Reconocimiento de Patrones Melódicos Vocales Repetidos en...
70
Reconocimiento de Patrones Melódicos Vocales Repetidos en Audios Polifónicos en Flamenco Proyecto Fin de Carrera Jesús Moreno Quesada Universidad de Sevilla. Julio 2015 Dirigido por Dr. D. José Miguel Díaz Báñez Dpto. Matemática Aplicada II Ingeniero Industrial
Transcript of Reconocimiento de Patrones Melódicos Vocales Repetidos en...

Reconocimiento de Patrones
Melódicos Vocales Repetidos en
Audios Polifónicos en Flamenco
Proyecto Fin de Carrera
Jesús Moreno Quesada
Universidad de Sevilla. Julio 2015
Dirigido por Dr. D. José Miguel Díaz Báñez
Dpto. Matemática Aplicada II
Ingeniero Industrial


Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco
Agradecimientos
Agradecimientos
Este proyecto no se podría haber llevado a cabo sin la ayuda y guía del Dr José
Miguel Díaz-Báñez debido a que me proporcionó la confianza para poder realizar
el proyecto y sin lugar a dudas su incansable ayuda y paciencia para la realización
del proyecto.
No puedo pasar por alto la imprescindible ayuda y colaboración de Nadine Kroher
y el Dr Aggelos Pikkrakis, quienes me han ayudado en gran medida aportando sus
importantes conocimientos y experiencia en la investigación computacional del
flamenco.
Agradecer inmensamente a mis compañeros de universidad con los cuales he
compartido buenos y malos momentos, y siempre nos hemos apoyado
mutuamente. Aunque haciendo resumen, puedo asegurar que han sido muchos
más los buenos que los malos.
Y en especial a mi familia, quienes me han acompañado y apoyado durante estos
años luchando por conseguir ser Ingeniero Industrial. Ellos son los principales
artífices de la ayuda necesaria cuando en ciertas etapas de la carrera las fuerzas se
desvanecían.
Un abrazo muy fuerte a mi padre, mi madre y mis dos hermanos.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Índice
INDICE CAPÍTULO 1. INTRODUCCIÓN Y ANTECEDENTES ................................................................. 7
CONTENIDO: .......................................................................................................................................... 7
1.1 INVESTIGACIÓN Y FLAMENCO.......................................................................................... 7
1.2 ETNOMUSICOLOGÍA COMPUTACIONAL ........................................................................ 7
1.3 ETNOMUSICOLOGÍA COMPUTACIONAL EN EL FLAMENCO ................................. 7
1.4 LÍNEAS DE INVESTIGACIÓN DEL GRUPO COFLA ...................................................... 7
1.1 INVESTIGACIÓN Y FLAMENCO ..................................................................................... 7
1.2 ETNOMUSICOLOGÍA COMPUTACIONAL ................................................................... 8
1.3 ETNOMUSICOLOGÍA COMPUTACIONAL EN EL FLAMENCO ...............................10
1.4 LINEAS DE INVESTIGACION DEL GRUPO COFLA .....................................................11
CAPÍTULO 2. OBJETIVO, METODOLOGÍA Y CORPUS DE ESTUDIO .................................15
2.1 MOTIVACIÓN Y OBJETIVO..................................................................................................15
2.2 METODOLOGÍA: Pasos del método .................................................................................17
2.3 CORPUS DE ESTUDIO ...........................................................................................................18
CAPÍTULO 3. EL ALGORITMO NO SUPERVISADO .................................................................25
3.1 MÉTODO DE DETECCIÓN DE LA VOZ ............................................................................25
3.2 ESTIMACIÓN DE LOS PUNTOS DE INICIO Y LA MEDIA DE LA DURACION DE
LOS PATRONES. .............................................................................................................................28
3.3 MÉTODO DE DETECCIÓN DE PATRONES MELÓDICOS REPETIDOS .................29
3.3.1 CÓMPUTO DE EMPAREJAMIENTOS A TRAVÉS DEL ALINEAMIENTO DE
SECUENCIAS ....................................................................................................................................30
3.3.2 AGRUPAMIENTO DE PATRONES .................................................................................32
CAPÍTULO 4. EVALUACIÓN ............................................................................................................35
CONTENIDO ........................................................................................................................................35
4.1 CREACIÓN DE LA “GROUND TRUTH” ...............................................................................35
4.1.1 ¿POR QUÉ ES NECESARIO CREAR UNA BASE DE DATOS “GROUND
TRUTH”? 35
4.1 CREACIÓN DE LA GROUND TRUTH ................................................................................35
4.2 EVALUACION DE RESULTADOS .......................................................................................39
CAPÍTULO 5. CONCLUSIONES FINALES ....................................................................................45
Referencias ...........................................................................................................................................47
CÓDIGOS MATLAB .............................................................................................................................51

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Índice

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
7
CAPÍTULO 1. INTRODUCCIÓN Y
ANTECEDENTES
CONTENIDO:
1.1 INVESTIGACIÓN Y FLAMENCO
1.2 ETNOMUSICOLOGÍA COMPUTACIONAL
1.3 ETNOMUSICOLOGÍA COMPUTACIONAL EN EL FLAMENCO
1.4 LÍNEAS DE INVESTIGACIÓN DEL GRUPO COFLA
1.1 INVESTIGACIÓN Y FLAMENCO
La mayor parte del esfuerzo investigativo sobre flamenco ha sido llevado a cabo
desde las humanidades: Antropología Social, Sociología, Literatura, etc. Sin
embargo, resulta sorprendente que trabajos rigurosos sobre la música flamenca no
estén apareciendo hasta la actualidad. En el campo que da marco a este proyecto,
Tecnología Musical, podemos decir que en los últimos años se ha introducido el
uso de herramientas informáticas en el campo de la investigación musical, más
concretamente en el ámbito de investigación en tecnologías del sonido y la música
(Herrera & Gómez, 2011).
Dichas herramientas no pretenden desplazar –ni mucho menos- las metodologías
tradicionales de investigación. Antes, al contrario, pretenden asistir las
metodologías tradicionales, complementarlas y permitir aumentar la capacidad de
análisis tanto en términos cuantitativos como cualitativos.
La mayor parte de la investigación en Tecnología Musical se ha centrado en
analizar la música occidental con notación escrita y sólo recientemente se ha
empezado a prestar atención a las músicas de tradición oral y no occidentales (ver
el ejemplo del proyecto CompMusic1, financiado por la Comisión Europea, que
aplica la tecnología musical al estudio de músicas no occidentales, en concreto
tradiciones musicales de India, Turquía, China y el Magreb).
El flamenco es un caso arquetípico de esta situación. El cante flamenco, cuyas
características musicales son ciertamente particulares, requiere para su
investigación un enfoque multidisciplinar. Un problema tan claro en otras músicas
como la transcripción musical, no está ni mucho menos resuelto. Pero hay otros,
tales como la clasificación y caracterización de estilos, el estudio de la similitud 1 http://compmusic.upf.edu/

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
8
melódica y rítmica entre interpretaciones, y la caracterización de intérpretes, que
merecen el estudio integrado desde diferentes disciplinas.
Desde la óptica de la ciencia, la música y las matemáticas han estado relacionadas
desde al menos 2.500 años, cuando Pitágoras descubrió que los sonidos más
consonantes venían de proporciones simples y pequeñas. Desde entonces, la
interacción entre música y matemáticas no ha hecho sino crecer. Y ha sido en las
últimas décadas cuando se ha producido una revitalización como consecuencia de
la introducción de los métodos computacionales en el análisis de la música.
Un campo muy interesante en la investigación sobre la música flamenca es la
conocida como Etnomusicología Computacional. Puesto que nuestro proyecto está
inmerso con este campo, desarrollamos aquí una sección que describe los objetivos
y antecedentes en esta área.
1.2 ETNOMUSICOLOGÍA COMPUTACIONAL
La Etnomusicología es el estudio de la música de las etnias. Asimismo la definición
de etnia se ha referido en distintos momentos a grupos minoritarios no
occidentales como los indios de Norteamérica o los pigmeos de África, por poner
un ejemplo. En la actualidad, la descripción étnica se refiere a cualquier grupo o
subgrupo humano que puede pertenecer tanto a culturas occidentales como a
culturas o sociedades minoritarias no occidentales. Así músicas como el Maqam
turco, la ópera china o la rumba cubana son susceptibles de ser analizadas desde la
óptima de la Etnomusicología. El etnomusicólogo es el investigador que estudia la
música de diversos grupos o subgrupos culturales y sociales, y por tanto su área de
investigación puede abarcar prácticamente todos los tipos de música en cualquier
parte del mundo. Para una lectura detallada de esta área citamos el texto de B.
Nettl. (Nettl, 1983)
Por su parte, el término Etnomusicología Computacional fue originalmente
introducido para referirse al diseño, desarrollo y uso de herramientas
computacionales que poseen potencial para ayudar a investigaciones en
Etnomusicología. (Tzanetakis, Kapur, Schloss, & Wright, 2007)
La Etnomusicología Computacional puede tener sobre 37 años de antigüedad,
cuando dos matemáticos y un ingeniero (Halmos, Köszegi, & Mandler, 1978),
tuvieron una interesante discusión acerca del rol de los ordenadores sobre cinco
líneas de investigación de la Etnomusicología: recopilación de datos,
administración, notación, selección y sistematización, y tratamiento científico.
Acorde con lo anterior, las herramientas computacionales pueden estar limitadas
para la recopilación de datos y para el tratamiento científico, debido a que estas
herramientas no pueden simular pensamientos y comportamientos históricos
humanos. Sin embargo, ha sido en mayor medida explorado el uso de ordenadores
para administración, notación, y selección y sistematización.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
9
La base principal de las investigaciones en musicología son composiciones,
sistemas de notaciones y transcripciones musicales, según (Tzanetakis G. , 2014).
Son representaciones que capturan en gran medida las características invariables
de la música, y permiten que la música pueda ser descompuesta, ralentizada y
repetida. En el caso de grabaciones, las herramientas computacionales nos han
abierto nuevas posibilidades en el análisis de grabaciones de audio en muchos
casos, manteniendo la misma flexibilidad ofrecida por representaciones
abstractas. Pero, la ayuda que podemos tener con dichas herramientas va mucho
más allá que las grabaciones, pues deben ser usadas como métodos objetivos de
transcripción y análisis.
Las herramientas computacionales para la Etnomusicología pueden sugerir
simplemente “teorías” o “hipótesis” sobre procesos y problemas estudiados por la
Etnomusicología (Gómez, Herrera, & Gómez-Martín, Computational
Ethnomusicology: Perspectives and Challenges, 2013). Si observamos la
Etnomusicología Computacional de este punto de vista, podemos adoptar una
nueva mentalidad que nos ayude a reestructurar problemas y percibir la
relaciones existentes entre sus elementos constitutivos bajo una perspectiva
diferente.
Como aclaración, es interesante dar una pincelada sobra la diferencia entre
Etnomusicología y Musicología, ya que el término “Etnomusicología” puede ser
problemático debido a que se refiere realmente al estudio de todas las músicas,
pues todas están afectadas por la cultura del creador de una forma u otra. Podemos
decir que la musicología se centra en el estudio de la música occidental y europea,
y por lo tanto, para incluir el resto de músicas necesitaremos añadirle el prefijo
“etno-“, dando a entender que el campo de trabajo será la música étnica. Esto,
puede llevarnos a confusión, ¿significa que Beethoven no estaba influido por la
cultura específica? Obviamente sí, por tanto aún debemos añadir que la
etnomusicología usará herramientas de trabajo prestadas del campo de la
antropología para poder establecer una clara diferencia entre los dos términos.
En la siguiente tabla se indican algunas de las diferencias entre los campos de
trabajo Musicología y Etnomusicología.
Disciplina Musicología Etnomusicología
Música estudiada Notación musical
occidental
Contexto musical
antropológico
Enseñanza musical Notación Transmisión oral
Metodología Análisis de notaciones Trabajo de campo,
Etnografía
Tabla 1. Esquema de diferencias entre Musicología y
Etnomusicología

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
10
1.3 ETNOMUSICOLOGÍA COMPUTACIONAL EN EL FLAMENCO
Pese a que el flamenco posee un gran peso específico en el marco cultural (y
comercial) español y un gran impacto mediático internacional, no ha sido hasta
hace relativamente poco tiempo, cuando se ha iniciado el estudio computacional de
la música flamenca.
Es en 2005, a raíz de un estudio sobre un análisis filogenético del compás
flamenco: “Similitud y evolución en la rítmica del flamenco: una incursión de la
matemática computacional” (Díaz-Bañez, Farigu, Gomez, Rappaport, & Toussaint,
2005), cuando la comunidad científica aborda el análisis de la música flamenca
desde la perspectiva de la Teoría Computacional y las Matemáticas. El citado
trabajo se publica en la revista La Gaceta de la Real Sociedad Matemática Española
y su versión en inglés en los Proceedings del congreso BRIDGES: El compás
flamenco: a phylogenetic analysis (Díaz-Bañez, Farigu, Gomez, Rappaport, &
Toussaint, 2005). Este trabajo dio pie a un nuevo campo de investigación
denominado Teoría Computacional de la Música Flamenca. Se analizan en este
trabajo primigenio aspectos rítmicos de los estilos ternarios del flamenco y se
extraen algunos indicios sobre genealogía y preferencia de estilos en lo que
respecta a patrones rítmicos. En dicho trabajo, y a modo de conclusiones, se insta a
musicólogos y otros investigadores del flamenco a contrastar este tipo de análisis
científico con otras metodologías usadas en sus áreas de investigación, a saber,
Historia, Antropología o Teoría Musical, creándose así el germen para la creación
del primer grupo de investigación multidisciplinar de Teoría computacional de la
música flamenca, el grupo COFLA. Debido a que el problema tratado en este
proyecto coincide con una de las líneas de trabajo del grupo, incluimos aquí una
perspectiva histórica del grupo de investigación COFLA2 para entender bien el
marco de trabajo.
En el año 2007 comienza el primer proyecto de investigación universitario
con subvención pública y relacionado con el flamenco, el proyecto COFLA
(COmputational analysis of FLAmenco Music) que surge como respuesta a las
inquietudes de un grupo de investigadores, encabezados por el Dr. José Miguel
Díaz Báñez, responsable del proyecto y tutor de este proyecto fin de carrera. Está
subvencionado por la Junta de Andalucía y su objetivo principal es el de realizar
una investigación exhaustiva y rigurosa de la música flamenca mediante un
enfoque multidisciplinar, combinando los conocimientos de áreas como la
literatura, la musicología, la psicología musical, las matemáticas, la recuperación de
información musical (MIR) o el procesamiento de señales de audio digital, entre
otros. Asimismo, se persigue fortalecer el estudio del flamenco como una cuestión
académica en la universidad y dejar las bases de una nueva área de investigación,
la Teoría Computacional del flamenco. Recientemente, se ha renovado el proyecto
2 http://mtg.upf.edu/research/projects/cofla

