







Idiomas
Páginas
Jurídico

SEMANA 2-B: Rango, Rango Intercuartil, Varianza, Desviación estándar,
Coeficiente de variación, teorema de Chebyshev, La regla empírica, detención
de valores atípicos. Profesor: Jorge Esponda Véliz
MEDIDAS DE VARIABILIDAD

MEDIDAS DE DISPERSIÓN
Se llaman medidas de dispersión aquellas que permiten
retratar la distancia de los valores de la variable a un cierto
valor central, o que permiten identificar la concentración de
los datos en un cierto sector del recorrido de la variable.
Llamadas también medidas de variabilidad. Son útiles
porque:
Permiten juzgar la confiabilidad de la medida de tendencia
central.
Los datos demasiados dispersos tienen un
comportamiento especial.
Es posible comparar dispersión de diversas muestras.

Las principales medidas de dispersión son:
Amplitud de variación
Desviación media
Varianza
Desviación estándar
AMPLITUD DE VARIACIÓN:
Es la medida de dispersión más sencilla, que trata de la
diferencia entre el valor más grande y el más pequeño en
un conjunto de datos.
Un defecto importante de la amplitud de variación es que
se basa sólo en dos valores, el máximo y el mínimo.
Amplitud de Variación = Valor más – Valor más
grande pequeño

EJEMPLO:
Veamos la producción de dos máquinas, una produce en promedio
por hora 13.375 botones y la otra máquina en promedio también
13.375 botones. Veamos la producción por hora:
Horas 1 2 3 4 5 6 7 8
Máquina 1 2 5 12 13 14 16 20 25
Máquina 2 11 12 13 13 13.5 14.5 15 15
Ahora veamos la amplitud de variación de cada máquina:
Máquina 1 25 – 2 = 23
Máquina 2 15 – 11 = 4
Vemos que la media de la máquina 2
es más representativa que la media
de la máquina 1, porque tiene menor
amplitud de variación.

EJEMPLO: Para hallar la amplitud de variación de la
siguiente tabla referida a las edades de los 100 empleados
de una cierta empresa:
Clase ni
16 - 20 2
20 - 24 8
24 - 28 8
28 - 32 18
32 - 36 20
36 - 40 18
40 - 44 15
44 - 48 8
48 - 52 3
100
Entonces hallamos la amplitud de
variación:
Amplitud de variación : 52 – 16 = 36 años
DESVIACIÓN MEDIA:
Es la media aritmética de los valores absolutos de las
desviaciones respecto a la media aritmética. La desviación
media viene a indicar el grado de concentración o de
dispersión de los valores de la variable. Si es muy alta,
indica gran dispersión; si es muy baja refleja un buen
agrupamiento y que los valores son parecidos entre sí.

n
XXDM
X: Es el valor de cada observación.
X : Es la media aritmética de los valores.
n: Es el número de observaciones en la muestra.
| |: Indica el valor absoluto.
EJEMPLO:
Del ejemplo anterior, de las máquinas:
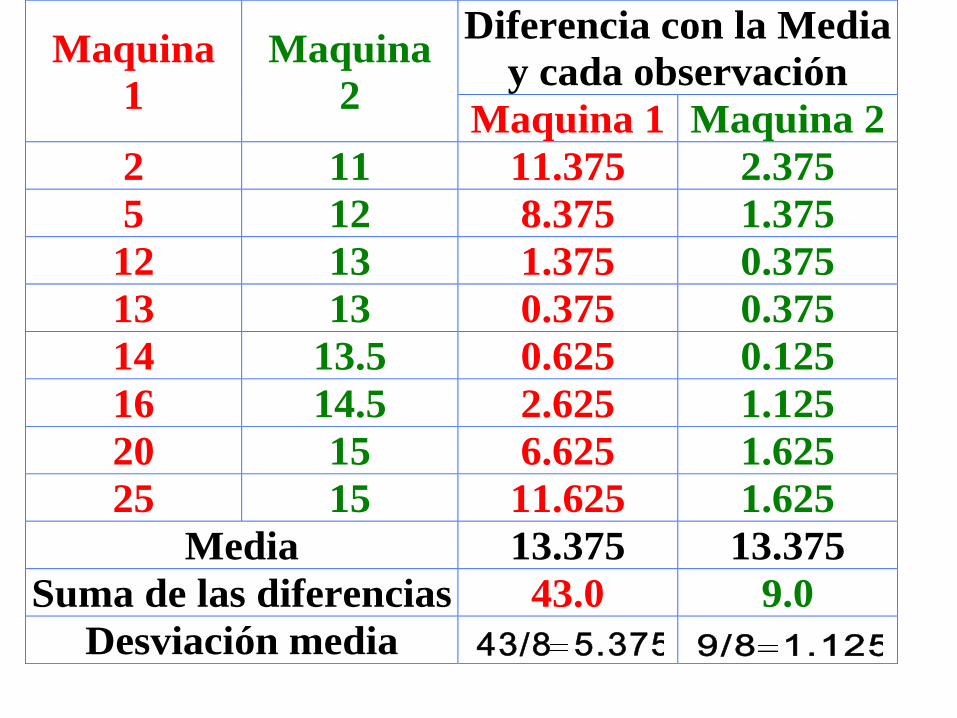
Maquina
1
Maquina
2
Diferencia con la Media
y cada observación
Maquina 1 Maquina 2
2 11 11.375 2.375
5 12 8.375 1.375
12 13 1.375 0.375
13 13 0.375 0.375
14 13.5 0.625 0.125
16 14.5 2.625 1.125
20 15 6.625 1.625
25 15 11.625 1.625
Media 13.375 13.375
Suma de las diferencias 43.0 9.0
Desviación media 5.37543/8 1.1259/8

