
J. L. Ruiz Reina Dpto. Ciencias de la Computacion e … · 2007-05-02 · Red bayesiana para el...
71
Inteligencia Artificial II - Tema 5 – p. 1/71 Inteligencia Artificial II Introducción a las Redes Bayesianas J. L. Ruiz Reina Dpto. Ciencias de la Computaci ´ on e Inteligencia Artificial Universidad de Sevilla
Transcript of J. L. Ruiz Reina Dpto. Ciencias de la Computacion e … · 2007-05-02 · Red bayesiana para el...

Inteligencia Artificial II - Tema 5 – p. 1/71
Inteligencia Artificial II
Introducción a las Redes Bayesianas
J. L. Ruiz Reina
Dpto. Ciencias de la Computacion e Inteligencia Artificial
Universidad de Sevilla

Inteligencia Artificial II - Tema 5 – p. 2/71
Redes bayesianas
• Como vimos en el tema anterior, las relaciones de independencia(condicional) nos permiten reducir el tamaño de la informaciónnecesaria para especificar una DCC
• Las redes bayesianas (o redes de creencia) constituyen una manerapráctica y compacta de representar el conocimiento incierto, basada enesta idea

Inteligencia Artificial II - Tema 5 – p. 3/71
Redes bayesianas
• Una red bayesiana es un grafo dirigido acíclico que consta de
• Un conjunto de nodos, uno por cada variable aleatoria del “mundo”• Un conjunto de arcos dirigidos que conectan los nodos; si hay un
arco de X a Y decimos que X es un padre de Y (padres(X) denotael conjunto de v.a. que son padres de X)
• Cada nodo Xi contiene la distribución de probabilidad condicionalP (Xi|padres(Xi))
• Intuitivamente, en una red bayesiana un arco entre X e Y significa unainfluencia directa de X sobre Y
• Es tarea del experto en el dominio el decidir las relaciones dedependencia directa (es decir, la topología de la red)
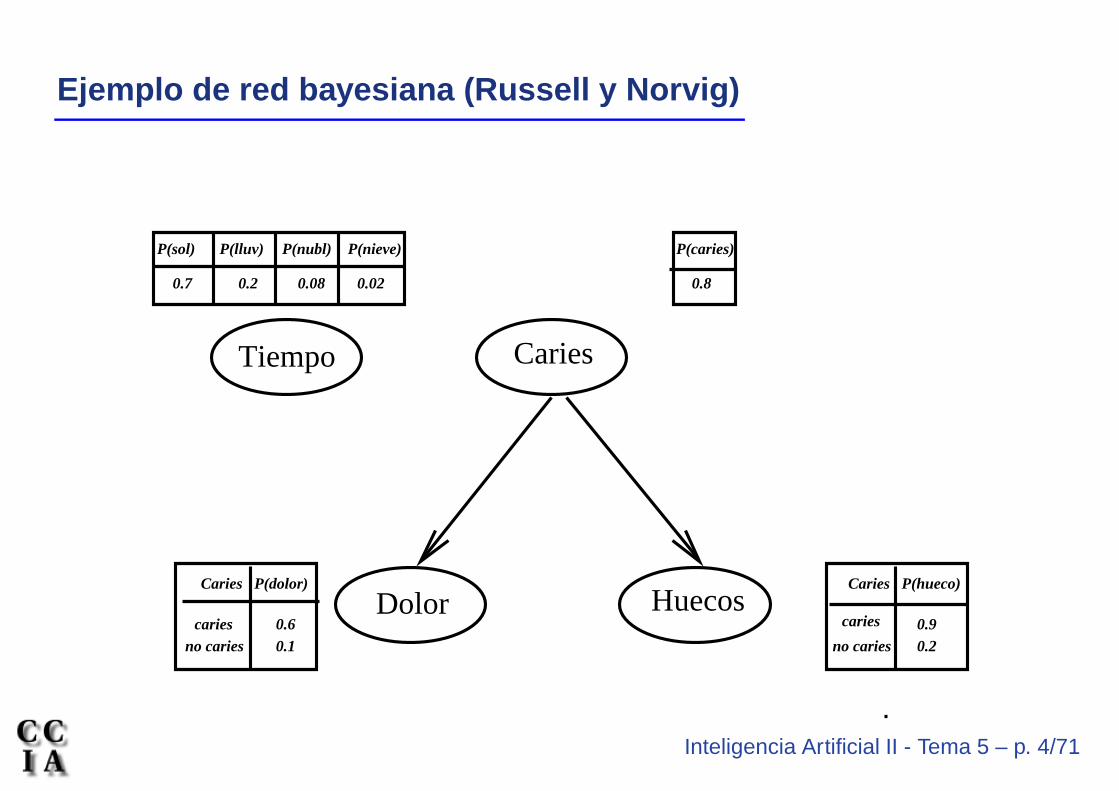
Inteligencia Artificial II - Tema 5 – p. 4/71
Ejemplo de red bayesiana (Russell y Norvig)
Dolor Huecos
CariesTiempo
Caries P(hueco)
no caries
caries 0.90.2no caries
caries
P(sol)
0.7 0.080.2 0.02
P(caries)
0.8
P(lluv) P(nubl) P(nieve)
Caries P(dolor)
0.60.1

Inteligencia Artificial II - Tema 5 – p. 5/71
Observaciones sobre el ejemplo
• La topología de la red anterior nos expresa que:
• Caries es una causa directa de Dolor y Huecos
• Dolor y Huecos son condicionalmente independientes dada Caries
• Tiempo es independiente de las restantes variables
• No es necesario dar la probabilidad de las negaciones de caries, dolor,. . .

Inteligencia Artificial II - Tema 5 – p. 6/71
Otro ejemplo (Pearl, 1990):
• Tenemos una alarma antirrobo instalada en una casa
• La alarma salta normalmente con la presencia de ladrones
• Pero también cuando ocurren pequeños temblores de tierra
• Tenemos dos vecinos en la casa, Juan y María, que han prometidollamar a la policía si oyen la alarma
• Juan y María podrían no llamar aunque la alarma sonara: por tenermúsica muy alta en su casa, por ejemplo
• Incluso podrían llamar aunque no hubiera sonado: por confundirlacon un teléfono, por ejemplo
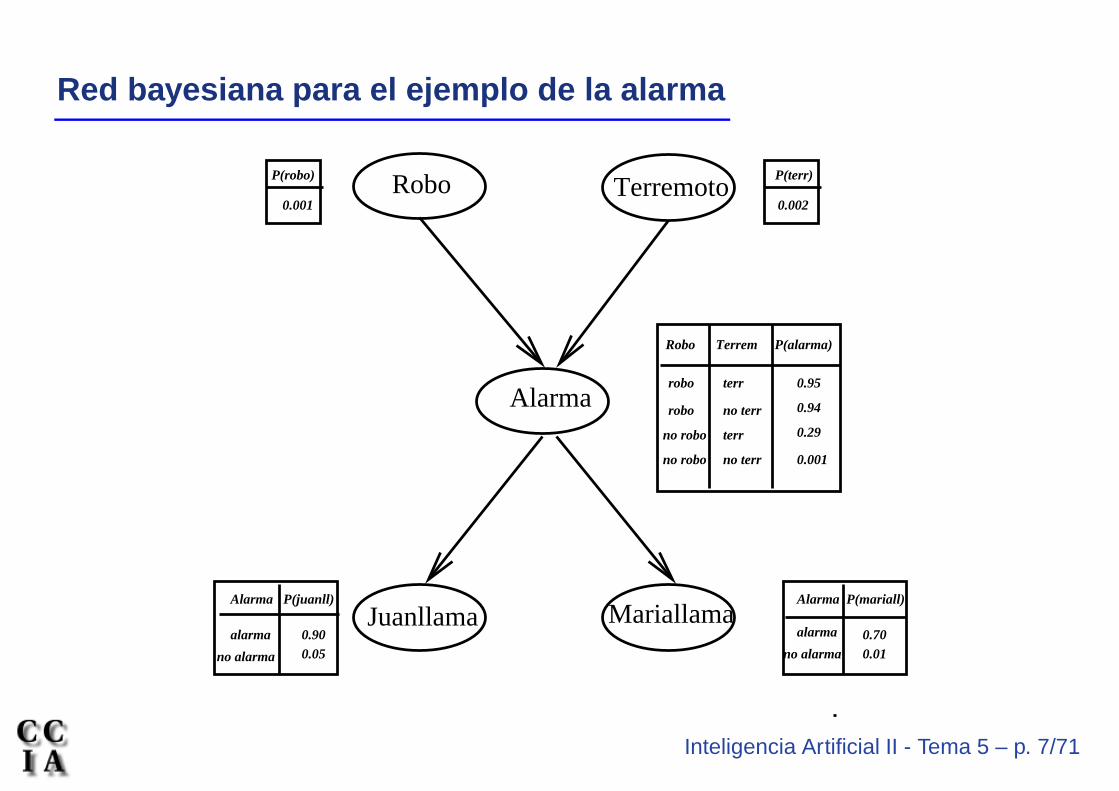
Inteligencia Artificial II - Tema 5 – p. 7/71
Red bayesiana para el ejemplo de la alarma
Alarma
alarma 0.70Juanllama Mariallama
Robo Terremoto
Robo Terrem P(alarma)
robo
robo no terr
no terr 0.001
P(robo)
0.001
P(terr)
0.002
no robo
no robo
terr
terr
0.95
0.94
0.29
Alarma P(juanll) Alarma P(mariall)
alarmano alarmano alarma
0.900.05 0.01

