







Idiomas
Páginas
Jurídico


UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
1 Mg. Miguel Angel Macetas Hernández
19 17 16 14 12 11
2 0
1 5
1 0
5
0

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
2 Mg. Miguel Angel Macetas Hernández
I. ESTIMACIÓN DE PARÁMETROS
1.1. Estimación puntual
Para estimar los parámetros de una población, es necesario disponer de algunos datos que
provengan de dicha población. Cualquier muestra de observaciones proporciona cierto conocimiento
acerca de la población de la cual proviene. Para medir el error muestral es necesario que dicha
muestra sea ALEATORIA.
Desde el punto de vista algebraico, el estimador de un parámetro es una función de las
observaciones muestrales t x x xn( , ,........ )1 2 , que puede ser lineal, cuadrática, etc.
Ejemplos:
2222 ˆnesobservaciolasdecuadraticafuncion1
ˆnesobservaciolasdelinealfuncion1
SXxn
S
Xxn
X
i
i
El resultado numérico que se obtiene es la estimación del parámetro, en tanto que la expresión
matemática (o algebraica) es el estimador del parámetro. Puede haber varios estimadores del
mismo parámetro, de los cuales se pretende elegir el mejor, en base a las características o
propiedades que se requiera del mismo.
1.2. Propiedades de los estimadores
a) Insesgado o no viciado:
Un estimador se dice Insesgado si su esperanza es igual al parámetro. Es decir:
)ˆ(ˆ Einsesgadoes
Por el contrario, el estimador se dice viciado si su esperanza es distinta al parámetro.
viciadoesE ˆ)ˆ(
b) Consistente:
Un estimador se dice consistente si converge al parámetro, es decir, si su distribución se
concentra alrededor del parámetro a medida que aumenta el tamaño de la muestra, de forma tal
que el error de muestreo tiende a desaparecer. Es decir:
pequeñomentearbitrarianparaP
sideeconsistentestimadorunes
,,1ˆ
:ˆ
Si un estimador es insesgado (o asintóticamente insesgado), será consistente si su variancia
tiende a cero. Es decir:
econsistentesVE ˆ0)ˆ()ˆ(
o bien : econsistentesVE ˆ0)ˆ()ˆ(
c) Eficiente:
Decimos que un estimador no viciado es eficiente si es de mínima variancia. O sea, el
estimador se dice eficiente si su variancia es menor que la de cualquier otro estimador del mismo
parámetro. Es decir:
Si ̂ es un estimador no viciado de , entonces ̂ es eficiente si *̂ :

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
3 Mg. Miguel Angel Macetas Hernández
1)ˆ(
)ˆ(,,)ˆ()ˆ(
*
*
V
VseaoVV
Eficiencia relativa:
Dados dos estimadores no viciados del mismo parámetro, se dice que es más eficiente aquél
que tiene menor variancia. Es decir:
Sean 1 2y dos estimadores de , decimos que
; ( ) ( )( )
( )
1 2 1 2
1
2
1es mas eficiente que si V VV
V
d) Suficiente:
Un estimador se dice suficiente si contiene (o absorbe) toda la información proporcionada por la
muestra, en lo que respecta al parámetro.
e) Invariancia:
Un estimador se dice invariante cuando una función del mismo es un buen estimador de la
función del parámetro. Es decir: es invariante g g( )
II. Métodos de estimación puntual
1.-Método de los momentos: Consiste en estimar los momentos poblacionales a través de los momentos
muestrales.
2.-Método de los Mínimos Cuadrados: Consiste en encontrar estimadores de los parámetros de forma tal
que minimicen la suma de los cuadrados de los desvíos. Con este método se obtienen estimadores
no viciados y consistentes, pues el mismo garantiza mínima variancia y suma de desvíos igual a
cero.
3.-Método de Máxima Verosimilitud: Consiste en encontrar estimadores de los parámetros de forma tal
que maximicen la función de probabilidad de la muestra. Para ello, es imprescindible conocer la
distribución de la variable en la población. Este método proporciona los mejores estimadores, que
gozan excelentes propiedades: Insesgado (o bien, asintóticamente insesgado), Consistente,
Eficiente, Suficiente, Invariantes y de distribución asintóticamente Normal.
Pasos a seguir para obtener los estimadores de máxima verosimilitud
Primero se obtiene la función de probabilidad de la muestra
n
iin xfxxxf
121 ,....., , también
llamada función de verosimilitud y su expresión está dada en términos de los parámetros y de las
observaciones. Comúnmente se la simboliza con ,XL , donde X es el vector aleatorio que
representa a la muestra (o valores observados) y es el parámetro que se quiere estimar.
Luego se pretende hallar el valor de que maximice a ,XL valor que también maximiza al
logaritmo de la función : ln ,XL , (ya que el logaritmo es una función monótona creciente). Por lo
tanto, el segundo paso es aplicarle logaritmo a la función de probabilidad de la muestra ( o de
verosimilitud) con el fin de simplificar la derivada.
Se sabe que una función continua y derivable alcanza su valor máximo en un punto para el cual se
anula su derivada. Si la función de probabilidad de la muestra satisface este requisito, entonces el tercer

