
Modelos ARDL
18
Modelos ARDL - Parte II - Pruebas Bounds [Nota: Para obtener una actualización importante de este post, relativa a EViews 9 , ver mi post 2015, aquí .] Bueno, al final me tengo hecho! Algunos de estos cargos toman más tiempo para preparar lo que podría pensar. La primera parte de esta discusión fue cubierto en un (especie de!) post reciente , en el que me di una breve descripción de Autoregresivo Lag distribuido (ARDL) modelos, junto con un poco de perspectiva histórica. Ahora es el momento para nosotros para llegar a trabajar y ver cómo han llegado estos modelos a jugar un papel muy importante recientemente en el modelado de datos de series de tiempo no estacionarias. En particular, vamos a ver cómo se utilizan para implementar los llamados "Bounds pruebas", para ver si las relaciones de largo plazo están presentes cuando tenemos un grupo de series de tiempo, algunos de los cuales pueden ser estacionaria, mientras que otros no lo son. Un ejemplo práctico detallado, usando EViews, está incluido. En primer lugar, recordemos que la forma básica de un modelo de regresión ARDL es: y t = β 0 + β 1 y t-1 + ....... + β k y tp + α 0 x t + α 1 x t- 1 + α 2 x t-2 + ......... + α q x tq + ε t , (1) donde ε t es una "perturbación" al azar plazo, lo que vamos a suponer es "bien comportado "en el sentido habitual. En particular, será en serie independiente. Vamos a modificar este modelo un tanto para nuestros propósitos aquí. En concreto, vamos a trabajar con una mezcla de las diferencias y niveles de los datos. Las razones de esto se pondrán de manifiesto a medida que avanzamos. Supongamos que tenemos un conjunto de variables de series de tiempo, y queremos modelar la relación entre ellos, teniendo en cuenta las raíces y / o cointegración unitarios asociados con los datos. En primer lugar, tenga en cuenta que hay tres situaciones sencillas que vamos a poner a un lado, ya que pueden ser tratados de forma estándar: 1. Sabemos que todas las series son I (0), y por lo tanto estacionaria. En este caso, simplemente podemos modelar los datos en sus niveles, utilizando la estimación MCO, por ejemplo. 2. Sabemos que todas las series están integradas del mismo orden ( por ejemplo , I (1)), pero están no cointegradas.En este caso, podemos simplemente (apropiadamente) Diferencia de cada serie, y estimar un modelo de regresión estándar utilizando MCO. 3. Sabemos que todas las series están integradas del mismo orden, y ellos están cointegradas . En este caso, se puede estimar dos tipos de modelos: (i) un modelo de regresión MCO utilizando los niveles de los datos. Esto proporcionará la relación equilibrante de largo plazo entre las variables. (Ii) Un modelo de corrección de errores (ECM), que se estima por MCO. Este modelo representará la dinámica de la relación entre las variables de corto plazo. 1. Ahora, volvamos a la situación más complicada se mencionó anteriormente. Algunas de las variables en cuestiónpuede ser estacionaria, algunos puede ser I (1) o incluso integrado fraccional, y también hay la posibilidad de cointegración entre algunos de los I (1) variables. En otras palabras, las cosas no son tan "clara", como en las tres situaciones mencionadas anteriormente. ¿Qué hacemos en estos casos si queremos modelar los datos adecuadamente y extraer relaciones tanto a largo plazo como a corto plazo? Aquí es donde el modelo ARDL entra en escena. La
-
Upload
erick-xocoyotzin-gomez-gonzalez -
Category
Documents
-
view
117 -
download
6
description
metodologia para modelos ARDL
Transcript of Modelos ARDL

Modelos ARDL - Parte II - Pruebas Bounds [Nota: Para obtener una actualización importante de este post, relativa a EViews 9 , ver mi post 2015, aquí .] Bueno, al final me tengo hecho! Algunos de estos cargos toman más tiempo para preparar lo que podría pensar. La primera parte de esta discusión fue cubierto en un (especie de!) post reciente , en el que me di una breve descripción de Autoregresivo Lag distribuido (ARDL) modelos, junto con un poco de perspectiva histórica. Ahora es el momento para nosotros para llegar a trabajar y ver cómo han llegado estos modelos a jugar un papel muy importante recientemente en el modelado de datos de series de tiempo no estacionarias.
En particular, vamos a ver cómo se utilizan para implementar los llamados "Bounds pruebas", para ver si las relaciones de largo plazo están presentes cuando tenemos un grupo de series de tiempo, algunos de los cuales pueden ser estacionaria, mientras que otros no lo son. Un ejemplo práctico detallado, usando EViews, está incluido. En primer lugar, recordemos que la forma básica de un modelo de regresión ARDL es: y t = β 0 + β 1 y t-1 + ....... + β k y tp + α 0 x t + α 1 x t- 1 + α 2 x t-2 + ......... + α q x tq + ε t , (1) donde ε t es una "perturbación" al azar plazo, lo que vamos a suponer es "bien comportado "en el sentido habitual. En particular, será en serie independiente.
