Adn y arn
12
CARACTERÍSTICAS DEL ADN Y ARN CARACTERISTICAS ADN ARN Azúcar 2-desoxirribosa Ribosa Función Síntesis de proteína, reproducción, herencia, evolución. Síntesis de proteínas, traducción de la secuencia de bases en los ribosomas. Composición Polinucleótido: azúcar, base nitrogenada, grupo fosfato. Polinucleótido: azúcar, base nitrogenada, grupo fosfato. Estructura Cadena bicatenaria (excepto en algunos virus). Cadena monocatenaria (excepto en algunos virus). Localización -Célula procariota: el ADN aparece desudo y dispuesto en el citoplasma. Aparecen también ADN circulares (plásmidos y episemas). -Célula eucariota: ADN en el núcleo, y ADN circular en las mitocondrias y en los cloroplastos. -Célula procariota: el ARN se sintetiza en el citoplasma. -Célula eucariota: el ARN se sintetiza y posteriormente se desplaza al citoplasma donde realiza su función. Bases Nitrogenadas Adenina, Guanina, Timina, Citocina. Adenina, Guanina, Uracilo, Citocina. Apareamiento de bases Adenina = Timina con dos puentes de hidrogeno. Citocina ≡ Guanina con tres puentes de hidrogeno. Adenina-Uracilo Citocina- Guanina Estructura espacial Doble hélice: A = T G ≡ C No existe ninguna configuración especial solo en el ARNt (hoja de trébol). Cadenas Doble cadena de nucleótidos (2, antiparalelas). Una cadena de nucleótidos. Tipos - ARNm, ARNr, ARNt.
-
Upload
anna-ramirez-turizo -
Category
Health & Medicine
-
view
78 -
download
0
Transcript of Adn y arn

CARACTERÍSTICAS DEL ADN Y ARN
CARACTERISTICAS ADN ARN
Azúcar 2-desoxirribosa
Ribosa
Función Síntesis de proteína, reproducción, herencia, evolución.
Síntesis de proteínas, traducción de la secuencia de bases en los ribosomas.
Composición Polinucleótido: azúcar, base nitrogenada, grupo fosfato.
Polinucleótido: azúcar, base nitrogenada, grupo fosfato.
Estructura Cadena bicatenaria (excepto en algunos virus).
Cadena monocatenaria (excepto en algunos virus).
Localización -Célula procariota: el ADN aparece desudo y dispuesto en el citoplasma. Aparecen también ADN circulares (plásmidos y episemas). -Célula eucariota: ADN en el núcleo, y ADN circular en las mitocondrias y en los cloroplastos.
-Célula procariota: el ARN se sintetiza en el citoplasma. -Célula eucariota: el ARN se sintetiza y posteriormente se desplaza al citoplasma donde realiza su función.
Bases Nitrogenadas Adenina, Guanina, Timina, Citocina.
Adenina, Guanina, Uracilo, Citocina.
Apareamiento de bases Adenina = Timina con dos puentes de hidrogeno. Citocina ≡ Guanina con tres puentes de hidrogeno.
Adenina-Uracilo Citocina- Guanina
Estructura espacial Doble hélice: A = T G ≡ C
No existe ninguna configuración especial solo en el ARNt (hoja de trébol).
Cadenas Doble cadena de nucleótidos (2, antiparalelas).
Una cadena de nucleótidos.
Tipos - ARNm, ARNr, ARNt.

