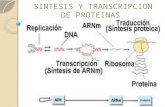
transcripcion
89
LA TRANSCRIPCIÓN ES LA SÍNTESIS DE RNA DIRIGIDA POR EL DNA COMPONENTES MOLECULARES DE LA TRANSCRIPCIÓN.
-
Upload
bernal-olivares -
Category
Documents
-
view
213 -
download
0
description
biologia molecular
Transcript of transcripcion

LA TRANSCRIPCIÓN ES LA SÍNTESIS DE RNA DIRIGIDA POR
EL DNACOMPONENTES MOLECULARES DE LA TRANSCRIPCIÓN.

TRANSCRIPCIÓN TRANSCRIPCIÓN.- Proceso mediante el cual, a partir de una molécula de
DNA en doble hélice, se sintetiza una molécula de RNA, complementaria de una de las hebras de DNA.
La cadena antiparalela respecto al RNA se denomina hebra molde[1] y la paralela, hebra complementaria[2].
Los tres tipos principales de RNA, presentes en todas las células, son: mensajero, transferente y ribosómico.
[1] La cadena de DNA que actúa como molde se denomina cadena con sentido.
[2] La cadena de DNA complementaria se denomina anti-sentido.

CARACTERÍSTICAS DE LA TRANSCRIPCIÓN
La transcripción tiene tres propiedades importantes: Selectiva.- Significa que no se transcribe todo el DNA de forma indiscriminada, sino
únicamente determinados segmentos, acotados con señales de iniciación y de terminación.
Monocatenaria.- Quiere decir que sólo se copia una de las hebras de DNA - hebra molde - ;
la hebra complementaria si bien es idéntica al mRNA que se copia sobre la hebra molde (cambiando T por U).
Reiterativa.- La misma región del DNA puede generar múltiples copias de RNA, tantas cuantas moléculas de RNA polimerasa se deslicen sobre ella.

COMPONENTES MOLECULARES DE LA TRANSCRIPCIÓN
En RNA mensajero, el portador de la información desde el DNA hasta la maquinaria sintetizadora de proteínas de la célula, se transcribe a partir de la cadena molde de un gen.
Una enzima denominada RNA polimerasa separa la dos cadenas del DNA y engancha los nucleótidos de RNA entre sí a medida que aparean sus bases a lo largo del molde de DNA.
Del mismo modo que las DNA polimerasa que actúan en la replicación del DNA, las RNA polimerasa solo pueden ensamblar un polinucleótido en la dirección 5’ 3’.
A diferencia de las DNA polimerasas, sin embargo, las RNA polimerasa son capaces de comenzar una cadena desde el principio; no necesitan un cebador.

COMPONENTES MOLECULARES DE LA TRANSCRIPCIÓN Las bacterias tienen un solo tipo de RNA polimerasa
que sintetiza no solo el mRNA sino también otros tipos de RNA que actúan en la síntesis proteica.
En contraste, los eucariotas tienen tres tipos de RNA polimerasa en su núcleo, numeradas I, II y III.
El que se emplea para la síntesis de mRNA es la RNA polimerasa II.
Los dos otros tipos transcriben moléculas de RNA que no se traducen en proteínas: ARN ribosómico y ARN transferente.

INICIACIÓN: SÍNTESIS DE UN TRANSCRITO DE RNA
Unión de la RNA polimerasa e iniciación de la transcripción.
El promotor de un gen incluye el punto de comienzo de la transcripción ( el nucleótido donde en realidad comienza la síntesis de RNA) y se extiende habitualmente varias docenas de nucleótidos en dirección 5’ desde el punto de comienzo.
Además de servir como sitio de unión para la RNA polimerasa y determinar cuándo empieza la transcripción, el promotor indica cuál de las dos cadenas de la hélice de DNA se usa como molde.
Ciertas secciones de un promotor son de especial importancia para la unión de la RNA polimerasa.

INICIACIÓN: SÍNTESIS DE UN TRANSCRITO DE RNA
En los procariotas, la RNA polimerasa por sí misma reconoce y se une al promotor.
En los eucariotas, un conjunto de proteínas llamadas factores de transcripción actúa como mediador en la unión de la RNA polimerasa y la iniciación de la transcripción.
Sólo después de que ciertos factores de transcripción se fijan al promotor, la RNA polimerasa II se une a él.
El ensamblaje completo de factores de transcripción y RNA polimerasa II unida al promotor se denomina complejo de iniciación de la transcripción.
La secuencia promotora de DNA, llamada caja TATA, es crucial en la formación de iniciación en los eucariotas..
La interacción entre la RNA polimeras II eucariota y los factores de transcripción es un ejemplo de la importancia de las interacciones proteína-proteína en el control de la transcripción eucariota.
Una vez que la polimerasa se fija con firmeza al promotor DNA, las dos cadenas de DNA se desenrollan y la enzima comienza a transcribir la cadena molde.

LE 17-7a-1
Promotor Unidad de transcripción
RNA polimerasaPunto de inicio
DNA53
35

LE 17-7a-2
Promotor
53
35
35
53
Transcription unit
DNA
Iniciacion
Punto de inicioRNA polimerasa
desenrolladoDNA
RNAtran-scrito
Cadena de DNA molde

LE 17-8
Promoter
53
35
TATA box
Punto de inicio
Factores de transcripción
53
35
Varios factores de transcripción
Otros factores de transcripción
RNA polimerasa IIFactores de transcripción
RNA transcrito
53
355
Complejo de iniciación de la transcripción
Promotores eucariotasers
Cadena de DNA molde

ELONGACIÓN DE LA CADENA DE RNA
A medida que la RNA polimerasa se mueve a lo largo del DNA, continúa desenrollando la doble hélice y expone de 10 a 20 bases de DNA a la vez para el apareamiento con nucleótidos de RNA.
La enzima añade nucleótidos al extremo 3’ de la molécula de RNA en crecimiento a medida que continúa a lo largo de la doble hélice.
Como resultado de esta onda progresiva de síntesis de RNA, la nueva molécula de RNA se despega de su molde de DNA y la doble hélice se vuelve a formar.
.