Vamos a modificar este modelo un tanto para nuestros propósitos aquí. En concreto, vamos a trabajar con una mezcla de las diferencias y niveles de los datos. Las razones de esto se pondrán de manifiesto a medida que avanzamos. Supongamos que tenemos un conjunto de variables de series de tiempo, y queremos modelar la relación entre ellos, teniendo en cuenta las raíces y / o cointegración unitarios asociados con los datos. En primer lugar, tenga en cuenta que hay tres situaciones sencillas que vamos a poner a un lado, ya que pueden ser tratados de forma estándar:
1. Sabemos que todas las series son I (0), y por lo tanto estacionaria. En este caso, simplemente podemos modelar los datos en sus niveles, utilizando la estimación MCO, por ejemplo.
2. Sabemos que todas las series están integradas del mismo orden ( por ejemplo , I (1)), pero están no cointegradas.En este caso, podemos simplemente (apropiadamente) Diferencia de cada serie, y estimar un modelo de regresión estándar utilizando MCO.
3. Sabemos que todas las series están integradas del mismo orden, y ellos están cointegradas . En este caso, se puede estimar dos tipos de modelos: (i) un modelo de regresión MCO utilizando los niveles de los datos. Esto proporcionará la relación equilibrante de largo plazo entre las variables. (Ii) Un modelo de corrección de errores (ECM), que se estima por MCO. Este modelo representará la dinámica de la relación entre las variables de corto plazo.
1. Ahora, volvamos a la situación más complicada se mencionó anteriormente. Algunas de las variables en cuestiónpuede ser estacionaria, algunos puede ser I (1) o incluso integrado fraccional, y también hay la posibilidad de cointegración entre algunos de los I (1) variables. En otras palabras, las cosas no son tan "clara", como en las tres situaciones mencionadas anteriormente.
¿Qué hacemos en estos casos si queremos modelar los datos adecuadamente y extraer relaciones tanto a largo plazo como a corto plazo? Aquí es donde el modelo ARDL entra en escena. La

metodología ARDL / Pruebas límites de Pesaran y Shin (1999) y Pesaran et al . (2001) presenta una serie de características que muchos investigadores se sienten darle algunas ventajas sobre las pruebas de cointegración convencional. Por ejemplo:
Se puede utilizar con una mezcla de I (0) y I (1) de datos.
Se trata simplemente de una sola ecuación puesta a punto, por lo que es fácil de aplicar e interpretar.
Diferentes variables se pueden asignar diferentes longitudes retardados al entrar en el modelo.
Necesitamos una hoja de ruta para ayudarnos. Estos son los pasos básicos que vamos a seguir (con los detalles que se añaden a continuación):
1. Asegúrese de que ninguna de las variables son I (2), ya que esos datos invalidará la metodología.
2. Formular un modelo "sin restricciones" de corrección de errores (ECM). Este será un tipo particular de modelo ARDL.
3. Determinar la estructura de rezagos apropiado para el modelo en el paso 2.
4. Asegúrese de que los errores de este modelo son en serie independiente.
5. Asegúrese de que el modelo es "dinámicamente estable".