Inteligencia Artificial II - Tema 5 – p. 8/71
Observaciones sobre el ejemplo
• La topología de la red nos expresa que:
• Robo y Terremoto son causas directas para Alarma
• También, Robo y Terremoto son causas para Juanllama y paraMariallama, pero esa influencia sólo se produce a través deAlarma: ni Juan ni María detectan directamente el robo ni lospequeños temblores de tierra
• En la red no se hace referencia directa, por ejemplo, a las causaspor las cuales María podría no oír la alarma: éstas están implícitasen la tabla de probabilidades P (Mariallama|Alarma)

Inteligencia Artificial II - Tema 5 – p. 9/71
Un tercer ejemplo (Charniak, 1991):
• Supongamos que quiero saber si alguien de mi familia está en casa,basándome en la siguiente información
• Si mi esposa sale de casa, usualmente (pero no siempre) enciendela luz de la entrada
• Hay otras ocasiones en las que también enciende la luz de laentrada
• Si no hay nadie en casa, el perro está fuera• Si el perro tiene problemas intestinales, también se deja fuera• Si el perro está fuera, oigo sus ladridos• Podría oír ladrar y pensar que es mi perro aunque no fuera así
• Variables aleatorias (booleanas) en este problema:
• Fuera (nadie en casa), Luz (luz en la entrada), Perro (perro fuera),Inst (problemas intestinales en el perro) y Oigo (oigo al perro ladrar)
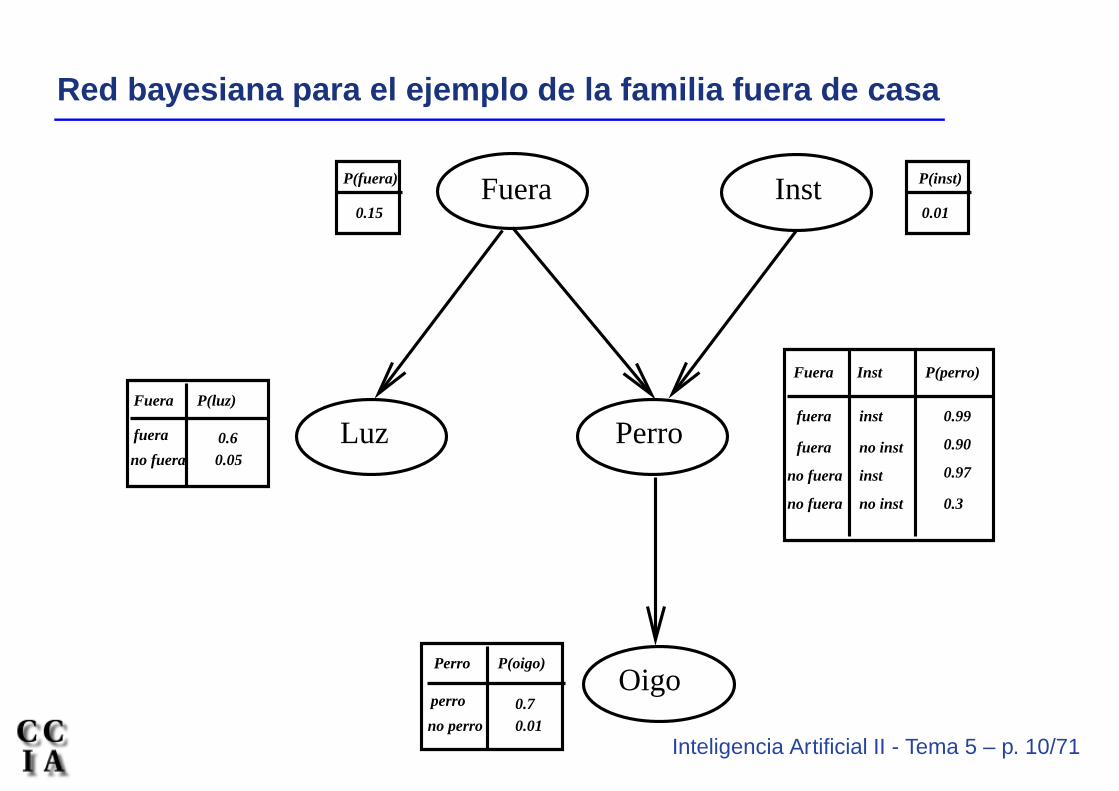
Inteligencia Artificial II - Tema 5 – p. 10/71
Red bayesiana para el ejemplo de la familia fuera de casa
Perro
Fuera
fuera
fuera no inst
P(fuera)
0.90
0.15Inst P(inst)
0.01
Fuera Inst P(perro)
no fuera
no fuera
inst
inst
no inst
0.99
0.97
0.3
Luz
Oigo
Fuera P(luz)
fuera
0.05no fuera0.6
Perro P(oigo)
no perro
perro 0.70.01

Inteligencia Artificial II - Tema 5 – p. 11/71
Las redes bayesianas representan DCCs
• Consideremos una red bayesiana con n variables aleatorias
• Y un orden entre esas variables: X1, . . . ,Xn
• En lo que sigue, supondremos que:
• padres(Xi) ⊆ {Xi−1, . . . ,X1} (para esto, basta con que el ordenescogido sea consistente con el orden parcial que induce el grafo)
• P (Xi|Xi−1, . . . ,X1) = P (Xi|padres(Xi)) (es decir, cada variable escondicionalmente independiente de sus anteriores, dados suspadres en la red)
• Estas condiciones expresan formalmente nuestra intuición alrepresentar nuestro “mundo” mediante la red bayesianacorrespondiente
• En el ejemplo de la alarma, la red expresa que creemos queP (Mariallama|Juanllama,Alarma, Terremoto,Robo) =P (Mariallama|Alarma)