LE 17-7a-3Promoter
53
Transcription unit
35DNAStart point
RNA polimerasaIniciacion
35
53
UnwoundDNA
RNAtran-scrito
Template strandof DNA
Elongacion
desenrolladoDNA
35
53 3
5
RNAtranscrito

TERMINACIÓN DE LA TRANSCRIPCIÓN
El mecanismo de terminación difiere entre los procariotas y los eucariotas.
En los primero, la transcripción avanza hasta una secuencia de terminación en el DNA.
El terminador transcrito como secuencia de RNA actúa como señal de terminación, haciendo que la polimerasa se despegue del DNA y libere el transcrito, que se halla disponible para su uso inmediato como mRNA.

TERMINACIÓN EN EUCARIOTAS ALTERACIÓN DE LOS EXTREMOS DEL mRNA Cada extremo de una molécula de pre-mRNA se modifica de
una manera determinada.
En el extremo 5’ del primero en transcribirse, se agrega un casquete con una forma modificada del nucleótido guanina después de la transcripción de los primeros 20 a 40 nucleótidos, formando el casquete 5’.
El extremo 3’ del pre-mRNA también se modifica antes de que el mRNA salga del núcleo.
En el extremo 3’ una enzima añade 50 o 200 nucleótidos de adenina formando una cola de poliadenilato (cola de poli A)

LE 17-7
ElongacionCadena de DNA complementariaNo molde
RNApolimerase
RNA nucleotidos
3 end3
5
5
RNA recién sintetizado
Cadena de DNA molde
Dirección de la transcripciónEn dirección 3’
Promoter
53
RNA polimerasePunto de inicio
DNA
Transcription unit
35
53
35
DNAdesenrollado
RNATranscrito
Cadena de DNA molde
iniciación
Elongacíon
Terminación
53
35
53
35
35
DNA transcrito
RNAtranscript
5
Transcrito de RNA completo
UNIDAD DE TRANSCRIPCIÓN
TRANSCRITO DE RNA

LE 17-7b
Elongacion Cadena de DNA complementaria No molde
RNApolimerasa
RNA nucleotidos
3 end3
5
5
RNA recién sintetizado
Cadena de DNA moldeDireccion de la transcripción(“en dirección 3’

LE 17-9
5
SegneNto codificante de proteina
5 Codon iniciacion Stop codon Poly-Acola
Señal de poliadenilaciçon
5 3Cap UTR UTR

LAS CÉLULAS EUCARIOTAS MODIFICAN EL RNA DESPUÉS DE LA TRANSCRIPCIÓN El casquete 5’ y la cola de poli-A comparte varias funciones
importantes.
Primero, parecen facilitar la exportación del mRNA maduro desde el núcleo.
Segundo, ayudan a proteger al mRNA de la degradación por las enzimas hidrolíticas.
Tercero, una vez que el mRNA alcanza el citoplasma, ambas estructuras ayudan a que los ribosomas se fijen ale extremo 5’ del mRNA.
En el esquema aparecen las UTR son partes del mRNA que no serán traducidas en proteína, pero tienen otras funciones, como la unión con el ribosoma.

GENES FRACCIONADOS, CORTE Y EMPALME DEL RNA La etapa mas destacable del procesamiento del ARN en el núcleo
eucariota es la eliminación de una gran parte de la molécula de ARN que fue sintetizada inicialmente, un trabajo de cortar y pegar llamado corte y empalme del RNA.
La molécula de ADN eucariota es de alrededor de 8000 nucleótidos, de modo que el transcrito primario de RNA también tiene esa longitud, pero se requieren solo unos 1200 nucleótidos para codificar una proteína de tamaño medio de 400 aminoácidos.
Esto significa que la mayoría de los genes eucariotas y sus transcritos de RNA tienen largos segmentos no codificantes, regiones que no serán traducidas.
Aun mas sorprendente es que la mayoría de estas secuencias no codificantes se encuentran intercaladas entre segmentos codficiantes del gen, y por lo tanto, entre segmentos codificantes del premRNA

LE 17-10
5 Exon Intron Exon Intron Exon 3Pre-mRNA
1 30 31 104 105 146
Segmento cofificante
Intrones cortados y exones empalmados
1 1465Cap
5Cap
Poly-A tail
Poly-A tail
5 3UTR UTR

MADURACIÓN:GENES FRACCIONADOSLas secuencias de nucleótidos de ADN que codifica para
un polipéptido eucariota, por lo general, no es continua, esta fraccionada en segmentos. Los segmentos no codificantes del acido nucleico que se halla entre las regiones codificantes se llaman secuencias interpuestas o intrones.
Las otras regiones se denominan exones, porque finalmente se expresan, en general, siendo traducidas en secuencias de aminoácidos.
Las excepciones incluyen las UTR de los exones en los extremos del RNA, que forman parte del mRNA pero no se traducen en proteína.

MADURACIÓN: CORTE Y EMPALME DEL ARN En la elaboración de un transcrito primario a partir de un gen
la ARN polimerasa II transcribe tanto intrones como exones del DNA, pero la molécula de mRNA que entra en el citoplasma es una versión condensada.
Se recortan los intrones de la molécula y se unen los exones, formando una molécula de mRNA con una secuencia codificante continua.
Este es el proceso de corte y empalme.

