







Idiomas
Páginas
Jurídico


Búsqueda
Eduardo Morales/L. Enrique Sucar
Sesión 02
Fundamentos de Inteligencia Artificial

• Identificación y definición del problema • Identificación del criterio de evaluación • Generación de alternativas• Búsqueda de una solución y evaluación• Selección de opción y recomendación• Implementación
Solución de Problemas
Solución de muchos problemas en IA: principalmente búsqueda y evaluación

• La búsqueda es necesaria en muchos problemas e involucra introducir heurísticas
• Criterios, métodos, principios para decidir entre alternativas
• Representan un compromiso entre: (i) simplicidad y (ii) poder discriminativo
• No garantizan la mejor acción• Ayudan a reducir el número de evaluaciones
Heurísticas

• Define un espacio de estados (explícito / implícito) • Especifica los estados iniciales • Especifica los estados finales (metas) • Especifica las reglas que definen las
acciones disponibles para moverse de un estado a otro
Representación del espacio de estados

En este contexto:
Representación de espacio de estados
El proceso de solución de problemas = encontrar una secuencia de operaciones que transformen al estado inicial en uno final
Se requiere una estrategia de búsqueda
Reinas (Q)
Tablerode
Ajedrez
A=8 B=9 C=10
Q
A B C
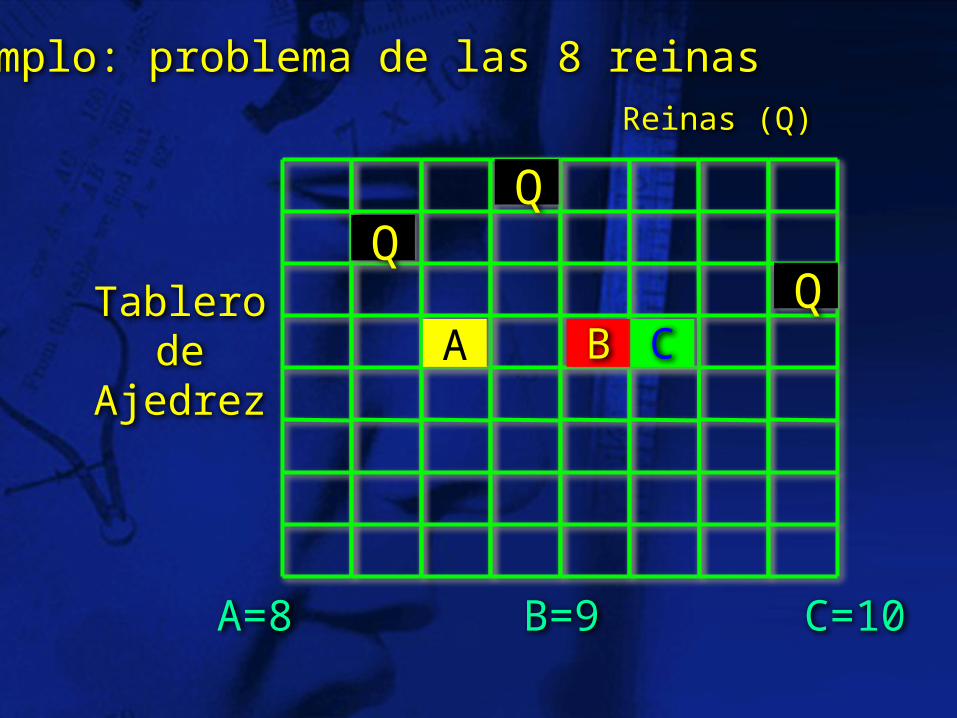
Ejemplo: problema de las 8 reinas

Ejemplo: problema de las 8 reinas
Posibles candidatos de heurísticas: • Preferir colocar reinas que dejes el
mayor número de celdas son atacar (mostrados en la figura)
• Ver cuál es el menor número de celdas no atacadas en cada renglón y escoger la que su número menor sea mayor. En el ejemplo: heu(A)=1, heu(B)=1, heu(C)=2

Para el problema de las 8 reinas podemos tener diferentes opciones:
• Solución incremental: acercarse a la meta haciendo decisiones locales
• Sistemática: no repetir y no excluir

• Transformar posibles soluciones globales hasta encontrar la meta
vs.• Construir poco a poco una solución
global
Medios (espacio de estados):

El problema del 8-puzzle

• Búsqueda exhaustica es impráctico• Se puede estimar qué tan cerca se está
de la solución• Posibles heurísticas:• Contar el número de cuadros que no
corresponden a la meta• Distancias Manhattan de los cuadros que
no corresponden a su lugar• Distancia del espacio al primer cuadro
fuera de su lugar
El problema del 8-puzzle

Otras ideas• Usar información extra (v.g., estimar distancias
con base en coordenadas)• Usar subestimaciones (e.g., TSP vs. árbol de
expansión mínimo)• Contruir una estrategia (e.g., detectar moneda
falsa. Con 12 monedas y pesando 3 veces)• Grafos AND/OR• Identificar meta crítica (e.g., Torres de Hanoi)

