
Correlacion,.++
52
www.monografias.com Correlación 1. Introducción 2. Teoría de regresión y correlación 3. Análisis de correlación A1 4. Diagrama de dispersión A2 5. Coeficiente de correlación de Pearson A4 6. Coeficiente de determinación A4.1 7. Coeficiente de correlación de Spearman 8. Procedimientos para llevar a cabo un análisis de correlación 9. Regresión 10. Variable dependiente A3 11. Variable independiente A3.1 12. Tipos de modelo de regresión 13. Métodos de los mínimos cuadrados 14. Forma general de la ecuación de regresión 15. Error estándar de estimación 16. Análisis residual 17. Supuestos para realizar un análisis de regresión 18. Análisis de series de tiempo 19. Modelos aditivos y sumativos para expresar una serie de tiempo 20. Índices de precios al consumidor 21. Conclusión 22. Bibliografía Introducción Se llama Series de Tiempo son mediciones estadísticas a un conjunto de mediciones de cierto fenómeno o experimento registrado secuencialmente en el tiempo. El primer paso para analizar una serie de tiempo es graficarla, esto permite: identificar la tendencia, la estacionalidad, las variaciones irregulares (componente aleatoria). Un modelo clásico para una serie de tiempo, puede ser expresada como suma o producto de tres componentes: tendencia, estacional y un término de error aleatorio. En adelante se estudiará cómo construir un modelo para explicar la estructura y prever la evolución de una variable que observamos a lo largo del tiempo. Unidad III Teoría de regresión y correlación El término correlación se utiliza generalmente para indicar la correspondencia o la relación recíproca que se da entre dos o más cosas, ideas, personas, entre otras. En tanto, en probabilidad y estadística, la correlación es aquello que indicará la fuerza y la dirección lineal que se establece entre dos variables aleatorias. Para ver trabajos similares o recibir información semanal so
-
Upload
annsonn-mascary-mar-y-puente-tesoro -
Category
Education
-
view
204 -
download
2
Transcript of Correlacion,.++

www.monografias.com
Correlación
1. Introducción 2. Teoría de regresión y correlación 3. Análisis de correlación A14. Diagrama de dispersión A25. Coeficiente de correlación de Pearson A46. Coeficiente de determinación A4.17. Coeficiente de correlación de Spearman 8. Procedimientos para llevar a cabo un análisis de correlación 9. Regresión 10. Variable dependiente A311. Variable independiente A3.112. Tipos de modelo de regresión 13. Métodos de los mínimos cuadrados 14. Forma general de la ecuación de regresión 15. Error estándar de estimación 16. Análisis residual 17. Supuestos para realizar un análisis de regresión 18. Análisis de series de tiempo 19. Modelos aditivos y sumativos para expresar una serie de tiempo 20. Índices de precios al consumidor 21. Conclusión 22. Bibliografía
IntroducciónSe llama Series de Tiempo son mediciones estadísticas a un conjunto de mediciones de cierto fenómeno o experimento registrado secuencialmente en el tiempo. El primer paso para analizar una serie de tiempo es graficarla, esto permite: identificar la tendencia, la estacionalidad, las variaciones irregulares (componente aleatoria). Un modelo clásico para una serie de tiempo, puede ser expresada como suma o producto de tres componentes: tendencia, estacional y un término de error aleatorio. En adelante se estudiará cómo construir un modelo para explicar la estructura y prever la evolución de una variable que observamos a lo largo del tiempo.
Unidad III
Teoría de regresión y correlaciónEl término correlación se utiliza generalmente para indicar la correspondencia o la relación recíproca que se da entre dos o más cosas, ideas, personas, entre otras.En tanto, en probabilidad y estadística, la correlación es aquello que indicará la fuerza y la dirección lineal que se establece entre dos variables aleatorias.
Se considera que dos variables de tipo cuantitativo presentan correlación la una respecto de la otra cuando los valores de una ellas varíen sistemáticamente con respecto a los valores homónimos de la otra.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Por ejemplo, si tenemos dos variables que se llaman A y B, existirá el mencionado fenómeno de correlación si al aumentar los valores de A lo hacen también los valores correspondientes a B y viceversa.De todas maneras, vale aclarar que la correlación que pueda darse entre dos variables no implicará por si misma ningún tipo de relación de causalidad. Los principales elementos componentes de una correlación de este tipo serán: la fuerza, el sentido y la forma.
Análisis de correlaciónEl análisis de correlación emplea métodos para medir la significación del grado o intensidad de asociación entre dos o más variables. Normalmente, el primer paso es mostrar los datos en un diagrama de dispersión. El concepto de correlación está estrechamente vinculado al concepto de regresión, pues, para que una ecuación de regresión sea razonable los puntos muéstrales deben estar ceñidos a la ecuación de regresión; además el coeficiente de correlación debe ser:
Grande cuando el grado de asociación es alto (cerca de +1 o -1, y pequeño cuando Es bajo, cerca de cero. Independiente de las unidades en que se miden las variables.
Diagrama de dispersión Un diagrama de dispersión se emplea cuando existe una variable que está bajo el control del experimentador. Si existe un parámetro que se incrementa o disminuye de forma sistemática por el experimentador, se le denomina parámetro de control o variable independiente = eje de x y habitualmente se representa a lo largo del eje horizontal. La variable medida o dependiente = eje de y usualmente se representa a lo largo del eje vertical. Si no existe una variable dependiente, cualquier variable se puede representar en cada eje y el diagrama de dispersión mostrará el grado de correlación (no causalidad) entre las dos variables.Un diagrama de dispersión puede sugerir varios tipos de correlaciones entre las variables con un intervalo de confianza determinado. La correlación puede ser positiva (aumento), negativa (descenso), o nula (las variables no están correlacionadas). Se puede dibujar una línea de ajuste (llamada también "línea de tendencia") con el fin de estudiar la correlación entre las variables. Una ecuación para la correlación entre las variables puede ser determinada por procedimientos de ajuste. Para una correlación lineal, el procedimiento de ajuste es conocido como regresión lineal y garantiza una solución correcta en un tiempo finito.Uno de los aspectos más poderosos de un gráfico de dispersión, sin embargo, es su capacidad para mostrar las relaciones no lineales entre las variables. Además, si los datos son representados por un modelo de mezcla de relaciones simples, estas relaciones son visualmente evidentes como patrones superpuestos.El diagrama de dispersión es una de las herramientas básicas de control de calidad, que incluyen además el histograma, el diagrama de Pareto, la hoja de verificación, los gráficos de control, el diagrama de Ishikawa y el diagrama de flujo.
Recta de regresión La recta de regresión es la que mejor se ajusta a la nube de puntos.
La recta de regresión pasa por el punto llamado centro de gravedad.Recta de regresión de Y sobre XLa recta de regresión de Y sobre X se utiliza para estimar los valores de la Y a partir de los de la X.La pendiente de la recta es el cociente entre la covarianza y la varianza de la variable X.
Recta de regresión de X sobre YLa recta de regresión de X sobre Y se utiliza para estimar los valores de la X a partir de los de la Y.La pendiente de la recta es el cociente entre la covarianza y la varianza de la variable Y.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Si la correlación es nula, r = 0, las rectas de regresión son perpendiculares entre sí, y sus eucaciones son:
y =
x = Ejemplo: Las notas de 12 alumnos de una clase en Matemáticas y Física son las siguientes:
Matemáticas 2 3 4 4 5 6 6 7 7 8 10 10
Física 1 3 2 4 4 4 6 4 6 7 9 10Hallar las rectas de regresión y representarlas.
xi yi xi ·yi xi2 yi2
2 1 2 4 1
3 3 9 9 9
4 2 8 16 4
4 4 16 16 16
5 4 20 25 16
6 4 24 36 16
6 6 36 36 36
7 4 28 49 16
7 6 42 49 36
8 7 56 64 49
10 9 90 100 81
10 10 100 100 100
72 60 431 504 380
1º Hallamos las medias ariméticas.
2º Calculamos la covarianza.
3º Calculamos las varianzas.
4ºRecta de regresión de Y sobre X.
4ºRecta de regresión de X sobre Y.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
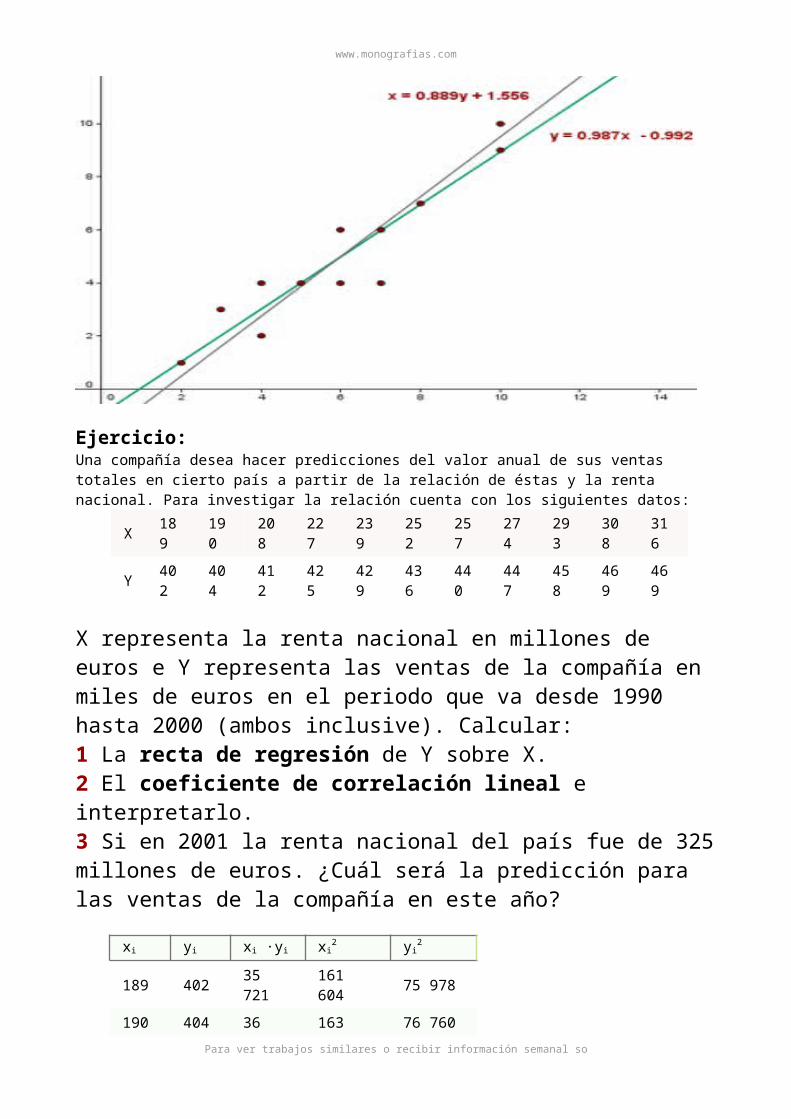
Ejercicio:Una compañía desea hacer predicciones del valor anual de sus ventas totales en cierto país a partir de la relación de éstas y la renta nacional. Para investigar la relación cuenta con los siguientes datos:
X 189 190 208 227 239 252 257 274 293 308 316
Y 402 404 412 425 429 436 440 447 458 469 469
X representa la renta nacional en millones de euros e Y representa las ventas de la compañía en miles de euros en el periodo que va desde 1990 hasta 2000 (ambos inclusive). Calcular:1 La recta de regresión de Y sobre X.2 El coeficiente de correlación lineal e interpretarlo.3 Si en 2001 la renta nacional del país fue de 325 millones de euros. ¿Cuál será la predicción para las ventas de la compañía en este año?