Inteligencia Artificial II - Tema 5 – p. 12/71
Las redes bayesianas representan DCCs
• En las anteriores condiciones, y aplicando repetidamente la regla delproducto:
P (X1, . . . ,Xn) = P (Xn|Xn−1 . . . ,X1)P (Xn−1 . . . ,X1) = . . .
. . . =
n∏
i=1
P (Xi|Xi−1, . . . ,X1) =
n∏
i=1
P (Xi|padres(Xi))
• Es decir, una red bayesiana representa una DCC obtenida mediante laexpresión P (X1, . . . ,Xn) =
∏ni=1
P (Xi|padres(Xi))
• Por ejemplo, en el ejemplo de la alarma, la probabilidad de que laalarma suene, Juan y María llamen a la policía, pero no hayaocurrido nada es (usamos iniciales, por simplificar):
P (j,m, a,¬r,¬t) = P (j|a)P (m|a)P (a|¬r,¬t)P (¬r)P (¬t) =
= 0.9 × 0.7 × 0.001 × 0.999 × 0.998 = 0.00062

Inteligencia Artificial II - Tema 5 – p. 13/71
Representaciones compactas
• Dominios localmente estructurados:
• Las relaciones de independencia que existen entre las variables deun dominio hacen que las redes bayesianas sean unarepresentación mucho más compacta y eficiente de una DCC que latabla con todas las posibles combinaciones de valores
• Además, para un experto en un dominio de conocimiento suele sermás natural dar probabilidades condicionales que directamente lasprobabilidades de la DCC

Inteligencia Artificial II - Tema 5 – p. 14/71
Representaciones compactas
• Con n variables, si cada variable está directamente influenciada por k
variables a lo sumo, entonces una red bayesiana necesitaría n2k
números, frente a los 2n números de la DCC
• Por ejemplo, Para n = 30 y k = 5, esto supone 960 números frente a230 (billones)
• Hay veces que una variable influye directamente sobre otra, pero estadependencia es muy tenue
• En ese caso, puede compensar no considerar esa dependencia,perdiendo algo de precisión en la representación, pero ganandomanejabilidad

Inteligencia Artificial II - Tema 5 – p. 15/71
Algoritmo de construcci on de una red bayesiana
• Supongamos dado un conjunto de variables aleatorias VARIABLESquerepresentan un dominio de conocimiento (con incertidumbre)
• CONSTRUYE_RED(VARIABLES)
1. Sea (X_1,...X_n) una ordenación de VARIABLES2. Sea RED una red bayesiana ‘‘vacía’’3. PARA i=1,...,n HACER
3.1 Añadir un nodo etiquetado con X_i a RED3.2 Sea padres(X_i) un subconjunto minimal de {X_{i-1},... ,X1}
tal que existe una independencia condicional entre X_i y cad aelemento de {X_{i-1},...,X1} dado padres(X_i)
3.3 Añadir en RED un arco dirigido entre cada elemento depadres(X_i) y X_i
3.4 Asignar al nodo X_i la tabla de probabilidad P(X_i|padre s(X_i))4. Devolver RED
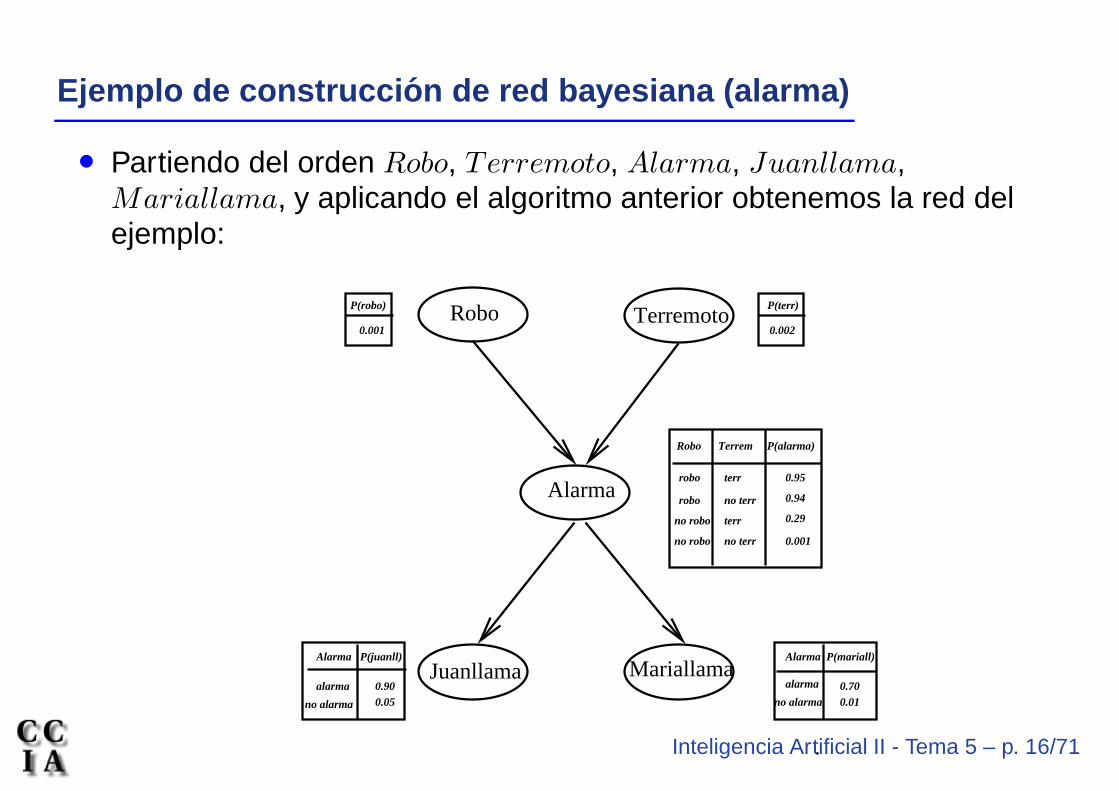
Inteligencia Artificial II - Tema 5 – p. 16/71
Ejemplo de construcci on de red bayesiana (alarma)
• Partiendo del orden Robo, Terremoto, Alarma, Juanllama,Mariallama, y aplicando el algoritmo anterior obtenemos la red delejemplo:
Alarma
alarma 0.70Juanllama Mariallama
Robo Terremoto
Robo Terrem P(alarma)
robo
robo no terr
no terr 0.001
P(robo)
0.001
P(terr)
0.002
no robo
no robo
terr
terr
0.95
0.94
0.29
Alarma P(juanll) Alarma P(mariall)
alarmano alarmano alarma
0.900.05 0.01

