una pasta térmica o instalar un disipador de calor nuevo.
Si tu sistema se cuelga durante la prueba de resistencia estándar, entonces es probable que haya un problema con el hardware que necesita solucionar antes de comenzar con el overclocking. Verifique la memoria RAM para ver si hay algún error.
Si todo ha salido bien se pasa a la segunda fase, que es la de aumentar el reloj base.

1. Abrir la BIOS. Realizará la mayoría de los cambios en la BIOS, accediendo al menú de configuración antes que cargue el sistema operativo. Puede acceder a la mayoría de las BIOS al presionar la tecla Supr durante el arranque. Otras teclas que puede utilizar son F10, F2 y F12.
Todas las BIOS son diferentes, así que las etiquetas de menú y las ubicaciones pueden variar entre sistemas.
2. Abra la opción “Frequency/Voltage Control” (Contol de frecuencia/voltaje). Este menú puede estar etiquetado de manera distinta, por ejemplo “Overclocking”. Este es el menú en el que pasará la mayor parte del tiempo, pues permitirá ajustar la velocidad del computador así como el voltaje que recibe.
3. Reducir la velocidad del bus de la memoria. Para evitar que la memoria cause errores, deberá reducir el bus antes de continuar. Esto puede estar señalado como “Memory Multiplier” (Multiplicador de memoria), “DDr Memory Frecuency” (Frecuencia de memoria DDR) o “Memory Ratio” (Relación de memoria). Bájar hasta el valor más bajo posible. Si no puede encontrar las opciones de frecuencia de memoria, presione: ^ Ctrl+⎇ Alt +F1 en el menú principal del BIOS.
4. Aumentae el reloj base en 10%. El reloj base, también denominado como bus frontal o velocidad del bus, es la velocidad base del procesador. Por lo general,

es una velocidad inferior que se multiplica para alcanzar la velocidad total del núcleo. La mayoría de los procesadores pueden manejar un aumento rápido del 10 % al principio del proceso. Por ejemplo, si el reloj base es de 100 MHz y el multiplicador es de 16, la velocidad de reloj será de 1,6 GHz. Aumentarlo en 10% de una sola vez cambiaría la base del reloj a 110 MHz y la velocidad de reloj a 1,76 GHz.
5. Ejecutar una prueba de resistencia. Una vez que haya realizado el aumento inicial del 10 %, reiniciar el computador e iniciar el sistema operativo. Inicie el programa LinX y ejecútelo durante algunos ciclos. Si no hay problemas, estará listo para proseguir. Si el sistema es inestable, quizás no pueda obtener un mayor rendimiento con el overclocking y deba restablecer la configuración predeterminada.
6. Aumentar el reloj base hasta que el sistema se vuelva inestable. En lugar
de aumentar en 10 % cada vez, querrá reducir los incrementos a 5 o 10 MHz por vez. Esto permitirá encontrar el punto óptimo con mayor facilidad. Ejecute un programa de benchmarking cada vez que hagas algún ajuste hasta alcanzar un estado inestable. Lo más probable es que la inestabilidad se deba a que el procesador no recibe la energía suficiente de la fuente de alimentación.
Tenga en cuenta que si la placa madre no permite ajustar el multiplicador, entonces puede pasar a la siguiente fase. Asegúrese de registrar la configuración que utilice actualmente en caso que quiera volver a ella después.
La siguiente fase es la de aumentar el multiplicador.
1. Disminuir el reloj base. Ante de empezar a aumentar el multiplicador, querrá disminuir un poco el reloj base. Esto permitirá aumentar el multiplicador de manera más precisa. Utilizar un reloj base inferior y un mayor multiplicador dará lugar a un sistema más estable, pero un reloj base más alto con un multiplicado más bajo producirá un mejor rendimiento. El objetivo es encontrar el equilibrio perfecto.

2. Aumentar el multiplicador. Una vez que haya bajado un poco el reloj base, comience a aumentar el multiplicador en aumentos de 0,5. El multiplicador puede tener el nombre de “Relación del CPU” o algo similar. Cuando lo encuentre por primera vez, podría estar configurado en “Automático” en lugar de en un número.[3]
3. Realizar una prueba de resistencia. Reiniciar el computador y ejecutar el programa de benchmarking. Si el computador no presenta ningún error al cabo de algunas pruebas con el programa de benchmarking, puede seguir aumentando el multiplicador. Repita este proceso cada vez que aumente el multiplicador.