xi yi xi ·yi xi2 yi2
189 402 35 721 161 604 75 978
190 404 36 100 163 216 76 760
208 412 43 264 169 744 85 696
227 425 51 529 180 625 96 475
239 429 57 121 184 041 102 531
252 436 63 504 190 096 109 872
257 440 66 049 193 600 113 080
274 447 75 076 199 809 122 478
293 458 85 849 209 764 134 194
308 469 94 864 219 961 144 452
Para ver trabajos similares o recibir información semanal so
www.monografias.com
316 469 99 856 219 961 148 204
2 753 4 791 708 933 2 092 421 1 209 720
Coeficiente de correlación de PearsonEl coeficiente de correlación de Pearson es un índice que mide la relación lineal entre dos variables aleatorias cuantitativas. A diferencia de la covarianza, la correlación de Pearson es independiente de la escala de medida de las variablesEl coeficiente de correlación entre dos variables aleatorias X e Y es el cociente
El valor del índice de correlación varía en el intervalo [-1, +1]: Si r = 1, existe una correlación positiva perfecta. El índice indica una dependencia total entre las dos
variables denominada relación directa: cuando una de ellas aumenta, la otra también lo hace en proporción constante.
Si 0 < r < 1, existe una correlación positiva. Si r = 0, no existe relación lineal. Pero esto no necesariamente implica que las variables son
independientes: pueden existir todavía relaciones no lineales entre las dos variables. Si -1 < r < 0, existe una correlación negativa. Si r = -1, existe una correlación negativa perfecta. El índice indica una dependencia total entre las
dos variables llamada relación inversa: cuando una de ellas aumenta, la otra disminuye en proporción constante.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Coeficiente de correlación lineal
El coeficiente de correlación lineal es el cociente entre la covarianza y el producto de lasdesviaciones típicas de ambas variables.El coeficiente de correlación lineal se expresa mediante la letra r.
Propiedades1. El coeficiente de correlación no varía al hacerlo la escala de medición.Es decir, si expresamos la altura en metros o en centímetros el coeficiente de correlación no varía.2. El signo del coeficiente de correlación es el mismo que el de la covarianza .Si la covarianza es positiva, la correlación es directa.Si la covarianza es negativa, la correlación es inversa.Si la covarianza es nula, no existe correlación.3. El coeficiente de correlación lineal es un número real comprendido entre −1 y 1.−1 ≤ r ≤ 14. Si el coeficiente de correlación lineal toma valores cercanos a −1 la correlación es fuerte e inversa , y será tanto más fuerte cuanto más se aproxime r a −1.5. Si el coeficiente de correlación lineal toma valores cercanos a 1 la correlación es fuerte y directa , y será tanto más fuerte cuanto más se aproxime r a 1.6. Si el coeficiente de correlación lineal toma valores cercanos a 0, la correlación es débil .7. Si r = 1 ó −1, los puntos de la nube están sobre la recta creciente o decreciente. Entre ambas variables hay dependencia funcional .Ejemplos:
Las notas de 12 alumnos de una clase en Matemáticas y Física son las siguientes:
Matemáticas 2 3 4 4 5 6 6 7 7 8 10 10
Física 1 3 2 4 4 4 6 4 6 7 9 10
Hallar el coeficiente de correlación de la distribución e interpretarlo.
xi yi xi ·yi xi2 yi2
2 1 2 4 1
3 3 9 9 9
4 2 8 16 4
4 4 16 16 16
5 4 20 25 16
6 4 24 36 16
6 6 36 36 36
7 4 28 49 16
7 6 42 49 36
8 7 56 64 49
10 9 90 100 81
10 10 100 100 100
72 60 431 504 380
Para ver trabajos similares o recibir información semanal so

www.monografias.com
1º Hallamos las medias aritméticas.
2º Calculamos la covarianza.
3º Calculamos las desviaciones típicas.
4º Aplicamos la fórmula del coeficiente de correlación lineal.
Al ser el coeficiente de correlación positivo, la correlación es directa.Como coeficiente de correlación está muy próximo a 1 la correlación es muy fuerteLos valores de dos variables X e Y se distribuyen según la tabla siguiente:
Y/X 0 2 4
1 2 1 3
2 1 4 2
3 2 5 0
Determinar el coeficiente de correlación .Convertimos la tabla de doble entrada en tabla simple.
xi yi fi xi · fi xi2 · fi yi · fi yi2 · fi xi · yi · fi
0 1 2 0 0 2 2 0
0 2 1 0 0 2 4 0
0 3 2 0 0 6 18 0
2 1 1 2 4 1 1 2
2 2 4 8 16 8 16 16
2 3 5 10 20 15 45 30
4 1 3 12 48 3 3 12
4 2 2 8 32 4 8 16
20 40 120 41 97 76
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Al ser el coeficiente de correlación negativo, la correlación es inversa.Como coeficiente de correlación está muy próximo a 0 la correlación es muy débil.
Coeficiente de determinaciónEn un modelo de regresión lineal el coeficiente de determinación se interpreta como el porcentaje de variación de la variable dependiente
El coeficiente de determinación, r2 - la proporción de la variación total en la variable dependiente Y que está explicada por o se debe a la variación en la variable independiente X.El coeficiente de determinación es el cuadrado del coeficiente de correlación, y toma valores de 0 a 1. Ejemplo: Dan Ireland, presidente de la sociedad de alumnos de la Universidad de Toledo, está preocupado por el costo de los libros. Para tener un panorama del problema elige una muestra de 8 libros de venta en la librería. Decide estudiar la relación entre el número de páginas del libro y el costo. Calcule el coeficiente de correlación.
r =.614 (verifique)Pruebe la hipótesis de que no existe correlación en la población. Use .02 de nivel de significancia.
Paso 1: H0 la correlación en la población es cero. H1 la correlación en la población es distinta de cero.Paso 2: H0 se rechaza si t>3.143 o si t<-3.143, gl = 6, a = .02 El estadístico de prueba es t = 1.9055, calculado por:
Con (n - 2) grados de libertad.
Paso 4: H0 no se rechaza 6 Coeficiente de Determinación La bondad de la predicción depende de la relación entre las variables. Si dos variables no covarían, no podremos hacer predicciones válidas, y si la intensidad de la covariación es moderada, las predicciones no serán demasiado buenas. En consecuencia, hay que disponer de alguna medida de la capacidad de la ecuación de Regresión para obtener predicciones buenas (en el sentido de que sean lo menos erróneas posible).Esta medida es el Coeficiente de Determinación, que es el cuadrado del coeficiente de correlación de Pearson, y da la proporción de variación de la variable Y que es explicada por la variable X (variable predictora o explicativa). Si la proporción es igual a 0, significa que la variable predictora no tiene NULA capacidad predictiva de la variable a predecir
Para ver trabajos similares o recibir información semanal so

www.monografias.com
(Y). Cuanto mayor sea la proporción, mejor será la predicción. Si llegara a ser igual a 1 la variable predictora explicaría TODA la variación de Y, y las predicciones NO tendrían error. EjemploEn el siguiente cuadro puedes comprobar:a) que la Varianza total de la variable Y (0.76) es igual a la suma de las Varianzas de las puntuaciones estimadas (Y') y de los errores de predicción (Y-Y').b) Que el coeficiente de determinación (r2xy) es igual a la proporción de la Varianza explicada (s2y') respeto de la Varianza total (s2y)
Coeficiente de correlación de SpearmanEl coeficiente de correlación de Spearman, ρ (ro) es una medida de la correlación (la asociación o interdependencia) entre dos variables aleatorias continuas. Para calcular ρ, los datos son ordenados y reemplazados por su respectivo orden.El estadístico ρ viene dado por la expresión:
Donde D es la diferencia entre los correspondientes estadísticos de orden de x - y. N es el número de parejas.Se tiene que considerar la existencia de datos idénticos a la hora de ordenarlos, aunque si éstos son pocos, se puede ignorar tal circunstanciaPara muestras mayores de 20 observaciones, podemos utilizar la siguiente aproximación a la distribución t de Student
La interpretación de coeficiente de Spearman es igual que la del coeficiente de correlación de Pearson. Oscila entre -1 y +1, indicándonos asociaciones negativas o positivas respectivamente, 0 cero, significa no correlación pero no independencia. La tau de Kendall es un coeficiente de correlación por rangos, inversiones entre dos ordenaciones de una distribución normal bivariante.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
La Ejercicio 1
Cinco niños de 2, 3, 5, 7 y 8 años de edad pesan, respectivamente, 14, 20, 32, 42 y 44
kilos.