Inteligencia Artificial II - Tema 5 – p. 17/71
Construcci on de redes bayesianas
• Problema: elección del orden entre variables
• En general, deberíamos empezar por las “causas originales”,siguiendo con aquellas a las que influencian directamente, etc...,hasta llegar a las que no influyen directamente sobre ninguna(modelo causal)
• Esto hará que las tablas reflejen probabilidades “causales” más que“diagnósticos”, lo cual suele ser preferible por los expertos
Inteligencia Artificial II - Tema 5 – p. 18/71
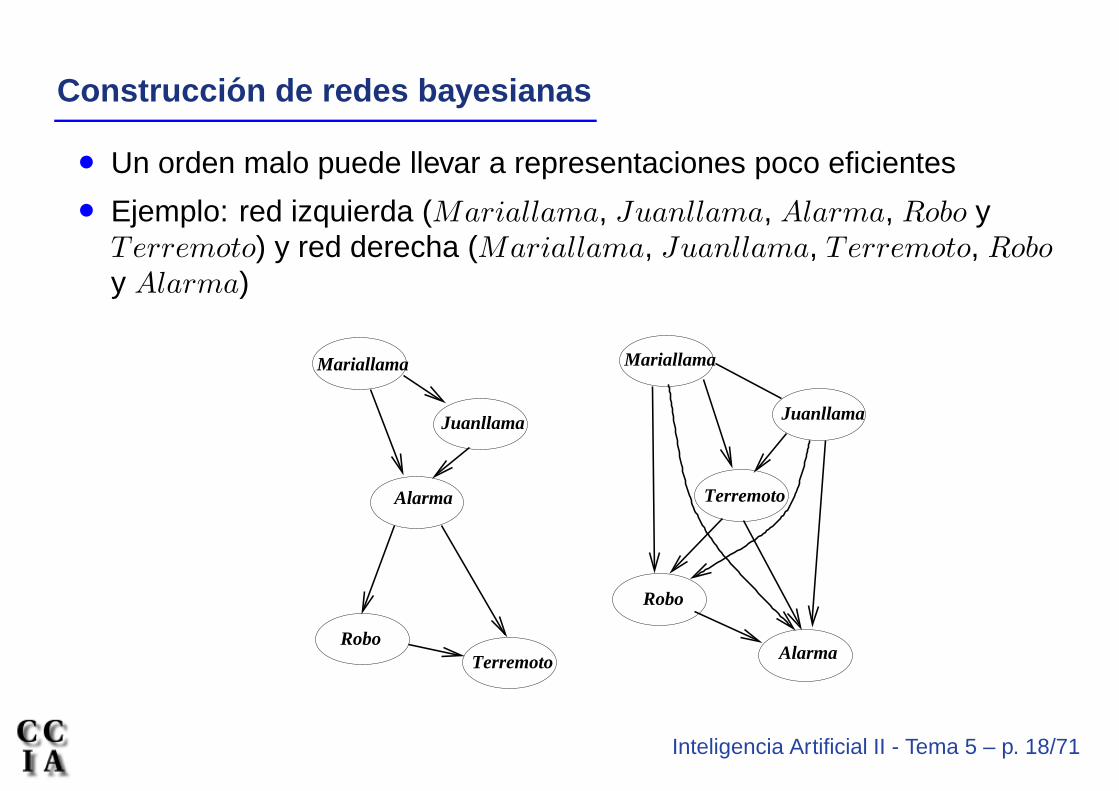
Construcci on de redes bayesianas
• Un orden malo puede llevar a representaciones poco eficientes
• Ejemplo: red izquierda (Mariallama, Juanllama, Alarma, Robo yTerremoto) y red derecha (Mariallama, Juanllama, Terremoto, Robo
y Alarma)
Alarma
Robo
Mariallama
Juanllama
Mariallama
Juanllama
Terremoto
AlarmaTerremotoRobo

Inteligencia Artificial II - Tema 5 – p. 19/71
Inferencia probabilıstica en una red bayesiana
• El problema de la inferencia en una red bayesiana:
• Calcular la probabilidad a posteriori para un conjunto de variablesde consulta, dado que se han observado algunos valores para lasvariables de evidencia
• Por ejemplo, podríamos querer saber qué probabilidad hay de querealmente se haya producido un robo, sabiendo que tanto Juancomo María han llamado a la policía
• Es decir, calcular P (Robo|juanllama,mariallama)

Inteligencia Artificial II - Tema 5 – p. 20/71
Inferencia probabilıstica en una red bayesiana
• Notación:
• X denotará la variable de consulta (sin pérdida de generalidadsupondremos sólo una variable)
• E denota un conjunto de variables de evidencia E1, E2, . . . , En y e
una observación concreta para esas variables• Y denota al conjunto de las restantes variables de la red (variables
ocultas) e y representa un conjunto cualquiera de valores para esasvariables

Inteligencia Artificial II - Tema 5 – p. 21/71
Inferencia por enumeraci on
• Recordar la fórmula para la inferencia probabilística a partir de unaDCC:
P (X|e) = αP (X,e) = α∑
y
P (X,e,y)
• Esta fórmula será la base para la inferencia probabilística:
• Puesto que una red bayesiana es una representación de una DCC,nos permite calcular cualquier probabilidad a posteriori a partir de lainformación de la red bayesiana
• Esencialmente, se trata de una suma de productos de loselementos de las tablas de las distribuciones condicionales

Inteligencia Artificial II - Tema 5 – p. 22/71
Un ejemplo de inferencia probabilıstica
• Ejemplo de la alarma (usamos iniciales por simplificar):
P (R|j,m) = α〈P (r|j,m), P (¬r|j,m)〉 =
= α〈∑
t
∑
a
P (r, t, a, j,m),∑
t
∑
a
P (¬r, t, a, j,m)〉 =
= α〈∑
t
∑
a
P (r)P (t)P (a|r, t)P (j|a)P (m|a),
∑
t
∑
a
P (¬r)P (t)P (a|¬r, t)P (j|a)P (m|a)〉

Inteligencia Artificial II - Tema 5 – p. 23/71
Un ejemplo de inferencia probabilıstica
• En este ejemplo hay que hacer 2 × 4 sumas, cada una de ellas con unproducto de cinco números tomados de la red bayesiana
• En el peor de los casos, con n variables booleanas, este cálculotoma O(n2n)
• Una primera mejora consiste en sacar factor común de aquellasprobabilidades que sólo involucran variables que no aparecen en elsumatorio:
P (R|j,m) = α〈P (r)∑
t
P (t)∑
a
P (a|r, t)P (j|a)P (m|a),
P (¬r)∑
t
P (t)∑
a
P (a|¬r, t)P (j|a)P (m|a)〉 =
= α〈0.00059224, 0.0014919〉 = 〈0.284, 0.716〉
Inteligencia Artificial II - Tema 5 – p. 24/71
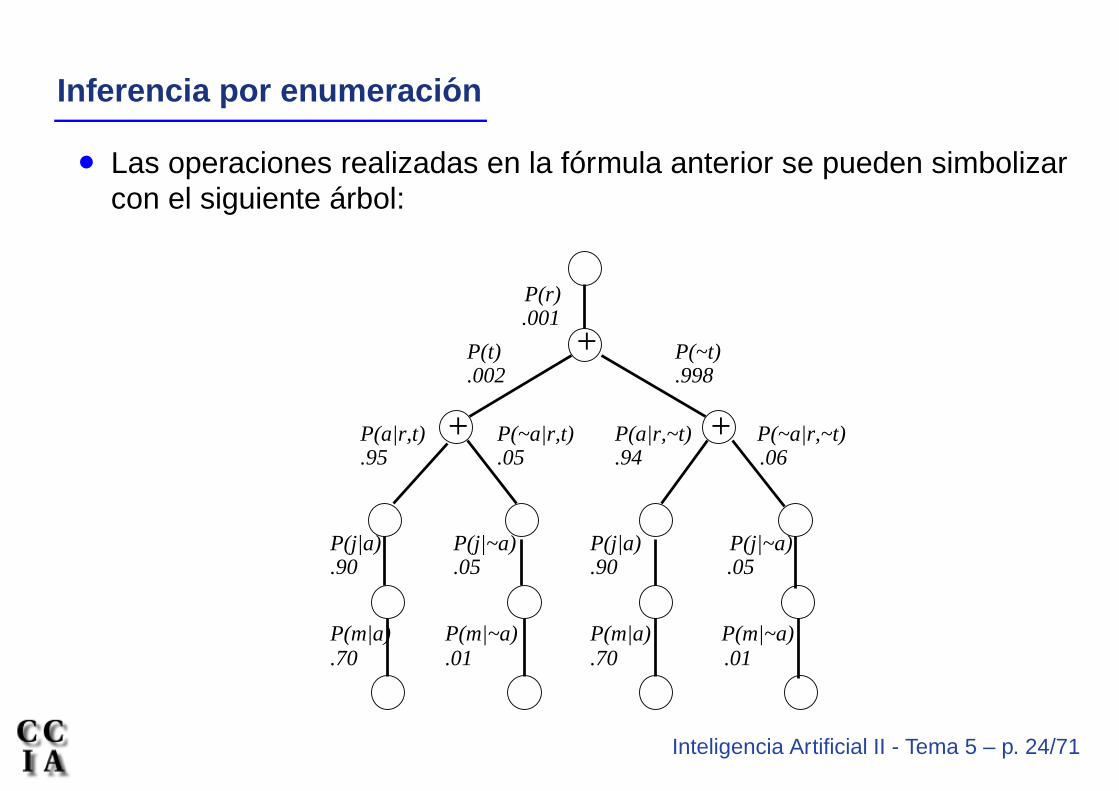
Inferencia por enumeraci on
• Las operaciones realizadas en la fórmula anterior se pueden simbolizarcon el siguiente árbol:
+
+ +
P(r).001
.002P(~t).998
.95P(~a|r,t).05
P(a|r,~t).94
P(~a|r,~t).06
.90P(j|~a).05
P(j|a).90
P(j|~a).05
P(m|a).70
P(m|a).70
P(j|a)
P(m|~a).01
P(m|~a).01
P(a|r,t)
P(t)

