
MB-613_Capitulo_7-Regresion-Lineal (1).pdf
68
Estadística y Probabilidades MB-613 Capítulo 7 Regresión Lineal Alberto Coronado Matutti Facultad de Ingeniería Mecánica Universidad Nacional de Ingeniería
-
Upload
johann-laime-chuquillanqui -
Category
Documents
-
view
23 -
download
0
Transcript of MB-613_Capitulo_7-Regresion-Lineal (1).pdf

Estadística y Probabilidades MB-613 Capítulo 7Regresión Lineal
Alberto Coronado Matutti
Facultad de Ingeniería MecánicaUniversidad Nacional de Ingeniería

1. Modelos de regresión con una variable predictora
2

3
1.0 Introducción
Anteriormente estimamos y testamos hipótesis concernientes a la media de una población haciendo uso de medidas de una sola variable.
Pero, frecuentemente la media de una variable depende de una o más variables relacionadas.
Por ejemplo, la cantidad media de energía requerida por el aire acondicionado de una oficina depende de su tamaño y de la temperatura ambiente exterior.

4
1.1 Una variable
Existen diversos tipos de relaciones posibles entre diferentes variables.
Algunas variables tienen una relación exacta entre ellas y los modelos asociados se llaman modelos determinísticos.
Por ejemplo, la conversión:

5
1.1 Una variable
El uso principal de modelos determinísticosestá en la descripción de leyes físicas.
Por ejemplo, la ley de Ohm (relación entre corriente y resistencia), la ley de Newton (relación entre fuerza y aceleración), la ley de Fourier (relación entre flujo de calor y gradiente de temperatura), etc.
Pero, estas leyes serán precisas solo bajo condiciones ideales. Experimentos raramente las reproducirán exactamente.

6
1.1 Una variable
En realidad, la mayoría de relaciones observadas no son determinísticas.
Por ejemplo, la relación entre el consumo pico de energía en un centro comercial y la temperatura exterior máxima.
El consumo pico depende de muchos factores, aparte de la temperatura: número de clientes, localización geográfica, etc.
Pero aún si incluimos todos esos factores, no podremos predecir la relación exactamente.

7
1.1 Una variable
Si creemos que existirán variaciones aleatorias, entonces deberemos usar un modelo probabilístico que considere el error aleatorio:
Y = componente determinística + error aleatorio
Siempre asumiremos que el valor medio del error aleatorio es igual a cero.
Esto es equivalente a asumir que el valor medio de Y, E(Y) es igual al componente determinístico del modelo.

8
1.1 Una variable
Anteriormente discutimos la forma más simple de un modelo probabilístico.
Se hicieron inferencias acerca de la mediade Y, E(Y), cuando E(Y)=μ.
Sin embargo, la estimativa no será exactamente igual a μ, sino que habrá un error aleatorio adicional.

9
1.1 Una variable
Si asumimos que Y tiene distribución normal con media μ y varianza σ2, el modelo probabilístico será Y = μ + ε.
Donde ε es la componente aleatoria normalmente distribuida con media 0 y varianza σ2.

10
1.1 Una variable
Una vez establecido que dos variables se relacionan una a otra, el próximo paso es cuantificar esa relación usando un modelomatemático.
Por ejemplo, un problema que enfrenta toda planta de generación de potencia es la estimación del pico de carga (energía) en función de la máxima temperatura del día.

11
1.1 Una variable
La figura muestra que una relación lineal podría ser adecuada.
Sin embargo no habrá ninguna recta que pase por todos los puntos a la vez.

12
1.1 Una variable
El proceso estadístico de encontrarmodelos (ecuaciones) que relacionan 2 ó más variables se llama análisis de regresión.
El modelo más simple es una recta, denominado modelo (ecuación) de regresión lineal simple.