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
11
hasta el año 2018.
El objetivo fundamental que se persigue en el proyecto COFLA es el de utilizar
las herramientas tecnológicas existentes en descripción de audio, procesado del
sonido y modelado computacional o diseñar otras nuevas para el estudio analítico de
las estructuras musicales del flamenco, su preservación y su difusión pública. Dichas
técnicas son ya utilizadas en otras músicas y explotadas en el contexto de sistemas
comerciales de navegación en grandes bases de datos musicales, recomendación
musical y transformación de sonido. De este modo, utilizando tecnología ya
consolidada o a desarrollar en el transcurso del proyecto, y contrastando los
resultados desde disciplinas tan dispares como la historia, semiótica, literatura,
musicología y antropología del Flamenco, se pretende seguir avanzando en el
conocimiento riguroso, la difusión y la preservación de la música flamenca. Entre los
aspectos musicológicos fundamentales en los que se pretende indagar desde el punto
de vista computacional pueden destacarse los orígenes del flamenco, evolución y
relación entre los distintos estilos, propiedades de preferencia de estilos, influencia
de músicas externas a Andalucía o búsqueda de estilos ancestrales. Todo ello
mediante un estudio analítico de las estructuras musicales flamencas usando técnicas
ya exploradas en otras músicas, que se basan en el uso herramientas
computacionales.
El proyecto COFLA trabaja en el estudio del flamenco desde una perspectiva
tecnológica. Se han hecho investigaciones de análisis, caracterización y síntesis de
la música flamenca. Existen numerosos trabajos e investigaciones. Encontramos
multitud de trabajos que podemos considerar dentro del área de Etnomusicología
Computacional. En el siguiente apartado exponemos las líneas de trabajo del
grupo.
1.4 LINEAS DE INVESTIGACION DEL GRUPO COFLA
La investigación del grupo COFLA ha estado centrada en las siguientes líneas fundamentales:
Línea 1. Matemáticas y Flamenco.
Línea 2. Transcripción automática, segmentación y separación de voces.
Línea 3. Similitud Musical.
Línea 4. Creación de corpus musical. Audios y transcripciones.
Línea 5. Detección automática de patrones distintivos.
Línea 6. Preferencia Musical. Etnomusicología.
Línea 7. Emoción.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
12
Línea 8. Divulgación científica y Educación.
Este proyecto está enmarcado en las líneas 2, 4 y 5 pues aunque ese centra en un
problema concreto de detección de patrones, requiere la transcripción automática
y creación de un corpus concreto de estudio y evaluación. Describimos brevemente
los avances del grupo en estas líneas.
Línea 2. Transcripción automática, segmentación y separación de voces.
Este problema resulta crucial para afrontar todo estudio computacional de la
música basado en audio y, por lo tanto, la gran mayoría de los estudios que se
planteen en el ámbito del análisis computacional de la música. Es un tema de gran
actualidad y el grupo está aportando metodología y algoritmos de impacto
internacional. Actualmente estamos diseñando un sistema de transcripción
automático especializado en música flamenca que esperamos esté disponible para
la comunidad científica próximamente. Algunos trabajos correspondientes a esta
línea de investigación son (Gómez & Bonada, Towards computer-assisted flamenco
transcription: An experimental comparison of automatic transcription algorithms
as applied to capella singing, 2013) (Salomon, Gómez, Ellis, & Richards, 2014)
Línea 4. Creación de corpus musical. Audios y transcripciones.
El grupo ha creado una base de datos para uso público que contiene la transcripción automática de un corpus amplio de cantes a capela del flamenco. Creemos que esto es crucial en el campo de investigación del proyecto pues es el primero que se realiza y permite que investigadores externos lo usen para sus estudios, llevando e incentivando la investigación de la música flamenca a todo el mundo académico. Esto implicara que al área de investigación que ha iniciado el grupo Cofla se adhieran más investigadores de otros grupos:
Corpus TONAS: “a dataset of flamenco a cappella sung melodies with
corresponding manual annotations”, published on March 15th, 2
0133.
Corpus COFLA, que contempla todas las antologías de cante flamenco y será
presentado en el congreso ISMIR 20154.
3 http://mtg.upf.edu/download/datasets/tonas
4 http://ismir2015.uma.es/

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
13
Línea 5. Detección automática de patrones distintivos.
El estudio de patrones melódicos distintivos es un tema íntimamente
relacionado con la definición de estilo musical, mucho más claro en el caso de
músicas de tradición oral. La conservación de los cantes flamencos de
generación en generación hace que la melodía juegue un papel crucial en la
evolución y clasificación de los distintos estilos del flamenco. La definición del
patrón melódico de cierta variante de un estilo o palo flamenco constituye uno
de los requisitos necesarios tanto en la clasificación de los cantes como en la
creación de textos para la didáctica y estudio del flamenco. De hecho, lo que
recuerda el cantaor es un esqueleto melódico sobre el cual puede añadir unas
ornamentaciones u otras que dependen de la influencia de otros cantaores
(escuelas) o de la propia capacidad vocal del intérprete (aportación personal).
Pongamos un ejemplo. Si aceptamos que el precursor del cante de debla fue
Tomás Pabón, tomamos su interpretación como modelo canónico. Sin embargo,
la debla interpretada por Antonio Mairena o Naranjito de Triana, aún
manteniendo un alto grado de similitud con el canon, aparece más
ornamentada, y con un contorno melódico bastante diferente.
Como ocurre en muchos temas de investigación musical del flamenco la
caracterización de estilos a través de patrones melódicos ha recibido escasa
atención. Podemos destacar dos estrategias o metodologías. Se analiza la
música para “descubrir” los patrones distintivos (método inductivo) o bien, se
parte de un conjunto de patrones considerados canónicos y se buscan en la
colección o corpus correspondiente (método deductivo).
Podemos decir que existen varias categorías de patrones, según sea la
posición en la pieza (exposición, remate, etc.) o el carácter (preceptivo del
cante, ornamental, etc.). En este marco aparecen cuestiones fundamentales que
están íntimamente relacionadas:
1. ¿Cuál es el patrón melódico común a todas las interpretaciones grabadas por maestros consagrados?
2. ¿Qué tipo de ornamentos son característicos en el estilo?
3. ¿Qué ornamentos son preceptivos del estilo y cuáles no?
4. ¿Qué patrones determinan la macro- y la micro-estructura del estilo?
Partimos de la base que toda conclusión en este sentido requiere ser
obtenida a partir de un corpus significativo en cantidad y variabilidad y, por
tanto, el tratamiento computacional, siempre combinado con el análisis manual
para algunas interpretaciones maestras- resultará crucial en este campo.
Por otra parte, cierta preferencia por un tipo u otro de interpretación
requiere un estudio etnográfico y de contexto cultural, lo que conecta con el
concepto de preferencia al que hace mención la línea de investigación 6.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 1 Introducción y antecedentes
14
A partir del planteamiento anterior, aparecen temas relevantes de
investigación referentes a los siguientes epígrafes. Enumeramos aquí algunos
problemas abiertos en este campo:
1. Codificación y clasificación de los ornamentos del flamenco. Ornamentos estéticos o preceptivos del cante.
2. Estudio del melisma flamenco. Carácter y similitudes con otras culturas.
3. Reconstrucción de arquetipos (patrones) ornamentales comunes a otros géneros melismáticos de tradición oral (Musicología comparada).
4. Diseño de algoritmos para la detección automática de patrones o motivos melódicos.
El último problema citado se refiere a búsqueda de patrones melódicos
estructurales: exposición de cante, ligados, caídas, etc. y es el antecedente
principal al problema estudiado en este proyecto. En el análisis de la
estructura melódica de un determinado cante flamenco aparecen varias tipos
de patrones según la localización de los mismos. De hecho, son estos micro
patrones los que definen las distintas variantes de un determinado palo
flamenco. Destacamos los patrones de exposición del cante (muchas veces
resultan suficientes para clasificar la variante cantada), los de ligado o
intermedios y los de caída o remate. El trabajo de (Pikrakis, Tracking melodic
patterns in flamenco singing by analyzing polyphonic music recordings, 2012)
recoge los primeros avances en el desarrollo de algoritmos para la detección
automática de patrones.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
15
CAPÍTULO 2. OBJETIVO, METODOLOGÍA Y
CORPUS DE ESTUDIO
CONTENIDO: 2.1 MOTIVACIÓN Y OBJETIVO
2.2 METODOLOGÍA
2.3 CORPUS DE ESTUDIO
2.3.1 FANDANGOS
2.3.2 ALBOREÁS
2.1 MOTIVACIÓN Y OBJETIVO
En este proyecto se va a presentar un método no supervisado para descubrimiento
de patrones melódicos vocales repetidos directamente de un audio de dos estilos
diferentes de la música flamenca como son las Alboreás y los fandangos. Un
algoritmo de detección se llama “no supervisado” si no se le da como entrada
ninguna información acerca de la estructura que se busca. Véase. Por ejemplo, el
texto (Hand, 2002) para un análisis detallado del estado del arte de los algoritmos
de detección de patrones.
Con objeto de diseñar un método no supervisado, no podemos incluir en la entrada
del algoritmo la longitud ni los puntos de inicio y final de los motivos melódicos
que queremos encontrar. Para simular esta información, realizaremos varias
rutinas que se van actuando secuencialmente. En un primer paso, un algoritmo de
detección de voz nos proporciona una segmentación aproximada de los patrones
repetidos basados en una estimación aproximada de la media de duración del
patrón. Esta estimación de duración es proporcionada computacionalmente por un
algoritmo que toma como entrada el audio y nos extrae una media de duración
aproximada del patrón. Más tarde un detector de patrones que usa un algoritmo de
alineación de secuencias nos cede un ranking de pares de patrones repetidos de los
dichos patrones segmentados anteriormente. Por último un algoritmo de
agrupamiento nos muestra finalmente los patrones repetidos. Este método es
novedoso en el contexto de la música flamenca ya que la realidad es que el
problema de la transcripción y representación simbólica es un problema muy
complejo debido a su tradición oral.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
16
Para empezar es necesario definir el concepto y estructura que queremos buscar:
patrón melódico repetido. Patrón repetido se define como conjunto de notas en
tiempo que se aparecen al menos dos veces (es decir se repite una vez como
mínimo) en una pieza musical. La segunda, tercera o cuarta repetición del patrón
estará desplazada en el tiempo y quizás transpuesta pero relativa a la primera
aparición. Idealmente un algoritmo deberá poder reconocer exactas e inexactas
repeticiones de un patrón en una pieza musical.
El desarrollo de algoritmos para el descubrimiento automático de patrones
melódicos repetidos en la música es un importante campo de trabajo dentro del
MIR (Music Information Retrieval), debido a que la extracción de patrones puede
ser útil para un gran número de aplicaciones como pueden ser Music
Thumbnailing, (encontrar la parte más característica o representativa de una
canción, la cual puede ser usada para búsquedas web, navegaciones web y
recomendaciones musicales), indexado de corpus, análisis estructural o
computación de similitud, por poner algunos ejemplos.
Recientemente un trabajo relacionado llamado “Discovery of Repeated Themes
and Sections” fue llevada a cabo en el contexto del MIREX (Downie, 2008) y
proporcionó un estudio de la evaluación de una serie de algoritmos existentes. La
mayoría de las soluciones a este problema hasta ahora han usado una
representación simbólica de la melodía extraída (Jansen, de Haas, Volk, & van
Kranenburg, 2013). Sin embargo, cuando se aplica este trabajo sobre
transcripciones automáticas de audios polifónicos (Collins, Boeck, Krebs, &
Widmer, 2014), los resultados son bastante insuficientes.
Este proyecto de fin de carrera está enfocado en la extracción automática de
patrones repetidos en cante flamenco. Esta tarea posee múltiples desafíos dadas
las particulares características del género flamenco (Gómez, Díaz-Báñez, Gómez, &
Mora, 2014). Al contrario de otros géneros, el cante flamenco es una tradición oral
y sus transcripciones son escasas y mayoritariamente referidas a la guitarra
flamenca.
Recientemente, un algoritmo para transcribir automáticamente melodías
flamencas ha sido desarrollado (Gómez & Bonada, 2013). Ha sido usado para
similitud melódica (Díaz-Báñez & Rizo, 2014) y reconocimiento de patrones con un
método supervisado (Pikrakis, 2012). Sin embargo, dada la poca eficiencia y la baja
precisión de la transcripción generada por el sistema de (Gómez & Bonada, 2013)
para el cante flamenco, no usaremos tal sistema de transcripción. Se propone aquí
un algoritmo computacional eficiente para reconocimiento de patrones de manera
no supervisada el cual funciona directamente sobre grabaciones de audio. Este tipo
de análisis podemos encontrarlo en el contexto de segmentación estructural
(Peeters, 2007) (Muller & Kurth, 2007) (Dannenberg, 2002) (Levy & Sandler,
2008), donde, al contrario que nuestro objetivo (encontrar motivos melódicos
pequeños), un archivo de audio es segmentado en secciones de largas repeticiones
de una pieza musical. En (Nieto & Farbood, 2012), una técnica de análisis
estructural es usada para extraer patrones más pequeños desde un audio

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
17
polifónico y en (Sankalp, 2014) podemos encontrar el uso de “Dinamic Time
Warping” para la detección de patrones usando el contorno melódico.
El método presentado en este trabajo será aplicado para el análisis de dos estilos flamencos de distinta factura como “Fandangos de Huelva” y “Alboreas”, en los cuales la repetición de patrones es un fenómeno frecuente, principalmente unido a la naturaleza folclórica de dichos estilos y su popularidad en representaciones artísticas. Encontrar patrones melódicos repetidos puede ser utilizado para subrayar características melódicas fundamentales dentro de diferentes estilos y poder implementarse en el estudio de los distintos estilos. Este tipo de procedimientos pueden obtener un importante rol en etnomusicología, ya que sería una buena herramienta objetiva para el estudio de las diferentes evoluciones de cada “palo” a lo largo de los años.
Concluyendo, la contribución de este proyecto a la investigación se basa en el
desarrollo de un algoritmo eficiente para el reconocimiento de patrones repetidos
directamente sobre un audio de manera no supervisada y que se aplique en el
campo de los cantes flamencos.
2.2 METODOLOGÍA: Pasos del método
Para la extracción de patrones repetidos en grabaciones de audio se han seguido
los siguientes pasos. Comenzamos con la elección de un corpus de estudio con el
que podamos trabajar y elegido a conciencia para nuestro fin. Una vez decidido el
corpus de estudio, trabajamos en concretar cuáles son los patrones que
caracterizan los estilos que vamos a estudiar, detallándolos y estableciendo una
terminología para ellos, como se explicara más adelante. Seguidamente se procede
a la creación de un registro manual que nos indique el inicio y final de cada patrón
en segundos de la grabación de audio los patrones melódicos decididos
anteriormente que buscaremos. Este registro lo llamaremos Ground Thruth o
Anotación de Expertos, que nos servirá para poder hacer una evaluación de los
resultados obtenidos. Para la implantación del algoritmo que detecte patrones
repetidos será necesario que se puedan obtener de manera no supervisada los
posibles inicios de cada patrón (que llamaremos Starting Points) y una estimación
de la media de duración de cada patrón. Una vez completados estos pasos se
procede a que el algoritmo actúe sobre todos los audios del corpus, obteniéndose
los resultados y para terminar, se procede a la evaluación mediante las medidas
usuales en MIR que estiman la precisión de los resultados obtenidos comparados
con la Ground Truth5 anotada manualmente.
5 Ground Truth es la selección manual de los patrones de las grabaciones del corpus seleccionadas

