Comunicacion de Datos - spd3.files.wordpress.com · Podría abrir conexiones múltiples de red para...
101
Softdownload Página 1 Comunicación de Datos • Introducción • Clases de redes • Jerarquías de protocolos • Problemas en el diseño de los niveles • Servicios • Modelos de referencia de redes • OSI • TCP/IP • OSI vs. TCP/IP • Un ejemplo: Novell NetWare • El nivel físico • La velocidad máxima de un canal • Medios de transmisión • El sistema telefónico • Los local loops • Los troncales y la multiplexación • MDT en el sistema telefónico • Conmutación • Narrowband ISDN • Broadband ISDN y ATM • Conmutadores de ATM • Satélites • El nivel de enlace • Asuntos de diseño • Servicios para el nivel de red • Marcos • Control de errores • Control de flujo • Detección y corrección de errores • Códigos de detección de errores • Códigos de CRC • Protocolos elementales de enlace • Protocolos de ventana deslizante • SLIP y PPP • El nivel de enlace de ATM • Redes de broadcast • ALOHA • Protocolos de acceso múltiple con sentido de portador • Protocolos de CSMA con la detección de choques • Protocolos libre de choques • IEEE 802.3 y Ethernet • Bridges • LANs de velocidad alta
Transcript of Comunicacion de Datos - spd3.files.wordpress.com · Podría abrir conexiones múltiples de red para...

Softdownload
Página 1
Comunicación de Datos
• Introducción• Clases de redes• Jerarquías de protocolos• Problemas en el diseño de los niveles• Servicios
• Modelos de referencia de redes• OSI• TCP/IP• OSI vs. TCP/IP• Un ejemplo: Novell NetWare
• El nivel físico• La velocidad máxima de un canal• Medios de transmisión• El sistema telefónico
• Los local loops• Los troncales y la multiplexación• MDT en el sistema telefónico
• Conmutación• Narrowband ISDN• Broadband ISDN y ATM• Conmutadores de ATM• Satélites
• El nivel de enlace• Asuntos de diseño
• Servicios para el nivel de red• Marcos• Control de errores• Control de flujo
• Detección y corrección de errores• Códigos de detección de errores
• Códigos de CRC• Protocolos elementales de enlace• Protocolos de ventana deslizante
• SLIP y PPP• El nivel de enlace de ATM
• Redes de broadcast• ALOHA• Protocolos de acceso múltiple con sentido de portador• Protocolos de CSMA con la detección de choques• Protocolos libre de choques• IEEE 802.3 y Ethernet• Bridges• LANs de velocidad alta

Softdownload
Página 2
• El nivel de red• Estructura interna de la subred• Algoritmos de ruteo
• Algoritmos estáticos• Ruteo de vector de distancia• Ruteo de estado de enlace• Ruteo jerárquico• Ruteo de broadcast
• Algoritmos de control de congestión• Formación del tráfico• Control de congestión en subredes de circuitos virtuales• Paquetes de bloqueo• Pérdida de carga
• Internets• El nivel de red en la Internet
• Protocolos de control• IPv6
• El nivel de transporte• Primitivas del servicio de transporte• Protocolos de transporte
• Establecimiento de una conexión• Desconexión• Control de flujo• Multiplexación• Recuperación de caídas
• El protocolo de TCP• Implementación del protocolo• El encabezamiento de TCP• Administración de conexiones• Política de transmisión• Control de congestión• Administración de relojes
• Rendimiento• Diseño para rendimiento mejor• Procesamiento rápido de TPDUs
• El nivel de aplicación• DNS--Domain Name System
• Espacio de nombres de DNS• Registros de recurso• Servidores de nombres

Softdownload
Página 3
Introducción• ¿Qué es una red de computadores? Una colección interconectada de computadores autónomos.• ¿Para qué se usan las redes?
• Compartir recursos, especialmente la información (los datos)• Proveer la confiabilidad: más de una fuente para los recursos• La escalabilidad de los recursos computacionales: si se necesita más poder computacional, se
puede comprar un cliente más, en vez de un nuevo mainframe• Comunicación
Clases de redes
• Podemos clasificar las redes en las dimensiones de la tecnología de transmisión y del tamaño.• Tecnología de transmisión
• Broadcast. Un solo canal de comunicación compartido por todas las máquinas. Un paquetemandado por alguna máquina es recibido por todas las otras.
• Point-to-point. Muchas conexiones entre pares individuales de máquinas. Los paquetes de A a Bpueden atravesar máquinas intermedias, entonces se necesita el ruteo (routing) para dirigirlos.
• Escala• Multicomputadores: 1 m• LAN (local area network): 10 m a 1 km• MAN (metropolitan area network): 10 km• WAN (wide area network): 100 km a 1.000 km• Internet: 10.000 km
• LANs• Normalmente usan la tecnología de broadcast: un solo cable con todas las máquinas conectadas.• El tamaño es restringido, así el tiempo de transmisión del peor caso es conocido.• Velocidades típicas son de 10 a 100 Mbps (megabits por segundo; un megabit es 1.000.000 bits,
no 220).• WANs
• Consisten en una colección de hosts (máquinas) o LANs de hosts conectados por una subred.• La subred consiste en las líneas de transmisión y los ruteadores, que son computadores dedicados
a cambiar de ruta.• Se mandan los paquetes de un ruteador a otro. Se dice que la red es packet-switched (paquetes
ruteados) o store-and-forward (guardar y reenviar).• Internet
• Una internet es una red de redes vinculadas por gateways, que son computadores que puedentraducir entre formatos incompatibles.
• La Internet es un ejemplo de una internet.• Redes inalámbricas
• Una red inalámbrica usa radio, microondas, satélites, infrarrojo, u otros mecanismos paracomunicarse.
• Se pueden combinar las redes inalámbricas con los computadores móviles, pero los dos conceptosson distintos:
Inalámbrico Móvil AplicaciónNo No Workstations estacionarias

Softdownload
Página 4
No Sí Uso de un portable en un hotelSí No LANs en un edificio antiguo sin cablesSí Sí PDA (personal digital assistant) para inventario
Jerarquías de protocolos
• El software para controlar las redes se tiene que estructurar para manejar la complejidad.• Se organiza la mayor parte de las redes en una pila de niveles.• Cada nivel ofrece ciertos servicios a los niveles superiores y oculta la implantación de estos servicios. Usa
el nivel inferior siguiente para implementar sus servicios.• El nivel n de una máquina se comunica con el nivel n de otra máquina. Las reglas y convenciones que
controlan esta conversación son el protocolo de nivel n.• Las entidades en niveles correspondientes de máquinas distintas son pares. Son los pares que se
comunican.• En la realidad el nivel n de una máquina no puede transferir los datos directamente al nivel n de otra. Se
pasa la información hacia abajo de un nivel a otro hasta que llega al nivel 1, que es el medio físico.• Entre los niveles están las interfaces. Las interfaces limpias permiten cambios en la implementación de un
nivel sin afectar el nivel superior.• Un nivel que tiene que transmitir un paquete a otra máquina puede agregar un encabezamiento al paquete y
quizás partir el paquete en muchos. Por ejemplo, el encabezamiento puede identificar el mensaje y eldestino. El nivel 3 de la mayor parte de las redes impone un límite en el tamaño de los paquetes.
Problemas en el diseño de los niveles
• Un mecanismo para identificar los remitentes y los recibidores.• Transferencia de datos:
• Simplex. Solamente en un sentido.• Half-duplex. En ambos, pero uno a la vez.• Full-duplex. En ambos a la vez.
• Control de errores y detección de recepción.• Orden de mensajes.• Velocidades distintas de transmisión y recepción.• Ruteo.
Servicios
• Cada nivel provee un servicio al nivel superior.• Hay dos tipos de servicios:
• Servicio orientado a la conexión. Como el sistema telefónico. La conexión es como un tubo, ylos mensajes llegan en el orden en que fueron mandados.
• Servicio sin conexión. Como el sistema de correo. Cada mensaje trae la dirección completa deldestino, y el ruteo de cada uno es independiente.