6. Realizar un "Test Límites" para ver si hay evidencia de una relación de largo plazo entre las variables.
7. Si el resultado en el paso 6 es positivo, estimar un modelo de "niveles" a largo plazo, así como una ECM separada "restringida".
8. Utilizar los resultados de los modelos estimados en el paso 7 para medir a corto plazo los efectos dinámicos, y el largo plazo de equilibrar la relación entre las variables.
Podemos ver en la forma del modelo ARDL genérico dado en la ecuación (1) anterior, que se caracterizan por tener tales modelos rezagos de la variable dependiente, así como rezagos (y tal vez el valor actual) de otras variables, como los regresores . Supongamos que hay tres variables que estamos interesados en el modelado: una variable dependiente, y, y otras dos variables explicativas, x 1 y x 2 . Más en general, habrá (k + 1) las variables - una variable dependiente, y k otras variables. Antes de empezar, vamos a recordar lo que una convencional ECM para datos cointegrado parece. Sería de la forma: Dy t = β 0 + Σ β i Dy ti + Σγ j ? x 1t-j + Σδ k Dx 2t-k + φz t-1 + e t ; (2) A continuación, z, el "término de corrección de errores", es la serie de residuos MCO de largo plazo "cointegración regresión", y t = α 0 + α 1 x 1t + α 2 x 2t + v t ; (3) Los rangos de la suma en (2) son de 1 a p, q 0 a 1 y 0 a q 2 respectivamente. Ahora, de vuelta a nuestro propio análisis-

Paso 1 : Podemos utilizar el ADF y KPSS pruebas para comprobar que ninguno de la serie que estamos trabajando son I (2). Paso 2 :
Formular el siguiente modelo: Dy t = β 0 + Σ β i Dy ti + Σγ j ? x 1t-j + Σδ k Dx 2t-k + θ 0 y t-1 + θ 1 x 1t-1 + θ 2 x 2t-1 + e t ; (4) Tenga en cuenta que esto es casi como una ECM tradicional. La diferencia es que ahora hemos reemplazado el término de corrección de errores, z t-1 con los términos y t-1 , x 1t-1 y x 2t-1 . A partir de (3), podemos ver que la serie de residuos rezagado sería z t-1 = (y t-1 - un 0 - un 1 x 1t-1 - un 2 x 2t-1 ), donde los a son los OLS estimaciones de la década de α. Por lo tanto, lo que estamos haciendo en la ecuación (4) es incluida en los mismos niveles rezagados como lo hacemos en un ECM regular, pero estamosno restringir sus coeficientes. Es por esto que podríamos llamar la ecuación (4) un "ECM sin restricciones" , o un "ECM sin restricciones". Pesaran et al . (2001) llaman a esto una "ECM condicional". Paso 3 :
Los rangos de la suma de los distintos términos en (4) son de 1 a p, q 0 a 1 y 0 a q 2 respectively.We necesitan seleccionar los valores adecuados para los desfases máximos, p, q 1 y q 2 . Además, tenga en cuenta que los "cero rezagos" en la? X 1 y? x 2 no necesariamente pueden ser necesarios. Por lo general, estos desfases máximos se determinan mediante el uso de uno o más de los "criterios de información" - AIC, SC (BIC), HQ, etc . Estos criterios se basan en un valor alto de log-verosimilitud, con una "pena" por la inclusión de más retrasos para lograrlo. La forma de la pena varía de un criterio a otro. Cada criterio se inicia con -2log (L), y luego