Esto quiere decir para la máquina 1, la variación (en
promedio) es de 5.375 botones por hora con respecto a la
media de 13.375 botones; y para la maquina 2, la
variación es de 1.125 botones por hora con respecto a la
media de 13.375 botones.
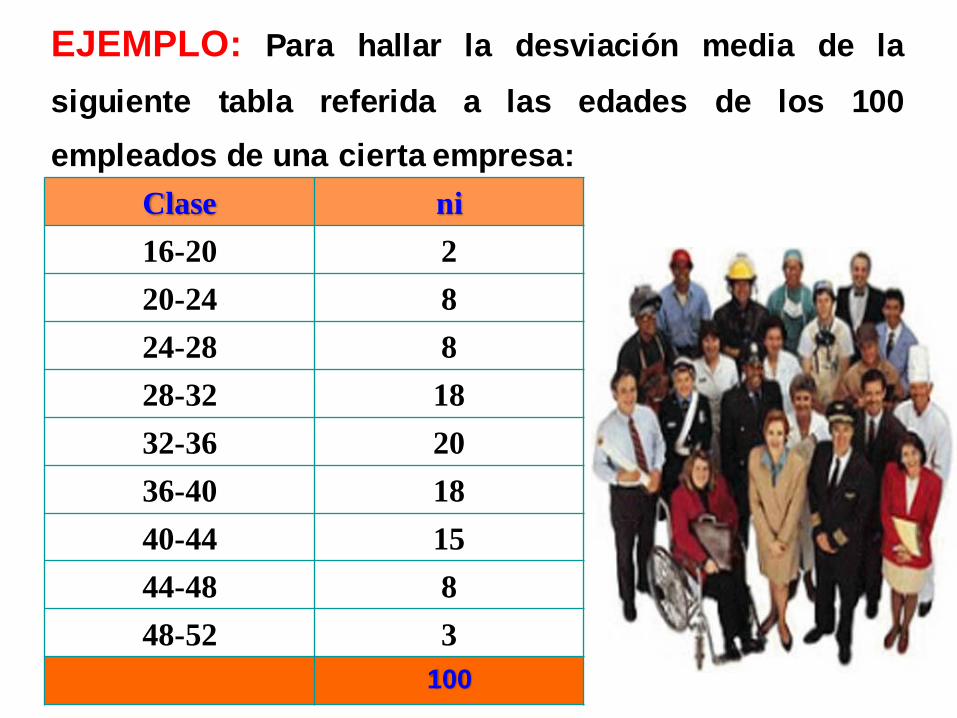
EJEMPLO: Para hallar la desviación media de la
siguiente tabla referida a las edades de los 100
empleados de una cierta empresa:
Clase ni
16-20 2
20-24 8
24-28 8
28-32 18
32-36 20
36-40 18
40-44 15
44-48 8
48-52 3
100
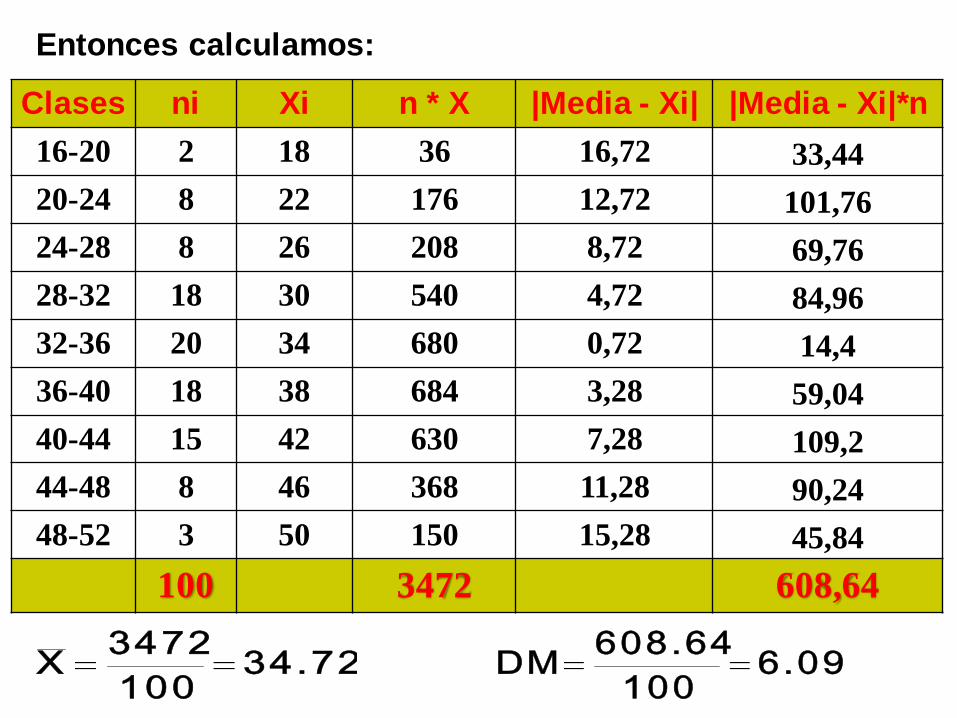
Entonces calculamos:
Clases ni Xi n * X |Media - Xi| |Media - Xi|*n
16-20 2 18 36 16,72 33,44
20-24 8 22 176 12,72 101,76
24-28 8 26 208 8,72 69,76
28-32 18 30 540 4,72 84,96
32-36 20 34 680 0,72 14,4
36-40 18 38 684 3,28 59,04
40-44 15 42 630 7,28 109,2
44-48 8 46 368 11,28 90,24
48-52 3 50 150 15,28 45,84
100 3472 608,64
34.72100
3472X 6.09
100
608.64DM

VARIANCIA.- Es una medida de desviación
promedio con respecto a la media aritmética.
POBLACIONAL MUESTRAL
N
X2
2
1
2
2
n
XXs
2: Es el símbolo para la
variancia de una población (es
la letra griega sigma).
μ: Es la media aritmética de la
población.
N: Es el número total de
observaciones en la población.
X: Es el valor de las
observaciones en la población.
s2: Es el símbolo para
representar la variancia
muestral.
X : Es la media de la muestra.
n: Es el número total de
observaciones en la muestra.
X: Es el valor de las
observaciones en la muestra.

Nos damos cuenta que los denominadores no son
semejantes. Aunque el uso de “n” sea lógico, tiende a
subestimar la variancia de la población. Es decir lo vuelve
más pequeño de lo que en realidad es. Los estadísticos
han encontrado que la corrección a esto, es restarle “1”
al número total de observaciones de la muestra.
Ahora para simplificar el cálculo de la variancia, haremos
una pequeña convergencia o equivalencia:
n
X)(XXX
2
22
La fórmula de la desviación muestral cambia, esto es solo
para facilidad del
cálculo. 1n
n
XX
s
2
2
2
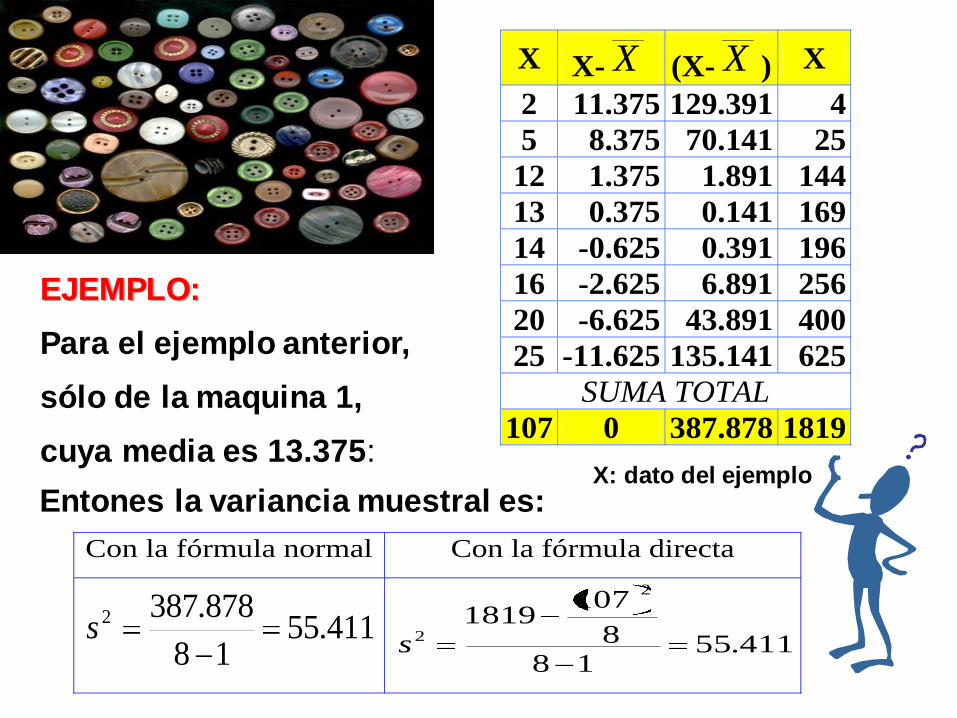
EJEMPLO:
Para el ejemplo anterior,
sólo de la maquina 1,
cuya media es 13.375:
X X- X (X- X ) X
2 11.375 129.391 4
5 8.375 70.141 25
12 1.375 1.891 144
13 0.375 0.141 169
14 -0.625 0.391 196
16 -2.625 6.891 256
20 -6.625 43.891 400
25 -11.625 135.141 625
SUMA TOTAL
107 0 387.878 1819
Entones la variancia muestral es:
Con la fórmula normal Con la fórmula directa
411.5518
878.3872s 411.55
18
8
1071819
2
2s
X: dato del ejemplo

