
SIG aplicados al análisis y cartografía de riesgos climáticos · algunos ejemplos de la...
70
SIG aplicados al análisis y cartografía de riesgos climáticos Francisco Alonso Sarria Dpto. Geografía Física, Humana y Análisis Geográfico Regional Universidad de Murcia [email protected] MÉTODOS Y TÉCNICAS DE ANÁLISIS DE RIESGOS CLIMÁTICOS II CURSO DE VERANO DE LA ASOCIACIÓN ESPAÑOLA DE CLIMATOLOGÍA 2 de julio de 2004 1 Introducción Riesgo natural implica la existencia de un proceso brusco de transferencia de materia y energía capaz de generar daños y un uso del territorio vulnerable a dichos procesos. Por tanto, cartografiar el riesgo implica hacer tanto una cartografía de los puntos vulnerables como un modelo de los procesos y su intensidad sobre estos puntos vulnerables. La herramienta más adecuada para la modelización y cartografía de riesgos es un Sistema de Información Geográfica. Sin embargo en muchos casos será conveniente enlazar el programa a otro tipo de herramientas como Sistemas de Gestión de bases de datos y Programas de análisis de datos. A continuación, en esta introducción, se hará un repaso de los conceptos básicos en modelización y de las características de los Sistemas de Información Geográfica. En secciones posteriores se tratarán los modelos de datos necesarios para introducir en un SIG la información relevante en análisis de risgos climáticos, así como algunos ejemplos de la modelización espacial de los mismos. 1.1 Cuestiones generales sobre modelización Un modelo es la representación simplificada de un sistema. Existen muchos tipos de modelos, normalmente cuando se trata de estudiar procesos naturales se utilizan modelos matemáticos. La construcción de un modelo de este tipo implica la selección y cuantificación de las variables para representar el sistema con el nivel de detalle requerido. 1
Transcript of SIG aplicados al análisis y cartografía de riesgos climáticos · algunos ejemplos de la...

SIG aplicados al análisis y cartografía de riesgos climáticos
Francisco Alonso SarriaDpto. Geografía Física, Humana y Análisis Geográfico Regional
Universidad de [email protected]
MÉTODOS Y TÉCNICAS DE ANÁLISIS DE RIESGOS CLIMÁTICOSII CURSO DE VERANO DE LA
ASOCIACIÓN ESPAÑOLA DE CLIMATOLOGÍA
2 de julio de 2004
1 Introducción
Riesgo natural implica la existencia de un proceso brusco de transferencia de materia y energía capaz de generardaños y un uso del territorio vulnerable a dichos procesos. Por tanto, cartografiar el riesgo implica hacer tantouna cartografía de los puntos vulnerables como un modelo de los procesos y su intensidad sobre estos puntosvulnerables.
La herramienta más adecuada para la modelización y cartografía de riesgos es unSistema de InformaciónGeográfica. Sin embargo en muchos casos será conveniente enlazar el programa a otro tipo de herramientascomoSistemas de Gestión de bases de datosy Programas de análisis de datos.
A continuación, en esta introducción, se hará un repaso de los conceptos básicos en modelización y de lascaracterísticas de los Sistemas de Información Geográfica. En secciones posteriores se tratarán los modelos dedatos necesarios para introducir en un SIG la información relevante en análisis de risgos climáticos, así comoalgunos ejemplos de la modelización espacial de los mismos.
1.1 Cuestiones generales sobre modelización
Un modelo es la representación simplificada de un sistema. Existen muchos tipos de modelos, normalmentecuando se trata de estudiar procesos naturales se utilizan modelos matemáticos. La construcción de un modelode este tipo implica la selección y cuantificación de las variables para representar el sistema con el nivel dedetalle requerido.
1

Los procesos que actúan sobre el territorio se caracterizan por su carácter tridimensional, su dependencia deltiempo y complejidad. Esta complejidad incluye comportamientos no lineales, componentes estocásticos, bu-cles de realimentación a diferentes escalas espaciales y temporales haciendo muy complejo, o incluso imposi-ble, expresar los procesos mediante un conjunto de ecuaciones matemáticas.
Estasecuaciones, junto con losesquemas de flujopara su resolución, consituyen hipótesis acerca del compor-tamiento de los procesos. Estas ecuaciones tomanvariables de entraday producen una serie devariables desalida en función deparámetrosque reflejan las características del territorio. Por otro lado existe un conjuntodevariables de estadointernas al sistema que se ven modificadas.
Los parámetros se distinguen de las variables en que aquellos son invariantes a la escala espacio-temporal delmodelo. Las variables de entrada y salida representan flujos de materia y enegía desde y hacia el interior delsistema (precipitación y caudal por ejemplo). Las variables de estado representan cambios en la cantidad demateria y energía disponible (humedad del suelo).
En definitiva, un sistema natural recibe entradas de materia y energía de su entorno que devuelve a dicho entornocon ciertas modificaciones:
• Desplazamiento en el espacio
• Modulación en el tiempo
Figura 1: Modelos de procesos
1.2 Tipos de modelos
Una clasificación de los modelos matemáticos podría basarse en una serie de características dicotómicas:
• Basados en estadística o basados en principios físicos
2

Figura 2: Modelos de radiación
El carácter estadístico o físico constituye la característica fundamental de un modelo. Un modelo físicose basa en las leyes físicas que rigen los procesos, un modelo estadístico se basa en relaciones estadís-ticamente significativas entre variables. Las ecuaciones que describen un modelo estadístico no son portanto físicamente o dimensionalmente consistentes ni universales, ya que en rigor sólo son válidas parael contexto espacio-temporal en el que se calibraron.
• Estocásticos o deterministas
Los primeros incluyen generadores de procesos aleatorios dentro del modelo que modifican ligeramentealgunas de las variables. De esta manera, para un mismo conjunto de datos de entrada, las salidas noserían siempres las mismas. La distinción ente modelos deterministas o estocásticos se confunde a vecescon la anterior, relacionando equivocadamente modelos estocásticos con empíricos y deterministas confísicos.
Los modelos aleatorios permiten determinar un rango de posibles valores de salida para obtener, enlugar de un único resultado, una muestra de posibles resultados que permiten un posterior tratamientoestadístico.
• Agregados o distribuidos
En el primer caso toda el área de estudio se considera de forma conjunta, por ejemplo una cuenca hidro-gráfica. Se tiene un único valor para todos los parámetros del modelo. El modelo predice unas salidaspara las entradas aportadas sin informar de lo que ocurre dentro del sistema.
En un modelo distribuido, tendremos el área de estudio dividida en porciones cada una de ellas con supropio conjunto de parámetros y sus propias variables de estado. Cada porción recibe un flujo de materiay energía de algunas de sus vecinas que a su vez reemite a otras.
3

Figura 3: Modelos de procesos en una cuenca
Una tercera posibilidad son los modelos semidistribuidos que se construyen a partir de la yuxtaposi-ción de diversos modelos agregados, por ejemplo diversas subcuencas de una cuenca hidrográfica. Otraposibilidad a menudo explorada en hidrología es dividir el área de trabajo enUnidades de RespuestaHidrológica. Se trata de segmentos de ladera homogeneos en cuanto a su pendiente, orientacion, litologíay uso a los que se asume una respuesta hidrológica única. En un modelo semidistribuido las diferentesunidades generan sus propias salidas de forma agregada pero aparecen entradas y salidas de unas a otras.
• Estáticos o dinámicos
Se refiere a la forma en que se trata el tiempo. Los modelos estáticos dan un resultado agregado para todoel período de tiempo considerado este puede ser por ejemplo uncaudal medio o un caudal punta. Losmodelos dinámicos devuelven las series temporales de las variables consideradas a lo largo del períodode estudio, siguiendo con el ejemplo anterior un hidrograma.
Sea cual sea el tipo de modelo con el que se trabaja, en un modelo matemático es necesario comenzar porcodificar las variables de entrada, salida y de estado, así como los parámetros en formato digital. Si se trabajacon modelos agregados o semidistribuidos hay que codificar, además, los límites de las diferentes unidades.Este proceso es más complejo de lo que pudiera parecer a primera vista e implica la creación de unmodelo dedatosy la manera más eficiente de hacerlo es mediante un Sistema de Información Geográfica.
Las características deseables de los modelos (Mooreet al., 1993) son:
• Parsimonia, un modelo no es necesariamente mejor por tener muchos parámetros. La simplicidad essiempre deseable.
• Modestia, deben tratar de alcanzarse sólo objetivos asequibles. Un modelo, al igual que un mapa, nodebe aspirar a imitar la realidad sino sólo a resaltar aquellos aspectos de interés para su aplicación.
4

• Exactitud, el modelo debe reproducir en la medida de lo posible el funcionamiento del sistema y generarvalores para las variables de salida y estado similares a los observados en la realidad.
• Verificabilidad , los resultados del modelo deben poder compararse con datos reales y determinar de estemodo el grado de exactitud del modelo.
• Por otro lado, no basta con que funcionen bien, deben funcinar bien por las razones correctas
1.3 Sistemas de Información Geográfica y Modelización
Una definición un poco antigua pero amplia de SIG es la que dieron Dueker y Kjerne (1989)Sistema de hard-ware, software, datos, personas, organizaciones y acuerdos institucionales para recopilar, almacenar, analizary diseminar información acerca de diferentes porciones de la superficie terrestre. Esta definición resalta elcarácter corporativo y complejo de los SIG.
Una definición más simple partiría de la definición de Sistema de Información comoConjunto de datos yherramientas para manejar esos datos para cubrir unos objetivos concretos. En el caso de un SIG la únicadiferencia es que se manejan datos espaciales.
Los SIG incluyen por tanto numerosas funciones para el manejo de datos espaciales en formato digital. Estasfunciones pueden clasificarse en:
1. Almacenamientode datos espaciales y temáticos. Para ello es necesario definir modelos de datos conlos que codificar los diferentes aspectos del territorio.
2. Visualizaciónde estos datos en forma de mapas, tablas o gráficos.
3. Consultasque permiten seleccionar aquellos elementos que cumplen un conjunto de condiciones, de tipoespacial o no espacial. Los resultados pueden obtenerse como un valor, una tabla o un mapa.
4. Análisis de datos. Búsqueda de regularidades en los datos que permitan verificar hipótesis acerca de losmismos.
5. Modelización. Bien utilizando los resultados de los análisis de datos (modelos estadísticos) o bien apli-cación de modelos físicos. Permiten utilizar el modelo matemático del territorio almacenado en el SIGpara utilizar y validar diversas hipótesis.
El campo de los SIG es altamante pluridisciplinar, integrando a especialistas de diversas ciencias; se ha hechotan amplio que hoy en día pueden distinguirse fácilmente tres tendencias en la utilización de los SIG:
• Catografía de alta presicióncombinada con herramientas de CAD con aplicaciones en arquitectura eingeniería. Se asume que los elementos cartografiados son estáticos (alta inversión).
• Servidores de mapasa través de Internet con aplicaciones en ordenación del territorio y servicios turís-ticos. Típica implementación AM/FM (Automated Mapping/Facilities Management)
5

• SIG para modelización ambiental, enlazado con herramientas de análisis de datos y modelizacióncon aplicaciones diversas en las ciencias de la Tierra. El asunto que nos concierne está más vinculado,evidentemente, a esta última.
Según Goodchild (1993) un SIG destinado al análisis de datos y modelización ambiental debe incorporar unconjunto de herramientas para:
• Preprocesar grandes volúmenes de datos y prepararlos para su análisis
• Análizar los datos con el objeto de descubrir regularidades y desarrollar modelos
• Implementar estos modelos
• Reorganizar los resultados en modo de tablas, gráficos o mapas de forma que sean útiles para el usuario
En muchos casos resulta preferible incorporar programas externos de modelización que trabajen en coordi-nación con un SIG. Las diferentes formas de integrar ambos programas fueron resumidas por Fedra(1993) en 4tipos de unión entre un SIG y un programa de modelización:
• Dos programas separados utilizando ficheros comunes. En muchos casos la utilización de un SIG paramodelización se ha centrado en el primero y el último de los puntos señalados anteriormente utilizandoun programa específico para analizar y modelizar con el que el SIG se comunica a través de archivos deintercambio. Este esquema se denomina enlace débil (loose coupling) entre el SIG y los modelos.
• Dos programas separados utilizando ficheros comunes y una interfaz de usuario común.
• Integración de funciones de diferentes programas en una arquitectura abierta en el que las diferentesherramientas se interrelacionana y se imbrican en un lenguaje.
• Integración de uno de los programas como parte del conjunto de funciones del otro.
Uno de los proyectos más interesantes de integración de SIG con programas de gestión de bases de datos yprogramas de análisis de datos se ha desarrollado, en un entorno de software abierto, para GRASS (Bivand yNeteler, 2000)
1.4 Modelos de datos
La codificación de los parámetros y variables de un modelo en un SIG requiere su simplificación y cuantifi-cación. En definitiva se trata de utilizar un modelo de datos. Los SIG presentan diferentes estructuras de datosque corresponden a diferentes modelos de la realidad. Tanto en SIG como en gestión de bases de datos engeneral, suele asumirse la existencia de diversos niveles de abstracción en la codificación de los elementos deun modelo de datos mediante determinados modelos de datos.
6

En primer lugar unmodelo conceptualacerca de como entendemos la realidad y en segundo lugar unmodelológicoque define las diferentes estrategias para codificar la realidad en función del modelo conceptual adoptado.Un tercer nivel, ya específico de cada programa concreto, sería unmodelo digital que define la implementacióndigital de un determinado modelo lógico.
1.4.1 El modelo conceptual. Objetos y variables
La realidad, por ejemplo el trozo de realidad representado en la figura 4 puede entenderse según dos modelosmentales (conceptuales) en principio contradictorios:
1. Como un continuo definido por una serie devariables que pueden ser de tipo cualitativo (litología, usosdel suelo, etc.) o cuantitativo(elevaciones, precipitación, etc.) (figura 5). De este modo una porción delterritorio puede caracterizarse por la superposición de unconjunto de superficies que se consideran comomás significativas.
2. Como la yuxtaposición deobjetos de límites definidos y con características homogeneas, por ejemploparcelas de propiedad, nucleos urbanos, carreteras , etc. Cada uno de estos objetos va a tener un identi-ficador único (figuras 6 y 7).Mientras que las variables cubren el espacio de forma completa, una capaformada por un conjunto de objetos puede no hacerlo.
Las superficies son objetos tridimensionales con dos dimensiones que representan los ejes espaciales y unatercera que representa una tercera variable cuantitativa representada en cada punto del espacio. Este tipo demodelos se suelen denominar como de dos dimensiones topológicas y media (gráficos 2,5D), pues en realidadla tercera dimensión (la Z) no se analiza en su totalidad, no se considera exactamente un hecho volumétrico, sinouna superficie (las dos dimensiones) ondulada, levantada en tres dimensiones (la media dimensión). Los gráficosy los análisis verdaderamente 3D necesitan emplear modelos de datos diferentes y bastante más complejos queson de especial utilidad para algunas aplicaciones prácticas como en Geología o en modelización atmosférica.
El ejemplo más típico de variable regionalizada es la elevación sobre el nivel del mar, representada mediantelos Modelos Digitales de Elevaciones (MDE)1 . Se trata de una superficie que representa la topografía delterreno, es decir, las alturas en cada punto de un territorio. Pero, en realidad, se puede crear superficies a partirde cualquier variable que cumpla unas mínimas características, esencialmente la continuidad espacial, sin queexistan saltos bruscos en el valor de la variable. De este modo, diversos aspectos físicos naturales, tales comolas precipitaciones, las temperaturas, 1a composición litológica o mineral, la acidez o basicidad de los suelos,etc., o también variables sociales: número de habitantes, densidad de población, etc., se pueden representar yanalizar como una superficie.
Por lo que se refiere a los objetos, podemos considerar a priori 6 categorías de información que caracterizan alos diferentes objetos geográficos:
1La razón de la importancia de los MDE estriba tanto en su carácter indispensable como base territorial de un SIG como en lafacilidad con que se piuede medir la elevación de cualquier punto del territorio en comparación con otras variables regionalizadas comoprecipitación, humedad del suelo, etc.)
7