4. Vigilar las temperaturas. Asegúrese de prestar mucha atención a los niveles de temperatura durante el proceso. Podría alcanzar un límite de temperatura antes que el sistema se vuelva inestable. Si este es el caso, podría haber alcanzado los límites de capacidad para hacer overclocking. En este punto, debe hallar el mejor equilibrio entre aumentar el reloj base y el multiplicador.
Si bien cada computador tiene un rango de temperatura segura distinto, la regla general es no permitir que alcance los 85 °C (185 °F).
5. Repita el proceso hasta llegar al límite y el computador se cuelgue. Ahora debe tener la configuración que apenas haga que el computador se vuelva inestable. Mientras la temperatura se mantenga dentro de los límites seguros, puede comenzar a ajustar los niveles de voltaje para permitir un mayor aumento.
La siguiente fase es la de aumentar el voltaje.
1. Eleve el voltaje del núcleo del CPU. Esto puede estar señalado como “Vcore Voltage” (voltaje del núcleo del procesador). Aumentar el voltaje más allá de los límites seguros puede dañar rápidamente el computador, así que esta es la parte más meticulosa y potencialmente peligrosa del proceso de overclocking. Cada CPU y cada placa madre pueden manejar aumentos de voltaje diferentes, así que preste atención extra a la temperatura.
Cuando aumente el voltaje del núcleo, hágalo en aumentos de 0,025. Si lo aumenta más, corre el riesgo de ir demasiado alto y dañar los componentes permanentemente.
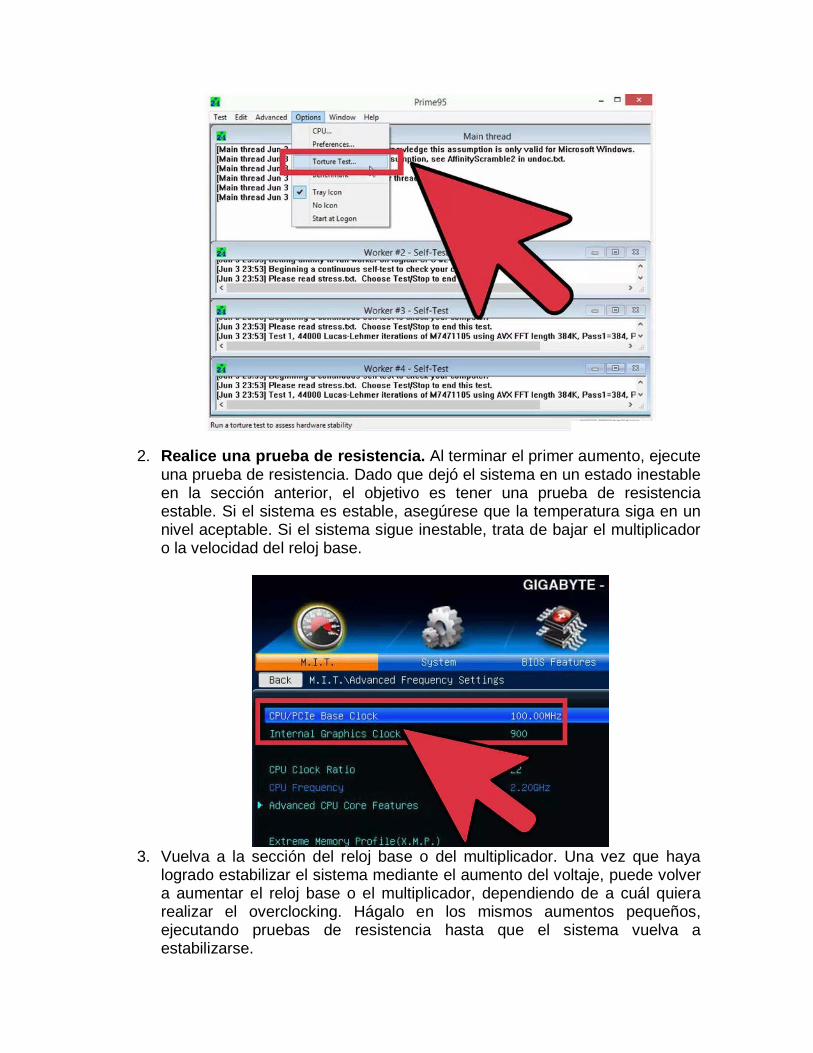
2. Realice una prueba de resistencia. Al terminar el primer aumento, ejecute una prueba de resistencia. Dado que dejó el sistema en un estado inestable en la sección anterior, el objetivo es tener una prueba de resistencia estable. Si el sistema es estable, asegúrese que la temperatura siga en un nivel aceptable. Si el sistema sigue inestable, trata de bajar el multiplicador o la velocidad del reloj base.
3. Vuelva a la sección del reloj base o del multiplicador. Una vez que haya
logrado estabilizar el sistema mediante el aumento del voltaje, puede volver a aumentar el reloj base o el multiplicador, dependiendo de a cuál quiera realizar el overclocking. Hágalo en los mismos aumentos pequeños, ejecutando pruebas de resistencia hasta que el sistema vuelva a estabilizarse.

Dado que la configuración de voltaje aumenta la temperatura al máximo, el objetivo debe ser maximizar la configuración del reloj base y del multiplicador para obtener el mayor rendimiento con el menor voltaje posible. Esto requerirá mucho ensayo y error además de experimentación a medida que prueba diferentes combinaciones.
4. Repita el ciclo hasta llegar a un voltaje o temperatura máxima. Al final, llegará a un punto en el que no puede realizar ningún aumento o la temperatura llegará a niveles peligrosos. Este es el límite de la placa madre y el procesador, y es probable que no pueda pasar más allá de este punto.
En general, no debe aumentar el voltaje en más de 0,4 por encima de su nivel original o en más de 0,2 si utiliza un sistema de refrigeración básico.
Si alcanza el límite de temperatura antes de llegar a un límite de voltaje, podría hacer más incrementos al mejorar el sistema de refrigeración en el computador. Puede instalar un disipador de calor o ventilador más potente u optar por una solución de refrigeración líquida más cara pero mucho más eficaz.
La última fase es la prueba de resistencia final:
1. Vuelva a la última configuración segura. Disminuya el reloj base o el multiplicador hasta la última configuración estable. Esta será la nueva velocidad de procesador y, si todo ha salido como se espera, será

notoriamente mayor a lo que era antes. Si todo arranca sin problemas, estará listo para la prueba final.
2. Aumente la velocidad de la memoria. Aumente la velocidad de la memoria hasta sus niveles iniciales. Hágalo lentamente, haciendo pruebas de resistencia en el proceso. Es posible que no pueda aumentarla nuevamente a sus niveles originales. Utilice Memtest86 para realizar pruebas en la memoria a medida que vuelves a aumentar la frecuencia. https://memtest.uptodown.com/windows, http://es.ccm.net/download/descargar-104-memtest86