Softdownload
Página 5
• Se caracterizan los servicios por la calidad de servicio.• Compara la transferencia de archivos con la comunicación de voz (ambas orientadas a la
conexión).• Para e-mail un servicio sin conexión y no confiable es suficiente, esto se llama servicio de
datagrama . Para dar confianza los servicios de datagrama con acuses de recibo son posibles.• Cada servicio define un conjunto de primitivas (tales como "solicitar" o "acusar recibo"). Por contraste el
protocolo es el conjunto de reglas que controlan el formato y significado de los paquetes intercambiadospor entidades de par. Se usan los protocolos para implementar los servicios.

Softdownload
Página 6
Modelos de referencia de redesExaminamos dos arquitecturas de red importantes: ISO OSI y TCP/IP.
OSI
• OSI es el Open Systems Interconnection Reference Model. Tiene siete niveles. En realidad no es unaarquitectura particular, porque no especifica los detalles de los niveles, sino que los estándares de ISOexisten para cada nivel.
• Nivel físico. Cuestiones: los voltajes, la duración de un bit, el establecimiento de una conexión, el númerode polos en un enchufe, etc.
• Nivel de enlace. El propósito de este nivel es convertir el medio de transmisión crudo en uno que esté librede errores de transmisión.
• El remitente parte los datos de input en marcos de datos (algunos cientos de bytes) y procesa losmarcos de acuse.
• Este nivel maneja los marcos perdidos, dañados, o duplicados.• Regula la velocidad del tráfico.• En una red de broadcast, un subnivel (el subnivel de acceso medio, o medium access sublayer)
controla el acceso al canal compartido.• Nivel de red. Determina el ruteo de los paquetes desde sus fuentes a sus destinos, manejando la congestión
a la vez. Se incorpora la función de contabilidad.• Nivel de transporte. Es el primer nivel que se comunica directamente con su par en el destino (los de
abajo son de máquina a máquina). Provee varios tipos de servicio (por ejemplo, un canal punto-a-punto sinerrores). Podría abrir conexiones múltiples de red para proveer capacidad alta. Se puede usar elencabezamiento de transporte para distinguir entre los mensajes de conexiones múltiples entrando en unamáquina. Provee el control de flujo entre los hosts.
• Nivel de sesión. Parecido al nivel de transporte, pero provee servicios adicionales. Por ejemplo, puedemanejar tokens (objetos abstractos y únicos) para controlar las acciones de participantes o puede hacercheckpoints (puntos de recuerdo) en las transferencias de datos.
• Nivel de presentación. Provee funciones comunes a muchas aplicaciones tales como traducciones entrejuegos de caracteres, códigos de números, etc.
• Nivel de aplicación. Define los protocolos usados por las aplicaciones individuales, como e-mail,telnet, etc.
TCP/IP
• Tiene como objetivos la conexión de redes múltiples y la capacidad de mantener conexiones aun cuandouna parte de la subred esté perdida.
• La red es packet-switched y está basada en un nivel de internet sin conexiones. Los niveles físico y deenlace (que juntos se llaman el "nivel de host a red" aquí) no son definidos en esta arquitectura.
• Nivel de internet. Los hosts pueden introducir paquetes en la red, los cuales viajan independientemente aldestino. No hay garantias de entrega ni de orden.Este nivel define el Internet Protocol (IP), que provee el ruteo y control de congestión.

Softdownload
Página 7
• Nivel de transporte. Permite que pares en los hosts de fuente y destino puedan conversar. Hay dosprotocolos:
• Transmission Control Protocol (TCP). Provee una conexión confiable que permite la entrega sinerrores de un flujo de bytes desde una máquina a alguna otra en la internet. Parte el flujo enmensajes discretos y lo monta de nuevo en el destino. Maneja el control de flujo.
• User Datagram Protocol (UDP). Es un protocolo no confiable y sin conexión para la entrega demensajes discretos. Se pueden construir otros protocolos de aplicación sobre UDP. También se usaUDP cuando la entrega rápida es más importante que la entrega garantizada.
• Nivel de aplicación. Como en OSI. No se usan niveles de sesión o presentación.
OSI vs. TCP/IP
• OSI define claramente las diferencias entre los servicios, las interfaces, y los protocolos.• Servicio: lo que un nivel hace• Interfaz: cómo se pueden accesar los servicios• Protocolo: la implementación de los servicios
TCP/IP no tiene esta clara separación.• Porque OSI fue definido antes de implementar los protocolos, los diseñadores no tenían mucha experiencia
con donde se debieran ubicar las funcionalidades, y algunas otras faltan. Por ejemplo, OSI originalmente notiene ningún apoyo para broadcast.
• El modelo de TCP/IP fue definido después de los protocolos y se adecúan perfectamente. Pero no otraspilas de protocolos.
• OSI no tuvo exíto debido a• Mal momento de introducción: insuficiente tiempo entre las investigaciones y el desarrollo del
mercado a gran escala para lograr la estandarización• Mala tecnología: OSI es complejo, es dominado por una mentalidad de telecomunicaciones sin
pensar en computadores, carece de servicios sin conexión, etc.• Malas implementaciones• Malas políticas: investigadores y programadores contra los ministerios de telecomunicación
• Sin embargo, OSI es un buen modelo (no los protocolos). TCP/IP es un buen conjunto de protocolos, peroel modelo no es general. Usarémos una combinación de los dos:
Nivel de aplicación
Nivel de transporte
Nivel de red
Nivel de enlace
Nivel físico
Un ejemplo: Novell NetWare
• Es el sistema de red más popular en el mundo de PC.• Modelo de cliente-servidor para los LANs.• Arquitectura:
Aplicación SAP, servidor de archivos, ...
Transporte NCP, SPX

Softdownload
Página 8
Red IPX
Enlace Ethernet, token ring, ARCnet
Físico Ethernet, token ring, ARCnet
• IPX es como IP, pero con direcciones de 10 bytes.• NCP está orientado a la conexión.• SAP (Service Advertising Protocol): Cada minuto cada servidor manda un broadcast de sus servicios y
dirección.

