
Apuntes ENM W Nicho Ecologico
66
2010 Laboratorio de Evolución Molecular y Experimental, del Instituto de Ecología de la UNAM Por Norberto Martínez APUNTES SOBRE MODELACIÓN DE NICHOS ECOLÓGICOS
-
Upload
victoria-torquemada -
Category
Documents
-
view
91 -
download
7
Transcript of Apuntes ENM W Nicho Ecologico

2010
Laboratorio de Evolución Molecular y Experimental, del
Instituto de Ecología de la UNAM
Por Norberto Martínez
APUNTES SOBRE
MODELACIÓN DE NICHOS
ECOLÓGICOS

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 2
Índice
Concepto de Nicho Ecológico 3
Conceptos clave del Nicho ecológico 5
Críticas al concepto de Nicho 6
Otros conceptos importantes 7
Modelado de Nicho Ecológico 8
Características y formatos de los distintos datos necesarios para
poder utilizarlos en la modelación de nichos ecológicos
14
Georreferenciación 14
Sistemas de Información geográfica 17
Principales algoritmos para modelado de nichos ecológicos 21
Maxent 21
Desktop GARP (Genetic Algorithm for Rule-set Production) 31
Pruebas de Solapamiento de Nicho 43
Prueba de Equivalencia 45
Prueba de Similitud 56
Literatura citada y recomendada 65

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 3
Apuntes sobre Modelación de Nichos Ecológicos
Concepto de Nicho Ecológico
Joseph Grinnell:
La unidad de distribución final, en la que cada especie está condicionada por sus
limitaciones instintivas y estructurales (1924) (“the ultimate distributional unit,
within which each species is held by its structural and instinctive limitations”
(1924)”).
O sea cada especie tiene sus características fisiológicas, morfológicas y de
comportamiento, lo que hace posible que ocupen determinados espacios ofrecidos
por la naturaleza (el nicho es una característica del medio no de los organismos).
Bajo este concepto existen nichos vacios y vacantes y la exclusión competitiva es
la interacción principal, donde no existe un balance y una especie homóloga
ecológicamente puede desplazar a la otra.
Los organismos que son equivalentes ecológicos son parte del “sustento” de este
concepto. Pues al existir nichos similares en distintos lugares estos son ocupados
por organismos también similares en características morfológicas, fisiológicas y
conductuales.
Charles Elton:
“El nicho describe el estatus de un animal en su comunidad, indicando que hace y
no solamente como se ve”
“El nicho de un animal es el lugar que ocupa en el ambiente biótico y su relación
con la comida y sus enemigos (naturales)”.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 4
Pone énfasis de la función de una especie dentro de una cadena alimenticia
(carnívoros, herbívoros), mientras que las condiciones abióticas no son tomadas
en cuenta.
Nuevamente bajo este concepto de la comunidad biótica no de los organismos en
sí. Por lo que el nicho en teoría no está restringido a una especie. Por tanto los
organismos relacionados como equivalentes ecológicos serían un indicio de
nichos similares, aunque las comunidades estuvieran en lugares muy alejados.
G. Evelyn Hutchinson (1944-58)
“El termino nicho se define como la suma de todos los factores que actúan en un
organismo; así el nicho se define como un hyperspacio n-dimensional” (1944). Las
variables pueden ser físicas o biológicas
Fig 1. Espacio ecológico

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 5
Conceptos clave del Nicho Ecológico
Nicho fundamental: Todos los aspectos (variables) del espacio o hipervolumen,
en la ausencia de otras especies. En pocas palabras es donde la especie puede
vivir.
Nicho realizado/efectivo (realized): Es un subconjunto del nicho fundamental en
el cual las especies están restringidas debido a sus interacciones interespecíficas.
De manera menos compleja, es el espacio ecológico y geográfico donde le
especie vive. Tener cuidado ya que para Soberón y Nakamura (2009) tiene una
leve pero fundamental diferencia: “el Nicho realizado (RN) es la parte del nicho
Potencial que las especies realmente usarían, después de tomar en cuenta los efectos
de competidores y depredadores”.
Bajo este modelo el nicho ecológico:
1- El nicho es una propiedad de la especie y no del medio ambiente
2- El nicho evoluciona
3- La estructura del nicho se constituye por el desempeño de una especie
medido en términos de adecuación.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 6
Fig. 2. Esquematización del concepto de Nicho ecológico (Soberon y Peterson, 2005)
Críticas al concepto de Nicho (enumeradas por Martínez-Meyer)
• Falta de un adecuada hipótesis nula y rigor estadístico
• La competencia no es necesariamente el proceso clave en ecología
(complementando esto, creo que en general es difícil demostrar
competencia realmente pero esto es algo que los demógrafos saben mejor).
• Uso ambiguo y confuso del término nicho.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 7
Otros conceptos importantes (tener reservas en cuanto a la competencia
como proceso que maneja las relaciones entre las especies)
• Amplitud de nicho (Niche breath): la variedad de recursos (hábitats)
utilizados por la especie.
• Partición de nicho (Niche partitioning): El grado de uso diferencial de las
especies para que coexistan.
• Solapamiento de nicho (Niche overlap): El uso mutuo de recursos por
diferentes especies.
• Ensamble de nicho (Niche assembly): Colonización y organización de las
especies en un Nuevo o abandonado nicho.
Un concepto reformulado de nicho:
Chase and Leibold (2003): “The niche of a species is the joint description of the
environmental conditions that allow a species to satisfy its minimum
requirements so that the birth rate of a local population is equal or greater
than its death rate along with the set of per capita impacts of that species on
these environmental conditions.”

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 8
Modelado de Nicho Ecológico
Desde la década de los ochentas, los australianos comenzaron con la modelación
“bioclimática” para estudios entomológicos (Climex). Después desarrollaron
Bioclim, DOMAIN y posteriormente GARP. Hoy en día existen cerca de 15
métodos para modelado de nicho, la mayoría de ellos de acceso libre.
El modelado del nicho ecológico es un instrumento que nos permite analizar los
factores ecológicos asociados a distintas poblaciones de determinada especie y
que la influyen en distintos grados y modos, información que analizada por
distintos tipos de algoritmos nos posibilita proyectar a nivel geográfico él área
potencial que ocupa la especie. Para Soberon y Nakamura (2009) el propósito del
modelado del nicho ecológico o de los modelados de distribución de especies y
del modelado de hábitat son el mismo: identificar los sitios adecuados para la
supervivencia de las poblaciones de una especie por medio de la identificación de
sus requerimientos ambientales.
En el sentido estricto lo que estamos modelando es el nicho efectivo o realizado
(nicho realizado Grinelleano, sensu J. Soberón) y el resultado del análisis nos
indica con cierto valor de probabilidad (y error estadístico asociado) el espacio
geográfico que es propicio para una especie
Por lo que las especies no podrían estar en el espacio predicho, ya sea por
efecto de:
a) Interacciones bióticas con otros organismos (competencia, depredación,
escases de alimento),
b) No se ha podido dispersar a esos lugares (por tiempo o barreras
geográficas y ecológicas).
c) Simplemente ha sido removida o se ha extinguido.
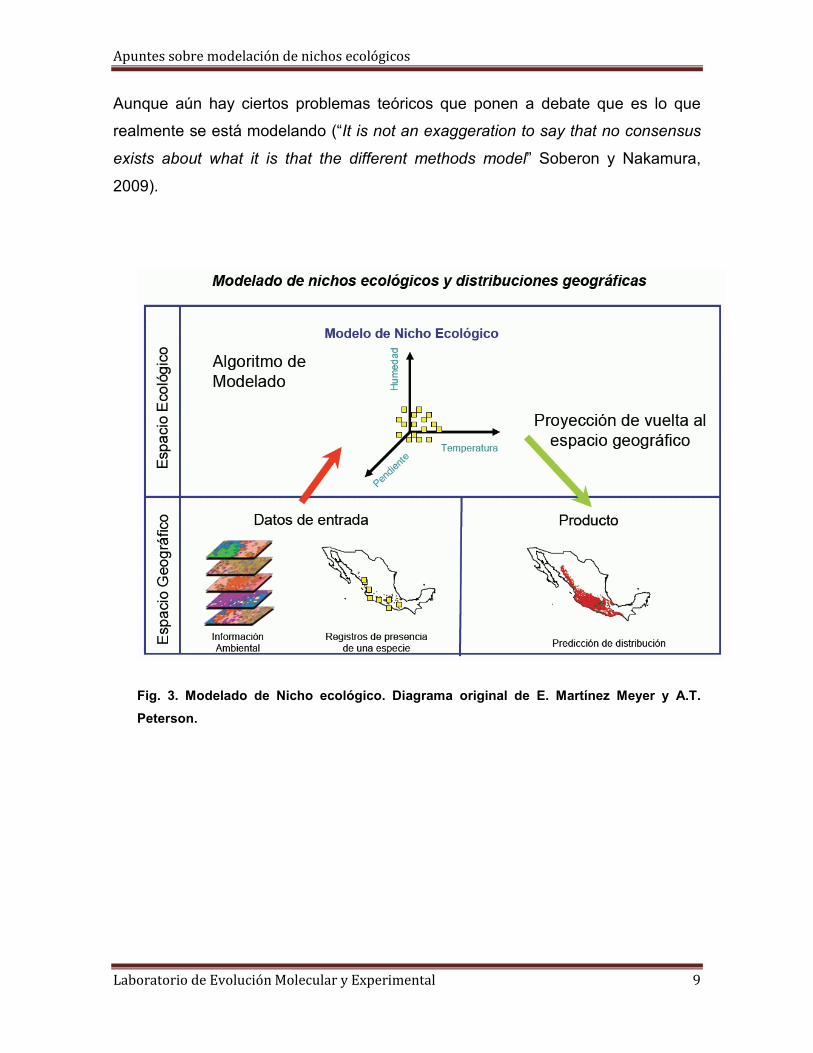
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 9
Aunque aún hay ciertos problemas teóricos que ponen a debate que es lo que
realmente se está modelando (“It is not an exaggeration to say that no consensus
exists about what it is that the different methods model” Soberon y Nakamura,
2009).
Fig. 3. Modelado de Nicho ecológico. Diagrama original de E. Martínez Meyer y A.T.
Peterson.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 10
Fig. 4. Modelado del Nicho ecológico, según Soberon and Peterson Biodiversity
Informatics 2005
Por lo anterior se deriva que:
1. Las especies responden a reglas ecológicas que determinan su distribución
en el espacio geográfico (en el modelado analizamos la interacción entre el
espacio ecológico y el geográfico).
2. Estas reglas ecológicas son independientes del espacio geográfico, por lo
que la especie puede ser predicha en lugares donde nunca ha sido

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 11
registrada (nicho potencial). Esto es importante ya que este aspecto nos
puede llevar a encontrar espacios geográficos en donde existen especies
nuevas que suelen ser especies hermanas de la que ha sido modelada (ver
Raxworthy et al. 2003 para un ejemplo con especies de camaleones de
Madagascar), lo que nos indica que el nicho ecológico tiende a ser
evolutivamente estable (conservadurismo del nicho).
3. Del párrafo anterior también se deriva que cada punto geográfico se
corresponde con sólo uno en el espacio ecológico, pero cada punto en el
espacio ecológico se puede corresponder con más de un punto en el
espacio geográfico.
Como hemos mencionado existen factores que influyen la distribución de las
especies que en forma general son la cantidad de calor (temperatura),
disponibilidad de agua y topografía, y de forma más particular pueden ser tipos de
suelo, evapotranspiración, calidad de la luz o días con temperaturas bajo cero etc.
Las distintas mediciones de estos factores registrados por un cierto tiempo en todo
el mundo se han estandarizado para formar capas bioclimáticas (Tabla 1). Estas
capas nos permitirán analizar el espacio ecológico de las especies, ya que se
pueden obtener los valores bioclimáticos correspondientes a cada dato de
presencia de alguna especie de interés y usarlos de insumos de un algoritmo de
modelación que nos permitirá obtener un modelos de nicho ecológico.
La modelación de nichos ecológicos aún es un área en desarrollo, que nos
permitirá resolver distintas preguntas biológicas y generar hipótesis de distribución
de especies bajo distintos escenarios geográficos y temporales, pero también
tienen limitaciones, por ejemplo:
1- Limitaciones asociadas a la incertidumbre de las capas y envolturas
bioclimáticas utilizadas (errores arrastrados desde la toma de datos e
incertidumbre asociada a la escala utilizada).