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
18
2.3 CORPUS DE ESTUDIO
Como ya se ha explicado con anterioridad, se va a trabajar el reconocimiento de
patrones repetidos en la música flamenca, probando los algoritmos sobre dos palos
del flamenco populares cercanos al folclore como son Los Fandangos y las
Alboreás. Debido a su carácter popular, poseen patrones melódicos que los
caracterizan y los diferencian de distintos estilos de la música flamenca.
La elección de estos dos “palos” tiene un sentido interés etnomusicológico y a la
vez computacional, debido a las diferencias intrínsecas de las melodías
características repetidas. Estas diferencias que explicaremos más adelante también
nos ayudaran significativamente a poder estimar la precisión e idoneidad del uso
de la herramienta que usaremos. A continuación se detallaran las características
de los patrones melódicos que podremos encontrar repetidos en cada estilo
elegido.
2.3.1 FANDANGOS
El Fandango es uno de los estilos fundamentales del flamenco. En Andalucía hay
dos regiones donde el fandango posee marcadas características musicales: Málaga
(Verdiales) y Huelva (Fandangos de Huelva). (Pikrakis, Tracking melodic patterns
in flamenco singing by analyzing polyphonic music recordings, 2012).
Este trabajo se centrará en fandangos de Huelva, los cuales suelen estar
acompañados de guitarra. Las referencias más antiguas de los fandangos de Huelva
se datan de la segunda mitad del siglo XIX. En el presente, los fandangos de Huelva
son los más conocidos popularmente, y poseen múltiples variantes. Tipos de
fandangos de la provincia de Huelva populares pueden ser: fandangos de Huelva,
fandangos de Alosno, fandangos de Santa Eulalia, Fandango de Valverde y un largo
etcétera debido a numerosas poblaciones en la serranía de la provincia de Huelva.
Tomando como ejemplo los fandangos de Alosno, podemos observar que dentro de
este subestilo encontramos variaciones como pueden ser el fandango cané o el
fandango valiente de Alosno.
Desde una perspectiva musicológica, todos los fandangos tienen una estructura
formal y armónica bimodal común, la cual se basa en el modo mayor frigio (modo
flamenco o cadencia andaluza) para marcar el compás en guitarra y en modo
mayor para las melodías de cante. La interpretación puede ser cercana al estilo
folclórico o al estilo flamenco estando este hecho relacionado con el uso de menos
o más ornamentación respectivamente. El estudio de los Fandangos de Huelva
tiene un interés en particular por las siguientes razones: (1) Identificación de los
procesos musicales que contribuyen a la evolución del estilo folclore hasta el
flamenco (2) Definición de los estilo a través de similitud melódica (3)
Identificación de variables musicales que definen cada estilo.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
19
Patrones característicos en los fandangos
Los fandangos de Huelva poseen distintas características dentro de cada estilo,
pero a su ver podemos encontrar similitudes tanto melódicas como armónicas.
También tienen en común una estructura de repetición de patrones.
Generalmente, podemos encontrar 6 frases melódicas dentro de cada fandango,
aunque en algunos estilos esto puede variar. Podemos llamarlas exp-1, exp-2, exp3,
exp4, exp-5 y exp-6. El número identifica en orden en el que aparece cada frase
melódica dentro de cada fandango.
Si tomamos como ejemplo un fandango de Valverde, vemos que exp-1, exp-2, exp-
3, exp-4, exp-6 son patrones con claras diferencias melódicas y a su vez
identificamos auditivamente que exp-1, exp-3 y exp-5 son patrones repetidos
dentro de cada fandango. En la figura 1 podemos los patrones principales dentro
del fandango de Valverde y sus acordes.
Figura 1. Representación en pentagrama de los patrones que
forman el fandango de Valverde
Cabe destacar que en una grabación podemos escuchar varios fandangos, uno
detrás de otro. Esta particularidad facilita al algoritmo usado para poder encontrar
patrones repetidos, debido a que dentro de un mismo audio el algoritmo deberá

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
20
identificar la repetición del patrón exp-6 tantas veces como fandangos del mismo
estilo haya en un mismo audio.
El corpus de fandangos que vamos a trabajar nos ha sido proporcionado por el
Centro Andaluz de flamenco de la Junta de Andalucía, una institución oficial cuya
misión en la preservación de la herencia cultural de la música flamenca. Esta
institución nos envió 1200 grabaciones de fandangos, de los cuales hemos tomado
para nuestro estudio 10 de ellas.
El criterio utilizado para la selección de los fandangos para el corpus se basa en las
siguientes propiedades que son deseables en la composición de un repertorio de
estudio:
(1) Archivos de audio que contengan guitarra y voz.
(2) Calidad de audio aceptable para permitir el procesado automática.
(3) Variedad de los diferentes tipos de estilos de fandangos de Huelva.
Los audios de fandangos de Huelva con los que trabajaremos son etiquetados como
sigue:
FAN01 Fandangos de Calañas. Intérprete: El Cabrero.
FAN02 Fandangos del Cerro, Valverde y Cabezas Rubias. Intérprete: Antonio González
“El Raya”.
FAN03 Fandangos de Valverde. Intérprete: Antonio González “El Raya”.
FAN04 Fandangos de Valverde. Intérprete: P. Marín.
FAN05 Fandangos de Valverde. Intérprete: P. Márquez
FAN06 Fandangos de Encinasola. Intérprete: Eduardo Garrocho.
FAN07 Fandangos de Alosno y Cané. Intérprete: José María de Lepe.
FAN08 Fandangos del Cerro y Santa Eulalia. Intérprete: Diego Clavel.
FAN09 Fandangos de Valverde. Intérprete: El Cabrero.
2.3.2 ALBOREÁS
La Alboreá es un palo flamenco que se ha basado históricamente en los cantes que los gitanos de Andalucía hacían en sus ceremonias de boda. Según algunas teorías, el origen de la palabra procede del término alborada, en relación al momento en que las bodas son celebradas, al alba. También es llamada a veces alborá, albolá o alboleá. Los gitanos consideran que la albolá es un cante exclusivo de su raza y cultura y sólo para sus rituales, y que por tanto no debe ser realizado fuera de este contexto de la ceremonia, pues para ellos es algo sagrado y esta es una norma que no debe ser “profanada”.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
21
Al igual que en otros palos flamencos, el origen de la alboreá está rodeado por bastante incertidumbre, aunque podemos encontrar una primera referencia en el año 1855, en una novela histórica de Vicente Barrantes sobre Juan de Padilla (Barrantes, 1855), “ Sólo oyendo a los gitanos cantar la Alboreá en sus aduares, cuando la luz empieza a llamear en los picos de las montañas, se puede comprender lo que dice la voz de los judíos, tan triste y tan dulce a la par, tan estridente y tan sonora” Parece ser en Granada, donde, a mediados del siglo XIX y en plena expansión flamenca, los gitanos empiezan a “aflamencar” la Alboreá, poniéndola en escena en algunas zambras gitanas, hecho que aprovechan algunos cantaores de la época para estilizarlas, personalizarlas y agregarlas a sus repertorios de cante flamenco, haciéndolas con un compás de soleá por bulerías y jaleos o tangos. Además de las de Granada, podemos encontrar en Andalucía Oriental otras variantes destacables, como son las Alboreás de Jaén, Córdoba y Málaga. Por otro lado, en la zona de Andalucía Occidental, es estilo de la Alboreá es más melismático, o sea, se interpretan varias notas con cada sílaba de la letra. Esto la hace emparentarse con la soleá. En este tipo de Alboreá, podemos encontrar y diferenciar la Alboreá de Cádiz y Los Puertos -que tiene aires de soleá romanceada bailable-, la Alboreá de Jerez, Lebrija y Utrera -con toques de soleá o soleá por bulerías y acento de romance-. No son muchas las Alboreás flamencas que encontramos registradas, sus grabaciones eran, y son, poco frecuentes; por la naturaleza íntima de la que hablábamos al principio. No obstante, son varios los cantaores importantes los que nos han dejado documentos sonoros.
En cuanto a rítmica se puede afirmar que en una gran mayoría podemos encontrar
las Alboreas en compases de bulería por soleá e incluso con un tempo más
acelerado convirtiéndose en bulerías. Armónicamente hablando las Alboreas se
encuentran en modo mayor frigio y en determinados momentos modula a modo
mayor para ciertas frases melódicas que detallaremos más adelante.
Patrones característicos en Alboreás
Para este proyecto se han identificado 4 patrones melódicos que podemos
considerar característicos y únicos de este estilo flamenco, que llamaremos así: P1,
P2, P3 y P4. Estos serían bloques melódicos que pueden aparecer y repetirse
dentro de cada archivo de audio. Cada patrón que hemos elegido está compuesto
por estructuras melódicas que llamaremos frases musicales mínimas, como se
detalla a continuación:
P1 está compuesto por tres patrones mínimos. P1.1, P1.2 y P1.3
P2 está formado por P2.1 y P2.2

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
22
P3 lo forman P3.1 P3.2 P3.3 P3.4
P4 por P4.1 y P4.2 (conocido como “el yeli”)
En las siguientes figuras podemos ver la transcripción realizada el musicólogo
Francisco Suárez, director de la Orquesta Sinfónica Europea Romaní, de los
patrones mencionados anteriormente:
Figura 2. Patrón 1.1
Figura 3. Patrón 1.2
Figura 4.Patrón 1.3
Figura 5. Patrón 2.1

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
23
Figura 6.Patrón 2.2
Figura 7. Patrón 4.1
Figura 8. Patrón 4.2
Para la creación del corpus de estudio de Alboreás, hemos partido de toda la
colección de Alboreás proporcionada por el Centro Andaluz de flamenco de la Junta
de Andalucía. Consta de 41 archivos de audio. Es notable la pequeña cantidad de
archivos de los que se dispone. Debido a la naturaleza exclusiva y sagrada que
posee este estilo flamenco, al ser prohibido su cante fuera de ceremonias
nupciales, el número de grabaciones que se poseen son muy inferiores a las de
fandangos de Huelva u otros estilos. Para la realización de este estudio se han
seleccionado 10 audios, que serán archivos de audio .wav, siguiendo las siguientes
pautas:
(1) Archivos de audio que contengas guitarra y voz.
(2) Calidad de audio aceptable para permitir el procesado automática.
(3) Que posean alguna de los cuatro patrones identificados, debido a que existen
alboreas dentro del corpus de 41 que solo son identificables por la temática de sus
letras.
ALB4 - Boda Gitana Intérprete: Antonio Heredia Año: 2000

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 2 Objetivo, metodología y corpus de estudio
24
ALB7 - Gitana de Azucena Interprete: Fosforito Año: 1991 ALB12 - Despierta la Novia Intérprete: Marcelo Sousa Año: 1996 ALB13- La Fuente Intérprete: Márquez el Zapatero Año: 1995 ALB14- Alborea Intérprete: Pastora Galván Año: 2005 ALB15- Boda Flamenca en Cádiz Intérprete: Pericón de Cádiz Año: 1987 ALB17- Alboreá de la Boda de Blas Intérprete: Piki Año: 1994 ALB19- Alboreá de Jaén Intérprete: Rafael Romero Año: 2004 ALB24- Salga la Madrina Intérprete: Raúl Montesinos Año: 2000 ALB25- Alboreá Intérprete: Trini Año: 2000