Crick (1970) alumbró la idea de un sistema fundamental de mantenimiento y flujo
de la información genética en los organismos vivos que denominó Dogma Central
de la Biología Molecular. De manera que la información genética contenida en el
ADN se mantiene mediante su capacidad de replicación. La información contenida
en el ADN se expresa dando lugar a proteínas, mediante los procesos
de transcripción, paso por el que la información se transfiere a una molécula de
ARN mensajero (ARN-m) y, mediante el proceso de la traducción el mensaje
transportado por el ARN-m se traduce a proteína.
DUPLICACION
La duplicación o replicación del ADN es el proceso por el cual se obtienen copias
o réplicas idénticas de una molécula de ADN. La replicación es fundamental para
la transferencia de la información genética de una generación a la siguiente y, por
ende, es la base de la herencia.
Se dieron muchas hipótesis sobre cómo se duplicaba el ADN hasta que Watson y
Crick propusieron la hipótesis semiconservativa (posteriormente demostrada por
Meselson Y Stahl en 1957), según la cual, las nuevas moléculas de ADN formadas
a partir de otra antigua, tienen una hebra antigua y otra nueva.
Según la hipótesis conservativa, quedarían las dos hebras antiguas juntas, y, por
otro lado, las dos hebras nuevas formando una doble hélice. Mientras que en la
hipótesis dispersiva, las hebras resultantes estarían formadas por fragmentos en
doble hélice ADN antiguo y ADN recién sintetizado.
Mediante consumo de ATP en dirección a la horquilla de replicación, es decir, en
dirección 5' → 3' en la hebra rezagada y 3' → 5' en la hebra adelantada, la

helicasa actúa rompiendo los puentes de hidrógeno que mantienen unida la doble
hélice. El siguiente conjunto de proteínas reclutadas son las denominadas
proteínas SSB (single-stranded DNA binding proteins, proteínas ligantes de ADN
monocatenario), estas proteínas se unen a la hebra discontinua de ADN,
impidiendo que ésta se una consigo misma, se unen de forma cooperativa, por lo
que su unión al ADN conforme avanza la helicasa es rápida. Por otro lado,
conforme las helicasas van avanzando se van generando superenrollamientos en
la doble cadena de ADN por delante de la horquilla y si éstos no fueran
eliminados, llegado a un punto el replisoma ya no podría seguir avanzando.
Las topoisomerasas son las enzimas encargadas de eliminar los
superenrollamientos cortando una o las dos cadenas de ADN y pasándolas a
través de la rotura realizada, sellando a continuación la brecha.
En el siguiente paso, la holoenzima ADN Polimerasa III cataliza la síntesis de las
nuevas cadenas añadiendo nucleótidos sobre el molde. Esta síntesis se da
bidireccionalmente desde cada origen, con dos horquillas de replicación que
avanzan en sentido opuesto. Cuando el avance de dos horquillas adyacentes las
lleva a encontrarse, es decir, cuando dos burbujas se tocan, se fusionan, y cuando
todas se han fusionado todo el cromosoma ha quedado replicado. en cada
horquilla de replicación se van formando dos copias nuevas a partir del cebador
sintetizado en cada una de las dos hebras de ADN que se separaron en la fase de
iniciación, pero debido a la unidireccionalidad de la actividad polimerasa de la ADN
Pol III, que sólo es capaz de sintetizar en sentido 5´ → 3', la replicación sólo puede
ser continua en la hebra adelantada; en la hebra rezagada es discontinua, dando
lugar a los fragmentos de Okazaki.
La hebra rezagada, cuando la ADN Pol III hace contacto con el extremo de otro
fragmento contiguo, el cebador de ARN de éste es eliminado y los dos fragmentos

de Okazaki de ADN recién sintetizado son unidos. Una vez se han juntado todos
se completa la doble hélice de ADN. En la eliminación del fragmento de Okazaki
(también denominado iniciador, cebador o primer) intervienen dos enzimas: por un
lado la ADN Pol I, que va eliminando el ARN con su actividad exonucleasa 5' → 3'
y simultáneamente rellenando con ADN mediante su actividad polimerasa 5' → 3'
(proceso denominado nick-traslation), por otra parte, , la ADN ligasa sella esa
rotura catalizando la reacción de condensación entre el grupo fosfato y el OH de
la desoxirribosa del nucleótido contiguo, completando el enlace fosfodiéster; para
ello, es preciso hidrolizar una molécula de ATP.
El final de la replicación se produce cuando la ADN polimerasa III se encuentra
con una secuencia de terminación. Se produce entonces el desacople de todo el
replisoma y la finalización de la replicación.
El ADN es usado como un modelo o una plantilla para la producción de más ADN.
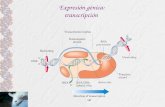
TRANSCRIPCIÓN
El proceso de síntesis de ARN o transcripción, consiste en hacer una copia
complementaria de un trozo de ADN. El ARN se diferencia estructuralmente del
ADN en el azúcar, que es la ribosa y en una base, el uracilo, que reemplaza a la
timina. Además el ARN es una cadena sencilla. Para que la transcripción funcione
bien, es necesario identificar de alguna manera cuándo el proceso debería de
empezar y cuándo debería de parar. Esto es llevado a cabo por proteínas