1 Hallar la ecuación de la recta de regresión de la edad sobre el peso.
2 ¿Cuál sería el peso aproximado de un niño de seis años?
xi yi xi · yi xi2 yi2
2 14 4 196 28
3 20 9 400 60
5 32 25 1 024 160
7 42 49 1 764 294
8 44 64 1 936 352
25 152 151 5 320 894
Ejercicio 2
Un centro comercial sabe en función de la distancia, en kilómetros, a la que se sitúe de un
núcleo de población, acuden los clientes, en cientos, que figuran en la tabla:
Nº de clientes (X) 8 7 6 4 2 1
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Distancia (Y) 15 19 25 23 34 40
1. Calcular el coeficiente de correlación lineal .
2. Si el centro comercial se sitúa a 2 km, ¿cuántos clientes puede esperar?
3. Si desea recibir a 500 clientes, ¿a qué distancia del núcleo de población debe situarse?
xi yi xi ·yi xi2 yi2
8 15 120 64 225
7 19 133 49 361
6 25 150 36 625
4 23 92 16 529
2 34 68 4 1 156
1 40 40 1 1 600
28 156 603 170 4 496
Correlación negativa muy fuerte .
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Ejercicio 3
Las notas obtenidas por cinco alumnos en Matemáticas y Química son:
Matemáticas 6 4 8 5 3. 5
Química 6. 5 4. 5 7 5 4
Determinar las rectas de regresión y calcular la nota esperada en Química para un alumno
que tiene 7.5 en Matemáticas.
xi yi xi ·yi xi2 yi2
6 6. 5 36 42. 25 39
4 4. 5 16 20. 25 18
8 7 64 49 56
5 5 25 25 25
3. 5 4 12. 25 16 14
26. 5 27 153. 25 152. 5 152
Ejercicio 4
Un conjunto de datos bidimensionales (X, Y) tiene coeficiente de correlación r = -0.9,
siendo las medias de las distribuciones marginales = 1, = 2. Se sabe que una de
las cuatro ecuaciones siguientes corresponde a la recta de regresión de Y sobre X:
y = -x + 2 3x - y = 1 2x + y = 4 y = x + 1
Seleccionar razonadamente esta recta .
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Como el coeficiente de correlación lineal es negativo , la pendiente de
la recta también será negativa , por tanto descartamos la 2ª y 4ª.
Un punto de la recta ha de ser ( , ), es decir, (1, 2).
2 ≠ - 1 + 2
2 . 1 + 2 = 4
La recta pedida es: 2x + y = 4.
Ejercicio 5
Las estaturas y pesos de 10 jugadores de baloncesto de un equipo son:
Estatura (X) 186 189 190 192 193 193 198 201 203 205
Pesos (Y) 85 85 86 90 87 91 93 103 100 101
Calcular:
1 La recta de regresión de Y sobre X.
2 El coeficiente de correlación .
3 El peso estimado de un jugador que mide 208 cm.
xi yi xi2 yi2 xi ·yi
186 85 34 596 7 225 15 810
189 85 35 721 7 225 16 065
190 86 36 100 7 396 16 340
192 90 36 864 8 100 17 280
193 87 37 249 7 569 16 791
193 91 37 249 8 281 17563
198 93 39 204 8 649 18 414
201 103 40 401 10 609 20 703
203 100 41 209 10 000 20 300
205 101 42 025 10 201 20 705
1 950 921 380 618 85 255 179 971
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Correlación positiva muy fuerte.
Ejercicio 6
A partir de los siguientes datos referentes a horas trabajadas en un taller (X), y a
unidades producidas (Y), determinar la recta de regresión de Y sobre X,
el coeficiente de correlación lineal e interpretarlo.
Horas (X) 80 79 83 84 78 60 82 85 79 84 80 62
Producción (Y)
300 302 315 330 300 250 300 340 315 330 310 240
xi yi xi ·yi xi2 yi2
80 300 6 400 90 000 24 000
79 302 6 241 91 204 23 858
83 315 6 889 99 225 26 145
84 330 7 056 108 900 27 720
78 300 6 084 90 000 23 400
60 250 3 600 62 500 15 000
82 300 6 724 90 000 24 600
85 340 7 225 115 600 28 900
79 315 6 241 99 225 24 885
84 330 7 056 108 900 27 720
80 310 6 400 96 100 24 800
62 240 3 844 57 600 14 880
936 3 632 73 760 1 109 254 285 908
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Correlación positiva muy fuerte
Ejercicio 7
Se ha solicitado a un grupo de 50 individuos información sobre el número de horas que
dedican diariamente a dormir y ver la televisión. La clasificación de las respuestas ha
permitido elaborar la siente tabla:
Nº de horas dormidas (X) 6 7 8 9 10
Nº de horas de televisión (Y) 4 3 3 2 1
Frecuencias absolutas (fi) 3 16 20 10 1
Se pide:
1 Calcular el coeficiente de correlación .
2 Determinar la ecuación de la recta de regresión de Y sobre X.
3 Si una persona duerme ocho horas y media, ¿cuánto cabe esperar que vea la televisión?
xi yi fi xi · fi xi2 · fi yi · fi yi2 · fi xi · yi · fi
6 4 3 18 108 12 48 72
7 3 16 112 784 48 144 336
8 3 20 160 1280 60 180 480
9 2 10 90 810 20 40 180
10 1 1 10 100 1 1 10
50 390 3082 141 413 1078
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Es una correlación negativa y fuerte .
Ejercicio 8
La tabla siguiente nos da las notas del test de aptitud (X) dadas a seis dependientes a prueba y
ventas del primer mes de prueba (Y) en cientos de euros.
X 25 42 33 54 29 36
Y 42 72 50 90 45 48
1 Hallar el coeficiente de correlación e interpretar el resultado obtenido.
2 Calcular la recta de regresión de Y sobre X. Predecir las ventas de un vendedor que
obtenga 47 en el test.
xi yi xi ·yi xi2 yi2
25 42 625 1 764 1 050
42 72 1 764 5 184 3 024
33 50 1 089 2 500 1 650
54 90 2 916 8 100 4 860
29 45 841 2 025 1 305
36 48 1 296 2 304 1 728
209 347 8 531 21 877 13 617
Para ver trabajos similares o recibir información semanal so

www.monografias.com
correlación trata de establecer la relación o dependencia que existe entre las dos variables que
intervienen en una distribución bidimensional.
Es decir, determinar si los cambios en una de las variables influyen en los cambios de la otra.
En caso de que suceda, diremos que las variables están correlacionadas o que
hay correlación entre ellas.
Tipos de correlación
1º Correlación directa
La correlación directa se da cuando al aumentar una de las variables la otra aumenta.
La recta correspondiente a la nube de puntos de la distribución es una recta creciente.
2º Correlación inversa
La correlación inversa se da cuando al aumentar una de las variables la otra disminuye.
La recta correspondiente a la nube de puntos de la distribución es una recta decreciente.
3º Correlación nula
La correlación nula se da cuando no hay dependencia de ningún tipo entre las variables.
En este caso se dice que las variables son incorreladas y la nube de puntos tiene una forma
redondeada.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Grado de correlación
El grado de correlación indica la proximidad que hay entre los puntos de la nube de puntos.
Se pueden dar tres tipos:
1. Correlación fuerte
La correlación será fuerte cuanto más cerca estén los puntos de la recta.
2. Correlación débil
La correlación será débil cuanto más separados estén los puntos de la recta.
3. Correlación nula
Procedimientos para llevar a cabo un análisis de correlaciónEL objetivo de un estudio de correlación es determinar la consistencia de una relación entre observaciones por partes. EL término “correlación “significa relación mutua, ye que indica el grado en el que los valores de una variable se relacionan con los valores de otra. Se considera tres técnicas de correlación uno para datos de medición, otro para datos jerarquizados y el último para clasificaciones nominales.La correlación indica la fuerza y la dirección de una relación lineal entre dos variables aleatorias. Se considera que dos variables cuantitativas están correlacionadas cuando los valores de una de ellas varían sistemáticamente con respecto a los valores homónimos de la otra: si tenemos dos variables (A y B) existe correlación si al aumentar los valores de A lo hacen también los de B y viceversa. La correlación entre dos variables no implica, por sí misma, ninguna relación de causalidad. Cuando r = 1 existe una relación funcional entre las dos variables de modo que el valor de cada variable se puede obtener a partir de la otra. Los puntos de la nube están todos situados sobre una recta de pendiente positiva. Esto ocurre, por ejemplo, cuando una barra metálica se somete a distintas temperaturas, x1, x2,…, xn, y se miden con precisión sus correspondientes longitudes, y1, y2,…, yn. Las longitudes se obtienen funcionalmente a partir de las temperaturas de modo que, conociendo la temperatura a que se va a calentar, se podría obtener la longitud que tendría la barra. Cuando r es positivo y grande (próximo a 1) se dice que
Para ver trabajos similares o recibir información semanal so

www.monografias.com
hay una correlación fuerte y positiva. Los valores de cada variable tienden a aumentar cuando aumentan los de la otra. Los puntos de la nube se sitúan próximos a una recta de pendiente positiva.Es el caso de las estaturas, x1, x2,…, xn, y los pesos, y1, y2,…, yn, de diversos atletas de una misma especialidad. A mayor estatura cabe esperar que tengan mayor peso, pero puede haber excepciones. Cuando r es próximo a cero (por ejemplo, r = -0,12 o r = 0,08) se dice que la correlación es muy débil (prácticamente no hay correlación). La nube de puntos es amorfa. Es lo que ocurriría si lanzáramos simultáneamente dos dados y anotáramos sus resultados: puntuación del dado rojo, xi; puntuación del dado verde, yi. No existe ninguna relación entre las puntuaciones de los dados en las diversas tiradas. Cuando r es próximo a -1 (por ejemplo, r = -0,93) se dice que hay una correlación fuerte y negativa. Los valores de cada variable tienden a disminuir cuando aumentan los de la otra. Los puntos de la nube están próximos a una recta de pendiente negativa. Si en un conjunto de países en vías de desarrollo se miden sus rentas per cápita, xi, y sus índices de natalidad, yi, se obtiene una distribución de este tipo, pues suele ocurrir que, grosso modo, cuanto mayor sea la renta per cápita menor será el índice de natalidad. Cuando r = -1 todos los puntos de la recta están sobre una recta de pendiente negativa. Existe una relación funcional entre las dos variables. La relación entre dos súper variables cuantitativas queda representada mediante la línea de mejor ajuste, trazada a partir de la nube de puntos. Los principales componentes elementales de una línea de ajuste y, por lo tanto, de una correlación, son la fuerza, el sentido y la forma:
La fuerza extrema según el caso, mide el grado en que la línea representa a la nube de puntos: si la nube es estrecha y alargada, se representa por una línea recta, lo que indica que la relación es fuerte; si la nube de puntos tiene una tendencia elíptica o circular, la relación es débil.
