
Selecccion de-variable-y-construccion-del-modelo
27
SELECCCION DE VARIABLE Y CONSTRUCCION DEL MODELO I. Introducción: En muchas situaciones se dispone de un conjunto grande de posibles variables regresoras, una primera pregunta es saber si todas las variables deben entrar en el modelo de regresión y, en caso negativo, se quiere saber qué variables deben entrar y que variables no deben entrar en el modelo. El analista debe determinar el subconjunto real de regresores que debe usarse en el modelo. La definición del subconjunto adecuado de regresores para el modelo es lo que se llama problema de selección de variable. La construcción de un modelo que solo incluya un subconjunto de los regresores disponibles implica dos objetivos contrapuestos: Se desea que el modelo incluya tantos regresores como sea posible, para que el contenido de la información en ellos pueda influir sobre el valor predicho de Y. Se desea que el modelo incluya los menos regresores que sea posible, porque la variancia de la predicción ^ y aumenta a medida que aumenta la cantidad de regresores. También, mientras mas regresores haya en el modelo, los costos de recolección de datos y los del mantenimiento del modelo serán mayores. Ninguno de los procedimientos de selección de variable que se describen a continuación tiene garantía de producir la ecuación de regresión óptima para un determinado conjunto de datos, en general no hay una sola ecuación optima, sino más bien varias igualmente buenas. II. Consecuencias de la mala especificación del modelo: Supongamos que el modelo completo tiene la siguiente forma: y i =β 0 + ∑ j=1 k β j x ij +ε i ,i=1,2 ,…,n.óy=Xβ+ ε Hay K variables regresoras candidatas, con n≥K +1 observaciones de estos regresores y la variable respuesta y. Se supondrá que la lista de los regresores candidatos contiene todas las variables importantes. También se supondrá que todas las ecuaciones incluyen un término de ordenada al origen. 1
-
Upload
clinton-davila-medina -
Category
Education
-
view
51 -
download
0
Transcript of Selecccion de-variable-y-construccion-del-modelo

SELECCCION DE VARIABLE Y CONSTRUCCION DEL MODELO
I. Introducción:
En muchas situaciones se dispone de un conjunto grande de posibles variables regresoras, una primera pregunta es saber si todas las variables deben entrar en el modelo de regresión y, en caso negativo, se quiere saber qué variables deben entrar y que variables no deben entrar en el modelo. El analista debe determinar el subconjunto real de regresores que debe usarse en el modelo. La definición del subconjunto adecuado de regresores para el modelo es lo que se llama problema de selección de variable.
La construcción de un modelo que solo incluya un subconjunto de los regresores disponibles implica dos objetivos contrapuestos:
Se desea que el modelo incluya tantos regresores como sea posible, para que el contenido de la información en ellos pueda influir sobre el valor predicho de Y.
Se desea que el modelo incluya los menos regresores que sea posible, porque la variancia de la predicción y aumenta a medida que aumenta la cantidad de regresores. También, mientras mas regresores haya en el modelo, los costos de recolección de datos y los del mantenimiento del modelo serán mayores.
Ninguno de los procedimientos de selección de variable que se describen a continuación tiene garantía de producir la ecuación de regresión óptima para un determinado conjunto de datos, en general no hay una sola ecuación optima, sino más bien varias igualmente buenas.
II. Consecuencias de la mala especificación del modelo:
Supongamos que el modelo completo tiene la siguiente forma:
y i=β0+∑j=1
k
β j x ij+εi ,i=1,2 ,…,n .ó y=Xβ+ε
HayK variables regresoras candidatas, con n≥ K+1 observaciones de estos regresores y la variable respuesta y.
Se supondrá que la lista de los regresores candidatos contiene todas las variables importantes. También se supondrá que todas las ecuaciones incluyen un término de ordenada al origen.Sean r la cantidad de variables regresoras que serán eliminadas de la ecuación, entonces la cantidad de variables que se retiene es p>=K+1-r; donde el modelo se puede escribir de la siguiente manera:
y=X p βp+X r βr+εSe puede observar que la matriz X se divide en dos matrices de orden (nxp) y (nxr ) respectivamente.Para el modelo completo β estimado es:
β=( X ' X )−1 X ' yY el estimado de la varianza residual es:
σ 2= y ' y− β ' X ' yn−K−1
De donde los:
β p=(X p' X p )
−1X p
' y ; βr=(X r' X r )
−1X r
' y
1

