







Idiomas
Páginas
Jurídico


Tesis
“Un agente basado en un razonador de ontologías”
Autora: Norka Natalia Aguirre Helguero
e-mail: [email protected]
Directora: Lic. Adriana Echeverría
2011

75.00 Tesis
2
Agradecimientos
En primer lugar a mis padres, Mario y Norka, mis hermanos,
Marito, Sebastián, Marco y Bernardo y todo el pequeño grupo de familiares por
su contención, paciencia y continuas palabras de aliento.
A mi directora de tesis, Adriana Echeverría, por darme su
orientación, sus consejos y comprensión, determinante para la realización del
presente trabajo.
A ellos mis esfuerzos y gratitud, de corazón.

75.00 Tesis
3
INDICE
TESIS ............................................................................................................................... 1
“Un agente basado en un razonador de ontologías” ............................................................................................. 1
INTRODUCCIÓN ............................................................................................................... 6
CAPÍTULO I.................................................................................................................... 10
Servicios Web ........................................................................................................................................................... 10 1.1 Generalidades ................................................................................................................................................ 10
1.1.1 Definiciones .......................................................................................................................................... 10
1.1.2 Características primarias ................................................................................................................... 11
1.1.3 Características secundarias ................................................................................................................ 13
1.2 Desarrollo orientado a servicios ................................................................................................................ 14
1.2.1 Beneficios .......................................................................................................................................... 14
1.2.2 Diferencias con el desarrollo orientado a objetos ...................................................................... 15
1.2.3 Composición de servicios ............................................................................................................... 15
1.2.4 Abstracción de Servicios ................................................................................................................. 16
1.3 Modelos de interoperabilidad en una arquitectura de servicios Web ......................................... 17
1.3.1 Modelo orientado a mensajes - MOM ............................................................................................ 17
1.3.2 Modelo orientado servicios - SOM ................................................................................................. 19
1.3.3 Modelo orientado a recursos – ROM .............................................................................................. 21
1.3.4 Modelo de políticas - PM .................................................................................................................. 23
1.4 Arquitectura orientada a servicios .................................................................................................... 24
1.4.1 Generalidades ................................................................................................................................... 24
1.4.2 Directorio de servicios ........................................................................................................................ 26
1.4.3 BPM ......................................................................................................................................................... 26
1.4.4 Gobierno de políticas y procesos ....................................................................................................... 27
1.4.5 Especificaciones ................................................................................................................................... 28
1.5 Servicios Web RESTFul ............................................................................................................................... 30
CAPÍTULO II .................................................................................................................. 31
Ontología ................................................................................................................................................................... 31 2.1 Generalidades ................................................................................................................................................ 31
2.2 Folksonomías y ontologías ......................................................................................................................... 33
2.3 Lógica y ontologías ....................................................................................................................................... 35
2.4 Aplicaciones .................................................................................................................................................. 36
2.5 Lenguajes ontológicos ................................................................................................................................. 39
2.5.1 RDF ..................................................................................................................................................... 39
2.5.1.1 Conceptos Básicos ........................................................................................................................ 39
2.5.1.2 RDF y la ambigüedad semántica XML ....................................................................................... 43
2.5.2 OWL .................................................................................................................................................... 45
2.5.2.1 Conceptos Básicos ........................................................................................................................ 45
2.5.2.2 Sub-Lenguajes ............................................................................................................................... 49
2.5.2.3 Semántica Formal ........................................................................................................................ 51
2.5.3 WSMO ................................................................................................................................................. 51
2.5.3.1 Principios de diseño .................................................................................................................... 52
2.5.3.2 Conceptos básicos ........................................................................................................................ 52
2.5.4 DAML-S............................................................................................................................................... 53
2.5.5 OWL-S ..................................................................................................................................................... 54
2.5.6 SWSF ................................................................................................................................................... 54
2.5.7 WSDL-S............................................................................................................................................... 55
2.5.8 SAWSDL ............................................................................................................................................. 56
2.6 Razonador ...................................................................................................................................................... 57
2.6.1 Clasificación .......................................................................................................................................... 59

75.00 Tesis
4
2.6.1.1 Razonadores de lógica descriptiva ............................................................................................. 59
2.6.1.2 Razonadores de programación lógica ....................................................................................... 60
2.7 SWRL .............................................................................................................................................................. 61
2.7.1 Motivaciones ......................................................................................................................................... 61
2.7.2 DL-Safe Rules ......................................................................................................................................... 62
2.8 Ejemplos ......................................................................................................................................................... 62
CAPÍTULO III ................................................................................................................. 81
Agentes ...................................................................................................................................................................... 81 3.1 Generalidades ................................................................................................................................................ 81
3.1.1 Agente y entorno ............................................................................................................................. 81
3.1.2 Agentes y objetos ............................................................................................................................. 85
3.1.3 Agentes y sistemas expertos .......................................................................................................... 86
3.1.4 Agentes y servicios .......................................................................................................................... 86
3.2 Clasificación................................................................................................................................................... 90
3.2.1 Clasificación dependiendo de la relación entre percepciones y acciones ............................... 92
3.2.2 Clasificación de acuerdo al tipo de aplicación ............................................................................. 92
3.2.3 Clasificación de acuerdo a características especiales ................................................................ 92
3.3 Matchmaking entre agentes heterogéneos ............................................................................................. 93
3.4 Información semántica que registran ...................................................................................................... 94
3.5 Aplicaciones de ontologías en agentes...................................................................................................... 97
3.6 Definición de las funcionalidades relacionadas con las capacidades esperadas de los agentes basados en razonadores. .................................................................................................................................... 99
3.7 Razonadores alternativos que puedan ser incorporados en el agente .............................................. 99
CAPÍTULO IV ............................................................................................................... 102
Composición dinámica de servicios ................................................................................................................... 102
4.1 Estudio de los últimos avances en composición dinámica de servicios como una solución eficiente y efectiva. ........................................................................................................................................... 102
4.2 Alternativas de composición semántica como OWL, Pellet, el algoritmo backward-chaining ...... 105
4.3 Agentes y la composición de servicios Web ........................................................................................... 106
CAPÍTULO V ................................................................................................................ 107
Caso práctico .......................................................................................................................................................... 107
5.1 Escenario de aplicación representativo del problema a resolver ...................................................... 107
5.2 El prototipo construido ............................................................................................................................. 108
5.2.1 Criterio adoptado ................................................................................................................................ 108
5.2.2 Componentes ...................................................................................................................................... 109
5.2.3 Herramientas ...................................................................................................................................... 111
5.3 Resultados ................................................................................................................................................... 114
CAPÍTULO VI ............................................................................................................... 121
Conclusiones y trabajos futuros ......................................................................................................................... 121
GLOSARIO.................................................................................................................... 124
REFERENCIAS .............................................................................................................. 129
ANEXO I ....................................................................................................................... 132
ANEXO II ...................................................................................................................... 133

75.00 Tesis
5
Objetivos ................................................................................................................................................................. 133

75.00 Tesis
6
Introducción
La visión del próximo paso en la evolución de la Web es la Web Semántica. En ella la
información será provista de significado explícito facilitando a los ordenadores procesar e integrar automáticamente la información disponible en la Web [W3C1; 2009]. La Web puede
alcanzar su máximo potencial si se convierte en un lugar donde la información pueda ser
compartida y procesada no sólo por personas sino también por herramientas automatizadas.
La Web Semántica permite diseñar agentes para que traten la información contenida en sus
páginas de manera automática a fin de convertir la información en conocimiento. Los datos
de las páginas Web son referenciados por esquemas de metadatos consensuados sobre un
dominio particular. Los esquemas de metadatos proporcionan información adicional, la cual
permite hacer deducciones y establecer axiomas y si son compartidos, realizar búsquedas de
información contextuales así como desarrollar aplicaciones Web más potentes. Las
ontologías brindan una representación consensuada de un dominio específico y legible por
ordenadores [Tello; 2001]
Según [Herman; 2010], el objetivo de la Web Semántica es crear un medio universal para el
intercambio de información, al mismo tiempo que prevé la interconexión de las
administraciones de información personal, integración de aplicaciones enterprise y el
intercambio global de información comercial, científica y cultural. La instalación de
información que se comprensible por los ordenadores en la Web se está convirtiendo
rápidamente en prioridad clave para organizaciones, individuos y comunidades.
La Web Semántica encuentra su propósito en una variedad de áreas de aplicación:
integración de datos; descubrimiento y clasificación de recursos (motores de búsqueda);
clasificación de páginas, sitios Web o bibliotecas digitales; en agentes de software para mayor
intercambio y acceso compartido de información; descripción de los derechos de propiedad
intelectual de páginas Web, etc.
La Web es uno de los repositorios públicos más grandes de información. Al 18 de diciembre
de 2010, se estima que en la Web existen 13.63 billones de páginas Web2. Esto representa
una cantidad extraordinaria de información. Desafortunadamente, la mayoría de esa
información es inaccesible a las computadoras debido a que fue diseñada para consumo
humano [Hebeler et al.; 2009]. Las máquinas fueron diseñadas para retransmitir
información, no para ser conscientes de los conceptos y relaciones contenidos en ella. Esto
es lo que hace difícil a las aplicaciones utilizar la Web como fuente de información de manera
automatizada.
Desde que la Web fue diseñada para humanos y basada sobre un concepto simple, la
información consiste de páginas de texto y gráficos que contienen links [Huhns; 2002]. Cada
link guía a otra página con información que una persona podría estar interesada en ver. Las
construcciones para la descripción y codificación, habitualmente empleadas en las páginas
1 World Wide Web Consortium o Consorcio World Wide Web es una comunidad internacional donde las
organizaciones Miembro, personal a tiempo completo y el público en general trabajan conjuntamente para
desarrollar estándares Web. Liderado por el inventor de la Web, Tim Berners-Lee y el Director Ejecutivo (CEO)
Jeffrey Jaffe, la misión del W3C es guiar la Web hacia su máximo potencial. 2www.worldwidewebsize.com

75.00 Tesis
7
(HTML) describen su apariencia pero no su contenido, mientras que a los agentes de
software sólo les interesaría su contenido. Pero a pesar de esta falencia, algunos agentes se las
ingenian para utilizar la Web en esas condiciones. Un shopbot 3 visita catálogos online de
vendedores para retornar precios de artículos según las preferencias registradas por el
usuario. Los shopbots operan por screen-scraping4, descargan páginas de catálogos y buscan
por nombre de artículo y por el conjunto de caracteres más cercano a un signo dólar, que
presumiblemente sería el precio del artículo. Los shopbots pueden entregar las mismas
formas que posiblemente entregaría una persona y analizar las páginas retornadas que un
comerciante esperaría que sus clientes vean. La Web Semántica hará la Web más accesible a
los agentes por utilizar construcciones semánticas como las provistas por ontologías,
representadas en lenguajes bien establecidos, y los agentes podrán comprender lo que hay en
una página.
[Berners-Lee et al.; 2006] afirman que los shopbots y los auctionbots5, de uso frecuente en la
Web, son trabajos artesanales de tareas específicas, con poca capacidad para interactuar con
diversidad de datos y tipos de información. Es con estándares bien establecidos que los
agentes de software pueden florecer y, en los últimos cinco años, estos estándares han
avanzado para expresar la información compartida.
En el contexto de la Web Semántica, ontologías, reglas e inferencia brindan soporte para
expresar restricciones adicionales sobre los recursos así como relaciones lógicas.
Las ontologías definen conceptos y relaciones por describir y representar un área de
conocimiento particular. Con ellas es posible clasificar términos en una determinada
aplicación, caracterizar relaciones y definir restricciones sobre esas relaciones. Sin embargo,
no es factible conseguir que todas las personas adhieran a una ontología. La actitud de la Web
con las ontologías es racionalizar6 la práctica de compartir información. Las aplicaciones
pueden interactuar sin tratar de lograr cobertura y consistencia global. No existen
requerimientos de acuerdo global o de traslación global entre ontologías específicas, excepto
para el subconjunto de términos relevantes de una transacción particular, que no es más que
un acuerdo local. Es importante tener presente que la adopción de ontologías existentes
favorece la integración y contribución de información, que algunas son más utilizadas que
otras y que su evolución es más del tipo bottom-up que top-down. [Herman; 2009]
Las reglas ofrecen una forma de expresar restricciones sobre las relaciones definidas por un
3 Agente que sirve para realizar la compra comparativa de programas informáticos que el usuario desea adquirir.
Analiza precios y especificaciones de los productos. Incluye características como heurísticas, patrones de
emparejamiento y técnicas de aprendizaje inductivo que le permiten desenvolverse en cualquier dominio de compra. 4 Screen scrapping consiste en obtener los datos mostrados por pantalla al capturar el texto vía software (visto
también como alternativa de conseguir los datos sin acceder a las fuentes como bases de datos). Las páginas
Web en formato HTML son un ejemplo. El software a ser utilizado debe ser escrito para reconocer datos
específicos. 5 Agente de subastas. Su propósito es pujar en la red para conseguir productos en las mejores condiciones
posibles. Implementan diferentes tipos de subastas y pueden gestionar varias simultáneamente. 6 Significa organizar una actividad social, laboral o comercial de forma de abaratar costos e incrementar el
rendimiento. En este sentido, el W3C proporciona especificaciones y estándares de los lenguajes ontológicos
que facilitan la codificación de conceptos mutuamente inteligibles lo que contribuye al progreso de la
comunicación dentro de la Web y, por lo tanto, al crecimiento de la utilidad Web.

75.00 Tesis
8
lenguaje ontológico (como RDF) y pueden ser empleadas para descubrir relaciones nuevas e
implícitas. No es posible definir un lenguaje de reglas para todos los sistemas basados en
reglas pero si un “core” comprendido por todas. Este core esta basado sobre tipos
restringidos de reglas, llamado reglas “Horn”, que tienen la forma if-then y establecen
restricciones sobre los tipos diferentes de condiciones y consecuencias. El Rule Interchange
Format (RIF) Working Group está trabajando en una definición precisa de un lenguaje de
reglas “core”, su extensibilidad, intercambio de expresiones de reglas entre sistemas y la
definición de su relación con OWL7 y su uso con triplas RDF.
A partir de la información adicional provista por las ontologías y conjuntos de reglas, los
razonadores pueden llevar a cabo procedimientos automáticos para inferir y generar nuevas
relaciones. Existe un amplio rango de razonadores automatizados disponibles y en general, la
inferencia utilizada en este contexto corresponde a lógica de primer orden.
La World Wide Web, inventada en 1989 por Tim Berners-Lee, cambio el modo en que las
personas reúnen y acceden información. Hoy la Web es un enorme repositorio de datos en
continuo crecimiento y existe un cuello de botella cada vez mayor cuando se intenta explotar
la información representada, es decir, piezas de información específicas. La Web Semántica
fue concebida con el propósito de resolver esta cuestión. Ella apunta a agregar semántica a la
información publicada en la Web (establecer el significado de los datos), tal que los
ordenadores puedan procesarla de manera similar a como lo harían los humanos y siendo la
columna vertebral tecnológica de ello las ontologías.
La Web fue concebida como una fuente de información distribuida y luego extendida, con la
aparición de tecnologías de servicios Web, a una fuente de funcionalidad distribuida. Esto es,
los servicios Web conectan computadoras y dispositivos utilizando Internet para
intercambiar y combinar datos en nuevas formas.
El crecimiento de la Web en tamaño y diversidad contribuye a una mayor necesidad para
automatizar aspectos de los servicios Web como descubrimiento, ejecución, selección,
composición e interoperación. De hecho, una de las ventajas de los servicios Web es que
hacen posible una composición dinámica de servicios utilizando componentes de software
reutilizables e independientes. El problema es que las actuales tecnologías (SOAP, UDDI,
WSDL) no proveen el soporte adecuado.
Las aplicaciones que emplean semántica en servicios Web son referidas como servicios Web
semánticos (SWS), los cuales, también, son anunciados como uno de los próximos pasos en el
camino hacia la evolución Web [Sánchez-García et al.; 2009]. Los SWS describen el contenido
de los servicios mediante anotaciones semánticas con el propósito de que el descubrimiento,
composición y la invocación de servicios pueda ser realizado automáticamente por agentes
inteligentes al procesar la información semántica provista.
Con el propósito de alcanzar estándares en la tecnología de SWS, el W3C ha recibido y
publicado diferentes presentaciones, algunas de las cuales han sido aprobadas y otras
7 Ontology Web Language o Lenguaje de Ontología Web.

75.00 Tesis
9
permanecen como potenciales entradas del proceso del W3C. Entre las primeras se
encuentra el estándar SAWSDL8, aprobado en el año 2007, realizado por SAWSDL Working
Group y basado en la presentación WSDL-S, realizada en el año 2005, por IBM y la
Universidad de Georgia. Entre los segundos siguen: 1) OWL-S, presentado en el año 2004, por
Nokia, Stanford Research Institute9 (SRI), y las universidades de Carnegie Mellon, Toronto,
Southampton, Yale, entre otras; 2) WSMO, presentado en el año 2005 por el WSMO Working
Group10; y 3) SWSF, presentado en el año 2005, por Hewlett Packard (HP), el Massachusetts
Institute of Technology11 (MIT), el National Research Council of Canada12, SRI y las
universidades de Stanford, Zurich, Toronto, California, entre otras.
En la presente tesis se estudiará cómo los servicios Web pueden interoperar combinando de
manera automática sus funcionalidades a fin de resolver situaciones que así lo requieren. Se
empleará un agente dotado con capacidades semánticas por medio de diferentes razonadores
y de las ontologías adecuadas al escenario elegido para el descubrimiento y combinación
automática de los servicios.
El aporte de esta tesis es establecer de qué manera la Web Semántica, descripta a través de
agentes, ontologías y razonadores podría contribuir a una área de investigación activa como
los servicios Web.
La tesis es organizada como sigue: en el capítulo I, se realiza una presentación de los
servicios Web; en el capítulo II se desarrollan las ontologías, los lenguajes ontológicos más
conocidos y más citados en las investigaciones de la Web Semántica, los razonadores y, se
adelanta una parte del prototipo construido por detallar las ontologías desarrolladas para el
escenario de aplicación representativo; en el capítulo III se exponen los agentes y su relación
con el software; en el capítulo IV se describen algunas de las investigaciones realizadas
acerca de la composición dinámica de servicios; el capítulo V trata del prototipo construido,
los criterios adoptados, sus componentes y las herramientas empleadas, el capítulo VI
enuncia las conclusiones finales y trabajo futuro y al final se anexan los objetivos que
formaron la primera presentación de este trabajo como propuesta .
8 Desarrollado en la sección 2.5.8 “SAWSDL”
9 Instituto de investigación sin fines de lucro cuya misión es el descubrimiento y la aplicación de la ciencia y la
tecnología al conocimiento, el comercio, la prosperidad y la paz. Las áreas principales incluyen comunicaciones y
redes, informática, sistemas de ingeniería, robótica, seguridad y defensa nacional, entre otras. 10
Su misión es alinear los proyectos de investigación europea en el área de los SWS, trabajando en la
estandarización de lenguajes y una arquitectura y plataforma común. 11
Instituto de Tecnología de Massachussets 12
Consejo Nacional de Investigación de Canadá

75.00 Tesis
10
Capítulo I
Servicios Web
1.1 Generalidades
1.1.1 Definiciones
Los servicios Web surgen como la mejor solución para la ejecución remota de funcionalidad.,
debido, parcialmente, a propiedades como independencia del sistema operativo y del
lenguaje de programación, interoperabilidad, ubicuidad y la posibilidad para desarrollar
sistemas débilmente acoplados. [García-Sánchez et al.; 2009]
Los servicios Web son diseñados para proveer interoperabilidad para diversas aplicaciones.
Los servicios Web son (por su diseño) independientes de las plataformas e interfaces de
lenguaje permitiendo una fácil integración entre diversos sistemas. Lenguajes Web como
UDDI, WSDL y SOAP definen estándares para descubrimiento, descripción y protocolos de
mensajes. [Sirin et al.; 2002]
Una perspectiva de negocios, los define como activos IT, como actividades del mundo real o
funciones de negocios reconocibles, posibles de ser accedidos cumpliendo políticas de
servicio (quien o qué es autorizado para acceder un servicio, cuando un servicio está
disponible, el costo de utilizar un servicio, niveles de confiabilidad por tiempo de restitución,
niveles de seguridad por requerimientos de privacidad e integridad, niveles de performance
por tiempo de respuesta, etc.).
Una perspectiva técnica, en cambio, los define como activos IT reutilizables, coarse-
grained13, con interfaces o contratos de servicio, que ocultan su implementación y
desacoplan la relación usuario-proveedor de servicio, permitiendo que ambos puedan
evolucionar independientemente, mientras los contratos de servicios permanecen sin
cambios (que un usuario pueda utilizar los servicios de otros proveedores o que un
proveedor pueda atender otros usuarios).
Los servicios pueden interactuar de manera consistente e independiente de la tecnología
gracias a estándares y facilidades provistas por la plataforma de servicios Web, la cual
constituye una infraestructura común para que usuarios y proveedores puedan localizar y
utilizar los servicios de otros o agregar nuevos servicios de manera estandarizada, siendo su
propósito principal el de facilitar la distribución de servicios.
Los servicios son un elemento clave en una arquitectura orientada a servicios. Un análisis
por capas, distingue entre contratos de servicios, servicios técnicos y línea de negocios.
13
En este contexto, denota características generales

75.00 Tesis
11
La capa de línea de negocios automatiza, de manera parcial o total, los servicios que una
organización presta directa (propios) o indirectamente14 (tercerización). La línea de
negocios establece un dominio de servicio (ingeniería, finanzas, ventas, marketing,
manufacturas, transporte, entre otros) a fin de que los servicios de ese dominio puedan
comunicarse mediante un vocabulario común y sea posible combinarlos. Generalmente,
servicios de diferentes dominios tendrán inconsistencias o vocabularios contradictorios y
por lo tanto, la plataforma de servicios Web necesitará proveer facilidades de transformación
de datos para pedidos de dominios diferentes.
La capa de servicios técnicos se ocupa de definir servicios reutilizables a lo largo de múltiples
líneas de negocios. Por ejemplo, servicios de transformación de datos, acceso a datos,
auditoría, acceso y administración de identidad (login). Los servicios de esta capa son
valiosos porque responden a un requerimiento especial de negocios como es la mitigación
del riesgo en escenarios cambiantes.
Cada servicio consta de una interfaz bien definida (es decir de una separación clara entre
interfaz e implementación) llamada formalmente, contrato de servicio. El contrato de servicio
es un mecanismo para formalizar un sistema y su alcance, minimizar dependencias,
maximizar adaptabilidad, emplear pruebas de caja negra, seleccionar servicios y cambiar de
proveedores.
Un proveedor de servicios (service provider) es un módulo de software que implementa un
contrato de servicio. Varios proveedores pueden implementar un mismo contrato de servicio
y ser instanciados por cada vez que son requeridos.
Un usuario de servicio (service requester) es un módulo de software que invoca el servicio
implementado por algún proveedor y utiliza las facilidades provistas por la plataforma de
servicios Web a fin de localizar el servicio y comunicarse con él.
Los servicios Web proponen un enfoque diferente para resolver algunos de los problemas IT
(especialmente en torno a la integración) que se desprenden de las nuevas capacidades
ofrecidas por la tecnología. Cabe destacar que considerando que los servicios Web son
tecnologías de interfaz basadas en XML, la utilización adecuada de servicios Web requiere de
un cambio en la forma de pensar la tecnología, la cual no consiste en simplemente aprender
una nueva gramática para la misma manera de construir y desplegar sistemas sino en tener
presente que los servicios Web hoy y siempre requerirán de una combinación de
tecnologías.
1.1.2 Características primarias Los servicios Web permiten obtener beneficios de negocios y técnicos debido a ciertas
características claves, las cuales deben estar presentes en el diseño, la implementación y
14
Outsourcing o tercerización. Contratar a otra empresa para que realice determinadas tareas que hacen a la
actividad empresarial pero no al núcleo del negocio. Realizado cuando se mejora la eficiencia en los resultados
(reducir costos, mejorar la calidad prestada) y se liberan recursos para reasignarlos a las tareas centrales de la
empresa

75.00 Tesis
12
administración. Estas características por grado de importancia se encuentran agrupadas en
características primarias, desarrolladas en esta sección y características secundarias,
desarrolladas a continuación.
Las características primarias son claves en la obtención de beneficios. Ellas incluyen: débil
acoplamiento, contratos de servicios bien definidos, útiles para el usuario y basados en
estándares. A continuación se describen brevemente.
Para que un servicio tenga débil acoplamiento hay que considerarlo a través de su interfaz, la
tecnología y los procesos. Idealmente, un usuario de servicio debería solicitar el servicio a
partir del contrato de servicio publicado y del acuerdo de nivel de servicio (SLA) pero nunca
requerir información acerca de su implementación. La dependencia de tecnología limitaría la
diversidad de usuarios que podrían acceder al servicio y la posibilidad de ser exteriorizado
para proveer a terceros. Por último, se debería tratar que los servicios no queden ligados a
procesos de negocios para que luego puedan ser reutilizados en diferentes procesos y
aplicaciones.
Cada servicio cuenta con una interfaz, bien definida llamada contrato de servicio, para definir
capacidades y modos de invocación, mientras oculta detalles de implementación. Así, un
estándar para contratos de servicios es provisto por WSDL. Por otro lado, un servicio puede
incluir metadatos sobre seguridad, políticas y con otros propósitos, utilizando la familia de
especificaciones WS-Policy15. Es importante destacar que un contrato de servicio debe ser
desarrollado con conocimiento del dominio de negocio y no simplemente derivado de la
implementación del servicio. Como primer corolario, el contrato de servicio debe ser
independiente de la implementación y manejado como un artefacto separado. Los contratos
de servicios son más valiosos que las implementaciones debido a que representan
conocimiento vital de negocios, son la base para compartir y reutilizar servicios y el
mecanismo primario para reducir acoplamiento de interfaz. Los cambios en los contratos de
servicios son más costosos que los cambios en la implementación dado que se propagan a los
usuarios, mientras que los cambios de implementación no tienen esos efectos. Como segundo
corolario entonces, es importante tener un mecanismo formal de extensión y versionado de
contratos de servicios para manejar dependencias y costos.
Servicios útiles son aquellos que poseen contratos de servicios definidos con un nivel de
abstracción apropiado y con sentido para los usuarios. Un nivel apropiado de abstracción es
aquel que captura la esencia del servicio sin restringir aplicaciones futuras, evita exponer a
los usuarios detalles técnicos como estructuras internas o convenciones y utiliza vocabulario
del dominio del servicio para definir el servicio y los documentos de entrada y salida. Una
interfaz abstracta promueve la sustitución, permitiendo cambiar de proveedores sin afectar a
los usuarios. En general, los servicios útiles ejecutan tareas discretas y proveen interfaces
simples a fin de lograr reutilización y débil acoplamiento.
Los servicios basados en estándares tienen varias ventajas: evitan depender de un vendedor
IT, aumentan las oportunidades que tiene un usuario de utilizar proveedores de servicios
alternativos, las oportunidades de los proveedores de soportar un amplio número de usuarios
15
Desarrollado por IBM, Microsoft, SAP y BEA. Políticas expresadas siguiendo un enfoque checklist para asociar
solicitudes con proveedores. Las políticas son declaraciones establecidas por el proveedor que solicitan al usuario
información adicional aparte de la provista por WSDL (requerimientos de seguridad, transacciones, etc.) a fin de
poder invocar el servicio.

75.00 Tesis
13
y de utilizar implementaciones open-source, a su vez, basadas en estándares, en tanto que,
para las comunidades de desarrolladores crecen las oportunidades en torno a las
implementaciones.
Además de adherir a estándares tecnológicos, resulta relevante poder respaldar el modelo de
datos y el modelo de procesos con estándares maduros del dominio de negocio y de la
industria vertical.
1.1.3 Características secundarias
Las características secundarias de los servicios permiten incrementar los beneficios. Ellas
incluyen:
� SLAs,
� stateless,
� diseño con soporte para múltiples estilos de invocación,
� diseño de contratos de servicios relacionados,
� compensación de transacciones,
� implementación independiente de otros servicios,
� descubrimiento y administración por metadatos.
A continuación se presenta una descripción de cada una de estas características.
Los acuerdos de nivel de servicio (SLA), definen métricas de servicios (tiempo de respuesta,
rendimiento, disponibilidad, tiempo entre fallas, entre otras) y permiten a los usuarios
determinar si un servicio satisface sus requerimientos no funcionales; a los proveedores
determinar la cantidad de instancias de servicios, provisión dinámica de servicios, servicios
centralizados o distribuidos geográficamente, entre otras. Un SLA debe ser establecido
tempranamente porque afecta el diseño, la implementación y la administración. Su función
es establecer, monitorear y permitir renegociar objetivos de negocios después de finalizada la
implementación.
Los metadatos permiten que los servicios sean publicados de manera especial para ser
descubiertos y consumidos sin intervención del proveedor. Esto reduce costos en localizar y
utilizar servicios, errores asociados con su utilización y permite una mejor administración.
Se deben implementar servicios autosustentables para minimizar dependencias entre
servicios, a fin de permitir que puedan interoperar sin dependencias internas y sin
compartir estado.
Una compensación de transacción corrige los errores producidos en una transacción
comercial. Ambas, la transacción y compensación, deben ser implementadas
simultáneamente por servicios distintos para asegurar consistencia entre ellas.

75.00 Tesis
14
El diseño y la implementación de operaciones de servicio deben soportar múltiples estilos de
invocación a fin de ser utilizadas en un amplio rango de situaciones y procesos de negocios.
En la mayoría de los casos la lógica de negocios implementada por un proveedor de servicio es
completamente independiente del estilo de invocación.
Los servicios stateless (servicios sin estado) son implementaciones donde las invocaciones
son independientes una de la otra y no dependen de un mantenimiento específico del cliente,
ni de estados persistentes entre invocaciones (no mantienen el estado de los procesos que
ejecutan ni los resultados que generan). Por lo tanto, resulta inmediato que las interacciones
stateless escalan eficientemente al permitir que cualquier pedido pueda ser enrutado a
cualquier instancia de servicio en oposición a los servicios stateful16 que no escalan
eficientemente dado que el servidor necesita recordar cuales servicios están sirviendo a cual
cliente y no se puede reutilizar un servicio hasta que éste haya terminado o por timeout.
Dado que los servicios no están aislados, al diseñar interfaces de servicios para un dominio de
negocios particular, se diseña el modelo de datos a nivel servicio (XML Schema) y
simultáneamente todas la interfaces. Esto es porque los servicios de ese dominio de negocios
utilizarán elementos del mismo modelo de datos. Además, asegura que los elementos de datos
sean definidos y aplicados de manera consistente y evita situaciones donde los servicios
utilicen definiciones similares aunque sutilmente diferentes. Es importante que todos los
servicios compartan el mismo modelo de datos a nivel servicio, incluyendo la estructura y
semántica de los documentos de negocios.
Los servicios deberían ser diseñados e implementados con todas sus características. Sin
embargo esto no siempre es posible y, puede ocurrir que el costo de agregar una
característica particular sea prohibitivo, comparada con los objetivos de la organización. Si
esto sucede, se deben privilegiar las características primarias, las cuales otorgaran los
mayores beneficios.
1.2 Desarrollo orientado a servicios 1.2.1 Beneficios El desarrollo orientado a servicios es complementario a otros enfoques como el desarrollo
orientado a objetos, el desarrollo por procedimientos, el desarrollo por mensajes y el
desarrollo de base de datos. Entre los beneficios que provee el desarrollo orientado a servicios
se encuentran:
� Reutilización: capacidad para crear servicios utilizables en múltiples aplicaciones.
� Eficiencia: capacidad para crear servicios y aplicaciones a partir de la combinación de los
servicios existentes y capacidad de enfocarse en los datos a ser compartidos (en lugar de la
implementación subyacente).
� Débil acoplamiento de tecnologías: capacidad para modelar servicios independientemente
16
Servicios con estado que suelen mantener las decisiones del usuario durante un proceso o una sesión, por
ejemplo un carrito de compras o los diferentes pasos para registrarse en una página Web.

75.00 Tesis
15
de su entorno de su ejecución y crear mensajes que puedan ser enviados a cualquier
servicio.
� División de responsabilidad: permite a los analistas de negocios y técnicos colaborar en el
desarrollo de servicios mediante los contratos de servicio.
El último beneficio es producto del cambio radical que exige la forma de pensar servicios (en
temas de diseño, desarrollo y despliegue) que conduce a una redistribución de
responsabilidades en los departamentos IT. Surgen el rol de analista de negocios, responsable
por montar nuevas aplicaciones compuestas y flujos de procesos que aseguren el
cumplimiento de requerimientos operacionales y estratégicos de negocios y, el rol de técnico,
responsable por manejar la complejidad de la tecnología de fondo en el despliegue de
servicios, asegurar que las descripciones de servicios XML/Web son las que el usuario
necesita y determinar los datos correctos a compartir.
1.2.2 Diferencias con el desarrollo orientado a objetos
Desarrollar un servicio es diferente a desarrollar un objeto. Un servicio es definido por los
mensajes que intercambia con otros servicios y no por métodos. Un servicio es definido a un
nivel de abstracción más alto (el denominador común menor) que el empleado en la
definición de un objeto, precisamente, eso es lo que hace posible que una definición de
servicio pueda ser implementada en un lenguaje orientado a procedimientos (COBOL), en un
sistema de encolado de mensajes (JMS) o en un sistema orientado a objetos (J2EE o .NET).
La granularidad en la definición de un servicio marca otra diferencia. Un servicio
generalmente define una interfaz general que acepta más datos en una invocación que un
objeto y que consume más recursos de procesamiento que un objeto a causa de su
necesidad de mapear a un entorno de ejecución, procesar el XML y permitir acceso remoto.
Aunque las interfaces de objetos pueden ser muy generales, el punto es que los servicios son
diseñados para solucionar problemas de interoperabilidad entre aplicaciones y para
componer nuevas aplicaciones (o sistemas de aplicación) pero no para crear lógica detallada
de negocios para las aplicaciones. [Newcomer y Lomov; 2004]
1.2.3 Composición de servicios
La Web crece en diversidad y tamaño incrementando la necesidad para automatizar aspectos
de los servicios Web como descubrimiento, ejecución, selección, composición e
interoperación. [García-Sánchez et al.; 2009]
Es posible crear una agregación de servicios Web de forma tal que el servicio Web publicado
encapsule otros servicios Web. Así una interfaz general puede ser descompuesta en un
número de servicios específicos (o múltiples servicios específicos ser combinados en una
interfaz general). Esto es frecuente en una composición estática de servicios efectuada por
medio de WS-BPEL17.
17
Web Services Business Process Execution Language. Es un lenguaje de composición orientado a procesos
para servicios Web. Depende de WSDL. Un proceso WS-BPEL puede ser expuesto como un servicio definido por
WSDL e invocado como cualquier otro servicio Web. Además WS-BPEL espera que todos los servicios incluidos

75.00 Tesis
16
A nivel proyecto, un arquitecto supervisa el desarrollo de servicios reutilizables e identifica
un medio para almacenar, administrar y recuperar descripciones de servicios. Una capa de
servicios separa las operaciones de negocios de variaciones en la implementación de la
plataforma de software subyacente, de la misma manera que los servidores Web y los
navegadores separan la WWW de variaciones en los sistemas operativos y lenguajes de
programación. Son los servicios reutilizables, por su capacidad para ser compuestos en
servicios más grandes rápida y fácilmente, lo que proveen a una organización de los
beneficios de la automatización de procesos y de la agilidad para responder a condiciones
cambiantes.
1.2.4 Abstracción de Servicios Un servicio tiene, en la red, una descripción de los mensajes que recibe y opcionalmente
retorna. En efecto, un servicio es definido en términos del patrón de intercambio de
mensajes (MEP) que soporta. Un esquema para los datos contenidos en el mensaje es
utilizado como parte principal del contrato (descripción) entre el servicio solicitante y el
servicio proveedor. Otros ítems de metadatos incluyen la dirección de red del servicio,
operaciones y requerimientos de confiabilidad, seguridad y transaccionalidad.
[Newcomer y Lomov; 2004]. Componentes de servicio.
Las partes de un servicio incluyen la implementación, una capa de mapeo y la descripción. La
implementación puede ser provista por cualquier entorno de ejecución. La implementación
en una composición sean definidos empleando contratos de servicio WSDL. Esto permite a un proceso WS-
BPEL invocar otros procesos WS-BPEL recursivamente.
J2EE .NET
CORBA IMS
Implementación de servicio / Agente ejecutable Usuario de servicio
Descripción de servicio
Capa traductora
(Mapping Layer)
Pedido de servicio

75.00 Tesis
17
del servicio también es llamada agente ejecutable. El agente ejecutable es responsable de
implementar el modelo de procesamiento definido por las especificaciones. El agente
ejecutable corre dentro de un entorno de ejecución, el cual es generalmente un sistema de
software o un lenguaje de programación.
La descripción se encuentra separada del agente ejecutable. Una descripción puede tener
múltiples agentes ejecutables asociados. Similarmente, un agente puede soportar múltiples
descripciones. Entre la descripción y el entorno de ejecución se encuentra la capa de mapeo
(algunas veces llamada capa de transformación), que es implementada por medio proxies o
stubs. La capa de mapeo es responsable de aceptar el mensaje, transformar los datos desde el
XML al formato original y despachar los datos obtenidos al agente ejecutable.
Los servicios Web pueden adoptar dos roles, como servicio solicitante, al iniciar la ejecución
de un servicio por enviar mensajes al servicio proveedor y como servicio proveedor, al
ejecutar el servicio y opcionalmente retornar resultados. Un agente ejecutable puede ocupar
uno o ambos roles.
La abstracción de servicios permite acceder a una variedad de servicios, incluyendo
aplicaciones legacy18 (wrapped o encapsuladas) y aplicaciones compuestas por otros
servicios.
1.3 Modelos de interoperabilidad en una arquitectura de servicios Web [Booth et al., 2004] definen una arquitectura de servicios Web (WSA - Web Service
Architecture) como una arquitectura de interoperabilidad, asegurada por identificar los
elementos de una red de servicios Web global. Estos elementos son combinados en cuatro
modelos diferentes.
1.3.1 Modelo orientado a mensajes - MOM
El modelo orientado a mensajes, también llamado MOM, por sus siglas en inglés (Message
Oriented Model), se centra sobre aspectos de la arquitectura relacionados a los mensajes y su
procesamiento.
El modelo no refiere el significado semántico del contenido de un mensaje o su relación con
otros mensajes.
MOM se centra en la estructura de los mensajes, las relaciones entre el emisor y el receptor y
cómo son transmitidos.
Los conceptos y relaciones en MOM son ilustrados a continuación:
18
Legacy usualmente significa aplicaciones remanentes, en versiones muy anteriores y que se han reemplazado por
más modernas, pero que siguen funcionando todavía.

75.00 Tesis
18
[Booth et al.; 2004] Modelo orientado mensajes
Algunos conceptos y relaciones son explicados a continuación.
� Dirección: es la información requerida por un mecanismo de transporte de mensaje a fin
de entregar el mensaje apropiadamente. Generalmente, la dirección dependerá del
transporte de mensajes particular. En el caso de transporte de mensajes HTTP, la dirección
tomará la forma de una URL.
� Mensaje: es la unidad básica de datos enviada desde un agente a otro. Las partes
principales de un mensaje son la envoltura, un conjunto de headers y el cuerpo. La
envoltura sirve para encapsular las partes componentes del mensaje y ubicar información
de direccionamiento. Los headers contienen información auxiliar acerca del mensaje y
facilidades de procesamiento modular. El cuerpo consta del contenido del mensaje.
� Cuerpo: provee un mecanismo para transportar información hacia el destinatario. La
forma del cuerpo y restricciones sobre el cuerpo pueden ser expresadas como parte de la
descripción de servicio. En muchos casos, la interpretación precisa del cuerpo del mensaje
dependerá de los headers del mensaje.
� Correlación: es la asociación de un mensaje con un contexto. Asegura que un agente
solicitante puede relacionar la respuesta con el pedido, especialmente cuando múltiples
respuestas son posibles.
� Envoltura: encapsula las partes componentes del mensaje, el cuerpo y los headers. En ella
se pueden encontrar la dirección de destino, información de seguridad que permite
autenticar el mensaje, información de calidad de servicio.
� Patrón de intercambio de mensajes: también llamado MEP (Message Exchange Pattern).
Es un template que describe un patrón genérico para el intercambio de mensajes entre
agentes. Los mensajes que son instancias de un MEP están correlacionados, explícita o
implícitamente. Los intercambios pueden ser sincrónicos o asincrónicos. La diferencia
precisa entre un MEP y una coreografía no está resuelta. Algunos sostienen que MEP
consiste de patrones atómicos y una coreografía de una composición de patrones. Un MEP

75.00 Tesis
19
es desprovisto de la semántica de la aplicación mientras que una coreografía incluye la
semántica en la descripción de patrones. A nivel de escala, una coreografía
frecuentemente utiliza MEP en la construcción de bloques.
� Header: contienen información acerca del mensaje. Su función primaria es facilitar el
procesamiento modular del mensaje. Parte del header puede incluir información
pertinente a funcionalidades extendidas de los servicios Web como seguridad, contexto de
transacción, información de orquestación, información de ruteo o administración. Pueden
ser procesados independientemente del cuerpo del mensaje, cada header puede identificar
un rol de servicio que indica el tipo de procesamiento que debería ser ejecutado sobre el
mensaje. Un mensaje puede tener varios headers identificando roles de servicios
diferentes.
� Destinatario: el destinatario de un mensaje es el agente que recibe un mensaje.
� Emisor: el emisor de un mensaje es el agente que transmite un mensaje. Aunque cada
mensaje tiene un emisor, la identidad podría no estar disponible en el caso de
interacciones anónimas.
� Confiabilidad: el objetivo es reducir la frecuencia de error y proveer suficiente
información acerca del estado de un envío. Esta información permite a un agente
participante tomar decisiones de compensación cuando se producen errores. Cuando más
de dos agentes están involucrados, es necesario utilizar una correlación de alto nivel como
“two-phase commit19”. El envío puede ser realizado por una combinación de
acknowledgement y correlación. Si un mensaje no ha sido recibido apropiadamente, el
emisor puede intentar un reenvío o alguna acción de compensación a nivel aplicación.
� Secuencia: conjunto ordenado de mensajes intercambiados entre un agente proveedor y
un agente solicitante durante una interacción. La secuencia puede ser realizada por un
MEP, usualmente identificado por una URI.
� Transporte: mecanismo empleado por los agentes para enviar mensajes. Ejemplos de
transporte de mensajes incluyen HTTP sobre TCP, SMTP, middleware20
orientado a mensajes,
etc.
1.3.2 Modelo orientado servicios - SOM
Se centra sobre aspectos de la arquitectura que relacionan servicio y acción. El propósito de
SOM es explicar las relaciones entre un agente con los servicios que provee y pedidos que
realiza. SOM se construye sobre MOM pero se ocupa de la acción que tiene lugar.
Los conceptos y relaciones en SOM son ilustrados a continuación.
19 Empleado en el procesamiento de transacciones, bases de datos y redes, es un algoritmo distribuido que coordina
todos los procesos que participan en una transacción atómica distribuida para el commit o rollback de la transacción
(tipo de protocolo por consenso). El protocolo es resistente, en muchos casos, a fallas temporales del sistema (por
procesos, nodos de red, comunicación). Sin embargo no es resistente a todas las posibles fallas de configuración y
en casos especiales puede requerir la intervención del usuario. 20
Software de conectividad que ofrece un conjunto de servicios que hacen posible el funcionamiento de
aplicaciones distribuidas sobre plataformas heterogéneas. Funciona como una capa de abstracción de software
distribuida que se sitúa entre las capas de aplicaciones y las capas inferiores (sistema operativo y red). El
middleware abstrae de la complejidad y heterogeneidad de las redes de comunicación subyacentes, así como de los
sistemas operativos y lenguajes de programación, proporcionando una API para la fácil programación y manejo de
aplicaciones distribuidas.