El sentido mide la variación de los valores de B con respecto a A: si al crecer los valores de A lo hacen los de B, la relación es positiva; si al crecer los valores de A disminuyen los de B, la relación es negativa.
La forma establece el tipo de línea que define el mejor ajuste: la línea rectal, la curva monotónica o la curva no monotónica.
La correlación, método por el cual se relacionan dos variables se pude graficar con un diagrama de dispersión de puntos, a la cual muchos autores le llaman nubes de puntos, encuadrado dentro de un gráfico de coordenadas X Y en la cual se pude trazar una recta y cuyos puntos más cercanos de una recta hablaran de una correlación más fuerte, a esta recta se le denomina recta de regresión, que puede ser positiva o negativa, la primera contundencia a aumentar y la segunda en descenso o decreciente.También se puede describir un diagrama de dispersión en coordenadas cartesianas valores como en la distribución diváriate, en donde la nube de puntos representa los pares de valores.
Regresión La regresión estadística o regresión a la media es la tendencia de una medición extrema a presentarse más cercana a la media en una segunda medición. La regresión se utiliza para predecir una medida basándonos en el conocimiento de otra.ANÁLISIS DE REGRESIÓNEl análisis de regresión consiste en emplear métodos que permitan determinar la mejor relación funcional entre dos o más variables concomitantes (o relacionadas).Una relación funcional matemáticamente hablando, está dada por:
Para elegir una relación funcional particular como la representativa de la población bajo investigación, usualmente se procede:
Una consideración analítica del fenómeno. Una consideración analítica del fenómeno que nos ocupa. Un examen de diagramas de dispersión.
Una vez decidido el tipo de función matemática que mejor se ajusta (o representa nuestro concepto de la relación exacta que existe entre las variables) se presenta el problema de elegir una expresión particular de
Para ver trabajos similares o recibir información semanal so

www.monografias.com
esta familia de funciones; es decir, se ha postulado una cierta función como término del verdadero estado en la población y ahora es necesario estimar los parámetros de esta función (ajuste de curvas).Como los valores de los parámetros no se pueden determinar sin errores por que los valores observados de la variable dependiente no concuerdan con los valores esperados, entonces la ecuación general replanteada, estadísticamente, sería:
Donde ε representa el error cometido en el intento de observar la característica en estudio, en la cual muchos factores contribuyen al valor que asume ε.
Variable dependienteEs el objeto o evento de estudio, sobre la cual se centra la investigación en general. Por ejemplo: Elementos contaminantes del lago de Valencia.También puede ser definida como los cambios sufridos por los sujetos como consecuencia de la manipulación de la variable independiente por parte del experimentador. En este caso el nombre lo dice de manera explícita, va a depender de algo que la hace variar.Por ejemplo: Como influye la música clásica en el crecimiento de los tomates.En este caso la variable dependiente sería el crecimiento de los tomates como consecuencia de la manipulación de la variable independiente la música clásica. Así se debe tomar nota que en el título de un trabajo siempre debe aparecer la variable dependiente, pues está es el objeto de estudio.
Variable independienteEs aquella propiedad de un fenómeno a la que se le va a evaluar su capacidad para influir, incidir o afectar a otras variables. Su nombre lo explica de mejor modo en el hecho que de no depende de algo para estar allí como es el caso del sexo de un sujeto, o la música en el ejemplo anterior. No obstante existen variables independientes en algunos estudios que en cierta medida dependerán de algo, como la entrada económica de una escuela puede depender del Ministerio de Educación, pero el objeto de estudio no está influyendo en la variable independiente. De este modo, la variable independiente en un estudio se cree que está influyendo en la variable dependiente, el estudio Correlacional se centra precisamente en esa relación.Algunas variables independientes como el Sexo, Nivel Socioeconómico son variables que el investigador no puede modificar, no son manipulables. No obstante, se desea saber si influye sobre la variable dependiente. Esta se llama variable independiente asignada o seleccionada, mientas que la variable independiente por manipulación es la que el investigador aplica según su criterio, se hace en estudios de carácter experimental. Todo aquello que el investigador manipula, debido a que cree que existe una relación entre ésta y la variable dependiente.
Variables independientesLas variables independientes son aquellas variables que se conocen al inicio de un experimento o proceso. En un estudio sobre la pérdida de peso, por ejemplo, una variable independiente puede ser el número total de calorías consumidas por los participantes en el estudio. Como la variable independiente, o el número de calorías varían, los resultados del experimento van a cambiar. Otra forma de explicarlo es decir que el valor de la variable independiente es controlado por el diseñador del problema de matemáticas o del experimento.
Variables dependientesLas variables dependientes son las que se crean como resultado del estudio o experimento. Si se toma el ejemplo de un estudio de la pérdida de peso, donde la variable independiente son las calorías consumidas, entonces una variable dependiente podría ser el peso total de los participantes del estudio. Así que el peso del participante en el estudio depende de la fluctuación de la variable independiente, que es lo que la hace dependiente.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Tipos de modelo de regresión Modelo de regresión lineal o ajuste lineal: Es un método matemático que modeliza la relación entre
una variable dependiente Y, las variables independientes Xi y un término aleatorio ε. Este modelo puede ser expresado como:
La regresión lineal puede ser contrastada con la regresión no lineal.Existen dos tipos de regresión lineal:
Regresión lineal simple: Sólo se maneja una variable independiente, por lo que sólo cuenta con dos parámetros. Si sabemos que existe una relación entre una variable denominada dependiente y otras denominadas independientes (como por ejemplo las existentes entre: la experiencia profesional de los trabajadores y sus respectivos sueldos, las estaturas y pesos de personas, la producción agraria y la cantidad de fertilizantes utilizados, etc.), puede darse el problema de que la dependiente asuma múltiples valores para una combinación de valores de las independientes.Dadas dos variables (Y: variable dependiente; X: independiente) se trata de encontrar una función simple (lineal) de X que nos permita aproximar Y mediante: Ŷ = a + bX.A (ordenada en el origen, constante)b (pendiente de la recta)A la cantidad e=Y-Ŷ se le denomina residuo o error residual.Así, en el ejemplo de Pearson: Ŷ = 85 cm + 0,5XDonde Ŷ es la altura predicha del hijo y X la altura del padre: En media, el hijo gana 0,5 cm por cada cm del padre.Regresión lineal múltiple: La regresión lineal nos permite trabajar con una variable a nivel de intervalo o razón, así también se puede comprender la relación de dos o más variables y nos permitirá relacionar mediante ecuaciones, una variable en relación a otras variables llamándose Regresión múltiple. Constantemente en la práctica de la investigación estadística, se encuentran variables que de alguna manera están relacionados entre sí, por lo que es posible que una de las variables pueda relacionarse matemáticamente en función de otra u otras variables. Maneja varias variables independientes. Cuenta con varios parámetros. Se expresan de la forma:
La regresión no lineal es un problema de inferencia para un modelo tipo:
Basado en datos multidimensionales x, y, donde f es alguna función no lineal respecto a algunos parámetros desconocidos θ. Como mínimo, se pretende obtener los valores de los parámetros asociados con la mejor curva de ajuste (habitualmente, con el método de los mínimos cuadrados). Con el fin de determinar si el modelo es adecuado, puede ser necesario utilizar conceptos de inferencia estadística tales como intervalos de confianza para los parámetros así como pruebas de bondad de ajuste.El objetivo de la regresión no lineal se puede clarificar al considerar el caso de la regresión polinomial, la cual es mejor no tratar como un caso de regresión no lineal. Cuando la función f toma la forma:
La función f es no lineal en función de x pero lineal en función de los parámetros desconocidos a, b, yc. Este es el sentido del término "lineal" en el contexto de la regresión estadística. Los procedimientos computacionales para la regresión polinomial son procedimientos de regresión lineal (múltiple), en este caso
Para ver trabajos similares o recibir información semanal so

www.monografias.com
con dos variables predictoras x y x2. Sin embargo, en ocasiones se sugiere que la regresión no lineal es necesaria para ajustar polinomios. Las consecuencias prácticas de esta mala interpretación conducen a que un procedimiento de optimización no lineal sea usado cuando en realidad hay una solución disponible en términos de regresión lineal. Paquetes (software) estadísticos consideran, por lo general, más alternativas de regresión lineal que de regresión no lineal en sus procedimientos.
Regresión segmentada o regresión por pedazos: Es un método en el análisis de regresión en que el variable independiente es particionada en intervalos ajustando en cada intervalo una línea o curva a los datos. La regresión segmentada se puede aplicar también a la regresión con múltiples variables independientes particionando todas estas.
Regresión segmentada lineal, tipo 3La regresión segmentada es útil cuando el variable dependiente muestra una reacción abruptamente diferente a la variable independiente en los varios segmentos. En este caso el límite entre los segmentos se llama punto de quiebra.Regresión segmentada lineal es la regresión segmentada en que la relación entre el variable dependiente e independiente dentro de los segmentos se obtiene por regresión lineal.
Métodos de los mínimos cuadradosLa mejor curva de ajuste se considera como aquella que minimiza la suma de las desviaciones (residuales) al cuadrado (SRC). Este es la aproximación por el método de mínimos cuadrados (MMC). Sin embargo, en aquellos casos donde se tienen diferentes varianzas de error para diferentes errores, es necesario minimizar la suma de los residuales al cuadrado ponderados (SRCP) (método de mínimos cuadrados ponderados). En la práctica, la varianza puede depender del valor promedio ajustado. Así que los pesos son recalculados para cada iteración en un algoritmo de mínimos cuadrados ponderados iterativos.En general, no hay una expresión de forma cerrada para los parámetros de mejor ajuste, como sucede en el caso de la regresión lineal. Métodos numéricos de optimización son aplicados con el fin de determinar los parámetros de mejor ajuste. Otra vez, en contraste con la regresión lineal, podría haber varios máximos locales de la función a ser optimizada. En la práctica, se suponen algunos valores iniciales los cuales junto con el algoritmo de optimización conducen a encontrar el máximo global.