DESVIACIÓN ESTÁNDAR.- Llamada también
desviación típica, representa la variabilidad (o desviaciones)
promedio de los datos con respecto a la media aritmética.
Es la raíz cuadrada positiva de la variancia.
Esto quiere decir que para una desviación pequeña, las
observaciones estarán localizadas cerca de la media. Y para
una desviación grande, las observaciones están lejos de la
media. POBLACIONAL MUESTRAL
N
X2
1
2
n
XXs

DESVIACIÓN ESTÁNDAR PARA DATOS AGRUPADOS:
Si los datos que interesan están en forma agrupada (en
una distribución de frecuencias), la desviación estándar
muestral puede aproximarse al sustituir ∑ (ni X2) por ∑
(X^2) y ∑ (ni X) por ∑X. La fórmula para la desviación
estándar muestral se convierte entonces en:
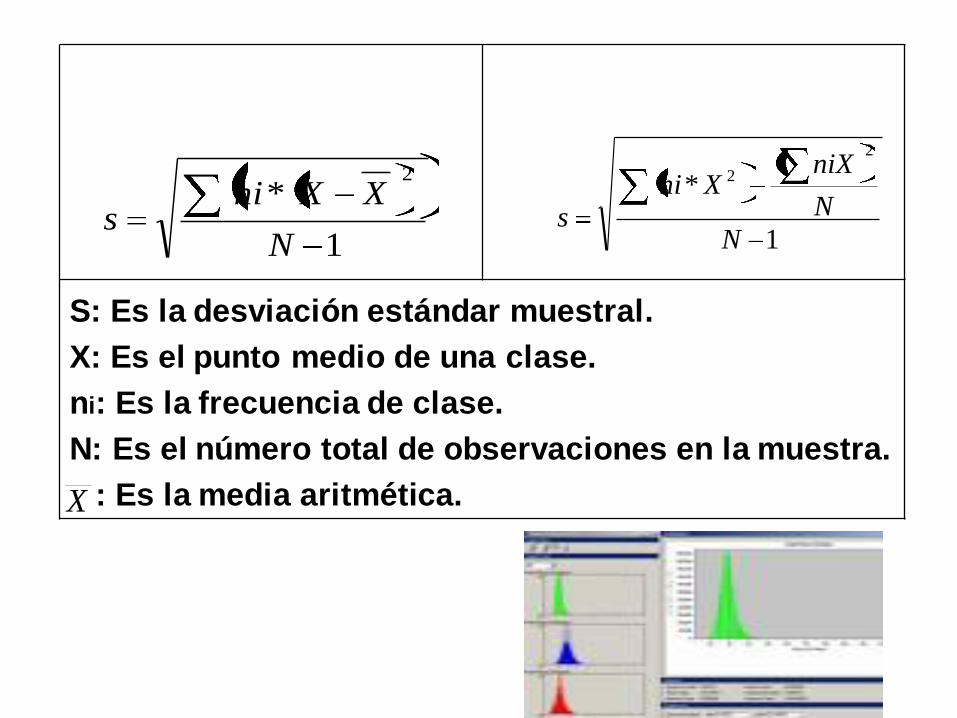
1
*2
N
XXnis
1
*
2
2
N
N
niXXni
s
X
S: Es la desviación estándar muestral.
X: Es el punto medio de una clase.
ni: Es la frecuencia de clase.
N: Es el número total de observaciones en la muestra.
: Es la media aritmética.
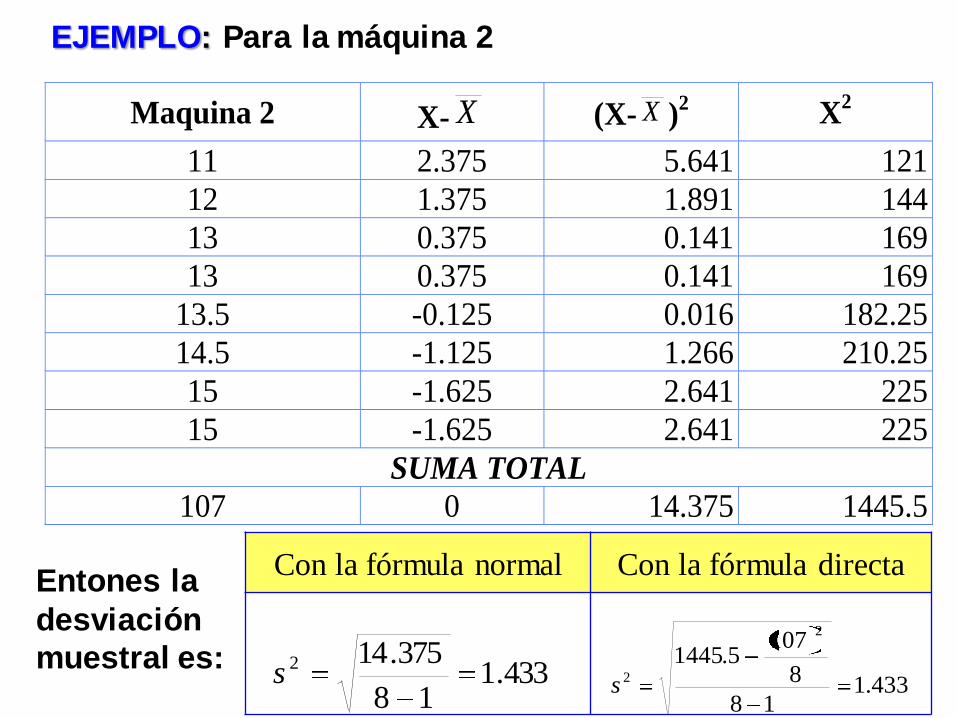
EJEMPLO: Para la máquina 2
Maquina 2 X- X (X- X )2 X
2
11 2.375 5.641 121
12 1.375 1.891 144
13 0.375 0.141 169
13 0.375 0.141 169
13.5 -0.125 0.016 182.25
14.5 -1.125 1.266 210.25
15 -1.625 2.641 225
15 -1.625 2.641 225
SUMA TOTAL
107 0 14.375 1445.5
Entones la
desviación
muestral es: 433.1
18
375.142s
Con la fórmula normal Con la fórmula directa
433.118
8
1075.1445
2
2s
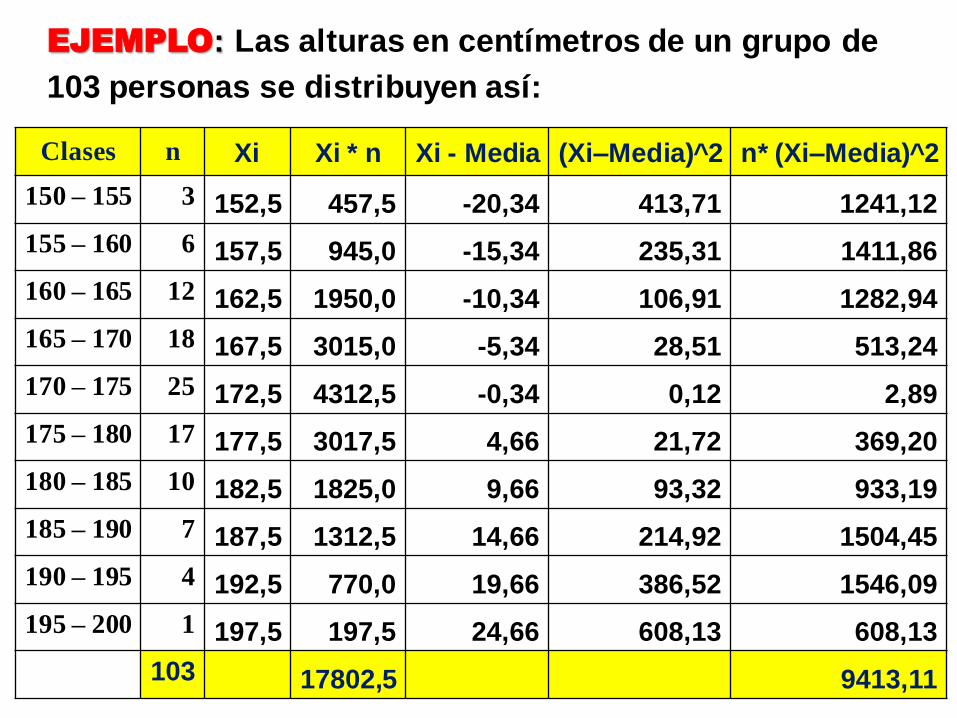
Clases n Xi Xi * n Xi - Media (Xi–Media)^2 n* (Xi–Media)^2
150 – 155 3 152,5 457,5 -20,34 413,71 1241,12
155 – 160 6 157,5 945,0 -15,34 235,31 1411,86
160 – 165 12 162,5 1950,0 -10,34 106,91 1282,94
165 – 170 18 167,5 3015,0 -5,34 28,51 513,24