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 12
2- La incertidumbre asociada a los algoritmos utilizados.
3- No poder modelar las distintas interacciones bióticas de las especies o su
capacidad de dispersión.
Antes de continuar tenemos que apuntar otros conceptos importantes y que vale
distinguir bien ya que son fuente de confusión o debate:
• Para J. Soberón, realmente se está trabajando con el nicho Grinelleano en
la escala a la que normalmente se modelan los nichos ecológicos (celdas >
100 km2). Ejemplo: La resolución espacial de las capas bioclimáticas de
Worldclim es de: 30 segundos (0.93 x 0.93 = 0.86 km2 en el ecuador) a 2.5,
5 y 10 minutos (18.6 x 18.6 = 344 km2 el ecuador).
• En esta escala los factores bióticos propios de los nichos definidos por
Elton, son menos relevantes que los factores abióticos, es decir la señal
está dominada por los factores abióticos y los factores bióticos actúan
como ruido.
• Y se entiende que:
• A) Los procesos eltonianos (Nicho según Elton) son de muy alta resolución.
Las variables consideradas en este concepto (variables tróficas e
interacciones ecológicas) como concentración de nutrientes, tamaño y
distribución de la comida, presas, depredadores, competidores, densidad
de mutualistas etc., son variables altamente interactivas.
• B) En la escala de modelado de nicho se utilizan las variables
scenopoeticas (scenopoetic variable, sensu J. Soberón) que generalmente
se entiende como elevación, orientación, geología y clima que son poco
interactivas. Puede existir una exclusión competitiva pero esta no afecta al
total de la población.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 13
• C) El nicho Grinelleano es multidimensional (forman un n- hiperespacio
dimensional) en el espacio de las variables scenopoeticas.
Tabla 1. Código de las variables bioclimáticas obtenidas de WordClim
(http://www.worldclim.org/bioclim)
BIO1 = Annual Mean Temperature
BIO2 = Mean Diurnal Range (Mean of monthly (max temp - min temp))
BIO3 = Isothermality (P2/P7) (* 100)
BIO4 = Temperature Seasonality (standard deviation *100)
BIO5 = Max Temperature of Warmest Month
BIO6 = Min Temperature of Coldest Month
BIO7 = Temperature Annual Range (P5-P6)
BIO8 = Mean Temperature of Wettest Quarter
BIO9 = Mean Temperature of Driest Quarter
BIO10 = Mean Temperature of Warmest Quarter
BIO11 = Mean Temperature of Coldest Quarter
BIO12 = Annual Precipitation
BIO13 = Precipitation of Wettest Month
BIO14 = Precipitation of Driest Month
BIO15 = Precipitation Seasonality (Coefficient of Variation)
BIO16 = Precipitation of Wettest Quarter
BIO17 = Precipitation of Driest Quarter
BIO18 = Precipitation of Warmest Quarter

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 14
Características y formatos de los distintos datos necesarios para
poder utilizarlos en la modelación de nichos ecológicos
Georreferenciación
Antes de abordar algunos de los programas más importantes para generación de
modelos de nicho ecológico es necesario indicar cómo es que los datos
geográficos y bioclimáticos se manejan y procesan para poder ser ingresados a
dichos programas.
La información sobre las colectas y poblaciones de distintas especies que nos
interesa modelara tienen que contar con coordenadas geográficas, que nos
permitan ubicarlas espacialmente y poder posteriormente relacionarlas con los
datos medioambientales, ecológicos o geológicos, etc., recabados para el sitio o la
región en donde se colecto el organismo. Actualmente cada vez que se realiza
una colecta es una regla tomar las coordenadas geográficas con GPS, sin
embargo las colectas más antiguas sólo contenían el nombre de las localidades y
si tenemos suerte se cita a cuantos kilómetros se encontraban del poblado o
carretera más importante. Por lo que si se quieren utilizar estos datos es necesario
encontrar las coordenadas geográficas de los puntos de colecta, o sea
georreferenciar el punto para obtener las coordenadas, que deben de estar en un
formato decimal que es el que la mayoría de los programas de modelado aceptan.
Este proceso se puede hacer de varias formas, la primera es localizando la
localidad en cartas geográficas de la región y extrayendo directamente las
coordenadas de las cartas, que por estar generalmente en formato de
coordenadas geodésicas o geográficas (grados, minutos y segundos, con latitud
referida desde el ecuador y longitud tomando como referencia el meridiano de
Greenwich) se tienen que transformar a grados decimales:
Grados decimales = grados(.)+(min/60)+(seg/3600)

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 15
Estás coordenadas se tienen que referir con un signo positivo o negativo de
pendiendo de la región del mundo. Para lo longitud, la convención es poner un
signo negativo a los puntos al oeste del meridiano de Greenwich y positivos los
que están al este. Asimismo para la latitud todos los puntos al norte del ecuador
geográfico se asignan con un valor positivo y todos al sur con un valor negativo,
ejemplo:
Centro de la Ciudad de México: Lat. 19.4342, Long. -99.1386.
Generalmente no se marca el signo positivo ni los símbolos (N) y (W), pues sólo
se utilizan en coordenadas geográficas. En realidad este proceso es sencillo pero
hay que tener cuidado ya que las coordenadas geográficas dependen del tipo de
proyección utilizada y el Datum.
Las proyecciones cartográficas pueden ser cónicas o cilíndricas y se refieren a la
forma en que la geografía real del globo terrestre se proyecta en un plano, es decir
cómo los distintos puntos sobre el área curva del planeta se corresponden o
transforman a una relación ordenada en un plano (auxiliándonos de los meridianos
y paralelos que forman una especie de malla). A muy grandes rasgos existen dos
grupos de proyecciones:
1. Cilíndricas. En que toda la tierra se proyecta a un cilindro
imaginario que la rodea y que después se abrirá para formar un plano.
Ejem.: proyección de Miller, Peter y quizá la más usada Mercator (de las
que se derivan las coordenadas UTM o Universal Transverse Mercator).
2. Cónicas. Que cómo indica el nombre se explican como conos
que se ponen sobre la esfera terrestre y en donde se proyectaran los
puntos, para luego abrir dicho cono en un plano. Ejem.: proyección de
Lambert y proyección de Albert.
En cuanto al Datum o Datum de referencia en nuestro caso, indica a un punto de
referencia sobre la superficie de la tierra asociado a un modelo de su forma

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 16
(elipsoide de referencia) y a partir del cual toman las coordenadas. Si bien no es el
fin de este manual extendernos sobre concepto topográficos baste decir que, el
elipsoide de referencia es una aproximación teórica a la superficie terrestre, dado
que la tierra no es una esfera o un elipse uniforme (no es un cuerpo regular) lo
cual dificulta hacer distintos cálculos de tipo topográfico. Pero cómo aún se tenían
dificultades para adaptar los cálculos a distintas regiones o países del globo, se
invento el Datum para tratar de aproximar mejor las coordenadas a la “realidad”
local de ciertas áreas. De lo cual se puede deducir que existen muchos Datums.
Aunque los Datums más recientes tratan de abarcar mayores áreas. Por esta
razón una localidad en mapas con Datums diferentes también tiene coordenadas
diferentes, esto hay que tenerlo en cuanta si queremos transformar coordenadas
de un tipo de proyección a otra.
Para Norteamérica los Datums más comunes son el NAD27, NAD83 y el WGS84 y
para Europa es el ETRS89. Sin embargo el Datum WGS84 (prácticamente igual al
NAD83) es un Datum con referencia al centro de la tierra y valido para todo el
globo, por lo que es el sistema de referencia mundial actual y el que manejan los
dispositivos GPS por default, aunque siempre hay que tener cuidado al tomar las
coordenadas con un dispositivo de estos pues hay la posibilidad de tomar datos
con distintos Datums y distintas proyecciones (ejemplo con coordenadas UTM)
dando variaciones de cientos o miles de metros.
Para el caso de México el INEGI, los mapas topográficos tienen una proyección
Cónica conforme de Lambert (CCL; conforme se refiere a que no se conservan las
áreas sino sólo los ángulos de la proyección) y UTM con Datums NAD27 y
ITRF92.
Volviendo a la goerreferenciación, otra posibilidad es recurrir a los gaceteros
geográficos en red, que son bases de datos que contiene georreferenciadas
cientos de localidades, a veces incluyendo datos como altitud, y poblaciones
cercanas. Estos gaceteros pueden contener información de un solo país o tener

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 17
datos a nivel mundial. Incluso herramientas como Google Earth, son útiles par la
búsqueda y georreferenciación de localidades. Los gaceteros se pueden buscar
en la red con el nombre de “Gazetters”, uno bastante útil para México y para otras
partes del mundo es el Global Gazetter ver. 2.2 que se puede encontrar en:
http://www.fallingrain.com/world
También puede consultar la siguiente página de internet en donde se citan
distintos recursos de georreferenciación, transformación de coordenadas y bases
de datos:
http://www.herpnet.org/Gazetteer/GeorefResources.htm
Sistemas de Información geográfica
Una vez que contamos con nuestras localidades de colecta georrefencenciadas,
se ingresan en hojas de Excel u otro tipo de programas de bases de datos. El
siguiente paso es transformar o guardar estos datos en formatos que puedan ser
leídos por los programas de modelación de nicho. Esto se hace por medio de los
Sistemas de Información geográfica (SIG):
“Un SIG es un sistema de hardware, software y procedimientos diseñados para
auxiliar en la captura, administración, manipulación, análisis, y presentación de
datos u objetos referenciados espacialmente llamados comúnmente datos
espaciales u objetos espaciales” (Harmon y Anderson, 2003).
Uno de estos programas es el ArcView que no es considerado propiamente un
SIG por algunos autores, aunque sí lo es ArcGis, un programa más grande con
distintos módulos en dónde se incluye también a ArcView. ArcView es un
programa desarrollado por ESRI (Enviromental Systems Research Institute) con
sede en Estados Unidos. Con este programa se pueden representar datos
georreferenciados y proyectarlos sobre mapas, hacer análisis básicos de las

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 18
características y patrones de distribución de esos datos, generar y manipular
mapas (unirlos, cortarlos etc.), además de producir informes y tablas con los
resultados de dichos análisis, y transformar y guardar datos geográficos en
distintos formatos de salida, así como manejar las distintas capas bioclimáticas.
Tampoco es objetivo de este manual hacer un tutorial de ArcView, ya que por ser
una herramienta muy utilizada se pueden encontrar varios manuales en la red
traducidos o hechos en castellano, por ejemplo en:
http://www.ecoatlas.org.ar/descargas_programas.html
Tipos de datos manejados en un SIG
Básicamente un SIG maneja dos tipos de datos los vectoriales y raster. El formato
vectorial se compone de pares de coordenadas para cada objeto (vértices) con los
que se construyen vectores. A su vez se tienen distintos formatos que son puntos
(feature data que son sólo un par de coordenadas), líneas y polígonos. Es decir
representa a los objetos mediante puntos, líneas y polígonos.
Los formatos vectoriales pueden ser guardados en distintos tipos de archivos: DXF
(autocad), CDR (corell draw) o SHP (Shape file para ArcView). Un archivo Shape
file se compone por lo menos de tres archivos con las siguientes extensiones:
*.shp : Almacena los objetos vectoriales
*.shx : Almacena la indexación del objeto vectorial
*.dbf : Almacena los atributos del objeto vectorial
Puede contener otros archivos como *.prj usado por ArcGis y que guarda la
proyección cartográfica.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 19
Ventajas de los modelos vectoriales:
1. Buena presentación y resolución.
2. Menor tamaño y por tanto mayor velocidad en el
procesamiento.
3. Buen manejo de variables categóricas.
Desventajas de los modelos vectoriales:
1. Estructura de datos y programas de tratamiento complejos.
2. No es bueno para el manejo de variables continuas.
3. Inexacto en el manejo de objetos bien definidos (problemas
con curvas de nivel, isotermas, etc.).
Los datos tipo raster representan a los objetos mediante la estructuración del
espacio en una rejilla compuesta de celdas cuadradas llamadas pixeles a los
cuales se le añade un valor (nunca hay pixeles vacios, pueden ser transparentes o
de valor cero). Formatos tipo raster pueden ser:
1. Formatos de imagen (Imagen Data y Image Analyst Data) que
son raster multibanda (se guardan en una matriz de valores) como *.png,
*jpg (por ejemplo tiene tres bandas: rojo, verde y azul), *tif o *gif.
2. Grids (grids data) como los que se utilizan en GARP y que
tienen una sola capa (banda):
a) Formato Arc/Info Binary Grids: Desarrollado por ESRI (al igual
que el Ascii raster format) con extensión *.ADF consiste en grids
binarios que se guardan en varios archivos en por lo menos dos
directorios (el directorio nombre y el directorio info). Estos archivos son:
el dblbnd.adf que contiene información de los límites de las porciones
utilizadas del grid; el hdr.adf que es el que contiene el encabezado e

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 20
información del tamaño y número de los “mosaicos” utilizados; el sta.adf
que contiene información estadística del raster; vat.adf que tiene datos
del valor de atributos en tablas; el prj.adf que tiene la proyección y su
parámetros; el tic.adf con coordenadas; el w001001.adf que tiene los
datos actuales del raster y el w001001x.adf que contiene un índice de
los puntos de cada mosaico contenido en el archivo w001001.adf.
b) Ascii raster grid o simplemente Ascii (ESRI ASCII Raster
Format): Es más bien sólo un formato para el almacenamiento e
intercambio de la información entre distintos sistemas que utilizan
rasters y su extensión es *.asc.
Por lo cual podemos tener mapas en formato Arc/Info Binary Grids y Ascii
raster grids. Extensiones como *.grd o *.gri son propias de otros programas
de SIG y modelado como el DivaGis.
Ventajas de los modelos raster:
1. Procesos rápidos, fáciles de programar por su simplicidad
lógica.
2. Captura rápida de la información.
3. Facilidad de análisis y simulación espacial.
4. Representan bien a variables continuas y categóricas.
5. Tecnología barata y es la que usan las imágenes satelitales y
modelos de elevación.
Desventajas de los modelos raster:
1. Volumen muy grande de datos, por lo que necesitan gran
cantidad de RAM y espacio en disco duro.
2. Menor resolución o inexactitud derivada del tamaño del pixel.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 21
Principales algoritmos para modelado de nichos ecológicos
A continuación tocaremos dos de los algoritmos más utilizados para la modelación
de nichos ecológicos y que han demostrado un buen desempeño y poder de
predictibilidad y que utilizan sólo datos de muestreo eliminando los inconvenientes
de los métodos de presencia-ausencia en especial para determinar con exactitud
la no presencia de una especie en un área. Además como señalamos en la
sección de nicho ecológico aún hay duda en qué realmente se está modelando
con este tipo de algoritmos, si el nicho realizado Grinelleano u otra casa. Por tanto,
otros tipos de algoritmos aún necesitan evaluarse más, pues la duda de lo que en
verdad modelan es aún más grande que en los algoritmos que revisaremos, por
ejemplo con BIOCLIM probablemente se está modelando algo entre el nicho
realizado y el nicho fundamental ( Soberón y Nakamura, 2009).
Maxent
La idea general de Maxent es estimar una probabilidad de distribución destino
(objetivo, blanco) por medio de encontrar la distribución de probabilidad de
máxima entropía (es decir, que es el más extendida, o más cercana a ser
uniforme), sujeta a una serie de restricciones que representan nuestra información
incompleta acerca de la distribución objetivo.
¿Qué es Maxent?
Es un programa que modela la distribución geográfica de las especies, utilizando
como datos sólo los sitios de presencia y las variables bioclimáticas asociadas a
cada uno de esos puntos de presencia. Para modelar las distribuciones se basa
en el principio de Máxima entropía.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 22
Algunas ventajas de Maxent:
1- Sólo requiere datos de presencia
2- Puede utilizar datos continuos y categóricos
3- Algoritmos (deterministas) eficientes que garantizan que se converja en la
distribución de probabilidades propia (máxima entropía).
4- El sobre ajuste se evita.
5- El resultado es continuo, permitiendo distinguir sutiles cambios en la
adecuación (suitability) modelada (para cada especie) en diferentes áreas.
¿Qué es la máxima entropía?
La entropía en este contexto es un concepto derivado de la teoría de la
información que nos dice qué tan aleatorio es algo (por ejemplo, una línea de
caracteres: werztxnknñlk u otro tipo de señal) o sea es una medida de la
aleatoriedad. Es decir en una señal o conjunto de datos, si todos sus elementos
son equiprobables cuando aparecen, entonces la entropía es máxima.
Aplicando de manera práctica este concepto, se buscaría encontrar aquella
distribución de probabilidades que maximice la entropía, dado ciertas restricciones
que representan la información disponible (información incompleta) sobre el
fenómeno o tema estudiado.
Para explicar mejor este concepto imaginemos que tenemos 3 cajas de
manzanas. Estás cajas están cerradas pero contamos con la única información
(información parcial) de que en total hay nueve manzanas en esas tres cajas:
a) ¿Cuál es la manera más probable en que estén distribuidas las manzanas?
R= La distribución de máxima entropía es la más probable
b) ¿Pero por qué?