13
1.1 Una variable
En general, la relación lineal entre dos variables está dada por:
donde y es la variable dependiente oexplicada, x es la variable independiente oexplicativa, β0 es la intersección en y, β1 es la pendiente de la recta.
Debemos hacer uso de los datos para estimar los parámetros de:

14
1.1 Una variable
En este capítulo generalizaremos el modelopara permitir que E(Y) sea una función de otras variables.
Asumiendo que la media de Y es una línea recta en función de x.
Un modelo de regresión linealproporciona una relación probabilística entre 2 variables como sigue:

15
1.1 Una variable
Donde Y es la variable dependiente o explicada, x es la variable independiente o explicativa, β0 es la intersección en Y, β1 es la pendiente de la línea y ε es el error aleatorio.
Para un x dado, la diferencia entre la medida observada y el valor esperadobasado en el modelo da un error igual a vbvbv .

16
1.1 Una variable
El método de los mínimos cuadradospermite elegir una recta que minimiza la suma de los cuadrados de los errores (sum of squared errors, SSE).
La recta resultantese llama recta demínimos cuadradoso recta de mejorajuste.

17
1.1 Una variable
Siendo , desearemos estimarm y para los datos muestreados.
La línea de regresión estimada será dada por , donde y son valores tales que la SSE sea mínima:
Derivando e igualando a cero:

18
1.1 Una variable
Resolviendo el sistema de dos ecuaciones con dos incógnitas:
La recta estimada tendrá la menor suma de cuadrados de errores.
La recta de mejor ajuste pasará siemprepor el punto . Luego:

19
1.1 Una variable: ej. 1
Se muestran los datos recolectados que relacionan la temperatura máxima a la carga pico:

20
1.1 Una variable: ej. 1
De los datos podemos calcular:

21
1.1 Una variable: ej. 1
Por tanto:

22
1.1 Una variable: ej. 1
No es posible interpretar adecuadamente la interceptación con el eje y, ya que nofueron tomados valores a 0 oF.
Si los datos tomados corresponden a la estación del verano (100 oF ≈ 37.78 oC), para invierno la relación será diferente.
Además nos indica que por cada grado oF de aumento la carga pico aumentará en promedio 6.7175 megawatts.

23
1.1 Una variable: ej. 1
El uso del modelo ajustado para predecirvalores fuera del rango donde están los datos (81 oF a 100 oF) no es recomendable.
Si el valor obtenido fuese a ser usado, se deberá tomar gran cuidado ya que estará asociado a un error significativo.

24
1.2 Coeficiente de correlación
Si se observa que la relación entre 2 variables parece ser lineal, el próximo paso es medir la fortaleza de dicha asociación.
Ello se puede realizar calculando el coeficiente de correlación Pearson:
donde zx y zy son los valores zestandarizados.

25
1.2 Coeficiente de correlación
Ya que los términos en el denominadorserán siempre positivos, el producto del numerador determinará el signo de r:
Siempre tendremos que .
Un valor de r cercano o igual a cero implica pequeña o ninguna relación lineal.
Un valor de r cercano a 1 ó -1 implica una fuerte relación lineal. Siendo que para todos los puntos coinciden con la recta.
Un valor positivo (negativo) implica que y aumenta (disminuye) conforme x aumenta.

26
1.2 Coeficiente de correlación

27
1.2 Coeficiente de correlación: ej. 2
Considerando los datos del ej. 1 correspondientes a la relación entre carga pico (y) y temperatura ambiente máxima (x).
Para determinar la fortaleza de la asociación usaremos el coeficiente de correlación.

28
1.2 Coeficiente de correlación: ej. 2
Realizando los cálculos correspondientes:

29
1.2 Coeficiente de correlación
No se debe inferir una relación causal en base a una alta correlación.
Aún cuando es probable que temperaturas altas produzcan un aumento en la demanda energética, lo mismo no será cierto en otros problemas.
Un valor alto del coeficiente de correlación solo indica que las 2 variables tienden a cambiar en conjunto.