Inteligencia Artificial II - Tema 5 – p. 25/71
Algoritmo de inferencia por enumeraci on
• Entrada: una v.a. X de consulta, un conjunto de valores observados e
para la variables de evidencia y una red bayesiana.
• Salida: P (X|e)
• FUNCION INFERENCIA_ENUMERACION(X,e,RED)
1. Sea Q(X) una distribución de probabilidad sobre X, inicia lmente vacía2. PARA cada valor x_i de X HACER
2.1 Extender e con el valor x_i para X2.2 Hacer Q(x_i) el resultado de ENUM_AUX(VARIABLES(RED), e,RED)
3. Devolver NORMALIZA(Q(X))

Inteligencia Artificial II - Tema 5 – p. 26/71
Algoritmo de inferencia por enumeraci on
• FUNCION ENUM_AUX(VARS,e,RED)
1. Si VARS es vacío devolver 12. Si no,
2.1 Hacer Y igual a PRIMERO(VARS)2.2 Si Y tiene un valor y en e,
devolver P(y|padres(Y,e)) ·ENUM_AUX(RESTO(VARS),e)Si no,devolver SUMATORIO(y,P(y|padres(Y,e)) ·ENUM_AUX(RESTO(VARS),e_y))(donde: padres(Y,e) es el conjunto de valores que toman en e
los padres de Y en la RED, y e_y extiende e con el valor y para Y)

Inteligencia Artificial II - Tema 5 – p. 27/71
Algoritmo de inferencia por enumeraci on
• Observación:
• Para que el algoritmo funcione, VARIABLES(RED) debe devolverlas variables en un orden consistente con el orden implícito en elgrafo de la red (de arriba hacia abajo)
• Recorrido en profundidad:
• El algoritmo genera el árbol de operaciones anterior de arriba haciaabajo, en profundidad
• Por tanto, tiene un coste lineal en espacio
• Puede realizar cálculos repetidos
• En el ejemplo, P (j|a)P (m|a) y P (j|¬a)P (m|¬a) se calculan dosveces
• Cuando hay muchas variables, estos cálculos redundantes soninaceptables en la práctica

Inteligencia Artificial II - Tema 5 – p. 28/71
Evitando c alculos redundantes
• Idea para evitar el cálculo redundante:
• Realizar las operaciones de derecha a izquierda (o,equivalentemente, de abajo a arriba en el árbol de operaciones)
• Almacenar los cálculos realizados para posteriores usos• En lugar de multiplicar números, multiplicaremos tablas de
probabilidades• Denominaremos factores a estas tablas

Inteligencia Artificial II - Tema 5 – p. 29/71
Evitando c alculos redundantes
• Por ejemplo, la operaciónP (R|j,m) = αP (R)
∑t P (t)
∑a P (a|R, t)P (j|a)P (m|a) puede verse
como la multiplicación de cinco tablas o factores en los que hayintercaladas dos operaciones de suma o agrupamiento
• Se trata de hacer esas operaciones entre factores de derecha aizquierda
• Es el denominado algoritmo de eliminación de variables
• Veremos con más detalle cómo actuaría este algoritmo para calcularP (R|j,m)

Inteligencia Artificial II - Tema 5 – p. 30/71
El algoritmo de eliminaci on de variables: un ejemplo
• En primer lugar, tomamos un orden fijado entre las variables de la red
• Un orden adecuado será esencial para la eficiencia del algoritmo(más adelante comentaremos algo más sobre el orden)
• En nuestro caso, tomaremos el inverso de un orden consistente conla topología de la red: M,J,A, T,R
• El factor correspondiente a M se obtiene a partir de la distribucióncondicional P (M |A)
• Como M es una variable de evidencia y su valor está fijado a true,el factor correspondiente a P (m|A), que notamos f(A), es la tablacon componentes P (m|a) y P (m|¬a):

Inteligencia Artificial II - Tema 5 – p. 31/71
El algoritmo de eliminaci on de variables: un ejemplo
• La siguiente variable en el orden es J
• De manera análoga f2(A) (tomado de P (j|A)) es el factorcorrespondiente
• Siguiente variable: A
• El factor correspondiente, notado f3(A,R, T ) se obtiene a partir deP (A|R,T )
• Ninguna de esas variables es de evidencia, y por tanto no estánfijados sus valores
• Es una tabla con 2 × 2 × 2, una por cada combinación de valores deR (variable de consulta) A y T (variables ocultas)
• En este caso, esta tabla está directamente en la propia red

Inteligencia Artificial II - Tema 5 – p. 32/71
El algoritmo de eliminaci on de variables: un ejemplo
• Hasta ahora, no hemos realizado ninguna operación
• Sólamente hemos construido los factores
• Pero A es una variable oculta, así que hemos de realizar el sumatoriosobre sus valores
• Por tanto, multiplicamos ahora los tres factores y sumamos sobre A
• La multiplicación de f1, f2 y f3, notada f4(A,R, T ) se obtienemultiplicando las entradas correspondientes a los mismos valoresde A, R y T
• Es decir, para cada valor v1 de A, v2 de R y v3 de T se tienef4(v1, v2, v3) = f1(v1)f2(v1)f3(v1, v2, v3)
• Por ejemplo: f4(true, false, true) =f1(true)f2(true)f3(true, false, true) = 0.70 × 0.90 × 0.29 = 0.1827

Inteligencia Artificial II - Tema 5 – p. 33/71
El algoritmo de eliminaci on de variables: un ejemplo
• Almacenamos f4 y nos olvidamos de f1,f2 y f3
• Nota: aunque no es éste el caso, si alguno de los factores no tuviera ala variable A como argumento , lo conservaríamos y no participaría enla multiplicación, ni en el agrupamiento posterior

Inteligencia Artificial II - Tema 5 – p. 34/71
El algoritmo de eliminaci on de variables: un ejemplo
• Ahora hay que agrupar el valor de A en f4 (realizar el sumatorio∑
a)
• Así, obtenemos una tabla f5(R,T ) haciendof5(v1, v2) =
∑a f4(a, v1, v2) para cada valor v1 de R y v2 de T , y
variando a en los posibles valores de A
• Llamaremos a esta operación agrupamiento• Hemos eliminado la variable A
• Una vez realizada la agrupación, guardamos f5 y nos olvidamos def4