3. Realizar una prueba de resistencia prolongada. Abra Prime95 y realice la prueba por 12 horas. Esto puede parecer mucho tiempo, pero el objetivo es asegurar una estabilidad sólida por periodos prolongados. Esto producirá un rendimiento mejor y más confiable. Si su sistema se vuelve inestable durante la prueba o la temperatura llega a niveles inaceptables, necesitará volver y reajustar la velocidad del reloj, el multiplicador y el voltaje.
Cuando abra Prime95, seleccione la opción “Just Stress Testing” (solo realizar una prueba de resistencia). Dé clic en Options (opciones) → Torture Test (prueba de tortura) y configúrar a “Small FFT”.
Por lo general, alcanzar una temperatura límite no es problema, dado que Prime95 fuerza al computador más que la mayoría de los programas. Quizás aún quiera disminuir el overclocking a un punto para estar seguro. La temperatura en estado inactivo no debe superar los 60 °C (140 °F).
4. Realice algunas pruebas en la vida real. Si bien los programas de prueba de resistencia son excelentes para asegurarse que el sistema sea estable, querrá cerciorarte que pueda manejar la aleatoriedad de las situaciones de la vida real. Si es un jugador de videojuegos, abra el juego más exigente que tenga. Si codifica videos, intente codificar un Bluray. Asegúrese que todo funcione como debería. ¡Quizás funcione aún mejor ahora!
5. Lleve el proceso más allá. Esta guía solo roza la superficie de lo que puede hacerse en lo que respecta a overclocking. Si quiere saber más, debe realizar una investigación y experimentación más profunda. Hay varias comunidades dedicadas al overclocking y a sus diversos campos relacionados, como la refrigeración. Algunas de las más populares son Overclockers.com, Overclock.net y Tom's Hardware, y todas son excelentes lugares para comenzar a buscar información más detallada.
Para finalizar, no sobra recordar lo siguiente:
− Realizar el overclocking con aumentos de voltaje acortará la vida del hardware.
− Dependiendo del fabricante, esto puede anular la garantía del computador. Algunas marcas como EVGA y BFG seguirán cumpliendo con la garantía aún después de haberle hecho overclocking al dispositivo.
− Necesitará un buen sistema de refrigeración para realizar un overclocking potente.
− En la mayoría de los computadores fabricados por Dell (a excepción de la línea XPS), HP, Gateway, Acer, Apple, etc. no es posible realizar el overclocking debido a que la opción para cambiar el FSB (siglas en inglés para bus frontal) y el voltaje del CPU no está disponible en el BIOS.

TARJETA GRÁFICA Una tarjeta gráfica, tarjeta de vídeo, placa de vídeo, tarjeta aceleradora de gráficos o adaptador de pantalla, es una tarjeta de expansión, encargada de procesar los datos provenientes de la CPU y transformarlos en información comprensible y representable en un dispositivo de salida (monitor o televisor).
Algunas tarjetas gráficas ofrecen funcionalidades añadidas como captura de vídeo, sintonización de TV, decodificación MPEG-2 y MPEG-4, conectores Firewire, de ratón, lápiz óptico o joystick. Las tarjetas gráficas se encuentran en otros dispositivos como los Commodore Amiga (conectadas mediante las ranuras Zorro II y III), Apple II, Apple Macintosh, Spectravideo SVI-328, equipos MSX y videoconsolas Como la Wii, Playstation 3 y Xbox360. GPU (graphics processing unit, unidad de procesamiento gráfico)
Es importante anotar, que la GPU es un procesador dedicado al procesamiento de gráficos u operaciones de coma flotante, para aligerar la carga de trabajo del procesador central en aplicaciones como los videojuegos y o aplicaciones 3D interactivas. De esta forma, mientras gran parte de lo relacionado con los gráficos se procesa en la GPU, la CPU puede dedicarse a otro tipo de cálculos (como en inteligencia artificial o los cálculos
mecánicos en el caso de los videojuegos).
Una GPU implementa ciertas operaciones gráficas llamadas primitivas optimizadas para el procesamiento gráfico. Una de las primitivas más comunes para el procesamiento gráfico en 3D es el antialiasing, que suaviza los bordes de las figuras para darles un aspecto más realista. Adicionalmente existen primitivas para dibujar rectángulos, triángulos, círculos y arcos. Las GPU actualmente disponen de gran cantidad de primitivas, buscando mayor realismo en los efectos.

Arquitectura de la GPU
Una GPU está altamente segmentada, lo que indica que posee gran cantidad de unidades funcionales. Estas unidades funcionales se pueden dividir principalmente en dos: aquéllas que procesan vértices, y aquéllas que procesan píxeles. Por tanto, se establecen el vértice y el píxel como las principales unidades que maneja la GPU.
Adicionalmente, se encuentra la memoria que es muy rápida y juega papel relevante a la hora de almacenar los resultados intermedios de las operaciones y las texturas que se utilicen.
Inicialmente, a la GPU le llega la información de la CPU en forma de vértices. El primer tratamiento que reciben estos vértices se realiza en el vertex shader. Aquí se realizan transformaciones como la rotación o el movimiento de las figuras. Tras esto, se define la parte de estos vértices que se va a ver (clipping), y los vértices se transforman en píxeles mediante el proceso de rasterización. Estas etapas no poseen una carga relevante para la GPU.
Tomado de: http://www.muycomputer.com/2015/04/19/mejor-tarjeta-grafica-200-euros
Donde sí se encuentra el principal cuello de botella del chip gráfico es en el siguiente paso: el pixel shader. Aquí se realizan las transformaciones referentes a

los píxeles, tales como la aplicación de texturas. Cuando se ha realizado todo esto, y antes de almacenar los píxeles en la caché, se aplican algunos efectos como el antialiasing, blending y el efecto niebla.
Otras unidades funcionales llamadas ROP toman la información guardada en la caché y preparan los píxeles para su visualización. También pueden encargarse de aplicar algunos efectos. Tras esto, se almacena la salida en el frame buffer. Ahora hay dos opciones: o tomar directamente estos píxeles para su representación en un monitor digital, o generar una señal analógica a partir de ellos, para monitores analógicos. Si es este último caso, han de pasar por un DAC, Digital-Analog Converter, para ser finalmente mostrados en pantalla.
Dentro de la potencia de las GPU, se puede sintetizar en tres aspectos relevantes, como son:
- Frecuencia de reloj del núcleo, que en la actualidad oscila entre 500MHz en las tarjetas de gama baja y 850 MHz en las de gama alta.
- Número de procesadores shaders.28
- Número de pipelines (vertex y fragment shaders), encargadas de traducir
una imagen 3D compuesta por vértices y líneas en una imagen 2D compuesta por píxeles.
28 La tecnología shaders es cualquier unidad escrita en un lenguaje de sombreado que se puede compilar independientemente. Es una tecnología reciente y que ha experimentado una gran evolución destinada a proporcionar al programador una interacción con la GPU hasta ahora imposible. Los shaders son utilizados para realizar transformaciones y crear efectos especiales, como por ejemplo iluminación, fuego o niebla. Para su programación los shaders utilizan lenguajes específicos de alto nivel que permitan la independencia del hardware.

