

Meetup spark + kerberos
51
Spark + Kerberos Noviembre 2016 Meetup
-
Upload
jorge-lopez-malla -
Category
Technology
-
view
97 -
download
1
Transcript of Meetup spark + kerberos

Spark + Kerberos
Noviembre 2016
Meetup

Jorge López-Malla Matute
INDEX
Abel Rincón [email protected]
Introducción al Big Data y la seguridad
● Seguridad Perimetral
1
3
Kerberos● Introducción
● El protocolo
2
4Arquitectura Spark y Seguridad● Standalone
● YARN/Mesos clietn
● Mesos Cluster
● YARN/Mesos y Kerberos.
● Spark y seguridad
RoadTrip● Stratio Requirements
● Spark Package
● Añadiendo user a RDD
● Task/Scheduler
● Kerberos User
● SaveAs…
● Wrappers
● SparkSQL
● Spark 2.0
Presentación
Presentación
JORGE LÓPEZ-MALLA
Tras trabajar con algunasmetodologías tradicionalesempecé a centrarme en el
mundo del Big Data, del cualme enamoré. Ahora soy
arquitecto Big Data en Stratio yhe puesto proyectos en
producción en distintas partesdel mundo.
SKILLS

Presentación
Presentación
ABEL RINCÓN MATARRANZ
SKILLS

Introducción al Big Data y la seguridad1

Seguridad y Big Data
• La mayoría de las tecnologías Big Data se toman la seguridad como algo secundario, en el mejor de los casos
• Una prueba de esto es: ¿habéis visto al claim de seguridad en estas tecnologías?
• Los cluster de Big Data normalmente relegan la seguridad en poner una barrera alrededor del cluster.
• Desde que HDFS se integró con Kerberos, Kerberos es el protocolo de autenticación por defecto para tecnologías Big Data
Introducción al Big Data y la seguridad
Seguridad Perimetral
Introducción al Big Data y la seguridad
Seguridad Perimetral
Introducción al Big Data y la seguridad
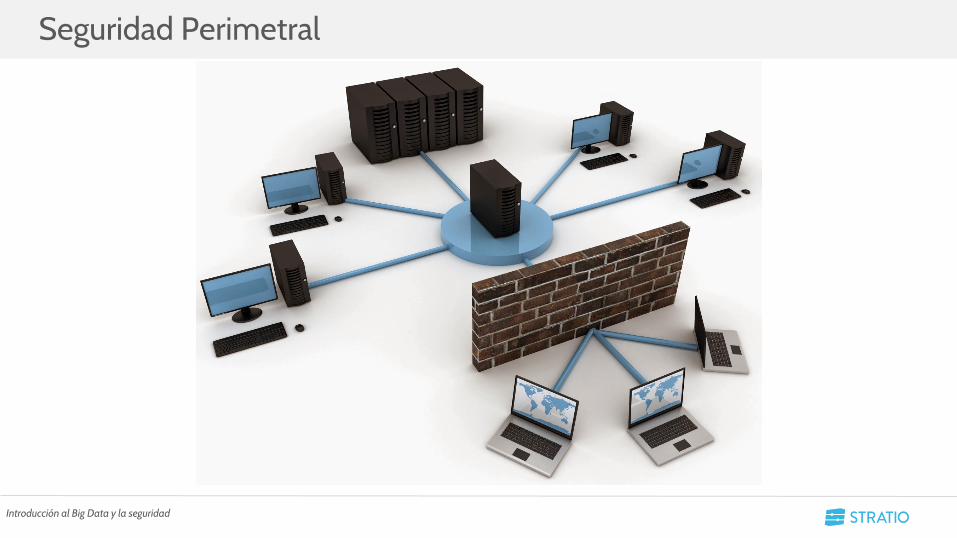
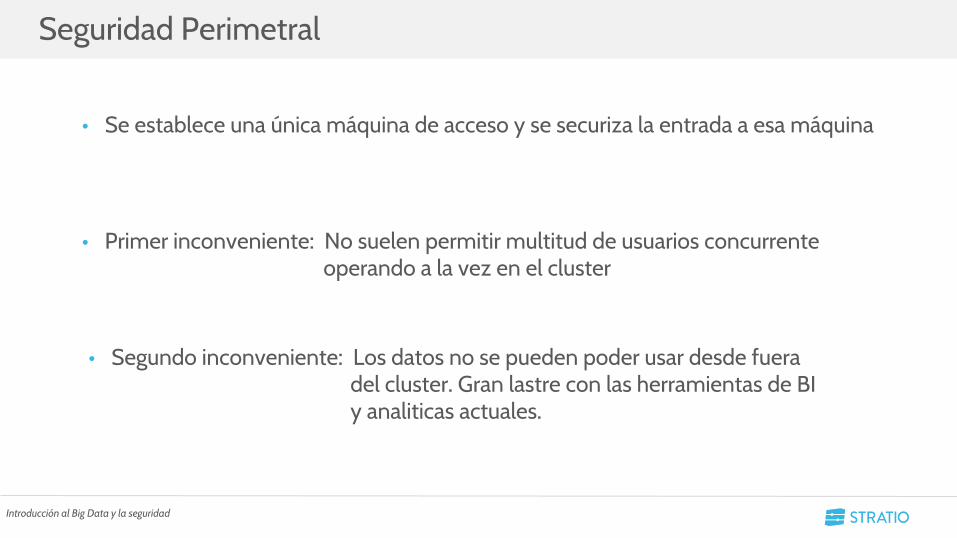
• Se establece una única máquina de acceso y se securiza la entrada a esa máquina
• Segundo inconveniente: Los datos no se pueden poder usar desde fuera del cluster. Gran lastre con las herramientas de BI y analiticas actuales.
• Primer inconveniente: No suelen permitir multitud de usuarios concurrente operando a la vez en el cluster

Kerberos2
Kerberos
Kerberos
• ¿Qué es Kerberos?○ Servicio de autenticación
■ Seguro■ Single-sign-on■ Basado en confianza■ Autenticación mutua