Inteligencia Artificial II - Tema 5 – p. 35/71
El algoritmo de eliminaci on de variables: un ejemplo
• Continuamos con la siguiente variable T :
• El factor correspondiente a esta variable, que notaremos f6(T ), esla tabla P (T )
• T es una variable oculta
• Por tanto, debemos multiplicar y agrupar, eliminando la variable T
• Notemos por f7(R) al resultado de multiplicar f6 por f5 y agruparpor T
• Podemos olvidarnos de f5 y f6

Inteligencia Artificial II - Tema 5 – p. 36/71
El algoritmo de eliminaci on de variables: un ejemplo
• Ultima variable: R
• El factor correspondiente a esta variable, que notaremos f8(R), esla tabla P (R)
• Para finalizar:
• Multiplicamos los factores que nos quedan (f7 y f8) para obtenerf9(R) y normalizamos para que sus dos entradas sumen 1
• La tabla finalmente devuelta es justamente la distribución P (R|j,m)

Inteligencia Artificial II - Tema 5 – p. 37/71
Observaciones sobre el algoritmo de eliminaci on de variables
• En cada momento tenemos un conjunto de factores, que va cambiando:
• Al añadir un nuevo factor, uno por cada variable que se considera• Al multiplicar factores• Al agrupar por una variable oculta
• Multiplicación de tablas:
• Si f1(X,Y ) y f2(Y ,Z) son dos tablas cuyas variables en comúnson las de Y , se define su producto f(X,Y ,Z) como la tablacuyas entradas son f(x,y,z) = f1(x,y)f2(y,z)
• Similar a una operación join en bases de datos, multiplicando losvalores correspondientes
• En el algoritmo de eliminación de variables, sólo multiplicaremos tablas:
• Previo a realizar cada operación de agrupamiento• Y en el paso final

Inteligencia Artificial II - Tema 5 – p. 38/71
Observaciones sobre el algoritmo de eliminaci on de variables
• Agrupamiento de tablas:
• Dado un conjunto de factores, la operación de agrupar (respecto delos valores de una v.a. X) consiste en obtener otro conjunto defactores
• Se dejan igual aquellos que no tienen a la variable X entre susargumentos
• Y el resto de factores se multiplican y se sustituyen por el resultadomultiplicarlos y sumar en la tabla por cada posible valor de X
• Por ejemplo, si en el conjunto de factoresf1(T ),f2(A,R, T ),f3(A),f4(A) tuvierámos que agrupar por lavariable T , dejamos f3 y f4 y sustituimos f1 y f2 por el resultado deagregar (por cada valor de T ) la multiplicación de f1 y f2
• La operación de sumar por un valor es similar a la agregación deuna columna en bases de datos

Inteligencia Artificial II - Tema 5 – p. 39/71
Un paso previo de optimizaci on: variables irrelevantes
• En el algoritmo de eliminación de variables, se suele realizar un pasoprevio de eliminación de variables irrelevantes para la consulta
• Ejemplo:
• Si la consulta a la red del ejemplo es P (J |r), hay que calcularαP (r)
∑t P (t)
∑a P (a|r, t)P (J |a)
∑m P (m|a)
• Pero∑
m P (m|a) = 1, así que la variable M es irrelevante para laconsulta
• Siempre podemos eliminar cualquier variable que sea una hoja dela red y que no sea de consulta ni de evidencia
• Y en general, se puede demostrar que toda variable que no seaantecesor (en la red) de alguna de las variables de consulta o deevidencia, es irrelevante para la consulta y por tanto puede sereliminada

Inteligencia Artificial II - Tema 5 – p. 40/71
El algoritmo de eliminaci on de variables
• Entrada: una v.a. X de consulta, un conjunto de valores observados e
para la variables de evidencia y una red bayesiana
• Salida: P (X|e)
• FUNCION INFERENCIA_ELIMINACION_VARIABLES(X,e,RED)
1. Sea RED_E el resultado de eliminar de RED las variables irr elevantespara la consulta realizada
2. Sea FACTORES igual a vacío3. Sea VARIABLES el conjunto de variables de RED_E4. Sea VAR_ORD el conjunto de VARIABLES ordenado según un ord en de
eliminación5. PARA cada V en VAR_ORD HACER
5.1 Sea FACTOR el factor correspondiente a VAR (respecto de e )5.2 Añadir FACTOR a FACTORES5.3 Si VAR es una variable oculta hacer FACTORES igual
a AGRUPA(VAR,FACTORES)6. Devolver NORMALIZA(MULTIPLICA(FACTORES))

Inteligencia Artificial II - Tema 5 – p. 41/71
Otro ejemplo (B ejar)
• Consideremos las siguientes variables aleatorias:
• D: práctica deportiva habitual• A: alimentación equilibrada• S: presión sanguínea alta• F : fumador• I: ha sufrido un infarto de miocardio
• Las relaciones causales y el conocimiento probabilístico asociadoestán reflejadas en la siguiente red bayesiana

Inteligencia Artificial II - Tema 5 – p. 42/71
Otro ejemplo: red bayesiana
F
D A
S
I
0.20.01
0.25
0.7
0.60.7
0.3
0.1
0.4
P(d) P(a)
0.4
a
no a
d
d
no d
P(f)
S F P(i)
s
no f
0.8
ano a
no d
no ss
no s
f
f
no f
A D P(s)

Inteligencia Artificial II - Tema 5 – p. 43/71
Ejemplo de inferencia probabilıstica
• Podemos usar la red bayesiana para calcular la probabilidad de serfumador si se ha sufrido un infarto y no se hace deporte, P (F |i,¬d)
• Directamente:
• Aplicamos la fórmula:P (F |i,¬d) = αP (F, i,¬d) = α
∑S,A P (F, i,¬d,A, S)
• Factorizamos según la red:P (F |i,¬d) = α
∑S,A P (¬d)P (A)P (S|¬d,A)P (F )P (i|S,F )
• Sacamos factor común:P (F |i,¬d) = αP (¬d)P (F )
∑A P (A)
∑S P (S|¬d,A)P (i|S,F )

Inteligencia Artificial II - Tema 5 – p. 44/71
Ejemplo de inferencia probabilıstica
• Calculemos:
• Para F = true:
P (f |i,¬d) = α · P (¬d) · P (f)·
·[P (a) · (P (s|¬d, a) · P (i|s, f) + P (¬s|¬d, a) · P (i|¬s, f))+
+P (¬a) · (P (s|¬d,¬a) · P (i|s, f) + P (¬s|¬d,¬a) · P (i|¬s, f))] =
= α·0.9·0.4·[0.4·(0.25·0.8+0.75·0.6)+0.6·(0.7·0.8+0.3·0.6)] = α·0.253
• Análogamente, para F = false, P (¬f |i,¬d) = α · 0, 274
• Normalizando, P (F |i,¬d) = 〈0.48, 0.52〉

Inteligencia Artificial II - Tema 5 – p. 45/71
Aplicando eliminaci on de variables
• Seguiremos el siguiente orden de variables, inspirado en la topologíade la red (de abajo a arriba): I, F, S,A,D
• Aunque igual otro orden sería más eficiente, pero eso no losabemos a priori
• Variable I:
• El factor fI(S,F ) es P (i|S,F ) (no depende de I ya que su valorestá determinado a i):
S F | f_{I}(S,F)=P(i|S,F)-----------------------------------------
s f | 0.8no s f | 0.6
s no f | 0.7no s no f | 0.3
• FACTORES = {fI(S,F )}

Inteligencia Artificial II - Tema 5 – p. 46/71
Aplicando eliminaci on de variables
• Variable F :
• El factor fF (F ) es P (F ):
F | f_{F}(F)=P(F)----------------------------------
f | 0.4no f | 0.6
• FACTORES = {fI(S,F ), fF (F )}