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
25
CAPÍTULO 3. EL ALGORITMO NO
SUPERVISADO
CONTENIDO:
3.1 MÉTODO DE DETECCIÓN DE LA VOZ
3.2 ESTIMACIÓN DE LOS PUNTOS DE INICIO Y LA MEDIA DE LA DURACION
DE LOS PATRONES
3.3 MÉTODO DE DETECCIÓN DE PATRONES MELÓDICOS REPETIDOS.
3.3.1 CÓMPUTO DE EMPAREJAMIENTOS A TRAVÉS DEL
ALINEAMIENTO DE SECUENCIAS
3.3.2 AGRUPAMIENTO DE PATRONES
3.1 MÉTODO DE DETECCIÓN DE LA VOZ
Puesto que nuestro objetivo es encontrar patrones repetidos en una línea melódica
para la voz, necesitamos en primer lugar, discriminar los segmentos de voz con
respecto a segmentos de voz y guitarra. Para ello vamos a usar descriptores de
bajo nivel, que en nuestro caso nos resultara eficiente ya que en flamenco
mayoritariamente tendremos audios con poca instrumentación, es decir, sólo
guitarra aparte de la voz. Podemos encontrar métodos anteriores que consiguen
aislar segmentos de voz (Ramona, Richard, & David, 2008) (Rao, Gupta, & Rao,
2011) , pero están enfocados para su aplicación en música occidental como puede
ser el rock o la música pop, donde existe un mayor número de instrumentación
aparte de la melodía vocal. Estos métodos usan algoritmos de aprendizaje
artificial6 para discriminar segmentos de voz y no-voz y, por supuesto, son
alternativa a ser usados cuando la instrumentación musical aumenta. Como hemos
dicho anteriormente, nuestro caso es de instrumentación sencilla, solo aparece
guitarra y voz.
Lo que proponemos para la detección de voz se basa en el hecho de que una vez
que analizamos el dominio espectral en una sección de audio con voz y guitarra,
observamos que se produce un incremento espectral en el rango de 500HZ-6KHz si
6 El Aprendizaje Automático o Aprendizaje de Máquinas es una rama de la Inteligencia Artificial cuyo objetivo es desarrollar técnicas que permitan a las computadoras aprender.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
26
lo comparamos con otra sección donde solo encontramos instrumentación. Esto
nos da una clara idea de los intervalos de frecuencia donde encontramos la voz
melódica.
Por lo tanto, ahora vamos a intentar extraer la ratio de banda espectral, b(t), de la
magnitud espectral normalizada, |X(t,f)|, utilizando una ventana que se mueve a los
largo del eje del tiempo con un tamaño de 4096 muestras y un salto de
movimiento de 128 muestras tal como podemos ver en la siguiente función:
𝑏(𝑡) = 20 ∙ 𝑙𝑜𝑔10∑ |𝑋(𝑓, 𝑡)|𝑓≤6000𝑓≥500
∑ |𝑋(𝑓, 𝑡)|𝑓≤400𝑓≥80
1
La magnitud espectral normalizada |X(t,f)| es la Transformada de Fourier de
tiempo reducido, y está relacionada con la transformada de Fourier usada para
determinar cambios en secciones locales de una señal, así como cambios con
respecto al tiempo. La función a ser transformada es multiplicada por una función
ventana, por tanto la transformada de Fourier es tomada como la ventana que se
desliza a lo largo del tiempo, resultando una representación en dos dimensiones de
la señal como sigue:
𝑺𝑭𝑻𝑵{𝑥[𝑛]} ≡ 𝑋(𝑡, 𝑓) = ∑ 𝑥[𝑛]𝑓[𝑛 − 𝑚]𝑒−𝑗𝑓𝑡∞
𝑛=−∞
2
donde, x[ ] es la señal y f[ ] es la ventana.
La mayoría de los audios con los que vamos a trabajar se encuentran en estéreo, es
decir, con dos canales independientes de audio y sabemos que en uno de ellos
siempre la voz tiene más energía que en el otro. Debemos extraer b(t) para ambos
canales y seleccionar el canal cuyo resultado posea un mayor valor resultante.
El siguiente paso será la extracción del valor eficaz de la señal, rms(t), usando los
mismos valores de movimiento y salto de ventana, para justo después estimar la
envolvente de rms(t), que llamaremos rmsenv(t). Para la estimación de los valores
de la función envolvente, tomaremos cada valor de rms(t), y se le proporcionará el
valor de su máximo local más cercano, con lo cual obtendremos una función por
partes y constantes.
Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
27
Una vez obtenidos el ratio espectral de banda b(t) del canal de voz dominante y la
función rmsenv(t), podremos obtener las secciones de voz haciendo una
combinación de las funciones anteriores. Tomaremos la función b(t) y la
desplazaremos sobre el eje vertical hasta que todos sus valores sean positivos
(sumándole a la función el mínimo absoluto de la función) y entonces b(t) se
pondera usando la función rmsenv(t) para obtener los valores más importantes.
Esta etapa nos dará una secuencia resultante que llamaremos v(t) normalizada con
media cero. Observando esta función v(t) asumimos que los valores positivos de
ella corresponden con segmentos de voz y los valores negativos lo contrario, ya sea
silencios o instrumentación. Si obtenemos la función de signo de v(t), la cual
llamaremos voicing(t), [voicing(t)=sgn(v(t)], y hacemos un proceso de alisado o
suavizado de voicing(t) para eliminar ruido y datos inútiles mediante un filtro de
media móvil7 con ventana de 30 ms, la función resultante, que llamaremos cv(t)
tomara valores entre 0 y 1 que interpretaremos como una función de confianza
para la segmentación de voz que se usara en la Sección 3.3.
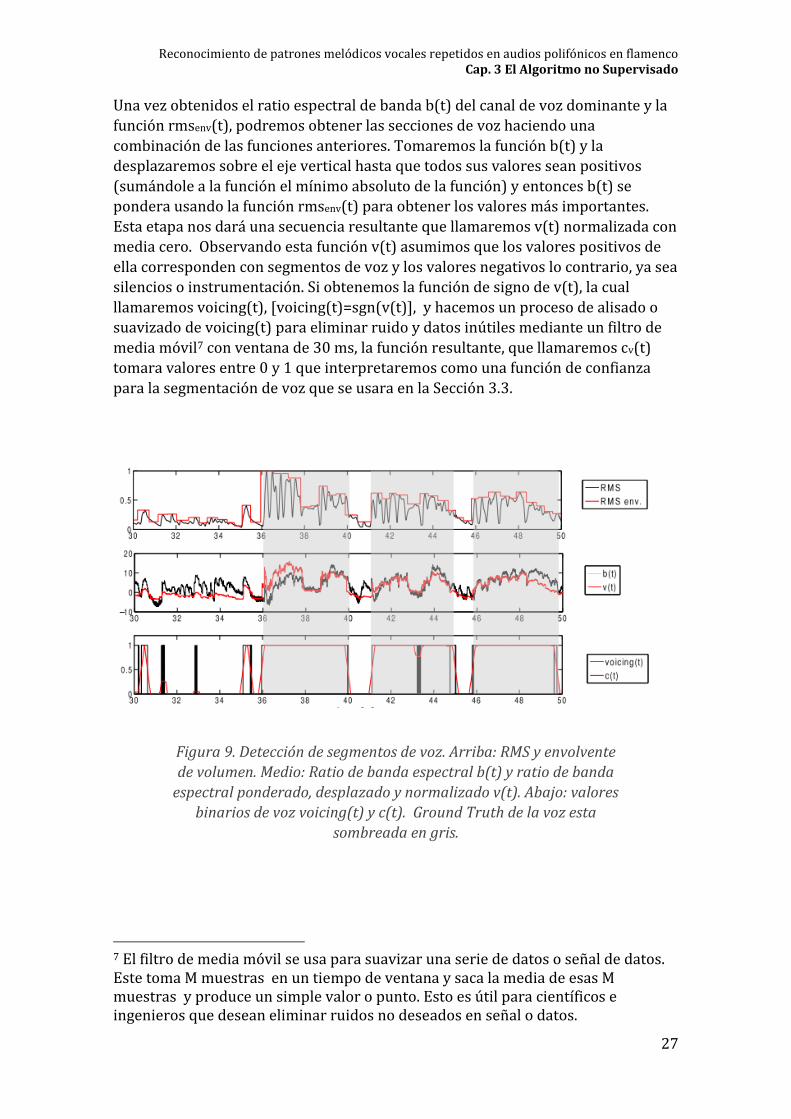
Figura 9. Detección de segmentos de voz. Arriba: RMS y envolvente
de volumen. Medio: Ratio de banda espectral b(t) y ratio de banda
espectral ponderado, desplazado y normalizado v(t). Abajo: valores
binarios de voz voicing(t) y c(t). Ground Truth de la voz esta
sombreada en gris.
7 El filtro de media móvil se usa para suavizar una serie de datos o señal de datos. Este toma M muestras en un tiempo de ventana y saca la media de esas M muestras y produce un simple valor o punto. Esto es útil para científicos e ingenieros que desean eliminar ruidos no deseados en señal o datos.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
28
3.2 ESTIMACIÓN DE LOS PUNTOS DE INICIO Y LA MEDIA DE LA DURACION DE
LOS PATRONES.
Existen trabajos anteriores para estimar la media de duración de patrones basados
en la rítmica de estilos musicales con patrones rítmicos simples. En estos métodos
se proponía que se pueden producir inicios melódicos de voz en instantes donde se
producen pulsos rítmicos, lo cual facilita mucho el trabajo. Debido a la complejidad
rítmica que posee el género musical que estamos estudiando, no es posible
establecer una relación trivial entre la rítmica y la acentuación de la voz para el
inicio de melodías vocales y los métodos conocidos no son aplicables.
El método propuesto de detección de voz nos servirá de utilidad tanto para la
sección 3.3 como para esta sección, ya que los segmentos de voz detectados nos
servirán para estimar una media de duración de patrones de voz para cada audio.
Suponemos que los inicios de voz fuertes coinciden con grandes cambios en la
parte vocal del espectro, y también con un aumento de volumen.
Se procederá a continuación a definir una función de detección de inicio de voz
p(t). Para establecer la función detección de inicio de voz haremos lo siguiente:
para cada frame8, se calcula la diferencia del ratio espectral de banda Δb(t) en un
instante t como:
∆𝑏(𝑡) = (∆𝑏𝑝𝑜𝑠𝑡(𝑡) − ∆𝑏𝑝𝑟𝑒𝑣) ∙ ∆𝑏𝑝𝑜𝑠𝑡(𝑡) 3
𝑏𝑝𝑟𝑒𝑣(𝑡) = ∑ 𝑏(𝑇)
𝑇=𝑡
𝑇=𝑡−435𝑚𝑠
4
𝑏𝑝𝑜𝑠𝑡(𝑡) = ∑ 𝑏(𝑇)
𝑇=𝑡+435𝑚𝑠
𝑇=𝑡
5
Donde bprev(t) es la suma del ratio de banda espectral antes en t-lw mas el ratio de
banda en t, y, similarmente, bpost(t) es la suma del ratio de banda en t más el ratio
de banda en t+lw, donde lw=435 ms.
Siguiendo el mismo procedimiento, calculamos la diferencia de la función
envolvente ΔrmsEnv(t) con lw=435 ms. 8 Los archivos de audio con los que trabajamos tienen 44,100 frames ó muestras por segundo. Cada frame contiene 16-bits de resolución.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
29
𝑅𝑀𝑆𝑝𝑟𝑒𝑣(𝑡) =∑𝑅𝑀𝑆(𝑡)
𝑡
𝑡1
6
𝑅𝑀𝑆𝑝𝑜𝑠𝑡(𝑡) =∑𝑅𝑀𝑆(𝑡)
𝑡2
𝑡
7
ΔRMS=(RMSpost-RMSprev)RMSpost
8
Donde t1=t-435ms y t2=t+435ms.
La función detección de inicio de voz será entonces:
𝑝(𝑡) =∆𝑏(𝑡)
∆𝑏̅̅̅̅∙∆𝑟𝑚𝑠𝐸𝑛𝑣(𝑡)
∆𝑟𝑚𝑠𝐸𝑛𝑣̅̅ ̅̅ ̅̅ ̅̅ ̅̅ ̅∙ 𝑣𝑜𝑖𝑐𝑖𝑛𝑔(𝑡) 9
Por tanto, los inicios de voz coincidirán con los máximos locales de la función p(t).
A raíz de esto, estimaremos un conjunto de posibles duraciones de patrones
analizando las distancias entre estos máximos locales en un histograma con ancho
de barra de 0.1 segundos. Supondremos que los “picos” del histograma
corresponden con pequeñas unidades rítmicas y decidimos que las duraciones
mínimas posibles de los patrones son múltiplos de estas unidades rítmicas y
mayores que 3 segundos, durmin. Esta duración mínima será la unidad con la que
buscaremos patrones repetidos.
3.3 MÉTODO DE DETECCIÓN DE PATRONES MELÓDICOS REPETIDOS
Una vez que se puede extraer la función de confianza c(t) y se puede estimar la
duración media de los patrones, podemos empezar a explicar el método de
detección de patrones repetidos.
Nuestro interés es encontrar patrones melódicos, por tanto, debemos establecer
una correcta segmentación de la secuencia c(t). Esta secuencia, como se indicó en
el apartado 3.1, es una secuencia binaria donde un 0 significa no-voz, y un 1
significa voz. Entonces es necesario hacer una segmentación de esta secuencia,
para tener intervalos de voz e intervalos sin voz. Se propone un método simple:

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
30
cualquier subsecuencia de c(t) que se encuentre entre dos subsecuencias de ceros
se trata como un segmento de audio que contiene voz, siempre que su duración sea
de al menos la mitad del patrón estimado (durmin).
Para el siguiente paso, se extraerá la “secuencia Chroma” de cada audio, esto es, el
vector que representa la escala cromática. La herramienta Chroma9 en Matlab es
una muy interesante y potente representación de audio musical donde todo el
espectro es representado en un mínimo de 12 cubos (bin) que a su vez
representan los semitonos entre 2 octavas.
Una secuencia Chroma se representa como un vector de 12 dimensiones 𝑥 tal
como se muestra:
𝑥 ≡ (𝑥(1), 𝑥(2), … , 𝑥(12))𝑇
donde 𝑥(1) corresponde a la nota Do, 𝑥(2)
corresponde a Do# y asi con las 12 notas tradicionales
Para la extracción de la secuencia Chroma se usará una técnica de procesado en
tiempo reducido con una ventana de 0.1 segundos y un salto de 0.02 segundos
(Bartsch & Wakefield, 2005). Después se normalizará cada dimensión del vector
Chroma a media cero y desviación estándar 1 y se conservarán las subsecuencias
Chroma que corresponden a los segmentos de voz previamente detectados. Debido
a la naturaleza microtonal del flamenco, adoptaremos una representación de 24
dimensiones en vez de 12 dimensiones, es decir, se dividirá cada octava en 24
notas diferentes. Por tanto, la salida de esta etapa de extracción para cada audio,
será un conjunto de M secuencias, xi, i=1,…,M , de vectores Chroma de 24
dimensiones.
3.3.1 CÓMPUTO DE EMPAREJAMIENTOS A TRAVÉS DEL ALINEAMIENTO DE
SECUENCIAS
Una vez extraídas las secuencias Chroma de los segmentos de voz, se examinarán
de dos en dos mediante un algoritmo de alineamiento de secuencias (Berndt &
Clifford, 1994). Las características principales del que usaremos algoritmo serán:
1- El algoritmo opera con una matriz de similitud. 2- Se usará el coseno de dos vectores Chroma a como medida de similitud
local. 3- Se penalizarán los huecos en transiciones horizontales y verticales de la red.
El resultado que buscamos en este proceso de alineamiento debe ser un conjunto
de pares de segmentos de voz. Este conjunto no nos proporciona garantía de que
estos pares de secuencias sean similares debido a que los segmentos de voz
extraídos no son precisos en cuanto a tiempo de duración o instantes de comienzo
9 http://labrosa.ee.columbia.edu/matlab/chroma-ansyn/

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
31
en el audio, es decir, si tomamos una par de secuencias seleccionadas por el
algoritmo como similares, éstas pueden estar desplazadas en el tiempo, que su
duración sea distinta o las dos cosas. Un proceso de depuración se levara a cabo en
el apartado 3.3.2.
A continuación detallamos cómo trabaja el algoritmo para el proceso de
alineamiento. Imaginemos que se toman dos secuencias Chroma de dos segmentos
de voz calculados, los llamaremos X e Y. Es conveniente recordar que estas
secuencias Chroma son vectores de 24 dimensiones. X={x1,…,xi, i=1,…,I} e
Y={y1,…,yj, j=1,…,J} donde J, I son la longitud de la secuencia segmentada de voz a
alinear y dependerá de la longitud de la segmentación de voz de c(t).
Debemos asumir que la secuencia X se encuentra en el eje de abscisas, e Y se aloja
en el eje de ordenadas de la matriz de similitud. Definimos s(j,i) como la similitud
local de dos vectores Chroma xi e yj el coseno del ángulo que forman.
𝑠(𝑖, 𝑗) =∑ 𝑦𝑗(k)∙𝑥𝑗(k)
𝐿
𝑘=1
√∑ 𝑦𝐽2(𝑘)
𝐿
𝑘=1∙√∑ 𝑥𝑖
2(𝑘)𝐿
𝑘=1
L=24 10
Construimos una matriz de similitud JxI y calculamos la similitud acumulada para
cada nodo. El cálculo de la similitud acumulada se realiza con programación
dinámica. A la similitud acumulada se le llamará H(j,i), y se define tal como sigue
en la siguiente ecuación:
𝐻(𝑗, 𝑖) = 𝑚𝑎𝑥
{
𝐻(𝑗 − 1, 𝑖 − 1) + 𝑠(𝑖, 𝑗) − 𝐺𝑝,
𝐻(𝑗, 𝑖 − 𝑘) − (1 + 𝑘𝐺𝑝), 𝑘 = 1,… , 𝐺𝑙 ,
𝐻(𝑗 − 𝑚, 𝑖) − (1 +𝑚𝐺𝑝), 𝑚 = 1,… , 𝐺𝑙 ,
0
11
donde j≥2, i≥2, Gp es la penalización de huecos y Gl es el máximo hueco permitido,
medido en número de vectores Chroma.
En la sección 3.3.2 se proporcionaran valores convenientes de Gp y Gl,, siendo unos
parámetros a variar por el usuario. Conviene resaltar que la transición diagonal
corresponde a s(i,j)-Gp, la cual puede ser positiva o negativa dependiendo del
grado de similitud entre yj y xi. Es más, cada eliminación vertical u horizontal
introduce una penalización de hueco igual a (1+K∙Gp), donde K es la longitud de la
supresión, medido en número de cuadros (frames).