Teniendo en cuenta las ecuaciones anteriores, a continuación se especifican las propiedades de los estimados de β y σ 2 del modelo de subconjunto.
1. El valor esperado de β p es:
E ( β p )=β p+(X ' X )−1 X p' X r βr
Entonces β p es un estimador sesgado de β p, a menos que los coeficientes de regresión que correspondan a las variables eliminadas (β¿¿ p)¿ sean cero, o que las variables estimadas sean ortogonales a las variables omitidas (X p
' X r=0).
2. Las variancias de β p y β son Var(βp)=σ 2(X ' pX p¿¿−1 y Var(β)=σ 2(X ’ X )−1 ,también la matriz Var(β)-Var(βp) es positiva semidefinida, lo cual indica que al eliminar las variables nunca se aumentan las varianzas de los estimados de los parámetros restantes.
3. β p es un estimado sesgado de βp y β no lo es ,es más razonable comparar la precisión de los estimados de los parámetros para los modelos completos y de subconjunto en términos del error cuadrático medio ,por ejemplo :
MSE (θ )=Var (θ )+ [E (θ )−θ ]2
Error cuadrático medio de βp es
MSE ( β p)=σ2 (X p' X p )
−1+A βr β 'r A
' ; A=(X p' X p )
−1X p' X r
Los estimadores por mínimos cuadráticos de los parámetros en el modelo de subconjunto tienen menor error cuadrático medio que los correspondientes del modelo completo, cuando las variables eliminadas tienen coeficientes de regresión que son menores que los errores estándares de sus estimados en el modelo completo.
4. El parámetro σ 2 es un estimado insesgado de σ 2, sin embargo para el modelo subconjunto:
E (σ 2 )=σ2+βr
' X r' [ I−X p (X p
' X p )−1X p' ]X r βr
n−pEsto es, σ 2 en general es sesgado hacia arriba como estimando de σ 2.5. Supóngase que se desea predecir la respuesta en el punto x ’=[ xp
' , xr' ]. Si se usa el
modelo completo, el valor predicho es y=x ' β, con media x ' β y variancia de la predicción :
Var ( y )=σ 2[1+x (X ’ X )−1 x ]
Sin embargo, si se usa el modelo de subconjunto, y p=x p' β p, con media
E ( y )=x p' β p+ xp
' A βr
Y el error cuadrático medio de predicción
MSE ( y )=σ2 [1+x p' (X p' X p )
−1x p ]+ (x p' A βr−xr' βr )
2
y es un estimado sesgado de y a menos que x p' A βr=0, que solo es cierto si
X p' X rβr=0, además la variancia de y procedente del modelo completo es no es
menor que la de y p del modelo de subconjunto. En términos de error cuadrático medio, se puede demostrar que:
2

Var ( y )≥MSE ( y p)
Siempre y cuando la matriz Var (β p )−βr βr' sea positiva semidefinida.
Al eliminar variables del modelo, se puede mejorar la precisión de los estimados de os parámetros de las variables retenidas, aun cuando algunas de las variables omitidas no sean despreciables. El omitir variables introduce sesgo potencial en los estimados de los coeficientes de las variables retenidas y la respuesta, sin embargo, si las variables eliminadas tienen efectos pequeños, el MSE de los estimados sesgados será menor que la variancia de los estimados insesgados, ya que, la cantidad de sesgo introducida es menor que la reducción en la varianza. Existe peligro al retener variables despreciables, lo que nos lleva a variables con coeficientes cero, o que sean menores que sus errores estándares correspondientes del modelo completo. El peligro es que aumentan las variancias de los estimados de los parámetros y de la respuesta predicha.
III. Criterios para evaluar modelos de regresión con subconjuntos de variables:
1. Coeficiente de determinación múltiple.
Coeficiente de regresión múltiple para un modelo de regresión con subconjuntos de p términos. Representa el porcentaje de variabilidad de la Y que explica el modelo de regresión.
El coeficiente aumenta al aumentar p y es máximo cuando p=k+1.
2. R2 ajustada
La estadística R2 Ajustada no necesariamente aumenta cuando se introducen más regresores al modelo.Si se agregan s regresores al modelo, R2Aj .(p+s ) será mayor que R2Aj . p, si y solo sí la estadística parcial de F es mayor que 1.
3