Softdownload
Página 9
El nivel físico
La velocidad máxima de un canal
• Se puede representar cualquiera señal de datos con una serie Fourier. La serie consiste en términos defrecuencias distintas, y se suman los términos para reconstruir la señal.
• Ningún medio de transmisión puede transmitir señales sin perder algún poder. Normalmente un mediopuede transmitir las frecuencias desde 0 hasta algún límite f; las frecuencias mayores se atenúanfuertemente.
• Cuanto más cambios por segundo de una señal (la razón de baud), tanto más términos de frecuencias altasque se necesitan.
• Entonces, el ancho de banda de un canal determina la velocidad de la transmisión de datos, aun cuando elcanal es perfecto.
• Si tenemos un canal de ancho de banda H (en Hertz) y V niveles discretos de señal, la velocidad máxima enun canal perfecto (en bits por segundo) es
vmax = 2H log2V
Esto es el teorema de Nyquist.• Una línea telefónica tiene un ancho de banda de aproximadamente 3000 Hz. No puede transmitir las
señales binarias más rápidamente que 6000 bps. ¿Cómo pueden transmitir los módems modernos avelocidades mayores?
• En realidad los canales no son perfectos y sufren del ruido aleatorio. Si el poder de la señal es S y el poderde ruido es R, la razón de señal a ruido es S/R. Normalmente se expresa esta razón en los decibeles (dB) ,que son 10log10S/R.
• La velocidad máxima en bps de un canal con ancho de banda H Hz y razón de señal a ruido de S/R es
vmax = H log2(1+S/R)
Es debido a Shannon.• Si una línea telefónica tiene un S/R de 30 dB (o 1000), un valor típico, no puede transmitir más de 30.000
bps, independientemente del número de niveles de señal.
Medios de transmisión
• Medios magnéticos. Si el costo por bit o ancho de banda es muy importante, las cintas magnéticas ofrecenla mejor opción.
• Una cinta de video (Exabyte) puede almacenar 7 GB.• Una caja de 50 cm puede almacenar 1000 cintas, o 7000 GB.• En los Estados Unidos se puede mandar una caja de este tipo de cualquier punto a cualquier otro
en 24 horas.• El ancho de banda entonces es 648 Mbps. Si el destino es solamente a una hora de distancia, el
ancho de banda es más de 15 Gbps.• Par trenzado (twisted pair). Consiste en dos alambres de cobre enroscados (para reducir interferencia
eléctrica). Puede correr unos kilómetros sin la amplificación. Es usado en el sistema telefónico.

Softdownload
Página 10
• Cable coaxial. Un alambre dentro de un conductor cilíndrico. Tiene un mejor blindaje y puede cruzardistancias mayores con velocidades mayores (por ejemplo, 1-2 Gbps).
• Fibra óptica. Hoy tiene un ancho de banda de 50.000 Gbps, pero es limitada por la conversión entre lasseñales ópticas y eléctricas (1 Gbps). Los pulsos de luz rebotan dentro de la fibra. En una fibra de modoúnico los pulsos no pueden rebotar (el diámetro es demasiado pequeño) y se necesita menor amplificación(por ejemplo, pueden cruzar 30 km a unos Gbps).
Además de estos hay también medios inalámbricos de transmisión. Cada uno usa una banda de frecuencias enalguna parte del espectro electromagnético. Las ondas de longitudes más cortas tienen frecuencias más altas, y asíapoyan velocidades más altas de transmisión de datos. De lambda f = c se deriva la relación entre la banda delongitud de onda y la banda de frecuencia: delta f = (c delta lambda)/lambda2
• Radio. 10 KHz-100 MHz. Las ondas de radio son fáciles de generar, pueden cruzar distancias largas, yentrar fácilmente en los edificios. Son omnidireccionales, lo cual implica que los transmisores y recibidoresno tienen que ser alineados.
• Las ondas de frecuencias bajas pasan por los obstáculos, pero el poder disminuye con el cubo de ladistancia.
• Las ondas de frecuencias más altas van en líneas rectas. Rebotan en los obstáculos y la lluvia lasabsorbe.
• Microondas. 100 MHz-10 GHz. Van en líneas rectas. Antes de la fibra formaban el centro del sistematelefónico de larga distancia. La lluvia las absorbe.
• Infrarrojo. Se usan en la comunicación de corta distancia (por ejemplo, controlo remoto de televisores).No pasan por las paredes, lo que implica que sistemas en distintas habitaciones no se interfieren. No sepueden usar afuera.
• Ondas de luz. Se usan lasers. Ofrecen un ancho de banda alto con costo bajo, pero el rayo es muy angosto,y el alineamiento es difícil.
El sistema telefónico
• En general hay que usarlo para redes más grandes que un LAN.• Consiste en las oficinas de conmutación, los alambres entres los clientes y las oficinas (los local loops), y
los alambres de las conexiones de larga distancia entre las oficinas (los troncales). Hay una jerarquía de lasoficinas.
• La tendencia es hacia la señalización digital. Ventajas:• La regeneración de la señal es fácil sobre distancias largas.• Se pueden entremezclar la voz y los datos.• Los amplificadores son más baratos porque solamente tienen que distinguir entre dos niveles.• La mantención es más fácil; es fácil detectar errores.
Los local loops
• Son analógicos. Los computadores tienen que usar un módem para convertir una señal digital en unoanalógica, y en la oficina de compañía de teléfonos un codec convierte a digital de nuevo.
• Tres problemas de transmisión:• Atenuación. Los componentes Fourier diferentes de una señal se atenúan por montos distintos.• Distorsión de retraso. Los componentes diferentes tienen velocidades diferentes. Dos bits en un
cable se pueden entremezclar.