• Calidad de la solución (a veces puede no importar)
• Diferencia en complejidad entre una solución y la solución óptima
• En general, se busca encontrar la solución más barata
Cómo encontramos una buena heurística?
Factores a considerar:

1. Estructura simbólica que represente subconjuntos de soluciones potenciales (agenda)
2. Operaciones/reglas que modifiquen símbolos de la agenda y produzcan conjuntos de soluciones potenciales más refinadas
3. Estrategia de búsqueda que decida qué operación aplicar a la agenda
Qué necesitamos:

La representación normalmente juega un papel fundamental. E.g., juego de seleccionar digitos de forma alternada tal que la suma de 3 de ellos sumen 15
Representación

Terminología:
nodo, árbol, hoja, nodo-raíz, nodo-terminal, branching factor (factor de arborescencia), ramas, padres, hijos, árbol uniforme, ...

• Nodos expandidos (closed): todos los sucesores• Nodos explorados pero no expandidos : sólo algunos sucesores• Nodos generados pero no explorados (open) • Nodos no generados
Paso computacional primordial: expansión de nodos

Nodo raíz
Padre
Hijos
Ramas
Nodos terminales/hojas
Profundidad

Nodo expandido (closed)
Nodos generadosNo explorados (open)
Nodo no generadoNodo exploradoNo expandido

La estrategia de control es sistemática si:
1. No deja un sólo camino sin explorar (completo)
2. No explora un mismo camino más de una vez (eficiencia)
Propiedades

1. Completo: si encuentra una solución cuando ésta existe
2. Admisible: si garantiza regresar una solución óptima cuando ésta existe
Propiedades de algoritmos de búsqueda (heurísticas):

3. Dominante: un algoritmo A1 se dice que domina a A2 si todo nodo expandido por A1 es también expandido por A2 (“más eficiente que”)
4. Óptimo: un algoritmo es óptimo sobre una clase de algoritmos si domina a todos los miembros de la clase
Propiedades de algoritmos de búsqueda (heurísticas):

• Sin información: depth-first (en profundo) breadth-first (a lo ancho) … • Con información: hill climbing beam search best first …
Procedimientos de Búsqueda
Algún camino:

minimax alpha-beta SSS* SCOUT
El mejor camino: British museum branch and bound A*
Juegos
A B C
I
D E F
M
3
34
4 4
42
5 5
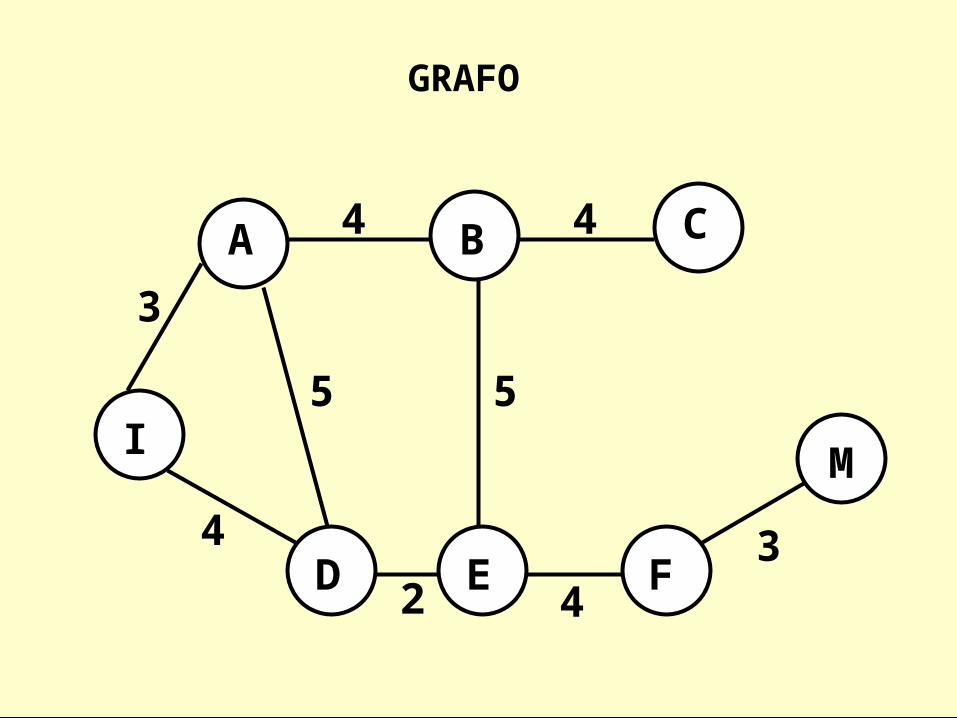
GRAFO

I
A D
B D A E
EC E B B F
D F B F C E A C M
M MC F
M
11
14
19 19 17
17
25
15 15 13
ÁRBOL DE BÚSQUEDA

Algoritmo Genérico de Búsqueda sin información
Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento y añade sus sucesores a la agenda

Depth first - backtracking (LIFO)
Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento y añade sus sucesores al frente de la agenda