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
32
El proceso será el siguiente, para cada nodo de la red, almacenamos su predecesor
máximo W(j,i). Si H(j,i) es cero por algún nodo, a W(j,i) es asignado el nodo ficticio
(0,0). La inicialización del método es como sigue:
𝑊(𝑗, 1) = (0,0), 𝑗 = 1,… , 𝐽 𝑊(1, 𝑖) = (0,0), 𝑖 = 1, … , 𝐼
𝐻(𝑗, 1) = 𝑚𝑎𝑥{𝑆(𝑗, 1) − 𝐺𝑝, 0} 𝑗 = 1, … , 𝐽
𝐻(1, 𝑖) = 𝑚𝑎𝑥{𝑆(1, 𝑖) − 𝐺𝑝, 0} 𝑖 = 1,… , 𝐼
12
Una vez que toda la matriz es calculada, se localiza el nodo que ha acumulado la
mayor puntuación en similitud, y al final se hace una camino de retroceso hasta
que se llegue a un nodo (0,0). El mejor camino resultante desde el nodo con
mayor similitud hasta el (0,0) nos mostrará las dos subsecuencias que poseen el
alineamiento más significativo. El nodo de mayor similitud es entonces
normalizado por el número de nodos existentes en la el camino óptimo. De esta
manera, el nodo de mayor similitud encontrado evita sesgos.
Si la longitud del par de subsecuencias que corresponden a la del mejor camino no
excede en duración la mitad de la duración del patrón esperado, durmin, no lo
damos por válido y seleccionamos el nodo con la segunda mayor similitud
acumulada y volvemos a hacer el procedimiento de retroceso hasta el nodo (0,0).
Este procedimiento iterativo se repite hasta que encontramos el primer par de
subsecuencias que poseen como mínimo la mitad de durmin. Si al final no es
encontrado ningún par, las secuencias Chroma originales X e Y son descartadas.
Una vez que el alineamiento de todos los segmentos de voz haya sido procesado, se
toman K pares, donde K es un parámetro que se define como entrada del
algoritmo. Por ejemplo, si K es 5, el algoritmo dará como salida los mejores 5 pares
de caminos la red. Estos caminos se mostraran con su punto inicial y final (en
frames) de las subsecuencias que fueron alineadas. Por tanto, obtendremos un
conjunto P con K pares de patrones en la forma
𝑃 = {{((𝑡11, 𝑡12), (𝑡13, 𝑡14)}, … , {(𝑡𝐾1, 𝑡𝐾2), (𝑡𝐾3, 𝑡𝐾4}}
donde {(ti1, ti2), (ti3, ti4)} representa el patrón (secuencia Chroma) que comienza
en ti1 y termina en ti2 y que ha sido alineado con el patrón que comienza en ti3 y
termina en ti4. (t se muestra en ventanas o frames).
3.3.2 AGRUPAMIENTO DE PATRONES
Una vez que hemos conseguido emparejar patrones melódicos repetidos, el
siguiente reto es conseguir que un algoritmo agrupe estos patrones emparejados

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
33
en grupos similares. Por ejemplo, si el algoritmo de emparejamiento extrae cinco
pares de patrones repetidos, necesitamos otro algoritmo que agrupe los patrones
que sean similares entre ellos.
El algoritmo propuesto no es especialmente óptimo en resultados, pero posee la
ventaja de tener muy baja complejidad computacional y con un rendimiento
bastante aceptable.
La idea propuesta se basa en la identificación de vectores Chroma que pueden
formar parte de uno o más pares de patrones y se usa la propiedad de transitividad
para agruparlos. Por tanto, si en dos pares de patrones encontrados podemos
reconocer que comparten vectores Chroma idénticos, se clasifican como pares del
mismo grupo. Si aparece otro par con algún elemento del grupo anterior, los
patrones del par serán asociados al grupo primero y por tanto, usarán la misma
etiqueta. Si un vector no se consigue identificar dentro de ningún par alineado, su
respectiva etiqueta será un conjunto vacío.
Si realizamos un barrido de izquierda a derecha por los segmentos de voz,
generaremos una secuencia C de etiquetas, es decir, C={c1,c2,…,cN }, donde N es la
longitud de la grabación de audio que se está procesando (medido en frames). En
este proceso se requiere completar segmentos maximales. Se define que una
subsecuencia de C que comienza en i y termina en j, forma un segmento máximo si:
𝑐𝑘 ∩ 𝑐𝑘+1 ≠ ∅, ∀𝑖 ≤ 𝑘 ≤ 𝑗 − 1 ( 1 ) 𝑐𝑖−1 ∩ 𝑐𝑖 = ∅ ó 𝑐𝑖−1 = ∅ ( 2 ) 𝑐𝑗 ∩ 𝑐𝑗+1 = ∅ ó 𝑐𝑗+1 = ∅ ( 3 )
Todos los segmentos máximos pueden ser fácilmente detectados escaneando la
secuencia C de izquierda a derecha. La condición (1) es usada para detectar los
puntos de comienzo posibles de cada patrón c, la condición (2) trata de expandir
segmentos y (3) sirve para parar la expansión de dichos segmentos y marcar el
final. Cada vez que un segmento máximo es completado, su etiqueta será
establecida como la unión de las etiquetas de todos sus frames. Después de que
todos los segmentos máximos han sido formados, asignamos a los mismos grupos
todos los segmentos que posean la misma etiqueta. De esta manera, los pares
encontrados están agrupados y etiquetados.
La figura 10 representa la salida de nuestro algoritmo para una grabación de audio,
incluyendo la Ground Truth anotada manualmente por expertos así como los
puntos de comienzo de patrones estimados. Los círculos señalan errores. Los
patrones repetidos 3 y 4 marcan error por no haber sido descubiertos y el patrón 2
estuvo erróneamente agrupado con el patrón 1. Esto puede deberse al hecho que el
patrón 2 es muy similar al patrón 1, incluso cuando es percibido en una audición.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 3 El Algoritmo no Supervisado
34
Figura 10. Arriba: Salida de algoritmo de reconocimiento de
patrones. Abajo: Patrones de la Ground Truth. Más abajo: puntos de
inicio estimados.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
35
CAPÍTULO 4. EVALUACIÓN
CONTENIDO
4.1 CREACIÓN DE LA “GROUND TRUTH”
4.1.1 ¿POR QUÉ ES NECESARIO CREAR UNA BASE DE DATOS
“GROUND TRUTH”?
4.1.2 PROCESO DE CREACION DE LA GROUND TRUTH
4.2 EVALUACIÓN DE RESULTADOS
4.2.1 ALGORITMO DE EVALUACIÓN
4.2.2 EVALUACIÓN
4.1 CREACIÓN DE LA GROUND TRUTH
4.1.1 ¿POR QUÉ ES NECESARIO CREAR UNA BASE DE DATOS “GROUND TRUTH”?
Para poder determinar el grado de precisión de los resultados obtenidos de cara al
objetivo principal del proyecto, esto es, descubrir patrones repetidos en
grabaciones de audio de manera no supervisada, es necesario hacer una evaluación
comparativa con una notación manual realizada por un musicólogo o experto en la
materia.
En al campo de MIR se suele denominar Ground Truth a una anotación manual
realizada por expertos en la música de estudio que etiqueta los aspectos que se
pretenden encontrar automáticamente. La salida del algoritmo no supervisado de
reconocimiento de patrones repetidos vendrá dada por los patrones encontrados y
agrupados en conjuntos que son considerados como patrones similares. El objetivo
principal de la creación de una Ground Truth es poder evaluar la precisión de los
resultados obtenidos del algoritmo comparándolos los con los que en realidad
debería haber encontrado. El carácter no supervisado del algoritmo, esto es, se
diseña sin dar ninguna información acerca de lo que se busca, salvo que son
segmentos melódicos repetidos, nos aventura a obtener resultados que pueden ser
muy distintos a los deseados.
El algoritmo propuesto en el capítulo anterior nos dará tres tipos de información:
a- Patrones repetidos visualizados en grupos. Estos grupos acogen patrones que el algoritmo considera como idénticos dentro de una tolerancia dada.
b- El número de veces que cada patrón se repite, lógicamente el mínimo será dos.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
36
c- Tiempo de inicio y fin de cada patrón.
Nuestra Ground Thruth será una base de datos que necesariamente tenga de alguna
manera las informaciones anteriores, para cuando se realice la evaluación
podamos ver con la mayor exactitud la precisión de los resultados obtenidos, es
decir, una vez realizada la evaluación, poder observar si el algoritmo no
supervisado ha encontrado:
a- Los distintos grupos de patrones que se repiten en el audio establecido en la Ground Truth.
b- El número de veces que se repite cada patrón en cada grupo. c- Exactitud de inicio y fin de los patrones encontrados comparados con los
establecidos en la Ground Truth. Se decidirá una cota de error suficiente o tolerancia para dar el visto bueno al resultado.
4.1.2 PROCESO DE CREACION DE LA GROUND TRUTH
Es conveniente definir qué tipo de patrón melódico estamos buscando. En este
caso, buscamos frases melódicas que se repiten en el cante y que provienen del uso
de éstos en el folklore, donde la repetición hace más fácil la interpretación a coro.
Primero hay que definir cuáles son los patrones melódicos que esperamos
encontrar y su duración en segundos. Como ya se ha explicado anteriormente, en
este proyecto se trabajará con Fandangos de Huelva y Alboreás.
Los patrones que caracterizan a los fandangos son básicamente frases melódicas
que se repiten. Por ejemplo, como dijimos en el capítulo 2, para el fandango de
Valverde aparecen repetidos los patrones exp-1, exp-3 y exp-5 y los esperados en
las Alboreás serán P1.1, P1.2 y P1.3; P2.1 y P2.2; P3.1, P3.2, P3.3, P3.4; P4.1 y P4.2.
El proceso de realización de la Ground Thruth se ha llevado a cabo mediante un
programa de visualización de audio “Sonic Visualiser”10, que puede ser usado para
múltiples aplicaciones. La razón de haber elegido este programa es que posee una
interfaz simple (figura (11)) y a la vez de enorme utilidad para ir marcando con
secciones sobre la interfaz mientras el audio se reproduce.
10 http://www.sonicvisualiser.org/

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
37
Figura 11. Captura de pantalla de la interfaz del programa Sonic
visualizer
La opción “Layer-> Add New Regions Layer” permite asignar una capa de líneas de
tiempo donde podremos, a la vez que se está escuchando la grabación, hacer una
selección de cada patrón melódico que nos interese. Esta opción también nos
permite colocar etiquetas sobre cada patrón marcado. Se usará esta opción para
identificar que a qué grupo de patrones pertenece la sección marcada. En la
siguiente figura podemos ver un ejemplo con líneas de tiempo sobre la grabación
de audio y su etiqueta. Las capas al mismo nivel de altura pertenecen a patrones
del mismo grupo como podemos ver en la figura 12.
Figura 12. Ejemplo realizado sobre el fandango FAN01, Fandango
de Calañas.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
38
Para estimar el comienzo y final de cada patrón se ha tomado un criterio unificado
para todas las grabaciones del corpus seleccionado. El comienzo de cada patrón
melódico ha de estar justo un instante antes del comienzo real del patrón
melódico, aproximadamente 0.2-0.5 segundos y aplicamos el mismo criterio para
el final de la melodía a señalar. Este cálculo se realiza gracias a que el algoritmo de
extracción de patrones melódicos repetidos es capaz de hacer su función con una
ventana de 1 segundo de error, y así garantizamos que la Ground Thruth no pierde
ninguna nota de un patrón a la hora de evaluar resultados, es decir, creamos una
base de datos de los patrones bastante fiel a la realidad.
La funcionalidad de Sonic Visualizer nos va permitir, una vez terminado el trabajo
de etiquetado de patrones característicos, guardar estos datos en formato de
extensión “.csv”, el cual puede abrirse en una hoja Excel y encontramos en cada
celda: (1) instante donde comienza el patrón en segundos; (2) etiqueta del patrón
identificado; (3) tiempo que dura el patrón en segundos, tal como muestra la figura
13.
Figura 13. Captura del archivo .csv abierto como una hoja Excel
En conclusión, una vez obtenido el archivo .csv con los tiempos, podemos
comprobar que obtenemos los tres tipos de información mencionados
anteriormente, (a) grupos de patrones repetidos (b) número de ocasiones que
aparece cada patrón de cada grupo (c) instantes de inicio y fin del patrón.
Este archivo .csv también lo usaremos para poder realizar la base de datos en
formato necesario, que se use como una de las entradas del algoritmo de
evaluación.
Como último proceso de creación de la Ground Thruth, es necesario pasar los
archivos .csv a archivos .mat en Matlab. Estos archivos .mat son matrices que nos

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
39
permitirán introducir los datos de inicio y final de cada patrón identificado. Por
cada fila introduciremos patrones repetidos del mismo tipo, los cuales serán dos
números que representan el inicio y final de cada patrón. Cada pareja representa
un patrón, por consiguiente, se repetirá ese patrón tantas veces como parejas
aparezcan. Podemos ver un ejemplo en la siguiente figura 14.
Figura 14. Archivo .mat visualizado en Matlab
4.2 EVALUACION DE RESULTADOS
4.2.1 ALGORITMO DE EVALUACIÓN
Para la evaluación de los resultados obtenidos, seguimos una estrategia adoptada
en MIREX, “The Music Information Retrieval Evaluation eXchange” MIREXes un
evento anual, donde se presentan trabajos de investigación referentes a técnicas y
algoritmos para la evaluación para trabajos y proyectos realizados en la
conferencia internacional sobre recuperación de información (ISMIR11). Mirex es
un proyecto realizado por IMIRSEL12 (“International Music Information Retrieval
Systems Evaluation Laboratory”), de la Universidad de Illinois.
Aunque esta estrategia está enfocada para anotaciones MIDI, se definen dos
categorías de diferentes medidas que pueden ser realmente aplicadas a nuestro
caso. La primera categoría incluye medidas precisión de “establecimiento” que se
refieren al hecho de encontrar el patrón, PrEst (precision), REst (recall) y Fest (F-
measure). La segunda categoría incluye medidas de “ocurrencia”, PrOcc, ROcc, y Fest,
que miden la habilidad del algoritmo para recuperar todas las ocurrencias de los
patrones repetidos. Para ver todos los detalles de estas medidas podemos
consultar los trabajos (Downie, 2005-2007) (Collins, Boeck, Krebs, & Widmer,
2014).
11 http://www.ismir.net/ 12 http://www.music-ir.org/