MADURACIÓN: CORTE Y EMPALME: PAPEL DE LAS RIBONUCLEOPROTEINAS NUCLEARES
PEQUEÑAS¿Como se lleva a cabo el corte y empalme del premRNA?La señal para el corte y empalme del RNA es una secuencia
corta de nucleotidos en cada extremo de un intron.Las partículas llamadas ribonucleoproteinas nucleares
pequeñas ¿snRNP? Reconocen esto sitios.Se localizan en el núcleo y están compuestas por RNA y
proteínas.El RNA en una partícula de snRNP se denomina RNA nuclear
pequeño cada molécula tienen alrededor de 150 nucleotidos de largo.
Varias snRNp diferentes se unen con otras proteínas para formar un conjunto aun mas grande llamado espliceosoma, que es casi del mismo tamaño que un ribosoma.
El espliceosoma interactúa con ciertos sitios a lo largo de un intron liberándolo y uniendo los dos exones que lo flanquean.

LE 17-11-1
Exon 15
Intron
Otras proteínasProtein
snRNA
snRNPs
RNA transcript o(pre-mRNA)
Espliceosoma
Exon 2

LE 17-11-2
5
Spliceosome
Intronescortados
mRNA
Exon 1 Exon 25
Spliceosomecomponentes

LE 17-11
Exon 15
Intron Exon 2
Other proteinsProtein
snRNA
snRNPs
RNA transcrito (pre-mRNA)o
Spliceosome
5
Spliceosomecomponents
Cut-outintron
mRNA
Exon 1 Exon 25

Función de las snRNP y los esplicesomas en el corte y empalme del premRNALas ribonucleoproteinas nucleares pequeñas y otras proteínas, forman un complejo molecular llamado espliceosoma sobre un premRNA que contiene exones e intrones.Dentro del esplicosoma, las snaRNp aparean sus bases con nucleótidos en sitios específicos a lo largo del intron.Se corta el transcrito del RNA liberando el intron y empalmando los exones al mismo tiempo.Luego se separa el espliceosoma, liberando el mRNA ya empalmado, que ahora solo contiene exones.

RIBOZIMASMoléculas de ARN que actúan como enzimas.El hecho de que el RNA sea una cadena simple
desempeña un papel importante, al permitir que ciertas moléculas de RNA actuasen como ribozimas. Una región de una molécula de RNA pueden aparear sus bases con una región complementaria en cualquier lugar de la misma molécula, otorgándole de este modo una estructura especifica a la molécula en su totalidad.
También algunas de las bases contienen grupos funcionales que pueden participar en la catálisis.

LA IMPORTANCIA FUNCIONAL Y EVOLUTIVA DE LOS INTRONES
CORTE Y EMPALME ALTERNATIVO DEL RNA

LE 17-12Gene
Transcription
RNA processing
Translation
Domain 2
Domain 3
Domain 1
Polypeptide
Exon 1 Intron Exon 2 Intron Exon 3
DNA

LE 17-4
DNAmolecule
Gene 1
Gene 2
Gene 3
DNA strand(template)
3
TRANSCRIPTION
Codon
mRNA
TRADUCCIÓN
Protein
Amino acid
35
5

Una vez que Crick (1958) propuso la Hipótesis de la Secuencia "existe una relación entre la ordenación lineal de nucleótidos en el ADN y
la ordenación lineal de aminoácidos en los polipéptidos", la comunidad científica la admitió y se plantearon dos preguntas:
¿Existe algún código o clave que permite pasar de la secuencia de nucleótidos en el ADN a la secuencia de aminoácidos en las proteínas?
¿Cómo se convierte la información contenida en la secuencia de ADN en una estructura química de proteína?
SEVERO OCHOA M.NIREMBERG G.KHORANA S. BRENNER

EL CÓDIGO GENÉTICO ¿Cuántas bases corresponden a un
aminoácido?.
4 nucleótidos han de codificar para 20
aminoácidos
Un nucleótido codifica un aminoácido
Dos nucleótidos codifican un aminoácido
Tres o más nucleótidos codifican un aminoácido

Descifrando el código genético Existen experimentos que verificaron que el flujo de la
información desde el gen hasta la proteína está basado en un código de tripletes: Las instrucciones genéticas de una cadena polipeptídica están escritas en el DNA como una serie de palabras de tres
nucleótidos no superpuestas

Las características del código genético fueron establecidas experimentalmente por Fancis Crick,
Sydney Brenner y colaboradores en 1961
Francis Crick Sydney Brenner


UTILIZACIÓN DE HOMOPOLÍMEROS
Un homopolímero es un ARN sintético que solamente contiene un tipo de ribonucleótido. Por ejemplo, el ARN sintético
UUUUUUUUUUUUU.......Gruberg-Manago y Ochoa (1955) aislaron a partir de timo de ternera un ezima denominada Polirribonucleótido fosforilasa que tenía la capacidad de sintetizar ARN a partir de ribonucleósidos difosfato y sin necesidad de molde. Este enzima iba tomando al
azar los ribonucleósidos del medio para originar un ARN.Matthei y Nirenberg (1961) consiguieron sintetizar polipéptidos "in vitro" añadiendo un ARN sintético de secuencia conocida a un
sistema acelular estable de traducción. Usando la Polirribonucleótido fosforilasa sintetizaron poli-uridílico (poli-U:
UUUUUUUUUUUUUU...). Cuando emplearon este ARN sintético en su sistema acelular de traducción daba lugar a la formación de un
polipéptido que solamente contenía el aminoácido fenilalanina (Poli-fenilalanina: phe-phe-phe-phe-..). Por tanto, el triplete UUU codificaba para fenilalanina (phe). También comprobaron que el ARN síntético Poli C (Poli-citidílico: CCCCCCCCCC....) daba lugar a un polipéptido que contenía solamente prolina (Poli-prolina: pro-pro-pro-pro-pro-...), por tanto, el codón CCC significaba prolina
(pro)..