Kerberos-Terminología
Kerberos
• Principal → Nombre (userName / serviceName)• Realm → Entorno( DEMO.MEETUP.COM)• Cliente/Servicio → usuario a nivel de kerberos• KDC → servicio de distribución de claves• TGT → contiene la sesión del cliente• TGS → contiene la sesión del servicio
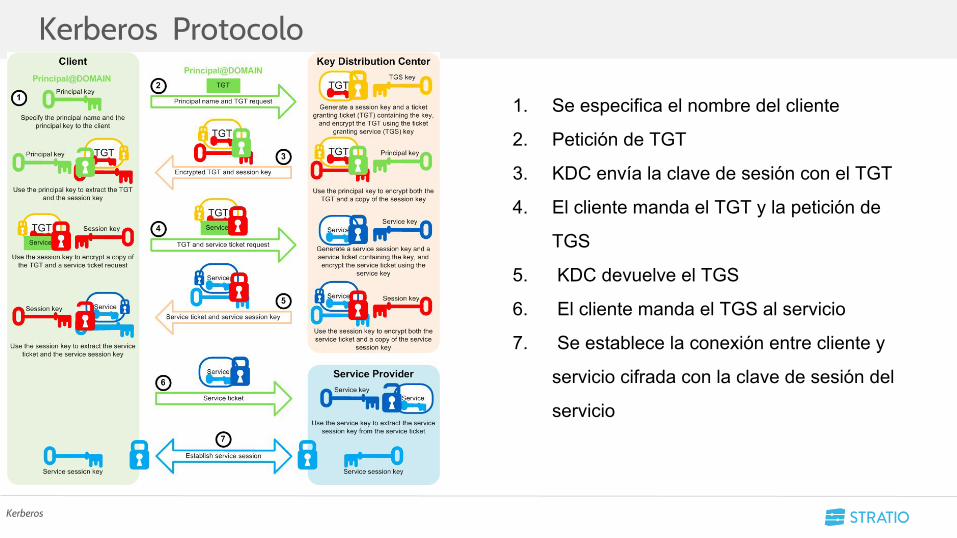
Kerberos Protocolo
Kerberos
1. Se especifica el nombre del cliente
2. Petición de TGT
3. KDC envía la clave de sesión con el TGT
4. El cliente manda el TGT y la petición de
TGS
5. KDC devuelve el TGS
6. El cliente manda el TGS al servicio
7. Se establece la conexión entre cliente y
servicio cifrada con la clave de sesión del
servicio
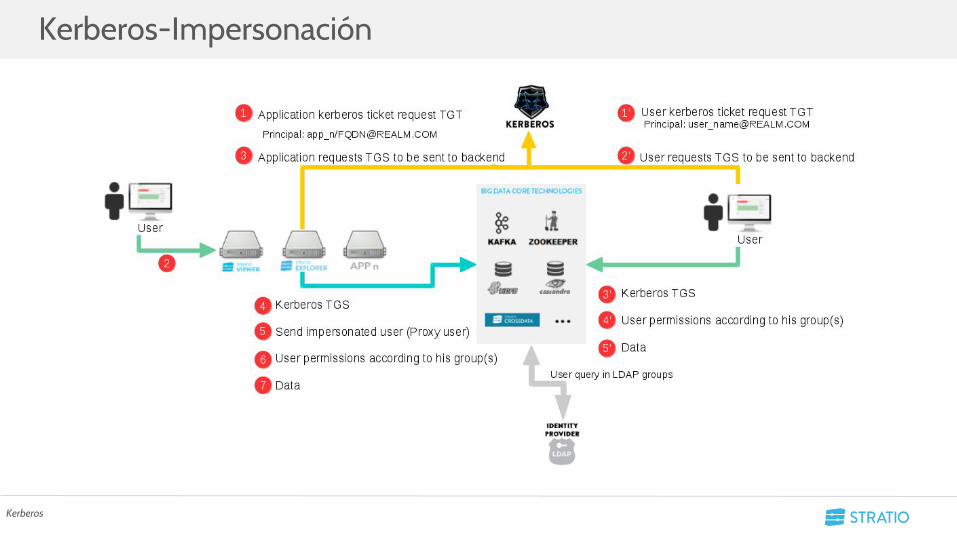
Kerberos-Impersonación
Kerberos