R2aj .=1−CMerror
SStotaln−1
3. Cuadrado medio de residuales.
La elección del modelo se basará en lo siguiente:
- El CM error(p) mínimo.- El valor de p, de modo que el CM error(p) sea aproximadamente igual a CM error para el
modelo completo.- Un valor de p cercano al punto en donde crece el CM error(p) mínimo.
4. Estadística C p de Mallows.
Los criterios anteriores se basan en el CM error, pero también es interesante tener en cuenta el sesgo en la selección del modelo ya que si se omite una variable regresora importante los estimadores de los coeficientes de regresión son sesgados y los criterios anteriores pueden elegir un modelo que tenga sesgo grande aunque su CM error sea pequeño. Un criterio que tenga en cuenta el sesgo ayudará a elegir el modelo adecuadamente. Un criterio que se relaciona con el error cuadrático medio de un valor ajustado.
C p=SC error
CMerror
−n+2 p
Ideal C p=p
Sobreexplicado C p> p Infraexplicados C p< p
5. Press
4
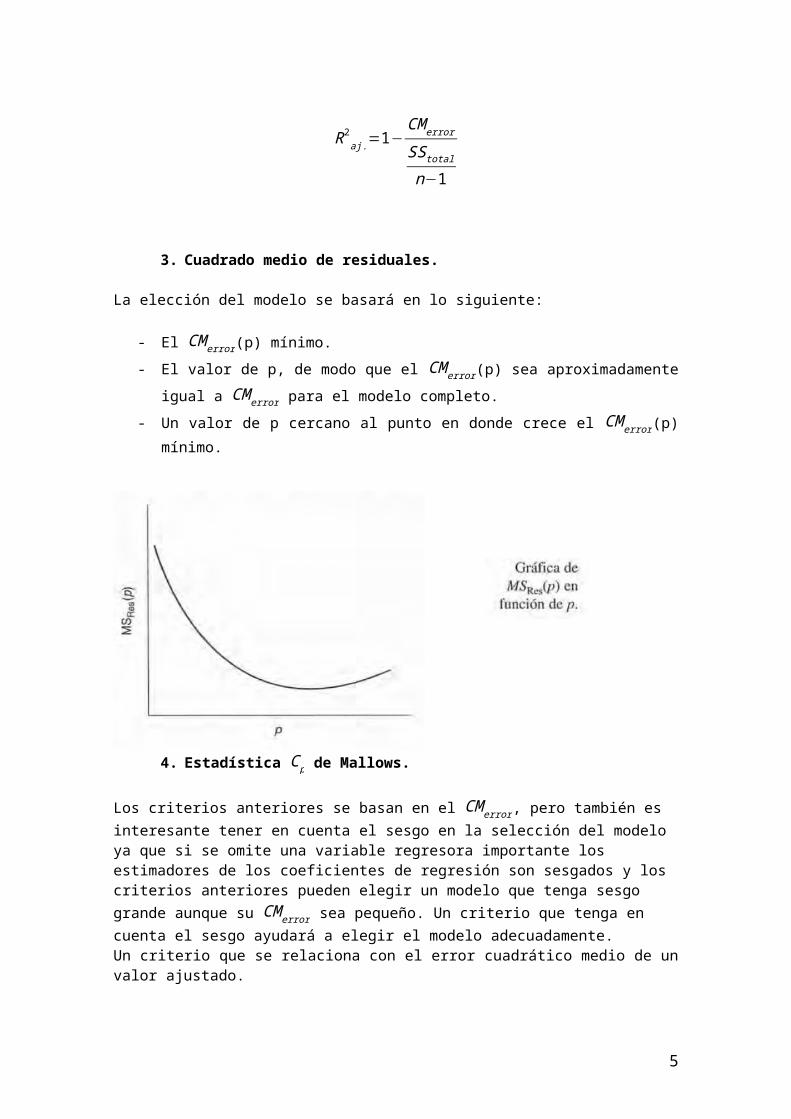
Es una medida de lo bien que función un modelo de regresión para predecir nuevos datos. Lo deseable es tener un modelo con valores relativamente pequeños, aunque por su definición siempre será mayor que la SCerror.
Press=∑i=1
n
[Yi− y (i)]2=∑i=1
n
[ ei1−hii
]2
H=x ' (x ' x )−1 x '
Press>SCerror, ideal es que hii tienda a cero para que sea igual al SCerror.IV. Técnicas computacionales para seleccionar variables
1. Todas las regresiones posibles.
Como hay K=4 regresores candidatos, hay 24 = 16 ecuaciones posibles de regresión, si se incluye siempre la ordenada al origen β0. Se muestran los resultados de ajustar esas 16 ecuaciones.
Se utiliza como medida de bondad de ajuste el coeficiente de determinación en función de p:
5

Al examinar esta figura se ve que después de que hay dos regresores en el modelo, hay poca ganancia en términos de R2 cuando se introducen variables adicionales. Los dos modelos de dos regresores (x1 , x2) y (x1 , x 4) tienen en esencia los mismos valores de R2, y en lo que respecta a este criterio, sería poca la diferencia si se escogiera cualquiera de los modelos como la ecuación final de regresión; podría ser mejor usar (x1 , x 4) porque x 4 produce el mejor modelo con un regresor (se observa el R2).
Todo el subconjunto de regresión para el que R2p > R20 es adecuado.
6