Memoria gráfica de acceso aleatorio Son chips de memoria que almacenan y transportan información entre sí,
no son determinantes en el rendimiento máximo de la tarjeta gráfica, pero bien unas especificaciones reducidas pueden limitar la potencia de la GPU. Existen de dos tipos, Dedicada cuando, la tarjeta gráfica dispone exclusivamente para sí esas memorias, ésta manera es la más eficiente y la que mejores resultados da; y compartida cuando se utiliza memoria en detrimento de la memoria RAM, ésta memoria es más lenta que la dedicada y por tanto rinde mucho peor, es recurrente en campañas de márketing con mensajes tipo Tarjeta gráfica de "Hasta ~ MB" para engañar al consumidor haciéndole creer que la potencia de esa tarjeta gráfica reside en su cantidad de memoria.
Las características de memoria de una tarjeta gráfica se expresan en 3 características: Capacidad: determina el número máximo de datos y texturas procesadas,
una capacidad insuficiente se traduce en un retardo a espera de que se vacíen esos datos.
Interfaz de Memoria (Bus de datos): es la multiplicación resultante del de ancho de bits de cada chip por su número de unidades. Es una característica importante y determinante, junto a la velocidad de la memoria, a la cantidad de datos que puede transferir en un tiempo determinado, denominado ancho de banda.
Velocidad de Memoria: transportan los datos procesados, es complemento a la interfaz de memoria para determinar el ancho de banda total de datos en un tiempo determinado. La velocidad se mide en HZ y se van diseñando tecnologías con más velocidad, destacamos las adjuntas en la siguiente tabla:

Programación de la GPU Al inicio, la programación de la GPU se realizaba con llamadas a servicios de interrupción de la BIOS. Tras esto, la programación de la GPU se empezó a hacer en el lenguaje ensamblador específico a cada modelo. Posteriormente, se introdujo un nivel más entre el hardware y el software, con la creación de APIs (Application Program Interface) específicas para gráficos, que proporcionaron un lenguaje más homogéneo para los modelos existentes en el mercado. La primera API usado ampliamente fue estándar abierto OpenGL (Open Graphics Language), tras el cual Microsoft desarrolló DirectX.
Tras el desarrollo de APIs, se decidió crear un lenguaje más natural y cercano al programador, es decir, desarrollar un lenguaje de alto nivel para gráficos. Por ello, de OpenGL y DirectX surgieron estas propuestas. El lenguaje estándar de alto nivel, asociado a la biblioteca OpenGL es el "OpenGL Shading Language", GLSL, implementado en principio por todos los fabricantes. La empresa californiana NVIDIA creó un lenguage propietario llamado Cg ("C for graphics"), con mejores resultados que GLSL en las pruebas de eficiencia. En colaboración con NVIDIA, Microsoft desarrolló su "High Level Shading Language", HLSL, prácticamente idéntico a Cg, pero con ciertas incompatibilidades menores.
Tomado de: http://www.muycomputer.com/2015/04/12/guia-mejor-tarjeta-grafica-100-euros
Con respecto a los gráficos, se intenta aprovechar la gran potencia de cálculo de las GPU para aplicaciones no relacionadas con los gráficos, en lo que desde recientemente se viene a llamar GPGPU, o GPU de propósito general (General-Purpose Computing on Graphics Processing Units).
Ancho de banda: Es la tasa de datos que pueden transportarse en una unidad de tiempo. Un ancho de banda insuficiente se traduce en un importante limitador de potencia de la GPU. Habitualmente se mide en "GBps (GigaBytes por segundo).

La fórmula del ancho de banda es el cociente del producto de la interfaz de memoria (expresada en bits) por la frecuencia efectiva de las memorias (expresada en Gigahertzios), entre 8 para convertir bits a bytes.
Por ejemplo, tenemos una tarjeta gráfica con 512 bits de interfaz de memoria y 4200 MHz de frecuencia efectiva. Cuál es el ancho de banda:
𝐴𝐴𝐴𝐴𝐴𝐴 =512 ∗ 4,2
8= 268,8𝐺𝐺𝐴𝐴𝐺𝐺𝐺𝐺
Diferencias con la CPU Si bien en un computador genérico no es posible reemplazar la CPU por una GPU, hoy en día las GPU son muy potentes y pueden incluso superar la frecuencia de reloj de una CPU antigua (más de 500MHz). Pero la potencia de las GPU y su alto ritmo de desarrollo reciente se deben a dos factores diferentes.
- La alta especialización de las GPU, ya que al estar pensadas para desarrollar una sola tarea, es posible dedicar más silicio en su diseño para llevar a cabo esa tarea más eficientemente. Por ejemplo, las GPU actuales están optimizadas para cálculo con valores en coma flotante, predominantes en los gráficos 3D.
- Muchas aplicaciones gráficas conllevan un alto grado de paralelismo inherente, al ser sus unidades fundamentales de cálculo (vértices y píxeles) completamente independientes. Por tanto, es una buena estrategia usar la fuerza bruta en las GPU para completar más cálculos en el mismo tiempo. Los modelos actuales de GPU suelen tener una media docena de procesadores de vértices (que ejecutan