Forma general de la ecuación de regresiónLa ecuación de regresión es una ecuación que define la relación lineal entre las dos variables.Y´= a+bX donde:Y´ se lee Y prima, es el valor pronosticado de la variable Y para un valor seleccionado de X.A es la ordenada de la intersección con el eje Y, es decir, el valor estimado de Y cuando X=0 o sea, corresponde al valor estimado de Y, donde la recta de regresión cruza el eje Y, cuando X=0.B es la pendiente de la recta, o el cambio promedio de Y´ por unidad de cambio en la variable independiente X.X es cualquier valor seleccionado de la variable independiente. Los valores de a y b en la ecuación de regresión se denominan coeficiente de regresión estimados, o simplemente coeficiente de regresión.Ojos: Simple/Linear Regression TutorialDefinición de regresión:Una regresión es un análisis estadístico de evaluar la asociación entre dos variables. Se utiliza para encontrar la relación entre dos variables.Regresión de la Fórmula:
Para ver trabajos similares o recibir información semanal so

www.monografias.com
La ecuación de regresión(y) = a + bx Pendiente(b) = (NΣXY - (ΣX)(ΣY)) / (NΣX2 - (ΣX)2) Interceptar(a) = (ΣY - b(ΣX)) / N Cuando, x e y son las variables. b =La pendiente de la recta de regresión a =El punto de intersección de la recta de regresión y el eje Y. N =Número de valores o elementos X = Primera puntuación Y =La puntuación de Segunda ΣXY = Suma del producto de las puntuaciones primero y segundo ΣX =La suma de las puntuaciones Primera ΣY = Suma de las puntuaciones de segunda ΣX2 = Suma de cuadrados Puntuación PrimeroEjemplo de regresión:Para encontrar la simple / Regresión lineal deX Valores Y Valores
60 3.1
61 3.6
62 3.8
63 4
65 4.1Para encontrar la ecuación de regresión, lo primero que se encuentra pendiente, intersección y usarla para formar la ecuación de regresión.Paso 1:Cuente el número de valores. N = 5Paso 2:Buscar XY, X2 Consulte la tabla siguienteX Valor Y Relación X*Y X*X
60 3.1 60 * 3.1 = 186 60 * 60 = 3600
61 3.6 61 * 3.6 = 219.6 61 * 61 = 3721
62 3.8 62 * 3.8 = 235.6 62 * 62 = 3844
63 4 63 * 4 = 252 63 * 63 = 3969
65 4.1 65 * 4.1 = 266.5 65 * 65 = 4225Paso 3:Buscar ΣX, ΣY, ΣXY, ΣX2. ΣX = 311 ΣY = 18.6 ΣXY = 1159.7 ΣX2 = 19359Paso 4:Suplente en la fórmula de la pendiente por encima de determinado. Slope(b) = (NΣXY - (ΣX)(ΣY)) / (NΣX2 - (ΣX)2) = ((5)*(1159.7)-(311)*(18.6))/((5)*(19359)-(311)2) = (5798.5 - 5784.6)/(96795 - 96721) = 13.9/74 = 0.19Paso 5:Ahora, de nuevo suplente en la fórmula anterior interceptar dado. Interceptar(a) = (ΣY - b(ΣX)) / N = (18.6 - 0.19(311))/5 = (18.6 - 59.09)/5 = -40.49/5 = -8.098Paso 6:A continuación, sustituir estos valores en la ecuación de regresión fórmula La ecuación de regresión(y) = a + bx = -8.098 + 0.19x. Supongo que si queremos saber el valor y aproximada de la variable x = 64. Entonces podemos sustituir el valor en la ecuación anterior. La ecuación de regresión(y) = a + bx = -8.098 + 0.19(64). = -8.098 + 12.16 = 4.06 Este ejemplo le guía para encontrar la relación entre dos variables mediante el cálculo de la regresión de los pasos anteriores.
PENDIENTE DE LA RECTA DE REGRESION
Llamamos línea de regresión a la curva que mejor se ajusta a nube de puntos, es una curva ideal en torno a la que se distribuyen los puntos de la nube.Se utiliza para predecir la variable dependiente (Y) a partir de la independiente (X). La diferencia entre el valor real (yi) y el teórico (yi*) se llama residuo.
En nuestro caso esta línea es una recta que se calcula imponiendo dos condiciones: Debe pasar por el punto (x, y), centro de gravedad de la distribución. La suma de los cuadrados de los residuos debe ser mínima.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Con esto obtenemos la ecuación de la RECTA de REGRESIÓN de Y sobre X:
La pendiente de esta recta es el llamado coeficiente de regresión= .
Error estándar de estimaciónEl error estándar nos permite deducir la confiabilidad de la ecuación de regresión que hemos desarrollado. Este error se simboliza Se y es similar a la desviación estándar en cuanto a que ambas son medidas de dispersión. El error estándar de la estimación mide la variabilidad, o dispersión de los valores observados alrededor de la línea de regresión. El error estándar de estimación se calcula con la finalidad de medir la confiabilidad de la ecuación de la estimación. El error estándar de estimación permite medir la variabilidad o dispersión de los valores de (y) los cuales encontramos en la muestra, alrededor de la línea recta de regresión. El resultado que se obtiene del cálculo del error estándar de estimación se expresa en término de los valores de la variable dependiente yi.
Análisis residualUn residual i r es la diferencia entre el valor observado i Y y el valor estimado por la línea de regresión Yˆi, es decir, i i i r = Y -Yˆ. El residual puede ser considerado como el error aleatorio i e observado. También se acostumbra usar el Residual estandarizado, el cual se obtiene al dividir el residual entre la desviación estándar del residual (siempre que hagamos análisis de residuales debemos utilizar Residual estandarizado), y el Residual estudentizado "deleted", que es similar al anterior pero eliminando de los cálculos la observación cuyo residual se desea hallar.El análisis de residuales permite cotejar si las suposiciones del modelo de regresión se cumplen.Se puede detectar:
Si efectivamente la relación entre las variables X e Y es lineal. Si hay normalidad de los errores. Si hay valores anormales en la distribución de errores (Si se usa Residual estandarizado, cualquier
observación con un residual mayor de 2 o menor de 2 es considerado “outlier”)d) Si hay varianza constante (propiedad de Homocedasticidad) ye) Si hay independencia de los errores.El análisis de residuales se puede llevar a cabo gráficamente o en forma analítica. En este texto sólo consideraremos un análisis gráfico, las cuales pueden obtenerse de dos maneras. La primera manera es escogiendo el botón Graphs de la ventana de diálogo Regresión.
Supuestos para realizar un análisis de regresiónClásica supuestos para el análisis de regresión son:
La muestra es representativa de la población para la predicción de inferencia. El error es una variable aleatoria con una media de cero condicionada a las variables explicativas. Las variables independientes se miden sin error. (Nota: Si no es así, el modelado se puede hacer
en lugar de utilizar los errores en las variables del modelo técnicas). Los predictores son linealmente independientes, es decir, no es posible expresar cualquier
predicción como una combinación lineal de los otros. Ver multicolinealidad. Los errores están correlacionados, es decir, la varianza-covarianza de los errores es diagonal y
cada elemento no nulo es la varianza del error. La varianza del error es constante a través de observaciones (Homocedasticidad). (Nota: Si no es
así, mínimos cuadrados ponderados u otros métodos en lugar podría ser utilizado). Estas son condiciones suficientes para el estimador de cuadrados por lo que poseen propiedades deseables, en particular, estos supuestos implican que las estimaciones de los parámetros será imparcial, coherente y eficiente en la clase de estimadores lineales insesgados. Es importante señalar que los datos reales rara vez se cumplen la hipótesis. Es decir, el método se utiliza a pesar de que las hipótesis no son ciertas. La variación de los supuestos a veces se puede utilizar como una medida de hasta qué punto el modelo es de ser útil. Muchos de estos supuestos pueden estar relajados en tratamientos más avanzados.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Los informes de los análisis estadísticos suelen incluir análisis de las pruebas en los datos de la muestra y la metodología para el ajuste y la utilidad del modelo.
PROCEDIMIENTOS PARA LLEVAR A CABO UN ANALISIS DE REGRESION LINEAL
La regresión múltiple comprende tres o más variables. Existe solo una variable dependiente, pero hay dos o más tipo independiente. Esta operación al desarrollo de una ecuación que se puede utilizar para predecir valore de y, respecto a valores dados de la diferencia variables independientes adicionales es incrementar la capacidad predicativa sobre la de la regresión lineal simple.Las técnicas de los mínimos cuadrados se utilizan para obtener ecuaciones de regresión.Yc= a +b1x1+b2x2+…bkxk.a = ordenada en el origenb1= pendientek = número de variables independientes Un análisis de regresión simple de dos variable da lugar a la ecuación de una recta, un problema de tres variables produce un plano, y un problema de k variables implica un hiperplano de a (K +1) dimensiones.Rectas de regresión Las rectas de regresión son las rectas que mejor se ajustan a la nube de puntos (o también llamado diagrama de dispersión) generada por una distribución binomial. Matemáticamente, son posibles dos rectas de máximo ajuste.
La recta de regresión de Y sobre X: La recta de regresión de X sobre Y:
La correlación ("r") de las rectas determinará la calidad del ajuste. Si r es cercano o igual a 1, el ajuste será bueno; si r es cercano o igual a 0, se tratará de un ajuste malo. Ambas rectas de regresión se intersecan en un punto llamado centro de gravedad de la distribución. Ejemplo: En una muestra de 1.500 individuos se recogen datos sobre dos medidas antropométricas X e Y. Los resultados se muestran resumidos en los siguientes estadísticos:Obtener el modelo de regresión lineal que mejor aproxima Y en función de X. Utilizando este modelo, calcular de modo aproximado la cantidad Y esperada cuando X=15. Solución: Lo que se busca es la recta, que mejor aproxima los valores de Y (según el criterio de los mínimos cuadrados) en la nube de puntos que resulta de representar en un plano (X, Y) las 1.500 observaciones. Los coeficientes de esta recta son: Así, el modelo lineal consiste en: Por tanto, si x=15, el modelo lineal predice un valor de Y de: En este punto hay que preguntarse si realmente esta predicción puede considerarse fiable. Para dar una respuesta, es necesario estudiar propiedades de la regresión lineal que están a continuación.