170 – 175 25 172,5 4312,5 -0,34 0,12 2,89
175 – 180 17 177,5 3017,5 4,66 21,72 369,20
180 – 185 10 182,5 1825,0 9,66 93,32 933,19
185 – 190 7 187,5 1312,5 14,66 214,92 1504,45
190 – 195 4 192,5 770,0 19,66 386,52 1546,09
195 – 200 1 197,5 197,5 24,66 608,13 608,13
103 17802,5 9413,11
EJEMPLO: Las alturas en centímetros de un grupo de
103 personas se distribuyen así:
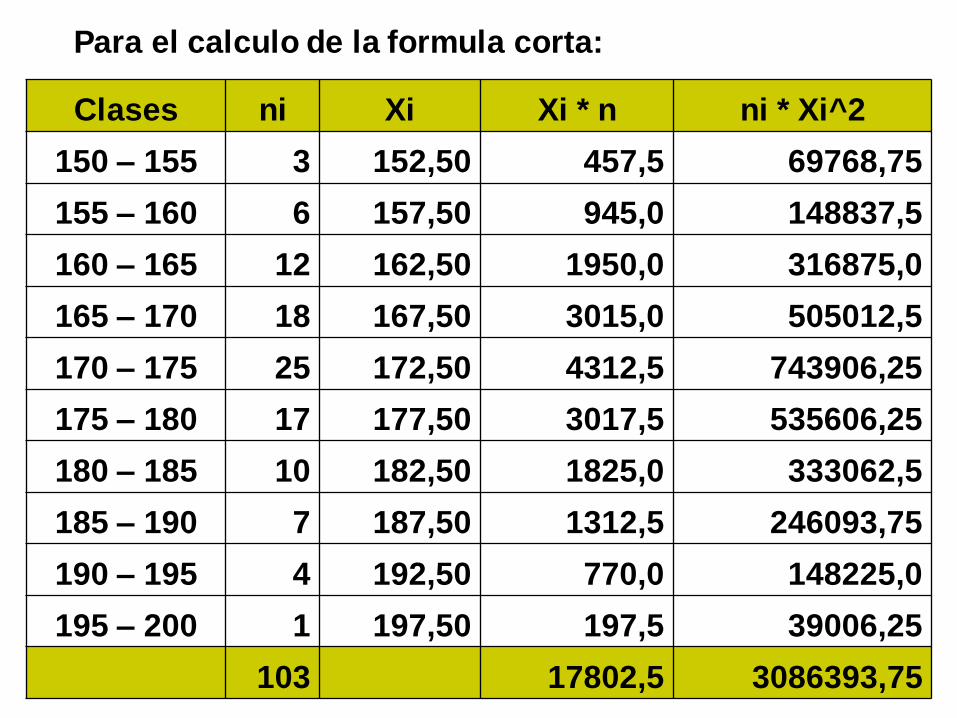
Clases ni Xi Xi * n ni * Xi^2
150 – 155 3 152,50 457,5 69768,75
155 – 160 6 157,50 945,0 148837,5
160 – 165 12 162,50 1950,0 316875,0
165 – 170 18 167,50 3015,0 505012,5
170 – 175 25 172,50 4312,5 743906,25
175 – 180 17 177,50 3017,5 535606,25
180 – 185 10 182,50 1825,0 333062,5
185 – 190 7 187,50 1312,5 246093,75
190 – 195 4 192,50 770,0 148225,0
195 – 200 1 197,50 197,5 39006,25
103 17802,5 3086393,75
Para el calculo de la formula corta:
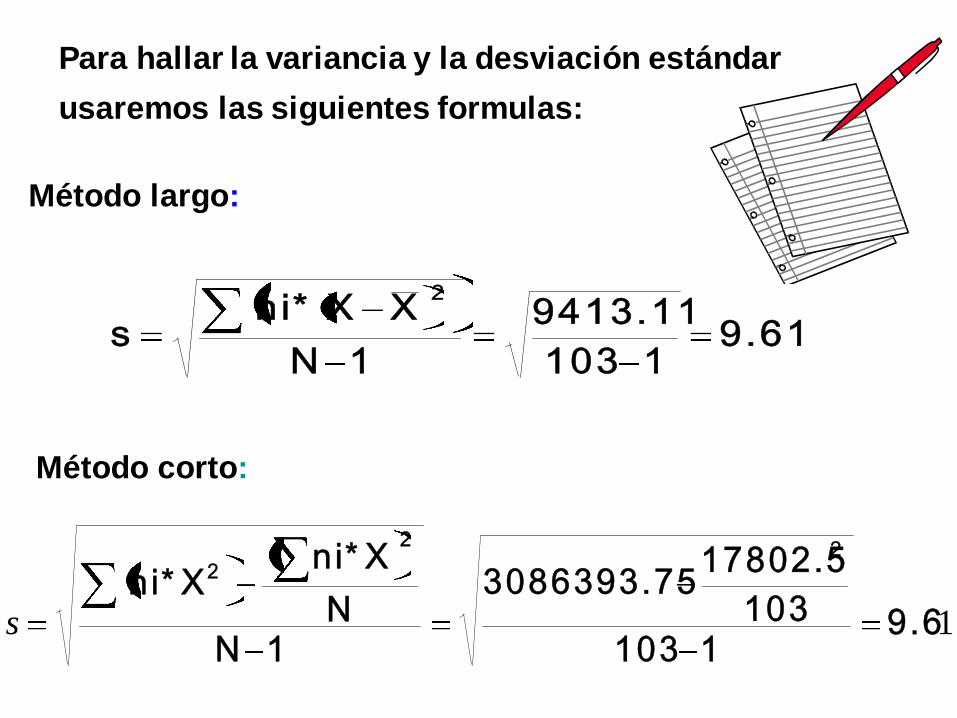
Para hallar la variancia y la desviación estándar
usaremos las siguientes formulas:
9.611103
9413.11
1N
XX*nis
2
19.61103
103
17802.53086393.75
1NN
X*niX*ni
22
2
s
Método largo:
Método corto:
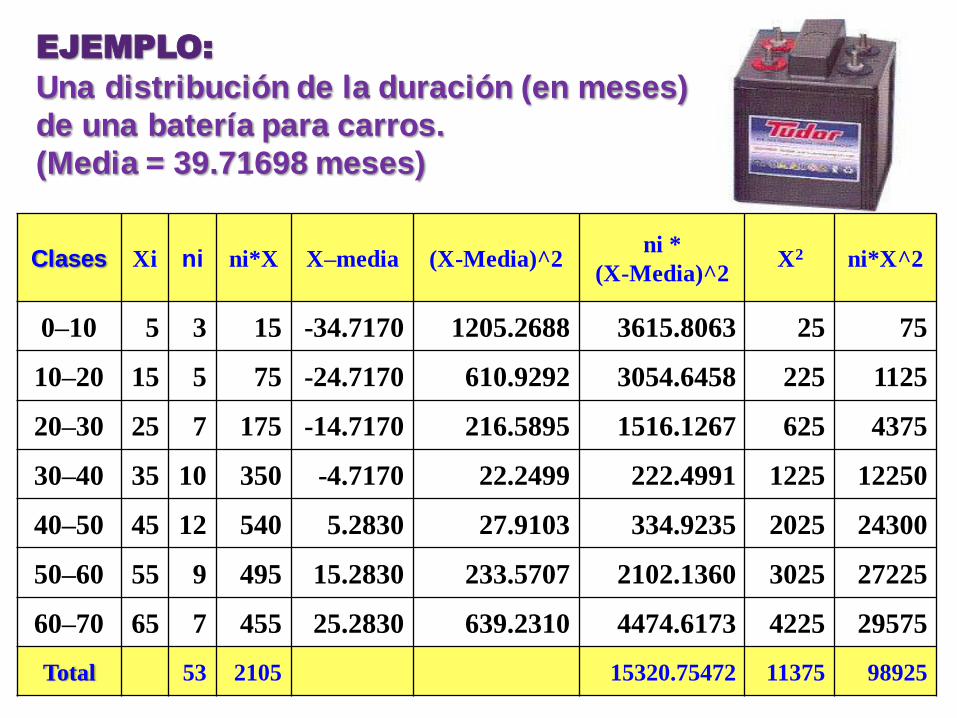
EJEMPLO:
Una distribución de la duración (en meses)
de una batería para carros.
(Media = 39.71698 meses)
Clases Xi ni ni*X X–media (X-Media)^2 ni *
(X-Media)^2 X2 ni*X^2
0–10 5 3 15 -34.7170 1205.2688 3615.8063 25 75
10–20 15 5 75 -24.7170 610.9292 3054.6458 225 1125
20–30 25 7 175 -14.7170 216.5895 1516.1267 625 4375
30–40 35 10 350 -4.7170 22.2499 222.4991 1225 12250
40–50 45 12 540 5.2830 27.9103 334.9235 2025 24300
50–60 55 9 495 15.2830 233.5707 2102.1360 3025 27225
60–70 65 7 455 25.2830 639.2310 4474.6173 4225 29575
Total 53 2105 15320.75472 11375 98925