Softdownload
Página 11
• Ruido. Tipos: termal, cross talk (inducción entre alambres), y impulsos (de puntos de poder).• Debido a estos problemas no es deseable tener un gran rango de frecuencias en la señal. Por desgracia las
ondas cuadradas de la señalización digital tienen un espectro grande. Por lo tanto los módems transmiten unportador de onda sinuosidal y modulan la amplitud, la frecuencia, o la fase.
• Otro problema es los ecos. Frecuentemente se refleja una parte de la señal. Una solución para la voz es unsupresor de eco, que cambia la línea de full-duplex a half-duplex y cambia el sentido de transmisiónrápidamente. Un tono de 2100 Hz puede desactivar los supresores (un ejemplo de la señalización enbanda). Una alternativa es un cancelador de eco, que preserva la transmisión full-duplex y resta unaestimación del eco a la señal.
• Al largo plazo hay que convertir los local loops a la fibra, pero es muy caro. Una solución intermedia esinstalar la fibra primero solamente en las calles y continuar usar el par trenzado para la conexión aldomicilio.
Los troncales y la multiplexación
• El costo de instalar y mantener una línea troncal es casi lo mismo para una línea de ancho de banda bajocomo para una línea de ancho de banda alta. Por lo tanto las compañías de teléfonos multiplexan llamadasmúltiples en una sola línea de ancho de banda alto.
• Multiplexación de división de frecuencias (MDF). Se usan filtros para restringir cada canal telefónico asolamente 3000 Hz. Para asegurar una buena separación se alocan 4000 Hz para cada canal. Se eleva lafrecuencia de cada canal de voz y entonces se combinan; cada canal es independiente de los otros.
• Multiplexación de división de longitud de onda. Es la misma idea como MDF, pero con luz y fibras. Yaque cada canal en una fibra no puede tener un ancho de más de unos gigahertz (debido a la velocidadmáxima de convertir entre señales ópticas y eléctricas), es una buena manera de usar el ancho de banda decerca 25.000 GHz de una fibra. En este caso los canales entrantes deben tener frecuencias distintas y secombinan con un prisma.
• Multiplexación de división de tiempo (MDT). El problema con MDF es que hay que usar circuiteríaanalógica. Por contraste se puede manejar la MDT completamente con la electrónica digital. En MDT cadausuario tiene sucesivamente todo el ancho de banda del canal por un momento. Se puede usar MDTsolamente con los datos digitales.
MDT en el sistema telefónico
• El primer paso en el uso de MDT es la conversión de las señales analógicas. Debido al teorema de Nyquist,se puede capturar toda la información de una señal de H Hertz con una frecuencia de muestras de 2H. Uncodec (coder-decoder) muestrea el flujo 8000 veces por segundo (125 microsegundos por muestra). Esteproceso se llama (en el mundo telefónico) Pulse Code Modulation (PCM).
• Un ejemplo de un portador de MDT es una línea T1, que multiplexa 24 canales de voz.• Un solo codec muestrea cada canal sucesivamente; cada uno produce 7 bits de dato y 1 bit de
control por muestra. Por tanto hay 7×8000 = 56.000 bps de datos por canal, y 8000 bps de control.• Cada marco del T1 tiene 24×8 = 192 bits, más un bit para control de marcos. Tenemos 193 bits
cada 125 microsegundos, que es 1,544 Mbps.• El bit 193 alterna entre 0 y 1. El recibidor lo usa para la sincronización.
• Un T2 (6,312 Mbps) consiste en 4 canales T1, un T3 (44,736 Mbps) de 6 T2, y un T4 (274,176 Mbps) de 7T3. Cada uno agrega bits de control y de marco.
• SONET (Synchronous Optical Network) es un sistema de MDT para la fibra. El marco cada 125microsegundos tiene 810 bytes, que implica 51,84 Mbps.

Softdownload
Página 12
Conmutación
• Los dos tipos principales son la conmutación de circuito y la conmutación de paquetes.•
de circuito de paqueteRuta dedicado de "cobre" Sí NoAncho de banda disponible Fijo DinámicoPosibilidad de malgastar ancho de banda Sí NoTransmisión de store-and-forward No SíCada paquete toma la misma ruta Sí NoInicialización de la ruta Necesario No necesarioPuntos donde la congestión puede ocurrir En inicialización Con cada paqueteCobrar Por minuto Por paquete
• Conmutadores de crossbar (travesaño). Tiene N inputs, N outputs, y N2 intersecciones. Problema: laescalabilidad. Si N=1000, tenemos 1.000.000 intersecciones.
• Conmutadores de división de espacio. Consisten en tres (o más) etapas de conmutadores de crossbar. Enla primera etapa hay N/n crossbars con n inputs y k outputs cada uno. En la segunda hay k crossbars de N/n× N/n. La tercera etapa es el revés de la primera.
• El número de intersecciones es 2kN + k(N/n)2. Si N=2000, n=50, y k=10, hay solamente 24.000.Empero permite solamente 200 conexiones simultáneas.
• Con valores de k mayores hay menor probabilidad de bloqueo, pero el costo del conmutadoraumenta.
• Conmutadores de división de tiempo. Es digital. La operación tiene unas etapas:• Se examinan los n canales de input sucesivamente para construir un marco de input con n entradas
de k bits. (En una línea T1 k=8 y se procesan 8000 marcos por segundo.)• El intercambiador de entradas de tiempo acepta los marcos de input. Ubica las entradas en orden
en una tabla de RAM y entonces lee las entradas a un marco de output usando la tabla de mapping.• Se mandan los contenidos del marco de output a los canales de output.
La limitación de conmutadores de división de tiempo es el tiempo de ciclo de la memoria. Si cada accesorequiere T microsegundos, el tiempo para procesar un marco es 2nT, y debe ser menos de 125microsegundos. Si T es 100 nanosegundos, n=625. Se puede construir conmutadores con etapas múltiplespara solucionar este problema.

Softdownload
Página 13
Narrowband ISDN
• ISDN es Integrated Services Digital Network. Es un servicio inventado en 1984 por las compañías deteléfonos para proveer una conexión digital directamente al cliente. Usa conmutación de circuito. Ahoraestá disponible en muchos mercados.
• Para la casa ofrece dos canales de 64 kbps para voz/dato y uno de 16 kbps para el control fuera de banda.Para la empresa, 23 o 30 canales de voz/dato en vez de dos.
• Problema: ¡Es demasiado lento! El proceso de estandarización duró años. Durante el mismo período latecnología de red avanzó rápidamente. Ahora LANs de 10 y 100 Mbps son comunes.
• Sin embargo, un uso interesante es conexiones de Internet de la casa.
Broadband ISDN y ATM
• Broadband ISDN provee un circuito virtual digital para transferir paquetes de tamaños fijos (celdas) conuna velocidad de 155 Mbps. Está basado en ATM (Asynchronous Transfer Mode), que es una tecnología deconmutación de paquetes.
• No se pueden usar los conmutadores de división de espacio ni de tiempo con ATM. Tampoco se puedenusar los local loops existentes. La conversión a ATM representa un cambio enorme.
• Broadband ISDN es una combinación de la conmutación de circuito y de paquetes. El servicio es orientadoa la conexión pero es implementado con conmutación de paquetes. Hay dos clases de conexiones:
• Circuitos virtuales permanentes. Persisten meses o años.• Circuitos virtuales conmutados. Temporales, como llamadas de teléfono.
• La creación de un circuito en ATM es el proceso de encontrar un camino por la red. Los conmutadores enla ruta guardan entradas de tabla y tal vez reserven recursos. Cuando un paquete llega en un conmutador,busca qué circuito virtual pertenece en el encabezamiento del paquete y determina en qué línea debierareenviar el paquete.
• ATM es asíncrono. Por contraste con T1, no hay ningún requerimiento que las celdas de fuentes distintas sealternan rígidamente. Los ordenes aleatorios y incluso brechas en el flujo son permisibles.
• ATM no especifica el medio; ambos los cables y las fibras son posibles. Las conexiones son punto-a-puntoy half-duplex. La velocidad principal es 155,52 Mbps; la alternativa es 622,08 Mbps (estas son compatiblescon SONET).
Conmutadores de ATM
• Las celdas de ATM llegan con una velocidad de alrededor de 150 Mbps, o 360.000 celdas por segundo(una celda cada 2,7 microsegundos; con el ATM más rápido, cada 700 nanosegundos). Un conmutadortiene desde 16 a 1024 líneas de input. Para poder construir los conmutadores es necesario que las celdassean cortas (53 bytes).
• Requerimientos:• La taza de perder paquetes debe ser muy baja (1 celda en 1012, por ejemplo).• Nunca se puede cambiar el orden de las celdas en un circuito virtual.
• Un problema básico: ¿Qué pasa cuando dos celdas quieren ir por la misma línea de output en el mismociclo?