75.00 Tesis
20
[Booth et al.; 2004] Modelo orientado a servicios
Los conceptos relacionados con agente proveedor, agente solicitante, entidad proveedor y
entidad solicitante son definidos en la sección agentes.
Para el modelo, un servicio es un recurso abstracto que representa la capacidad de ejecutar
tareas y posee funcionalidad coherente desde el punto de vista de una entidad proveedor y
solicitante y que para ser utilizado debe ser implementado por un agente proveedor.
Los servicios Web se distinguen de otros recursos Web en que no necesariamente tienen
una representación. Los servicios Web son interacciones entre agentes proveedor y
solicitante, centrados en acciones, que con propósitos de caracterizar la semántica son
capturadas en términos de tareas (la semántica de cualquier sistema está ligado al
comportamiento del sistema). Las tareas combinan el concepto de acción con intención: los
servicios Web son invocados con un propósito, que puede ser expresado como un objetivo de
estado deseado.
Algunos conceptos y relaciones son explicados a continuación.
� Acción: ejecutada por un agente, por recibir un mensaje o enviar un mensaje o cualquier
otro cambio de estado observable que satisface un objetivo de estado deseado.
� Coreografía: define la secuencia y condiciones bajo las cuales múltiples agentes
intercambian mensajes a fin de alcanzar el objetivo de estado de la tarea a ejecutar. Se
apoya en interfaces de servicio, puede pertenecer a una tarea, define la relación entre los
mensajes intercambiados y las tareas de un servicio. Mientras una orquestación define la
secuencia y condiciones bajo las cuales un servicio Web invoca a otro para realizar alguna
función, una coreografía puede ser descripta utilizando un lenguaje de descripción de
coreografía sobre cómo componer servicios Web, cómo establecer roles y asociaciones en
los servicios Web y cómo manejar el estado de los servicios compuestos.
� Capacidad: pieza de funcionalidad soportada o requerida por un agente. Tiene un

75.00 Tesis
21
identificador URI, una descripción semántica, puede ser publicada por un agente
proveedor o solicitante y referenciada por una descripción de servicio.
� Objetivo de estado: es el estado deseable de algún servicio o recurso desde el punto de vista
de una persona u organización. Asociado con las tareas provistas por un servicio, los
objetivos son caracterizados por predicados que son verdaderos para ese estado.
� Descripción: contiene detalles de la interfaz y del comportamiento esperado del servicio y
puede ser utilizada para facilitar la construcción y despliegue de servicios, por personas
para localizar servicios apropiados y por agentes solicitantes para automáticamente
descubrir agentes proveedores.
� Interfaz: define los diferentes tipos de mensajes que un servicio envía y recibe, junto con
el patrón de intercambio de mensajes (MEPs) empleado tal como request/response21,
one-way asynchronous22 o publish/subscribe23.
� Rol: es un conjunto de tareas de servicio, que puede ser definido en términos de
propiedades de mensajes y establecido por el propietario del servicio. Un mensaje recibido
por un servicio puede involucrar procesamiento asociado con varios roles. Similarmente,
los mensajes emitidos pueden involucrar más de un rol de servicio.
� Semántica: es el contrato entre una entidad proveedora y una entidad solicitante
concerniente a los efectos y requerimientos pertenecientes al uso de un servicio. Trata
sobre las tareas que constituyen el servicio. Debería ser identificada en una descripción de
servicio y descripta formalmente por un lenguaje procesable por máquina. Las
descripciones semánticas procesables por máquina proveen un uso sofisticado de los
servicios Web. Aparte del comportamiento esperado de un servicio, otros aspectos de la
semántica de un servicio incluyen restricciones sobre políticas, la relación entre la entidad
proveedor y la entidad solicitante y cuáles características de manejabilidad están asociadas
con el servicio.
� Tarea: es una abstracción que encapsula los efectos deseados de invocar un servicio. Las
tareas están asociadas con objetivos de estado. La performance de una tarea es observable
por el intercambio de mensajes entre un agente solicitante y un agente proveedor. El
patrón específico de mensajes define la coreografía asociada con la tarea. Las tareas
representan una unidad útil en el modelado de la semántica de un servicio y de hecho, del
rol de un servicio.
1.3.3 Modelo orientado a recursos – ROM
También llamado ROM (Resource Oriented Model). Los recursos son un concepto
fundamental que sustenta gran parte de la Web y gran parte de los servicios Web. Por
ejemplo, un servicio Web es un tipo particular de recurso. El modelo se centra en
características claves de los recursos tales como propiedad de recursos y políticas
asociadas con recursos. Dado que los servicios Web son recursos, estas propiedades son
heredadas por ellos.
Los conceptos y relaciones en ROM son ilustrados a continuación:
21
Patrón para el intercambio de dos mensajes entre dos nodos SOAP adyacentes. Un mensaje “request” es
transferido desde el nodo solicitante al nodo receptor para luego transferir un mensaje “response” desde el nodo
receptor al nodo solicitante. 22
Patrón para el envío de mensajes que no requiere que el emisor y el receptor estén on-line simultáneamente.
Limitado a la transmisión de mensajes desde un nodo emisor a cero o más nodos SOAP receptores. 23 Patrón por eventos, en el que eventos “subscribers” indican los eventos de su interés en un broker de eventos para
recibir notificaciones cuando los eventos indicados son generados por los eventos “publishers”. Permite
interacciones del tipo many-to-many.

75.00 Tesis
22
[Booth et al.; 2004] Modelo orientado a recursos
Algunos conceptos y relaciones son explicados a continuación.
� Servicio de descubrimiento: utilizado para publicar y buscar descripciones conformes con
ciertos criterios funcionales o semánticos. Facilita a las entidades solicitantes el proceso de
encontrar un agente proveedor apropiado para una tarea particular. También,
dependiendo de la implementación y políticas de descubrimiento, puede ser utilizado por
entidades proveedoras para publicar sus descripciones de servicio.
En un servicio de descubrimiento dinámico, la interacción es directa con el agente
solicitante para encontrar el agente proveedor más conveniente. En un servicio de
descubrimiento estático, la interacción es indirecta con una persona a través de un agente
apropiado, tal como un navegador.
� Identificador: la arquitectura utiliza URIs para identificar recursos.
� Representación: pieza de información que describe el estado de un recurso.
� Recurso: es el corazón de la arquitectura Web. La Web es un universo de recursos. Desde
una perspectiva del mundo real, un aspecto interesante de un recurso es su propiedad. Un
recurso es algo que puede ser apropiado y por lo tanto está sujeto a políticas. Las políticas
aplicadas a recursos son relevantes para la administración de recursos Web, seguridad de
acceso a servicios Web y otros aspectos del rol que un recurso tiene en el mundo.
� Descripción: procesable por computadora, son utilizadas por los agentes para el
descubrimiento de recursos. Su propósito principal es facilitar descubrimiento de
recursos. Para lograrlo, provee información sobre la ubicación del recurso, accesibilidad y
políticas aplicadas. Cuando el recurso es un servicio Web, la descripción puede contener
información acerca de los efectos esperados de utilizar el servicio. La descripción de un
servicio es distinta de la representación. Esta última es un snapshot24 que refleja el estado
del recurso, la descripción consiste de meta-información acerca del recurso.
24
En sistemas informáticos, es el estado de un sistema en un punto particular en el tiempo.
75.00 Tesis
23
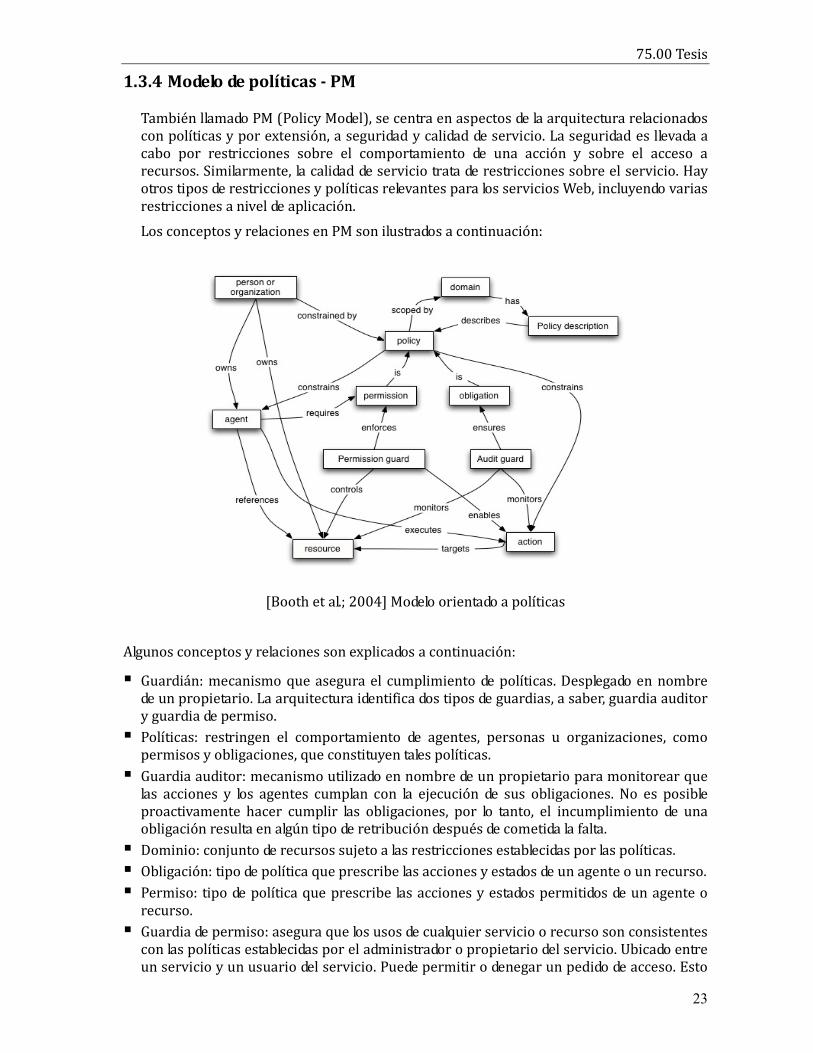
1.3.4 Modelo de políticas - PM
También llamado PM (Policy Model), se centra en aspectos de la arquitectura relacionados
con políticas y por extensión, a seguridad y calidad de servicio. La seguridad es llevada a
cabo por restricciones sobre el comportamiento de una acción y sobre el acceso a
recursos. Similarmente, la calidad de servicio trata de restricciones sobre el servicio. Hay
otros tipos de restricciones y políticas relevantes para los servicios Web, incluyendo varias
restricciones a nivel de aplicación.
Los conceptos y relaciones en PM son ilustrados a continuación:
[Booth et al.; 2004] Modelo orientado a políticas
Algunos conceptos y relaciones son explicados a continuación:
� Guardián: mecanismo que asegura el cumplimiento de políticas. Desplegado en nombre
de un propietario. La arquitectura identifica dos tipos de guardias, a saber, guardia auditor
y guardia de permiso.
� Políticas: restringen el comportamiento de agentes, personas u organizaciones, como
permisos y obligaciones, que constituyen tales políticas.
� Guardia auditor: mecanismo utilizado en nombre de un propietario para monitorear que
las acciones y los agentes cumplan con la ejecución de sus obligaciones. No es posible
proactivamente hacer cumplir las obligaciones, por lo tanto, el incumplimiento de una
obligación resulta en algún tipo de retribución después de cometida la falta.
� Dominio: conjunto de recursos sujeto a las restricciones establecidas por las políticas.
� Obligación: tipo de política que prescribe las acciones y estados de un agente o un recurso.
� Permiso: tipo de política que prescribe las acciones y estados permitidos de un agente o
recurso.
� Guardia de permiso: asegura que los usos de cualquier servicio o recurso son consistentes
con las políticas establecidas por el administrador o propietario del servicio. Ubicado entre
un servicio y un usuario del servicio. Puede permitir o denegar un pedido de acceso. Esto

75.00 Tesis
24
es posible porque las políticas de permisos son proactivamente controladas.
� Descripción: descripción procesable de un conjunto de políticas.
1.4 Arquitectura orientada a servicios
1.4.1 Generalidades
Una arquitectura orientada a servicios o SOA (Service Oriented Arquitecture) es definida por
[Newcomer y Lomov; 2004] como un estilo de diseño que dirige los aspectos de crear y
utilizar servicios de negocios a lo largo del ciclo de vida del servicio (desde su concepción
hasta su retiro). Es también una manera para definir y disponer una infraestructura IT que
posibilita a diferentes aplicaciones intercambiar datos y participar en procesos de negocios,
sin considerar los sistemas operativos o lenguajes de programación que sostienen esas
aplicaciones.
En SOA, los servicios de negocios (servicios para operar con clientes, socios o empleados)
son el principio clave para alinear sistemas IT con los objetivos estratégicos de negocios IT.
Las empresas que implementan sus sistemas IT de esta manera reaccionan más rápido a
nuevos requerimientos dejando atrás competidores con sistemas ligados a los entornos de
ejecución. Resulta más sencillo combinar servicios Web, más fácil cambiar composiciones de
servicios Web y más barato cambiar servicios Web y datos XML que cambiar entornos de
ejecución. Las ventajas de SOA con servicios Web incluyen un mejor retorno de la inversión
(ROI) por los gastos IT en proyectos, proyectos más rápidos y capacidad para responder en
corto tiempo a nuevos requerimientos de negocios y del gobierno.
La orientación a servicios reduce los costos y los calendarios de proyectos exitosos por
adaptar la tecnología a las personas, en lugar de enfocarse en la tecnología en sí. La mayor
ventaja de un desarrollo orientado a servicios es que permite concentrarse en la descripción
de un problema de negocios en oposición a enfoques anteriores que prestaban atención a las
tecnologías de un entorno de ejecución particular.
El concepto SOA no es nuevo. Lo nuevo es la capacidad para mezclar y asociar entornos de
ejecución, separando claramente la interfaz de servicio de la tecnología de ejecución,
permitiendo que los departamentos IT puedan elegir el mejor entorno de ejecución para cada
trabajo y vincularlos utilizando un enfoque de arquitectura consistente.
La idea de separar una interfaz de su implementación para crear un servicio ha demostrado
buenos resultados. Pero la capacidad de separar clara y completamente una descripción de
servicio de su entorno de ejecución es nueva, una capacidad otorgada por los conceptos Web
y las tecnologías a los servicios Web. Las implementaciones tradicionales del concepto de
interfaz no consideraron una separación como ésta, debido a las implicaciones negativas de
performance. Sin embargo, algunas veces, la performance es menos importante que la
capacidad para alcanzar más interoperabilidad, algo que la industria ha luchado por lograr
pero que sólo ha conseguido parcialmente [Newcomer y Lomov; 2004].
SOA no depende de avances en software, traídos por los servicios Web, sino de un cambio de

75.00 Tesis
25
enfoque. Separar la descripción de servicio de la tecnología de implementación significa que
los negocios pueden centrarse en pensar y planificar inversiones IT en torno a la realización
de consideraciones de negocios, en lugar de ocuparse de las capacidades de un producto
individual o de la tecnología elegida para ejecutar una descripción. En este caso, la
descripción convierte la definición del conjunto de características y funciones en el
denominador común que cualquier producto o tecnología debe soportar. Sin embargo, esto es
posible si se produce un cambio en la manera de pensar los negocios IT. El mundo es diverso
por naturaleza y un SOA con servicios Web no sólo abraza esta diversidad sino que provee la
capacidad para crear sistemas IT acordes con las operaciones de negocios. En un mundo
SOA, las empresas tienen que aprender a pensar servicios como diferentes a entornos de
ejecución y, además, a tener que ensamblar aplicaciones a partir de componentes de una
variedad de proveedores IT.
El valor real de SOA proviene de las últimas etapas de implementación, cuando nuevas
aplicaciones pueden ser desarrolladas enteramente, o casi enteramente, por componer los
servicios existentes. Es, en este momento, cuando se alcanzan los mayores valores por el
esfuerzo realizado (menores costos, resultados más rápidos, mejora del ROI). Sin embargo,
toma tiempo alcanzar este punto, además de una inversión significativa en desarrollo
orientado a servicios.
La clave es determinar el diseño correcto y el funcionamiento de los servicios en bibliotecas
reutilizables, las cuales deben reflejar las características operacionales de la organización.
Estas características operacionales necesitan ser automatizadas y un proyecto SOA,
finalizado con buen éxito, garantiza que los servicios reutilizables se encuentran
apropiadamente alineados con los procesos de negocios operacionales. Una alineación
correcta de servicios de negocios y su implementación asegura poder cambiar rápida y
fácilmente los procesos de negocios operacionales a medida que cambios externos causan
que una organización se adapte y evolucione.
Las principales dificultades para adoptar SOA incluyen la formación del personal adecuado y
el mantenimiento del nivel de disciplina que se requiere para garantizar que los servicios
que se desarrollen sean reutilizables. Cualquier tecnología, por prometedora que sea, puede
ser objeto de abuso y un uso inadecuado. Los servicios deben ser desarrollados no sólo para
beneficio inmediato sino principalmente para prestaciones a largo plazo. Dicho de otro
modo, la existencia de un servicio individual no es de mucho valor a menos que se ajuste a
una colección más grande de servicios que puedan ser consumidos por múltiples
aplicaciones y de las cuales nuevas aplicaciones se puedan componer.
Otras dificultades incluyen la gestión de costos a corto plazo. La construcción de un SOA no es
barata; la reingeniería de los sistemas existentes cuesta dinero y el ROI se extiende en el
tiempo. Resulta necesario contar con analistas de negocios para definir los procesos de
negocios, arquitectos de sistemas para convertir los procesos en especificaciones,
ingenieros de software para desarrollar nuevas aplicaciones y lideres de proyecto para
realizar un seguimiento de toda la reingeniería.
Algunas aplicaciones pueden necesitar ser modificadas para participar en SOA y esto podría
representar una dificultad. Estas aplicaciones podrían carecer de una interfaz para

75.00 Tesis
26
convertirlas en servicios. Existen aplicaciones que sólo son accesibles vía transferencia de
archivos o entrada/salida de datos por lotes y que, por lo tanto, ciertos programas adicionales
resultarían indispensables a fin de habilitarlas como servicios.
1.4.2 Directorio de servicios
Un directorio de servicios permite que ciertos componentes puedan localizar otros
componentes, donde los componentes pueden ser aplicaciones, agentes, proveedores de
servicios Web, usuarios de servicios Web, objetos o procedimientos [Huhns; 2002]. Existen
dos tipos generales de directorios según sus entradas: white-pages cuyas entradas listan los
nombres de servicios y yellow-pages, cuyas entradas listan las características y capacidades
de los servicios.
Implementar un directorio básico es un mecanismo simple como una base de datos que
permite a los participantes insertar descripciones sobre los servicios ofrecidos y consultar
los servicios ofrecidos de otros participantes. Un directorio más avanzado podría ser más
activo que otros al proveer no sólo búsqueda de servicios sino también brokering25 o
facilidades de servicios. Por ejemplo, un participante podría solicitar un servicio de brokering
para reclutar los agentes necesarios a fin de responder una consulta. El servicio de brokering
utilizaría la información acerca de las características y capacidades de los proveedores de
servicios registrados para determinar a qué proveedores enviar la consulta. De esta manera,
el directorio podría enviar la consulta a esos proveedores, retornar las respuestas a quien las
solicitó y aprender acerca de las propiedades de las respuestas que gestiona.
UDDI es en sí mismo un servicio Web basado en XML y SOAP. Provee servicios de white-
pages y yellow-pages pero no facilidades de servicios [Newcomer y Lomov; 2004].
1.4.3 BPM
Un administrador de procesos de negocios (BPM o Business Process Management) denota
un conjunto de sistemas de software relacionados y de metodologías para el desarrollo,
despliegue y manejo de procesos de negocios. Un proceso de negocio puede incluir sistemas
IT que requieran interacción humana o sistemas IT completamente automatizados.
El objetivo de los sistemas BPM es alinear los sistemas IT con los procesos de negocios y por
lo tanto con los objetivos de negocios.
Todos los sistemas IT implementan procesos de negocios pero BPM separa explícitamente la
lógica de procesos de negocios del código de aplicación (en contraste con otras formas de
desarrollo de sistema donde la lógica de proceso esta embebida en el código de aplicación).
25
Desarrollado en la sección 3.3, “Matchmaking entre agentes heterogéneos”.

75.00 Tesis
27
Separar la lógica de procesos del código de aplicación ayuda a aumentar la productividad,
reduce los costos operacionales y mejora la agilidad. Correctamente implementado, las
organizaciones pueden responder rápidamente a condiciones cambiantes del mercado y
aprovechar oportunidades para ganar ventaja competitiva.
BPM simplifica el problema de combinar la ejecución de múltiples servicios Web para
resolver un problema particular. Si se piensa en un servicio como la alineación de un sistema
IT con una función de negocio, como puede ser el procesamiento de una orden de compra,
BPM estaría representado por una capa con varios servicios unidos por un flujo de ejecución
para completar la función. Por definir el flujo de proceso fuera del código de aplicación, el
proceso de negocio puede ser fácilmente cambiado y actualizado por nuevas características y
funciones.
El flujo de proceso es dividido en tareas individuales llamadas servicios Web. Cada parte de
un flujo es probado basado en los resultados de ejecutar una tarea.
1.4.4 Gobierno de políticas y procesos
Algunas organizaciones creen haber adoptado SOA simplemente por utilizar tecnologías de
servicios Web como SOAP o WSDL. Sin embargo, SOA no es una aplicación sino más bien
una disciplina que abarca casi la totalidad de la actividad IT, incluyendo procesos, métodos y
herramientas para diseño, desarrollo, administración y mantenimiento de activos IT.
El propósito de un gobierno26 SOA es alinear los gobiernos de negocios y de software,
incluyendo la coordinación del desarrollo y la adquisición de software y su reutilización para
lograr mayor agilidad y economía de escala. El gobierno SOA es una extensión del gobierno
IT para manejar servicios y abstracciones a nivel servicios.
La necesidad de un gobierno surge de reconocer que los servicios son activos, proveen una
unidad común para administración de requerimientos, acuerdos de servicios (SLA),
performance de negocios y técnica y reutilización de recursos y por lo tanto requieren ser
manejados durante su ciclo de vida.
Un gobierno SOA es un cuerpo dentro de la empresa con representantes de cada dominio de
servicio, de cada unidad de negocio y de expertos en la materia que puedan hablar acerca de
los diferentes componentes tecnológicos de una solución.
Entre sus responsabilidades se encuentran establecer las políticas y procesos que permitan
identificar, implementar, desplegar y versionar servicios llevando a cabo un proceso
descentralizado (cada departamento o proyecto es responsable por identificar, implementar y
desplegar servicios) o centralizado (donde el cuerpo de gobierno revisa la adición,
modificación y eliminación de servicios antes de autorizar su implementación y despliegue),
determinar las herramientas a utilizar (en administración de proyectos, modelado de
26
Entendido aquí como la acción de dirigir, decidir, guiar.

75.00 Tesis
28
negocios, modelado de servicios, modelado de datos, desarrollo, administración de sistemas,
entre otras) y el intercambio de información entre ellas y determinar la formación
obligatoria y opcional de miembros del equipo de SOA y de equipos de proyectos grandes en
la implementación de procesos y utilización de herramientas SOA. En cualquier caso, es
importante que haya algún nivel de estandarización que atraviese los departamentos y
proyectos para promover la reutilización de servicios.
1.4.5 Especificaciones
Una arquitectura de servicios Web consiste de especificaciones WSDL, SOAP y UDDI, a fin de
soportar interacción entre un usuario, un proveedor de servicio y algún mecanismo
potencial para descubrimiento de servicios. Un proveedor publica una descripción WSDL de
sus servicios en un registro UDDI (o algún otro tipo de registro), otro agente accede a la
descripción publicada y envía un mensaje SOAP al proveedor solicitando la ejecución del
servicio.
Según el W3C, WSDL es un protocolo de comunicación. Define una gramática XML para
describir los servicios Web como una colección de endpoints capaces de intercambiar
mensajes. Es utilizado frecuentemente en combinación con SOAP. Un programa cliente
conectándose a un servicio Web puede leer su archivo WSDL a fin de determinar cuáles
operaciones están disponibles en el servidor. El cliente luego utiliza SOAP para invocar
alguna de las operaciones listadas.
WSDL 2.0 es la última versión de la especificación y fue aprobada en el año 2007 por el W3C.
Esta especificación soporta todos los métodos HTTP request, ubicándola como el mejor
soporte para servicios Web RESTful27, además de ser mucho más simple de implementar. Sin
embargo, todavía son pocas la herramientas que la incluyen entre sus funcionalidades
ofrecidas y pocas las aplicaciones que la incluyen en sus implementaciones (la última versión
de BPEL28 sólo soporta WSDL 1.1).
WSDL define un servicio como una colección de endpoints (WSDL 2.0) o ports (WSDL 1.1).
Un endpoint, a su vez, es definido por asociar una dirección de red con una interfaz
reutilizable. Los mensajes describen de manera abstracta los datos intercambiados y los
portypes (se explica más abajo su significado), de manera abstracta también, el conjunto de
operaciones disponibles. El protocolo concreto y el formato de datos de un portype particular
constituyen un binding reutilizable, donde las operaciones y los mensajes son vinculados a un
protocolo de red concreto y a un formato de mensaje. De esta manera WSDL define la
interfaz pública de un servicio. Los elementos que componen WSDL son presentados e
identificados a continuación, según su denominación en WSDL 1.1/WSDL 2.0:
27
Desarrollado en las siguientes secciones 28
El Business Process Execution Language, nombre corto del Web Services Business Process Execution Language
(WS-BPEL) es un lenguaje ejecutable estándar OASIS (consorcio global que dirige el desarrollo, convergencia y
adopción de estándares e-business y servicios Web) por especificar las acciones que ocurren dentro de los procesos
de negocios con servicios Web. Los procesos en BPEL exportan e importan información por utilizar interfaces de
servicios Web exclusivamente.

75.00 Tesis
29
� Types/Types: contiene las definiciones de los tipos de datos utilizados. XML-Schema es
utilizado (inline o por referencia) para este propósito.
� Message/No aplica: un mensaje corresponde a una operación. El mensaje contiene la
información necesaria para ejecutar la operación. Cada mensaje consiste de una o más
partes lógicas. Cada parte está asociada con un atributo del tipo de mensaje. El atributo
nombre del mensaje provee un nombre único entre todos los mensajes. El atributo
nombre de la parte provee un nombre único entre todas las partes que conforman el
mensaje. Las partes son una descripción lógica del contenido del mensaje. Los mensajes
fueron removidos en WSDL 2.0 donde los tipos XML-Schema para definir los input, output
y faults (entradas, salidas y fallas) son referidos directamente.
� Operation/Operation: cada operación puede ser comparada con la llamada a un método o
función en un lenguaje de programación tradicional. Define las acciones SOAP y la manera
en que el mensaje SOAP es codificado (por ejemplo un valor “literal” indica que el
mensaje es intercambiado tal cual es, sin información de tipo incluida, un valor “encoged”,
en cambio, indica que se trata de un mensaje con información de tipos incluida).
� PortType/Interface: el elemento portype fue renombrado en WSDL 2.0 como interface.
Define las operaciones que pueden ser ejecutadas y los mensajes empleados para ejecutar
la operación.
� Binding/Binding: especifica la interfaz, define el estilo de binding SOAP (RPC/Document)
y transporte (protocolo SOAP).
� Port/Endpoint: definido por una combinación binding - dirección de red, a menudo, es
representado mediante un URL HTTP.
� Service/Service: colección de endpoints relacionados que representa el conjunto de las
funciones de sistema que han sido expuestas basadas en los protocolos Web.
WSDL no introduce un lenguaje para la definición de tipos sino que debido a la importancia de
incorporar sistemas de tipos poderosos para describir mensajes a largo plazo soporta XSD
como sistema de tipos canónico y permite utilizar otros lenguajes de definición de tipos vía
extensibilidad.
WSDL introduce extensiones específicas de binding para los siguientes protocolos y
formatos de mensajes: SOAP, HTTP GET/POST y MIME.
Según el W3C, SOAP es un protocolo para intercambiar información estructurada en
entornos descentralizados o distribuidos. Emplea tecnologías XML para definir un marco
extensible de mensajes proporcionando una estructura de mensaje que puede ser
intercambiada sobre una variedad de protocolos de transporte.
Las ventajas que ofrece la especificación SOAP incluyen independencia de cualquier lenguaje
de programación, independencia del protocolo de transporte, independencia de cualquier
infraestructura de objetos distribuidos, utilización de estándares como XML para codificación
de los mensajes y de HTTP y SMTP como protocolos de transporte y permite
interoperabilidad entre múltiples entornos.

75.00 Tesis
30
Aparte de las especificaciones principales de servicios Web (WSDL y SOAP) existen otras
especificaciones que extienden los servicios Web como especificaciones de seguridad,
confiabilidad, transacciones, administración de metadatos y orquestación, las cuales proveen
soluciones basadas en SOA a un nivel de calidad de servicio empresarial en proyectos
corporativos grandes y de misión crítica.
1.5 Servicios Web RESTFul En general, los servicios Web son construidos utilizando SOAP y estándares WS-*29 pero los
servicios Web REST30 prescinden de SOAP y utilizan HTTP y XML [Mandel; 2008]. Cada uno
de estos estilos de arquitectura de servicios Web es ampliamente utilizado por la comunidad
de desarrollo.
REST es un estilo de arquitectura que trata a la Web como una aplicación centrada en
recursos. Los principios de diseño claves de esta arquitectura enuncian que 1) las
aplicaciones RESTFul deben ser stateless, es decir, que cada mensaje HTTP debe contener
toda la información necesaria para procesar una petición. Como resultado, ni el cliente ni el
servidor necesitan recordar ningún estado de las comunicaciones entre mensajes (en la
práctica un número de aplicaciones basadas en HTTP utilizan cookies y otros mecanismos a
fin de mantener el estado de la sesión, algunas de las cuales no son permitidas por REST); 2)
un conjunto de operaciones bien definidas mediante el estilo CRUD31 el cual a su vez utiliza
el amplio rango de verbos HTTP (POST, GET, PUT y DELETE); 3) una sintaxis universal para
identificar recursos (URI) y 4) utilización de hipermedios, explicado a continuación.
El Dr. Roy Fielding acuñó el término REST en la disertación de su Ph.D.32 donde refirió los
hipervínculos como el motor de los estados de la aplicación. Esto significa que para que una
transición pueda tener lugar, ya sea por cambiar el estado de un recurso o por transferir a
otro recurso, un recurso debe contener hipervínculos. Mientras los hipervínculos son
pensados para consumo humano, en general, no son utilizados en XML, los cuales, a su vez,
son pensados para ser procesados por computadora. Los servicios Web REST (al igual que
HTML) reúnen ambas características por utilizar hipervínculos en XML.
29 Se refiere a las especificaciones que extienden los servicios Web: WS-Addressing, WS-Security, WS-Policy, WS-
Transactions, son algunas de ellas. 30
REpresentational State Transfer refiere a una arquitectura de servicios Web basada en recursos 31
Acrónimo para create, read, update y delete. 32 Philosophy Doctor significa Doctorado en investigación. Reconocimiento al doctorando sobre su capacidad de
hacer investigación científica a partir de la presentación de una tesis doctoral que represente una contribución al
menos modesta al conocimiento humano.

75.00 Tesis
31
Capítulo II
Ontología 2.1 Generalidades Un modelo conceptual es la descripción de un dominio de interés (sus conceptos y
relaciones). En el campo de la informática, los modelos conceptuales deben transformarse de
tal manera que puedan almacenarse en la memoria de los ordenadores y permitan aplicar
algoritmos.
El propósito de las ontologías (originarias del campo de la Inteligencia Artificial) se apoya en
proporcionar los modelos conceptuales almacenables y computables. En informática, una
ontología designa la descripción de un dominio mediante un vocabulario común de
representación.
La definición más citada es la de [Gruber; 1993]: “una ontología es una especificación
explícita de una conceptualización”. Una conceptualización es una visión abstracta,
simplificada del mundo. Toda base de conocimiento, utilizada por un sistema o un agente de
conocimiento está vinculada, explícita o implícitamente, a una conceptualización.
Una ontología es un vocabulario controlado que describe de manera formal los objetos y las
relaciones entre ellos, y proporciona una gramática para utilizar los términos del vocabulario
con el fin de expresar algo con significado, dentro del dominio de interés específico. El
vocabulario puede ser empleado para hacer búsquedas y aserciones.
Los compromisos ontológicos acuerdan utilizar el vocabulario de una manera consistente a
fin de compartir conocimiento.
Las ontologías pueden incluir glosarios, taxonomías y diccionarios pero normalmente tienen
mayor expresividad y reglas más estrictas que las anteriores.
Una ontología formal es un vocabulario controlado que se expresa en un lenguaje de
representación de ontologías. Es conveniente aclarar que una ontología formal es una
semántica formal, es decir, describe el significado del conocimiento de manera precisa,
logrando una interpretación única por parte de máquinas y personas, y utiliza lógica de
primer orden o un subconjunto de ella (como la lógica descriptiva). Disponer de una
semántica formal resulta indispensable para implementar sistemas de inferencia o de
razonamiento automático.
Las ontologías son, también, una herramienta para compartir información y conocimiento,
es decir, para conseguir interoperabilidad. Al definir un vocabulario formal de los conceptos
del dominio y un conjunto de las relaciones entre ellos, permiten que las aplicaciones
“comprendan” la información.

75.00 Tesis
32
Por lo general, las ontologías toman la forma de una jerarquía de términos que representan
los conceptos básicos de un determinado dominio. En el entorno de la Web lo usual es
representarlas en formato XML. A diferencia de las ontologías, XML carece de una semántica
que permita razonamiento automático.
Según [Tello; 2001] para representar conocimiento de dominio, las ontologías poseen los
siguientes componentes:
� Conceptos: ideas básicas que se intentan formalizar. Pueden ser clases de objetos,
métodos, planes, estrategias, procesos de razonamiento, etc.
� Relaciones: representan la interacción y enlace entre los conceptos de dominio. Suelen
formar la taxonomía de dominio: “subclase de”, “parte de”, “parte exhaustiva de”,
“conectado a”, etc.
� Funciones: son un tipo concreto de relación donde se identifica un elemento mediante el
cálculo de una función que considera varios elementos de la ontología. Por ejemplo, pueden
aparecer funciones como categorizar clase, asignar fecha, etc.
� Instancias: se utilizan para representar objetos que pertenecen a un concepto
determinado.
� Axiomas: proposiciones que se declaran sobre las relaciones que deben cumplir los
elementos de la ontología. Por ejemplo: “Si A y B son de clase C, entonces A no es subclase
de B”, “Para todo A que cumpla condición C1, A es B”, etc.
Los axiomas, junto a la herencia de conceptos, permiten inferir el conocimiento oculto detrás
de una taxonomía de conceptos.
La Web, vista como una gran fuente de conocimiento, requiere de lenguajes apropiados para
representar ontologías. En este sentido, RDFS soporta algunos aspectos sobre conceptos de
dominio y permite crear, mediante relaciones taxonómicas, una jerarquía. Sin embargo, sirve
mejor como base de lenguajes con mayor expresividad y capacidad de razonamiento. Tello
sostiene que, a fin de potenciar la utilización de ontologías en la Web, se debería disponer de
aplicaciones de búsqueda de ontologías a fin de que los usuarios puedan utilizarlas en sus
sistemas.
La unificación de contenidos semánticos que formalicen conocimiento consensuado y
reutilizable a través de ontologías, conduce a la Web Semántica y, por lo tanto, a ventajas
como el desarrollo de aplicaciones con esquemas de datos compartidos, fomento de
transacciones entre empresas y búsqueda de información por inferencias.
Según [Dickinson; 2009] RDFS es el lenguaje ontológico más débil. Menciona que con RDFS
es posible construir una jerarquía de conceptos y propiedades simples pero no es posible
construir expresiones interesantes. Afirma que RDFS es suficiente para aplicaciones que
sólo necesiten de un vocabulario básico.
Por otro lado, existen ontologías profundas y poco profundas. Las ontologías profundas
requieren de considerables esfuerzos para construir y desarrollar conceptualizaciones y,

75.00 Tesis
33
algunos ejemplos se pueden encontrar en ciencia e ingeniería. Las ontologías poco
profundas, en cambio, comprenden algunas conceptualizaciones que son términos fijos y
que permiten organizar grandes cantidades de datos.
La complejidad asociada a las ontologías profundas ha llevado a buscar diferentes enfoques
como las folksonomías33, las cuales son utilizadas principalmente dentro del contexto de la
Web 2.034.
En el proceso de desarrollo de una ontología, la dificultad real es comprender el problema a
modelar y lograr un acuerdo a nivel comunidad. En esta línea, RDFS y OWL proveen el marco
para formalizar ontologías en un lenguaje específico; el tiempo y la energía necesarias para
aprender y utilizar estos lenguajes es sólo una fracción mínima del tiempo requerido en el
desarrollo de una ontología. Herramientas de desarrollo de ontologías como Protégé o
SWOOP, ocultan la complejidad de sintaxis y permiten al usuario concentrarse en temas de
representación real.
2.2 Folksonomías y ontologías
El término folksonomía deriva de taxonomía y es un neologismo atribuido a Thomas Vander
Wall. Literalmente folksonomía significa “clasificación gestionada por el pueblo”.
Una folksonomía es el resultado del tagging35 de información y objetos36, el cual es personal,
libre y contempla la posterior recuperación de información por parte de otros usuarios. Este
proceso de tagging conduce a un índice de tags que sirve como herramienta de búsqueda y
acceso a otros recursos.
Partiendo de premisas como distribución y desnormalización del trabajo de indización37, una
folksonomía habilita a los usuarios a indizar recursos utilizando cualquier palabra que
deseen. Esta dimensión colectiva y colaborativa le otorga al proceso de tagging el nombre de
indización social. La indización social representaría un nuevo modelo de indización, en el
que los usuarios llevarían a cabo la descripción de los recursos. Una agregación de todas las
descripciones (un mismo recurso sería indizado por numerosos usuarios) daría como
resultado una descripción intersubjetiva y más fiable que la realizada por el autor del recurso
[Navoni y González; 2009].
33
Desarrollado en la siguiente sección. 34 El término es empleado para enfatizar el carácter social de la red. Prácticamente todas las herramientas que
definen la Web 2.0 (blogs, wikis, Flickr, You Tube, RSS, folksonomías, entre otras) son calificadas como software
social a través de las cuales se crean comunidades, se exponen conocimientos de forma abierta y se desarrolla
aprendizaje colaborativo. El poder de la colectividad es completo en los blogs, las wikis, el editor de videos You
Tube, la herramienta para colgar fotos Flickr, el sistema de gestión de favoritos del.icio.us., los cuales, permiten al
usuario añadir valor, elegir, decidir, ser parte activa del proceso de construcción de la red que más que nunca tiene al
usuario en el centro de la escena. A diferencia de la Web 1.0, caracterizada, entre otras cosas, por un usuario receptor
pasivo. 35
Etiquetado realizado en un contexto social 36 Aquí refiere a recursos Web 37
Se refiere a un cambio en los métodos habitualmente aplicados en los procesos de indización. La indización
consiste en registrar los datos ordenadamente, a fin de elaborar un índice con ellos.

75.00 Tesis
34
Las folksonomías tienen a su favor simplicidad en su utilización y posibilidades constantes
de expansión y actualización. Pero presentan problemas de representación de información
en lenguaje natural y no poseen herramientas de control de vocabulario. Hacer uso de esta
opción requiere diseñar sistemas que procuren integrar las folksonomías con los
vocabularios controlados ya existentes de las aplicaciones.
La naturaleza múltiple del tagging y la falta de control de su terminología hacen que las
folksonomías sean incapaces de representar de forma consistente un dominio o contexto
específico y de brindar estructuras sólidas de navegación entre conceptos.
Las ontologías se encuentran en las antípodas de las folksonomías. Las ontologías son
diseñadas por expertos para hacer explícito y unívoco el significado de los documentos
utilizados en la comunicación interpersonal, en las interacciones humano-computadora y
computadora- computadora. Expresan conceptualizaciones formales de un área del
conocimiento a través de conceptos (clases), casos (individuos) y las relaciones entre ellos.
Las ontologías parten de relaciones jerárquicas como base estructural para diseñar un
dominio y van más allá permitiendo definir y modelar libremente relaciones entre conceptos
de un mismo dominio, haciendo explícitas todas las interrelaciones posibles y volviendo
transparente su estructura conceptual. Las ontologías son una representación formal y
explícita de la estructura conceptual del campo sobre el cual se está trabajando, logrando
economizar la codificación de la información al incluir a la herencia38 como mecanismo de
inferencia. Las ontologías funcionan como base de conocimiento de una comunidad (al
contener información sobre áreas, objetos y contextos), pudiendo ser utilizadas en
aplicaciones de representación y recuperación de información como estructuras de
navegación interconceptual para indizar o buscar información.
Las ontologías y las folksonomías presentan características complementarias que, explotadas
de manera conveniente, pueden generar sinergias productoras de más valor mediante apoyo
mutuo y suma de ventajas.
Las aplicaciones basadas en folksonomías se benefician de su naturaleza dinámica y
extensible y, de su potencial para canalizar la colaboración entre usuarios (por habilitar
mecanismos sencillos de indización).
Las aplicaciones basadas en ontologías explotan su rigor y son capaces de ofrecer una
estructura de conocimiento bien definida, respuestas basadas en razonamiento lógico y el
formalismo necesario para el back-end de la aplicación.
Como alternativa, las folksonomías pueden ser enriquecidas con ontologías aplicándolas en
el backstage39 del tagging social a fin de realizar recomendaciones por tags relacionados
explícita e implícitamente. Otra alternativa es utilizar las ontologías como mecanismo de
38 Los conceptos superiores transmiten sus características a los conceptos inferiores. 39
“Detrás de escena”. Se refiere a una implementación que ofrezca sugerencias de tagging o asista en las búsquedas
al usuario.

75.00 Tesis
35
ampliación de consultas, por medio de tags relacionados, dentro de las plataformas del tagging
social.
De la misma manera, las ontologías pueden ser enriquecidas con folksonomías, brindando
información acerca del vocabulario empleado en el tagging de documentos y, por lo tanto,
capturando el lenguaje de uso actual, ayudando a actualizar los sistemas existentes y a evaluar
la oportunidad, perceptibilidad e idoneidad de un sistema de representación de conocimiento
diseñado por profesionales. Los términos de la folksonomía pueden, de esta forma, utilizarse
como sugerencias para nuevos términos (conceptos o individuos) controlados.
El tagging, a escala Web es un desarrollo novedoso como fuente potencial de metadatos y
posibilita que las folksonomías puedan emerger como una variante de búsqueda por
palabras claves en el proceso de recuperación de información [Berners-Lee et al.; 2006].
Pero mientras las ontologías son definidas siguiendo un proceso cuidadoso, explícito, de
inferencia lógica y sin ambigüedades, los tags, por el contrario, son definidos siguiendo un
proceso arbitrario, implícito, de inferencia estadística y con la presencia de ambigüedades.
2.3 Lógica y ontologías Los términos lógica de predicados, lógica descriptiva o lógica son utilizados frecuentemente
cuando se trata la Web Semántica o alguna de sus partes, como las ontologías. En esta sección
se expone en qué consisten y la utilidad que brindan en este contexto.
Para las máquinas actuales, el término “comprender” no debe entenderse en el sentido de la
comprensión humana40 sino en el de inferir, deducir. Las máquinas son capaces de inferir
conclusiones a partir de datos mediante procesos lógico-matemáticos. Estos datos
incorporan información en los documentos en la forma de metadatos y por medio de un
lenguaje formal41, posibilitando que las máquinas puedan procesar la información mediante
la aplicación de reglas lógicas y seguidamente extraer inferencias lógicas.
Según [Abián; 2005] la Lógica resulta de suma relevancia en la Web Semántica por tres
motivos, a saber: 1) permite desarrollar lenguajes formales para representar conocimiento;
2) proporciona semánticas bien definidas42; 3) proporciona reglas de inferencia a partir de
las cuales se pueden extraer consecuencias del conocimiento. Lo que se conoce como
“interpretación semántica automática de documentos” no pasa de ser la aplicación de reglas
lógicas a datos presentados en algún lenguaje formal (como OWL o DAML+OIL).
Los lenguajes formales (OWL o DAML+OIL) se basan en lógica descriptiva. La lógica
descriptiva proporciona un formulismo para representar y expresar conocimiento humano,
basándose en métodos de razonamiento bien establecidos y procedentes de un subconjunto
de la lógica de predicados o lógica de primer orden43. Los lenguajes naturales no resultan ser
los más apropiados para expresar conceptos sin ambigüedad. Con la lógica que hay detrás de
los lenguajes de la Web Semántica, las máquinas pueden realizar inferencias de manera
40 Asociación automática entre los símbolos y los conceptos que realiza el cerebro humano a partir de la
información almacenada a lo largo de la vida de una persona. 41 Lenguaje lógico y axiomático o lenguaje de representación de conocimiento. 42
Se refiere a un sistema lógico donde cada símbolo y cada expresión tiene un significado único y preciso 43
Más conocido en inglés como First Order Logic o FOL.