La desviación muestral es:
165.17153
75472.15320s
165.17153
53
210598925
2
s
Forma normal Forma rápida

DISPERSIÓN RELATIVA
Cuando queremos comparar dos o más medidas de
dispersión que no están en las mismas unidades
podemos utilizar el coeficiente de variación.
COEFICIENTE DE VARIACIÓN:
Es la razón (cociente) de la desviación estándar y la
media aritmética, llamada también como coeficiente de
Pearson, expresada en porcentaje:
100*X
sCV

EJEMPLO: En una cierta empresa se hizo un estudio de las
notas obtenidas en un curso de capacitación y los años de
servicio de los mismos empleados que tomaron el curso de
capacitación. La calificación media de los empleados fue de 14
puntos, y la desviación estándar de 2 puntos. Y la media de los
años de servicio fue de 18 años y la desviación estándar fue de
3 años. Para las notas Para los años de servicio
%29.14100*14
2CV %67.16100*
18
3CV
Podemos ver que hay menor dispersión relativa con
respecto a las media en la distribución de notas que
en la distribución de años de servicio (14.29% <
16.67%).

ASIMETRÍA: Es la medida de la falta de simetría en una
distribución. Es decir que una distribución es simétrica si no
tienes sesgo, esto se da cuando los valores de tendencia
central (media, moda, mediana) están en un solo punto.
Asimetría Negativa.- Esto se da cuando hay observaciones
muy pequeñas, esto va hacer que la media se vuelva la
menor de las 3 medidas de tendencia central.
Asimetría Positiva.- Esto se da cuando hay observaciones
muy grandes, esto va hacer que la media se vuelva la mayor
de las 3 medidas de tendencia central.

estándarDesviación
MedianaMediaCA
_
*3
Generalmente el coeficiente de asimetría se
encuentra entre -3 y +3.
EJEMPLO:
En un estudio de salarios de empleados de una
cierta empresa. Se encontró que la media se calculó
en S/. 5 000, la moda en S/. 6 800, y la mediana en S/.
5 600 y la desviación estándar en S/. 800.
Para evaluar esto tenemos el coeficiente de asimetría (CA)
o también llamada el coeficiente de Kurtosis:

Ahora nos damos cuenta que el coeficiente de asimetría es
-2.25, esto indica un sesgo negativo importante. Esto indica
que a la mayoría de empleados se le paga un salario mayor
que la media.
25.2800
56005000*3CA
Vemos que la media es la menor de todas, entonces
tiene una asimetría negativa.

SELECCIÓN DE UN PROMEDIO PARA DATOS
DE UNA DISTRIBUCIÓN DE FRECUENCIAS
Obviamente, si todas las observaciones estuvieran
concentradas en un solo valor de la variable, media,
mediana y moda coincidirían en el mismo. Si las
observaciones se fueran distribuyendo en forma simétrica,
a la izquierda y a la derecha de ese valor central, media,
mediana y modo seguirían coincidiendo.

Supongamos ahora que las observaciones de la parte
izquierda se alejan del valor central más que las
observaciones de la parte derecha, generando una
distribución asimétrica hacia la izquierda; en este caso como
la media es la suma de los valores de las observaciones
dividido por la cantidad total de observaciones, su valor se
correrá a la izquierda también y por el mismo motivo, la
media será menor que la mediana y ambas menor que la
moda. En una distribución asimétrica a la derecha, la media,
es mayor que la mediana y que la moda.