Softdownload
Página 14
• No podemos descartar una de las celdas.• Podemos usar una cola para cada línea de input. Introduce el efecto de bloqueo de la cabeza de
cola: Puede ser celdas que se pueden rutear tras de la cuál está bloqueada.• Otra posibilidad es una cola para cada línea de output.
• Conmutador de knockout. Tiene un bus de broadcast para cada línea de input. La activación de lasintersecciones determinan las líneas de output. Cada línea de output tiene una sola cola virtual que serepresenta con n reales y un shifter. Porque n es normalmente menos que el número de líneas de input, unconcentrador escoge las celdas a descartar si demasiados llegan.
• Conmutador de Batcher-banyan. El problema con el conmutador de knockout es que semejante a unconmutador de crossbar. El Batcher-banyan es un conmutador de etapas múltiples para los paquetes.
Satélites
• Funcionan como repetidores de microondas. Un satélite contiene algunos transponedores que reciben lasseñales de alguna porción del espectro, las amplifican, y las retransmiten en otra frecuencia.
• Hay tres bandas principales: C (que tiene problemas de interferencia terrenal), Ku, y Ka (que tienenproblemas con la lluvia).
• Un satélite tiene 12-20 transponedores, cada uno con un ancho de banda de 36-50 MHz. Un velocidad detransmisión de 50 Mbps es típica. Se usa la multiplexación de división de tiempo.
• La altitud de 36.000 km sobre el ecuador permite la órbita geosíncrona, pero no se pueden ubicar lossatélites con espacios de menos de 1 o 2 grados.
• Los tiempos de tránsito de 250-300 milisegundos son típicos.

Softdownload
Página 15
• Los fuertes del medio son la comunicación broadcast, la comunicación móvil, y la comunicación en losáreas con el terreno difícil o la infraestructura débil. Otra posibilidad es el ancho de banda grande perotemporal.

Softdownload
Página 16
El nivel de enlace• El tema principal es los algoritmos para la comunicación confiable y eficiente entre dos máquinas
adyacentes.• Problemas: los errores en los circuitos de comunicación, sus velocidades finitas de transmisión, y el tiempo
de propagación.
Asuntos de diseño
Servicios para el nivel de red
• Servicio sin conexión y sin acuses de recibo. La máquina de fuente manda marcos al destino. Esapropiado si la frecuencia de errores es muy baja o el tráfico es de tiempo real (por ejemplo, voz).
• Servicio sin conexión y con acuses de recibo. El recibidor manda un acuse de recibo al remitente paracada marco recibido. Los acuses son una optimización; el nivel de transporte también los usa, pero con eluso en este nivel se pueden confirmar y posiblemente reenviar los marcos individuales.
• Servicio orientado a la conexión con acuses de recibo. Provee un flujo confiable de bits. Las máquinasde fuente y recibo establecen una conexión antes de mandar los datos (inicializar variables, reservarbuffers, etc.). Los marcos son numerados, y todos son recibidos exactamente una vez y en el ordencorrecto.
Marcos
• El nivel físico toma un flujo de bits y intenta entregar al destino. Los bits entregados pueden ser más,menos, o distintos a estos mandados.
• El nivel de enlace trata de detectar y corregir los errores. Normalmente se parte el flujo de bits en marcos yse calcula un checksum para cada uno.
• Para partir el flujo no se pueden usar brechas de tiempo en la transmisión, porque no hay ninguna garantíapor el nivel físico que estas brechas serán preservadas.
• Número de caracteres. Un campo del encabezamiento guarda el número. Pero si el número es cambiadoen una transmisión, es difícil recuperar.
• Caracteres de inicio y fin, con relleno de caracteres. Cada marco empieza con la secuencia ASCII deDLE STX y termina con DLE ETX. Si la secuencia está en los datos, se duplica el DLE. Pero este sistemaes muy vinculado a ASCII y caracteres de 8 bits.
• Flags de inicio y fin, con relleno de bits. Cada marco empieza y termina con 01111110. En los datos seinserta un 0 después de cada cinco 1s consiguientes. El recibidor elimina cada 0 después de cinco 1s.
• Infracciones en el estándar de codificación del nivel físico. Se usa en sistemas con redundancia.Ejemplo: LANs donde se usa dos bits físicos para cada bit lógico. Entonces quedan dos combinaciones parala señalización.
• Una combinación del número de caracteres con uno de otros métodos es también posible.
Control de errores

Softdownload
Página 17
• Se usan los acuses de recibo positivos y negativos.• Para manejar el caso donde se pierde el marco o el acuse, el remitente mantiene temporizadores.• Para evitar marcos duplicados se usan números de secuencia.
Control de flujo
• Se usan protocolos que prohiben que el remitente pueda mandar marcos sin la permisión implícita oexplícita del recibidor.
• Por ejemplo, el remitente puede mandar n marcos y entonces tiene que esperar.
Detección y corrección de errores
• Los errores en los troncales digitales son raros. Pero son comunes en los local loops y en la transmisióninalámbrica.
• En algunos medios (por ejemplo, el radio) los errores ocurren en grupos (en vez de individualmente). Ungrupo inicia y termina con bits invertidos, con algún subconjunto (posiblemente nulo) de los bitsintermedios también invertidos.
• Ventaja: Si tuviésemos una taza de 0,001 errores por bit y bloques de 1000 bits, la mayoría de losbloques tendrían errores. Pero con los errores en grupos, no.
• Desventaja: Los errores en grupo son más difíciles de detectar.• Enfoques:
• La corrección de errores. Transmitir información redundante que permite deducir que debía serun carácter transmitido.
• La detección de errores. Transmitir solamente suficiente información para detectar un error.• Términos:
• Un codeword de n bits consiste en m bits de dato y r bits de redundancia o chequeo.• La distancia de Hamming de dos codewords es el número de bits distintos. Es decir, haga el XOR
de los codewords y cuenta el número de unos.• Normalmente todos los 2m mensajes de dato son legales, pero no los 2n codewords debido a la manera en
que se calcula los bits de chequeo.• Se pueden construir todos los codewords legales y entonces encontrar los dos con la distancia de Hamming
mínima. Esta es la distancia de Hamming del código.• Para detectar d errores se necesita un código de distancia de Hamming de d+1, porque entonces d errores
únicos de bit no pueden cambiar un codeword válido a otro codeword válido.• Para corregir d errores se necesita una distancia de 2d+1. Aun cuando hay d cambios, el codeword original
todavía está más cerca que cualquier otro.• Ejemplos:
• Un código usa un solo bit de paridad que se añade así que el número de unos es par. Tiene unadistancia de dos y puede detectar los errores únicos.
• Un código tiene los cuatro codewords 0000000000, 0000011111, 1111100000, y 1111111111. Ladistancia es cinco; el código puede corregir dos errores. Por ejemplo, interpreta 0000000111 como0000011111.
• Supon que queremos corregir los errores de un bit. Necesitamos un código con una distancia de tres. Dadom, ¿qué debe ser r?
• Hay 2m mensajes legales. Cada uno tiene n codewords ilegales a una distancia de uno que seforman invirtiendo individualmente cada uno de los n bits del codeword.