75.00 Tesis
36
similar a los humanos, y justificarlas. Los usuarios de la Web Semántica no tienen que
preocuparse por conocer la lógica formal de los lenguajes, sino modelar mediante dichos
lenguajes, las áreas de conocimiento de interés; luego, los lenguajes realizarán las inferencias
correspondientes a los datos introducidos.
La lógica de primer orden permite establecer formalmente sentencias sobre cosas y
colecciones de cosas, sus tipos y propiedades, y también, clasificarlas y describirlas.
En la lógica de primer orden, cada sentencia se divide en un sujeto y un predicado, donde el
predicado modifica o define las propiedades del sujeto. En ésta lógica, los predicados siempre
se refieren a individuos u objetos y los cuantificadores (∀ para todo, ∃ existe) sólo se
permiten para individuos. Las sentencias se expresan en la forma R(x), donde R es el
predicado y x es el sujeto, formulado como variable. R(x) es una función proposicional; estas
funciones se convierten en proposiciones sujeto-predicado cuando se asignan valores a sus
predicados. Por ejemplo, “Todos los hombres son débiles” se expresa en lógica de primer
orden:
∀x: P(x) -> M(x)
Donde P representa el predicado “es hombre” y M representa el predicado “es débil”. Por las
reglas del modus ponens, un sujeto Adán por ser hombre es débil
P(Adán) - > M(Adán)
Ciertos subconjuntos de la lógica de primer orden, especializados en clasificar cosas, se
denominan lógicas descriptivas. Si bien las lógicas descriptivas carecen de la potencia
expresiva de la LPO44 (no pueden expresar tantas cosas como ésta) son matemáticamente
trazables y computables.
2.4 Aplicaciones Una de las áreas de aplicación más prominente de las ontologías es la medicina y ciencias de
la vida, entre las que se destacan las ontologías “Systematized Nomenclature of Medicine
Clinical Terms (SNOMED CT)”45, GALEN46, el “Foundational Modelo of Anatomy (FMA)”47, el
“National Cancer Institute (NCI) Thesaurus”48 y el OBO Foundry49. Todas en OWL. Este tipo
de ontologías están reemplazando gradualmente a los clasificadores médicos existentes por
plataformas que reúnen y comparten conocimiento médico. Por capturar los registros
médicos empleando ontologías se reduce la posibilidad de errores de interpretación en los
datos y posibilita el intercambio de información entre diferentes aplicaciones e institutos.
El W3C afirma que las ontologías pueden mejorar las aplicaciones Web existentes y abrir
nuevos usos de la Web y describe seis casos de aplicación los cuales son desarrollados a
continuación:
44 Lógica de primer orden. 45
http://www.birncommunity.org 46
http://www.opengalen.org/ 47 http://sig.biostr.washington.edu/projects/fm/index.html 48
http://www.cancer.gov/ 49
http://www.obofoundry.org/

75.00 Tesis
37
El primer caso de aplicación es un portal Web. Un portal Web es un sitio con información
sobre algún tema en especial. Las personas interesadas en un determinado tema pueden
recibir noticias, participar de una comunidad o seguir enlaces a otros recursos de interés.
Para que un portal Web sea útil debe tener un punto de partida que describa el contenido
interesante del sitio. Habitualmente, el contenido es subido por miembros de la comunidad
y agrupado mediante tagging 50 o indizado bajo algún subtema de interés. No obstante, la
indización puede carecer de la habilidad requerida para la búsqueda. Para permitir una
agrupación más inteligente, los sitios Web pueden definir una ontología acorde con la
comunidad y realizar inferencias para obtener resultados imposibles en los sistemas
convencionales actuales. Esta técnica requiere un lenguaje de ontología que posibilite
capturar relaciones con alta calidad (mayor detalle). Un ejemplo de un portal basado en
ontología es OntoWeb51.
El segundo caso de aplicación corresponde a las colecciones multimedia. Las ontologías
pueden proveer de anotaciones semánticas a las colecciones de imágenes, audio u otros
objetos no textuales. Para los ordenadores es más difícil extraer significado semántico de la
multimedia que del texto. Estos recursos son indizados mediante captions52 o metatags53.
Las ontologías, idealmente capturarían el conocimiento adicional acerca del dominio para
mejorar la recuperación de imágenes.
El tercer caso de aplicación es sobre la administración de un sitio Web corporativo. Las
corporaciones tienen varias páginas Web concernientes a comunicados de prensa, ofertas
de productos, estudios de casos, procedimientos corporativos, white-papers, etc. Las
ontologías pueden ser utilizadas para indizar estos documentos y prestar mejores medios
de recuperación. Las corporaciones emplean taxonomías para organizar la información, las
cuales resultan insuficientes dado que las categorías constitutivas quedan restringidas a la
representación de un dominio. La habilidad de trabajar con múltiples ontologías haría a las
descripciones más completas y las búsquedas por parámetros serían más útiles que las
búsquedas por palabras claves con taxonomías.
El cuarto caso de aplicación tiene relación con la documentación empleada en ingeniería.
Los documentos sobre diseño, por ejemplo, tienen una estructura diferente a los
documentos de testing o a los documentos de producción. La definición y descripción
completa de algún ítem dado es obtenida por seguir la traza de los documentos
relacionados. Las ontologías servirían para construir un modelo de información que
permitiría la exploración del espacio de información (en términos de representación,
asociación y propiedades de ítems), con enlaces a las descripciones y definiciones de ítems
a fin de conseguir la documentación completa. Esto significa que las ontologías y
taxonomías no son independientes de los ítems físicos que representan pero pueden ser
desarrolladas/exploradas en tándems. Este tipo de ontologías también podrían ser
utilizadas para la visualización y edición de gráficos las cuales mostrarían capturas del
espacio de información, sobre un concepto en particular (diagramas de actividades, reglas
o diagramas de entidad-relación).
50 Desarrollado en la sección 2.2 “Folksonomías y ontologías”. 51 http://www.ontoweb.org/ 52
Títulos 53
Tags sobre los tags

75.00 Tesis
38
El quinto caso de aplicación describe un escenario con agentes y servicios. La Web
Semántica provee agentes con la capacidad de comprender e integrar diversos recursos de
información. Un ejemplo es un planificador de actividades sociales que toma las preferencias
del usuario (tipos de películas, tipo de comidas, etc.) para planear una salida. La tarea de
planificar las actividades depende de la variedad del entorno de servicios ofrecidos y de las
necesidades del usuario. Durante el proceso de búsqueda se pueden consultar comentarios y
tarifas de servicios a fin de encontrar aquellos que mejor se ajusten a las preferencias del
usuario. Este tipo de agente requiere ontologías de dominio que representen los términos
relacionados a restaurantes, hoteles, etc. y ontologías de servicios con términos relacionados
a servicios reales, permitiendo capturar información interesante para el usuario. Tal
información puede ser provista por un número de fuentes, como portales, sitios de servicios,
sitios de reservas y la Web en general.
En un escenario como el descripto es necesario resolver cuestiones relacionadas con:
� Uso e integración de múltiples ontologías separadas a través de diferentes dominios y
servicios,
� Ubicación distribuida de ontologías a través de Internet,
� Ontologías potencialmente diferentes para cada dominio o servicio (traslación de
ontologías/referencias cruzadas),
� Representación simple de ontologías.
El sexto caso de aplicación es sobre ubiquitous computing54 El ubiquitous computing es un
paradigma emergente del “personal computing”55, caracterizado por desplazar la
capacidad de procesamiento de los ordenadores al entorno cotidiano de las personas.
Dispositivos de procesamiento pequeños, wireless y de mano son ejemplos de “ubiquitous
computing”. La naturaleza wireless y ubicua de estos dispositivos requieren arquitecturas
de red que soporten configuración automática y ad-hoc a fin de simplificar al usuario el
manejo de los mismos.
Una tecnología clave de las redes ad-hoc es el descubrimiento de servicios (funciones
ofrecidas a dispositivos como teléfonos celulares, impresoras, etc.). El descubrimiento de
servicios y los mecanismos de descripción de capacidades están basados en esquemas de
representación ad-hoc y dependen fuertemente de la estandarización. El objetivo que
persigue ubiquitous computing es la interoperabilidad fortuita, es decir, que dispositivos
que no fueron necesariamente diseñados para trabajar juntos (por ser construidos con
diferentes propósitos, por diferentes fabricantes, en diferentes tiempos, etc.) puedan
descubrir y tomar ventaja de la funcionalidad del otro. Los escenarios ubiquitous
computing involucran un número considerable de dispositivos y, llevar a cabo una
estandarización a priori, de los casos de aplicación, sería una tarea inmanejable. Por eso
comprender otros dispositivos y razonar acerca de sus servicios/funcionalidad se vuelve
indispensable. Los escenarios de interoperación son dinámicos por naturaleza (los
dispositivos aparecen y desaparecen en cualquier momento debido al movimiento de los
propietarios). Las tareas en la utilización de servicios involucran descubrimiento,
contratación y composición. Un contrato de servicios requiere representar información
sobre seguridad, privacidad, confianza y detalles relacionados a la compensación de
servicios.
54
Computación ubicua. Ubicua denota lo que esta presente al mismo tiempo y en todas partes. Omnipresente. 55
Computación personal.

75.00 Tesis
39
En este contexto, un lenguaje de ontología podría ser de utilidad en la descripción de las
características, los medios de acceso, las políticas de uso de los dispositivos y demás
restricciones técnicas y los requerimientos que afecten incorporar un nuevo dispositivo en
una red ubiquitous computing.
2.5 Lenguajes ontológicos
2.5.1 RDF 2.5.1.1 Conceptos Básicos Según el W3C, el Resource Framework Description (RDF) es un lenguaje para representar
recursos Web56, apoyándose en ideas de Inteligencia Artificial, grafos conceptuales y de
representación de conocimiento basado en lógica, entre otras y, cuyo objetivo radica en
especificar datos en XML de manera estandarizada a fin de posibilitar interoperabilidad.
Debido a su carácter general, también puede ser utilizado para representar datos
simplemente.
Según [Dickinson; 2009] es un lenguaje ontológico débil que permite construir jerarquías de
conceptos y propiedades siendo suficiente para aplicaciones que sólo necesitan establecer un
vocabulario básico. [Abián; 2005] prefiere definir que si bien RDF es un modelo de
representación de metadatos puede utilizarse como lenguaje general para la representación
del conocimiento.
En RDF, la construcción básica es la tripla (sujeto, propiedad, objeto). Toda tripla RDF
corresponde a una sentencia RDF: la parte que identifica a qué se refiere la sentencia es el
sujeto; la parte que identifica la característica del sujeto es la propiedad o predicado y la parte
que identifica el valor de la propiedad es el objeto.
Los sujetos, las propiedades y los objetos son recursos. Los recursos con los que trabaja RDF
no son necesariamente recursos presentes en la Web. En general, un recurso RDF es
cualquier cosa con identidad. Para identificarlos se recurre a URIs57.
Los URIs no tiene significado por sí mismos: son identificadores y la persona u organización
que los crea se responsabiliza de otorgarles significado. Un concepto puede tener asociados
diferentes URIs. Dos empresas pueden asignar un significado distinto a una propiedad y
utilizar para ello dos URIs distintos. Dos o más recursos pueden utilizar el mismo URI,
reflejando una comprensión compartida de un concepto.
56
Los recursos Web refieren aquí a dispositivos físicos (impresoras, ordenadores, agendas electrónicas) o estructuras
de datos de software (páginas web, imágenes, videos, directorios) accesibles a través de una red. 57
Uniform Resource Identifier o identificador uniforme de recurso. La principal diferencia con URL es que el
URI no se limita a identificar entidades con localizaciones en la Web o accesibles mediante aplicaciones
informáticas. Cualquier organización o persona puede crear sus URIs y utilizarlos para trabajar con sus
dominios de interés. Frente a URL, el URI permite referirse a un mismo recurso ubicado en distinta
localizaciones.

75.00 Tesis
40
Las triplas RDF pueden representarse en forma gráfica mediante grafos (los nodos
corresponden a recursos y los arcos a propiedades) o en formato RDF/XML (representación
XML de RDF). La ventaja de utilizar este último estriba en poder reutilizar todas las
herramientas existentes para XML (analizadores sintácticos, transformaciones XSLT,
representaciones en memoria de objetos XML mediante DOM/SAX, etc.). Es oportuno aclarar
que RDF no está ligado a XML; se puede utilizar otra representación para RDF, sin que ello
produzca cambios en la sintaxis de triplas y su semántica.
Cada persona u organización puede definir su propio vocabulario mediante un esquema RDF
llamado RDFS (RDF Schema). Un esquema permite comprobar si un conjunto de triplas RDF
es válido para el esquema o no (comprobar si las propiedades aplicadas a los recursos son
correctas y si los valores vinculados a las propiedades tienen sentido). RDFS permite controlar
la validez de los valores y restringir las entidades a las cuales pueden aplicarse ciertas
propiedades.
El modelo de metadatos que RDFS permite expresar coincide con el de los lenguajes de
programación orientada a objetos pues permite expresar clases e instancias. Cabe señalar
que las propiedades definidas en RDFS son globales; esto es, no están encapsuladas como
atributos en las definiciones de clases. A diferencia de lo que ocurre en LOO58, RDFS permite
asignar a una clase, sin modificarla, nuevas propiedades.
Las restricciones que RDFS introduce son análogas a las empleadas en lenguajes OO con
tipos.
Tabla Clases RDF predeterminadas Clase Descripción rdfs:type Subclase de
rdfs:Class Clase de todas las clases. Equivalente al
concepto de clase en LOO
rdfs:Class
rdfs:Resource Toda cosa descripta por RDF es un recurso
e instancia de rdfs:Resource
rdfs:Class
rdfs:Literal Clase para los literales rdfs:Class rdfs:Resource
rdfs:Datatype Clase para los literales tipados como
Datatype
rdfs:Class rdfs:Literal
rdf:XMLLiteral Clase para XML literal rdfs:Datatype rdfs:Literal
rdf:Property Clase para las propiedades RDF rdfs:Class
rdf:Statement Clase para representar un statement RDF. rdfs:Class
rdfs:Container Clase para representar contenedores. rdfs:Class
rdf:Bag Clase para indicar un contenedor sin orden rdfs:Class rdfs:Container
rdf:Seq Clase para indicar un contenedor con
orden
rdfs:Class rdfs:Container
rdf:Alt Clase para indicar un contenedor donde
sólo se elige uno de los miembros. La
elección por defecto es el valor de la
property rdf:_1
rdfs:Class rdfs:Container
rdf:List Clase para construir listas y otras
estructuras
rdfs:Class
[Brickley y McBride; 2004]. Fragmento del vocabulario de clases de RDF Schema
recomendado por el W3C.
58
Lenguajes orientados a objetos.
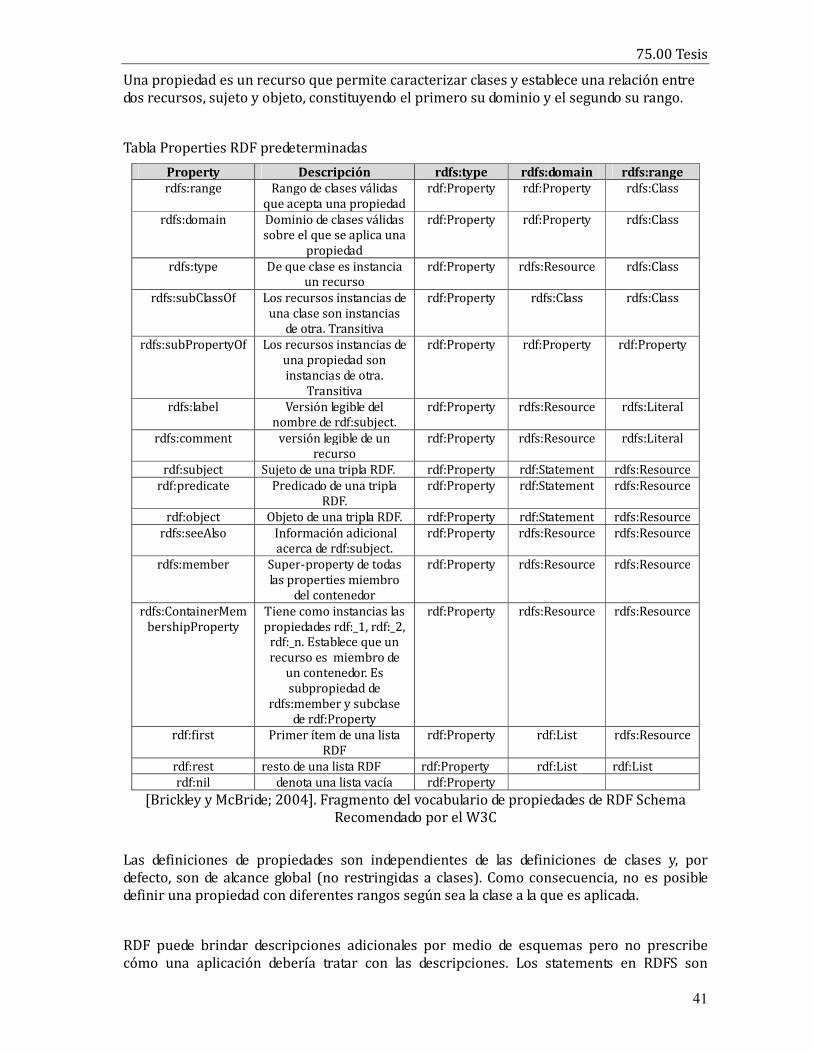
75.00 Tesis
41
Una propiedad es un recurso que permite caracterizar clases y establece una relación entre
dos recursos, sujeto y objeto, constituyendo el primero su dominio y el segundo su rango.
Tabla Properties RDF predeterminadas
Property Descripción rdfs:type rdfs:domain rdfs:range rdfs:range Rango de clases válidas
que acepta una propiedad
rdf:Property rdf:Property rdfs:Class
rdfs:domain Dominio de clases válidas
sobre el que se aplica una
propiedad
rdf:Property rdf:Property rdfs:Class
rdfs:type De que clase es instancia un recurso
rdf:Property rdfs:Resource rdfs:Class
rdfs:subClassOf Los recursos instancias de
una clase son instancias
de otra. Transitiva
rdf:Property rdfs:Class rdfs:Class
rdfs:subPropertyOf Los recursos instancias de
una propiedad son
instancias de otra.
Transitiva
rdf:Property rdf:Property rdf:Property
rdfs:label Versión legible del
nombre de rdf:subject.
rdf:Property rdfs:Resource rdfs:Literal
rdfs:comment versión legible de un
recurso
rdf:Property rdfs:Resource rdfs:Literal
rdf:subject Sujeto de una tripla RDF. rdf:Property rdf:Statement rdfs:Resource
rdf:predicate Predicado de una tripla
RDF.
rdf:Property rdf:Statement rdfs:Resource
rdf:object Objeto de una tripla RDF. rdf:Property rdf:Statement rdfs:Resource
rdfs:seeAlso Información adicional
acerca de rdf:subject.
rdf:Property rdfs:Resource rdfs:Resource
rdfs:member Super-property de todas
las properties miembro
del contenedor
rdf:Property rdfs:Resource rdfs:Resource
rdfs:ContainerMem
bershipProperty
Tiene como instancias las
propiedades rdf:_1, rdf:_2, rdf:_n. Establece que un
recurso es miembro de
un contenedor. Es
subpropiedad de
rdfs:member y subclase
de rdf:Property
rdf:Property rdfs:Resource rdfs:Resource
rdf:first Primer ítem de una lista
RDF
rdf:Property rdf:List rdfs:Resource
rdf:rest resto de una lista RDF rdf:Property rdf:List rdf:List
rdf:nil denota una lista vacía rdf:Property
[Brickley y McBride; 2004]. Fragmento del vocabulario de propiedades de RDF Schema
Recomendado por el W3C
Las definiciones de propiedades son independientes de las definiciones de clases y, por
defecto, son de alcance global (no restringidas a clases). Como consecuencia, no es posible
definir una propiedad con diferentes rangos según sea la clase a la que es aplicada.
RDF puede brindar descripciones adicionales por medio de esquemas pero no prescribe
cómo una aplicación debería tratar con las descripciones. Los statements en RDFS son

75.00 Tesis
42
siempre descripciones. Pueden ser prescriptivos (introducir restricciones) sólo si a la
aplicación que los interpreta es requerida tratarlos de ese modo. Todo lo que RDFS hace es
proveer información adicional.
RDF es utilizado como base para lenguajes más expresivos como DAM+OIL o DAML y OWL.
En resumen RDFS proporciona clases, jerarquías de clases, propiedades, jerarquías de
propiedades y restricciones sobre dominios y rangos.
La semántica de RDF y RDFS es expresada mediante lógica de predicados59, un lenguaje
formal que resulta conveniente a fin de evitar ambigüedades y hacer la semántica
“comprensible” a las máquinas, proporcionando una base firme para razonamiento
automático.
Por eficacia computacional, la semántica de RDF y RDFS es expresada mediante triplas. La
semántica en RDF y RDFS incluye un sistema de inferencia robusto y completo. Las reglas del
sistema de inferencia son de la forma if-then y permiten a una máquina realizar deducciones.
En situaciones con cientos, miles de clases, subclases, instancias, propiedades y
subpropiedades resultará apreciable la verdadera potencia de la interpretación semántica
automática, la cual permitirá extraer deducciones escondidas entre avalanchas de datos,
aparentemente inconexos.
¿Es posible construir la Web Semántica con la interoperabilidad sintáctica que provee XML y
la interoperabilidad semántica que presta RDFS?
La respuesta a este interrogante es no, no es posible debido a las carencias que RDFS posee:
� No es posible declarar restricciones de rango que sean válidas sólo para algunas clases;
� No es posible representar ciertas características de las propiedades (propiedades
transitivas, simétricas, inversas o funcionales);
� No es posible reflejar clases disjuntas;
� No permite expresar restricciones de cardinalidad (cantidad de valores que puede tomar
una propiedad);
� Existen expresiones cuya semántica no es la estándar (es decir que no pueden expresarse
mediante lógica de primer orden) provocando que dado un sistema de axiomas no se
pueda afirmar o negar nada.
RDFS no es completo para describir los recursos de la Web con el detalle que se requiere. Se lo
59 Desarrollado en la sección 2.3 “Lógica y ontologías”

75.00 Tesis
43
utiliza porque es tan general que puede emplearse en muchos dominios y porque sirve como
puente entre vocabularios diferentes.
2.5.1.2 RDF y la ambigüedad semántica XML ¿Por qué se recurre a RDF para describir recursos y no a XML? Antes de responder es
conveniente recordar para qué sirve XML.
XML es un lenguaje de marcado para documentos de toda clase. Permite al programador
definir una gramática por medio de un DTD60 o XML-Schema utilizando etiquetas
(metadatos) en todas sus combinaciones posibles y, por medio, de un analizador de sintaxis
comprobar si el documento cumple con la gramática definida (si es un documento XML
válido).
XML es un gran paso hacia la interoperabilidad sintáctica. Cualquier documento y tipo de
dato puede expresarse como un documento XML. Los datos son definidos en forma
independiente del lenguaje de programación o plataforma utilizada convirtiéndolo en un
formato universal para el intercambio de datos. Entre sus ventajas cabe señalar:
� Un documento XML es autodescriptivo, almacena datos y la estructura de éstos y por ser
de fácil procesamiento en un medio para compartir documentos entre personas y empresas.
� Un documento XML es customizable. Permite a una empresa desarrollar los DTDs (o XML-
Schema) de los documentos de negocios (facturas, pedidos, órdenes de producción…) y
realizar sus operaciones con clientes y proveedores a través de los documentos XML
conforme a los DTDs o (o XML-Schema) desarrollados.
� La estructura de los documentos XML puede comprobarse automáticamente, de manera de
rechazar aquellos documentos que no estén construidos de acuerdo a los DTDs o XML-
Schema exigidos. Si dos empresas trabajan con un conjunto común de DTDs, XML-
Schema, pueden analizar cualquier documento que una vaya a enviar a la otra y evitar el
envío de documentos incorrectos.
� Un documento XML se basa en texto ordinario y lo hace idóneo para ser transportado a
través de Internet, donde conviven muchas plataformas y sistemas informáticos, cada una
con sus propios formatos de archivos.
� El juego de caracteres predefinido para XML es UNICODE. Esto permite crear documentos
XML internacionalizables (en cualquier lenguajes humano).
� XML ha tenido un enorme impacto sobre las tecnologías de las empresas IT. Se ha
convertido en el formato universal para el intercambio de datos entre organizaciones
públicas y privadas; ha modificado radicalmente el panorama de las transacciones B2B61
(productos compatibles con especificaciones XML para el intercambio comercial
desarrollados por organizaciones como OASIS62, ebXML63, RosettaNet64, etc.), ha logrado
60 Document Type Definition 61
Para denotar el origen y destino de una actividad comercial entre empresas, diferente al B2C. 62
Organization for the Advancement of Structured Information Standards 63
Electronic Business using eXtensible Markup Language. Conjunto modular de especificaciones que posibilita a
las empresas realizar negocios en Internet. http://www.ebxml.org/ 64
Define estándares para la cadena de suministro global, los cuales permiten la automatización de procesos de
negocios. http://www.rosettanet.org/

75.00 Tesis
44
imponerse como solución para la integración de aplicaciones, sistemas y bases de datos;
se ha introducido como parte clave de las plataformas de software más difundidas (J2EE y
.NET); ha liberado a las empresas de desarrollar en una plataforma determinada al
permitir desarrollar servicios Web, los cuales al emplear XML son independientes de la
plataforma; la mayor parte de los sistemas de gestión de bases de datos relacionales lo ha
incorporado a sus productos y también ha tenido gran impacto en el desarrollo de portales
(distintos portales pueden tener un mismo esqueleto XML y distintas presentaciones en
XSLT65 lo que reduce el trabajo de realizar cambios en el front-end).
A pesar de las ventajas señaladas, XML no incorpora mecanismos para garantizar
interoperabilidad semántica y, en consecuencia, ofrecer una interoperabilidad completa.
Las estadísticas muestran que en Europa el 20-30% de los gastos relacionados con el
comercio electrónico deriva de la falta de interoperabilidad semántica [Abián; 2005]. Este
gasto se debe a que, aunque los SI66 empresariales utilicen las mismas tecnologías (por
ejemplo XML para describir los datos), el significado de sus modelos de negocios suele diferir.
Nociones habituales como “pedido” o “cliente” pueden significar cosas muy distintas, en cada
empresa. Como consecuencia el intercambio de información entre empresas, en el mejor de
los casos, resulta en un proceso semi-manual. La principal dificultad a la que se enfrenta el
modelado empresarial reside en traducir los objetos de negocio de una empresa a los de otras
y viceversa. Sin esa traducción, la integración automática de los SI de las empresas que
forman parte de una misma cadena de aprovisionamiento resulta imposible sin un
entendimiento común.
Con XML es posible realizar la especificación del formato y la estructura de cualquier
documento pero no impone ninguna interpretación semántica acerca de esos datos. En
consecuencia, desde el punto de vista semántico, XML resulta inútil: dado un documento XML
no es posible reconocer en él los objetos y relaciones de un dominio de interés.
El marcado de los documentos XML es efectuado por medio de metadatos. Cuando una
persona lee un DTD, puede extraer la semántica prestando atención a los nombres de los
elementos o a los comentarios que figuran en él, interpretando semánticamente el DTD. Por
el contrario, para un programa que procesa los documentos XML, las etiquetas, por sí solas,
no tienen significado alguno.
Volviendo al planteo que abrió esta sección, cabe responder que XML no es apropiado para
incluir semántica desde que el modelo de datos de un dominio puede ser representado por
diferentes DTDs (o XML Schema) y, al mismo tiempo, un DTD (o XML Schema) puede
representar varios modelos de datos distintos. En cambio, RDFS proporciona una
representación única de un modelo de datos, al considerar la semántica de los datos.
Pese a la similitud entre los términos “esquema RDF” (RDFS) y “esquema XML” (XML
Schema), sus significados son muy distintos. Los esquemas XML, al igual que los DTD,
especifican el orden y las combinaciones de etiquetas que son aceptables en un documento
65
Stylesheet Language Transformation, transformación del lenguaje de hojas de estilo. 66
Sistema de información

75.00 Tesis
45
XML. En cambio, los esquemas RDF especifican qué interpretación hay que dar a las
sentencias de un modelo de datos RDF; es más, dejan libre la representación sintáctica del
modelo.
Los esquemas XML modelan datos expresados en XML mientras que los esquemas RDF
(RDFS) modelan conocimiento o dicho de otra manera: XML y los esquemas XML son un
lenguaje de modelado de datos y RDF y RDFS son un lenguaje de modelado de metadatos.
2.5.2 OWL 2.5.2.1 Conceptos Básicos El Ontology Web Language (OWL) es una especificación de lenguaje desarrollado por el W3C
para describir ontologías, es decir, representar el significado y las relaciones de términos en
vocabularios de manera que la información contenida en los documentos pueda ser
procesada por aplicaciones.
Es una extensión de RDFS y mantiene una buena relación entre eficacia computacional y
poder expresivo.
A continuación, las tablas muestran algunos de los términos del vocabulario OWL empleados
en la descripción de clases, object-properties, data-properties y properties-restriction
respectivamente. [Hebeler et al.; 2009].
Tabla términos OWL para describir clases
Clase Descripción owl:equivalentClass Relación que especifica que las extensiones de dos clases son equivalentes
owl:Thing Clase de todos los individuos
owl:OneOf La pertenencia a la clase está limitada a los miembros especificados en la
colección de individuos
owl:intersectionOf Los miembros de esta clase son miembros de todas las clases especificadas
owl:unionOf Los miembros de esta clase son miembros de al menos alguna de las clases especificadas
owl:complementOf Los miembros de esta clase no son miembros de la clase especificada
owl:disjointWith Relación que establece que los miembros de las dos clases especificadas no comparten individuos
owl:AllDisjointClasses Una clase utilizada con owl:members para especificar un conjunto de clases
que son disjuntas por pares
owl:disjointUnionOf Una relación que especifica que esta clase es la unión del conjunto de clases
especificadas las cuales son disjuntas por pares
owl:Restriction La clase de todas las restricciones

75.00 Tesis
46
Tabla términos OWL para describir object-properties
Object-Property Descripción owl:objectProperty La clase de todas las propiedades que relacionan dos individuos owl:DataProperty La clase de todas las propiedades que relacionan un individuo con un valor
literal
owl:topObjectProperty Propiedad que conecta todos los posibles pares de individuos
owl:bottomObjectProperty Propiedad que no conecta pares de individuos
owl:topDataProperty Propiedad que conecta todos los posibles individuos con todos los posibles
literales
owl:bottomDataProperty Propiedad que no conecta ningún individuo con un literal
owl:SymmetricProperty La clase de todas las propiedades que son simétricas. Para todas las
propiedades simétricas p, el statement (A p B) implica la existencia del
statement (B p A)
owl:AsymmetricProperty La clase de todas las propiedades que son explícitamente no simétricas. Para
todas las propiedades asimétricas p, el statement (A p B) implica la no
existencia del statement (B p A)
owl:equivalentProperty Propiedad que especifica que dos propiedades son equivalentes
owl:ReflexiveProperty La clase de todas las propiedades que son reflexivas. Para todas las
propiedades reflexivas p y los individuos A, A esta relacionado a sí mismo
por p (A p A)
owl:IrreflexiveProperty La clase de todas las propiedades que no son reflexivas. Para todas las
propiedades irreflexivas p y los individuos A, no existe un statement p (A p
A)
owl:TransitiveProperty La clase de todas las propiedades que son transitivas. Para todas las
propiedades transitivas p, (A p B) y (B p C) implica (A p C)
owl:FunctionalProperty La clase de todas las propiedades para las cuales un valor de dominio dado
tiene sólo un valor de rango
owl:InverseFunctionalProperty La clase de todas las propiedades para las cuales un valor de rango dado tiene
sólo un valor de dominio
owl:inverseOf Propiedad que especifica que dos propiedades son una la inversa de la otra.
Si una propiedad p1 es la inversa de una propiedad p2, la existencia de un
statement (A p1 B) implica la existencia del statement (B p2 A)
owl:propertyChain Propiedad que es utilizada para construir una cadena de propiedades que representa la superproperty en una relación subproperty-of
Owl:propertyDisjointWith Relación que establece que dos propiedades son disjuntas. Si dos
propiedades p1 y p2 son disjuntas, implica que dos statements con el
mismo sujeto y objeto no pueden tener los predicados p1 y p2
owl:AllDisjointProperties Una clase que es utilizada con owl:members para describir colecciones de
propiedades que son disjuntas por pares.
Tabla términos OWL para describir data-properties
Data-Property Descripción owl:onDataType Propiedad que identifica el datatype al cual se aplican las restricciones
owl:intersectionOf Propiedad que identifica un conjunto de datatypes tal que el datatype
descripto contiene los valores contenidos en todos los datatypes del
conjunto
owl:unionOf Propiedad que identifica un conjunto de datatypes tal que el datatype
descripto contiene algún valor que está contenido en al menos uno de los
datatypes del conjunto
owl:oneOf Propiedad que identifica un conjunto de valores que conforman al datatype
owl:datatypeComplementOf Propiedad que especifica que el datatype descripto contiene todos los
valores que no están en el datatype que la propiedad identifica
Una property-restriction describe a la clase de individuos que cumplen con las condiciones
especificadas sobre la propiedad. La restricción es declarada empleando la construcción

75.00 Tesis
47
owlRestriction y la propiedad a la cual refiere la restricción es identificada utilizando la
propiedad owl:onProperty. Las restricciones son relacionadas a clases utilizando
rdfs:subclassOf o owl:equivalentClass.
Tabla términos OWL para describir property resctriction
Property Restrictions Descripción owl:onProperty Propiedad que identifica la propiedad a la cual la restricción aplica
owl:allValuesFrom Propiedad que especifica que todas las instancias en esta clase deben tener
valores solo del rango especificado para la propiedad
owl:someValuesFrom Propiedad que especifica que todas las instancias en esta clase deben tener
al menos una propiedad con un valor del rango especificado
owl:hasValue Propiedad que especifica que todas las instancias de esta clase deben tener
el valor especificado por la propiedad
owl:minCardinality Propiedad que especifica que debe haber al menos N de las propiedades
especificadas sobre cada instancia de esta clase
owl:maxCardinality Propiedad que especifica que debe haber a lo sumo N de las propiedades
especificadas sobre cada instancia de esta clase
owl:cardinality Propiedad que especifica que debe haber exactamente N de las propiedades
especificadas sobre cada instancia de esta clase
Además OWL dispone de los siguientes términos para individuos:
� owl:sameAs: relación que especifica que dos individuos son el mismo individuo;
� owl:differentFrom: relación que especifica que dos individuos no son el mismo individuo;
� owl:AllDifferent: una clase utilizada con owl:distinctMembers para definir una colección
de individuos que son diferentes por pares.
Como puede observarse, OWL tiene mucha más capacidad expresiva que RDFS. OWL facilita
la importación y exportación de clases por medio de propiedades como sameAs,
equivalentClass, equivalentProperty, differentFrom, etc.
OWL soporta una sintaxis abstracta (independiente de cualquier representación
computacional), una basada en XML y otra basada en RDF.
La primera versión de la especificación fue OWL 1 (también conocida como OWL), la cual fue
aprobada por el W3C en el año 2004. La segunda fue OWL 2, aprobada en el año 2009 con el
agregado de nuevas características mientras mantiene compatibilidad con la anterior.
OWL tiene más facilidades para expresar significado y semántica que XML, RDF y RDF-S:
� XML: provee una base sintáctica para documentos estructurados aunque no impone
restricciones semánticas en el significado de esos documentos
� XML Schema: extiende XML con datatypes y provee un lenguaje para restringir la
estructura de documentos XML.

75.00 Tesis
48
� RDF: modela recursos y sus relaciones utilizando una representación y semántica simple
por medio de sintaxis XML
� RDF Schema: brinda un vocabulario para describir propiedades y clases de recursos RDF,
con una semántica para la generalización de jerarquías de clases y propiedades
� OWL: agrega más vocabulario para describir clases y propiedades. Entre otras: relaciones
entre clases, cardinalidad, igualdad, más propiedades, características de propiedades y
enumerados de clases.
OWL es un componente de la actividad de la Web Semántica. Dado que la Web Semántica es
por naturaleza distribuida, OWL permite que la información pueda ser reunida desde fuentes
remotas. Esto es parcialmente logrado por relacionar ontologías y permitir importar
información desde otras ontologías.
OWL2 es un lenguaje declarativo y utiliza lógica descriptiva en la representación de cualquier
situación, lo cual constituye una base formal que propicia el uso de herramientas de
inferencia como razonadores, ampliando la información disponible.
Las inferencias son realizadas algorítmicamente y no forman parte del documento OWL sino
que dependen de implementaciones específicas. La respuesta correcta a una cuestión es
predeterminada por la semántica formal (Direct Model-Theoretic o RDF-Based).
El tipo de conocimiento capturado por OWL no refleja todos los aspectos de conocimiento
humano sino una parte de él. OWL es considerado como un lenguaje de modelado de
propósito general, poderoso, que como resultado del proceso de modelado logra una
ontología.
A fin de formular conocimiento explícito, OWL asume que éste consiste de piezas
elementales llamadas statements (o proposiciones). Los statements obtenidos a partir de la
ontología son llamados axiomas y pueden ser verdaderos o falsos según la situación.
Un statement es cierto siempre que los otros statements lo sean. En términos OWL: un
conjunto de statements A implican un statement a, si en cualquier situación donde todos los
statements de A son ciertos, también lo es a. La semántica formal de OWL especifica las
posibles situaciones en las que un conjunto de statements es verdadero. Existen herramientas
OWL, y razonadores que pueden procesar consecuencias.
Los statements poseen componentes atómicos llamados entidades. Las entidades pueden
representar objetos, categorías o relaciones o en términos de OWL2 individuos, clases y
propiedades, respectivamente. A su vez, las propiedades se dividen en:
� object-property: relaciona individuos. El orden en que los individuos aparecen es
importante.
� datatype-property: relaciona individuos con valores de datos y se pueden utilizar datatypes
XML-Schema.

75.00 Tesis
49
� annotation-property: comentarios relacionados con partes de la ontología, como autor y
fecha de creación de un axioma. Permite anotaciones de anotaciones. Son empleadas, por
herramientas, en interfaces de ayuda para proveer acceso a texto en lenguaje natural.
Las expresiones son combinaciones de entidades (individuos, clases y propiedades). Una
expresión de clase puede ser utilizada en statements o en otras expresiones. En este sentido,
las expresiones pueden ser vistas como nuevas entidades definidas por sus estructuras.
2.5.2.2 Sub-Lenguajes
OWL es, en general, un lenguaje muy expresivo y puede resultar difícil de implementar y
trabajar con él.
Los sublenguajes fueron diseñados como subconjuntos de OWL 2 y lo suficientemente
accesibles para ser utilizados en una variedad de aplicaciones. Al igual que en OWL 2 DL, los
mayores requerimientos de los sublenguajes tienen que ver con consideraciones de
procesamiento.
En la primera versión de OWL se definieron tres sublenguajes:
� OWL DL: soporta lógica descriptiva y provee un subconjunto del lenguaje con propiedades
de cómputo propicias para sistemas de razonamiento. Establece restricciones sobre la
combinación con RDF y requiere separación estricta de clases, propiedades, individuos y
valores de datos.
� OWL Lite: es parte de OWL DL, diseñado para una fácil implementación y proveer a los
usuarios con un subconjunto funcional a fin de iniciarlos en el uso de OWL.
� OWL FULL: provee un lenguaje completo y relaja algunas de las restricciones de OWL DL.
A diferencia de OWL DL, permite combinar libremente OWL con RDF Schema y, como
éste, no posee una separación estricta entre clases, propiedades, individuos y valores de
datos.
Como consecuencia del despliegue de ontologías OWL, estos sublenguajes resultaron
insuficientes para responder a nuevos requerimientos.
Varias aplicaciones, particularmente en las ciencias de la vida, emplean ontologías de gran
tamaño (FMA, NCI Thesaurus, SNOMED CT, Gene Ontology y OBO). Tales ontologías, que
necesitan representar entidades complejas o permitir la propagación de propiedades, poseen
un enorme número de clases y hacen uso intensivo de mecanismos de clasificación para
simplificar el desarrollo y el mantenimiento. Las aplicaciones, por lo tanto, prestan mayor
atención a la escalabilidad del lenguaje y performance de razonamiento, sacrificando algo de
expresividad por calidad de procesamiento, particularmente clasificación.
Otras aplicaciones, en cambio, utilizan bases de datos y priorizan la interoperabilidad de
OWL con tecnologías y herramientas de bases de datos. Las ontologías utilizadas en estas
aplicaciones son ligeras y empleadas para ejecutar consultas sobre grandes conjuntos de
individuos almacenados en dichas bases de datos. Por lo tanto existen requerimientos para
acceder a datos directamente vía consultas relacionales (es decir, por SQL).