DEPTH-FIRST SEARCH
(I)
(A D)
(B D D)
(C E D D)
(E D D)
(D F D D)
(F D D)
(M D D)
I
A D
B D A E
EC E B B F
D F B F C A C M
M MC F
M
11
14
19 19 17
17
25
15 15 13
E

• Backtracking: genera un solo sucesor a la vez
• Depth-bound (casi todos): limitar la búsqueda hasta cierto límite de profundidad
• Interative-deepening: explorar a profundidad progresivamente
• Con algo de información: ordena los nodos expandidos
Problemas: árboles con caminos de profundidad muy grande
Variantes:

Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento y añade sus sucesores al final de la agenda
Problemas: árboles con arborescencia muy grande
Variantes: búsqueda de costo uniforme
Breadth first

I
A D
B D A E
EC E B B F
D F B F C E A C M
M MC F
M
11
14
19 19 17
17
25
15 15 13
ÁRBOL DE BÚSQUEDA

BR
EA
DT
H-F
IRS
T S
EA
RC
H(I)
(A D)
(D B D)
(B D A E)
(D A E C E)
(A E C E E)
(E C E E B)
(C E E B B F)
1
2
3
0
(E E B B F)
(E B B F D F)
(B B F D F B F)
(B F D F B F C E)
( F D F B F C E A C)
(D F B F C E A C M)4
(F B F C E A C M)
(B F C E A C M M)
(F C E A C M M C)
(C E A C M M C M)
(E A C M M C M)
(A C M M C M F)
(C M M C M F)
(M M C M F)5

Es completo (encuentra una solución si existe) y óptimo (encuentra la más corta) si el costo del camino no decrece con la profundidad del nodo
Problemas: Requiere mucha memoria y tiene problemas con árboles con arborescencia muy grande
Variantes: búsqueda de costo uniforme
Breadth-first (búsqueda a lo ancho)

Requerimientos de tiempo y memoria para breadth-first. Factor de arborecencia = 10; 1,000 nodos/sec; 100 bytes/nodo
Profund.
Nodos Tiempo Memoria
10
2
4
68
0
1214
1 1 miliseg. 100 bytes111 .1 seg.
11,111 terabytes
11 kilobytes1 megabyte
111 megabytes
11 gigabytes
1 terabyte111 terabytes
11,111
10 6
10 8
10 10
10 12
10 14
11 seg.
18 min.
31 hr.128 días35 años3500 años

• Se explora al mismo tiempo del estado inicial a la meta y de la meta al estado inicial
• Si el factor de arborecencia es igual en ambos sentidos se pueden hacer grandes ahorros
• Se requieren operadores reversibles• Pueden existir muchas metas• Se requiere una estrategia eficiente para revisar
si un nodo aparece en la otra mitad de la búsqueda
Búsqueda Bidireccional

Comparación en nodos buscados: Si n = profundidad del árbol b = braching factor d = profundidad de un nodo meta
Complejidad

depth-first: • mejor caso: d nodos buscados • peor caso:
-n
i= 0
bi-
i= 0
bi
n d
= bn+1- bn+1- d
b-1 b
n

• mejor caso:
-
i= 0
bid 1
=b 1-- 1bd
bd 1-
breadth-first:
• peor caso:
i= 0
bid
=b 1-- 1b
d+1 bd

Comparación de estrategias. b = factor de arborecencia; d = profundidad solución; m = máxima profundidad árbol; l = límite de profundidad.
Criterio Breadth Costo Depth Depth Iterative Bidireccionalfirst uniforme first limited deepening
Tiempo
Espacio
Completo
Optimo
bd
bd
bd
bd
si
si si
si
bm
bl
bd
bd/2
b X m b X l b X d bd/2
no
no
no si si
sisisi(si l ≥d)

Algoritmo Genérico de Búsqueda con información
Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento, añade sus sucesores a la agenda ordena todos los elementos de la agenda

Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento y añade sus sucesores a la agenda ordena todos los elementos de la agenda selecciona el mejor y elimina el resto
Algoritmos con Información
Hill-Climbing

Hill climbing
Heurística: ve a la ciudad más cercana
(I)
(A D)
(D B)
(E C)
I
A D
B D A E
EC E B B F
D F B F C A C M
M MC F
M
11
14
19 19 17
17
25
15 15 13
E
BÚSQUEDA HILL-CLIMBING

Hill Climbing
• Problemas obvios: máximos/mínimos locales, valles y riscos
• Para evitarlos a veces se empieza la búsqueda desde diferentes puntos aleatorios (random-restart hill-climbing)
• Dado su bajo costo computacional es una de las estratgias más utilizadas en optimización y en aprendizaje computacional