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
4 Mg. Miguel Angel Macetas Hernández
paso es derivar la función obtenida ln ,XL respecto del parámetro , y luego hallar el valor de
(o la expresión de ) para el cual se satisface:
0,
XL.
Inconvenientes:
El método de máxima verosimilitud asegura que los estimadores obtenidos son los de mínima
variancia, pero no indica cual sea esta variancia.
El método de máxima verosimilitud asegura que los estimadores obtenidos son los que asignan
máxima probabilidad a la muestra, pero obviamente se admite que dicha muestra sea posible de
obtener aún con diferentes valores del parámetro.
Estas son razones por las cuales la estimación puntual se torna impracticable (sin interés práctico), y se
prefiere la estimación por intervalos, ya que provee de más información.
III. Estimación por Intervalos
Consiste en encontrar un conjunto de números reales que conforman posibles valores del
parámetro.
La estimación por intervalo se realiza utilizando un nivel de confianza, que simbolizamos con 1- y
que representa la probabilidad de que dicho intervalo contenga al verdadero valor del parámetro .
La construcción del intervalo de confianza consiste en hallar los límites inferior y superior en función
de la muestra obtenida. Para su obtención es necesario conocer la distribución del estimador del
parámetro (distribución que obviamente dependerá del parámetro .). Generalmente se
construye una nueva variable en la cual intervienen el estimador y el parámetro , dicha variable
recibe el nombre de estadística de prueba y la simbolizamos g( , ) .
Su ventaja reside en que la distribución de la estadística de prueba ya no depende del parámetro
siendo una distribución standard con los valores de probabilidad tabulados correspondiente a un
gran número de valores posibles de la variable.
Construcción de los intervalos de confianza
3.1.1. Intervalo de Confianza para la media en poblaciones normales
Sea (X1, X2,..., Xn) una muestra aleatoria extraída de una población normal, luego,
i = 1... n : X ~ N( , ) .
Por lo tanto tenemos que:
X1 , X2 , ... , Xn iid N( , ). Xn
Xi
Nn
1
~ ( , )
y X
n
N
~ ,0 1
a) Si 2 es conocido, entonces el intervalo para se obtiene
122
z
n
XzP

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
5 Mg. Miguel Angel Macetas Hernández
siendo z/2: el valor de la variable normal standarizada que está superado con una probabilidad /2.
De dicha expresión se obtiene que:
confianzadeelconn
zXn
zX )%1(22
b) Si 2 es desconocido, se utiliza su estimador S2 y la distribución : X
sn
tn
~ 1
Entonces el intervalo para se obtiene de :
1
2,1
2,1 nn t
ns
XtP
siendo tn-1,/2 el valor de la variable t-student con n grados de libertad, superado con probabilidad /2
De dicha expresión se obtiene que :
confianzadeelconn
stX
n
stX
nn)%1(..
2,1
2,1
Intervalo de Confianza para la proporción
Sean X1 , X2 , ... , Xn iid Bi ( p ) . X = Xi ~ B ( n , p ) .
Para n suficientemente grande, la variable binomial se distribuye aproximadamente normal ,
aproximadamente : X ~ npqnpN , y
n
pqpNX
nh
i,~
1
donde hn
pq es un valor desconocido puesto que no se conoce el valor del parámetro p, por lo
tanto se utiliza el estimador del desvío sh h
nh h
( )
1, obteniendo la siguiente distribución, que es
aproximadamente normal: h p
h h
n
N
( )~ ,
10 1
Dicha aproximación es buena para muestras de tamaño suficientemente grandes, y el mínimo tamaño de
muestra depende del valor de h. W.G. Cochran da una regla práctica para ser utilizada en la búsqueda de
intervalos de confianza del 95%, correspondientes a la proporción poblacional p.
Proporción empírica h Tamaño mínimo de muestra n
0.5 30
0.4 o 0.6 50
0.3 o 0.7 80
0.2 0 0.8 200
0.1 o 0.9 600
0.05 o 0.95 1400
Para estos valores de n se obtiene una buena aproximación Normal válida para la construcción de
intervalos del 95% de confianza.

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
6 Mg. Miguel Angel Macetas Hernández
n
hhzhp
n
hhzh
)1()1(22
con el (1-).100% de confianza
Intervalo de Confianza para la diferencia de medias de dos poblaciones normales independientes
Sean ( X1 , X2 , ... , Xn ) y ( Y1 , Y2 , ... , Ym ) dos muestras aleatorias extraídas de poblaciones
normales , luego :
i = 1 .. n : Xi ~ N(x, x ) .
j = 1 .. m : Yj ~ N(y, y ).
Por lo tanto tenemos que X1 , X2 , ... , Xn iid N( x, x )
Y1 , Y2 , ... , Ym iid N( y, y ) con Xi independiente de Yj
ntesindependieYeXconm
NYm
Y
nNX
nX
y
yi
xxi
),(~1
),(~1
Entonces
X Y Nn m
X Y
n m
Nx yx y x y
x y
~ ; ~ ,
2 2
2 20 1
a) Si x
yy
2 2 son conocidos, el intervalo de confianza para yx se obtiene de la siguiente
manera:
mnzYX
mnzYX
yxyx
yx
22
2
22
2
con el (1-).100% de confianza
b) Si x
yy
2 2 son desconocidos pero iguales 222 yx , entonces el estimador de ambos es
mnSy
mn
SmSnS Ayx
yx
A
11ˆ
2
11ˆ 22
22
22
Luego, como :
2
2
~11
mn
A
yxt
mnS
YX
el intervalo de confianza para x y se obtiene de la siguiente manera :
mnStYX
mnStYX AgyxAg
11.
11. ,2,2
con el (1-).100% de confianza , siendo g = n+m-2