especiales, que se asocian con el inicio de los genes que necesitan ser transcritos.
Estas proteínas se conocen como los factores de transcripción.
El factor de transcripción reconoce el inicio (el promotor) de un gen que
necesita ser transcrito. La enzima, ARN-polimerasa se asocia a una región del
promotor del ADN, la enzima pasa de una configuración cerrada a abierta, y
desenrolla una vuelta de hélice, permitiendo la polimerización del ARN a partir
de una de las hebras de ADN, la enzima procede a lo largo del ADN,
haciendo una copia hasta que llega al final del gen.
La ARN-polimerasa, se desplaza por la hebra patrón, insertando nucleótidos de
ARN, siguiendo la complementariedad de bases. Cuando se ha copiado toda la
hebra, al final del proceso, la cadena de ARN queda libre y el ADN se cierra de
nuevo, por apareamiento de sus cadenas complementarias. De esta forma, las
instrucciones genéticas copiadas o transcritas al ARN están listas para salir al
citoplasma, siempre y cuando el ARN codifique para una proteína.
La actividad inapropiada de los factores de transcripción ha sido identificada en
casi todos los tipos de cánceres que se conocen hasta la fecha. Como estos
factores son esenciales para la actividad correcta de las células, un componente
errático puede tener efectos desastrosos para todas las otras partes de la célula.
Regresando a la analogía de la línea de la producción, un factor de transcripción
errático puede causar que la línea de ensamblaje se coloque donde no deba estar,

creando demasiado producto. Alternativamente, la línea de ensamblaje puede ser
que no esté en donde y cuando se necesita, creando un déficit en el producto final.
El ADN, por tanto, es la "copia maestra" de la información genética, que
permanece en "reserva" dentro del núcleo. El ARN, en cambio, es la "copia de
trabajo" de la información genética.
TRADUCCION
Es la última parte del proceso de la síntesis proteica (parte del proceso general de
la expresión génica). La traducción se da después de que el ARN mensajero
(ARNm) es producido por medio de la transcripción. La traducción ocurre tanto en
el citoplasma, donde se encuentran los ribosomas, como también en el retículo
endoplasmático rugoso (RER).
Los genes están formados por ADN, y este a su vez almacena información en una
secuencia de cuatro compuestos químicos que funcionan como “letras” de un
código (A, G, T, C). Las células leen este código y siguen las instrucciones de los
genes.
La unidad codificadora del código genético es un grupo de tres nucleótidos
(triplete), representado por las tres letras iníciales de las bases nitrogenadas (por
ej., ACT, CAG, TTT). Los tripletes del ADN se transcriben en sus bases
complementarias en el ARN mensajero, y en este caso los tripletes se
denominan codones (para el ejemplo anterior, UGA, GUC, AAA).
En el citoplasma hay una partícula llamada ribosoma, que es donde el nuevo
filamento mensajero se convertirá en una proteína de acuerdo con el código
genético. En el ribosoma cada codón del ARN mensajero interacciona con una
molécula de ARN de transferencia (ARNt) que contenga el triplete
complementario, denominado anticodón. Cada ARNt porta el aminoácido
correspondiente al codón de acuerdo con el código genético, de modo que a
medida que el mensajero atraviesa el ribosoma el aminoácido se une por su grupo
carboxilo con el -OH del ARNt mediante un enlace de tipo éster (cuando el ARNt
está enlazado con un aminoácido, se dice que está "cargado"), formando así, una
cadena de proteínas.

