
SOCIEDAD ARTIFICIAL DE ROBOTS …148.206.53.84/tesiuami/UAMI13390.pdf · Evento de Premio con...
109
SOCIEDAD ARTIFICIAL DE ROBOTS RECOLECTORES por Deloya Cruz José de Jesús García López Gustavo Alberto Juárez Romero José Manuel Reporte propuesto como cumplimiento de requisito para el Proyecto Terminal de Licenciatura en el Laboratorio de Cibernética (T-210) Licenciatura en Ciencias de la Computación UNIVERSIDAD AUTÓNOMA METROPOLITANA UNIDAD IZTAPALAPA CBI Aprobada por ___________________________________________________ Ing. Joel Ricardo Jiménez Cruz Fecha ______________________________________________________
Transcript of SOCIEDAD ARTIFICIAL DE ROBOTS …148.206.53.84/tesiuami/UAMI13390.pdf · Evento de Premio con...

SOCIEDAD ARTIFICIAL DE ROBOTS RECOLECTORES
por
Deloya Cruz José de Jesús
García López Gustavo Alberto
Juárez Romero José Manuel
Reporte propuesto como cumplimiento de requisito para el Proyecto Terminal de
Licenciatura en el Laboratorio de Cibernética (T-210)
Licenciatura en Ciencias de la Computación
UNIVERSIDAD AUTÓNOMA METROPOLITANA
UNIDAD IZTAPALAPA
CBI
Aprobada por ___________________________________________________
Ing. Joel Ricardo Jiménez Cruz
Fecha ______________________________________________________

UNIVERSIDAD AUTÓNOMA METROPOLITANA
RESUMEN
SOCIEDAD ARTIFICIAL DE ROBOTS RECOLECTORES
Por
Deloya Cruz José de Jesús
García López Gustavo Alberto
Juárez Romero José Manuel
Responsable de Proyecto Terminal: Profesor Joel Ricardo Jiménez Cruz Área de Ingeniería Biomédica
El proyecto de robot recolector consiste en el diseño y construcción de un programa que haga la simulación de un conjunto o sociedad de robots recolectores que se desenvuelvan en un mismo entorno. El programa contará con las siguientes características:
- Representación de un mundo o entorno virtual en el cual se encontraran los robots y los objetos a recolectar
- Representación de al menos un robot en el entorno. Se considera la posibilidad de representar muchos robots en el mismo entorno.
- La navegación o la decisión del robot para tomar una dirección se procesara a través de una red neuronal.
- Los sensores del robot se encargaran de diferenciar entre objetos, obstáculos u otros robots cercanos.
- El robot, al detectar un objeto lo recolectara. - Una vez recolectado el objeto, el robot regresara a su lugar de origen. - Para encontrar la ruta de regreso más rápida, se utilizara el algoritmo
A-star. - Simulación de un conjunto de varios robots recolectores, coexistiendo
en un mismo entorno, pero siendo individuos que trabajan en distintos procesadores.

i
TABLA DE CONTENIDO
Introducción........................................................................................................................ iii Propuesta del Proyecto .....................................................................................................vi Objetivo General y Objetivos Particulares..................................................................viii Capítulo I: SOCIEDADES ARTIFICIALES............................................................... 1
El Concepto de MEME.............................................................................................. 2 Los Algoritmos Meméticos........................................................................................ 3 Esquema Básico de un Algoritmo Memético......................................................... 4 Consideraciones a Tomar Para la Implementación............................................... 5 Memes Egoístas y Memes Altruistas ........................................................................ 9 El “Swap Shop Model” (SSM) ................................................................................12 Células y Memes en el SSM......................................................................................13 Eventos y Comportamientos...................................................................................14 Codificación del Sistema...........................................................................................15 Experimentos..............................................................................................................16 Descripción y Codificación de Eventos Comunes en los 3 Experimentos ....18 Evento de Interacción Cultural ...............................................................................20 Evento de Premio con Recursos Para el Experimento A..................................28 Evento de Premio con Recursos Para los Experimentos C y E.......................29
Capítulo II: SISTEMA DE NAVEGACIÓN PARA UN ROBOT MÓVIL......31 Redes Neuronales de Tipo Biológico.....................................................................31 La Red Neuronal Artificial .......................................................................................33 Conexiones Entre Neuronas....................................................................................34 El Aprendizaje en una Red Neuronal Artificial....................................................35 Estructura de las Redes Neuronales Artificiales...................................................36 Las Fases de Aprendizaje de una Red Neuronal..................................................37 Métodos de Aprendizaje...........................................................................................37 Redes Neuronales de Aproximación/Optimización...........................................38 Modelos No Supervisados .......................................................................................39 El Perceptrón Unicapa..............................................................................................39 El Perceptrón Multicapa con Backpropagation ...................................................40 Red Neuronal Para un Robot Móvil ......................................................................40 Vector de Datos de los Sensores: (Sensor F, Sensor D, Sensor I, Sensor A).41 El Diseño y Entrenamiento de la Red Neuronal .................................................43 Entrenamiento de la Red con Backpropagation ..................................................44 El Entrenamiento.......................................................................................................45 Resultados con la Red Construida ..........................................................................47
Capítulo III: EL ROBOT RECOLECTOR................................................................49 La Toolbox SIMROBOT.........................................................................................51

ii
Sistema de Coordenadas y Modelo de la Cinemática del Robot.......................52 Percepción...................................................................................................................56 El Algoritmo de Bresenham ....................................................................................57 El Sistema de Percepción .........................................................................................59 La Red Neuronal Implementada.............................................................................61 La Tarea de Recolección...........................................................................................64 El Sistema de Recolección........................................................................................64 La Memoria del Robot y el Algoritmo A-Star ......................................................65 Representación del Entorno en la Memoria del Robot ......................................66 Implementación de A-Star .......................................................................................68 Sistema de Retorno....................................................................................................70
Capítulo IV: COMUNICACIÓN ENTRE ROBOTS .............................................71 Presentación ................................................................................................................71 Antes de Implementar...............................................................................................71 Implementación del Programa de Monitoreo de Actividades...........................78
Capítulo V: LA IMPLEMENTACIÓN DE LA SIMULACIÓN..........................80 El Algoritmo Principal ..............................................................................................80 La Interfaz Gráfica.....................................................................................................85 Como Incluir OpenGL.............................................................................................86 Flujo de un Programa en OpenGL ........................................................................87 Sistema de Coordenadas en OpenGL....................................................................88 Los Objetos en el Entorno Virtual .........................................................................89 Construcción de los Archivos de Datos ................................................................92 Datos Iniciales de los Robots y los Objetos .........................................................94
Capítulo VI: IDEAS Y CONSEJOS PARA LA CONTINUACIÓN DEL PROYECTO .....................................................................................................................95
Implementación de una Sociedad Artificial .........................................................95 Ideas Para la Comunicación en la Sociedad Artificial .........................................96
Bibliografía..........................................................................................................................97

iii
INTRODUCCIÓN
Entre los principales campos de estudio y desarrollo de la inteligencia artificial se encuentra el de dotar de un sistema de control eficiente a los robots del tipo móvil.
Sin duda, al escuchar la palabra robot, nuestra imaginación nos recrea
aquellos entes imaginados por escritores de ciencia ficción como Isaac Asimov o Hebert George Wellls entre otros. Estos entes artificiales, fruto del genio de estos renombrados escritores se han basado en visiones futuristas, en la mayoría de los casos muy bien fundamentadas para la época en que fueron desarrolladas, pero que en todos los casos tenían en común la tendencia de humanizar a estos entes creándolos con muchas características propias del ser humano, incluso lanzando preguntas sobre si la inteligencia artificial es capaz de dotarlos de una conciencia y sentimientos. Aunque en esta literatura podemos encontrarnos con estos entes, en realidad los avances existentes hasta ahora aun están muy lejos de conseguir lo que estos visionarios nos cuentan.
Sin embargo, en la actualidad podemos encontrar en Internet, en revistas,
en la televisión y en los medios de comunicación en general, numerosos desarrollos de maquinas o software creados y diseñados para ayudar en la solución de problemas científicos, en la elaboración de productos, en la prestación de servicios; todo ello para beneficio del hombre en muchos aspectos, pronosticar el clima, controlar la iluminación, vigilar en las tiendas de autoservicio, toma de datos e incluso en la exploración en otros planetas; en fin, en muchas labores que bien pueden ser tediosas o incluso peligrosas para el hombre, o que se necesita producir o conocer con rapidez. Pero todos estos sistemas, ya se desarrollen por medios físicos o software, tienen algo en común, un termino que se escucha últimamente, son llamados sistemas inteligentes.
Y contra toda la imaginería que va asociada a los robots que conocemos
de la ciencia ficción, en la actualidad han aparecido muchos tipos de vehículos, instrumentos mecatrónicos y automatizados, que son controlados desde lejos o por sistemas de control automáticos, que caen dentro de la categoría de robot. Aunque también se han desarrollado algunos prototipos mas parecidos a lo que se menciona en la ciencia ficción, pero eso aun esta en pañales. El principal auge se ha dado en la automatización, creación de vehículos no tripulados y en sistemas inteligentes.

iv
Mención especial, con respecto al tema de este reporte, es la aparición de vehículos aéreos, marítimos, submarinos y terrestres los cuales no son tripulados y deben ser controlados por sistemas de control automáticos instalados en los propios vehículos. Un muy buen ejemplo lo tenemos en los vehículos terrestres embarcados en misiones de exploración planetaria tales como el Sojourney, el Spirit y Oportunity, los cuales han sido enviados para la exploración del planeta Marte, como parte de un programa para preparar la visita por parte de la raza humana.
En este tipo de vehículos los sistemas inteligentes son de importancia
vital, ya que el control de estos a grandes distancias resulta afectado o bien debido al peligro de la tarea, puede resultar una acción difícil o aburrida para el ser humano, sobre todo si la operación del robot requiere de una respuesta en tiempo real o una respuesta preventiva que no pueda ser ejecutada por control remoto.
En pocas palabras, la presencia de sistemas inteligentes a bordo de los vehículos libera al ser humano de labores rutinarias y agobiantes de vigilancia, de reconocimiento o de navegación en medios donde existen factores que afectan la percepción completa y precisa del entorno para las capacidades del ser humano. Es por esto que dicho campo ha originado el máximo de esfuerzos para buscar soluciones al problema de control inteligente de dichos vehículos.
En este campo se han tenido grandes avances, pero cabe mencionar que
esto se ha realizado en general para entes individuales, o que conforman un conjunto donde las tareas o propósitos están diferenciados. En cuanto a que estos entes realicen un conjunto de labores en equipo (en sociedad), compartiendo conocimientos y recursos, los avances son menores. Por ejemplo, imaginemos un conjunto de robots encargados de recolectar un objeto en particular. También consideremos que los robots son colocados en un entorno el cual nunca han explorado, así que deben de iniciar de forma aleatoria las posibles rutas. Una vez que los robots inicien su exploración, tendrán como misión recolectar un objeto a la vez y regresar a su lugar de origen. Y así, continuar explorando el mundo para recolectar todos los objetos posibles.
Aquí es donde surgen algunas preguntas: ¿será posible que los robos no
se estorben al realizar su tarea de recolección?, ¿Será posible compartir información del entorno explorado por cada uno de ellos para localizar rutas optimas o bien para establecer zonas donde abunden objetos? Estas preguntas surgen al plantear el problema como una entidad real, ya que se deben de considerar cuestiones como el combustible de los robots, por lo que es importante encontrar rutas optimas.

v
Ya que es una sociedad la que estamos considerando y se busca encontrar
la mayor eficiencia, una opción es que los robots puedan comunicarse para compartir datos importantes del entorno y así realizar sus tareas con mayor rapidez.
El presente reporte tiene la finalidad de presentar los resultados de la
simulación de un conjunto de robots recolectores cuyo sistema de navegación fue realizado haciendo uso de una red neuronal de retropropagación (adiestramiento supervisado).

vi
PROPUESTA DEL PROYECTO
La primera parte del proyecto se realizara reproduciendo el programa
cuyo seudo código se presenta en el artículo publicado por el investigador David Hales, de la Universidad de Essex, en Reino Unido. Y para complementar los conocimientos necesarios con respecto al tema de sociedades artificiales se ha tomado como base los avances genéricos sobre los llamados Algoritmos Meméticos (MA), como se discutirá mas adelante.
Con respecto a la parte que corresponde a la implementación de la red
neuronal se tomara en cuenta el artículo publicado por Alejandro Ramírez Serrano titulado “un control inteligente con características de autoaprendizaje utilizado en robots móviles”. En este artículo se habla, como lo indica el titulo, de un aprendizaje por parte de un robot para moverse en un entorno o terreno con obstáculos. El controlador de dicho robot esta basado en una red neuronal del tipo backpropagation, la cual recibe información del medio ambiente y le indica en que dirección ha de moverse. En esta parte lo que nos interesa conocer con respecto al articulo y la propuesta que se hace para este proyecto, es la de familiarizarnos con las características de las redes neuronales, cual es su arquitectura, sus posibles aplicaciones, su funcionamiento, etc., para posteriormente construir y entrenar una o varias redes neuronales y realizar experimentos y construir una pequeña simulación del movimiento del robot (solo considerando lo que corresponde a redes neuronales).
Para la segunda parte del proyecto se propone el diseño de un programa
que simule una sociedad de robots. Este programa se hará tomando como ejemplo los desarrollos hechos por investigadores de compañías tales como Kepera, Python Robotics, las cuales además de construir robots físicos ofrecen al público en general información, datos y hasta software para poder realizar o ver simulaciones de los tipos de robots autónomos.
Sin embargo, la propuesta para esta parte consiste en no tomar las
herramientas que se ofrecen, si no construir desde cero la simulación del entorno de los robots recolectores, aunque cabe mencionarlo, el modelo de construcción y cinemática del robot se basa en la configuración de un toolbox de Matlab llamado SIMROBOT, a partir del cual se harán las modificaciones correspondientes para nuestra simulación.

vii
El no tomar herramientas prefabricadas para la elaboración de la
simulación implica, desde el punto de vista de los que lo proponen, una mayor comprensión de los temas necesarios, los cuales abarcan diversos campos detallados en su momento, y que se dividen principalmente en la resolución de los problemas de navegación, percepción del entorno, respuesta e interacción a/con los elementos del entorno, y políticas de recolección principalmente.
Hasta aquí ya tenemos la simulación de un robot que realiza ya las tareas
de navegación y recolección necesarias para nuestro proyecto, pero es solo un robot. Como tercera parte de nuestro proyecto, nos dimos a la tarea de crear un entorno simulado que tome en cuenta no solo a un robot, sino a varios robots en este mismo entorno. Para lograr esto sin tener que modificar el código original de las políticas de navegación, recolección e interacción con el ambiente, se tuvo que recurrir a la comunicación en red, lo cual nos permitió dejar intactas todas las políticas usadas en cada robot.
Para esta comunicación, se vio la necesidad de crear un programa
monitor, que es el encargado de repartir información entre todos los robots que coexisten en este entorno, esto es, es el simulador de un mundo físico que va indicando a cada robot si ya se recolectó un objeto o si hay algún otro robot en su camino. Mas adelante se explica con detalle su funcionamiento.

viii
OBJETIVO GENERAL
El objetivo general del proyecto es el de desarrollar un programa que simule un conjunto de agentes autónomos de forma parecida a los creados por kepera, los cuales sean capaces de desenvolverse en un entorno en donde el objetivo de cada uno de los agentes es recolectar objetos evitando obstáculos y otros agentes, además de compartir información del entorno a los otros agentes con la finalidad de optimizar la rapidez del trabajo de recolección Objetivos Particulares a) Investigación sobre sociedades artificiales basadas en la teoría de memes y reproducir el programa “la tiendita del cambalache” para pruebas. b) Desarrollar el modelo de la red neuronal que se utilizara en los agentes para la toma de decisiones de orientación/navegación basado en el artículo publicado por el investigador Alejandro Ramírez Serrano. c) Diseñar el modelo de representación de los agentes y su entorno virtual y especificar sus características, tales como estructura, sistema de coordenadas, modelo de cinemática traslacional y rotacional, variables y parámetros; y lo que sea necesario para la implementación del mismo. d) Diseñar los sistemas y establecer las políticas de percepción de los agentes con respecto al entorno para el reconocimiento y diferenciación entre obstáculos, objetos a recolectar y otros agentes. e) Implementar los sistemas de percepción y conjuntarlos con el modelo de la red neuronal para establecer el sistema de navegación en el entorno virtual. f) Diseñar (tomando en cuenta las características del sistema de percepción) el sistema y las políticas para la recolección de objetos. g) Diseñar e implementar un método para que los agentes puedan aprender y reconocer el entorno virtual recorrido (darle una memoria) para encontrar la ruta mas corta entre el objeto recolectado y el lugar de recopilación de los mismos.

ix
h) Analizar las diferentes estrategias posibles sobre un problema global, considerando la coexistencia de múltiples agentes en el entorno como una sociedad artificial y establecer las políticas de comunicación entre los mismos. i) Desarrollar e implementar un sistema de control y monitoreo para las comunicaciones entre los agentes, con el objetivo de que cada uno de los agentes exista en un dispositivo individual. j) Implementar el programa definitivo de la sociedad artificial de agentes recolectores y probar su funcionamiento en un entorno donde coexistan varios agentes.

1
C a p í t u l o I
SOCIEDADES ARTIFICIALES
La interacción entre agentes artificiales en un entorno para realizar tareas en equipo (sociedad artificial) es un problema que abarca conceptos tomados de la genética y evolución humana. Representar un individuo o agente, ha sido desde los orígenes de este campo de investigación un problema que no siempre se puede resolver satisfactoriamente. La experiencia ha llevado a la concepción de técnicas de representación muy variadas y en algunos casos muy complicadas. Una forma de representación muy usado en el campo de los algoritmos genéticos (GA), es el conocido “cromosoma”, el cual es un arreglo con valores binarios, donde cada elemento representa un “gen” que el individuo posee (1) o no posee (0). En términos simples, se puede decir que, si en un particular cromosoma se tiene un gen con 0, este indica que ese gen no es parte de la solución, en cambio si tiene un 1 se puede decir que si es parte de la solución. Por ejemplo, tomando el problema de la ruta más corta entre dos ciudades un cromosoma puede representar que el camino entre dos ciudades que pertenezca a la solución se represente con un 1 y si no es parte de la solución entonces se representa con un 0.
Continuando con el ejemplo de los Algoritmos Genéticos, consideremos
un cromosoma con un determinado número de genes. La configuración u orden del mismo representan una solución, pero esta solución puede no ser la óptima, por lo que se le aplican diferentes técnicas para que este cromosoma “evolucione” hacia una mejor solución. Es aquí donde entra el concepto de población. Una población es un conjunto de cromosomas con diferentes valores, los cuales, al evolucionar en grupo nos dan un mayor espacio de posibles soluciones. Sin embargo, si las técnicas de evolución que se apliquen no son las adecuadas para el problema que se requiere resolver, el proceso de evolución de toda la población puede llevar a soluciones que no sean del todo satisfactorias. Como se puede ver, todo se centra en un problema de aproximación u optimización.
En una sociedad real el objetivo de cada individuo en particular es,
además de la simple sustentación para su supervivencia, adaptarse, aprender e interactuar con su entorno utilizando para eso sus aptitudes, virtudes y características personales. Sabemos que el éxito de las grandes sociedades depende mucho de cómo se comunican y se comparten sus conocimientos, y además de cómo se organizan para realizar alguna tarea o alcanzar un propósito en común para el beneficio de cada uno y de todos. Considerando esto desde el

2
punto de vista computacional, el problema a resolver es la representación de un agente artificial capaz de transmitir a otros agentes sus características, o bien copiarlas de otros con mejores aptitudes; y construir sociedades artificiales con agentes de características similares, y en consecuencia, capaces realizar de forma más productiva y en conjunto la tarea o el propósito de su concepción.
Aunque la explicación desde el punto de vista de planteamiento pueda
resultar comprensible, el problema principal desde el punto de vista computacional radica en que técnicas de programación son las más eficientes de acuerdo a las características de la sociedad que se quiere simular. El desarrollo computacional a este respecto aun se encuentra literalmente en pañales. Muchos investigadores han encaminado sus esfuerzos utilizando conceptos de Algoritmos Genéticos, Algoritmos Evolutivos, Inteligencia Artificial y otras técnicas heurísticas. De cualquier forma los avances en general son lentos, o bien solo se dan algunos buenos avances dentro de algunos contados campos de interés. Para el desarrollo del presente proyecto se ha tomado como base los avances genéricos sobre los llamados Algoritmos Meméticos; y en especial; un estudio realizado por el investigador David Hales, que adscribe en el Departamento de ciencias de la computación de la Universidad de Essex, en Reino Unido.
El Concepto de MEME.
En la década de 1980 el campo de la computación evolutiva se afianzo en
los desarrollos de investigadores de todo el mundo. Los diferentes problemas a atacar llevaron al nacimiento de variadas técnicas y conceptos de programación, y es en esta época donde surge la primera concepción de algoritmo memético.
Los problemas de los algoritmos evolutivos para conseguir mejoras
individuales de soluciones en una población tratadas con procesos de cooperación y competición entre las mismas, fueron las que llevaron al investigador ingles R. Dawkins a acuñar el término de “meme”. Dawkins establece que el meme es el análogo del gen en el contexto de la evolución cultural. Para entender mejor que significa esto nos apoyamos en la siguiente cita textual:
“Ejemplos de `memes' son melodías, ideas, frases hechas, modas en la vestimenta, formas de hacer vasijas, o de construir bóvedas. Del mismo modo que los genes se propagan en el acervo genético a través de gametos, los `memes' se propagan en el acervo memético saltando de cerebro a cerebro en un proceso que, en un amplio sentido, puede denominarse imitación."

3
Los Algoritmos Meméticos.
No es una ha sido coincidencia que se hayan tomado como ejemplo
algunas características de los Algoritmos Genéticos, ya que los Algoritmos Meméticos combinan muchos aspectos tanto de los primeros como de los Algoritmos Evolutivos. Por este motivo se hará una breve descripción de los Algoritmos Meméticos partiendo de algunos de los aspectos heredados de estas técnicas.
Los Algoritmos Meméticos han heredado de sus antecesores la
estructura principal que consiste en la manipulación de una población de soluciones con técnicas de selección, mutación y cruza, entre otras, con la ayuda de una función de aptitud para determinar que tan buena es cada solución. Y análogamente la repetición de este proceso a través de espacios temporales a los que se conoce como generaciones.
En los Algoritmos meméticos el concepto de población de soluciones
cambia al de concepto de población de agentes, ya que el tratamiento de estos no es el mismo que en sus antecesores, ya que aquí la solución es la abstracción de un individuo, ya que los agentes cuentan con elementos distintivos como se vera mas adelante. La base de esta abstracción radica en que estos agentes se interrelacionan entre si en un marco de competición y de cooperación, de manera muy semejante a lo que ocurre en la Naturaleza entre los individuos de una misma especie (los seres humanos, sin ir mas lejos).
Las técnicas de selección, mutación, cruza, reemplazo y otras técnicas
heurísticas, apoyadas en la calificación de aptitudes mediante una función de aptitud, tienen como finalidad forzar el ambiente competitivo y obtener mejores agentes en cada generación. La selección y el reemplazo inciden en el aspecto competitivo, encargándose de la importante tarea de limitar tamaño de la población, esto es, eliminar algunos agentes para permitir la entrada de otros nuevos y así optimizar la tarea de búsqueda. En tanto la tarea de creación de nuevos agentes es responsabilidad de una etapa reproductiva o cruza, o bien de la mutación u otra técnica heurística. Una técnica propia de los Algoritmos Meméticos es la llamada recombinación, que es la responsable de llevar a cabo los procesos de cooperación. Dicha cooperación se entiende como la de compartir algunas características, y esta tiene lugar mediante la construcción de nuevos agentes empleando información de otros e incluso información externa, aunque esto ultimo normalmente se hace mediante operadores heurísticos o de mutación.