Arquitectura Spark3
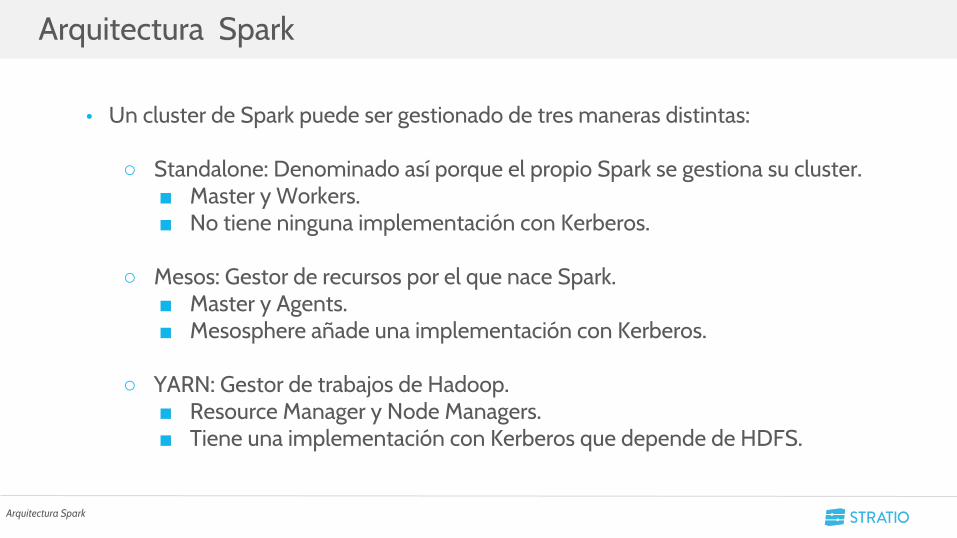
Arquitectura Spark
• Un cluster de Spark puede ser gestionado de tres maneras distintas:
○ Standalone: Denominado así porque el propio Spark se gestiona su cluster.■ Master y Workers.■ No tiene ninguna implementación con Kerberos.
○ Mesos: Gestor de recursos por el que nace Spark.■ Master y Agents.■ Mesosphere añade una implementación con Kerberos.
○ YARN: Gestor de trabajos de Hadoop.■ Resource Manager y Node Managers.■ Tiene una implementación con Kerberos que depende de HDFS.
Arquitectura Spark
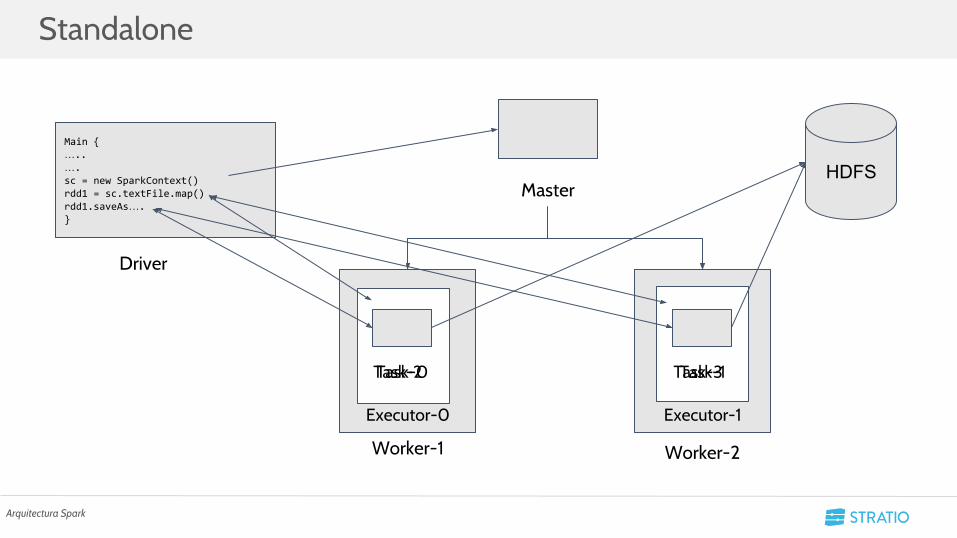
Standalone
Arquitectura Spark
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….}
Driver
Master
Worker-1 Worker-2
Executor-0 Executor-1
Task-0 Task-1Task-2 Task-3
HDFS
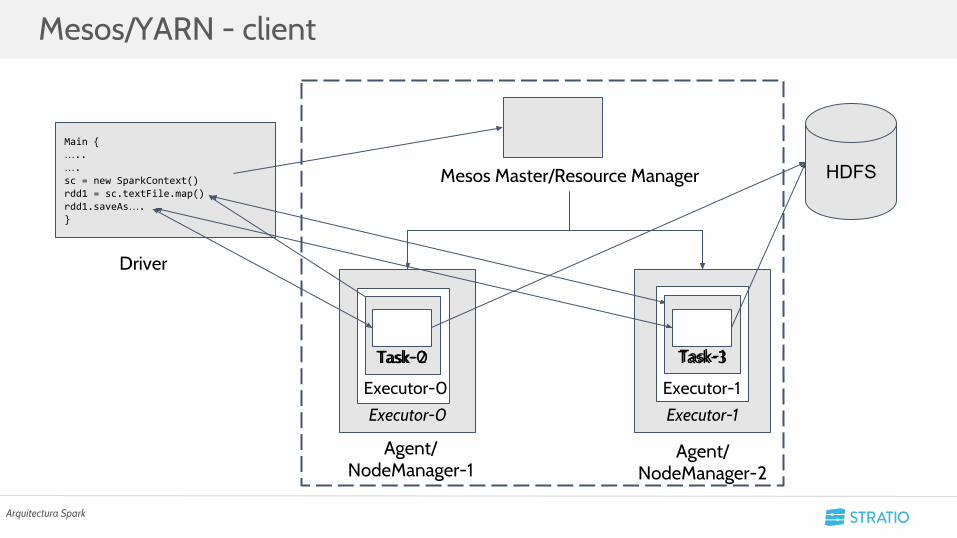
Mesos/YARN - client
Arquitectura Spark
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….}
Driver
Mesos Master/Resource Manager
Agent/NodeManager-1
Executor-0 Executor-1
Task-0 Task-1Task-2 Task-3
HDFS
Agent/NodeManager-2
Executor-0 Executor-1
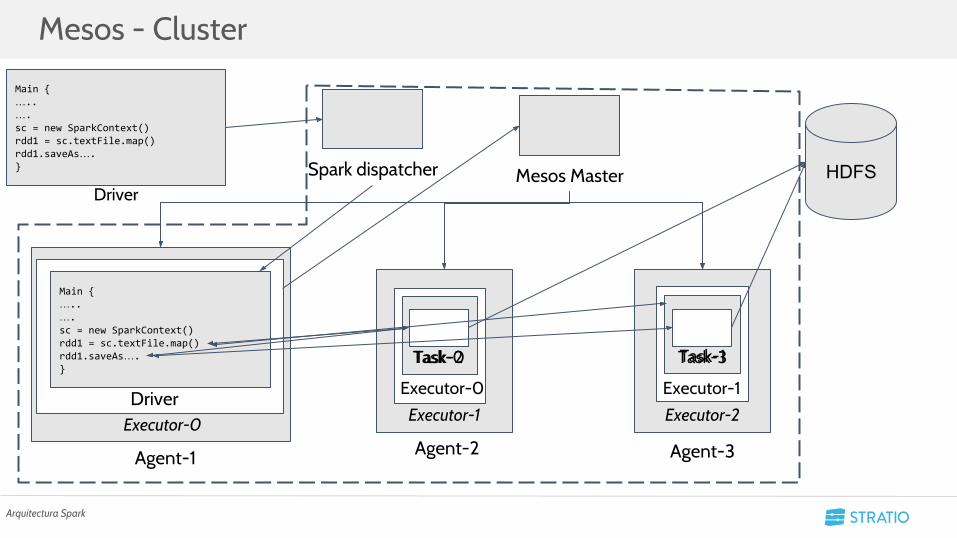
Mesos - Cluster
Arquitectura Spark
Mesos Master
Agent-2
Executor-1 Executor-2
Task-0 Task-1Task-2 Task-3
HDFS
Agent-3
Executor-0 Executor-1
Agent-1
Executor-0
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….}
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….} Spark dispatcher
Driver
Driver
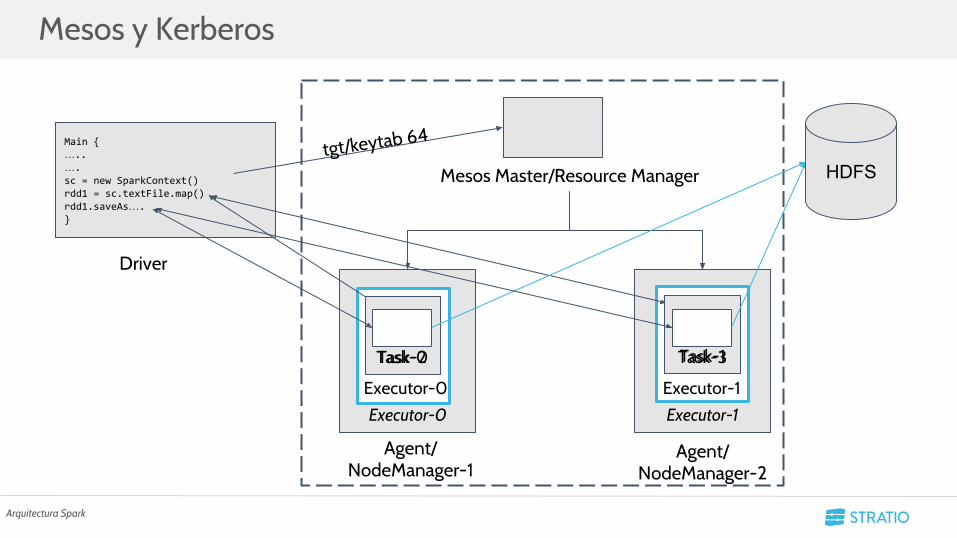
Mesos y Kerberos
Arquitectura Spark
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….}
Driver
Mesos Master/Resource Manager
Agent/NodeManager-1
Executor-0 Executor-1
Task-0 Task-1Task-2 Task-3
HDFS
Agent/NodeManager-2
Executor-0 Executor-1
tgt/keytab 64