Este corrimiento de la media se explica porque si tomamos
un conjunto de datos cualquiera a los cuales calculamos
media, mediana y moda y agregamos un dato extremo y
volvemos a calcular la media, la mediana y la moda, veremos
que la media puede variar notablemente, mientras que la
mediana y la moda permanecen idénticas.
Esta no variación de la mediana y la moda reciben el nombre
de robustez. Las medidas basadas en el orden (la mediana)
gozan de ésta en tanto que las medidas basadas en la suma
(la media) se ven más afectadas por las observaciones
extremas y son, por lo tanto, poco robustas.
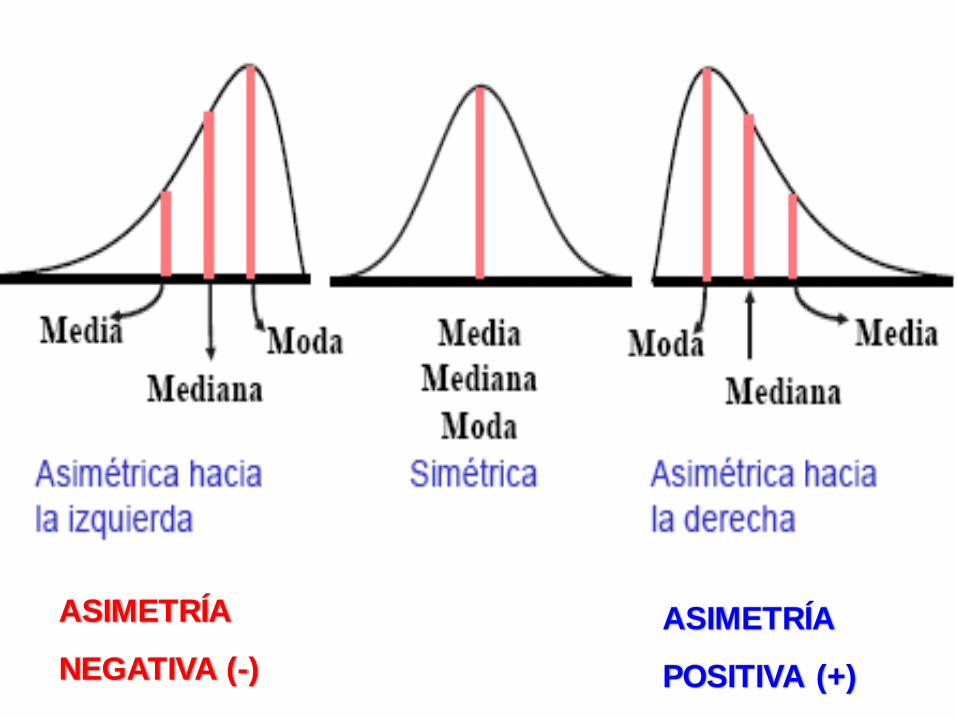
ASIMETRÍA
NEGATIVA (-)
ASIMETRÍA
POSITIVA (+)
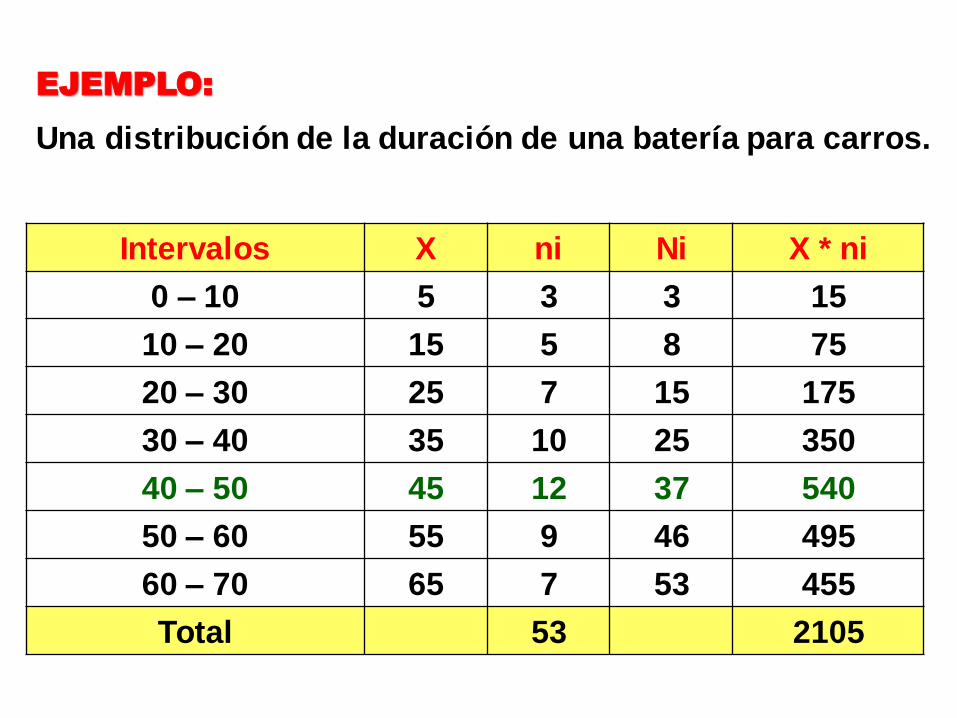
EJEMPLO:
Una distribución de la duración de una batería para carros.
Intervalos X ni Ni X * ni
0 – 10 5 3 3 15
10 – 20 15 5 8 75
20 – 30 25 7 15 175
30 – 40 35 10 25 350
40 – 50 45 12 37 540
50 – 60 55 9 46 495
60 – 70 65 7 53 455
Total 53 2105

Los resultados son:
72.3953
2105X
25.4110*12
252
53
40Mediana
0.4410*)1012()912(
101240Moda
Media Mediana
Moda

En resumen:
Media Mediana Moda
39.72 41.25 44.0
Asimetría hacia la izquierda
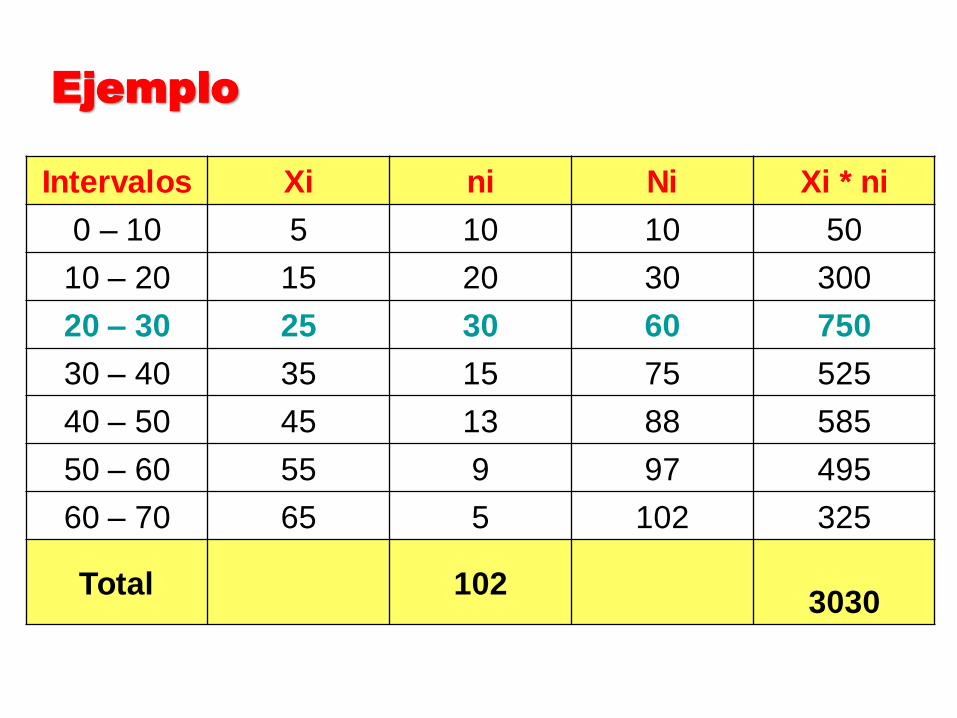
Intervalos Xi ni Ni Xi * ni
0 – 10 5 10 10 50
10 – 20 15 20 30 300
20 – 30 25 30 60 750
30 – 40 35 15 75 525
40 – 50 45 13 88 585
50 – 60 55 9 97 495
60 – 70 65 5 102 325
Total 102 3030
Ejemplo