4
Precisamente, la inclusión de información externa no contenida en ninguno de los agentes involucrados es responsabilidad del operador de mutación o técnica heurística. Básicamente, estos tipos de operadores generan un nuevo agente mediante la modificación parcial de uno existente, y su objetivo es lograr una mejora en la aptitud del agente, por los que se les denomina optimizadotes locales. El empleo de estos operadores es uno de los rasgos más distintivos de los Algoritmos Meméticos.
Concretamente, podemos decir un Algoritmo Memético se caracteriza
por una colección de agentes que buscan la optimización realizando exploraciones autónomas en el espacio de soluciones: cooperando con la población a través de los operadores de recombinación, compitiendo continuamente a través de la selección y el reemplazo, y evolucionando mediante la mutación u otra técnica heurística. Esquema Básico de un Algoritmo Memético
A continuación se muestra el esquema básico, que como se puede ver es
muy parecido al de un algoritmo genético.
FUNC MA ( tamanoPob : N; ops : Operador[ ]) -> Agente Variables pob : Agente[ ]; Inicio pob = Iniciar-población(tamanoPob); REPETIR pob = Paso-Generacional (pob, ops) SI Convergencia(pob) ENTONCES pob = Reiniciar-población(pob); FIN SI HASTA QUE terminación Algoritmo memético() DEVOLVER i-esimo-Mejor(pob, 1); Fin
Los problemas con los que nos podemos enfrentar al diseñar un
Algoritmo Memético son clásicos, tales como un buen planteamiento del problema, buenas funciones de evaluación de aptitud, buenas heurísticas y criterios de selección y reemplazo. Una de las cosas más importantes a considerar es la función para la creación de la población inicial con características adecuadas.
Todo esto es importante para que se haga un uso apropiado de los recursos del sistema, o los resultados podrían degenerar en un conjunto de agentes, con una gran similitud no óptima. Esto es lo que se conoce como convergencia, y es algo que puede ser controlado empleando buenos operadores.

5
Consideraciones a Tomar Para la Implementación
Si se quiere un diseño de un Algoritmo Memético efectivo para un
problema en particular, hay que pensar que no existe ningún procedimiento sistemático que arroje soluciones, ya que se puede entrar en conflicto con resultados teóricos ya conocidos. Esto implica que únicamente deben diseñarse heurísticas aplicables al problema para encontrar un algoritmo efectivo que arroje resultados variados y validos dentro del espacio de soluciones, pero aun así no se puede garantizar que las soluciones son óptimas.
Por lo anterior es imprescindible determinar una buena representación
de las soluciones al problema. Por ejemplo, consideremos que se busca una solución para el problema del viajante (TSP). Por lo general el problema se define a partir de una matriz de distancia entre pares de ciudades y las soluciones son rutas cerradas que visitan n ciudades solo una vez y se pueden representar como un arreglo donde la ruta es una permutación de las ciudades. Entonces el problema se centra en encontrar operadores que manipulen los valores existentes (identificadores de ciudades) en posiciones específicas de dicha permutación. Un enfoque muy recurrente, y que funciona mejor sobre otros enfoques, consiste en manipular la información relativa a la adyacencia entre elementos de las permutaciones.
En el problema del ejemplo anterior y en otros parecidos se han
encontrado buenos resultados después del ensayo de muchas heurísticas, y en consecuencia se han desarrollado algunos criterios para facilitar la búsqueda de nuevas heurísticas. Tanto en los algoritmos Genéticos, Evolutivos, Meméticos, como en otros parecidos estos criterios están determinados por la necesidad de encontrar la manera de medir la relación que existe entre la representación de una solución de un problema y su bondad con respecto al tratamiento de los operadores que quieran aplicársele. Esto quiere decir que la representación de una solución debe de ser orientada a su fácil manipulación de operadores, y además tomar en cuenta que la relación entre estos (soluciones y operadores) no caiga en ambigüedades y redundancias; como se menciono anteriormente, se tiene que considerar que no existe ningún procedimiento sistemático que arroje soluciones ya establecido, ya que esto puede llevar a la convergencia de soluciones no tan buenas como las buscadas.
A continuación se mencionan algunos de los criterios para la búsqueda
de representaciones y operadores, de los cuales algunos son generalizaciones de conceptos propios de los Algoritmos Genéticos y Evolutivos, mientras que otro si son más específicos del modelo de los Algoritmos Meméticos.

6
Minimización de la epistaxis: Cuando la manipulación de los operadores llevan a la convergencia de una solución solo a óptimos locales y no globales, es decir, las diferentes soluciones convergen o degeneran hacia una solución o soluciones parecidas, se dice que la epistaxis es alta. Esto se da cuando los operadores manipulan información sobre elementos básicos de las soluciones de manera independiente con respecto a otros operadores y otros elementos de la solución, de manera al ser evaluados por la función de aptitud esta conduce el conjunto de soluciones a un optimo local, extraviando la búsqueda hacia otros espacios de la solución. Para minimizar la epistaxis se deben de encontrar operadores que permitan la descomposición de la función de aptitud en términos que permitan la optimización de las diferentes propiedades y características de la solución de manera independiente. Así, cuanto mas se pueda descomponer los términos de la función de aptitud mayor será la relevancia de los elementos de información manipulados por los operadores, y menos propensa encaminar la búsqueda a la convergencia.
Minimización de la varianza de bondad: El uso de una función aptitud que evalué la calidad de las soluciones para seleccionar las mejores adecuada y que pueda optimizar de manera independiente los diferentes elementos de información de una solución es básico para poder encontrar un conjunto representativo de soluciones con un especifico elemento de información, y así mismo encontrar soluciones con una semejante calidad, aunque con elementos de información optimizados diferentes a las otras soluciones. Es decir, que la función encuentre un conjunto de buenas soluciones con diferentes características en sus elementos de información. La bondad de un algoritmo se mide tomando en cuenta la calidad de las soluciones que encuentra, y esto sin caer en la convergencia, y si un conjunto de estas variadas soluciones tiene una buena calidad en general, mientras menor sea la varianza entre estas soluciones, entonces los resultados son mas relevantes, de ahí la importancia del primer punto.

7
Maximización de la correlación de bondad: Sabemos que la fase de
selección se encarga de elegir las soluciones o agentes de mayor aptitud, por lo que la búsqueda se ira desplazando gradualmente hacia los mejores espacios de solución, aunque es necesario aplicar operadores para ampliar o explorar con mayor profundidad dichos espacios. Por ejemplo, uno de los operadores para estimular esta búsqueda es el de reproducción, por lo que este operador debe de ser efectivo para crear y reemplazar nuevos elementos que puedan ayudar a ampliar ese espacio de búsqueda. La correlación de la bondad se mide entre los agentes que serán reemplazados y los nuevos, determinando si estos nuevos tienen características para seguir evolucionando a mejores soluciones. .Si esta correlación es alta, los agentes buenos seleccionados para la reproducción tendrán una descendencia buena por lo general.
Como se puede ver en los criterios anteriores el adoptar luna representación depende de los operadores que quieran aplicarse y de una función de aptitud capaz de evaluar la aptitud de los agentes de forma que estos permitan la descomposición en los diferentes aspectos a encontrar en las soluciones y que la varianza de bondad entre las mismas sea mínima. En cualquier caso, lo que resulta claro tanto para la representación como para la función, estas dependen en alto grado de la selección y diseño de los operadores. Para encontrar los operadores adecuados existen dos opciones: la selección de un operador de entre un conjunto de operadores preexistentes, o la definición de nuevos operadores.
La selección de operadores preexistentes requiere de un conocimiento
previo del problema que puede llevar a un análisis exhaustivo. Si se ha decidido tomar esta opción, existe lo que se denomina como análisis inverso de operadores, ya que en cierto sentido se realiza una cierta ingeniería inversa para determinar el operador y representación más ventajosa. Este análisis cuenta con los siguientes pasos:
1. Sea = O = { w1, w2, w3, ….wk} el conjunto de operadores disponibles. En primer lugar se identifica la representación manipulada por cada uno de ellos.
2. Usar cualquiera de los criterios anteriormente mencionados para evaluar la bondad de cada representación.
3. Seleccionar el operado wi que manipule la representación de mayor bondad.

8
La otra alternativa para encontrar operadores es el análisis directo, en el
que se diseñan nuevos operadores, y se lleva cabo como sigue :
1. Identificar varias representaciones para el problema considerado. 2. Usar cualquiera de los criterios anteriormente mencionados para evaluar
la bondad de cada representación. 3. Crear nuevos operadores 0’ = {w1’, w2’, w3’, ….wk’} a través de la
manipulación de los elementos de información mas relevantes.
Para el tercer paso del análisis directo pueden emplearse algunas plantillas genéricas (independientes de los elementos de información manipulados) diseñadas por varios investigadores, de las cuales solo se mencionaran y entre las que destacan:
1. “random respectful recombination" (R3) 2. “Random Assorting Recombination" (RAR) 3. "Random Transmitting Recombination" (RTR)
Tanto en el caso de selección de un operador clásico como de creación de
un operador a partir de plantillas genéricas mencionadas anteriormente, se estarán empleando típicamente operadores ciegos, que manipulan información relevante pero lo hacen sin usar información de las soluciones del problema que se pretende resolver.
Otro de las técnicas muy populares y muchas veces efectivas en la
selección o creación de operadores es la de introducir conocimiento adicional para poder enfocar la manipulación que ejercen estos operadores. En los Algoritmos Meméticos a los operadores que usan este conocimiento del problema se les denomina heurísticos o híbridos. Por ejemplo hay operadores de reproducción o cruza que se caracterizan por utilizar información de los progenitores para usarla en la descendencia, y selección de información externa. En general un operador hibrido o heurístico la propiedad de transmisión de características comunes o inserción de nuevos datos a los agentes en la mayoria de los experimentos resulta beneficiosa.
Como ejemplos de estos operadores tenemos el desarrollado por
Radcliffe y Surry que proponen el empleo de optimizadores locales, o técnicas de enumeración implícita. Ambas técnicas se basan en completar las soluciones empleando información, ya sea depurando características negativas o añadiendo otras positivas heredadas o introducidas por medios externos. Este enfoque se conoce recombinación dinásticamente óptima (DOR), y tiene la propiedad de que cualquier descendiente es al menos tan bueno como el mejor de sus progenitores.

9
También existen otros operadores desarrollados mediante el empleo de
heurísticas constructivas. Un ejemplo de este enfoque es el operador EAX (Edge Assembly Crossover) el cual esta especializado para el problema del agente viajero y emplea una heurística voraz para la construcción de la descendencia.
Las ideas expuestas en los párrafos anteriores también son aplicables a
los operadores de mutación, aunque con ciertas diferencias, ya que estos operadores están forzados a introducir nueva información. Estos operadores se encargan del reemplazo o la eliminación de elementos de información de una solución aplicando un procedimiento de completado con el que se obtiene la mutación orientada.
Como se pudo apreciar a lo largo de esta sección, la filosofía de los
Algoritmos Meméticos es muy flexible y desde luego inducida y apoyada por ideas de otras técnicas de optimización basadas en el desarrollo de meta heurísticas. Es por eso que para el estudio de los Algoritmos Meméticos es imprescindible el estudio de otras técnicas que se usan hoy en día, ya sean anteriores o posteriores a esta vertiente, ya que de ellas se pueden nuevas ideas y herramientas útiles en la concepción de nuevas y más potentes técnicas de diseño de operadores y representación de soluciones.
Memes Egoístas y Memes Altruistas
Anteriormente se menciono que para esta parte del proyecto se ha
tomado como base el artículo publicado por el investigador David Hales, que consiste en la representación de agentes que comparten un espacio donde se requiere repartir un recurso de vida. Los agentes se representan como células agrupadas en una rejilla o matriz en la que se aplican reglas de aprendizaje cultural simple en la que selectivamente se reproducen y/o rechazan memes que caracterizan a un grupo o vecindario de la sociedad representada. Estos memes representan rasgos o características culturalmente aprendidos o asimilados, y también la influencia que se tiene de los recursos y comportamiento de dichas células o agentes que conforman dicha sociedad. En los experimentos que se presentan en el articulo se consideran múltiples agrupaciones con rasgos culturales propios, y que con una evolución altruista, los miembros de estos grupos terminan conformando grupos más dominantes, por lo que emerge o prevalece al final del proceso evolutivo un grupo donde la cooperación y el altruismo son las características principales. La conclusión David Hales es que se demuestra que los métodos aplicados a la evolución cultural para la formación de grupos producen sociedades con resultados mas cerca del optimo que los métodos evolutivos convencionales para las situaciones de cooperación y altruismo planteadas en sus experimentos en particular; y que estos resultados

10
ofrecen una gran posibilidad de aplicación en áreas como la robótica colectiva, en la creación de aplicaciones de software que trabajen en conjunto, en la resolución de problemas cooperación colectiva en trabajos específicos, formación y en la evolución autónoma de sociedades u organizaciones.
Una pregunta fundamental que se plantea dentro de esta área de estudio
y de cuya respuesta depende una buena implementación de un Algoritmo Memético es la siguiente:
¿Dado un nivel de racionalidad limitado y de conocimiento, qué condiciones producen la idea de colectiva de cooperación y/o el comportamiento altruista en la interacción de los agentes de un vecindario?
Una parte importante para responder a esta pregunta involucra la aplicación de reglas de aprendizaje simples dentro del conocimiento y aprendizaje teórico del ambiente o entorno. Esta simplicidad en las reglas corresponde al surgimiento intuitivo de sociedades reales, tal como lo demuestran las teorías evolutivas de las ciencias naturales: no pueden existir reglas complicadas o racionales sin antes existir reglas intuitivas e instintivas para la supervivencia. En el ámbito computacional que estamos tratando se tiene la ventaja que este conocimiento empírico puede ser desechado y aplicar un conocimiento un poco mas avanzado, es decir, el investigador puede establecer reglas mas complicadas o encaminadas a obtener un resultado en particular. Aunque esto también tiene sus dificultades. Mientras mas complicada sea una regla mas complicada será su codificación. Esto nos lleva a una idea donde se asume que los agentes deben de satisfacer individualmente sus necesidades de conocimiento de ciertas particularidades de su entorno, y así, de manera autónoma evolucionar. Una manera practica de conseguir conocimiento del entorno, interactuando directamente con dicho entorno y otros agentes vecinos consiste en la imitación selectiva de un "barrio" o “vecindario” situado en una región o espacio (rejilla), la cual se sostiene en la idea de un “pago máximo” o contribución de recursos vitales al interactuar (adquirir conocimiento del entorno), al que llamaremos de aquí en adelante “vida de contribución” o “tarifa de vida”. La vida de contribución se justifica en el hecho de que no se puede producir un altruismo de manera sostenida o regular, ya que las necesidades de conocimiento de un individuo dependen de las necesidades de la sociedad, esto en detrimento del individuo; es decir, sin cooperación, comunicación y un grado de altruismo no se puede sostener una sociedad.

11
En un sociedad real el progreso se da trabajando en conjunto,
compartiendo conocimiento y recursos, un solo individuo muy difícilmente conseguirá el éxito si no trabaja con sus semejantes, o bien no toma algo, imita o aprende de las mejores aptitudes o “memes” de los demás. De esta ultima apreciación se ha acuñado la idea de que un agente debe tener un meme que indique un grado altruismo, es decir nos diga si un individuo es egoísta o es capaz de compartir sus recursos o conocimientos; y en el ámbito de la evolución cultural que se aplica en esta investigación, el objetivo es desechar aquellos individuos con un “meme” egoísta y que predominen los que tienen un “meme” altruista.
En este trabajo se intenta simular a las sociedades humanas para resolver
muchos problemas de cooperación y organización de grupo, aunque estos pueden parecer más complejos, interdependientes y expansivos en la vida real. La siguiente pregunta a responder es:
¿Es posible reproducir o capturar alguna de las dinámicas de tales procesos? ; Y en ese caso, ¿se pueden aplicar estos procesos a Algoritmos Meméticos para encontrar soluciones satisfactorias a problemas de la cooperación u organización?
Los intentos de responder a esta pregunta ha llevado a muchos investigadores a observar desde diversos puntos de vista la esencia de los procesos evolutivos, en especial de la evolución cultural, para poder capturarla y representarla de manera abstracta. David Hales, en el mismo articulo, considera que una manera de capturar esta esencia consiste en considerar que las sociedades se pueden descomponer en unidades de cultura que pueden comunicarse, reproducirse, y cambiar (mutar y evolucionar); y que estas unidades de cultura se pueden representar con “memes”.
Continuando con la idea de la descomposición de la sociedad en unidades de cultura, se puede decir que existen unidades tanto negativas como positivas; en nuestro caso podemos decir que una unidad de cultura negativa es el egoísmo y una positiva es el altruismo. Al representar con un meme ambas unidades podemos determinar que el meme que nos interesa prevalezca y domine es el meme altruista. Es decir, nos interesa, en términos de la evolución, que el meme altruista sea un meme exitoso.

12
Un meme exitoso es aquel que se reproduce y se dispersa en una
población, aunque no necesariamente sea un meme benéfico a aquéllos que lo tienen y comparten. Por eso es importante estudiar en que condiciones un meme dañino puede ser de tendencia dominante y determinar que mecanismos son adecuados para detener la dispersión de este. Una solución un tanto satisfactoria a este problema (que puede ser de difícil solución si las reglas son un poco complicadas), consiste en la “selección de grupo”, que se basa en la influencia social de los vecinos mas parecidos y mas próximos a un determinado agente, para desarrollar agentes que trabajen cooperativamente u organizados, y que tengan una forma simple de satisfacer sus necesidades, aprendiendo reglas.
En los experimentos presentados por David hales en su artículo, se considera un espacio donde cohabitan múltiples agrupaciones culturales. Al aplicar una selección altruista, se da una agrupación de agentes, mediante una forma de selección de grupo. Esta selección altruista determina grupos regidos por las conductas o comportamientos predominantes de un número de individuos, aun cuando esto es en detrimento de algunos individuos dentro de ese grupo; y eventualmente la aplicación del Algoritmo Memético produce una cultura homogénea y con un alto grado de altruismo.
El “Swap Shop Model” (SSM)
Una cercana traducción al español de esta expresión, que titula el articulo
David Hales, puede ser “El Modelo de la Tienda de Cambalache”; y nos sugiere que se trata de un intercambio, en este caso de memes. Este modelo es de tipo autómata celular, aunque no tiene todas las características de este modelo. En un autómata celular, como su nombre lo indica, la evolución debe de ser de manera síncrona, es decir, todos y cada uno de sus elementos se desenvuelven en un mismo espacio temporal: envejecen, mutan, se reproducen, evolucionan o mueren al mismo tiempo. Como puede suponerse, la simulación de un autómata celular con estas características resulta demasiado complejo. Para el SSM una simulación síncrona podría parecer la idónea, sin embargo, en estudios realizados por algunos investigadores se ha elegido una aplicación asíncrona para evitar el uso de funciones complicadas.
El espacio de trabajo del SSM fue modelado después del modelo cultural de Axelrod publicado en 1995. En su trabajo Axelrod investigo el surgimiento de “atributos culturales” compartidos en regiones espaciales, y también las reglas de propagación de estos atributos individuales simples dentro de esa región espacial. Se puede pensar que para la propagación de un atributo cultural sea suficiente la cercanía entre dos agentes; pero, en el estudio de Axelrod

13
se considero un nuevo concepto (solo en la aplicación) de distancia no espacial, al que este investigador llamo “distancia cultural”. La forma en como la propagación de un atributo entre células o agentes bajo este nuevo concepto sólo tiene lugar cuando estos comparten un atributo por lo menos, es decir, hay un grado de similaridad entre los agentes. Las células en este modelo están completamente formadas por colecciones de atributos, pero estos atributos no tienen un impacto definitivo en el comportamiento. Para el SSM que se estudia aquí los atributos se verán como memes, los cuales sí pueden influir en el comportamiento de las células. Células y Memes en el SSM
El SSM esta formado por una rejilla de células bidimensional. Cada
célula representa a un agente estacionario y tiene cuatro variables locales de tipo entero asociadas a el:
1. Nivel de energía (0 <= EL <= 9), (Energy Level) 2. Nivel de altruismo (0 <= SL <= 4), (Sharing level) 3. Nivel de similitud (0 <= SSL <= 4) (SSimilarity level) 4. Atributo Cultural (0 <= C <= 4). (Cultural)
En donde las variables SL, SSL, y C se tratan como memes. Por
consiguiente estos pueden propagarse y también pueden mutar. Los valores de estas variables locales determinan el comportamiento de una célula o agente.
El meme SSL indica la similitud mínima requerida de un agente parra
que este pueda o tenga la capacidad de compartir recursos con las células similares al del vecindario. La similitud se define como el número de memes que comparten dos células.
El meme SL indica la cantidad de recurso compartido cuando eso
sucede. El meme C no tiene impacto directo en el comportamiento, pero
contribuye para determinar la pertenencia de grupo de un agente. La variable EL, como su nombre lo indica, es el nivel de energía que
tiene un agente y determina la vida del mismo como se explicara mas
adelante.

14
Eventos y Comportamientos
Durante la ejecución del SS uno de tres eventos puede ocurrir:
El impuesto o disminución de esperanza de vida después de un
periodo de tiempo, ya que esto se aplicara desde el punto de vista evolutivo, el pago de este recurso de vida se dará después de cada generación. Un evento de impuesto de vida involucra la energía de una célula. La variable EL que indica el nivel de energía que tiene una célula, se va reduciendo en un punto (el mínimo es cero) al pagar este impuesto de vida o “vida de contribución”. Si una célula llega a un nivel cero entonces pueden deformarse los memes o bien reemplazar a este agente con uno nuevo.
Premiación con recursos: El evento de premio o recompensa con recursos que involucran a una célula, se da otorgando cuatro puntos de energía a esa célula. Estos puntos de energía son divididos entre los vecinos y la célula premiada en proporciones que dependen de los valores de los memes SL y SSL. Esto se logra seleccionando aleatoriamente las células del vecindario qué satisfaga el valor del meme SSL de la célula seleccionada compartiendo y otorgando un solo punto de energía si se requiere (es decir, el meme EL del vecino es menor que el máximo permitido de 9). Este proceso se mantiene hasta que los puntos de SL hayan sido compartidos o el máximo numero de vecinos se haya seleccionado.
Interacción cultural: Un evento de interacción cultural involucra una célula y que el vecino armonice con la célula, es decir, que están tengan al menos un meme en común. Cuando ambas células son culturalmente idénticas (es decir tiene una similitud de tres) la interacción cultural no tendrá ningún efecto. Adicionalmente una célula con el meme EL = 0, nunca puede propagar un meme, y una célula con el EL = 9 nunca recibirá un nuevo meme. Esto representa que una célula “satisfecha” no cambia, y que una célula “insatisfecha” o “muerta” no puede propagar memes.
Hay que notar que en una rejilla los vecinos están definidos como las ocho células que rodean una determinada célula (el llamado vecindario de Moore), tomando en cuenta que en los bordes y en las esquinas la cantidad de vecinos es menor, como se explicara mas adelante.

15
Codificación del Sistema
Un solo "ciclo" o iteración del sistema esta implementado de la siguiente manera: PARA el número total de células en la rejilla haz { Con probabilidad PT (evento de impuesto de vida): { Seleccionar una célula (z) al azar SI el meme EL de z>0 ENTONCES se reduce en uno el valor del meme EL de z SI el meme EL de z = 0 ENTONCES se muta los memes SL, C, SSL con probabilidad PM } Con probabilidad PR (evento de premio con recursos): { Seleccionar una célula al azar Otorgar puntos de energía a la célula seleccionada (Incrementar en 4 el meme EL de la célula seleccionada) Basándose en los valores de SL, SSL de las células vecinas: Distribuir 4 puntos } Con la probabilidad PC (evento de la interacción cultural): { Seleccionar una célula (z) al azar Seleccionar una célula vecina (n) al azar Calcular la similitud (s) entre z y n SI s >= 1 Y el meme EL de n > 0 Y el meme EL de z < 9 ENTONCES Propaga un meme elegido al azar (que difiera) de n a z } } TERMINA PARA

16
Experimentos
De los experimentos que se mencionan en el artículo de David Hales se
han reconstruido los correspondientes al Experimento A y al Experimento C, aunque con algunas variantes las cuales se mencionara su justificación en su momento. También se ha realizado otro experimento, el cual se incluye en este reporte como el experimento E.
Estos experimentos se han diseñado desde el punto de vista de la
evolución cultural, es decir, no se toman en cuenta las aptitudes del agente, si nos sus grados de altruismo o egoísmo para compartir recursos con otros vecinos en base a su similaridad y la cantidad de recursos con los que ha sido premiado. También la evolución cultural se refiere a la interacción cultural que existe entre agentes que habitan en una misma zona, y de la misma manera que con los recursos, las características culturales (o memes) son transmitidas o propagadas a los vecinos de acuerdo a su grado de altruismo o egoísmo, o bien, de acuerdo a su similitud. A continuación se dará una breve descripción de los mencionados experimentos.
Experimento A “evolución cultural con evento de premiación condicionada”
Este experimento consiste en distribuir de manera aleatoria los recursos
que se otorgan a un agente en el evento de premiación con recursos entre los individuos que forman parte de su vecindario de Moore. Esta distribución se hace tomando en cuenta el nivel de similaridad entre la célula premiada y el vecino que se ira seleccionando aleatoriamente. Esto nos indica que en este experimento existe un grado de “preferencia” hacia los vecinos que mas se parecen, además de que al ser aleatoria la selección del vecino a compartir recursos, alguno de estos vecinos podría ser beneficiado mas que otros con dichos recursos. En pocas palabras, todos los agentes que se encuentren en el vecindario de Moore del agente premiado tienen la misma probabilidad de recibir recursos, si bien se cumplen con las condiciones mencionas.
0 1 2
7 X 3
6 5 4
Figura 1.1. Vecinos (en rojo) con probabilidades de ser beneficiados por la repartición de recursos por parte del agente X en el vecindario de Moore para el
experimento A.