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
7 Mg. Miguel Angel Macetas Hernández
Nota:
Para n y m suficientemente grandes, 1,02 NtD
mn
Distribución de la diferencia de proporciones muestrales de dos poblaciones independientes
X1 , X2 , ... , Xn iid Bi(p1)
Y1 , Y2 , ... , Ym iid Bi(p2) con Xi independiente de Yj i , j
Sean hn
X y hm
Yi j1 2
1 1
Luego, h1 y h2 son independientes y se distribuyen aproximadamente normal :
m
qp
n
qpppNhh
ntesindependien
qppNhy
n
qppNh
22112121
2222
1111
;~
,~,~
donde
p q
n
p q
m h h
1 1 2 2
1 2
es desconocido, ya que no se conocen los parámetros p1 y p2 . Luego se
utiliza el estimador de este desvío: m
hh
n
hhS hhhh
)1()1(ˆ
2211)( 2121
obteniendo la siguiente distribución aproximadamente normal h h p p
h h
n
h h
m
N1 2 1 2
1 1 2 21 10 1
( )
( ) ( )~ ( , )
válida para muestras suficientemente grandes.
Los intervalos de confianza para p p1 2 serán de la forma:
h h z S p p h h z Sh h h h1 2
21 2 1 2
21 2 1 2
con el (1-).100% de confianza
Intervalo de Confianza para la variancia en poblaciones normales
Sean X1 , X2 , ... , Xn iid N( , ). Entonces X
N i ni
~ ( , ) ,....0 1 1
Xi
i
n
n
1
22~ y
X Xi
i
n
n
1
2
12~
Como X X n S
i
i
n x
1
2 2
2
1 tenemos que:
( ).~
( )n S x
n
12
2 1
2
Basado en esta información, sabemos que:

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
8 Mg. Miguel Angel Macetas Hernández
1
).1(2
2;12
2)(2
21;1 n
x
n
SnP
de donde se obtiene el intervalo de confianza para 2
221;1
2)(2
22;1
2)(
221;1
2)(
2
22;1
).1().1(
1
).1(
1
n
x
n
x
nxn
SnSn
Sn
con el (1-).100% de confianza .
Distribución del cociente de variancias muestrales de poblaciones normales independientes
X1 , X2 , ... , Xn iid N(x, x ); Y1 , Y2 , ... , Ym iid N(y, y ) con Xi independiente de Yj i , j
Luego se deduce que:
x x n S
yy y n S
i
xi
nx
x
n
j
yj
m y
y
m
1
2 2
2 1
2
1
2 2
2 1
2
1
1
( ).~
( ).~
( )
( )
Por ser independientes resulta que :
( )
( )
( )
( )
( ). ~
( )
,
n S
n
m Sy
m
S
S
y
x
F
x
x
y
x
y
n m
1
1
1
1
2
2
2
2
2
2
2
2 1 1
y análogamente se deduce que:
S y
S y
F
x
xm n
( ). ~ ,
2
2
2
2 1 1
Basado en esta información, sabemos que:
P F
Sy
Sy
Fm n
x
xm n
1 1 1 2
2
2
2
2 1 1 2 1, ; , ;
( ).
que equivale a:
PF
Sy
Sy
F
m n x
xm n
11
1 1 2
2
2
2
2 1 1 2
, ;
, ;
( ).
de donde se obtienen los intervalos de confianza para los cocientes de las variancias
x
xy
yy
2
2
2
2

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
9 Mg. Miguel Angel Macetas Hernández
Sx
S Fy
Sx
SF
y m n
x
y
m n
( ).
( ).
, ;
, ;
2
2
1 1 2
2
2
2
2 1 1 2
1
con el (1-).100% de confianza
Sy
S Fx
Sy
SF
x m n
y
x
m n
( ).
( ).
, ;
, ;
2
2
1 1 2
2
2
2
2 1 1 2
1
con el (1-).100% de confianza
Aplicaciones del Teorema Central del Límite
Intervalo de confianza para la media en poblaciones de distribución desconocida
Si la distribución de X no se conoce, pero se trata de una muestra suficientemente grande, se aplica el
Teorema Central del Límite y así se obtienen los intervalos para
a)
finitasspoblacioneen1
yinfinitasspoblacioneen
)%1(..
22
2
N
nN
nncon
confianzadeelconzXzXconocesesi
xx
xx
xx
b)
finitasspoblacioneen1
yinfinitasspoblacioneenˆ
)%1(..
22
2
N
nN
n
SS
n
SScon
confianzadeelconSzXSzXconocesenosi
xx
xxx
xx
Intervalo de confianza para la diferencia de medias en poblaciones de distribución desconocida
Si las distribuciones de X y de Y no se conocen, pero se trata de muestras suficientemente grandes, se
aplica el Teorema Central del Límite y así se obtienen los intervalos para la diferencia entre las medias
poblacionales usando la distribución Normal:
a) si se conocen las variancias poblacionales
X Y zn m
X Y zn m
x y
x yx y
2
2 2
2
2 2
. . con el (1-).100% de confianza
b) si no se conocen las variancias poblacionales, pero se las supone iguales, entonces
X Y z Sn m
X Y z Sn m
A x y A 2 2
1 1 1 1. . con el (1-).100% de confianza
c) si no se conocen las variancias poblacionales, y tampoco puede suponérselas iguales, entonces
X Y zS
n
S
mX Y z
S
n
S
m
x y
x yx y
2
2 2
2
2 2
. . con el (1-).100% de confianza