castiga, por lo que el más pequeño el valor de un criterio de información mejor será el resultado. Yo generalmente uso el criterio de Schwarz (Bayes) (SC), ya que es una constante -selector de modelos. Algunos cuidados tiene que tener cuidado de no "sobre-seleccionar" los retrasos máximos, y por lo general también prestar un poco de atención a la (aparente) significación de los coeficientes del modelo. Paso 4 : Un supuesto clave en la metodología ARDL / Pruebas límites de Pesaran et al . (2001) es que los errores de la ecuación (4) deben ser en serie independiente. Como esos autores (p.308), este requisito también puede ser influyente en nuestra elección final de los retardos máximos de las variables del modelo. Una vez una versión aparentemente adecuada de (4) se ha estimado, se debe utilizar la prueba LM para probar la hipótesis nula de que los errores son en serie independiente, en contra de la hipótesis alternativa de que los errores son (tampoco) AR (m) o MA (m), para m = 1, 2, 3, ...., etc.
Paso 5 : Tenemos un modelo con una estructura autorregresiva, así que tenemos que estar seguros de que el modelo es "dinámicamente estable". Para más detalles de lo que esto significa, ver mi post reciente, ¿Cuándo es un modelo dinámicamente estable Autoregresivo? Lo que tenemos que hacer es comprobar que todas las raíces inversas de la ecuación característica asociada con nuestro modelo se encuentran estrictamente dentro del círculo unitario. Ese puesto mío reciente mostró cómo engañar EViews para que nos dé la información que queremos con el fin de comprobar que se cumple esta condición. No voy a repetir eso aquí. Paso 6 : Ahora estamos listos para llevar a cabo la "Prueba de Límites"!Aquí está la ecuación (4), de nuevo: Dy t = β 0 + Σ

β i Dy ti + Σγ j ? x 1t-j + Σδ k Dx 2t-k + θ 0 y t-1 + θ 1 x 1t-1 + θ 2 x 2t-1 + e t ; (4) Todo lo que vamos a hacer es preformas una "F-test" de la hipótesis, H 0 : θ 0 = θ 1 = θ 2 = 0; frente a la alternativa de que H 0 no es cierto. Bastante simple - pero ¿por qué estamos haciendo esto igual que en las pruebas de cointegración convencional, estamos probando para la ausencia de un largo plazo relación de equilibrio entre las variables. Esta ausencia coincide con coeficientes cero para y t-1 , x 1t-1 y x 2t-1 en la ecuación (4). Un rechazo de H 0implica que tenemos una relación de largo plazo. Hay una dificultad práctica que tiene que ser abordado cuando realizamos la prueba F. La distribución de la estadística de prueba es totalmente no-estándar (y también depende de un "parámetro de ruido", el rango de cointegración del sistema), incluso en el caso asintótica donde tenemos una infinitamente grande tamaño de la muestra. (Esto es algo parecido a la situación con la prueba de Wald cuando probemos para Granger no causalidad en la presencia de datos no estacionarios. En ese caso, el problema se resuelve mediante el uso de la Toda-Yamamoto (1995) procedimiento, para asegurar que la estadística de Wald asintótica chi-cuadrado, como se discute aquí .) Exact valores críticos para la prueba F no están