Inteligencia Artificial II - Tema 5 – p. 47/71
Aplicando eliminaci on de variables
• Variable S:
• El factor fS(S,A) es P (S, |¬d,A) (no depende de D ya que su valorestá determinado a ¬d):
S A | f_{S}(S,A)=P(S|no d,A)-----------------------------------------
s a | 0.25s no a | 0.7
no s a | 0.75no s no a | 0.3
• FACTORES = {fI(S,F ), fF (F ), fS(S,A)}

Inteligencia Artificial II - Tema 5 – p. 48/71
Aplicando eliminaci on de variables
• Como S es una variable oculta, agrupamos por S
• Para ello, primero multiplicamos fI(S,F ) y fS(S,A) obteniendog(S,A, F )
S A F | g(F,A)=P(S|no d,A) x P(i|S,F)----------------------------------------------------
s a f | 0.25 x 0.8s no a f | 0.7 x 0.8s a no f | 0.25 x 0.7s no a no f | 0.7 x 0.7
no s a f | 0.75 x 0.6no s no a f | 0.3 x 0.6no s a no f | 0.75 x 0.3no s no a no f | 0.3 x 0.3

Inteligencia Artificial II - Tema 5 – p. 49/71
Aplicando eliminaci on de variables
• Y ahora, sumamos g(S,A, F ) por la variable S, obteniendo h(A,F )
A F | h(A,F)=SUM_{S}g(S,A,F)----------------------------------------------
a f | 0.25 x 0.8 + 0.75 x 0.6 = 0.65no a f | 0.7 x 0.8 + 0.3 x 0.6 = 0.74
a no f | 0.25 x 0.7 + 0.75 x 0.3 = 0.4no a no f | 0.7 x 0.7 + 0.3 x 0.3 = 0.58
• Acabamos de eliminar la variable S
• FACTORES = {h(A,F ), fF (F )} (nótese que fF (F ) no se ha usado)

Inteligencia Artificial II - Tema 5 – p. 50/71
Aplicando eliminaci on de variables
• Variable A:
• El factor fA(A) es P (A):
A | f_{A}(A)=P(A)--------------------------------
a | 0.4no a | 0.6
• FACTORES = {fA(A), h(A,F ), fF (F )}

Inteligencia Artificial II - Tema 5 – p. 51/71
Aplicando eliminaci on de variables
• Como A es una variable oculta, agrupamos por A
• Para ello, primero multiplicamos fA(A) y h(A,F ) obteniendo k(A,F )
A F | k(F,A)=P(A) x h(A,F)-------------------------------------------
a f | 0.4 x 0.65 = 0.26no a f | 0.6 x 0.74 = 0.444
a no f | 0.4 x 0.4 = 0.16no a no f | 0.6 x 0.58 = 0.348

Inteligencia Artificial II - Tema 5 – p. 52/71
Aplicando eliminaci on de variables
• Y ahora, sumamos k(A,F ) por la variable A, obteniendo l(F ) (yeliminando, por tanto, la variable S)
F | l(F)=SUM_{A}k(A,F)--------------------------------
f | 0.26 + 0.444 = 0.704no f | 0.16 + 0.348 = 0.508
• FACTORES = {l(F ), fF (F )}

Inteligencia Artificial II - Tema 5 – p. 53/71
Aplicando eliminaci on de variables
• Variable D:
• Factor fD() (no depende de D, ya que su valor está fijado a ¬d, portanto se trata de una tabla con una única entrada): 0.9
• FACTORES = {fD(), l(F ), fF (F )}

Inteligencia Artificial II - Tema 5 – p. 54/71
Aplicando eliminaci on de variables
• Ultimo paso: multiplicamos y normalizamos
• Obsérvese que sólo hasta este paso hacemos uso del factorcorrespondiente a F
• Multiplicación
F | m(F)=f_d() x l(F) x f_F(F)-------------------------------------f | 0.9 x 0.704 x 0.4 = 0.253
no f | 0.9 x 0.508 x 0.6 = 0.274
• Normalizando obtenemos finalmente: P (F |i,¬d) = 〈0.48, 0.52〉
• Por tanto, la probabilidad de ser fumador, dado que se ha tenido uninfarto y no se hace deporte, es del 48%

Inteligencia Artificial II - Tema 5 – p. 55/71
Complejidad del algoritmo de eliminaci on de variables
• La complejidad del algoritmo (tanto en tiempo como en espacio) estádominada por el tamaño del mayor factor obtenido durante el proceso
• Y en eso influye el orden en el que se consideren las variables (ordende eliminación)
• Podríamos usar un criterio heurístico para elegir el orden deeliminación
• En general, es conveniente moverse “desde las hojas hacia arriba”(consistentemente con la topología de la red)
• Si la red está simplemente conectada (poliárbol) se puede probar quela complejidad del algoritmo (en tiempo y espacio) es lineal en eltamaño de la red (el número de entradas en sus tablas)
• Una red está simplemente conectada si hay a lo sumo un camino(no dirigido) entre cada dos nodos

Inteligencia Artificial II - Tema 5 – p. 56/71
Complejidad de la inferencia exacta
• Pero en general, el algoritmo tiene complejidad exponencial (en tiempoy espacio) en el peor de los casos
• Cuando la inferencia exacta se hace inviable, es esencial usar métodosaproximados de inferencia
• Métodos estocásticos, basados en muestreos que simulan lasdistribuciones de probabilidad de la red

Inteligencia Artificial II - Tema 5 – p. 57/71
Muestreo
• Por muestreo (en ingles, sampling) respecto de una distribución deprobabilidad entendemos métodos de generación de eventos, de talmanera que la probabilidad de generación de un evento dado coincidecon la que indica la distribución
• El muestreo más sencillo: consideremos una v.a. booleana A tal queP (A) = 〈θ, 1 − θ〉
• Basta con tener un método de generación aleatoria y uniforme denúmeros x ∈ [0, 1]
• Si se genera x < θ, se devuelve a; en caso contrario ¬a
• En el límite, el número de muestras generadas con valor a entre elnúmero de muestras totales es θ
• De manera sencilla, se generaliza esta idea para diseñar unprocedimiento de muestreo respecto de la DCC que representa una redbayesiana.

Inteligencia Artificial II - Tema 5 – p. 58/71
Ejemplo de red bayesiana (Russell & Norvig)
• Consideremos las siguientes variables aleatorias booleanas:
• N : el cielo está nublado• A: el aspersor se ha puesto en marcha• LL: ha llovido• HM : la hierba está mojada
• Las relaciones causales y el conocimiento probabilístico asociadoestán reflejadas en la siguiente red bayesiana
• Nótese que es un ejemplo de red que no está simplementeconectada.

Inteligencia Artificial II - Tema 5 – p. 59/71
Otro ejemplo: red bayesiana
P(n)
lla
N
A Ll
HM
0.5
n
no n
n
no n 0.2
N P(a)
0.5
0.1
N P(ll)
0.8
N Ll P(hm)
no n lln no ll
no n no ll
0.990.90.9
0.00

Inteligencia Artificial II - Tema 5 – p. 60/71
Ejemplo de muestreo a priori
• Veamos cómo generar un evento aleatorio completo a partir de la DCCque especifica la red anterior
• Muestreo de P (N) = 〈0.5, 0.5〉; supongamos que aplicamos elmétodo anterior y obtenemos n
• Muestreo de P (A|n) = 〈0.1, 0.9〉; supongamos que se devuelve ¬a
• Muestreo de P (LL|n) = 〈0.8, 0.2〉; supongamos que obtenemos ll
• Muestreo de P (HM |¬a, ll) = 〈0.9, 0.1〉; supongamos que sedevuelve hm
• Por tanto el evento generado por muestreo ha sido el 〈n,¬a, ll, hm〉
• La probabilidad de generar ese evento es 0.5 × 0.9 × 0.8 × 0.9 = 0.324,ya que cada muestreo individual se realiza independientemente