75.00 Tesis
50
Por otro lado, existen aplicaciones que prestan especial cuidado a la interoperabilidad del
lenguaje de ontología con máquinas de reglas. Las ontologías utilizadas en estas aplicaciones
son ligeras y permiten consultar grandes datasets siendo conveniente operarlas directamente
en la forma de triplas RDF. Casos típicos de tales aplicaciones son aquellas que priorizan
eficiencia por expresividad y aplicaciones RDF que necesitan de la mayor expresividad
provista por OWL.
Ninguno de los sublenguajes presentados a continuación incluye al otro. Idealmente se puede
utilizar un razonador (o una herramienta) conforme a un superlenguaje en un sublenguaje
sin que se observen cambios en los resultados derivados (este principio se mantiene en
OWL2 EL y OWL 2 QL en relación a OWL 2 DL desde que cada razonador conforme a OWL2
DL es un razonador para OWL 2 EL y OWL 2 QL con las diferencias evidentes en rendimiento
desde que un razonador OWL DL trata un conjunto más general de casos).
A fin de satisfacer los requerimientos expuestos, la segunda versión de OWL definió tres
nuevos sublenguajes con propiedades útiles de procesamiento, a saber:
� OWL EL: fue diseñado pensando en las aplicaciones que emplean ontologías de gran
tamaño. Captura el poder expresivo en ontologías de gran escala. No permite negación y
disyunción de clases, cuantificación universal sobre propiedades ni propiedades inversas
El acrónimo EL refleja el origen del sublenguaje en la familia EL de lógica descriptiva. Las
herramientas (en proceso de alcanzar conformidad con OWL 2) que ofrecen soporte para
OWL 2 EL son: FaCT++, Hermit, Pellet, CEL, ELLY, REL, entre otras.
� OWL QL: fue diseñado pensando en aplicaciones que priorizan la interoperabilidad de
OWL con bases de datos. Utilizado en ontologías simples como Thesuari, permite
integración con RDBMS y la implementación de razonadores sobre la misma. Este
sublenguaje es adecuado para aplicaciones con ontologías ligeras pero con un gran
número de individuos, las cuales necesitan acceder a los datos directamente vía consultas
relacionales. El razonamiento puede ser implementado eficientemente mediante técnicas
de re-escritura de consultas. El acrónimo QL refleja el hecho de que la respuesta a una
consulta puede ser implementada por re-escribir las consultas en el Standard Relational
Query Language. Las herramientas (en proceso de alcanzar conformidad con OWL 2) que
ofrecen soporte para OWL 2 QL son QuOnto, Quill, FaCT++, Hermit, Pellet, entre otras.
� OWL 2 RL: fue diseñado pensando en aplicaciones que priorizan la interoperabilidad de
OWL con máquinas de reglas. Define un subconjunto sintáctico de reglas para su
implementación a través de tecnologías basadas en reglas. Tales implementaciones pueden
operar directamente sobre triplas RDF y pueden ser aplicadas arbitrariamente a grafos
RDF. En este último caso no hay garantía de obtener todas las respuestas correctas desde
que la ontología puede estar incompleta. El acrónimo RL refleja el hecho de que el
razonamiento puede ser implementado utilizando el Standard Rule Language. Las
herramientas (en proceso de alcanzar conformidad con OWL 2) que ofrecen soporte para
OWL 2 RL son: Oracle Database 11g OWL Reasoner, Jena, FaCT++, Hermit y Pellet.
La elección de un sublenguaje depende principalmente de la expresividad requerida por la
aplicación, la prioridad dada al razonamiento sobre clases o datos, el tamaño de los datasets y
la importancia de la escalabilidad, entre otros.

75.00 Tesis
51
Para requerimientos de un sublenguaje escalable en ontologías grandes y con buenos
tiempos de performance en razonamiento ontológico, la recomendación es OWL 2 EL. Para
requerimientos de interoperabilidad con sistemas de BD relacionales y razonamiento
escalable sobre grandes datasets, la recomendación es OWL 2 QL mientras que para
requerimientos de interoperabilidad con máquinas de reglas y reglas extendidas de BD y
razonamiento escalable sobre grandes BD, la recomendación es OWL 2 RL.
2.5.2.3 Semántica Formal
La semántica formal utilizada en OWL 2 puede ser:
� Direct Model-Theoretic (Modelo Teórico Directo): provee significado en un estilo lógico
descriptivo. Una ontología con interpretaciones (I) realizadas por esta semántica es
referida como OWL 2 DL.
� RDF-Based: la visión de grafos de OWL 2. Es una extensión de la semántica RDFS. Una
ontología con interpretaciones (I) realizadas por esta semántica es referida como OWL 2
FULL.
Las diferencias entre ambas son sutiles siendo las inferencias realizadas utilizando el Direct
Model-Theoretic también válidas en RDF-Based, salvo las obtenidas de anotaciones que
mientras para la primera no tienen significado formal para la segunda son una fuente más de
inferencia.
Conceptualmente, se puede agregar que OWL 2 DL es la versión sintácticamente restringida
de OWL 2 FULL, haciendo el trabajo de desarrollo más sencillo. OWL DL permite construir un
razonador que, en principio, puede retornar respuestas del tipo si-no, siendo variada la
producción de razonadores que cubren el lenguaje OWL 2 DL bajo la semántica Direct Model-
Theoretic. En cambio, no existen razonadores para OWL 2 FULL bajo la semántica RDF-
Based.
2.5.3 WSMO El Web Service Modeling Framework67 (WSMF) satisface requerimientos claves como
máximo desacoplamiento y fuerte mediación, a fin de definir un modelo conceptual para el
desarrollo y la descripción de servicios Web.
El Web Service Modeling Ontology68 (WSMO) extiende WSMF proporcionando un marco
conceptual para la descripción semántica de los aspectos relevantes de los servicios Web
como la automatización del descubrimiento, combinación e invocación.
Comprende el Web Service Modeling Language69 (WSML), el cual establece la sintaxis y la
semántica formal y se basa en formalismos lógicos (lógica descriptiva, lógica de primer orden
y programación lógica), y el Web Service Execution Environment70 (WSMX), el cual define
67
Marco de Modelado de Servicios Web 68 Ontología de Modelado de Servicios Web 69
Lenguaje de Modelado de Servicios Web 70
Entorno de Ejecución de Servicios Web

75.00 Tesis
52
una arquitectura SWS prestando una implementación inicial para descubrimiento, selección,
mediación, invocación e interoperación de servicios Web. El objetivo de WSMX es
proporcionar un ambiente de prueba para WSMO y demostrar la viabilidad de utilizarlo
como modelo para alcanzar la interoperabilidad dinámica de SWS.
2.5.3.1 Principios de diseño
Como se mencionó, WSMO es un marco para la descripción de servicios Web, que integra
principios básicos y semánticos de diseño Web y principios de diseño para procesamiento
distribuido. A continuación se enumeran los principios de diseño de WSMO:
1. Conformidad Web: abarca el concepto de URI para identificación única de recursos, el
concepto de namespaces para denotar espacios de información consistentes, XML,
recomendaciones del W3C y recursos descentralizados.
2. Basado en ontologías: refiere a descripciones de servicios e intercambio de datos.
3. Desacoplamiento estricto: cada recurso WSMO deber ser especificado en forma
independiente, sin considerar posibles usos o interacciones con otros recursos.
4. Mediación centralizada: la mediación se ocupa de manejar la heterogeneidad que
naturalmente surge en entornos abiertos.
5. Separación de rol ontológico: los pedidos de usuario son formulados independientemente
de los servicios Web disponibles.
6. Ejecución semántica: la ejecución semántica de implementaciones de referencia como
WSMX proveen realización técnica y verificación de la especificación WSMO.
7. Servicios vs. Servicios Web: un servicio Web es una entidad computacional que puede
(por ser invocado) alcanzar un objetivo. Por el contrario, un servicio es el valor actual
provisto por esta invocación. WSMO no especifica servicios sino servicios Web.
2.5.3.2 Conceptos básicos Partiendo de la base conceptual establecida por WSMF, WSMO refina y extiende cuatro
elementos de modelado: ontologías, servicios Web, objetivos y mediadores, adoptando las
definiciones dadas a continuación.
Las ontologías son un elemento clave al proveer las terminologías específicas de dominio
para describir otros elementos. Cumplen un doble propósito: definir la semántica formal de la
información y vincular terminologías humanas y de computadora.
Los servicios Web utilizan protocolos basados en estándares Web para intercambiar y
combinar datos, son independientes de la plataforma y cada servicio Web es visto como una
pieza atómica de funcionalidad que puede ser reutilizada para construir servicios más
complejos. Además WSMO incluye tres perspectivas en la descripción de los servicios Web:

75.00 Tesis
53
propiedades no funcionales, funcionalidad y comportamiento.
Los objetivos (goals) especifican las funcionalidades que un servicio Web debe proveer desde
la perspectiva del usuario. La co-existencia de objetivos y servicios Web como entidades no
superpuestas asegura el desacoplamiento entre un pedido y un servicio Web. Esta forma de
establecer problemas, en la que el usuario formula objetivos sin considerar los servicios Web
de la solución es conocido como Goal-Driven Approach71, derivado del AI Racional Agent
Approach72.
Los mediadores resuelven incompatibilidades a nivel de datos, mediando entre diferentes
terminologías, específicamente solucionan problemas a nivel de procesos, de integración de
ontologías y median entre patrones de comunicación heterogéneos (este tipo de
heterogeneidad aparece durante la comunicación de servicios Web). Existen cuatro tipos de
mediadores: mediadores de ontologías, de servicios Web, de objetivos y mediadores entre
servicios Web y objetivos.
2.5.4 DAML-S
El Darpa Agent Markup Language for Services73 (DAML-S) es un intento por cerrar la
brecha entre la Web Semántica y los estándares de servicios Web [Paolucci y Sycara, 2003].
Permite una descripción estándar (WSDL y SOAP) de los servicios Web garantizando que
usuarios y servicios puedan descubrir e invocar otros servicios. Como ontología, define un
concepto de servicio Web utilizando construcciones DAML+OIL74. Además, las anotaciones
semánticas y ontológicas le permiten relacionar descripciones de servicios Web con
descripciones de dominio operacional.
Un servicio Web DAML-S es especificado por cuatro descripciones: el Service Profile, el
Process Model, el Service Grounding y el DAML-S Service Description, el cual es una especie
de contenedor de los anteriores. A nivel mensajes y transporte, DAML-S es consistente con el
resto de los estándares propuestos (WSDL, SOAP y otros protocolos).
El Service Profile provee una visión de alto nivel de un servicio Web, similar a la
representación de servicio Web UDDI. Ambos proveen información del proveedor de servicio
pero el Service Profile soporta propiedades como representación de capacidades (tareas
ejecutadas por el servicio) que UDDI no soporta. Por otro lado, UDDI describe los puertos que
el servicio Web utiliza, mientras que DAML-S relega esa información a otros módulos de la
descripción como el Service Grounding.
El Process Model especifica qué tareas ejecuta un servicio Web, el orden en que las ejecuta y
71
Enfoque Dirigido por Objetivos 72
Enfoque de Inteligencia Artificial de Agente Racional. 73 Lenguaje de Marcado de Agentes DARPA para Servicios 74
Lenguaje de marcado semántico para recursos Web, fue construido sobre los primeros estándares del W3C, RDF y
RDFS, extiende estos lenguajes con primitivas de modelado. http://www.w3.org/TR/daml+oil-reference

75.00 Tesis
54
las consecuencias de las mismas. Un cliente puede utilizar el Process Model para derivar la
coreografía del servicio o el patrón de intercambio de mensajes por seguir las entradas que
espera y cuando y las salidas que produce y cuando. El Process Model tiene un rol similar a
los estándares emergentes como BPEL4WS75 y WSCI76, pero se enfoca más en los efectos de
ejecutar los componentes de diferentes servicios.
El Service Grounding vincula la descripción abstracta de intercambio de información de un
servicio Web (definido en términos de entradas y salidas en el Process Model) con una
operación WSDL explícita, que luego WSDL vincula a mensajes SOAP e información de la
capa de transporte.
La dependencia de DAML-S sobre DAML+OIL, así como WSDL sobre SOAP, muestra cómo los
servicios Web pueden ser enriquecidos con información semántica. DAML-S agrega a las
especificaciones de servicios Web, representación formal de contenido y razonamiento
acerca de interacciones y capacidades. DAML-S permite que los servicios Web empleen UDDI,
WSDL y SOAP para descubrir e interactuar con otros servicios y que ellos utilicen DAML-S
para integrar estas interacciones en problemas propios a resolver.
2.5.5 OWL-S Se trata de una ontología de servicios Web basada en OWL que permite describir las
propiedades y capacidades de los servicios Web. OWL-S fue construido sobre la
recomendación OWL del W3C. Las publicaciones anteriores de este lenguaje fueron llamadas
DAML-S y construidas sobre DAML+OIL (predecesor de OWL). La última versión de OWL-S
es la 1.2. OWL-S puede ser comprendido a partir de DAML-S, desarrollado en la sección
anterior.
2.5.6 SWSF
En el año 2005, el W3C publicó el Semantic Web Services Framework (SWSF), presentado
por Hewlett Packard (HP), el Massachusetts Institute of Technology (MIT), el National
Research Council of Canada, SRI y las universidades de Stanford, Zurich, Toronto y California,
entre otras.
Dicha publicación empieza por mencionar la necesidad de estándares para servicios Web
(parcialmente logrados con WSDL, BPEL4WS y UDDI) y al mismo tiempo destaca la
necesidad creciente de especificaciones semánticas más ricas, basadas en un framework que
extienda el rango completo de conceptos relacionados a servicios Web. Un framework
debería permitir una automatización más completa y flexible en la provisión y utilización de
servicios, soportar la construcción de herramientas y metodologías más poderosas y
promover la utilización de razonamientos semánticos acerca de servicios. Dado que un
framework de representación expresivo permite la especificación de diferentes aspectos de
los servicios, puede proporcionar una base para un amplio rango de actividades a lo largo del
ciclo de vida de los servicios Web: semánticas más ricas pueden soportar mayor
75
Business Process Execution Language for Web Services, es un lenguaje para la especificación formal de procesos
de negocios y protocolos de interacción de negocios. Por esto, extiende el modelo de interacción de servicios Web y
lo habilita para soportar transacciones de negocios. 76
Web Service Choreography Interface. http://www.w3.org/TR/wsci/

75.00 Tesis
55
automatización de selección e invocación de servicios, traslación automática de contenido de
mensajes entre servicios, enfoques automatizados o semiautomatizados para la composición
de servicios, enfoques más comprensivos para monitoreo de servicios y recuperación de
fallas y una automatización más completa de verificación, simulación, configuración,
administración de la cadena de proveedores, contratación y negociación de servicios [Battle et
al., 2005].
Las tecnologías presentadas en el trabajo SWSF realizan esta visión de Servicios Web
Semánticos. En él exponen sus dos componentes principales: el Semantic Web Services
Language (SWSL) y el Semantic Web Service Ontology (SWSO).
SWSL se utiliza para especificar caracterizaciones formales de los conceptos de servicios
Web y las descripciones de los servicios individuales. Incluye dos sublenguajes: SWSL-FOL,
basado en lógica de primer orden para expresar la caracterización formal de conceptos de
servicio Web, y SWSL-Rules, basado en el paradigma de programación lógica (o reglas), para
soportar la utilización de la ontología de servicio en razonamiento y entornos de ejecución
basados sobre este paradigma.
SWSO presenta una axiomatización (caracterización formal) del modelo conceptual
empleado para describir los servicios Web. La axiomatización completa se encuentra en
lógica de primer orden utilizando SWSL-FOL en combinación con el Model–Theoretic
Semantic77 el cual especifica el significado preciso de los conceptos.
La forma FOL de la ontología es llamada FLOWS78 y la ontología resultante por trasladar
sistemáticamente axiomas FLOWS al lenguaje SWSL-Rules es llamada ROWS79.
Una contribución clave de la ontología FLOWS es el desarrollo de un modelo de proceso rico
de comportamiento basado en la ISO 18629 Process Specification Language (PSL)80.
2.5.7 WSDL-S
En el año 2005, el W3C publicó el trabajo “Web Service Semantics – WSDL-S”, entregado por
representantes del IBM Research, IBM Software Group y LSDIS Lab of the University of
Georgia.
[Miller et al.; 2004] sostienen que los servicios Web fueron diseñados para proveer
interoperabilidad entre aplicaciones de negocios. Las tecnologías actuales requieren de una
gran cantidad de interacción humana para integrar dos aplicaciones. Esto es debido a que la
integración de procesos de negocios necesita de la comprensión de los datos y las funciones
de las entidades involucradas. Las tecnologías semánticas apuntan a sumar mayor significado
al contenido Web, por anotar los datos con ontologías. Las ontologías proporcionan un
mecanismo para compartir conceptualizaciones de dominio. Esto permite a los agentes
conseguir una comprensión de los contenidos de los usuarios de la Web y reducir la
interacción humana en búsquedas Web significativas. Un enfoque similar puede ser
empleado por agregar significado a las descripciones de los servicios Web, las cuales
77
Ver sección 2.4.2.3 “Semántica Formal” 78
First Order Logic Ontology for Web Services 79 Rules Ontology for Web Services 80 Originalmente diseñado para soportar interoperabilidad entre lenguajes de modelado de procesos, PSL provee una
base para la interoperabilidad entre los modelos de procesos de los servicios Web emergentes mientras soporta la
realización de automatización de tareas asociadas con la visión de Servicios Web Semánticos.

75.00 Tesis
56
permiten mayor automatización por reducir el involucramiento humano en comprender los
datos y funciones de los servicios.
Debido a la tardía alineación de OWL-S con WSDL, el diseño de OWL-S puede ser
innecesariamente complejo. WSDL-S busca crear descripciones semánticas de los servicios
Web por agregar semántica por medio de extensiones simples a WSDL. La ontología de
servicio WSDL-S, es por lo tanto, más alineada con WSDL 2.0 y más compacta que OWL-S sin
perder expresividad.
Conceptualmente, la especificación WSDL 2.0 posee las siguientes construcciones para
representar descripciones de servicios: interface, operation, message, binding, service y
endpoint. Las primeras tres construcciones tratan con la definición abstracta de un servicio
mientras que las últimas tres tratan con la implementación del servicio. WSDL-S se enfoca en
anotar semánticamente la definición abstracta de un servicio a fin de permitir
descubrimiento, composición e invocación de servicios. Para ello, emplea mecanismos de
referencia URI vía elementos de extensibilidad en las construcciones interface, operation y
message los cuales apuntan a las anotaciones semánticas definidas en los modelos de dominio
de los servicios.
Los elementos y atributos de extensiblidad que [Akkiraju et al.; 2005] proponen son: 1) un
atributo de extensión, “modelReference”, para especificar la asociación entre una entidad
WSDL y un concepto en algún modelo semántico; 2) un atributo de extensión,
“schemaMapping”, para manejar diferencias estructurales entre los elementos Schema de un
servicio Web y sus correspondientes conceptos en el modelo semántico; 3) dos nuevos
elementos, “precondition” y “effect”, las cuales son utilizadas principalmente en el
descubrimiento de servicios y 4) un atributo de extensión sobre el elemento interface,
“category”, el cual provee información de categorización al publicar un servicio en un
registro como UDDI.
2.5.8 SAWSDL
“Semantic Annotations for WSDL” (o SAWSDL) fue aprobado en el año 2007 como una
recomendación del W3C y realizado por el SAWSDL Working Group basándose en la
presentación WSDL-S (desarrollada en la sección anterior).
SAWSDL propone un enfoque similar a WSDL-S. Define algún WSDL y extiende los atributos
XML-Schema a fin de permitir la descripción semántica de los componentes WSDL. Esto
requiere vincular los elementos WSDL con modelos semánticos como ontologías. SAWSDL
no está sujeto a ningún lenguaje de representación semántica pero proporciona los
mecanismos para referenciar conceptos del modelo semántico desde documentos WSDL.
Los principios de diseño de SAWSDL son: 1) permitir anotaciones semánticas en servicios
Web por utilizar el framework de extensibilidad de WSDL; 2) es agnóstico81 de los lenguajes
de representación semántica y 3) permite anotaciones semánticas en los servicios Web no
sólo para descubrimiento sino también para invocación.
A partir de estos principios de diseño, SAWSDL define tres nuevos atributos de extensibilidad
para elementos WSDL 2.0 a fin de habilitar la anotación semántica de componentes WSDL: 1)
un atributo de extensión, “modelReference”, para especificar la asociación entre un
81
Sin conocimiento.

75.00 Tesis
57
componente WSDL y un concepto en algún modelo semántico y 2) dos atributos de
extensión, “liftingSchemaMapping” y “loweringSchemaMapping”82, los cuales son agregados
a declaraciones de elementos y a definiciones de tipos de XML-Schema por especificar las
asociaciones entre datos semánticos y XML y utilizados durante la invocación del servicio.
2.6 Razonador
El desarrollo y aplicación de ontologías depende de razonamiento. Un razonador es un
componente clave para trabajar con ontologías OWL DL [Horridge; 2009].
Una base de conocimiento (KB)83 se compone de un TBox y un ABox. Un TBox describe
conocimiento intencional en la forma de conceptos (clases) y definiciones de roles
(propiedades) y un ABox describe conocimiento por extensión y consiste de un conjunto
finito de aserciones acerca de los individuos mientras utiliza los términos de la ontología.
Conviene notar que un ABox representa un conocimiento incompleto acerca del mundo.
Las clases pueden ser organizadas en una jerarquía de superclases-subclases, conocido como
taxonomía. Las subclases especializan (“son subsumidas por”) superclases. Estas relaciones
pueden ser procesadas por un razonador en OWL-DL. Virtualmente toda consulta a una
ontología OWL DL debe ser realizada utilizando un razonador que deduzca conocimiento
implícito. El OWL API incluye varias interfaces para acceder a razonadores OWL DL. La
interfaz OWL Reasoner del OWL API es implementada por FACT++, Hermit, Pellet y
RacerPro, entre otros.
Un razonador también es conocido como clasificador por la tarea de computar una jerarquía
de clases inferidas.
Como consecuencia de la naturaleza inherentemente distribuida de la Web, el razonamiento
en OWL DL se apoya en lo que se conoce como Open World Assumption84 (OWA) o como
Open World Reasoning85 (OWR). OWA establece que la verdad de un statement es
independiente de si es conocido, esto es, no saber si un statement es explícitamente
verdadero no implica que el statement sea falso (en todo caso se asume que no se ha
agregado suficiente conocimiento a la base de conocimiento). Bajo OWA, información nueva
es manejada de forma aditiva debido a que no se puede remover la información afirmada
previamente. OWA impacta el tipo de inferencia que puede ser ejecutada sobre la
información. En OWL, esto significa que la inferencia sólo puede ser ejecutada sobre
información que es conocida. La ausencia de una pieza de información no puede ser utilizada
para inferir la presencia de otra información. La correcta inferencia de las semánticas de
OWL en el mundo distribuido de la Web Semántica depende sobre la adhesión al supuesto de
mundo abierto.
En oposición a OWA, el Closed World Assumption86 (CWA) afirma que todo statement que no
sea verdadero es asumido como falso. La mayoría de los sistemas operan con supuestos de
82 El primero se refiere a levantar datos desde el XML al modelo semántico y el segundo a bajar datos desde el
modelo semántico al XML. Los mapping son útiles cuando la estructura de los datos de instancia (servicio) no se
corresponden con los de la organización de datos semánticos. Los mapping son utilizados cuando código de
mediación es generado para soportar invocación de servicios. 83 Las siglas corresponden al término en inglés Knowledge Base 84 Supuesto de Mundo Abierto. 85
Razonamiento de Mundo Abierto. 86
Supuesto de mundo cerrado.

75.00 Tesis
58
mundo cerrado. Ellos asumen que la información es completa y conocida. Sin embargo, en
algunos casos CWA puede limitar la expresividad de un sistema debido a que es más difícil
diferenciar entre información incompleta e información que es desconocida.
A fin de lograr una Web Semántica robusta, las ontologías deben procurar balancear entre la
complejidad computacional requerida por los mecanismos de razonamiento y el poder
expresivo de los conceptos definidos. RDF y RDFS proveen un poder expresivo muy limitado,
insuficiente para representar la semántica asociada a un dominio. OWL provee mayor poder
expresivo y promueve motores de inferencia por suministrar un soporte de razonamiento
apropiado. Nuevos dialectos que necesitan más servicios de razonamiento e inferencia,
plantean nuevos desafíos para los razonadores DL quienes deben controlar subsunción,
consistencia y satisfactibilidad de las ontologías.
La inferencia hace un dato mucho más valioso debido a que podría tener un efecto en la
creación de nueva información y conducir a efectos positivos o negativos. Cada pieza de
información tiene la capacidad de agregar gran cantidad de información nueva vía inferencia.
Por ello, se deben tomar cuidados extras para validar la información. El proceso de inferencia,
como todo sistema es vulnerable al fenómeno “garbage in, garbage out” pero la inferencia
amplía este asunto [Hebeler et al.; 2009].
A continuación, se exponen las limitaciones encontradas en relación a la utilización de
razonadores, servicios Web e inferencia y finalmente inferencia.
[Fahad et al.; 2008] sostuvieron que un soporte de razonamiento preciso es fundamental
para las ontologías de la Web Semántica, lo cual sólo puede ser posible si el estado del arte de
los razonadores de lógica descriptiva es capaz de detectar inconsistencias y ordenar
taxonomías en ontologías. Ellos discutieron errores y anomalías de diseño en ontologías y
realizaron un caso de estudio incorporando esos errores. Evaluaron consistencia,
subsunción y satisfactibilidad de los razonadores DL. El experimento determinó errores
dentro de los algoritmos utilizados por los razonadores. Especialmente errores circulares y
varios tipos de errores de inconsistencia semántica que podrían causar graves efectos
colaterales, los cuales deberían ser detectados por los razonadores DL a fin de asegurar un
razonamiento preciso sobre ontologías.
[Li et al.; 2006] propusieron un mecanismo de composición de servicios para realizar el
modelado semántico y el razonamiento de la composición de servicios con la incorporación
de preferencias de usuario. Sus pruebas fueron realizadas utilizando una base de
conocimiento con individuos y un TBox acíclico debido a que en un TBox acíclico las clases
primitivas determinan de manera unívoca la extensión de las clases definidas mientras que en
un TBox cíclico no sucede lo mismo.
[Baader et al.; 2005] propusieron un formalismo que describía la funcionalidad de los
servicios Web partiendo de las investigaciones realizadas en los campos de representación de
conocimiento, de razonamiento por ingeniería de ontologías y de razonamiento acerca de
acciones. Su formalismo se restringió a una base de conocimiento con individuos y un TBox
acíclico dado que un TBox cíclico presentaba problemas semánticos. En su trabajo adoptaron la definición de un TBox acíclico por no utilizar las mismas clases definidas en relación al

75.00 Tesis
59
TBox.
2.6.1 Clasificación
Los razonadores pueden ser agrupados en dos categorías: razonadores de lógica descriptiva y
razonadores de programación lógica.
2.6.1.1 Razonadores de lógica descriptiva
Como se mencionó en la sección 2.3 “Lógica y ontologías”, las lógicas descriptivas permiten
representar bases de conocimiento que describen un dominio particular. Una lógica
descriptiva se representa a través de clases (conceptos), individuos, roles (propiedades).
Además existe un conjunto de extensiones que incluyen el dominio y rango de las
restricciones. [Rodríguez et al.; 2010].
Los razonadores DL brindan los siguientes servicios de inferencia:
� Validación de la consistencia de una ontología: el razonador puede comprobar si una
ontología no contiene hechos contradictorios
� Validación del cumplimiento de los conceptos de la ontología: el razonador determina si es
posible que una clase tenga instancias. En el caso de que un concepto no sea satisfecho la
ontología será inconsistente.
� Clasificación de la ontología: el razonador computa a partir de los axiomas declarados en el
TBox, las relaciones de subclase entre todos los conceptos declarados explícitamente a fin
de construir la jerarquía de clases.
� Posibilita la resolución de consultas durante la recuperación de información basada en
ontologías: a partir de la jerarquía de clases se pueden formular consultas como conocer
todas las subclases de un concepto, inferir nuevas subclases de un concepto, las
superclases directas, etc.
� Precisiones sobre los conceptos de la jerarquía: el razonador puede inferir cuáles son las
clases a las que directamente pertenece y mediante la jerarquía inferida obtener todas las
clases a las cuales indirectamente pertenece una clase o individuo dentro de la ontología.
Algunos razonadores DL son Pellet, HermiT, FacT++, Racer Pro. Los tres primeros serán
desarrollados en las siguientes secciones dejando para esta sección, el razonador RacerPro.
Racer87 fue desarrollado en LISP88. Creado inicialmente por la Universidad de Hamburgo
luego se convirtió en software propietario. Su nombre comercial es RacerPro. Soporta OWL
DL excepto para los nominales (clases definidas por enumeración de sus miembros) y para
tipos de datos no estándar; maneja ABoxes largas en combinación con TBoxes largas y
expresivas, además de proveer servicios de inferencia sofisticados. Implementa un
procedimiento de decisión basado en calculus tableaux89 para TBoxes (subsunción,
87
Renamed ABox and Concept Expression Reasoner 88
Lenguaje de programación de tipo funcional especificado en 1958 es el segundo lenguaje de programación más
viejo de alto nivel. Utilizado frecuentemente en IA. 89
O tablas semánticas se encuentran dentro de lo que se conoce como algoritmos de razonamiento [Rodríguez et al.;
2010] y se basan en las semánticas de las fórmulas. De acuerdo a su tipo, una formula genera una extensión en el

75.00 Tesis
60
satisfactibilidad, clasificación) y ABoxes (consultas). Soporta la OWL-API, la interfaz DIG,
transformaciones SPARQL y SWRL a nRQL, diferentes formatos y sintaxis, conectividad con
software externo (Protégé, etc.), entre otras características. La última versión comercial es
RacerPro 1.9.0 que será reemplazada por RacerPro 2.0 a liberarse en el 2011.
2.6.1.2 Razonadores de programación lógica Entre los razonadores de programación lógica se encuentran: KAON2, FLORA-2, TRIPLE,
DLV, MINS, Jena, entre otros. A continuación se desarrollarán algunos.
KAON2 es un razonador con sistema de razonamiento híbrido que soporta SHIQ(D), Datalog y
DL-Safe. Fue desarrollado por la Universidad de Manchester, la Universidad de Karlsruhe y el
FZI90
. Dentro de KAON2, las reglas DL-Safe pueden ser agregadas a la salida de un DataLog
disyuntivo y no requieren preprocesamiento adicional, lo que mejora el rendimiento Su
razonamiento es implementado a través de algoritmos Novel, que reducen una base de
conocimiento SHIQ(D) a un programa de registro de datos disyuntivos. Posee una versión
comercial llamada OntoBroker OWL. KAON2 no maneja nominales ni números grandes en
sentencias de cardinalidad.
FLORA-2 es un sistema basado en conocimiento y un entorno completo para el desarrollo de
aplicaciones que hacen uso de conocimiento. FLORA-2 extiende el cálculo de predicados con el
concepto de objeto, clase y tipo, adaptados de la POO.
TRIPLE es un lenguaje de consulta, inferencia y transformación para la Web Semántica.
Proporciona soporte para RDF y para un subconjunto de OWL Lite. Su sintaxis está basada en F-
Logic y brinda soporte para símbolos de función, tratamiento de la igualdad o negación por
defecto, transformaciones, modelos y extensión sintáctica de la lógica de Horn. El motor de
inferencia de TRIPLE se basa en el sistema PROLOG XSB.
Jena es un framework open source para construir aplicaciones de la Web semántica sobre
modelos RDF. Soporta varios formatos como XML/RDF, N3 y N-Triples (formatos para grafos
abreviados). Los grafos son representados internamente como un modelo abstracto, que se puede
consultar mediante el lenguaje de consultas para RDF y SPARQL. Permite el tratamiento del
lenguaje OWL, al utilizar el modelo semántico de RDF y proporciona conexión de forma externa
a través de la interfaz DIG hacia razonadores DL como Pellet o FaCT++. Jena posee la
capacidad para conectarse con motores de inferencia externos tipo Plug-in a través de una
interface DIG y también ofrece un subsistema de inferencia propio el cual consiste en un motor
híbrido con encadenamiento hacia delante y hacia atrás, utilizando el algoritmo RETE (algoritmo
de reconocimiento de patrones). Ofrece razonadores para RDF, OWL, DAML, razonador
transitivo y motor de reglas multipropósito.
tableaux. La clasificación de las fórmulas son tipo α, para las formulas conjuntivas; tipo β, para las fórmulas
disyuntivas; tipoγ para las fórmulas universales y tipo δ, para las fórmulas existenciales. La base de este método es
el principio de refutación: dado un conjunto de premisas ϕ y una conclusión ϕ, mostrar que el conjunto ϕ ∪ {¬ϕ}
no tiene un modelo que lo satisfaga, demostrando que ϕ es una consecuencia de ϕ. 90 Universidad en Inglaterra, Universidad en Alemania y una de las más prestigiosas de ese país, Organización de
investigación por contratos sin fines de lucro para proveedores de inversión, productos de consumo y servicios de
información que soporta el desarrollo de aplicaciones innovadoras, principalmente en ingeniería, sobre la base de
técnicas recientes y probadas. La organización permite a profesores extender sus esfuerzos en la investigación
académica en la dirección de actividades más orientadas al mercado por prestar una infraestructura técnica y
organizacional que es congenial a establecer relaciones estrechas con la industria y organizaciones de servicios.
http://www.fzi.de/

75.00 Tesis
61
2.7 SWRL El Semantic Web Rule Language se basa en OWL DL y OWL Lite y utiliza el subconjunto de
reglas RuleML del Rule Markup Language91 las cuales son modeladas sobre cláusulas Horn. El
propósito de SWRL es extender el conjunto de axiomas OWL al incluir cláusulas Horn que
puedan ser combinadas con la base de conocimiento de OWL92.
Las cláusulas Horn representan condicionales if-then o más formalmente implicaciones. De
esta manera, las reglas tienen la forma de una implicación entre un antecedente (referido
como body en la sintaxis) y un consecuente (referido como head en la sintaxis). Una regla
puede ser interpretada como “si las condiciones especificadas en el antecedente son
verdaderas entonces, las condiciones especificadas en el consecuente también son
verdaderas”.
Ambos, el antecedente y el consecuente consisten de cero o más átomos. Un antecedente
vacío es tratado trivialmente como verdadero y por lo tanto, el consecuente también es
verdadero. Un consecuente vacío es tratado trivialmente como falso y por lo tanto, el
antecedente también es falso.
Los átomos pueden ser de la forma C(x), P(x, y), sameAs (x, y), differentFrom (x, y), donde C
es una descripción OWL, P es una propiedad OWL y x, y pueden representar variables,
individuos OWL o valores de datos OWL. Cabe destacar que OWL DL pierde decidibilidad93
cuando es extendido de esta manera porque las reglas pueden ser utilizadas para simular
asociaciones rol valor.
SWRL utiliza una extensión de la semántica model-theoretic94 de OWL. SWRL es construido
sobre OWL DL y provee más expresividad que OWL DL sólo. Sin embargo, comparte la
semántica formal: las conclusiones alcanzadas por SWRL tienen la misma garantía formal
que las conclusiones alcanzadas por construcciones OWL.
La expresividad adicional de SWRL es lograda a expensas de perder decidibilidad (mientras
es posible garantizar que un razonador OWL completará la clasificación de una ontología
OWL, no ocurre lo mismo a partir de la inferencia con SWRL). En general, se debería utilizar
OWL siempre que sea posible y recurrir a SWRL, sólo cuando resulte necesario disponer de
expresividad adicional.
[Hebeler et al.; 2009] enuncian a las reglas como un medio para representar conocimiento
que con frecuencia no es posible en OWL 1 o que resulta más fácil de comprender que las
expresiones que OWL 1 puede ofrecer.
2.7.1 Motivaciones Según [Hebeler et al.; 2009] las reglas surgieron por la falta de expresividad de OWL 1.
OWL 1 no presenta soporte para la composición de propiedades. Este problema también es
91
http://ruleml.org/ 92
http://www.w3.org/Submission/SWRL/#owls_Rule 93
En lógica, el término decidible refiere a la existencia de un método efectivo para determinar la pertenencia a un
conjunto de fórmulas, Por ejemplo, los sistemas lógicos, como la lógica proposicional, son decidibles si
efectivamente se puede determinar la pertenencia a los conjuntos de fórmulas válidas lógicamente. 94
Desarrollado en la sección 2.5.2.3, “Semántica Formal”.

75.00 Tesis
62
conocido como “uncle problem”. Es imposible, en OWL 1, determinar que un individuo A
tiene una relación uncle con un individuo B debido a la necesidad de dos piezas de
información: que A tenga una relación father con C y que C tenga una relación sibling con B.
Las reglas soportan la existencia de ambas piezas de información que resultan en la creación
de la relación uncle. OWL 2 parcialmente resolvió este problema mediante la
owl:propertyChain. Cabe aclarar que SWRL en anterior a OWL 2.
La utilización de built-ins permite realizar transformaciones comunes sobre los datos. No es
posible en OWL 1 verificar si una URI tiene una data-property que empieza con una palabra
dada y utilizar esa información como base para agregar una nueva propiedad al mismo
sujeto. La asociación por patrones, operaciones matemáticas, verificación de condicionales o
conversión de unidades son algunas de las necesidades para built-ins.
Las reglas pueden ser utilizadas para limitar el Open World Assumption (OWA) de OWL
(empleando una técnica conocida como Negation as Failure95 o NAF) o soportar el supuesto
de individuos únicos96.
Así, aparte de las ya mencionadas, existen otras carencias en OWL 1 que son superadas por
la utilización de reglas.
2.7.2 DL-Safe Rules
Las DL-Safe Rules poseen como propiedad decidibilidad y solucionan algunos de los
problemas asociados con la pérdida de decidibilidad que ocasiona SWRL.
Las DL-Safe Rules son un subconjunto de SWRL y asocian instancias conocidas de la base de
conocimiento o la ontología con las variables utilizadas por las reglas. Si no existe una
instancia que se pueda asociar con una consulta, entonces el consecuente de una regla DL-
Safe no se ejecutará sin importar que las reglas sean perfectamente válidas. La decidibilidad
sólo puede ser garantizada por tener toda la información necesaria al momento de evaluar la
regla. Restringiendo las reglas sólo a individuos conocidos asegura decidibilidad como fue
demostrado en [Motik et al., 2005].
2.8 Ejemplos Los trabajos de investigación estudiados han empleado ontologías sencillas a fin de concentrarse
en los aspectos de una solución al problema de composición dinámica de servicios: [Paolucci et
al.; 2002] utilizaron una ontología de vehículos hecha en DAML; [Li et al.; 2006] eligieron
como escenario el de una biblioteca universitaria, utilizando OWL-S para la descripción y OWL
para el modelado y razonamiento de la composición de servicios; en [Yong-Feng et al.; 2007]
utilizaron OWL-S para la composición de servicios y OWL para describir la interacción de
agentes; [Fahad et al.; 2008] emplearon una ontología de automóviles en OWL a fin de
evaluar los razonadores DL con respecto a su capacidad para clasificar e identificar
inconsistencias en las ontologías. Por otro lado, el W3C utiliza como ejemplo en sus
publicaciones relacionadas a la Web Semántica una ontología de vinos (wine.owl). Además
de las ontologías en el área de la medicina, mencionadas anteriormente en la sección 2.4,
95
Por ejemplo if Adan isn’t known to have a brother, then assert he is brotherless 96
En OWL los individuos son supuestos ser iguales salvo que explícitamente sea establecido lo contrario.

75.00 Tesis
63
existen ontologías disponibles en el sitio “Semantic Web”97, en el sitio del laboratorio LSDIS
del Departamento de Computación de la Universidad de Georgia98, en DAML99, en el sitio
del proyecto Co-Ode del Departamento de Computación de la Universidad de
Manchester100 y por medio del buscador semántico Swoogle101 (con 10.000 ontologías
disponibles), entre otras.
La ontología mostrada a continuación fue desarrollada en OWL con el editor de ontologías
Protégé 4.1.0. Después de evaluar las ontologías utilizadas en los trabajos mencionados, se
eligió construir una ontología que describiera la bolsa de trabajo de una facultad.
Jerarquía de clases de http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl.
En el panel izquierdo se puede observar la jerarquía y en el panel central el grafo
correspondiente.
97
http://semanticweb.org/wiki/Ontology 98
http://lsdis.cs.uga.edu/projects/ 99 http://www.daml.org/index.html 100
http://www.co-ode.org/ 101
http://swoogle.umbc.edu/
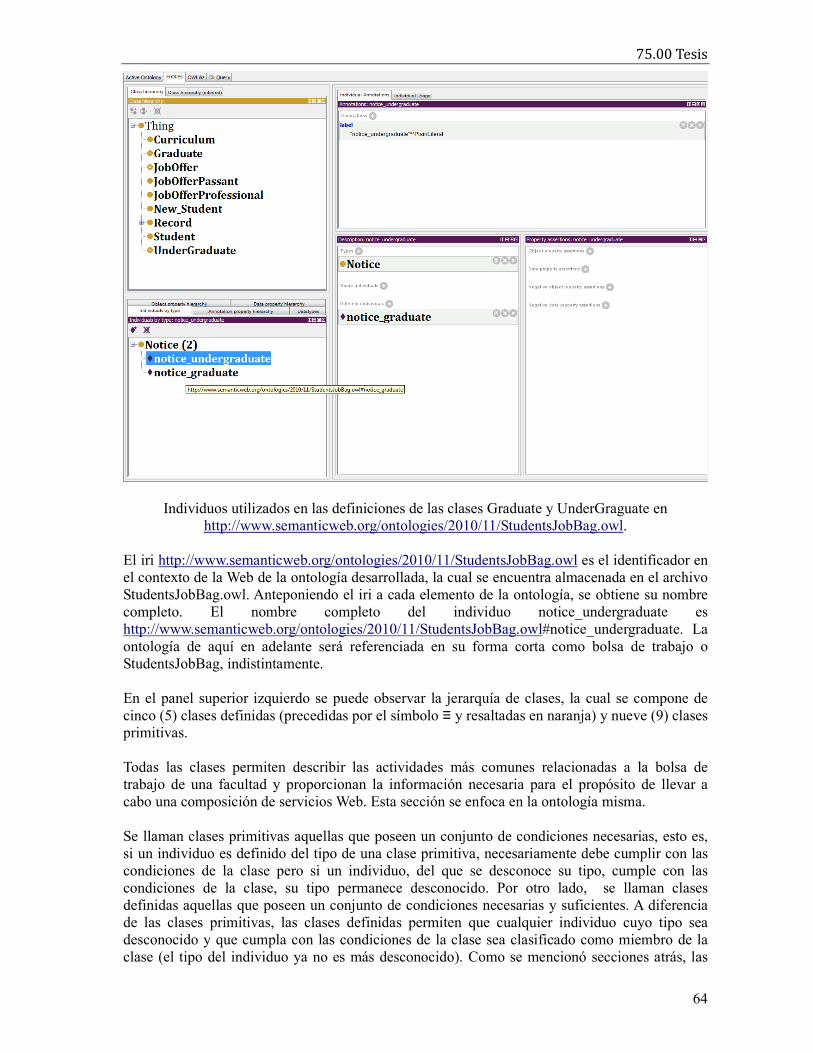
75.00 Tesis
64
Individuos utilizados en las definiciones de las clases Graduate y UnderGraguate en
http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl.
El iri http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl es el identificador en
el contexto de la Web de la ontología desarrollada, la cual se encuentra almacenada en el archivo
StudentsJobBag.owl. Anteponiendo el iri a cada elemento de la ontología, se obtiene su nombre
completo. El nombre completo del individuo notice_undergraduate es
http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl#notice_undergraduate. La
ontología de aquí en adelante será referenciada en su forma corta como bolsa de trabajo o
StudentsJobBag, indistintamente.
En el panel superior izquierdo se puede observar la jerarquía de clases, la cual se compone de
cinco (5) clases definidas (precedidas por el símbolo ≡ y resaltadas en naranja) y nueve (9) clases
primitivas.
Todas las clases permiten describir las actividades más comunes relacionadas a la bolsa de
trabajo de una facultad y proporcionan la información necesaria para el propósito de llevar a
cabo una composición de servicios Web. Esta sección se enfoca en la ontología misma.
Se llaman clases primitivas aquellas que poseen un conjunto de condiciones necesarias, esto es,
si un individuo es definido del tipo de una clase primitiva, necesariamente debe cumplir con las
condiciones de la clase pero si un individuo, del que se desconoce su tipo, cumple con las
condiciones de la clase, su tipo permanece desconocido. Por otro lado, se llaman clases
definidas aquellas que poseen un conjunto de condiciones necesarias y suficientes. A diferencia
de las clases primitivas, las clases definidas permiten que cualquier individuo cuyo tipo sea
desconocido y que cumpla con las condiciones de la clase sea clasificado como miembro de la
clase (el tipo del individuo ya no es más desconocido). Como se mencionó secciones atrás, las

75.00 Tesis
65
clases definidas proporcionan información suficiente para que un razonador DL pueda realizar
clasificación automática.
En la ontología bolsa de trabajo, las clases definidas incluyen la clase Student, la cual representa
al conjunto de individuos de tipo Estudiante; la clase Graduate, para el conjunto de individuos de
tipo Graduado; la clase UnderGraduate, para el conjunto de individuos de tipo No Graduados, la
clase JobOffer, para el conjunto de individuos de tipo Oferta de Trabajo y la clase PostulationJob
para el conjunto de individuos de tipo Postulación de trabajo.
Los individuos fueron definidos en una ontología aparte (como se explicará más adelante en esta
sección); salvo aquellos individuos que forman parte de las definiciones de las clases Graduate y
Undergraduate; a saber, los individuos notice_graduate y notice_undergraduate, pertenecientes a
la clase Notice.
Las definiciones empleadas en las clases Student, UnderGraduate, Graduate, JobOffer y
PostulationJob son mostradas aquí a continuación:
TBox = {
Graduate ≡ hasNotice value notice_graduate
UnderGraduate ≡ hasNotice value notice_underGraduate
Student ≡ Graduate ∪ New_Student ∪ UnderGraduate
JobOffer ≡ JobOfferPassant ∪ JobOfferProfessional
PostulationJob ≡ PostulationJobProfessionalJob ∪
PostulationJobPassantJob
}
La definición de la clase Graduate afirma que los individuos que tienen una nota de graduado
son graduados. La restricción “value” empleada aquí equivale semánticamente a una restricción
existencial ya que no reduce la propiedad hasNotice a un individuo específico. Cualquier
individuo que posea la propiedad hasNotice y además como valor de la misma al individuo
específico notice_graduate automáticamente será clasificado como miembro de la clase
Graduate. Un individuo miembro de la clase Graduate puede poseer más valores en su propiedad
hasNotice y seguir siendo miembro de la clase Graduate siempre que mantenga una relación
hasNotice con un individuo notice_graduate. En general las restricciones value relacionan un
conjunto de individuos con una clase enumerada, la cual incluye al el individuo de la restricción.
La definición de la clase UnderGraduate afirma que los individuos con la propiedad hasNotice y
el valor notice_underGraduate son no graduados. La restricción empleada aquí también es una
restricción value, de manera que los individuos de esta clase pueden tener otros valores en su
propiedad hasNotice, es decir, estar relacionados con otros individuos mientras mantengan la
relación hasNotice con el individuo específico notice_undergraduate. La intención de esta clase
es representar al conjunto de individuos no graduados.
La clase Student es definida por la unión de tres conjuntos de individuos, a saber los individuos
miembros de las clases Graduate, New_Student y UnderGraduate, respectivamente. Un
razonador DL, partiendo de esta definición, detecta una relación de subsunción e inmediatamente
infiere a las clases Graduate, New_Student y UnderGraduate como subclases de la clase Student.
De esta manera, los individuos miembros de cualquiera de las tres clases son también
clasificados como miembros de la clase Student.