disponibles para una mezcla arbitraria de I (0) y I (1) variables. Sin embargo, Pesaran et al . (2001) de suministro de límites en los valores críticos para la asintóticadistribución del estadístico F. Por diversas situaciones ( por ejemplo ., diferente número de variables, (k + 1)), dan límites inferior y superior de los valores críticos. En cada caso, el límite inferior se basa en la suposición de que todas las variables son I (0), y el límite superior se basa en la suposición de que todas las variables son I (1). De hecho, la verdad puede estar en algún lugar entre estos dos extremos polares. Si el computada F-estadística cae por debajo del límite inferior llegaríamos a la conclusión de que las variables son I (0), por lo que no cointegración es posible, por definición. Si la estadística F excede el límite superior, llegamos a la conclusión de que tenemos cointegración. Por último, si el estadístico F se encuentra entre los límites, la prueba no es concluyente. ¿Te recuerda de la antigua prueba de Durbin-Watson para la independencia de serie? ! Debe Como comprobación cruzada, que debe también realizar un "Límites t-test" de H 0 : θ 0 = 0, contra H 1 : θ 0 <0. Si el estadístico t para y t-1 en la ecuación (4) es mayor que el "I (1) unido" tabulados por Pesaran et al. (2001; pp.303-304), esto permite concluir que existe una relación de largo plazo entre las variables. Si la estadística t es menor que el "I (0), vinculado", nos gustaría concluir que los datos son estacionarias. Paso 7 : Si se asume que los límites de prueba lleva a la conclusión de cointegración, se puede estimar de manera significativa el plazo ejecutar relación de equilibrio entre las variables: y t = α 0 + α 1 x 1t + α 2 x 2t + v t ; (5) , así como el ECM habitual: Dy t = β 0 + Σ β i Dy ti + Σγ j ? x 1t-j + Σδ k Dx 2t-k + φz t-1 + e t ; (6) donde z t-1 = (y t-1 -a 0 - un 1 x 1t-1 - un 2 x 2t-1 ), y las a son las estimaciones MCO de la década de α en (5). Paso 8 : Podemos "extraer" efectos de largo plazo de la ECM sin restricciones. Mirando hacia atrás en la ecuación (4), y observando que en un equilibrio a largo plazo, Dy t = 0,? x 1t = Dx 2t = 0, vemos que los coeficientes de largo plazo para x 1 y x 2 son - (θ 1 / θ 0 ) y - (θ 2 / θ 0 ), respectivamente. Un ejemplo: Ahora estamos listos para ver un ejemplo muy simple empírico. Voy a utilizar los datos para EE.UU. y los precios europeos del gas natural que he hecho disponible como un segundo ejemplo en mi post,Pruebas de Causalidad de Granger . Yo no fui a través de los detalles de las pruebas de causalidad de Granger con ese conjunto de datos, pero ya he mencionado, cerca de la final de la entrada, y el archivo de EViews (que incluía un objeto "Read_Me" con comentarios sobre los resultados) es allí en el código de la página de este blog (de fecha 29 de abril de 2011). Si uno mira hacia atrás en ese archivo antes, usted encontrará que usé la Toda-Yamamoto procedimiento (1995) las pruebas para determinar que no es causalidad de Granger que va desde los EE.UU. serie de la serie europea, pero noviceversa . Un