Figura 4: Realidad
Figura 5: Superficie
8

Figura 6: Objetos
1. Identificador . Se trata de una variable cuantitativa que identifica cada objeto dentro de un conjunto deobjetos del mismo tipo. El identificador será un valor único y las propiedades de los objetos se almace-narán en una base de datos a la que se accede cada vez que es necesario.
2. Propiedades geométricas. Indica la ubicación del objeto en un espacio, generalmente bidimensional.Implicitamente indica también su dimensión y su forma. De este modo cada tipo de objeto tiene, en fun-ción de su número de dimensiones, una serie de propiedades espaciales de tamaño y forma directamenteextraibles de su codificación espacial:
• Los objetos lineales tienen longitud, sinuosidad y orientación.
• Los objetos poligonales tienen area, perímetro, elongación máxima y diversos índices de formadirectamente calculables a partir de estas.
3. Propiedades espaciales. Son variables cuantitativas medidas en magnitudes espaciales y que indicanalgún aspecto de la extensión espacial de los objetos no representable debido a la escala de trabajo, atratarse de una magnitud en la tercera dimensión o a la dificultad de representarla por el tipo de abstrac-ción que implica su representación (por ejemplo la profundidad de un cauce).
4. Propiedades no espaciales. Son variables cualitativas o cuantitativas que no tienen nada que ver con elespacio pero que se relacionan con el objeto. Resultan de mediciones simples o de descripciones. Puedenser constantes o variables en el tiempo. Por ejemplo toda la información relativa a la demografía de unmunicipio. Existen diversas operaciones que permiten derivar propiedades nuevas a partir de otras yaexistentes.
9

• Combinación aritmética:Densidad = Poblacion/Superficie
• Combinación lógica: SiPoblacion < x & PIB > y => Riqueza = 1
• Reclasificación: SiPoblacion < 1000 & Poblacion > 500 => Recl = 2
5. Propiedades topológicas. Todos los objetos geográficos tienen unas relaciones con su entorno, es decircon el resto de los objetos del mismo o distinto tipo que aparecen a su alrededor. Estas relaciones puedenser de tipo puramente topológico (polígonos vecinos) o de tipo físico (cauces tributarios que se conectanal cauce principal). Pueden codificarse de forma explícita en la base de datos asociada al objeto o estarimplícita en al codificación de su localización espacial. Estas relaciones pueden dar lugar a la creaciónde tipos compuestos (redes, mapas de polígonos, etc.).
En la figura 7 aparecen diversos ejemplos de objetos. El escoger un tipo u otro para representar determinadoobjeto dependerá en gran manera de la escala y del tipo de abstracción que se pretenda hacer, de forma similar alo que ocurre en la generalización cartográfica. Así una ciudad puede ser puntual o poligonal y un cauce fluviallineal o poligonal. Una ciudad sólo tendra sentido considerarla poligonal en estudios de planificación urbana.Para casi todas las aplicaciones hidrológicas tiene más sentido representar los cauces como objetos lineales ycodificar su anchura y profundidad como propiedades espaciales.
1.4.2 Modelos lógicos. Formato raster y vectorial
El modelo logico hace referencia a como se muestrean y organizan las variables y objetos para lograr unarepresentación lo más adecuada posible. En un SIG existen básicamente dos modelos lógicos que se conocencomo formato raster y formato vectorial y que dan lugar a los dos grandes tipos de capas de informaciónespacial.
En el formato raster se divide el espacio en un conjunto regular de celdillas, cada una de estas celdillascontiene un número que puede ser el identificador de un objeto (si se trata de una capa que contiene objetos) odel valor de una variable (si la capa contiene esta variable). Puede considerarse por tanto que el modelo rástercubre la totalidad del espacio. Este hecho supone una ventaja fundamental respecto a las otras tres alternativasya que pueden obtenerse valores de forma inmediata para cualquier punto del espacio.
Los elementos que componen una capa raster (figuras 8 y 9) son:
• Unamatriz de datosque puede contener los valores, en caso de que se trate de una variable cuantitativa,o bién un identificador numérico único para cada valor, en caso de que sea una variable cualitativa. Estamatriz se almacenará en un fichero como una lista de valores numéricos, por tanto una capa raster necesitamás información que permita al programa y al usuario ubicarla en el espacio, leer sus valores y entendersu significado, concretamente.
• Información geométricaacerca de la matriz y de su posición en el espacio:
– Número de columnas (nc)
10

Figura 7: Representación de objetos en formato vectorial (carreteras, red de drenaje, nucleos urbanos y límitesmunicipales) en un SIG en las cercanías de la ciudad de Murcia
11

Figura 8: Modelos digitales. Codificación de una variable cuantitativa en formato raster
– Número de filas (nf )
– Coordenadas de las esquinas de la capa (e, w, s, n)
– Resolución o tamaño de pixel en latitud (rx) o en longitud (ry)
• Unatabla de coloresque permita decidir de que color se pintará cada celdilla en la pantalla
• En caso de que la variable sea cualitativa, una tabla que haga corresponder a cada identificador numéricounaetiqueta de texto.
En el formato vectorial cualquier entidad que aparezca en el espacio (casas, carreteras, lagos, tipos de roca,etc.) puede modelizarse a la escala adecuada como un objeto extraido de la geometría euclidiana. Pueden serclasificados por su dimensionalidad en tres tipos: puntos, lineas o polígonos (figura 10).
• Puntos (figura 10.a). Objetos geométricos de dimensión cero, su localización espacial se representa porun par de coordenadas (X,Y).
• Lineas (figura 10.b). Objetos geométricos de dimensión uno, su localización espacial se representa comouna sucesión de pares de coordenadas llamados vértices, salvo el primero y el último que se denominannodos (en la figura 10 aparecen en negro).
• Polígonos. Objetos geométricos de dimensión dos. Se representan como una linea cerrada (figura 10.c)o como una sucesión de lineas denominadas arcos (figura 10.d). La representación de puntos o lineas esinmediata, sin embargo al representar polígonos aparecen dos situaciones diferentes:
12

Figura 9: Modelos digitales. Codificación de una variable cualitativa en formato raster
– Si los polígonos aparecen aislados los unos de los otros, como en el caso de los nucleos urbanos,cada poligono se codifica como una linea cerrada, se trata de un modeloOrientado a Objetos
– Si los polígonos se yuxtaponen, como en el caso de los términos municipales. En este caso, codificarlos polígonos como lineas cerradas tiene el problema de que habría que repetir cada una de las lineasinteriores. El formato alternativo es el modeloArco-Nodocuya mayor virtud es ahorrar memoria yfacilitar algunas de las operaciones de análisis SIG. En el modelo Arco-Nodo se codifican las lineaspor separado y, pposteriormente, se define cada uno de los polígonos a partir del conjunto de lineasque lo componen.
1.5 Problemas y limitaciones
La utilización de un SIG para resolver problemas de modleización y representación medioambiental y de ries-gos, presenta diversas dificultades:
• Dentro del mercado de los SIG, la mayor demanda es para sistemas cuya prioridad es la visualización yconsulta de datos y no el análisis de datos o la modelización.
• El carácter deprograma para hacer mapasque tienen los SIG obligan a que cada capa de informaciónque se crea deba almacenarse como un fichero. Esto supone en primer lugar la necesidad de disponer deun gran espacio en disco duro y en segundo lugar la disminución de la velocidad de proceso debido a las
13

Figura 10: Tipos de objetos en formato vectorial a) Punto, b) Linea, c) Polígono en formato OO, d) Polígonoen formato Arco-Nodo.
continuas lecturas y escrituras en el disco. Si parte de los datos, que pueden considerarse temporales sealmacenan en memoria y se borran despues de utilizarse se solucionan ambos problemas.
• Los modelos de datos espaciales utilizados en SIG son muy eficientes para manejar grandes cantidadesde datos espacialmente distribuidos pero estáticos. En modelización la perspectiva es más local pero conun gran número de capas de información que además varian con el tiempo. Los SIG no permiten unarepresentación explícita del tiempo.
• Los parámetros efectivos de una celdilla pueden no corresponderse con los valores medios en esa celdilla.La estimación de los parámetros depende del método inicial y de la escala de trabajo
Los dos primeros pueden solucionarse en gran parte mediante la utilización de programas específicos para elmanejo de bases de datos (series temporales) y el análisis de datos.
2 Herramientas SIG útiles en la modelización y cartografía de riesgos
A lo largo del desarrollo teórico de los SIG, una de las lineas más interesantes se centra en un análisis de lasdiferentes herramientas de SIG como elementos, operadores y funciones, que forman parte de un lenguaje parala codificación y resolución de algoritmos que resuelven determinados problemas espaciales (Tomlin, 1990;Berry, 1993; Verbyla, 2002). Uno de los objetivos de esta linea es lograr una clasificación de las diferentesoperaciones.
14

Figura 11: Esquema de base de datos relacional
A continuación se presentan 3 grandes tipos de herramientas SIG que resultan imprescindibles en la mayoría delas aplicaciones y específicamente en el análisis, modelización y cartografía de riesgos. Se trata de los accesosa bases de datos, las diferentes técnicas de interpolación y el álgebra de mapas.
2.1 Enlaces con bases de datos
Mucha de la información necesaria para trabajar en análisis de riesgos no es información estrictamente espa-cial sino información temática. Los SIG son programas diseñados para el manejo de bases de datos espacialesutilizando diferentes modelo lógicos. Para la gestión de información temática, se dispone de otro tipo de pro-gramas que son los gestores de bases de datos.
A lo largo del desarrollo de las tecnologías ligadas a los SIG desde los setenta hasta la actualidad, una de lastendencias más claras es el papel, cada vez más importante, que tiene el uso de SGBD para la gestión de datostemáticos como apoyo al SIG. En principio se utilizaron para almacenar los atributos temáticos de los objetosespaciales, hoy en día se están empezando a utilizar para el almacenamiento de la información geométrica(conjunto de coordenadas) de los objetos espaciales.
Una base de datos relacional es básicamente un conjunto de tablas, similares a las tablas de una hoja de cálculo,formadas por filas (registros) y columnas (campos). Los registros representan cada uno de los objetos descritosen la tabla y los campos los atributos (variables de cualquier tipo) de los objetos. En el modelo relacionalde base de datos, las tablas comparten algún campo entre ellas. Estos campos compartidos van a servir paraestablecer relaciones entre las tablas que permitan consultas complejas (figura 11).
Un sistema de bases de datos relacionales dispone de un lenguaje estandarizado para hacer consultas (lenguajeSQL), los resultados de una consulta hecha con este lenguaje van a ser datos individuales, tuplas o tablas queincluyen valores extraidos de la base de datos en función de diversas condiciones.
La integración de un SIG y una base de datos relacional da lugar a lo que se ha dado en llamar modelogeo-relacional de base de datos (Bosque Sedra, 2000). En este se utiliza la base de datos para almacenar la informa-ción temática y el SIG para la información geométrica y topológica. Una de las funcionalidades de este modelo
15

Figura 12: Esquema de base de datos geo-relacional
será el enlazado de ambos tipos de información que se almacenana de formas completamente diferentes (figura12).
La clave del modelo georelacional es que el identificador de los diferentes objetos codificados en el SIG es elmismo que un campo identificador presente en alguna de las tablas de la base de datos relacional. De este modolos resultados numéricos de una consulta pueden asociarse a los diferentes objetos espaciales para, por ejemplo,representar cada objeto con un color diferente en función del resultado obtenido (figura 13).
En estos casos se necesita un módulo específico que transforme los resultados de las consultas en una serie dereglas para pintar los polígonos asignando al mismo tiempo una paleta de colores definida por el usuario.
En definitiva la única diferencia entre el trabajo de un gestor tradicional de bases de datos y el enlace de un SIGa base de datos es el modo de presentación (tabla o mapa). Casi todo el trabajo lo hace el gestor de bases dedatos y el Sistema de Información Geográfica, se limita a presentar los resultados. La auténtica novedad de losSIG vectoriales está en la yuxtaposición de mapas de diverso tipo para realizar análisis complejos del territorio.
Hasta ahora lo que hemos hecho es obtener objetos espaciales como resultado de una consulta, pero cuando setrabaja con un SIG enlazado a una base de datos, se pretende que las consultas incluyan tambien condicionesespaciales. Incluso deberíamos ser capaces de llevar a cabo consultas interactivas en las que las condiciones seformulan en función de donde haya pinchado el usuario en un mapa mostrado en pantalla.
Sin embargo en el modelo geo-relacional toda la información geométrica y topológica está en el SIG no en elSGBD por tanto las consultas deberánpreprocesarsey postprocesarse.
Preprocesamientosignifica que el módulo encargado de construir de forma automática consultas SQL comolas que hemos visto antes, y lanzarlas al programa servidor de bases de datos, deberá hacerlo teniendo en cuentauna serie de criterios espaciales definidos por el usuario. Por ejemplo, si el usuario pincha en la pantalla dentrode un polígono esperando obtener nombre y población del municipio, el módulo deberá determinar de quepolígono se trata e incluir su identificador, por ejemplo 17, como condición que debe cumplirse:
16
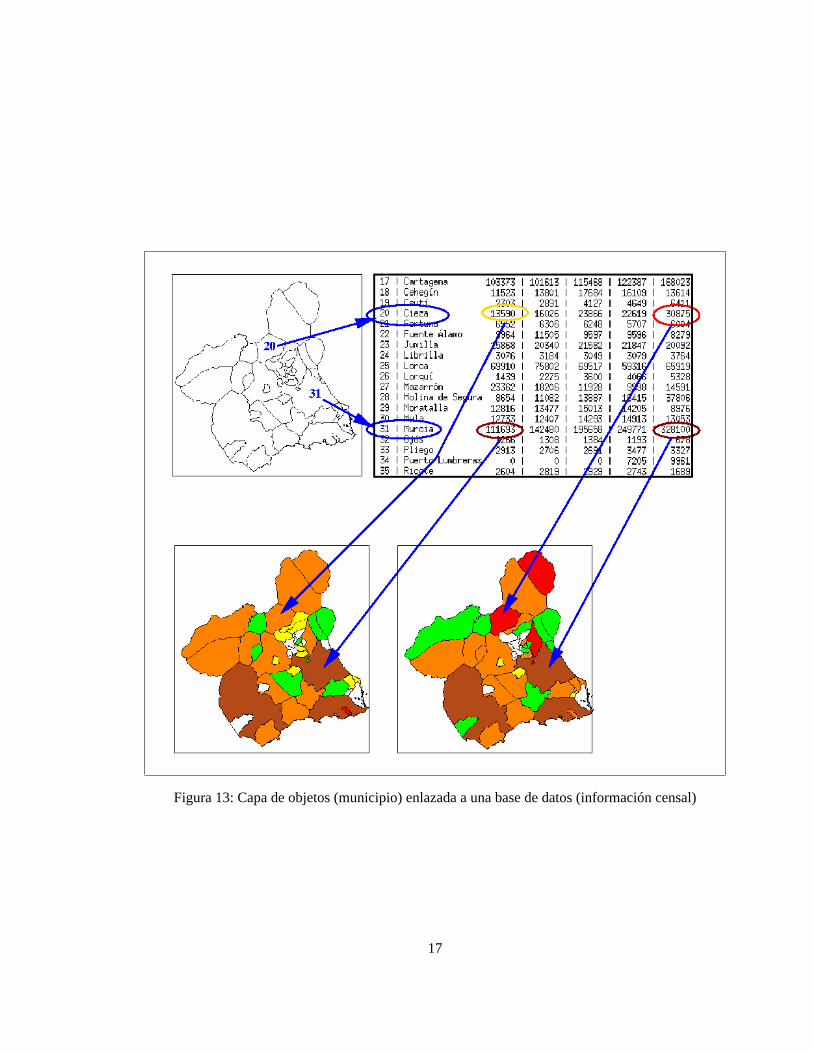
Figura 13: Capa de objetos (municipio) enlazada a una base de datos (información censal)
17