Best-first
Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento y añade sus sucesores a la agenda ordena todos los elementos de la agenda
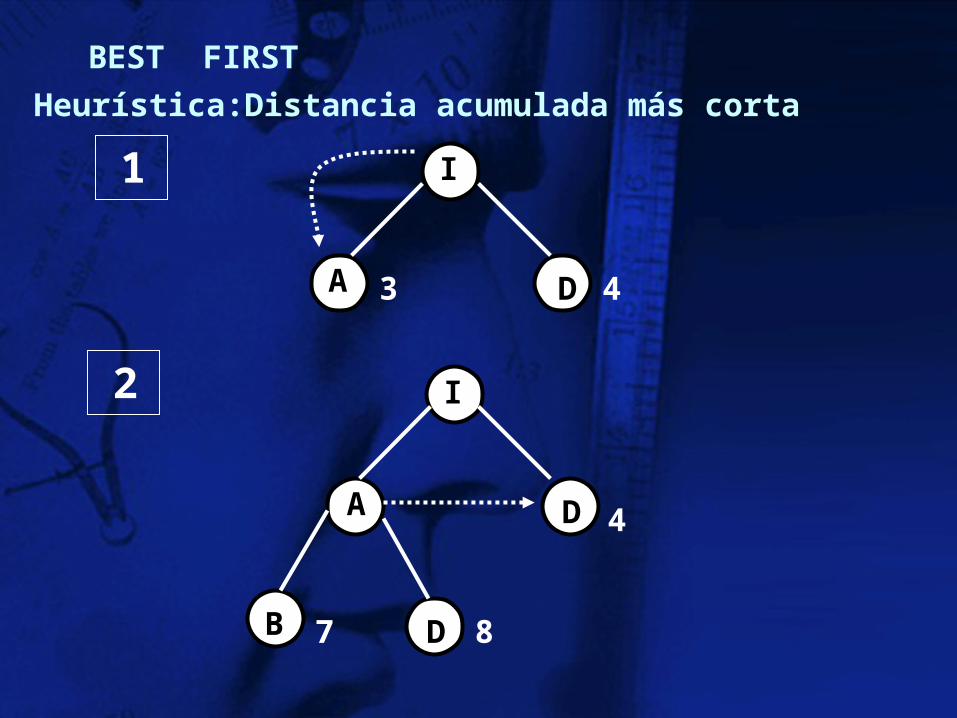
BEST FIRST
Heurística:Distancia acumulada más corta
I
A D
I
A D
B D
3 4
7 8
4
1
2

I
A D
B D A E
7 8 9 6
3

I
A D
B D A E
7 8 9
E
B F
11 10
4

I
A D
B D A E
8 9
E
B F
11 10
5
B
C E
1211

I
A D
B D A E
9
E
B F
11 10
6
B
C E
1211
D
E10

I
A D
B D A E
F B B E E C E
F B
11 12
15 14
13 11 10
7
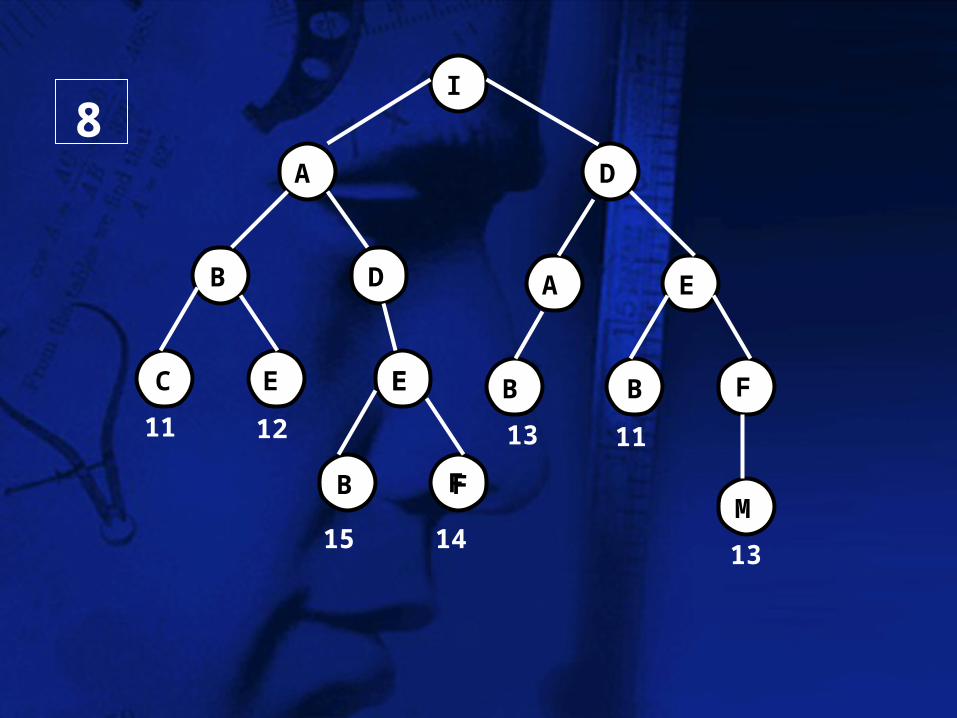
I
A D
B D A E
F B B E E C E
F
11 12
15 14
13 11
F B M
13
8