75.00 Tesis
66
La clase JobOffer es definida de manera similar a la clase Student. Comprende el conjunto de
individuos resultante de la unión de dos conjuntos de individuos, a saber los individuos
miembros de las clases JobOfferPassant y JobOfferProfessional, respectivamente. Un razonador
DL, siguiendo esta definición, detecta una relación de subsunción e inmediatamente infiere que
las clases JobOfferPassant y JobOfferProfessional son subclases de la clase JobOffer. De esta
manera, los individuos miembros de cualquiera de las dos clases son también clasificados como
miembros de la clase JobOffer.
La clase PostulationJob es definida de manera similar a la clase JobOffer. Comprende el
conjunto de individuos resultante de la unión de dos conjuntos de individuos, a saber los
individuos miembros de las clases PostulationJobProfessionalJob y PostulationJobPassantJob,
respectivamente. Un razonador DL, siguiendo esta definición, detecta una relación de subsunción
e inmediatamente infiere que las clases PostulationJobProfessionalJob y PostulationJobPassantJob
son subclases de la clase PostulationJob. De esta manera, los individuos miembros de cualquiera
de las dos clases son también clasificados como miembros de la clase PostulationJob.
Como se mencionó, las clases primitivas poseen un conjunto de condiciones necesarias y las
clase definidas un conjunto de condiciones necesarias y suficientes. Estas condiciones, también
llamadas condiciones de clase, constituyen una parte de los axiomas utilizados por la ontología y
son las que posibilitan agregar más información sobre la información.
En la ontología bolsa de trabajo, las clases primitivas incluyen la clase Curriculum, la clase
JobOfferPassant, la clase JobOfferProfesional, la clase New_Student, la clase Record, la clase
JobPostulant, la clase Notice, la clase PostulationJob, la clase PostulationPassantJob y la clase
PostulationProfessionalJob. Un razonador no puede inferir que un individuo desconocido que
cumpla con las condiciones de alguna de estas clases primitivas sea miembro de algunas de ellas
debido a que las condiciones son condiciones necesarias pero no suficientes.
En la ontología se declaran las clases Curriculum, Student, Record y JobOffer como
DisjointClasses (disjuntas). De esta manera, un individuo declarado de tipo Curriculum y
Student provocaría una inconsistencia en la ontología y esto sería detectado por un razonador
DL.
El axioma DisjointClasses (disyunción) se utilizó para las clases de todos los niveles (las clases
del nivel tres PostulationPassantJob y PostulationProfessionalJob son disjuntas y un individuo no
puede pertenecer a ambas).
A continuación, se muestra la jerarquía de clases inferidas utilizando Pellet 2.2.1 como razonador
DL.

75.00 Tesis
67
Jerarquía de clases inferidas en
http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl.
El razonador DL dejó en el primer nivel de la jerarquía a la clase Curriculum y a las superclases
JobOffer, Record y Student. La clase JobOffer es una superclase de JobOfferProfessional y
JobOfferPassant; la clase Record es superclase de las clases Notice, JobPostulant y
PostulationlJob, y la clase Student como superclase de las clases (por inferencia) Graduate,
New_Student y UnderGraduate. La clase PostulationlJob, ubicada en el segundo nivel, quedó
como superclase de las clases PostulationPassantJob y PostulationProfessionalJob y subclase de
la clase Record.
A continuación se describen las propiedades.

75.00 Tesis
68
Jerarquía de object-properties en
http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl.
Como se describió en la sección 2.5.2.1, la propiedad topObjectProperty (introducida en OWL2)
es la propiedad de nivel superior y representa al conjunto de pares ordenados de todas las
propiedades. De acuerdo con la convención de utilizar clases definidas para la definición de
rangos y dominios de las propiedades, no se definieron rangos ni dominio salvo para la
propiedad hasRecord cuyo dominio es representado por la clase definida Student. El motivo de
esta convención surge a causa de que la definición del rango o dominio de una propiedad
constituye un axioma, y un razonador puede inferir erróneamente el tipo de un individuo por
asociarlo con las clases del rango o dominio, conduciendo a inconsistencias que luego son
difíciles de detectar en ontologías más grandes. El hecho de utilizar axiomas de rangos y
dominios con clases definidas conduce a que un razonador infiera correctamente el tipo de un
individuo por recurrir a la definición de la clase.
Las propiedades hasJobPostulant, hasNotice y hasPostulationJob son subproperties de hasRecord
o, lo que es lo mismo, hasRecord es una superproperty de ellas. Este tipo de relación jerárquica
entre propiedades provoca que para un par ordenado de individuos (i1, i2) relacionados por la
propiedad hasNotice (por ejemplo), el individuo i1 sea inferido y clasificado por un razonador
DL como miembro de la clase Student, debido a que el dominio de la propiedad hasNotice es
inferido ser del mismo tipo que el dominio de su superproperty hasRecord, el cual fue definido
de tipo Student y, por otro lado, el mismo par ordenado es clasificado como miembro de la
propiedad hasRecord o sea que, los dos individuos son también asociados por la propiedad
hasRecord.
Las propiedades RecordOf, CurriculumOf, JobPostulantOf, NoticeOf y PostulationJobOf son
propiedades inversas de hasRecord hasCurriculum, hasJobPostulant, hasNotice y
hasPostulationJob, respectivamente. Por ser la clase Student dominio de la propiedad hasRecord,
un razonador DL infiere que el rango de la propiedad RecordOf debe ser de tipo Student y al ser
la propiedad RecordOf superproperty de CurriculumOf, JobPostulantOf, NoticeOf y

75.00 Tesis
69
PostulationJobOf, infiere el mismo rango para estas últimas.
Las propiedades hasNotice, hasJobPostulant, hasCurriculum, NoticeOf, JobPostulantOf y
CurriculumOf son definidas como propiedades funcionales. Esto significa que un individuo
inscripto en la bolsa de trabajo de una facultad tendrá un registro llamado postulación de trabajo
(JobPostulant) con sus datos. Este registro es único para cada individuo. Si otro individuo tuviera
el mismo registro un razonador inferirá que, por ser la propiedad hasJobPostulant funcional, se
trata del mismo individuo. Si ambos individuos fueran declarados como distintos
(DifferentIndividuals) esto provocaría una inconsistencia con la ontología. De esta manera se
establece que un individuo puede tener solamente un curriculum, puede registrarse una vez en la
bolsa de trabajo y puede tener solamente una nota (de graduado o no graduado para el escenario
planteado y descripto más adelante).
Hasta aquí se ha utilizado una parte de las posibilidades expresivas que OWL brinda. La
documentación OWL102
(W3C) es bastante completa al respecto y muchos de los trabajos
consultados por esta tesis han elegido a OWL como el lenguaje de ontología Web para
comunicar sus servicios y respaldar sus investigaciones.
A continuación se describen las data-properties.
Jerarquía de data-properties en
http://www.semanticweb.org/ontologies/2010/11/StudentsJobBag.owl.
Un data-property relaciona un individuo con datatypes XML-Schema o literales RDF.
El rango de la propiedad contractType fue definido de tipo string, de manera que un individuo
podría tener como valor de la propiedad contractType el string “relación de dependencia”.
El rango de las data-properties fue definido de tipo string, salvo para las data-properties year y
numberReg con rango de tipo int.
102
http://www.w3.org/TR/2009/REC-owl2-primer-20091027/

75.00 Tesis
70
OWL ofrece variedad de datatypes como float, long, date, decimal, base64binary, QName,
positiveinteger, XMLLiteral, ENTITY, NMToken, ID, IDREF, IDREFS, etc., pero para los fines
de este trabajo fue suficiente con los tipos mencionados.
La jerarquía de data-properties consta de las propiedades contractType, employer, expiration,
horaryJobPosting, matriculate, numberReg, place, profession, reference, registrationDate,
requirements, tasks, university y year.
El iri http://www.semanticweb.org/ontologies/2010/11/membersStudentsJobBag.owl es el
identificador en el contexto de la Web de la ontología de individuos desarrollada y la misma se
encuentra almacenada en el archivo membersStudentsJobBag.owl. Anteponiendo el iri, se
obtiene el nombre completo de los individuos que componen la ontología. . La ontología será
referenciada de aquí en adelante como individuos o miembros de la bolsa de trabajo
indistintamente.
Como se mencionó anteriormente, los individuos fueron definidos en un archivo aparte. [Hebeler
et al.; 2009] sugieren que este tratamiento paralelo produce un razonamiento más eficiente el
cual resulta más apreciable en ontologías grandes. La ontología de individuos se apoya en la
ontología bolsa de trabajo para realizar la definición de los individuos. A continuación, se
muestra la ontología de miembros de la bolsa de trabajo.
Individuos en
http://www.semanticweb.org/ontologies/2010/11/membersStudentsJobBag.owl
Los individuos son mostrados a partir de su tipo definido. Así, el individuo c fue definido de
tipo Curriculum, el individuo jp de tipo JobPostulant, el individuo nt de tipo New_Student, el
individuo n de tipo Notice, el individuo ppas de tipo PostulationPassantJob y el individuo

75.00 Tesis
71
pprof de tipo PostulationProfessionalJob. Para definir el individuo gd se utilizó la aserción
“hasNotice notice_graduate”, que afirma que el individuo gd tiene una nota de graduado. Su
tipo permanece desconocido. De la misma manera, el individuo ug fue definido utilizando la
aserción “hasNotice notice_undergraduate”, que afirma que el individuo ug tiene una nota de
no graduado. Su tipo también permanece desconocido. Con estas definiciones y las
presentadas para Graduate y UnderGraduate, un razonador DL puede inferir los tipos para
gd y ug, respectivamente.
Es oportuno aclarar que los individuos de una clase también son llamados instancias de la
clase. De aquí en más se empleará el término instancia o individuo indistintamente.
ABox = {
c (Curriculum)
gd (hasNotice notice_graduate)
jp (JobPostulant )
nt (New_Student)
n (Notice)
ppas (PostulationPassantJob)
pprof (PostulantProfessionalJob)
r (Record)
ug (hasNotice notice_undergraduate)
}

75.00 Tesis
72
Por último se presentan las métricas de la ontología recogidas por Protégé.
Métricas para la ontología miembros de la bolsa de trabajo
(http://www.semanticweb.org/ontologies/2010/11/membersStudentsJobBag.owl)
Se puede observar que las métricas contabilizan los axiomas de las ontologías importadas (la
ontología bolsa de trabajo). Los indicadores reflejan los siguientes valores: 14 clases, 10
object-properties, 14 data properties, y 10 individuos. Para las clases tenemos 5 axiomas de
subclase, 5 axiomas de clases equivalentes, 5 axiomas de clases disjuntas. Para las object-
properties, 6 axiomas de subproperties, 4 axiomas de propiedades inversas, 7 axiomas de
propiedades funcionales, 1 axioma de dominio. Para las data-properties, 1 axioma de dominio
y 14 axiomas de rango. Y para los individuos, 8 axiomas de aserción de clase y 2 axiomas de
aserción de propiedad.
Las clases equivalentes mencionadas en las métricas corresponden a las clases definidas
Student, JobOffer, Graduate, UnderGraduate y PostulationJob, descriptas anteriormente. Los
axiomas utilizados en la definición de cada clase son considerados como una clase anónima y
por lo tanto, la métrica de clases equivalentes corresponde a la equivalencia entre las clases
definidas y las clases anónimas utilizadas en sus definiciones.

75.00 Tesis
73
Por último, se mostrarán las reglas DL-Safe Rules las cuales fueron definidas empleando
ontologías separadas.
rulesMatriculate: DL-Safe Rule del servicio Web semántico wsMatriculate en
http://www.semanticweb.org/ontologies/2010/11/rulesMatriculate.owl
El iri http://www.semanticweb.org/ontologies/2010/11/rulesMatriculate.owl es el
identificador, en el contexto de la Web, de la ontología reglas de matriculación (almacenada en el
archivo rulesMatriculate.owl), desarrollada para describir las operaciones del servicio Web
Matriculate (o también llamado wsMatriculate). La ontología de reglas se apoyo en las
ontologías anteriores, bolsa de trabajo y miembros de la bolsa de trabajo para la elaboración de la
misma.
La regla rulesMatriculate es empleada para anotar la operación proofRegister del servicio
wsMatriculate. Esta regla establece que si un individuo es un nuevo estudiante y presenta una
nota de inscripción entonces el nuevo estudiante es registrado con la nota de inscripción
presentada. Por lo tanto, la condición que debe cumplirse para que la operación pueda
ejecutarse satisfactoriamente es que previamente exista una instancia nt de la clase
New_Student y una instancia n de la clase Notice. El resultado de la acción realizada por la
operación proofRegister será la creación de la relación NoticeOf entre n, de la clase Notice con
la instancia nt de la clase New_Student.
En el panel derecho superior se puede observar el enunciado de la regla. A la izquierda se
encuentran las clases, propiedades e individuos importados de las ontologías bolsa de trabajo
y miembros de la bolsa de trabajo, respectivamente.
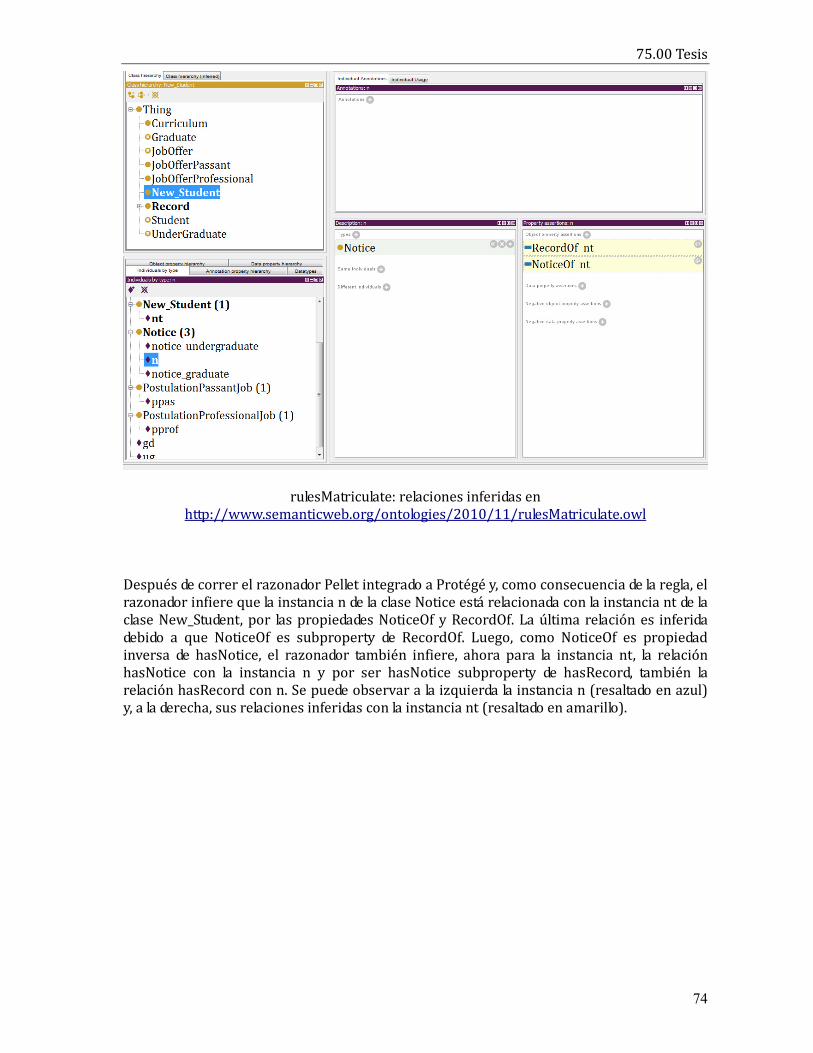
75.00 Tesis
74
rulesMatriculate: relaciones inferidas en
http://www.semanticweb.org/ontologies/2010/11/rulesMatriculate.owl
Después de correr el razonador Pellet integrado a Protégé y, como consecuencia de la regla, el
razonador infiere que la instancia n de la clase Notice está relacionada con la instancia nt de la
clase New_Student, por las propiedades NoticeOf y RecordOf. La última relación es inferida
debido a que NoticeOf es subproperty de RecordOf. Luego, como NoticeOf es propiedad
inversa de hasNotice, el razonador también infiere, ahora para la instancia nt, la relación
hasNotice con la instancia n y por ser hasNotice subproperty de hasRecord, también la
relación hasRecord con n. Se puede observar a la izquierda la instancia n (resaltado en azul)
y, a la derecha, sus relaciones inferidas con la instancia nt (resaltado en amarillo).
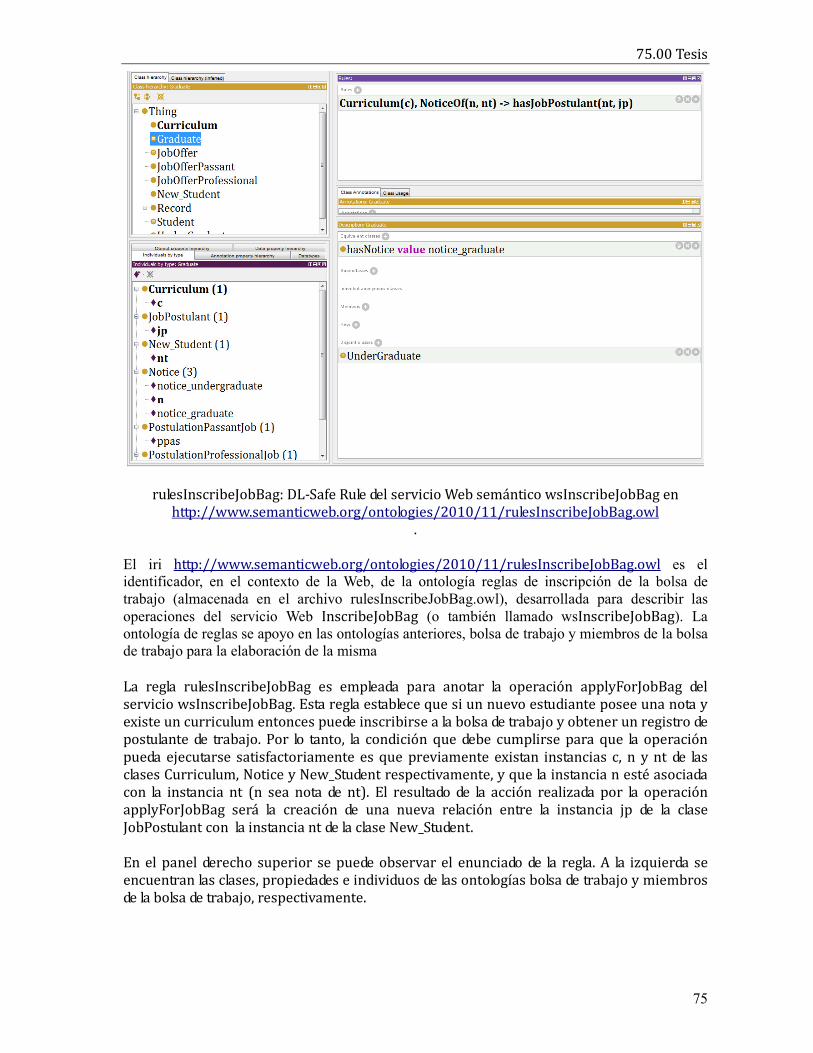
75.00 Tesis
75
rulesInscribeJobBag: DL-Safe Rule del servicio Web semántico wsInscribeJobBag en
http://www.semanticweb.org/ontologies/2010/11/rulesInscribeJobBag.owl
.
El iri http://www.semanticweb.org/ontologies/2010/11/rulesInscribeJobBag.owl es el
identificador, en el contexto de la Web, de la ontología reglas de inscripción de la bolsa de
trabajo (almacenada en el archivo rulesInscribeJobBag.owl), desarrollada para describir las
operaciones del servicio Web InscribeJobBag (o también llamado wsInscribeJobBag). La
ontología de reglas se apoyo en las ontologías anteriores, bolsa de trabajo y miembros de la bolsa
de trabajo para la elaboración de la misma
La regla rulesInscribeJobBag es empleada para anotar la operación applyForJobBag del
servicio wsInscribeJobBag. Esta regla establece que si un nuevo estudiante posee una nota y
existe un curriculum entonces puede inscribirse a la bolsa de trabajo y obtener un registro de
postulante de trabajo. Por lo tanto, la condición que debe cumplirse para que la operación
pueda ejecutarse satisfactoriamente es que previamente existan instancias c, n y nt de las
clases Curriculum, Notice y New_Student respectivamente, y que la instancia n esté asociada
con la instancia nt (n sea nota de nt). El resultado de la acción realizada por la operación
applyForJobBag será la creación de una nueva relación entre la instancia jp de la clase
JobPostulant con la instancia nt de la clase New_Student.
En el panel derecho superior se puede observar el enunciado de la regla. A la izquierda se
encuentran las clases, propiedades e individuos de las ontologías bolsa de trabajo y miembros
de la bolsa de trabajo, respectivamente.
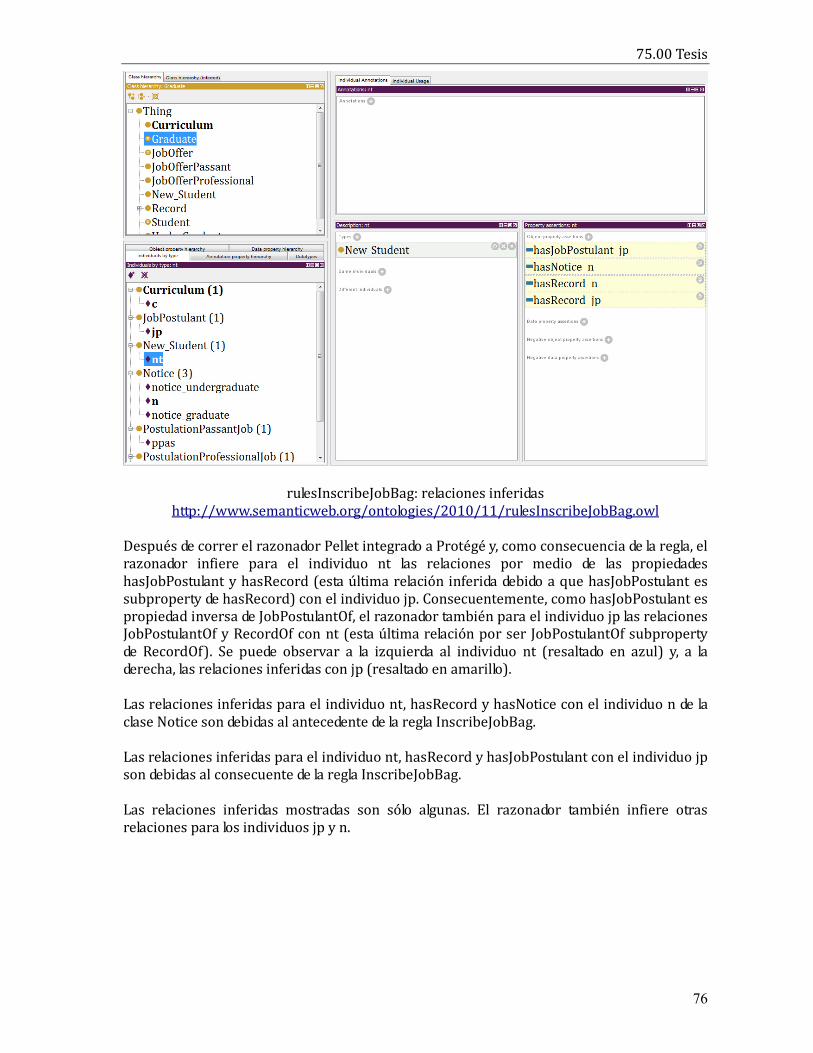
75.00 Tesis
76
rulesInscribeJobBag: relaciones inferidas
http://www.semanticweb.org/ontologies/2010/11/rulesInscribeJobBag.owl
Después de correr el razonador Pellet integrado a Protégé y, como consecuencia de la regla, el
razonador infiere para el individuo nt las relaciones por medio de las propiedades
hasJobPostulant y hasRecord (esta última relación inferida debido a que hasJobPostulant es
subproperty de hasRecord) con el individuo jp. Consecuentemente, como hasJobPostulant es
propiedad inversa de JobPostulantOf, el razonador también para el individuo jp las relaciones
JobPostulantOf y RecordOf con nt (esta última relación por ser JobPostulantOf subproperty
de RecordOf). Se puede observar a la izquierda al individuo nt (resaltado en azul) y, a la
derecha, las relaciones inferidas con jp (resaltado en amarillo).
Las relaciones inferidas para el individuo nt, hasRecord y hasNotice con el individuo n de la
clase Notice son debidas al antecedente de la regla InscribeJobBag.
Las relaciones inferidas para el individuo nt, hasRecord y hasJobPostulant con el individuo jp
son debidas al consecuente de la regla InscribeJobBag.
Las relaciones inferidas mostradas son sólo algunas. El razonador también infiere otras
relaciones para los individuos jp y n.
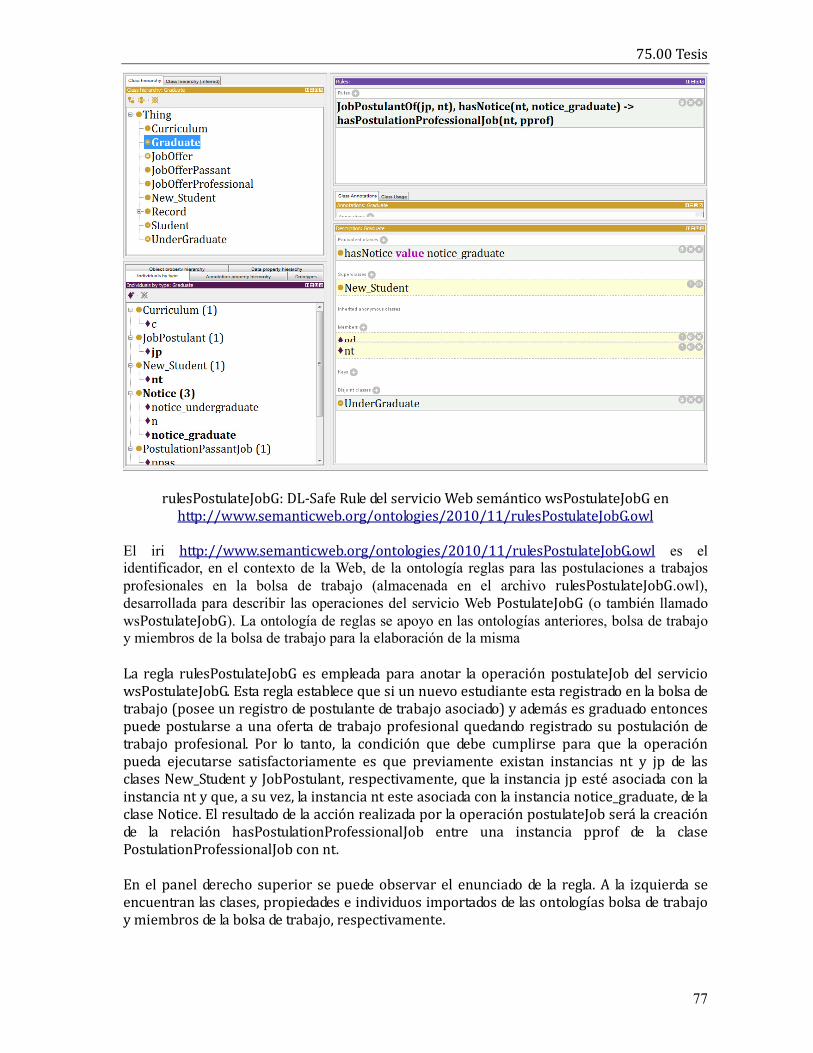
75.00 Tesis
77
rulesPostulateJobG: DL-Safe Rule del servicio Web semántico wsPostulateJobG en
http://www.semanticweb.org/ontologies/2010/11/rulesPostulateJobG.owl
El iri http://www.semanticweb.org/ontologies/2010/11/rulesPostulateJobG.owl es el
identificador, en el contexto de la Web, de la ontología reglas para las postulaciones a trabajos
profesionales en la bolsa de trabajo (almacenada en el archivo rulesPostulateJobG.owl),
desarrollada para describir las operaciones del servicio Web PostulateJobG (o también llamado
wsPostulateJobG). La ontología de reglas se apoyo en las ontologías anteriores, bolsa de trabajo
y miembros de la bolsa de trabajo para la elaboración de la misma
La regla rulesPostulateJobG es empleada para anotar la operación postulateJob del servicio
wsPostulateJobG. Esta regla establece que si un nuevo estudiante esta registrado en la bolsa de
trabajo (posee un registro de postulante de trabajo asociado) y además es graduado entonces
puede postularse a una oferta de trabajo profesional quedando registrado su postulación de
trabajo profesional. Por lo tanto, la condición que debe cumplirse para que la operación
pueda ejecutarse satisfactoriamente es que previamente existan instancias nt y jp de las
clases New_Student y JobPostulant, respectivamente, que la instancia jp esté asociada con la
instancia nt y que, a su vez, la instancia nt este asociada con la instancia notice_graduate, de la
clase Notice. El resultado de la acción realizada por la operación postulateJob será la creación
de la relación hasPostulationProfessionalJob entre una instancia pprof de la clase
PostulationProfessionalJob con nt.
En el panel derecho superior se puede observar el enunciado de la regla. A la izquierda se
encuentran las clases, propiedades e individuos importados de las ontologías bolsa de trabajo
y miembros de la bolsa de trabajo, respectivamente.

75.00 Tesis
78
rulesPostulateJobG: relaciones inferidas en
http://www.semanticweb.org/ontologies/2010/11/rulesPostulateJobG.owl
Después de correr el razonador Pellet integrado a Protégé y, como consecuencia de la regla, el
razonador infiere para el individuo nt las relaciones hasPostulationProfessionalJob y
hasRecord con el individuo pprof de la clase PostulationProfessionalJob (la última relación es
inferida debido a que hasPostulationProfessionalJob es subproperty de hasRecord). Se puede
observar a la izquierda al individuo nt (resaltado en azul) y, a la derecha, las relaciones
inferidas con pprof y con jp (resaltado en amarillo) y las relaciones afirmadas (resaltadas en
verde).
Las relaciones inferidas para el individuo nt, hasJobPostulant y hasRecord con el individuo jp
son debidas al antecedente de la regla rulesPostulateJobG.
La relaciones inferidas para el individuo nt, hasPostulationProfessionalJob y hasRecord con
el individuo pprof son debidas al consecuente de la regla rulesPostulateJobG.
Las relaciones inferidas mostradas son sólo algunas. El razonador también infiere relaciones
para el individuo jp y gd. Para el caso de pprof, como RecordOf es propiedad inversa de
hasRecord, el razonador infiere que el individuo pprof tiene una relación RecordOf con nt.

75.00 Tesis
79
rulesPostulateJobU: DL-Safe Rule del servicio Web semántico wsPostulateJobU en
http://www.semanticweb.org/ontologies/2010/11/rulesPostulateJobU.owl
El iri http://www.semanticweb.org/ontologies/2010/11/rulesPostulateJobU.owl es el
identificador, en el contexto de la Web, de la ontología reglas para las postulaciones a trabajos
profesionales de la bolsa de trabajo (almacenada en el archivo rulesPostulateJobG.owl),
desarrollada para describir las operaciones del servicio Web PostulateJobG (o también llamado
wsPostulateJobG). La ontología de reglas se apoyo en las ontologías anteriores, bolsa de trabajo
y miembros de la bolsa de trabajo para la elaboración de la misma
La regla rulesPostulateJobU es empleada para anotar la operación postulateJob del servicio
wsPostulateJobU. Esta regla establece que si un nuevo estudiante está registrado en la bolsa de
trabajo (posee un registro de postulante de trabajo asociado) y además es no graduado
entonces puede postularse a una oferta de pasantía quedando registrado la postulación de
pasantía efectuada. Por lo tanto, la condición que debe cumplirse para que la operación pueda
ejecutarse satisfactoriamente es que previamente existan instancias nt y jp de las clases
New_Student y JobPostulant, respectivamente, que la instancia jp esté asociada con la
instancia nt y que, a su vez, la instancia nt este asociada con la instancia
notice_undergraduate, de la clase Notice. El resultado de la acción realizada por la operación
postulateJob será la creación de la relación hasPostulationPassantJob entre una instancia
ppas de la clase PostulationPassantJob con nt.
En el panel derecho superior se puede observar el enunciado de la regla. A la izquierda se
encuentran las clases, propiedades e individuos de las ontologías bolsa de trabajo y miembros
de la bolsa de trabajo, respectivamente

75.00 Tesis
80
rulesPostulateJobU: relaciones inferidas en
http://www.semanticweb.org/ontologies/2010/11/rulesPostulateJobU.owl
Después de correr el razonador Pellet integrado a Protégé y, como consecuencia de la regla, el
razonador infiere para el individuo nt las relaciones hasPostulationPassantJob y hasRecord
con el individuo ppas de la clase PostulationPassantJob (la última relación es inferida debido a
que hasPostulationPassantJob es subproperty de hasRecord). Se puede observar a la
izquierda al individuo nt (resaltado en azul) y, a la derecha, las relaciones inferidas con ppas y
con jp (resaltado en amarillo) y las relaciones afirmadas (resaltadas en verde).
Las relaciones inferidas para el individuo nt, hasJobPostulant y hasRecord con el individuo jp
son debidas al antecedente de la regla rulesPostulateJobU.
La relaciones inferidas para el individuo nt, hasPostulationPassantJob y hasRecord con el
individuo ppas son debidas al consecuente de la regla rulesPostulateJobU.
Las relaciones inferidas mostradas son sólo algunas. El razonador también infiere relaciones
para el individuo jp y ug. Para el caso de ppas, como RecordOf es propiedad inversa de
hasRecord, el razonador infiere que el individuo ppas tiene una relación RecordOf con nt.

75.00 Tesis
81
Capítulo III
Agentes
3.1 Generalidades
3.1.1 Agente y entorno La IA es el campo de las ciencias computacionales que trata de mejorar el desempeño de las
computadoras al dotarlas de características asociadas con la inteligencia humana, como la
capacidad de entender el lenguaje natural o de razonar bajo condiciones de incertidumbre
para tomar mejores decisiones. Los agentes provienen de la IA (robótica, minería de datos,
manipulación inteligente de base de datos, etc.). [Mansilla Espinosa; 2008]
[Mansilla Espinosa; 2008] Diagrama de tipos de agentes
Según [Mancilla Espinosa; 2008], un agente es aquello que percibe su ambiente mediante
sensores y responde o actúa en él mediante efectores. Un tipo de agente particular son los
agentes de software, un programa de computación que se ejecuta en un ambiente y realiza
acciones dentro de éste para alcanzar las metas para las cuales fue diseñado y sus
percepciones y acciones están dadas por instrucciones de programas en algún lenguaje en
particular.
Qué es un agente es una cuestión abierta, exhibiendo el riesgo de que cualquier programa
sea denominado agente. Se pueden distinguir dos nociones extremas de agentes: una débil y
otra fuerte.
Autonomous Agents
Software Agents
Computational Agents Robotic Agents Biological Agents
Artificial Life Agents
Task-Specific Agents Entertaiment Agents Virus

75.00 Tesis
82
Una noción débil consiste en definir un agente como una entidad capaz de intercambiar
mensajes utilizando un lenguaje de comunicación de agentes. Esta definición es la más
utilizada dentro de la ingeniería de software con el fin de conseguir la interoperabilidad entre
aplicaciones a nivel semántico utilizando la tecnología emergente de agentes.
Una noción más fuerte surge de una propuesta de programación orientada a agentes (AOP).
Un agente es visto como una entidad dotada de componentes mentales como creencias,
capacidades, elecciones y acuerdos.
Los agentes inteligentes son considerados una pieza de software que ejecuta una tarea
determinada, utilizando información recolectada del ambiente, para actuar de manera
apropiada y completar la tarea de manera exitosa. El software debe ser capaz de auto
ajustarse basándose en los cambios que ocurren en su ambiente, de forma tal, que un cambio
en las circunstancias produzca el resultado esperado.
[Wooldridge; 1998] citó que un agente, situado en algún entorno, es un sistema de
computadora capaz de actuar de manera autónoma en ese entorno a fin de cumplir sus
objetivos.
En la mayoría de dominios de complejidad razonable, un agente no tiene control completo
sobre su entorno. En el mejor de los casos, tiene control parcial desde que puede influir en él.
Desde el punto de vista del agente, significa que la misma acción ejecutada dos veces bajo las
mismas circunstancias podría tener efectos diferentes y, en particular, podría fallar en
conseguir el efecto deseado. Los agentes deben estar preparados para la posibilidad de fallas.
Esta situación es formalmente resumida diciendo que los entornos son no deterministas.
Normalmente, el agente tendrá un repertorio de acciones y efectos asociados que
representarán la capacidad del agente para modificar su entorno. Un conjunto de
precondiciones asociadas a las acciones definen situaciones posibles de aplicación. El
problema clave que deben enfrentar los agentes es decidir cuál de esas acciones ejecutar para
satisfacer, de la mejor manera posible, sus objetivos. La toma de decisiones es un proceso
complejo afectado por propiedades del entorno: accesible o inaccesible, determinista o no
determinista, episódico o no episódico, estático o dinámico, discreto o continuo.
Un entorno accesible permite al agente obtener información completa, precisa y actualizada.
La mayoría de entornos medianamente complejos (el mundo físico, Internet) son
inaccesibles. Cuanto más accesible sea el entorno más fácil es construir agentes para operar
sobre él. En un entorno determinista cualquier acción tiene un efecto garantizado, no hay
incertidumbre sobre el estado que resultará de ejecutar una acción. El mundo físico es
considerado no determinista. En un entorno episódico, la performance de un agente es
dependiente de un número de episodios discretos sin vínculo entre la performance de un
agente en diferentes escenarios. Un ejemplo de un entorno episódico es un sistema de
ordenamiento de mails. Un entorno estático permanece sin cambios excepto por la
performance de las acciones realizadas por el agente. Un entorno dinámico tiene otros
procesos operando en él y los cambios están más allá del control del agente. Un entorno

75.00 Tesis
83
discreto tiene un número de acciones y percepciones fijas y finitas. Un ejemplo de entorno
discreto es el juego de ajedrez y de entorno dinámico la conducción de un taxi. Los entornos
más complejos son inaccesibles, no deterministas, no episódicos, dinámicos y continuos.
Como ejemplo de agentes se pueden mencionar los sistemas de control y los “daemons” de
software.
Un sistema de control simple es el termostato. El termostato tiene un sensor para detectar la
temperatura del lugar. El sensor es ubicado dentro del lugar y produce como salida una de dos
señales: una que indica que la temperatura está demasiado baja y otra que indica que la
temperatura está bien. Las acciones disponibles para el termostato son calentar y no calentar.
La acción calentar tendrá el efecto de calentar la temperatura del lugar pero este efecto no
puede ser garantizado (la puerta del lugar podría estar abierta). El componente de toma de
decisiones del termostato (extremadamente simple) implementa las siguientes reglas: si está
frío entonces encender calefactor, si la temperatura está bien entonces apagar el calefactor.
Sistemas de control más complejos tienen que considerar estructuras de decisión más ricas
(sondas espaciales autónomas, reactores nucleares).
Los daemons (como los procesos background en UNIX) son otro ejemplo de agentes, ellos
monitorean un entorno de software y ejecutan acciones para modificarlo. Mientras el agente
termostato estaba en un entorno físico, los daemons están en un entorno de software. Ellos
obtienen información del entorno por ejecutar funciones y acciones de software. El
componente de toma de decisiones es simple como el del termostato. Por lo tanto, los agentes
son simples sistemas de computadora capaces de acciones autónomas de manera de
encontrar sus objetivos de diseño. Un agente típicamente sensará su entorno (por sensores
físicos en el caso de agentes ubicados en el mundo físico o por sensores de software en el
caso de agentes de software) y tendrá disponible un repertorio de acciones para modificar su
entorno, las cuales pueden responder en forma no determinista.
Los agentes exhiben proactividad cuando la decisión de tomar la iniciativa contribuya a lograr
sus objetivos. En entornos que cambian y en particular cuando las condiciones de un
procedimiento cambian mientras se está ejecutando, su comportamiento podría quedar
indefinido (con frecuencia se romperá). En entornos dinámicos, ejecutar un procedimiento
sin considerar que las condiciones que lo sustentan sean válidas es una estrategia pobre. En
tales entornos el agente debe ser reactivo. Es decir, debe ser sensible a 1) los eventos que
ocurran en su entorno y que afecten sus objetivos o, 2) a las condiciones que sustentan sus
procedimientos en ejecución, a fin de alcanzar sus objetivos. La habilidad social permite a los
agentes interactuar con otros agentes como un medio más hacia la concreción de sus
objetivos.
En otros casos, un sistema multi-agente (MAS) presenta ventajas sobre agentes individuales
como fiabilidad, robustez, modularidad, escalabilidad, adaptabilidad, concurrencia,
paralelismo y dinamismo. Aparece entonces la necesidad de lenguajes de comunicación y de
mecanismos que permitan coordinar a un grupo de agentes. En particular, los agentes
pueden cooperar (si tienen los mismos objetivos) o competir (si existe conflicto de
objetivos) distinguiendo de esa manera sistemas que resuelven problemas distribuidos (por
cooperación entre agentes) de sistemas abiertos (agentes con diferentes objetivos). Los
mecanismos más habituales en agentes cooperativos son las estructuras organizacionales
(centralizadas y distribuidas), la planificación multi-agente, contratos y cooperación de

75.00 Tesis
84
funcionalidad mientras que en agentes competitivos lo habitual son mecanismos de
negociación (formación de coaliciones, mecanismos de mercado, teoría de negociación, voto,
subastas, asignación de tareas, etc.). Lenguajes de comunicación de agentes son el
“Knowledge Query and Manipulation Language”103 (KQML) y “Foundations for Intelligent
Physical Agents-Agents Communication Language104” (FIPA-ACL).
La programación orientada a agentes (AOP) emerge como un nuevo paradigma de
programación que, basado en un MAS, es apropiado para desarrollar sistemas que operan
en entornos complejos, dinámicos e impredecibles (como control de tráfico aéreo, cuidado de
la salud y sistemas de control industriales). El Agent-Oriented Software Engineering (AOSE)
permite crear metodologías y herramientas que facilitan el desarrollo y mantenimiento de
software basado en agentes. Las metodologías extienden las metodologías tradicionales de
software y son propuestas a fin de aclarar el proceso de desarrollo de un MAS (MAS-
CommonKADS105, ZEUS106, GAIA107, MaSE108, INGENIAS109).
Esfuerzos hacia la estandarización de la tecnología de agentes son llevados a cabo por
organizaciones como FIPA y OMG Agent PSIG. FIPA apunta a producir estándares para la
interoperación de agentes de software. Las especificaciones desarrolladas identifican roles
necesarios para la plataforma y la administración de agentes como el Agent Managment
System (AMS) y el Directory Facilitator (DF) los cuales actúan como white-pages y yellow-
pages110, respectivamente. Existen diferentes implementaciones de la plataforma de agentes
que adhieren al estándar FIPA como la Java Agent Development Enviroment (JADE) y ZEUS,
entre las más utilizadas.
Como trabajo futuro en el campo de la tecnología de agentes [Sanchez-García et al.; 2009]
queda la creación de herramientas, técnicas y metodologías que soporten el desarrollo de
sistemas de agentes, automatización de la especificación, desarrollo y administración de
sistemas de agentes, integración de componentes y características, definición del balance
apropiado entre predicción y adaptabilidad y la vinculación con otras ramas de la
computación y disciplinas como economía, sociología y biología. En su trabajo destacan que
tendencias emergentes sugieren que las tecnologías de agentes serán vitales en el corto y
103
Lenguaje de Consulta y Manipulación del Conocimiento. 104 Fundamentos para Agentes Físicos Inteligentes - Lenguaje de Comunicación de Agentes. 105
Para el análisis y desarrollo de sistemas intensivos de conocimiento, proporciona herramientas para la
administración de conocimiento corporativo, el desarrollo de sistemas de conocimiento para los procesos de
negocios seleccionados, entre otras. http://www.commonkads.uva.nl/ 106 Herramienta para construir sistemas multi-agentes colaborativos. Define un enfoque de diseño y soporta un
entorno visual para capturar las especificaciones de agentes que son utilizadas para generar el código Java de los
agentes. http://sourceforge.net/projects/zeusagent/ 107
Metodología para análisis y diseño de agentes. Aplicable a un amplio rango de sistemas multi-agentes, trata los
aspectos a nivel macro (social) y micro (agente) de los sistemas. Se basa en la visión de un sistema multi-agente
como una organización computacional, consistente de varios roles interactuando. 108
Metodología de propósito general para el desarrollo de sistemas multi-agentes que se basa en principios de la
ingeniería de software. Divide el proceso de desarrollo en dos fases: análisis y diseño. Para cada fase provee el
conjunto de etapas necesarias: objetivos, casos de uso y roles para el análisis y creación de clases, interacción,
despliegue de clases y diseño del sistema, para el diseño. 109
Metodología para el desarrollo de sistemas multi-agentes que integra resultados del área de la tecnología de
agentes con procesos de desarrollo de software como RUP (Rational Unified Process). La metodología se basa sobre
la definición de un conjunto de metamodelos que describen los elementos que forman un MAS y permite definir un
lenguaje de especificación para MAS. http://grasia.fdi.ucm.es/main/node/220 110
Desarrollado en la sección 1.4.2, “Directorio de Servicios”.