Postprocesamientoimplica que los resultados de la consulta SQL deberán filtrarse para determinar cualescumplen determinadas condiciones relacionada con el espacio. Para ello, una de las columnas pedidas en laconsulta ha de ser el identificador a partir del cual se obtiene, ya en el SIG, la geometría del polígono a la quese puede aplicar la operación de análisis espacial (distancia, cruce, inclusión, adyacencia, etc.) necesaria paraderminar si se cumple o no la condición. Aquellos casos en los que si se cumple constituye la salida del módulo,el resto se deshechan.
Una alternativa recientemente desarrollada al modelo Geo-relacional es el uso de bases de datos objeto-relacionales.Estas permiten la inclusión de objetos espaciales en sus tablas y extienden el lenguaje SQL para incluir fun-ciones y operadores espaciales.
2.2 Interpolación a partir de puntos
El proceso deinterpolación espacialconsiste en la estimación de los valores que alcanza una variable Z en unconjunto de puntos definidos por un par de coordenadas (X,Y), partiendo de los que adopta Z en una muestrade puntos situados en el mismo área de estudio, la estimación de valores fuera del área de estudio se denominaextrapolación. En algunos casos pueden utilizarse otrasvariables de apoyoV a la interpolación/extrapolación.El área de estudio vendría definida, aunque no de forma muy clara, por el entorno de los puntos en los que sí sedispone de datos. Un estudio en profundidad de las diferentes técnicas de interpolación aplicadas al campo delos SIG puede encontrarse en Burrough & McDonnell (1998).
Cuando se trabaja con un SIG la interpolación espacial suele utilizarse para obtener capas raster que representanla variable a interpolar. En esos casos cada celdilla de la capa raster constituye un punto en el que hay querealizar la interpolación.
Lo más habitual es partir de medidas puntuales (variables climáticas, variables del suelo) o de isolineas (cur-vas de nivel), los métodos que se utilizan en uno u otro caso son bastante diferentes. Todos los métodos deinterpolación se basan en la presunción lógica de que cuanto más cercanos esten dos puntos sobre la superficieterrestre más se parecerán, y por tanto los valores de cualquier variable cuantitativa que midamos en ellos seránmás parecidos, para expresarlo más técnicamente, las variables espaciales muestranautocorrelación espacial.
Los diferentes métodos de interpolación desarrollados pueden dividirse en dos tipos fundamentales:
1. Métodos globales, utilizan toda la muestra para estimar el valor en cada punto de estimación. Se dividenen métodos de regresión y de clasificación (figura 15). Asumen la dependencia de la variable a interpolarde otras variables de apoyo.
2. Métodos locales, utilizan solo los puntos de muestreo más cercanos. Destacan las medias ponderadas porinverso de la distancia elevado a una potencia, kriggeado, TIN y splines.
2.2.1 Métodos de clasificación
La variable de apoyoes cualitativa (usos del suelo, tipos de suelo o roca, etc). En este caso se asume que lavariable adopta en cada punto el valor medio correspondiente al valor de la variable de apoyo en ese punto. Por
18

Figura 14: Puntos de muestreo de precipitación
19
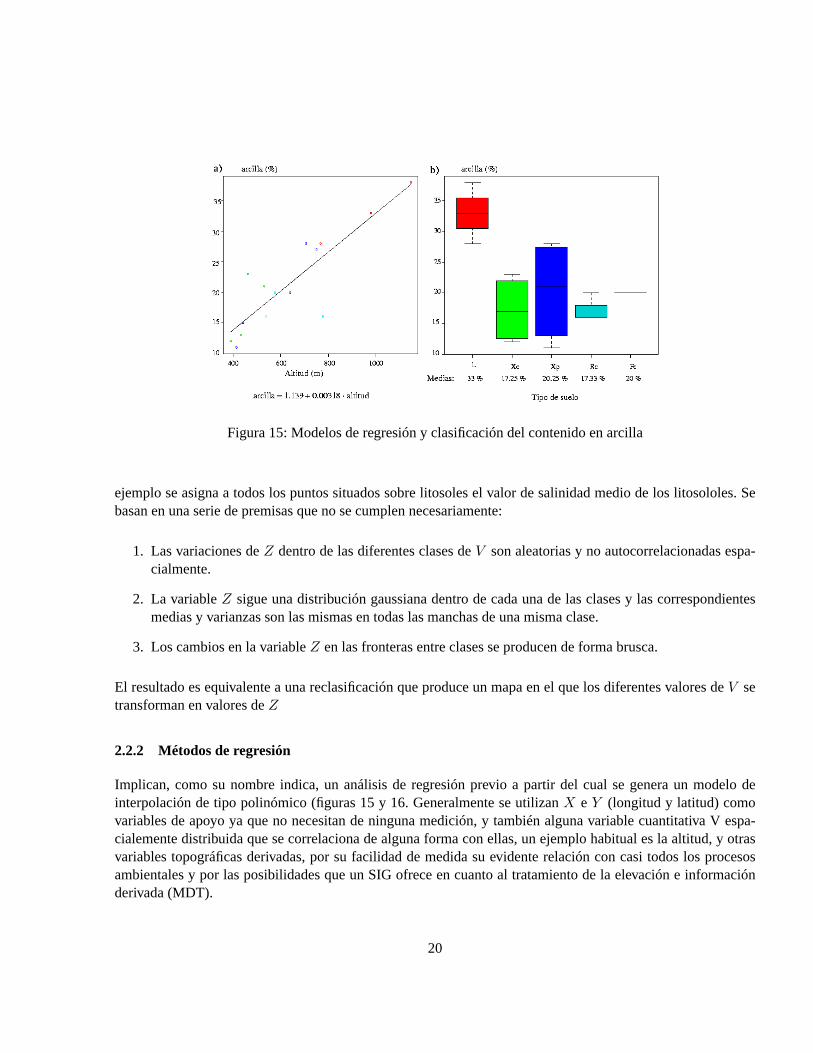
Figura 15: Modelos de regresión y clasificación del contenido en arcilla
ejemplo se asigna a todos los puntos situados sobre litosoles el valor de salinidad medio de los litosololes. Sebasan en una serie de premisas que no se cumplen necesariamente:
1. Las variaciones deZ dentro de las diferentes clases deV son aleatorias y no autocorrelacionadas espa-cialmente.
2. La variableZ sigue una distribución gaussiana dentro de cada una de las clases y las correspondientesmedias y varianzas son las mismas en todas las manchas de una misma clase.
3. Los cambios en la variableZ en las fronteras entre clases se producen de forma brusca.
El resultado es equivalente a una reclasificación que produce un mapa en el que los diferentes valores deV setransforman en valores deZ
2.2.2 Métodos de regresión
Implican, como su nombre indica, un análisis de regresión previo a partir del cual se genera un modelo deinterpolación de tipo polinómico (figuras 15 y 16. Generalmente se utilizanX e Y (longitud y latitud) comovariables de apoyo ya que no necesitan de ninguna medición, y también alguna variable cuantitativa V espa-cialemente distribuida que se correlaciona de alguna forma con ellas, un ejemplo habitual es la altitud, y otrasvariables topográficas derivadas, por su facilidad de medida su evidente relación con casi todos los procesosambientales y por las posibilidades que un SIG ofrece en cuanto al tratamiento de la elevación e informaciónderivada (MDT).
20

Figura 16: Interpolación por regresión de la temperatura respecto a la altitud
En ambos casos (clasificación y regresión) se requiere una análisis estadístico previo para determinar que losdatos se ajustan al modelo estadístico implicado. En el caso de la clasificación que las medias de las diferentesclases son significativamente diferentes y que las desviaciones típicas dentro de las clases son pequeñas (figura15). En el caso de la regresión es necesario verificar que el coeficiente de correlación es significativamenteelevado.
El problema de los métodos globales es que sólo consiguen modelizar una componente a escala global de laestructura de variación, pero no las componentes a escala más detallada. De hecho no resulta recomendableutilizar polonómios de grado mayor que 3 ya que, a pesar de un ajuste cada vez mejor, se hacen cada vez mássensibles a los valores extremos con lo que cualquier error en los datos podría generar distorsiones importantesen el resultado final. Por tanto se utilizan parafiltrar esa componente global y eliminarla de los valores medidospara, posteriormente, estimar tan sólo la componente local mediante métodos locales.
2.2.3 Métodos locales basados en medias ponderadas
Losmétodos localesse basan en la utilización de los puntos más cercanos alpunto de interpolaciónpara estimarla variable Z en este. Asumen autocorrelación espacial y estiman los valores de Z como una media ponderadade los valores de un conjunto de puntos de muestreo cercanos. Exigen tomar una serie de decisiones:
1. Decidir que puntos cercanos van a formar parte delconjunto de interpolaciónen función de los siguientescriterios (figura 17):
• Aquellos cuya distancia al punto de interpolación sea inferior a un valor umbralr
• Losn puntos más cercanos al punto de interpolación
21

El semivariograma nos permite determinar un valor de distancia de forma objetiva, lógicamente el valorumbral no debe superar el valor del alcance de este..
2. Cual será elmétodo de interpolación
• La solución más simple, asignar el valor del punto más cercano (método delvecino más próximoo de los poligonos de Thyessen), se utilizó antes de la existencia de ordenadores ya que resultabasencillo hacerlo a mano.
• Media de los valores de los puntos incluidos en el conjunto de interpolación.
• Sin embargo es lógico pensar que cuanto más apartados esten dos puntos más diferentes serán susvalores de Z. Para tener en cuenta este hecho se utilizan medias ponderadas utilizando como factorde ponderación funciones del inverso de la distancia. El criterio de ponderación más habital es elinverso de la distancia elevado al cuadrado.
Z ′j =
N∑i=1
WiZi (1)
Wi =1/d2
j,i∑Ni=1 1/d2
j,i
(2)
En la figura 18 aparece el resultado de una interpolación por inverso de la distancia de los datos queaparecen en la figura 14.
• Utilización delkriggeado, método desarrollado en el marco de la teoríageoestadísticay que uti-liza toda la información procedente del semivariograma para obtener unos factores de ponderaciónoptimizados. Se trata de un método muy extendido, pero es bastante complejo matemáticamentey muy exigente en cuanto a la calidad de la muestra de puntos y la variable que se interpola. Siesta no es adecuada son preferibles los modelos de medias ponderadas que son los más utilizadostradicionalmente debido a la sencillez de su manejo y a su robustez.
Los programas de SIG suelen disponer de herramientas para su utilización o bien de modos deintegrar programas específicos de geoestadística. En la figura 19 aparece el resultado de una inter-polación por kriggeado de los datos que aparecen en la figura 14.
Uno de los problemas más importantes de los métodos basados en medias ponderadas es que, como su propionombre indica, interpolan basándose en el valor medio de un conjunto de puntos situados en las proximidades,por tanto nunca se van a obtener valores mayores o menores que los de los puntos utilizados para hacer lamedia. En consecuencia no se van a interpolar correctamente máximos o mínimos locales y además los puntosde muestreo aparecen en el mapa final como máximos y mínimos locales erroneos. En la figura 20 se muestracomo en el punto X=7, un método de media ponderada por inverso de la distancia al cuadrado genera un valorpoco razonable (la X roja) dada la tendencias observada en los puntos.
22
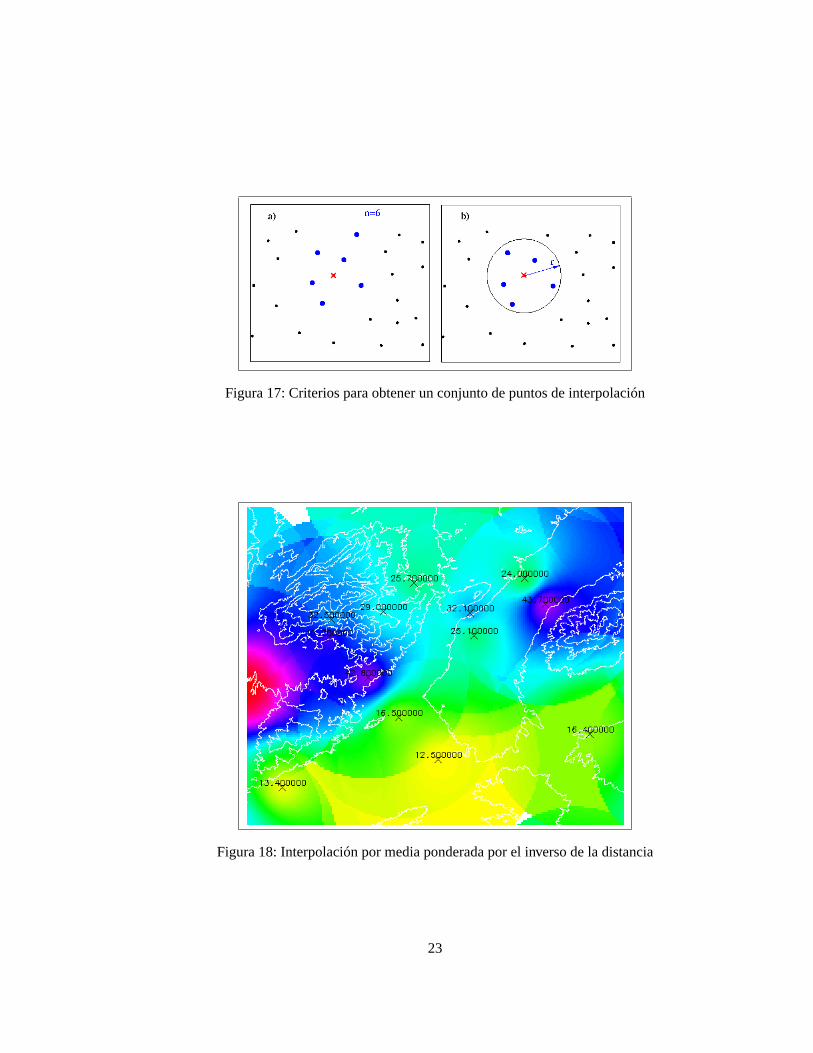
Figura 17: Criterios para obtener un conjunto de puntos de interpolación
Figura 18: Interpolación por media ponderada por el inverso de la distancia
23