Vertex Shaders), y hasta dos o tres veces más procesadores de fragmentos o píxeles (que ejecutan Pixel Shaders (O Fragment Shaders)). De este modo, una frecuencia de reloj de unos 600-800MHz (el estándar hoy en día en las GPU de más potencia), muy baja en comparación con lo ofrecido por las CPU (3,8-4 GHz en los modelos más potentes [no necesariamente más eficientes]), se traduce en una potencia de cálculo mucho mayor gracias a su arquitectura en paralelo.
Cabe mencionar, que una de las mayores diferencias con la CPU estriba en su arquitectura. A diferencia del procesador central, que tiene una arquitectura de von Neumann, la GPU se basa en el Modelo Circulante. Este modelo facilita el procesamiento en paralelo, y la gran segmentación que posee la GPU para sus tareas.
Fuente: https://heuristech.wordpress.com/2014/07/03/graphics-memory-misconceptions-and-how-to-choose-a-gpu/
NVIDIA
Es una empresa multinacional especializada en el desarrollo de unidades de procesamiento gráfico y tecnologías de circuitos integrados para estaciones de trabajo, ordenadores personales y dispositivos móviles. NVIDIA produce notables productos incluyendo la serie GeForce para videojuegos, la serie NVIDIA Quadro de diseño asistido por ordenador y la creación de contenido digital en las estaciones de trabajo, y la serie de circuitos integrados nForce para placas base.
A partir de la serie GeForce, los chipsets se ocupan prácticamente de todo el proceso gráfico, constituyendo lo que NVIDIA nombró GPU (Graphic Processing Unit - Unidad de proceso gráfico).

Para el año 2012, NVIDIA Roadmap Confirmó la GPU Kepler, para el 2014 la Maxwell de 20nm, para el 2016 Pascal y se espera que para el 2018 Volta.
NVIDIA GPUs Maxwell de 20nm, cuenta con más del doble de rendimiento por vatio que la arquitectura Kepler actual generación. Maxwell GPU también se integra con el proyecto Denver de Nvidia que fusiona núcleos ARM de propósito general en conjunto con el núcleo de la GPU.
Hay otro proyecto llamado Denver, que es básicamente un procesador de 64-bits que será beneficioso para la informática de propósito general, tales como estaciones de trabajo y servidores.
Maxwell GPU será capaz de procesar de 14 a 16 GFlops, con sus diseños mucho más eficientes de energía en comparación con Kepler de 28nm. Sin embargo, el régimen de Kepler está lejos de terminar, ya que en 2013 la compañía ha lanzado una actualización de su línea de Kepler, llamados Kepler GK110 utilizado en el sistema de cómputo Tesla K20 y Tesla K20X.
De igual manera, la serie GeForce 700, GeForce GTX 780 podría tener más de 2.000 núcleos. Un número real sería 2304. NVIDIA también ahora con una interfaz de memoria de 3 GB GDDR5 que opera a lo largo de una interfaz de 384-bit, con lo que pone fin a las restricciones de ancho de banda conocidos a los que enfrentan la GTX 680. Las velocidades de reloj de la tarjeta van de 1100 MHz a 1150 MHz, mientras que el aumento de la memoria puede funcionar a 6,5 GHz de frecuencia efectiva.

Flagship GPU Para Visual Computing29
SIGGRAPH - NVIDIA en el 2013 sacó la NVIDIA ® Quadro ® K6000 GPU, uno de los más rápidos del mercado hasta ahora 2013. Ofrece cinco veces mayor desempeño de cómputo y casi el doble de la capacidad gráfica de su predecesora, la GPU NVIDIA Quadro 6000, y cuenta con memoria gráfica más grande y más rápida del mundo.
Combinando las capacidades de rendimiento de vanguardia y avanzada en un diseño de bajo consumo de energía, la GPU Quadro K6000 permite a las organizaciones líderes como Pixar, Nissan, Apache Corporation y The Weather Channel entre otros, hacer frente a la visualización y el análisis las cargas de trabajo de tamaño y alcance sin precedentes.
• Animación y Efectos Visuales – Pixar
". Las características de Kepler son clave para nuestra próxima generación de iluminación en tiempo real y la manipulación de geometría Nos quedamos encantados de tener una primera impresión de la K6000 de la nueva memoria y otras características permiten a nuestros artistas para ver mucho más de la escena final en una forma en tiempo real, interactivo y permitirá a muchas iteraciones más artísticas. " -Guido Quaroni, Pixar vicepresidente de Software de I + D
• Styling producto – Nissan
"Con la Quadro K6000 12 GB de memoria, ahora soy capaz de cargar los modelos de vehículos casi completos en RTT Deltagen y tienen
29 NVIDIA Unveils New Flagship GPU For Visual Computing. Consultado el 1 de Septiembre de 2013. http://nvidianews.nvidia.com/Releases/NVIDIA-Unveils-New-Flagship-GPU-for-Visual-Computing-9e3.aspx

impresionante realismo fotográfico casi instantáneamente En lugar de gastar mucho tiempo la simplificación de los modelos para encajar en hardware anterior, podemos ahora. dedicar más tiempo a la revisión y la iteración diseños en la delantera que ayuda a evitar costosos cambios en las herramientas. " -Dennis Malone, ingeniero asociado, Nissan North America
• Exploración Energía – Apache
"En comparación con el Quadro K5000, la Quadro K6000 triplicó el rendimiento al ejecutar trabajos de aplicación InsightEarth de Terraspark Con trabajos en ejecución en cuestión de minutos, podemos correr más simulaciones y obtener un mejor conocimiento de dónde perforar.
Rendimiento sin precedentes
La GPU Quadro K6000 está basada en la arquitectura NVIDIA Kepler ™ - arquitectura de la GPU más rápida del mundo, más eficiente. Características clave de rendimiento y capacidades incluyen:
• 12 GB de memoria GDDR5 ultrarrápida gráficos permite a los diseñadores y los modelos de animadores y personajes de renderizado y escenas en una escala sin precedentes, la complejidad y la riqueza
• 2.880 núcleos multiprocesador de streaming (SMX) ofrecen la visualización rápida y calcular la potencia que los productos de la generación anterior
• Soporta cuatro pantallas simultáneas y hasta 4k de resolución con DisplayPort ™ 1.2
• Ultra-bajo soporte de vídeo latencia de E/S y para visualizaciones de gran escala
Nueva Estación de trabajo móvil GPU
NVIDIA ha sacado al mercado la tarjeta gráfica profesional GPU para portátiles y estaciones de trabajo NVIDIA Quadro K5100M GPU. Presenta altos niveles de rendimiento y memoria de gráfica, hay variantes como la Quadro K4100M, K3100M, K2100M, K1100M, K610M y K510M GPUs.
La NVIDIA Quadro K6000 estará disponible a finales de este año (2013) en equipos Dell, HP, Lenovo y otros proveedores de estaciones de trabajo, a partir de los integradores de sistemas, incluyendo BOXX Technologies y Supermicro, y de los distribuidores autorizados, como PNY Technologies en América del Norte y Europa, ELSA y Ryoyo en Japón, y Leadtek en Asia Pacífico.