Los resultados son:
71.29102
3030X 0.2710*
30
302
102
20Mediana
0.2410*)1530()2030(
203020Moda
Media Mediana
Moda
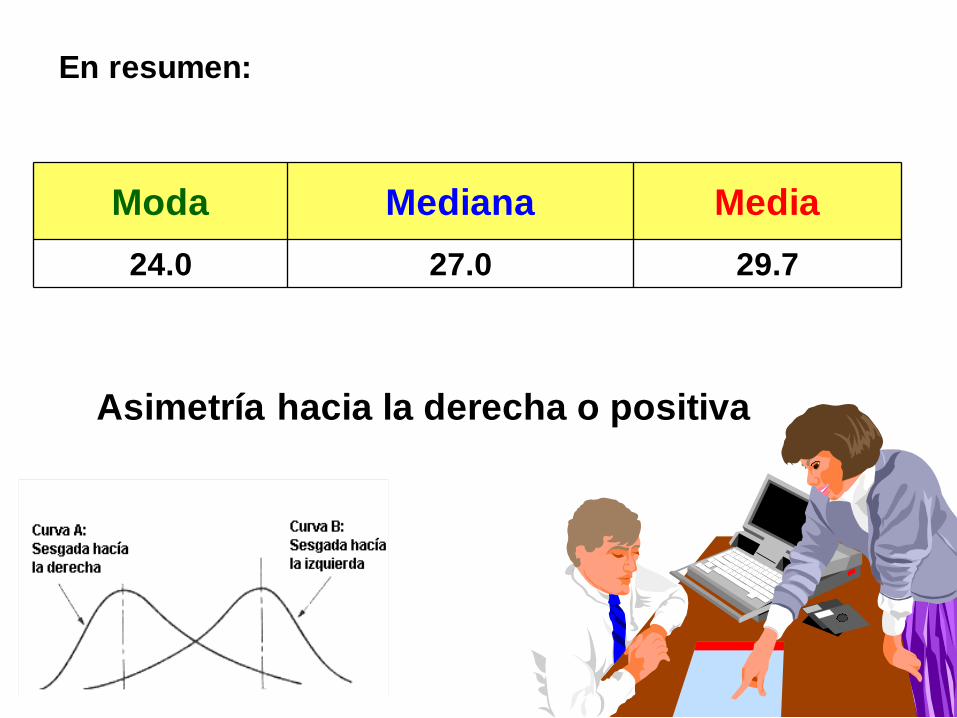
En resumen:
Moda Mediana Media
24.0 27.0 29.7
Asimetría hacia la derecha o positiva

TEOREMA DE CHEBYSHEV
Este teorema permite determinar la proporción mínima de
los valores que se encuentran dentro de un número
específico de desviaciones estándares con respecto a la
media. Es decir para un conjunto cualquiera de
observaciones (puede tomar cualquier forma), la proporción
mínima de los valores que se encuentran dentro de “k”
desviaciones estándares desde la media es al menos (1 –
1/k2), donde k es una constante mayor que 1.

EJEMPLO:
Una distribución de la duración (en meses)
de una batería para carros. Cuya media es 39.72
meses, con una desviación estándar de 17.165 meses.
¿Qué porcentaje de las duraciones de la batería se
encuentra a una distancia de ±2 desviaciones
estándares, respecto a la media y ±3 desviaciones
estándares?
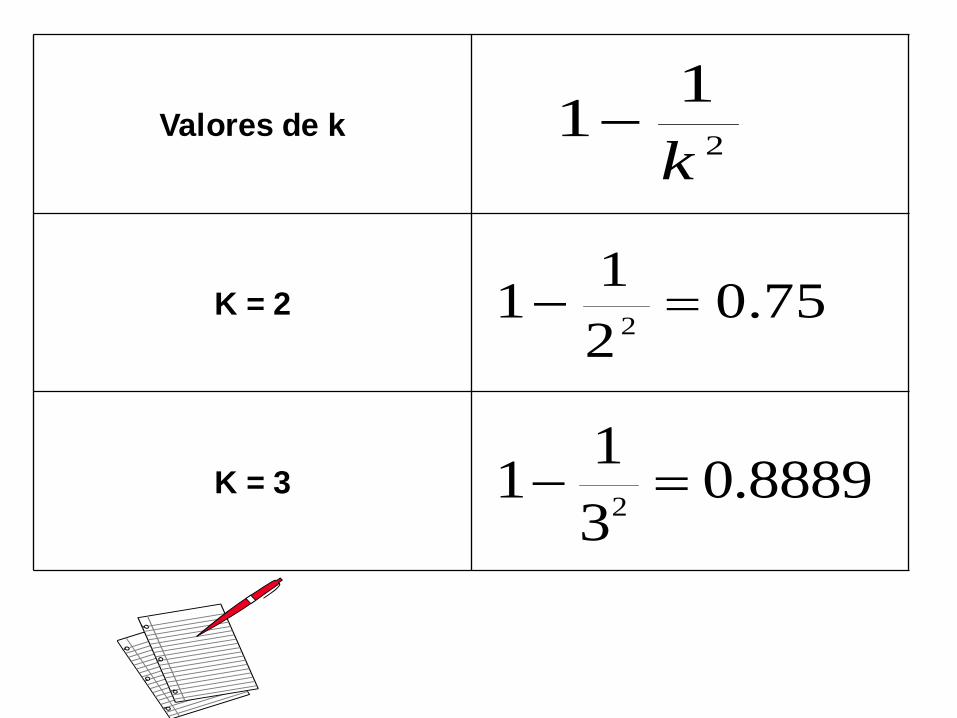
2
11
k
75.02
11
2
8889.03
11
2
Valores de k
K = 2
K = 3
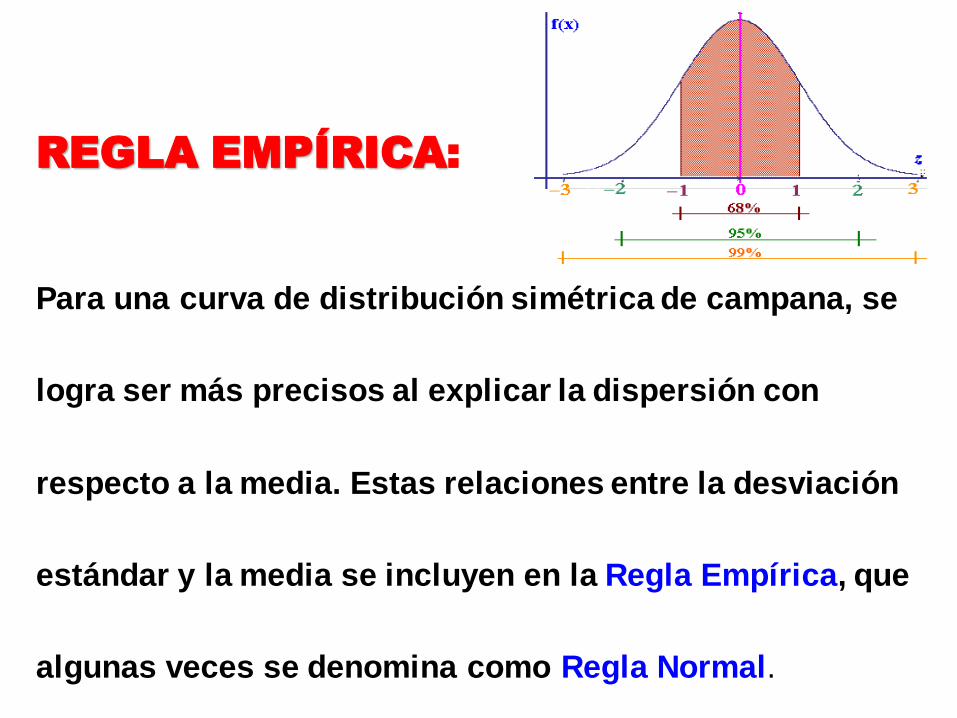
REGLA EMPÍRICA:
Para una curva de distribución simétrica de campana, se
logra ser más precisos al explicar la dispersión con
respecto a la media. Estas relaciones entre la desviación
estándar y la media se incluyen en la Regla Empírica, que
algunas veces se denomina como Regla Normal.
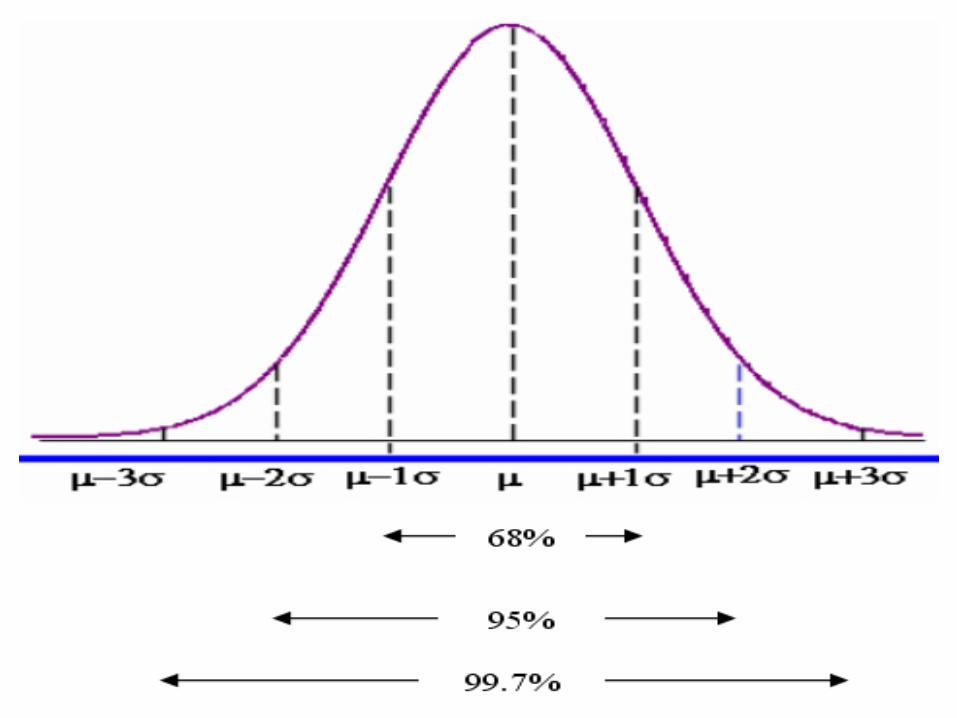