Figura 19: Interpolación por kriggeado
2.2.4 Interpolación local porsplines
El método de los splines ajusta funciones polinómicas en las que las variables independientes son X e Y. Essimilar a una interpolación global mediante regresión, pero ahora esta interpolación se lleva a cabo localmente.En general producen resultados muy buenos con la ventaja de poder modificar una serie de parámetros enfunción de la estructura de variación local de los datos.
La técnica desplinesconsiste en el ajuste local de ecuaciones polinómicas en las que las variables indepen-dientes son X e Y. La forma de la superficie final va a depender de un parámetro de tensión que hace que elcomportamiento de la superficie interpolada tienda a asemejarse a una membrana tensa o aflojada.
La ventaja fundamental del método desplinesrespecto a los basados en medias ponderadas es que, con estos úl-timos, los valores interpolados nunca pueden ser ni mayores ni menores que los valores de los puntos utilizadospara interpolar. Por tanto resulta imposible interpolar correctamente máximos y mínimos. En la figura 21 pode-mos ver como el método de splines genera en este caso una estimación mucho mejor, al menos visualmente, delos datos que se presentaron en la figura 14.
2.2.5 Interpolación local mediante TIN
Las Redes Irregulares de Triángulos (TIN son las iniciales en inglés) se generan a partir de valores puntualestratando de conseguir triángulos que maximicen la relación área/perímetro, el conjunto de todos los triángulos
24
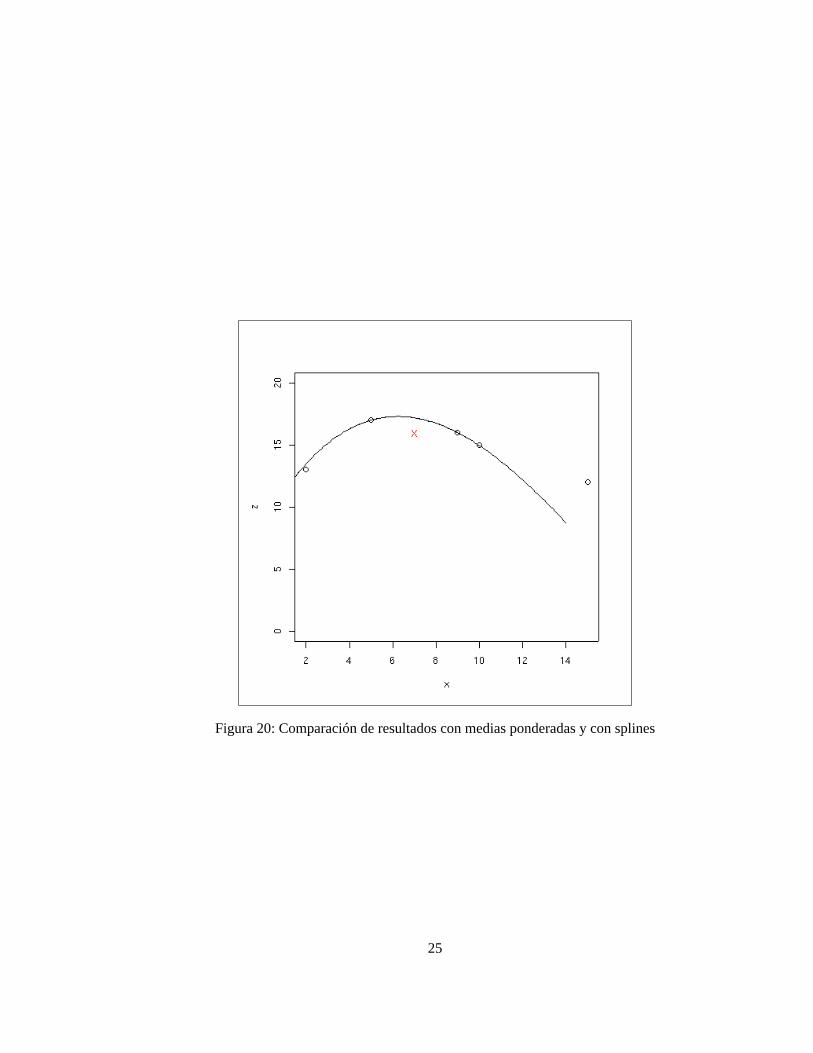
Figura 20: Comparación de resultados con medias ponderadas y con splines
25

Figura 21: Interpolación por splines
forma un objeto geométrico denominadoconjunto convexo. Suelen utilizarse como método para representarmodelos de elevaciones (y producen resultados visualmente muy buenos) sin embargo a la hora de integrarloscon el resto de la información raster es necesario interpolar una capa raster a partir de los triángulos (figuras 22y 23).
Cada uno de los tres vértices de los triángulos tienen unos valores X, Y y Z a partir de los cuales puedeobtenerse un modelo de regresiónZ = AX + BY + C que permite interpolar la variable Z en cualquier puntodel rectángulo.
En definitiva puede asimilarse a un método de media ponderada ya que el resultado siempre va estar acotadopor los valores máximo y mínimo de Z en los vértices del triángulo y será más parecido al del vértice máscercano.
El resultado final de una interpolación TIN es similar a los de media ponderada aunque sin la aparición deartefactos circulares. Sin embargo, al ser la estimación en cada celdilla un punto en un plano inclinado (cadauno de los triángulos), el valor de Z será siempre una media ponderada por el inverso de la distancia (sinexponente) de los valores de Z situados en los vértices. La particularidad es que siempre se cogen 3 puntoslocalizados de tal manera que se cubre el máximo de direcciones posibles.
La figura 24 muestra los resultados de una interpolación TIN a partir de los datos presentados en la figura 14.
26

Figura 22: Red Irregular de Triángulos formando un conjunto convexo
2.2.6 Validación y validación cruzada
Para verificar la calidad de un mapa interpolado debe utilizarse unconjunto de validaciónformado por una seriede puntos de muestreo (de los que por tanto se conoce el valor real) en los que se va a hacer una estimaciónde dicho valor real (sin utilizar por supuesto el valor medido en ellos). La diferencia entre el valor medido y elestimado es el error de estimación en ese punto. De este modo a cada punto de validación se asigna un error. Elconjunto de los errores debe tener las siguientes características:
1. Media de errores y media de errores al cuadrado próxima a cero
2. Los valores de error deben ser independientes de su localización en el espacio y no estar autocorrela-cionados
3. La función de distribución de los errores debe aproximarse a la distribución normal
El problema es que en muchos casos se dispone de pocos puntos de muestreo, por lo que no resulta convenientereservar algunos de ellos como puntos de validación, la alternativa es el procedimiento de validación cruzada.Este consiste en la estimación del valor de la variable Z, con el procedimiento de interpolación que quierevalidarse, en cada uno de los puntos de muestreo, aunque sin incluir dicho punto de muestro. De esta manerase conoce para cada punto de muestreo tanto el valor real como el valor estimado de forma que puede llevarsea cabo el análisis estadístico de errores antes mencionado.
27
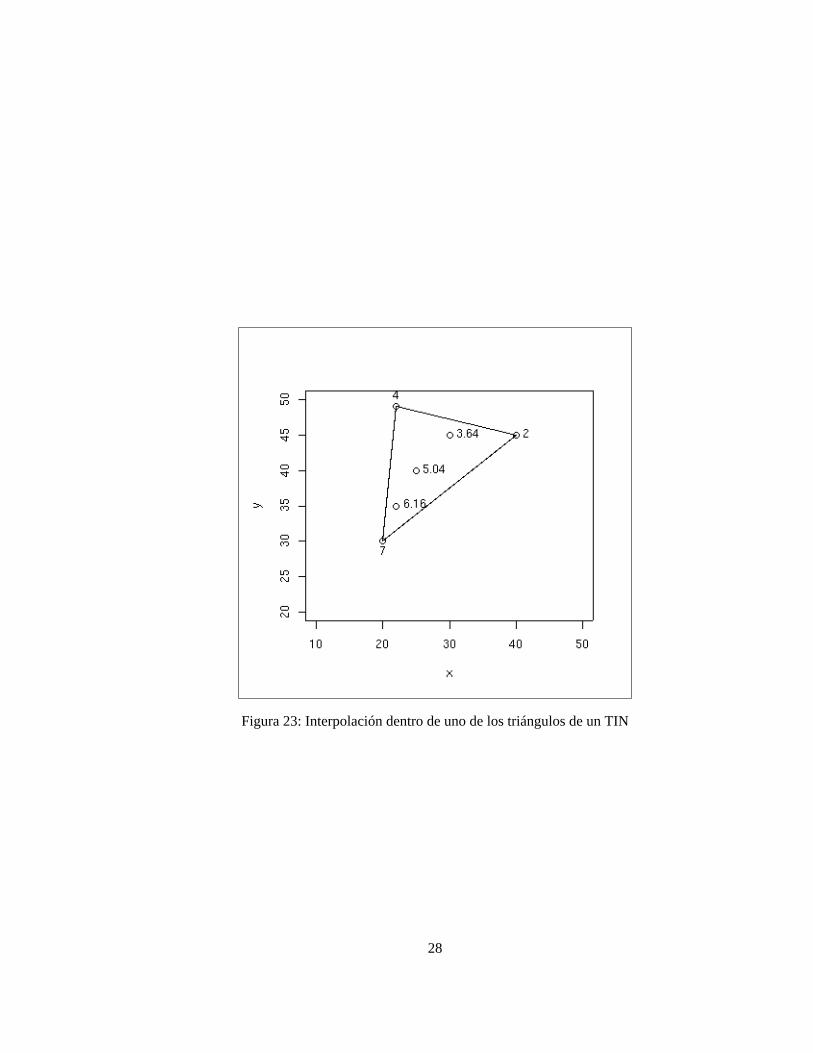
Figura 23: Interpolación dentro de uno de los triángulos de un TIN
28

Figura 24: Interpolación mediante Red Irregular de Triángulos
2.2.7 Combinación de diferentes métodos
Generalmente se asume que la distribución espacial de una variable cuantitativa está condicionada por la sumade tres procesos:
• Una tendencia a escala global y que por tanto puede modelizarse mediante métodos de interpolaciónglobal
• Una variación local autocorrelacionada que puede modelizarse mediante métodos locales
• Un conjunto de factores indeterminados y errores de medida que se agrupan en un término final de error
La lluvia recogida durante un episodio de precipitación concreto puede servir como ejemplo. En primer lugarla dispoisición de los frentes de lluvia puede dar lugar a una tendencia global por la que la precipitación varíaen función de las coordenadas X e Y; en segundo lugar la dinámica de los nucleos convectivos (nubes de tor-menta) genera una variabilidad autocorrelacionada, a una escala más detallada, que se superpone a la tendencia;finalmente diversos factores aleatorios introducen una última fuente de variabilidad dificil de modelizar.
La técnica más habitual para interpolar las variables resultantes, es utilizar en primer lugar un procedimientoglobal, a ser posible fundamentado en bases físicas. Por ejemplo, la temperatura disminuye con la altitud, portanto si se dispone de un mapa de elevaciones y temperaturas medidas en observatorios de altitud conocida
29

resulta sencillo estimar un modelo de regresión y aplicarlo posteriormente con las técnicas de álgebra de mapasvistas en temas anteriores. En el caso de propiedades del suelo, estas van a depender del tipo y uso de suelo,por lo que un procedimiento de clasificación va a dar buenos resultados.
Una vez que se ha aplicado un método global, deben analizarse los residuales, es decir las diferencias en-tre los valores originales medidos y los valores estimados por el método. Si estos residuales no cumplen lascondiciones expuestas en el apartado anterior (especialmente si se comprueba que no son espacialmente ide-pendientes) debería procederse a utilizar métodos locales para la interpolación de estos residuales ya que resultaobvio que existe una estructura de variación espacial local independiente de la estructura general modelizadamediante métodos globales.
2.3 Algebra de mapas
Para que un SIG pueda utilizarse en modelización ambiental el usuario debe ser capaz de trabajar con repre-sentaciones simbólicas de las variables espaciales utilizando un lenguaje que permita combinarlas en opera-ciones aritméticas, lógicas o geométrica y que incuya funciones típicas utilizadas en modelización. Es decirdebe existir unlenguaje. Este lenguaje debe permitir la creación de nuevos atributos para objetos existentes yla creación de nuevos objetos.
Berry (1993) concibe a un SIG como un entorno que nos ofrece un conjunto de operaciones analíticas primitivassimilar al de la estadística o el álgebra. Estas operaciones constituyen los elementos básicos de este lenguaje.
El álgebra de mapas incluye un amplio conjunto de operadores aritméticos y lógicos que se realizan sobre unao varias capas raster de entrada para producir una capa raster de salida. Por operador se entiende un algoritmoque realiza una misma operación en todas las celdillas de una capa raster. Estos operadores se definen medianteecuaciones, por ejemplo el operadorB = A ∗ 100 genera una nueva capa (B) asignando a cada celdilla elvalor de la celdilla correspondiente multiplicado por 100. (figura 25). Se trata de operaciones entre capas rastercompletas, cada una de ellas es una matriz de números y la operación se realiza para todos los números de lamatriz, por tanto para todas las celdillas de la capa raster.
Pueden definirse infinitos operadores, aunque normalmente se clasifican (Tomlin, 1990) en función de las celdil-las implicadas en el cálculo en:
• Operadores locales
• Operadores de vecindad
• Operadores de area
• Operadores de area extendida
2.3.1 Operadores locales
Los operadores localesgeneran una nueva capa a partir de una o más capas previamente existentes. Cadaceldilla de la nueva capa recibe un valor que es función de los valores de esa mismo celdilla en las demás capas.
30

Figura 25: Operador local aritmético
Zmx,y = f(Z1x,y, Z2x,y, .., Znx,y) (3)
la función representada porf() puede ser aritmética, lógica o una combinación de ambas.
El caso más simple de operador local de tipo lógico es lareclasificacióno cálculo del nuevo valor a partir delvalor de la misma celdilla en otra capa (figura 26) en base a un conjunto de reglas sencillas de reclasificación.
Un ejemplo de reclasificación sería la creación de mapas de diversas propiedades del suelo a partir de un mapade suelos y de una tabla en la que a cada suelo se le asignara un conjunto de valores característicos de dichasvariables.
En cuanto a operadores de tipo aritmético (figura??), puede tratarse de operaciones sencillas como la multipli-cación por 100 de una capa de altitudes en metros para obtener una capa de altitudes en centímetros o la sumade 12 capas de precipitación mensual para obtener una capa de precipitación anual. Sin embargo se admitencasos más complejos utilizando varias capas y coeficientes para obtener índices de diverso tipo.
2.3.2 Operadores de vecindad
Los operadores de vecindadadjudican a cada celdilla un valor que es función de los valores de un conjuntode celdillas contiguas, en una o varias capas. El conjunto de celdillas contiguas a la celdillaX más ella mismaconstituye unavecindad. Generalmente se trabaja con vecindades de forma cuadrada y tamaño variable, eltamaño se define como el número de celdillas que hay en el lado del cuadrado, siempre un número impar (3, 5,7, etc.).
Los ejemplos más habituales de operador de vecindad son el filtrado de capas utilizado en análisis de imágenesde satélite o de fotografías aéreas digitalizadas , los operadores estadísticos empleados para estimar estadísticos
31

Figura 26: Reclasificación
en el entorno de una celdilla, y los operadores direccionales.
Los operadores direccionales son un tipo de operador de vecindad que permiten estimar un conjunto de parámet-ros relacionados con la ubicación de los diferentes valores dentro de la vecindad. Su utilidad primordial es elanálisis de Modelos Digitales de Terreno (pendiente, orientación, curvatura, etc.).
2.3.3 Operadores de vecindad extendida, operadores extendidos
Son aquellos que afectan a zonas relativamente extensas que cumplen determinado criterio pero cuya local-ización precisa no se conoce previamente. Por tanto el operador (programa) debe determinar previamente cuales el área que cumple dichas características. Entre los casos más habituales están:
1. Areas situadas a una distancia, inferior a un valor umbral, de un objeto definido por una o varias celdillas.Se genera así una zona tampón (buffer). El resultado sería una capa en la que se codificaría de un modoel objeto de otro modo el área tampón y de un tercero el área exterior al tampon (figura 27).
Siguiendo con el ejemplo anterior, la especie a reintroducir puede requerir la presencia de una superficiede agua a una distancia determinada. Este operador permitirá discriminar cuales son las celdillas quecumplen esta condición.
2. Lineas de flujo y cuencas de drenaje (figura 28). A partir del operador de dirección de drenaje vistoanteriormente, puede construirse otro que de modo recursivo genere la linea de flujo que seguiría unvolumen de agua depositado sobre el territorio. La unión de todas las lineas de flujo que coinciden a unpunto constituye la cuenca de drenaje de ese punto. Dada un celdilla, incluye todas las que drenan a este.Se trata de un operador fundamental en el desarrollo de modelos hidrológicos.
32
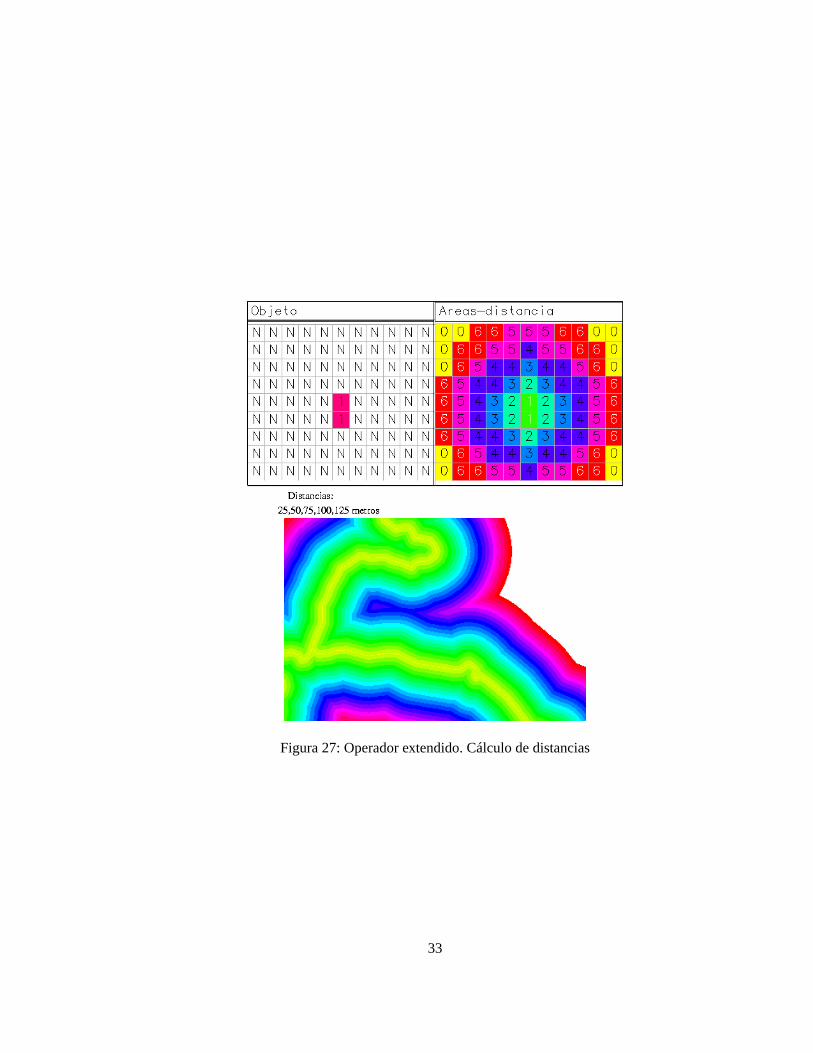
Figura 27: Operador extendido. Cálculo de distancias
33