30
1.2 Coeficiente de correlación: ej. 3
Se muestra la relación entre el consumo per cápita de chocolate y el número de nobeles por país.
El valor p indica que sólo existe una chance de 1/10,000 dedeberse al azar.
Does chocolate make you clever?http://www.bbc.co.uk/news/magazine-20356613

31
1.3 Coeficiente de determinación
Una manera de medir la contribución de x en la predicción de Y es calculando que tanto los errores de la predicción de Y son reducidos usando la información en x.
Si no se usa x, la mejor predicción para cualquier valor de Y será , y la suma de los cuadrados totales (SSyy o SST) de las desviaciones de los valores observados de y con respecto a será:

32
1.3 Coeficiente de determinación
Suponga los datosmostrados a la dere-cha.
Si asumimos que x nocontribuye informaciónpara la predicción de y, la mejor predicción será , que se mues-tra como la recta ho-rizontal.

33
1.3 Coeficiente de determinación
Las líneas verticales son las desviacionesrespecto a . Y la suma de los cuadrados totales (SSyy o SST) será:
Ahora supongamos que ajustamos una recta por mínimos cuadrados y calcula-mos las desviaciones respecto a la recta.

34
1.3 Coeficiente de determinación
Calculando las desviaciones en las dos últimas figuras podemos observar que:
Si x (casi) no contribuye información a la predicción de y, las sumas de los cuadrados de las desviaciones para las dos rectas serán aprox. iguales, ya que son (casi) horizontales:
Si x no contribuye información a la predicción de y, SSE será menor a SSyy. Si todos los puntoscaen sobre la recta, SSE=0. Además se muestra que:

35
1.3 Coeficiente de determinación
La tercera sumatoria se denomina suma de los cuadrados de la regresión (sum of squares for regression, SSR). Por tanto:
de donde se obtiene:
SSR toma cuenta de las diferencias entre e .

36
1.3 Coeficiente de determinación
Resumiendo, la suma de los cuadrados totales SSyy o SST será iguales a:

37

38
1.3 Coeficiente de determinación
Si la recta de regresión tiene pendiente cercana a cero, entonces e serán cercanas para todo i, y SSR será pequeña.
Entonces la reducción en la suma de los cuadrados de las desviaciones que pueden atribuirse a x, expresada en proporción de SSyy, es:
Se muestra que esta cantidad es igual al cuadrado del coeficiente de correlación.

39
1.3 Coeficiente de determinación
El cuadrado del coeficiente de correlación se denomina coeficiente de determinación.
Este representa la proporción de la suma de los cuadrados de la desviación de los valores de y respecto a la media que pueden ser atribuidos a la relación lineal entre x e y:

40
1.3 Coeficiente de determinación
El coeficiente de determinación toma valores entre 0 y 1.
Cuanto más cerca está a 1, la suma de los cuadrados de los errores SSE será menor respecto a la suma de los cuadrados de la regresión SSR.
Por tanto, valores altos de R2 indican que los datos están cerca de la recta ajustada.

41
1.3 Coeficiente de determinación
Sin embargo, un valor bajo de R2 no necesariamente indica que la recta no es apropiada.
Una recta puede ser apropiada aún para R2 pequeños si es que la varianza del error es grande.

42
1.3 Coeficiente de determinación:ej. 4
El coeficiente de determinación para el ejemplo de carga pico será:
Por tanto, para la muestra considerada, la variabilidad de la carga pico respecto a su media es reducida 89% cuando la carga media pico es modelada como una función lineal de la temperatura.

2. Distribución de probabilidad del error
43

44
2. Distribución del error
Al hacer inferencias acerca de los parámetros de un modelo de regresión, haremos suposiciones acerca de la distribución del error.
La componente asociada al error será normalmente distribuida con media cero y varianza constante.
Los errores asociados a diferentesobservaciones son aleatorios e independientes.

45
2. Distribución del error
Las suposiciones serán las siguientes:
La componente del errores normalmente distribu-ída, aproximadamente.
La media es cero.
La varianza es constantepara todos los valores dex.
Los errores asociados a diferentes observacionesson aleatorios e independientes.