Ochoa sintetizó Poli-adenílico (Poli-A: AAAAAAAAA....) y observó que el polipéptido que aparecía solamente tenía el aminoácido lisina (Poli-lisina:
lys-lys-lys-lys-....). Por consiguiente el triplete AAA codificaba para el aminoácido lisina (lys). También corroboró que el Poli-C daba lugar a Poli-prolina. El ARN Poli-guanílico no producía proteína alguna, probablemente
debido a que adquiría una estructura terciaría helicoidal que impedía su traducción a proteína.
Triplete Aminoácido
CCC prolina
UUU fenilalanina
AAA lisina

El desciframiento del código genético se ha realizado fundamentalmente en la bacteria E. coli, por tanto, cabe preguntarse si el código genético de esta bacteria es igual que el de otros organismos tanto procarióticos como eucarióticos. Los experimentos realizados hasta la fecha indican que el código genético nuclear es universal, de manera que un determinado triplete o codón lleva información para el mismo aminoácido en diferentes especies. Hoy día existen muchos experimentos que demuestran la universalidad del código nuclear, algunos de estos experimentos son:Utilización de ARN mensajeros en diferentes sistemas acelulares. Por ejemplo ARN mensajero y ribosomas de reticulocitos de conejo con ARN transferentes de E. coli. En este sistema se sintetiza un polipéptido igual o muy semejante a la hemoglobina de conejo. Las técnicas de ingeniería genética que permiten introducir ADN de un organismo en otro de manera que el organismo receptor sintetiza las proteínas del organismo donante del ADN. Por ejemplo, la síntesis de proteínas humanas en la bacteria E. coli.
El desciframiento del código genético dio como resultado la siguiente asignación de aminoácidos a los 64 tripletes.
EL CÓDIGO GENÉTICO ES UNIVERSAL

El código genético mitocondrial es la única excepción a la universalidad del código, de manera que en algunos organismos los aminoácidos determinados por el mismo triplete o codón son diferentes en el núcleo y en la mitocondria.Excepciones a la Universalidad del Código
Organismo Codón Significado en Código Nuclear
Significado en Código
MitocondrialTodos UGA FIN Trp
Levadura CUX Leu Thr
Drosophila AGA Arg Ser
Humano, bovino AGA, AGC Arg FIN
Humano, bovino AUA Ile Met (iniciación)
Ratón AUU, AUC, AUA Ile

EVOLUCIÓN DEL CÓDIGO GENÉTICO En los experimentos de laboratorio se pueden transcribir y
traducir los genes después de ser trasplantados de una especie a otra.
Es posible programar a las bacterias para sintetizar ciertas proteínas humanas de uso médico mediante la inserción de genes humanos.
Estas aplicaciones han producido muchos desarrollos estimulantes en biotecnología.

EVOLUCIÓN DEL CÓDIGO GENÉTICO Una planta de tabaco expresando un gen de la
luciérnaga. Como las formas diversas de la vida comparten un
código genético común, es posible programar una especie para que produzca proteínas características de otra especie transplantándole el DNA.
En este experimento, los investigadores pudieron incorporar el gen de una luciérnaga en el DNA de una planta de tabaco.
El gen de la luciérnaga codifica una enzima que cataliza una reacción química que libera energía luminosa.

Figure 17-06

LE 17-5Second mRNA base
Firs
t mR
NA
bas
e (5
end
)
Third
mR
NA
bas
e (3
end
)

LA LECTURA DEL CÓDIGO GENÉTICO ES "SIN COMAS"Teniendo en cuenta que la lectura se hace de tres en tres bases, a partir de un punto de inicio la lectura
se lleva a cabo sin interrupciones o espacios vacíos, es decir, la lectura es seguida "sin comas". De manera, que si añadimos un nucleótido (adición) a la secuencia, a partir de ese punto se altera el
cuadro de lectura y se modifican todos los aminoácidos. Lo mismo sucede si se pierde (deleción) un nucleótido de la secuencia. A partir del nucleótido delecionado
se altera el cuadro de lectura y cambian todos los aminoácidos. Si la adición o la deleción es de tres nucleótidos o múltiplo de tres, se añade un aminoácido o más de uno
a la secuencia que sigue siendo la misma a partir del la última adición o deleción. Una adición y una deleción sucesivas vuelven a restaurar el cuadro de lectura.
Secuencia normal: ejemplo con una frase
UNO MAS UNO SON DOS
Adición de una A después de la primera N: cambia el cuadro de lecturaUNA OMA SUN OSO NDO S
Deleción (pérdida) de la primera O: cambia el cuadro de lecturaUNM ASU NOS OND OS
Adición de A y deleción de A: se recupera el cuadro de lecturaUNA OMS UNO SON DOS
Adición de tres letras (AAA)UNO AAA MAS UNO SON DOS

EL CÓDIGO GENÉTICO ES NO SOLAPADO O SIN SUPERPOSICIONESUn nucleótido solamente forma parte de un triplete y, por
consiguiente, no forma parte de varios tripletes, lo que indica que el código genético no presenta superposiciones.