Figura 28: Operador extendido. Cálculo de lineas de flujo y cuencas
2.3.4 Operadores de área
Son aquellos que calculan algún parámetro (superficie, perímetro, índices de forma, distancias, estadísticos)para una zona previamente conocida. Puede tratarse de diferentes niveles de una variable cualitativa (superficiescon diferente litología por ejemplo) o digitalizada e introducida por el usuario.
Uno de los casos más habituales es la obtención del valor medio de una variable cuantitativa para diferentesvalores de una variable cualitativa (figura 29). Por ejemplo obtener la altitud media para cada tipo de uso desuelo a partir de un mapa de elevaciones y de otro de usos del suelo. Otro caso sería el cálculo de la superficieocupada por cada uno de los usos del suelo.
2.3.5 Propagación de errores en álgebra de mapas
Toda operación de álgebra de mapas implica la estimación de una variable a partir de otras, por tanto implicala existencia de errores.
Los errores pueden proceder de las fuentes u originarse en el proceso de digitalización y posterior procesado delos datos. Además los errores pueden propagarse y aumentar al llevar a cabo operaciones con los datos. Seríadeseable que las fuentes de los datos informaran acerca de los errores esperables en los datos.
La digitalización supone errores en la localización de los objetos digitalizados. Un error de digitalización de unmilímetro en un mapa 1:50.000 supone un error de 50 metros que se añade al propio error de partida del mapa.
Algunos de los operadores previamente tratados tienen capacidad para propagar y multiplicar la magnitud delos errores. Si una pendiente tiene un error de+ − 5% y elevamos al cuadrado un valor de 20, el resultado
34

Figura 29: Altitud media por áreas
estará entre 225 y 625 con lo que la indeterminación aumenta de forma considerable.
2.3.6 Implementación del álgebra de mapas en los SIG
Los primeros programas de SIG incorporaban módulos para los operadores más comunes (pendiente, ori-entación, aritmética). Con el tiempo se fueron desarrollando módulos de propósito general que permitían es-tablecer operadores locales simples, operaciones matemáticas entre mapas o con un sólo mapa; mientras quelos operadores de vecindad o área más comunes seguían realizándose en módulos aparte debido a su dificultad.
Las últimas versiones de los SIG más avanzados como GRASS disponen de un módulo que es prácticamenteun lenguaje de programación que permite realizar operaciones locales, de vecindad, de vecindad extendida ode área. Los operadores de vecindad extendida más complejos (cuencas de drenaje o cuencas visuales) siguenrealizándose en módulos aparte ya que son difíciles de programar y siguen unos esquemas muy poco flexiblesque siempre se van a programar igual.
En el Departamento de Geografía de la Universidad e Utrech se ha desarrollado PCRaster. Se trata de un SIGrelativamente barato que es exclusivamente un interprete de un lenguaje de álgebra de mapas muy potente queincluye operadores de vecindad extendida muy potentes y fáciles de programar. Se utiliza fundamentalmenteen estudios de tipo hidrológico y geomorfológico.
2.3.7 El álgebra de mapas como lenguaje
El uso del álgebra de mapas supone la superación de la fase inicial de presentación y consulta de datos enun SIG e iniciar un uso más avanzado (análisis, modelización de procesos, toma de decisiones, etc.). Unode los conceptos fundamentales e álgebra de mapas es el deoperadorentendiendo como tal cada una de lasoperaciones (más o menos complejas) que a partir de una o más capas de entrada y texto producen una o máscapas de salida o incluso salida en formato texto (figura 30).
35

Figura 30: Ejemplos del concepto de operador
Pusto que los operadores de álgebra de mapas toman una o varias capas de entrada y producen una capade salida, el análisis SIG puede concebirse como una especie demecano lógicomediante el cual diferentespiezas(operadores) se ensamblan formando análisis complejos que, en definitiva, consituyen nuevosmacroop-eradores.
El desarrollo de un proyecto SIG consistiría de esta manera en la división sucesiva de un problema en subtareascada vez más simples hasta el momento en que cada una de estas subtareas pudiera expresarse como un operadorde álgebra de mapas (figura 30 parte baja); este es el concepto fundamental del trabajo con un SIG. Por tantoel álgebra de mapas se convierte en un lenguaje de programación y el trabajo con un SIG en el desarrollo dealgoritmos.
Una vez que se ha explicitado un determinado trabajo en SIG como una serie de ordenes escritas en el lenguajeformal del álgebra de mapas lo que tenemos es un programa con todas las de la ley. Por tanto podemos escribirloen un fichero y utilizarlo con otra base de datos diferente. Evidentemente para hacer esto necesitamos un SIGbasado en comandos, es decir basado en un lenguaje.
36

3 Modelos de datos para el análisis y la cartografía de riesgos
3.1 Modelos de datos climáticos
La recogida de datos meeorológico-climáticos se ha hecho tradicionalmente en observatorios fijos. La propiadefinición de clima exige disponer de una serie temporal suficientemente larga para poder considrerarla comosignificativa. Por tanto, el estudio de datos climáticos se ha hecho mediante el análisis de series temporales.
Apesar de que estas series tienen una ubicación espacial, es preferible almacenarlas en una base de datos debidoa las limitaciones de los SIG para trabajar con la componente temporal. Una estructura de datos adecuada, paraevitar repeticiones innecesarias de información, sería mantener en una tabla la información referente a losobservatorios y en otras las referidas a las diferentes series temporales manejadas. En la figura 31 apareceun ejemplo y en la figura 32 el resultado de una consulta en la que se pide a la base de datos que devuelvalas coordenadas del observatorio y la precipitación en ese observatorio en una determinada fecha. Se puedecomprobar en la figura 31 que existe un campo común que es el que permite relacionar ambas tablas.
Figura 31: Tablas de observatorios y datos meteorológicos
Figura 32: Resultado de una consulta para obtener un mapa de puntos de precipitación
37

El resultado de la consulta es en definitiva un mapa de puntos que puede visualizarse (figura 14), analizarsepara determinar la existencia de factores que puedan ayudar a la interpolación (figura 16) o interpolarse (figuras16 a 24).
Hoy en día se dispone de sensores remotos de diverso tipo que permiten captar imágenes con las que hacerestimaciones más o menos precisas de diversas variables climáticas y su variación espacial en un momentoconcreto. Los satélites meteorológicos (Meteosat, NOAA) y los radares meteorológicos se han utilizado parahacer estimaciones de la precipitación, sin embargo requieren un trabajo de calibración importante con datosde pluviógrafo para poder dar estimaciones fiables.
La estructura de la información proporcionada por estos sensores es siempre en formato raster por lo que esfácilmente incorporable a un SIG. Su análisis se basa en operadores de álgebra de mapas:
• Operadores de vecindad para filtrar la imagen y resaltar determinados aspectos de la misma
• Operadores locales, índices que permiten obtener variables climáticas a partir de la reflectividad medidapor el sensor
Visible Infrarrojo térmico Vapor de agua
Figura 33: Imágenes de cada uno de los canales del satélite Meteosat
Los estudios de riego suelen basarse en el concepto de período de retorno. En el caso de precipitaciones inten-sas, avenidas e inundaciones se determina en primier lugar cual es la lluvia máxima esperable en 24 horas yposteriormente se descompone en un yetograma de diseño (Ferrer Polo, 2000).
3.2 Modelos de datos topográficos
Uno de los elementos básicos de cualquier representación digital de la superficie terrestre son los ModelosDigitales de Terreno (MDT). Constituyen la base para un gran número de aplicaciones en ciencias de la Tierra,ambientales e ingenierías de diverso tipo. El análisis de MDT y su aplicación en modelos hidrológicos y climáti-cos ha sido objeto de númerosos trabajos (Felicisimo, 1994; 1999; Olaya Ferrero, 2004; Weibel & Heller, 1991;Wood, 1996).
38

Se denomina MDT al conjunto de mapas que representan distintas características de la superficie terrestrederivadas de un mapa de elevaciones (Modelo Digital de Elevaciones, MDE). Algunas definiciones incluyendentro de los MDT prácticamente cualquier variable cuantitativa regionalizada. Siguiendo la primera de estasaproximaciones se va a considerar al MDE como la pieza clave de un MDT de la que se derivan todas las demásy, por tanto, aquella que va a requerir más atención en su obtención.
3.2.1 Estructuras de codificación de la elevación
Un Modelo Digital de Elevaciones puede representarse de forma genérica mediante la ecuación:
z = f(x, y) (4)
que define un campo de variación continua. La imposibilidad de resolver la ecuación anterior para todos lospuntos del territorio obliga a definir elementos discretos sobre el mismo que permitan simplificar la codificaciónde la elevación. Las más habituales son:
• Curvas de nivel, se trata de lineas, definidas por tanto como una sucesión de pares de coordenadas, quetienen como identificador el valor de la elevación en cada unos de los puntos de la linea. Generalmenteel intervalo entre valores de las curvas de nivel es constante.
• Red Irregular de Triángulos (TIN) ,a partir de un conjunto de puntos, en los que se conoce la elevación,se traza un conjunto de triángulos. En principio pueden formarse triángulos a partir de puntos extraidosde la misma curva de nivel, pero al tener el mismo valor daran lugar a triángulos planos. Tienen entresus ventajas el adaptarse mejor a las irregularidades del terreno, ocupar menos espacio y dar muy buenosresultados a la hora de visualizar modelos en 3D. Entre los inconvenientes destaca un mayor tiempo deprocesamiento y el resultar bastante ineficientes cuando se intenta integrarlos con información de otrotipo.
• Formato raster, es el más adecuado para la integración de las elevaciones en un SIG ya que va a permitirla utilización de diversas herramientas para la obtención de nuevos mapas a partir del MDE; por tanto vaa ser el que se trate en este tema.
3.2.2 La construcción del MDE
Existen diversos métodos para construir un MDE:
• Métodos directos mediante sensores remotos:
– Altimetría , altímetros transportados por aviones o satélites que permiten determinar las diferenciasde altitud entre la superficie terrestre y el vehículo que transporta el altímetro (que se supone con-stante). El inconveniente es la baja resolución (celdillas muy grandes) de los datos y su sensibilidada la rugosidad del terreno. Por ello se limita al seguimiento de hielos polares.
39

– Radargrametría o interferometría de imágenes radar. Un sensor radar emite un impulso electro-magnético y lo recoge tras reflejarse en la superficie terrestre, conociendo el tiempo de retardo delpulso y su velocidad puede estimarse la distancia entre satélite y terreno. En 1999 la NASA inicióel proyecto SRTM (http://www2.jpl.nasa.gov/srtm/) para elaborar un mapa topográfico de toda laTierra a partir de interferometría radar.
• Métodos directos sobre el terreno:
– Topografía convencional, estaciones topográficas realizadas en el campo mediante dispositivosque permiten la grabación de datos puntuales que se interpolan posteriormente.
– Sistemas de Posicionamiento GPS, sistema global de localización mediante satélites, que permiteestimaciones suficientemente precisas de latitud, longitud y altitud de un punto, posteriormentedeben interpolarse los datos.
• Métodos indirectos:
– Restitución fotogramétrica a partir de fuentes analógicas (fotografía aérea) o digitales (imágenesde satélite). El paralaje2 de un punto en una fotografía aérea o imagen de satélite es proporcional ala distancia del objeto respecto al fondo.
– Digitalización de curvas de nivel de un mapa mediante escáner o tablero digitalizador e interpo-lación de las mismas.
Los trabajos de campo son bastante precisos y su resolución se decidea priori. Además es posible adaptar elmuestreo a las condiciones y las irregularidades del terreno. EL principal inconveniente es su elevado coste entiempo y dinero. Sólo resulta rentable cuando se quiere conseguir un MDE muy detallado de una porció deterreno reducida.
La fotogrametría implica también un muestreo de puntos sobre los que calcular el paralaje, se trata sin em-bargo de un muestreo en gabinete por lo que no resulta tan costoso. Existen dispositivos que convierten lafotogrametría en un proceso semiautomáticos sin embargo resultan bastante caros. Al final tras obtener laselevaciones en una serie de puntos es necesario interpolar resultados.
3.2.3 Obtención de variables derivadas
Un MDE no solamente contiene información explícita acerca de la altitud en un área muestreada en diversospuntos (modelo TIN) o celdillas (modelo raster) sino que también aporta información relativa a las relaciones(distancia y vecindad) entre los diferentes valores de altitud. Ello permite el cálculo, a partir de diversos proced-imientos de álgebra de mapas, de nuevas variables topográficas. En la figura 34 aparece el Modelo Digital deElevaciones de una pequeña zona de poco más de 2Km2 situada un kilómetro al Sur de Pliego. El MDE se hahecho a partire de curvas de nivel a escala 1:5000 y se utilizará para presentar los diferentes mapas derivados.
2movimiento aparente de un objeto sobre el fondo de la imagen cuando se observa desde dos puntos de vista diferentes. Un ejemplosencillo se obtiene al mirar un lápiz con uno y otro ojo sobre un fondo alejado. Cuando se mira con el ojo izquierdo el objeto parecedesplazarse a la derecha y viceversa.
40