La terminación de la síntesis de la proteína sucede cuando la zona A del ribosoma
se encuentra con un codón de parada (sin sentido); estos codones de
terminación o codones de parada son UAA, UGA y UAG (en inglés, nonsense
codons o stop codons). Cuando la maquinaria celular lee alguno de estos 3
codones stop, la síntesis de la proteína codificada se detiene. Es decir, los
codones stop determinan el final de la proteína y no codifican para ningún
aminoácido. Cuando esto sucede, ningún ARNt puede reconocerlo, pero el factor
de liberación puede reconocer los codones sin sentido y provoca la liberación de la
cadena polipeptídica. La capacidad de desactivar o inhibir la traducción de la
biosíntesis de proteínas se utiliza en antibióticos como la anisomicina, la
cicloheximida, el cloranfenicol y la tetraciclina.
Existen 64 codones posibles, formados a partir de combinar los 4 nucleótidos del
ADN, por lo cual corresponde más de uno para cada aminoácido (por esta
duplicidad de codones se dice que el código genético es un código degenerado:
no es unívoco), sin embargo existen sólo 20 aminoácidos y algunos aminoácidos
están codificados en más de un codón.

Para poder obtener la secuencia proteica codificada en una secuencia de ADN
conocida debemos utilizar el código genético.
Jacob y Monod en 1961 propusieron la Hipótesis del mensajero: "debe existir una
molécula que transporte la información fielmente desde el ADN hasta las
proteínas". En ese mismo año Brenner y colaboradores (1961) demostraron la
existencia del este intermediario que resultó ser una molécula de ácido
ribonucleico que se denominó ARN mensajero (ARN-m). Posteriormente, el ARN-
m tenía que ser traducido a proteína.
LAS PROTEINAS
Los cromosomas en nuestras células contienen una cantidad enorme de
información. Se estima que los humanos tenemos alrededor de 30,000 genes.
Cada gen codifica para una molécula de ARN que puede ser usada directamente
o como una guía para la formación de una proteína en particular, como la insulina.
La información en nuestras células generalmente fluye en el orden de la forma
almacenada de la información (ADN) hacia una forma funcional (ARN) y, por
último, hacia el producto final (la proteína). Este orden es usado por todos los
organismos.
La serie de genes que están "encendidos" en un momento dado es de una
importancia crítica. El medio ambiente variado en el cual vivimos significa que
diferentes genes tienen que "encenderse" en tiempos diferentes. Por ejemplo, si
una comida contiene grandes cantidades de lactosa, un azúcar encontrado en la
leche, entonces nuestro cuerpo responde activando (transcribiendo) los genes que

llevan a la producción de las enzimas que descomponen la lactosa. Si un azúcar o
nutriente diferente está presente, los genes adecuados son encendidos para poder
procesarlos.
Se define proteína como, biopolímeros formados por cadenas lineales
de aminoácidos (monómeros). En la conformación de la proteína, las moléculas de
los aminoácidos se unen entre sí por medio de enlaces covalentes conocidos
como enlaces peptídicos que se establecen entre el grupo carboxílico de un
aminoácido y el grupo amino de otro.
Las proteínas figuran entre los componentes más abundantes en la mayoría de los seres vivos; en los animales representan un 50% o un poco más de su peso seco, mientras que en los vegetales constituyen un poco menos de la mitad de su peso seco.
Los seres vivos utilizan a las proteínas como materia prima para su desarrollo y control de los procesos químicos propios del metabolismo. La ingestión adecuada de proteínas favorece, entre otras cosas, la formación de musculatura, dientes, pelo, uñas, sangre, la oxigenación de las células, transporte de desechos del metabolismo, etc.
Pueden distinguirse varios niveles de organización en las proteínas. El primer nivel
se llama Estructura Primaria, que depende de la serie de aminoácidos en la
cadena de polipéptidos. Esta serie está determinada a su vez, por la serie de
nucleótidos de ADN y ARN del núcleo de la célula.
Un segundo nivel de organización supone la adopción de forma de hélice u otra
configuración regular por la cadena. Los aminoácidos, a medida que van siendo
enlazados durante la síntesis de proteínas y gracias a la capacidad de giro de sus
enlaces, adquieren una disposición espacial estable, la estructura secundaria en
donde la cadena se va enrollando en espiral. Una de las estructuras secundarias
de las moléculas proteicas es el hélice en α, que se supone una formación
espiralizada de la cadena de polipéptidos básica. Estos se debe a la formación de