17
Experimentos C y E “evolución cultural con evento de premiación esparcida”
Este experimento tiene en general las mismas características que el
experimento A, con la diferencia de que en este los recursos sólo son distribuidos a las células designadas en lugar de a todas las células. Para el experimento C la distribución se hará a las células que se cuenten con los números de fila y columna pares del vecindario de Moore (ver figura), mientras que para el experimento E se hará considerando a los vecinos que cuenten con el mismo numero de fila o columna que el agente seleccionado para la repartición de recursos (ver figura).
0 1 2
7 X 3
6 5 4
Figura 1.2. Vecinos (en rojo) con probabilidades de ser beneficiados por la repartición de recursos por parte del agente X en el vecindario de Moore para el
experimento C.
0 1 2
7 X 3
6 5 4
Figura 1.3. Vecinos (en rojo) con probabilidades de ser beneficiados por la repartición de recursos por parte del agente X en el vecindario de Moore para el
experimento E.
Como se puede notar en la breve descripción de los experimentos, para los tres experimentos los eventos son prácticamente los mismos, solo cambia la forma en como se reparten los recursos en el evento de premiación de recursos, por lo que se describirá como se llevan a cabo los eventos de “pago de impuesto de vida”, mutación e “interacción cultural que son los mismos para los tres experimentos.

18
Descripción y Codificación de Eventos Comunes en los Tres
Experimentos.
Estructuras de datos usadas:
Agente o celda: Como sabemos un individuo tiene cuatro variables locales a considerar, por lo que se propuso la siguiente estructura para representar a un agente o celda:
typedef struct { int SL; //meme: Monto de recursos compartidos int C; //meme: Atributo cultural int SSL; //meme: Similaridad mínima requerida int EL; //Nivel de energía } celda;
Rejilla o matriz de enteros para indicar las posiciones (x, y) de las celdas,
del tipo celda propuesto: celda aldea[X][Y];
Evento de impuesto de vida y mutación:
En la codificación propuesta de los experimentos a este evento se le llamo
“Vida de contribución”, y tal como se puede ver en la descripción del ciclo del sistema antes expuesta, en este pueden ocurrir dos situaciones para una celda (z) seleccionada aleatoriamente: si el valor de la celda z es mayor que cero se reduce el valor de EL , y si el valor de EL es 0 entonces se muta. El código propuesto para este evento es el siguiente: void Vida_de_contribucion() { int x = Num_Aleatorio(MAX), y = Num_Aleatorio(MAX); if(aldea[x][y].EL > 0) aldea[x][y].EL = aldea[x][y].EL - 1; else Mutacion(x,y); }
La primera parte del código en donde se reduce el valor de EL es clara,
pero para la mutación en el caso de ser necesaria se consideraron varias pruebas, de las cuales se considero un método heurístico para que dicha mutación ayudara a la evolución “hacia delante”, es decir, generando, en la mayoría de los casos nuevos agentes con un mayor nivel de altruismo.

19
Mutación de agente seleccionado (EL = 0)
El código propuesto para la mutación es el siguiente: void Mutacion(int x, int y) { if(Num_Aleatorio(100) <= PM) // PM = probabilidad de mutación { if(aldea[x][y].SL - aldea[x][y].SSL <= 1) { if(aldea[x][y].SSL > 1 && aldea[x][y].SL < 4) { aldea[x][y].SSL = aldea[x][y].SSL - 1; aldea[x][y].SL = aldea[x][y].SL + 1; } } else if(aldea[x][y].SSL < 4 ) aldea[x][y].SSL = aldea[x][y].SSL + 1; aldea[x][y].C = Num_Aleatorio(L1); } aldea[x][y].EL = Num_Aleatorio(L2-1)+1; }
Primero se ve la probabilidad de que esta celda mute (aleatoriamente), si
esta probabilidad se cumple, entonces se procede a mutar los valores de sus variables de acuerdo a los valores que en ese momento tiene. Como se menciono el objetivo de esta mutación heurística es que el agente mutado tenga más probabilidades de propagar sus características al efectuarse los siguientes eventos (si es seleccionada para estos).
Tomemos en cuenta que un nivel de similaridad mínima (SSL) para poder compartir alto (3 o 4), las posibilidades de compartir se reducen, pero también un nivel de altruismo alto indica que un agente puede compartir “altruistamente” sus recursos o propagar sus memes. Por eso se ha considerado que estos niveles pueden ser inversamente proporcionales: “mientras mayor sea el nivel de altruismo y mientras menor sea el nivel de similaridad mínima requerida, es mas fácil que un agente transmita sus características”. En el código se ha considerado que si al restar el valor del meme SL al valor del meme SSL este es menor que 1, es decir, tienen el mismo valor, o es mayor el valor del meme SSL, entonces es conveniente (si se puede) aumentar el valor del meme SL (para hacerlo mas altruista) y/o disminuir (si se puede) el valor del meme SSL (para que la similaridad mínima requerida pueda permitir la propagación de las características del agente).

20
Ahora bien, si esta ultima consideración no se ve en el agente, es decir, su meme SL es mayor que su meme SSL, se ha considerado aumentar el valor del meme SSL, para capturar la idea de que no todas las mutaciones deben de ser beneficiosas y abarcar este aspecto de degeneración que daría una mayor diversidad en la sociedad artificial. Siguiendo con esta idea sea considerado también alterar el meme C, el atributo cultural, y esto se hace generando aleatoriamente un valor permitido (entre 0 y 4), que bien podría ser el mismo que tenia antes de entrar en este ámbito de la mutación.
Ahora recordemos que en el articulo se maneja que la mutación se debe de hacer sobre los memes SL, C y SSL del agente, sin embargo, desde el punto de vista de que este agente con EL = 0 “esta muerto”, de muy poco sirve que este meme sea mutado si sus características no se podrán propagar, tal como lo indican los otros eventos. Así, finalmente, en la codificación se puede ver que se asigna un valor para EL mayor a cero, con lo que se asegura que al menos en una iteración las características de este nuevo agente mutado pueden ser propagadas, claro, tomando en cuenta que si estas características se propagan podrían no ser beneficiosas al conjunto de agentes. Esto también repercute en que se disminuye el número de agentes “muertos” o improductivos al terminar el ciclo del sistema. Evento de Interacción Cultural
De acuerdo al articulo, el evento de interacción cultural se lleva a cabo seleccionando aleatoriamente una celda (z) o agente de la sociedad; después seleccionar un vecino (n) aleatoriamente y “propagar” a el alguno de sus memes. Esta propagación debe cumplir con algunas condiciones, las cuales se dan de acuerdo a que tan similares son estas celdas. La similaridad entre dos agentes se considera así:
Si los agentes tienen el mismo valor en alguno de sus memes SL, SSL y C se dice que son similares con respecto a ese meme.
La similaridad que se tiene entonces puede ser de:
- 0 si no se comparte ningún valor entre los memes C, SL, y SSL - 1 si se tiene el mismo valor en solo uno de los memes C, SL o SSL - 2 si se tiene el mismo valor en dos de los memes C. SL. o SSL - 3 si los memes C, SL, o SSL tienen los mismos valores para cada celda
21
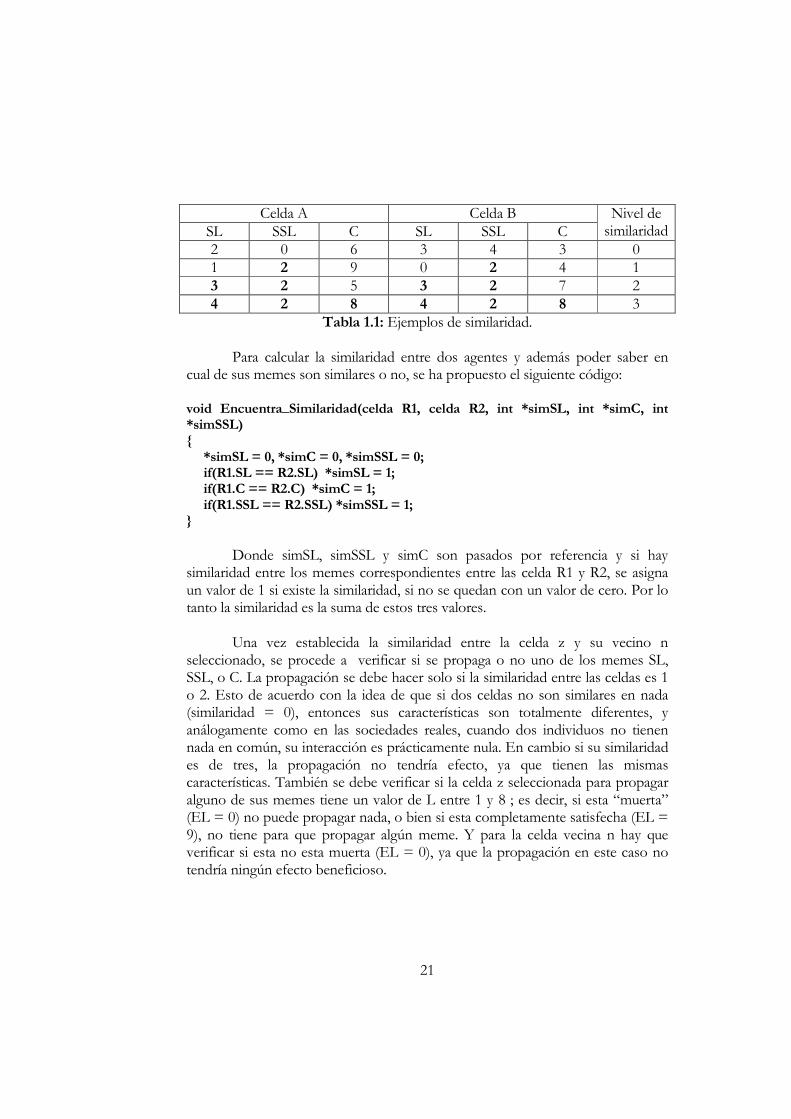
Celda A Celda B
SL SSL C SL SSL C Nivel de
similaridad 2 0 6 3 4 3 0 1 2 9 0 2 4 1 3 2 5 3 2 7 2 4 2 8 4 2 8 3
Tabla 1.1: Ejemplos de similaridad. Para calcular la similaridad entre dos agentes y además poder saber en
cual de sus memes son similares o no, se ha propuesto el siguiente código: void Encuentra_Similaridad(celda R1, celda R2, int *simSL, int *simC, int *simSSL) { *simSL = 0, *simC = 0, *simSSL = 0; if(R1.SL == R2.SL) *simSL = 1; if(R1.C == R2.C) *simC = 1; if(R1.SSL == R2.SSL) *simSSL = 1; }
Donde simSL, simSSL y simC son pasados por referencia y si hay
similaridad entre los memes correspondientes entre las celda R1 y R2, se asigna un valor de 1 si existe la similaridad, si no se quedan con un valor de cero. Por lo tanto la similaridad es la suma de estos tres valores.
Una vez establecida la similaridad entre la celda z y su vecino n seleccionado, se procede a verificar si se propaga o no uno de los memes SL, SSL, o C. La propagación se debe hacer solo si la similaridad entre las celdas es 1 o 2. Esto de acuerdo con la idea de que si dos celdas no son similares en nada (similaridad = 0), entonces sus características son totalmente diferentes, y análogamente como en las sociedades reales, cuando dos individuos no tienen nada en común, su interacción es prácticamente nula. En cambio si su similaridad es de tres, la propagación no tendría efecto, ya que tienen las mismas características. También se debe verificar si la celda z seleccionada para propagar alguno de sus memes tiene un valor de L entre 1 y 8 ; es decir, si esta “muerta” (EL = 0) no puede propagar nada, o bien si esta completamente satisfecha (EL = 9), no tiene para que propagar algún meme. Y para la celda vecina n hay que verificar si esta no esta muerta (EL = 0), ya que la propagación en este caso no tendría ningún efecto beneficioso.

22
Código propuesto para este evento: void Interaccion_cultural() { int res, sim, n, x = Num_Aleatorio(MAX), y = Num_Aleatorio(MAX); int simSL, simC , simSSL, numvec, sel; celda vecino; n = Vecindario_de_Moore(x, y); vecino = Selecciona_Vecino(n, x, y); Encuentra_Similaridad(aldea[x][y], vecino,&simSL,&simC,&simSSL); sim = simSL + simC + simSSL; if((sim == 1) && vecino.EL > 0 && aldea[x][y].EL <9) { res = Num_Aleatorio(2); if(simSL) { if(res) aldea[x][y].SSL = vecino.SSL; else aldea[x][y].C = vecino.C; } if(simC) { if(res) aldea[x][y].SSL = vecino.SSL; else aldea[x][y].SL = vecino.SL; } if(simSSL) { if(res) aldea[x][y].SL = vecino.SL; else aldea[x][y].C = vecino.C; } } if((sim == 2) && vecino.EL > 0 && aldea[x][y].EL <9) { aldea[x][y].SSL = vecino.SSL; aldea[x][y].C = vecino.C; aldea[x][y].SL = vecino.SL; } }
En el código se puede ver que si el nivel de similaridad es de 1, entonces
se tiene que propagar alguno de los otros memes en los que difiere, de tal forma que después del evento la similaridad entre z y n será de 2. Por ejemplo, si el meme SL de z es igual al meme SL de n, entonces se debe de propagar a n alguno de los valores de los memes SSL o C de z; esto se hace de manera aleatoria.

23
Si el nivel de similaridad es de 2, entonces al final los memes del vecino n
deben de tener los mismos valores que los memes de la celda z, tal como se aprecia en código arriba anexado.
Hasta este momento se ha descrito el código propuesto omitiendo la forma en como se selecciona un vecino aleatoriamente, ya que para poder seleccionar adecuadamente un vecino se debe conocer a que vecindario pertenece. Uno de los problemas se da cuando la celda seleccionada z para propagar un meme (o bien para el evento de recompensa de recursos) a sus vecinos en primera instancia se encuentra en alguno de los bordes. Para esto se ha planteado dividir la rejilla en 9 zonas, tal como se puede ver en la siguiente figura. Por ejemplo, si la posición de la celda z esta dada por x = 0 y y = 0, su vecindario corresponde a la zona 0, por lo que solo tiene tres vecinos.
A B C
D E F
G H I
Figura 1.4. Zonas de la rejilla.
Para obtener las zonas de la rejilla, o bien la configuración que le corresponde al vecindario de Moore para la celda z se ha obtenido el siguiente código, que devuelve valores 0 a 8 correspondientes a las zonas de la rejilla (A –I). int Vecindario_de_Moore(int x, int y) { int a = 0, b = 0; if(x==0) a = -3; if(x==MAX-1) a = 3; if(y==0) b = -1; if(y==MAX-1) b = 1; return 4+a+b; }

24
Donde MAX corresponde al valor máximo o limite que puede tomar x o
y para una rejilla de dimensiones MAX*MAX. Siguiendo con análisis de las zonas de la rejilla se puede ver que para cada una de estas se tienen diferentes configuraciones de vecinos si se respeta el orden asignado por el vecindario de Moore. El vecindario de Moore esta determinado como:
0 1 2
7 X 3
6 5 4
Figura 1.5. Vecindario de Moore
En el código, y considerando que se esta manejando una rejilla, entonces estas zonas quedan definidas como (siendo la celda z con posición (x,y)): {
0: vecino = aldea[x-1][y-1]; 1: vecino = aldea[x-1][y]; 2: vecino = aldea[x-1][y+1]; 3: vecino = aldea[x][y+1]; 4: vecino = aldea[x+1][y+1]; 5: vecino = aldea[x+1][y]; 6: vecino = aldea[x+1][y-1]; 7: vecino = aldea[x][y-1];
} De esta forma podemos determinar los vecinos, ahora solo se necesita conocer cuales son los vecinos para cada una de las zonas (configuraciones posibles). Esto se obtiene llenando la tabla de zonas respetando el orden asignado por el vecindario de Moore. La tabla llena queda así:
A 3 7 B 3 7 C
5 4 6 5 4 6 5
1 2 0 1 2 0 1
D 3 7 E 3 7 F
5 4 6 5 4 6 5
1 2 0 1 2 0 1
G 3 7 H 3 7 I
Figura 1.6. Configuraciones posibles del vecindario de Moore.

25
Entonces las posibles configuraciones quedan así:
A: 3,4,5 B: 3,4,5,6,7 C: 5,6,7 D: 1,2,3,4,5 E: 0,1,2,3,4,5,6,7 F: 0,1,5,6,7 G: 1,2,3 H: 0,1,2,3,7 I: 0,1,7
Una vez que hemos determinado las diferentes zonas con sus diferentes posibles vecinos, se puede explicar como se ha codificado la parte de cómo se selecciona u vecino. Esta descripción nos servirá más adelante para explicar el evento de recompensa de recursos de manera más sencilla.
Hay que mencionar primero que se han establecido como constantes una matriz que contiene los vecinos para cada uno de las posibles zonas en las que puede estar una celda. El arreglo queda así: int vecinos[9][8] = {
3,4,5,0,0,0,0,0, 3,4,5,6,7,0,0,0, 5,6,7,0,0,0,0,0, 1,2,3,4,5,0,0,0, 0,1,2,3,4,5,6,7, 0,1,5,6,7,0,0,0, 1,2,3,0,0,0,0,0, 0,1,2,3,7,0,0,0, 0,1,7,0,0,0,0,0 };
Primero encontramos en que zona n se encuentra la celda z seleccionada aleatoriamente con la función Vecindario_de_Moore. A continuación se tiene que seleccionar un vecino, por lo que se necesita la zona n, y la posición de la celda z. Una vez que se llama a la función Selecciona_Vecino esta trabaja de la siguiente manera:

26
1. Se calcula el número de vecinos que se encuentran en ese vecindario (ver lista de vecinos):
Si la zona n es 4 entonces hay 8 vecinos
En otro caso, si la zona n es divisible entre 2, entonces hay 3 vecinos Si n es impar entonces hay 5 vecinos
2. Se genera aleatoriamente un numero que va de cero hasta el numero de vecinos – 1
3. Se busca en la matriz (ver la matriz int vecinos) la entrada
correspondiente: Entrada = vecinos[n][l] (donde l es el numero generado aleatoriamente
en el paso 2)
4. Por ultimo se regresa el vecino correspondiente al valor de la entrada. Veamos un ejemplo para comprender el concepto:
a) Sea z el agente seleccionado aleatoriamente con posición (0,19) en una rejilla de 20x20.
b) Se busca la zona n donde se encuentra, la cual corresponde a la zona 2, es decir n = 2 (ver código de la función Vecindario_de_Moore)
c) Se busca un vecino s valido para propagar algún meme (se llama a la función Selecciona_Vecino con los parámetros 2,0,19)
d) Ya una vez ejecutándose la función de selección de vecino:
- Se calcula el numero de posibles vecinos: ya que el valor de n es 2, entonces el numero de vecinos (numvec) = 3
- Se genera un numero aleatorio (numal) entre 0 y 2, ya que el numero de vecinos es 3, y necesitamos un índice de 0 a 2. Supongamos que ese valor generado es 2.
- Se busca en la matriz de vecinos la entrada vecinos[n][numal], en este ejemplo vecinos[2][numal] = 7
- Finalmente se envía el vecino correspondiente al vecindario de Moore cuyo identificador es 7 (ver la tabla) que corresponde a vecino = aldea[x][y-1], es decir, el vecino seleccionado es el agente con posición (0,18). Como se puede ver en la tabla de zonas es un vecino valido para la celda z
e). Después se continua con el algoritmo de propagación de memes, como ya
se explico anteriormente.

27
El código propuesto finalmente para seleccionar el vecino es el siguiente:
celda Selecciona_Vecino(int n, int x, int y) { int numvec, sel, vec; celda vecino; if(n == 4) numvec = 8; else if(n%2 == 0) numvec = 3; else numvec = 5; sel = Num_Aleatorio(numvec); vec = vecinos[n][sel]; switch(vec) { case 0: vecino = aldea[x-1][y-1]; break; case 1: vecino = aldea[x-1][y]; break; case 2: vecino = aldea[x-1][y+1]; break; case 3: vecino = aldea[x][y+1]; break; case 4: vecino = aldea[x+1][y+1]; break; case 5: vecino = aldea[x+1][y]; break; case 6: vecino = aldea[x+1][y-1]; break; case 7: vecino = aldea[x][y-1]; break; } return (vecino); }
Ahora que conocemos como funcionan las funciones comunes para
todos los experimentos se procede a explicar el evento de premio con recursos para cada uno de los experimentos.

28
Evento de Premio con Recursos Para el Experimento A
Tal como se puede ver en la codificación del sistema planteada en el
artículo, se selecciona al azar con cierta probabilidad una celda z, a la cual se le otorgan 4 puntos de energía (de ser posible por el límite de 9). Una vez que se le han agregado estos cuatro puntos, se selecciona también de forma aleatoria un vecino, si este vecino tiene el mismo o un valor mayor de similaridad mínima (el meme SSL) comparado con la similaridad entre z y su vecino, se le otorga un punto, con la condición de que si se sobrepasa el limite permitido de 9 puntos, este se ajustara con esta máxima cantidad. Esto se hace hasta que se hayan repartido 4 puntos entre los vecinos, o bien se hayan visitado el doble de vecinos posibles del vecindario (por ejemplo si z se encuentra en la zona 0 se generara aleatoriamente 6 posibles visitas a vecinos si aun no se han repartido todos los recursos). Los posibles agentes beneficiados pueden sor todos los miembros del vecindario correspondiente, si cumplen con las características mencionadas.
El código propuesto utiliza las funciones de reconocimiento de vecindario al que pertenece la celda elegida (Vecindario_de_Moore) y la de selección de vecino (Seleccióna_Vecino) que ya se han explicado. El código propuesto es el siguiente: void Recompensa_recursos() {
int sim,n,cont=0, x=Num_Aleatorio(MAX), y=Num_Aleatorio(MAX), rw=REC; int simSL, simC, simSSL, numvec, sel; celda vecino; aldea[x][y].EL = aldea[x][y].EL + rw; if(aldea[x][y].EL > 9) aldea[x][y].EL = 9; n = Vecindario_de_Moore(x, y); while(rw > 0 && cont < 16) {
vecino = Selecciona_Vecino(n, x, y); Encuentra_Similaridad(aldea[x][y], vecino,&simSL,&simC,&simSSL); sim = simSL + simC + simSSL; if(sim >= aldea[x][y].SSL || aldea[x][y].SL > aldea[x][y].SSL) {
vecino.EL = vecino.EL + 1; if(vecino.EL > 9) vecino.EL = 9;
} cont++;
} }

29
Esta forma de repartir recursos puede beneficiar a una celda mas que otras, ya que existe la condición de que estos agentes deben de cumplir un grado de similaridad, así que si en una visita una celda es beneficiada, y después de visitar a otros vecinos se vuelve a visitar esa celda por que los recursos no han podido ser repartidos, esta puede recibir otro recurso mas si el limite lo permite. También puede suceder que si algunos de los vecinos visitados cumpla las características de similaridad requeridas para recompensarlo, entonces algunos e incluso todos los recursos pueden ser desperdiciados. Evento de Premio con Recursos Para los Experimentos C y E
Como ya se menciono en la breve descripción de estos experimentos,
estos eventos se efectúan sobre celdas vecinas designadas previamente. Sabemos que en el experimento C se esparcen los puntos de energía entre los vecinos con identificador par, y para el experimento E los que tienen un identificador impar.
Puesto que la repartición de recursos ya no es aleatoria, ya no es necesario
que en la función selecciona_ vecino se lleve a cabo la generación de un número aleatorio, por lo que sea modificado esta función para que solo regrese el vecino a recompensar con recursos, el código: celda Selecciona_Vecino(int n, int x, int y) {
celda vecino; switch(n) {
case 0: vecino = aldea[x-1][y-1]; break; case 1: vecino = aldea[x-1][y]; break; case 2: vecino = aldea[x-1][y+1]; break; case 3: vecino = aldea[x][y+1]; break; case 4: vecino = aldea[x+1][y+1]; break; case 5: vecino = aldea[x+1][y]; break; case 6: vecino = aldea[x+1][y-1]; break; case 7: vecino = aldea[x][y-1]; break;
} return (vecino);
}
La función de recompensa de recursos para una celda seleccionada también tiene algunos cambios con respecto al experimento A. la función es muy similar, y se explicara el proceso que se lleva considerando el experimento c:

30
1. Se selecciona el agente z y se premia de ser posible con 4 puntos de la misma manera que en el experimento A
2. Se verifica en que zona n de la reja se encuentra ubicado (vecindario de Moore)
3. Se calcula el número de vecinos (numvec) en el vecindario n tal como se hace en el experimento A
4. Se recorre el arreglo predeterminado de correspondientes vecinos de 0 hasta el numero de vecinos para obtener los vecinos validos (se hace un PARA de 0 hasta numvec – 1 visitando el renglón n de la matriz vecinos[n]) para cada valor visitado se obtiene su vecino (función Selecciona_Vecino). En el caso del experimento C, si el valor de vecinos[n][i] (con 0 <= i < numvec) es par, entonces se reparte el recurso si es posible.
5. Se realiza el paso 4 hasta que todos los recursos sean distribuidos, o bien se haya visitado al menos dos veces a los posibles vecinos.
El código propuesto es: void Recompensa_recursos() {
int sim,n, x = Num_Aleatorio(MAX), y = Num_Aleatorio(MAX), rw = REC; int simSL, simC, simSSL, numvec, i = 0; celda vecino; aldea[x][y].EL = aldea[x][y].EL + rw; if(aldea[x][y].EL > 9) aldea[x][y].EL = 9; n = Vecindario_de_Moore(x, y); if(n == 4) numvec = 8; else if(n%2 == 0) numvec = 3; else numvec = 5; while(i < numvec*2 && rw > 0) {
vecino = Selecciona_Vecino(vecinos[n][i%numvec], x, y); Encuentra_Similaridad(aldea[x][y], vecino,&simSL,&simC,&simSSL); if(vecino.EL < 9 && i%2 == 1) if(sim >= aldea[x][y].SSL &&vecino.EL < 9 && i%2 == 1) {
vecino.EL = vecino.EL + 1; rw--;
} i++;
} }
Finalmente, para el experimento E solo se necesita considerar que en el
paso 4 el valor del arreglo de vecinos leído sea impar.