Figura 34: Modelo Digital de Elevaciones
41

Figura 35: Operador de vecindad, cálculo de pendientes y orientaciones
La pendienteen un punto del terreno se define como el ángulo existente entre el vector normal a la superficieen ese punto y la vertical. Su estimación es sencilla a partir del MDE, aunque existen diferentes procedimientosque dan lugar a diferentes resultados (cuando se trabaja con un programa es importante conocer cual es elalgoritmo que utiliza para calcular pendientes) entre los métodos habituales están:
• Pendiente máxima de la celdilla central con respecto a los valores vecinos, adecuado para evaluación dela erosión
• Pendiente media de la celdilla central con respecto a los valores vecinos
• Pendiente en el sentido del flujo descendente, adecuado en celdillas correspondientes a cauces en aplica-ciones de tipo hidrológico
• Ajuste de una superficie a los 9 valores de elevación correspondientes a la celdilla central y sus 8 celdillasvecinas
La orientación (figuras 35 y 37) en un punto puede definirse como el ángulo existente entre el vector queseñala el Norte y la proyección sobre el plano horizontal del vector normal a la superficie en ese punto. Comoen el caso de la pendiente, el valor de orientación se estima directamente a partir de los parámetros obtenidosde ajustar una superficie cuadrática a los nueve valores de la celdilla central y su entorno:
42
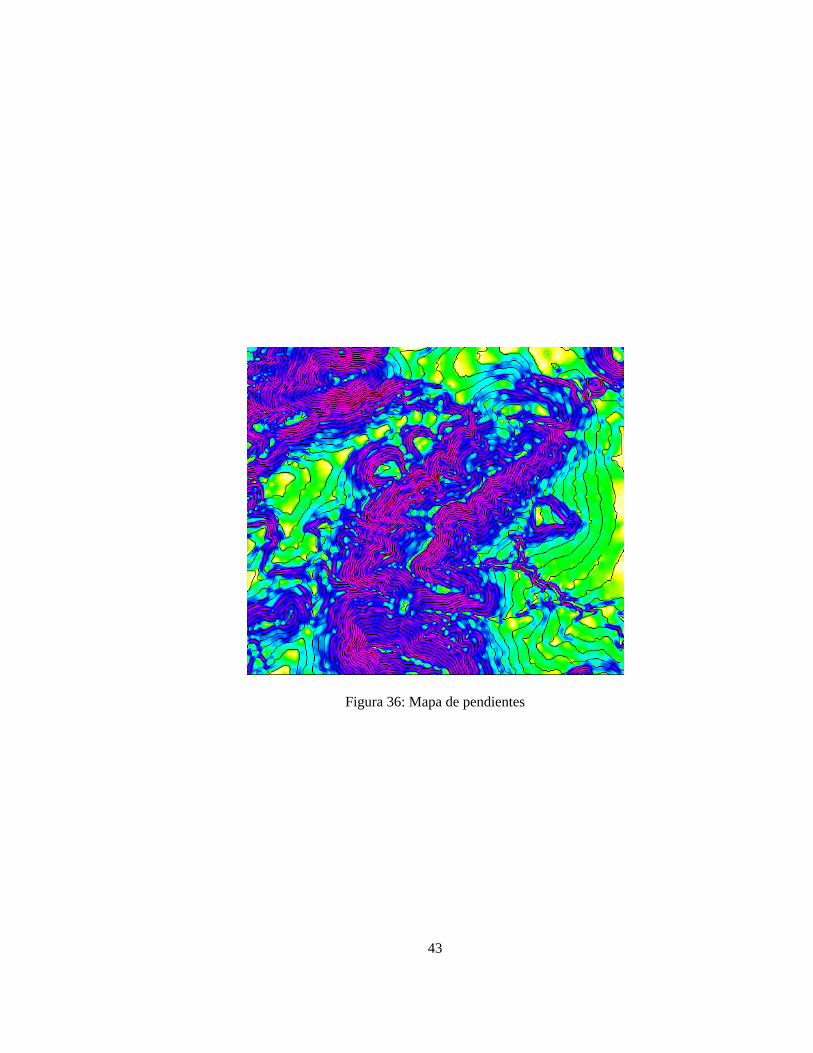
Figura 36: Mapa de pendientes
43

Figura 37: Mapa de orientaciones
44

Figura 38: Operador de vecindad. Cálculo de la dirección de flujo
3.3 Modelos de datos hidrológicos
En los estudios de hidrología computacional (Olaya Ferrero, 2004), resulta difícil establecer una separación en-tre obtención de datos topográficos y datos hidrológicos. En el apartado anterior se ha finalizado presentando laorientación y la pendiente como operadores direccionales. Otro operador direccional es la dirección de drenaje,se trata de determinar a cual de las 8 celdillas vecinas drenará la celdilla considerada. La solución fácil es aplicarel algoritmo D8 (O’Callaghan y Mark, 1984), se trata de dirigir el flujo de forma determinista a la celdilla que,estando situada a menor elevación, siga la dirección de máxima pendiente. Existen otras posibilidades (Moore,1996) como el algoritmo Rho8 que utiliza un procedimiento estocástico para asignar el flujo o los algoritmosFD8 y FRho8 que permiten la difusión del flujo entre varias de las celdillas vecinas.
La dirección de flujo calculada con el algoritmo D8 representa la dirección hacia la que drenaría un volumende agua situado sobre una celdilla. Puesto que toda celdilla está rodeada por otras 8, puede tomar 8 valoresdiferentes (figuras 38 y 39).
Se denominalínea de flujoal trayecto que, a partir de un punto inicial, seguiría la escorrentía superficial sobreel terreno
Las líneas de flujo siguen la línea de máxima pendiente por lo que pueden deducirse del modelo digital dependientes con las únicas limitaciones que las derivadas de la calidad del MDE original.
A partir del trazado de las líneas de flujo es posible definir la red hidrológica, elárea subsidiaria de una celday, por extensión, las cuencas hidrológicas: Se define el área subsidiaria de una celda como el conjunto de celdascuyas líneas de flujo convergen en ella; una cuenca hidrológica está formada por el área subsidiaria de una celdasingular, que actúa como sumidero
La magnitud del área subsidiaria de una celda del MDE está directamente relacionada con elcaudal máximopotencial, CMP, en el mismo. En efecto, el caudal que puede circular en un momento dado en un punto delterreno depende, entre otros factores, de la magnitud del área subsidiaria, de las precipitaciones sobre ella y de
45

Figura 39: Mapa de dirección del flujo
46

Figura 40: Red de drenaje extraida por procedimientos automáticos a partir del modelo de elevaciones.
la pendiente de la zona, que permite la circulación con menor o mayor rapidez. En función de estos parámetroses posible simular el CMP en un modelo digital del terreno.
Otra información de gran interés hidrológico directamente extraible de un MDT son las redes de drenaje. Paraello se parte de la hipótesis de que hay un valor umbral de área subsidiaria por encima del cual el cauce encuestión puede considerarse como perteneciente a un cauce. Por tanto basta con reclasificar el mapa de áreassubsidiarias para asignar un valor 1 a aquellas celdillas con área subsidiaria mayor que dicho umbral y valor 0 onulo a las restantes. Finalmente, si se quiere el mapa de redes de drenaje en formato vectorial se deberá realizarel correspondiente cambio de formato.
Las redes de drenaje extraidas con este procedimiento presentan algunas deficiencias (figura 40):
• El que en una determinada celdilla se inicie un cauce depende no sólo de su área subsidiaria sino tambiénde las caracteristicas litológicas e incluso de uso del suelo de la misma. Por tanto utilizar un sólo valorumbral para todo el área de trabajo resulta bastante simplista.
• Debido al algoritmo que genera las direcciones de flujo y los mapas de área subsidiaria, los caucesresultantes tienden a adoptar un carácter rectilineo
En muchos casos, es preferible trabajar con representaciones vectoriales de las redes de drenaje. Estas puedendigitalizarse directamente utilizando las curvas de nivel presentes en los mapas topográficos o vectorizarse apartir de las redes de drenaje en formato raster generadas mediante el procedimiento antes mencionado. Puedenobtenerse diferentes modelos de red de drenaje a partir de diferentes valores de área vertiente umbral paraconsiderar que una celdilla es un cauce (figura 41).
47

Figura 41: Red de drenaje automatizada de la Rambla Salada con diferentes valores umbral
Una vez que se tiene la red de drenaje digitalizada, la reconstrucción de las relaciones topológicas entre losdiferentes tramos permite aplicar cualquier sistema de ordenación de redes de drenaje (Horton, Strahler, etc.).Para ello basta con construir una tabla en la que se anote para cada tramo cuales sonlos tramos aguas arriba ycual es el tramo aguas abajo.
La aplicación de un algoritmo de ordenación de redes de drenaje (figura 42) va a a permitir la evaluación au-tomática de diferentes parámetros, como la razón de bifurcación, razón de longitud, longitus del cauce principal,etc. (Chorleyet al., 1984) que pueden utilizarse para caracterizar de manera global la red y calcular parámetrosde modelos hidrológicos agregados.
3.4 Datos temáticos
Se incluyen aquí aquellos datos de los que habitualmente se ha ocupado la cartografía temática. Se trata demapas de variable cualitativa por lo que pueden almacenarse tanto en formato raster como vectorial.
3.4.1 Usos de suelo
Aunque existen mapas publicados de usos de suelo, e incluso los mapas topográficos incluyen este tipo deinformación en sus yeyendas, se trata de una variable con una variabilidad temporal tan alta que los mapasquedan rápidamente obsoletos, quizás incluo antes de su publicación. La solución al problema vendría dada
48

Figura 42: Red de drenaje de la Rambla Salada. Ordenación de Horton
por la utilización de mapas de suelos obtenidos por técnicas de teledetección a partir de satélites dedicados alanálisis de recursos naturales como los de la serie landsat (figura 43).
Las diversas técnicas de clasificación utilizadas han tenido siempre el problema de las bajas resoluciones es-pectral (número de bandas) y radiométricas (número de niveles de reflectividad observables). Hoy en día hanempezado a lanzarse satélites con una capacidad prospectiva mayor por lo que en el futuro cabe esperar unaclasificación mucho más exacta y rápida de las imágenes. La clasificación de imágenes de satélite debe siempreapoyarse, en todo caso, en trabajo de campo.
Uno de los problemas de los mapas de uso de suelo obtenidos a partir de imágenes de satélite es la relativamentebaja capacidad de discriminación que se limita a unas pocas categorías generales de uso del suelo (figura 44)
3.4.2 Mapas litológicos
Al contrario que el caso anterior, la información litológica puede considerarse invariante con el tiempo. ElITGME ha publicado mapas geológicos a escala 1:50000 de casi toda España. Sin embargo estos mapas no seencuentran disponibles en formato digital. No obstante pueden escanearse y georreferenciarse, casi todos losprogramas de SIG disponen de los módulos apropiados para hacerlo.
49

Figura 43: Imagen landsat. Embalse de puentes, valle del Guadalentín y la ciudad de Lorca
3.4.3 Mapas de suelos
Estos mapas suelen ser más difíciles de conseguir. El antiguo ICONA a través del Proyecto LUCDEME publicóvarios mapas de suelo del Sureste ibérico a escala 1:50000 (aunque la edición se hizo a escala 1:100000).Recientemente, la Consejería de Agricultura Pesca y Medio Ambiente de la Comunidad Autónoma de la Regiónde Murcia ha publicado en formato digital las correspondientes a la Región. Esta publicación incluye diversastablas con las propiedades de los diferentes polígonos de suelo, perfiles y muestras de capa arable. Tanto losperfiles como las muestras de capa arable se guardan en una base de datos acompañadas de sus correspondientescoordenadas, por lo que resulta sencillo obtener un mapa de puntos de cada una de las varibales medidas einterpolarla.
Se trata de una información de gran interés en cualquier trabajo acerca del riesgo de inundación ya que permitehacer una buena caracterización de las propiedades físicas e hídricas del suelo para estimar su capacidad deinfiltración. Una vez que se dispone de mapas raster interpolados de las diferentes variables de interés bastacon utilizar un modelo de infiltración basado en parámetros que puedan calcularse mediante operadores localesa partir de estas capas. Los métodos de Green-Ampt o del número de curva (figura 45) son buenos ejemplos(Tragsa-Tragsatec, 1998).
Una posibilidad más sencilla sería reclasificar (operador local) el mapa de suelos asignando a cada tipo de sueloun valor medio de determinada variable recopilado en la bibliografía.
50

4 Modelos de procesos
4.1 Modelos de radiación y evapotranspiración
La radiación solar incidente sobre la superficie de la Tierra es resultado de un complejo de interacciones entrela atmósfera y la superficie terrestre. La topografía es el principal factor, a escala local, que condiciona laenergía solar incidente sobre la superficie terrestre. La variedad de altitudes, pendientes y orientaciones creanfuertes contrastes locales que afectan directa e indirectamente a procesos biológicos y físicos. Algunos deestos factores son modelizables con los MDT. Así la radiaciaón incidente sobre una determinada celdillaRi esfunción de la radiación que alcanzaría a una celdilla perpendicular a la dirección de los rayos solaresRs por unfactor corrector que es función de la inclinación de los rayos solares sobre el horizonteh y de la pendientes yorientacióna de la celdilla:
Ri = Rs(cos(h)sen(s)cos(a) + sen(h)cos(s)) (5)
Pendiente y orientación se obtienen del MDE y la altura del sol sobre el horizonte como:
h = arcsen(sen(δ)sen(L) + cos(L)cos(w)cos(δ)) (6)
dondeL es la latitud,w el ángulo horario yδ la declinación en cuyo cálculo interviene el día del año. En laestimación deRs se debe tener en cuenta la atenuación de la radiación por absorción atmosférica.
Otro efecto a tener en cuenta es la existencia de zonas de sombra es una variable de gran interés en regionesmontañosas, donde el relieve puede ser el factor determinante más importante del clima local. Se define lainsolación potencial en un punto como el tiempo máximo que ese lugar puede estar sometido a la radiaciónsolar directa en ausencia de nubosidad. La insolación potencial depende directamente del ángulo de incidenciadel sol respecto a la superficie terrestre y del ocultamiento topográfico ante una trayectoria concreta del Sol.
Los módulos de SIG que modelizan la radiación incidente suelen permitir obtener mapas de ángulo solar paraun instante determinado,arcsen(cos(h)sen(s)cos(a) + sen(h)cos(s)), o integrar la radiación total recibidadurante un período de tiempo y expresada en unidades energía partido por espacio. períodos de tiempo mayoresde tiempo mayores.
El ángulo solar resulta además de utilidad en aplicaciones relacionadas con la teledetección (corrección poriluminación y cálculo de reflectividades). En cuanto a la radiación recibida se utiliza en:
1. Modelos de estimación de variables climáticas (temperatura, evapotranspiración)
2. Modelos de distribución potencial de especies animales o vegetales
51

4.2 El Hidrograma Unitario Geomorfológico. Un modelo agrgado
Se trata de un modelo desarrollado por Rodriguez Iturbe (1993) que utiliza el método del Hidrograma Uni-tario pero utilizando un conjunto de índices geomorfológicos para calibrarlo. De esta manera no es necesariodisponer de datos de aforos para su aplicación.
El Hidrograma Unitario es la respuesta de una cuenca a una precipitación uniforme, efectiva (es decir lluviaque cae con igual intensidad en toda la cuenca y produce sólo escorrentía rápida) y que además es de valorunitario. (Tragsa-Tragsatec, 1998). Esta respuesta se prolonga más o menos en el tiempo, en función de lascaracterísticas de la cuenca, y se define:
h(t) = GUH(t) = (t
k)α−1 e−t/k
kΓ(α)(7)
Si la precipitación instantanea fuera de un volumen cualquiera (v), en lugar de unitaria, el hidrograma resultantesería
H(t) = vh(t) (8)
Si la precipitación, en lugar de instantanea, se prolonga a lo largo de una serie de intervalos discretos (formandoun yetograma), el hidrograma resultante puede calcularse mediante un procedimiento de convolución siempreque se haya utilizado la misma discretización temporal en el yetograma que en el hidrograma unitario:
H(t) =t∑
i=1
v(i)h(t− i + 1) (9)
La hipótesis del Hidrograma Unitario Geomorfológico permite estimar los parámetros deh(t) a parir de unaserie de parámetros geomorfológicos:
• RB Indice de bifurcación de Horton
• RA Indice de areas
• RL Indice de longitudes
• LΩ Longitud en el cauce principal
y de la velocidad en el cauce principal
α = 3.29(RB
RA)0.78R0.07
L (10)
k = 0.7(RA
(RBRL))0.48LΩv−1 (11)
52