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 23
R= Según la fórmula de Shannon (1948) la entropía es
S=∑j nj ln(nj)
Donde nj es igual al número de manzanas en las cajas. Por tanto la
distribución de máxima entropía es (3,3,3). Ejemplo:
Caja 1 Caja 2 Caja 3 Entropía
3 3 3 -9.9
1 5 3 -11.3
0 1 8 -16.6
Vemos que la mayor entropía se corresponde a tener las tres cajas con tres
manzanas cada una (distribución uniforme y la más probable).Se puede
comprobar fácilmente estos resultados con una calculadora.
Pero podemos poner restricciones en la forma de organizar las manzanas, por
ejemplo: Pedimos que además que la distribución sea de máxima entropía cumpla
con que el número de manzanas en la segunda casilla sea de 5. Entonces
tenemos:
Caja 1 Caja 2 Caja 3 Entropía
2 5 2 -10.8
1 5 3 -11.3
4 5 0 -13.6
La distribución que maximiza la entropía es la primera (2, 5, 2), que es una
distribución más cercana a la distribución uniforme y la más probable bajo estas
condiciones

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 24
Ahora piense que en lugar de cajas tenemos pixeles (de un área de estudio) y en
lugar de manzanas tenemos presencias de especies, y las restricciones son los
valores empíricos promedio de las llamadas “características” de la información
disponible; en este caso variables bioclimáticas. Es decir, los pixeles del área de
estudio son el espacio de donde la probabilidad de distribución de Maxent es
definida. Los pixeles con presencia de una especie (records) constituyen los
puntos de muestreo y las características son las variables climáticas y ecológicas.
La información disponible sobre la distribución de los valores bioclimáticos
asociados con la presencia de especies, se presenta como un conjunto de valores
de variables reales, llamadas "características", y las restricciones son: que el valor
esperado para cada característica debe coincidir con su valor empírico promedio
(valor promedio de un conjunto de puntos de muestreo tomado de la distribución
objetivo o de destino).
Está sería la forma más sencilla de tratar de entender el principio bajo el cual
funciona Maxent. Claro que en realidad las cosas son un poco más complicadas
como veremos a continuación.
De acuerdo a lo anterior Maxent estima distribuciones que deben de estar de
acuerdo con todo lo que se conoce (aunque sea de manera incompleta) de la
información inferida de las condiciones ambientales de las localidades de
ocurrencia y evitar restricciones infundadas. Maxent entonces trata de encontrar la
distribución de probabilidad de máxima entropía (cercana a la uniforme) sujeta a
las limitaciones impuestas por la información disponible sobre la distribución
observada de las especies y las condiciones ambientales en el área de estudio.
Maxent computa una distribución de probabilidades basado en las variables
ambientales de toda el área de estudio. Si el área es muy grande (> 600,000
pixeles) se toma una muestra aleatoria de unos 100,000 pixeles “background” para
representar las condiciones ambientales de la región.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 25
Además del principio de máxima entropía, Maxent necesita de un algoritmo que le
permita encontrar las distribuciones con mayor entropía. Este algoritmo (sequential
update algorithm (Dudik et al., 2004). Utiliza iteraciones en donde va dando
distintos pesos a las variables utilizadas y va ajustándolas. Es un algoritmo
determinístico que según los autores y distintas pruebas empíricas garantiza que
convergerá en la distribución de probabilidades Maxent. Al terminar el proceso de
iteración Maxente asigna una probabilidad negativa cada pixel del área total de
estudio, que al final deben sumar 1, por lo que se aplica un valor de corrección
para hacerlos positivos y que sumen entre todos 100%. Pero como cada pixel
presenta valores muy pequeños, Maxent los presenta con un valor que es el
resultado de la suma del valor de ese pixel y de todos los demás pixeles con un
valor de probabilidad igual. Esos valores pueden ir de 0 a 100 e indican
probabilidad de ocurrencia de la especie.
El programa se carga con variables o capas bioclimáticas en formato ASCII (Que
se pueden bajar de la página de WorldClim o ser generadas por el usuario) y con
datos de presencia con nombre le la especie y coordenadas decimales guardados
en archivos de formato CSV (disponible en Excel). Se pueden mantener los
valores default como el umbral de convergencia = 10-5 e iteraciones de 500. Que
empíricamente se han observado que funcionan bien, y que son conservativos
pero que permiten al algoritmo llegar cerca de la convergencia, más adelante
tocaremos el tema de los umbrales. El resultado son mapas de probabilidad de
distribución en Ascii y una hoja de resultados en Html con imágenes de los
mismos mapas en (*png) y una serie de estadísticos de validación que tocaremos
más adelante. Los datos se cargan fácilmente por medio de una interfaz gráfica
como la que se muestra a continuación (del manual Maxent):

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 26
Fig. 5. Pantalla de entrada de la interface gráfica de Maxent.
Umbral de decisión
Para decidir la validación de un modelo y su interpretación es deseable distinguir
entre áreas adecuadas (para la especie) de las inadecuadas, por medio de
establecer un umbral de decisión, por arriba del cual el modelo resultante es
considerado como una predicción de presencia. Para el caso de modelos de sólo
presencia como Maxent y GARP, el umbral se puede encontrar de dos maneras:
1. Se escoge el valor de predicción más bajo asociado con algún record de
presencia. Este será el umbral de presencia más bajo (LPT, por sus siglas
en inglés). Y es un umbral conservativo.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 27
2. La aproximación más liberal. Consiste en aplicar un umbral fijo que refute
sólo el 10% más bajo de los posibles valores predichos. Para Maxent se
usa un umbral de 10 (T10) y para GARP un umbral de 1 (T1). Estos
umbrales se pueden escoger también de pruebas preliminares que den
valores de LPT más altos que los umbrales fijados.
Después de que Maxent ha terminado sus búsquedas, tiene la posibilidad de
hacer algunas pruebas estadísticas para determinar la validez estadpsitica de los
modelos encontrados. Asimismo muestra que variables son las que han
influenciado más o son las más importantes para el modelo determinado. Estás
últimas pruebas no las tocaremos a fondo ya que en el manual de Maxent, si están
suficientemente explicadas. Nos avocaremos a citar algunas de las pruebas que
no son explicadas con suficiente profundidad en la documentación existente.
Jackknife (Jackknife model testing)
Para esta prueba se excluyen las localidades observadas una en cada caso (o
corrida). Para cada predicción un umbral se aplica basado en localidades de
entrenamiento (1) y se prueba la habilidad de predecir las localidades excluidas.
Entonces se calcula un valor de probabilidad P para cada especie a través del set
de todas las predicciones de jackknife. También por medio de un procedimiento de
Jackknife se hace un análisis en Maxent para estimar que variables son más
importantes para la presencia de la especie.
(1) Nota: subconjunto de puntos que sí se utilizaran en el análisis, pero que
sirven para comenzar a entrenar o calentar el modelo iterativo. No confundir
con los puntos de prueba que se utilizan para validar el modelo al
compararlos con los de entrenamiento, ver más adelante.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 28
Curvas de omisión (Omission)
Antes tenemos que hablar de los tipos de errores que hay en las predicciones y en
los algoritmos de datos de sólo presencia, por lo que la explicación aplica también
para GARP.
Tabla 2. Matriz de confusión
Matriz de confusión
Presente Ausente
Predicho como
presente
a b
Predicho como ausente c d
Entonces a y d son predicciones correctas, pero:
b = Es un falso positivo o una sobrepredicción. Llamado error de comisión
(commission error).
c = Es un falso negativo o subpredicción. Llamado error de omisión (ommission
error).
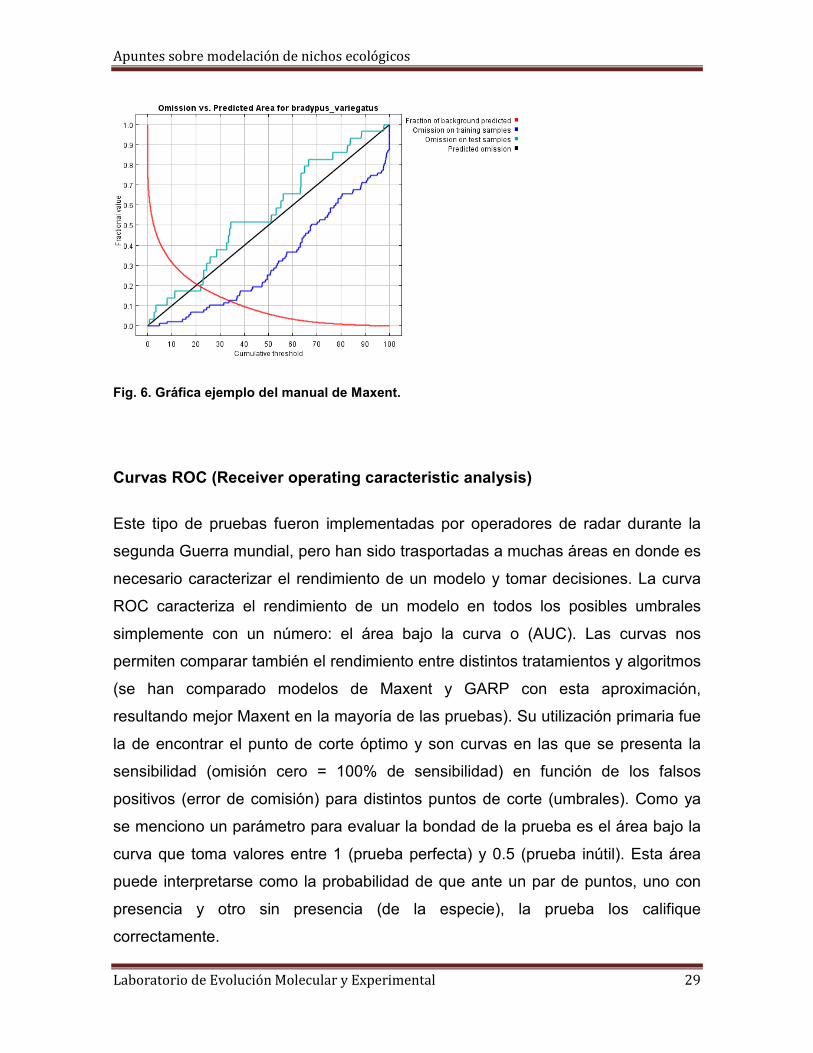
Maxent presenta una curva de omisión de datos de prueba (un 25% de puntos
aleatorios) contra omisión de datos de entrenamiento. En estás gráficas se
observa cómo el área predicha varía con la elección de un umbral acumulativo. Se
busca que la omisión de prueba se ajuste a la omisión de entrenamiento.
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 29
Fig. 6. Gráfica ejemplo del manual de Maxent.
Curvas ROC (Receiver operating caracteristic analysis)
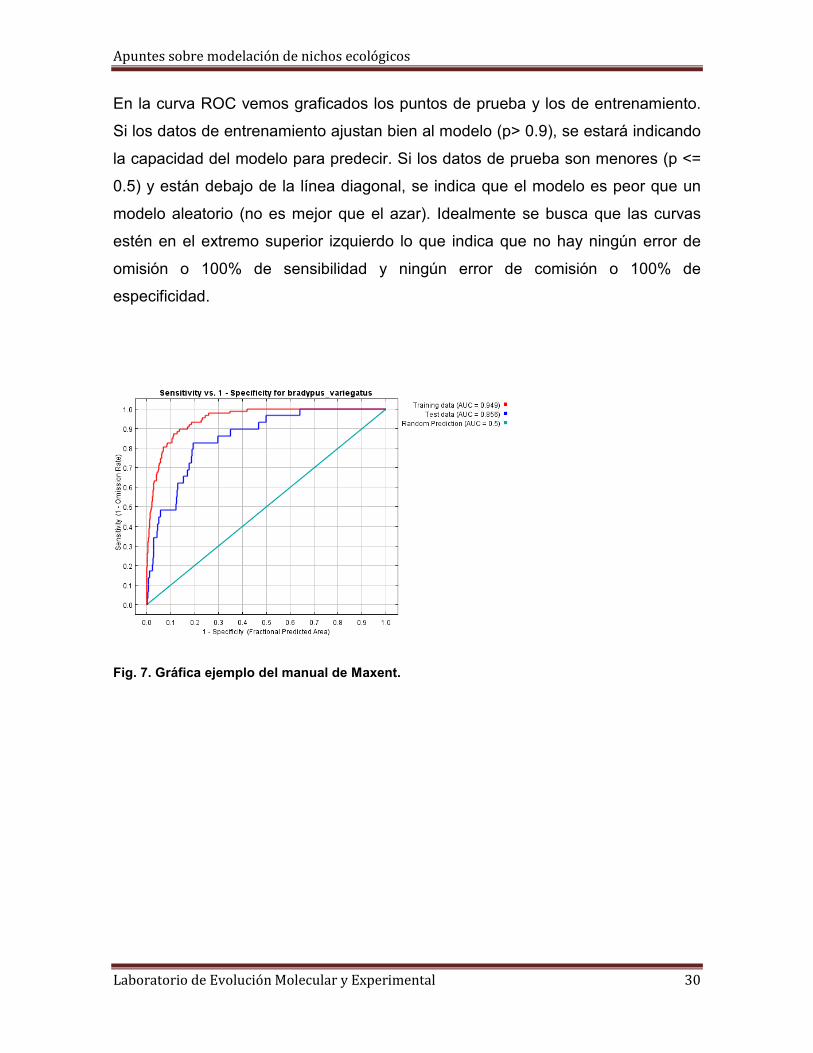
Este tipo de pruebas fueron implementadas por operadores de radar durante la
segunda Guerra mundial, pero han sido trasportadas a muchas áreas en donde es
necesario caracterizar el rendimiento de un modelo y tomar decisiones. La curva
ROC caracteriza el rendimiento de un modelo en todos los posibles umbrales
simplemente con un número: el área bajo la curva o (AUC). Las curvas nos
permiten comparar también el rendimiento entre distintos tratamientos y algoritmos
(se han comparado modelos de Maxent y GARP con esta aproximación,
resultando mejor Maxent en la mayoría de las pruebas). Su utilización primaria fue
la de encontrar el punto de corte óptimo y son curvas en las que se presenta la
sensibilidad (omisión cero = 100% de sensibilidad) en función de los falsos
positivos (error de comisión) para distintos puntos de corte (umbrales). Como ya
se menciono un parámetro para evaluar la bondad de la prueba es el área bajo la
curva que toma valores entre 1 (prueba perfecta) y 0.5 (prueba inútil). Esta área
puede interpretarse como la probabilidad de que ante un par de puntos, uno con
presencia y otro sin presencia (de la especie), la prueba los califique
correctamente.
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 30
En la curva ROC vemos graficados los puntos de prueba y los de entrenamiento.
Si los datos de entrenamiento ajustan bien al modelo (p> 0.9), se estará indicando
la capacidad del modelo para predecir. Si los datos de prueba son menores (p <=
0.5) y están debajo de la línea diagonal, se indica que el modelo es peor que un
modelo aleatorio (no es mejor que el azar). Idealmente se busca que las curvas
estén en el extremo superior izquierdo lo que indica que no hay ningún error de
omisión o 100% de sensibilidad y ningún error de comisión o 100% de
especificidad.
Fig. 7. Gráfica ejemplo del manual de Maxent.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 31
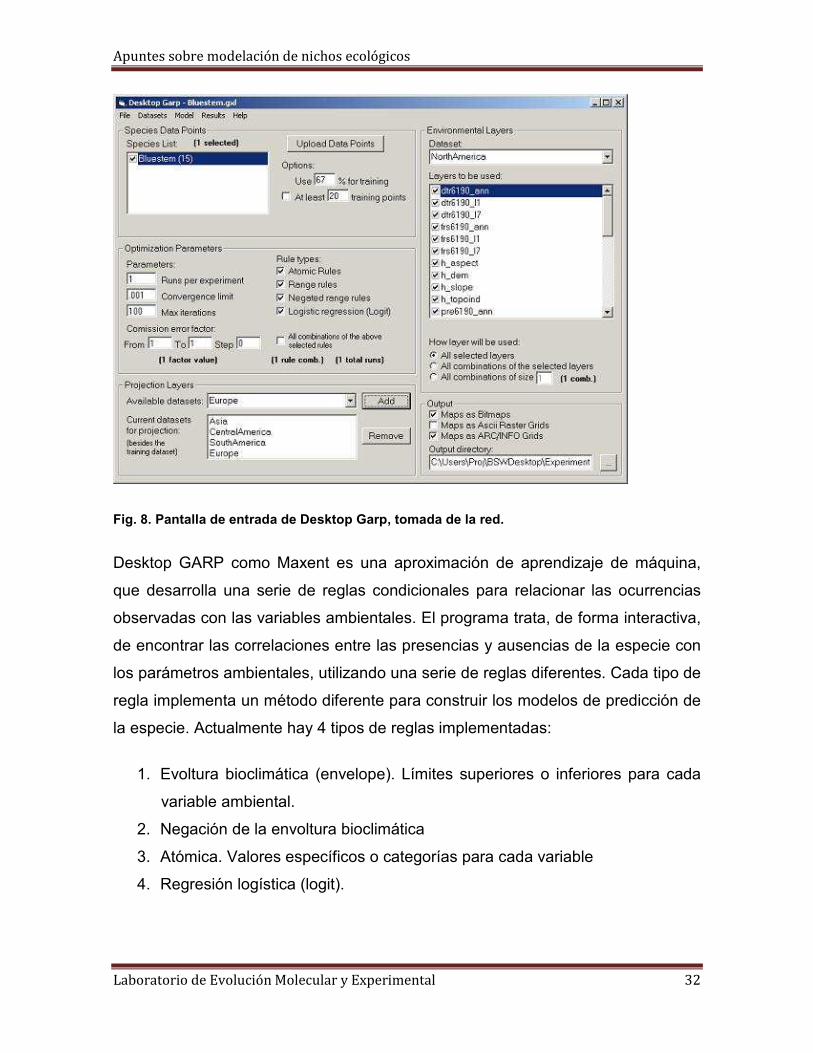
Desktop GARP (Genetic Algorithm for Rule-set Production)
Desktop Garp es un software para predecir y analizar la distribución de especies, y
es la versión de “escritorio” del algoritmo GARP (Genetic Algorithm for Rule-set
Production, por sus siglas en inglés) o algoritmo genético basado en reglas. GARP
está desarrollado por David Stockwell en Australia (ERIN Unit of Environment) y
que posteriromente fue mejorado en EU en el “San Diego Supercomputer Center”.
¿Qué es el algoritmo GARP?
GARP es un algoritmo genético que crea un modelo de nicho ecológico para una
especie que representa las condiciones ambientales donde dicha especie sería
capaz de mantener su población. GARP utiliza como entrada un conjunto de
localidades en archivos con coordenadas decimales en formato delimitado por
comas (Comma delimited), en hoja de cálculo de Excel (Spreadsheets) o SHP
(Shapefiles) de ArcView , donde se sabe que la especie está presente y un grupo
de coberturas geográficas que representan los parámetros ambientales (que
pueden limitar la capacidad de supervivencia de la especie) que pueden ser las
capas de WorldClim que se transforman en formato RAW por medio de la
extensión Garp Dataset cargada previamente en ArcView.
En cuanto al uso del programa es muy sencillo, tiene una interfaz gráfica en donde
el usuario puede cargar todos los datos requeridos y que una vez terminado el
programa devuelve archivos de predicciones de tipo binario (adecuado-no
adecuado) en mapas con formato en grids más una hoja de resultados en *xls.
También tiene una sección par proyectar los análisis útiles en el análisis de
especies invasivas o en cambio climático (ver manual de Desktop GARP):
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 32
Fig. 8. Pantalla de entrada de Desktop Garp, tomada de la red.
Desktop GARP como Maxent es una aproximación de aprendizaje de máquina,
que desarrolla una serie de reglas condicionales para relacionar las ocurrencias
observadas con las variables ambientales. El programa trata, de forma interactiva,
de encontrar las correlaciones entre las presencias y ausencias de la especie con
los parámetros ambientales, utilizando una serie de reglas diferentes. Cada tipo de
regla implementa un método diferente para construir los modelos de predicción de
la especie. Actualmente hay 4 tipos de reglas implementadas:
1. Evoltura bioclimática (envelope). Límites superiores o inferiores para cada
variable ambiental.
2. Negación de la envoltura bioclimática
3. Atómica. Valores específicos o categorías para cada variable
4. Regresión logística (logit).