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
10 Mg. Miguel Angel Macetas Hernández
PRUEBAS DE HIPÓTESIS
Definición: Hipótesis estadística es un supuesto acerca de la distribución de una variable aleatoria. Podemos
especificar una hipótesis dando el tipo de distribución y el valor del parámetro (o valores de los
parámetros) que la definen.
Ejemplos:
1. X está normalmente distribuida con 100 10y .
2. Y es una variable binomial con p = 0.25
Frecuentemente (en la práctica), la distribución poblacional está implícita, y la hipótesis estadística sólo
especifica el valor del parámetro.
Ejemplos :
3. La tasa media salarial es $185..
4. La proporción de productos defectuosos en cierto proceso es inferior a 0.05, o sea p < 0.05.
Una hipótesis estadística puede considerarse como un conjunto de hipótesis elementales. Al respecto, una
hipótesis estadística puede ser simple o compuesta .
Una hipótesis simple es una especificación del valor de un parámetro, como en el ejemplo (3).
En cambio, una hipótesis compuesta contiene más de un valor del parámetro, como en el ejemplo (4), y se
la considera constituida por el conjunto de todas las hipótesis simples compatibles con ella.
Con el objeto de probar la validez de tales hipótesis, se lleva a cabo un experimento, y la hipótesis
formulada es desechada si los resultados obtenidos del experimento son improbables bajo dicha hipótesis.
Si los resultados no son improbables, la hipótesis no es desechada por falta de evidencia.
Una hipótesis compuesta es considerada verdadera (lo cual significa que no será rechazada o desechada)
cuando alguna de las hipótesis simples que la componen pueda considerarse verdadera.
Ejemplo :
Supongamos que queremos probar la hipótesis de que la probabilidad de obtener un as al arrojar un
dado, es de 1/6 , y con tal fin arrojamos un dado 600 veces .
Si se obtienen 600 ases , este resultado es improbable bajo la hipótesis supuesta, lo cual nos lleva a
rechazarla pues la evidencia indica que ella es falsa .
Si se obtienen 100 ases , este resultado no sería improbable bajo la hipótesis supuesta, y sin duda la
hipótesis no será rechazada , por falta de evidencia.
Obteniendo resultados como éstos, la intuición y el sentido común son suficientes para tomar una
decisión. Sin embargo, en la práctica los experimentos no conducen a conclusiones tan obvias, de donde
surge la necesidad de un método para probar la hipótesis, y esto implica establecer reglas de decisión .
El hecho de rechazar una hipótesis no significa que ésta sea falsa, como tampoco el no rechazarla
significa que sea verdadera. La decisión tomada no esta libre de error. A este respecto, consideraremos
dos tipos de error que pueden ser cometidos, y que los denominaremos error de tipo I y error de tipo II, y
que consisten en:
Error I :Rechazar una hipótesis que es verdadera .
Error II : No rechazar una hipótesis que es falsa .
La forma de medir estos errores es mediante la probabilidad. Simbolizaremos con a la probabilidad de
rechazar una hipótesis verdadera, y con a la probabilidad de no rechazar una hipótesis falsa; por lo
tanto = P( rechazar H / H es verdadera ) y = P( no rechazar H / H es falsa )
Es deseable que estas dos probabilidades de error sean pequeñas. Una forma cómoda de especificar lo que
se requiere de un procedimiento de prueba es concentrar la atención en dos conjuntos posibles de valores
del parámetro, es decir, en dos hipótesis estadísticas, a las cuales llamaremos hipótesis nula designada
por H0 e hipótesis alternativa designada por H1 .
La prueba de hipótesis es un procedimiento de toma de decisiones , relacionada principalmente con la
elección de una acción entre dos posibles . Por lo tanto, cada hipótesis (nula y alternativa) la asociaremos
con una de las acciones. Esta designación, en principio, es arbitraria, pero típicamente la hipótesis nula

