


Modelado de los computadores paralelos -...
26
1 Modelado de los computadores paralelos Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal: Introducción a la Programación Paralela, Paraninfo Cengage Learning, 2008 Figuras tomadas directamente del libro y de la conferencia de Casiano Rodríguez sobre OpenMP
Transcript of Modelado de los computadores paralelos -...

1
Modelado de los computadores paralelos
Francisco Almeida, Domingo Giménez, José Miguel Mantas, Antonio M. Vidal:
Introducción a la Programación Paralela,
Paraninfo Cengage Learning, 2008
Figuras tomadas directamente del libroy de la conferencia de Casiano Rodríguez sobre OpenMP

2
Programación paralela Uso de varios procesadores trabajando juntos para resolver
una tarea común: Cada procesador trabaja en una porción del problema Los procesos pueden intercambiar datos, a través de:
la memoria (Modelo de Memoria Compartida)
por una red de interconexión (Modelo de Paso de
Mensajes)

3
Paralelismo en monoprocesadores Segmentación encauzada. Pipeline Múltiples unidades funcionales Unidades vectoriales (SSE de Intel) Procesadores de E/S Jerarquía de memorias División de memoria en bloques Paralelismo a nivel de instrucción (VLIW) Ejecución fuera de orden Especulación Multithreading (posible programación paralela) ...

4
Segmentación – múltiples unidades

5
Jerarquía de memorias
6
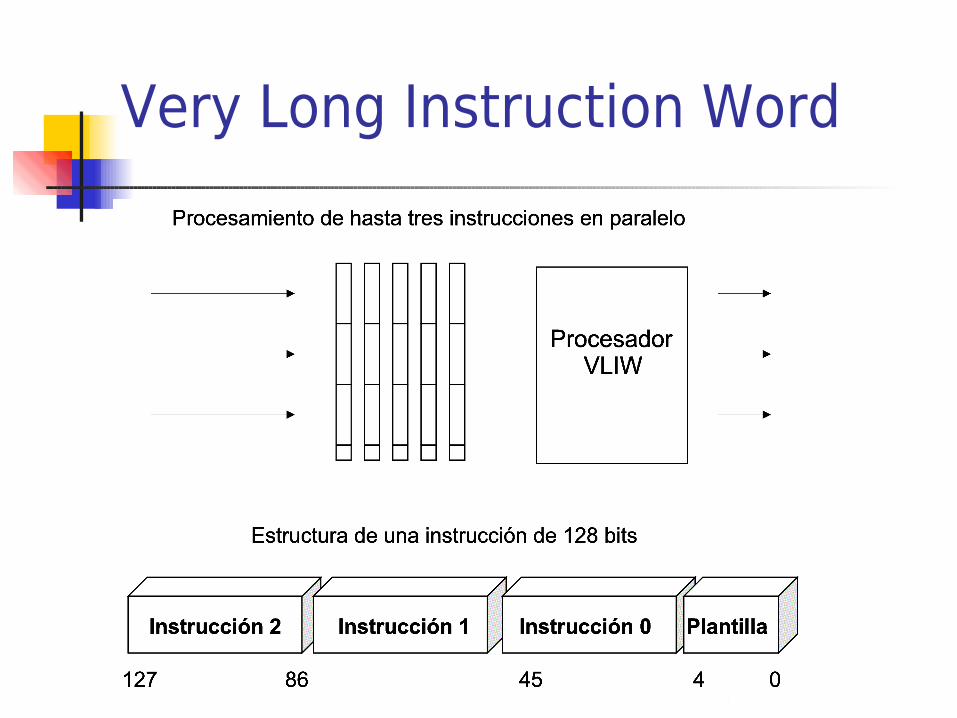
Very Long Instruction Word
7
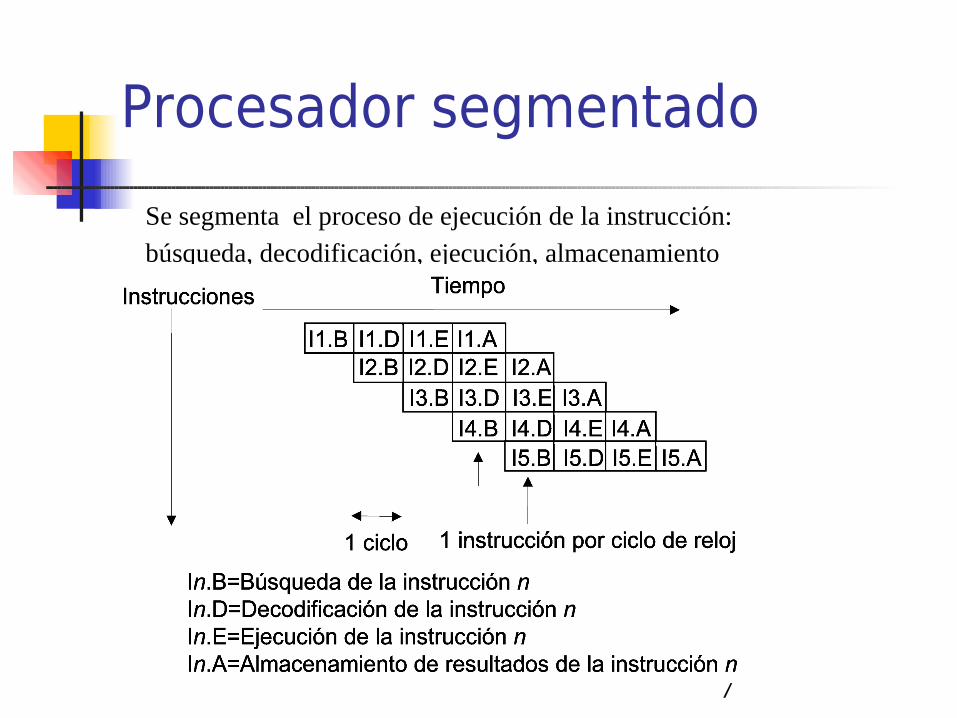
Procesador segmentado
Se segmenta el proceso de ejecución de la instrucción:
búsqueda, decodificación, ejecución, almacenamiento