Usando costo estimado
• Usar costo acumulado no necesariamente guía la búsqueda hacia la meta
• En general se utiliza una estimación del costo del camino hacia la meta
• Debido a que se guardan todos los nodos en memoria su complejidad en espacio es igual a la del tiempo

Híbidos
• Usar BF hasta agotar memoria seguido de BT• Usar BT hasta cierta profundidad seguido de
BF• Tener un BF local con un BT global

Beam search
Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta si el primer elemento es la meta entonces acaba si no elimina el primer elemento y añade sus sucesores a la agenda ordena todos los elementos de la agenda y selecciona los N mejores (los demás eliminalos)
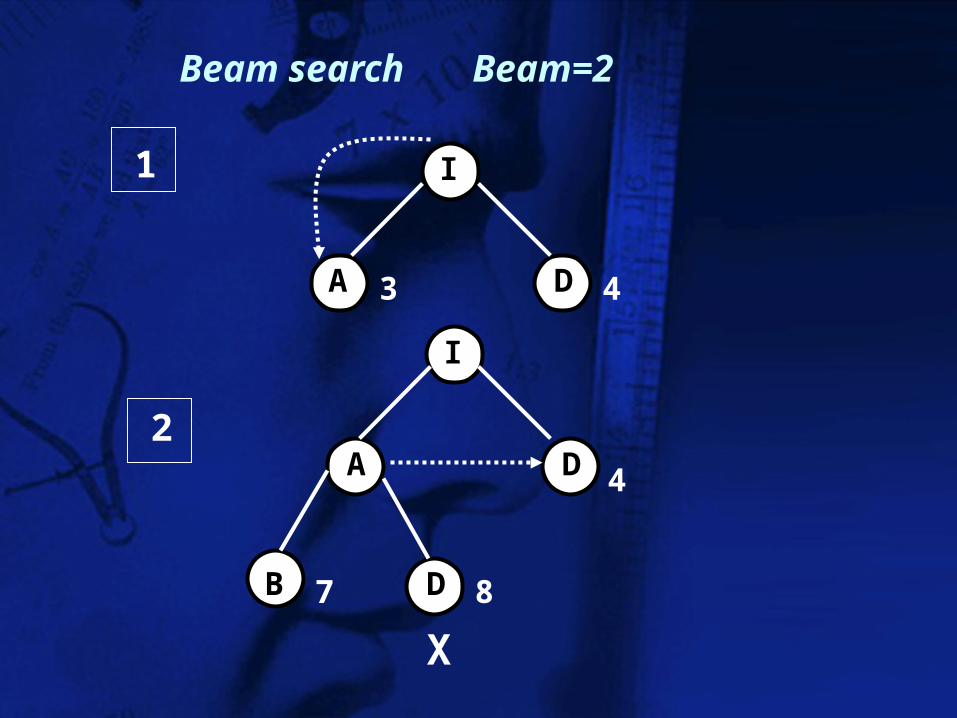
Beam search Beam=2
I
A D
I
A D
B D
3 4
7 8
4
X
1
2

I
A D
B A E7 9 6
X
3

I
A D
B E7
E
B F11 10
X
4

I
A D
B EE
F 10
B
C E 1211
X
5
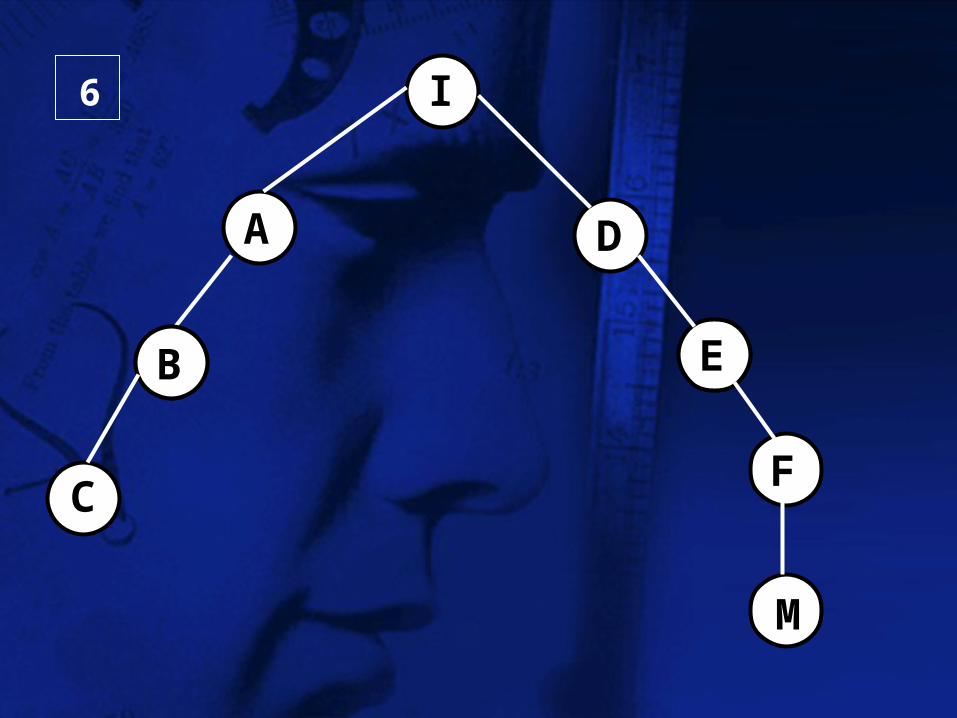
I
A D
B EE
F
B
C
M
6