75.00 Tesis
85
mediano plazo como hoy son los servicios Web, grid computing, etc.
Es necesario mencionar que las tecnologías de agentes presentan deficiencias al utilizar
protocolos de comunicación como IIOP o RMI los cuales no pueden atravesar firewalls
empresariales. Una solución a este problema implicaría la creación de gateways entre pares
de empresas. No obstante, este enfoque presenta un problema adicional relacionado al
tratamiento de enlaces dinámicos, los cuales no podrían ser establecidos entre dos entidades
que no hayan sido preparadas para eso, limitando claramente el dinamismo.
3.1.2 Agentes y objetos Los programadores acostumbrados a trabajar con objetos, no suelen ver cuál es la idea con
agentes. Se hace necesario recordar a los objetos definidos como entidades computacionales
que encapsulan algún estado, que pueden ejecutar acciones o métodos sobre ese estado y
comunicarse entre ellos mediante el paso de mensajes.
Similitudes y diferencias existen entre objetos y agentes. La primera diferencia trata con el
nivel de autonomía que cada uno posee. Desde que una variable de instancia (o métodos)
puede ser declarada privada para ser accesible sólo desde dentro del objeto, un objeto puede
ser pensado como exhibiendo autonomía (control) sobre su estado pero no sobre su
comportamiento. Si un método m es declarado público, el objeto no puede controlar ejecutar
el método o no. Los agentes no son pensados como invocando métodos sino como solicitando
ejecutar acciones. El foco de control con respecto a la decisión de ejecutar una acción, en el
caso orientado a objetos, se encuentra en el objeto que invoca el método y en el caso de
agentes, en el agente que recibe el pedido. El siguiente slogan, en inglés, destaca esta
diferencia entre objetos y agentes: “Objects do it for free; agents do it for money”.
Otra diferencia importante tiene que ver con la noción de comportamiento autónomo y
flexible (reactivo, proactivo, social) de un sistema de agentes. El modelo estándar de objetos
nada menciona acerca de construir sistemas que integren este comportamiento. Se podría
objetar que es posible construir programas orientados a objetos que integren el
comportamiento pero sólo se perdería el punto, que es que tal comportamiento no hace a la
programación orientada a objetos.
La siguiente diferencia es que cada agente tiene su propio hilo de control (en el modelo de
objetos estándar hay un simple hilo de control en el sistema). A pesar de que existen varios
lenguajes que permiten concurrencia en programación orientada a objetos, no capturan la
idea de agentes como entidades autónomas (con reactividad, proactividad y habilidad social).
Tal vez, lo más cercano en la comunidad orientada a objetos se encuentre en la idea de
objetos activos. Un objeto activo es el que abarca su propio hilo de control. Los objetos
activos son generalmente autónomos lo que aquí significa que pueden exhibir algún
comportamiento sin que exista otro objeto que los opere por encima. Los objetos pasivos, en
cambio, sólo pueden someterse a un cambio de estado cuando explícitamente son operados
por encima. Por lo tanto, los objetos activos son esencialmente agentes los cuales no
necesariamente tienen la habilidad para exhibir comportamiento flexible autónomo.
La visión tradicional de un objeto y de un agente concluye con la lista a continuación:

75.00 Tesis
86
� Los agentes encarnan una noción más fuerte de autonomía que los objetos y en particular
deciden si ejecutar una acción a partir del pedido de otro agente o no.
� Los agentes son capaces de comportamiento flexible (reactivo, proactivo, social) y el
modelo estándar de objetos no dice nada al respecto.
� Un sistema multi-agente es inherentemente multi-hilo donde cada agente posee al menos
un hilo de control.
3.1.3 Agentes y sistemas expertos Los sistemas expertos constituyen una etapa de la Inteligencia Artificial. Un sistema experto
es capaz de resolver problemas o dar consejos en algún dominio de conocimiento. Un
ejemplo de un sistema experto es MYCIN, el cual asiste a los médicos en el tratamiento de
infecciones de la sangre en personas. Un usuario presenta al sistema un número de casos, los
cuales el sistema emplea a fin de derivar alguna conclusión. MYCIN actúa como consultor: no
opera directamente sobre humanos o sobre algún entorno. Entonces, la diferencia más
importante entre agentes y sistemas expertos es que los sistemas expertos son
inherentemente incorpóreos [Wooldridge, 1998]. Esto significa que los mismos no
interactúan directamente con el entorno, ellos no consiguen su información vía sensores
sino a través de un usuario actuando como intermediario. De la misma manera, ellos no
actúan sobre algún entorno sino más bien entregan una respuesta o aconsejan a terceros.
Además, a los sistemas expertos no se les requiere el ser capaces de cooperar con otros
sistemas expertos. A pesar de estas diferencias, algunos sistemas expertos (particularmente
los que ejecutan control de tareas en tiempo real) logran un gran parecido con agentes.
Comparación entre sistemas expertos y agentes.
3.1.4 Agentes y servicios A fin de despejar confusiones en torno de agentes y servicios se enuncian primero las
características desarrolladas hasta acá.
Los agentes poseen conocimiento de sí mismos, de su entorno y de mecanismos de
resolución de problemas, están fuertemente basados en enfoques teóricos; son un recurso
limitado y persistente; proveen a sus pares de servicios en cualquier momento y cuentan con
limitado soporte pragmático para la comunidad de usuarios (sistemas, software y
herramientas). Esto último es consecuencia de que la investigación de sistemas multi-agente
se enfocó en desarrollar principios y mecanismos formales para resolver problemas
distribuidos a nivel conocimiento, en términos de los objetivos que la comunidad multi-
agente debía abarcar y las tareas que podían solucionar.
Sistemas expertos Agentes
� Sistemas cerrados
� Sistemas de decisión centralizados
� Interacción con el usuario bajo petición del
usuario
� Interactúan con el entorno
� Distribución de la toma de decisiones:
comportamiento emergente
� Mayor grado de interacción con el usuario
� Interacción con otros agentes

75.00 Tesis
87
Los servicios, en cambio, son procesos transitorios y stateless111, que existen sólo durante la
ejecución del servicio. Son instanciados para ejecutar una tarea específica siendo posible la
provisión de servicios escalables y concurrentes. A diferencia de la tecnología de agentes, la
investigación de servicios se enfocó en la comunidad de usuarios, resultando en una
tecnología bottom-up pragmática que permitía la construcción de sistemas orientados a
servicios. Los puntos principales fueron el desarrollo de estándares para lograr interfaces
bien definidas y declarativas, workflows y protocolos y no en mecanismos que ayudan al
servicio a ejecutar la tarea. Se desarrollaron herramientas para construir y desarrollar
software distribuido a gran escala. El desarrollo de servicios Grid112 se debió al desarrollo
pragmático de tecnologías, estándares, políticas, ontologías compartidas y plataformas que
permiten la realización de entornos distribuidos.
[Huhns; 2002] Los servicios Web utilizan tres protocolos diferentes a fin de publicar, buscar
y conectarse. Los agentes, en cambio, utilizan un protocolo para todas sus interacciones, el
Agent-Communication Language (ACL)
Los servicios Web se basan en una tríada de funcionalidades, a saber, SOAP provee los
protocolos necesarios para la comunicación entre sistemas, WSDL describe los servicios en
una forma legible por computadora, especificando nombres de funciones, parámetros
requeridos y resultados, UDDI permite a los clientes (usuarios y negocios) una manera para
encontrar servicios por especificar un registro o un yellow-pages de servicios.
Sin embargo, diferenciar agentes y servicios es problemático porque alguien podría
argumentar que un agente puede ser implementado empleando tecnología de servicios Web o
que se puede incorporar mecanismos adaptativos e inteligentes en el diseño de servicios
111
Desarrollado en la sección 1.1.3 “Características Secundarias”. 112 Combinación de recursos computacionales desde múltiples dominios administrativos a fin de lograr un objetivo
común. Se distingue de sistemas de procesamiento convencionales y alto rendimiento por ser ofrecer mayor
desacoplamiento, heterogeneidad y dispersión geográfica. Son construidos con la ayuda de middlewares.
BIND
SOAP ACL
PUBLISH
WSDL ACL
FIND
UDDI ACL
Servicio broker
Agente broker
Proveedor de servicio
Sistema multi-agente
(servicio distribuido
cooperativo)
Usuario de servicio
Agente de usuario
Servicio
Agente

75.00 Tesis
88
Web. Los investigadores han propuesto muchas definiciones para agentes, no obstante,
siempre aparece un ejemplo que a pesar de satisfacer estrictamente la definición en espíritu,
no es un agente.
[Payne; 2008] distingue agentes y servicios Web al discutir las cinco características de
agentes propuestas por Jennings.
La primera característica es que los agentes son entidades que resuelven problemas con
interfaces y límites bien definidos. Los servicios Web existen como workflows claramente
articulados y con protocolos formalmente validados. Los tipos y estructuras de datos definidos
crean los mecanismos para dirigir mensajes y desarrollar herramientas a fin de utilizar
servicios Web. En la visión de agentes, una variedad de métodos de interacción pueden ser
utilizados. Esas interacciones ocurren a nivel conocimiento de mensajes en lenguajes
declarativos como KQML o FIPA. Existe énfasis en razonar los mensajes recibidos, obtener
conocimiento del entorno y de las motivaciones y capacidades de sus pares para determinar
dinámicamente como resolver un problema durante una ejecución. Un agente puede
descomponer un problema en partes y elegir delegar tareas o coordinar con otros agentes
como resolver el problema. Esta descomposición al no ser prescripta sino realizada
dinámicamente permite una mejor adaptación a entornos y contextos cambiantes.
La segunda característica es que los agentes son capaces de exhibir una comportamiento
flexible para la resolución de problemas a fin de cumplir sus objetivos de diseño (reactivo y
proactivo). Los agentes son inherentemente comunicativos y socialmente conscientes. Ellos
responden a cambios en su entorno y a mensajes de pares como resultado de tareas internas
planificadas. Estos disparadores pueden motivar la intención de lograr algún objetivo,
resultando en comportamiento proactivo cuando es necesario. Los servicios Web, en cambio,
son procesos transitorios cuya instanciación y existencia es disparada por un Web Server
que recibe un mensaje. Una ventaja de esta instanciación (factory-based113) por cada
invocación de servicio recibida es que los proveedores pueden ofrecer servicios
concurrentes en respuesta a pedidos simultáneos.
Aunque un servicio Web puede iniciar comunicación con otro servicio Web cuando ejecuta
su tarea, es todavía reactivo porque aún forma parte de las acciones preescritas que se
disparan luego del mensaje instanciador original. Aunque se construya un servicio para que
sea proactivo, esto al final introduciría nociones de agentes en el diseño de servicios Web.
La tercera característica es que los agentes son diseñados para cumplir roles específicos, con
objetivos particulares. Un servicio Web existe para ejecutar una tarea, como sería ofrecer
una funcionalidad e-business. Compañías como eBay y Amazon.com ofrecen acceso a sus
tecnologías por servicios Web, ya sea para facilitar el comercio con terceros o para ofrecer
acceso a sus recursos. El comportamiento de agente es motivado por nociones más
abstractas, mentales como knowledge, intention, belief y obligation. Típicamente un agente
es diseñado para maximizar alguna utilidad a través de comportamiento racional. Cuando se
ejecuta una tarea, un agente puede intentar determinar la utilidad ganada en ejecutar su
113 Patrón de diseño creacional en la que una clase implementa métodos para crear instancias de objetos (las
instancias pueden ser de la misma clase o de otras). Esta clase tiene entre sus responsabilidades la creación de
instancias de objetos pero puede tener también otras responsabilidades adicionales.

75.00 Tesis
89
acción sobre la base de una posible recompensa o ventaja percibida (considerando los costos
incurridos). Si un agente no percibe ventaja alguna, podría decidir no ejecutar la tarea,
mientras que, un servicio Web recibiendo el mismo pedido ejecutará la tarea.
La cuarta característica es que los agentes son ubicados en un entorno particular, el cual
observan y sobre el cual tienen control parcial; ellos reciben entradas relacionadas con el
estado de su entorno por medio de sensores y actúan sobre él por medio de sus efectores.
Esta característica es atribuida a agentes de hardware pero igualmente aplica a agentes de
software. Sin embargo, los sensores pueden proveer sólo conocimiento parcial de su
entorno. Además en entornos dinámicos con numerosos agentes, el conocimiento puede ser
pasado. Como los agentes tienen control parcial sobre su entorno necesitan evaluar su
contexto. Esto, con frecuencia, necesita de la colaboración entre pares para lograr los
cambios deseados más allá de su esfera de influencia. Los agentes que son conscientes de su
entorno también tienen conocimiento de nuevos agentes, los cuales podrían utilizar para
resolver problemas futuros. Sin embargo la habilidad para observar e interrogar pares puede
producir un modelo de entorno más sofisticado, el cual pone en duda si a los agentes puede
ser confiada lograr una tarea o gozar de reputación para engañar o incumplir contratos. Los
servicios son igualmente limitados con respecto al alcance de observar hechos y las acciones
que pueden ejecutar para manipular y afectar su entorno. Sin embargo porque los servicios
Web son típicamente reactivos, el conocimiento que ellos procesan es sólo el que el
desarrollador consideró necesario cuando los diseñó. Esto elimina la posibilidad de
aprovechar conocimiento oportunista.
La quinta característica es que los agentes son autónomos, ellos controlan su estado interno y
su comportamiento. Autonomía es una característica esencial de los agentes. Los agentes
son conscientes de sí mismos. Por adquirir y retener conocimiento en el tiempo, ellos
pueden aprender estrategias alternativas y soluciones a problemas para producir soluciones
más optimas. Un agente puede evolucionar en sus comportamientos sin dirección del
usuario o su propietario. Los servicios Web raramente son autónomos, salvo que la noción
de autonomía sea incluida en el diseño del servicio, lo cual involucraría construir servicios
stateful114 y persistentes. Ya algunos investigadores han empezado a explorar esas nociones
de autonomía y comportamiento autónomo para servicios Web, pero hasta ahora se han
utilizado nociones de agentes para lograr tal autonomía.
Agregar persistencia, autonomía e identidad a los servicios Web debilitaría la distinción entre
agentes y servicios.
Debido a 1) inconvenientes de las tecnologías de agentes, 2) la necesidad inherente de
entidades de software en entornos de SWS y 3) los beneficios anunciados por tener agentes y
servicios trabajando cooperativamente, numerosos proyectos desarrollaron frameworks
integrando ambas tecnologías[Sánchez-García et al.; 2009]. Sin embargo, surgen
discusiones sobre la formas de lograr esa integración. Los escenarios posibles son: 1) que los
servicios Web provean la funcionalidad de bajo nivel y los agentes la funcionalidad de alto
nivel por usar, combinar y coreografiar servicios Web, obteniendo funciones de valor
agregado, 2) que la comunicación en servicios Web y agentes sea equivalente (agentes como
wrappers de servicios) y 3) ambos tipos permanezcan separados creando un espacio de
114
Desarrollado en la sección 1.1.3 “Características secundarias”

75.00 Tesis
90
servicios heterogéneos e interoperando a través de gateways y procesos de traslación.
Tecnologías de agentes inteligentes y servicios Web semánticos permiten alcanzar logros
notables con, en algunos casos, superposición de funcionalidades [Sánchez-García et al.;
2009]. Sin embargo, independientemente de los beneficios de estas tecnologías, su
funcionalidad se ve limitada cuando son aplicadas por separado, lo que impide que sean
utilizadas a escala masiva en la sociedad, particularmente en la industria. A pesar de que
los paradigmas de agentes y servicios, a menudo, son considerados similares, y por lo tanto
compitiendo entre sí, diferentes investigaciones demostraron que una interacción
cooperativa puede conducir al desarrollo de mejores aplicaciones. Como ejemplo, los
mecanismos factory115 utilizados por los servidores Web para crear instancias de servicios
(alivian el problema de acceso concurrente por crear nuevas instancias de servicios sobre
demanda) en entornos de recursos limitados (poder de procesamiento bajo o equipamiento
físico pobre), en proveedores con excesiva demanda o con múltiples partes generando
workflows sin formar compromisos o contratos, conducen a fallas o demoras en la ejecución
de los servicios, por lo tanto la existencia de mecanismos autónomos para soportar la
cooperación o refinar la planificación o el aprovisionamiento de servicios durante su
ejecución es sólo posible a través de agentes.
El Agents and Web Services Interoperability Working Group116 (AWSI WG) trabaja en la idea
de construir un middleware117 para manejar las principales diferencias entre tecnología de
agentes y servicios Web, a saber, utilización de protocolos de comunicación (ACL vs. SOAP),
lenguajes de descripción de servicios (DF-AgentDescription vs. WSDL) y mecanismos de
integración de servicios (DF vs. UDDI). Si bien esto facilita la integración, sin cambiar las
especificaciones e implementaciones existentes de ambas tecnologías, hace que los servicios
Web y agentes permanezcan al mismo nivel de abstracción, Como afirman [Sánchez-García
et al.; 2009], la funcionalidad provista por agentes y servicios Web es complementaria. La
idea original de las tecnologías de agentes es actuar como entidades autónomas que
incorporan capacidades inteligentes y cognitivas, lo que les permite mostrar un
comportamiento proactivo orientado a objetivos y establecer procesos de interacción,
cooperativos o competitivos, con otros agentes a fin de conseguir sus objetivos. Por otro lado,
los servicios Web involucran una evolución en cómputo distribuido y su propósito es
proveer funcionalidad accesible a todo el mundo. Estas diferencias conceptuales entre
tecnología de agentes y SWS llevan a la necesidad de tener ambas tecnologías trabajando en
entornos integrados y apreciar las ventajas de su combinación en el desarrollo de sistemas
complejos.
3.2 Clasificación Un sinfín de definiciones enuncian características de los agentes y contribuyen a que
pertenezcan a una clasificación o no. Las características más importantes de los agentes
inteligentes son:
115.Patrones creacionales como el Factory method, Abstract factory, Builder, entre otros. 116 Grupo de Trabajo para la Interoperabilidad de Servicios Web y Agentes. 117
Desarrollado en la sección 1.3.1 “Modelo orientado a mensajes – MOM”

75.00 Tesis
91
� Autonomía: un agente opera sin intervención directa humana, además tiene control
sobre sus acciones y su estado interno.
� Habilidad social: capacidad para interactuar con otros agentes inteligentes o el
usuario.
� Reactividad: perciben el entorno y responden en un tiempo razonable a los cambios
que ocurren en él.
� Proactividad: los agentes pueden reaccionar por iniciativa propia sin necesidad de
que el usuario tenga que activarlo.
� Orientación hacia el objeto final: divide una tarea compleja en varias actividades más
pequeñas a fin de lograr la meta compleja asociada.
� Racionalidad: el agente siempre actúa para lograr sus metas y nunca de forma de
evitar la consecución de las mismas.
� Adaptabilidad: el agente debe ser capaz de ajustarse a los hábitos, formas de trabajo y
necesidades del usuario.
� Colaboración: el agente debe ser capaz de determinar información importante ya que
el usuario puede proporcionar información ambigua.
Los agentes inteligentes son racionales, utilizan razonamiento basado en conocimiento.
Suelen considerar una base de conocimiento, que incorpora una serie de hechos y reglas, de
los cuales se vale un motor de inferencias.
Un agente racional ideal tiene un elemento al que hay que prestarle atención y es la “Parte de
Conocimiento Integrado”. Si las acciones que emprende el agente se basan exclusivamente
en un conocimiento integrado, haciendo caso omiso de sus percepciones, se dice que el
agente es autónomo. El auténtico agente inteligente autónomo debe ser capaz de funcionar
satisfactoriamente en una amplia gama de ambientes, considerando que se le da tiempo
suficiente para adaptarse.
[Mansilla Espinosa; 2008] Tipología de agentes
Una vez que se han revisado las características de los agentes, es posible encontrar una
Agent
Tipology
Interface
Agents
Colaborative
Agents
Information
Agents
Hybrid
Agents
Smart
Agents
Heteroeneous
Agents
Mobile
Agents
Reactive
Agents

75.00 Tesis
92
tipología; sin embargo, una reclasificación ha sido propuesta por [Mansilla Espinosa; 2008]
Su clasificación general de agentes inteligentes se basa en la relación existente entre
percepciones y acciones, aplicación a la que sirven y características especiales.
3.2.1 Clasificación dependiendo de la relación entre percepciones y acciones
� Agentes de reflejo simple: actúan encontrando una regla cuya condición coincida con
la situación actual (definida por la percepción) y efectuando la acción que corresponda
a tal regla.
� Agentes bien informados de todo lo que pasa: actualizan constantemente la
información que les permite discernir entre estados del mundo y su evolución,
además de necesitar conocer como las acciones del propio agente estarán afectando al
mundo, así se mantiene informado acerca de esas partes no visibles de él.
� Agentes basados en metas: deben ser flexibles con respecto a dirigirse a diferentes
destinos, ya que al marcar un nuevo destino, se crea en el agente una nueva conducta.
� Agentes basados en utilidad: la utilidad es una función que correlaciona un estado y
un número real mediante el cual se caracteriza el correspondiente grado de
satisfacción.
3.2.2 Clasificación de acuerdo al tipo de aplicación
� Agente de interfaz de usuario: funciona como un asistente personal, sus
características principales son la autonomía y aprendizaje. Enseña al usuario a
utilizar una aplicación en particular, poseen una base de conocimiento donde
almacena el conocimiento adquirido por el usuario o por otros agentes.
� Agentes de búsqueda: no se limitan a emplear técnicas de búsqueda, sino que además
tienen que interpretar patrones de búsqueda. Deben ser capaces de crear
información útil para el usuario a partir de pedazos de información.
� Agentes de monitoreo: avisan a los agentes de interfaz sobre algún cambio en el
contenido de alguna página Web.
� Agentes de filtrado: trabaja en base al perfil definido por el usuario. Interactúan con
los agentes de monitoreo a fin de mantener información actualizada de la Web y de los
intereses del usuario.
3.2.3 Clasificación de acuerdo a características especiales
� Agentes deliberantes o proactivos: son agentes que poseen mucho conocimiento del
entorno en el que se encuentran y son capaces de crear nuevos planes y adelantarse a
lo que va a ocurrir en su entorno. En esta clasificación se encuentra el modelo BDI118
118
Se trata de un modelo de agentes. Beliefs representa el estado del mundo (computacionalmente puede ser el valor
de una variable o una base de datos relacional), Desires (objetivos) es otro componente esencial del estado del
mundo, representa el estado final deseado (computacionalmente puede ser el valor de una variable o una estructura
de registro), Intentions representan los planes o procedimientos (computacionalmente a un conjunto de hilos
ejecutándose en un proceso a fin de lograr sus objetivos (desires). Beliefs, Desires, Intentions son los componentes
básicos de un sistema de agentes diseñado para un mundo dinámico. Los agentes de un sistema que siga el modelo

75.00 Tesis
93
(Beliefs, Desires, Intentions) y BVG119 (Beliefs, Values, Goals).
� Agentes reactivos: son sistemas estímulo-respuesta que actúan a partir de la
observación directa y continua del entorno. Se adaptan perfectamente a los entornos
dinámicos ya que no tienen que actualizar ninguna representación interna del
entorno como los agentes BDI.
� Agentes estacionarios: son un tipo de agente que no posee la capacidad de
desplazarse y salir del entorno.
� Agentes móviles: son agentes que tienen la capacidad de desplazarse a través de una
red; de esta forma cambian el entorno en el que se ejecutan. Esto reduce el consumo
de recursos en la máquina en la que se encontraba inicialmente el agente.
3.3 Matchmaking entre agentes heterogéneos En un entorno abierto como Internet, donde fuentes de información, enlaces de
comunicación y agentes pueden aparecer y desaparecer, los agentes intermediarios ayudan a
localizar soluciones alternativas. Existen dos tipos de agentes intermediarios, a saber,
matchmakers120 (también conocidos como yellow-pages services) y brokers. [Sycara et al.,
1998].
Para que un agente proveedor pueda prestar sus capacidades a otros (servicio de búsqueda,
comercio electrónico) debe primero registrarse con el matchmaker. Para eso, publica sus
capacidades enviando un mensaje en el que describe el tipo de servicio que ofrece. Otro
agente envía al matchmaker un pedido solicitando información y servicios.
Cada pedido que el matchmaker recibe es comparado con su colección actual de
publicaciones. Si existen coincidencias, el matchmaker retorna un conjunto ordenado con los
proveedores apropiados.
Un agente broker trata de contactar a los proveedores relevantes, transmitiendo el pedido al
proveedor y comunicando los resultados al solicitante.
Un matchmaker devuelve una lista de servicios y a continuación deja que interactúen los
agentes usuario y proveedor. En cambio, un broker interviene de principio a fin en esa
interacción. Un agente matchmaker reduce cuellos de botella a expensas de producir un
mayor número de interacciones entre agentes. Por el contrario, un agente broker reduce el
número de interacciones a expensas de producir un cuello de botella entre agentes.
BDI deben tener objetivos explícitos (desires) para alcanzar o manejar eventos, un conjunto de planes (intentions)
para describir como lograr esos objetivos y un conjunto de datos (beliefs) que describan el estado del mundo. 119
Se trata de un modelo de agentes basado en creencias, valores y objetivos (belief, values y goals). En este modelo
los Values (valores) son utilizados como mecanismos de decisión por el agente, los cuales no son rígidos y pueden
cambiar durante la interacción. Las Beliefs (creencias) representan lo que el agente cree saber, los Goals (objetivos)
lo que el agente quiere y los Values (valores) sus preferencias. 120 Agente intermediario que se ocupa de encontrar el proveedor apropiado.

75.00 Tesis
94
3.4 Información semántica que registran
El proceso de descubrimiento de servicios es posible si existe un lenguaje común que
describa los servicios, de manera, que otros agentes comprendan las funciones ofrecidas y
como utilizarlas. Las descripciones de servicios y agentes pueden ser depositadas en
directorios similares a las páginas amarillas.
Una forma de lograr una comprensión compartida entre agentes sería intercambiar las
ontologías necesarias para una comunicación y utilizar nuevas capacidades de
razonamiento. De esta manera se lograría una flexibilidad superior a la provista por
estandarización. [Berners-Lee et al.; 2001]
Los agentes muestran un comportamiento dual: por un lado son programas dirigidos por
objetivos que, de manera autónoma y proactiva, resuelven problemas de usuario y por otro,
poseen una dimensión social cuando interactúan como parte de un sistema multi-agente.
A fin de resolver problemas de manera autónoma, surge la necesidad de desarrollar un
modelo de su entorno, que les permita razonar acerca de cómo las acciones que ejecutan
afectan su entorno y cómo los cambios que producen conducen a sus objetivos.
Las ontologías proporcionan el framework conceptual que les permite construir esos
modelos: ellas describen el tipo de entidades que pueden encontrar, sus propiedades y que
relaciones existen entre ellas.
En su dimensión social, los agentes en un MAS, interactúan unos con otros, pueden competir
por recursos o colaborar hacia la consecución de objetivos. Mientras algunas interacciones
son accidentales (un agente esperando para acceder a un recurso que otro agente mantiene
ocupado), la herramienta principal que tienen para interactuar es la comunicación.
Mediante ella pueden intercambiar información y pedidos de servicio. Cuando se combina
comunicación con un problema a resolver, la solución involucra otros agentes. Las ontologías
prestan la representación básica que permite a los agentes razonar acerca de sus
interacciones y comunicarse y trabajar por compartir ese conocimiento.
Diferentes enfoques de ontología reflejan ese comportamiento dual, a saber, ontologías
privadas y ontologías públicas.
El propósito de las ontologías privadas es dar al agente un contexto del problema a resolver.
Con frecuencia, resulta difícil distinguir entre ontologías como conceptualización del dominio
del agente y ontologías como representación del conocimiento requerido por su proceso de
resolución de problemas.
Por otro lado, el propósito de las ontologías públicas es soportar interacción de agentes,
especialmente comunicación e intercambio de información. Las ontologías públicas prestan
una descripción de un dominio MAS, compartido por todos los agentes, y un vocabulario
compartido, de manera que los agentes pueden comprender el contenido de los mensajes que

75.00 Tesis
95
intercambian. Las ontologías públicas deben respetar la heterogeneidad de agentes en un
MAS y, por lo tanto, ser independientes del proceso de resolución de problemas de cada
agente.
Una parte crucial del dominio de un agente es el MAS al cual pertenece. Otros agentes en el
MAS afectan lo que el agente hace y cómo lo hace. Consecuentemente, las ontologías deben
soportar descripción de agentes en términos de capacidades, información básica de contacto,
protocolo de interacción, confiabilidad, reputación, seguridad, entre otras. La dimensión
social de un MAS emerge de la necesidad de los agentes de una infraestructura y de servicios
(como registros de ubicación y protocolos estándares) para interactuar. Por lo tanto, las
ontologías deben, también, soportar descripción de una infraestructura MAS, tipo de registros
empleados, tipo de protocolos, entre otros.
Dado que los agentes inteligentes han sido desarrollados sobre diferentes mecanismos de
resolución de problemas provistos por la AI121, encontrar un denominador común entre
ontologías privadas es, virtualmente, imposible.
Por la comunicación, el trabajo de un agente puede contribuir al trabajo de otro y
proporcionar mecanismos de coordinación (los agentes negocian cómo compartir recursos
o como colaborar hacia la solución de un problema). La interacción y colaboración de agentes
resulta en la aparición de una sociedad de agentes, con una estructura social propia. Los
agentes necesitan ser dotados de conocimiento social, que especifique qué agentes trabajan
juntos y normas de comportamiento social aceptable. Las normas actúan como una
herramienta para representar, de manera explícita, lo que un agente espera en una situación
particular; la utilidad de las normas es hacer a los agentes y los MAS predecibles. Es a través
de normas, que los agentes pueden desarrollar predicciones sobre el comportamiento de sus
pares, lo que a su vez permite mayores niveles de cooperación. A nivel conocimiento, las
normas especifican restricciones sobre el comportamiento del agente dentro de lo aceptable
por el resto de agentes. Mientras, en principio, las normas pueden ser empleadas para
expresar cualquier restricción social, ellas encuentran su inmediata aplicación en la
definición de conceptos como contratos y demás compromisos, que los agentes desarrollan a
fin de trabajar juntos.
Así, las normas, en este caso sociales, suministran una fuente de ontologías para la
especificación del comportamiento social en una comunidad de agentes. Sin embargo, a
pesar de su importancia, aún no se ha desarrollado una representación ontológica para estas
normas.
Otras fuentes de ontología son la representación de leyes en razonamiento legal. Las tareas
principales en una ontología de este tipo son la recuperación de información mediante
indización de leyes y verificación de regulaciones. Una ontología legal provee una noción
diferente de norma, básicamente, la descripción de una ley y los actos a los cuales esas leyes
aplican. Una segunda fuente de ontología viene de la comunidad e-commerce y sus
necesidades para expresar conceptos como contratos que regulen transacciones electrónicas.
121
Artificial Intelligence

75.00 Tesis
96
El proceso de descubrimiento de agentes tiene cuatro características distintivas:
� representación del agente en el sistema,
� proceso que identifica similitudes entre un pedido y una publicación de agente (servicio
ofrecido) en el MAS,
� componentes de infraestructura (como registros y protocolos) y,
� resolución de problemas.
Los esquemas de descubrimiento propuestos en la literatura se distinguen por la manera en
que dirigen estos cuatro aspectos, conduciendo a varios niveles de flexibilidad en la
reconfiguración dinámica y regímenes de coordinación de agentes en el MAS.
Las ontologías son un ingrediente esencial para descubrimiento de agentes. Proporcionan
los medios para representar diferentes aspectos de los agentes y los mecanismos básicos
para relacionar pedidos y publicaciones. Desde que los agentes modifican sus entornos, sus
descripciones necesariamente refieren a la descripción ontológica de su entorno.
Los agentes pueden estar representados con diferentes niveles de abstracción. A nivel físico,
son caracterizados por puertos y protocolos de red (de manera similar a la representación
provista por las especificaciones WSDL y UDDI para servicios Web). A nivel abstracto, los
agentes interactúan por medio de un lenguaje de comunicación, empleando un conjunto de
ontologías para codificar e interpretar mensajes.
Desde otro punto de vista, los agentes son caracterizados por sus capacidades, sus protocolos
de interacción, procedimientos de resolución de problemas, la entidad legal responsable de su
correcto funcionamiento, entre otras. La representación de las capacidades es crucial para
descubrimiento de agentes (inteligentes y autónomos). En algunos sistemas, los agentes son
conscientes de las necesidades del problema a resolver que emergen durante su
razonamiento pero no conocen otros agentes que puedan satisfacer sus necesidades. La
tarea de un agente es abstraer del problema específico las capacidades que espera de un
proveedor.
Un número de esquemas de representación de capacidades han sido propuestos por la
comunidad de agentes y, más recientemente, por las comunidades de servicios Web y la Web
Semántica. Se distinguen entre dos tipos de esquemas de representación: el primero supone
que las ontologías proveen una representación explícita de las tareas ejecutadas por los
agentes. En esas ontologías cada tarea es descripta por un concepto diferente, mientras que
los agentes son descriptos por enumerar las tareas que ejecutan. El segundo esquema de
representación describe agentes por la transformación de estados que producen, no hay
mención de la tarea ejecutada por el agente sino que la tarea es implícitamente representada
por información de estado de las entradas del agente a las salidas que produce. Los dos
enfoques de representación brindan dos maneras de utilizar ontologías.
Los esquemas de representación explícita permiten, dadas las capacidades deseadas del
agente, localización simple. Pero requieren que las ontologías asignen un concepto a cada
tarea ejecutada por el agente. Dado que los agentes pueden ejecutar varias tareas, estas
ontologías pueden crecer, volviéndose inmanejables, y no escalar al ingresar agentes con

75.00 Tesis
97
nuevas capacidades. Otro inconveniente de este tipo de esquema es que no representan que
información el agente proveedor y el agente solicitante necesitan para interactuar. Estas
ontologías son difíciles de construir.
Los esquemas de representación implícita requieren sólo de conceptos que describan la tarea
procesada por el agente y que el agente solicitante provea información (en términos de
entradas y salidas) para interactuar con un agente proveedor. No necesita una codificación
explícita de tareas en la ontología sino que proporcionan una expresión natural de tareas al
utilizar los dominios de las ontologías disponibles.
La ventaja de un esquema de representación explícita es que facilita la asociación de
solicitudes y publicaciones y no busca una relación de subsunción entre solicitud y
publicación. En cambio, la asociación por capacidades expresadas implícitamente es más
compleja. El hecho de que no exista una manera sencilla para clasificar las tareas, hace que la
asociación requiera una cuidadosa comparación entre la transformación de entradas y salidas
descripta en la solicitud con las transformaciones de entradas y salidas descriptas en las
publicaciones.
Otro enfoque para representación de capacidades utiliza una combinación de ambas
representaciones, explícita e implícita. Este enfoque combina la facilidad de uso provista por
el primero con la habilidad para describir la capacidad de una agente, provista por el
segundo. El ejemplo más notable de este enfoque es DAML-S.
3.5 Aplicaciones de ontologías en agentes En la Web Semántica, las anotaciones semánticas que describen la información posibilitan a
agentes procesarla automáticamente, presentándose nuevas oportunidades para usuarios y
desarrolladores.
Las tecnologías de SWS dependen de entidades de software de nivel superior con capacidades
cognitivas que puedan acceder al contenido semántico de sus descripciones, que puedan
procesarlas y comprenderlas a fin de hacer un uso apropiado de las funcionalidades provistas.
El marco semántico el cual describe las capacidades de los servicios Web semánticos (OWL-S,
WSMO, etc.) hace que los agentes puedan comprender, procesar y utilizar las capacidades
publicadas que representen un paso hacia el logro de sus objetivos. De esta manera,
mediante la combinación de agentes y servicios Web semánticos se automatiza la tarea de
descubrir, seleccionar, componer, ejecutar y monitorear servicios Web y la adaptación a
cambios en el entorno pasa a ser dinámica.
[Yong-Feng y Jason JEN-Yen; 2007] presentaron una descripción de interacción de agentes
en un marco de comunicación delimitado por el lenguaje de ontologías Web (OWL) y la
“Foundation of Intelligent and Physical Agents (FIPA)”. Estos autores sostuvieron que los
servicios Web se convirtieron en recursos extremadamente populares dejando atrás la
publicación de páginas Web. En la era Web, los servicios suelen ser representados por HTML

75.00 Tesis
98
y transferidos por HTTP mientras que las tecnologías de servicios Web, como WSDL y SOAP
agregan interoperabilidad a la Web. Su trabajo se centró en la invocación dinámica de
servicios por describir una interacción de agentes. Plantearon un escenario donde un
usuario solicitaba a su agente la ejecución de un servicio (Video Broadcast Service). El
agente buscaba el servicio en un registro OWL/UDDI y como no podía ejecutarlo puesto que
el servicio requería un ancho de banda superior a 2 Mbps solicitaba a otro agente su
ejecución quién, al cumplir con el requerimiento de ancho de banda, entregaba el servicio al
usuario. En general, la capa de interacción de agentes consiste de un protocolo preacordado
para el intercambio de mensajes, siendo frecuentemente empleados COOL (COOrdination
Language, basado en KIF/LQML) y IOM/T (Interaction-Oriented Model by Textual
representation). COOL es un framework para conversación de agentes que provee reglas
conversacionales y reglas de recuperación de errores. IOM/T sigue la notación de AUML
(Agent-based Unified Modeling Language) para definir la interacción. Como el anidamiento
de interacciones en IOM/T era complejo de procesar, definieron una máquina de estados
finita junto con una ontología OWL para la interacción de agentes en combinación con FIPA.
[Paolucci et al.; 2003] propusieron una solución DAML-S y analizaron los problemas
relacionados con los servicios Web autónomos. Sus resultados fueron que los servicios Web
podían ser desplegados a fin de proporcionar información e interactuar dinámicamente y
que una transacción podía ser llevada a cabo automáticamente sin intervención del
programador. Sostuvieron que tratar con ontologías (en su trabajo utilizaron DAML) era
fundamental porque permitía en servicios Web inferir sobre los statements de una
descripción DAML-S.
Construyeron una arquitectura de servicios Web DAML-S con dos partes principales: el
servicio proveedor y el DAML-S Port, que administraba la interacción con otros servicios.
Realizar una composición de servicios o, analizar y elegir de las opciones provistas por el
workflow (descripto en el Process Model) aquellas que estuvieran en línea con sus objetivos,
requería del servicio tomar decisiones no deterministas. Por tal motivo dotaron al servicio
con el planificador RESINA (basado sobre el paradigma de planificación HTN).
El DAML-S Port consistía de tres módulos: el DAML Parser (permitía cargar ontologías DAML
desde la Web); el DAML-S VM (definía conocimiento a partir de reglas que implementaban la
semántica axiomática DAML) y el Web service Invocation. La DAML-S VM era el corazón de
la arquitectura. Su tarea principal era comprender el Process Model del proveedor y para ello
había sido dotada de dos componentes: 1) un Process Model Rules semántico, que contenía
normas para la ubicación del próximo proceso a ejecutar, la extracción de entradas y salidas
de cada proceso y la administración de decisiones no deterministas, y 2) el Grounding Rules,
que especificaba la correspondencia de los procesos atómicos del Process Model con
operaciones WSDL y la relación de entradas y salidas de los procesos atómicos con las del
Process Model.
Sus pruebas se basaron en dos aplicaciones. Una aplicación B2B en la que un agente de
interfaz permitía a un operador interactuar con un agente planificador que se ocupaba de
comparar los costos de diferentes proveedores de hardware. El agente planificador
consultaba dos matchmakers, uno de hardware y otro de finanzas (análisis de solvencia) a fin
de obtener y organizar una cadena de proveedores de acuerdo con los límites