La nueva línea de productos Quadro mobile workstation gráfica, también estará disponible a partir de este año de los principales fabricantes de estaciones de trabajo móviles.
Tarjetas gráficas para PCs de sobremesa (2013-2014)
− GeForce GTX TITAN − GeForce GTX 780 − GeForce GTX 770 − GeForce GTX 760 (¡nueva!) − GeForce GTX 690 − GeForce GTX 680 − GeForce GTX 670 − GeForce GTX 660 Ti − GeForce GTX 660 − GeForce GTX 650 Ti BOOST − GeForce GTX 650 Ti − GeForce GTX 650 − GeForce GTS 450 − GeForce GTS 250 − GeForce GT 640 − GeForce GT 630 − GeForce GT 620 − GeForce GT 610
Tarjetas gráficas para portátiles
− GeForce GTX 780M (¡nueva!) − GeForce GTX 770M (¡nueva!) − GeForce GTX 765M (¡nueva!) − GeForce GTX 760M (¡nueva!) − GeForce GTX 680MX − GeForce GTX 680M − GeForce GTX 675MX − GeForce GTX 675M − GeForce GTX 670MX − GeForce GTX 670M − GeForce GTX 660M − GeForce GT 755M (¡nueva!) − GeForce GT 750M − GeForce GT 745M − GeForce GT 740M − GeForce GT 735M − GeForce GT 730M

− GeForce GT 720M − GeForce GT 650M − GeForce GT 645M − GeForce GT 640M − GeForce GT 640M LE − GeForce GT 635M − GeForce GT 630M − GeForce GT 625M − GeForce GT 620M − GeForce 710M − GeForce 610M
Línea de productos geforce - OEM
− GEFORCE GTX − GEFORCE GTS Y GT − GEFORCE
Tarjetas gráficas para PCs de sobremesa
− GeForce GTX 660 − GeForce GTX 645 (¡nueva!) − GeForce GTX 560 Ti − GeForce GTX 560 − GeForce GTX 555 − GeForce GT 640 − GeForce GT 630 − GeForce GT 620 − GeForce 605
Para citar un ejemplo de lo que trae la GeForce Serie 600, que presenta la arquitectura Kepler, sustituyendo a la anterior arquitectura Fermi, que es una de las primeras con esta tecnología. El GK104, el producto de la primera arquitectura Kepler, tiene 1536 procesadores de flujo, en ocho grupos de 192 y 3,5 mil millones de transistores, fabricados por TSMC en un proceso de 28 nm. Es el primer chip de Nvidia para soportar Direct3D 11.1 y PCI Express 3.0.

Año de lanzamiento 2012
Versión DirectX 11.1
Número de transistores 3540 millones
Tecnología de fabricación 28 y 40nm
En la actualidad como referente, el número de transistores se ha cuadruplicado
Características destacadas:
Soporte para Direct3D 11.1 y PCI Express 3.0
Chips gráficos para uso profesional y científico
• Quadro • Tesla
Chipset para placas bases
• nForce 6 Series o 600
• nForce 7 Series o 730i o 750i o 780i o 790i SLI o 790i Ultra SLI o 980a SLI Para AMD (Release)
Chipsets para dispositivos móviles
• NVIDIA GoForce - serie de procesadores gráficos creados especialmente para dispositivos móviles (PDAs, Smartphones y teléfonos móviles). Incluyen la tecnología nPower para un uso eficiente de energía.
o GoForce 2150 – Soporta teléfonos móviles con cámara de hasta 1,3 megapíxeles, aceleración gráfica en 2D.

o GoForce 3000 – Versión de bajo coste de la GoForce 4000 con algunas características recortadas.
o GoForce 4000 – Soporte de cámara de hasta 3,0 megapíxeles con grabación y reproducción de vídeos en MPEG-4/H.263.
o GoForce 4500 – Aceleración de vídeo en 2D y 3D con pixel shaders programable y geometría
o GoForce 4800 – Soporte de cámara hasta 3,0 megapíxeles con aceleración de vídeo en 2D y 3D con píxel shader programable.
o GoForce 6100 – Soporte de cámara hasta 10 megapíxeles, aceleración en 2D y 3D, y codecH.264.
Quadro Digital Video Pipeline: es la plataforma más avanzada para introducir una nueva dimensión en la televisión. Sus avanzadas herramientas de desarrollo y los controladores unificados establecen un nuevo estándar para la producción y difusión de contenidos en 3D estereoscópico y permite a los desarrolladores integrarla fácilmente en sus aplicaciones utilizando las interfaces de programación OpenGL o Direct3D. El uso de los mismos controladores elimina la complejidad de programar para almacenar vídeo procedente de dispositivos de distintas marcas, con lo que se crea una solución integrada y unificada.
Tomada de: http://www.gpureview.com/Quadro-FX-4500-card-348.html
Quadro Digital Video Pipeline es la base de cualquier proceso de producción de contenidos para visión 3D estereoscópica.
− Recibe hasta cuatro señales de vídeo de varias cámaras en tiempo real directamente en la GPU.