31
C a p í t u l o I I
SISTEMA DE NAVEGACION PARA UN ROBOT MÓVIL
En el articulo publicado por Alejandro Ramírez Serrano titulado “un control inteligente con características de autoaprendizaje utilizado en robots móviles” se habla, como lo indica el titulo, de un aprendizaje por parte de un robot para moverse en un entorno o terreno con obstáculos. El controlador de dicho robot esta basado en una red neuronal del tipo backpropagation (retro propagación) la cual recibe información del medio ambiente y le indica en que dirección ha de moverse.
Las Redes Neuronales Artificiales son sistemas paralelos para el
procesamiento de la información, inspirados en el modo en el que las redes de neuronas biológicas del cerebro procesan esta. La tarea del modelo de red neuronal artificial es la de realizar una simplificación, averiguando cuales son los datos o elementos relevantes de un sistema, bien porque la cantidad de información que se dispone es excesiva o bien porque es redundante. Una elección adecuada de las características, más una estructura conveniente, a la hora de construir una red neuronal es el principal problema a resolver para construir redes capaces de realizar una determinada tarea.
En esta parte del reporte lo que nos interesa conocer con respecto al
articulo y la propuesta que se hace para este proyecto es la de familiarizarnos con las redes neuronales a partir de las características del robot, y determinar sus posibles movimientos y posteriormente entrenar una o varias redes neuronales para realizar experimentos para implementarlas en la simulación del movimiento del robot. Redes Neuronales de Tipo Biológico
En la construcción de sistemas basados en redes neuronales artificiales se
busca que estas características propias de la neuronas reales, tales como su robustez y su tolerancia a fallos, su flexibilidad para adaptarse a nuevas circunstancias, que puedan trabajar con información borrosa, incompleta, probabilística, con ruido; que sean capaces de trabajar en paralelo, entre otras. En si, el punto clave en la construcción de neurona artificial es la simulación y estructuración de estas características para el procesamiento de información.

32
La información es el elemento primordial de las neuronas tanto reales como artificiales. Es a partir de esta información como muestra o ejemplo, que las neuronas aprenden. En los sistemas biológicos la principal función de una red neuronal es el desarrollo de elementos sintéticos para verificar las hipótesis que conciernen a los sistemas biológicos a partir de ese aprendizaje que involucra la modificación de la interconectividad entre las neuronas; y es este concepto es el que sustenta la estructura de las redes neuronales artificiales. Por eso es importante conocer la estructura de una neurona real.
Una neurona biológica consta de cuatro partes:
1. El cuerpo de la neurona (núcleo celular) 2. Ramas de extensión (dendritas) para recibir las entradas 3. Un axón que lleva la salida de una neurona a las
dendritas de otras neuronas 4. Las conexiones que tienen con otras neuronas llamadas
sinapsis.
Figura 2.1. Neurona Biológica.
La mayoría de las neuronas tienen una estructura parecida a la de un árbol (dendritas) que reciben las señales de entrada que vienen de otras neuronas a través de las conexiones (sinapsis). En el cerebro humano hay aproximadamente 12 billones de células nerviosas o neuronas cada una con un total de entre 5600 y 60000 conexiones dendríticas provenientes de otras neuronas. En el sistema nervioso hay 1014 sinapsis, teniendo cada neurona más de 1000 a la entrada y a la salida. Cabe mencionar que aunque el tiempo de conmutación de una neurona real es casi un millón de veces menor que las computadoras actuales, esta tiene una conectividad miles de veces superior.

33
La Red Neuronal Artificial
Consideremos n neuronas ordenadas arbitrariamente y designadas como
unidades. El trabajo que hace cada neurona es simple y único: consiste en recibir las entradas de las células vecinas y calcular un valor de salida, el cual es enviado a todas las células restantes.
Figura 2.2. Neurona Artificial.
Si ordenamos estas n neuronas de forma que las entradas provengan de
la misma fuente (que puede ser otro conjunto de neuronas) y cuyas salidas se dirigen al mismo destino (que puede ser otro conjunto de neuronas) se dice que tenemos una capa o nivel de neuronas. En la siguiente figura se puede apreciar una red neuronal donde se destacan tres tipos de unidades que conforman diferentes capas.
Figura 2.3. Diagrama conceptual de una red neuronal.
Las unidades de entrada reciben señales desde el entorno (son señales
que proceden de sensores o de otros sectores del sistema de percepción de señales). Las unidades de salida envían la señal fuera del sistema (son señales que pueden controlar directamente otros sistemas).

34
Las neuronas de la capa intermedia, a la que se denomina capa oculta ya
que no es visible desde el entorno, es decir, se encuentran dentro del sistema y las señales que procesan no tienen contacto con el exterior. Una red neuronal puede tener varias capas ocultas. Ademas estas capas pueden estar interconectadas de distinta manera, por lo que existen diferentes topologias, determinadas por el número de capas o bien como consecuencia del fin para el que es construida la red. Conexiones Entre Neuronas
Las conexiones que unen a las neuronas que forman una red neuronal
artificial, tienen asociado un valor al que llamaremos peso, y este es el medio por el cual la red adquiere conocimiento. Una neurona recibe un conjunto de señales que le dan información del estado de activación de todas las neuronas o entradas externas con las que se encuentra conectada.
Consideremos N conexiones para una neurona donde cada conexión i y
la neurona (representada con j para cada conexión) está ponderada por un peso wji, Ahora llamaremos a los valores de cada señal como yi, es decir la información que recibe la neurona. Así, de forma simplificada, se considera que el efecto de cada señal es aditivo, de tal forma que el valor neto de la información recibida (potencial post sináptico) es la suma del producto individual por el valor de la sinapsis que conecta ambas neuronas y se representa con la formula:
∑ ⋅=
N
i
ijijywnet
En donde netj es el valor neto de la información recibida. Esta regla muestra el procedimiento a seguir para combinar los valores de entrada a una unidad con los pesos de las conexiones que llegan a esa unidad y se conoce como regla o función de propagación (también se le conoce como función de excitación) ya que el valor obtenido se envía a otras neuronas u otros dispositivos. En la siguiente figura podemos ver la representación de una red donde x1, x2, x3 representan las entradas para la capa 1. Los pesos representados con w’s indican las conexiones con las neuronas. El valor net es calculado por cada neurona y propagado (de manera análoga que los valores de entrada) hacia las neuronas de la capa 2. Las neuronas de la capa 2 ya no están conectadas a su derecha con otra capa, por lo que los valores y1 y y2 representan las salidas.

35
Figura 2.4. Red neuronal artificial de 2 capas.
El Aprendizaje en una Red Neuronal Artificial
Sabemos que el funcionamiento optimo de una red de computadores
depende del numero de elementos de los que disponga y de como estén conectados entre si, como resultado de la necesidad que necesita cubrir. En el caso de las redes neuronales artificiales el proceso de aprendizaje se da modificando los valores de los pesos de la red, ya que de estos dependen los valores de salida respectivos a cada conjunto de valores de entrada.
Entonces el problema se centra en como encontrar los pesos que han de
existir en las conexiones de la red. Las soluciones que se dan dependen del problema a resolver, por lo que es importante encontrar una buena estructura para la red además de tener un buen y gran conjunto de datos muestra para que una vez terminada la red esta se probada y determinar si se obtienen buenos resultados. Como se puede notar se esta hablando de un proceso donde se necesita conocer a fondo el problema, determinar una estructura, analizar y experimentar con datos muestra representativos y determinar en una fase de prueba si la red trabaja bien.
Hablando de la estructura adecuada es difícil establecer un proceso para
encontrar la mas adecuada, por lo general es intuitivo y después de varios ensayos se puede llegar a una estructura que de buenos resultados. Una vez que ya se tiene un modelo estructural de la red se deben llevar dos fases en la aplicación. Estas fases son llamadas la fase de entrenamiento o aprendizaje y la fase de prueba. Si no se obtienen buenos resultados se debe de modificar la estructura, tomar mas datos muestra, o incluso replantear de nuevo el problema; para después de nuevo aplicar las dos fases mencionadas, y así continuar el ciclo hasta encontrar buenos resultados.

36
También hay otra parte importante que hay que determinar en el modelo de una rede neuronal, el cual consiste en el método de aprendizaje. Existen varios métodos documentados como se mencionara mas adelante, sin embargo también no existe un proceso para determinar cual o cuales usar para problemas particulares. Estructura de las Redes Neuronales Artificiales
La estructura de una red neuronal se determina por la cantidad de capas
y las conexiones entre ellas. Como ya se menciono, existen tres tipos de capas de neuronas: la de entrada, la de salida y las ocultas. Hablando en términos de programación, entre dos capas de neuronas existe una matriz de valores que representan los pesos de conexión. Estas conexiones son las que determinan el funcionamiento de la red, y hay varios tipos de estas:
- Conexión hacia delante: los datos de las neuronas de una capa
inferior son propagados hacia las neuronas de la capa superior.
- Conexión hacia atrás: los datos de las neuronas de una capa superior son llevados a otra de capa inferior.
- Conexión lateral: un ejemplo típico de este tipo de conexión es “el
ganador toma todo”, que cumple un papel importante en la elección del ganador.
- Conexión de retardo: es la conexión en la cual se le incorporan unos
elementos de retardo o espera para implementar modelos dinámicos y temporales, es decir, modelos que precisan memoria.
Otra parte fundamental de la estructura de una red es el tamaño. Para
determinar el tamaño de una red a menudo se cuenta a partir del número de capas de pesos, debido a que en una red multicapa existen una o más capas de neuronas ocultas. El número de neuronas ocultas está directamente relacionado con las capacidades y necesidades de la red, debido a que un comportamiento correcto de la red viene determinado por el número de neuronas de la capa oculta.

37
Las Fases en el Aprendizaje de una Red Neuronal
Fase de entrenamiento. Consiste en alimentar las entradas de la red
con datos tomados de manera aleatoria y adaptar los pesos de acuerdo a la información extraída de patrones (salidas esperadas) predeterminados o nuevos. Una vez examinados todos los valores de entrada se determinaran los patrones correspondientes que constituyan las entradas habituales analizando las salidas finales de la red.
Fase de prueba. Una vez acabada la fase de entrenamiento la red es
sometida a pruebas con valores aleatorios para comprobar su efectividad. Es decir, para validar el diseño, una vez calculados los pesos, se comparan los valores de las neuronas de la última capa con la salida deseada. Métodos de aprendizaje.
Clasificación general. La clasificación general sería la siguiente:
Aprendizaje Supervisado. Basadas en la decisión. De Aproximación/Optimización.
Aprendizaje No Supervisado. Entrenamiento Competitivo. Redes asociativas de pesos fijos.
Cada uno de estos métodos cuenta con sus reglas de entrenamiento
específicas. A continuación se comentarán brevemente los diferentes tipos de entrenamiento.
Aprendizaje supervisado.
En el aprendizaje supervisado (aprender con un maestro), la adaptación sucede cuando el sistema compara directamente la salida que proporciona la red con la salida que se desearía obtener de dicha red. Existen tres tipos básicos: por corrección de error, por refuerzo y estocástico.

38
En el aprendizaje por corrección de error el entrenamiento consiste en
presentar al sistema un conjunto de pares de datos, representando la entrada y la salida deseada para dicha entrada (este conjunto recibe el nombre de conjunto de entrenamiento). El objetivo es minimizar el error entre la salida deseada y la salida que se obtiene.
El aprendizaje por refuerzo es más lento que el anterior. No se dispone de un ejemplo completo del comportamiento deseado pues no se conoce la salida deseada exacta para cada entrada sino que se conoce el comportamiento de manera general para diferentes entradas. La relación entrada-salida se realiza a través de un proceso de éxito o fracaso, produciendo este una señal de refuerzo que mide el buen funcionamiento del sistema. La función del supervisor es más la de un crítico que la de un maestro.
El aprendizaje estocástico consiste básicamente en realizar cambios
aleatorios de los valores de los pesos y evaluar su efecto a partir del objetivo deseado.
Aprendizaje supervisado basado en la Decisión.
En la regla de entrenamiento basada en la decisión, se actualizan los pesos sólo cuando se produce un error en la clasificación. Esta regla de entrenamiento es localizada y distributiva, además comprende el aprendizaje reforzado y la subred correspondiente a la clase correcta y el entrenamiento antirreforzado en la subred ganadora. Redes Neuronales de Aproximación/Optimización.
Las formulaciones basadas en la aproximación se pueden ver como una
aproximación/regresión para el conjunto de datos entrenados. Los datos para el entrenamiento se dan en pares de entrada/salida esperada. El objetivo es encontrar los pesos óptimos minimizando el error entre los valores esperados y las salidas de respuesta actual.

39
Modelos No Supervisados
Como ejemplo de modelos de entrenamiento no supervisado tenemos
las redes de Memoria Asociativa, que se usan para obtener patrones originales libres de ruido a partir de señales incompletas o distorsionadas. La principal característica de las redes asociativas de pesos fijos es que sus pesos son preestablecidos y precalculados, lo que es una limitación ya que no se pueden adaptar a “ambientes cambiantes”.
Hay otra variedad de redes no supervisadas, llamadas Redes de
Aprendizaje Competitivo, basadas únicamente en la información de los patrones de entrada, es decir no necesitan la supervisión de un maestro a la salida.
Los procedimientos de clasificación no supervisados se basan a menudo
en algunas técnicas de clasificación, que forman grupos de patrones parecidos. Esta técnica de clasificación es muy importante para establecer una medida de similaridad de los patrones.
El Perceptrón Unicapa
Un perceptrón unicapa no es más que un conjunto de neuronas no
unidas entre sí, de manera que cada una de las entradas del sistema se conectan a cada neurona, produciendo cada una de ellas su salida individual; y en él podemos utilizar los métodos de aprendizaje mencionados.
Figura 2.5. Modelo de Perceptrón Unicapa.

40
En el Aprendizaje Supervisado se presentan al Perceptrón unas entradas con las correspondientes salidas que queremos que aprenda. De esta manera la red primeramente calcula la salida que da ella para esas entradas y luego, conociendo el error que está cometiendo, ajusta sus pesos proporcionalmente al error que ha cometido. En el Aprendizaje No Supervisado, solo se presentan al Perceptrón las entradas y, para esas entradas, la red debe dar una salida parecida. En el Aprendizaje Por Refuerzo se combinan los dos anteriores, y de cuando en cuando se presenta a la red una valoración global de como lo está haciendo. El Perceptrón Multicapa con Backpropagation
Esta estructura nació con la intención de dar solución a las limitaciones
del Perceptrón clásico o unicapa, y supuso el resurgimiento de las tendencias conexionistas. Como su nombre indica, se trata de unos cuantos perceptrones unicapa conectados en cascada. El problema de este tipo de Perceptrón está en su entrenamiento, ya que es difícil modificar correctamente los pesos de las capas ocultas. Para poder hacer aprender cosas a un Perceptrón de este tipo, se implementó el algoritmo de Retropropagación o BackPropagation, el cual, como su nombre indica, tiene la función de ir propagando los errores producidos en la capa de salida hacia atrás.
Para el proyecto de investigación que se esta realizando se utilizara en
primer instancia una red neuronal con aprendizaje supervisado y el ajuste de los pesos se hará con el algoritmo de backprogation, cuyo algoritmo se vera mas adelante. El modelo esta basado en el artículo publicado por Alejandro Ramírez Serrano y que para la parte de la navegación de nuestro agente se describe en la siguiente sección del capítulo. Red Neuronal Para un Robot Móvil
El objetivo principal de esta parte del proyecto propuesto es la de
primera parte que nos interesa es la de familiarizarnos con las necesidades de un robot móvil con respecto a su sistema de navegación, determinar sus posibles movimientos y posteriormente construir y entrenar una o varias redes neuronales para realizar pruebas y experimentos. Como ya sabemos, en primera instancia se tomara como base el sistema planteado por el investigador Alejandro Ramírez Serrano, aunque cabe mencionar que para la simulación final se modifico dicho sistema como se vera en otro capitulo.

41
La arquitectura del robot que se plantea en el artículo consiste en un
pequeño dispositivo móvil de cuatro ruedas capaz de moverse en cualquier dirección. Para reconocer su entorno, es decir, los objetos u obstáculos con los que puede enfrentarse en su recorrido se utilizaran cuatro sensores de proximidad: un sensor para cada una de sus caras, como se muestra en la figura:
Estos sensores de proximidad deben de detectar obstáculos en cuatro diferentes direcciones (enfrente, derecha, izquierda y atrás) del robot. La principal tarea del robot es la de encontrar una ruta libre de obstáculos y moverse en dicha dirección. Para ello debe de utilizar la información obtenida por sus sensores, los cuales únicamente indican si hay un obstáculo o no de manera binaria, es decir, si un sensor detecta un obstáculo el sensor informara al robot que existe dicho obstáculo con un 1, y si no lo hay entonces lo informara con un 0. Tomando en cuenta esta forma de interpretar si un sensor ha detectado un objeto o no, se ha decidido interpretarlo como un vector, el cual se propone así:
Vector de Datos de los Sensores: (Sensor F, Sensor D, Sensor I, Sensor A)
Esta interpretación nos da 16 posibles combinaciones que se muestran
en la siguiente tabla, donde las lineas indican obstáculos o muros y se colorea en rojo el sensor que lo ha detectado.
Sensor F
Sensor I Sensor D
Sensor A
Figura 2.6. El Robot y sus Sensores
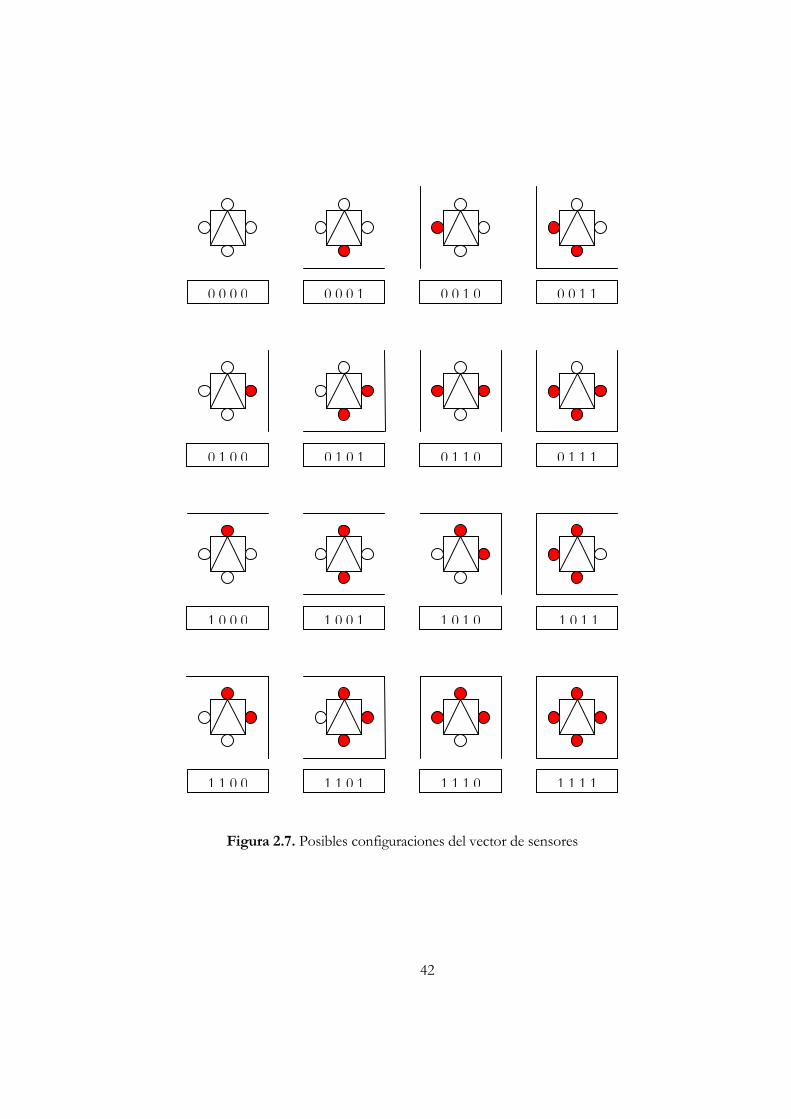
42
0 1 1 1 0 1 1 0 0 1 0 1 0 1 0 0
0 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0
1 0 1 1 1 0 1 0 1 0 0 1 1 0 0 0
1 1 1 1 1 1 1 0 1 1 0 1 1 1 0 0
Figura 2.7. Posibles configuraciones del vector de sensores

43
El Diseño y Entrenamiento de la Red Neuronal
El siguiente problema a resolver una vez que se ha planteado como es
que el robot ha de detectar los objetos u obstáculos de su entorno es el de que ha de hacer al interpretar dichos datos (del vector de sensores) y así decidir que nueva dirección tomar. Aquí es donde entra la tarea de la red neuronal: recibir los datos del sensor e indicar al robot la dirección que ha de tomar. Siguiendo el esquema basado en el articulo ya mencionado se ha considerado reproducir la red neuronal que utilizo el autor en sus experimentos. Dicha red neurona consiste en tres niveles o capas:
- Capa de entrada: Obviamente consiste en una capa de cuatro neuronas correspondientes a cada uno de los sensores representados en el vector.
- Capa oculta: Se manejara una capa de 10 neuronas - Capa de salida: Esta capa consta de cuatro neuronas
correspondientes a cuatro salidas para calcular un vector de dirección del movimiento del robot (como se vera a continuación)
En resumen las entradas reciben la información del medio ambiente
proporcionada por cada uno de los sensores de proximidad. Como desde este momento este vector de sensores es la entrada a nuestra red neuronal, dicho vector se escribirá de la siguiente forma:
Entradas = (EA, ED, EI, EA)
Donde cada uno corresponde a la entrada de enfrente, de la derecha, de la izquierda y de atrás. Continuando, las salidas representan en magnitudes vectoriales la dirección en que el robot debe de moverse con respecto a si mismo: moverse hacia el frente, moverse hacia la derecha, moverse hacia la izquierda, moverse hacia atrás, respectivamente. Análogamente con el vector de entrada que se usara tendremos un vector de salida correspondiente que representaremos como:
Salidas = (SE, SD, SI, SA)
La dirección a la cual se moverá el robot se obtiene al realizar una suma vectorial sobre estas salidas. Dicha suma se hace de la siguiente manera:
Dirección del movimiento de robot: (SD - SI)i + (SE –SA)j

44
Donde i y j representan vectores unitarios dirigidos a la derecha y al frente del robot respectivamente, tal y como se interpreta un vector en el plano cartesiano. Una vez que tenemos la idea de cómo se vera nuestra red neuronal, es necesario programarla para poder entrenarla. Para su entrenamiento se ha decidido usar el algoritmo de propagación con función sigmoidal. La siguiente parte es una breve descripción de este algoritmo. Entrenamiento de la Red con Backpropagation
La regla de entrenamiento
Una de las características importantes por definir en una red de aprendizaje supervisado es lo que se conoce como la regla de entrenamiento. En muchas redes esta regla de entrenamiento se basa en un conjunto de funciones que se utilizan para ayudar a la red a encontrar mas rápido los pesos requeridos. Una de esas funciones, la más básica, es la ya mencionada regla o función de propagación. A veces con el valor que devuelve esta función es suficiente para que la neurona se active, es decir, pueda propagar ese valor.
Sin embargo en el esquema de backpropagation este valor obtenido de
la función de propagación es manipulado para garantizar una mejor convergencia hacia los pesos óptimos y disminuir los posibles errores. Dicha manipulación es hecha por una función (diferenciable en todos sus puntos para garantizar la convergencia) y que se conoce como función de activación, y cuyo valor de salida es propagado a la siguiente capa o salida de la red. La función de activación para modificar la salida (OUT) que se usa en backpropagation es la sigmoidea, de la cual utilizaremos también su derivada:
Función sigmoidea: OUT = 1/(1 + e ^ - net)
y su derivada es: OUT* (1-OUT))
Donde NET es la ya mencionada formula: ∑ ⋅=
N
i
ijijywnet
Además la función de activación se utiliza para comprimir el rango de net, de modo que OUT oscile entre 0 y 1, permitiendo un rango aceptable para el manejo de datos. Se pueden utilizar otras funciones, la única condición que tendrían que cumplir es que fueran diferenciables en todos sus puntos.