75.00 Tesis
99
presupuestarios y fechas indicadas. Finalmente, el agente planificador contactaba a los
proveedores para negociar plan de pagos y costos. La otra aplicación fue del tipo B2C, donde
un agente permitía a un usuario planificar un viaje a una conferencia (suponían que los
organizadores habían publicado un servicio con información de la conferencia como fechas,
lugares, expositores y otros). El agente verificaba la disponibilidad y utilizaba un
matchmaker para encontrar aerolíneas, alquilar coches y hoteles. Finalmente retornaba el
viaje programado. Dejaron como cuestión abierta proceder con un modelo computacional
más simple dado que los requerimientos computacionales de un planificador fueron
sumamente considerables.
3.6 Definición de las funcionalidades relacionadas con las capacidades esperadas de los agentes basados en razonadores. Como se mencionó en la sección 2.6 el desarrollo y aplicación de ontologías depende de
razonamiento. Por incluir ontologías en los procedimientos que implementan los agentes,
indirectamente se incluye algún razonador dado que las ontologías sólo describen de forma
explícita algún vocabulario de dominio y los razonadores obtienen el vocabulario implícito
oculto en las mismas. Los razonadores otorgan a los agentes de un mayor caudal de
información a fin de mejorar los resultados de los objetivos que persiguen. A continuación se
mencionan algunos de los cambios que introducirían en el agente los razonadores:
Realizar inferencias como hacen los humanos y justificarlas. Un agente que tenga
programada la regla “las compras de más de 300 € tienen un descuento del 10%” podrá
justificar lógicamente porque permite descuentos a unos clientes y a otros no.
Realizar búsquedas consultando la Web Semántica por medio de lenguajes que reconozcan
RDF como la sintaxis principal. Con esta base, consultando lenguajes basados en RDF tal
como OWL desde una perspectiva RDF pura no requiere procedimientos especiales o
características de lenguaje siendo, de esta manera, posible aprovechar los servicios ofrecidos
(sección 2.6) por un razonador en la resolución de consultas.
Buscar servicios Web y utilizarlos automáticamente sin intervención humana por acceder a
las ontologías que acompañen a los servicios Web y comprender e integrar esas ontologías.
Buscar productos, negociar compras, acuerdos de nivel de servicio, calidad de datos, cantidad
de datos, localizar servicios de interés para los usuarios. Por el uso de ontologías en las
empresas, los agentes podrán combinarlas con sus algoritmos de negociación y hacer
negocios electrónicos con otras empresas, de manera automática.
3.7 Razonadores alternativos que puedan ser incorporados en el agente
Se han estudiado los siguientes razonadores alternativos: HermiT, Pellet, FaCT++.
A continuación, se describen sus principales características.
HermiT es uno de los actuales proyectos de investigación del Laboratorio de Computación de
la Universidad de Oxford. Aunque puede ser empleado con cualquier ontología, los
investigadores toman como punto de partida los requerimientos de ontologías médicas a fin
de construir un razonador potente. Las ontologías médicas, sostienen, están fuertemente
relacionadas con las lógicas descriptivas, las cuales constituyen una base formal para muchos

75.00 Tesis
100
lenguajes de ontologías como OWL. Las ontologías médicas poseen significantes desafíos
para la teoría y la práctica de lenguajes basados en DL. Los razonadores existentes pueden
eficientemente tratar con ontologías enormes (como NCI) pero existen otras ontologías
importantes que están fuera del alcance de las herramientas disponibles (ninguno de los
razonadores existentes puede clasificar correctamente GALEN o FMA). El objetivo del
proyecto HermiT es, por lo tanto, desarrollar algoritmos de razonamiento escalables e
implementar un prototipo que pueda eficientemente manejar 1) ontologías enormes y
complejas y 2) volúmenes importantes de datos. El desarrollo de un razonador semejante
será clave para el éxito de aplicaciones basadas en ontologías.
En general, HermiT es un razonador para ontologías escritas empleando OWL y construido
empleando cálculo hypertableau a fin de proveer razonamiento más eficiente. Se anuncia
como un razonador veloz y capaz de resolver ontologías complejas. Utiliza Direct Semantic y
ha superado las pruebas de conformidad de OWL 2 DL, OWL 2 EL, OWL 2 QL y OWL 2 RL. La
última versión es HermiT 1.3.1, liberada en octubre de este año, la cual utiliza la reciente
OWL API 3.1.0. y es compatible con Java 1.5. HermiT es open-source y liberado bajo LGPL122.
Pellet fue desarrollado por el laboratorio Mindswap123 de la Universidad de Maryland (USA)
Empezó como una prueba de concepto de sistema para ayudar al W3C a satisfacer los
requerimientos de experiencia de implementación para OWL y posteriormente se
convirtió en una herramienta popular y práctica para trabajar con OWL. Entre sus
características se destacan que admite la expresividad completa de OWL DL, razonamiento
acerca de nominales (clases enumeradas o definidas por extensión), absorción, ramificación
semántica y fue extendido para soportar las nuevas características propuestas en OWL 1.1 y
OWL 2.
Pellet trata de un razonador DL basado sobre algoritmos tableaux. El núcleo del razonador, es
el algoritmo tableaux (desarrollado para lógicas descriptivas potentes) el cual verifica la
consistencia de la KB124, es decir del par ABox y TBox125. Las ontologías OWL son cargadas al
razonador después de validar las especies OWL (DL, RL, QL) y “reparar” ontologías. Este paso
asegura que todos los recursos tienen un tipo de tripla apropiado (un requerimiento para
OWL DL pero no para OWL FULL). Durante la fase de carga, los axiomas acerca de las clases
(subclase, clase equivalente o axiomas disjuntos) son ubicados en el componente TBox y las
aserciones acerca de individuos (aserciones de tipo y propiedad) son almacenadas en el
componente ABox. Los axiomas TBox pasan antes por un preprocesamiento estándar de
razonadores DL y luego por el razonador tableaux.
Esencialmente un razonador tableaux posee sólo la funcionalidad de verificar la
satisfactibilidad de un ABox con respecto a un TBox. Todas las otras tareas de razonamiento
pueden ser reducidas a pruebas de consistencia con la KB mediante la transformación
apropiada. El System Programming Interface (SPI) de Pellet provee funciones genéricas para
administrar tales transformaciones.
122
GNU Lesser General Public License. 123
Maryland Information and Network Dynamics Lab Semántica Web Agents Project o MINDSWAP, Laboratorio
Maryland de Información y Redes Dinámicas del Proyecto de Agentes de Web Semántica. La información del
razonador actualmente se encuentra disponible en el sitio Web http://pellet.owldl.com. 124
Knowledge Base. 125
Desarrollado en la sección 2.6 “Razonador”

75.00 Tesis
101
Este razonador implementa las mejores técnicas de optimización, lo que hace que su
desempeño sea bueno, en especial cuando debe evaluar ontologías con mayor complejidad y
expresividad; sin embargo no es tan eficiente como RacerPro o FACT++ en clasificaciones
[Rodriguez et al.; 2010].
Implementado en Java, soporta la interfaz Jena, la interfaz OWL API, la interfaz DIG y puede
trabajar con el editor Protégé. Es ofrecido bajo un modelo de licencia dual126. Ha superado las
pruebas de conformidad de OWL 2 DL, OWL 2 EL, OWL 2 QL y OWL 2 RL. La última versión
es Pellet 2.2.2, liberada en septiembre de este año.
FaCT++, desarrollado por la Universidad de Manchester bajo el proyecto europeo
“WonderWeb”, es un razonador DL basado en el algoritmo tableaux para lógica descriptiva.
Cubre los lenguajes de ontología OWL y OWL2.
FaCT++ es un buen razonador para la TBox de una ontología, sin embargo, carece de soporte
para otros tipos de datos que no sean string o integer (como si ocurre con Pellet) y tampoco
posee soporte para razonamiento con la ABox de una ontología. En el caso de los tipos de
datos en un entorno Web, es necesario que exista soporte para los tipos de datos de XML
Schema. Entre sus características se destaca: 1) trabaja de forma eficiente con TBox de
ontologías de tamaño grande y mediano y 2) es posible utilizar el lenguaje de consultas para
RDF: SPARQL, el cual permite consultar el modelo inferido de una ontología OWL-DL.
Mediante el algoritmo tableaux implementa un procedimiento de decisión para TBox y ABox.
También implementa nuevas características y optimizaciones, que permite personalizar
para adicionar nuevas tácticas de razonamiento y la capacidad de razonar con lógicas
descriptivas más potentes y cercanas a la expresividad de OWL-DL. Es un software open
source, distribuido bajo los términos de licencia GPL/LGPL e implementada en C++. Soporta
la OWL-API y la interfaz DIG. Ha superado la mayoría de las pruebas de conformidad de OWL
2 en todas sus especies quedando pendiente algunas pruebas. La última versión fue FaCT
++ 1.2.3, liberada en el año 2009.
126 En aplicaciones open source, Pellet puede ser utilizado según los términos de la licencia AGPL versión 3 y en
aplicaciones closed source, propietarias u otras aplicaciones comerciales, según los términos de licencia
alternativos establecidos por los autores.

75.00 Tesis
102
Capítulo IV
Composición dinámica de servicios
4.1 Estudio de los últimos avances en composición dinámica de servicios como una solución eficiente y efectiva.
Una transacción entre servicios involucra tres o más componentes: un usuario, uno o más
proveedores y un registro que soporta los servicios durante la transacción y posiblemente
actúe de mediador entre ambos. La composición de servicios Web sigue un ciclo que puede
ser segmentado en dos partes: la ubicación del proveedor y la interacción entre el usuario y
el proveedor. Un proveedor se inscribe en el registro y hace públicos sus servicios. La
inscripción no es parte de la transacción pero si una condición necesaria para que la
transacción tome lugar.
El proceso de localizar un proveedor se compone de tres etapas: el usuario prepara un
pedido y lo envía al registro, el registro busca y envía los servicios candidatos y el usuario
elige el proveedor que más se ajusta a sus necesidades. El usuario espera que un proveedor
resuelva su petición pero no conoce proveedores. Para encontrar los proveedores, necesita
consultar el registro a fin de localizar servicios con ciertas capacidades. La compilación
automática requiere una abstracción del problema por las capacidades que el usuario espera
que el proveedor posea para resolver sus requerimientos. Resulta crucial en esta situación
un lenguaje que posibilite efectuar publicaciones y consultas y permita al registro obtener y
procesar información de las capacidades publicadas. La tarea del registro es localizar las
publicaciones que coincidan con un pedido. Diferentes partes con diferentes perspectivas
pueden proveer descripciones radicalmente diferentes del mismo servicio. Por lo tanto, el
proceso de búsqueda no debe restringirse a encontrar una coincidencia exacta entre pedido y
servicio sino a establecer los niveles necesarios a fin de determinar servicios similares. El
resultado es una lista de proveedores potenciales entre los que el usuario elige.
En general, no hay una manera fácil y rápida de elegir un proveedor sino que pasa a ser una
decisión específica de dominio. Lo más simple es seleccionar el proveedor con el mayor
puntaje entre los servicios reportados por el registro. Un enfoque más general podría estar
basado sobre razonamiento teórico de decisión, en el cual los usuarios elijan el proveedor
que maximiza alguna función de utilidad, sin embargo, en la práctica es poco probable que los
servicios hagan uso de un modelo de utilidad explícito.
Para permitir descubrimiento e interacción automática de servicios, [Paolucci et al., 2003]
han propuesto una arquitectura de servicios Web que utilizaba DAML-S y un planificador
HITAP (modelo computacional con soporte de razonamiento no determinista), dejando como
una cuestión abierta encontrar un modelo computacional más simple con menores
requerimientos de procesamiento (a causa del planificador).
[Qiu et al., 2008] definieron los servicios Web como aplicaciones modulares autónomas, auto
descriptas que pueden ser publicadas, localizadas e invocadas a través de la Web. En su
trabajo expusieron que con el desarrollo de Internet, emergió un gran número de
organizaciones que implementaron sus negocios y los exteriorizaron como servicios Web.

75.00 Tesis
103
Cuando un sólo servicio no puede satisfacer un pedido de usuario, la capacidad para
seleccionar y componer servicios heterogéneos a lo largo de diferentes organizaciones,
eficiente y efectivamente, se transforma en un paso importante en el desarrollo de
aplicaciones Web, convirtiéndose la tecnología de composición automática de servicios en
uno de las principales cuestiones dentro del proceso de desarrollo de una aplicación Web. La
investigación para permitir fácil integración incluye UDDI, WSDL, BPEL4WS, donde la
representación de composición de servicios realizada a través del flujo de proceso y de la
conexión entre servicios es conocida a priori. La composición de servicios, afirman, es una
tarea compleja debido a 1) el incremento de servicios Web, 2) a cambios “on the fly” que las
aplicaciones de composición deben detectar en tiempo de ejecución a fin de tomar decisiones
correctas sobre información actualizada y 3) la falta de un lenguaje único para definir y
evaluar servicios. Estos autores aseguran que la Web semántica es un paso clave para la
composición de servicios. En su trabajo, extendieron WSDL con capacidades semánticas,
definieron una ontología en OWL y elaboraron un plan (a través de BPEL4WS) para analizar
la estructura de los servicios que mejor combinaba.
Un Framework de composición y adaptación dinámica basado en semántica fue propuesto
por [Hibner y Zielinski; 2007]. Como resultado, automatizaron el proceso de orquestación de
SOA utilizando el algoritmo backward-chaining.
[Thakker et al., 2007] utilizaron una metodología conocida como Case Based Reasoning
(CBR) para modelar descubrimiento y matchmaking dinámico de servicios Web. Su trabajo
consideraba la experiencia de ejecución de un servicio Web a fin de determinar si era
adaptable al pedido de un usuario. Desarrollaron un framework con descripciones
semánticas (OWL) para la implementación de los componentes CBR y matchmaking. Un
proceso CBR es un ciclo de cuatro fases: 1) representación del caso, que consiste del
problema, el contexto y la solución; 2) almacenamiento e indización de casos, donde se utiliza
una biblioteca de casos; 3) recuperación de casos, que utiliza índices para expresar el
contenido del caso y 4) matchmaking, que compara los casos recuperados con el pedido a fin
de verificar si una solución anterior puede ser reutilizada. Argumentaron que como el
comportamiento de un servicio no puede ser conocido con antelación, sólo puede ser
generalizado si los valores de su ejecución son almacenados y razonados para decidir la
capacidad del servicio.
A veces los casos anteriores no pueden ser reutilizados sin hacer cambios que requieren
conocimiento específico del dominio para modelar una adaptación. Tal conocimiento podría
surgir por relacionar los conceptos definidos en una ontología utilizando una taxonomía de
relaciones y reglas semánticas. El rol del conocimiento en reparar los casos existentes
requiere relajar las descripciones de servicios o sus parámetros funcionales y los valores de
ejecución de los casos candidatos (parámetros no funcionales) para encontrar descripciones
de servicios suficientemente similares. Sugirieron, y es más, dejaron como trabajo futuro el
desarrollo de sustitución basado en conocimiento para adaptar los atributos funcionales y no
funcionales de los casos candidatos como solución a un pedido, descartando completamente
un planificador de IA, por ser un recurso sumamente costoso.
[Küster et al., 2005] definieron composición de servicios como un servicio integrado,
obtenido por combinar componentes de servicios disponibles en situaciones donde un
pedido de cliente no podía ser satisfecho por un sólo servicio sino por una combinación de

75.00 Tesis
104
ellos. En términos de ingeniería de software, la composición automática de servicios podría
mejorar la capacidad de una arquitectura de servicios porque posibilitaría superar
dificultades como 1) especificar y combinar, manualmente, los servicios básicos a utilizar y
2) fortalecer el proceso de composición contra la falta de disponibilidad de un servicio o por
la aparición de otros nuevos. Por otro lado, mencionaron que la composición de servicios por
síntesis consiste de un plan para lograr el comportamiento deseado al combinar las
habilidades de múltiples servicios y que la composición de servicios por orquestación trata
del control y flujo de datos entre varios componentes de software cuando ese plan se ejecuta.
Sostuvieron que la composición por síntesis era más relevante en la composición
automática, quedando la orquestación como un elemento complementario. En su trabajo
estudiaron las capacidades requeridas y las generalmente utilizadas en los trabajos de
composición automática de servicios para finalmente concluir que: 1) un encadenamiento de
servicios podía introducir un nivel de incertidumbre, que en algunas situaciones era
inaceptable para el usuario, 2) los pedidos con múltiples efectos necesitaban capacidades
como escalabilidad estable y propiedades transaccionales, 3) los problemas relacionados con
falta de conocimiento requerían de servicios que recopilasen la información y 4) mejores
descripciones semánticas requerían del desarrollo de bases semánticas sólidas, entre otras.
[Aversano et al.; 2004] propusieron un algoritmo para descubrimiento de servicios. El
algoritmo tenía por objetivo aumentar la probabilidad de responder a un pedido de servicio
mediante composición de servicios. Se basaron en el Service Profile de DAML-S y en
ontologías DAML-OIL. La implementación incluyó entradas y salidas de servicio, dejando
como trabajo futuro sus precondiciones y efectos. El algoritmo propuesto tomaba la salida de
un pedido de servicio como objetivo. En el mejor caso, el objetivo podía ser alcanzado por un
sólo servicio. Caso contrario, la solución comprendía el conocido algoritmo backward-
chaining (BCA) con las siguientes variantes: 1) el algoritmo entity matching (EMA) y 2)
selección basada en meta-valores (SBM). BCA verificaba la posibilidad de componer varios
servicios, EMA evaluaba similitud entre entidades de distintas ontologías por considerar
entidades por su nombre, por sus características a nivel semántico (object-properties y data-
properties de DAML-OIL) y por sus relaciones semánticas (utilizaron SuperClass, SubClass,
DisjointWith, DifferentFrom, EquivalentClasses de DAML-OIL). SBM permitía establecer un
conjunto de atributos de calidad de servicios (QoS, disponibilidad, tiempo de respuesta, costo,
entre otros) y asignar un peso a cada atributo según los intereses del usuario. El Service
Profile de DAML-S ha permitido insertar atributos de calidad y los valores deseados.
Como conclusión, mencionaron que los servicios son desplegados por varias personas en el
mundo y es poco probable encontrar un servicio Web que perfectamente proveyese a otro,
que la capacidad de cubrir conceptos utilizados en diferentes ontologías es el tema más
importante en la Web Semántica y que desde que EMA evaluaba ontologías, la clasificación de
un servicio Web en un dominio semántico era innecesario.
[Paolucci et al., 2002] destacaron que UDDI y WSDL no prestaban capacidad de búsqueda de
servicios por match semántico al responder a un pedido de usuario y lo propusieron como
mejora. Para representar las capacidades de servicios utilizaron la sección Profile de DAML-S.
Para realizar inferencias sobre una jerarquía utilizaron las ontologías DAML. Un algoritmo
buscaba salidas de servicios que coincidieran con al menos una salida del pedido de usuario.
Las entradas de servicios eran utilizadas como complemento cuando había más de un
servicio que proveía las mismas salidas siendo elegido el que tenía más entradas similares
con el pedido. Como resultado daba un conjunto ordenado de servicios de acuerdo al nivel de

75.00 Tesis
105
matching de cada uno. El algoritmo fue dotado de cierta flexibilidad (configurable por el
usuario) para establecer los niveles de match que podían ser exacto (la salida coincidía con el
pedido o era una superclase directa del pedido suponiendo que el proveedor se comprometía
a prestar el servicio publicado a un nivel de profundidad de uno en la jerarquía de clases),
plug-in (superclases del pedido que podían incluirlo), subsumidos (salidas parciales, es decir
que el servicio proveía una parte del pedido) y fail (no match).
A partir de lo investigado y expuesto nuestra definición de servicio para el desarrollo del caso
práctico es: “un servicio es un activo que establece prestaciones y calidad a través de
contratos de servicio. Un servicio Web es funcionalidad disponible en la Web según
estándares estipulados (SOAP, WSDL, UDDI) a fin de garantizar interoperabilidad. Un servicio
Web semántico posee descripciones realizadas por ontologías las cuales agregan un nivel
más de procesamiento a fin de optimizar el ciclo de descubrimiento, selección, invocación y
composición de los servicios Web.”
4.2 Alternativas de composición semántica como OWL, Pellet, el algoritmo backward-chaining Una situación común es encontrar servicios que generan los efectos pedidos pero que
alguna precondición no pueda ser cubierta. Una solución es utilizar encadenamiento de
servicios. El encadenamiento considera recursivamente los efectos de un servicio como las
precondiciones del siguiente hasta que el efecto deseado es alcanzado. Los enfoques de
encadenamiento de servicios incluyen:
� Graph-Search: construye una representación de grafo de todos los servicios disponibles.
Los nodos representan servicios y las aristas las salidas de un servicio que sirven como
entradas de otro. Además, las aristas son pesadas de acuerdo al nivel de correspondencia de
entradas y salidas asociadas. Una adaptación del algoritmo de Bellman-Ford es utilizado
para encontrar el camino más corto entre las entradas del usuario y las salidas deseadas
que represente la mejor composición disponible. Como desventaja, este tipo de enfoque
no es escalable con el número de servicios ofrecidos, llegando a trabajar con complejidades
de orden O(n3) .
� Forward-Chaining: típico de sistemas de planificación basados en lógica, utiliza el
conocimiento disponible, precondiciones y entradas del servicio para inferir
conocimiento adicional hasta conseguir todos los efectos requeridos. Como desventaja,
para cubrir todos los efectos de un pedido tiende a buscar en direcciones innecesarias por
abarcar el máximo conocimiento posible.
� Backward-Chaining: supera la propuesta anterior. Se diferencia del forward-chaining en
que la composición considera aquellos servicios que generen los efectos deseados en lugar
de esos cuyas precondiciones son concedidas. Cualquier algoritmo recursivamente trata de
crear las precondiciones necesarias usando otros servicios hasta cubrir todas las
precondiciones. Mientras que el backward-chaining implementa una búsqueda dirigida
mejorada, el espacio del problema es todavía grande.
� Estimated-Regression planning: es un intento por mejorar la performance de la búsqueda
por implementar un forward chaining por una heurística basada en backward-chaining.
En general, los enfoques de encadenamiento están basados en sistemas de planificación de AI,

75.00 Tesis
106
los que generalmente conducen a problemas de escalabilidad en caso de un incremento en el
número de servicios.
4.3 Agentes y la composición de servicios Web
A fin de conseguir los beneficios anunciados por tener agentes y servicios trabajando
cooperativamente, ambas tecnologías se relacionan en un escenario donde el agente provee
la funcionalidad de alto nivel por utilizar, combinar y coreografiar los servicios Web
obteniendo funciones de valor agregado mientras que los servicios Web prestan la
funcionalidad de bajo nivel.
Los agentes con capacidades semánticas y los servicios Web semánticos permiten
automatizar una situación en la que fuera necesario ejecutar varios servicios a fin de
proporcionar el servicio requerido.
El agente consulta un registro de servicios a fin de localizar servicios con ciertas capacidades.
La compilación automática requiere una abstracción del problema por las capacidades que se
espera que el servicio posea, a fin de resolver el problema. Un lenguaje como SAWSDL
posibilita realizar publicaciones y consultas y permite al agente obtener y procesar
información acerca de las capacidades publicadas. La tarea del agente es localizar las
publicaciones que coincidan con un pedido. El proceso de búsqueda no se restringe a
encontrar una coincidencia exacta entre pedido y servicio sino que previamente se
establecen niveles (desarrollado en la sección 5.2.1) para que servicios similares puedan ser
elegidos. El resultado es una lista de servicios potenciales que cubren un pedido.
El agente accede a las publicaciones dadas por las descripciones WSDL de los servicios a fin
de conocer lo que hace el servicio. Las ontologías utilizadas por el servicio, sus entradas,
salidas y las reglas requeridas para su ejecución es lo que permite al agente conocer las
acciones y efectos del servicio. La forma en que el agente logra ese conocimiento es
desarrollado en la sección 5.2.1.

75.00 Tesis
107
Capítulo V
Caso práctico
5.1 Escenario de aplicación representativo del problema a resolver
El escenario de aplicación trata de la bolsa de trabajo de una facultad. Un nuevo estudiante
puede postularse a las ofertas publicadas por la bolsa de trabajo por presentar una nota de
inscripción, su curriculum y la oferta a la cual postula. Los graduados sólo pueden postularse
a ofertas de trabajo profesional y los no graduados a ofertas de pasantía.
El servicio Web semántico wsMatriculate define una interfaz con la operación Registration
para realizar la inscripción en la facultad de un nuevo estudiante recibiendo los datos del
nuevo estudiante y una nota de inscripción. El servicio retorna una nota con la inscripción
realizada (de tipo nota de graduado o de tipo nota de no graduado).
El servicio Web semántico wsInscribeJobBag define una interfaz con la operación
ApplyForJobBag para realizar la inscripción en la bolsa de trabajo de un nuevo estudiante
recibiendo un curriculum y la nota de inscripto en la facultad. El servicio retorna un registro
con la inscripción realizada en la bolsa de trabajo (de tipo postulación de trabajo).
El servicio Web semántico wsPostulateJobG define una interfaz PostulateJobOffer con la
operación postulateJob para realizar la postulación de trabajo profesional de un nuevo
estudiante graduado recibiendo la oferta de trabajo profesional elegida y el registro de
inscripto en la bolsa de trabajo. El servicio retorna un registro con la postulación a la oferta de
trabajo profesional realizada (de tipo postulación de trabajo profesional).
El servicio Web semántico wsPostulateJobU define una interfaz PostulateJobOffer con la
operación postulateJob para realizar la postulación de pasantía de un nuevo estudiante no
graduado recibiendo la oferta de pasantía elegida y el registro de inscripto a la bolsa de
trabajo. El servicio retorna un registro con la postulación a la oferta de pasantía realizada (de
tipo postulación de pasantía).
Dado un nuevo estudiante graduado que posea un curriculum y desee anotarse a una
búsqueda de trabajo profesional, la combinación de los servicios wsMatriculate,
wsInscribeJobBag y wsPostulateJobG responderían al pedido.
Para un nuevo estudiante con curriculum e intención de anotarse a una búsqueda de
pasantía, la combinación de los servicios wsMatriculate, wsInscribeJobBag y
wsPostulateJobU responderían al pedido.
Como puede observarse, los servicios propuestos ofrecen las posibles salidas requeridas y
cuál servicio se ejecutará para resolver el pedido es determinado en tiempo de ejecución.
Con este escenario se pretende estudiar de que manera los servicios Web semánticos pueden
ser combinados de manera automática por un agente provisto con las ontologías necesarias.

75.00 Tesis
108
5.2 El prototipo construido
5.2.1 Criterio adoptado
Se utilizaron estándares en la construcción de los servicios Web como WSDL y SOAP.
Se utilizaron estándares para la anotación semántica de los servicios Web como SAWSDL a
fin de convertir los servicios Web en servicios Web semánticos.
A fin de dotar a los servicios con información acerca de sus pre y postcondiciones de manera
que fuera compatible con el estándar SAWSDL, se eligió emplear el lenguaje de reglas SWRL.
Se implementaron reglas DL-Safe Rules con el propósito de conservar y disponer de las
capacidades de inferencia y clasificación sobre ontologías, entre otras, ofrecidas por un
razonador DL.
Se empleo el estándar OWL como lenguaje de ontología para lograr la máxima expresividad
semántica con las ontologías.
Para realizar la asociación de un pedido de servicio con los servicios ofrecidos se
consideraron los siguientes tipos de asociaciones [Paolucci et al.; 2002]:
� exact: cuando el pedido de servicio coincide exactamente con la salida de un servicio o
cuando el pedido de servicio coincide con algún subtipo directo de los tipos utilizados en la
salida del servicio. Esta decisión se sostiene bajo el supuesto de que un proveedor se
compromete a prestar salidas consistentes con cada subtipo inmediato de la salida con la
que publica su servicio.
� plug in: cuando la salida de un servicio subsume el pedido de un servicio. Esta relación
corresponde a un tipo de relación débil. El proveedor de servicio podría responder al
pedido de servicio. Esta asociación ocurre cuando el pedido de servicio es un subtipo no
directo de la salida de servicio (existe una relación lejana en la jerarquía).
� subsume: cuando el pedido de servicio incluye la salida de un servicio. El proveedor de
servicio no cumple completamente con el pedido de servicio. En este caso, el pedido de
servicio subsume la salida de servicio.
� fail: cuando ninguna relación de subsunción existe entre el pedido y el servicio ofrecido.
Se eligió realizar las asociaciones de acuerdo al primer tipo. Los tipos restantes fueron
implementados y dejados como trabajo futuro.
Lo anterior contempla sólo las salidas de un pedido de servicio y de un servicio ofrecido. Para
evaluar la asociación de las entradas de un pedido de servicio y de un servicio ofrecido se
consideró la propuesta de [Akkiraju y Sapkota; 2007] por aceptar que las entradas pueden
ser satisfechas por sus supertipos directos en la jerarquía de clases.
El agente lleva a cabo la composición mediante el algoritmo de backward-chaining y reglas
DL-Safe Rules.
Una composición es válida si el pedido de servicio y las entradas y las reglas de los servicios
elegidos son satisfechos. Los resultados finales son comunicados por el agente.

75.00 Tesis
109
La ontología de datos fue construida implementando un TBox acíclico127 a fin de evitar los
problemas semánticos que surgen con un TBox cíclico.
5.2.2 Componentes El prototipo consiste de un agente dotado con las capacidades de encontrar, combinar y
comunicar los servicios Web semánticos a fin de responder a un pedido de servicio
determinado, el cuál podría ser realizado por uno o varios servicios.
A fin de procesar las anotaciones semánticas incluidas en los documentos WSDL de los
servicios, el agente fue implementado incorporando, como razonador OWL-DL, la versión
Pellet 2.2.1.
Se definió la siguiente estructura de directorios:
� /repository/ontologies
� /repository/servicesDescription
� /AgentClient/request
� /AgentClient/response
� /AgentClient/temp
El directorio ontologies contiene las ontologías owl de todos los servicios. Cada servicio
incluye en su documento WSDL tres ontologías: una ontología para anotar los tipos de datos
de sus operaciones, otra ontología para describir las reglas asociadas a sus operaciones y una
tercera ontología que permite anotar la categoría a la que pertenece el servicio, en el
elemento interface, que integra la especificación WSDL 2.0.
La ontología de datos fue presentada en la sección 2.8, desde la perspectiva del lenguaje de
ontología OWL y, en la sección 5.1, por mencionar en detalle el escenario modelado. En la
sección 2.8, también se mencionó que la ontología de datos había sido dividida en dos partes:
una ontología para contener los axiomas de clases y propiedades y otra ontología, para
contener a los individuos. Los archivos StudentsJobBag.owl y membersStudentsJobBag.owl,
que corresponden a las ontologías bolsa de trabajo y miembros de la bolsa de trabajo, fueron
explicadas en esa sección y se encuentran en este directorio.
[Akkiraju y Sapkota; 2007] sugirieron que, a fin de agregar la categoría a la cual pertenecía
un servicio, antes de publicarlo en un registro de servicios, los servicios Web podían ser
anotados semánticamente por los mecanismos de extensión provistos con SAWSDL. Para
ello, plantearon las siguientes dos formas:
127
Desarrollado en la sección 2.6, “Razonador”.

75.00 Tesis
110
� Categorización por URI: a partir de un modelo semántico de categorías existente anotar
semánticamente los elementos operation o interface del documento WSDL 2.0 que
acompaña a un servicio por agregar la categoría del servicio. Esta forma presentaba el
inconveniente de que el modelo de categorías no fuera completo y, que fuera necesario
recurrir, a múltiples piezas de información para identificar la categoría del servicio.
� Categorización por identificadores: en esta forma los usuarios podían definir la categoría
según sus requerimientos empleando categorías definidas por otros usuarios. Así, la
categoría del servicio era obtenida por indicar una taxonomía y un identificador dentro de
esa taxonomía.
Se adoptó la segunda forma en el prototipo. El modelo de categorías definido fue
“categorización.owl”, el cual utilizó algunas de las categorías publicadas por NAICS128 para
anotar, en primer lugar, los pedidos de servicio y, en segundo lugar, los servicios ofrecidos,
con las categorías más adecuadas, de manera de que, si el servicio ofrecido resultaba
pertenecer a la misma categoría que el pedido, el servicio era elegido y posteriormente
procesado a fin de determinar si podía ser considerado para responder al pedido recibido,
reduciendo de manera considerable los costos de procesamiento.
Las ontologías de reglas, las cuales fueron empleadas para anotar las operaciones de un
servicio, fueron definidas con el propósito de habilitar al agente con la capacidad de decidir
acerca de las condiciones asociadas a la ejecución de un servicio. Estas reglas fueron definidas
en OWL como DL-Safe Rules del SWRL y explicadas en la sección 2.8. Sin embargo, es
necesario destacar, que las reglas hacen posible que el agente pueda determinar si un
servicio se ejecutará correctamente o no, y, qué cambios puede producir su ejecución, de
manera similar, a las pre y post condiciones utilizadas en OWL-S. Además, si bien para
ejecutar un servicio, éste debe ser invocado con las entradas requeridas por la firma de sus
operaciones, resulta indispensable considerar las condiciones que aseguren su buen
desempeño. Esta última verificación se logra mediante la utilización de reglas las cuales
permiten al agente disponer de la información necesaria a tal fin.
Las ontologías de reglas empleadas fueron cuatro: rulesMatriculate.owl,
rulesInscribeJobBag.owl, rulesPostulateJobG.owl y rulesPostulateJobU.owl. Para definir las
reglas, estas ontologías importaron las ontologías StudentsJobBag.owl y
membersStudentsJobBag.owl. Las cuatro ontologías de reglas fueron descriptas en la sección
2.8.
En el directorio servicesDescription se reúnen los documentos WSDL 2.0 de los servicios
Web semánticos creados. Este directorio actúa como un registro de servicios al que el agente
accede para resolver un pedido.
El directorio request es donde el agente recibe los pedidos de servicios. Los pedidos de
servicios fueron construidos siguiendo la propuesta de [Akkiraju y Sapkota; 2007] por
utilizar WSDL 2.0.
128
North American Industry Classification System. http://www.census.gov/eos/www/naics/

75.00 Tesis
111
El directorio response es donde el agente ubica el resultado de los pedidos recibidos. El
agente informa si encontró el o los servicios que corresponden al pedido, si el o los servicios
se pueden ejecutar por disponer de las entradas requeridas por los mismos y si se cumplen
las reglas asociadas a cada servicio para una ejecución exitosa.
El directorio temp fue el contenedor temporal de los archivos empleados a lo largo de las
pruebas realizadas durante el desarrollo del prototipo y finalmente movido al directorio
/AgentClient.
El directorio /AgentClient contiene stubs que automáticamente generan y envian pedidos a
los servicios Web para los contratos de servicio que implementan como clientes.
Su propósito es presentar pedidos y ejecutar los servicios compuestos encontrados por el
agente.
Finalmente, el archivo agent.properties permite configurar las rutas de la estructura de
directorios definida. Se encuentra en el directorio /AgentClient.
5.2.3 Herramientas
Para construir los servicios Web semánticos se utilizó la herramienta versión Axis2-1.5.2.
Axis2 es un proyecto de la Apache Software Foundation. Es una herramienta open-source
para crear y utilizar servicios Web e incluye SOAP 1.1 y SOAP 1.2, MTOM, XML/HTTP y los
estándares WS-*. Incluye un motor de ejecución veloz pudiendo desplegar servicios mientras
el sistema se está ejecutando (pueden agregarse nuevos servicios sin necesidad de detener el
servidor). Incorpora flexibilidad para soportar patrones de intercambio de mensajes
(Message Exchange Patterns o MEPs). Soporta la invocación de servicios Web asincrónicos
por utilizar clientes y transportes no-bloqueantes. Presta soporte para WSDL 1.1 y WSDL
2.0 y permite construir a partir de las descripciones WSDL stubs para acceder a servicios
remotos o exportar automáticamente las descripciones de los servicios Web, entre otras
características. Además Axis2 puede ejecutarse sólo o en algún contenedor de servlets como
Tomcat y posee dos implementaciones: Axis2/C y Axis2/Java.
Axis2 fue desplegado empleando la herramienta Tomcat - 6.0.29 como servidor Web.
Tomcat es otro proyecto de la Apache Software Foundation. Es una implementación open-
source de las tecnologías Java Servlet y Java Server Pages (especificaciones que son
desarrolladas por la Java Community Process129). Funciona como servidor Web con soporte
para servlets y JSP.
Los servicios fueron construidos empleando la versión WSDL 2.0 y SOAP 1.1 y SOAP 1.2.
129
http://jcp.org/en/home/index

75.00 Tesis
112
Las descripciones WSDL de los servicios Web fueron obtenidas a partir de su código en java
con la herramienta java2wsdl130 de Axis2. Las descripciones WSDL correspondían a la
versión WSDL 1.1 por lo que hubo que utilizar otra herramienta para obtener la versión
WSDL 2.0, Por medio de la herramienta comercial Altova XMLSPy 2011131 se pudo convertir
las descripciones WSDL 1.1 a descripciones WSDL 2.0, adhiriendo a la recomendación más
reciente del W3C.
Una vez obtenidas las descripciones WSDL 2.0 de los servicios y con la herramienta
wsdl2java132 de Axis2 se generaron los skeletons de los servicios. Finalmente los servicios
fueron ejecutados por ubicar el archivo de despliegue de cada servicio (estos archivos poseen
extensión .aar) en el directorio /webapps/axis2/WEB-INF de Tomcat.
Las herramientas presentadas hasta ahora resultaron adecuadas a los fines de conseguir los
servicios con los que el agente trabajó para la composición de servicios. Además, hay que
mencionar que dichas herramientas poseen una documentación completa y clara y son,
debido a una aceptación relativamente amplia, respaldadas por una comunidad de
desarrolladores que contribuyen con sus aportes a superar inconvenientes durante la
implementación.
A fin de agregar semántica a los servicios se recurrió a la herramienta Woden4SAWSDL.
Woden4SAWSDL es una API provista como parte de la infraestructura de APIs y
herramientas ofrecidas por el proyecto METEOR-S, del laboratorio LSDIS del Departamento
de Computación de la Universidad de Georgia. Permite la creación y el manejo de
documentos SAWSDL133 basados en WSDL 2.0.
Las ontologías fueron generadas a partir de la herramienta versión Protégé 4.1.0. Protégé 134
fue desarrollado por el Stanford Center for Biomedical Informatics Research de la Stanford
University School of Medicine como un editor de ontologías open source. Soporta dos formas
para modelar ontologías: mediante Protégé Frames y Protégé OWL. Entre sus características
se pueden mencionar la exportación de ontologías en una variedad de formatos (RDF, RDFS,
OWL y XML-Schema entre otros), es construido en Java, extensible y provee un entorno plug
and play que lo convierte en una base flexible para prototipado y desarrollo de aplicaciones
veloz.
El Protégé Frames es un conjunto de elementos de interfaz personalizables a fin de permitir
a los usuarios modelar conocimiento e ingresar datos de forma amigable. Provee una
arquitectura del tipo plug-in extensible mediante elementos diseñados por el usuario como
componentes gráficos (grafos y tablas), multimedia (sonido, imagen y video), herramientas
de soporte adicional (visualización de ontologías, inferencia y razonamiento, etc.), entre
otras. Dispone de una API basada en Java para acceder, utilizar y visualizar las ontologías
130 Script que genera el archivo WSDL apropiado a partir de la clase java especificada. 131
http://www.altova.com/xmlspy/wsdl-editor.html 132
Script que genera código Java de acuerdo al archivo WSDL especificado a fin de manejar las invocaciones de
servicio (stubs del lado del cliente). El script también puede generar los skeletons de los servicios de acuerdo al
WSDL especificado. 133
Desarrollado en la sección 2.5.8, “SAWSDL”. 134
http://protege.stanford.edu.