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
11 Mg. Miguel Angel Macetas Hernández
corresponde a la ausencia de una modificación en la variable investigada, pudiendo considerar que
nulifica el efecto de un tratamiento , y por lo tanto se especifica de una forma exacta : H0 : = 0 ; en
tanto que la hipótesis alternativa generalmente indica una variación de valores que prevalecería si la
variable sufre alguna modificación, pudiendo pensar que el tratamiento fue efectivo , por lo cual esta
hipótesis (alternativa) se especifica de manera más general :
H1: 0 ó H1 : > 0 ó H1 : < 0. Observemos que en general la hipótesis alternativa es compuesta. Raramente la hipótesis alternativa es
una hipótesis simple, como por ejemplo: H1 : = 1 , sino que, normalmente ésta es el complemento de
la hipótesis nula .
ERRORES Y RIESGOS DE LA PRUEBA
La práctica de probar la hipótesis nula contra una alternativa, sobre la base de la información de la
muestra, conduce a dos tipos posibles de error, debido a fluctuaciones al azar en el muestreo. Es posible
que la hipótesis nula sea verdadera pero rechazada debido a que los datos obtenidos en la muestra sean
incompatibles con ella ; como puede ocurrir que la hipótesis nula sea falsa pero no se la rechace debido a
que la muestra obtenida no fuese incompatible con ella .
Cuadro de decisiones y errores
Estado Naturaleza Ho es verdadera Ho es falsa
Decisión
Rechazar Ho error I – incorrecto Correcto
No Rechazar Ho Correcto error II - incorrecto
Las probabilidades de cometer errores de tipo I y II se consideran los "riesgos" de decisiones
incorrectas. Así, la probabilidad de cometer un error de tipo I se llama nivel de significación de la prueba
y se simboliza con . .
. = P( error I ) = P( rechazar Ho / H0 es verdadera )
y la probabilidad de cometer un error de tipo II se designa por . Entonces :
= P( error II ) = P( no rechazar Ho / Ho es falsa )
Prueba de hipótesis simple contra alternativa única
Consideremos el caso de una hipótesis nula simple contra una hipótesis alternativa también simple.
H0 : = 0 ; H1 : = 1
Sea la variable aleatoria X con distribución conocida : X ~ f(x , ) , y sea ),,....,,(21
n
xxxf
un
estimador de . Entonces, la estadística de prueba
tiene distribución conocida siempre que se
conozca el valor del parámetro . Luego, dicha distribución queda completamente definida suponiendo
verdadera la hipótesis nula H0 : = 0. Las reglas de decisión sobre el rechazo o no de Ho se
establecen respecto a la amplitud de
y el resultado particular de la muestra. Se clasifica la amplitud de
en dos subconjuntos que son : R = región de rechazo o región crítica que contiene los resultados
menos favorables a Ho , y A = región de aceptación o región de no rechazo que contiene los resultados
más favorables a Ho . De esta forma, si
R rechazamos Ho y si A no rechazamos Ho . El
valor de
que separa R de A se denomina valor critico de la estadística de prueba, y se representa
por c .
UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
12 Mg. Miguel Angel Macetas Hernández
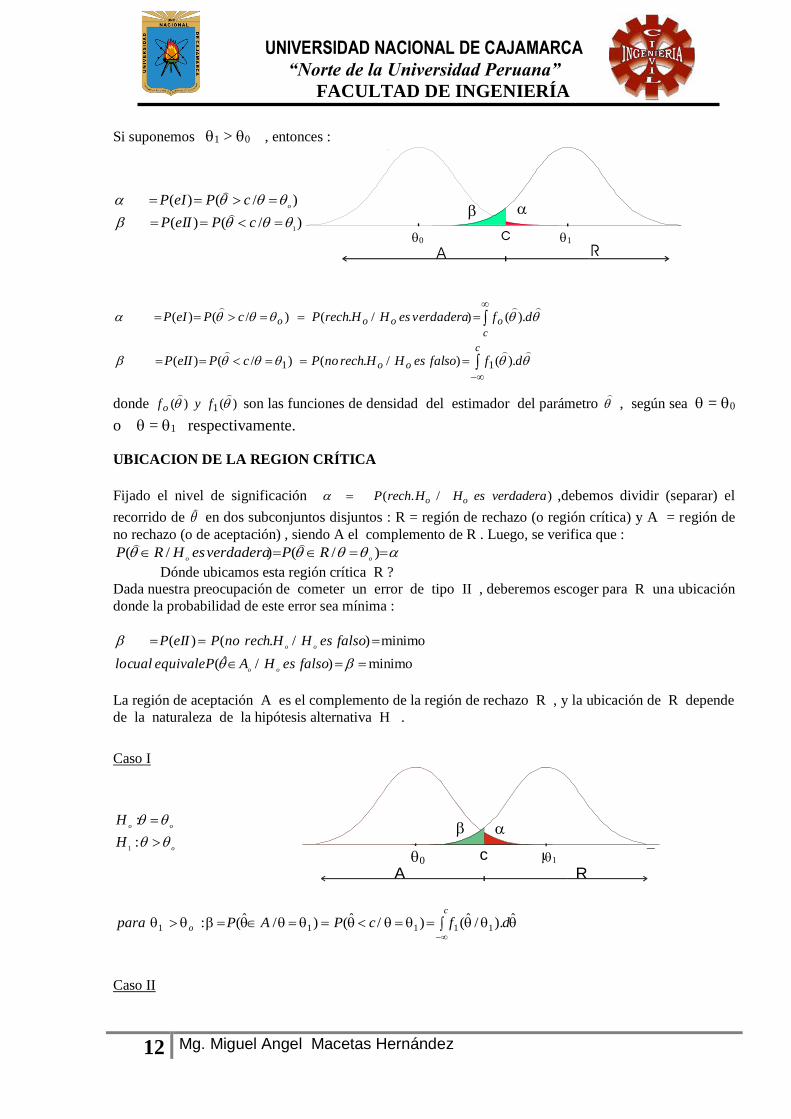
Si suponemos 1 > 0 , entonces :
)/()(
)/()(
1
cPeIIP
cPeIPo
dffalsoesHHrechnoPcPeIIP
dfverdaderaesHHrechPcPeIP
c
oo
coooo
).()/.()/()(
).()/.()/()(
11
donde )()( 1
fyfo son las funciones de densidad del estimador del parámetro
, según sea = 0
o = 1 respectivamente.
UBICACION DE LA REGION CRÍTICA
Fijado el nivel de significación P rech H H es verdaderao o( . / ) ,debemos dividir (separar) el
recorrido de
en dos subconjuntos disjuntos : R = región de rechazo (o región crítica) y A = región de
no rechazo (o de aceptación) , siendo A el complemento de R . Luego, se verifica que :
)/()/(oo
RPverdaderaesHRP
Dónde ubicamos esta región crítica R ?
Dada nuestra preocupación de cometer un error de tipo II , deberemos escoger para R una ubicación
donde la probabilidad de este error sea mínima :
minimo)/ˆ(
minimo)/.()(
falsoesHAPequivalecuallo
falsoesHHrechnoPeIIP
oo
oo
La región de aceptación A es el complemento de la región de rechazo R , y la ubicación de R depende
de la naturaleza de la hipótesis alternativa H .
Caso I
o
oo
H
H
:
:
1
A R
c x
ˆ)./ˆ()/ˆ()/ˆ(: 11111 dfcPAPparac
o
Caso II
1
0
0
0
1 0
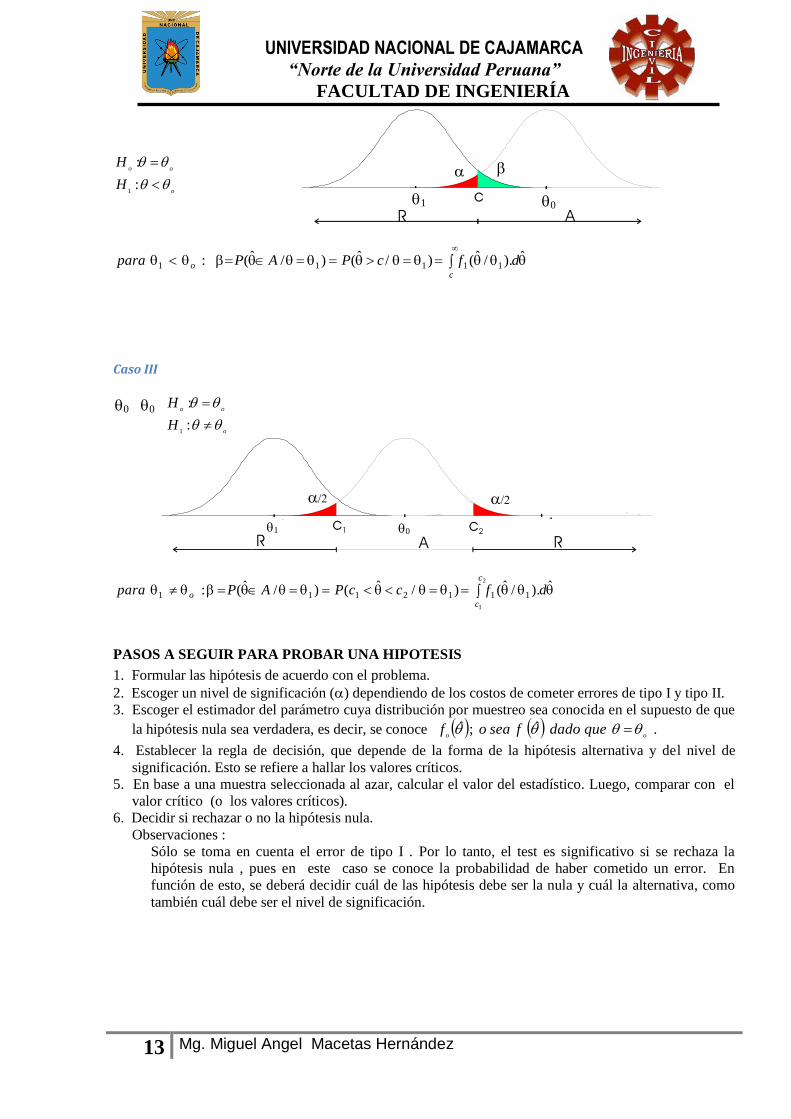
UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
13 Mg. Miguel Angel Macetas Hernández
o
oo
H
H
:
:
1
ˆ)./ˆ()/ˆ()/ˆ(: 11111 dfcPAPparac
o
Caso III
o
oo
H
H
:
:
1
ˆ)./ˆ()/ˆ()/ˆ(: 1112111
2
1
dfccPAPparac
co
PASOS A SEGUIR PARA PROBAR UNA HIPOTESIS
1. Formular las hipótesis de acuerdo con el problema.
2. Escoger un nivel de significación () dependiendo de los costos de cometer errores de tipo I y tipo II.
3. Escoger el estimador del parámetro cuya distribución por muestreo sea conocida en el supuesto de que
la hipótesis nula sea verdadera, es decir, se conoce oo
quedadofseaof ˆ;ˆ .
4. Establecer la regla de decisión, que depende de la forma de la hipótesis alternativa y del nivel de
significación. Esto se refiere a hallar los valores críticos.
5. En base a una muestra seleccionada al azar, calcular el valor del estadístico. Luego, comparar con el
valor crítico (o los valores críticos).
6. Decidir si rechazar o no la hipótesis nula.
Observaciones :
Sólo se toma en cuenta el error de tipo I . Por lo tanto, el test es significativo si se rechaza la
hipótesis nula , pues en este caso se conoce la probabilidad de haber cometido un error. En
función de esto, se deberá decidir cuál de las hipótesis debe ser la nula y cuál la alternativa, como
también cuál debe ser el nivel de significación.
0 0
1
1
0
0
0
0 1