Inteligencia Artificial II - Tema 5 – p. 61/71
Algoritmo de muestreo a priori
• Supongamos dada una RED bayesiana con un conjunto de variablesX1, . . . ,Xn ordenadas de manera consistente con el orden implícito enla red
• MUESTREO-A-PRIORI(RED)
1. PARA i=1,...,n HACER x_i el resultadode un muestreo de P(X_i|padres(X_i))
2. Devolver (x_1,...,x_n)

Inteligencia Artificial II - Tema 5 – p. 62/71
Propiedades del algoritmo de muestreo a priori
• Sea SMP (x1, . . . , xn) la probabilidad de que el evento (x1, . . . , xn) seagenerado por MUESTREO-A-PRIORI
• Es fácil ver (deduciéndolo exclusivamente del algoritmo) queSMP (x1, . . . , xn) =
∏ni=1
P (xi|padres(Xi))
• Por tanto, si repetimos el muestreo anterior N veces y llamamosNMP (x1, . . . , xn) al número de veces que se devuelve el evento(x1, . . . , xn), entonces
NMP (x1, . . . , xn)
N≈ P (x1, . . . , xn)
• Donde ≈ significa que en el límite (cuando N tiende a ∞) esaigualdad se convierte en exacta (según la ley de los grandesnúmeros)
• Es lo que se llama una estimación consistente

Inteligencia Artificial II - Tema 5 – p. 63/71
Muestreo con rechazo
• La propiedad anterior será la base para los algoritmos de inferencia noexacta que veremos a continuación
• Recordar que el problema de la inferencia probabilística es el decalcular P (X|e) donde e denota un conjunto de valores concretosobservados para algunas variables y X es la variable de consulta
• Muestreo con rechazo: generar muestras y calcular la proporción deeventos generados en los que e “se cumple”
• Ejemplo: para estimar P (LL|a) generar 100 muestras con el algoritmoanterior; si de estas muestras hay 27 que tienen valor de A igual a a, yde estas 27 LL es ll en 8 de los casos y es ¬ll en 19, entonces laestimación es:
P (LL|a) ≈ Normaliza(〈8, 19〉) = 〈0.296, 0.704〉
• La respuesta exacta sería 〈0.3, 0.7〉

Inteligencia Artificial II - Tema 5 – p. 64/71
Algoritmo de inferencia: muestreo con rechazo
• Entrada: una v.a. X de consulta, un conjunto de valores observados e
para la variables de evidencia, una RED bayesiana (con n variables) ynúmero N de muestras totales a generar
• MUESTREO-CON-RECHAZO(X,e,RED,N)
1. Sea N[X] un vector con una componente por cada posible valo rde la variable de consulta X, inicialmente todas a 0
2. PARA k=1,...,N HACER2.1 Sea (y1,...,yn) igual a MUESTREO-A-PRIORI(RED)2.2 SI y = (y1,...,yn) es consistente con e entonces HACER
N[x] igual a N[x]+1, donde en el evento y la v.a. Xtoma el valor x
3. Devolver NORMALIZA(N[X])
• Es fácil ver, deducido de las propiedades de MUESTREO-A-PRIORI,que este algoritmo devuelve una estimación consistente de P (X|e)
• Problema: se rechazan demasiadas muestras (sobre todo si el númerode variables de evidencia es grande)

Inteligencia Artificial II - Tema 5 – p. 65/71
Ponderaci on por verosimilitud
• Es posible diseñar un algoritmo que sólo genere muestras consistentescon la observación e
• Los valores de las variables de evidencia no se generan: quedanfijados de antemano
• Pero no todos los eventos generados “pesan” lo mismo: aquellos en losque la evidencia es más improbable deben contar menos
• Por tanto, cada evento generado va a ir a compañado de un peso igualal producto de las probabilidades condicionadas de cada valor queaparezca en e

Inteligencia Artificial II - Tema 5 – p. 66/71
Ejemplo de ponderaci on por verosimilitud
• Supongamos que queremos calcular P (LL|a, hm); para generar cadamuestra con su correspondiente peso w, hacemos lo siguiente (w = 1.0inicialmente):
• Muestreo de P (N) = 〈0.5, 0.5〉; supongamos que se devuelve n
• Como A es una variable de evidencia (cuyo valor es a) hacemos w
igual a w × P (a|n) (es decir, w = 0.1)• Muestreo de P (LL|n) = 〈0.8, 0.2〉; supongamos que se devuelve ll
• HM es una variable de evidencia (con valor hm); por tanto,hacemos w igual a w × P (hm|a, ll) (es decir, w = 0.099)
• Por tanto, el muestreo devolvería 〈n, a, ll, hm〉 con un peso igual a 0.099
• Este evento contaría para LL = true, pero ponderado con 0.099(intuitivamente, refleja que es poco probable que funcionen losaspersores un día de lluvia)

Inteligencia Artificial II - Tema 5 – p. 67/71
Algoritmo de inferencia: ponderaci on por verosimilitud
• Entrada: una v.a. X de consulta, un conjunto de valores observados e
para la variables de evidencia, una RED bayesiana (con n variables) yun número N de muestras totales a generar
• PONDERACION-POR-VEROSIMILITUD(X,e,RED,N)
1. Sea W[X] un vector con una componente para cada posible val orde la variable de consulta X, inicialmente todas a 0
2. PARA k=1,...,N HACER2.1 Sea [(y1,...,yn),w] igual a MUESTRA-PONDERADA(RED,e)2.2 Hacer W[x] igual a W[x]+w, donde en el evento y la v.a. X
toma el valor x3. Devolver NORMALIZA(W[X])

Inteligencia Artificial II - Tema 5 – p. 68/71
Algoritmo de inferencia: ponderaci on por verosimilitud
• MUESTRA-PONDERADA(RED,e)
1. Hacer w=1.02. PARA i=1,...,n HACER
2.1 SI la variable X_i tiene valor x_i en eENTONCES w = w·p(X_i=x_i|padres(X_i))
SI NO, sea x_i el resultado de un muestreo de P(X_i|padres(X_ i))3. Devolver [(x_1,...,x_n),w]
• Se puede demostrar que el algoritmoPONDERACION-POR-VEROSIMILITUDdevuelve una estimaciónconsistente de la probabilidad buscada
• En el caso de que haya muchas variables de evidencia, el algoritmopodría degradarse, ya que la mayoría de las muestras tendrían un pesoinfinitesimal

Inteligencia Artificial II - Tema 5 – p. 69/71
Mas sobre algoritmos de inferencia aproximada
• Existen muchos otros algoritmos de inferencia aproximada en redesbayesianas, más sofisticados que los vistos aquí
• Uno de ellos es el algoritmo Monte Carlo de cadenas de Markov
• En él, cada evento se genera a partir del anterior, haciendo cambiosaleatorios en el valor de las variables no observadas y dejando fijoel valor de las variables de evidencia

Inteligencia Artificial II - Tema 5 – p. 70/71
Aplicaciones de las redes bayesianas
• Aplicaciones en empresas
• Microsoft: Answer Wizard (Office), diagnóstico de problemas deimpresora, . . .
• Intel: Diagnóstico de fallos de procesadores• HP: Diagnóstico de problemas de impresora• Nasa: Ayuda a la decisión de misiones espaciales
• Otras aplicaciones: diagnóstico médico, e-learning, . . .
• En general, sistemas expertos que manejan incertidumbre

Inteligencia Artificial II - Tema 5 – p. 71/71
Bibliografıa
• Russell, S. y Norvig, P. Inteligencia artificial (Un enfoque moderno),segunda edición (Prentice–Hall Hispanoamericana, 2004)• Cap. 14: “Razonamiento Probabilístico”


