8
Procesador supersegmentado
Cada etapa se divide en subetapas,
y se lanzan subetapas sin completar el ciclo de reloj

9
Procesador superescalar
Lanzar varias instrucciones de forma simultánea
(ejecución fuera de orden, especulación...)

10
MultithreadingSe lanzan varios hilos simultáneamente, que comparten recursos

11
Modelos computadores paralelos–clasificación de Flynn

12
SISD
Procesador
Memoria
SECUENCIAL (SISD)Modelo Von Neuman
Instrucciones:de memoria a procesador
Datos:entre memoriay procesador

13
SIMD
Una única Unidad de Control. La misma instrucción se ejecuta síncronamente por todas las unidades de procesamiento.
Procesador Procesador Procesador
programa
instrucciones
datos

14
MIMD
Cada procesador ejecuta un programa diferente independientemente de los otros procesadores.
Procesador
programa
instrucciones
datos
Procesador
programa
instrucciones
datos
Procesador
programa
instrucciones
datos
...

15
Modelos de computadores paralelos
Memoria compartida – un único espacio de memoria. Todos los procesadores tienen acceso a la memoria a través de una red de conexión: - Bus - Red de barras cruzadas - Red multietapa
Memoria distribuida – cada procesador tiene su propia memoria local. Se utiliza paso de mensajes para intercambiar datos.
P P P P P P
B U S
M e m o r y
M
P
M
P
M
P
M
P
M
P
M
P
Network
16
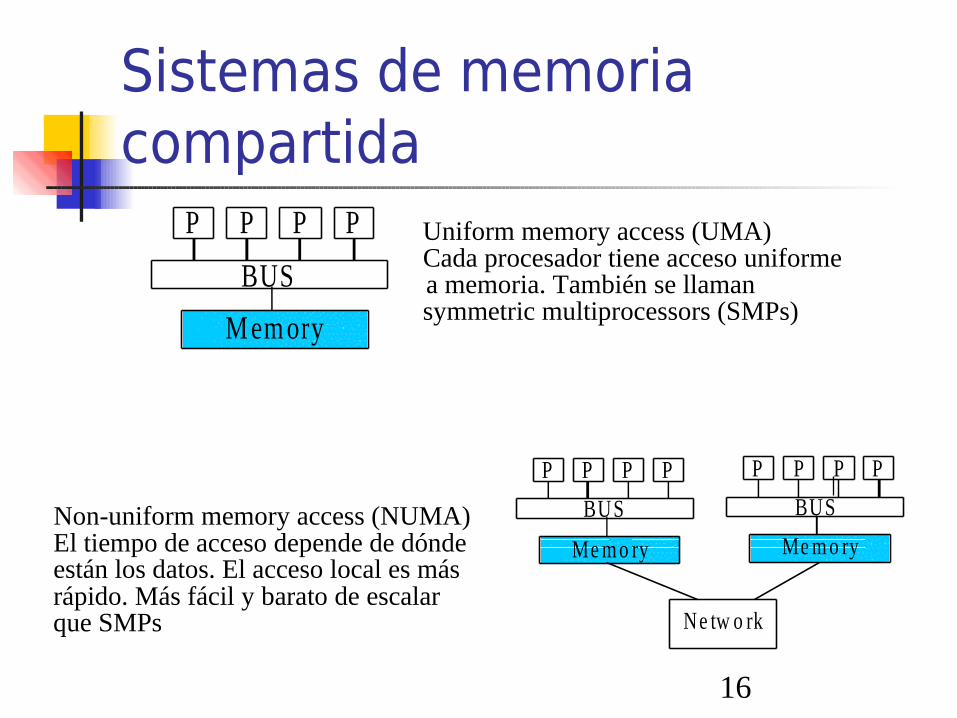
Sistemas de memoria compartida
Uniform memory access (UMA)Cada procesador tiene acceso uniformea memoria. También se llamansymmetric multiprocessors (SMPs)
P P P P
BUS
M em ory
Non-uniform memory access (NUMA)El tiempo de acceso depende de dónde están los datos. El acceso local es más rápido. Más fácil y barato de escalarque SMPs
P P P P
BUS
Me m o ry
Ne tw o rk
P P P P
BUS
Me m o ry
17
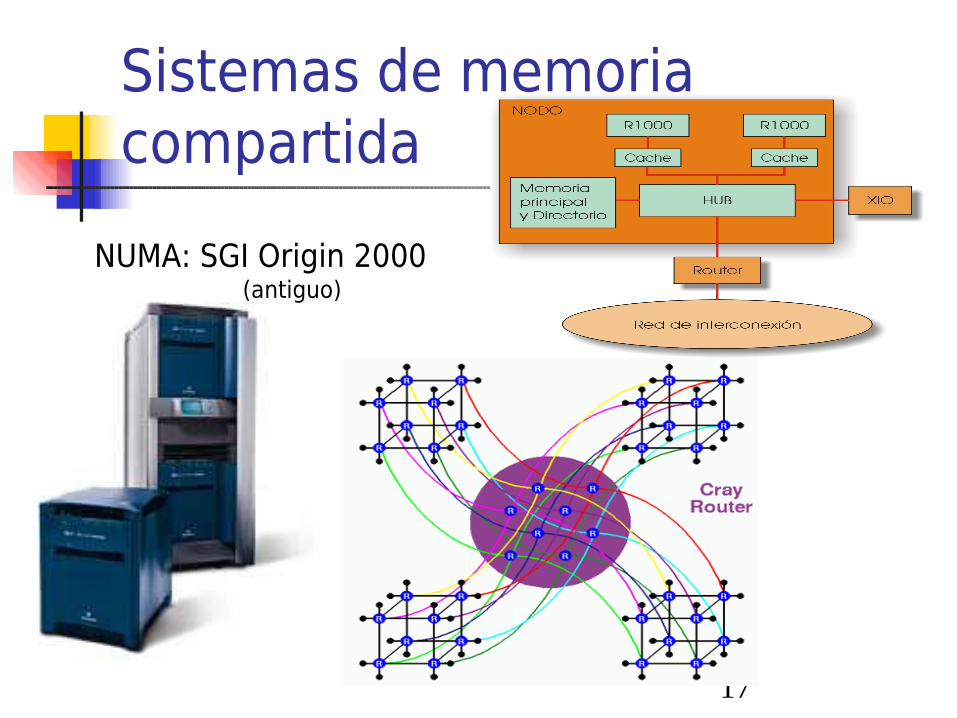
Sistemas de memoria compartida
NUMA: SGI Origin 2000(antiguo)