Es ilustrativo examinar los pares de correlaciones entre x i y x j
Los pares de regresores (x1 , x3)Y (x2 , x 4) están muy correlacionados, porque
r13=−0.824 y r24=−0.973
En consecuencia, si se agregan más regresores cuando(x1 , x2) o cuando (x1 , x 4) ya están en el modelo será de poco provecho, porque el contenido de información en los regresores excluidos está presente en los regresores que ya están en el modelo.
Ahora analizamos la gráfica del CMerror:
7
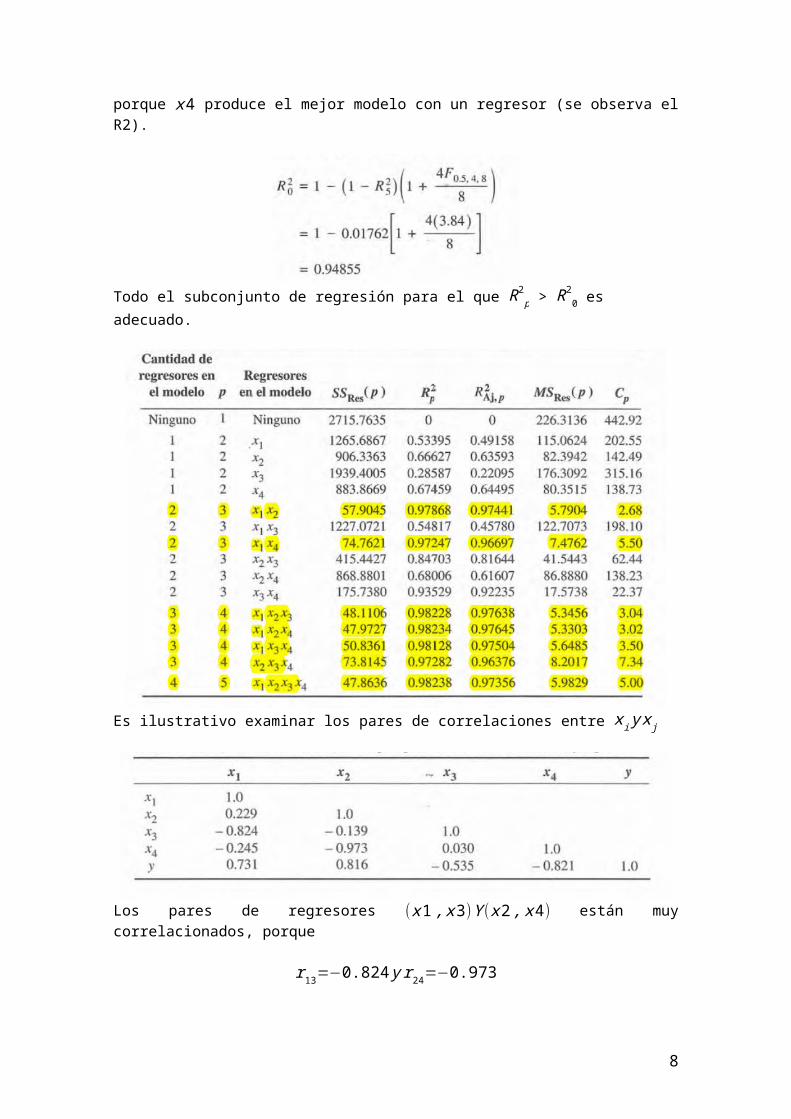
El modelo con cuadrado medio residual mínimo es el (x1 , x2 , x 4) para el que MSRes (4 )=5.3303, nótese que, como era de esperarse, el modelo que minimiza a MSRes (P) también maximiza la R2 ajustada, sin embargo, dos de los otros modelos con tres regresores, (x1 , x2 , x3) y (x1 , x3 , x 4), y los dos modelos de dos regresores (x1 , x2) y ¿), tienen valores comparables del cuadrado medio residual; si en el modelo está ya sea (x1 , x2)o(x 1 , x 4), hay poca reducción en el cuadrado medio de residuales cuando se agregan más regresores. El modelo con subconjunto (x1 , x2) puede ser más adecuado que el (x1 , x 4) porque tiene menor valor del cuadrado medio de residuales.
Observamos la gráfica de Cp:
8
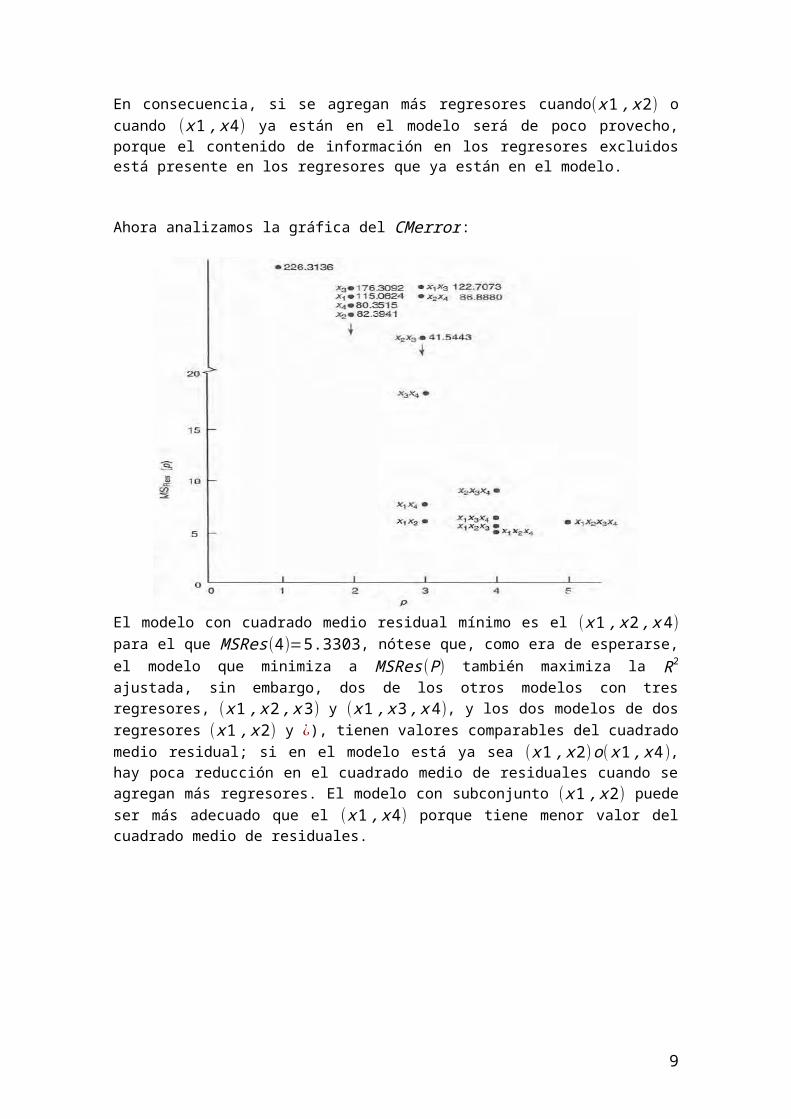
Al examinar esta gráfica se ve que hay cuatro modelos que podrían ser aceptables: (x1 , x2) ,(x1 , x2 , x3) ,(x1 , x2 , x 4) y ( x1 , x 3 , x 4 ). Sin considerar factores adicionales, como la información técnica acerca de los regresores, o los costos de la recolección de datos, podría ser adecuado elegir el modelo más sencillo (x1 , x2) como modelo final, porque tiene el Cp mínimo (es ideal igual a p o menor a p).