nuevo archivo EViews que utiliza los mismos datos para nuestro modelo ARDL está disponible en el código de la página, debajo de la fecha para el puesto actual. Los datos para el dos de series de tiempo que va a utilizar también están disponibles en la información página para este blog. Los datos son mensuales, a partir de 1995 (01) y 2011 (03). En términos de la notación que se introdujo antes, tenemos (k + 1) = 2 variables, por lo que k = 1 cuando se trata de la prueba de límites. He aquí un gráfico de los datos que va a utilizar ( recuerde que usted puede ampliar la mayoría de estos insertos haciendo clic sobre ellos ):

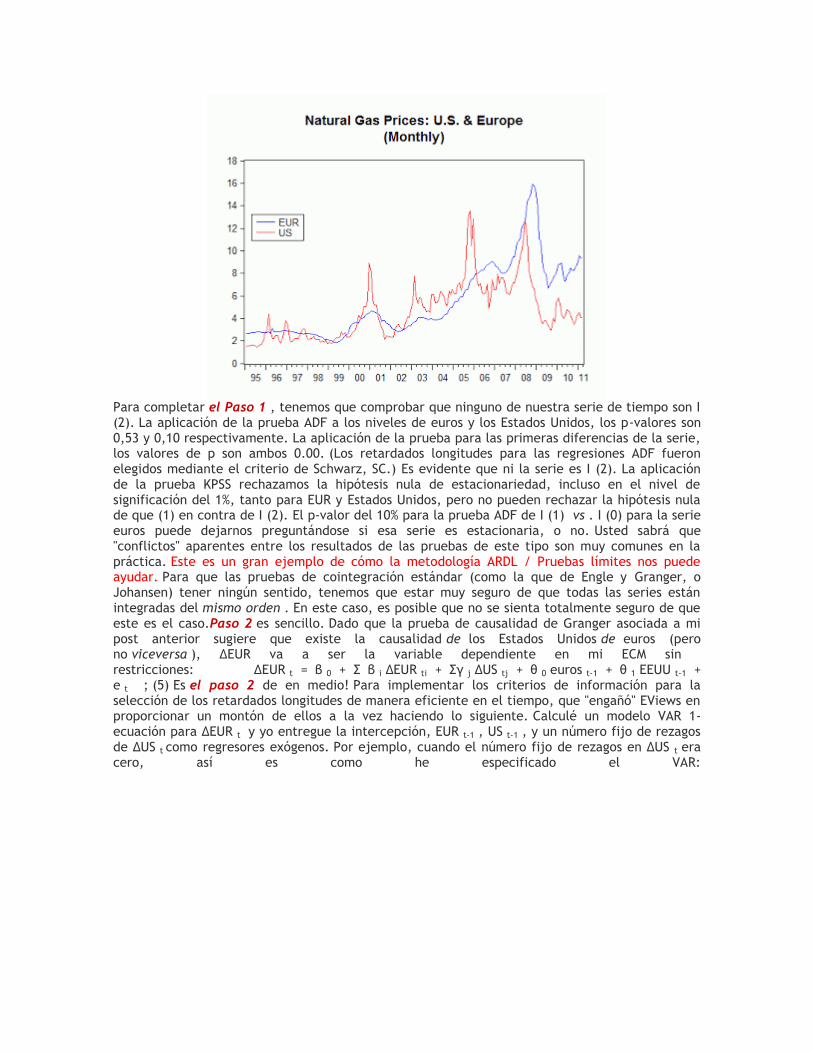
Para completar el Paso 1 , tenemos que comprobar que ninguno de nuestra serie de tiempo son I (2). La aplicación de la prueba ADF a los niveles de euros y los Estados Unidos, los p-valores son 0,53 y 0,10 respectivamente. La aplicación de la prueba para las primeras diferencias de la serie, los valores de p son ambos 0.00. (Los retardados longitudes para las regresiones ADF fueron elegidos mediante el criterio de Schwarz, SC.) Es evidente que ni la serie es I (2). La aplicación de la prueba KPSS rechazamos la hipótesis nula de estacionariedad, incluso en el nivel de significación del 1%, tanto para EUR y Estados Unidos, pero no pueden rechazar la hipótesis nula de que (1) en contra de I (2). El p-valor del 10% para la prueba ADF de I (1) vs . I (0) para la serie euros puede dejarnos preguntándose si esa serie es estacionaria, o no. Usted sabrá que "conflictos" aparentes entre los resultados de las pruebas de este tipo son muy comunes en la práctica. Este es un gran ejemplo de cómo la metodología ARDL / Pruebas límites nos puede ayudar. Para que las pruebas de cointegración estándar (como la que de Engle y Granger, o Johansen) tener ningún sentido, tenemos que estar muy seguro de que todas las series están integradas del mismo orden . En este caso, es posible que no se sienta totalmente seguro de que este es el caso.Paso 2 es sencillo. Dado que la prueba de causalidad de Granger asociada a mi post anterior sugiere que existe la causalidad de los Estados Unidos de euros (pero no viceversa ), ΔEUR va a ser la variable dependiente en mi ECM sin restricciones: ΔEUR t = β 0 + Σ β i ΔEUR ti + Σγ j ΔUS tj + θ 0 euros t-1 + θ 1 EEUU t-1 + e t ; (5) Es el paso 2 de en medio! Para implementar los criterios de información para la selección de los retardados longitudes de manera eficiente en el tiempo, que "engañó" EViews en proporcionar un montón de ellos a la vez haciendo lo siguiente. Calculé un modelo VAR 1-ecuación para ΔEUR t y yo entregue la intercepción, EUR t-1 , US t-1 , y un número fijo de rezagos de ΔUS t como regresores exógenos. Por ejemplo, cuando el número fijo de rezagos en ΔUS t era cero, así es como he especificado el VAR:

Después de estimar este modelo, entonces me decidí VIEW, ESTRUCTURA GAL, GAL CRITERIOS DE LONGITUD:
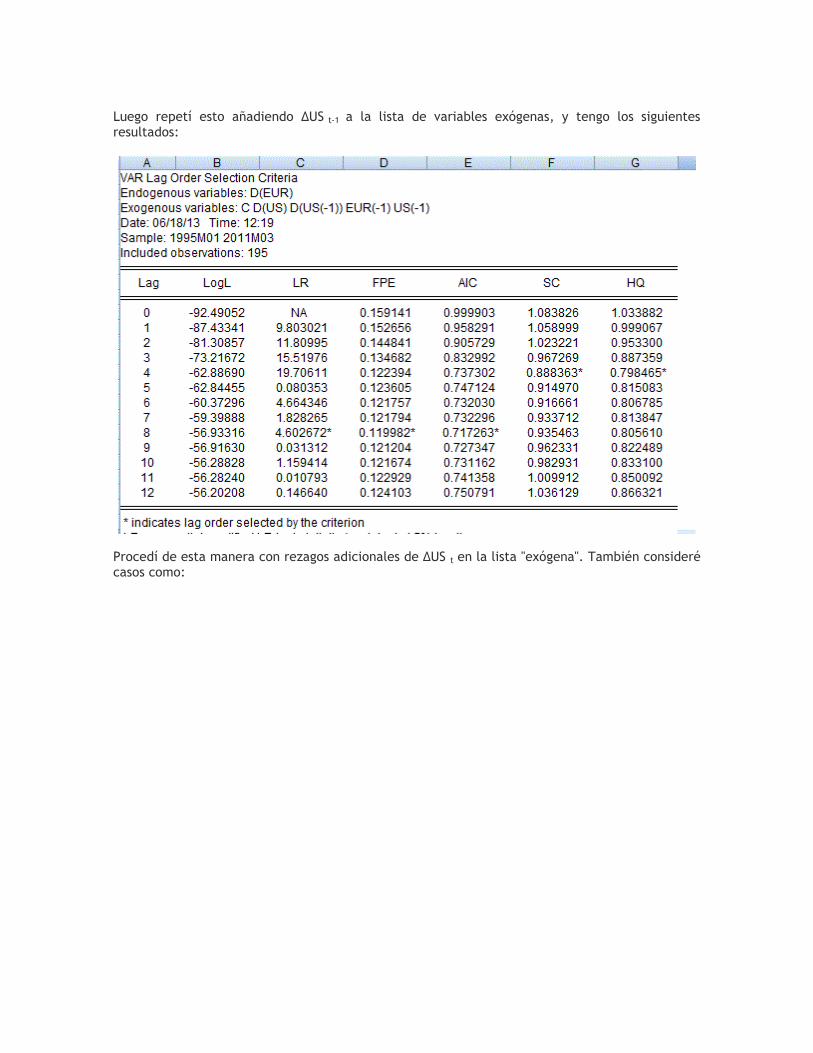
Luego repetí esto añadiendo ΔUS t-1 a la lista de variables exógenas, y tengo los siguientes resultados:
Procedí de esta manera con rezagos adicionales de ΔUS t en la lista "exógena". También consideré casos como:
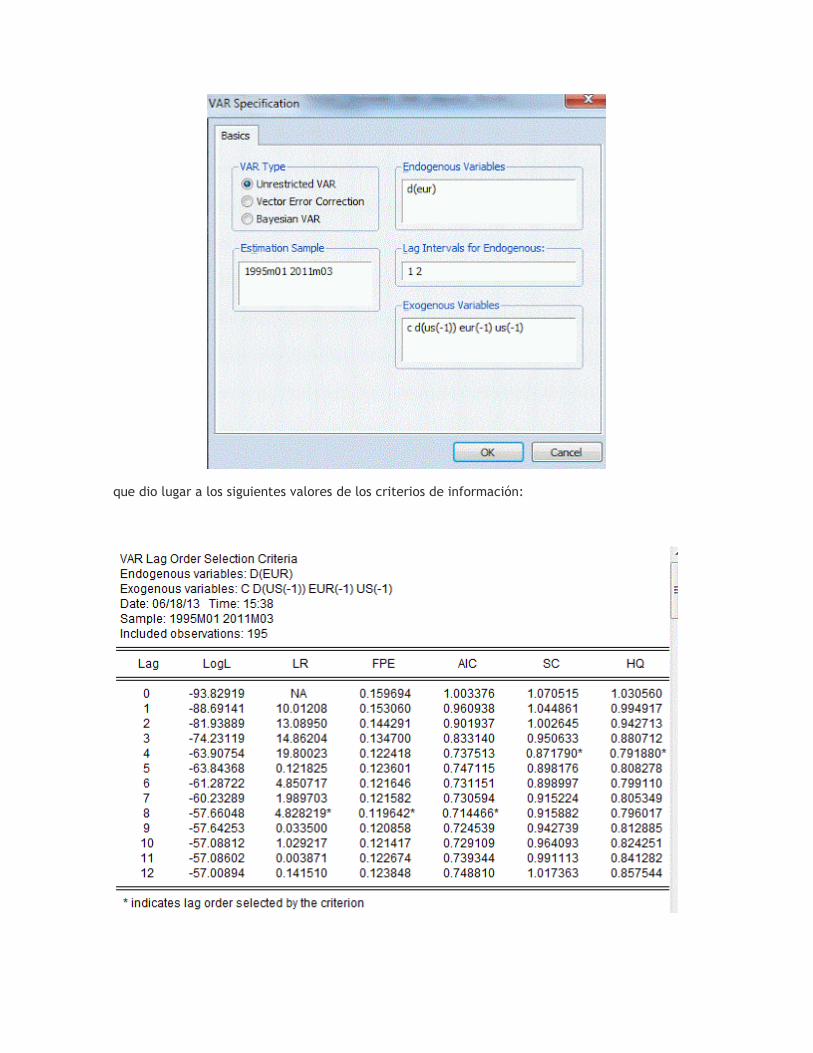
que dio lugar a los siguientes valores de los criterios de información:

En cuanto a los valores de SC en estos tres cuadros de resultados, vemos que se sugiere un retraso máximo de 4 para ΔEUR t. (Los valores de AIC indican que 8 rezagos de ΔEUR t pueden ser apropiados, pero un poco de experimentación con esto no fue fructífera.) Prácticamente no hay diferencia entre los valores de CL para el caso en que el modelo incluye sólo US t como regresor (0.8714), y el caso en que sólo ΔUS t-1 se incluye (0,8718). Para obtener algunas dinámicas en el modelo, voy a ir con el último caso. Con el paso 3 ha completado, y con esta especificación retraso en mente, vamos a ver ahora la ECM sin restricciones estimado:
Paso 4 implica la comprobación de que los errores de este modelo son en serie independiente. OPINIÓN Selección, DIAGNÓSTICO RESIDUALES, TEST LM correlación serial, me sale el siguiente resultado: m LM p-valor 1 0,079 0,779 2 2.878 0.237 3 5.380 0.146 4 11,753 0,019 Bien, tenemos un problema con la correlación serial! Para tratar con él, experimenté con uno o dos retardos adicionales de la variable dependiente como regresores, y terminó con la siguiente especificación para la ECM sin restricciones:

Los resultados de la independencia de serie ahora se ven mucho más satisfactorio: m LM p-valor 1 0,013 0,911 2 3.337 0.189 3 5.183 0.159 4 7.989 0.092 5 8.473 0.132 6 11,023 0,088 7 12,270 0,092 8 12,334 0,137 A continuación, Paso 5 implica la comprobación de la estabilidad dinámica de este modelo ARDL. Aquí están las raíces inversas de la ecuación característica asociada:

Todo parece estar bien - estas raíces son todos dentro del círculo unitario. Antes de proceder a la Prueba de límites, vamos a echar un vistazo a la "forma" de nuestra ECM sin restricciones. La trama "Real / Amueblada / Residuales" se ve así:

Cuando "descifrar" estos resultados, y miramos el ajuste del modelo en términos de explicar el nivel de sí mismo de euros, en lugar de ΔEUR, las cosas se ven bastante bien:
Ahora estamos listos para la Etapa 6 - la propia prueba de límites. Queremos probar si los coeficientes de ambas euros (-1) y Estados Unidos (-1) son cero en nuestro modelo estimado (repetido a continuación):
La prueba F asociado se obtiene como sigue:
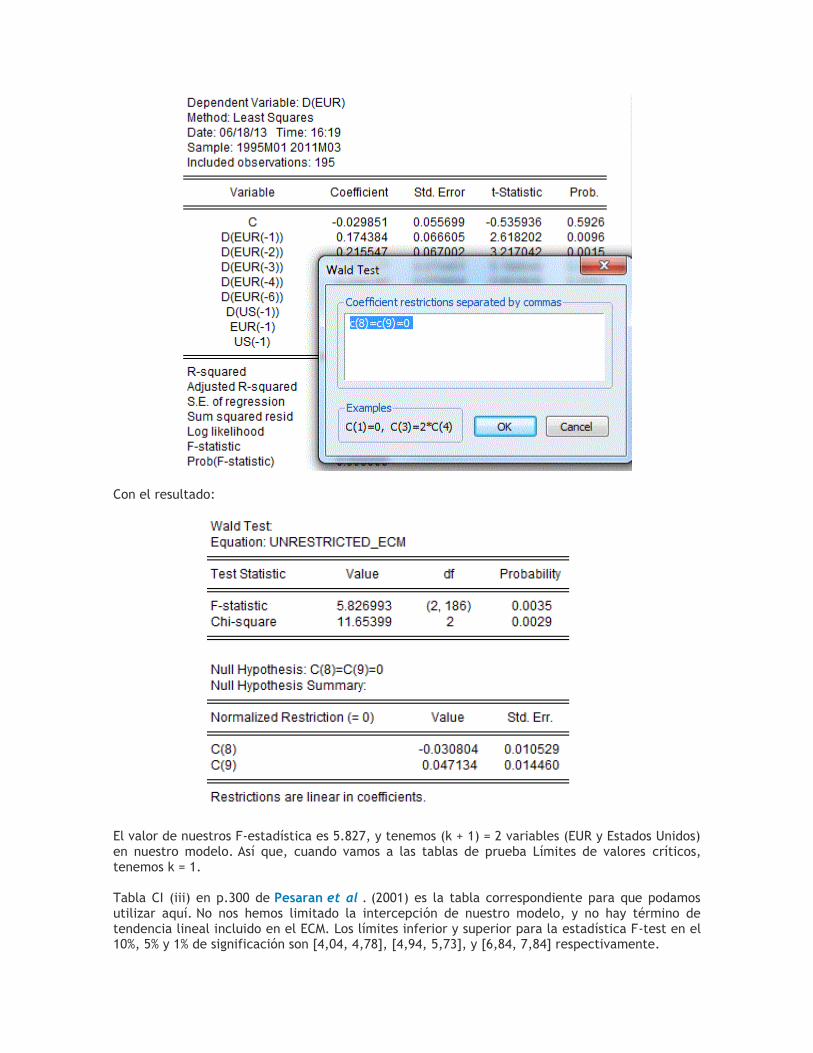
Con el resultado:
El valor de nuestros F-estadística es 5.827, y tenemos (k + 1) = 2 variables (EUR y Estados Unidos) en nuestro modelo. Así que, cuando vamos a las tablas de prueba Límites de valores críticos, tenemos k = 1. Tabla CI (iii) en p.300 de Pesaran et al . (2001) es la tabla correspondiente para que podamos utilizar aquí. No nos hemos limitado la intercepción de nuestro modelo, y no hay término de tendencia lineal incluido en el ECM. Los límites inferior y superior para la estadística F-test en el 10%, 5% y 1% de significación son [4,04, 4,78], [4,94, 5,73], y [6,84, 7,84] respectivamente.