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
40
Definición de Precision, Recall y F-measure
Llamaremos np al número de patrones que aparecen en la Ground Truth 𝝅 ={𝑷𝟏,𝑷𝟐,… , 𝑷𝒏𝒑} y nq al número de patrones que aparecen en la salida del
algoritmo 𝜩 = {𝑸𝟏,𝑸𝟐,… ,𝑸𝒏𝒒}. Si el algoritmo consigue identificar un número k
de patrones repetidos de la Ground Truth, entonces definiremos:
Precisión P=k/nq 13
Recall: R=k/np 14
F-measure: F-measure= 2∙P∙R/(P+R)
15
Las medidas explicadas son usadas en (Collins, Boeck, Krebs, & Widmer, 2014),
una de las primeras evaluaciones de descubrimiento de patrones y son bastante
estrictas. Es decir, un patrón PA a la salida del algoritmo podría tener solo un punto
diferente en comparación con su Ground Truth PT, pero no se contará como un
descubrimiento satisfactorio. Por tanto, se proponen las siguientes medidas, las
cuales, son más robustas a la hora de leves diferencias entre patrones encontrados
y Ground Truth.
Definición de la matriz Score.
Suponemos que en la Ground Truth hay un patrón P con ocurrencias 𝑷 ={𝑷𝟏,𝑷𝟐,… , 𝑷𝒎𝒑}, y también suponemos que en la salida de un algoritmo hay un
patrón Q con ocurrencias 𝑸 = {𝑸𝟏,𝑸𝟐,… ,𝑸𝒎𝒒}. La idea de la evaluación del
algoritmo es la medida en la cual Q constituye el descubrimiento de P por parte del
algoritmo. Para llevarlo a cabo, necesitamos ser capaces de obtener la similitud
musical entre Pi y Qj, (este proceso se ha llevado a cabo en el apartado 3.3).
La matriz score nos mostrará una medida de cómo las ocurrencias de Q
corresponden al patrón P.
𝑠(𝑃, 𝑄) = (
𝑠(𝑃1, 𝑄1) ⋯ 𝑠(𝑃1, 𝑄𝑚𝑄⋮ ⋱ ⋮
𝑠(𝑃𝑚𝑃, 𝑄1 ⋯ 𝑠(𝑃𝑚𝑃, 𝑄𝑚𝑄)) 16

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
41
Precisión establecida, recall establecido y F -measure establecido
La matriz score deberá necesariamente evaluar todos los patrones reconocidos
por el algoritmo contra todos los patrones de la Ground Truth. Podríamos estar
más interesados en saber si un algoritmo es capaz de establecer que un patrón P se
encuentra repetido al menos una vez en una pieza musical y menos interesados en
saber si el algoritmos es capaz de reconocer todas las ocurrencias Q (exactas e
inexactas). En este caso, para la Ground Thruth 𝝅 = {𝑷𝟏,𝑷𝟐,… , 𝑷𝒏𝒑} y los
patrones encontrados por el algoritmo 𝜩 = {𝑸𝟏,𝑸𝟐,… ,𝑸𝒏𝒒} podemos decir que
es posible medir la capacidad del algoritmo de establecer qué patrones de Π están
repetidos al menos una vez en la pieza, usando la que llamamos matriz score
establecida:
𝑆(Π, 𝜩) = (
𝑆(𝑃1, 𝑄1) ⋯ 𝑆(𝑃1, 𝑄𝑛𝑄)
⋮ ⋱ ⋮𝑆(𝑃𝑛𝑃, 𝑄1) ⋯ 𝑆(𝑃𝑛𝑃 , 𝑄𝑛𝑄)
) 17
La precisión establecida puede calcularse como:
𝑃𝑒𝑠𝑡 =1
nq∑max {𝑆(𝑃𝑖, 𝑄𝑖) |𝑖 = 1,… , 𝑛𝑝}.
𝑛𝑞
𝑗=1
18
Si un algoritmo descubre k patrones de exactamente de la Ground Truth, y pierde
nQ-k patrones, entonces la precisión establecida es igual a la precisión estándar
k/nQ.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
42
La llamada (recall) establecida es:
𝑅𝑒𝑠𝑡 =1
np∑max {𝑆(𝑃𝑖, 𝑄𝑖) |𝑗 = 1, … , 𝑛𝑞}.
𝑛𝑝
𝑖=1
19
F-measure establecida es:
F-measureest= 2∙Pest∙Rest/(Pest+Rest)
20
Precisión de ocurrencia, recall ocurrencia y F -measure
Tal como ya se mencionó anteriormente, existe una diferencia entre la capacidad
del algoritmo para establecer la existencia de patrones repetidos y la capacidad de
retornar todas las repeticiones de patrones que se definen en la Ground Thruth.
Ahora nos enfocamos en la capacidad del algoritmo de proveer todas las
ocurrencias de un patrón dado, exactas e inexactas. Esta medida de ocurrencias
favorecerá al algoritmo que sea fuerte a la hora de encontrar todas las ocurrencias
de los patrones que descubre a la salida y desfavorecerá a aquel algoritmo que
encuentre pocas repeticiones.
Los índices de la matriz de establecimiento con valores mayores o iguales a algún
umbral, (por defecto 0.75), indican cuáles de los patrones de la Ground Thruth
deben ser considerados como descubiertos por el algoritmo. Nos centraremos en
estos índices para definir lo que llamaremos como matriz de ocurrencias.
Llamaremos a esta matriz O(Π,Ξ) y comenzara como una matriz de ceros
dimensión np x nq. Para cada par de índices (i,j), calculamos la precisión de la
matriz score s(Pi,Qj), y utilizamos este escalar como elemento (i,j) de O(Π,Ξ). La
precisión de s(Pi,Qj) indica la precisión con que la salida Qj recupera patrones de
la ground thruth Pi. La precisión de ocurrencia, que llamaremos Pocc , se define
como la precisión de la matriz de ocurrencia O(Π,Ξ) y la suma de las columnas que
no son cero. Llamaremos Rocc a la llamada o recall de ocurrencia, que se define
analógicamente ala precisión pero en vez de columnas usaremos filas. F-measure
se calcula usando los términos Pocc y Rocc.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
43
4.2.2 EVALUACIÓN
Como hemos dicho, evaluaremos el funcionamiento del método propuesto usando
la metodología de MIREX y lo compararemos con los resultados del algoritmo de
reconocimiento de patrones repetidos propuesto en el trabajo reciente (Nieto &
Farbood, 2014).
Hay que reseñar que el método de Nieto y Farbood no está pensado para voz
cantada y asume tempo constante, lo cual no ocurre en el cante flamenco, objeto de
nuestro estudio. De todas maneras, para el caso de fandangos, el tempo no varía
tano como para las Alboreás.
Como vimos en el capítulo anterior, nuestro método usa tres parámetros en el
proceso de detección de patrones, a saber, penalización de huecos (Gp), longitud
de hueco (Gl) y un número K de emparejamientos.
En la Tabla 2 se muestran los resultados de la medida F-measure en el corpus de
fandangos para diferentes valores de los parámetros tomando K=15, esto es, los
mejores 15 pares. Hemos detectado que para los valores Gp =0.1 y Gl = 0.6 se
obtienen buenos resultados, Fest =0,60 y Focc= 0,33 .
En la tabla 2 podemos observar los resultados para distintos valores de K y
notamos que para k=15 nuestro método es competitivo con respecto al de Nieto y
Farbood. De hecho, su algoritmo ofrece mejor precisión pero muy mala medida de
recall, lo que hace que la medida F-measure sea peor que la nuestra.
Tabla 2. Valores extraídos para tres valores distintos de K. Gp=0.1 y
Gl=0.6. NF-14 representa los resultados con el algoritmo de Nieto y
Farbood.
En el corpus de Alboreás los resultados son sensiblemente inferiores. Los mejores
resultados para Alboreás han sido F-measureest= 0.52 y F-measureocc=0.16 para
valor de K=10.
Observamos que la medida de precisión F-measureocc es aproximadamente la
mitad en alboreas con respecto a fandangos.
K=10 K=15 K=20 NF-14
Prest 0.43 0.48 0.50 0.63 Rest 0.71 0.80 0.78 0.37
Fest 0.54 0.60 0.61 0.47 Procc 0.23 0.23 0.22 0.30
Rocc 0.32 0.56 0.07 0.07 Focc 0.27 0.33 0.31 0.11

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 4 Evaluación
44
Este resultado mucho más pobre que en fandangos era esperable para nuestro
algoritmo debido a las siguientes consideraciones en el corpus de alboreás:
1. No existen tantas repeticiones de sus patrones característicos.
2. El tempo y la ornamentación es muy variable en las distintas
interpretaciones, cosa que no ocurre en los fandangos. Esto hace que la
estimación de la longitud de los patrones que realiza el algoritmo no ofrezca
buenos resultados.
3. Los ataques en notas iniciales no son tan claros y la estimación de los
puntos de inicio de los patrones tampoco son muy precisos.
4. Finalmente, si bien en los fandangos elegidos los cantaores siguen con
cierta fidelidad los cánones establecidos por los maestros del cante, en el
cante por alboreás se observa un alto grado de improvisación, lo que
dificulta todo el cálculo de similitud melódica.
Como consecuencia, se requieren otros algoritmos que se adapten a esta
naturaleza musical mucho más compleja. Queda esta tarea como un nuevo reto de
investigación en el campo de la etnomusicología computacional aplicada al cante
flamenco.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 5 Conclusiones finales
45
CAPÍTULO 5. CONCLUSIONES FINALES
La búsqueda de patrones o cédulas melódicas repetidas es un problema
interesante tanto para el área de investigación de Tecnología Musical como para la
Etnomusicología. En efecto, si dos interpretaciones tienen patrones repetidos será
muy probable que pertenezcan al mismo grupo y esto podrá ser usado para tareas
como la clasificación automática o los sistemas de recomendación musical. Por otra
parte, un patrón melódico que se repita varias veces en un o varias
interpretaciones de un mismo estilo puede interpretarse musicalmente como una
“seña de identidad” del estilo y ayudar a los musicólogos a definir con precisión los
distintos géneros , estilos y variantes del flamenco con una herramienta objetiva y
no sesgada por gustos o pensamientos románticos personales. En definitiva, se
propone, desde la Tecnología, una herramienta adicional a los etnomusicólogos.
En este proyecto fin de carrera se ha propuesto un método de detección de
patrones repetidos en el contexto de la música flamenca, concretamente, el cante
flamenco.
Debido a la ausencia de transcripciones del cante flamenco, se ha trabajado
directamente desde los audios y se ha evitado pasar por un proceso de
transcripción automática que, a día de hoy, es un problema no resuelto para el
flamenco.
En nuestro estudio hemos tomado dos estilos de cante donde aparecen claramente
repeticiones de frases melódicas como son los fandangos de la sierra Huelva y en
menor medida las Alboreás.
El método propuesto tiene varias etapas que incluyen detección de voz cantada,
estimación de comienzo y duración de frases melódicas, algoritmo de alineación y
visualización de clusters o grupos de patrones muy similares que constituyen las
repeticiones.
La evaluación de resultados indicó que nuestro método es competitivo para esta
tarea no supervisada de reconocimiento de patrones. Es más, los resultados son
similares a los que se han obtenido para otras músicas cuando se trabaja con datos
simbólicos obtenidos de partituras, lo cual ayuda en la precisión de resultados.
Creemos que nuestro método puede ser fácilmente adaptado a otras tradiciones
musicales distintas del flamenco así como al estudio de otros estilos dentro del
flamenco, donde la detección automática de estos patrones pueden refrendar

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Cap. 5 Conclusiones finales
46
teorías sobre la evolución de los cantes o definir qué patrón define o es
característico de un determinado grupo de variantes.
En resumen, podemos decir que nuestro método posee las siguientes propiedades
de interés:
1. Es eficiente. 2. No requiere transcripción. Actúa directamente desde el audio. 3. Es no supervisado, esto es, no se le da ninguna información de los patrones
que ha de buscar, salvo que son secuencias repetidas. 4. Obtiene resultados de precisión similares a los mejores métodos que hay en
el área y que requieren una transcripción o representación simbólica y, por tanto, ni siquiera pueden ser aplicados cuando solo consideramos descriptores de bajo nivel como la frecuencia fundamental del “pitch”.
5. Se ha implementado pensando en cante flamenco pero puede ser usado para otras músicas de tradición oral donde no se dispone de partituras.
6. Puede adaptarse fácilmente a estudiar otros estilos del flamenco distintos a los considerados aquí.
Pensamos que la metodología seguida en este trabajo es coherente y puede dar
mucho mejor resultado se mejoran los algoritmos parciales que se han usado en
las distintas etapas del proceso. Esperemos que se lleve a cabo la continuación y
mejora de nuestra propuesta y que esto signifique un progreso parcial pero real en
el análisis y conocimiento de la música más reconocida de nuestro país, tanto
desde el punto de vista comercial como cultural.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Referencias
47
Referencias
Barrantes, V. (1855). Juan de Padilla. En V. Barrantes.
Bartsch, M., & Wakefield, G. (2005). “Audio thumbnailing of popular music using
chroma-based representations. Multimedia, IEEE Transactions , 96-104.
Berndt, D., & Clifford, J. (April de 1994). Using Dynamic Time Warping to Find
Patterns in Time Series. Information Systems Department, págs. 361-363.
Collins, T., Boeck, S., Krebs, F., & Widmer, G. (2014). Bridging the audio Symbolic
gap: The discovery of repeated pa note content directly from polyphonic
music audio. 53rd AES Conference. . Semantic Audio.
Collins, T., Boeck, S., Krebs, F., & Widmer, G. (2014). Bridging the audio-symbolic
gap: The discovery of repeated note content dircty from polyphonic music
audio. 53rd AES Conference: Semantic audio, (págs. 119-126).
Dannenberg, R. B. (2002). Discovering musical structure in audio recordings. Music
and Artificial Intelligence, 43-57.
Díaz-Báñez, J., & Rizo, J. (2014). Un algoritmo eficiente. Seville.
Díaz-Bañez, J., Farigu, G., Gomez, F., Rappaport, D., & Toussaint, G. T. (2005).
Similitud y evolución en la rítmica del flamenco: una incursión de la
matemática computacional. La Gaceta de la RSME, págs. 489-509.
Downie, J. (2005-2007). The music information retrieval evaluation. A window into
music information retrieval. Acoustical Science and Tecnology, 247-255.
Downie, J. (2008). The music information retrieval evaluation exchange (2005-
2007). Acoustic science and tecnology, 247-255.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Referencias
48
Gómez, E., & Bonada, J. (2013). Towards computer-assisted flamenco transcription:
An experimental comparison of automatic transcription algorithms as
applied to capella singing. Computer Music Journal, 73-90.
Gómez, E., Herrera, P., & Gómez-Martín, F. (2013). Computational
Ethnomusicology: Perspectives and Challenges. Journal of Music Research, 1.
Gómez, F., Díaz-Báñez, J., Gómez, E., & Mora, J. (2014). Flamenco music and its
computational study. Mathematical Connections in Art, Music andScience,
119-126.
Halmos, I., Köszegi, G., & Mandler, G. (1978). Computational Ethnomusicology in
Hungary. MI Publishing. Michigan: Ann Arbor.
Hand, D. (2002). Pattern detection and discovery . Springer Berlin Heideberg, 1-12.
Herrera, P., & Gómez, E. (2011). Tecnologías para el análisis del contenido musical
de archivos sonoros y para la generación de nuevos metadatos. . Boletín de
la Asociación Española de Documentación Musical, 28-38.
Jansen, B., de Haas, W., Volk, A., & van Kranenburg, P. (2013). Discovering repeated
patterns in music: state of knowledge, challenges perspectives.
Levy, M., & Sandler, M. (2008). Structural segmentation of musical audio by
constrained clustering. Audio, S`peech, and Language Processing, 318-326.
Muller, M., & Kurth, F. (2007). Towards structural analysis of audio recordings in
the presence of musical variations. EURASIP Journal on Applied Signal
Processing, 163-163.
Nettl, B. (1983). The study of ethnomusicology: twenty-nine issues and concepts.
University of Illinois Press, pág. 39.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Referencias
49
Nieto, O., & Farbood, M. (2012). Identifying polyphonic patterns from audio
recordings using music segmentation techniques. ISMIR. taiwan.
Nieto, O., & Farbood, M. (2014). Identifyinf polyphonic patternes from audio
recordings using segmentation techniques. ISMIR. Taipei.
Peeters, G. (2007). Sequence representation of music structure using higher-order
similarity matrix and maximun likelihod approach. ISMIR, (págs. 35-40).
Pikrakis, A. (2012). Tracking melodic patterns in flamenco singing by analyzing
polyphonic music recordings. ISMIR, (págs. 421-426).
Salomon, J., Gómez, E., Ellis, D. P., & Richards, G. (2014). ). Melody Extraction from
Polyphonic Music Signals: Approaches, Applications and Challenges. . IEEE
Signal Processing Magazine.
Sankalp, G. (2014). Mining melodic patterns in large audio collections of indian art
music. International conference on signal image tecnology & Internet based
systems. Marrakesh.
Tzanetakis, G. (2014). Computational Ethnomusicology: A music Information
Retrieval Pperspective. Proceedings ICMC|SMC| , (pág. 1). Athens.
Tzanetakis, G., Kapur, A., Schloss, A., & Wright, M. (2007). Computational
Ethnomusicology. Journal of interdisciplinary music estudies.