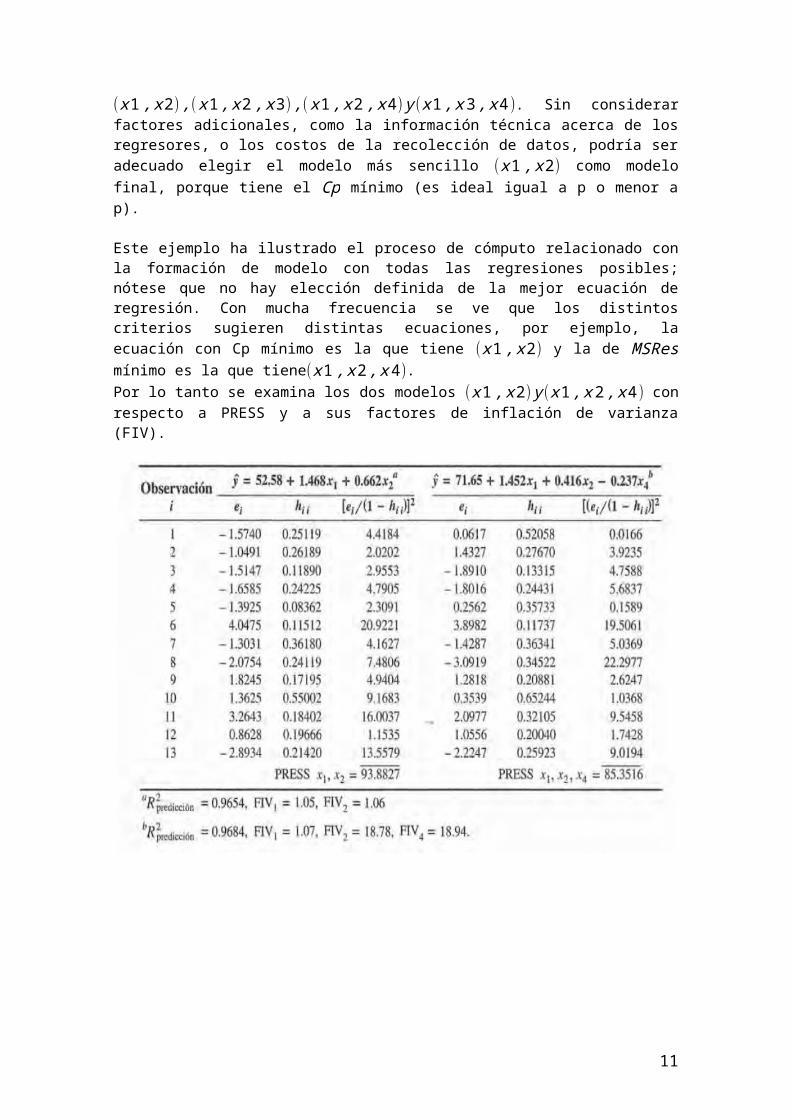
Este ejemplo ha ilustrado el proceso de cómputo relacionado con la formación de modelo con todas las regresiones posibles; nótese que no hay elección definida de la mejor ecuación de regresión. Con mucha frecuencia se ve que los distintos criterios sugieren distintas ecuaciones, por ejemplo, la ecuación con Cp mínimo es la que tiene (x1 , x2) y la de MSRes mínimo es la que tiene(x1 , x2 , x 4).Por lo tanto se examina los dos modelos (x1 , x2) y (x1 , x2 , x4 ) con respecto a PRESS y a sus factores de inflación de varianza (FIV).
9
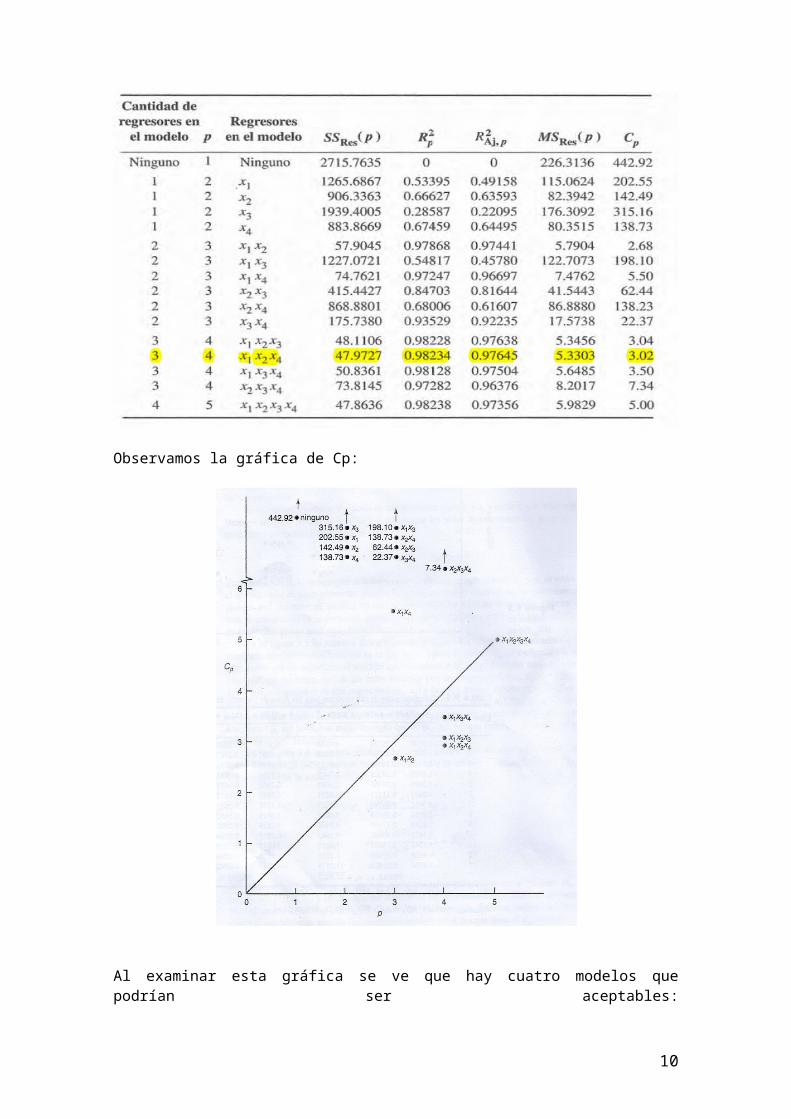
R2prediccion=(1−PRESSSStotal
)
FIV j=1
1−R2 jPara (x1 , x2)
10
FIV 1=1
1−0.0522=1.05
FIV 2=1
1−0.0522=1.05
Para (x1 , x2 , x 4)
- FIV 1=1
1−0.062=1.066
- FIV 2=1
1−0.9468=18.797
- FIV 4=1
1−0.9472=18.939
Ambos modelos tienen valores de PRESS muy parecidos (más o menos el doble de la suma de cuadrados de residuales para la ecuación con MSRes mínima), y la R2para predicción. Sin embargo, x2 y x4 son muy multicolineales, lo que se ve por los mayores factores de inflación de varianza en (x1 , x2 , x 4). Ya que ambos modelos tienen estadísticas PRESS equivalentes, se recomendaría el modelo con (x1 , x2), con base en la falta de colinealidad en él.
11