45
Otras funciones importantes en la regla de entrenamiento del modelo de
backpropagation son las que manipulan los valores para obtener los respectivos errores al compararlos con los patrones de salida y las funciones de correcciones de modificación de pesos, como se vera mas adelante. El entrenamiento
El objetivo del entrenamiento es ajustar los pesos de la red. Antes de
empezar el entrenamiento, todos los pesos de los perceptrones que formen la red multicapa se inicializarán con números aleatorios pequeños, (generalmente entre 0 y 1) para asegurar que la red no se sature con valores altos. El entrenamiento consta de los siguientes pasos:
1. Seleccionar el siguiente par de entrenamiento del conjunto de entrenamiento, aplicando el vector de entrada a la entrada de la red.
2. Calcular la salida de la red.
3. Calcular el error entre la salida de la red y la salida deseada (vector
objetivo del par de entrenamiento).
4. Ajustar los pesos de la red para minimizar este error
5. Repetir los pasos del 1) al 4) para cada vector del conjunto de entrenamiento hasta que el error del conjunto entero sea aceptablemente bajo.
De los pasos descritos antes, podemos separarlos en "pasos hacia
adelante" y "pasos hacia atrás"
Pasos hacia adelante (pasos 1 y 2): Se empieza por la capa más cercana a las entradas. El valor net se halla para cada perceptrón, la función de activación "aplasta" net para producir OUT y una vez hallados todos los OUT de una capa, estos sirven de entrada para la siguiente capa, repitiéndose el proceso capa a capa, hasta producir las salidas.
Pasos hacia atrás (pasos 3 y 4): Cuando ajustemos los pesos de la red,
distinguiremos entre ajustar los pesos de la capa de salida y ajustar los pesos de las capas intermedias (capas ocultas).

46
Para ajustar los pesos de la capa de salida se utiliza una variante de la
llamada regla Delta. Esta regla consiste en restar la salida de una neurona en la capa k (la última) del valor de salida para hallar el error que denominaremos ERROR. Esto es multiplicado por la derivada de la función de activación o ajuste para “comprimir los valores entre 0 y 1” calculada para esa neurona de la capa k, que produce sigma.
Después sigma se multiplica primero por OUT de la neurona de la capa j (la anterior a la última) y después por un coeficiente de entrenamiento que oscila entre 0,01 y 1 y el resultado se suma al peso. Generalizando:
Para ajustar los pesos de las capas ocultas, Backpropagation lo que hace es propagar el error de salida a través de la red capa a capa hacia atrás, ajustando los pesos en cada capa. Las ecuaciones son las mismas que las utilizadas en el caso anterior, salvo que sigma se tiene que hallar sin tener el vector objetivo.
Si consideramos una sola neurona en la capa oculta anterior a la capa de
salida, en los pasos hacia adelante se propaga el error del perceptrón a la capa de salida mediante los pesos. Cuando nos encontramos en el entrenamiento de la red, los pesos operan al revés, cada peso es multiplicado por el valor de sigma del perceptrón al que se conecta de la capa de salida. Esta sigma se halla sumando todos los productos posibles y multiplicando por la derivada de la función de aplastamiento (sigmoidea). Generalizando:
Esto se realiza en todas las capas hasta que todos los factores están
ajustados.
En ocasiones también es conveniente agregar un umbral o sesgo b, como si fuera una entrada mas para cada capa, ya que esto aumenta la capacidad y velocidad de procesamiento de la neurona y que eleva o reduce la entrada a la neurona, según sea su valor positivo o negativo. Para nuestro diseño de la red que se utilizo se propuso un sesgo con un valor de 1, el cual derivo en un entrenamiento mas rápido. La red que se diseño se muestra en la siguiente página.
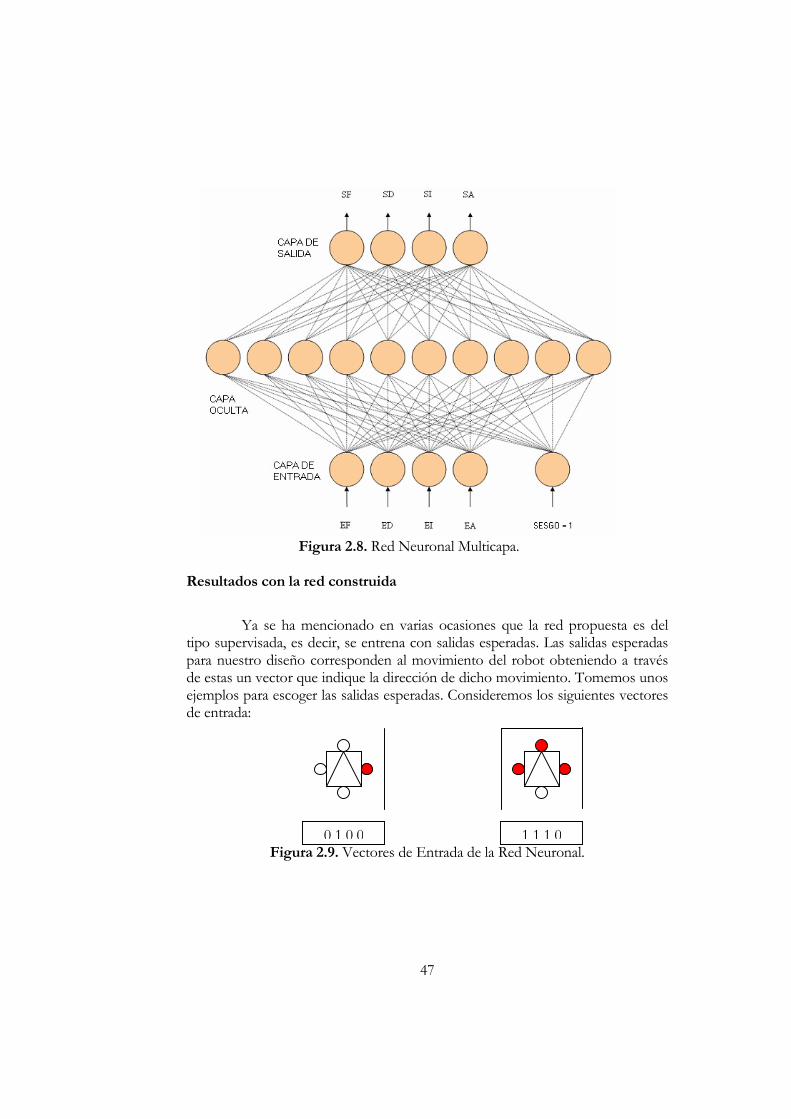
47
Figura 2.8. Red Neuronal Multicapa.
Resultados con la red construida
Ya se ha mencionado en varias ocasiones que la red propuesta es del
tipo supervisada, es decir, se entrena con salidas esperadas. Las salidas esperadas para nuestro diseño corresponden al movimiento del robot obteniendo a través de estas un vector que indique la dirección de dicho movimiento. Tomemos unos ejemplos para escoger las salidas esperadas. Consideremos los siguientes vectores de entrada:
Figura 2.9. Vectores de Entrada de la Red Neuronal. 0 1 0 0 1 1 1 0
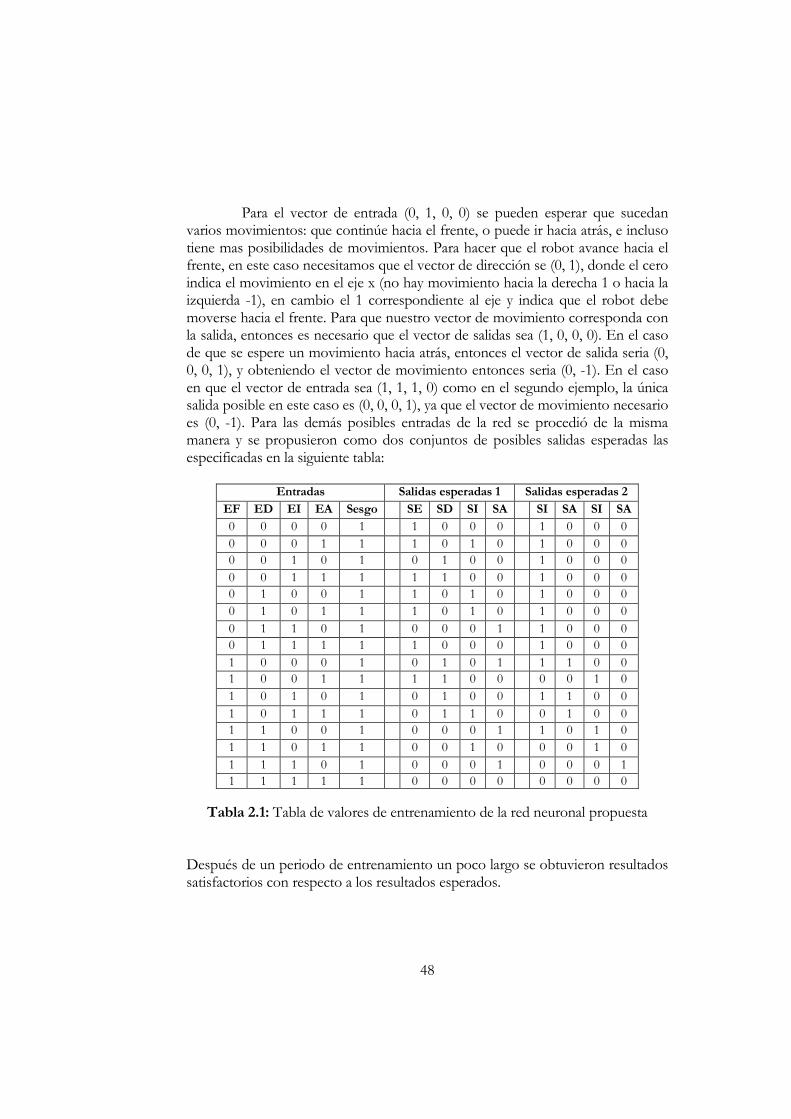
48
Para el vector de entrada (0, 1, 0, 0) se pueden esperar que sucedan
varios movimientos: que continúe hacia el frente, o puede ir hacia atrás, e incluso tiene mas posibilidades de movimientos. Para hacer que el robot avance hacia el frente, en este caso necesitamos que el vector de dirección se (0, 1), donde el cero indica el movimiento en el eje x (no hay movimiento hacia la derecha 1 o hacia la izquierda -1), en cambio el 1 correspondiente al eje y indica que el robot debe moverse hacia el frente. Para que nuestro vector de movimiento corresponda con la salida, entonces es necesario que el vector de salidas sea (1, 0, 0, 0). En el caso de que se espere un movimiento hacia atrás, entonces el vector de salida seria (0, 0, 0, 1), y obteniendo el vector de movimiento entonces seria (0, -1). En el caso en que el vector de entrada sea (1, 1, 1, 0) como en el segundo ejemplo, la única salida posible en este caso es (0, 0, 0, 1), ya que el vector de movimiento necesario es (0, -1). Para las demás posibles entradas de la red se procedió de la misma manera y se propusieron como dos conjuntos de posibles salidas esperadas las especificadas en la siguiente tabla:
Entradas Salidas esperadas 1 Salidas esperadas 2
EF ED EI EA Sesgo SE SD SI SA SI SA SI SA
0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 1 1 1 0 1 0 1 0 0 0 0 0 1 0 1 0 1 0 0 1 0 0 0 0 0 1 1 1 1 1 0 0 1 0 0 0 0 1 0 0 1 1 0 1 0 1 0 0 0 0 1 0 1 1 1 0 1 0 1 0 0 0 0 1 1 0 1 0 0 0 1 1 0 0 0 0 1 1 1 1 1 0 0 0 1 0 0 0 1 0 0 0 1 0 1 0 1 1 1 0 0 1 0 0 1 1 1 1 0 0 0 0 1 0 1 0 1 0 1 0 1 0 0 1 1 0 0 1 0 1 1 1 0 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 1 1 0 1 1 0 0 1 0 0 0 1 0 1 1 1 0 1 0 0 0 1 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0
Tabla 2.1: Tabla de valores de entrenamiento de la red neuronal propuesta
Después de un periodo de entrenamiento un poco largo se obtuvieron resultados satisfactorios con respecto a los resultados esperados.

49
C a p í t u l o I I I
EL ROBOT RECOLECTOR
Desde el origen de lo que el hombre ha denominado civilización ha existido la necesidad idear métodos o mecanismos ya sean físicos o conceptuales que lo ayuden en sus múltiples labores, ya sean estas de primera necesidad o bien como simple curiosidad o entretenimiento. Con el transcurso del tiempo la civilización humana ha desarrollado un sinfín de estos métodos o mecanismos que se han concebido como teorías del todo fundamentadas y que han llevado a una manipulación de su entorno para le creación, invención y la misma evolución de artefactos que le sean útiles para realizar sus propósitos. Esta evolución y constante creación de nuevos artefactos, así como la aparición de nuevas necesidades que conlleva la misma evolución humana, su crecimiento poblacional y su expansión territorial; es una de las características de la humanidad, cuyo principal motor es la búsqueda de nuevas vías para mejorar sus condiciones de vida.
Reducir la cantidad de trabajo humano, realizar tareas en el menor tiempo posible, ejecutar trabajos donde se requiere una considerable fuerza, son solo unos ejemplos en donde el ser humano ha encaminado sus esfuerzos. Métodos y maquinas han ido cambiando con el tiempo, los progresos obtenidos en muchos campos de estudio han permitido dirigir estos esfuerzos a otros campos, y así, han surgido nuevos y variados campos de estudio. Uno de los campos de estudio que en estos días ha tomado un considerable auge es el de la imitación de procesos similares a los procesos inteligentes humanos.
Aunque la necesidad de imitación de la inteligencia humana no es nueva, hoy en día hay múltiples investigaciones para encontrar la forma de realizar tareas donde la presencia, control o supervisión del hombre no es del todo requerida o bien puede hacer lento y tedioso su desarrollo, o bien, también para evitar la misma presencia del hombre, hablando en términos de ahorro de recursos o seguridad. Aunque muchas de estas investigaciones están prácticamente en pañales, el objetivo principal de estas es, como ya se menciono, es la creación de métodos o maquinas que tengan un cierto grado de inteligencia artificial. Así es como los investigadores han denominado este nuevo campo de estudio: INTELIGENCIA ARTIFICIAL (AI). Los desarrollos científicos actuales se dirigen al estudio de las capacidades humanas, como fuente de ideas para el diseño y la creación de dichos métodos o maquinas: “la inteligencia artificial es un intento por descubrir y describir aspectos de la inteligencia humana que pueden ser simulados mediante métodos y maquinas”.

50
Actualmente existen mecanismos que se han denominado máquinas inteligentes porque permiten implementar algoritmos para resolver problemas que antes resultaban lentos, y tediosos de solucionar. Sin embargo, en estas maquinas no se pueden implementar problemas donde se requiere de un aprendizaje, o una decisión que no se puede diseñar de manera matemática o algorítmica; por ejemplo, una maquina cuya función sea la recolección de objetos que tengan una determinada característica, la identificación y clasificación de estos objetos de acuerdo a sus rasgos comunes o su localización en cierto entorno es un problema que abarca muchas ideas de la inteligencia artificial: el campo de visión artificial, reconocimiento de patrones, conocimiento del entorno, orientación en el entorno, identificación de mejores o diferentes rutas, entre otros.
En el presente capitulo se hablara del desarrollo de un mecanismo algorítmico para la orientación y desplazamiento de una maquina o agente en un terreno en el cual se encuentran objetos que este mismo debe de recolectar. Aunque en el reporte solo se hablara sobre la orientación y desplazamiento de dicho agente, al final del mismo se plantea como una propuesta la solución al problema de decisión de las mejores rutas en un terreno, o bien, como identificar otras posibles rutas para la búsqueda de nuevos lugares de recolección.
Para el sistema de navegación del robot recolector se ha propuesto utilizar como base un sistema ya desarrollado en MATLAB conocido como SIMROBOT, tema con el que inicia este capitulo. De este sistema ya diseñado se han tomado las características correspondientes a la cinemática del robot y su forma, así como el sistema de percepción que simula la operación de sensores ultrasónicos con el algoritmo de Bresenham. Para la interpretación de patrones que detecte el sistema de percepción se propone una red neuronal para la toma de decisiones de orientación así como una variante del algoritmo de Bresenham para la diferenciación de los diferentes objetos y obstáculos que se encuentren en el entorno y el agente pueda decidir entre seguir la exploración del entorno o recolectar un objeto y regresar a su lugar de partida. También se propone implementar como alternativa para la búsqueda de la mejor ruta de regreso una variante del conocido algoritmo A-star.
Por último, en la parte final del capitulo se hablara de la implementación del programa que simula la sociedad de robots, y se especificaran las características y herramientas con las que fue construido. Esta ultima parte continuara en el siguiente capitulo en el cual se hablara de las políticas y reglas del sistema de comunicación y su integración en el programa, así como una propuesta para la implementación de la sociedad de robots haciendo uso de la teoría de memes que se describe en el capitulo 1.

51
La Toolbox SIMROBOT
SIMROBOT es el anagrama de SIMulated ROBOTs, una herramienta
de simulación desarrollada en la Universidad Brno de República Checa con el conocido programa MATLAB. Las principales funciones de esta toolbox son:
- Simular comportamientos de uno o más robots en movimiento en un entorno virtual.
- Simular sensores ultrasónicos y láser que pueden utilizarse para algoritmos de control como la Lógica Difusa y las Redes Neuronales. Estos sensores se pueden equipar a los robots.
Para la aplicación de estas funciones la toolbox cuenta con un Editor
que permite crear y modificar la simulación permitiendo la creación del entorno virtual, la definición de robots y la edición de los algoritmos de control. Una vez que ya se ha editado una simulación esta se puede ejecutar permitiendo, si es el caso, que cada robot creado se comporte de acuerdo a la forma en que fueron editados sus propios algoritmos de control. Esta simulación se muestra en una ventana llamada Simulator Window y se muestra a continuación.
Figura 3.1. Simulator Window de la toolbox SIMROBOT
Dentro de las opciones de edición se encuentran mini editores propios
del sistema donde se pueden modificar los parámetros básicos del robot, tales como su posición en el entorno, su color, su tipo y su forma, el tipo de sensores que usa y su posición, entre otros. La toolbox también cuenta con otros mini editores que permiten la configuración individual de cada robot para la implementación de sus algoritmos de control.

52
Otras características relevantes que cabe mencionar son la de poder usar e interactuar con otras toolbox de MATLAB, la de contar con un sistema que detecta colisiones y puede simular paso a paso, además de que le asigna a cada robot una memoria que permite reproducir una simulación por completo e incluso dibujar el recorrido de cada robot. También, en beneficio del usuario, se permite el acceso a estos datos para su posterior análisis.
El entorno virtual de simulación esta representado por una matriz que
permite valores desde 0 hasta 255, donde el cero representa que no hay un solo objeto y otro número representa ya sea un obstáculo u otro robot. Es importante decir que si el robot no detecta un obstáculo puede salirse del entorno virtual, por lo que es importante en la simulación usar mapas que estén limitados.
Los robots admiten sensores ultrasónicos o láser para evaluar distancias
largas y cortas. Estos sensores están simulados con los algoritmos de Bresenham para el dibujo de líneas y círculos. En este proyecto se ha optado por simular el sensor ultrasónico, aunque se ha modificado con respecto al que se tiene en la toolbox para el reconocimiento de objetos a recolectar y otros robots, como se vera en otra sección de este capitulo.
Ahora que se conocen las características propias de la toolbox se puede
hablar del modelo de representación que asume como sistema de coordenadas, la forma y modelo cinemático del robot. El detenernos en estas descripciones tiene el fin de indicar que características se han tomado del modelo que usa esta toolbox para el desarrollo de este proyecto.
Sistema de Coordenadas y Modelo de la Cinemática del Robot
Para la representación de un robot virtual se ha tomado la misma que
utiliza la toolbox, la cual esta basada en un robot que cuenta con dos ruedas motrices, además de una rueda loca en el frente, lo cual permite dos grados de libertad para la locomoción. Esto quiere decir que se necesita un modelo cinemático que permita una conducción diferencial, usando las velocidades de cada rueda y calcular así la velocidad rotacional y traslacional del robot.
Entonces para calcular la orientación y nueva posición del robot es
necesario definir un sistema de coordenadas usando la forma del robot. La orientación básica del robot se da con orientación a la cabecera (a la que llamaremos heading de aquí en adelante). En la posición inicial (que se aprecia en la figura 3.2) el heading será de O grados, y se incrementará si el robot gira a la izquierda y disminuirá si gira a la derecha.

53
Figura 3.2. Posición original del heading.
Ya que se conoce el sistema de coordenadas y que se necesitan las
velocidades de ambas llantas para calcular en la simulación la nueva posición del robot se especifica el modelo de la cinemática, el cual esta basado en las siguientes ecuaciones:
Donde: - VBx y VBy corresponden a la velocidad traslacional en unidades/s
del punto B (ver figura 3.3) que corresponde al centro del robot. - WBz corresponde a la velocidad rotacional del mismo punto B en
rad/s. - WW1 y WW2 corresponden a las velocidades de rotacion de las dos
ruedas en rad/s. - -la, lb y R corresponden a las proporciones del robot. En la figura
3.3 estas proporciones equivalen a 3, 0 y 1 unidades respectivamente.

54
Figura 3.3. Modelo del robot.
Esta ecuación corresponde al modelo cinemático directo con el cual se
obtienen a partir de las velocidades de rotacion de las dos ruedas la velocidad y orientación del punto B. Como se puede ver el valor de WBz se utiliza para determinar el heading del robot. La siguiente ecuación corresponde al modelo cinematico inverso, es decir, con esta se obtiene a partir de las velocidades del punto B las velocidades rotacionales de las ruedas.
La solución a la ecuación correspondiente al modelo cinemático directo y la cual se utiliza en este proyecto se ha modificado a partir de la función mmodel.m de la toolbox por lo que también se le ha asignado el mismo nombre. Esta función ha quedado como sigue:
void mmodel(float *xs, float *ys, float *rs, Robot *Bot) { float R, la, lb, conv, sps, vx, vy; R = 1; la = 3; lb = 0; sps = 1; conv = (Bot->heading[0] + 180)/57.3; vx = (R/(2*la))*(-lb*Bot->vel_der + lb*Bot->vel_izq); vy = (R/(2*la))*(-la*Bot->vel_der - la*Bot->vel_izq); *xs = (vx * cos(conv) + vy * cos(conv)) / sps; *ys = (vx * sin(conv) + vy * sin(conv)) / sps; *rs = ((R/(2*la))*(-(Bot->vel_der) + Bot->vel_izq)*57.3) / sps; }

55
Donde xs, ys, representan los valores que modificarán el centro del robot, mientras que rs representa el grado que ha girado. Es decir, estos valores se sumarán a los que ya tiene el centro robot para así obtener su nueva posición en el entorno virtual. Con respecto al entorno virtual y la forma de representar el robot en este, así como los métodos para simular el movimiento se hablará mas adelante.
El parámetro Bot de tipo robot es un objeto que contiene todos los
datos del robot cuya nueva posición se esta calculando. Como se puede ver en el código, Bot contiene los valores de la velocidad en la rueda izquierda, rueda derecha y el heading, entre otros.
Los valores de R, la y lb, como ya se menciono corresponden a las
proporciones del robot. Es pertinente mencionar que si se desea modificar la forma del robot será necesario modificar también las formulas par el modelo cinemático y de hacerlo, se debe también considerar que dichos cambios sean consistentes.
Por ultimo, los valores de vx y vy son las velocidades traslacionales del
punto B necesarias para calcular los valores de xs y ys, que se calculan con la ecuación del modelo cinemático directo. También rs se calcula con la misma ecuación.
El modelo permite que el punto B y su heading que determinan la
posición del robot se puedan desplazar en cualquier dirección y trazar cualquier trayectoria si las velocidades son las adecuadas. Para llamar a la función en la toolbox los parámetros necesarios para simular el movimiento son los de las velocidades de las ruedas. Para ejemplificar el funcionamiento básico del modelo consideremos el par de velocidades (VI, VD), y los valores que se le pueden asignar a VI y VD sean -1, 0, 1. En la siguiente tabla se muestran los pares de entradas posibles con estos valores y los movimientos resultantes.
VI VD Movimiento resultante -1 -1 En línea recta hacia atrás -1 0 Giro hacia atrás (eje de rotación centro de la rueda derecha) 0 -1 Giro hacia atrás (eje de rotación centro de la rueda izquierda) 0 0 Alto total 0 1 Giro hacia delante (eje de rotación centro de la rueda izquierda) 1 0 Giro hacia delante (eje de rotación centro de la rueda derecha) 1 1 En línea recta hacia el frente -1 1 Giro (eje de rotación centro del robot) 1 -1 Giro (eje de rotación centro del robot) Tabla 3.1: Movimientos del robot de acuerdo a las velocidades de las llantas.