− Permite procesar vídeo y añadir efectos 3D virtuales directamente en la GPU.
− Permite emitir el resultado final directamente desde la GPU a través de plataformas de TV en directo o de Internet.
Quadro SDI Capture
Es una tarjeta para transferir vídeo sin compresión directamente a la memoria GPU para SDI de Quadro.
- Captura hasta 4 fuentes HD-SDI Single link de manera simultánea. - Admite todos los formatos SMPTE (3G, 2K, HD y SD) mediante conectores
BNC de 75 ohmios. - Con los indicadores LED del soporte se detectan los errores con facilidad. - La salida de monitor se puede utilizar como fuente de sincronización de la
tarjeta SDI Output opcional
Quadro SDI Output
Esta tarjeta proporciona una solución gráfica con salida a vídeo integrada que permite incorporar efectos 2D y 3D a imágenes de vídeo 2K, HD y SD en tiempo real (de momento no admite 3G).
- Puede sincronizarse con una fuente de señal externa o con la tarjeta Quadro SDI de captación.
- Admite vídeo SDI de 8, 10 o 12 bits sin compresión con resoluciones 2K, HD y SD.
- Puede combinarse con la tarjeta gráfica Quadro con conexión SDI.
Quadro Fx
Soluciones gráficas Quadro SDI profesionales que ofrecen lo último en rendimiento y funcionalidad.
- GPU con arquitectura CUDA, que permite ejecutar cualquier aplicación basada en el lenguaje CUDA.
- Hasta 6 GB de memoria gráfica.
- Soluciones de dos y una ranura.
Soluciones compatibles:

SOLUCIÓN QUADRO QUADRO 6000
QUADRO K5000 (¡NUEVA!)
QUADRO 5000 QUADRO 4000
MEMORIA GRÁFICA 6 GB 4 GB 2.5 GB 2 GB NÚCLEOS DE PROCESAMIENTO PARALELO CUDA
448 1536 352 256
Nº DE RANURAS Doble Doble Doble Sencilla ATI30 La tarjeta gráfica ATI Radeon™ HD Serie 4000 posee las características más recientes y ofrecen el rendimiento necesario para llevar a un nivel superior tu experiencia con la alta definición en casa, en la oficina o mientras juegas. Reproduce las películas en formato Blu-ray y el contenido en alta definición con increíble fidelidad visual31, alcanza niveles insospechados de realismo gráfico y disfruta de los últimos juegos con compatibilidad para Microsoft DirectX® 10.1 en adelante. Las familias de tarjetas ATI están distribuidas así: Entusiastas ATI Radeon™ HD 4870 X2 ATI Radeon™ HD 4890 Rendimiento ATI Radeon™ HD 4870 ATI Radeon™ HD 4850 ATI Radeon™ HD 4830 ATI Radeon™ HD 4770 Entretenimiento avanzado ATI Radeon™ HD 4600 Entretenimiento ATI Radeon™ HD 4550 ATI Radeon™ HD 4350 30 Familia de tarjetas gráficas ATI Radeon™ HD 4000. Consultado el 2 de septiembre de 2013. http://www.amd.com/la/products/desktop/graphics/ati-radeon-hd-4000/Pages/ati-radeon-hd-4000-series.aspx 31 Se necesita monitor compatible de alta definición y una unidad Blu-ray.

Los chips de las tarjetas gráficas ATI Radeon™ HD tienen numerosas funciones integradas en el mismo procesador (p.ej. HDCP, HDMI, etc.). Los fabricantes de productos basados en o que incorporan los chips de la tarjeta ATI Radeon™ HD deciden qué funciones quieren activar. Si hay alguna función que desea en concreto, pregunte al fabricante sobre su disponibilidad en los diferentes productos. Además, algunas características o tecnologías pueden requerir la compra de componentes adicionales para poder usarlas en su totalidad (p.ej. unidad Blu-ray, DVD preparado para alta definición, monitor preparado para HDCP, etc.). INTERRUPCIONES Las interrupciones surgen de las necesidades que tienen los dispositivos periféricos de enviar información al CPU. La primera técnica que se empleó fue que el propio procesador se encargara de sondear (polling) el dispositivo cada cierto tiempo para averiguar si tenía pendiente alguna comunicación para él. Este método era ineficiente, ya que el procesador constantemente consumía tiempo en realizar todas las instrucciones de sondeo. El mecanismo de interrupciones fue la solución que permitió al procesador delegar en el dispositivo la responsabilidad de comunicarse con la CPU cuando lo necesitaba. El procesador, en este caso, no sondea a ningún dispositivo, sino que queda a la espera de que estos le avisen (le "interrumpan") cuando tenga algo que comunicarle (ya sea un evento, una transferencia de información, una condición de error, etc.). Tipos de interrupciones Se pueden evaluar por causas internas o externas al procesador, que está íntimamente ligado con que las interrupciones síncronas o asíncronas:
- Interrupciones hardware: Estas son asíncronas a la ejecución del procesador, es decir, se pueden producir en cualquier momento independientemente de lo que esté haciendo la CPU en ese momento. Las causas que lo producen son externas al procesador y a menudo suelen estar ligadas con distintos dispositivos de E/S.
- Interrupciones software o excepciones: Son aquellas que se producen de forma síncrona a la ejecución del procesador y por tanto podrían predecirse si se analiza con detenimiento la traza del programa que en ese momento estaba siendo ejecutado en la CPU. Normalmente las causas de estas interrupciones suelen ser realizaciones de operaciones no permitidas tales como la división por 0, el desbordamiento, el acceso a una posición de memoria no permitida, etc.