Por tanto el parámetro k depende de la velocidad del flujo en el cauce principal, se tratra de un parámetro demuy difícil estimación y variable con el tiempo. Para solventar este problema se ha utilizado una aproximacióndiferente:
Rosso (1984) propone utilizar como estimación dek:
k =tlα
(12)
dondetl es el tiempo de retardo yα el parámetro de forma del Hidrograma Unitario Geomorfológico.
Este modelo fue aplicado en un proyecto de detección y cartografía de áreas susceptibles de inundación que re-alizó el Instituto del Agua y del Medio Ambiente de la Universidad de Murcia en colaboración con la DirecciónGeneral de Protección Civil de la Comunidad Autónoma de la Región de Murcia.
Para su aplicación, se desarrollo un módulo específico para GRASSv.GUHs que muestra en pantalla la red dedrenaje requerida. El usuario, tras pinchar en uno de sus tramos, obtiene (utilizando los algoritmos detalladosanteriormente) la reconstrucción de la cuenca y de la red de drenaje tributaria de este tramo, su ordenaciónpor los criterios de Strahler y los parámetros necesarios para aplicar el método del Hidrograma Unitario Geo-morfológico. Al mismo tiempo se obtiene un valor de número de curva y valores de precipitación máxima enla cuenca para los períodos de retorno considerados. Estos valores se calculan a partir de los valores mediosregistrados en las celdillas pertenecientes a las cuencas.
Con estos valores se entra en otro módulo programado paraR. R es un entorno para el análisis estadístico queproporciona un gran número de técnicas estadísticas y gráficas, así como un lenguaje con el que resulta sencilloprogramar modelos matemáticos.
Este programa es el encargado de llevar a cabo:
• Creación del yetograma de la tormenta de diseño
• Cálculo de la precipitación efectiva
• Estimación de los parámetros del Hidrograma Unitario Geomorfológico
• Convolución y obtención de los caudales máximos para 50, 100 y 500 años.
Seleccionando los tramos que afectan a cada uno de los nucleos de población considerados se obtiene unhidrograma de avenida para cada uno de ellos.
En la figura??aparece la cuenca de la Rambla del Ramonete, mientras que en la figura 48 aparece el resultadode seleccionar el punto, Ermita de Ramonete, para el que se quiere llevar a cabo un análisis hidrológico. Laselección de este punto implica al mismpo tiempo la reconstrucción de toda su cuenca vertiente que actúa comomáscara para obtener un mapa de Número de Curva y de precipitación para determinados períodos de retorno(figuras 50 y 51). La integración de toda esta información permite generar un yetograma de período de retorno,modelizar la infiltración para obtener un yetograma de precipitación efectiva; generar el Hidrograma UnitarioGeomorfológico y hacer la convolución para obtener hidrogramas de diseño (figura 51).
53

4.3 Modelos hidrológicos distribuidos de tipo físico
El flujo de agua y materiales en el espacio y a través del tiempo, es gobernado por una serie de principiosbásicos.
• Conservación de la masa (ecuación de la continuidad):
δQ
δx+
δA
δt= q (13)
• Conservación del momento (segunda ley de Newton) que en su forma simplificada puede escribirse:
A = αQβ (14)
• Conservación de la energía: Primera ley de la termodinámica
∆E = Ic −W (15)
Dejando al margen la conservación de la energía, el proceso queda simplemente regido por dos ecuacionesque se pueden integrar en un único modelo. En estas ecuaciones,Q es el caudal,A es el área de la secciónmojada,δt el intervalo de tiempo,δx el intervalo espacial equivalente a la resolución o tamaño de la celdilla.Finalmente,α y β son dos parámetros que dependen del tipo de formulación que se emplea para relacionarcaudal con área de la sección mojada. Si se emplea la formulación de Manning:
α = (nP 23
1.49√
S)3/5 (16)
β = 3/5 (17)
Diferenciando la ecuación 14 y sustituyendoδAδt por su equivalente según la ecuación 13 se obtiene:
δQ
δx+ abQb−1 δQ
δt= q (18)
Esta ecuación corresponde al modelo de onda cinemática, una simplificación de las ecuaciones de SaintVenant(Chowet al., 1984) y puede resolverse mediante un procedimiento de diferencias finitas haciendo las siguientessustituciones:
δQ
δx=
Qj+1,i+1 −Qj+1,i
∆x(19)
δQ
δt=
Qj+1,i+1 −Qj,i+1
∆t(20)
54

Q =Qj+1,i + Qj,i+1
2(21)
q =qj+1,i+1 + Qj,i+1
2(22)
Los subíndicesj ei hacen referencia a los diferentes intervalos temporales y espaciales, respectivamente, segúnel esquema de la figura 52. Esta representa una malla espacio-temporal que simboliza el proceso de resolucióndel modelo de modo que el cauda en el puntoj + 1, i + 1 se resuelve a partir de los valores ya conocidos enj, i + 1, j + 1, i y j, i. Esta resolución requiere conocer:
• Las condiciones iniciales, es decir el valor de caudal en todos los puntosi cuandoj = 0.
• Las condiciones de contorno o hidrograma de entrada al sistema, es decir el valor del caudal eni = 0para todoj
• Las entradas al sistema (precipitación efectiva), es decir los valores deq para todoi y j
Sustituyendo y despejando paraQj+1,i+1 se obtiene:
Qj+1,i+1 =( ∆t∆xQj+1,i + αβQj,i+1(
Qj,i+1+Qj+1,i
2 )β−1 + ∆t( qj+1,i+1+qj,i+1
2 ))∆t∆x + αβ(Qj,i+1+Qj+1,i
2 )β−1(23)
Este algoritmo asume un cauce lineal que se divide en intervalos discretos, en el caso de una cuenca tenemosuna cuenca bidimensional, pero puesto que cada celdilla recibe el flujo de sus celdillas tributarias (figura 53),el valor deQj,i y Qj+1,i se calcula como la suma de los caudales de las celdillas tributarias
El inverso del parámetro∆t∆x equivale a la máxima velocidad que puede alcanzar el flujo para que la resolución
del modelo conserve la estabilidad. Se trata de la condición de Courant que establece que:
Vmax <∆x
∆t∆x > Vmax∆t (24)
ya que en otro caso el sistema se vuelve inestable. Una forma intuitiva de entenderlo es que si no se cumpliesese daría la paradoja de queVmax∆t, que es el espacio recorrido por un determinado volumen de agua entre dosintervalos de tiempo del modelo, sería mayor queδx y por lo tanto el agua habría saltado de una celdilla a otrasin pasar por la intermedia.
La condición de Couran implica que las escalas espaciales y temporales de los modelos físicos estén uy vin-culadas. Si se quiere trabajar con un modelo de elevaciones detallado, debe hacerse con intervalos temporalesbajos.
55

4.4 Modelos atmosféricos
El comportamiento de la atmósfera puede ser descrito como un sistema de ecuaciones diferenciales que de-scriben el conjunto de fuerzas que actúan sobre la atmódfera y la respuesta de esta. Para resolver el sistema esnecesario disponer de información acerca de las condiciones iniciales y de contorno. Las condiciones inicialeshacen referencia a los valores e las diferentes variables implicadas al inicio de la simulación, las condiciones decontorno se refieren a las características de las superficies que limitan la atmósfera y que pueden actuar comofuentes o sumideros, en este caso la superficie terrestre.
Las ecuaciones utilizadas son:
• Conservación de la velocidad
• Conservación de la energía
• Conservación de la masa (materia), y de cada uno de los componentes de la masa atmosférica por sepa-rado.
Puesto que se desarrolla en 3 dimensiones es necesario dividir el espacio en celdillas tridimensionales denomi-nadasvoxelsque viene a ser algo así comopixelcon volumen.
Los modelos atmosféricos presentan una gran variación en cuanto a la escala, van desde modelos globales conuna resolución de 400x400 Km a modelos de un kilómetro cuadrado o menos y de horas a siglos por lo que serefiere a la escala temporal.
Aquellos procesos que ocurren a escalas más detalladas que la resolución del modelo se parametrizan. Estoimplica la utilización de modelos empíricos para introducir las variables necesarias. Un ejemplo típico son losfenómenos termoconvectivos producto de la radiación acumulada en superficies especialmente expuestas quedan lugar a nubes de desarrollo vertical.
Las ecuaciones pueden resolverse con una aproximación similar a la de la figura 52 pero la condición deCourant resulta aún más limitante debido a que los flujos que se tratan presentan velocidades característicasmucho mayores.
Un ejemplo de modelo atmosférico sencillo puede ser el cálculo de la temperatura potencial en un dominiotridimensional. Habitualmente se calcula con la ecuación:
θ = T (p0
p)
RCp (25)
dondep es la presión atmosférica,p0 una presión de referencia yRCp= 0.28571 para el aire seco.
La temperatura potencial puede también expresarse como una función lineal de la altitudz y un término∆θ:
θ = A + Γdz + ∆θ(n)∆θ(n) = Ce−nl cos(n/l) (26)
56

donden es la distancia entre cadavoxely la superficie terrestre medida en un ángulo normal a esta,l es unparámetro de escala yC un parámetro térmico en superficie. Por lo tanto se requiere un MDE para resolver elmodelo. En la figura 54 aparece un resultado de este tipo de simulación.
5 Referencias
• Berry,J.K. 1993: Cartographic Modeling: The analytical Capabilities of GIS en M.F. Goodchild, B.O.Parks & L.T. SteyaertEnvironmental Modeling with GISOxford University Press, New York, Oxford.pp. 58-
• Bivand,R. & Neteler,M., 2000. Open Source geocomputation: using the R data analysis language inte-grated with GRASS GIS and PostgreSQL data base systems inGeocomputation 2000http://reclus.nhh.no/gc00/gc009.htm
• Bosque Sendra,J., 1992.Sistemas de Información Geográfica, Ed. Rialp. 451 pp.
• Burrough,P.A. and McDonnell,R.A., 1998.Principles of Geographical Information Systems, Oxford Uni-versity Press, Oxford, 2nd edition.
• Chorley,R.J.; Schumm,S.A. & Sugden,D.E., 1984:Geomorphology, Methuen, London, 607 p.
• Chow,V.T.; Maidment,D.R.; Mays,L.W., 1994.Hidrología aplicadaMcGraw Hill, 580 pp.
• Dietrich,W.E. & Dunne,T., 1993. The Channel Head in K.Beven & M.J. KirkbyChannel Network Hy-drologyJohn Wiley & sons 175-219
• Fedra,K. 1993: GIS and Environmental Modeling en M.F. Goodchild, B.O. Parks & L.T. SteyaertEnvi-ronmental Modeling with GISOxford University Press, New York, Oxford. pp. 35-50
• Felicísimo,A.M. (1994)Modelos digitales del terreno. Introducción y aplicaciones en ciencias ambi-entales118 pp. (http://www.etsimo.uniovi.es/ feli/pdf/libromdt.pdf)
• Felicísimo,A.M. (1999) La utilización de los MDT en los estudios del medio físico, 16 pp.(http://www.etsimo.uniovi.es/ feli/pdf/ITGE_150a.pdf)
• Ferrer Polo,F.J., 2000.Recomendaciones para el cálculo hidrometeorológico de avenidasCEDEX, Cen-tro de Estudios Hidrográficos, 76 pp.
• Goodchild,M.J. 1993: The state of GIS for Environmetal Problem-Solving en Goodchild, B.O. Parks &L.T. SteyaertEnvironmental Modeling with GISOxford University Press, New York, Oxford. pp. 8-15
• Moore,I.D., 1996: Hydrological Modelling and GIS en M.Goodchild, L.T.Steyaert & B.O.ParksGIS andEnvironmental Modeling: Progress & Research IssuesGIS world books pp. 143-148.t
• Olaya Ferrero,V. (2004)Hidrología Computacional y Modelos Digitales de Terreno365 pp.
57

• Rodríguez Iturbe,I., 1993. THe Geomorphological Unit Hydrograph in K.Beven & M.J. KirkbyChannelNetwork HydrologyJohn Wiley & sons 43-68
• Tomlin,C.D. 1990:Geographical Information Systems and Cartographic ModelingEnglewood Cliffs,N.J.
• Tragsa, Tragsatec, 1998.Restauración Hidrológico-Forestal de Cuencas y Control de la ErosiónMundiPrensa,Madrid, 945 pp.
• Verbyla,D.L., 2002:Practical GIS analysisTaylor & Francis, London 288 pp.
• Weibel, R. & Heller, M. (1991) Digital Terrain ModellingGeographical Information Systems: Principlesand ApplicationsJohn Wiley & sons pp. 269297 (http://www.wiley.co.uk/wileychi/gis/resources.html)
• Wood, J. (1996)The Geomorphological Characterisation of Digital Elevation Models(http://www.soi.city.ac.uk/ jwo/phd/)
58

6 Bibliografía
• DIHMA, 1997. Delimitación del Riesgo de Inundación a Escala Regional en la Comunidad ValencianaGeneralitat Valenciana, 56 pp + mapa + CDROM
• García García,A.I.; Martínez Álvarez,V.; Regoyos Sainz,M. y Ayuga Tëllez,F., 2002. Simulación de even-tos hidrológicos en pequeñas cuencas hidrográficas en L.Laín Huerta (Ed.)Los Sistemas de InformaciónGeográfica en la Gestión de Riesgos Geológicos y en el Medio AmbienteITGE, 63-84
• Harvey,C.A. & Eash,D.A., 2003. Basinsoft, a computer program to quantify drainage basin characteris-tics en J.G.Lyon (Ed.)GIS for Water Resources and Watershed Management, Taylor & Francis, London,39-52.
• Kraus,R.A., 2000. Floodplain Determination using ArcView GIS and HEC-RAS in D.Maidment &D.Djokic (Eds.),Hydrologic and Hydraulic modeling support with Geographic Information Systems,ESRI press. 177-189.
• López-Bermúdez,F.; Conesa García,C. & Alonso-Sarría,F., 2002. Floods:Magnitude and Frequency inEphemeral Streams of the Spanish Mediterranean Region in L.J.Bull & M.J.Kirkby (Eds.)Hydrologyand Geomorphology of Semi-arid Channels. John Wiley & sons, 329-350.
• Martínez,V.; Dal-Ré,R.; García,A.I. y Ayuga,F., 2000. Modelación distribuida de la escorrentía superficialen pequeñas cuencas mediante S.I.G. Evaluación experimentalIngeniería Civil, 104, 141-146.
• Martz,L.W & Garbrecht,J., 2003. Channel Network Delineation and Watershed Segmentation in theTOPAZ Digital Landscape Analysis System en J.G.Lyon (Ed.)GIS for Water Resources and WatershedManagement, Taylor & Francis, London, 7-16.
• Mateu Bellés,J.F., 1989. Ríos y ramblas mediterráneosAvenidas fluviales e inundaciones en la cuencadel MediterráneoInstituto Universitario de Geografía de la Universidad de Alicante y Caja de Ahorrosdel Mediterráneo pp. 133-150.
• Mateu Belles,J.F. y Camarasa Belmonte, A.M., 2000. Las inundaciones en España en los últimos veinteaños. Una perspectiva geográfica.Serie Geográfica9:11-15
• Miller,S.N.; Guertin,D.P. & Goodrich, D.C., 2003. Deriving stream channel morphology using GIS-basedwatershed analysis en J.G.Lyon (Ed.)GIS for Water Resources and Watershed Management, Taylor &Francis, London, 53-60.
• Olivera,F. & Maidment,D.R., 1999. GIS Tools for HMS Modeling Support. in D.Maidment & D.Djokic(Eds.),Hydrologic and Hydraulic modeling support with Geographic Information Systems, ESRI press.85-112.
• Romero Díaz,M.A. y Maurandi Guirado,A., 2000. Las inundaciones en la cuenca del Segura en las dosúltimas décadas del siglo XX. Actuaciones de prevenciónSerie Geográfica9:93-120
59