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
14 Mg. Miguel Angel Macetas Hernández
CASOS PARTICULARES DE PRUEBAS DE HIPÓTESIS
Prueba de hipótesis de la media en poblaciones normales
Sea ( X1 , X2 , ... , Xn ) una muestra aleatoria extraída de una población normal, luego, i = 1 .. n :
X ~ N( , ) .
Por lo tanto tenemos que: X1 , X2 , ... , Xn iid N( , ).
Xn
X Nn
i 1
~ ( , )
, )1,0(~ NX
n
H0 : = 0 vs H1 : 0
Si la hipótesis nula H0 es verdadera, entonces = 0 y por lo tanto )1,0(~0 NX
n
Como la prueba es bilateral, se rechazará la hipótesis nula tanto como cuando se tenga evidencia de que la
media poblacional sea mayor que el valor postulado como cuando se tenga evidencia de que sea menor
que el valor postulado. Luego, se calculan dos valores críticos (zc1 y zc2) para la variable pivotal o
estadístico de prueba, que son los valores de la distribución Normal que dejan una probabilidad de
por debajo y por encima respectivamente: zc1 es tal que ( zc1) = y zc2 es tal que ( zc2) = 1-
Se estandariza el valor observado de la media muestral n
obs
o
xz
0 del cual dependerá la
decisión : si zo > zc2 zo < zc1 Se rechaza H0
si zc1 < zo < zc2 No se rechaza H0
Prueba de hipótesis de comparación de medias de dos poblaciones normales independientes.
Sean ( X1 , X2 , ... , Xn ) y ( Y1 , Y2 , ... , Ym ) dos muestras aleatorias extraídas de
poblaciones normales, luego:
i = 1 .. n : Xi ~ N(x, x ) j = 1 .. m : Yj ~ N(y, y ).
Por lo tanto tenemos que
ntesindependieYeXconm
NYm
Y
nNX
nX
y
yi
xxi
),(~1
),(~1
Entonces
X Y Nn mx yx y
~ ; 2 2
1;0~)(
22N
mn
YX
yx
yx