2. Métodos de regresión por segmentos.
a. Selección hacia delante(forward).
Este procedimiento comienza con la hipótesis que no hay regresores en el modelo además de la ordenada a origen. Se trata de determinar un subconjunto óptimo insertando regresores. El primer regresor que se selecciona para entrar a la ecuación es el que tenga la máxima correlación simple con la variable de respuesta Y. Supóngase que este regresor es X1, este también es el regresor que producirá el máximo valor de la estadística F en la prueba de significancia de la regresión. El regresor se introduce si la estadística F es mayor que un valor predeterminado de F. El segundo regresor para entrar es el que ahora tenga la máxima correlación con y, después de ajustar y por el efecto del primer regresor que se introdujo, X1. A esas correlaciones se les llama correlaciones parciales, que son las correlaciones sencillas entre los residuales de la regresión y=β0 + β1X1 y los residuales de las regresiones de los demás regresores candidatos sobre X1.Supóngase que en el paso 2 el regresor con la máxima correlación parcial con Y es X 2, eso implica que la estadística parcial F con mayor valor es
F=SSR ¿¿
Si este valor de F es mayor que F IN ,entonces se agrega X2 al modelo el regresor que tenga la máxima correlación parcial y si su estadística parcial F es mayor que el valor preseleccionado para entrar ,FIN ,o cuando se ha agregado el ultimo regresor candidato al modelo.Ejemplo: Data : Dato de cementos de Hald.
En primer lugar se observa en la tabla, cual de las variables candidatas tiene mayor correlación parcial con la variables respuesta; claramente que se puede observar que X 4 tpresenta mayor correlacion con y que es igual cor (x 4 , y)=−0.821 con F=22.80 siendo mayor al F ¿=4.84, entra x 4 al modelo.Por lo tanto en primera instancia el modelo es : y= β0+ β X4+εEl siguiente paso es ver cual de las variables restantes tiene mayor correlación con la variable respuesta teniendo en cuenta a la variable introducida(x 4); se aprecia que el siguiente variable con mayor correlación es x1 con 0.9567 y el F=108.22, siendo mayor a F I N=4.96, también se agrega x1 al modelo.En el siguiente paso x2 tiene mayor correlación parcial con F=5.03, resultando menor al F ¿=5.12, por lo tanto x2 no entra al modelo y termina el procedimiento.
Haciendo uso del software (Minitab 17), se obtiene el siguiente modelo:
12