enlaces de hidrógeno entre el -C=O de un aminoácido y el -NH- del cuarto
aminoácido que le sigue. Esta estructura se forma al enrollarse helicoidalmente
sobre sí misma la estructura primaria.
El tercer nivel de la estructura de las moléculas proteicas, es el doblamiento de la
cadena de péptidos sobre sí misma para formar proteínas globulares (esta
conformación globular facilita la solubilidad en agua y así realizar funciones de
transporte, enzimáticas, hormonales, etc). De nuevo enlaces débiles como enlaces
de hidrogeno, iónicos e hidrófobicos se forman entre una pare de la cadena de
péptidos y la otra parte, de modo que la cadena se desdobla de una manera
específica para dar una estructura general especifica de la molécula proteica.
Enlaces covalentes como los de disulfuros (S-S) son importantes en la estructura
terciaria de muchas proteínas. La actividad biológica de una proteína y la
estructura secundaria y terciaria está determinada por la estructura primaria
específica que es mantenida junto por esos enlaces.
La estructura cuaternaria informa de la unión, mediante enlaces débiles (no
covalentes) de varias cadenas polipeptídicas con estructura terciaria, para formar
un complejo proteico. Cada una de estas cadenas polipeptídicas recibe el nombre
de protómero.
El número de protómeros varía desde dos, como en la hexoquinasa; cuatro, como
en la hemoglobina, o muchos, como la cápsida del virus de la poliomielitis, que
consta de sesenta unidades proteicas.
Las proteínas que constan de una sola cadena polipeptídica carecen de
estructura cuaternaria.

La forma específica de las proteínas depende del orden exacto de los
aminoácidos que intervienen en su formación, además de que es determinante
para su funcionamiento. Pero éstas determinan la forma y la estructura de las
células y al controlar la producción de estas sustancias clave (proteínas), el ADN
controla la finalidad y el funcionamiento de todas nuestras células y, por ende, el
crecimiento y desarrollo de todos los órganos y tejidos. Las funciones de las
proteínas son específicas de cada una de ellas y permiten a las células mantener
su integridad, defenderse de agentes externos, reparar daños, controlar y regular
funciones, etc.
ENZIMAS
Las enzimas son moléculas de naturaleza proteica y estructural que
catalizan reacciones químicas, siempre que sean termodinámicamente posibles:
una enzima hace que una reacción química que es energéticamente posible , pero
que transcurre a una velocidad muy baja, sea cinéticamente favorable, es decir,
transcurra a mayor velocidad que sin la presencia de la enzima.
Las actividades de las enzimas vienen determinadas por su estructura
tridimensional, la cual viene a su vez determinada por la secuencia de
aminoácidos. Sin embargo, aunque la estructura determina la función, predecir
una nueva actividad enzimática basándose únicamente en la estructura de una
proteína es muy difícil, y un problema aún no resuelto.
En la replicación del ADN interviene la ADN polimerasa copia la cadena molde con
alta fidelidad. Sin embargo, introduce en promedio un error cada 107 nucleótidos

incorporados. Tiene, además, la capacidad de corregir sus propios errores, ya que
puede degradar ADN que acaba de sintetizar.
Otras enzimas que participan en este proceso son: la ADN primasa (que sintetiza
el primer de ARN), la ADN ligasa (que une extremos 5’ con 3’ que hayan quedado
luego de la síntesis), la ADN helicasa y las ADN topoisomerasas (que evitan que
el ADN se “enrede” en el proceso), las proteínas de unión al ADN (facilitan la
apertura de la doble hebra).
En la transcripción a enzima responsable es la ARN polimerasa, la cual se une a
una secuencia específica en el ADN denominada promotor y sintetiza ARN a partir
de ADN. En eucariontes hay diferentes polimerasas encargadas de sintetizar
distintos tipos de ARN.
La ARN polimerasa I: sintetiza los precursores del ARN ribosómico (ARN-r).
La ARN polimerasa II: produce ARN heterogéneo nuclear (ARN-hn) que
tras el procesamiento da lugar a los ARN mensajeros (ARN-m) que se
traducen a proteínas.
La ARN polimerasa III: transcribe los precursores de los ARN transferentes
(ARN-t), los ARN nucleares y citoplásmicos de pequeño tamaño y los genes
para el ARN 5S que forma parte de la subunidad grande de los ribosomas.