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
15 Mg. Miguel Angel Macetas Hernández
H0 : x = y vs H1 : x y
Si la hipótesis nula H0 es verdadera, entonces x = y y por lo tanto 1;0~22
N
mn
YX
yx
Como la prueba es bilateral, se rechazará la hipótesis nula cuando se tenga evidencia de que las medias
poblacionales difieren entre sí. Luego, se calculan dos valores críticos (zc1 y zc2) para la variable pivotal
o estadístico de prueba, que son los valores de la distribución Normal que dejan una probabilidad de
por debajo y por encima respectivamente: zc1 es tal que (zc1) = y zc2 es tal que (zc2) = 1-
Se estandariza el valor observado de la diferencia entre las medias muestrales
mn
yxz
yx
obsobs
o22
del cual dependerá la decisión :
si zo > zc2 zo < zc1 Se rechaza H0
si zc1 < zo < zc2 No se rechaza H0
Prueba de hipótesis de la proporción
Sean X1 , X2 , ... , Xn iid Bi ( p ) . A través de las propiedades de la Función Generatriz de
Momentos se demuestra que : X = Xi ~ B ( n , p ) .
Para n suficientemente grande, la variable binomial se distribuye aproximadamente normal ,
aproximadamente : X ~ N( n.p , npq ) .
De donde se deduce que la proporción muestral hX
n
X
n
i
también tiene una
distribución aproximadamente normal :
hn
X N ppq
ni
1~ , , 1,0~ N
n
pq
ph
H0 : p = p0 vs H1 : p p0
Si la hipótesis nula H0 es verdadera, entonces p = p0 y por lo tanto 1,0~)1( 00
0 N
n
pp
ph
Como la prueba es bilateral, se rechazará la hipótesis nula tanto como cuando se tenga evidencia de que la
proporción poblacional sea mayor que el valor postulado como cuando se tenga evidencia de que sea
menor que el valor postulado. Luego, se calculan dos valores críticos (zc1 y zc2) para la variable pivotal o
estadístico de prueba, que son los valores de la distribución Normal que dejan una probabilidad de
por debajo y por encima respectivamente: zc1 es tal que (zc1) = y zc2 es tal que (zc2) = 1-
Se estandariza el valor observado de la proporción muestral
n
pp
phz obs
o)1( 00
0
del cual dependerá
la decisión : si zo > zc2 zo < zc1 Se rechaza H0
si zc1 < zo < zc2 No se rechaza H0

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
16 Mg. Miguel Angel Macetas Hernández
Prueba de hipótesis de comparación de proporciones de dos poblaciones independientes
X1 , X2 , ... , Xn iid Bi(p1)
Y1 , Y2 , ... , Ym iid Bi(p2) con Xi independiente de Yj i j
Sean hn
X y hm
Yi j1 2
1 1
Luego, h1 y h2 son independientes y se distribuyen aproximadamente :
m
qp
n
qpppNhh
m
qppNhy
n
qppNh
22112121
2222
1111
;~
,~,~
1;0~
2211
2121 N
m
qp
n
qp
pphh
H0 : p1 = p2 vs H1 : p1 p2
Si la hipótesis nula H0 es verdadera, entonces p1 = p2 1;0~11
)ˆ1(ˆ
21 N
mnpp
hh
donde mn
hmhnp
21 ..
ˆ es la proporción de éxitos (total) .
Como la prueba es bilateral, se rechazará la hipótesis nula cuando se tenga evidencia de que las
proporciones poblacionales sean diferentes. Luego, se calculan dos valores críticos (zc1 y zc2) para la
variable pivotal o estadístico de prueba, que son los valores de la distribución Normal que dejan una
probabilidad de por debajo y por encima respectivamente: zc1 es tal que ( zc1) = y zc2 es
tal que ( zc2) = 1-
Se estandariza el valor observado de la diferencia entre las proporciones muestrales
mnpp
hhz obsobs
o11
)ˆ1(ˆ
21
del cual dependerá la decisión :
si zo > zc2 zo < zc1 Se rechaza H0
si zc1 < zo < zc2 No se rechaza H0

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
17 Mg. Miguel Angel Macetas Hernández
Prueba de hipótesis de la variancia en poblaciones normales
Sean X1 , X2 , ... , Xn iid N( , )
Entonces : 2
1
2
1
~
n
n
i
i XX
La variancia muestral está definida como S
x x
nx
ii
n
( )
( )2 1
2
1
de donde se obtiene que
2
1
2
1
~
n
n
i
i XX
212
2)(
~)1(
n
xSn
H0 : 2 = 2
0 vs H1 : 2 2
0
Si la hipótesis nula H0 es verdadera, entonces 2 = 20 y por lo tanto 2
1
0
2)(
~).1(
2
n
xSn
Como la prueba es bilateral, se rechazará la hipótesis nula tanto como cuando se tenga evidencia de que la
variancia poblacional sea mayor que el valor postulado como cuando se tenga evidencia de que sea menor
que el valor postulado. Luego, se calculan dos valores críticos (2c1 y 2
c2) para la variable pivotal o
estadístico de prueba, que son los valores de la distribución 2n-1 que dejan una probabilidad de
por debajo y por encima respectivamente : 2c1 es tal que P(2
n-1 < 2c1) = y 2
c2 es tal que
P(2n-1 > 2
c2) = .
Se calcula el valor observado de la estadística de prueba o variable pivotal que relaciona la variancia
muestral con la poblacional 2
0
22 ).1(
obso
Sn del cual dependerá la decisión :
si 2o > 2
c2 2o < 2
c1 Se rechaza H0
si 2c1 < 2
o < 2c2 No se rechaza H0
Prueba de hipótesis de comparación de variancias de poblaciones normales independientes
X1 , X2 , ... , Xn iid N(x, x) , Y1 , Y2 , ... , Ym iid N(y, y) con Xi independiente de Yj
1,0,......,)1,0(,......,
.....1)1,0(~.....1)1,0(~:
11 NiidYY
yNiidXX
mjNY
yniNX
Luego
y
ym
y
y
x
xn
x
x
y
yi
x
xi