75.00 Tesis
113
creadas con Protégé Frames.
El editor Protégé OWL soporta el Ontology Web Language u OWL permitiendo cargar y
almacenar ontologías OWL y RDF, editar y visualizar clases, propiedades y reglas SWRL,
definir expresiones OWL como características de las clases, ejecutar razonadores como
clasificadores DL y editar individuos OWL.
Además, Protégé cuenta con el respaldo de una gran comunidad de desarrolladores y usuarios
universitarios (University of Manchester), del gobierno (DARPA) y empresas (eBay) quienes
utilizan Protégé para soluciones en áreas tan diversas como la biomedicina, recopilación de
información y el modelado de empresas.
El razonador empleado fue Pellet 2.2.1 descripto en la sección 3.7.
Para administrar las ontologías programáticamente en las primeras versiones del prototipo
se trabajó con el framework Jena 2.2.3.
Jena135 es un framework java, open-source, que creció como parte del Programa de la Web
Semántica de los laboratorios HP136. Actualmente, el proyecto fue desvinculado debido a la
decisión de la administración HP Labs de no continuar con el Programa, encontrándose la
propiedad de los derechos del código de Jena en proceso de transferencia desde HP a un
cuerpo comercialmente neutral. Sin embargo, HP asegura la continuidad del proyecto y su
participación en el papel de colaborador.
El Framework Jena incluye una API RDF, soporta los formatos RDF/XML, N3 y N-Triples, la
OWL API, el motor de consultas SPARQL, manejo de ontologías en memoria y persistencia,
entre otras características. Pero no provee soporte para DL-Safe Rules. Por este motivo fue
reemplazada por la OWL API versión 3.1.0.
La OWL API versión 3.0.0 en adelante fue desarrollada por la University of Manchester. Es
open-source y la última versión se enfocó hacia OWL 2. Es una API Java y una
implementación de referencia para crear, manipular y serializar ontologías OWL. Entre sus
componentes se encuentran: analizadores de sintaxis y escritura para RDF/XML, OWL/XML,
OWL Functional Syntax, Turtle, KRSS, interfaces para trabajar con razonadores como
FaCT++, HermiT, Pellet y Racer y una API para OWL 2, entre otros.
Con la OWL API, en su versión 3.1.0, fue posible implementar DL-Safe Rules.
135 También desarrollado en la sección 2.6.1.2, “Razonadores de programación lógica”.
http://jena.sourceforge.net/ 136 Hewlett-Packard Development Company

75.00 Tesis
114
5.3 Resultados
La pruebas realizadas utilizaron los pedidos de servicios del directorio temp, los cuales
fueron construidos siguiendo la propuesta de [Akkiraju y Sapkota; 2007] y la especificación
WSDL 2.0.
Los archivos “servicerequestXX.wsdl” corresponden a pedidos de servicio, los archivos
“reportCompositeServiceServiceRequestXX” son reportes de los servicios compuestos
encontrados y están ubicados en el directorio response/r1 y los archivos
“reportRunTimeServiceRequestXX” son reportes de las ejecuciones de los servicios
compuestos encontrados y están ubicados en el directorio response/r2.
Inicialmente, un pedido es ubicado en el directorio temp y movido al directorio request. El
agente levanta el pedido del directorio de entrada (request), lo procesa, elabora el reporte y lo
deposita en el directorio de salida (response). El directorio temp posibilitó incrementar los
pedidos a medida que se avanzaron con las pruebas. La última prueba fue con un lote de
diecisiete pedidos.
Como se mencionó secciones atrás, las reglas se componen de dos partes principales:
antecedente y consecuente. El antecedente y el consecuente están formados por átomos.
Los átomos comprenden predicados y los predicados argumentos. Los predicados pueden
ser descripciones de clases, propiedades y los argumentos variables o individuos. La
estructura de una regla queda como se muestra a continuación:
Rule ([ATOM1 (PREDICATE1(ARG1 ,.., ARGN) , ..., ATOMN (PREDICATEN (ARG1, .., ARGN))]) => ([ATOM1
(PREDICATE1 (ARG1, .., ARGN)])
SWS1 wsMatriculate Rule [New_Student (nt), Notice (n)] => [NoticeOf (n, nt)] Input {New_Student (a), Notice (n)}
Output {Notice (n)}
Descripción: realiza la inscripción en la facultad de un nuevo estudiante recibiendo los datos del nuevo
estudiante y una nota de inscripción. El servicio retorna una nota de inscripción realizada (de tipo nota de
graduado o de tipo nota de no graduado). SWS2 wsInscribeJobBag Rule [Curriculum(c), NoticeOf (n, nt)] => [hasJobPostulant (nt, jp)]
Input {Notice (n)}, Curriculum (c)}
Output {JobPostulant (jp)}
Descripción: realiza la inscripción en la bolsa de trabajo de un nuevo estudiante recibiendo un curriculum y
la nota de inscripto en la facultad. El servicio retorna el registro de inscripción en la bolsa de trabajo (de tipo
postulación de trabajo).
SWS3 wsPostulateJobG Rule [JobPostulantOf (jp, nt), hasNotice (nt, notice_graduate)] => [hasPostulationProfessionalJob (nt, pprof)] Input {JobPostulant (jp), JobOfferProfessional (joprof)}
Output {PostulationProfessionalJob (pprof)}
Descripción: realiza la postulación de trabajo profesional de un nuevo estudiante graduado recibiendo la oferta
de trabajo profesional elegida y el registro de inscripto en la bolsa de trabajo. El servicio retorna un registro con
la postulación a la oferta de trabajo profesional realizada (de tipo postulación de trabajo profesional).
SWS4 wsPostulateJobU Rule [JobPostulantOf (jp, nt), NoticeOf (notice_undergraduate, nt)] => [hasPostulationPassantJob (nt, ppas)] Input {JobPostulant (jp), JobOfferPassant (jopas)}
Output {PostulationProfessionalJob (pprof)}
Descripción: realiza la postulación de pasantía de un nuevo estudiante no graduado recibiendo la oferta de

75.00 Tesis
115
pasantía elegida y el registro de inscripto a la bolsa de trabajo. El servicio retorna un registro con la postulación
a la oferta de pasantía realizada (de tipo postulación de pasantía).
La primera prueba (reportCompositeServiceRequest10) fue un pedido de servicio por una
nota de inscripción presentando los datos del nuevo estudiante. El agente determinó que el
pedido podía ser resuelto por un servicio, el servicio wsMatriculate pero que como el pedido
era incompleto y no cumplía las reglas no podía ser ejecutado. Faltaba la presentación de una
nota como entrada.
La segunda prueba (reportCompositeServiceRequest11) fue un pedido de servicio por una
nota de inscripción presentando los datos del nuevo estudiante y una nota. El agente
determinó que el pedido podía ser resuelto por un servicio, el servicio wsMatriculate el cual
podía ser ejecutado porque el pedido era completo y cumplía con las reglas del servicio.
SWScompuesto = SWSsimple = {wsMatriculate}
ABoxpedido= { INPUT {x1 (Student), x2 (Notice)},
OUTPUT {x2 (Notice)}
}
ABoxinferido= { x1 (Student) superclass nt (New_Student),
x2 = n (Notice)
}
El reporte reportRunTimeServiceRequest11 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
La tercera prueba (reportCompositeServiceRequest20) fue un pedido de servicio para
realizar una postulación de trabajo profesional presentando una nota y un curriculum. El
agente determinó que el pedido podía ser resuelto por dos servicios, los servicios
wsInscribeJobBag y wsPostulateJobG pero que como el pedido era incompleto y no cumplía
las reglas no podía ser ejecutado. Faltaba la presentación de la oferta de trabajo profesional a
la cual postulaba.
La cuarta prueba (reportCompositeServiceRequest21) fue un pedido de servicio para
realizar una postulación de trabajo profesional presentando una nota, un curriculum y la
oferta de trabajo profesional elegida. El agente determinó que el pedido podía ser resuelto
por los servicios wsInscribeJobBag y wsPostulateJobG pero que como el pedido no cumplía
las reglas no podía ser ejecutado. La regla asociada del servicio wsInscribeJobBag establecía la
existencia de una nota de graduado inscripto.
La quinta prueba (reportCompositeServiceRequest22) fue un pedido de servicio para
realizar una postulación de trabajo profesional presentando una nota de graduado, un
curriculum y la oferta de trabajo profesional elegida. El agente determinó que el pedido podía
ser resuelto por dos servicios, los servicios wsInscribeJobBag y wsPostulateJobG los cuales
podían ser ejecutados porque el pedido era completo y por cumplir con las reglas de los
servicios.
SWScompuesto = {wsInscribeJobBag, wsPostulateJobG}
ABoxpedido= { INPUT {x1 (Curriculum), notice_graduate (Notice),
x2 (JobOfferProfessional)},

75.00 Tesis
116
OUTPUT {x7 (PostulationProfessionalJob)}
}
ABoxinferido= { x6 = x3 = notice_graduate = n (Notice),
x1 = c (Curriculum), gd (Graduate) = nt (New_Student),
x4 = jp (JobPostulant),
x7 = pprof (PostulationProfessionalJob)
}
El reporte reportRunTimeServiceRequest22 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
La sexta prueba (reportCompositeServiceRequest30) fue un pedido de servicio para realizar
una postulación de pasantía presentando un curriculum y la oferta de trabajo elegida. El
agente determinó que el pedido podía ser resuelto por tres servicios, los servicios
wsMatriculate, wsInscribeJobBag y wsPostulateJobU pero que como el pedido era
incompleto y no cumplía las reglas no podía ser ejecutado. Faltaba la presentación de los datos
del nuevo estudiante y una nota de inscripción.
La séptima prueba (reportCompositeServiceRequest31) fue un pedido de servicio para
realizar una postulación de pasantía presentando un curriculum, la oferta de trabajo elegida y
una nota de inscripción. El agente determinó que el pedido podía ser resuelto por dos
servicios, los servicios wsInscribeJobBag y wsPostulateJobU pero como el pedido no cumplía
las reglas no podía ser ejecutado. La regla del servicio wsInscribeJobBag exigía la existencia
de una nota de no graduado inscripto.
La octava prueba (reportCompositeServiceRequest32) fue un pedido de servicio para
realizar una postulación de pasantía presentando un curriculum, la oferta de trabajo elegida y
una nota de no graduado. El agente determinó que el pedido podía ser resuelto por dos
servicios, los servicios wsInscribeJobBag y wsPostulateJobU los cuales podían ser ejecutados
porque el pedido era completo y por cumplir con las reglas de los servicios.
SWScompuesto = {wsInscribeJobBag, wsPostulateJobU}
ABoxpedido= { INPUT {x1 (JobOffer), x2 (Curriculum),
notice_undergraduate (Notice)},
OUTPUT {x7 (PostulationPassantJob)}
}
ABoxinferido= { x2 = c (Curriculum),
x3 = x6 = notice_undegraduate = n (Notice),
x4 = jp (JobPostulant), ug (UnderGraduate) = nt (New_Student),
x7 = pprof (PostulationProfessionalJob)
}
El reporte reportRunTimeServiceRequest32 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
La novena prueba (reportCompositeServiceRequest40) fue un pedido de servicio por una
nota de inscripción de no graduado presentando los datos del nuevo estudiante. El agente

75.00 Tesis
117
determinó que el pedido podía ser resuelto por un servicio, el servicio wsMatriculate pero
que como el pedido era incompleto, el servicio no podía ser ejecutado. Faltaba la
presentación de una nota.
La décima prueba (reportCompositeServiceRequest41) fue un pedido de servicio por una
nota de inscripción de no graduado presentando los datos del nuevo estudiante y una nota de
no graduado. El agente determinó que el pedido podía ser resuelto por un servicio, el
servicio wsMatriculate, el cual podía ser ejecutado porque el pedido era completo y cumplía
con las reglas del servicio.
SWScompuesto = SWSsimple = {wsMatriculate}
ABoxpedido= { INPUT {x1 (New_Student), notice_undergraduate (Notice)},
OUTPUT {notice_undergraduate (Notice)}
}
ABoxinferido= { x1 = ug (UnderGraduate) = nt (New_Student),
x2 = x3 = notice_undegraduate = n (Notice)
}
El reporte reportRunTimeServiceRequest41 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
La undécima prueba (reportCompositeServiceRequest50) fue un pedido de servicio por una
nota de inscripción de no graduado y la inscripción a la bolsa de trabajo de la facultad
presentando los datos del nuevo estudiante y un curriculum. El agente determinó que el
pedido podía ser resuelto por dos servicios, el servicio wsMatriculate y el servicio
wsInscribeJobBag pero que como el pedido era incompleto y no cumplía las reglas no podía
ser ejecutado. Faltaba la presentación de una nota.
La duodécima prueba (reportCompositeServiceRequest51) fue un pedido de servicio por
una nota de inscripción de no graduado y la inscripción a la bolsa de trabajo de la facultad
presentando los datos del nuevo estudiante, un curriculum y una nota de no graduado. El
agente determinó que el pedido podía ser resuelto por dos servicios, el servicio
wsMatriculate y el servicio wsInscribeJobBag, los cuales podían ser ejecutados porque el
pedido era completo y cumplía con las reglas del servicio.
SWScompuesto = {wsMatriculate, wsInscribeJobBag}
ABoxpedido= { INPUT {x1 (New_Student), x2(Curriculum),
notice_undergraduate (Notice)},
OUTPUT {notice_undergraduate (Notice), x6 (JobPostulant)}
}
ABoxinferido= { x1 = ug (UnderGraduate) = nt (New_Student),
x2 = c (Curriculum),
x5 = x4 = x3 = notice_undegraduate = n (Notice),
x6 = jp (JobPostulant)
}
El reporte reportRunTimeServiceRequest51 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.

75.00 Tesis
118
La decimotercera prueba (reportCompositeServiceRequest60) fue un pedido de servicio
para realizar una postulación de pasantía presentando la inscripción a la bolsa de trabajo y la
oferta de pasantía elegida. El agente determinó que el pedido podía ser resuelto por un
servicio, el servicio wsPostulateJobU pero que como el pedido no cumplía la regla del
servicio no podía ser ejecutado. Faltaba la existencia de una nota de no graduado inscripto.
La decimocuarta prueba (reportCompositeServiceRequest61) fue el pedido de servicio para
realizar una postulación de trabajo de pasantía presentando una inscripción a la bolsa de
trabajo, la oferta de pasantía y los datos del nuevo estudiante no graduado. El agente
determinó que el pedido podía ser resuelto por un servicio, el servicio wsPostulateJobU
pero no podía ser ejecutado porque no se cumplía la regla asociada con el servicio. Faltaba la
presentación de una nota de no graduado inscripto.
La decimoquinta prueba (reportCompositeServiceRequest62) consistió de un pedido de
servicio para realizar la postulación a una oferta de pasantía presentando la oferta de
pasantía, el registro de inscripto en la bolsa de trabajo y una nota de no graduado. El agente
determinó que el pedido podía ser resuelto por un servicio, el servicio wsPostulateJobU el
cual podía ser ejecutado porque el pedido era completo y cumplía con las reglas de los
servicios.
SWScompuesto = SWSsimple = {wsPostulateJobU}
ABoxpedido= { INPUT {x1(JobPostulant), x2(JobOfferPassant),
notice_underGraduate (Notice)},
OUTPUT {x4 (PostulationPassantJob)}
}
ABoxinferido= { x1 = jp (JobOfferPassant),
x3 = notice_underGraduate = n (Notice),
x4 = ppas (PostulationPassantJob),
ug (UnderGraduate) = nt (NewStudent)
}
El reporte reportRunTimeServiceRequest62 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
La decimosexta prueba (reportCompositeServiceRequest70) consistió de un pedido de
servicio para realizar la postulación a una oferta de trabajo profesional presentando los datos
del nuevo estudiante, una nota de inscripción de graduado, un curriculum y la oferta de
trabajo profesional elegida. El agente determinó que el pedido podía ser resuelto por tres
servicios, el servicio wsMatriculate, wsInscribeJobBag y wsPostulateJobG los cuales podían
ser ejecutados porque el pedido era completo y cumplía con las reglas de los servicios.
SWScompuesto = {wsMatriculate, wsInscribeJobBag, wsPostulateJobG}
ABoxpedido= { INPUT {x1(Curriculum), x2(JobOfferProfessional),
x3(New_Student), x6 = notice_graduate (Notice)},
OUTPUT {x10 (PostulationProfessionalJob)}
}
ABoxinferido= { x1 = c (Curriculum),

75.00 Tesis
119
x3 = gd (Graduate)= nt (New_Student),
x4 = x7 = x8 = x9 = notice_graduate = n (Notice),
x5 = jp (JobPostulant),
x10 = pprof (PostulationProfessionalJob)
}
El reporte reportRunTimeServiceRequest70 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
La decimoséptima prueba (reportCompositeServiceRequest80) consistió de un pedido de
para realizar la postulación a una oferta de pasantía y de una nota de inscripción presentando
los datos del nuevo estudiante, una nota de inscripción de no graduado, un curriculum y la
oferta de pasantía elegida. El agente determinó que el pedido podía ser resuelto por tres
servicios, el servicio wsMatriculate, wsInscribeJobBag y wsPostulateJobU los cuales podían
ser ejecutados porque el pedido era completo y cumplía con las reglas de los servicios.
SWScompuesto = {wsMatriculate, wsInscribeJobBag, wsPostulateJobU}
ABoxpedido= { INPUT {x1(Curriculum), x2(JobOfferPassant),
x3(New_Student), x6 = notice_undergraduate (Notice)},
OUTPUT {x4(Notice), x10 (PostulationPassantJob)}
}
ABoxinferido= { x1 = c (Curriculum),
x3 = ug (UnderGraduate)= nt (New_Student),
x4 = x7 = x8 = x9 = notice_undergraduate = n (Notice),
x5 = jp (JobPostulant),
x10 = ppas (PostulationPassantJob)
}
El reporte reportRunTimeServiceRequest80 con la ejecución del servicio compuesto se
puede ver en el directorio test/r2.
Para la composición de servicios el agente fue provisto con el razonador Pellet 2.2.1
desarrollado en la clase ReasonerEngine.java y utilizado por la clase Compositor.java. La
primera otorga al agente la capacidad de realizar inferencias y de encontrar relaciones de
tipo superclase, subclase, subsumido entre entradas y salidas de los servicios y de los pedidos,
todas marcadas con clases o instancias de la ontología StudentsJobBag.owl. La segunda
otorga al agente la capacidad de componer los servicios para el pedido recibido, utilizando la
clase ReasonerEngine, el algoritmo de backward-chaining y los algoritmos de verificación de
reglas (DL-Safe Rules).
Se pueden observar en las pruebas la utilización de clases superiores de la ontología como la
clase JobOffer definida, en la ontología, como superclase directa de las clases JobOfferPassant
y JobOfferProfessional y aceptada ontológicamente como entrada válida de los servicios
wsPostulateJobU y wsPostulateJobG respectivamente. De la misma manera, se puede
observar la utilización de la instancia notice_graduate, miembro de la clase Notice para
solicitar una nota de inscripción particular y aceptada ontológicamente como entrada válida
de los servicios que requiren una nota para ejecutar un pedido.
Los algoritmos de verificación de reglas hacen uso de la inferencia permitiendo controlar la

75.00 Tesis
120
ejecución correcta de los servicios. En varias pruebas, por ejemplo, al presentar una nota de
graduado, el razonador infería inmediatamente que la instancia gd pertenecía a la clase
Graduate y que era igual a la instancia nt de la clase New_Student por tener una nota de
graduado. Con esto satisfacía parte de la regla asociada al SWS wsPostulateJobG. Los axiomas
considerados fueron:
Graduate ≡ hasNotice value notice_graduate
en la ontología StudentsJobBag.owl
gd (hasNotice notice_graduate)
en la ontología members StudentsJobBag.owl Rule [JobPostulantOf (jp, nt), hasNotice (nt, notice_graduate)] => [hasPostulationProfessionalJob (nt, pprof)]
en la ontología rulePostulateJobG.owl.
Inferencias similares fueron realizadas por el agente por medio del razonador DL en el resto
de las pruebas, como se puede observar en los reportes finales ubicados en el directorio test .
El marcado ontológico de los SWS fue una aproximación al funcionamiento general que
tendría la bolsa de trabajo de una facultad. Tal aproximación fue determinante en la
elaboración de las ontologías que permitieron agregar la semántica necesaria a los servicios
a fin de que el agente pudiera realizar la composición dinámica de servicios como finalmente
fue presentado en esta sección.

75.00 Tesis
121
Capítulo VI
Conclusiones y trabajos futuros
Los servicios Web fueron construidos adoptando estándares a fin de asegurar servicios
independientes de la tecnología y capaces de interoperar con otros servicios Web.
WSDL y SOAP emplean tecnologías XML para 1) describir los contratos de servicio de los
servicios Web y 2) permitir la combinación de tecnologías complejas en la construcción de
servicios Web.
Los contratos de servicios son más valiosos que las implementaciones por representar
conocimiento vital de negocios, son el mecanismo primario para reducir acoplamiento de
interfaz y la base para compartir y reutilizar servicios por lo cual deben ser manejados como
un artefacto separado, utilizando un mecanismo formal de extensión y versionado que
permita controlar dependencias y costos.
Los servicios requieren de un cambio radical en la manera de pensarlos. Para esto, el
desarrollo orientado a servicios plantea una división de responsabilidades donde surgen los
roles del analista de negocios y el técnico. El primero es responsable de montar flujos de
procesos a fin de asegurar el cumplimiento de requerimientos operacionales y estratégicos
de negocios. El segundo es responsable de manejar la complejidad de tecnologías en el
despliegue de servicios, asegurar que las descripciones XML/Web son las que el usuario
necesita y determinar los datos correctos a compartir.
Un servicio es un activo que establece prestaciones y calidad a través de contratos de servicio.
Un servicio Web es funcionalidad disponible en la Web según estándares estipulados (SOAP,
WSDL, UDDI) a fin de garantizar interoperabilidad. Un servicio Web semántico posee
descripciones realizadas por ontologías las cuales agregan un nivel más de procesamiento a
fin de optimizar el ciclo de descubrimiento, selección, invocación y composición de los
servicios Web.
Los servicios Web son recursos Web y son capturados en términos de tareas, las cuales
combinan el concepto de acción con intención: los servicios Web son invocados con un
propósito, que puede ser expresado como un objetivo de estado deseado.
Una ontología es una semántica formal la cual por describir el significado del conocimiento
de manera precisa logra una interpretación única por parte de máquinas y personas.
Disponer de una semántica formal resulta imprescindible para implementar sistemas de
inferencia o de razonamiento automático
Las ontologías actúan como una herramienta para compartir información y conocimiento, y
por lo tanto, para conseguir interoperabilidad semántica. Las ontologías asisten a la Web
Semántica por unificar contenidos semánticos y formalizar conocimiento consensuado y
reutilizable. Brindan ventajas como el desarrollo de aplicaciones con esquemas de datos
compartidos, el impulso de transacciones entre empresas y la búsqueda de información por
inferencias.

75.00 Tesis
122
Las máquinas son capaces de inferir, mediante procesos lógico-matemáticos, conclusiones a
partir de datos representados en un lenguaje formal (lógico y axiomático). Representar los
datos en un lenguaje formal posibilita que las máquinas puedan realizar inferencias lógicas.
Al anotar las descripciones de los servicios Web con ontologías, se consigue mayor
automatización, reduciendo el involucramiento humano en la comprensión datos y
funciones de servicios.
Entre los lenguajes ontológicos, OWL presta el mejor soporte de razonamiento al proveer
mayor poder expresivo y promover motores de inferencia.
El desarrollo y aplicación de ontologías depende de razonamiento. Un razonador es un
componente clave para trabajar con ontologías OWL DL. Los razonadores DL verifican
subsunción, consistencia y satisfactibilidad de ontologías, entre otras.
En el proceso de inferencia, cada pieza de información tiene la capacidad de producir nueva
información. Dicho proceso es vulnerable al fenómeno “garbage in, garbage out” y por ello
se deben aplicar cuidados extras a fin de validar la información inferida.
La composición automática por medio de servicios Web semánticos es conseguida con
ontologías cuidadosamente construidas las cuales reflejen los objetivos de dominio. El proceso
de desarrollo de una ontología es un proceso iterativo, compuesto de sucesivas
aproximaciones interviniendo en él expertos de dominio hasta conseguir una versión final
de la misma. Este proceso iterativo se extiende a lo largo del ciclo de vida de la ontología.
Varias metodologías generales existen para desarrollar ontologías, destacándose Diligence,
Competency Questions, Methontology, On-To-Knowledge [Contreras y Comeche; 2007].
La combinación de agentes y servicios fue realizada en un escenario donde los SW proveen la
funcionalidad de bajo nivel y los agentes la funcionalidad de alto nivel por utilizar, combinar y
coreografiar SW, obteniendo funciones de valor agregado. El agente construido reúne las
soluciones más recientes y distinguidas en relación a los avances en la composición de
servicios Web, a saber: implementado según la recomendación SAWSDL del W3C (extensión
semántica de WSDL) posee la capacidad de servirse de la información provista por servicios
Web semánticos para 1) determinar de qué categoría el servicio es miembro reduciendo
costos asociados con la búsqueda de servicios; 2) realizar la correcta utilización de los SWS
por incorporar reglas DL-Safe en las operaciones de SWS y 3) utilizar las ontologías
construidas correspondientes al dominio de datos asociado con la actividad dentro de la
categoría a la cual pertenecen los servicios.
Respecto del caso práctico, desde el punto de vista ontológico, 1) las limitaciones impuestas al
incorporar reglas DL-Safe y una ontología con una base de conocimiento formada por un
TBox acíclico y 2) los beneficios otorgados por la elección de un razonador DL posibilitó al
agente en el primer caso aprovechar la mayor expresividad ofrecida por OWL y en el
segundo, mejorar la búsqueda de servicios al considerar las relaciones semánticas de los
contratos de servicios.
Para ejecutar la composición de servicios, el agente fue implementado con el algoritmo de
backward-chaining para analizar los tipos de asociación entre entradas y salidas de servicios
y seleccionar aquellos que resolvieran el pedido. Además, para dotar al agente con la
capacidad de componer servicios se considero en el diseño de los servicios el formalismo de

75.00 Tesis
123
acciones desarrollado por [Baader et al.; 2005] quienes basaron en lógica descriptiva y
razonamiento de acciones la descripción de funcionalidad de los SW.
Como trabajo futuro queda investigar la posibilidad de ampliar los tipos de asociación
empleados en la composición de servicios con el fin de mejorar provisión de servicios,
investigar heurísticas del algoritmo de backward-Chaining, estudiar la capacidad del agente
para componer servicios en un MAS (sistema distribuido), innovar con la mediación de
ontologías al indicar en nuevas ontologías equivalencias de clases y de individuos entre las
ontologías que acompañan los SWS. Las ontologías obtenidas deberían ser sencillas y de
carácter público.

75.00 Tesis
124
Glosario
PLATAFORMA
Una plataforma es una base sólida sobre la cual construir algo. Puede estar basada sobre
estándares y especificaciones, siendo su grado de apertura a los mismos y la adherencia a ella
por parte de vendedores IT, de considerable importancia. Como ejemplos de plataformas
basadas en especificaciones y estándares se encuentran la plataforma de aplicación Web
(navegadores, URLs, HTML, CSS y HTTP/S), J2EE y CORBA. Por otro lado, los estándares de
servicios Web (SOAP, WSDL) son elementos claves de ella (pueden ser extendidos utilizando
otros estándares a fin de ajustar requerimientos específicos de negocios, de la industria o de
la organización).
URL
RFC 1738137. Los recursos disponibles en Internet son representados mediante secuencias
de caracteres llamadas Uniform Resource Locators (URL).
Los URL son utilizados para localizar recursos. Proveen un identificador abstracto de la
ubicación de un recurso. Un URL es escrito como sigue:
<scheme>:<scheme-specific-part>
El URL contiene el nombre del esquema empleado seguido por dos puntos y una secuencia
cuya interpretación depende del esquema. Los componentes de la jerarquía son separados
mediante “/”.
URL cubre los siguientes esquemas, además de permitir la especificación de esquemas
futuros:
� FTP: File Transfer Protocol,
� HTTP: Hypertext Transfer Protocol,
� GOPHER: protocolo Gopher,
� MAILTO: Electronic Mail Address,
� NEWS: USENET NEWS,
� NNTP: USENET NEWS utilizando acceso NNTP,
� TELNET: Referencia a sesiones interactivas,
� WAIS: Wide Area Information Servers,
� FILE: nombre específico de un archivo en un host y
� PROSPERO: directorio de servicios PROSPERO.
137
http://www.faqs.org/rfcs/rfc1738.html

75.00 Tesis
125
En algunos casos, los URL son utilizados para localizar recursos que contienen punteros a
otros recursos. Esos punteros son representados como enlaces relativos donde la expresión
de ubicación del segundo recurso está en términos del primero.
Mientras que el esquema elegido determina la sintaxis del resto del URL, los protocolos
basados en el protocolo IP para especificar un host en Internet utilizan una sintaxis común
para datos específicos del esquema:
//<user>:<password>@<host>:<port>/<url-path>.
Los datos específicos del esquema comienzan con una doble barra “//” para indicar su
conformidad con la sintaxis común de esquemas en Internet. Los componentes usuario y
clave son opcionales, host corresponde al nombre de dominio completo de un host en
Internet, port al número de puerto para conectarse y url-path a los datos específicos del
esquema.
El URL con esquema HTTP determina recursos de Internet accesibles utilizando HTTP. Un
URL HTTP es
http://<host>:<port>/<path>?<searchpart>
El valor por defecto de port es 80, <path> representa un selector HTTP y <searchpart> una
cadena de consulta. Los dos últimos son opcionales y dentro de ellos los caracteres “/”, ”;”, ”?”
son reservados. El carácter “/” puede ser utilizado dentro de HTTP para designar la estructura
jerárquica.
El URL con esquema file es utilizada para indicar archivos accesibles sobre un host
particular. Este esquema, a diferencia de los otros esquemas de URL, no representa un
recurso universalmente accesible en Internet. Un URL file es
file://<host>/<path>
La parte <host> es el nombre de dominio completo del sistema sobre el cual el path es
accesible y <path> es la jerarquía de directorios.
Un caso especial de <host> es la cadena “localhost” o la cadena vacía, donde ambas son
interpretadas para referir a la máquina donde el URL es interpretado.

75.00 Tesis
126
URI
RFC 3986138. El Uniform Resource Identifier (URI) es una secuencia compacta de caracteres
que identifica un recurso abstracto o físico. La especificación define la sintaxis genérica del
URI y un proceso para resolver las referencias URI que podrían estar en forma relativa, junto
con pautas y consideraciones de seguridad para la utilización de URIs en Internet. La sintaxis
URI define una gramática que es un superconjunto de todos los URIs válidos, posibilitando
implementar un analizador sintáctico de los componentes comunes de una referencia URI,
sin conocer los requerimientos específicos de esquema. La especificación no define una
gramática para URIs; esa tarea es ejecutada por las especificaciones individuales de cada
esquema URI.
Un URI es caracterizado como sigue:
� Uniform: provee varios beneficios. Permite que diferentes tipos de identificadores de
recursos puedan ser utilizados en el mismo contexto, aún cuando los mecanismos
utilizados para acceder a esos recursos puedan diferir. Esto permite una interpretación
semántica uniforme de convenciones sintácticas comunes, a través de diferentes tipos de
identificadores de recursos. Permite la introducción de nuevos tipos de identificadores de
recursos sin interferir con los identificadores existentes. Permite la reutilización de los
identificadores en diferentes contextos, brindando a las aplicaciones la posibilidad de
aprovechar un conjunto de identificadores ampliamente utilizados.
� Resource: la especificación no limita el alcance de lo que puede ser un recurso sino que el
término es utilizado en un sentido más general para cualquier cosa que pueda ser
identificado por un URI como un documento electrónico, una imagen, un servicio, etc. Un
recurso no es necesariamente accesible desde Internet (personas, empresas, libros). Del
mismo modo, los conceptos abstractos pueden ser recursos (operadores en una operación
matemática, tipos de relación o valores numéricos).
� Identifier: incorpora información para distinguir aquello que está siendo identificado.
Un URI es un identificador consistente de una secuencia de caracteres que sigue las reglas
definidas por la especificación. Permite la identificación uniforme de recursos por medio de
un conjunto extensible de esquemas de nombres. Cada esquema debe determinar cómo
acompañar la identificación, asignarla o habilitarla.
Los URIs tienen alcance global y son interpretados consistentemente sin importar el
contexto, aunque el resultado de esa interpretación podría estar en relación al contexto del
usuario final139. Sin embargo, una acción puede ser realizada sobre la base de que la
referencia tomará lugar en relación al contexto del usuario final, lo cual implica que una
acción que intenta referir a una cosa única globalmente debe utilizar un URI que diferencie
ese recurso de todas las otras cosas. Los URIs que identifican en relación al contexto local del
usuario final deberían ser utilizados sólo cuando el contexto mismo es un aspecto definido
del recurso140.
Cada URI comienza con un esquema, que posee su especificación para asignar
138 http://www.faqs.org/rfcs/rfc3986.html 139 http://localhost tiene la misma interpretación para cada usuario final de esa referencia, aunque la interfaz de
red correspondiente a “localhost” puede ser diferente para cada usuario final: la interpretación es
independiente del acceso 140
Como un manual de ayuda on-line que apunta a un archivo en el sistema de archivos del usuario final
(“file:///etc/hosts”).

75.00 Tesis
127
identificadores dentro de ese esquema. Así la sintaxis URI, es un sistema de nombres federado
y extensible, donde cada especificación de esquema puede restringir la sintaxis y semántica
de los identificadores utilizados en el esquema.
Esta especificación define los elementos de la sintaxis URI requeridos por todos los esquemas
URIs o comunes a muchos esquemas URIs. Define la sintaxis y semántica necesaria para
implementar un analizador sintáctico independiente del esquema, por el cual los manejos
dependientes del esquema de un URI pueden ser pospuestos hasta que la semántica
dependiente del esquema sea requerida.
La sintaxis URI genérica consiste de una secuencia de componentes jerárquicos, a saber,
esquema, autoridad, path, query y fragmento.
URI = scheme “:” hier-part [“?” query] [“#” fragment]
hier-part = “//” autoridad
/ path-absolute
/ path-rootless
/ path-empty
Los componentes path y esquema son requeridos, aunque el path puede estar vacío. Cuando
la autoridad está presente, el path debe empezar con el carácter “/” o puede estar vacío.
Cuando la autoridad no está presente, el path no puede empezar con los caracteres “//”.
La especificación detalla los caracteres, los componentes de la sintaxis, los usos, la resolución
por referencia, normalización y comparación, entre otras. Acá hemos mencionado sólo
algunas partes con el propósito de aclarar y diferenciar lo que URI representa.
IRI
RFC 3987141. El Internationalized Resource Identifier (IRI) extiende la sintaxis URI con un
repertorio más amplio de caracteres.
El URI es una secuencia de caracteres limitada a un subconjunto dentro del repertorio de
caracteres US-ASCII. Los caracteres en el URI representan palabras en lenguaje natural. Esta
utilización tiene varias ventajas: son más fáciles de memorizar, de interpretar, transcribir,
crear y adivinar. Para otros lenguajes diferentes del inglés, un script en lenguaje natural
utiliza caracteres distintos que no están dentro del rango de caracteres A-Z. Para muchas
personas manejar caracteres en Latín es tan difícil como lo sería para las personas que sólo
manejan caracteres del alfabeto latino scripts con otros caracteres. Scripts en otros lenguajes
son transcriptos al latín. Estas transcripciones, con frecuencia, son utilizadas en URIs pero
con la introducción adicional de ambigüedades. La infraestructura para la correcta utilización
de caracteres en los scripts locales es provista por sistemas operativos y aplicaciones de
software que pueden manejar simultáneamente una amplia variedad de scripts y lenguajes.
El incremento en el número de protocolos y formatos conduce a un amplio rango de
caracteres. Por este motivo, la RFC define un nuevo elemento de protocolo, llamado
Internationalized Resource Identifier (IRI) como un complemento del URI. Una IRI es una
secuencia de caracteres del conjunto universal de caracteres (Unicode/ISO 10646). Los IRIs
pueden ser utilizados en lugar de los URIs cuando sea necesario gracias al mapeo definido
por la RFC entre IRI y URI.
141 http://tools.ietf.org/html/rfc3987

75.00 Tesis
128
Los IRIs han sido diseñados para ser compatibles con los URIs. Esta compatibilidad es la
especificación de mapeos entre una secuencia de caracteres IRI y una secuencia de
caracteres URI.
La RFC describe los mapeos IRIs a URIs, conversión URIs a IRIs, utilización de los IRIs, pautas
para el procesamiento IRI y URI, entre otras.

75.00 Tesis
129
Referencias
http://hermit-reasoner.com/
HermiT OWL Reasoner
http://owlapi.sourceforge.net/index.html
The OWl API
http://www.w3.org/2001/sw/Activity.html
Herman I. 2010, última revisión. “Semantic Web Activity Statement”.
Rodríguez C. M., Montaño W. C., Martínez J.M. 2010. “Razonadores semánticos: en estado del
arte”. Revista Ingenium de la Facultad de Ingeniería, Universidad de San Buenaventura,
Bogotá, Colombia. Año 11. Nº 21. Enero-Junio de 2010.
http://jena.sourceforge.net/ontology/index.html
Dickinson I. 2009. “Jena Ontology API”.
http://www.w3.org/2001/sw/SW-FAQ
Herman I. 2009, última revisión. “W3c Semantic Web Frequently Asked Questions”.
http://www.w3.org/standards/techs/owl#w3c_all
W3C. 2009. “OWL Web Ontology Language Current Status”.
http://lsdis.cs.uga.edu/projects/meteor-s/
“METEOR-S: Semantic Web Services and Processes”.
http://www.w3.org/2002/ws/sawsdl/
Semantic Annotations for WSDL Working Group
García-Sánchez F., Valencia-García R., Martínez-Béjar R., Fernández-Breis J. 2009. “An
ontology, intelligent agent-based Framework for the provision of semantic web service”.
Expert Systems with Applications Vol. 36, Issue 2, Part 2, March 2009. Pages 3167-3187.
Navoni N., González P. 2009. “Indización social y control de vocabulario”. II Encuentro
Nacional de Catalogadores. “La Cooperación y las Normas para la Organización y Tratamiento
de la Información en las Bibliotecas Argentinas”.
http://www.ibm.com/developerworks/webservices/library/ws-restwsdl/
Hebeler J., Fisher M., Blace R., Perez-Lopez A. 2009. “ Semantic Web Programming”. 651
páginas. Editorial Wiley Publishing, Inc. ISBN 978-0-470-41801-7.
Mandel L. 2008. “Describe REST Web Services with WSDL 2.0”.
Ketel M. 2008. “Mobile Agents Based Infrastructure for Web services Composition”. 978-1-
4244-1884-8/08 IEEE.
Qiu Y., Ge J., Yin S. 2008. “Web Services Composition Method Based on OWL”. IEEE
International Conference on Computer Science and Software Engineering.
Mansilla Espinosa L. 2008. “¿Qué son los Agentes Inteligentes de Software?”. CONCYTEG. Año
3. Núm. 31, 21 de enero de 2008.
Fahad, M., Qadir, M.A. and Shah, S.A.H., 2008. In IFIP International Federation for
Information Processing, Volume 288; Intelligent Information Processing IV; Zhongzhi Shi, E.
Mercier-Laurent, D. Leake; (Boston: Springer), pp. 17–27.
Payne T. 2008. “Web Services from Agent Perspective”. IEEE Intelligent Systems. Vol. 23. Nro.
2.

75.00 Tesis
130
Contreras J., Martínez Comeche J.A. 2007. “Tutorial Ontologías”. Grupo de Trabajo sobre
“Normalización para la Recuperación de Información en Internet” (Normaweb).
http://www.sedic.es/gt_normalizacion.asp
Thakker D., Osman T., Al-Dabass D. 2007. “Semantic-Driven Matchmaking and Composition
of Web services Using Case-Based Reasoning”. Fifth European Conference on Web services.
Yong-Feng L., Jason Jen-Yen C. 2007. “OWL-Based Description for Agent Interaction”. 31st
Annual International Computer Software and Applications Conference (COMPSAC 2007)
IEEE.
Akkiraju R., Sapkota B. 2007. “Semantic Annotations for WSDL and XML Schema – Usage
Guide”. W3C Working Group.
http://www.w3.org/TR/sawsdl-guide/#registries
Berners-Lee T., Shadbolt N., Hall W. 2006. “The Semantic Web Revisited”. IEEE Intelligent
Systems.
Li Y., Yu X., Geng L. Wang L. 2006. “Research on Reasoning of The Dynamic Semantic Web Services Composition”. Proceedings of the 2006 IEEE/WIC/ACM International Conference on
Web Intelligence (WI 2006 Main Conference Proceedings) (WI’06)
Küster U., Stern M., König-Ries B. 2005. “A Classification of Issues and approaches in
Automatic Service Composition”. Intl. Workshop WESC’05.
Elenius D., Denker G., Martin D., Gilham F., Khouri J., Sadaati S., Senanayake R. 2005. “THE
OWL-S Editor – A Development Tool for Semantic Web Services”. Lecture Notes in Computer
Science, Vol. 3532/2005, 78-92. Springer Link.
Martin D., Paolucci M., McIlraith S., Burstein M., McDermott D., McGuinness D., Parsia B.,
Payne T., Sabou M., Solanki M., Srinivasan N., Sycara K. 2005. “Bringing Semantics to Web
Services: The OWL-S Approach”. SWSWPC 2004. LNCS 3387, pp. 26-42, 2005. Springer-
Verlag.
Battle S., Berstein A., Boley H., Grosof B., Gruniget M., Hull R., Kifer M., Martin D., Mcllraith S.,
McGuinness D., Su J., Tabet S. 2005. “Semantic Web Services Framework (SWSF)”.
http://www.w3.org/Submission/SWSF/
Akkiraju R., Farrell J., Miller J., Nagarajan M., Schmidt M., Sheth A., Verma K. 2005. “Web
Service Semantics – WSDL-S”.
http://www.w3.org/Submission/WSDL-S/#Terminology
Abián M. 2005. “El Futuro de la Web, XML, RDF/RDFS, ontologías y la Web Semántica”.
http://www.javahispano.org
Motik B., Sattler U., Studer R. 2005. ”Query Answering for OWL-DL with Rules”. Web
Semantics: Science, Services and Agents on the World Wide Web, Volume 3, Issue 1, Rule
Systems, July 2005, Pages 41-60.
Baader F., Lutz C., Milicic M., Sattler U., Wolter F. 2005. “Integrating Description Logics and
Action Formalisms for Reasoning about Web Services”. LTCS-Report 05-02, Chair for
Automata Theory, Institute for Theoretical Computer Science, Dresden University of
Technology, Germany, 2005.
Miller J., Verma K., Rajasekaran P. Sheth A., Aggarwal R., Sivashanmugam K. 2004. “WSDL-S
Adding Semantic to WSDL - White Paper”. LSDIS Lab, University of Georgia.
http://lsdis.cs.uga.edu/projects/meteor-s/wsdl-s/
Manola F, Miller E. 2004. “RDF Primer”. http://www.w3.org/TR/2004/REC-rdf-primer-

75.00 Tesis
131
20040210/#reification
Booth D., Haas H., McCabe F., Newcomer E., Campion M., Ferris C., Orchard D. 2004. “Web
Services Arquitecture”.
http://www.w3.org/TR/ws-arch/
Newcomer E.; Lomov G. 2004. “Understanding SOA with Web Services”. 480 Pags. Editorial
Addison Wesley Professional. ISBN 0-321-18086-0.
Sycara K., Paolucci M. 2004. “Ontologies in Agent Arquitectures” in Handbook on Ontologies
in Information Systems.
Aversano L., Canfora G., Ciampi A. 2004. “An algorithm for Web Service Discovery through
their composition”. Proceedings of the IEEE International Conference on Web Services
(ICWS’04).
Aversano L., Canfora G., Ciampi A. 2004. “An algorithm for Web Service Discovery through
their composition”. Proceedings of the IEEE International Conference on Web Services
(ICWS’04).
Rao J., Su X. 2004. “A Survey of Automated Web Service Composition Methods”. In Proceedings
of the First International Workshop on Semantic Web Services and Web Process
Composition, SWSWPC 2004.
Brickley D., Guha R.V. 2004. “RDF Vocabulary Description Language 1.0: RDF Schema”.
http://www.w3.org/TR/2004/REC-rdf-schema-20040210/
Paolucci M., Sycara K. 2003. “Autonomous Semantic Web Services”. In IEEE Internet
Computing, vol. 7, #5, Septiembre/Octubre 2003, pp 34-41.
Paolucci M., Kawamura T., Payne T., Sycara K. 2003. “Delivering Semantic Web Services”. In
Proceedings of the Twelves World Wide Web Conference (WWW2003).
Salazar Serrudo C. 2003. “Agentes en Comercio Electrónico”. Acta Nova. Vol. 2. Num.3,
Diciembre 2003.
Paolucci M., Kawamura T., Payne T., Sycara K. 2002. “Semantic Matching of Web Services
Capabilities”. In Proceedings of the 1st International Semantic Web Conference (ISWC2002).
Huhns M. 2002. “Agents as Web Services”. IEEE Internet Computing Vol. 6. Nro. 4. Pag. 93-95
ISSN: 1089-7801.
Sirin E., Hendler J., Parsia B. 2002. “Semi-Automatic Composition of Web Services using
Semantic Descriptions”.
Sycara K., Lu J., Klusch M. 1998. “Interoperability among Heterogeneous Software Agents on
the Internet”. Technical Report CMU-RI-TR-98-22, CMU Pittsburgh, USA.
Wooldridge M. 1998. “Intelligent Agents”. In Gehard Weiss, editor, Multiagent Systems: A
modern Approach to Distributed Artificial Intelligence, chapter 1, pages 27-77. The MIT
Press, 1999.

75.00 Tesis
132
Anexo I
El código desarrollado para la construcción del prototipo se encuentra disponible en el cd que
acompaña el presente trabajo. Se recomienda ver los reportes en html utilizando algún navegador
(IE, Mozilla).

75.00 Tesis
133
Anexo II Objetivos 1) Aportar al área de investigación de la composición dinámica de servicios una solución
eficiente y efectiva.
2) Proveer a un agente, que habitualmente actúa como un intermediario entre un usuario y
un proveedor, de información semántica acerca de los servicios que tiene registrados.
3) Utilizar ontologías apropiadas relacionadas a los servicios registrados para agregar
información semántica al agente.
4) Dotar al agente con la funcionalidad de establecer relaciones lógicas, realizar inferencias
a fin de poder vincular servicios de forma correcta para responder a un pedido que no puede
ser resuelto por un solo servicio sino por la combinación de varios servicios.
5) Determinar un escenario de aplicación representativo del problema a resolver.
6) Construir un prototipo para llevar a cabo los experimentos y elaborar las conclusiones
finales en relación a los resultados obtenidos.
7) Utilizar estándares de la industria en relación a la comunicación entre servicios como
WSDL y SOAP.
8) Investigar alternativas de composición semántica como OWL, Pellet, el algoritmo
backward-chaining.
9) Utilizar, preferentemente, herramientas open-source en la construcción de la solución.
10) Investigar razonadores alternativos que puedan ser incorporados en el agente.
11) Brindar una breve reseña acerca de los servicios Web y su creciente utilización, en
especial en una arquitectura orientada a servicios.
Top Related