Spark y seguridad
• Kerberos no es la única medida de seguridad de Spark
• ACLs para modificación de Jobs.
• Securización de comunicaciones mediante TLS.
○ Driver con Executors -> Sólo en versiones anteriores a la 2.0.
○ File Server: files y broadcast -> todas las versiones.
○ Webs: Standalone Master/Slave, history Server y Application UI.
• La seguridad mejora en cada nueva versión de Spark.
Arquitectura Spark
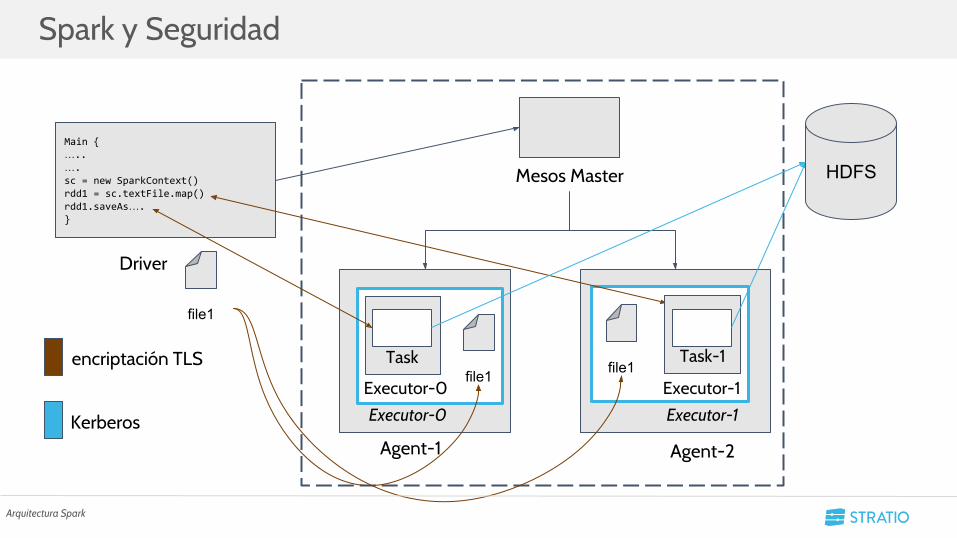
Spark y Seguridad
Arquitectura Spark
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….}
Driver
Mesos Master
Agent-1
Executor-0 Executor-1
Task Task-1
HDFS
Agent-2
Executor-0 Executor-1encriptación TLS
Kerberos
file1
file1 file1
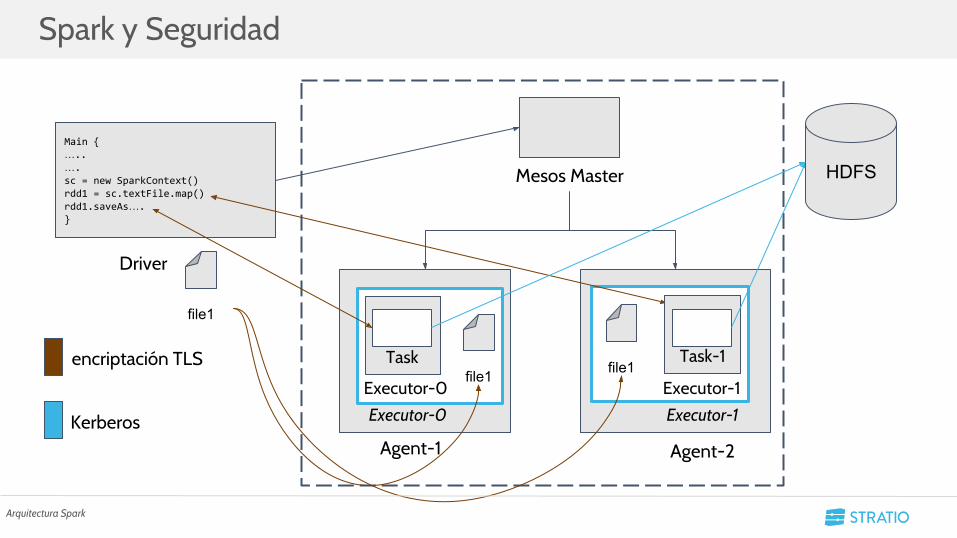
Spark y Seguridad
Arquitectura Spark
Main {…..….sc = new SparkContext()rdd1 = sc.textFile.map()rdd1.saveAs….}
Driver
Mesos Master
Agent-1
Executor-0 Executor-1
Task Task-1
HDFS
Agent-2
Executor-0 Executor-1encriptación TLS
Kerberos
file1
file1 file1

Road Trip4
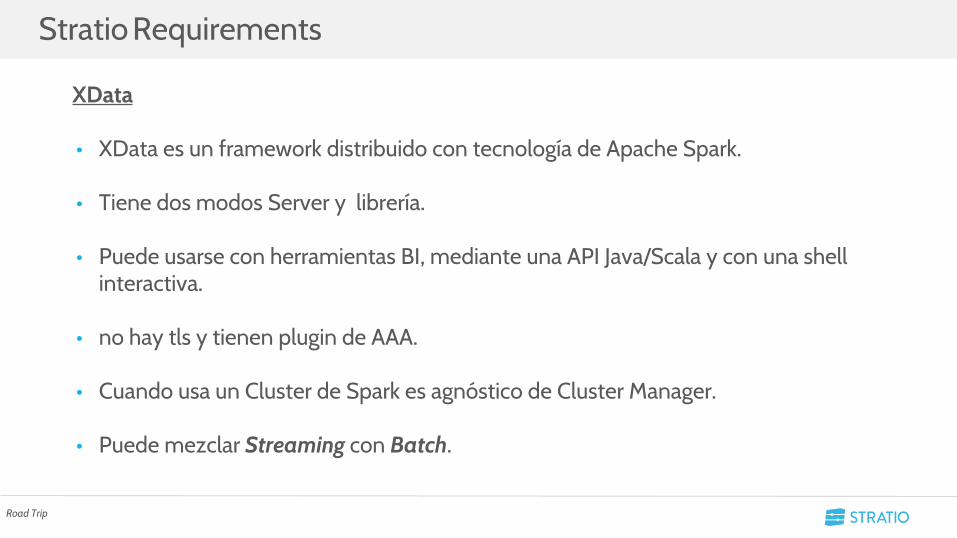
XData
• XData es un framework distribuido con tecnología de Apache Spark.
• Tiene dos modos Server y librería.
• Puede usarse con herramientas BI, mediante una API Java/Scala y con una shell interactiva.
• no hay tls y tienen plugin de AAA.
• Cuando usa un Cluster de Spark es agnóstico de Cluster Manager.
• Puede mezclar Streaming con Batch.
Stratio Requirements
Road Trip

Stratio Requirements
Impersonación en tiempo real
• Como Usuario Final de Crossdata necesito autenticarme contra el backend de datos en mi nombre para tener una gestión de permisos individualizada en él.
• Crossdata en modo servidor tiene como particularidad, el uso de un contexto “infinito”
• Crossdata usará un principal propio para el servicio• Crossdata da soporte a varios usuarios sobre la misma sesión• Spark se debe autenticar sobre hdfs como el usuario final no como crossdata
Road Trip

¿Por qué no nos valen las soluciones actuales?
• CrossData es agnóstico al cluster manager, ergo debería poder usar cualquiera de los tres.
• Ninguna de las dos soluciones actuales (YARN ni Mesos) permite la impersonación
• Sólo se permite un usuario por Executor/YARN Containner
• Además de autenticar en los Executors hay que autenticar en el Driver
• No deberíamos limitarnos a Hadoop ni a Kerberos.
Stratio Requirements
Road Trip
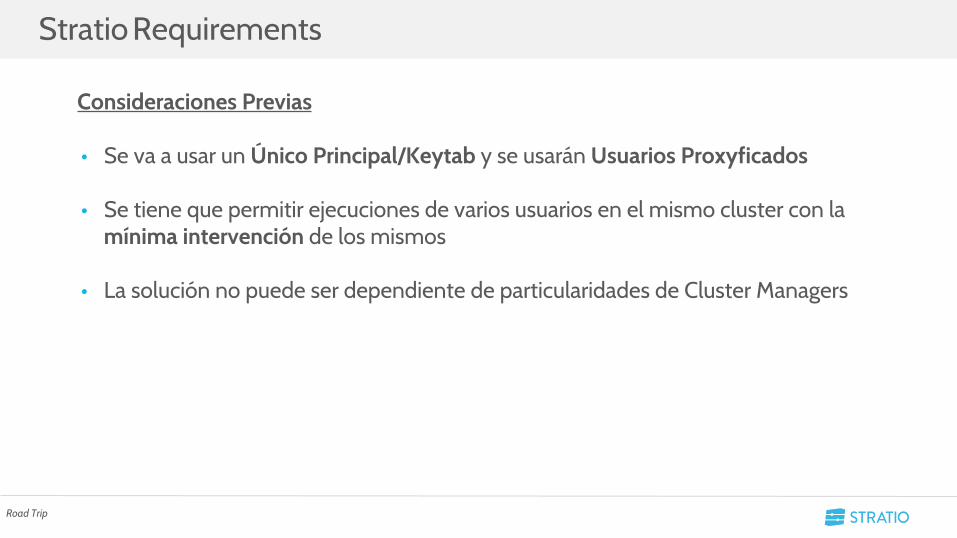
Consideraciones Previas
• Se va a usar un Único Principal/Keytab y se usarán Usuarios Proxyficados
• Se tiene que permitir ejecuciones de varios usuarios en el mismo cluster con la mínima intervención de los mismos
• La solución no puede ser dependiente de particularidades de Cluster Managers
Stratio Requirements
Road Trip