18
Sistemas de memoria compartida (cc-NUMA)
Ben-Arabí (Centro de Supercomputación de Murcia):Memoria compartida + cluster: 944 coresArabí: cluster de 102 nodos con 2 quad-core Ben: HP Superdome, cc-NUMA con 128 cores
Composición jerárquica con interconexiones crossbar: los computadores y 2 placas de crossbard.
Cada computador tiene 4 dual-core Itanium-2 y un controlador para conectar la CPU con memoria local y los commutadores crossbar
El ancho de banda máximo a memoria en un computador es 17.1 GB/s y con los conmmutadores 34.5 GB/s: el acceso a la memoria es no uniforme, y los usuarios no controlan a qué cores van sus threads, uso de sistema de colas

19

21
Sistemas de memoria distribuida – Topologías de red
anilloDiámetro: p/2 Malla
Diámetro: √p
Servidorde ficheros
Estaciones de trabajo
red
Hipercubo

22
Sistemas de memoria distribuida: híbrido, heterogéneo, jerárquico
mercurio
GPU
512 512
marte
GPU
512 512 luna
GPU112

24
En Murcia– Personal:
• Uso de OpenMP y MPI en monoprocesadores, bipros, quad; GPU
– Empresas y Administración:• Redes o multiprocesadores de reducido tamaño• Uso para manejo de volúmenes de datos grandes, sin programación paralela• Uso de programas paralelos desarrollados por otros• Ben-Arabí: supercomputador MC+clusters, computación científica+empresas
– Universidad:• Cartagena: híbrido MC+MD, 12 nodos de 8 núcleos + 2 nodos de 16 núcleos• Murcia: híbrido MC+MD, ¿12 nodos de 8 núcleos?• Resolución de problemas científicos, uso mínimo de paralelismo
– Grupos de investigación Computación Científica y Programación Paralela:• Redes, clusters, GPU: para computación científica o paralelismo• PCGUM: tetra con GPU 112 c (luna)+2 hexa (marte, mercurio) con GPU 1024 c cada
uno; cluster (sol): 3 bipro con duales+ 2 bipros; multicore 24 c con GPU 448 c (saturno)

25
Sistemas actuales y futuros
• Multicore– Actual: Bipro y Quad en
portátiles, y en sobremesa también hexa, octa...
• Procesadores específicos– Gráficos GPU– De tratamiento de señal DSP– FPGA y heterogéneos
embebidos– De juegos, PS3
• Computadores heterogéneos– CPU+GPU– Futuro: Plataformas
híbridas Itanium2+Xeon con MC
• Distribuidos
– Redes, Grid, Web, Cloud
– P2P, móviles

26
Para la próxima sesión
• Ir pensando temas alternativos para presentaciones del día 7 de noviembre. Ejemplos: cuántica, paralelismo en .net...
• Se verá programación en memoria compartida, con OpenMP. Consultar la parte correspondiente del capítulo 3 del libro de IPP.
• ¿Traer los portátiles para hacer las prácticas a continuación de la clase y en el mismo aula?
• La primera práctica (común) se hará con el problema D del concurso de programación paralela de 2011. Es una multiplicación de cuatro matrices. La entrega es el 30 de noviembre.
Consultar en la página del concurso: cpp.fpcmur.es. Está resuelto, pero habrá que hacerlo en OpenMP, MPI y MPI+OpenMP, y se valorarán innovaciones y batir el record.


