A medida que el valor de nuestro F-estadística excede el límite superior en el nivel de significación del 5%, se puede concluir que existen pruebas de una relación de largo plazo entre las dos series de tiempo (en este nivel de importancia o mayor). Además, el estadístico t de euros (-1) es -2,926. Cuando nos fijamos en la Tabla CII (iii) en p.303 de Pesaran et al .(2001), nos encontramos con que el I (0) y yo (1) límites para el estadístico t en el 10%, 5%, y 1% de significación son [-2,57, -2,91], [-2,86, -3,22], y [-3.43, -3.82] respectivamente. Por lo menos en el nivel de significación del 10%, este resultado refuerza nuestra conclusión de que existe una relación de largo plazo entre EUR y USA. Así pues, aquí estamos en el paso 7 y el paso 8 . Recordando nuestra ECM sin restricciones preferido:
vemos que el multiplicador de largo plazo entre los Estados Unidos y el EUR es - (0.047134 / (-0.030804)) = 1,53. En el largo plazo, un aumento de 1 unidad en Estados Unidos conducirá a un aumento de 1,53 unidades en euros. Si estimamos el modelo de niveles, EUR t = α 0 + α 1 EEUU t + v t , por MCO, y construimos la serie residuales, {z t }, deacuerdo a una normal (restringido) ECM:

Observe que el coeficiente del término de corrección de errores, z t-1 , es negativo y muy significativo. Esto es lo que cabría esperar si existe cointegración entre EUR y USA. La magnitud de este coeficiente implica que casi el 3% de cualquier desequilibrio entre EUR y USA se corrige dentro de un período (un mes). Este ECM final es dinámicamente estable:
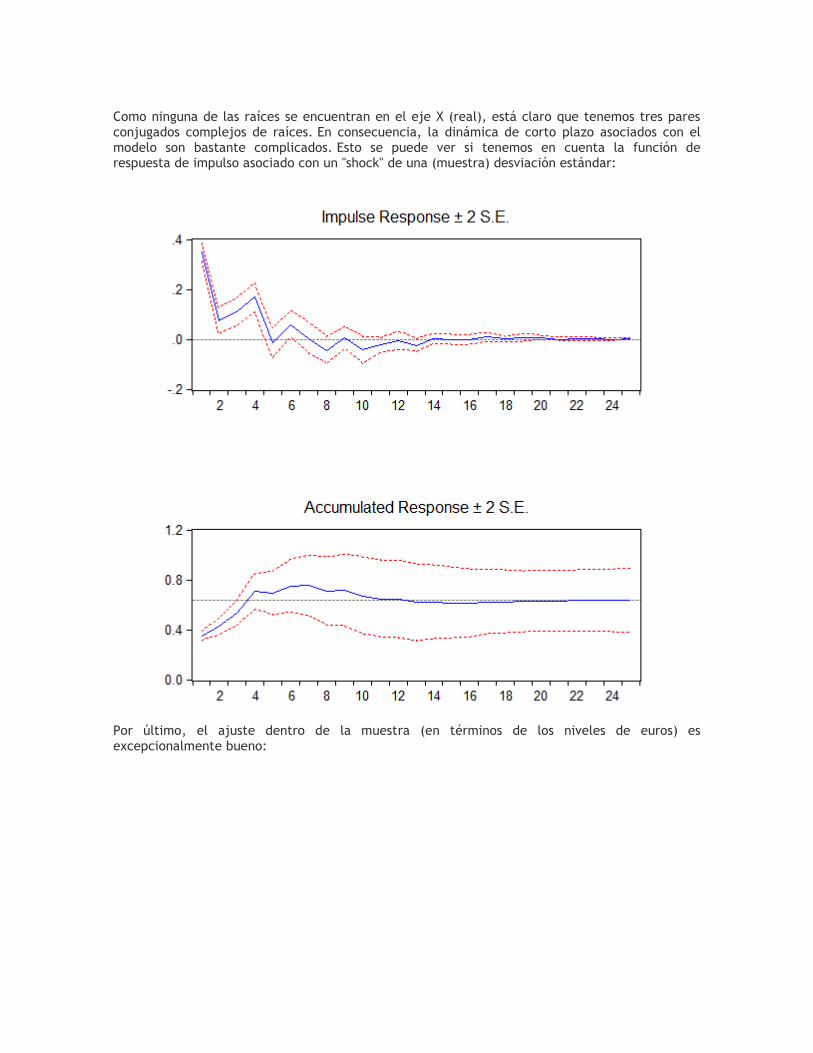
Como ninguna de las raíces se encuentran en el eje X (real), está claro que tenemos tres pares conjugados complejos de raíces. En consecuencia, la dinámica de corto plazo asociados con el modelo son bastante complicados. Esto se puede ver si tenemos en cuenta la función de respuesta de impulso asociado con un "shock" de una (muestra) desviación estándar:
Por último, el ajuste dentro de la muestra (en términos de los niveles de euros) es excepcionalmente bueno:

De hecho, las correlaciones simples entre el "ajustado" series de euros de los de libre disposición y regulares de ECM de euros y son cada 0.994, y la correlación entre las dos series equipada es 0.9999. Así que, ahí lo tenemos - la prueba sale con un modelo ARDL.








![ELS LLIRIS ]ARDl DE LA REINA - traduccionliteraria.org · conciencia de la vostra dignitat i de la vos ... negra o blava, que corre lliure i nua per les selves pestilents o per les](https://static.fdocumento.com/doc/165x107/5c5c828d09d3f2d72f8b7c4b/els-lliris-ardl-de-la-reina-conciencia-de-la-vostra-dignitat-i-de-la-vos.jpg)