El código está organizado en tripletes o codones: cada tres nucleótidos (triplete) determinan un aminoácido.
El código genético es degenerado: existen más tripletes o codones que aminoácidos, de forma que un determinado aminoácido puede estar codificado por más de un triplete.
El código genético es no solapado o sin superposiciones: un nucleótido solamente pertenece a un único triplete.
La lectura es "sin comas": el cuadro de lectura de los tripletes se realiza de forma continua "sin comas" o sin que existan espacios en blanco.
El código genético nuclear es universal: el mismo triplete en diferentes especies codifica para el mismo aminoácido. La principal excepción a la universalidad es el código genético mitocondrial.
CARACTERÍSTICAS DEL CÓDIGO GENÉTICO

Las moléculas encargadas de transportar los aminoácidos hasta el ribosoma y de reconocer los codones del ARN mensajero durante el proceso de traducción son los ARN transferentes (ARN-t). Los ARN-t tienen una estructura en forma de hoja de trébol con varios sitios funcionales:•Extremo 3': lugar de unión al aminoácido (contiene siempre la secuencia ACC).
•Lazo dihidrouracilo (DHU): lugar de unión a la aminoacil ARN-t sintetasa o enzimas encargadas de unir una aminoácido a su correspondiente ARN-t.
•Lazo de T ψ C: lugar de enlace al ribosoma.
•Lazo del anticodón: lugar de reconocimiento de los codones del mensajero.
Los ARN-t suelen presentar bases nitrogenadas poco frecuentes como son la pseudouridina (ψ),
metilguanosina (mG), dimetilguanosina (m2G), metilinosina (mI) y dihidrouridina (DHU, UH2 )

La degeneración del código se explica teniendo en cuenta dos motivos:
A. Algunos aminoácidos pueden ser transportados por distintas especies moleculares (tipos) de ARN transferentes (ARN-t) que contienen distintos anticodones.
B. Algunas especies moleculares de ARN-t pueden incorporar su aminoácido específico en respuesta a varios codones, de manera que poseen un anticodón que es capaz
de emparejarse con varios codones diferentes.
Este emparejamiento permisivo se denomina Flexibilidad de la 3ª base del anticodón o tambaleo.

En la siguiente tabla se indican los emparejamientos codón-anticodón permitidos por la regla del tambaleo:
Emparejamientos codón-anticodón permitidos
Extremo 5' del anticodón (ARN-t)
Extremo 3' del codón (ARN-m)
G U o C
C sólo G
A sólo U
U A o G
I

LE 17-3-1
TRANSCRIPCIONDNA
Prokaryotic cell

LE 17-3-2
TRANSCRIPCIONDNA
CÉLULA PROCARIOTARibosoma
Polipéptido
mRNA
Prokaryotic cell

LE 17-3-3
TRANSCRIPTION
TRANSLATION
DNA
mRNARibosome
Polypeptide
DNA
Prokaryotic cell
Nuclearenvelope
TRANSCRIPTION
Eukaryotic cell

LE 17-3-4
TRANSCRIPTION
TRANSLATION
DNA
mRNARibosome
Polypeptide
DNA
Pre-mRNA
Prokaryotic cell
Nuclearenvelope
mRNA
TRANSCRIPTION
PROCESAMIENTO ARN
Eukaryotic cell

LE 17-3-5
TRANSCRIPTION
TRANSLATION
DNA
mRNARibosome
Polypeptide
DNA
Pre-mRNA
Prokaryotic cell
Nuclearenvelope
mRNA
TRADUCCIÓN
TRANSCRIPTION
RNA PROCESSING
Ribosome
Polypeptide
Eukaryotic cell

LA TRADUCCIÓN ES LA SÍNTESIS DE UN POLIPÉPTIDO DIRIGIDA POR EL ARNCOMPONENTES MOLECULARES DE LA TRADUCCIÓN

TRADUCCIÓN A medida que una molécula de ARNm se traduce en el
ribosoma, se traducen los codones en aminoácidos, uno a uno.
Los intérpretes son moléculas de ARNt, cada tipo con un anticodon específico en un extremo y un aminoácido correspondiente en el otro.
Un ARNt añade su carga de aminoácido a una cadena polipeptídica en crecimiento cuando el anticodon se une a un codon complementario sobre el ARNm.

LE 17-13
polipéptido
RNAt con aminoácidosadheridos
Ribosoma
tRNA
Anticodon
35 mRNA
aminoácidos
Codon

COMPONENTES MOLECULARES DE LA TRADUCCIÓN En el proceso de la traducción una célula interpreta un mensaje genético y construye
un polipéptido en conformidad. El mensaje es una serie de codones a lo largo de una molécula de ARNm y el
intérprete se llama ARNt. La función del ARNt es transferir aminoácidos desde el conjunto de aminoácidos
citoplasmático hacia el ribosoma. Una célula mantiene su citoplasma con reservas de los 20 aminoácidos, ya sea sintetizándolos a partir de otros compuestos, o capturándolos de la solución circundante.
El ribosoma añade cada aminoácido traído por el ARNt al extremo en crecimiento de una cadena polipeptídica.
Las moléculas de ARNt no son idénticas, la clave para traducir un mensaje genético en aminoácidos específicos es que cada tipo de molécula de ARNt traduzca un codon particular en un determinado aminoácido.
Cuando una molécula de ARNt llega a un ribosoma, lleva un aminoácido específico en un extremo.
En el otro extremo del ARNt existe un triplete nucleotidico llamado anticodon, que aparea sus bases con un codon complementario del ARNm.
El mensaje genético se traduce en la medida que los ARNt depositan aminoácidos en el orden prescrito y el ribosoma los une en una cadena, la molécula de ARN t actúa como traductora porque puede leer una palabra del ácido nucleico ( el codon del ARN m) e interpretarla como una palabra proteica (el aminoácido)

ARN MENSAJERO Codifica la información genética copiada del DNA en forma de una secuencia de bases
que especifica una secuencia de aminoácidos. Está formado por largas cadenas de polinucleótidos de tamaño variables. Sólo
presentan estructura primaria, por lo que tienen aspecto filamentoso. Su nombre hace referencia a la función que desempeña consistente en transportar la
información desde el núcleo al citoplasma celular para que se sinteticen las proteínas. Cada mRNA contiene la información necesaria para la síntesis de una proteína
determinada. Tienen una vida muy efímera y sus bases integrantes no presentan prácticamente modificaciones químicas[1]. Representa un 3% del total de RNA.
[1] En procariotas, los mRNA poseen en el extremo 5' un grupo trifosfato. En los eucaritoas, por su parte, la mayoría de los mRNA poseen en el extremo 5' una especie de "caperuza" compuesta por un residuo de metilguanosina unida al grupo tirfosfato, y en el extremos 3' presentan una "cola" formada por un fragmento de unos 200 nucleótidos de adenina, denominada poli A; además, estos mRNA contienen secuencias de bases que codifican para la síntesis de proteínas (exones) intercaladas con otras secuencias que no contienen información para la síntesis de proteínas (intrones); es decir, la información genética aparece fragmentada, por lo que requieren un proceso de maduración antes de convertirse en mRNA funcionales.