UNIDAD IV
Análisis de series de tiempoSERIE DE TIEMPO
Es un conjunto de mediciones de cierto fenómeno o experimento registradas secuencialmente en el tiempo. Estas observaciones serán denotadas por {x (t1), x (t2),..., x (tn)} = {x (t): t Î T Í R} con x (ti) el valor de la variable x en el instante ti. Si T = Z se desee que la serie de tiempo es discreta y si T = R se dice que la serie de tiempo es continua. Cuando ti+1 - ti = k para todo i = 1,..., n-1, se dice que la serie es equiespaciada, en caso contrario será no equiespaciada.
COMPONENTES DE UNA SERIE DE TIEMPOExisten 4 componentes de una serie de Tiempo: La Tendencia, La Variación Cíclica, Variación Estacional y la Variación Irregular.
Tendencia Secular: Las tendencias a largo plazo (sin alteraciones de una serie de tiempo) de las ventas, el empleo, los precios de las acciones, y otras series económicas y comerciales.
Muchas variables macroeconómicas, como el Producto Nacional Bruto (PNB), el empleo y la producción industrial están dominadas por una fuerte tendencia. La tendencia de una serie de tiempo es el componente de largo plazo que representa el crecimiento o disminución en la serie sobre un periodo amplio. Las fuerzas básicas que ayudan a explicar la tendencia de una serie son el crecimiento de la población, la inflación de precios, el cambio tecnológico y los incrementos en la productividad.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
La figura muestra gráficamente la recta de tendencia ajustada a los datos trimestrales. La recta de trazos después de 1972 representa proyecciones.
Es decir, Movimientos seculares contienen los movimientos suaves de largo plazo, los cuales están dominados fundamentalmente por factores de tipo económico.
Variación Cíclica: Es la segunda componente de un serie de Tiempo es la Variación Cíclica; ascenso y descenso de una serie de Tiempo en periodos mayores de un año.
El componente cíclico es la fluctuación en forma de onda alrededor de la tendencia, afecta por lo regular por las condiciones económicas generales. Los patrones cíclicos tienden a repetirse en los datos aproximadamente cada dos tres o más años. Es común que las fluctuaciones cíclicas estén influidas por cambios de expansión y contracción económicas, a los que comúnmente se hace referencia como el ciclo de los negocios. Movimientos cíclicos o variaciones cíclicas o ciclo: Se refieren a las oscilaciones de larga duración alrededor de la curva de tendencia, los cuales pueden o no ser periódicos, es decir, pueden o no seguir caminos análogos en intervalos de tiempo iguales. Se caracterizan por tener lapsos de expansión y contracción. En general, los movimientos se consideran cíclicos solo si se produce en un intervalo de tiempo superior al año (3). En el Gráfico los movimientos cíclicos alrededor de la curva de tendencia están trazados en negrita.
Variación Estacional: Se refiere a los patrones de cambio en una serie de tiempos en un año. Tales patrones tienden a repetirse cada año. El componente estacional se refiere a un patrón de cambio que se repite a si mismo año tras año. En el caso de las series mensuales, el componente estacional mide la variabilidad de las series de enero, febrero, etc. En las series trimestrales hay cuatro elementos estaciónales, uno para cada trimestre. La variación estacional puede reflejar condiciones de clima, días festivos o la longitud de los meses del calendario.
Movimientos estaciónales o variaciones estaciónales: Se refieren a las fluctuaciones periódicas que se observan en series de tiempo cuya frecuencia es menor a un año (trimestral, mensual, diaria, etc.), aproximadamente en las mismas fechas y casi con la misma intensidad. Por ejemplo, el mayor monto de recaudación del Impuesto a la Renta se observa en el mes de marzo de todos los años o la mayor brecha
Para ver trabajos similares o recibir información semanal so

www.monografias.com
entre el tipo de cambio de compra y venta se produce los días viernes década semana o la mayor cotización de los títulos que se mueven en la Bolsa de Valores de Lima se observa diariamente entre las 11 a.m. y 12 m. Las variaciones estaciónales, como veremos, responden fundamentalmente a factores relacionados al clima, lo institucional o las expectativas y no a factores de tipo económico. En el Gráfico no se observa ningún movimiento estacional, puesto que se trata de una serie anual.Las principales fuerzas que causan una variación estacional son las condiciones del tiempo, como por ejemplo:
En invierno las ventas de helado. En verano la venta de lana. Exportación de fruta en marzo.
Todos estos fenómenos presentan un comportamiento estacional (anual, semanal, etc.)
Variación Irregular: El componente aleatorio mide la variabilidad de las series de tiempo después de que se retiran los otros componentes. Contabiliza la variabilidad aleatoria en una serie de tiempo ocasionada por factores imprevistos y no ocurrentes. La mayoría de los componentes irregulares se conforman de variabilidad aleatoria. Sin embargo ciertos sucesos a veces impredecibles como huelgas, cambios de clima (sequías, inundaciones o terremotos), elecciones, conflictos armados o la aprobación de asuntos legislativos, pueden causar irregularidad en una variable.
TÉCNICAS O MÉTODOS DE LOS PROMEDIOS MOVILESEl método de promedio móvil no solo es útil para alisar una serie de tiempo, sino que es el método básico utilizado para medir la fluctuación estacional. A diferencia del método del mínimo cuadrado, que expresa la tendencia en términos de una ecuación (Y´ =a+bt), el método de promedios móviles simplemente suaviza las fluctuaciones de la información. Esto se realiza moviendo los valores de la media aritmética a través de una serie de tiempo.Para aplicar el método de promedio móvil a una serie de tiempo, los datos deben tener una tendencia bastante lineal y un esquema de fluctuaciones rítmico definido (que se repite por ejemplo cada tres años).Si la duración de los ciclos es constante y si las amplitudes de tales ciclos son iguales, las fluctuaciones cíclicas e irregulares pueden eliminarse por completo usando el método de promedio móvil. El resultado es una línea recta.Hay dos grupos distintos de los métodos de suavizado
Un promedio de Métodos Exponencial Métodos
TÉCNICAS O MÉTODOS DE LA EXPONENCIALUna media móvil exponencial (EMA), también conocido como un promedio móvil ponderado exponencialmente (EWMA), es un tipo de respuesta al impulso infinita filtro que aplica los factores de ponderación que disminuyen exponencialmente. La ponderación de cada punto de datos mayores de esa edad disminuye exponencialmente, sin llegar nunca a cero. La gráfica de la derecha muestra un ejemplo de la disminución de peso.
La fórmula para el cálculo de la EMA en períodos de tiempo t> 2 es
Dónde: El coeficiente α representa el grado de disminución de peso, un factor de suavizado constante entre
0 y 1. Un descuentos α mayor edad observaciones más rápido. Por otra parte, α se puede expresar en términos de períodos de tiempo N, donde α = 2 / (N +1). Por ejemplo, N = 19 es
Para ver trabajos similares o recibir información semanal so

www.monografias.com
equivalente a α = 0.1. La vida media de los pesos (el intervalo en el que la disminución de peso por un factor de dos) es de aproximadamente N / 2,8854 (a menos de 1% si N> 5).
Y t es la observación en un período de tiempo t. S t es el valor de la EMA, en cualquier período de tiempo t.
S 1 es indefinido. S 2 puede ser inicializado en un número de maneras diferentes, por lo general mediante el establecimiento de S 2 Y 1, aunque existen otras técnicas, tales como el establecimiento de S 2 a un promedio de los primeros 4 o 5 observaciones. La importancia de S 2 de inicialización de efecto sobre la media móvil resultante depende de α, α valores menores que la elección de los valores de S 2 relativamente más importante α más grande que, desde un α descuentos superiores mayores observaciones más rápido. Esta formulación está de acuerdo con Hunter (1986).
Esta es una suma infinita de términos disminuyendo. Los períodos de N en un N-día EMA sólo especificar el factor α. N no es un punto de parada para el cálculo en la forma en que se encuentra en un SMA o WMA. Para N suficientemente grande, la primera de datos N puntos en un EMA representan alrededor del 86% del peso total en el cálculo:
La fórmula de energía por encima de da un valor de partida para un día determinado, después de lo cual los primeros días se muestra la fórmula puede ser aplicada a los sucesivos. La cuestión de hasta qué punto volver a ir para un valor inicial depende, en el peor de los casos, en los datos. Si hay grandes valores de los precios p en los datos de edad, entonces van a tener un efecto sobre el total, aunque su ponderación es muy pequeña. Si uno asume los precios no varían demasiado violentamente a continuación, sólo la ponderación puede ser considerada. El peso se omite por detener después de los términos k es
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Modelos aditivos y sumativos para expresar una serie de tiempoLos métodos descritos en esta sección representan una generalización de la regresión múltiple (que es un caso especial de modelos lineales generales). En concreto, en la regresión lineal, un ajuste lineal por mínimos cuadrados se calcula para un conjunto de variables explicativas o X, para predecir una variable dependiente Y. La ecuación de regresión lineal conocido con predictores m, para predecir una variable dependiente Y, se puede plantear como:
Y = b 0 + b 1 X * 1 +... M + a * b * X m
Donde Y representa el (los valores pronosticados de la) variable dependiente, X 1 a m X representan los valores de m para las variables de predicción, y b 0 y b 1 a m b son los coeficientes de regresión estimados por regresión múltiple. Una generalización del modelo de regresión múltiple sería la de mantener el carácter aditivo de la modelo, pero para sustituir los términos simples de la ecuación lineal b * i X i con f i (X i) donde f i
es una función no paramétrica del predictor X i. En otras palabras, en lugar de un coeficiente único para cada variable (término aditivo) en el modelo, en los modelos de un aditivo sin especificar (no paramétrica) la función se estima para cada predictor, para lograr la mejor predicción de los valores de las variables dependientes.
INDICES ESTACIONALES EN UNA SERIE DE TIEMPOMedida del efecto estacional en una serie de tiempo. Un índice estacional arriba de 1 indica un efecto positivo (el dato mayor que el marcado por la tendencia), un índice estacional de 1 indica que no hay efecto estacional y un índice estacional menor que 1 indica un efecto negativo (el dato es menor que el indicado por la tendencia).