• Primera Idea
○ El primer intento fue hacer un SecuredRDD.
○ Se añadiría al Spark Packages
○ Sólo se permite un usuario por Executor/YARN Containner
Spark Packages
Road Trip
• Resultado○ Aunque podíamos autentificar en el Driver NO se puede hacer nada en los
Executor -> Hay que tocar el API de Task
○ Se aprende que hay que meter el usuario en los RDD para poder pasarlos del Driver a los executors
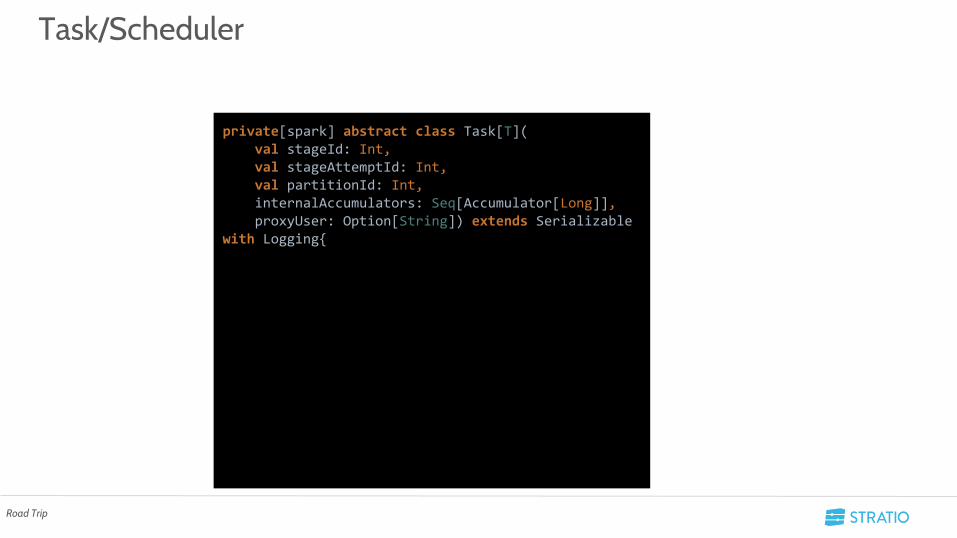
Task/Scheduler
Road Trip
private[spark] abstract class Task[T]( val stageId: Int, val stageAttemptId: Int, val partitionId: Int, internalAccumulators: Seq[Accumulator[Long]], proxyUser: Option[String]) extends Serializable with Logging{
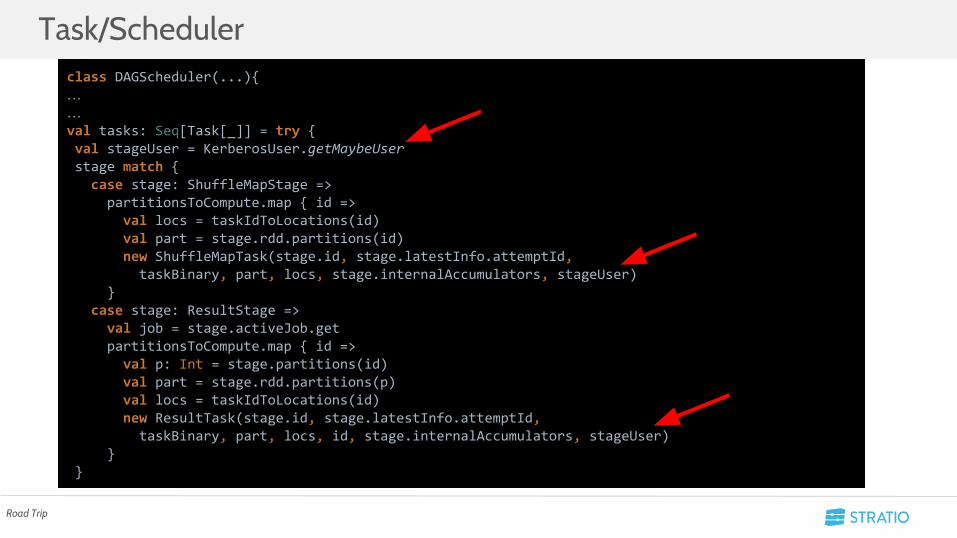
class DAGScheduler(...){……val tasks: Seq[Task[_]] = try { val stageUser = KerberosUser.getMaybeUser stage match { case stage: ShuffleMapStage => partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = stage.rdd.partitions(id) new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.internalAccumulators, stageUser) } case stage: ResultStage => val job = stage.activeJob.get partitionsToCompute.map { id => val p: Int = stage.partitions(id) val part = stage.rdd.partitions(p) val locs = taskIdToLocations(id) new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, stage.internalAccumulators, stageUser) } }
Task/Scheduler
Road Trip

• Se vio que era necesario añadir un usuario a cada RDD para controlar los accesos en Driver/Executor
• Primero se optó por añadir campos a los métodos que crean RDD provenientes de Hadoop
• Primera prueba con usuarios dentro de RDDs:
○ Resultado:
Añadiendo Usuarios a RDD
Road Trip
¡Éxito!