ARN TRANSFERENTE Es la clave para el código; los aminoácidos especificados por la
secuencia de bases de una molécula de mRNA son transportados en el extremo creciente de una cadena polipeptídica por moléculas específicas de tRNA. Esta clase de RNA se compone de moléculas pequeñas (80-100 nucleótidos).[1]
Algunas regiones presentan estructura secundaria, ya que contienen secuencias de bases complementarias que permiten el apareamiento y la consiguiente formación de una doble hélice, mientras las zonas que no se aparean adoptan el aspecto de bucles, como una hoja de trébol, aunque, en realidad, el plegamiento es mucho más complejo y la conformación real de los RNA, ofrece una imagen tortuosa y retorcida, que en nada se parece a una hoja de trébol; manifiesta estructura terciaria con forma de L, como un bumerang.
[1] El tRNA representa el 15% del total de RNA celular.

ARN TRANSFERENTE Se conocen unas cincuenta especies diferentes tRNA, y aunque las
secuencias de bases sean distintas, todos ellos presentan una serie de estructuras características:
El extremo 5', que en todos lo tRNA contiene un nucleótido de guanina con su grupo fosfato libre.
El bucle o brazo D, cuya secuencia es reconocida de manera especifica por uno de los veinte enzimas, llamados aminoacil-ARN- sintetasas, encargados de unir cada aminoácido con su correspondiente molécula de ARNr.
El extremo 3'; que en todos los tRNA, posee la secuencia CCA, cuyo grupo -OH terminal sirve de lugar de unión con el aminoácido.
El bucle o brazo TC, que actúa como lugar de reconocimiento del ribosoma.
El bucle situado en el extremo del brazo largo que contiene una secuencia de tres bases llamada anticodón. Cada tRNA cargado con su correspondiente aminoácido se une, mediante la región del anticodón, con tripletes de bases del mRNA en el proceso de la traducción del código genético que conduce a la síntesis de proteínas.

LE 17-14a
Sitiio de fijaciónAl aminoácido
Enlaces de hidrógeno
3
5
Two-dimensional structureAnticodon
Sitio de fijacióndel aminoácido
35
Enlaces de hidrógeno
Anticodon Anticodon
Symbol used in this bookThree-dimensional structure
3 5

LE 17-14b
Enlaces dehidrógeno
Sitio de uniónDel aminoácido5
3
3 5
Anticodon
Symbol used in this book
Anticodon
Three-dimensional structure

Aminoacil-ARNt sintetasa Para la traducción exacta de un mensaje genético se requieren dos pasos de reconocimiento. Primero, debe haber una concordancia correcta entre un ARNt y un aminoácido. Un ARNt que se une a un
codon del ARNm que específica un determinado aminoácido debe transportar solo ese aminoácido al ribosoma.
Cada aminoácido se une al ARNt adecuado pro meido de una enzima específica llamada aminoacil-ARNt sintetasa.
El sitio activo de cada tipo de aminoacil-ARNt sintetasa encaja solo con una combinación específica de aminoácido y ARNt.
Existen 20 sintetasas diferentes, una para cada aminoácido, cada sintetasa es capaz de unir todos los ARNt diferentes que codifican para ese aminoácido específico. La sintetasa cataliza el enlace ocvalente del aminoácido a su ARNt en un proceso impulsado por la hid´rolisis del ATP. El aminoacil ARNt resultante, también llamado aminoácido activado, se libera de la enzima y entrega su aminoácido a una cadena polipeptídica en crecimiento sobre un ribosoma.
El segundo paso de reconocimiento implica una correcta concordancia entre el el anticodon del ARNt y el codon del ARNm.
Si existiera una variedad de ARNt para cada uno de los codones del ARNm que específicara un aminoácido, habría 61 ARNt.
En realidad solo hay alrededor de 45 lo que significa que algunos ARNt deben ser capaces de unirse a más de un codon.
Esta versatilidad es posible porque las reglas del apareamiento de las bases entre la tercera base de un codon y la base correspondiente de un anticdon del ARNt no son tna estrictas como para los codones del ADn y ARNm. Esta relajación de las reglas de apareamiento de bases se denomina tambaleio.
El tambaleo explica por qué los codones sinónimos para un amioácido determinado pueden diferir en su tercera base, pero, por lo general no en las otras.