46
2. Distribución del error
Todo ello es equivalente a decir que Y1, Y2,…, Yn son muestras aleatorias de poblaciones normalmente distribuidas.
Siendo que los Yi tienen media y varianza independiente de X.
Las variaciones entre observaciones se miden usando la desviación estándar.
Sin embargo, ahora estamos interesados en la variación en torno a la recta de mejor ajuste.

47
2. Distribución del error
La distribución de probabilidad de estará completamente especificada si la varianzaes conocida.
Para estimar usaremos la SSE del modelo de mínimos cuadrados.
La estimativa de es calculada dividiendo la SSE por los grados de libertad asociados al error.

48
2. Distribución del error
Fueron usados 2 grados de libertad para estimar la intersección en Y y la pendientede la recta.
Por tanto, quedarán (n-2) grados de libertad para estimar la varianza del error.
Así el estimador imparcial de será:
Donde:

49
2. Distribución del error: ej. 5
En el ejemplo de la carga pico, fueron calculados
Entonces, la SSE será:
Ya que tenemos 10 datos, habrán grados de libertad para estimar .
La desviación estándar estimada será:

50
2. Distribución del error
La desviación estándar nos muestra, en promedio, cuan lejos los valores observados de la potencia están de los valores predichos.
Recordemos que el 95% de las observaciones caen dentro de 2 desviaciones estándar.
Así el 95% de las observaciones caerán dentrode 2s de .
Para la carga pico, las 10 observaciones caen dentro de:

3. Inferencias sobre la pendiente
51

52
3. Inferencias sobre la pendiente
Diferentes pares de muestras (mismo tamaño) de la misma población resultan en diferentes estimaciones de la pendiente.
Por tanto, es necesario tener en cuenta la distribución muestral de para hacer inferencias acerca de .
Si asumimos que el error tiene distribución normal con media cero y varianza , la distribución muestral del estimadorserá normal, con media (pendiente real) y desviación estándar .

53
3. Inferencias sobre la pendiente
Debido a que , de la distribución muestral de , es usualmente desconocida, el estadístico:
tendrá una distribución t de Student con (n-2) grados de libertad, donde es la desviación estándar estimada de la distribución muestral de .

54
3. Intervalo de confianza de la pendiente
Una manera de hacer inferencias acerca de la pendiente es estimarla usando un intervalo de confianza.
El intervalo de confianza del de la pendiente es:

55
3. Intervalo de confianza de la pendiente: ej. 6
El intervalo de confianza del 95% de la pendiente para el ejemplo del pico de potencia será:
Donde la pendiente estimada para la potencia pico en función de la temperatura es 6.7175, el valor t es 2.306, , y SSxx está en la tabla del ej. 1.

56
3. Test de hipótesis de la pendiente
Otra manera de hacer inferencias acerca de la pendiente es a través del test de hipótesis.
Supongamos que la potencia pico no está relacionada a la máxima temperatura del día.
Ello implica que la media no cambia conforme x cambia, es decir la pendiente será igual a cero.

57
3. Test de hipótesis de la pendiente
Si , el modelo se reduce a
Por tanto, testaremos la hipótesis nula de que x no contribuye información a la predicción de Y:

58
3. Test de hipótesis de la pendiente

59
3. Test de hipótesis de la
pendiente: ej. 7
Considerando el ejemplo de la potencia pico, testaremos versus usando .
Para 10 pares de datos , así la región de rechazo será
Anteriormente calculamos:
Al ser este valor mayor a 2.306 rechazaremos la hipótesis nula.

4. Análisis de regresión múltiple
60

61
4. Análisis de regresión múltiple
La mayoría de aplicaciones prácticas de regresión usan modelos más complejos que una simple recta.
Un modelo más realista del pico de carga de una planta de potencia deberá incluirotros factores aparte de la temperatura.
Por ejemplo, humedad, día de la semana, estación del año, son algunas variablesadicionales relacionadas.