56
Percepción
La principal característica del robot para desenvolverse en el entorno es
la de poder obtener datos del mismo para poder realizar la acción que requiere llevar a cabo. Los datos que necesita conocer son la proximidad de los objetos que lo rodean e identificarlos ya sea como objetos a recolectar, obstáculos u otros robots para poder tomar una decisión. En la práctica, los datos necesarios para poder calcular estas proximidades se obtienen a través de sensores que, como ya se planteo anteriormente, para este proyecto son del tipo ultrasónico.
Los sensores ultrasónicos (también conocidos como sensores de sonar)
están basados en sonidos que son iguales a los que el oído humano percibe, con la diferencia de que estos son emitidos en una frecuencia mucho mayor que la necesaria para ser audible al ser humano. El rango de frecuencia en que el oído humano puede percibir sonidos oscila entre los 16 y los 20 khz. La mayoría de los sensores ultrasónicos industriales utilizan una frecuencia igual o un poco superior a los 40 khz.
El funcionamiento básico de los ultrasonidos como medidores de
distancia se muestra en el siguiente esquema, donde se tiene un receptor que emite un pulso de ultrasonido que rebota sobre un determinado objeto y la reflexión de ese pulso es detectada por un receptor de ultrasonidos.
Figura 3.4. Esquema del sensor sónico.
Para calcular la distancia a la que se encuentra un objeto se mide el
tiempo que transcurre entre la emisión del sonido y la percepción del eco. La formula que se utiliza para calcular esta distancia es:
Donde V es la velocidad del sonido en el aire y t es el tiempo transcurrido entre la emisión y recepción del pulso ultrasónico.

57
Puesto que en este proyecto se esta haciendo una simulación, el proceso de emisión de ultrasonidos al ser modelado para nuestro robot resulta mas sencillo que en la realidad, ya que el interés principal aquí radica en como obtener datos rápidamente del entorno del robot, pero en la practica si hay que considerar lo que se menciono al respecto de la formula mencionada.
La mayoría de los sensores de ultrasonido de bajo costo se basan en la
emisión de un pulso de ultrasonido cuyo campo de acción es de forma cónica como se puede ver en la figura 3.5. Esta señal puede ser representada por el arco de una circunferencia a diferentes distancias. Para la simulación se utiliza el algoritmo de Bresenham, el cual es comúnmente usado para la representación grafica de líneas, elipses, circunferencias, entre otros.
Figura 3.5. Representación de la señal de un sensor.
El Algoritmo de Bresenham
Bresenham ideó un algoritmo para dibujar círculos en graficadores cuya
resolución es cuadrada, lo que implica un problema pues los círculos no son exactos. Para acercarse lo más exacto posible en la representación de un círculo en estos graficadores, Bresenham consideró un círculo como un conjunto de puntos representados por píxeles que se encuentran, en su totalidad a una distancia "r" de una posición central (Xcentral, YCentral). Como sabemos, esta relación de distancia se expresa por medio del Teorema de Pitágoras en coordenadas cartesianas con la siguiente ecuación:
(X-Xcentral) ² + (Y-Ycentral) ² = r ²
El problema principal radica en determinar el píxel a iluminar, es decir, se debe determinar el punto más cercano a la trayectoria de la circunferencia. Para resolver el problema consideró lo que conoce como punto medio (este algoritmo también se conoce como el del punto medio), para el cual es necesario trabajar la ecuación de la circunferencia de la siguiente forma:
f(X, Y) = X ² + Y ² - r ²

58
Donde cualquier punto (X, Y) en la frontera de la circunferencia con radio r satisface la ecuación f(X, Y) = 0. Si el punto se encuentra dentro de la circunferencia, se dice que la función es negativa, si se encuentra en el exterior, es positiva, tal como se muestra a continuación:
< 0, si (x, y) está dentro de la frontera f (x, y) = = 0, si (x, y) está en la frontera
> 0, si (x, y) está afuera de la frontera
El Algoritmo del Punto Medio retoma el comportamiento de cada punto evaluado en la función, y realiza pruebas, entre los píxeles cercanos a la trayectoria en cada punto evaluado. De esta forma la función se convierte en el parámetro de decisión, que permite identificar el píxel a iluminar. Esto lo hace utilizando adiciones y sustracciones de enteros, tomando en cuenta que los parámetros de la circunferencia se especifican en coordenadas enteras del graficador.
La figura 3.6 muestra el punto medio entre los dos píxeles candidatos en la posición de muestreo Xk + 1. Suponiendo que acabamos de trazar el píxel en (xk, yk) en seguida necesitamos determinar si el píxel en la posición (xk +1, yk) o aquel en la posición (xk +1, yk-1) está más cerca de la circunferencia. Nuestro parámetro de decisión es la función de circunferencia evaluada en el punto medio entre estos dos píxel: .
Figura 3.6. Punto medio
Considerando esto los pasos del algoritmo se pueden resumir en los
siguientes pasos:
1. Se capturan el radio r y el centro de la circunferencia (xc, yc) y se obtiene el primer punto de una circunferencia centrada en el origen como (x0, y0) = (0, r).

59
2. Se calcula el valor inicial del parámetro de decisión como p0=5/4—r , que no es más que la forma simplificada de la función de la circunferencia al evaluar el punto (0, r).
3. En cada Xk posición, al iniciar en k = 0, se realiza la prueba siguiente. Si pk < 0, el siguiente punto a lo largo de la circunferencia centrada en (0, 0)
es (xk+1, yk) y . De otro modo, el siguiente punto a lo largo de la circunferencia es (xk+1, yk-1) y
donde 2xk+1 = 2xk +2 y 2yk+1 = 2yk +2
4. Dado que este algoritmo solo sirve para dibujar los píxeles de un octante, se tienen que determinar los puntos de simetría en los otros siete octantes, lo que realmente es sencillo solo aplicando sumas y restas, solo teniendo cuidado como lo maneja la plataforma en que se programe.
5. Se mueve cada posición de píxel calculada (x, y) a la trayectoria circular centrada en (xc, yc) y trazamos los valores de las coordenadas: x = x + xc; y =y + yc
6. Se repiten los pasos 3 a 5 hasta que x >= y.
A partir de este algoritmo que también es utilizado por la toolbox, se pueden simular los sensores ultrasónicos usando una variación para explorar muchos arcos continuos a partir del punto donde se localice el sensor. El Sistema de Percepción
Tomando en cuenta que los sensores serán capaces de reconocer
obstáculos, objetos a recolectar y otros robots, el sistema de percepción se ha diseñado con las siguientes reglas y características:
Sea R el rango de emisión del pulso ultrasónico. Sea r el radio explorado a partir de la posición del sensor en el robot, su
valor inicial es 0 y se incrementara como máximo hasta R. Sea Arc la amplitud del pulso ultrasónico medida en radianes. Sea Angulo la posición del sensor con respecto al sistema de
coordenadas. Sean Angini y Angfin los ángulos donde se inicia y termina el arco y que
es determinado por Arc, por lo tanto Angini = Angulo - Arc/2 y Angfin = Angulo + Arc/2.
Sea T el tipo de objeto encontrado, si su valor es 0 indicara que no hay objeto detectado, si es 1 que hay un obstáculo fijo u otro robot, 2 si se ha detectado un objeto a recolectar .

60
1. Se explorará, en vez de dibujar, con el algoritmo de Bresenham, los puntos que conforman un arco de radio r de amplitud Arc, que inicia en Angini y termina en Angfin.
2. Si al ir explorando el arco de la circunferencia se encuentra con algún objeto, entonces la exploración se detendrá y se identificara que tipo de objeto detuvo la exploración asignando a T un valor diferente de 0 y entonces el valor actual de r es la distancia a la que se encuentra.
3. En caso de no encontrar obstáculo u objeto al terminar la exploración de la amplitud Arc, el robot explorara el siguiente radio, es decir, el valor de r siguiente aumentado en la unidad de medida seleccionada.
4. En caso de no encontrar ningún obstáculo u objeto al explorar todos los valores de r posibles hasta R, entonces T no modificara su valor de 0 indicando que no se detecto nada.
Para concluir con la sección de percepción es necesario hacer una
aclaración: al implementar el algoritmo de Bresenham en la aplicación final se considero modificarlo debido a que dicho algoritmo, a pesar de ser efectivo en la exploración de las zonas indicadas por el rango del sensor, hace muchos cálculos para definir cual es el mejor punto a explorar, lo que ocasionaba que dicha exploración fuera muy lenta.
A fin de cuentas si se decidió modificar el algoritmo de exploración de
Bresenham aunque la información con respecto a el mismo se ha dejado como referencia. En cuanto a los pasos del sistema de percepción se implementó tal como se ha descrito, solo se ha cambiado la forma en como se decide que punto explorar para acelerar el proceso. La modificación del algoritmo de Bresenham para dibujar un arco es la siguiente:
1. Se guardaran los datos Angini y Angfin, r, y xs y xy que son los puntos del centro de la circunferencia que corresponden al arco a dibujar.
2. Sea una variable Aux = Angini.
3. Sean x y y los puntos para definir el punto (x,y) que se va a dibujar.
4. Para calcular los puntos (x,y) se utilizan las siguientes formulas: x = xs +
r*cos(Aux) y y = ys +r*sin(ini)
5. Se dibuja el punto (x,y).
6. Se incrementa el valor de Aux en un tamaño razonable
7. Se repiten los punto 3 a 6 hasta que Aux = Angfin.

61
La Red Neuronal Implementada
Una de las cuestiones a considerar en esta parte corresponde a la
diferenciación de situaciones a las que se pueda enfrentar el robot cuando esta explorando, las cuales son encontrarse con un obstáculo, con otro robot o encontrar un objeto a recolectar. En el caso de los obstáculos y de otros robots, estos dos tipos de objetos se consideran como elementos que se tienen que esquivar o bordear. Para el caso de un objeto a recolectar el robot se tendrá que dirigir hacia dicho objeto y recolectarlo y después regresar a su lugar de origen. A tal efecto de diferenciar las diferentes tareas cuando el robot esta explorando se han implementado métodos específicos para cada función y se han nombrado diferentes estados que se irán nombrando en su momento. La red neuronal se encargara de decidir la dirección del robot cuando este explorando (por lo que el estado que maneja la red se conocerá como estado de EXPLORACION) mientras que para las tareas de recolección y de regreso a su lugar de origen los métodos empleados se verán mas adelante.
El siguiente paso para la construcción de la simulación ahora que se ha
descrito el sistema de percepción consiste en determinar cuantos sensores y en que posiciones se van a colocar en el robot. Remitiéndonos a lo visto en el capitulo 2 del presente reporte se decidió colocar cuatro sensores con las mismas características tal como se puede ver en la siguiente figura.
Figura 3.7. Ubicación de los sensores en el robot
Análogamente a la red del capitulo 2 se implemento una red con 4
entradas correspondientes a los sensores y un sesgo, para tener un vector de entradas de 5 datos. La diferencia de esta red con la del capitulo 2 radica en las salidas. Como se vio en la sección donde se explica la Toolbox, el robot se mueve con dos ruedas motrices. En consecuencia, de acuerdo al modelo cinemático directo es necesario conocer las velocidades de dichas ruedas, por lo que se decidió que la red se encargara de encontrar esos datos asignándole dos neuronas como salida (ver figura 3.8).

62
Figura 3.8. Red neuronal implementada en la simulación
Las características tomadas de la toolbox permiten al robot hacer
desplazamientos hacia delante y hacia atrás, así como variar la velocidad del robot. En pruebas de la simulación se pudieron observar varios inconvenientes relacionados con la velocidad del robot, por lo que se decidió establecer un rango de velocidades que pudiera ser controlado por el usuario. En consecuencia se tuvo que cambiar la representación de las salidas de la que en un principio eran las velocidades de cada rueda.
El esquema final consiste en solo indicar cual rueda esta funcionando y
cual no. Para esto se eligió una representación binaria que simplificó el entrenamiento de la red, pues solo se tienen 4 salidas posibles para 16 posibles entradas. Los pares correspondientes a las entradas y salidas se pueden ver en las primeras columnas de la tabla 3.2, recordando que estos datos solo contienen entradas en las que solo se han detectado obstáculos u otros robots.
Entradas Si ind = 0 Si ind = 1
EF ED EI EA Sesgo SI SD SI SA
0 0 0 0 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 1 0 1 1 1 1 1
0 0 1 1 1 1 1 1 1 0 1 0 0 1 1 1 1 1 0 1 0 1 1 1 1 1 1
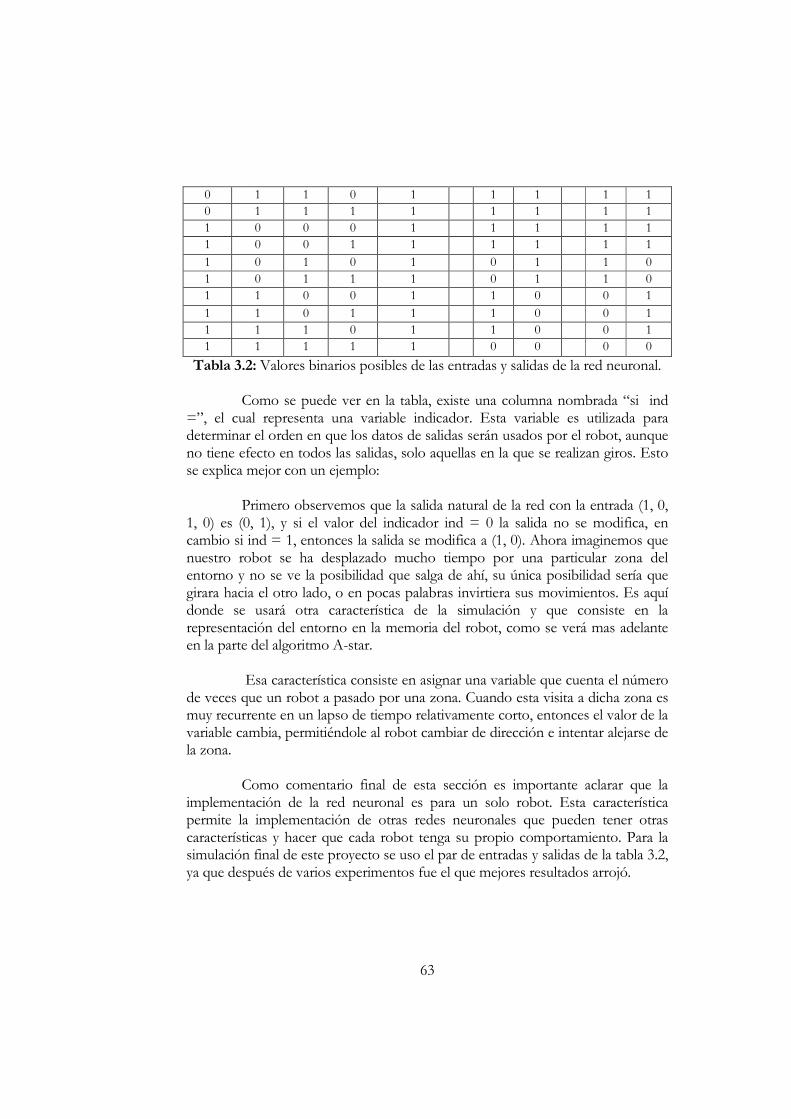
63
0 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 1 1 1 1 1 1
1 0 1 0 1 0 1 1 0 1 0 1 1 1 0 1 1 0 1 1 0 0 1 1 0 0 1
1 1 0 1 1 1 0 0 1 1 1 1 0 1 1 0 0 1 1 1 1 1 1 0 0 0 0
Tabla 3.2: Valores binarios posibles de las entradas y salidas de la red neuronal.
Como se puede ver en la tabla, existe una columna nombrada “si ind =”, el cual representa una variable indicador. Esta variable es utilizada para determinar el orden en que los datos de salidas serán usados por el robot, aunque no tiene efecto en todos las salidas, solo aquellas en la que se realizan giros. Esto se explica mejor con un ejemplo:
Primero observemos que la salida natural de la red con la entrada (1, 0,
1, 0) es (0, 1), y si el valor del indicador ind = 0 la salida no se modifica, en cambio si ind = 1, entonces la salida se modifica a (1, 0). Ahora imaginemos que nuestro robot se ha desplazado mucho tiempo por una particular zona del entorno y no se ve la posibilidad que salga de ahí, su única posibilidad sería que girara hacia el otro lado, o en pocas palabras invirtiera sus movimientos. Es aquí donde se usará otra característica de la simulación y que consiste en la representación del entorno en la memoria del robot, como se verá mas adelante en la parte del algoritmo A-star.
Esa característica consiste en asignar una variable que cuenta el número
de veces que un robot a pasado por una zona. Cuando esta visita a dicha zona es muy recurrente en un lapso de tiempo relativamente corto, entonces el valor de la variable cambia, permitiéndole al robot cambiar de dirección e intentar alejarse de la zona.
Como comentario final de esta sección es importante aclarar que la
implementación de la red neuronal es para un solo robot. Esta característica permite la implementación de otras redes neuronales que pueden tener otras características y hacer que cada robot tenga su propio comportamiento. Para la simulación final de este proyecto se uso el par de entradas y salidas de la tabla 3.2, ya que después de varios experimentos fue el que mejores resultados arrojó.

64
La Tarea de Recolección
Como se ha mencionado a lo largo del capítulo, la principal función del
robot es recolectar objetos. Ya se ha especificado como es que el robot decide hacia donde se desplaza explorando por el entorno y como funcionan sus sensores, lo que sigue es especificar como el robot realiza la tarea de recolección una vez que ha encontrado un objeto.
Cuando un robot en estado de exploración, detecta un objeto a
recolectar, suprime su labor de explorar y se prepara para dirigirse a la zona donde se encuentra dicho objeto. La información que obtiene por parte del sensor es el tipo del objeto (en este caso uno a recolectar) y la posición (x, y) de dicho objeto. Con esta información el robot se posiciona, en caso de ser necesario, con un giro hasta que su heading “apunte” hacia el objeto. Una vez posicionado se desplaza en línea recta hasta ocupar la posición del objeto.
En la simulación cuando un objeto a recolectar y un robot ocupan un
mismo espacio o región, se considera que el objeto ha sido recolectado y este último desaparece del entorno virtual y el robot continua la función de recolección cambiando a un estado de retorno a su lugar de origen que supone el depósito de objetos recolectados. Para la labor de recolección se han considerado dos estados importantes que son el estado GIRO y el estado AVANCE. El Sistema de Recolección
Sea un robot que se encuentra en estado de EXPLORACION y detecta
un objeto. Entonces contamos con la posición (x, y) del objeto. Los pasos a seguir para la recolección son los siguientes:
1. Con la posición (x, y) se calcula el ángulo ANG con respecto al centro del robot con funciones trigonométricas.
2. Se cambia al estado GIRO que consiste en cambiar las velocidades de las ruedas del robot de forma que este de un giro sobre su eje (dar una velocidad positiva a la rueda izquierda y una positiva a la derecha, o viceversa). El estado GIRO finaliza cuando el valor del heading y el de ANG sean iguales. Se cambia al estado avance.
3. El estado AVANCE consiste en poner la misma velocidad en ambas ruedas del robot. Este estado finaliza cuando el robot ha llegado a una distancia razonable del punto (x, y)
4. Se elimina el objeto del entorno virtual y se pasa al estado de RETORNO. Dicho estado se explicará en la siguiente sección del capítulo.

65
La Memoria del Robot y el Algoritmo A-Star
Una de las necesidades prioritarias que se intentó resolver en la
implementación de la simulación es conseguir que los robots se desplacen desde un punto del escenario hasta otro evitando los obstáculos, objetos y otros robots presentes. Y claro, siempre buscando la ruta mas corta.
En este proyecto se han considerado los siguientes puntos:
- Todos o cada uno de los robots tiene un punto de origen, al que
llamaremos nicho. - El nicho del robot es el lugar donde este depositará (uno a la vez)
los objetos que encuentre en el escenario. - Al partir del nicho cada robot solo explorará el escenario, sin llevar
una ruta en específico, para buscar objetos a recolectar. - Una vez que el robot ha encontrado un objeto, este es recolectado y
llevado al nicho, para que una vez que este haya depositado el objeto, inicie de nuevo la exploración del entorno en la búsqueda de mas objetos.
Como se puede notar en los puntos que se acaban de mencionar la
necesidad en la implementación consiste en que un robot, una vez que ha encontrado un objeto, pueda regresar por la ruta mas corta posible. Cabe mencionar que se ha considerado que el robot no conoce, en el inicio, nada de su entorno, por lo que en la implementación solo se ha considerado que el robot solo encontrará buenas rutas de regreso a su nicho analizando el entorno reconocido por el mismo en anteriores exploraciones. Para esta simulación la rapidez y eficacia con que un robot pueda regresar a su nicho se vuelve algo imprescindible y además tomando en cuenta que puede haber muchos más robots es necesario un método rápido y eficiente.
El algoritmo que se eligió es el conocido A-star, el algoritmo de
búsqueda de caminos mas documentado y utilizado en este tipo de problemas y también muy popular en la programación de videojuegos. A continuación se explicara brevemente como funciona A-star, las modificaciones que se hicieron de este para el proyecto y como se implementó el regreso al nicho del robot.

66
Consideremos un grafo bi-dirigido con cierta cantidad de nodos, donde cada uno de estos esta conectado con otros por medio de las aristas o caminos. Supongamos que queremos ir de un nodo (origen) a otro (destino), para lo cual se tendrá que ir “saltando” de nodo en nodo hasta llegar al nodo destino. Como se puede ver en la siguiente imagen, se pueden encontrar muchas rutas por las cuales se puede llegar del nodo A al nodo B, pero lo importante del algoritmo es encontrar una ruta lo mas optima posible, es decir, la ruta más corta.
Figura 3.9. Grafo de caminos posibles.
Como se puede notar en la figura la ruta mas corta entre A y B es
saltando de A a h, luego de h a i y finalmente de i a B. Esa es la ruta que el algoritmo A-star se encargará de encontrar, y para esto tiene que conocer las distancias entre todos los puntos. En ocasiones conocer la distancia entre los puntos no es suficiente para encontrar una ruta óptima, por lo que en ocasiones es necesario contar con una función de aptitud de esa ruta que nos indique si es conveniente. Sin embargo para nuestro propósito es suficiente conocer las distancias. Ahora vamos a explicar como es que hace esto nuestro algoritmo Representación del Entorno en la Memoria del Robot
Originalmente lo que se hace comúnmente para el algoritmo A-star es
construir una maya o rejilla que nos represente todo el mundo, de modo que los nodos se pueden representar como zonas cuadradas. De esta forma quedan conectados entre sí y se puede considerar de dos formas con respecto a los nodos que los rodean, es decir, el vecindario de Moore puede ser de 4 o de 9 vecinos como se nota en las figuras.
Figura 3.10. Representación del mundo recorrido mediante una rejilla.

67
Esto se hace normalmente en juegos donde ya está predeterminado un escenario o un entorno que en realidad ya es conocido por los entes o vehículos que en él se desarrollan. En nuestra simulación, aunque en realidad el mundo o entorno ya esta predeterminado suponemos que el robot no conoce su entorno, por lo que cada uno de los robots que cohabiten en el mundo tendrá que ir construyendo (en su memoria) un mapa que represente las zonas ya exploradas en sus recorridos.
Para esto se ha utilizado una lista que va creciendo conforme el robot va
reconociendo el mundo, y en la cual se manejan los siguientes datos:
- Coordenadas (solo se toman en cuentan las correspondientes a “X” y “Y”)
- El primer nodo contiene la posición del nicho u origen del robot. - Cada nodo puede tener muchos hijos, es decir, se comunica con
otros nodos. - Cada nodo tiene un numero que lo identifica (in incrementum). - Cada nodo cuenta con un radio de acción, que es determinado por
la distancia recorrida por el robot o su proximidad a los obstáculos. Veamos la siguiente figura que representa el recorrido de un robot. Se
ha tomado como referencia un plano donde el punto (0,0) corresponde a el nicho del robot (en verde). El valor de R, o radio de libertad en este ejemplo lo consideraremos como 5.
Figura 3.11. Representación gráfica de los nodos del recorrido del robot.