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
18 Mg. Miguel Angel Macetas Hernández
212
2)(2
12
2)(
~).1(
~).1(
m
y
y
n
x
x Sny
Sn
que por ser independientes resulta que el cociente :
( )
( )
( ) ( )
( )
( ). ~
( )
( ),
n S
n
m S y
m
S
S
y
x
F
x
x
y
x
yn m
1
1
1
1
2
2
2
2
2
2
2
2 1 1
H0 : 2
x = 2y vs H1 :
2x 2
y
Si la hipótesis nula H0 es verdadera, entonces 2x = 2
y y por lo tanto 1,12
)(
2
~)(
mn
y
xF
S
S
Como la prueba es bilateral, se rechazará la hipótesis nula cuando se tenga evidencia de que las variancias
poblacionales difieren entre sí. Luego, se calculan dos valores críticos (Fc1 y Fc2) para la variable pivotal
o estadístico de prueba, que son los valores de la distribución F-Snedecor con n-1 y m-1 grados de
libertad, que dejan una probabilidad de por debajo y por encima respectivamente Fc1 es tal
que P(Fn-1;m-1< Fc1) = y Fc2 es tal que P(Fn-1;m-1> Fc2) = .
Se calcula el valor observado de la estadística de prueba o variable pivotal del cociente de las variancias
muestrales 2
)(
2)(
obsy
obsx
oS
SF del cual dependerá la decisión :
si Fo > Fc2 Fo < Fc1 Se rechaza H0
si Fc1 < Fo < Fc2 No se rechaza H0
Prueba de hipótesis de la media en poblaciones normales con variancia desconocida.
Sean (X1 , X2 , ... , Xn ) una muestra aleatoria extraída de una población normal, luego i=1,.,n
Xi ~ N( , ).
Por lo tanto tenemos que X1 , X2 , ... , Xn iid N( , ). de donde se deduce que:
)1,0(~,~ N
n
Ximplicaque
nNX
y 2
12
2)(2
11
2
~)1(
~
n
x
n
n
i
XXSn
i
Como X y S2(x) son independientes, lo son también
2
2)()1(
x
n
Sny
X , de distribución normal
y chi cuadrado respectivamente. Luego, realizando el cociente entre ellas, obtenemos :

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
19 Mg. Miguel Angel Macetas Hernández
1)(
~
n
n
xSt
X
H0 : = 0 vs H1 : 0
Si la hipótesis nula H0 es verdadera, entonces = 0 y por lo tanto 1)(
0~
n
n
xSt
X
Como la prueba es bilateral, se rechazará la hipótesis nula cuando se tenga evidencia de que la media
poblacional sea mayor que el valor postulado como cuando se tenga evidencia de que sea menor que el
valor postulado. Luego, se calculan dos valores críticos (tc1 y tc2) para la variable pivotal o estadístico de
prueba, que son los valores de la distribución t-Student con n-1 grados de libertad que dejan una
probabilidad de por debajo y por encima respectivamente: tc1 es tal que P(tn-1 < tc1) = y tc2 es
tal que P(tn-1 > tc2) = .
Se estandariza el valor observado de la media muestral n
xS
obs
o
xt
)(
0 del cual dependerá la
decisión : si to > tc2 to < tc1 Se rechaza H0
si tc1 < to < tc2 No se rechaza H0
Nota: Para tamaños grandes de muestra, esta distribución tiende a la distribución normal con parámetros
=0 y =1 .
nN
n
xS
X)1,0(~
)(0
Prueba de hipótesis de comparación de medias de dos poblaciones normales independientes, con variancias desconocidas pero supuestamente iguales.
Sean (X1 , X2 , ... , Xn ) y (Y1 , Y2 , ... , Ym ) dos muestras aleatorias extraídas de
poblaciones normales independientes con igual variancia . Entonces x y
luego , i=1..n , Xi ~ N(x, ) y i=1..m , Yj ~ N(y, ).
Por lo tanto tenemos que
X1, X2, ... , Xn iid N(x, ); Y1, Y2, ... , Ym iid N(y, ). con Xi independiente de Yj
De la distribución normal de las variables X e Y, se deduce que:
)1,0(~11
)(,;~
22
N
mn
YXtantolopory
mnyxNYX
yx
como también

UNIVERSIDAD NACIONAL DE CAJAMARCA “Norte de la Universidad Peruana”
FACULTAD DE INGENIERÍA
20 Mg. Miguel Angel Macetas Hernández
212
2)(2
12
2)(
~)1(
~)1(
m
y
n
x Smy
Sn
que por ser independientes:
222
2)(
2)(
~)1()1(
mn
yx SmSnresulta
Luego, realizando el cociente, obtenemos:
X Y
n S m S
n m n m
tx y
x y
n m
( )
( ) ( )
( )
~
( ) ( )
1 1
2
1 12 2
2
donde ( ) ( )
( )
( ) ( )n S m S
n m
x y
1 1
2
2 2
es el estimador de la variancia común 2, y lo simbolizaremos con S2A
H0 : x = y vs H1 : x y
Si la hipótesis nula H0 es verdadera, entonces x = y y por lo tanto
22
)(2
)(
~
11
)2(
)1()1(
mn
yx
t
mnmn
SmSn
YX o bien 2~
11.
mn
A
t
mnS
YX
Como la prueba es bilateral, se rechazará la hipótesis nula cuando se tenga evidencia de que las medias
poblacionales sean diferentes. Luego, se calculan dos valores críticos (tc1 y tc2) para la variable pivotal
o estadístico de prueba, que son los valores de la distribución t-Student con n+m-2 grados de libertad
que dejan una probabilidad de por debajo y por encima respectivamente :
tc1 es tal que P(tn+m-2 < tc1) = y tc2 es tal que P(tn+m-2 > tc2) = .
Se estandariza el valor observado de la diferencia entre las medias muestrales
mnS
yxz
A
obsobs
o11
.
del
cual dependerá la decisión : si to > tc2 to < tc1 Se rechaza H0
si tc1 < to < tc2 No se rechaza H0
Nota: Para tamaños grandes de muestra, esta distribución tiende a la distribución normal con parámetros
=0 y =1 .
)()1,0(~11
.
mnN
mnS
YX
A
Top Related