Softdownload
Página 18
• Entonces cada uno de los 2m mensajes necesita n+1 patrones de bit propios.• Tenemos 2n codewords posibles. Entonces, 2m(n+1) <= 2n, o usando n = m+r, m+r+1 <= 2r.• Dada m tenemos un límite inferior del número de bits de chequeo r. El código de Hamming logra
este límite.• Se pueden usar un código de corrección para los errores de un bit para corregir los errores en grupo usando
un truco: Transmite los datos como las columnas de un matriz donde cada fila tiene su propio bits dechequeo.
Códigos de detección de errores
• Aunque se usa a veces la corrección de errores, normalmente se prefiere la detección de errores ya que esmás eficiente.
• Por ejemplo, asume que tenemos un canal con una taza de errores de 10-6 por bit (es decir, un bit en cada106). Usamos mensajes de 1000 bits de dato.
• Para la corrección debemos añadir 10 bits por mensaje. En la transmisión de 106 bits de datomandamos 10.000 bits de chequeo para detectar y corregir el un bit de error que esperamos.
• Para la detección usamos solamente un bit de paridad por mensaje. Para 106 bits de dato usamossolamente 1000 bits. Pero uno de los mensajes tiene un error, así que tenemos que retransmitirlocon su bit de paridad (1001 bits). En total usamos 2001 bits para este esquema.
• Si usamos un solo bit de paridad y tenemos un grupo de errores, la probabilidad de detección es solamente1/2. Podemos aumentar la capacidad a detectar un grupo de errores usando el truco de la transmisión de unmatriz de k×n: Se transmiten los datos por columna, y cada fila tiene un bit de paridad. Podemos detectarlos errores en grupo hasta n, el número de filas. No podemos detectar n+1 si el primer bit y el último bit soninvertidos y todos los otros son correctos. Si tenemos muchos errores en el bloque la probabilidad deaceptarlo es solamente (1/2)n.
Códigos de CRC
• Un método más usado es el código polinomial (también llamado el cyclic redundancy code, o CRC). Setrata los strings de bits como polinomios con coeficientes de solamente 0 y 1. Un mensaje de k bits con ungrado de k-1 corresponde a
bit0xk-1 + ...+ bitnxk-1-n + ...+ bitk-1x0
La aritmética con estos polinomios es módulo 2 sin llevar, es decir la adición y la sustracción sonequivalentes a XOR. La división usa XOR en ves de sustracción y A se divide en B si el número de bits enB es mayor de o igual a el número en A.
• El remitente y el recibidor usan el mismo polinomio de generación, G(x), con bits alto y bajo de 1.• Para calcular el checksum de r bits, que también es el grado de G(x),
• Añade r bits de 0 a M(x), el mensaje, produciendo xrM(x).• Divide xrM(x) por G(x), produciendo un resto.• Transmite T(x) = xrM(x) - resto. T(x) es divisible por G(x). Sus últimos r bits son el checksum.
• Si hay errores en la transmisión recibiremos T(x)+E(x) en vez de T(x). El recibidor divide T(x)+E(x) porG(x). Ya que el resto debido a T(x) es 0, el resto obtenido es completamente debido a E(x). Si E(x) tieneG(x) como un factor, el resto será 0 y no detectaremos el error, de otro modo, sí.
• Si hay un error de un bit, E(x) = xi . Si G(x) tiene más de un término, no puede dividir E(x). Entoncespodemos detectar todos los errores de un bit.

Softdownload
Página 19
• Con dos errores tendremos E(x) = xi + xj = xj (xi-j+1). Podemos usar un G(x) que no divide xk +1 paracualquier k hasta el valor máximo de i-j (que es la longitud del marco). Por ejemplo, x15+x14+1 no dividexk +1 para k<32768.
• Si x+1 es un factor de G(x), podemos detectar todos los errores que consisten en un número impar de bitsinvertidos. Prueba por contradicción: Asume que E(x) tiene un número impar de términos y es divisible porx+1. Entonces E(x) = (x+1)Q(x) por algún Q(x). E(1) = (1+1)Q(1) = (0)Q(1) = 0. Pero E(1) debe ser 1porque consiste en la suma de un número impar de 1's.
• Podemos detectar todos los errores en grupo con longitudes menos de o igual a r. Si el grupo tiene unalongitud de k, lo podemos escribir como xi(xk-1+...+1) (i ubica el grupo en el marco). Si G(x) contiene untérmino de x0, xi no puede ser un factor y G(x) no puede ser igual a xk-1+...+1 (el grado k-1 es menos de r).Si el grupo tiene una longitud de r+1, la probabilidad que el grupo es G(x) es la probabilidad que los r-1bits intermedios del grupo son iguales (por definición el primer y el último bits del grupo son 1), que es(1/2)r-1.
• Para los grupos con longitudes mayor de r+1, la probabilidad es (1/2)r.• Estándares internacionales:
• CRC-12 = x12 + x11 + x3 + x2 + x + 1• CRC-16 = x16 + x15 + x2 + 1• CRC-CCITT = x16 + x12 + x5 + 1
Los dos últimos detectan todos los errores de uno y dos bits, los errores con un número impar de bitsinvertidos, los grupos de errores con longitudes menos de o igual a 16, 99,997% con longitudes de 17, y99,998% con longitudes mayor o igual a 18.
Protocolos elementales de enlace
• Suposiciones iniciales:• Máquina A quiere mandar un flujo de datos a B usando un servicio confiable orientada a la
conexión. El servicio es simplex.• Los niveles de red de A y B están siempre listos. Por ejemplo, A siempre tiene datos listos para
mandar.• El canal nunca pierde ni daña los marcos.• El hardware hace el checksum (necesario cuando eliminamos la condición precedente).
sender1() receiver1(){ { frame s; frame r; packet buffer; event_type event;
while (true) { while (true) { from_network_layer(&buffer); wait_for_event(&event); s.info = buffer; from_physical_layer(&r); to_physical_layer(&s); to_network_layer(&r.info); } }} }
• Cambio: El nivel de red de remitente no puede aceptar siempre los datos. Debemos prevenir que elremitente satura el recibidor.
• Insertar un retraso fijo no es deseable, porque fija el caso peor como el caso normal.• El recibidor manda un acuse de recibo después de cada marco; el remitente tiene que esperar el
acuse (un protocolo de parar-y-esperar).• El medio tiene que ser half-duplex aunque el servicio todavía es simplex.
sender2: receiver2: while (true) while (true)