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 33
Las reglas son desarrolladas usando un algoritmo genético, el cual refina la
solución en una manera “evolutiva” probando y seleccionando reglas en
subconjuntos aleatorios de los datos disponibles. Es implementada para manejar
datos de sólo presencia, seleccionando localidades de pseudoausencias de
manera aleatoria del área de estudio. Además utiliza localidades de
entrenamiento.
Con GARP se buscó encontrar un análisis robusto que produjera resultados
confiables bajo una gran variedad de condiciones de operación o problemas de
dominio. Entre todos los sistemas de aprendizaje de máquina se escogió el
algoritmo genético (GA, por sus siglas en inglés) que como otros de su tipo
(árboles de decisión, redes neuronales, etc,) están diseñados para analizar datos
pobremente estructurados (o dominios pobremente estructurados). El algoritmo
GA fue originalmente desarrollado por Holland (1975) y ha sido aplicado a una
gran variedad de campos (dominios) como funciones de optimización numérica,
diseño de sistemas de control adaptativo e inteligencia artificial. Una ventaja de
GA en GARP es la capacidad de generar y probar una gran gama de posibles
soluciones y modelos (categóricos, logísticos etc.).
¿Cómo entender que son las reglas?
Antes de continuar es conveniente un pequeño paréntesis para tratar de explicar
qué es una regla y entender de una manera básica cómo se calculan y hacen las
predicciones. Para este objetivo, GARP antes de utilizar el algoritmo genético tiene
que recabar los datos necesarios sobre distribución y condiciones medio
ambientales y unirlos o ligarlos de alguna forma. Esta forma es por medio de la
lógica y la probabilidad. Es decir se llevan a cabo procedimientos de tipo lógico
deductivo para asignar y comenzar a tener valores para construir las reglas que
más adelante veremos. Consideremos la figura 9 que esquematiza un área de
estudio, con localidades de muestreo y datos sobre el medio físico:

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 34
Fig. 9. Esquema de localidades y coberturas, para ejemplificar la forma básica del cálculo de
las probabilidades asociadas a las reglas de uso en GARP.
Primero se define la probabilidad de A, que se denota como P(A) y es igual a la
probabilidad de todos los puntos de muestreo en A (estrellitas en la figura). Y se
calcula esta probabilidad como P(A) = #A/n, que son las celdas o concretamente
los pixeles donde se encuentra la especie. Después tenemos que ligar la
probabilidad de la ocurrencia de una especie con los datos de por ejemplo
cobertura vegetal o datos bioclimáticos. Para lo cual se utilizan probabilidades
condicionales o sea la probabilidad de que un evento A ocurra dado un evento B:
P (A|B),
Y P(A|B) = P (AB)/P(B).

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 35
La probabilidad de B se calcula de una manera un tanto similar a la de A (por sus
valores en los pixeles) y P(AB) es la intersección de los eventos A y B, o sea la
probabilidad de que los dos eventos ocurran. Y la predicción se hace de la
siguiente manera: dado que si A entonces B, y A es verdad entonces predice B
(área de distribución predicha). Esta es una manera muy general de calcular las
probabilidades, ya que podemos tener diferentes conformaciones lógicas de los
conjuntos señalados en la figura anterior y por tanto A puede componerse de
muchas proposiciones por el uso de conjunciones y disyunciones (por considerar
otros conjuntos de datos como las demás capas bioclimáticas). Cuando una
predicción se satisface una porción del espacio de búsqueda se selecciona. Esto
significa que usa la predicción para seleccionar las porciones de área de estudio
para asignarles “presente” o “ausente”. Con este tipo de lógica básica se
construyen los distintos tipos de reglas que veremos más adelante.
Entonces GARP utiliza una gama de modelos para modelar los límites de las
potenciales relaciones entre los datos. Estás modelos tienen las citadas reglas,
que son diferentes en tipo para cada modelo, pero que son evaluadas de la misma
forma por el programa en cuanto a significancia estadística y precisión predictiva.
GARP selecciona automáticamente diferentes reglas para las predicciones en
cada celda (pixel), basado en el estimado de precisión de predictividad de cada
regla. Quizá lo anterior aún no tenga mucho sentido pero extrayendo algunos
datos de las primeras versiones de GARP pueda quedar más claro:
La intersección de límites (ranges) para todas la variables es una envoltura
bioclimática (profile), nos indica las regiones geográficas donde el clima es
adecuado para la especie, adjuntando percentiles de valores fijados para cada
parámetro
IF TANN=(23,29]degC AND RANN=(609,1420]mm AND GEO=(6,244]c THEN
SP=PRESENT
En otras palabras esta regla dice que si la temperatura anual (TANN) cae entre 23
a 29° C, y la precipitación anual (RANN) cae entre 609 y 1420 mm, y el valor de

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 36
categoría geológica (GEO) cae entre los límites de 6 a 244, entonces se predice
que la especie está presente. Una regla en GARP es similar a una regla de
envoltura (envelope), excepto que las variables pueden ser irrelevantes. Esto es,
una variable es irrelevante si los puntos pueden caer dentro de todo el límite. Una
modificación que ilustra una regla GARP modificada como lo antes dicho es:
IF TANN=(23,29]degC AND GEO=(6,244]c
THEN SP=ABSENT
Una regla atómica, es una es una conjunción de categorías o de valores simples
de algunas variables. En un lenguaje más coloquial tenemos:
Si la categoría geología tiene un valor 128 y la elevación (TMNEL) es 300 m.s.n.m.
entonces la predicción dice que la especie es ausente (ejemplo).
IF GEO=128c AND TMNEL=300masl
THEN SP=ABSENT
La regal logit es una adaptación de la regresión logística. La regresión logística es
una forma de regresión donde la salida o el resultado puede ser transformado en
una probabilidad. Por ejemplo, la regresión logística da un resultado con una
probabilidad p que determina si una regla debe se aplicada cuando p es calculada
usando:
p= 1/(1-e-y)
y y es la suma de la ecuación lineal en el precedente de la regla, ejem:
IF 0.1- GEO 0.1+TMNEL 0.3
THEN SP=ABSENT