62
4. Análisis de regresión múltiple
Modelos probabilísticos que incluyen términos tales como x2, x3, …, o más de una variable independiente se denominan modelos de regresión múltiple.
La forma general de dichos modelos es:
La variable dependiente Y es escrita en función de k variables independientes

63
4. Análisis de regresión múltiple
El error aleatorio es adicionado para permitir una desviación entra la parte determinística y el valor de Y.
El valor de los coeficientes determina la contribución de la variable independiente , y es la intersección en Y.
Los coeficientes son normalmente desconocidos, ya que representan los parámetros de la población.

64
4. Análisis de regresión múltiple
A primera vista puede parecer que el modelo de regresión presentado no permite más que relaciones lineales.
Pero en realidad pueden ser funciones de variables siempre y cuando no contengan parámetros desconocidos.
Por ejemplo, aún cuando:
contenga un término cuadrático, el modelo es lineal considerando los parámetros .

65
4. Análisis de regresión múltiple
Modelos de regresión múltiple que son lineales en los parámetros se denominan modelos lineales, aún cuando contengan variables independientes no lineales.
El modelo de regresión polinomial de grado k es dado por:
De entre ellos, modelos cuadráticos son los más comúnmente usados.
66
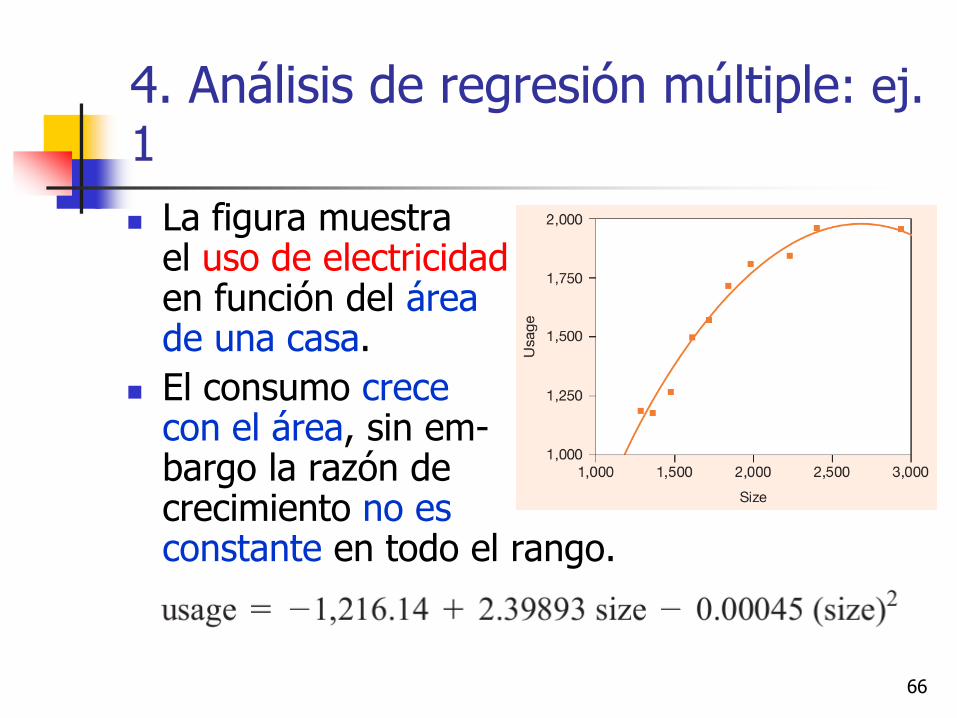
4. Análisis de regresión múltiple: ej. 1
La figura muestra el uso de electricidaden función del área de una casa.
El consumo crece con el área, sin em-bargo la razón de crecimiento no es constante en todo el rango.

67
4. Análisis de regresión múltiple
Aún cuando muchas relaciones son no lineales por naturaleza, algunas pueden ser transformadas en relaciones lineales.
Por ejemplo, el modelo describe una relación no lineal.
Tomando logaritmos en ambos lados de la ecuación: , el cual es un modelo de regresión múltiple lineal.

68
4. Análisis de regresión múltiple:ej. 2
La figura muestra el esfuerzo (fuerza/área) en recipientes de presión usados en plantas de generación de potencia.
La relación no lineal transformada es la siguiente:


