Softdownload
Página 20
from_network_layer(&buffer) wait_for_event(&event) s.info = buffer from_physical_layer(&r) to_physical_layer(&s) to_network_layer(&r.info) wait_for_event(&event) to_physical_layer(&s)
• Cambio: Se pueden dañar o perder los marcos.• Una posibilidad: Añadir un temporizador al remitente. El remitente manda el marco, y el recibidor
manda un acuse solamente si los datos fueron recibidos correctamente (se descartan los marcosdañados). Después de algún tiempo el remitente manda el marco de nuevo. ¿Cuál es el problema?Se pueden duplicar los marcos si un acuse es perdido.
• Solución: El remitente inserta un número de secuencia en en encabezamiento del marco. Estepermite que el recibidos pueda distinguir entre marcos nuevos y duplicados.
• ¿Cuántos bits necesitamos para el número de secuencia? Necesitamos distinguir solamente entre my m+1 después de que el recibidor manda el acuse de m (depende de que el acuse es recibido porel remitente o no). No podemos recibir el marco m+2 porque el recibidor no va a mandar el acusede m+1 (que permite al remitente mandar el marco m+2) hasta que reciba el marco m+1. Entoncesse necesita solamente un bit para distinguir entre las dos posibilidades.
sender3: receiver3: next_frame_to_send = 0 frame_expected = 0 from_network_layer(&buffer) while (true) while (true) wait_for_event(&event) s.info = buffer if (event == frame_arrival) s.seq = next_frame_to_send from_physical_layer(&r) to_physical_layer(&s) if (r.seq == frame_expected) start_timer(s.seq) to_network_layer(&r.info) wait_for_event(&event) inc(frame_expected) if (event == frame_arrival) to_physical_layer(&s) // ACK from_network_layer(&buffer) inc(next_frame_to_send)El período de espera en el remitente tiene que ser suficiente largo para prevenir las expiracionesprematuras. ¿Por qué?
Protocolos de ventana deslizante
• Hemos tenido la restricción que la transmisión de datos es simplex, aunque el canal de transmisión esdúplex o full-dúplex. Esta restricción malgasta la mitad del ancho de banda del canal.
• Nuestro primer paso es eliminar esta restricción. Ambos los marcos de datos y los acuses de recibo puedenfluir en ambas direcciones. Podemos usar un campo en el encabezamiento de cada marco que especifica suclase (datos o acuse).
• Un segundo mejoramiento es lo siguiente: Cuando un marco de datos llega, el recibidor no mandainmediatamente un acuse. En vez de esto, espera hasta que su nivel de red le pase un paquete de datos(recuerda que el flujo de datos ahora es full-dúplex). Cuando el paquete está listo, se añade el acuse para elmarco recibido antes. Entonces, se combinan en un solo marco un acuse y un paquete de datos. Se llamaeste proceso piggybacking.
• Ventajas principales de piggybacking:• Mejor uso del ancho de banda. El campo de acuse de recibo en un encabezamiento de marco de
datos es solamente pocos bits, mientras que un marco que es solamente un acuse consiste en losbits, un encabezamiento, y un checksum.
• Menos marcos mandados implica menos interrupciones de llegada de marco en el recibidor, yquizás menos buffers en el recibidor también.

Softdownload
Página 21
• ¿Cuál es el lado negativo de piggybacking? Introduce una nueva complicación. ¿Por cuánto tiempo debieraesperar el nivel de enlace para un paquete de datos antes de que mande un acuse? Si espera demasiadolargo, el remitente retransmitirá el marco.
• En protocolo 3 teníamos también problemas si el mandador no espera por suficiente tiempo. Queremos unprotocolo que puede continuar funcionando en tal caso. Una clase de protocolos que son mas robustos sonlos protocolos de ventana deslizante.
• En estos protocolos cada marco tiene un número de secuencia con un rango de 0 hasta algún n. Encualquier instante, el mandador mantiene un conjunto de números de secuencia que corresponden a losmarcos que puede mandar (los marcos dentro de la ventana del mandador). El recibidor mantiene unaventana del recibidor que es el conjunto de marcos que puede aceptar. Las dos ventanas pueden tenertamaños distintos.
• Los números de secuencia en la ventana del mandador representan los marcos mandados pero nodados acuses. Cuando un paquete llega desde el nivel de red, se le asigna el próximo número desecuencia (modulo n) y la ventana crece por uno. Cuando un acuse llega, la ventana disminuye poruno. En esta manera la ventana mantiene siempre la lista de marcos sin acuses. (Nota: Requerimosque el nivel físico entrega marcos en el orden mandado.)
• Ya que es posible que se pierdan o se dañen los marcos en la ventana del mandador, el mandadorlos tiene que guardar para una retransmisión eventual. Con una ventana de tamaño n el mandadornecesita n buffers. Si la ventana crece a su tamaño máximo, el nivel de enlace de mandador nopuede aceptar paquetes nuevos desde el nivel de red hasta que un buffer está vacío.
• En el recibidor la ventana siempre mantiene el mismo tamaño y representa los marcos que sepueden aceptar. El recibidor tiene un buffer para cada posición en la ventana; el propósito de estosbuffers es permitir que se pueden entregar los marcos en orden al nivel de red aun cuando losmarcos llegan en un orden distinto (debido a retransmisiones, marcos perdidos, etc.). Se descartanlos marcos que llegan con números de secuencia fuera de la ventana.
• El caso más sencillo es un protocolo con ventanas de tamaños máximos de 1. Cuando un marco llega cuyonúmero de secuencia es igual al número único en la ventana, se genera un acuse de recibo, se entrega elpaquete a nivel de red, y se desplaza la ventana arriba por uno (es decir, invertir el número en la ventana).
• Tal protocolo es de tipo parar-y-esperar, ya que el mandador transmite un marco y espera su acuse antes demandar el próximo. ¿Qué pasa en este tipo de protocolo cuando el tiempo de ida y vuelta es largo (porejemplo, con una conexión de satélite)? El mandador malgasta ancho de banda esperando los acuses derecibo. Ejemplo:
• Canal de satélite de 50 kbps con una latencia de 250 msegs y marcos de 1000 bits.• En t=0 mandamos un marco. En t=20 msegs es completamente mandado.• Llega completamente en t=270. El acuse llega en t=520.• El mandador espera 500/520 = 96% del tiempo.
• Solución: pipelining. El mandador puede mandar hasta n marcos sin esperar. Si n es suficiente grande losacuses llegarán siempre antes de que el mandador haya mandado n marcos (es decir, el tamaño de suventana).
• Con el pipelining tenemos un problema si se daña o se pierde un marco en la mitad del flujo. Muchosmarcos llegarán en el recibidor antes de que el mandador sepa que hay un error. Cuando el recibidor notaun marco dañado o faltando, ¿qué debiera hacer con los marcos correctos que siguen?
• Repetir n. En esta estrategia el recibidor descarta los marcos que siguen y no manda ningúnacuse. Es decir, el recibidor tiene una ventana de tamaño 1 y no acepta ningún marco excepto elpróximo que le debe dar a nivel de red. Con tiempo el mandador notará la ausencia de acuses yretransmitirá los marcos en orden. Este enfoque malgasta ancho de banda si la taza de errores esalta.
• Repetir selectivamente. En esta estrategia el recibidor guarda los marcos correctos después delmalo. Cuando el mandador nota que falta un acuse, solamente retransmitirá el marco malo. Si estaretransmisión tiene éxito, el recibidor tendrá muchos marcos correctos en secuencia y le podrápasar al nivel de red y mandar un acuse de recibo para el número de secuencia más alto. Esteenfoque requiere una ventana del recibidor con un tamaño más de 1, y su costo es el espacio para