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 37
La capacidad del set de reglas para tener la cobertura del área analizada y tener
un nivel de precisión determinado es diferente por si solas que si se les combina
en un solo modelo. La precisión puede ser mayor en alguna de las reglas, pero
con el modelo combinado la cobertura es total sin perder demasiada precisión.
Es decir la región predicha por cada una de las reglas por si sola es usualmente
menor que el área total. La precisión predictiva de los modelos compuestos por
diferentes grupos de reglas generalmente es equivalente o excede la precisión de
los modelos compuestos por una sola regla. Entonces el programa hace uso de
las más altas precisiones en cuanto a las reglas para aplicarlas en diferentes
áreas para alcanzar el óptimo en toda el área de estudio.
De manera teórica los diferentes tipos de modelos y el potencial número de
variables, imponen un problema de cómo encontrar el grupo de mejores modelos
en espacio de búsqueda muy grande. Estudios teóricos de DeJong (1975) y de
Holland (1975) junto con estudios experimentales de otros autores (ejem. Bethke,
1981) han mostrado que los GAS son eficientes para solucionar problemas en los
cuales se involucran muchas variables con mucho ruido y que potencialmente
pueden tener muchas soluciones.
Las reglas son desarrolladas por un proceso de refinamiento que se incrementa
gradualmente por el algoritmo genético. Cada iteración se conoce como una
generación, en el cual el conjunto de reglas son probadas, reproducidas y
mutadas. La manera en que se hace tiene los siguientes pasos:
1. Inicializa poblaciones de estructuras
2. Selección de subgrupos aleatorios de datos
3. Evaluación de una población (la población actual)
4. Salva las mejores reglas en un archivo
5. Termina la salida o resultado del archivo de reglas, o continua
6. Selecciona nuevas poblaciones, usando el archivo de reglas y generaciones
aleatorias.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 38
7. Aplica operadores heurísticos a la población (para elegir el mejor grupo)
8. Regresa a 2.
El algoritmo de GARP comienza imponiendo un grupo de reglas generadas por el
programa inicial. El primer paso iterativo en el ciclo de GARP es seleccionar los
datos por un muestreo aleatorio de la mitad de los datos disponibles. El segundo
paso es evaluar las reglas con los datos de muestreo. Para cada n punto de
colecta (presencia) los siguientes valores van incrementando:
1. no – el número de puntos que se aplica a las reglas.
2. pYs - el número de datos con la misma conclusión que la regla.
3. pX Ys – el número de datos que la regla predice correctamente
Los siguientes valores son calculados para evaluar el desempeño de cada regla:
1. Covertura=no/n
2. Probabilidad Prior =pYs/n
3. Probabilidad posterior =pX Ys/no
4. Significancia =(pX Ys – no * pYs/n)/ √ no * pYs *(1- pYs/n)/n
En terminología de algoritmos genéticos, cada regla es miembro de una población
e implementa un método diferente para construir los modelos de predicción de una
especie. Pero en general tenemos que la composición de una población cambia
con cada generación t, y los miembros de la población P (t +1) son escogidos de
la población P(t) de manera aleatoria por un proceso de selección. El
procedimiento asegura que el número esperado de veces que una estructura es
escogida es proporcional al rendimiento de la estructura, relativo al resto de la
población. Esto es si xj tiene dos veces el promedio de rendimiento de todas las

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 39
estructuras en P(t ) entonces xj se espera que aparezca dos veces más frecuente
en la población P( t+1 ). Al final del mecanismo de selección, la población P(t+1 )
contiene duplicados exactos de las estructuras seleccionadas en la población P(t ).
La variación es introducida en la reglas de cada nueva población por medio de
operadores genéticos recombinatorios idealizados, también llamados operadores
heurísticos, que son:
1. Unión
2. Mutación: a) Mutación aleatoria. El límite del nuevo valor está entre un
límite de valores; b) Mutación incrementada. El nuevo valor se obtiene al
sumarle uno al viejo valor.
3. “Crossover”. Es el más importante operador recombinatorio.
Bajo el operador crossover, dos estructuras en la nueva población intercambian
segmentos. Esto puede ser implementado escogiendo dos puntos al azar e
intercambiando segmentos entre los puntos. En la mayoría de los algoritmos
genéticos, la recombinación ocurre en cadenas binarias. En GARP sin embargo la
recombinación actúa en valores o límites de valores de variables, dependiendo del
tipo de regla. Por ejemplo dos reglas GARP pueden intercambiar límites de
variables climáticas en la recombinación crossover. Ejemplos:
Regla 1:
IF TANN=(23,29]degC AND RANN=(10,16]degC
THEN SP=PRESENT
Regla 2:
IF TANN=(35,38]degC AND TMNEL=(19,27]degC
THEN SP=PRESENT

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 40
Dado las dos reglas de arriba, suponga que el punto de crossover ha sido
escogido entre las variables. Y la estructura resultante podría ser:
Regla 3:
IF TANN=(23,29]degC AND TMNEL=(19,27]degC
THEN SP=PRESENT
Regla 4:
IF TANN=(35,38]degC AND RANN=(10,16]degC
THEN SP=PRESENT
El operador de mutación cambia el valor de una variable en un Nuevo valor.
Mientras que la mutación produzca pequeños cambios a las reglas, el crossover
introduce nuevas estructuras representativas o combinaciones de variables dentro
de la población. Si esta estructura representa un área de alto desempeño del
espacio de búsqueda, se conducirá a una nueva exploración en esta parte del
espacio de búsqueda. El algoritmo genético termina cuando un número fijado de
generaciones se alcanza o cuando la modificación o descubrimiento de nuevas
reglas es más baja (o muy baja) que una tasa fijada. El conjunto de reglas con
significancia estadística, es producido una vez que los ajustes han caído por
debajo de un porcentaje fijado.
Selección y validación de modelos en GARP
A continuación hablaremos un poco de la evaluación de la adecuación de cada
modelo generado, que no es otra cosa que la utilidad de las reglas. Los criterios
que GARP toma para realizar esto, los describiremos brevemente:

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 41
1. Probabilidad posterior. Escoge las reglas con mayor precisión.
2. Fuerza de selección. Se refiere a las reglas que aplican para muchos
puntos.
3. Significancia. De las reglas que expresan patrones persistentes en los
datos.
4. (De) Espacios ecológicos. Reglas que incluyen un volumen grande de
variables.
5. Inverso de la longitud de la regla. La cual regresa las reglas más cortas.
De manera muy general podemos decir que para hacer estas evaluaciones se
escoge una muestra aleatoria de la población, entonces el número de veces que
una regla es escogida, es una medida proporcional del desempeño o medida de
utilidad de la regla. También tenemos que generalmente la probabilidad posterior
(probabilidad de ocurrencia después de que una regla se aplica) se comporta
como una variable con distribución normal. Por tanto se pueden calculara valores
de la distribución Z (Z-scores) para realizar una prueba de significancia. Valores
altos de puntuación (score) indican que es altamente improbable que el resultado,
o sea la regla (probabilidad posterior) se producto del azar.
Lo anterior sólo se refirió a cómo encontramos las reglas más adecuadas y las
calificamos para generar un modelo, pero aún falta saber cómo evaluamos todos
los modelos de distribución generados por GARP, lo que se equivalente a escoger
el mejor subconjunto de modelos y evaluar su calidad.
Lo que hace GARP es escoger un subconjunto de puntos al azar lo que equivale a
particionar los datos (también se podrían incluir nuevos puntos de muestreo o de
verificación). Una parte de los datos servirá para hacer los modelos (training data)
y la otra servirá para probarlos (testing data). A continuación se calculan los
errores de comisión y omisión de cada modelo, esto se hace comparando los
puntos de prueba con los modelos generados (recordar la tabla de confusión antes
vista para Maxent):

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 42
Tabla 3. Matriz de Confusión
Matriz de confusión
Presente Ausente
Predicho como
presente
a b (error de comisión)
Predicho como ausente c (error de omisión) d
Y se grafican los resultados en un el espacio de errores de omisión y comisión Lo
anterior queda mejor ejemplificado en las siguiente figura (de autor anónimo).
Fig. 10. Gráfico del espacio de errores de comisión y omisión (autor anónimo).

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 43
Los errores de comisión son por decirlo así los errores más tolerados (no hard
error), ya que pueden implicar que el área predicha pueda ser adecuada para la
especie pero está ausente por errores o bajo esfuerzo de muestreo, por barreras
vicariantes o por competencia. Aunque también queda la posibilidad del verdadero
error de comisión (true comisión error) por ser el área predicha no adecuada para
la especie. Pero en general se van a preferir aquellos modelos con baja omisión y
alta comisión. Ya que aquellos modelos con ningún error de comisión y cero error
de omisión son modelos sobre ajustados y no tienen capacidad predictiva.
Generalmente en GARP se puede indicar al programa un umbral de tolerancia
para los errores de comisión (generalmente es una regla de dedo poner un 50 %)
y para los errores de omisión (un 20 %).
Pruebas de Solapamiento de Nicho
Desde hace algunos años ha ido en aumento el debate entre distintos
investigadores sobre si las especies filogenéticamente cercanas son
ecológicamente similares a lo que se le conoce como Conservadurismo
Filogenético del Nicho (CFN). Algunos autores como Peterson et al (1999)
concluyen de sus trabajos que la especiación se da en primera instancia en un
contexto geográfico y no en uno ecológico, y el cambio y las diferencias ecológicas
evolucionaran posteriormente. Graham et al. (2004) con datos de dendrobátidos
sugieren que el medioambiente tiene una gran importancia en la divergencia de
las especies. Incluso algunos investigadores han sugerido que el CFN
prácticamente es un fenómeno inevitable en la evolución de las especies, sin
embargo Losos (2008) concluye que para muchos clados algunos caracteres
ecológicos no presentan un CFN. Además el autor hace hincapié en distinguir la
señal filogenética del CFN. La primera se refiere a que las diferencias o similitudes
en el nicho ecológico entre especies hermanas son un efecto sólo de sus
relaciones filogenéticas, y el CFN se refiere más bien a que las especies pueden
tener mayores similitudes ecológicas que las esperadas sólo por sus relaciones

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 44
filogenéticas. Esto último indicaría que algún proceso está restringiendo la
divergencia entre especies filogenéticamente cercanas.
Asimismo algunos autores han tratado de desarrollar métodos para medir que tan
parecidos son los nichos entre especies y tratar de probar hipótesis acerca del
CFN, por ejemplo Peterson et al. (1999) que desarrollan una prueba de similitud
de nicho. Recientemente Warren et al. (2008) desarrollan una serie de pruebas
para cuantificar la similitud del nicho ecológico y comparar la equivalencia contra
el conservadurismo del nicho. Pensamos que estás pruebas tienen un buen
potencial para el estudio de la cuestión del CFN, además de que los autores han
implementado un programa que entre otras pruebas realiza las pruebas de
similitud y equivalencia de nicho, que nos interesan. Este programa se llama
ENMtools (Warren et al., 2009) y se puede bajar junto con el manual de instalación
y operación en:
http://enmtools.blogspot.com/
Describiremos brevemente las pruebas antes señaladas haciendo énfasis en
algunos detalles sobre su ejecución que no son explícitos en el artículo y manual
señalado. Además que el programa ENMtools a pesar de ser muy útil, aún tiene
muchos “bugs” que han tratado de ser corregidos en actualizaciones constantes
del programa.
Las pruebas citadas se basan en dos conceptos que son la similitud y la
equivalencia de nicho. La similitud de nicho se refiere a cómo el modelo de nicho
ecológico de una especie predice a otra especie mejor de lo que se esperaría por
azar bajo un modelo nulo específico. La equivalencia de nicho se refiere a si dos
modelos de nicho de distintas especies son indistinguibles uno del otro. Sin
embargo estas dos definiciones sólo califican a dos caso extremos de un continuo,
ya que se espera que el grado de conservación de un nicho ecológico este situado
en cualquier parte entre los dos extremos mencionados.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 45
Para evaluar la similitud y la equivalencia Warren et al. (2008) idearon dos medida
de solapamiento de nicho (D e I) que luego se sonetearían a distintas pruebas
estadísticas para cuantificar la similitud y la equivalencia de nicho. El primer
índice llamado (D) deriva del antiguos índice de Schoener utilizado en la Ecología
para cuantificar solapamientos de nicho alimenticio y microhabitat. El segundo
índice llamado (I), deriva de la distancia de Hellinger (H) y no deriva de supuestos
biológicas sino solamente se basa en la comparación de distribuciones de
probabilidad. Ambos índices pueden tomar un valor de 0 que indica no
solapamiento hasta 1 que indica que los modelos son idénticos.
Sin embargo las complicaciones con las pruebas de similitud y equivalencia
derivan de la parte práctica de su ejecución y un poco menos de los supuestos
que las sustentan. Por tal motivo trataremos de explicar el procedimiento a seguir
en cada caso, una vez instalado el programa como se índica en el manual, ya que
cómo mencionamos los procedimientos no están suficientemente explicados y
libres de ambigüedades.
Prueba de Equivalencia
Para esta prueba y para la de similitud es necesario tener una carpeta donde se
tengan juntas las capas bioclimáticas, instalado Maxent y los modelos de nicho
generados por este programa, de aquellas especies que queremos probar.
Además ENMtools funciona en conjunto con Maxent para analizar conjuntos de
datos aleatorios y generar nuevos modelos que sirven para obtener
pseudoréplicas y así producir distribuciones nulas de los índices I y D, y poder
probar la significancia estadística de estos índices sobre los datos observados.
Una vez que se abre ENMtools se tiene que decirle al programa en dónde están
las capas bioclimáticas y Maxent, para que lo utilice automáticamente una vez que
comiencen los análisis, además de indicar en qué archivo queremos los
resultados. Esto se hace en la sección de opciones:

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 46
Fig.11. Pantalla de ENMtools, en la pestaña de opciones, en la que se indica al programa
dónde están las capas bioclimáticas y Maxent.
La prueba de equivalencia consiste en tomar datos aleatorios de los sitios de
ocurrencia de las dos especies a comparar. Con cada uno de estos datos o
pseudoréplicas se genera modelos de nicho ecológico (con ayuda de Maxent) y
estos se comparan por medio de los índice de I y D. Según los autores apoyados
en distintas pruebas con muchas especies un número de 100 pseudoréplicas es
suficiente para generar una distribución nula que pueda refutar la hipótesis nula
de que los nichos de dos especie no son estadísticamente diferentes
(equivalencia ecológica) con un nivel de significancia alto.
Los índices I y D calculados para el par de especies en estudio se comparan con
la distribución nula de los valores I y D de las pseudoréplicas por medio de
percentiles y así determinar los niveles de significancia en los que se puede refutar
la hipótesis. El proceso de manera práctica es el siguiente:

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 47
1° Generar los valores I y D observados. Nos vamos a la pantalla de entrada de
ENMtools y en la primera pestaña seleccionamos “Niche overlap”.
Fig.12. Pantalla de comienzo ENMtools
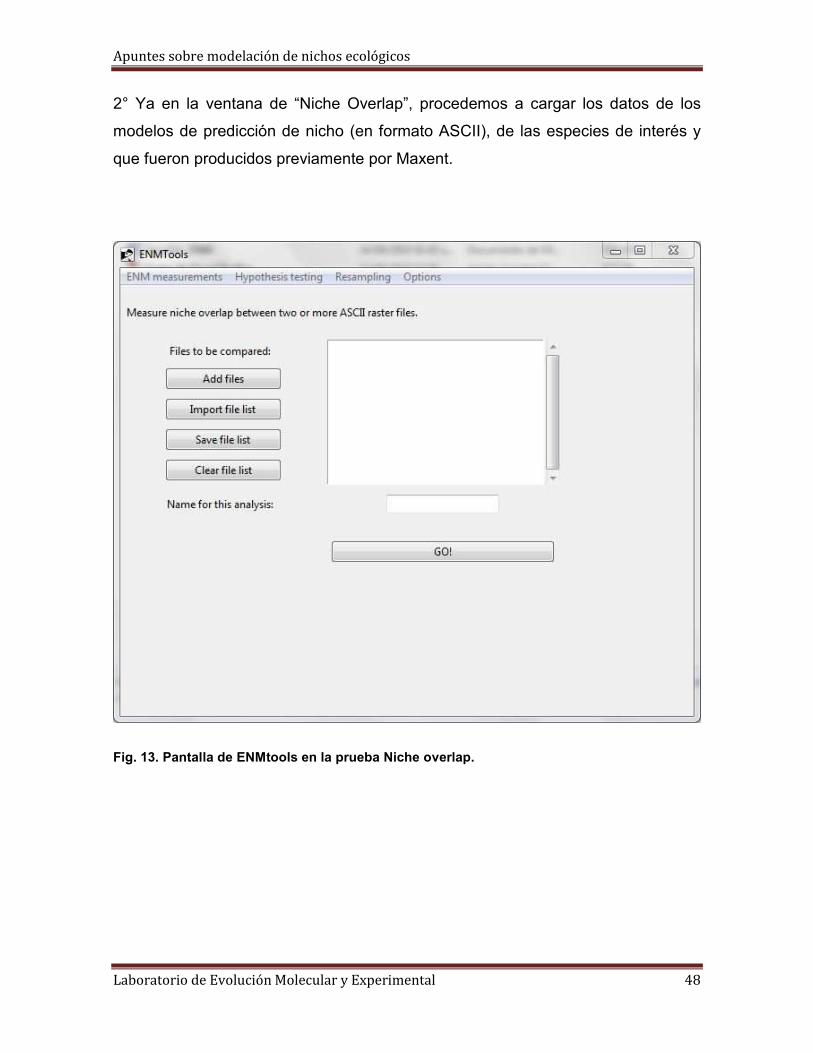
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 48
2° Ya en la ventana de “Niche Overlap”, procedemos a cargar los datos de los
modelos de predicción de nicho (en formato ASCII), de las especies de interés y
que fueron producidos previamente por Maxent.
Fig. 13. Pantalla de ENMtools en la prueba Niche overlap.
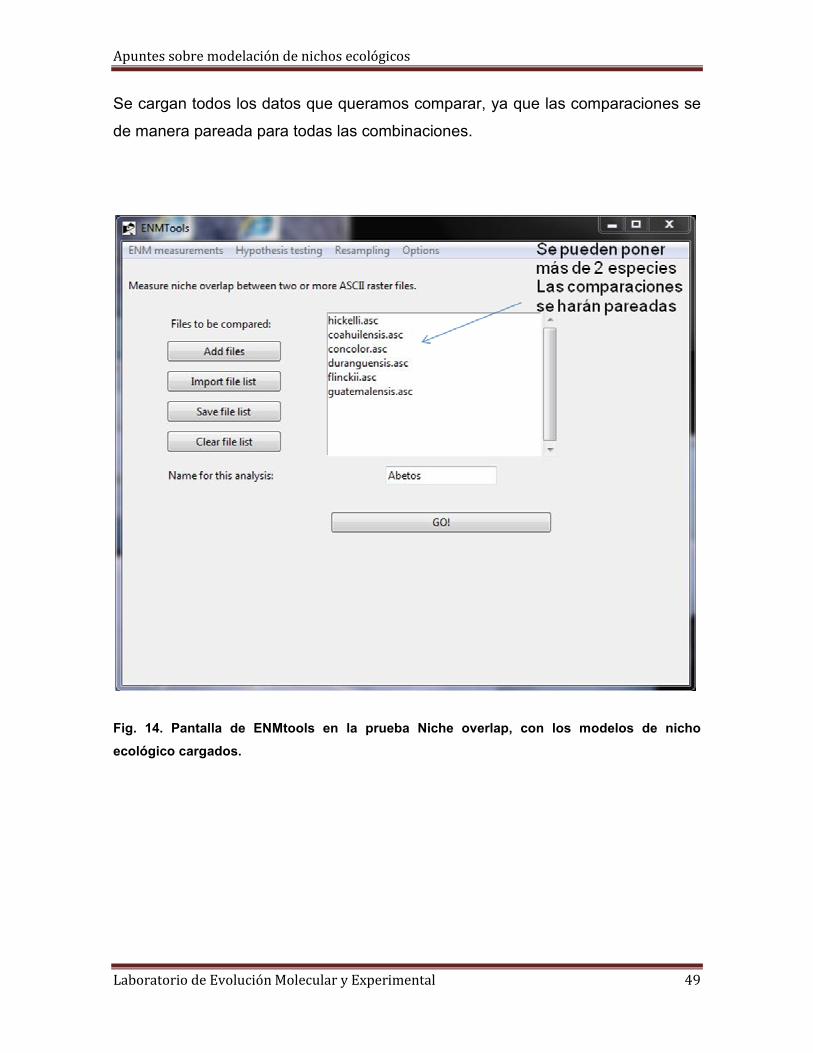
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 49
Se cargan todos los datos que queramos comparar, ya que las comparaciones se
de manera pareada para todas las combinaciones.
Fig. 14. Pantalla de ENMtools en la prueba Niche overlap, con los modelos de nicho
ecológico cargados.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 50
Una vez que se termina la prueba el archivo de salida es una página de Excel,
como la que se muestra en seguida:
Fig. 15. Resultados de la prueba de Overlap. Sólo se muestran los datos del índice D
observados.
En la figura anterior podemos ver la tabla de los índices D observados de todas las
combinaciones pareadas de las especies introducidas.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 51
3° Se realiza la prueba de equivalencia. Para esto vamos a la pestaña de
“Hypothesis testing” y tecleamos la primera opción “Identity test”.
Fig. 16. Pantalla de entrada de ENMtools.
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 52
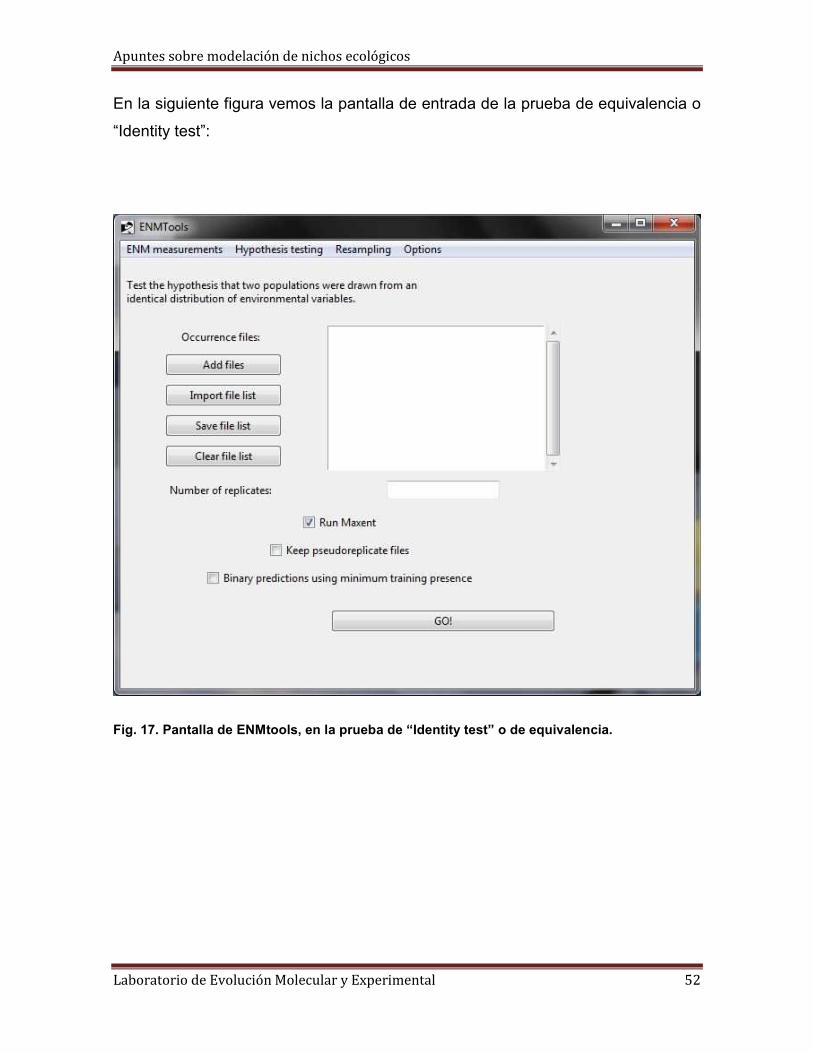
En la siguiente figura vemos la pantalla de entrada de la prueba de equivalencia o
“Identity test”:
Fig. 17. Pantalla de ENMtools, en la prueba de “Identity test” o de equivalencia.
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 53
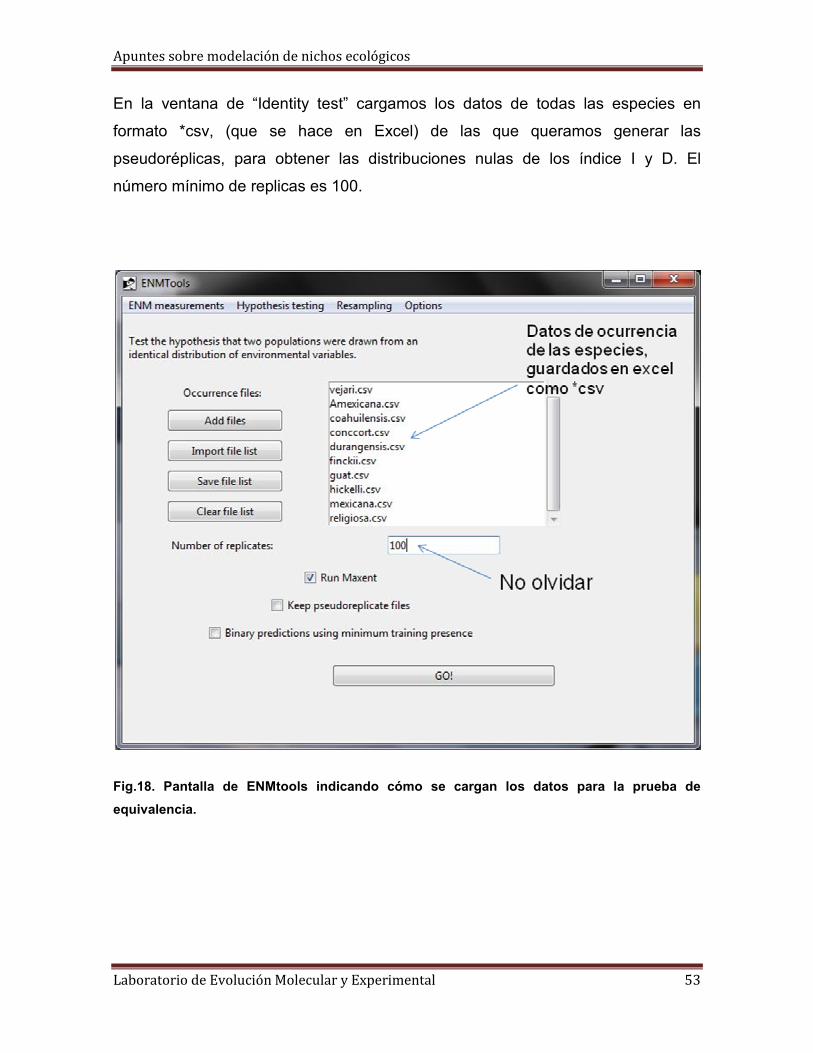
En la ventana de “Identity test” cargamos los datos de todas las especies en
formato *csv, (que se hace en Excel) de las que queramos generar las
pseudoréplicas, para obtener las distribuciones nulas de los índice I y D. El
número mínimo de replicas es 100.
Fig.18. Pantalla de ENMtools indicando cómo se cargan los datos para la prueba de
equivalencia.
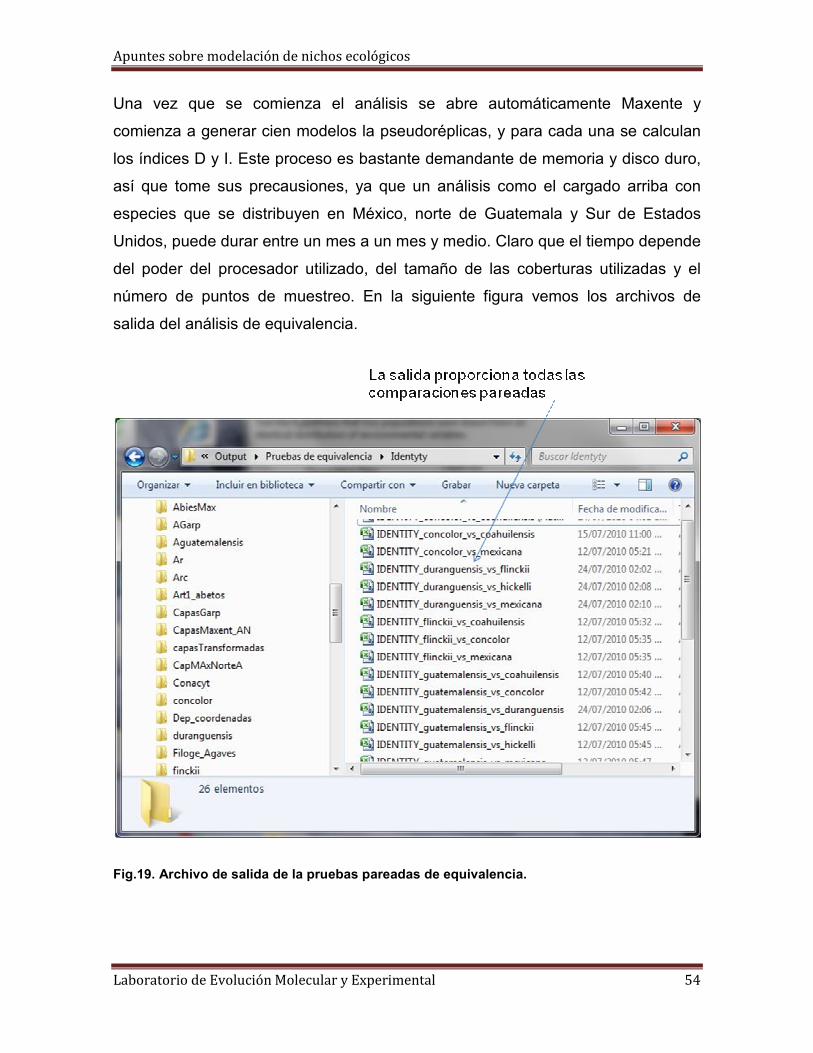
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 54
Una vez que se comienza el análisis se abre automáticamente Maxente y
comienza a generar cien modelos la pseudoréplicas, y para cada una se calculan
los índices D y I. Este proceso es bastante demandante de memoria y disco duro,
así que tome sus precausiones, ya que un análisis como el cargado arriba con
especies que se distribuyen en México, norte de Guatemala y Sur de Estados
Unidos, puede durar entre un mes a un mes y medio. Claro que el tiempo depende
del poder del procesador utilizado, del tamaño de las coberturas utilizadas y el
número de puntos de muestreo. En la siguiente figura vemos los archivos de
salida del análisis de equivalencia.
Fig.19. Archivo de salida de la pruebas pareadas de equivalencia.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 55
En la siguiente figura vemos los resultados de uno de los archivos arrojados por el
análisis de equivalencia.
Fig.20. Apertura de unos de los archivos de salida de la prueba de equivalencia, que muestra la distribución nula de los índices de I y D para las pseudoréplicas. En la misma página de Excel se muestran las gráficas de las distribuciones de las frecuencias de los índices I y D para compararlos con los índices I y D observados. También se muestran los percentiles de la distribución nula de I y D, calculados también con Excel para obtener los límites de confianza a niveles de significancia de 0.05 y 0.01 como prueba de una cola. En este caso se rechaza la hipótesis nula, existen diferencias significativas, para el índice D= 0.1770 (observado), p<0.01, por las especies son ecológicamente distintas.
En la misma página hemos puestos las gráficas de frecuencia de los índices de I y
D, como se indica en el manual de ENMtools y en dónde podemos ver que los
valores observados de I y D para estas especies no están dentro de la distribución
nula construida, por lo que se concluye que son distintos y las especies no son
equivalentes. Sin embargo en el manual no se índica como se establecen los