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Referencias
50

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
51
CÓDIGOS MATLAB
% Archivo getDFT.m
function [FFT, Freq] = getDFT(signal, Fs, PLOT)
% % function [FFT, Freq] = getDFT(signal, Fs, PLOT) %
% Esta función devuelve la DFT de una señal discreta y su respectiva
%frecuencia. % % ARGUMENTOS: % - Signal: vector containing the samples of the signal % - Fs: the sampling frequency % - PLOT: usa este argumento si la FFT (y sus respectivos
% valores de frecuencia) need to be returned in the % [-fs/2..fs/2] range. De otra manera sólo la mitad
% del espectro es devuelto % % RETURNS: % - FFT: the magnitude of the DFT coefficients % - Freq: the corresponding frequencies (in Hz) %
N = length(signal); % longitud de la señal % computa la magnitud del espectro % (y normalize por el numero de muestras): FFT = abs(fft(signal)) / N;
if nargin==2 % devuelve la primera mitad del espectro: FFT = FFT(1:ceil(N/2)); Freq = (Fs/2) * (1:ceil(N/2)) / ceil(N/2);
else if (nargin==3) % ... o devuelve el espectro completo % (in the range -fs/2 to fs/2) FFT = fftshift(FFT); if mod(N,2)==0 % define la frecuencia Freq = -N/2:N/2-1; % if N is even else Freq = -(N-1)/2:(N-1)/2; % if N is odd end Freq = (Fs/2) * Freq ./ ceil(N/2); end end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
52
Archivo chromagram_e.m
function Y = chromagram_E(d,sr,fftlen,nbin,f_ctr,f_sd) % Y = chromagram_E(d,sr,fftlen,nbin) % Calculate a "chromagram" of the sound in d (at sampling rate sr) % Use windows of fftlen points, hopped by ffthop points % Divide the octave into nbin steps % Weight with center frequency f_ctr (in Hz) and gaussian SD f_sd (in
octaves) % 2006-09-26 [email protected]
if nargin < 3; fftlen = 2048; end if nargin < 4; nbin = 12; end if nargin < 5; f_ctr = 1000; end if nargin < 6; f_sd = 1; end
fftwin = fftlen/2; ffthop = fftlen/4; % always for this
D = abs(specgram(d,fftlen,sr,fftwin,(fftwin-ffthop)));
A0 = 27.5; % Hz A440 = 440; % Hz
f_ctr_log = log(f_ctr/A0) / log(2);
CM = fft2chromamx(fftlen, nbin, sr, A440, f_ctr_log, f_sd); % Chop extra dims CM = CM(:,1:(fftlen/2)+1);
Y = CM*D;

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
53
Archivo chromagram_IF
function Y = chromagram_IF(d,sr,fftlen,nbin,f_ctr,f_sd) % Y = chromagram_IF(d,sr,fftlen,nbin,f_ctr,f_sd) % Calculate a "chromagram" of the sound in d (at sampling rate sr) % Use windows of fftlen points, hopped by ffthop points % Divide the octave into nbin steps % Weight with center frequency f_ctr (in Hz) and gaussian SD f_sd % (in octaves) % Use instantaneous frequency to keep only real harmonics. % 2006-09-26 [email protected]
% Copyright (c) 2006 Columbia University. % % This file is part of LabROSA-coversongID % % LabROSA-coversongID is free software; you can redistribute it
and/or modify % it under the terms of the GNU General Public License version 2 as % published by the Free Software Foundation. % % LabROSA-coversongID is distributed in the hope that it will be
useful, but % WITHOUT ANY WARRANTY; without even the implied warranty of % MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU % General Public License for more details. % % You should have received a copy of the GNU General Public License % along with LabROSA-coversongID; if not, write to the Free Software % Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA % 02110-1301 USA % % See the file "COPYING" for the text of the license.
if nargin < 3; fftlen = 2048; end if nargin < 4; nbin = 12; end if nargin < 5; f_ctr = 1000; end if nargin < 6; f_sd = 1; end
A0 = 27.5; % Hz A440 = 440; % Hz f_ctr_log = log(f_ctr/A0) / log(2);
fminl = octs2hz(hz2octs(f_ctr)-2*f_sd); fminu = octs2hz(hz2octs(f_ctr)-f_sd); fmaxl = octs2hz(hz2octs(f_ctr)+f_sd); fmaxu = octs2hz(hz2octs(f_ctr)+2*f_sd);
ffthop = fftlen/4; nchr = 12;
% Calculate spectrogram and IF gram pitch tracks... [p,m]=ifptrack(d,fftlen,sr,fminl,fminu,fmaxl,fmaxu);
[nbins,ncols] = size(p);
%disp(['ncols = ',num2str(ncols)]);

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
54
% chroma-quantized IF sinusoids Pocts = hz2octs(p+(p==0)); Pocts(p(:)==0) = 0; % Figure best tuning alignment nzp = find(p(:)>0); %hist(nchr*Pmapo(nzp)-round(nchr*Pmapo(nzp)),100) [hn,hx] = hist(nchr*Pocts(nzp)-round(nchr*Pocts(nzp)),100); centsoff = hx(find(hn == max(hn))); % Adjust tunings to align better with chroma Pocts(nzp) = Pocts(nzp) - centsoff(1)/nchr;
% Quantize to chroma bins PoctsQ = Pocts; PoctsQ(nzp) = round(nchr*Pocts(nzp))/nchr;
% map IF pitches to chroma bins Pmapc = round(nchr*(PoctsQ - floor(PoctsQ))); Pmapc(p(:) == 0) = -1; Pmapc(Pmapc(:) == nchr) = 0;
Y = zeros(nchr,ncols); for t = 1:ncols; Y(:,t)=(repmat([0:(nchr-
1)]',1,size(Pmapc,1))==repmat(Pmapc(:,t)',nchr,1))*m(:,t); end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
55
Archivo chromagram_p.m
function Y = chromagram_P(d,sr,fftlen,nbin,f_ctr,f_sd) % Y = chromagram_E(d,sr,fftlen,nbin) % Calculate a "chromagram" of the sound in d (at sampling rate sr) % Use windows of fftlen points, hopped by ffthop points % Divide the octave into nbin steps % Weight with center frequency f_ctr (in Hz) and gaussian SD f_sd (in
octaves) % 2006-09-26 [email protected]
if nargin < 3; fftlen = 2048; end if nargin < 4; nbin = 12; end if nargin < 5; f_ctr = 1000; end if nargin < 6; f_sd = 1; end
fftwin = fftlen/2; ffthop = fftlen/4; % always for this
D = abs(specgram(d,fftlen,sr,fftwin,(fftwin-ffthop)));
[nr,nc] = size(D);
A0 = 27.5; % Hz A440 = 440; % Hz
f_ctr_log = log(f_ctr/A0) / log(2);
CM = fft2chromamx(fftlen, nbin, sr, A440, f_ctr_log, f_sd); % Chop extra dims CM = CM(:,1:(fftlen/2)+1);
% Keep only local maxes in freq Dm = (D > D([1,[1:nr-1]],:)) & (D >= D([[2:nr],nr],:)); Y = CM*(D.*Dm);

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
56
Archivo chromsynth.m
function [x,CF,CM] = chromsynth(F,bp,sr) % [x,CF,CM] = chromsynth(F,bp,sr) % Resynthesize a chroma feature vector to audio % F is 12 rows x some number of columns, one per beat % bp is the period of one beat in sec (or a vector of beat times) % sr is the sampling rate of the output waveform % x is returned as a 12 semitone-spaced sines modulated by F % CF,CM return actual sinusoid matrices passed to synthtrax % Actual Shepard tones now implemented! 2007-04-19 % 2006-07-14 [email protected]
if nargin < 2; bp = 0.5; end % 120 bpm if nargin < 3; sr = 22050; end
[nchr,nbts] = size(F);
% resynth if length(bp) == 1 bups = 8; % upsampling factor framerate = bups/bp; ncols = nbts*bups; CMbu = zeros(nchr, ncols); for i = 1:bups CMbu = CMbu + upsample(F', bups, i-1)'; end else % vector of beat times - quantize framerate = 50; % frames per sec nbeats = length(bp); lastbeat = bp(nbeats) + (bp(nbeats) - bp(nbeats-1)); ncols = round(lastbeat * framerate); CMbu = zeros(nchr, ncols); xF = [zeros(12,1),F]; for i = 1:ncols CMbu(:,i) = xF(:,max(find(i/framerate >= [0,bp]))); end end
%CFbu = repmat(440*2.^([0:(nchr-1)]'/nchr),1,ncols); %x = synthtrax(CFbu,CMbu,sr,round(sr/framerate)); octs = 7; basefrq = 27.5; % A1; +6 octaves = 3520 CFbu = repmat(basefrq*2.^([0:(nchr-1)]'/nchr),1,ncols); CF = []; CM = []; % what bin is the center freq? f_ctr = 440; f_sd = 0.5; f_bins = basefrq*2.^([0:(nchr*octs - 1)]/nchr); f_dist = log(f_bins/f_ctr)/log(2)/f_sd; % actually just = ([0:(nchr*octs - 1)]/nchr-log2(f_ctr/basefrq))/f_sd % Gaussian weighting centered of f_ctr, with f_sd f_wts = exp(-0.5*f_dist.^2); for oct = 1:octs CF = [CF;(2^oct)*CFbu]; % pick out particular weights CM = [CM;diag(f_wts((oct-1)*nchr+[1:nchr]))*CMbu]; end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
57
% Remove sines above nyquist CFok = (CF(:,1) < sr/2); CF = CF(CFok,:); CM = CM(CFok,:); % Synth the sines x = synthtrax(CF,CM,sr,round(sr/framerate));
% Playing synth along with audio: %>> rdc = chromsynth(Dy.F(:,160+[1:300]),Dy.bts(160+[1:300]) -
Dy.bts(160),sr); %>> Dy.bts(161)*sr %ans = % 279104 %>> size(rdc) %ans = % 1 498401 %>> ddd = db(279104+[1:498401]); %>> soundsc([ddd,rdc'/40],sr)

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
58
Archivo detectSegments.m
function S=detectSegments(f,estDur,Th,winS)
x=f(:,2); L=length(x);
ind=find(x>0);
S(1,1)=ind(1); S(1,2)=0; k=2; while k<=length(ind) if ind(k)==ind(k-1)+1 ; else S(end,2)=ind(k-1); S(end+1,:)=[ind(k) 0]; end k=k+1; end
if S(end,2)==0 S(end,2)=ind(end); end
for m=1:size(S,1) S(m,1)=f(S(m,1),1); S(m,2)=f(S(m,2),1); end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
59
Archivo displayGroundTruth.m
function displayGroundTruth(rootdir,fname)
fhandle=2;
[x,fs,~]=wavread([rootdir fname]); load([rootdir fname '.mat']);
eval(['GT=' fname]);
t=[]; for k=1:length(GT) t=[t;[GT{k} k*ones(size(GT{k},1),1)]]; end
P=size(t,1);
FigHandle = figure(fhandle); clf;hold; L=ceil(length(x)/fs); set(FigHandle, 'Position', [100, 300, 4*L+100, 100])
for k=1:P mid=(t(k,1)+t(k,2))/2; plot(t(k,1):0.01:t(k,2),ones(size(t(k,1):0.01:t(k,2)))); plot(t(k,1)*ones(size(0.9:0.01:1.1)),0.9:0.01:1.1,'r') plot(t(k,2)*ones(size(0.9:0.01:1.1)),0.9:0.01:1.1,'r') text(mid,1.2,num2str(t(k,3))); end axis([0 L 0 2]) xlabel('Seconds'); ylabel('Pattern class');
while(1) d=ginput(1); if d(2)<0 break; end d=d(1); ind=find(d>=t(:,1) & d<=t(:,2)); a1=round(t(ind,1)*fs); a2=round(t(ind,2)*fs); sound(x(a1:a2),fs); end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
60
Archivo find_phrase_start.m
function find_phrase_start(path)
root='/Users/GinSonic/MTG/PatternDetection/alboreas gt/'; [w,fs]=audioread(strcat(root,path,'.wav')); hopSize=128; windowSize=4096; fftSize=2*windowSize; numFrames=floor((size(w,1)-windowSize)/hopSize); t=zeros(numFrames,1); for i=1:numFrames t(i)=i*128/44100; end
%% EXTRACT ENERGY RATIO minFreqLow=80.0; maxFreqLow=400.0; minFreqHigh=500.0; maxFreqHigh=6000.0; minBinLow=round(minFreqLow/(fs/2)*fftSize); maxBinLow=round(maxFreqLow/(fs/2)*fftSize); minBinHigh=round(minFreqHigh/(fs/2)*fftSize); maxBinHigh=round(maxFreqHigh/(fs/2)*fftSize);
% for stereo tracks if size(w,2)==2 wL=w(:,1); wR=w(:,2); eL=zeros(numFrames,1); eR=zeros(numFrames,1); for i=1:numFrames frameL=wL(i*hopSize:i*hopSize+windowSize); frameR=wR(i*hopSize:i*hopSize+windowSize); specL=fft(frameL, fftSize); specL=abs(specL(1:fftSize/2)); specL=specL./max(specL); lowEL=sum(specL(minBinLow:maxBinLow)); highEL=sum(specL(minBinHigh:maxBinHigh)); eL(i)=20*log10(highEL/lowEL); specR=fft(frameR, fftSize); specR=abs(specR(1:fftSize/2)); specR=specR./max(specR); lowER=sum(specR(minBinLow:maxBinLow)); highER=sum(specR(minBinHigh:maxBinHigh)); eR(i)=20*log10(highER/lowER); end eR(isnan(eR))=0; eL(isnan(eL))=0;
% SELECT CHANNEL averageERLeft=mean(eL); averageERRight=mean(eR); if averageERLeft>averageERRight energyRatio=eL; w=w(:,1); else energyRatio=eR; w=w(:,2); end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
61
% for mono tracks else energyRatio=zeros(numFrames,1); for i=1:numFrames frame=w(i*hopSize:i*hopSize+windowSize); spec=fft(frame, fftSize); spec=abs(spec(1:fftSize/2)); spec=spec./max(spec); lowEL=sum(spec(minBinLow:maxBinLow)); highEL=sum(spec(minBinHigh:maxBinHigh)); energyRatio(i)=20*log10(highEL/lowEL); end energyRatio(isnan(energyRatio))=0; end
energyRatioInit=energyRatio;
%% EXTRACT RMS vol=zeros(numFrames,1); for i=1:numFrames frame=w(i*hopSize:i*hopSize+windowSize); vol(i)=rms(frame); end
% volume envelope vol=vol./max(vol); vol=smooth(vol,10); volEnv=zeros(length(vol),1); [Ymax,Imax]=findpeaks(vol, 'minpeakheight', min(vol),
'minpeakdistance', 100); volEnv(1:Imax(1))=Ymax(1); for i=1:length(Imax)-1 dist=Imax(i+1)-Imax(i); volEnv(Imax(i):Imax(i)+round(dist/2))=Ymax(i); volEnv(Imax(i)+round(dist/2):Imax(i+1))=Ymax(i+1); end
%% ESTIMATE VOICED SECTIONS % normalize features energyRatio=energyRatio+abs(min(energyRatio)); volEnv=volEnv./max(volEnv); for i=1:length(energyRatio) energyRatio(i)=energyRatio(i)*volEnv(i); end eRatioMean=mean(energyRatio); eRatioStd=std(energyRatio); energyRatio=(energyRatio-eRatioMean)./eRatioStd;
% assign voicing voicing=zeros(length(energyRatio),1); voicing(energyRatio>0)=1; voicing=smooth(voicing, 100); energyRatio=energyRatioInit;
%% DIFFERENCE FUNCTION volDiff=zeros(numFrames,1); energyRatioDiff=zeros(numFrames,1);