Espacio Usado
• depth-first:(b-1)*n + 1 • breadth-first: b• hill-climbing: 1 • best-first: entre b y b• beam-seach: beam
d
dn

Mejor Solución
Cuando importa el costo de encontrar una solución
Si g(P) es el costo de camino o solución parcial, la solución óptima es aquella con g(P) mínima.
Una forma segura: búsqueda exhaustiva y seleccionar el de menor costo (Brittish Museum)

Best-first no es admisible, pero con una pequeña variante ya lo es.
Branch and Bound trabaja como best-first pero en cuanto se encuentra una solución, sigue expandiendo los nodos de costos menores al encontrado

Branch and Bound
Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta y los demás nodos sean de costos mayores o iguales a la meta si el primer elemento es la meta y los demás nodos son de menor o igual costo a la meta entonces acaba si no elimina el primer elemento y añade sus sucesores a la agenda ordena todos los elementos de la agenda
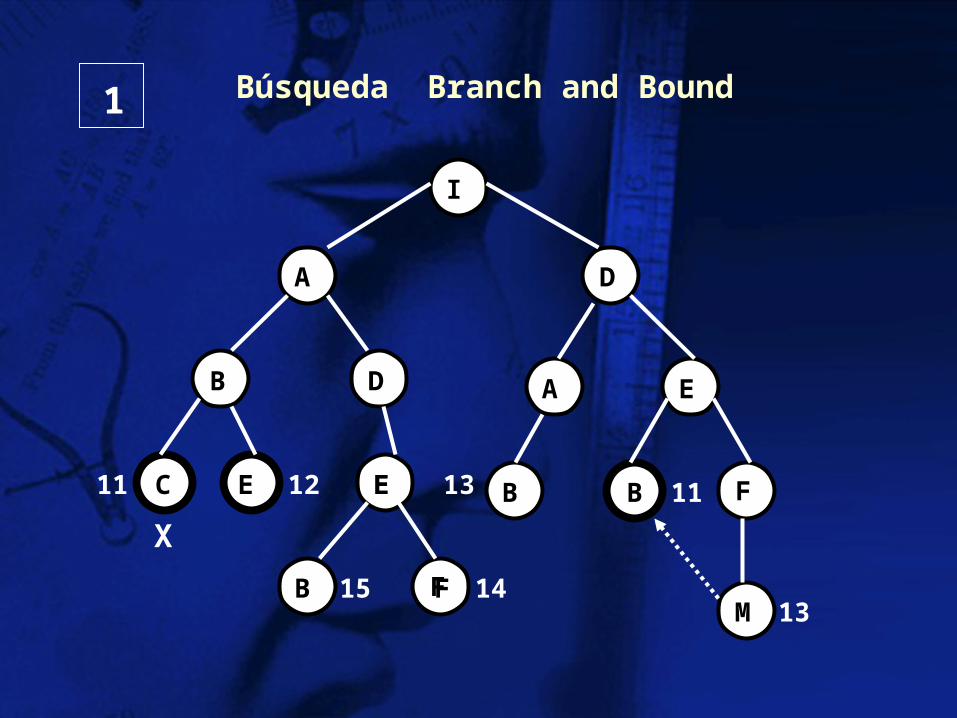
I
A D
B D A E
F B B E E C E
F
11 12
15 14
13 11
F M 13
X
Búsqueda Branch and Bound
B
1