Entonces vemos que si una distribución es simétrica con
forma de campana, prácticamente todas las
observaciones se encuentran entre la media ±3
desviaciones estándares.
EJEMPLO:
Para una distribución de salarios, sigue
aproximadamente una distribución de frecuencias
simétrica de campana. La media se calculó que es S/. 5
000 y la desviación estándar de S/. 500. Utilizando la regla
empírica:
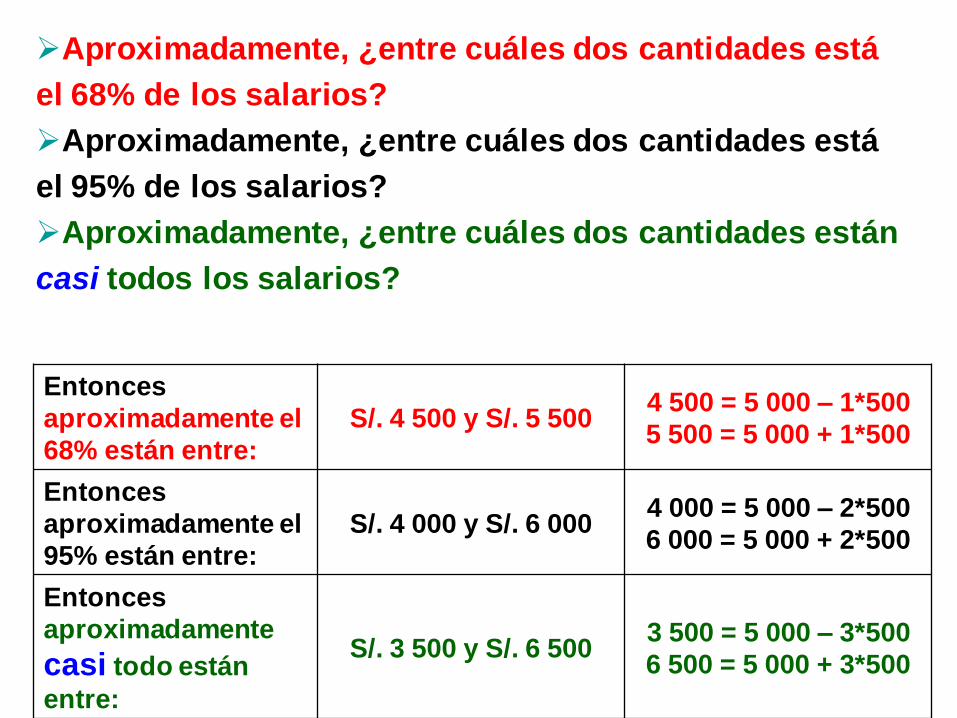
Aproximadamente, ¿entre cuáles dos cantidades está
el 68% de los salarios?
Aproximadamente, ¿entre cuáles dos cantidades está
el 95% de los salarios?
Aproximadamente, ¿entre cuáles dos cantidades están
casi todos los salarios?
Entonces
aproximadamente el
68% están entre:
S/. 4 500 y S/. 5 500 4 500 = 5 000 – 1*500
5 500 = 5 000 + 1*500
Entonces
aproximadamente el
95% están entre:
S/. 4 000 y S/. 6 000 4 000 = 5 000 – 2*500
6 000 = 5 000 + 2*500
Entonces
aproximadamente
casi todo están
entre:
S/. 3 500 y S/. 6 500 3 500 = 5 000 – 3*500
6 500 = 5 000 + 3*500

Gracias
Jack Welch , General Electric
“Nuestra conducta es impulsada por
una creencia central básica: el deseo
y habilidad para aprender
constantemente y de cualquier fuente,
y convertir rápidamente ese
aprendizaje en acción, esta es la
verdadera ventaja competitiva “
Top Related