• No termina de ser una solución “limpia”
○ Si se crea un método para crear RDDs lo deberíamos sobreescribir
• Se opta por añadir un método setUser a nivel de RDD que configura los usuarios antes de calcular sus particiones
• Primera prueba con usuarios en un método de RDD:
○ Resultado:
Añadiendo Usuarios a RDD
Road Trip
¡Fracaso!
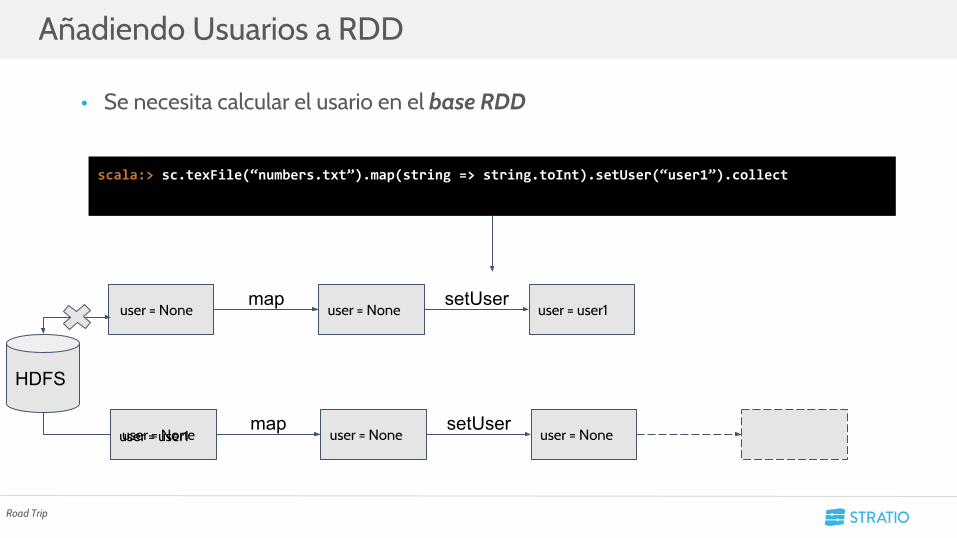
user = user1user = None
• Se necesita calcular el usario en el base RDD
Añadiendo Usuarios a RDD
Road Trip
scala:> sc.texFile(“numbers.txt”).map(string => string.toInt).setUser(“user1”).collect
HDFS
map setUseruser = None user = None user = user1
map setUseruser = None user = None
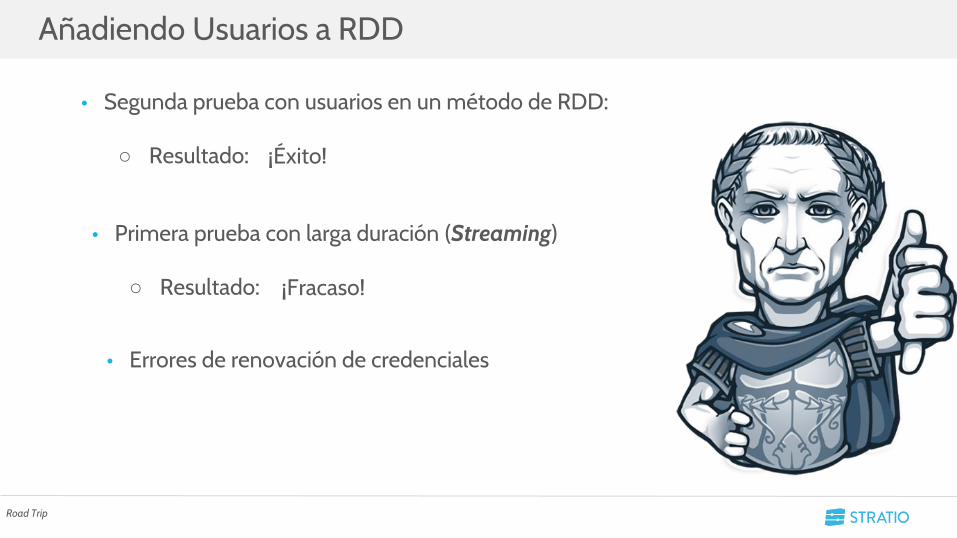
• Segunda prueba con usuarios en un método de RDD:
○ Resultado:
Añadiendo Usuarios a RDD
Road Trip
¡Éxito!
• Primera prueba con larga duración (Streaming)
○ Resultado: ¡Fracaso!
• Errores de renovación de credenciales
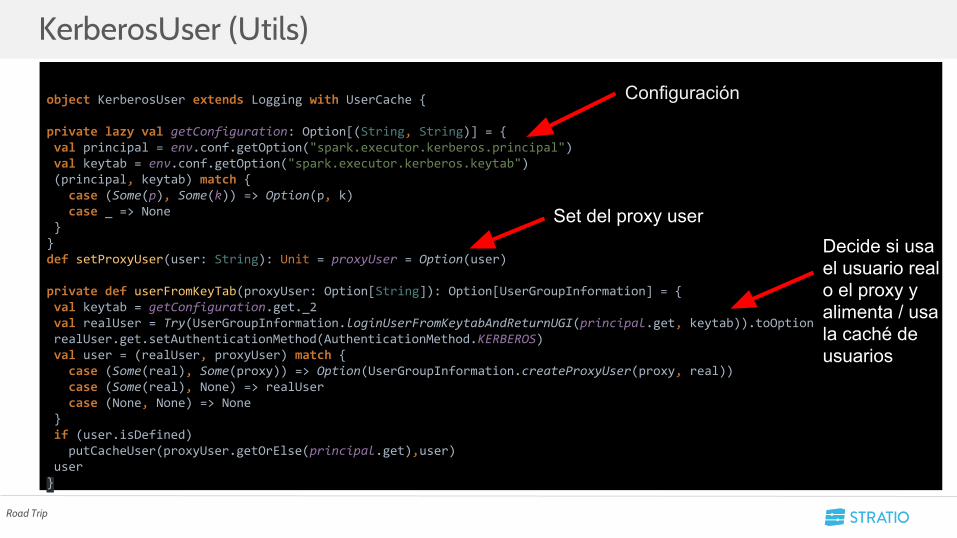
KerberosUser (Utils)
object KerberosUser extends Logging with UserCache {
private lazy val getConfiguration: Option[(String, String)] = { val principal = env.conf.getOption("spark.executor.kerberos.principal") val keytab = env.conf.getOption("spark.executor.kerberos.keytab") (principal, keytab) match { case (Some(p), Some(k)) => Option(p, k) case _ => None }}def setProxyUser(user: String): Unit = proxyUser = Option(user)
private def userFromKeyTab(proxyUser: Option[String]): Option[UserGroupInformation] = { val keytab = getConfiguration.get._2 val realUser = Try(UserGroupInformation.loginUserFromKeytabAndReturnUGI(principal.get, keytab)).toOption realUser.get.setAuthenticationMethod(AuthenticationMethod.KERBEROS) val user = (realUser, proxyUser) match { case (Some(real), Some(proxy)) => Option(UserGroupInformation.createProxyUser(proxy, real)) case (Some(real), None) => realUser case (None, None) => None } if (user.isDefined) putCacheUser(proxyUser.getOrElse(principal.get),user) user}
Configuración
Set del proxy userDecide si usa el usuario real o el proxy y alimenta / usa la caché de usuarios
Road Trip

class PairRDDFunctions[K, V](self: RDD[(K, V)]) (implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null)...def saveAsHadoopDataset(conf: JobConf): Unit = self.withScope {
val internalSave: (JobConf => Unit) = (conf: JobConf) => { // Rename this as hadoopConf internally to avoid shadowing (see SPARK-2038). val hadoopConf = conf ... val writeToFile = (context: TaskContext, iter: Iterator[(K, V)]) => { …. } self.context.runJob(self, writeToFile) writer.commitJob() }KerberosUser.getUserByName(self.user) match { case Some(user) => { user.doAs(new PrivilegedExceptionAction[Unit]() { @throws(classOf[Exception]) def run: Unit = internalSave(conf) }) } case None => internalSave(conf)}
}
saveAs….
Road Trip
Método real de guardado con Spark
wrapper de método de guardar hecho por Spark
ejecución autentificada con Kerberos
• Segunda prueba EndToEnd
○ Se prueba el mismo fichero con SparkSQL
○ Resultado: ¡Fracaso!
• Primera prueba EndToEnd
○ Se prueba una lectura de un fichero txt para luego escribirlo tras ordenarlo en otro fichero
○ Resultado: ¡Éxito!
SparkSQL
Road Trip
• Al ser los Datasources de Spark “cajas negras” cada uno hace lo que considera necesario para funcionar
○ Ej: Parquet lanza un trabajo de Spark sólo para leer el esquema.
• Ya no vale con tener un usuario dentro del RDD, tenemos que tener control sobre el usuario actual (se cambia en SQL mediante Options)
• ¡Kerberos User!
• Idéntico resultado al guardar (Fallo)
• No sólo tenemos que controlar la carga de datos sino que también la ejecución de queries
SparkSQL
Road Trip