Minitab, tiene entre sus funciones el calculo de la selección de modelos por segmentos, en este caso seleccionamos el de selección hacia delante y nos muestra directamente el modelo final que seria el mismo haciendo mediante el calculo manual.
b. Eliminación hacia atrás(backward).
Eliminación hacia atrás:En la eliminación hacia atrás se trata de determinar un buen modelo trabajando en dirección contraria, es decir, se comienza con un modelo que incluya todos los K regresores candidatos. Luego se pasa a calcular la estadística parcial F para cada regresor, como si fuera la última variable que entro al modelo.La mínima de las estadísticas parciales F se compara con un valor preseleccionado denominado F sal o Fout , entonces si la mínima estadística parcial F es menor que el valor ya mencionado se pasa a eliminar ese regresor, ahora se ajusta un modelo de regresión con K – 1 regresores, se vuelven a calcular las estadísticas parciales F para el nuevo modelo, y se repite el procedimiento ya mencionado. El algoritmo de eliminación hacia atrás termina cuando el valor mínimo de F parcial no es menor que Fout, el valor preseleccionado de corte.Ejemplo: (Usando minitab 17)Como el algoritmo inicia con todos K regresores candidatos, se pasa a correr una regresión con todos, obteniéndose los siguientes resultados:
13

Como se observa el valor mínimo de las estadísticas parciales de F es 0.02, el cual le pertenece al regresor x3.Se establece el valor de Fout=F(0.95,1,8)=5.317655 , con el cual basaremos nuestras decisiones. Entonces como F<Fout se pasa a quitar del modelo al regresor x3.Como se quitó del modelo al regresor x3, se corre nuevamente una regresión pero ahora con solo 3 regresores (x1, x2 y x4), el resultado se muestra a continuación:
14

Como se observa en esta nueva regresión, el mínimo estadístico parcial F es 1.86, el cual le pertenece al regresor x4. Entonces se pasa a comparar con Fout , mostrando que F<Fout , por lo tanto se pasa a quitar al regresor x4 del modelo.Ahora se tienen solo 2 regresores(x1 y x2) con los cuales se corre una regresión nueva, los resultados se muestran en la siguiente imagen:
Como se muestran en la imagen en mínimo de los estadísticos parciales F es 146.52, el cual le pertenece al regresor x1. A continuación se pasa a comparar dicho valor con Fout, mostrando lo siguiente: F>Fout ; por lo tanto el algoritmo termina en este paso, quedando en el modelo los regresores x1 y x2, y obteniendo como resultando el modelo final:
y=52.58+1.468x 1+0.6623 x2Como comentario, este algoritmo puede ser realizado directamente por el minitab, mostrando los mimos resultados.
15

c. Regresión por segmentos(paso a paso ó Stepwise).
La regresión por segmentos es una modificación de la selección hacia delante, en la que a cada paso se reevalúan todos los regresores que habían entrado antes al modelo, mediante sus estadísticas parciales F. Un regresor agregado en una etapa anterior puede volverse redundante, debido a las relaciones entre él y los regresores que ya estén en la ecuación. Si la estadística parcial F de una variable es menor que FOUT, esa variable se elimina del modelo. En este método se requieren dos valores de corte, F ¿ y FOUT, algunos analistas prefieren definir F ¿=FOUT , aunque eso no es necesario, con frecuencia se opta por F ¿>FOUT, con lo que se hace algo mas difícil agregar un regresor que eliminar uno.El método termina cuando ya no hay variables candidatas a ser incluidas o a ser eliminadas. Veamos el siguiente ejemplo:
Data: Datos de cemento de HaldYa explicado el método, pasamos a hacer los cálculos.En este caso se hará uso de software libre R.Primeramente definiremos las funciones para calcular las correlaciones parciales:
calculamos las correlaciones:
Se observa que la mayor correlación con la variable respuesta es cor ( y , x 4)=−0.821, entonces introducimos al modelo:
16

> summary.aov(lm(y~x4)) Df Sum Sq Mean Sq F value Pr(>F) x4 1 1831.9 1831.9 22.8 0.000576 ***Residuals 11 883.9 80.4 ---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1> n <- 13> p <- 0> Fexp <- (cor(x4,y)^2*(n-p-1))/(1-cor(x4,y)^2)> Fexp[1] 24.87111> Fteo <- qf(0.95,1,n-p-1)> Fteo[1] 4.747225> # Fexp > Fteo, entra x4 al modelo.
Paso 1:
> n <- 13> p <- 0> Fexp <- (cor(x4,y)^2*(n-p-1))/(1-cor(x4,y)^2)> Fexp[1] 24.87111> Fteo <- qf(0.95,1,n-p-1)> Fteo[1] 4.747225> # Fexp > Fteo, entra x4 al modelo
Paso 2:
> pcor(x1,y,x4)[1] 0.9567731> pcor(x2,y,x4)[1] 0.1302149> pcor(x3,y,x4)[1] -0.8950818> p <- p+1> # mayor correlacion parcial de primer orden: x1> Fexp <- (pcor(x1,y,x4)^2*(n-p-1))/(1-pcor(x1,y,x4)^2)> Fexp[1] 119.0463> Fteo <- qf(0.95,1,(n-p-1))> Fteo[1] 4.844336> # como Fexp > Fteo, entra x1 al modelo.
Paso 3:
> p <- p+1> # prueba de la significancia de las variables introducidas anteriormete: x4> Fexp <- (pcor(x4,y,x1)^2*(n-p-1))/(1-pcor(x4,y,x1)^2)> Fexp[1] 159.2952> Fteo <- qf(0.95,1,(n-p-1))> Fteo
17