68
La forma en como el robot va guardando los datos del entorno funciona
de la siguiente manera:
1. Al inicio se crea la lista con un único nodo, en el cual se ponen las coordenadas del origen o nicho, y este nodo se considera el numero 1 y el radio de acción inicial es de 5 (en este ejemplo) ya que no existen otros obstáculos.
2. El robot toma los datos del nodo actual como su radio de acción. 3. En cuanto el robot empieza avanzar va calculando la distancia a la que
está del último nodo que visitó (en este caso el origen) con respecto a su centro en su posición actual.
4. Si la distancia es igual o mayor al radio de acción que tenia el nodo anterior entonces se verifica si no hay otro nodo que tenga esas coordenadas, es decir, que tomando en cuenta el centro del área de acción de los demás nodos se calcula si la posición actual del robot cae en el radio de acción de otro nodo.
5. Si ya existe un nodo que abarque ese campo de acción, se agrega a la lista de nodos hijos del nodo actual, y viceversa.
6. Si no existe un nodo que abarque ese campo de acción se crea uno nuevo y también se agrega a lista de hijos del nodo actual y viceversa.
7. Finalmente se cambian los datos del nodo actual por los datos del nodo en donde el robot se encuentra.
Otra función agregada que corresponde a este método y que es usado
por la salida de la red, consiste en contar la cantidad de veces que el robot visita un lugar, es decir, mientras no se agregue un nuevo nodo la variable encargada de este valor se incrementara, y como ya vimos en la parte de la red neuronal, esto puede tener repercusiones en el comportamiento del robot.
Todo esto se va haciendo mientras el robot se encuentra en estado de
exploración, es decir, esta buscando objetos que recolectar. Una vez que el robot ha encontrado un objeto a recolectar y lo ha recogido del mundo, este se dispone a regresar a su nicho para almacenar dicho objeto. Es aquí donde entra el algoritmo A-star, para encontrar la ruta optima para regresar lo mas rápido posible. Implementación de A-Star
La idea general para implementar A-star consiste en usar la lista que nos
describe el mundo en la memoria del robot, y a partir de esta buscará una ruta, que también es almacenada en otra lista auxiliar, pero esta última solo tendrá las coordenadas que debe de visitar el robot para regresar.

69
Esto ha dado como resultado una variación al algoritmo general de A-Star que a continuación se describe:
Sea el nodo S el nodo inicial, es decir la posición del robot después de
recolectar el objeto y G el nodo meta. También tendremos un nodo auxiliar al que llamaremos nodo_actual. Se tienen las siguientes funciones para el manejo de las listas:
a) novacia(L), que nos indica si la lista L es vacía o no. b) Prim(L), que copia el primer nodo de la lista L c) Resto(L), que elimina el primer nodo de la lista L haciendo L el
resto de la lista. d) Hijos(nodo), la cual busca los hijos del nodo, recordemos que
tenemos una lista en la memoria del robot, y de esta es donde se usa.
e) c(nodo), esta función nos devuelve el costo del recorrido entre el nodo inicial y el que nos interesa llegar, es decir el total de la distancia recorrida.
f) AgregarO(L, nodo), agrega ordenadamente a la lista L el nodo, el criterio es el costo.
g) Agregar(L, nodo), agrega al final de la lista L el nodo
1. Sea la lista A = S, y se crea una lista vacía C. 2. Mientras (novacia(A)) 3. nodo_actual = Prim(A), A =Resto(A) 4. Si nodo_actual = G entonces se termina el Mientras con éxito. 5. Se crea una lista auxiliar L = Hijos del nodo actual. 6. Para n de la lista L hacer 7. Se calcula el costo c(n) de la distancia del nodo origen al nodo n 8. Si existe una copia de n en A y su costo es menor entonces eliminar y
continuar al siguiente hijo. 9. Si existe una copia de n en C y su costo es menor entonces eliminar y
continuar al siguiente hijo. 10. Remover todas las copias de n en A y C. 11. Asignar el padre de n al nodo_actual 12. AgregarO(A, (n)) 13. Termina el Para 14. Agregar(C, (nodo_actual)) 15. Se regresa la lista C que es la lista de la mejor ruta a seguir.

70
El Sistema de Retorno
Ahora que ya se explicado de que forma el robot crea su mapa del
mundo virtual y como se ejecuta el algoritmo A-star, se explicará el procedimiento del estado de RETORNO implementado.
Sea un robot que ha recolectado un objeto en la posición (x, y) del
entorno y se dispone a regresar a depositarlo a su nicho, por lo que cambia su estado actual a RETORNO. Dicho robot también cuenta con un mapa virtual del entorno que ha visitado al que llamaremos Lista_nodos. Los pasos para este procedimiento son:
1. Se llama al algoritmo A-star para obtener la lista de la mejor ruta de retorno Lista_ruta.
2. Se toman los datos (x, y) del primer nodo de Lista_ruta y se elimina ese
primer nodo.
3. Con la posición (x, y) se ejecutan los pasos 1 a 3 descritos en el sistema de recolección.
4. Se ejecutan los pasos 2 y 3 mientras Lista_ruta tenga elementos.
5. Una vez que el robot haya llegado a su lugar de origen cambia su estado
a EXPLORACION.

71
C a p í t u l o I V
COMUNICACIÓN ENTRE ROBOTS
Presentación:
En este capítulo nos concentraremos en el como se logró la interacción de los robots en un mundo virtual generado por un programa servidor al cual llamaremos programa monitor de actividades.
En primera instancia, lo que se debe de saber es que el simulador original
contempla solo un robot en un ambiente de recolección de objetos, es decir, el simulador está diseñado para enviar información con respecto al entorno a los censores del robot para que este pueda realizar la tarea adecuada de acuerdo a lo que el sensor le da. La información que el simulador le da a los censores del robot es, por ejemplo, si existe un objeto a recolectar o si es un obstáculo a esquivar.
Para realizar las menores modificaciones posibles al programa simulador
original, se observó que creando al programa monitor de actividades, sólo había que insertar en el simulador a los demás robots tan solo como un obstáculo dinámico.
Antes de Implementar:
Antes de revisar como se realizó la implementación de este monitor de actividades, se necesita hablar un poco de redes y de los mecanismos IPC del sistema UNIX 4.3 BSD.
La interfaz de comunicación entre procesos del sistema 4.3BSD permitirá
comunicar procesos que se estén ejecutando bajo el control de la misma máquina o bajo el control de máquinas distintas. En el segundo caso, es necesario que entren en juego redes de conexión entre ordenadores.
Siempre que se habla de una red de ordenadores hay que distinguir entre
protocolos y servicios de la red. En realidad, un estudio exhaustivo de las redes debe empezar por el modelo de referencia OSI. Este es un modelo que estructura en siete capas los diferentes elementos que intervienen en las comunicaciones. Cada una de las capas ofrece una serie de servicios a la capa superior y utiliza los servicios que le brinda la capa inferior. Los servicios de una capa pueden verse como una interfaz de comunicación con la misma. Los protocolos, por su parte, definen la forma que van a tener las tramas de bits que se intercambian las distintas capas y cómo se va a llevar a cabo esa comunicación. El objetivo que se

72
persigue al separar protocolos de servicios es aislar los aspectos tecnológicos de los aspectos de uso de una red. Así, se procura definir servicios lo menos cambiantes posible con objeto de que los usuarios no tengan que estar modificando sus aplicaciones continuamente. Por otro lado, las mejoras en las tecnologías de las redes van a repercutir en diseño de protocolos que garanticen una transmisión más fiable, segura y rápida. Esto va a complicar los protocolos, pero no los servicios.
Figura 4.1. Modelo de Referencia OSI.
Las siete capas que propone el modelo de referencia OSI son:
1. Capa física. Se encarga de la transmisión de bits a lo largo de un canal de
comunicación. 2. Capa de enlace. La tarea principal de la capa de enlace consiste en
transformar el medio de transmisión, que va a ser ruidoso, en una línea sin errores, y por lo tanto fiable, para la capa de red (capa inmediatamente superior a esta en la jerarquía).
3. Capa de red. Se ocupa de la obtención de paquetes procedentes de la
fuente y de encaminarlos por la red y las subredes hasta alcanzar su destino.
4. Capa de transporte. La función principal de la capa de transporte
consiste en aceptar los datos de la capa de sesión, dividirlos, siempre que sea necesario, en unidades más pequeñas, pasarlos por la capa de red y asegurar que todos ellos lleguen correctamente al otro extremo.

73
5. Capa de sesión. Permite que los usuarios de diferentes máquinas puedan
establecer sesiones de trabajo en máquinas remotas. Un ejemplo de sesión consiste en acceder a un sistema remoto en tiempo compartido y conectarnos a trabajar con él, tal y como hacemos con nuestro sistema local (rlogin o telnet). Otro ejemplo puede ser transferir ficheros entre dos ordenadores (scp bajo Linux).
6. Capa de presentación. Se ocupa de los aspectos de sintaxis y semántica
de la información que se transmite. Un ejemplo típico de servicio de la capa de presentación es la codificación de los datos de acuerdo con unas normas. La información que un ordenador envía a otro ocupa unidades tales como caracteres, números enteros o números en coma flotante, y puede que en una red haya ordenadores que representen estas unidades de diferente forma. Por ejemplo, un ordenador envía un nombre codificado en caracteres ASCII mientras que el ordenador que lo recibe codifica los caracteres en EBCDIC; la capa de presentación se va a encargar de realizar los cambios necesarios de ASCII a EBCDIC para que el nombre recibido sea inteligible y no una secuencia de símbolos sin significado.
7. Capa de aplicación. La capa de aplicación contiene una variedad de
protocolos que se necesitan frecuentemente. Un problema típico a resolver en esta capa es la compatibilización de los distintos terminales que hay en el mercado, con objeto de que los programas de aplicación no tengan que preocuparse de conocer las características hardware de los mismos.
La interfaz con la red que ofrece el sistema 4.3BSD corresponde al nivel 4
(capa de transporte) del modelo anterior. Así, dos programas que se comuniquen mediante conectores van a despreocuparse totalmente de aspectos tales como:
• Canal físico de comunicación, tipo de transmisión (analógica o digital), tipo de modificación (PSK, FSK,…). Corresponde a la capa física.
• Forma de codificar las señales para disminuir la probabilidad de error en
la transmisión. Corresponde a la capa de enlace.
• Nodos de la red por los que tienen que pasar las tramas de bits y gestión de las redes involucradas. Corresponde a la capa de red.

74
• Formar paquetes a partir de la información a transmitir y buscar una ruta que una el ordenador origen con el destino. Corresponde a la capa de transporte.
Protocolos y conexiones
La filosofía de la división por capas de un sistema es encapsular, dentro
de cada una de ellas, detalles que conciernen sólo a la capa, y presentársela al usuario como una caja negra con unas determinadas entradas y salidas, de tal forma que el usuario pueda trabajar con ella sin necesidad de conocer sus detalles de implementación.
La interfaz de acceso a la capa de transporte del sistema 4.3BSD no está
totalmente aislada de las capas inferiores, por lo que a la hora de trabajar con conectores es necesario conocer algunos detalles sobre esas capas. En concreto, a la hora de establecer una conexión, es necesario conocer la familia o dominio de la conexión y el tipo de conexión.
• Una familia agrupa a todos aquellos conectores que comparten
características comunes, tales como protocolos, convenios para formar direcciones de red, convenios para formar nombres, etc.
• El tipo de conexión indica el tipo de circuito que se va a establecer entre
los dos procesos que se están comunicando. El circuito puede ser virtual (orientado a conexión) o datagrama (no orientado a conexión). Para establecer un circuito virtual, se realiza una búsqueda de enlaces libres que unan los dos ordenadores a conectar. Es algo parecido a lo que hace la red telefónica conmutada para establecer una conexión entre dos teléfonos. Una vez establecida la conexión, se puede proceder al envío secuencial de los datos, ya que la conexión es permanente. Por el contrario, los datagramas no trabajan con conexiones permanentes. La transmisión por los datagramas es a nivel de paquetes, donde cada paquete puede seguir una ruta distinta y no se garantiza una recepción secuencial de la información.

75
Modelo cliente-servidor
El modelo cliente-servidor es el modelo estándar de ejecución de
aplicaciones en una red. Un servidor es un proceso que se está ejecutando en un nodo de la red y
que gestiona acceso a un determinado recurso. Un cliente es un proceso que se ejecuta en el mismo o en diferente nodo y que realiza peticiones al servidor. Las peticiones están originadas por la necesidad de acceder al recurso que gestiona el servidor.
Figura 4.2. Modelo Cliente-Servidor.
El servidor está continuamente esperando peticiones de servicio. Cuando
se produce una petición, el servidor despierta y atiende al cliente. Cuando el servicio concluye, el servidor vuelve al estado de espera. De acuerdo con la forma de prestar el servicio, podemos considerar dos tipos de servidores:
• Servidores interactivos. El servidor no sólo recoge la petición de servicio, sino que él mismo se encarga de atenderla. Esta forma de trabajo presenta un inconveniente: si el servidor es lento en atender a los clientes y hay una demanda de servicio muy elevada, se van a originar unos tiempos de espera muy grandes.
• Servidores concurrentes. El servidor recoge cada una de las peticiones
de servicio y crea otros procesos para que se encarguen de atenderlas. Este tipo de servidores sólo es aplicable en sistemas multiproceso, como es UNIX. La ventaja que tiene este tipo de servicio es que el servidor puede recoger peticiones a muy alta velocidad, porque está descargado de la tarea de atención al cliente. En aquellas aplicaciones donde los tiempos de servicio son variables, es recomendable implementar servidores del tipo concurrente. Este es el tipo de servidor que se implementó para el monitor de actividades de los robots, y además, puede llegar a ser usado con la comunicación para la implementación de los algoritmos de las sociedades artificiales.

76
Esquema genérico de un servidor y de un cliente Las acciones que debe llevar a cabo el programa servidor son las siguientes:
1. Abrir el canal de comunicaciones e informar a la red tanto de la dirección a la que responderá como de su disposición para aceptar peticiones de servicio.
2. Esperar a que un cliente le pida servicio en la dirección que el tiene
declarada.
3. Cuando recibe una petición de servicio, si es un servidor interactivo, atenderá al cliente. Los servidores interactivos se suelen implementar cuando la respuesta necesita el cliente es sencilla e implica poco tiempo de proceso. Si el servidor es concurrente, creará un proceso mediante fork para que le de servicio al cliente.
4. Volver al punto 2 para esperar nuevas peticiones de servicio.
El programa cliente, por su parte, llevará a cabo las siguientes acciones:
1. Abrir el canal de comunicaciones y conectarse a la dirección dada por el servidor. Naturalmente, esta dirección debe ser conocida por el cliente y responderá al esquema de generación de direcciones de la familia de conectores que se esté empleando.
2. Enviar al servidor un mensaje de petición de servicio y esperar hasta
recibir respuesta.
3. Cerrar el canal de comunicaciones y terminar la ejecución. Los Esquemas anteriores son aplicables de forma general, independientemente de la interfaz con la capa de transporte que empleen el servidor y el cliente. Si nos fijamos en los servicios del sistema 4.3BSD, la secuencia de llamadas al sistema que deben realizar ambos procesos va a depender del tipo de conexión que se establezca entre ellos.
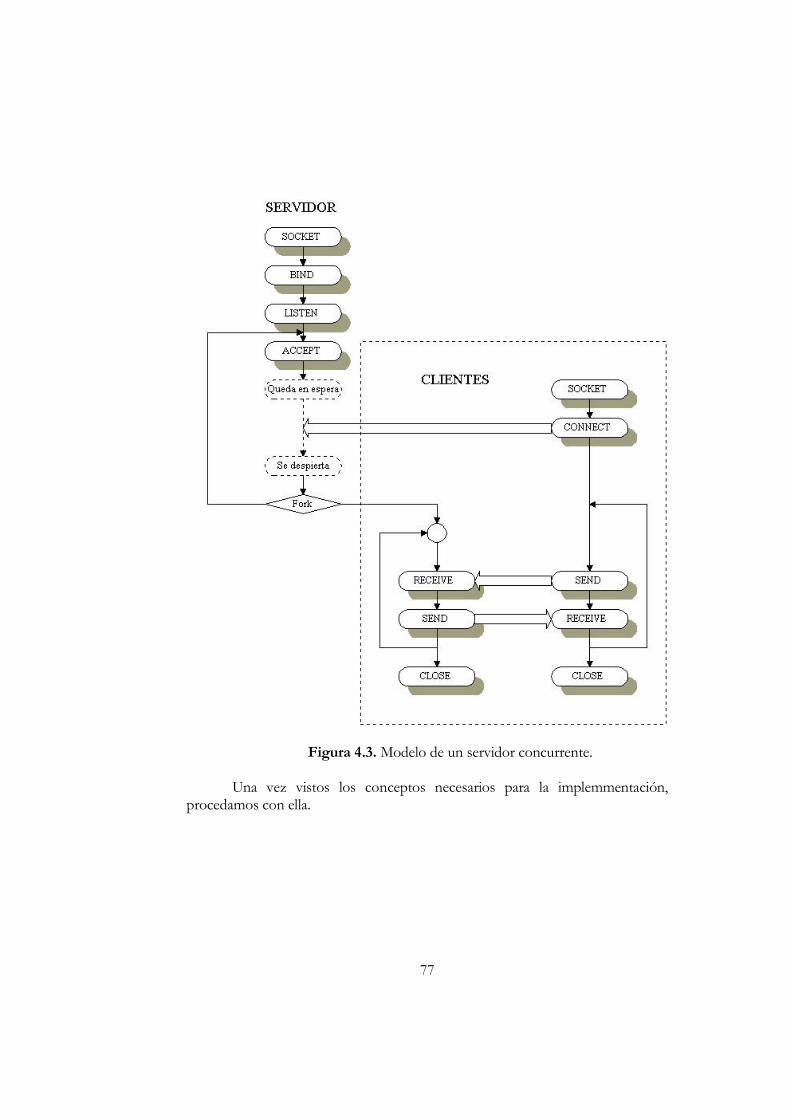
77
Figura 4.3. Modelo de un servidor concurrente.
Una vez vistos los conceptos necesarios para la implemmentación, procedamos con ella.

78
Implementación del Programa de Monitoreo de Actividades:
Vamos a entrar de lleno a como fue implementado el monitor de actividades del simulador de la sociedad artificial de robots recolectores.
Como ya se vio, el monitor de actividades se puede definir como un
servidor concurrente. El servicio proporcionado por este monitor, es el de la simulación del medio físico dinámico, es decir proporciona para cada simulador información de donde están situados los robots en cada instante, si un robot recolecta un objeto, este debe de proporcionar información a cerca de cual fue recolectado para que el simulador pueda actualizar esta información y evitar que su respectivo robot recoja un objeto previamente recolectado.
En este monitor de actividades, lo primero que se debe de hacer es pedir
información de cuantos robots se van a conectar, para poder implementar una barrera que permita esperar a que todos los robots estén listos, es decir, cuando un robot se conecta con el monitor de actividades, lo primero que hace es mandar sus coordenadas y esperar las coordenadas de los demás robots para poder así iniciar la simulación.
Como ya se vio, un servidor concurrente crea procesos con la instrucción
fork para que sean estos los que atiendan las peticiones y así poder seguir esperando más peticiones. Pero existe un pequeño problema para esto, si un robot actualiza sus coordenadas en uno de los procesos hijo, estas coordenadas no son actualizadas en el proceso padre del monitor de actividades, es decir, la instrucción fork, crea un proceso hijo que es una copia exacta del proceso padre pero este proceso hijo se crea con su propio espacio de direcciones de memoria y por ello cada variable del proceso hijo es completamente independiente de las variables del proceso padre.
Para resolver este problema, se implementó lo que es la memoria
compartida entre procesos en el programa monitor de actividades. Los datos que fueron compartidos entre los procesos del programa monitor son:
• Un arreglo de objetos que contiene la posición de cada robot que
existe en el mundo virtual. Este arreglo se comparte así por que el servicio de actualización de datos de los robots tiene que cambiar en el proceso hijo, ya que como ya se mencionó, cada vez que un robot se conecta con el monitor, lo primero que hace es actualizar su posición y luego espera la actualización de los otros robots.

79
• Un arreglo de objetos que contiene la información de en donde
se encuentra cada objeto que el robot recolecta. Este arreglo es compartido de esta manera, ya que, con cada conexión, además de actualizar su posición y esperar la posición de los demás robots, también dice si recolectó un objeto, y en caso de haber recolectado algún objeto, también dice que objeto fue recolectado para que este objeto se borre de la lista de objetos por recolectar, después se actualiza nuevamente el mundo en el monitor para que deje de existir ese objeto visualmente. Después de todo eso, un robot que no ha recolectado ningún objeto espera la nueva actualización de los objetos recolectados y así, el robot actualiza de la misma forma su lista de objetos recolectados y después actualiza su mundo para que el objeto recolectado sea borrado visualmente.
Con esto, el monitor de actividades, ya puede hacer la tarea de un
simulador de ambiente dinámico, ya que lo único que siempre va a cambiar en nuestra simulación es la posición de los robots en cada instante de la ejecución y si un objeto es recolectado, este debe de desaparecer tanto en el programa monitor, como en cada uno de los simuladores de un robot para que el objeto no sea recolectado 2 veces por distintos robots.

80
C a p i t u l o V
LA IMPLEMENTACIÓN DE LA SIMULACIÓN
El Algoritmo Principal.
Al integrar todos los sistemas descritos a lo largo del presente capitulo se
realizaron varias pruebas de las cuales se obtuvieron diversos resultados que derivaron en la necesidad de mejorar algunas características del sistema implementado, en consecuencia, se construyeron varias versiones. En su mayor parte los problemas que se suscitaron fueron resueltos satisfactoriamente, siendo el algoritmo que se describe en esta sección el que corresponde a la ultima versión del sistema.
La simulación consiste en la representación de un entorno virtual en
donde cohabitan varios robots diseñados para la recolección de objetos. El comportamiento del robot depende de varios sistemas que no son visibles desde el entorno, los cuales corresponden a lo que hemos llamado la memoria y percepción del robot. Son los sensores, la red neuronal y la lista de regiones conocidas del entorno. Estos sistemas fueron diseñados de manera separada pero con las características necesarias para trabajar integrados en un solo sistema y obtener un comportamiento determinado. Los comportamientos requeridos se han diferenciado en varios estados, los cuales son EXPLORACION, GIRO, AVANCE y RETORNO.
El lenguaje utilizado para la construcción de la simulación fue C++, y
aunque en este reporte no se incluye código fuente. El primer paso para la simulación consiste en crear el entorno virtual, el cual es una región cerrada el cual es un laberinto formado por muros en el que se encuentran varias esferas pequeñas que representan los objetos a recolectar. Lo concerniente a como se diseño este entorno virtual y se implemento la interfaz grafica se describe en el siguiente capitulo.
A continuación se describirá el algoritmo principal del sistema omitiendo
lo que respecta al entorno virtual, solo se hablara del comportamiento esperado de un robot, explicando brevemente la integración de los sistemas ya especificados (para mas información ver la sección correspondiente) e incluyendo los diferentes estados determinados. Los pasos del algoritmo son:

81
1.- Se crean los robots asignándoles sus respectivos valores. En la implementación esto se hace a través de archivos preeditados que contienen los datos necesarios, en los siguientes incisos se describe como se hace esto para cada un solo robot:
a) Se asigna la posición del robot en el entorno virtual y su dirección o
heading (el punto importante es el centro del robot el cual también indica el punto de recolección). El estado del robot es EXPLORACION.
b) a partir del centro del robot y su heading se obtienen los otros
puntos importantes del robot como son sus vértices, las posiciones de las ruedas, las posiciones de los sensores (sensor1, sensor2, sensor3, sensor4) y sus respectivos ángulos de dirección con respecto al centro del robot.
c) se crean las respectivas listas de nodos para la memoria del robot:
- Lista L, que contiene las respectivas zonas recorridas y las ligas con que se unen (es una lista que contiene “padres e hijos”, en términos de estructuras de datos es una lista de listas). Se crea con los valores correspondientes al centro del robot. también se crea un nodo de este tipo de lista como auxiliar en las operaciones que se necesitan y se llama nodo.
- Lista Ruta que se inicializa vacía y que se utiliza para crear la ruta de regreso una vez recolectado un objeto. Esta es una lista de nodos que contienen cada uno las coordenadas correspondientes a la ruta encontrada por A-star.
d) Se crean dos vectores correspondientes para las entradas y salidas
que usa la red neuronal. e) Se crean tres variables que son el indicador, visitas y bandera con un
valor de 0, las cuales son usadas por los sistemas de la red neuronal y la lista L del robot respectivamente. También se crea otra variable como auxiliar del heading cuando haya que dar un giro (haux) y dos variable x y y necesarias para identificar el centro de una región u objeto.
f) Con respecto a las velocidades de las ruedas están se obtienen al
inicializar la exploración del robot y sus valores corresponden a lo que los sensores detecten, aunque es conveniente inicializarlas en cero (que el robot este detenido).