LE 17-15Amino acid Aminoacyl-tRNA
sintetasa(enzyme)
Pirofosfato
Phosphates
tRNA
AMP
Aminoacyl tRNA(con el aminóacidoActivado)
El sitio activo une el aa y el ATP
El ATP pierde dos grupos P y une El aminoácido como AMP
El tRNA adecuado se uneEn forma covalente con elAminoácido y desplaza al AMP
La enzima liberaEl aminoácido activado

ARN RIBOSÓMICO Se combina con un grupo de proteínas para formar los ribosomas, que tienen
sitios de unión para todas las moléculas necesarias para la síntesis de proteínas (mRNA, tRNA y factores proteicos). Los ribosomas, que llevan tRNAs y proteínas especiales, pueden moverse físicamente a lo largo de la cadena de mRNA para traducir su información genética codificada.
Lo constituyen moléculas de diferentes tamaños, con estructura secundaria en algunas regiones de la molécula, que participan en la formación de las subunidades ribosómicas, cuando se unen a más de setenta proteínas distintas.
EL rRNA contribuye a que los ribosomas posean una estructura acanalada, con hendiduras o sitios capaces de albergar simultáneamente a una molécula de mRNA y a los diferentes aminoácidos unidos a los tRNA que participan en la síntesis de una cadena polipeptídica.
Como criterio de clasificación se adopta el peso molecular medio de las cadenas de rRNA, cuyo valor se deduce de la velocidad con que se sedimentan las moléculas sometidas a un campo centrífugo. El peso molecular y, por tanto, las dimensiones de la molécula se expresan en cantidades Svedberg(S)[1].
[1] Su concentración celular es la más elevada un 71%. Completar información con los apuntes de citología.

LE 17-16
Amino end
mRNA
5
3
Growing polypeptide
Next amino acidto be added topolypeptide chain
tRNA
Schematic model with mRNA and tRNA
Computer model of functioning ribosome
5 3
E
Codons
Schematic model showing binding sites
Smallsubunit
Largesubunit
A site (Aminoacyl-tRNA binding site)E site
(Exit site)E P A
mRNAbinding site
P site (Peptidyl-tRNAbinding site)
Smallsubunit
Largesubunit
Exit tunnelGrowingpolypeptidetRNA
molecules
E P A
mRNA

RIBOSOMAS Si bien los ribosomas de los procariotas y eucariotas
son muy similares en estructura y función, los de estos últimos son ligeramente más grandes y difieren en cierta medida de los primeros en su composición molecular.
Las diferencias son significativas desde el punto de vista médico.
Algunos antibióticos pueden inactivar los ribosomas de los procariotas sin inhibir la capacidad de los ribosomas de los eucariotas para sintetizar proteínas. Estos fármacos, como la tetraciclina y la estreptomicina, se utilizan para combatir las infecciones bacterianas.

Figure 17-01

RIBOZIMA Cuatro décadas de investigación genética y bioquímica
acerca de la estructura del ribosoma bacteriano. Investigaciones recientes sustentan fuertemente la hipótesis
de que el rRNA no la proteína, es el responsable primario de la estructura y de la función del ribosoma.
Las proteínas, que se encuentran principalmente en el exterior, soportan los cambios conformacionales de las moléculas de rRNA a medida que llevan a cabo la catálisis durante la traducción.
El RNA es el constituyente de la interfase entre las dos subunidades y de los sitios A y P y es el catalizador de la formación principal del enlace peptídico.

LE 17-16a
tRNAmolecules
Tunel de salidaPolipéptidoEn crecimiento
Subunidadgrande
mRNA 3
Modelo computerizado de un ribosoma en funcionamiento
Subunidadpequeña
5
E P A

LE 17-16b
Sitio P (sitio de uniónPeptidil-RNAt
E site (Exit site)
mRNASitio de unión
A site (sitio de uniónAminoacil-tRNA)
Subunidadgrande
Subunidadpequeña
Modelo esquemático que muestra los sitios de unión
E P A

LE 17-16c
Extremo amino
mRNA
5
3
Polipéptido en crecimiento
Next amino acidto be added topolypeptide chain
tRNA
Codon
Modelo esquemático con mRNA y tRNA
E

TRADUCCION:INICIACION Iniciación de la síntesis de proteinas.- El primer acontecimiento en la iniciación de la síntesis de proteinas es la unión
de una molécula de metionina libre en el extremo de un tRNA met por medio de una aminoacil-t RNA-sintetasa específica.
Hay dos tipos de tRNA met pero sólo uno llamado tRNA met i puede iniciar la síntesis de proteínas[1].
El met-tRNA met junto con una molécula de GTP y la subunidad pequeña del ribosoma se unen al mRNA con la ayuda de unas proteínas denominadas factores de iniciación, en un lugar específico localizado cerca del codón de iniciación AUG
La traducción se realiza en sentido 5'3' a lo largo del mRNA. Al final de la etapa de iniciación se liberan los factores de iniciación y dejan paso
a la subunidad mayor del ribosoma, que se acopla con el complejo de iniciación para formar un ribosoma completo y funcional dotado de tres hendiduras o sitios de fijación: el sitio P,(peptidil) que queda ocupado con el tRNAmet, y el sitio A,(aminoacil) que está libre para recibir a un segundo tRNA cargado con su correspondiente aminoácido, y el sitio E ,( salida=exit).
[1] En bacterias el grupo amino de la metionina está modificado por el grupo formil, y se le denomina como N-formilmetionil-tRNA i f-met.

LE 17-17
Met
GTPInitiaDor tRNA
mRNA
5 3
Sitio de unión del RNAm
Smallribosomalsubunit
CODÓN DE INICIACIÓN
P site
5 3
Complejo de iniciación de la traducción
E A
SubunidadGrandeDelribosoma
GDP
Met
ASOCIACIÓN DE RIBOSOMAS E INICIACIÓN DE LA TRADUCCIÓN

TRADUCCION: ELONGACION Para que empiece el crecimiento de la cadena peptídica, es
necesario que un segundo tRNA unido a un aminoácido se coloque en la posición apropiada en el ribosoma.
Dos sitios del ribosoma están ocupados por moléculas de tRNA: Esta fase puede considerarse como una repetición de procesos
cíclicos que se suceden mientras dura la traducción del ARNm, pero a su vez cada ciclo de elongación consta de tres fases sucesivas.
B1) El sitio P está ocupado inicialmente por el tRNA y en el sitio A, que está vacío se introduce el tRNA cargado con su correspondiente aminoácido, cuyo anticodón es complementario al triplete siguiente. En esta etapa interviene el factor de elongación y la energía suministrada por la hidrólisis del GTP.