• Métodos que requieren autentificarse con Kerberos:DataframeReader:
■ load-> carga un RDD desde un Datasource
○ QueryExecution:■ toRDD -> ejecuta un queryPlan y lo transforma en RDD[Row]
○ ResolvedDataSource:■ apply -> crea un nuevo Resolved Datasource para poder leerlo.
SparkSQL
Road Trip
• Segunda prueba EndToEnd
○ Se prueba el mismo fichero con SparkSQL dos veces cambiando el usario
○ Resultado: ¡Éxito!
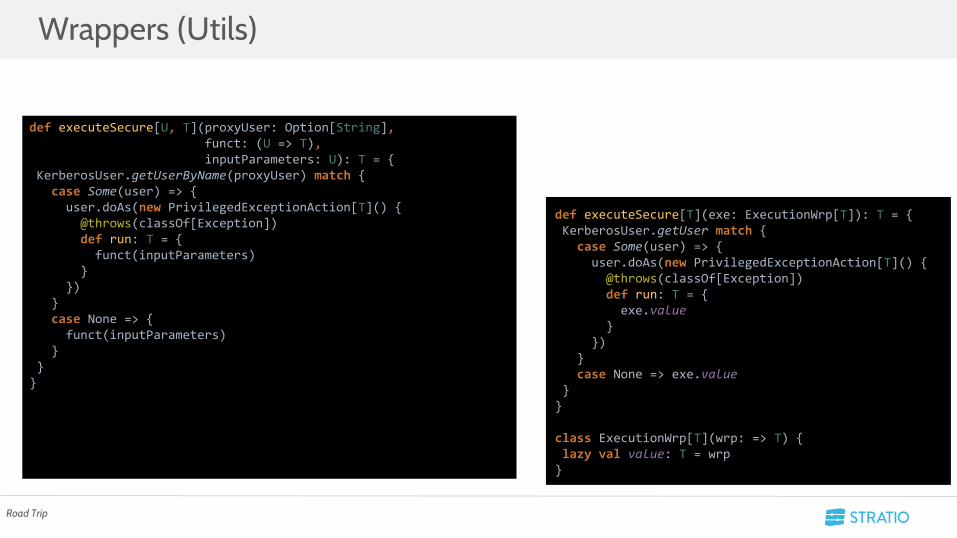
Wrappers (Utils)
def executeSecure[U, T](proxyUser: Option[String], funct: (U => T), inputParameters: U): T = { KerberosUser.getUserByName(proxyUser) match { case Some(user) => { user.doAs(new PrivilegedExceptionAction[T]() { @throws(classOf[Exception]) def run: T = { funct(inputParameters) } }) } case None => { funct(inputParameters) } }}
def executeSecure[T](exe: ExecutionWrp[T]): T = { KerberosUser.getUser match { case Some(user) => { user.doAs(new PrivilegedExceptionAction[T]() { @throws(classOf[Exception]) def run: T = { exe.value } }) } case None => exe.value }}
class ExecutionWrp[T](wrp: => T) { lazy val value: T = wrp}
Road Trip
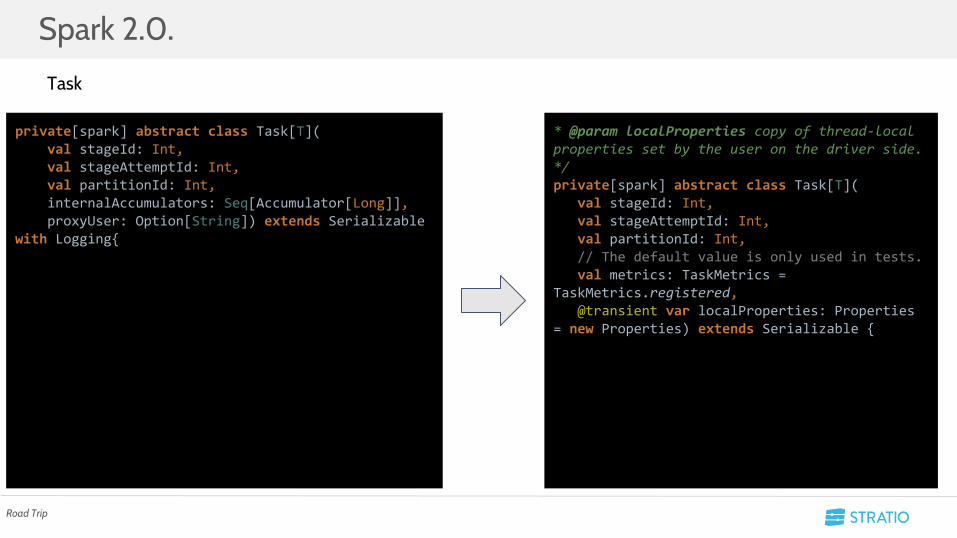
• Cambios principales:
○ Los Task tiene un properties dentro -> NO SE TOCA SU API
○ La lectura de los Datasources en SQL se hace principalmente en una clase
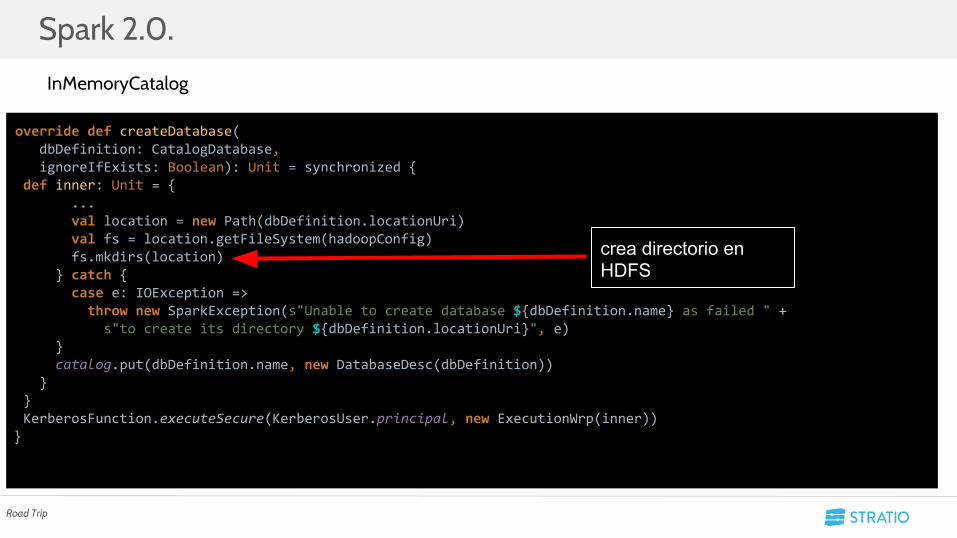
○ Se intenta guardar el catálogo de SparkSQL en HDFS.
Spark 2.0.
Road Trip
Spark 2.0.
private[spark] abstract class Task[T]( val stageId: Int, val stageAttemptId: Int, val partitionId: Int, internalAccumulators: Seq[Accumulator[Long]], proxyUser: Option[String]) extends Serializable with Logging{
Road Trip
Task
* @param localProperties copy of thread-local properties set by the user on the driver side.*/private[spark] abstract class Task[T]( val stageId: Int, val stageAttemptId: Int, val partitionId: Int, // The default value is only used in tests. val metrics: TaskMetrics = TaskMetrics.registered, @transient var localProperties: Properties = new Properties) extends Serializable {
Spark 2.0.