82
2.- La simulación funcionará mientras no haya una señal del usuario que
le indique que se detenga. Esta simulación se hace paso a paso en un ciclo en el cual cada robot realiza sus respectivas tareas de acuerdo a los datos que obtiene del entorno. Hay sistemas que funcionan en cada ciclo y hay otros que solo se activan en ciertas condiciones. Por ejemplo los sensores siempre se encuentran activos en cada ciclo, en cambio el sistema de retorno solo se activa cuando el robot ha recolectado un objeto. La siguiente descripción corresponde a lo que puede hacer un robot en un solo paso, considerando los estados ya mencionados en las secciones anteriores:
2.1.- Se obtienen los datos de los sensores y se asignan a su respectiva
posición en el vector de entrada. Esto se hace usando la función ssonic la cual “escanea“ la zona respectiva y devuelve el identificador respectivo a lo que detecto. Para efectos de esta explicación definiremos los tres tipos de objetos con los siguientes nombres:
- OBS para obstáculos (pueden ser paredes u otros robots) - REC para los objetos a recolectar. - VAC para indicar que no hay nada.
Haciendo alusión al tipo de sensor ultrasónico la función que devuelve
uno de estos tres valores se llamo ssonic, y para llenar el vector de entradas se llama de la siguiente forma:
entradas[0] = ssonic(sensor1); entradas[1] = ssonic(sensor2); entradas[2] = ssonic(sensor3); entradas[3] = ssonic(sensor4); 2.2.- La siguiente función que el robot siempre realiza corresponde al
sistema de conocimiento o memoria del entorno. Como ya se explico en la parte correspondiente consiste en ir llenando la lista L agregando nuevos nodos si la nueva zona no había sido explorada o asignando nuevas conexiones entre los nodos existentes con métodos de estructuras de datos.
Lo que es importante mencionar en este punto es la función
actualiza_mapa que se encarga de verificar si la actual posición del robot se encuentra dentro de alguna región ya considerada en la lista L, de ser así se incrementa el contador visitas, en caso contrario este contador se va a cero. El valor de ese contador se utiliza para cambiar el valor de indicador, el cual se usa para cambiar las salidas de la red como se vera mas adelante.

83
2.3.- Una vez obtenidos los datos del entorno y actualizado el mapa o memoria del robot pueden ocurrir los siguientes eventos relacionados con el estado del robot. Esto se hace con la función verifica_entradas. Si el estado del robot es:
a) EXPLORACION: Se revisan los valores de las entradas (iniciando por el índice 0 del vector
entradas). Si alguno de ellos tiene un valor REC, basta con detectar el primero en el
caso de que sea más de un objeto detectado, entonces se procede a:
- Calcular el valor del ángulo haux a girar con respecto al centro del robot
- Se asignan los valores respectivos (x,y) de la región a la que se tiene que ir.
- Se cambia el estado a GIRO. - Se regresa al paso 2.1, es decir se iniciara un nuevo ciclo para
este robot con el nuevo estado. En caso de no encontrar un objeto se procede a llamar a la red con la
función obten_salida usando el vector de entradas. Una vez obtenido el vector de salidas se llama a la función velocidades el cual utiliza el parámetro indicador para actualizar las velocidades de las ruedas como se explico en la parte de la red neuronal implementada y se procede a iniciar otro ciclo (paso 3.1) con el mismo estado EXPLORACION.
b) GIRO: Sabemos que este estado se usa para orientar al robot hacia una región del
entorno específica usando una dirección que corresponde al centro de una región donde se encuentra un objeto o a una perteneciente a la lista Ruta de regiones de retorno. En cualquier caso un giro se detiene hasta que se alcanza una razonable cercanía al ángulo haux y después se procede a avanzar. En el estado GIRO ocurre lo siguiente:
Si se alcanza una cercanía razonable al ángulo haux se detiene el robot
asignándole cero a las velocidades de ambas llantas y se cambia al estado AVANCE.
En caso contrario se asignan velocidades de giro como ya se explico y se
procede a iniciar un nuevo ciclo manteniendo el mismo estado de GIRO.

84
c) AVANCE Este estado de avance hace referencia a un movimiento del robot en línea
recta. Para avanzar en línea recta es necesario que las velocidades de ambas ruedas sean iguales. Este avance se termina cuando el robot ha alcanzado una región determinada por los puntos (x, y), los cuales se obtienen en dos circunstancias: cuando el robot ha encontrado un objeto a recolectar o bien cuando esta visitando las regiones de la lista Ruta. Para diferenciar estas dos situaciones se usa la variable bandera, la cual con el valor 0 nos indica que el robot no ha recogido el objeto (pero se dispone a) y un 1 que ya lo tiene y en consecuencia se encuentra visitando las regiones en el retorno a su origen. De acuerdo a estas consideraciones el estado de avance consiste en:
Asignar el mismo valor de velocidad a cada rueda. Si el valor de bandera es 0 se verifica con la función dentro_de_region
si ya se ha alcanzado la región a del objeto a recolectar. Si ya se alcanzo esa región entonces se cambia el estado a RETORNO y se inicia otro ciclo. En caso de no haber alcanzado la nueva región entonces se inicia otro ciclo con el mismo estado de AVANCE.
Si el valor de bandera es 1 se verifica con la función dentro_de_region
si ya se ha alcanzado la región a visitar. Si ya se alcanzo esa región entonces se tiene que comprobar lo siguiente:
- Si la región alcanzada es la región correspondiente al lugar de
recolección del robot o nicho entonces se cambia el valor de bandera a 0 y el estado del robot a EXPLORACION y se inicia otro ciclo.
- Si la región alcanzada no es la región correspondiente al lugar de recolección del robot o nicho entonces el estado del robot pasa al estado de RETORNO y se inicia otro ciclo.
- En ambos casos, ya que se están visitando las regiones obtenidas de una lista y solo se usan estos datos una vez, se elimina el primer nodo de dicha lista, en esta caso la lista Ruta (nótese que en el caso de ser el ultimo nodo que existe en la lista, este corresponde al del nicho del robot, por lo que al eliminarlo se garantiza que para otra exploración la lista estará vacía).

85
d) RETORNO Una vez que el robot ha recolectado un objeto es necesario saber que lo
esta transportando hacia el punto de recolección. Esto lo hacemos con la ayuda de la variable bandera, asignándole un valor de 1. También necesitamos conocer la ruta de regreso, y esto lo hacemos con el algoritmo A-star, que esta implementado de manera que nos da una lista con los valores (x,y) (para cada nodo) correspondientes al centro de cada región a visitar. Estas regiones se visitan una a una hasta que la lista se termina, es decir, el robot llega a su nicho y entonces tiene que regresar a un estado de exploración como se especifica en el estado GIRO. Los pasos necesarios en este estado son:
Si la lista Ruta es vacía entonces es necesario crearla (esto se hace con las
funciones genera_ruta y ruta_regreso). Ya creada la lista se cambia el valor de bandera a 1, y se inicia un nuevo ciclo con el mismo estado RETORNO.
Si la lista Ruta no es vacía entonces se toman los valores (x,y) del primer
nodo de esta lista y se calcula el haux correspondiente. Con el valor actualizado de haux se cambia el estado del robot a GIRO y se inicia un nuevo ciclo. Nótese que el valor de bandera en este caso será de 1, lo que garantiza que en los siguientes ciclos (que corresponden primero al estado de GIRO y después al de AVANCE) se llegara a la región buscada y posteriormente se obtendrán los datos de la siguiente región visitar en el estado de RETORNO, o bien se terminara la lista con lo que un proceso de recolección será concluido.
La Interfaz Gráfica
La interfaz gráfica se programó utilizando OpenGL, ya que esta
herramienta permite el manejo de gráficos 3D, ventanas, etc., además de ser gratuita. Otra razón por la que se decidió el uso de OpenGL es la compatibilidad con el sistema operativo, ya que al diseñar el programa en LINUX, fue necesario buscar una forma de mostrar gráficos pues no se puede usar el modo gráfico del lenguaje C.
OpenGL es un conjunto de librerías que permiten el manejo de gráficos
2D/3D, imágenes; mostrar ventanas, botones, controles; recibir comandos por medio del teclado o del ratón. También facilita el manejo de fuentes de luz, sombreado y coloreado.

86
Cómo Incluir OpenGL
Debido a que OpenGL es un conjunto de librerías, su inclusión se realiza
de la misma forma en que se incluyen las librerías del lenguaje utilizado (en este caso lenguaje C++). Por lo tanto, para indicar al compilador que se quiere usar OpenGL se escribe la siguiente línea.
#include <GL/glut.h> Inicialización de OpenGL Para inicializar OpenGL se creó el procedimiento ‘initgl( )’, el cual se
muestra a continuación. void initgl() { glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGBA |
GLUT_DEPTH); glutInitWindowPosition(20,20); glutInitWindowSize(500,500); glutCreateWindow("Robot recolector 06I"); glDepthFunc(GL_LEQUAL); glClearColor(0.0,0.0,1.0,0.0); glClearDepth(1.0); } glutInitDisplayMode. Con esta instrucción se inicializa el modo gráfico,
se le están pasando 3 parámetros: GLUT_DOUBLE .- Se indica que se utilizará un buffer doble. Con esto
se evita que la imagen parpadee ya que cuando se muestra un cuadro de la misma utilizando el buffer primario, en el secundario se guarda el siguiente cuadro y sólo se hace un ‘flip’ entre las 2 imágenes, quedando a la vista lo que hay en el buffer secundario y el primario se actualiza. Si se utilizara sólo un buffer, el tiempo que le toma este actualizarse y mostrar la imagen, para volver a actualizarse y mostrar el siguiente cuadro, se vería como un parpadeo en la imagen que no permitiría la correcta visualización.
GLUT_RGBA .- Con esto sólo se indica el modo de color que se va a
usar.

87
GLUT_DEPTH .- Se indica que utilizaremos el modo en profundidad. Con esto sólo se dibujan los vértices que están en primer plano y no los que no están a la vista.
glutInitWindowPosition. Aquí sólo se indica la posición de la esquina
superior izquierda inicial de la ventana donde se desplegarán las imágenes de acuerdo a las coordenadas de la pantalla. La posición inicial está dada por ( X , Y ) en pixeles.
glutInitWindowSize. Se especifican las dimensiones de la ventana,
ancho y alto respectivamente. glutCreateWindow. Se crea la ventana con las características anteriores,
indicando el título de la ventana como parámetro. glDepthFunc. Se indica el criterio de profundidad, GL_LEQUAL
significa que se dibujaran los puntos que sean menores o iguales a los que ya se tenían.
glClearColor. Se indica el color de fondo por defecto. Como se escogió
el modo de color RGBA, se especifica la cantidad de rojo, verde, azul y alfa (transparencia). En el ejemplo del código, se escogió que el fondo fuera de color azul.
glClearDepth. Se limpia el buffer de profundidad. Como usamos
GL_LEQUAL, limpiamos el buffer con 1.0.
Flujo de un Programa en OpenGL
Una vez que se ha hecho la inicialización con ‘initgl( )’, es necesario meter
al programa en un ciclo de ejecución indefinido. Para esto se establecen las funciones que se deberán ejecutar en el ciclo.
glutDisplayFunc(display). Este procedimiento establece que la función
que se encargará de ‘dibujar’ en pantalla será la función ‘display’. glutIdleFunc(idle). Aquí se establece qué función será llamada para
realizar alguna acción entre cuadro y cuadro de imagen que se va mostrando. Permite realizar cambios a los objetos que se dibujarán antes de dibujarlos.

88
glutReshapeFunc(reshape). Se utiliza para indicar qué función hará cambios en la ventana de visualización, así como al punto de vista de la escena.
glutKeyboardFunc(keyboard). Indica cuál es la función que se
encargará de atender las solicitudes del usuario por medio del teclado. glutMainLoop( ). Con está función se indica que han sido establecidas
las funciones que necesitaremos y que el programa deberá seguirlas en un ciclo hasta que el usuario decida terminar el programa.
Sistema de Coordenadas en OpenGL
El sistema de coordenadas en OpenGL es igual a lo que comúnmente
conocemos. Es decir en 2D es un sistema cartesiano normal, mientras que en 3D mantiene las coordenadas X y Y agregando Z para dar profundidad. Como se muestra en la siguiente figura.
Figura 5.1. Sistema de coordenadas 3D en OpenGL.
X
Y
Z
- X
- Z
- Y

89
Los Objetos en el Entorno Virtual
La abstracción de los diferentes elementos del entorno virtual se
representan por medio de objetos en el lenguaje C++. Para asignar los respectivos atributos de estos objetos se utilizan varios archivos de datos. La forma de utilizar estos archivos se describe mas adelante. A continuación se muestran los diferentes objetos, sus propiedades y sus métodos.
ROBOT typedef class Robot { private: public: Nodos *L; Rutas *camino; int nvert; int ncaras; int nsens; int regiones; int estado; int bandera; int gr; float haux; int id; V color; int entradas[4]; int salidas[2]; float datos_sensor[4][5]; int tipo; float heading[5]; float distancia; float reg_ant[4]; GLfloat centro[3]; V *limites; V sensores[4]; GLfloat vel_izq; GLfloat vel_der; V *vertices; C *caras;

90
Robot(); void dibujate(); }Robot; Ahora se dará una breve descripción de las propiedades relacionadas con
el aspecto gráfico. nvert, ncaras, nsens, regiones: Sirven para saber de cuántos vértices,
caras, sensores y regiones cúbicas está formado el robot respectivamente. color, centro: Estos son arreglos de 3 flotantes, los cuales guardan el
color del robot (rojo, verde, azul) y el centro geométrico (x, y, z) del mismo. limites: Es un apuntador hacia un arreglo que indicará de acuerdo a
‘regiones’ cuáles son las regiones que ocupa el robot. Sabemos que en una región cúbica existen 8 vértices que la limitan, pero almacenar tantos vértices sería innecesario dado que la región es cúbica. Por eso sólo se guardan primero los valores mínimos de X, Y y Z que alcanza la región, seguido de los valores máximos. Es decir, si se tuviera por ejemplo una región cúbica de longitud 1 centrada en el origen, los valores almacenados serían limites[0] = {-0.5,-0.5,-0.5} y limites[1] = {0.5,0.5,0.5}.
vertices: Apunta a donde se almacenará el arreglo para los vértices que
forman al robot. caras: Apunta a donde se almacenará el arreglo para almacenar la
configuración de las superficies que forman al robot. robot( ): Es el constructor, sólo pone los apuntadores a NULL. dibujate( ): Como su nombre lo dice, dibuja al robot en pantalla en la
posición en la que se encuentre. OBJETOS Esta clase se utiliza para representar los correspondientes a los objetos a
recolectar y los muros. typedef class Objeto { private:

91
public: int nvert; int ncaras; int tipo; int ident; int regiones; GLfloat centro[3]; V *limites; V *vertices; C *caras; Objeto(); void dibujate(); void dibuja_esfera(float r,float g,float b); }Objeto; nvert.- Número de vértices que forman al objeto. ncaras.- Número de caras que forman al objeto. tipo.- Sirve para saber de que tipo de objeto se trata. ident.- Se utiliza para saber de que objeto se trata de entre todos. regiones.- Indica cuántas regiones contienen al objeto. centro.- Almacena la posición del centro geométrico del objeto. limites.- Igual que con el robot almacena los valores mínimos y máximos
de cada región. vertices.- Apunta a donde se almacenará el arreglo para los vértices que
forman al robot. caras.- Apunta a donde se almacenará el arreglo para almacenar la
configuración de las superficies que forman al robot. objeto().- Es el constructor del objeto, sólo coloca los apuntadores a
NULL.

92
dibujate().- Dibuja al objeto en la posición en la que se encuentre. dibuja_esfera().- Utilizado para dibujar objetos en caso de tener forma
esférica. Los parámetros recibidos son el color del objeto
(R,G,B).
Construcción de los Archivos de Datos
En el archivo ‘carga_datos.h’ se encuentran las funciones que utilizan los
archivos de datos de los robots, los objetos a recolectar y del entorno. La manera en que se deben crear dichos archivos para el correcto funcionamiento del programa se explica a continuación.
Robots.- Se necesitan 2 archivos. Uno para los vértices (robotv.dat) y
otro para las caras (robotc.dat). Los nombres pueden cambiar, sólo debe darse el nombre correcto al llamar a las funciones ‘carga_vertices_R’ y ‘carga_caras_R’.
robotv.dat 1.- Número de vértices. 2.- Coordenadas de los vértices (X, Y, Z). Un vértice por línea. Cada
valor separado por un espacio. 3.- Número de sensores. 4.- Posición de cada sensor (X, Y, Z). 5.- Centro geométrico del robot (X, Y, Z). 6.- Número de regiones cúbicas que contienen al robot. 7.- Valores mínimos (X min, Y min, Z min) para la región 1. 8.- Valores máximos (X max, Y max, Z max) para la región 1. 9.- Se repiten los pasos 7 y 8 si existieran más regiones. robotc.dat 1.- Número de caras. 2.- Conjunto de vértices que forman la cara 1. 3.- Conjunto de vértices que forman la cara 2. Así sucesivamente. Consideraciones: En el caso de robotv.dat no hay otras indicaciones que las que ya se
hicieron. Pero en el caso de robotc.dat es importante tener en cuenta lo siguiente:

93
1.- El método utilizado para dibujar las caras dibuja caras de 4 lados. 2.- Los valores utilizados son números enteros comenzando con el cero. 3.- Si se quiere utilizar la misma función para dibujar caras de 3 lados, se tiene que repetir el 4 vértice. 4.- Es debe utilizar sentido anti-horario para dibujar las caras, ya que se
indica a OpenGL que sólo dibuje una cara y la que dibuja primero es la que
está en sentido anti-horario. Como ejemplo se muestra la siguiente imagen.
Figura 5.2. Orientación de las Caras
En el triángulo del lado derecho se utiliza sentido horario. Como se ve
los vértices comienzan con V0. Debido a que se desactiva el dibujado de ambos lados, este triángulo no se dibujaría. En el caso del triángulo del lado derecho, se utiliza sentido anti-horario. Por tanto, este si se dibujaría. Otra forma quizá más fácil de saber que lado se dibujaría, es utilizando el ‘método de la mano derecha’.
Entorno de navegación.- Igualmente utilizamos 2 archivos (vertices.dat
y caras.dat). De igual forma, los nombres se pueden cambiar teniendo cuidado. vertices.dat 1.- Tipo de objeto. 2.- Número de vértices. 3.- Coordenadas de los vértices (X, Y, Z). Un vértice por línea. Cada
valor separado por un espacio. 4.- Número de regiones cúbicas que contienen al entorno. 5.- Valores mínimos (X min, Y min, Z min) para la región 1. 6.- Valores máximos (X max, Y max, Z max) para la región 1. 7.- Se repiten los pasos 5 y 6 si existieran más regiones.

94
8.- Centro geométrico del entorno. caras.dat.- Igual que el archivo de caras para el robot. Objetos de recolección.- Se explica la forma general y la utilizada
actualmente (esferas). Los objetos pueden ser distintos a los utilizados al igual que los nombres de los archivos (2 archivos).
objeto_vert.dat 1.- Tipo de objeto. 2.- Número de vértices. En este caso será 0. 3.- Coordenadas de los vértices. Un vértice por línea. Cada valor separado por un espacio. En este caso sin vértices, no se toma en cuenta este paso. 4.- Número de regiones cúbicas que contienen al objeto. 5.- Valores mínimos (X min, Y min, Z min) para la región 1. 6.- Valores máximos (X max, Ymax, Z max) para la región 1. 7.- Se repiten los pasos 5 y 6 si existieran más regiones. 8.- Centro geométrico del objeto. Tomando en cuenta que está situado sobre el origen. objeto_car.dat.- Igual que los anteriores. En el caso particular, como se
trata de esferas, sólo se pone un 0 para decir que no hay caras.
Datos Iniciales de los Robots y los Objetos.
Al inicio, el programa preguntará ¿cuántos robots serán simulados? De
acuerdo a la respuesta, leerá del archivo “robots.dat” la posición inicial de cada robot y el color del mismo. Así mismo, del archivo “objetos.dat” obtendrá el número de objetos a colocar y la posición de cada uno.

95
C a p í t u l o V I
IDEAS Y CONSEJOS PARA LA CONTINUACIÓN DEL PROYECTO
A lo largo del presente reporte se plantearon diferentes situaciones que pueden ocurrir cuando un conjunto de robots recolectores cohabiten en un mismo entorno. En general estas ideas se expresaron con la intención de dotar a la simulación de un modelo que permita una buena comunicación entre los robots y en consecuencia un mejor desempeño de estos como conjunto. Pero antes de la comunicación es importante establecer características comunes entre los robots que le permitan el intercambio de información que se considere necesaria. Para esto nos remitimos al capitulo 1 donde se habla de algoritmos meméticos.
Implementación de una Sociedad Artificial.
La idea general para implementar un algoritmo memético en el proyecto que se recomienda para continuar con el desarrollo consiste en asignar varios memes al robot, los cuales pueden ser: Energía.
Este meme va explícitamente relacionado con el combustible que da la energía necesaria al robot.
Efectividad.
El robot debe contar con un grado de efectividad relacionado a cuantos objetos a recolectado y en cuanto tiempo.
También se ha considerado tomar en cuenta los memes
correspondientes al grado de similaridad y la grado de altruismo descritos en el capitulo 1, modificando lo necesario.

96
La idea general en algoritmos memeticos con los memes mencionados
consiste en:
La comunicación será constante en todos los robot, de manera que se pueda compartir información con respecto al entorno virtual y tomando como parámetro decisivo el meme de altruismo.
Cada robot al ir realizando su exploración modifique sus memes de
acuerdo a los parámetros respectivos e incrementar el meme de altruismo a aquellos robots que tengan un buen nivel de efectividad.
Si un robot tiene un buen nivel de altruismo y en consecuencia de
efectividad, será recompensado con “combustible” para que no disminuya su meme de ENERGIA y pueda seguir operando.
Si un robot tiene un bajo nivel de efectividad no será recompensado, si
no que esperara que un robot de mayor nivel de efectividad y altruismo le comparta información
Ideas Para la Comunicación en la Sociedad Artificial:
Para crear la simulación de la sociedad artificial siguiendo los algoritmos meméticos, hemos pensado que la mejor manera de atacar el problema sería haciendo que cada robot creara un proceso servidor concurrente, el cual solo esté en ejecución cierto tiempo aleatorio, después de ese tiempo, el robot puede matar a ese proceso.
Con esto, se pretende que mientras no existe el proceso servidor
concurrente, el robot puede mandar un mensaje broadcast solicitando que todo aquel proceso servidor que exista, le conteste para que el robot cliente pueda tener la dirección de los servidores activos y así pueda comunicarse con ellos y solicitar información a cerca de los memes que se deben compartir, así este robot cliente puede revisar y quedarse con las características del robot que sea mejor. Este cliente se debe de crear como otro proceso, y una vez actualizadas las características del robot, el proceso debe cerrar la conexión y terminar.
Otra cosa a considerar es que si el proceso servidor recibe una petición, se
debe de inicializar nuevamente el cronómetro para que el robot no lo tire antes de actualizar.

97
Bibliografía
Francisco M. Márquez. UNIX Programación Avanzada.
AlfaOmega, 2ª Edición. Jesús Bernal y Jesús Bobadilla.
Reconocimento de voz y fonética acústica. Alfaomega, 2000.
David Hales. Swap Shop Model.
Artículo publicado por la Universidad de Essex, U.K., 1993.
Alejandro Ramírez Serrano. Un control
inteligente con características de autoaprendizaje utilizado en robots móviles. Articulo publicado en 1998.
. Diego Pérez de Diego. Sensores de
distancia por ultrasonido. www.depeca.uah.es/alcabot/seminario2006/Trabajos/DiegoPerezDeDiego.pdf, 2006.
Donald Hearn y M. Pauline Baker. Gráficas por Computadora. Prentice Hall. 2ª Ed. México , 1994. http://www.opengl.org http://www.uamt.feec.vutbr.cz/robo
tics/simulations/amrt/simguide_en.html
http://edevi.zonared.com/esp/article
.php.htm



