TRADUCCION: ELONGACION B2) La metionina unida con su grupo carboxilo al tRNA, rompe su
enlace y se vuelve a asociar mediante un enlace peptídico con el grupo amino (-NH2) del siguiente aminoácido que continua enlazado a su tRNA.
Esta reacción está catalizada por el enzima peptidil-transferasa, que se encuentra, a su vez, firmemente asentado en el centro del edificio ribosomal. El resultado es la formación de un dipéptido unido al tRNA alojado en el sitio A.
B3) Intervienen ahora en segundo factor de elongación que, utilizando la energía suministrada por el GTP, obliga al ribosoma a desplazarse exactamente tres nucleótidos a lo largo del ARNm (en sentido 5’3’).
Este desplazamiento provoca la expulsión del tRNA de la metionina del sitio P al E y la traslocación de todo el complejo peptídil del sitio A y el sitio P. De esta forma el sitio P queda ocupado por el péptido en formación unido al tRNA, y el sitio A está vacante y dispuesto para recibir a otro tARN cargado con otro aminoácido.

LE 17-18
Ribosoma preparado Para el próximo amioacil-tRNA
mRNA
5
Extremo aminoDel polipéptido
E
Psite
Asite
3
2
2 GDP
E
P A
GTP
GTP
GDP
E
P A
E
P A
1. Reconocimiento del codón
2. Formación del enlacePeptídico (peptidil transferasa)
3. Translocación

TRADUCCION. TERMINACION La síntesis de la cadena polipeptídica se detienen cuando,
en el momento de producirse la última traslocación, aparece en el sitio A uno de los tres codones de terminación en el ARNm (UAA,UAG,UGA).
En este momento, un factor proteico de terminación se une al codón de terminación e impide que algún aminoacil-tRNA se aloje en el sitio A, por lo que el peptidil transferasa se ve obligado a catalizar la transferencia de la cadena polipeptídica, no a otro aminoácido, puesto que está vacío el sitio A, sino a una molécula de agua, se produce la hidrólisis del enlace entre el péptido y el t RNA y la cadena proteica, separándose las dos subunidades ribosomales.

LE 17-19
Factor deliberación
Stop codon(UAG, UAA, or UGA)
5
3
5
3
5
Polypeptidelibre
3
Cuando un ribosoma alcanza un codón de terminación en el mRNAEl sitio A del ribosoma acepta unaProteína llamada factor de liberaciónEn lugar del tRNA
.El factor de liberación hidroliza el Enlace entre el tRNA en el sitio p y ´el último aminoácido de la cadenaPolipeptídica. De este modo se liberaEl polipéptido del ribosoma.
.Se liberan las dos subunidadesRibosómica s y los otros Componentes del complejo

POLIRRIBOSOMA Un solo ribosoma puede producir un polipéptido de tamaño
medio en menos de un minuto. Por lo general, sin embargo, se utiliza un único mRNA para
fabricar muchas copias de un polipéptido de forma simultánea porque varios ribosomas pueden traducir el mensaje de un mRNA al mismo tiempo.
Una vez que un ribosoma ha sobrepasado el codón de iniciación, un segundo ribosoma puede unirse al mRNA; de este modo, numerosos ribosomas pueden colgar a lo largo de un mRNA.
Con un M.E. se me pueden observar estos rosarios de ribosomas, llamados polirribosomas o polisomas.
Los polirribosomas se encuentran tanto en las célula s procariotas como eucariotas.
Permiten que las células fabriquen rápidamente muchas copias de un polipéptido.

LE 17-20
Ribosomes
mRNA
This micrograph shows a large polyribosome in a prokaryotic cell (TEM).
An mRNA molecule is generally translated simultaneouslyby several ribosomes in clusters called polyribosomes.
Incomingribosomalsubunits
Growingpolypeptides
End ofmRNA(3 end)
Start ofmRNA(5 end)
Polyribosome
Completedpolypeptides
m0.1

LE 17-20a
Incomingribosomalsubunits
Polipéptidosen crecimiento
Polipéptido completo
Inicio delmRNA(5)
Final delmRNA(3)
Polyribosoma
Una molécula de mRNA por lo general, se traduce de forma simultánea por varios ribosomas, en grupos llamados polirribosomas.

LE 17-20b
Ribosomas
mRNA
Microfotografía muestra un polirribosoma grande en una célula procariota(TEM).
m0.1

LE 17-21
Ribosomes
mRNAPéptidoseñal
PartículaDe reconocimientoDe la señal(SRP) Proteína
de laSRPCYTOSOL
El LUMEN ComplejoDe translocación
PéptidoSeñaleliminado
Membrana del RE
Proteina
MECANISMO DE SEÑALIZACIÓN PARA DIRIGIR LAS PROTEÍNAS AL RE.

LE 17-22RNA polymerase
DNA
Polyribosome
RNApolymerase
Direction oftranscription
mRNA
0.25
DNA
Polyribosome
Polypeptide(amino end)
Ribosome
mRNA (5 end)
m

LE 17-26TRANSCRIPTION
RNA PROCESSING
RNAtranscript5
Exon
NUCLEUS
FORMATION OFINITIATION COMPLEX
CYTOPLASM
3
DNA
RNApolymerase
RNA transcript(pre-mRNA)
Intron
Aminoacyl-tRNAsynthetase
AminoacidtRNA
AMINO ACID ACTIVATION
3
mRNA
A
P
E Ribosomalsubunits
5
Growingpolypeptide
E A
Activatedamino acid
Anticodon
TRANSLATION
Codon
Ribosome

FUENTES:GENÉTICA GRIFFITHS, BIOLOGIA CAMPBELL REECE, BRUÑO, S.M.