override def createDatabase( dbDefinition: CatalogDatabase, ignoreIfExists: Boolean): Unit = synchronized { def inner: Unit = { ... val location = new Path(dbDefinition.locationUri) val fs = location.getFileSystem(hadoopConfig) fs.mkdirs(location) } catch { case e: IOException => throw new SparkException(s"Unable to create database ${dbDefinition.name} as failed " + s"to create its directory ${dbDefinition.locationUri}", e) } catalog.put(dbDefinition.name, new DatabaseDesc(dbDefinition)) } } KerberosFunction.executeSecure(KerberosUser.principal, new ExecutionWrp(inner))}
Road Trip
InMemoryCatalog
crea directorio en HDFS
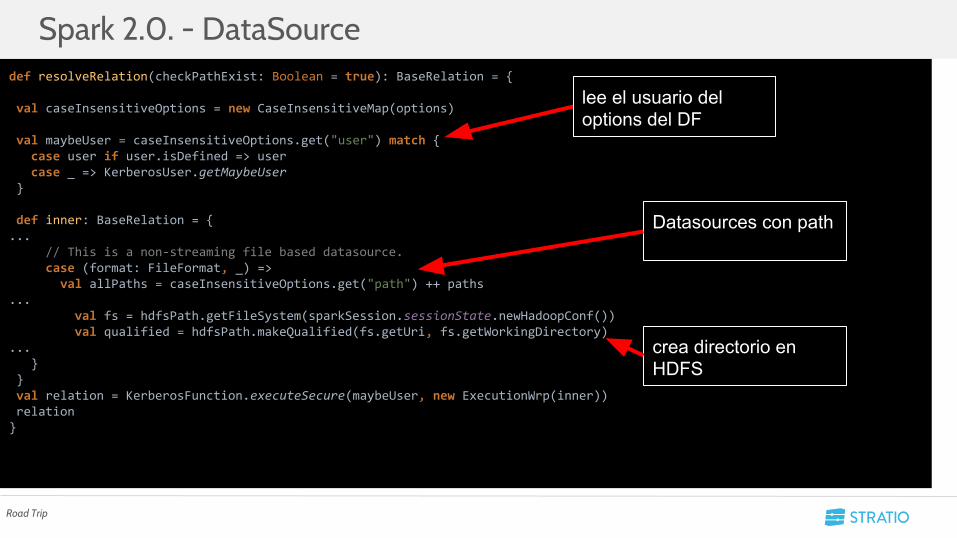
def resolveRelation(checkPathExist: Boolean = true): BaseRelation = {
val caseInsensitiveOptions = new CaseInsensitiveMap(options)
val maybeUser = caseInsensitiveOptions.get("user") match { case user if user.isDefined => user case _ => KerberosUser.getMaybeUser }
def inner: BaseRelation = {... // This is a non-streaming file based datasource. case (format: FileFormat, _) => val allPaths = caseInsensitiveOptions.get("path") ++ paths... val fs = hdfsPath.getFileSystem(sparkSession.sessionState.newHadoopConf()) val qualified = hdfsPath.makeQualified(fs.getUri, fs.getWorkingDirectory)... } } val relation = KerberosFunction.executeSecure(maybeUser, new ExecutionWrp(inner)) relation}
Spark 2.0. - DataSource
Road Trip
lee el usuario del options del DF
crea directorio en HDFS
Datasources con path
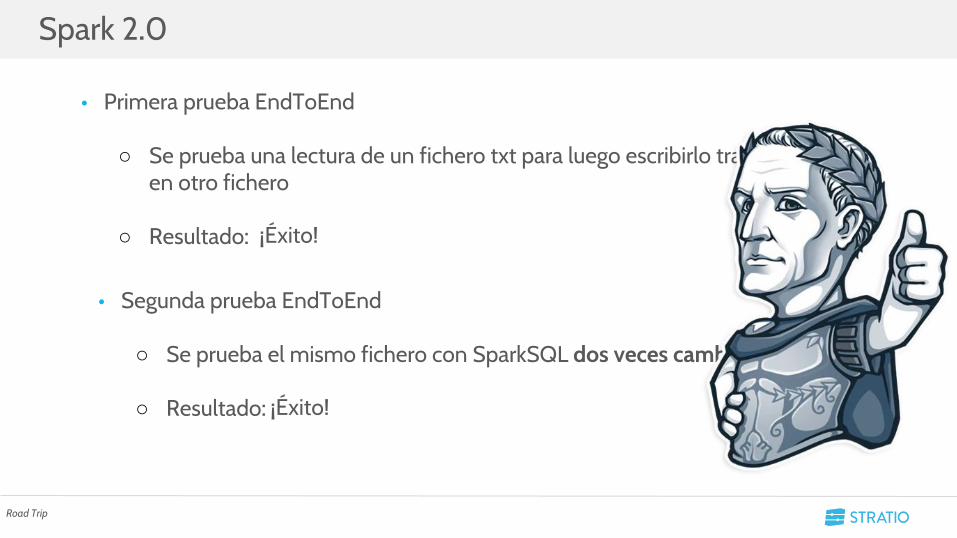
• Segunda prueba EndToEnd
○ Se prueba el mismo fichero con SparkSQL dos veces cambiando el usario
○ Resultado:
• Primera prueba EndToEnd
○ Se prueba una lectura de un fichero txt para luego escribirlo tras ordenarlo en otro fichero
○ Resultado:
Spark 2.0
Road Trip
¡Éxito!
¡Éxito!
tgstgt
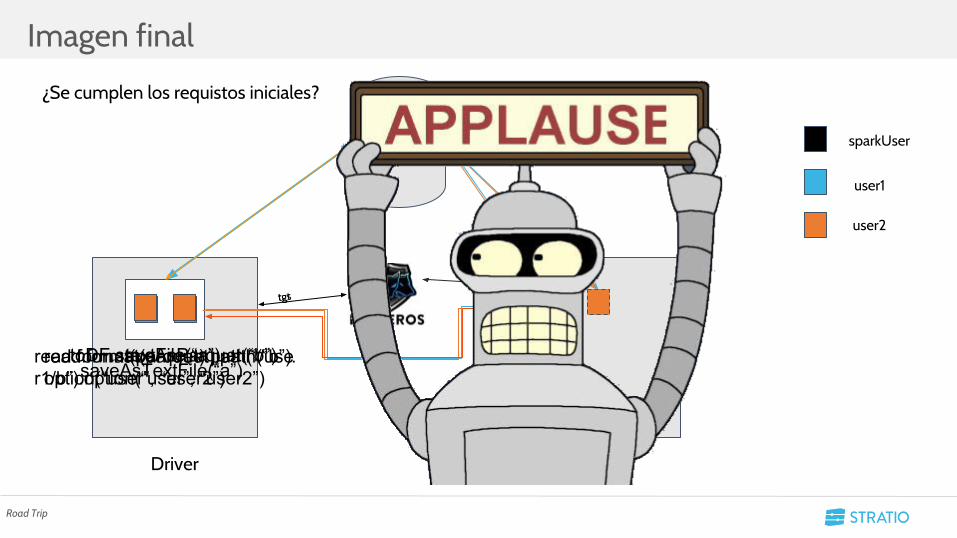
read.format(parquet).path(“/user1/b”).option(“user”, “user2”)read.format(parquet).path(“b”).option(“user”, “user2”)
toDF.saveAsParquet(“b”)textFile(“a”)saveAsTextFile(“a”)
Imagen final
Road Trip
Driver Executor
sparkUser
user1
user2
HDFS
tgttgs
¿Se cumplen los requistos iniciales?
• Entrar en Apache Spark*
• Asociar la creación del RDD al “usuario activo”
• Kerberizar sólo las acciones que requieran ser Kerberizadas
• ¿Siempre Kerberos? ¿Por qué?
• Caché de usuarios distribuida
• La dominación mundial
Y después de esto, ¿qué viene?
Road Trip

Ruegos y preguntas
Ruegos y preguntas

¡Esto es todo amigos!
MUCHAS GRACIAS Y ANIMAROS A COMPARTIR CONOCIMIENTO



