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Las fluctuaciones estacionales son variaciones que se repiten regularmente en un periodo de un año. Existen 2 objetivos generales para aislar el componente estacional de una serie cronológica. El primero es eliminar ese patrón a fin de estudiar las fluctuaciones cíclicas. La segunda finalidad es identificar factores estacionales, de esta manera que se puedan considerar en la toma de decisiones. Por ejemplo si una compañía productora se da cuenta de que existen fluctuaciones estacionales en la demanda de un determinado, producto, es posible que desee ajustar sus presupuestos, mano de obra e inventarios, teniendo esto en mente. Por lo general tales ajustes resultan muy costosos. Por ejemplo, compañía puede buscar un producto complementario. El cual presente variaciones estacionales en su de manda opuesta alas del mismo. La demanda de equipo de calefacción.Para probar y encarar los patrones estacionales, es necesario identificar y determinar primero la extensión de estas variaciones. La Técnica más difundida para el análisis estacional es el método de la razón al promedio móvil.
NUMEROS INDICESUn número índice: es un número que expresa la variación relativa del precio, la cantidad o el valor, en comparación con un periodo base. EjemploLa oficina de censo de estados unidos informa que el número de granjas de ese país disminuyo de 3157857, en 1964, a aproximadamente 1200000, en el año 2000. ¿Cuál es el índice correspondiente a la cantidad de granjas en el año 2000, con base en el número en 1964?El índice es 38.0 que se obtiene de:Cantidad de granjas en el año 2000; 1200000P = ---------------------------------------------- (100) = ----------------- (100) = 38.0Cantidad de granjas en 1964; 3157857Esto indica que la cantidad de granjas en 2000 era 38% de la cantidad de granjas en 1964. En otras palabras, la cantidad de granjas en estados unidos disminuyó 62.0% (lo cual proviene de 100-38) en ese periodo.El índice también sirve para comparar un artículo con otro. En 1999 la población en la propicia de Colombia británica era de 4023100 y en Ontario era 11513800. ¿Cuál es la proporción de la población en Columbia británica comparada con la población de Ontario?El índice de población de Columbia británica es 34.9 que se obtiene mediante la formulaPoblación de Columbia británica 4023100P = ------------------------------------------- (100) = --------------- (100) = 34.9Población de Ontario 11513800¿Por qué convertir los datos en índices?Un índice es una forma de expresar una variación en un grupo heterogéneo de elementos. Los índices nos permiten expresar una variación en precio, cantidad o valor, como un porcentaje. Por ejemplo, el índices de precios al consumidor (IPC) abarca, una serie de artículos, incluyendo pelotas de golf, podadoras de césped, hamburguesas, servicios funerarios y honorarios de dentistas Los precios se expresa en bolívares por libra, caja, yarda, y otras muchas unidades.Convertir los datos en índices también facilita la evaluación de la tendencia en una serie compuesta por números excepcionalmente grandes.
INDICES PONDERADOS Y NO PONDERADOSÍndices No Ponderados: En muchos casos se desea combinar varios elementos y elaborar un índice para comparar el costo de un grupo de artículos en dos diferentes periodos. Por ejemplo, si se desea un índice para elementos relacionados con los gastos de uso y mantenimiento de un automóvil, los elementos del índice podrían incluir llantas, cambios de aceites y precios de la gasolina. O tal vez interese un índice de gastos de estudiantes universitario. Este índice podría comprender el costo de libros, colegiatura, vivienda, alimentación y entretenimiento. Existen muchas maneras de combinar los elementos para determinar el índice.Índices Ponderados: Existen dos métodos para calcular un índice de precios ponderados: el método de Laspeyres y el de Paasche, los cuales difieren solo en el periodo utilizado para la ponderación.
El Índice De Precios De Laspeyres
Emplea las ponderaciones del periodo base; es decir, los precios y las cantidades originales de los artículos comparados se utilizan para hallar el cambio porcentual respecto a un periodo o intervalo de tiempo, tanto en precio como en cantidad consumida, dependiendo del problema. El método de paasches utiliza las ponderaciones del año actual para el denominador del índice ponderado.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Índice De Precios De PaascheEl índice de Paasche es una alternativa. El procedimiento es similar, pero en vez de usar los pesos periodos base, se emplean los pesos del año actual.
¿Cómo se decide que índice usar? ¿Cuándo es más apropiado el de Laspeyres, y cuando el de Paasche? Laspeyres
Ventajas requiere datos de cantidad solo del periodo base. Esto permite una mejor comparación conforme pasa el tiempo. Los cambios en el índice pueden atribuirse a cambios en el precio.Desventajas no refleja cambios en los patrones de compra conforme pasa el tiempo. Además, podría ponderar en más los artículos cuyos precios aumentan.
PaascheVentajas debido a que se utilizan cantidades del periodo actual, refleja los hábitos actuales de compra.Desventajas requiere datos de cantidad de cada año, lo cual puede ser difícil de obtener. Debido a que se emplean diferentes cantidades cada año, es imposible atribuir cambios en el índice únicamente a cambios en el precio. Tienden a ponderar en más los artículos cuyos precios han bajado. Requieren que los precios se calculen cada año.
Índices de precios al consumidorEl (IPC) mide los cambios en los precios de una canasta básica fija de artículos y servicios en el mercado, de un periodo a otro.El IPC cumple con varias funciones importantes. Permite a los consumidores determinar el grado de deterioro de su poder adquisitivo por el aumento de los precios. A este respecto es un criterio para la revisión de sueldos y salarios, pensiones y otros tipos de ingresos, a fin de mantener el paso con los cambios en los precios. Igualmente importante, es un indicador económico de la tasa de inflación.El índice incluye cerca de 400 elementos, y unos 250 inspectores recopilan mensualmente los datos de los precios. Los precios se obtienen de más de 21000 establecimientos de comercio al menudeo, y de 60000 unidades habitacionales en 91 áreas urbanas del país. Los precios de cunas para bebes, pan, cerveza, cigarros, gasolina, cortes de cabellos, tasa de interés hipotecario, honorarios médico, impuestos y cargos por uso de salas para cirugías, son solo algunos de las elementos que se incluyen en lo que se ha dominado con frecuencia canasta básica de bienes y servicios que se consumen.Usos especiales del índice de precios al consumidor:Ingreso real: Determina el poder de compra de la unidad monetaria, y para evaluar el aumento del costo de vida.
Poder adquisitivo del dinero:
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Ventas deflacionadas: Importante para mostrar la tendencia en ventas reales.
La Correlación Estadística
La correlación estadística constituye una técnica estadística que nos indica si dos variables están relacionadas o no.
Por ejemplo, considera que las variables son el ingreso familiar y el gasto familiar. Se sabe que los aumentos de ingresos y gastos disminuyen juntos. Por lo tanto, están relacionados en el sentido de que el cambio en cualquier variable estará acompañado por un cambio en la otra variable.De la misma manera, los precios y la demanda de un producto son variables relacionadas; cuando los precios aumentan la demanda tenderá a disminuir y viceversa.
Si el cambio en una variable está acompañado de un cambio en la otra, entonces se dice que las variables están correlacionadas. Por lo tanto, podemos decir que el ingreso familiar y gastos familiares y el precio y la demanda están correlacionados.
Relación Entre las Variables
La correlación puede decir algo acerca de la relación entre las variables. Se utiliza para entender:
1. si la relación es positiva o negativa
2. la fuerza de la relación.
La correlación es una herramienta poderosa que brinda piezas vitales de información.
En el caso del ingreso familiar y el gasto familiar, es fácil ver que ambos suben o bajan juntos en la misma dirección. Esto se denomina correlación positiva.
En caso del precio y la demanda, el cambio se produce en la dirección opuesta, de modo que el aumento de uno está acompañado de un descenso en el otro. Esto se conoce como correlación negativa.
Coeficiente de Correlación
La correlación estadística es medida por lo que se denomina coeficiente de correlación (r). Su valor numérico varía de 1,0 a -1,0. Nos indica la fuerza de la relación.En general, r> 0 indica una relación positiva y r <0 indica una relación negativa, mientras que r = 0 indica que no hay relación (o que las variables son independientes y no están relacionadas). Aquí, r = 1,0 describe una correlación positiva perfecta y r = -1,0 describe una correlación negativa perfecta.
Cuanto más cerca estén los coeficientes de +1,0 y -1,0, mayor será la fuerza de la relación entre las variables.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Como norma general, las siguientes directrices sobre la fuerza de la relación son útiles (aunque muchos expertos podrían disentir con la elección de los límites).
Valor de r Fuerza de relación
-1,0 A -0,5 o 1,0 a 0,5 Fuerte
-0,5 A -0,3 o 0,3 a 0,5 Moderada
-0,3 A -0,1 o 0,1 a 0,3 Débil
-0,1 A 0,1 Ninguna o muy débil
La correlación es solamente apropiada para examinar la relación entre datos cuantificables significativos (por ejemplo, la presión atmosférica o la temperatura) en vez de datos categóricos, tales como el sexo, el color favorito, etc.
Desventajas
Si bien 'r' (coeficiente de correlación) es una herramienta poderosa, debe ser utilizada con cuidado.
*Los coeficientes de correlación más utilizados sólo miden una relación lineal. Por lo tanto, es
perfectamente posible que, si bien existe una fuerte relación no lineal entre las variables, r
está cerca de 0 o igual a 0. En tal caso, un diagrama de dispersión puede indicar
aproximadamente la existencia o no de una relación no lineal.
*Hay que tener cuidado al interpretar el valor de 'r'. Por ejemplo, se podría calcular 'r' entre el
número de calzado y la inteligencia de las personas, la altura y los ingresos. Cualquiera sea el
valor de 'r', no tiene sentido y por lo tanto es llamado correlación de oportunidad o sin sentido.
* 'R' no debe ser utilizado para decir algo sobre la relación entre causa y efecto. Dicho de otra
manera, al examinar el valor de 'r' podríamos concluir que las variables X e Y están
relacionadas. Sin embargo, el mismo valor de 'r no nos dice si X ínfluencia a Y o al revés. La
correlación estadística no debe ser la herramienta principal paraestudiar la causalidad, por el
problema con las terceras variables.