I
A D
B D A E
F B B E E C E
F
11
12
15 14
13
F B M 13 A C
15 15
2

I
A D
B D A E
F B B E C E
F
11
15 14
13
F B M
13
A C
15 15
D F
14 16
3

Idea: no explorar caminos a los que ya llegamos por caminos más cortos/baratos
El algoritmo es igual sólo hay que añadir la condición:
elimina todos los caminos que lleguen al mismo nodo excepto el de menor costo
Dynamic Programming
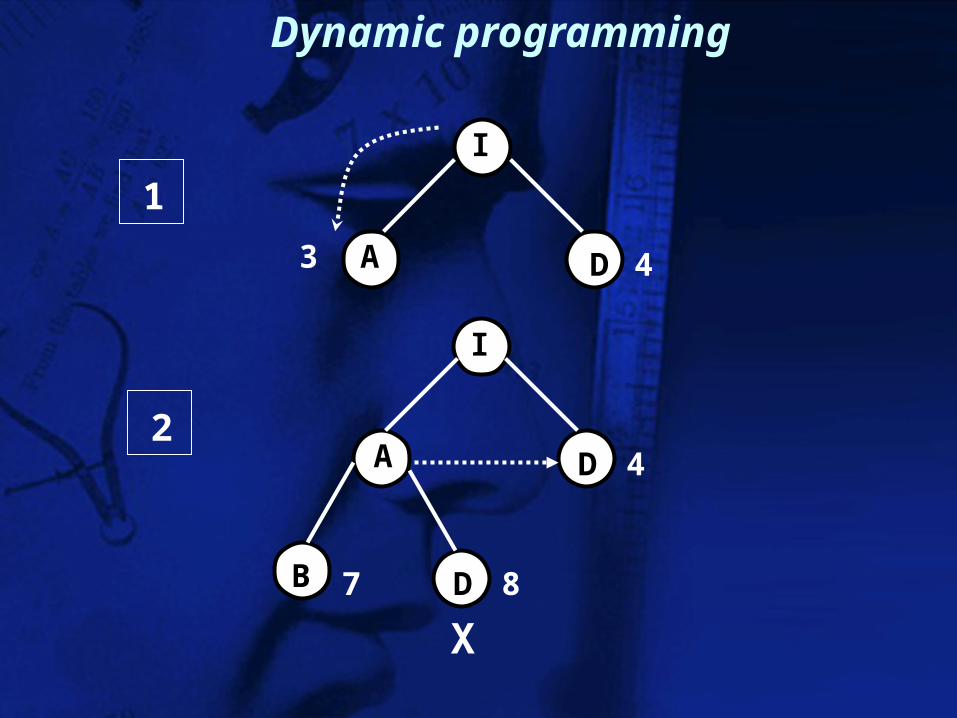
I
A D3 4
Dynamic programming
I
A D
B D7 8
X
4
1
2

I
A D
B A E7 9 6
X
43
3

I
A D
B E7 E
B F13 10
3 4
6
X
4

I
A D
B E7 E
E11 10
3 4
6
X
F12C
5

I
A D
B E7 E
1110
3 4
6
FC
M
6

A*: utiliza dos medidas
Idea: usar estimaciones de los costos/distancias que faltan junto con los costos/distancias acumuladas
estim(camino que falta) +costo(camino recorrido)estim(total) =
Las estimaciones no son perfectas, por lo que se usan sub-estimaciones

subestim(total) =subestim(camino que falta)
+
De nuevo expande hasta que los demás tengan sub-estimaciones más grandes (v.g., subestimaciones de distancias entre ciudades pueden ser líneas rectas)
Es admisible si nunca sobrestima
costo(camino recorrido)

Crea una agenda de un elemento (el nodo raíz) hasta que la agenda este vacía o se alcance la meta y los demás nodos sean de costos mayores o iguales a la meta si el primer elemento es la meta y los demás nodos son de menor o igual costo a la meta entonces acaba si no elimina el primer elemento y añade sus sucesores a la agenda ordena todos los elementos de la agenda de acuerdo al costo acumulado más las subestimaciones de los que falta

I
A D13.4 12.9
I
A D
A E
13.4
19.4 12.9
A*1
2

I
A D
EE
F 13.0
13.4
B17.7
A19.4
3

I
AD
EE
F
13.0
13.4
B17.7
A19.4
M
4

Comparación Interactive Deepening (IDS) con A* con dos heurísticas (h1 y h2). Resultados promedios de 100 instancias del 8-puzzle.
Costo de búsqueda Arborescencia
d
24
8
10121416
18202224
6
IDS
10112680
638447127
3644043473941
---
--
A*(h )1 A*(h )2 IDS
613203993
22753913013056
727618094
39135
61218253973
113211363
6761219
1641
2.452.872.732.802.792.782.83---
--
1.791.481.341.331.381.421.441.451.461.471.481.48
A*(h )1 A*(h )2
1.791.45 1.301.241.221.241.231.251.261.271.281.26
efectiva

Variantes de A*
• Pesar la combinación de g y h: f(n) = (1-w)g(n) + w h(n)• Interactive deepening A*: IDA*• Aceptar un margen de error: A*• Con memoria limitada: MA*• Mejoras dinámicas: actualizar
dinámicamente la subestimación

• Si el tamaño de búsqueda es pequeño (rara vez), podemos hacer búsqueda exhaustiva • Sin información depth-first con
progressive- deepening • Branch and bound en general está bien • Dynamic programming cuando existen muchos posibles caminos con cruces • A* cuando podemos tener una buena subestimación
¿Cuándo usamos cada una?