[1] 4.964603> # como Fexp > Fteo, se mantiene x4 en el modelo.
Paso 4:
> pcor2(x2,y,x4,x1)[1] 0.5986053> pcor2(x3,y,x4,x1)[1] -0.5657105> # mayor correlacion parcial de segundo orden: x2> Fexp <- (pcor2(x2,y,x4,x1)^2*(n-p-1))/(1-pcor2(x2,y,x4,x1)^2)> Fexp[1] 5.584294> Fteo <- qf(0.95,1,(n-p-1))> Fteo[1] 4.964603> # como Fexp > Fteo, entra x2 al modelo.
Paso 5:
> # prueba de la significancia de las variables introducidas anteriormente: x4 y x1> p <- p+1> Fexp <- (pcor2(x4,y,x1,x2)^2*(n-p-1))/(1-pcor2(x4,y,x1,x2)^2)> Fexp[1] 1.863262> Fteo <- qf(0.95,1,(n-p-1))> Fteo[1] 5.117355> # como Fexp < Fteo, se debe eliminar x4 del modelo.> Fexp <- (pcor2(x1,y,x2,x4)^2*(n-p-1))/(1-pcor2(x1,y,x2,x4)^2)> Fexp[1] 154.0076> Fteo <- qf(0.95,1,(n-p-1))> Fteo[1] 5.117355> # como Fexp > Fteo, se mantiene x1 en el modelo.
Paso 6:
> #solo queda x3,se calcula su correlacion parcial.> pcor2(x3,y,x2,x1)[1] 0.4112643> Fexp <- (pcor2(x3,y,x2,x1)^2*(n-p-1))/(1-pcor2(x3,y,x2,x1)^2)> Fexp[1] 1.832128> Fteo <- qf(0.95,1,(n-p-1))> Fteo[1] 5.117355> # como Fexp < Fteo, x3 no entra al modelo.
> # ** FINALMENTE EL MODELO QUEDA CON X1 Y X2 COMO VARIABLES REGRESORAS**.
18

Resumen del modelo final: > summary.aov(lm(y~x1+x2)) Df Sum Sq Mean Sq F value Pr(>F) x1 1 1450.1 1450.1 250.4 2.09e-08 ***x2 1 1207.8 1207.8 208.6 5.03e-08 ***Residuals 10 57.9 5.8 ---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1> summary(lm(y~x1+x2))
Call:lm(formula = y ~ x1 + x2)
Residuals: Min 1Q Median 3Q Max -2.893 -1.574 -1.302 1.363 4.048
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 52.57735 2.28617 23.00 5.46e-10 ***x1 1.46831 0.12130 12.11 2.69e-07 ***x2 0.66225 0.04585 14.44 5.03e-08 ***---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.406 on 10 degrees of freedomMultiple R-squared: 0.9787, Adjusted R-squared: 0.9744 F-statistic: 229.5 on 2 and 10 DF, p-value: 4.407e-09
Usando el método computacional de Minitab 17:
19

Haciendo uso del software SPSS se obtiene el siguiente resultado:
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA CHANGE ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT y /METHOD=STEPWISE x1 x2 x3 x4 /RESIDUALS NORMPROB(ZRESID).
20

V. Recomendaciones finales para la práctica.
Como se ha visto existen varios procedimientos de selección de variables en regresión lineal. Se puede clasificarse como por etapas o de todas las regresiones posibles. Las ventajas del tipo por etapas son el ser rápido, fáciles de implementar y se consiguen con facilidad para casi todos los sistemas de computo. Sus desventajas está en que no producen modelos de subconjunto que sean necesariamente los mejores con respecto algún criterio común, y además, como se orientan hacia la producción de una sola ecuación final, el usuario con poco conocimiento puede ser conducido a creer que ese modelo sea optimo, en algún sentido.
21

Si la cantidad de variables candidatas es considerable, el costo de todas las regresiones posibles es casi lo mismo que por etapas, pero no se puede conseguir con tanta facilidad como los demás métodos en etapas, en especial para computadoras personales.Cuando la cantidad de regresores candidatos es demasiado grande como para emplear de entrada el método de todas las regresiones posibles, se recomienda una estrategia de dos etapas. En primer paso se puede filtrar y eliminar los regresores que tengan efectos despreciables, y ya teniendo una lista mas pequeña se puede analizar con el método de todas las regresiones posibles. Un analista siempre debe recurrir a sus conocimientos de su entorno del problema y al sentido común para evaluar los regresores candidatos. Con frecuencia se ve que algunas variables se pueden eliminar con base en la lógica o en el sentido técnico.Un analista se debe hacerse las siguientes preguntas, después de elegir un modelo:
¿Es razonable la ecuación?, ¿tienen sentido los regresores en el modelo, considerando el entorno del problema?.
¿Es útil el modelo para el objeto que se pretendía? ¿Es razonable los coeficientes de regresión? ¿Son satisfactorios las comprobaciones comunes de diagnostico de adecuación
de modelo?Por ultimo, aunque la ecuación ajuste bien a los datos , y pase las pruebas normales de diagnostico, no hay seguridad de que haya a predecir con exactitud nuevas observaciones.
VI. Anexo
22

a. Data: Datos de cemento de Hald
Caso: Calor producido(y), en calorías por gramos de cemento, en función de la cantidad de cada uno de los cuatro ingredientes en la mezcla: aluminato tricálcico (x1), silicato tricálcico (x2), aluminoferrito tetra cálcico (x3) y silicato di cálcico(x4).
Y x1 x2 x3 x478,50 7 26 6 6074,30 1 29 15 52104,30 11 56 8 2087,60 11 31 8 4795,90 7 52 6 33109,20 11 55 9 22102,70 3 71 17 672,50 1 31 22 4493,10 2 54 18 22115,90 21 47 4 2683,80 1 40 23 34113,30 11 66 9 12109,40 10 68 8 12
23


