ConclusiónLa serie de tiempo en estadística es un procesamiento de señales, y econometría, una serie temporal es una secuencia de puntos de datos, medidos típicamente a intervalos de tiempo sucesivos, y espaciados (con frecuencia) de forma uniforme. El análisis de series temporales comprende métodos que ayudan a interpretar este tipo de datos, extrayendo información representativa, tanto referente a los orígenes o relaciones subyacentes como a la posibilidad de extrapolar y predecir su comportamiento futuro.De hecho uno de los usos más habituales de las series de datos temporales es su análisis para predicción y pronóstico. Por ejemplo de los datos climáticos, o de las acciones de bolsa, o las series pluviométricas.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
BibliografíaPÁGINAS WEB:www.monografias.com/trabajos30/ series-de-tiempo / series-de-tiempo .www.scribd.com/doc/2255206/Correlacion- Series-de-Tiempo .LIBRO:Introducción A La Estadística Para Administración Y Dirección De Empresas.Autor: José Miguel Casas Sánchez.Editorial: Universitaria Ramón Areces.Berenson, Mark y LEVINE, David 1991 estadística para la administración y economía. Conceptos y aplicaciones. Editorial MC. Graw- Hill. Interamericana. ISBM: 968-713-2. MéxicoLIND, MARCHAL, MASON 2004 Estadística para Administración y Economía (onceava edición) Grupo editor Alfa omega ISBN: 970-15-0974-9 México D.F.
Autor:Gaby [email protected]
Conceptos de Estadística
Se llama estadística al conjunto de procedimientos destinados a recopilar, procesar y analizar la información que se obtiene con una muestra para inferir las características o parámetros de una población o de un problema determinado.
En la practica, el investigador se encuentra con muchas limitaciones reales para conocer con detalle un problema o situación que le preocupa, por lo que debe deducir las características principales utilizando los procedimientos estadísticos.
La muestra es una parte, generalmente pequeña, que se toma del conjunto total para analizarla y hacer estudios que le permitan al investigador inferir o estimar las características de un problema.
La persona interesada en resolver un problema no tiene siempre a la mano toda la información, por lo que debe conformarse con pequeños detalles, carentes de precisión, que le ayuden a tomar decisiones bajo riesgo.
A un paciente que debe ser operado quirúrgicamente se le analiza su sangre tomando una muestra pequeña para conocer el grado de coagulación. No es necesario extraerle toda la sangre.
El industrial que desea saber si en alambre que produce tiene la resistencia necesaria a la tensión deseada, toma solamente una muestra de su producción, debido a que el alambre que se destruye con la prueba y de otra manera tendría que destruir toda la existencia.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Generalmente, los resultados obtenidos en una muestra son satisfactorios y permiten al investigador tener un conocimiento aceptable del problema.
La información o características que se encuentran en la muestra se llaman estimadores y sirven para deducir cómo son las características llamadasparámetros de la población.
Al investigador le puede interesar conocer de la población, entre otras cosas, lo siguiente:
El valor medio. El grado de dispersión de los valores incluidos.
La proporción de una característica.
Si hay una causa que origina la variación.
El grado de influencia en las variables.
Si las variaciones son aleatorias.
La probabilidad de ocurrencia de un valor.
Un valor fututo o un valor anterior.
La diferencia entre dos o más poblaciones.
Poblaciones
En estadística, población es el conjunto de cosas, personas, animales o situaciones que tiene una o varias características o atributos comunes, por ejemplo: los habitantes de El Salvador en el presente año, las personas menores de edad en el año 2001; los estudiantes de la Universidad, las reacciones de un nuevo medicamento, las diferencias entre los tratamientos de diferentes formulaciones de insecticidas, entre otras.
Población Finita: es el conjunto compuesto por una cantidad limitada de elementos, como el número de especies, el numero de estudiantes, el número de obreros.
Población Infinita: es la que tiene un número extremadamente grande de componentes, como el conjunto de especies que tiene el reino animal.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Población Real: es todo el grupo de elementos concretos, como las personas que en Europa se dedican a actividades artísticas.
Población Hipotética: es el conjunto de situaciones posibles imaginables en que puede presentarse un suceso, como por ejemplo las formas de reaccionar de una persona ante una catástrofe.
Población estable: es aquella en que sus calores o cualidades no presentan variaciones, o éstas, por pequeñas que sean, son despreciables, como la rotación de la tierra o la velocidad de la luz.
Población inestable: es la que contienen los valores en constante cambio. Prácticamente la totalidad de las poblaciones corresponden a este tipo. El cambio de los valores se presentan en el tiempo o en el espacio.
Población aleatoria: es la que presenta cambios en sus calores debidos al azar, sin que exista una causa aparente, como las variaciones en el contenido del producto.
Población dependiente: es la que cambia sus valores debido a una causa determinada y medida. La dependencia puede ser total, como las variaciones obtenidas en una función matemática, la regresión lineal, por ejemplo. La dependencia es parcial cuando la causa influye en la variable dependiente en una proporción menor a la total, por ejemplo, el incremento en las ventas proveniente de una mayor gasto publicitario. Esta última influencia no es proporcional.
Población binomial es aquella en la que se busca la presencia o ausencia de una característica, por ejemplo, la presencia de ozono en el aire.
Población polinomial: es la que tiene varias características que deben ser definidas, medidas o estimadas, como la obediencia, la inteligencia y la edad de los alumnos de postgrado.
Tipos de variables
La variable es una medida en un experimento, representada por una (x) o por una (y) que puede tomar un valor de un conjunto de valores.
Como ejemplos de variables se pueden mencionar: la agresividad, la memoria, la formación de grupos sociales, la oferta y la demanda, la calidad de los productos, el nivel del mar, la duración de los objetos, la inteligencia, la velocidad del viento, el grado de contaminación, el clima, el nivel de ingresos, el números de accidentes, la observación en un tratamiento, entre otros.
Variable aleatoria: es la que toma al azar los probables resultados de un experimento.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Variable dependiente: es la que toma los valores correspondientes de un modelo matemático o que los toma debido a la influencia de otra variable independiente.
Variable continua: es la que puede tomar cualquier valor decimal, del intervalo de una recta, como consecuencia de una medición.
Variable discreta: es la que puede tomar, por conteo, cualquier valor.
Variable cuantitativa: es la que se expresa en cantidades, por ejemplo: 18.9, 3, 75.4, 98891, etc.
Variable cualitativa: es la que se manifiesta en atributos, como pueden ser, bueno, malo, peor, regular, aceptable, defectuoso, feo, bonito, etc.
Medición de variables
La medición de las variables puede hacerse por: clasificación, ordenación, intervalo y proporción.
a) Clasificación. Los objetos, personas o asuntos se distribuyen por clases, rotulando cada clase con un nombre o número distintivo que indica las características de dicha clase.
Como ejemplo de esta medición se pueden mencionar los hoteles que se clasifican en establecimientos de una, dos, tres, cuatro y cinco estrellas de acuerdo a los servicios que proporcionan al público.
Los artículos almacenados pueden clasificarse en materias primas, materiales, accesorios, lubricantes, artículos de aseo, productos terminados, etcétera.
Según el estado civil, las personas se clasifican en solteros, casados, separados, unión libre, viudos, dejados, entre otros.
Los objetos o personas que están asignadas en una clase determinada se pueden contar. El total de cada clase representa la Frecuencia de clase.
La frecuencia dividida entre el total de los objetos o personas clasificados constituye la frecuencia relativa o proporción de elementos existentes en la clase.
Ejercicio 1.- Clasificar los siguientes sabores de comida:
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Salado Dulce Acido Amargo Dulce Acido Amargo Salado Dulce Dulce
Acido Dulce Salado Amargo Amargo Salado Dulce Dulce Acido Salado
Salado Salado Acido Salado Dulce Acido Amargo Acido Salado Dulce
1.- Se cuentan los elementos que forman el conjunto de datos: El total da 30
2.- Se identifica cada uno de los elementos, para el caso de este ejemplo se utilizará un color para cada sabor de comida.
Salado Dulce Acido Amargo Dulce Acido Amargo Salado Dulce Dulce
Acido Dulce Salado Amargo Amargo Salado Dulce Dulce Acido Salado
Salado Salado Acido Salado Dulce Acido Amargo Acido Salado Dulce
3.- Se va a formar una tabla con cada uno de los sabores, cada sabor se coloca en un renglón diferente, por ejemplo:
Salado
Dulce
Acido
Amargo
4.- Se agregan dos columnas a la derecha de los sabores y un renglón en la parte superior:
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Salado
Dulce
Acido
Amargo
5.- En el primer renglón coloque Frecuencia de clase y Frecuencia relativa como se muestra a continuación:
Frecuencia de clase Frecuencia relativa
Salado
Dulce
Acido
Amargo
6.- Para llenar la columna de Frecuencia de clase cuente en la primera tabla las veces que aparece la palabra Salado y escriba el resultado. Se debe repetir este proceso para las palabras Dulce, Acido y Amargo.
Frecuencia de clase Frecuencia relativa
Salado 9
Dulce 9
Acido 7
Amargo 5
Para ver trabajos similares o recibir información semanal so

www.monografias.com
7.- Para llenar la columna de Frecuencia relativa repita el número obtenido en la Frecuencia de clase y divídalo entre el número de elementos como se muestra en la tabla siguiente:
Frecuencia de clase Frecuencia relativa
Salado 9 9 / 30
Dulce 9 9 / 30
Acido 7 7 / 30
Amargo 5 5 / 30
b) Ordenación. Se colocan los valores de menor a mayor o de mayor a menor formando una sucesión. En esta serie no existen equidistancias ni proporciones, solamente indican orden de valor, de importancia o de jerarquía, desde el primer valor hasta el último.
Ejemplo 2.- Ordenar las estaturas tomadas de 10 alumnos en metros
1.67 1.87 1.65 1.56 1.94 1.47 1.54 1.43 1.79 1.74
Los datos ordenados de menor a mayor son las siguientes:
1.43 1.47 1.54 1.56 1.65 1.67 1.74 1.79 1.87 1.94
c) Intervalos. Se usa para indicar distancias relativas entre dos puntos. Por ejemplo: La escala de grados Centígrados.
d) Proporción. A esta medición se le llama de razón por establecer proporciones a partir del cero absoluto. Por ejemplo el sistema decimal.
Para ver trabajos similares o recibir información semanal so

www.monografias.com
Para ver trabajos similares o recibir información semanal so


