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
62
for i=151:length(vol)-151 valV=(mean(vol(i:i+150))-mean(vol(i-150:i)))*mean(vol(i:i+150)); volDiff(i)=valV; valE=(mean(energyRatio(i:i+150))-mean(energyRatio(i-
150:i)))*mean(energyRatio(i:i+150)); energyRatioDiff(i)=valE; end
% normalization volDiff=volDiff+abs(min(volDiff)); volDiff=volDiff./mean(volDiff); volDiff=smooth(volDiff,20); energyRatioDiff=energyRatioDiff+abs(min(energyRatioDiff)); energyRatioDiff=energyRatioDiff./mean(energyRatioDiff); energyRatioDiff=smooth(energyRatioDiff,20);
% joint probability jointProbab=energyRatioDiff.*volDiff.*voicing; jointProbab=jointProbab./mean(jointProbab);
% phrase start estimation [pks, locs]=findpeaks(jointProbab, 'minpeakheight', 2,
'minpeakdistance', 340); estStartTimes=t(locs);
%% estimate phrase duration estStartTimes dur=[]; for i=2:length(estStartTimes) dur=[dur; estStartTimes(i)-estStartTimes(i-1)]; end
x=0:0.1:round(max(dur)); N=hist(dur,x); [Y,I]=max(N); smallest=x(I);
j=2; while smallest<3 smallest=x(I)*j; j=j+1; end
estimatedDuration=smallest;
%% write to file csvwrite(strcat(root,path,'.wav_estStartTimes.csv'), estStartTimes); csvwrite(strcat(root,path,'.wav_estDuration.csv'), estimatedDuration);
end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
63
Archivo find_phrase_start.m
dirName = '/Users/GinSonic/MTG/PatternDetection/alboreas gt/';
%# folder path files = dir( fullfile(dirName,'*.wav') ); %# list all *.xyz files files = {files.name}';
for i=21:length(files) filename=files(i); filename=filename{1}; filename=filename(1:length(filename)-4) find_phrase_start(filename); end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
64
Archivo musicThumbnailing.m
function [t,Chromagram] =
musicThumbnailing(x,fs,winSize,winStep,featureparams,numofPairs,stpoin
ts,penalty,timegap,estDur)
% SHORT-TERM FEATURE EXTRACTION
if strcmp(featureparams.feature, 'chroma') Features = stFeatureExtraction(x, fs, winSize, winStep); Chromagram = Features(23+1:23+12, :); % feature starts at row 23+1 elseif strcmp(featureparams.feature, 'chroma-inst-IF') Chromagram = chromagram_IF(x,fs,round(winSize*fs)); elseif strcmp(featureparams.feature, 'chroma-inst-E-12') Chromagram = chromagram_E(x,fs,round(winSize*fs),12); elseif strcmp(featureparams.feature, 'chroma-inst-E-24') Chromagram = chromagram_E(x,fs,round(winSize*fs),24); elseif strcmp(featureparams.feature, 'mfccs') Features = stFeatureExtraction(x, fs, winSize, winStep); Chromagram = Features(9:21, :); elseif strcmp(featureparams.feature, 'chroma+mfccs') Features = stFeatureExtraction(x, fs, winSize, winStep); Chromagram = Features([9:21 23+1:23+12], :); elseif strcmp(featureparams.feature, 'pitch') Chromagram=load('/home/aggelos/Dropbox/JESUS/Ground
Thruth/Fandangos/FAN01_f0.csv'); Chromagram(:,1)=[]; Chromagram=Chromagram(1:4:end); Chromagram=Chromagram'; end
if strcmp(featureparams.norm, 'zero-mean-unit-std') mval=mean(Chromagram'); Chromagram = Chromagram - repmat(mval',1,size(Chromagram,2)); sval=std(Chromagram'); Chromagram = Chromagram ./
repmat(eps+sval',1,size(Chromagram,2)); elseif strcmp(featureparams.norm, 'zero-mean') mval=mean(Chromagram'); Chromagram = Chromagram - repmat(mval',1,size(Chromagram,2)); end
if strcmp(featureparams.dimsreduction, 'pca') [COEFF, ~,LATENTS]=pca(Chromagram'); Chromagram=COEFF(:,1:featureparams.numofdims)'*Chromagram; end
stpoints=round(stpoints/winStep);
pats=zeros(size(stpoints,1)); winner11=zeros(size(stpoints,1)); winner12=zeros(size(stpoints,1)); winner21=zeros(size(stpoints,1)); winner22=zeros(size(stpoints,1));
timegap=round(timegap/winStep); if stpoints(1,1)==0 stpoints(1,1)=1;

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
65
end
for i=1:length(stpoints) for j=i+1:length(stpoints)
[~,~,~,tmp,bp]=smithWaterman(Chromagram(:,stpoints(i,1):stpoints(i,2))
,Chromagram(:,stpoints(j,1):stpoints(j,2)),penalty,timegap); if ~isempty(bp) pats(i,j)=tmp/size(bp,1); winner11(i,j)=stpoints(i,1)+bp(1,1)-1; winner21(i,j)=stpoints(j,1)+bp(1,2)-1; winner12(i,j)=stpoints(i,1)+bp(end,1)-1; winner22(i,j)=stpoints(j,1)+bp(end,2)-1; end end end
num=0; while num<numofPairs mv=max(max(pats)); if mv==0 break; end [x1,y1]=find(pats==mv); x1=x1(1);y1=y1(1); xc=winner11(x1,y1); yc=winner21(x1,y1); pats(x1,y1)=0; if (winner12(x1,y1)-winner11(x1,y1)+1)*winStep<0.5*estDur || ... (winner12(x1,y1)-winner11(x1,y1)+1)*winStep>1.5*estDur continue; end
num=num+1; t(num,1) = xc; t(num,2) = winner12(x1,y1); t(num,3) = yc; t(num,4) = winner22(x1,y1); t(num,5)=mv;
end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
66
Archivo postProcessing.m
function [G,t,Q]=postProcessing(t,Th,winS)
Gor=[]; for k=1:size(t,1) Gor=[Gor;[t(k,1) t(k,2) k]]; Gor=[Gor;[t(k,3) t(k,4) k]]; end [G,~,~,~,~]=projectClasses(Gor);
% prepare for evaluation Q=cell(1); g=max(G(:,3)); counter=0; for k=1:g ind=find(G(:,3)==k); if ~isempty(ind) counter=counter+1; Q{counter}=G(ind,1:2)*winS; end end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
67
Archivo patternDiscoveryEvaluation.m
function [sEST,sOCCp,sOCCr] = patternDiscoveryEvaluation(P,Q,Th)
nP=length(P); nQ=length(Q);
% ESTABLISHMENT sEST=zeros(nP,nQ); sOCCp=zeros(nP,nQ); sOCCr=zeros(nP,nQ); for i=1:nP for j=1:nQ pLoc=P{i}; qLoc=Q{j}; % score matrix score=zeros(size(qLoc,1), size(pLoc,1)); for m=1:size(qLoc,1) for n=1:size(pLoc,1) stOL=max(qLoc(m,1), pLoc(n,1)); endOL=min(qLoc(m,2), pLoc(n,2));
% overlap Percentage score(m,n)=max((endOL-stOL),0)/max((qLoc(m,2)-
qLoc(m,1)),(pLoc(n,2)-pLoc(n,1)));% % onset and offset within limitation (1.5s) end end sEST(i,j)=max(max(score)); score(score<Th)=0; sOCCp(i,j)=sum(max(score'))/size(score,1); sOCCr(i,j)=sum(max(score))/size(score,2); end end

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
68
Archivo manualExperiment.m
clc; clear; close('all'); fclose('all');
genre='Alboreas'; % Folder where the filename is located audiodir=['C:\Users\JESUS\Dropbox\JESUS\Ground Thruth\' genre '/']; % Folder where the file with the estimated parameters is located annotationsdir=['C:\Users\JESUS\Dropbox\JESUS\Ground Thruth\' genre
'/']; %%%%% resfile = [genre '.txt'];
% Filename (do not use the .wav suffix) D=dir([audiodir '*.wav']); EstPall=0; EstRall=0; OccPall=0; OccRall=0; denEstPall=0; denEstRall=0; denOccPall=0; denOccRall=0; %winl=1102*4/44100; winl=511*4/44100; wins=winl/4;
for EvalThreshold=0.75:0.05:0.75 for penalty=0.1:0.1:0.1 for timegap=0.8:0.1:0.8 for NumOfImportantResults=15:5:15 for filec=1:length(D) EstPall=0; EstRall=0; OccPall=0; OccRall=0; denEstPall=0; denEstRall=0; denOccPall=0; denOccRall=0;
param=D(filec).name(1:end-4); audiofile=[param '.wav'];
% Filename containing the estimations annotationsfile=[param '.wav_estStartTimes.csv'];
% Load starting points stpoints=load([annotationsdir annotationsfile]);
% Load wav and average channels if necessary durfile=[param '.wav_estDuration.csv'];
[x,fs,bits]=wavread([audiodir audiofile]); if size(x,2)==2

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
69
x=0.5*(x(:,1)+x(:,2)); end
% Load estimated pattern length estDur=load([annotationsdir durfile]);
% Load confidence conffile=[param '.wav_vconf.csv']; conffunction=load([annotationsdir conffile]); segs=detectSegments(conffunction,estDur,1,wins); ind=find(segs(:,2)-segs(:,1)<0.5*estDur); segs(ind,:)=[];
% Compute pairs of patterns. Just one run is used
in this version of the % algorithm. featureparams.feature='chroma-inst-E-24'; featureparams.norm='zero-mean-unit-std'; %featureparams.norm='zero-mean'; %featureparams.norm='none'; featureparams.dimsreduction='none'; featureparams.numofdims=0;
localcostfun='cosine'; tic fprintf('Scanning %s ...\n',param); [t,Chromagram] =
musicThumbnailing(x,fs,winl,wins,featureparams,NumOfImportantResults,s
egs,penalty,timegap,estDur); toc %%%%%%%%%%%%%%%%%
Th=1; proxTh=inf; [tnew,tt,Q]=postProcessing(t,Th,wins); %plotPatterns(tnew,length(x)/fs/wins);
% evaluate load([annotationsdir param '.mat']); eval(['P=' param ';']); [sEST{filec},sOCCp{filec},sOCCr{filec}] =
patternDiscoveryEvaluation(P,Q,EvalThreshold);
EstP=sum(max(sEST{filec}'))/size(sEST{filec},1); EstPall=EstPall+sum(max(sEST{filec}')); denEstPall=denEstPall+size(sEST{filec},1);
EstR=sum(max(sEST{filec}))/size(sEST{filec},2); EstRall=EstRall+sum(max(sEST{filec})); denEstRall=denEstRall+size(sEST{filec},2);
EstF=(2*EstP*EstR/(EstP+EstR));
OccP=sum(max(sOCCp{filec}'))/size(sOCCp{filec},1); OccPall=OccPall+sum(max(sOCCp{filec}')); denOccPall=denOccPall+size(sOCCp{filec},1);

Reconocimiento de patrones melódicos vocales repetidos en audios polifónicos en flamenco Anexo: Códigos Matlab
70
OccR=sum(max(sOCCr{filec}))/size(sOCCr{filec},2); OccRall=OccRall+sum(max(sOCCr{filec})); denOccRall=denOccRall+size(sOCCr{filec},2);
OccF=(2*OccP*OccR/(OccP+OccR));
Res(filec,:)=[EstP EstR EstF OccP OccR OccF];
EstPall=EstPall/denEstPall; EstRall=EstRall/denEstRall; EstFall=(2*EstPall*EstRall/(EstPall+EstRall));
OccPall=OccPall/denOccPall; OccRall=OccRall/denOccRall; OccFall=(2*OccPall*OccRall/(OccPall+OccRall)); end if ~exist(resfile,'file') fid=fopen(resfile,'w');
fprintf(fid,'Feature,FeatureNorm,DimReduction,NumofDims,winl, wins,
NumofResults,GapPenalty,Gaplength,MergeTimeTh,MergeSimTh,EstP,EstR,Est
F,OccP,OccR,OccF,EvalThreshold\n'); fclose(fid); end fid=fopen(resfile,'a');
fprintf(fid,'%s,%s,%s,%d,%3.2f,%3.2f,%d,%3.2f,%3.2f,%3.2f,%3.2f,%5.4f,
%5.4f,%5.4f,%5.4f,%5.4f,%5.4f,%5.2f\n',featureparams.feature,
featureparams.norm, featureparams.dimsreduction,
featureparams.numofdims,...
winl,wins,NumOfImportantResults,penalty,timegap,Th, proxTh,
EstPall,EstRall,EstFall,OccPall,OccRall,OccFall,EvalThreshold); fclose(fid); end end end end