• Saunders,W., 2000. Preparation of DEMs for Use in Environmental Modeling Analysis in D.Maidment& D.Djokic (Eds.),Hydrologic and Hydraulic modeling support with Geographic Information Systems,ESRI press. 29-51.
• Tachikawa,Y.; Shiiba,M. & Takasao,T.; 2003. Development of a Basin Geomorphic Information SystemUsing a TIN-DEM Data Structure en J.G.Lyon (Ed.)GIS for Water Resources and Watershed Manage-ment, Taylor & Francis, London, 25-37.
7 Programas utilizados
El Sistema de Información Geográfica con el que se ha preparado todo el material presentado se basa ensoftware abierto que puede descargarse directamente de Internet. Las versiones que se han utilizado son paraLinux, sin embargo existen, de todos ellos, versiones también gratuitas para otros sistemas.
A continuación se hace un listado de estos programas y las páginas web de donde pueden descargarse
• GRASS,SIG:http://grass.itc.it/index.html
• R, programa de análisis de datoshttp://cran.r-project.org/
• PostgreSQL, programa de gestión de bases de datoshttp://www.postgresql.org/
• gstat, programa de geoestadísticahttp://www.gstat.org/
• postgis, extensión espacial para PostgreSQLhttp://postgis.refractions.net/
60

Indice
1 Introducción 1
1.1 Cuestiones generales sobre modelización . . . . . . . . . . . . . . . . . . . . . . . . . . . .1
1.2 Tipos de modelos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2
1.3 Sistemas de Información Geográfica y Modelización . . . . . . . . . . . . . . . . . . . . . .5
1.4 Modelos de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .6
1.4.1 El modelo conceptual. Objetos y variables . . . . . . . . . . . . . . . . . . . . . . . .7
1.4.2 Modelos lógicos. Formato raster y vectorial . . . . . . . . . . . . . . . . . . . . . . .10
1.5 Problemas y limitaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .13
2 Herramientas SIG útiles en la modelización y cartografía de riesgos 14
2.1 Enlaces con bases de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .15
2.2 Interpolación a partir de puntos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .18
2.2.1 Métodos de clasificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .18
2.2.2 Métodos de regresión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .20
2.2.3 Métodos locales basados en medias ponderadas . . . . . . . . . . . . . . . . . . . . .21
2.2.4 Interpolación local porsplines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.5 Interpolación local mediante TIN . . . . . . . . . . . . . . . . . . . . . . . . . . . .24
2.2.6 Validación y validación cruzada . . . . . . . . . . . . . . . . . . . . . . . . . . . . .27
2.2.7 Combinación de diferentes métodos . . . . . . . . . . . . . . . . . . . . . . . . . . .29
2.3 Algebra de mapas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .30
2.3.1 Operadores locales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .30
2.3.2 Operadores de vecindad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .31
2.3.3 Operadores de vecindad extendida, operadores extendidos . . . . . . . . . . . . . . .32
2.3.4 Operadores de área . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .34
2.3.5 Propagación de errores en álgebra de mapas . . . . . . . . . . . . . . . . . . . . . . .34
2.3.6 Implementación del álgebra de mapas en los SIG . . . . . . . . . . . . . . . . . . . .35
2.3.7 El álgebra de mapas como lenguaje . . . . . . . . . . . . . . . . . . . . . . . . . . .35
61

3 Modelos de datos para el análisis y la cartografía de riesgos 37
3.1 Modelos de datos climáticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .37
3.2 Modelos de datos topográficos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .38
3.2.1 Estructuras de codificación de la elevación . . . . . . . . . . . . . . . . . . . . . . .39
3.2.2 La construcción del MDE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .39
3.2.3 Obtención de variables derivadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . .40
3.3 Modelos de datos hidrológicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
3.4 Datos temáticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
3.4.1 Usos de suelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
3.4.2 Mapas litológicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .49
3.4.3 Mapas de suelos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .50
4 Modelos de procesos 51
4.1 Modelos de radiación y evapotranspiración . . . . . . . . . . . . . . . . . . . . . . . . . . .51
4.2 El Hidrograma Unitario Geomorfológico. Un modelo agrgado . . . . . . . . . . . . . . . . .52
4.3 Modelos hidrológicos distribuidos de tipo físico . . . . . . . . . . . . . . . . . . . . . . . . .54
4.4 Modelos atmosféricos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .56
5 Referencias 57
6 Bibliografía 59
7 Programas utilizados 60
62

Figura 44: Mapa de suelos de la Región de Murcia del año 2001 obtenido de datos del satélite landsat
63
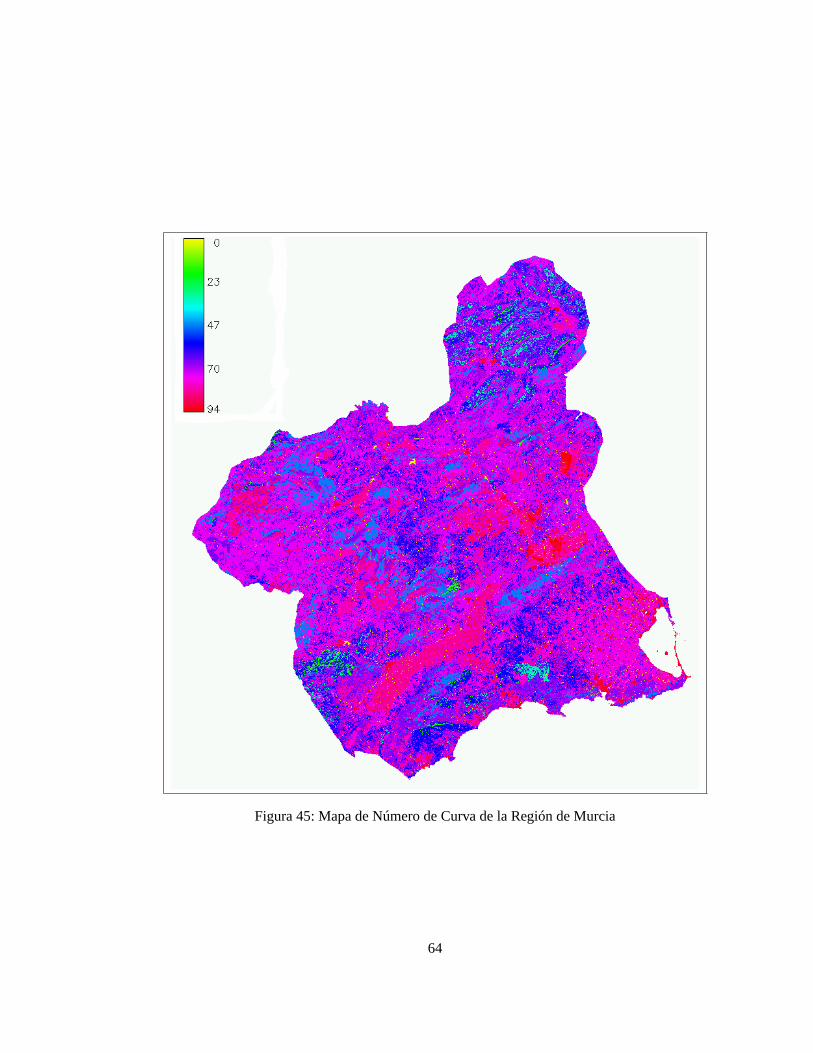
Figura 45: Mapa de Número de Curva de la Región de Murcia
64

Figura 46: Insolación recibida el 17 de Enero a las 10:00 AM hora solar
Figura 47: Rambla del Ramonete. Area drenada y red de drenaje reconstruida.
65
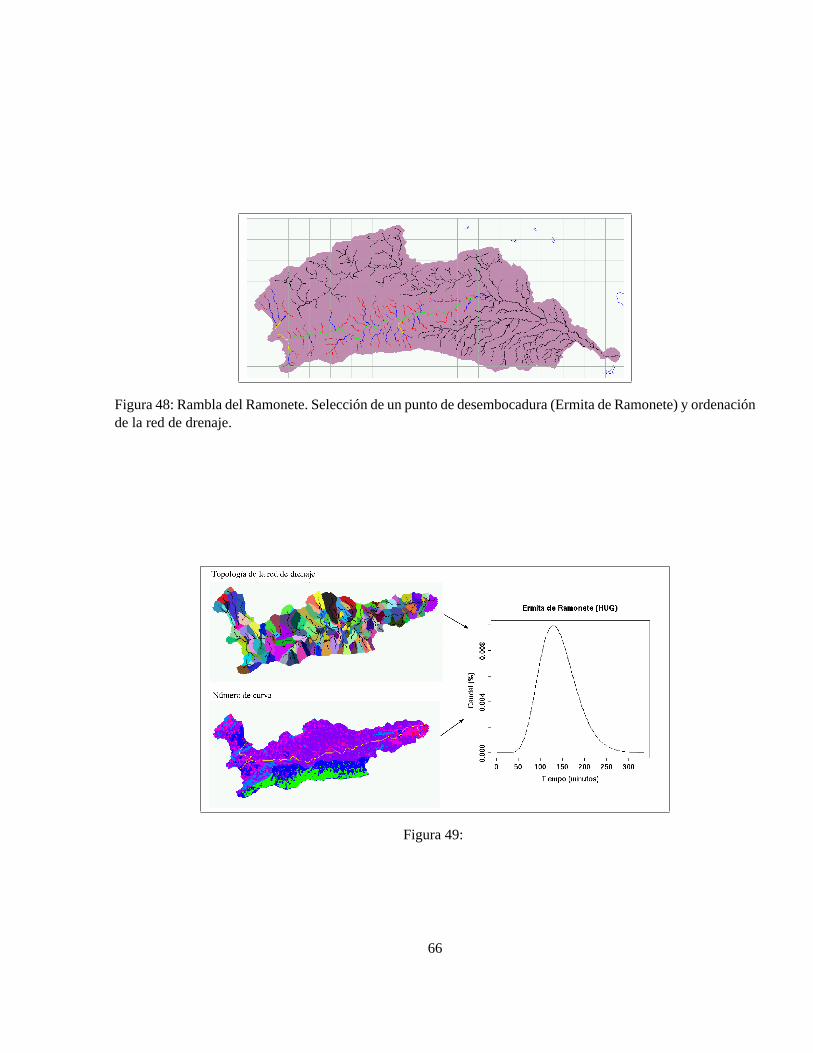
Figura 48: Rambla del Ramonete. Selección de un punto de desembocadura (Ermita de Ramonete) y ordenaciónde la red de drenaje.
Figura 49:
66
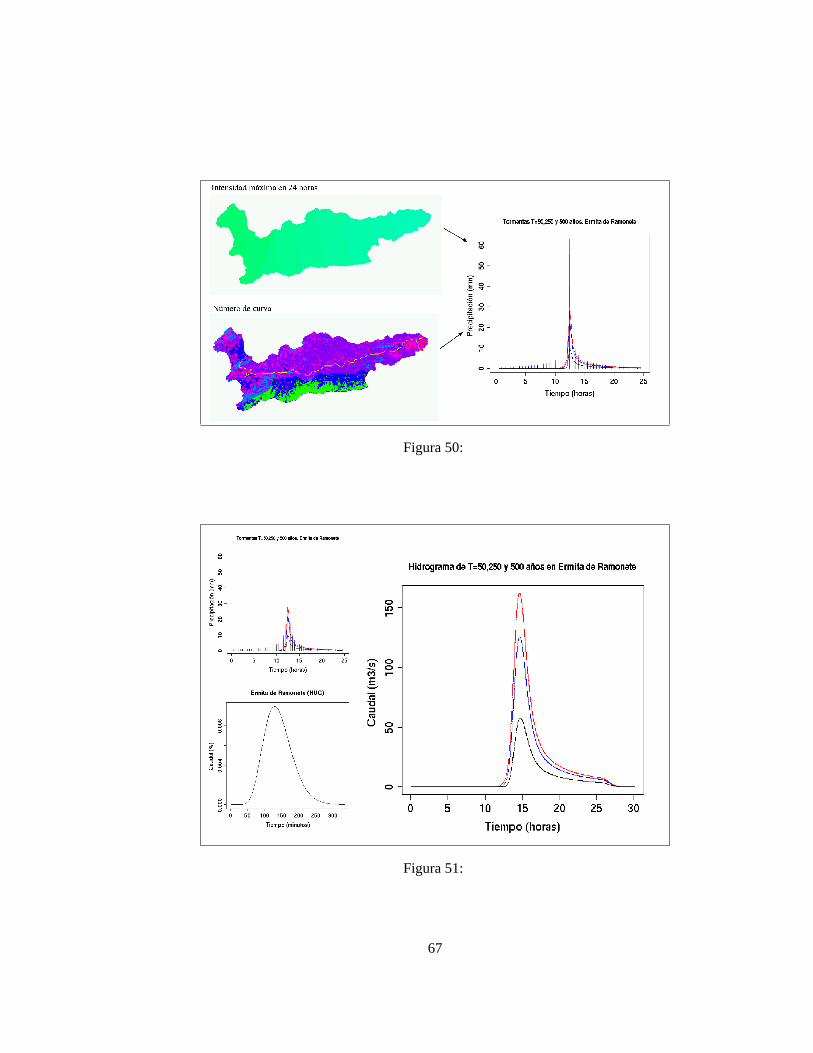
Figura 50:
Figura 51:
67

Figura 52: Dominio espacio-tiempo para resolver el flujo en un cauce. El caudal y altura de agua se calculan encada punto de la malla (i+1,j+1) a partir de los valores en los puntos anteriores tanto en el espacio como en eltiempo (i,j; i+1,j; i,j+1).Basdo en Chowet al., (1994)
68
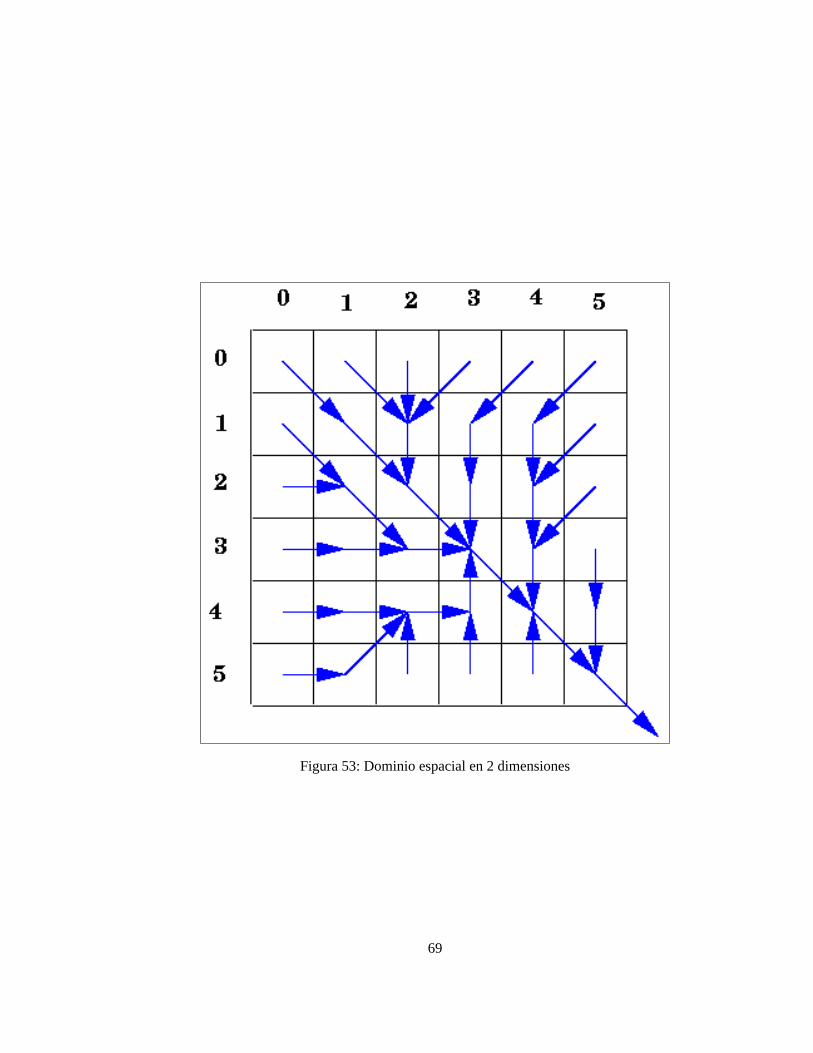
Figura 53: Dominio espacial en 2 dimensiones
69
Figura 54: Resultado de la modelización tridimensional de la temperatura potencial
70


