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 56
niveles de significancia para rechazar o no la hipótesis nula. Esto se realiza
calculando los percentiles (Warren y Turelli, 2008) aunque los autores no dan más
detalle de este proceder. Pero para distribuciones nulas lo que se hace es calcular
el percentil 0.01 y 0.05 que equivalen a p=0.01 y p=0.05. Entonces en nuestro
caso calculamos los percentiles de todos los datos de las pesudréplicas para los
índices I y D, y así si nuestro valor observado es menor que el valor de los
percentiles 0.01 y 0.05 decidimos que los valores son estadísticamente diferentes,
se refuta la hipótesis nula y no existe equivalencia ecológica.
Prueba de Similitud
Un aspecto que puede ser un tanto confuso al revisar el artículo de Warren et al
(2008) es el manejo de la hipótesis nula de similitud, ya que es un poco anti-
intuitiva cuestión que se arrastra desde el trabajo de Peterson et al. (1999). La
hipótesis nula es: la distribución una especie no aporta ningún dato para
predecir la distribución de otra. Es decir, si la prueba es significativa no indica
diferencias significativas entre especies, sino que estas son similares
ecológicamente, y una prueba no significativa indica que las especies no son
similares. Aunque no necesariamente si dos especies no son similares indica que
son equivalentes o hay conservadurismo del nicho, ya que sólo pueda ser un
artefacto por números de muestra muy bajos (por ejemplo <5). Además eta prueba
se hace en dos sentidos y se trata como una prueba a dos colas, lo que se traduce
como probar si la especie A es similar a la especie B y después si la especie B es
similar a la especie A. La prueba es muy estricta ya que sólo considera que dos
especies son similares si la prueba tiene valores estadísticos significativos en
ambas direcciones.
La prueba se basa en usar datos aleatorios para determinar si dos especies son
más o menos similares que lo esperado basado en las diferencias en los datos
ambientales de fondo o “background” (Warren et al, 2009). “Bacground” se refiere
a las área o pixles en dónde no se ha predicho la especie.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 57
El uso de datos externos o “background” se entiende por qué se quiere saber si
una especie tolera o no las mismas condiciones ecológicas de otra y la única
forma de hacerlo es comparando con un lugar donde hay certeza que las
condiciones ecológicas no son toleradas por una especie, ya que no se distribuye
en ese lugar.
La prueba también calcula distribuciones nulas de los índices I y D, pero en dos
sentidos como se mencionó antes, o sea tenemos una distribución nula de 100
índices para la especie A vs B y 100 para B vs A. Y sólo con valores significativos
para ambas direcciones se puede afirmar que una especie comparte similitud
ecológica. La prueba en ENMtools es como sigue:
1° Abrimos “Bacground test” en la pestaña de “Hypothesis testing”
Fig. 21. Pantalla de entrada de ENMtools, mostrando en dónde está la entrada para la prueba
de similitud “Background test”.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 58
3° Tenemos que tener listos cuatro archivos de dos tipos distintos: dos archivos
con formato *csv con las localidades para las especies A y B respectivamente; dos
archivos (uno para A y otro para B) con formato *asc (ASCII) en donde se
encuentran los datos correspondientes del área “background”, de donde se
tomaran puntos aleatorios para la prueba. En la figura siguiente se ilustra el
concepto de área de muestreo “background”.
Fig.22. Ejemplo del área de “background” que muestra donde se toman los puntos externos
al área de distribución predicha para una de las especies comparadas, para usarlas en la
prueba de similitud (Warren y Turelli, 2010). Que en nuestro caso se necesita hacer con una
máscara.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 59
Para tener un archivo “background” es necesario tener un archivo de predicción de
distribución de la especie correspondiente y enmascarar las áreas en donde se
predice la especie. Esto se puede hacer con ArcGis como se índica en el manual
de ENMtools o en Arcview.
Una manera útil para gnerar el archivo “background” es abrir en Arcview la
predicción y utilizar la función de Reclasificar. Lo que haremos es reclasificar él
área de predicción para igualarla a cero, equivalente a poner una máscara sobre
el área de predicción con valores de pixel iguales a -9999 (que se interpretan
como ausencia de dato “no data”), claro que se puede hacer de otras maneras.
También recomendamos limitar el área de “background” a las mínimas áreas
alrededor del área predicha o si la predicción cae sobre un área geológica
determinada como una cadena montañosa, solo tomar en cuenta un área pequeña
afuera de esa cadena montañosa, o si la predicción sólo cubre un área
determinada de esta cadena montañosa (desierto etc.) tomar también sólo un
poco de área sobre esa misma cadena montañosa, en donde no se predice la
especie. Esto se hace recortando área en el mismo Arcview, en donde se abre la
función de Manual grid editor, se escoge el área a recortar y se corta con la
función de Clip data set que se encuentra dentro de la pestaña Garp. Si no están
estás pestañas es probable que no estén cargadas las extensiones
correspondiente. Las extensiones son pequeños programas escritos en lenguaje
Avenue que es el que utiliza Arcview y que uno puede bajar de distintos lugares de
la red principalmente la pagina de ESRI. Una vez que se tiene la extensión que se
necesita se va a la carpeta que contiene el Progrma Arcview que se llama Esri y
se guarda dicha extensión. Luego la extensión se habilita al abrir Arcview,
abriendo Files y luego Extensiones y de ahí se escoge la extensión que
necesitemos.
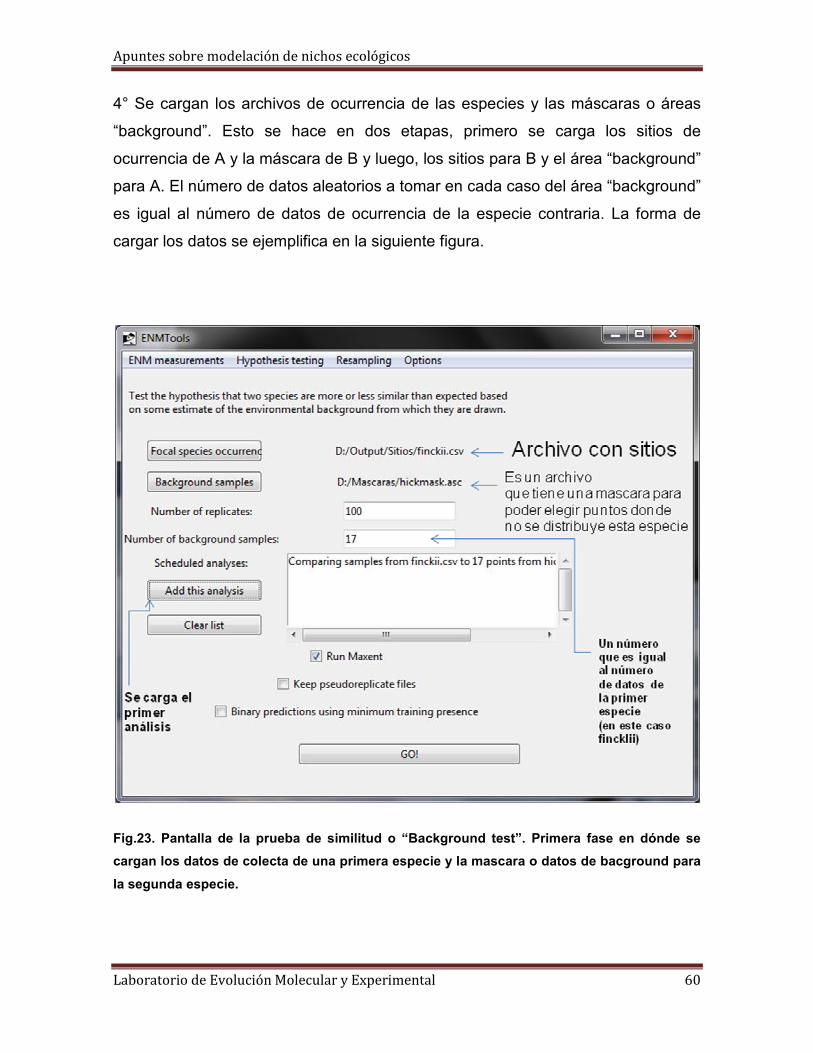
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 60
4° Se cargan los archivos de ocurrencia de las especies y las máscaras o áreas
“background”. Esto se hace en dos etapas, primero se carga los sitios de
ocurrencia de A y la máscara de B y luego, los sitios para B y el área “background”
para A. El número de datos aleatorios a tomar en cada caso del área “background”
es igual al número de datos de ocurrencia de la especie contraria. La forma de
cargar los datos se ejemplifica en la siguiente figura.
Fig.23. Pantalla de la prueba de similitud o “Background test”. Primera fase en dónde se
cargan los datos de colecta de una primera especie y la mascara o datos de bacground para
la segunda especie.
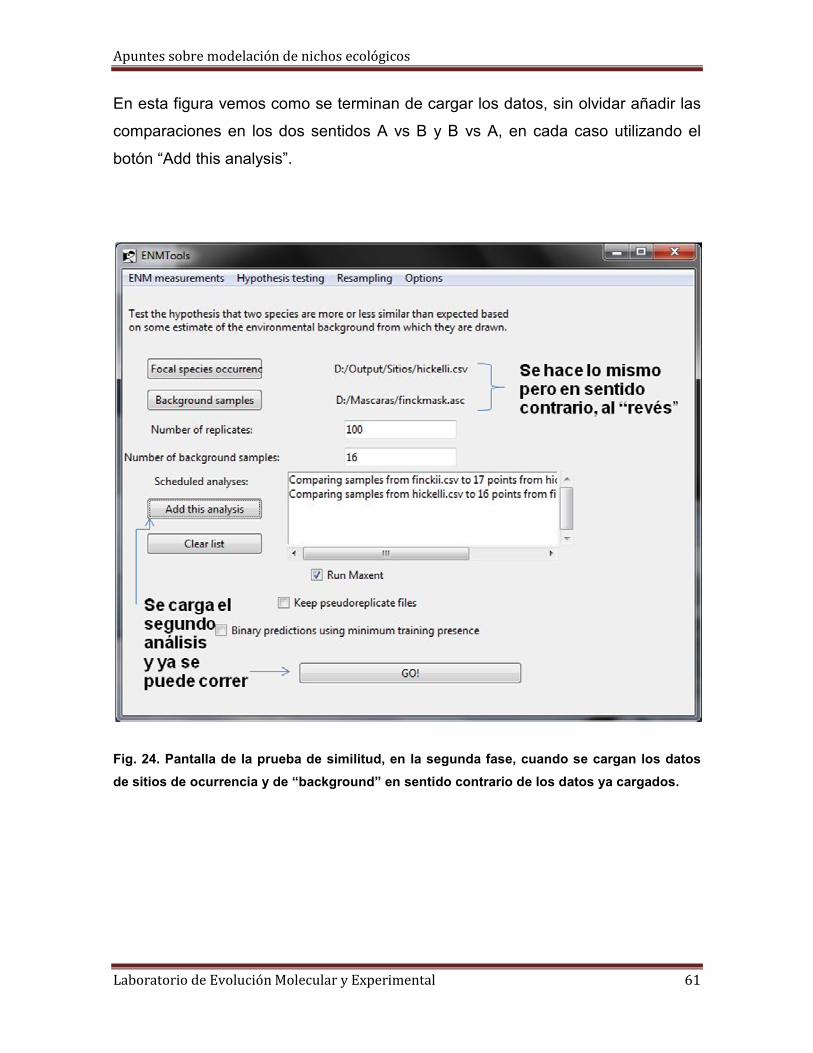
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 61
En esta figura vemos como se terminan de cargar los datos, sin olvidar añadir las
comparaciones en los dos sentidos A vs B y B vs A, en cada caso utilizando el
botón “Add this analysis”.
Fig. 24. Pantalla de la prueba de similitud, en la segunda fase, cuando se cargan los datos
de sitios de ocurrencia y de “background” en sentido contrario de los datos ya cargados.
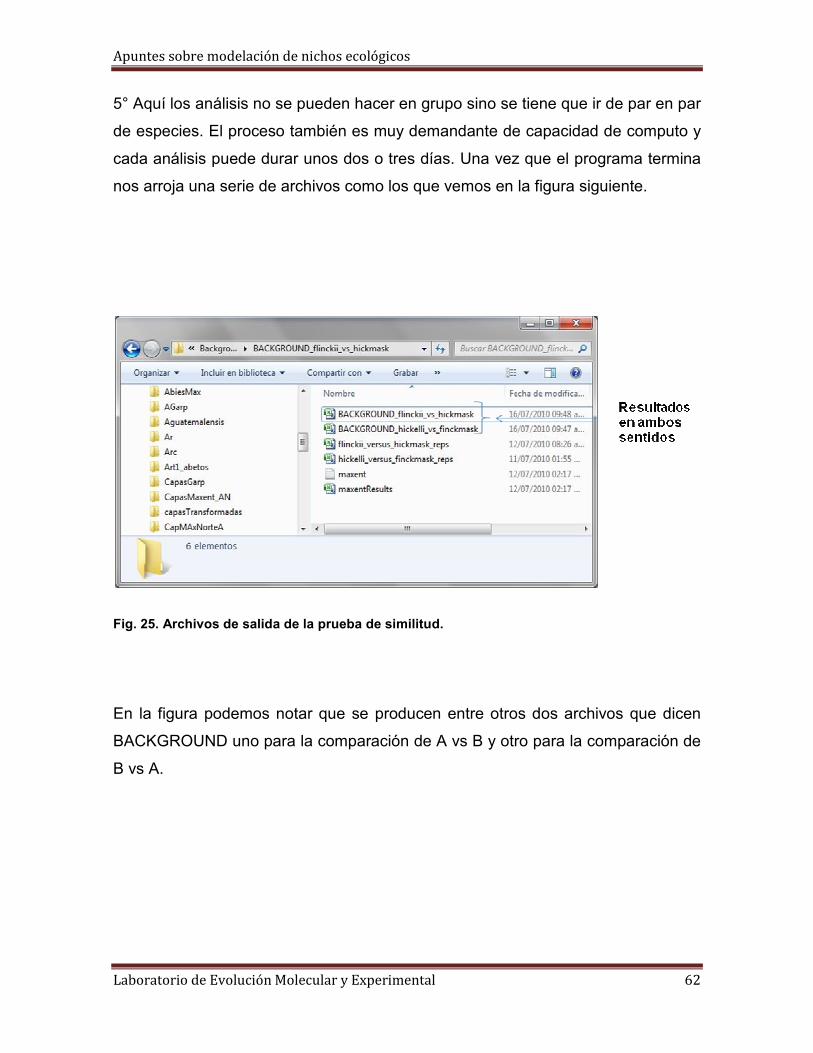
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 62
5° Aquí los análisis no se pueden hacer en grupo sino se tiene que ir de par en par
de especies. El proceso también es muy demandante de capacidad de computo y
cada análisis puede durar unos dos o tres días. Una vez que el programa termina
nos arroja una serie de archivos como los que vemos en la figura siguiente.
Fig. 25. Archivos de salida de la prueba de similitud.
En la figura podemos notar que se producen entre otros dos archivos que dicen
BACKGROUND uno para la comparación de A vs B y otro para la comparación de
B vs A.
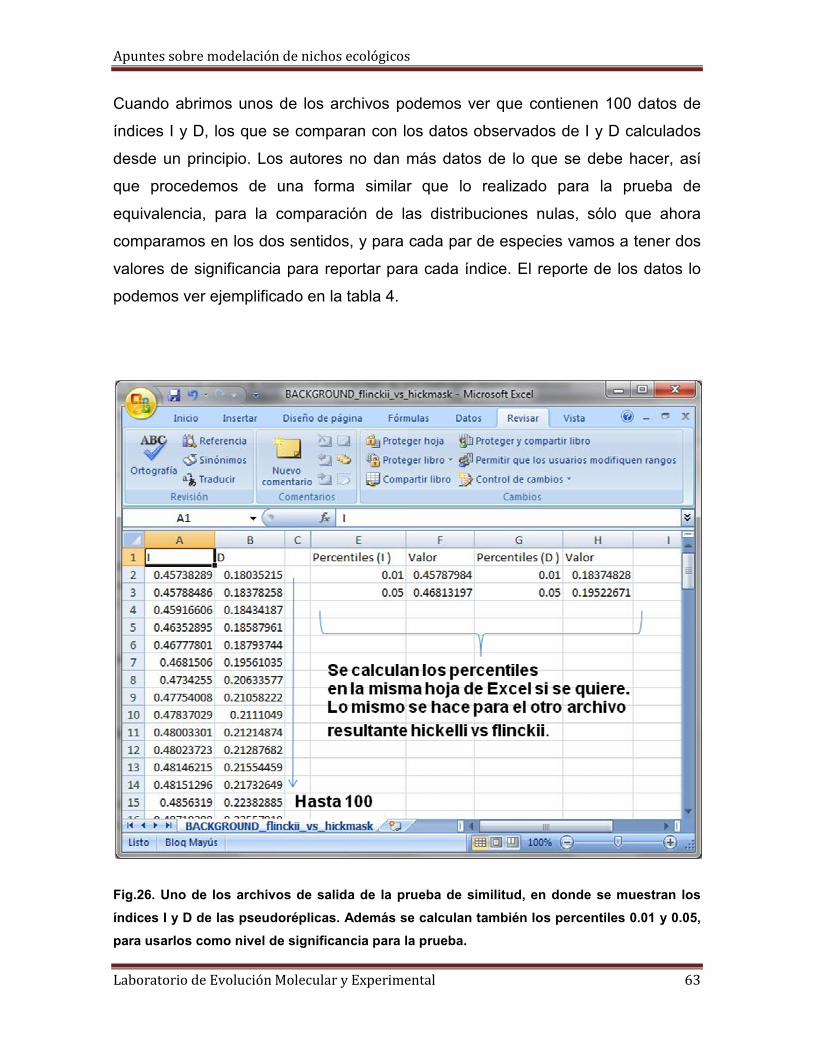
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 63
Cuando abrimos unos de los archivos podemos ver que contienen 100 datos de
índices I y D, los que se comparan con los datos observados de I y D calculados
desde un principio. Los autores no dan más datos de lo que se debe hacer, así
que procedemos de una forma similar que lo realizado para la prueba de
equivalencia, para la comparación de las distribuciones nulas, sólo que ahora
comparamos en los dos sentidos, y para cada par de especies vamos a tener dos
valores de significancia para reportar para cada índice. El reporte de los datos lo
podemos ver ejemplificado en la tabla 4.
Fig.26. Uno de los archivos de salida de la prueba de similitud, en donde se muestran los
índices I y D de las pseudoréplicas. Además se calculan también los percentiles 0.01 y 0.05,
para usarlos como nivel de significancia para la prueba.
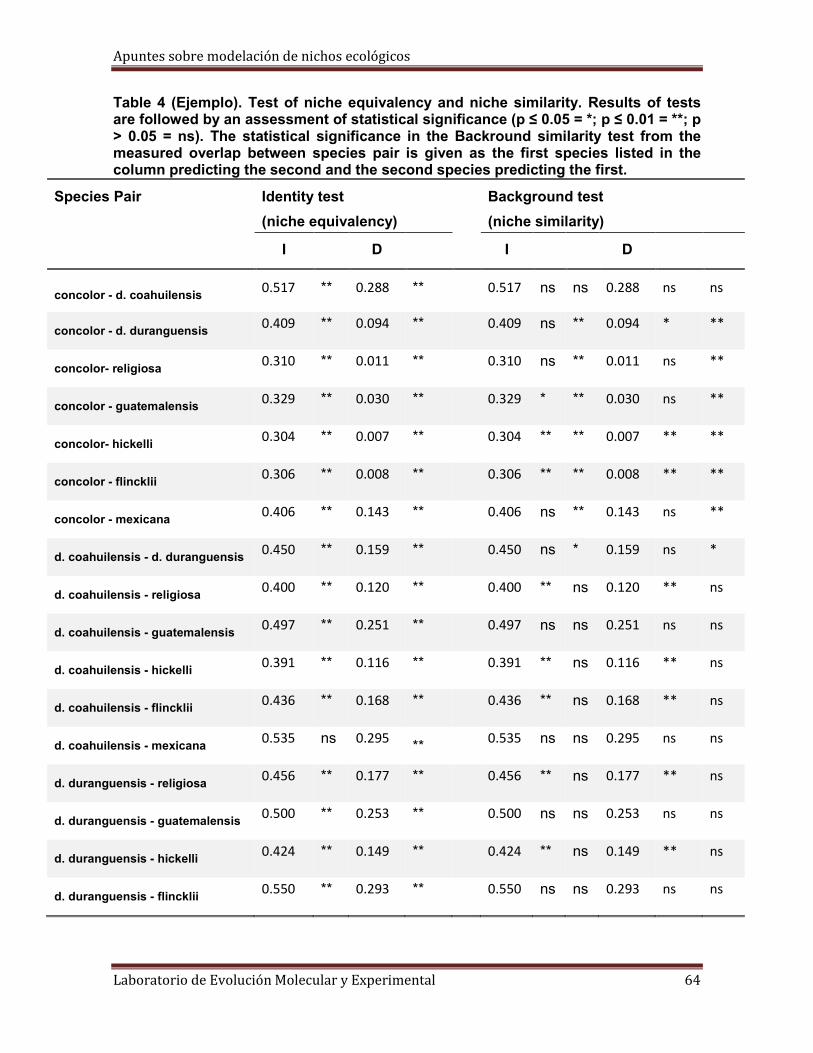
Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 64
Table 4 (Ejemplo). Test of niche equivalency and niche similarity. Results of tests are followed by an assessment of statistical significance (p ≤ 0.05 = *; p ≤ 0.01 = **; p > 0.05 = ns). The statistical significance in the Backround similarity test from the measured overlap between species pair is given as the first species listed in the column predicting the second and the second species predicting the first.
Species Pair Identity test
(niche equivalency)
Background test
(niche similarity)
I D I D
concolor - d. coahuilensis 0.517 ** 0.288 ** 0.517 ns ns 0.288 ns ns
concolor - d. duranguensis 0.409 ** 0.094 ** 0.409 ns ** 0.094 * **
concolor- religiosa 0.310 ** 0.011 ** 0.310 ns ** 0.011 ns **
concolor - guatemalensis 0.329 ** 0.030 ** 0.329 * ** 0.030 ns **
concolor- hickelli 0.304 ** 0.007 ** 0.304 ** ** 0.007 ** **
concolor - flincklii 0.306 ** 0.008 ** 0.306 ** ** 0.008 ** **
concolor - mexicana 0.406 ** 0.143 ** 0.406 ns ** 0.143 ns **
d. coahuilensis - d. duranguensis 0.450 ** 0.159 ** 0.450 ns * 0.159 ns *
d. coahuilensis - religiosa 0.400 ** 0.120 ** 0.400 ** ns 0.120 ** ns
d. coahuilensis - guatemalensis 0.497 ** 0.251 ** 0.497 ns ns 0.251 ns ns
d. coahuilensis - hickelli 0.391 ** 0.116 ** 0.391 ** ns 0.116 ** ns
d. coahuilensis - flincklii 0.436 ** 0.168 ** 0.436 ** ns 0.168 ** ns
d. coahuilensis - mexicana 0.535 ns 0.295 ** 0.535 ns ns 0.295 ns ns
d. duranguensis - religiosa 0.456 ** 0.177 ** 0.456 ** ns 0.177 ** ns
d. duranguensis - guatemalensis 0.500 ** 0.253 ** 0.500 ns ns 0.253 ns ns
d. duranguensis - hickelli 0.424 ** 0.149 ** 0.424 ** ns 0.149 ** ns
d. duranguensis - flincklii 0.550 ** 0.293 ** 0.550 ns ns 0.293 ns ns