- Trampas: A menudo se tiende a confundir las interrupciones software y las trampas, ya que su naturaleza es similar. Sin embargo las excepciones se producen al realizar una operación no permitida por lo que de algún modo podemos decir que no es controlada directamente por el programador sino que, por un fallo al programar, se producen. No obstante las trampas sí que son provocadas por el programador. Para provocar una trampa existen distintas instrucciones en el código máquina que permiten al programador producir una interrupción al ejecutar dicha instrucción. Suelen tener nemotécnicos tales como INT. Suelen ser de vital importancia ya que a partir de las trampas se pueden pedir al SO que realice determinadas funciones, para ello, en DOS se realiza la instrucción INT 0x21 y en Unix se utiliza INT 0x80.
Interrupciones hardware: Son interrupciones que se producen como resultado de, normalmente, una operación de E/S. No son producidas por ninguna instrucción sino que son señales que producen los dispositivos para indicarle al procesador que necesitan ser 'atendidos'. Las interrupciones hardware son interesantes en cuanto a que permiten mejorar la productividad del procesador ya que este último puede ordenar una operación de E/S y en lugar de tener que esperar a que el dispositivo acabe realizando una espera activa, es decir, sin hacer ningún trabajo útil, se puede dedicar a atender a otro proceso o aplicación y cuando el dispositivo este de nuevo disponible será el encargado de notificarle al procesador mediante la línea de interrupción ya que está preparado para continuar/terminar la operación de E/S. Interrupciones software o excepciones: Es un tipo de interrupción sincrónica típicamente causada por una condición de error, por ej. Una división por 0 o un acceso inválido a memoria en un proceso de usuario. Normalmente genera un cambio de contexto a modo supervisor para que el sistema operativo atienda el error. De manera que podemos ver como las excepciones son un mecanismo de protección que permite garantizar la integridad de los datos tanto en el espacio de usuario como en el espacio kernel. El SO cuando detecta una excepción intenta solucionarla pero en caso de no poder simplemente notificará la condición de error a la aplicación y abortará la misma. Trampas: Se consideran las llamadas al SO mediante una instrucción, normalmente de Entrada/Salida. Una interrupción por software, se prevé en qué momento de la ejecución de un programa sucederá. En general actúa de la siguiente manera:
- Un programa que se venía ejecutando luego de su instrucción I5, llama al SO, por ejemplo para leer un archivo de disco.
- A tal efecto, luego de I5 existe en el programa, la instrucción de código de máquina CD21, simbolizada INT 21 en Assembler, que realiza el requerimiento del paso 1. Puesto que no puede seguir le ejecución de la

instrucción I6 y siguientes del programa hasta que no se haya leído el disco y esté en memoria principal dicho archivo, virtualmente el programa se ha interrumpido, siendo, además, que luego de INT 21, las instrucciones que se ejecutarán no serán del programa, sino del Sistema Operativo.
- La ejecución de INT 21 permite hallar la subrutina del SO.
- Se ejecuta la subrutina del Sistema Operativo que prepara la lectura del disco.
- Luego de ejecutarse la subrutina del SO, y una vez que se haya leído el disco y verificado que la lectura es correcta, el SO ordenará reanudar la ejecución del programa autointerrumpido en espera.
- La ejecución del programa se reanuda.
Nota: Un Mebibyte (contracción de mega byte binario) o, MiB, es una unidad de información o memoria cuyo valor es de 220, equivalente a 1.048.576 bytes.
1 MiB = 220 bytes = 1.048.576 bytes = 1.024 kibibytes
El mebibyte está estrechamente relacionado con el megabyte (MB), el cual no es sinónimo de mebibyte pero suele usarse incorrectamente como si lo fuera. El MB se refiere a 106 bytes = 1.000.000 bytes. Los dos números están relativamente cercanos, pero no se deben confundir.
Un mebibyte equivale a 1.024 (= 210) kibibytes, y 1.024 mebibytes equivale a un gibibyte.
Ejemplo de lo anterior, se cita la arquitectura de procesadores Phenom triple-core 8-series, nombre clave "Toliman" (65nm, triple core).
Todos los modelos soportan: MMX, SSE, SSE2, SSE3, SSE4a, Enhanced 3DNow!, NX bit, AMD64 (AMD's x86-64 implementation), Cool'n'Quiet.
Modelo Frecuencia L2-Cache L3 cache
Phenom 8700 2500 MHz 3 x 512 KiB 2 MB
Phenom 8600 2300 MHz 3 x 512 KiB 2 MB
Para el caso de intel Core i5) se tiene Nombre clave Modelo Núcleos Caché nivel 3 Zócalo TDP

Lynnfield Core i5-7xx 4 8 MiB
LGA 1156 95 W
Core i5-7xxS 82 W Clarkdale Core i5-6xx
2
4 MiB 73-87 W
Arrandale Core i5-4xxM
3 MiB µPGA-989 35 W
Core i5-5xxM Core i5-5xxUM 18 W
Taller
1. Destape cuidadosamente su equipo y registre fotográficamente sus componentes, entre ellos la RAM y ROM, Board, Disco duro y procesador (es), buses de datos entre otros (consulte sus características de fábrica y cómo trabaja). No es desarmar el equipo, su trabajo es netamente observacional, destapar tomar fotos y no más. Consulte y defina los componentes generales asociados a la placa base que posee su computador señalándolos en una imagen de la misma.
2. Consulte los puertos que posee, describa sus características. (anexar imágenes), al igual que la tarjeta gráfica (calcular el ancho de banda).
3. Indagar sobre las características de las siguientes tarjetas gráficas:
- EVGA Nvidia GTX Titan 6GB DDR5 - AMD ZEN X370 - GigaByte ATI HD 7650 3GB DDR5/860MHz/384Bit - Nvidia Quadro M5500,GPU para Workstations
4. Indagar sobre las características de las siguientes Board ( y sus familias): - Asus Crosshair V - Asus Sabertooh 990X REV y Z77/LGA - GigaByte GA-990FXA-UDP5 y GA X79-UP4 LGA 2011 - Asrock Z87 Extreme 4/LGA 1150