Todas estas estrategias tienen su equivalente para árboles AND-OR
Para hacer un depth first en un árbol del tipo AND - OR
IF alguno de los nodos AND falla, realiza backtracking hasta el ultimo nodo OR IF alguno de los nodos OR falla realiza backtracking al nodo inmediato anterior

En general se usan 2 funciones de estimación:
• f1: evalúa sobre los nodos (como antes) • f2: evalúa sobre árboles

IF nodo terminal es meta: S Else: N IF nodo no-terminal es AND: S si todos son S N si alguno es N IF nodo no-terminal es OR: S si alguno es S N si todos son N
Para etiquetar Solución (S) / no-solución (N):
Similarmente para A* existe un correspondiente AO*

Búsqueda en árbol And/Or
E
N N N N NS S S

Búsqueda en grafos And/Or

Búsqueda en grafos And/Or

Búsqueda en grafos And/Or

Búsqueda en grafos And/Or
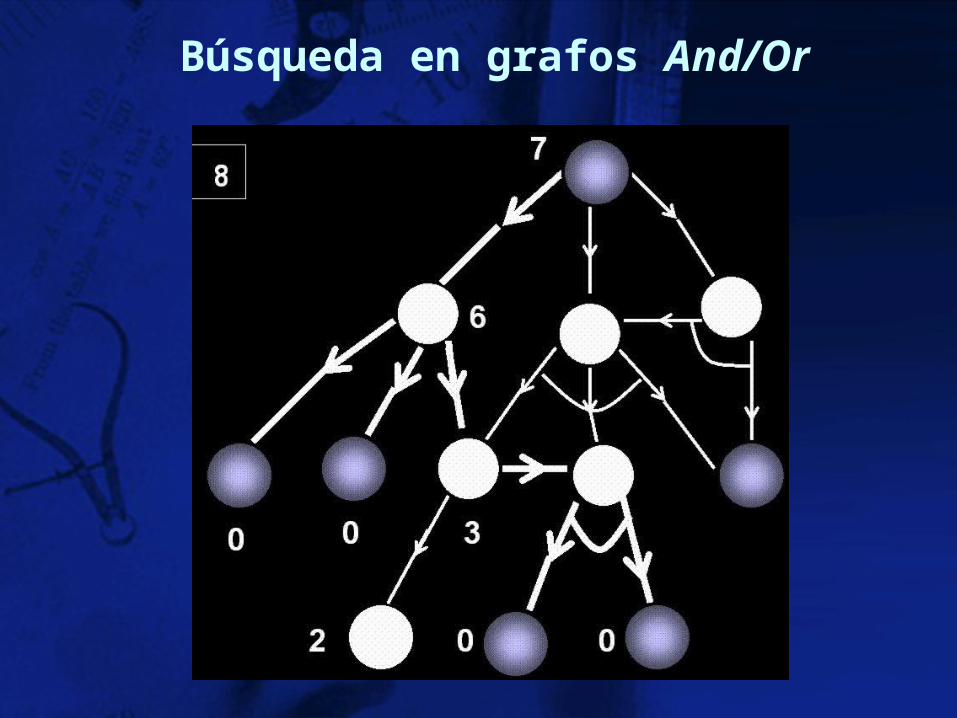
Búsqueda en grafos And/Or

• analizando modelos simplificados
¿Cómo encontrar heurísticas?
• soluciones por descomposición: si cada submeta se puede solucionar independientemente de las otras
• soluciones parcialmente ordenadas• usar probabilidades

busca(NodoI,NodoF) :- busca_aux([NodoI],NodoF).
busca_aux([NodoF | __],NodoF). busca_aux(Agenda,NodoF) :- nva_agenda(Agenda,NAgenda), busca_aux(NAgenda,NodoF).
Búsqueda en Prolog

% depth-first nva_agenda([N1 Agenda],NAgenda) :- expande(N1,Nodos), append(Nodos,Agenda,NAgenda). % breadth-first nva_agenda([N1 Agenda],NAgenda) :- expande(N1,Nodos), append(Agenda,Nodos,NAgenda).

% best first nva_agenda([N1 Agenda],NAgenda) :- expande(N1,Nodos), append(Nodos,Agenda,AgendaInt), sort(AgendaInt,NAgenda).
% hill-climbing nva_agenda([N1 Agenda],[Mejor]) :- expande(N1,Nodos), append(Nodos,Agenda,AgendaInt), sort(AgendaInt,[Mejor __]).

% beam-search nva_agenda(Beam,[N1 Agenda],NAgenda) :- expande(N1,Nodos), append(Nodos,Agenda,AgendaInt), sort(AgendaInt,AgendaOrd), nthelems(Beam,AgendaOrd,NAgenda).

(defun busca (nodoI, nodoF) (busca2 (list nodoI) nodoF)) (defun busca2 (agenda nodoF) (cond ((null agenda) nil) ((equal (car agenda) nodoF)) (t (busca2 (nva_agenda (car agenda) (cdr agenda)) nodoF))))
Búsqueda en Lisp

; breath-first (defun nva_agenda (nodo agenda) (append (expande nodo) agenda)) ; depth search (defun nva_agenda (nodo agenda) (append agenda (expande nodo))) ; best-first search (defun nva_agenda (nodo agenda) (sort (append (expande nodo) agenda)))

; hill-climbing (defun nva_agenda (nodo agenda) (list (car (sort (append (expande nodo) agenda))))) ; beam search (defun nva_agenda (beam nodo agenda) (nthelems beam (sort (append (expande nodo) agenda))))

Partiendo del siguiente estado inicial del 8-puzzle y con el siguiente estado final realiza las siguientes estrategias de búsqueda:• Breadth-first• Beast-first• Hill-climbing
TAREA
Top Related