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 65
Literatura citada y recomendada
Graham, C. H., Ron, S. R., Juan, C., Schneider, C. J. y Moritz, C. (2004). ''Integrating phylogenetics and environmental niche models to explore speciation mechanisms in dendrobatid frogs. Evolution 58(8): 1781-1793.
Harmon, J. E. y S. J. Anderson. 2003. The Design and Implementation of Geographic Information System, Editorial: John Wiley & Sons, New Jersey.
Losos, J.B. (2008). Phylogenetic niche conservatism, phylogeneticsignal and the relationship between phylogenetic relatedness and ecological similarity among species. Ecol. Lett., 11, 995–1003.
Peterson, A. T., J. Soberón, y V. Sánchez-Cordero. 1999. Conservatism of ecological niches in evolutionary time. Science 285:1265–1267.
Phillips, S. J. y Dudík, M. 2008. Modeling of species distributions with Maxent: new extensions and a comprehensive evaluation. _ Ecography 31: 161_175.
Phillips, S. J. et al. 2006. Maximum entropy modeling of species geographic distributions. _ Ecol. Model. 190: 231_259.
Soberón, J. y M. Nakamura. 2009. Niches and distributional areas: Concepts, methods,and assumptions. PNAS, 17: 19644-19650.
Warren, D. L., R. E. Glor y M. Turelli. 2008. Environmental niche equivalency versus conservatism: Quantitative aproches to niche evolution. Evolution 62: 2868-2883.

Apuntes sobre modelación de nichos ecológicos
Laboratorio de Evolución Molecular y Experimental 66
Warren, D. L., Glor, R. E. y Turelli, M. 2009. ENMtools ver1.0 users manual.
Warren, D. L., Glor, R. E. y Turelli, M. 2010. ENMTools: a toolbox for comparative studies of environmental niche models. Ecography 000: 000_000.





![RollOver (71.139) [Corr y Enm]](https://static.fdocumento.com/doc/165x107/5695cf181a28ab9b028c93a8/rollover-71139-corr-y-enm.jpg)