Softdownload
Página 22
los buffers. El tamaño de la ventana debiera ser la mitad del número de números de secuencia.¿Por qué? El recibidor tiene que poder distinguir entre marcos duplicados y marcos nuevos.
• Se pueden usar acuses negativos de recibo (NAKs), los cuales el recibidor puede usar para acelerar laretransmisión de marcos.
SLIP y PPP
• Dos protocolos populares para las conexiones de Internet temporales entre los PCs de usuarios y losproveedores de servicios de Internet son SLIP y PPP. Se pueden usar estos protocolos también para lasconexiones entre ruteadores sobre líneas dedicadas en la subred de la Internet.
• SLIP (de 1984) es muy sencillo. Se mandan paquetes crudos de IP (es decir, paquetes del nivel de la red)sobre la línea, con un byte de flag al fin para indicar los marcos. Se usa el relleno de caracteres para el casodonde el byte de flag ocurre dentro de los datos de un paquete. Algunas versiones nuevas de SLIP apoyanla compresión de encabezamientos de TCP y IP, aprovechando del hecho que los paquetes consecutivosnormalmente tienen muchos campos comunes. Pero SLIP tiene algunos problemas:
• No provee ninguna detección de errores.• Apoya solamente IP.• Cada lado tiene que saber la dirección IP del otro antes.• No provee ningún sistema de autenticación.• Hay muchas versiones incompatibles.
• PPP se aplica a las deficiencias de SLIP. Provee tres cosas:• Un sistema de enmarcar que distingue el fin de un marco y el inicio del próximo, que también
maneja la detección de errores.• Un protocolo de control de enlace (LCP, Link Control Protocol) para subir una conexión, probarla,
negociar opciones, y bajarla.• Un método para negociar opciones del nivel de red que es independiente del protocolo de nivel de
red usado. Hay un protocolo de control de red (NCP, Network Control Protocol) para cada clasede nivel de red apoyada.
• Un marco de PPP:
• El campo de dirección es normalmente constante.• El campo de control también es normalmente constante y indica un servicio de datagrama (no
confiable y sin acuses de recibo), pero se pueden negociar servicios confiables con marcosenumerados en ambientes ruidosos.
• El campo de protocolo indica el tipo de paquete (por ejemplo, LCP, NCP, IP, AppleTalk, etc.).• El campo de datos tiene una longitud variable hasta algún máximo negociado.

Softdownload
Página 23
• Se establece una conexión de PPP en unos pasos. La línea empieza en el estado DEAD (muerto) conninguna conexión física. Después de que la conexión física exista, el estado es ESTABLISHED(establecido). Ahora se negocian las opciones de LCP, que (si tiene éxito) produce el estadoAUTHENTICATE (autenticar). Si este tiene éxito se entra el estado de NETWORK (red), donde el NCPconfigura el nivel de la red. Este produce el estado de OPEN (abierto), y se pueden intercambiar datos.Después del transporte de datos se entra el estado de TERMINATE (terminar) y desde allí a DEAD denuevo.
El nivel de enlace de ATM
• Este nivel se llama el subnivel de TC (transmission convergence, o convergencia de transmisión).• Este nivel recibe celdas del nivel arriba (que se llama el nivel de ATM). Ellos tienen un encabezamiento de
4 bytes seguido por un checksum de 1 byte. Este checksum de CRC es solamente para el encabezamiento,no para los datos. ¿Por qué?
• Se quiero reducir la probabilidad que una celda es entregada al destino equivocado.• Se quiero evitar el costo de hacer un checksum para los datos. En algunas aplicaciones (por
ejemplo, transmisión de video) errores en los datos no son tan importantes. Si se necesita másconfianza en los datos, los niveles más altos tienen que proveerla.
• ATM es dirigido a la fibra, que tiene pocos errores.• Si el medio físico es síncrono, el subnivel de TC controla la inyección de las celdas en él. También genera
cualquiera información de marco necesitada por el medio; esto es necesario con SONET, por ejemplo.• La tarea más difícil del subnivel de TC del recibidor es identificar los límites de las celdas que llegan. No
hay ningún byte de flag. A veces el nivel físico ayuda (por ejemplo, en SONET) pero no siempre. Lasolución:
• Se usan el encabezamiento y su checksum. El subnivel de TC mantiene un registro dedesplazamiento de 40 bits. Desplaza un bit a la vez hasta que tiene un checksum válido para elencabezamiento.
• Ya que la probabilidad de encontrar un checksum válido en una secuencia aleatoria de bits essolamente 1/256, se repite la prueba con n celdas siguientes antes de decidir que se hayanencontrado la sincronización.
• Para identificar la pérdida de la sincronización, el subnivel de TC espera hasta que m celdas tienenchecksums malos.
• Para prevenir que un usuario inserte una secuencia de bits que parecen como encabezamientos ychecksum, se arreglan de otro modo los bits de dato para la transmisión.
• Nota que el subnivel de TC usa un encabezamiento creado por el nivel arriba para encontrar los marcos.Esto es una violación de las reglas de buen diseño de protocolos.

Softdownload
Página 24
Redes de broadcast• En una red de broadcast la cuestión principal es como determinar quien usa un canal para el cual existe
competencia. Los protocolos para esto pertenecen a un subnivel del nivel de enlace que se llama el subnivelde MAC (Medium Access Control, o control de acceso al medio). Es muy importante en las LANs, quenormalmente usan canales de broadcast.
• Se puede asignar un solo canal de broadcast usando un esquema estático o dinámico.• Asignación estática. Se usa algún tipo de multiplexación (MDF o MDT) para dividir el ancho de banda en
N porciones, de que cada usuario tiene uno. Problemas:• Si menos de N usuarios quieren usar el canal, se pierde ancho de banda.• Si más de N usuarios quieren usar el canal, se niega servicio a algunos, aun cuando hay usuarios
que no usan sus anchos de banda alocados.• Porque el tráfico en sistemas computaciones ocurre en ráfagas, muchos de los subcanales van a
estar desocupados por mucho del tiempo.• Asignación dinámica. Usa el ancho de banda mejor. Hay muchos protocolos basados en cinco
suposiciones principales:• Modelo de estación. Hay N estaciones independientes que generan marcos para la transmisión. La
probabilidad de generar un marco en el período delta t es lambda delta t, donde lambda es unconstante. Después de generar un marco una estación hace nada hasta que se transmita el marcocon éxito.
• Canal único. Hay un solo canal disponible para la comunicación. Todos pueden transmitirusándolo y pueden recibir de él.
• Choques. Si se transmiten dos marcos simultáneamente, se chocan y se pierden ambos. Todas lasestaciones pueden detectar los choques.
• Tiempo continuo o dividido. En el primer caso se puede empezar con la transmisión de un marcoen cualquier instante. En el segundo se parte el tiempo con un reloj de maestro que lastransmisiones empiezan siempre al inicio de una división.
• Detección del portador o no. Las estaciones pueden detectar que el canal está en uso antes detratar de usarlo, o no. En el primer caso ninguna estación trataré transmitir sobre una línea ocupadahasta que sea desocupada. El el último las estaciones transmiten y solamente luego puedendetectar si hubo un choque.
ALOHA
• Desarrollado en los años 70 en Hawaii, ALOHA es un sistema de broadcast que usa el radio. Hay dosversiones, ALOHA puro y ALOHA dividido, que son distintos en el tratamiento del tiempo.
• ALOHA puro. Los usuarios pueden transmitir marcos en cualquier instante. Habrá choques, y los marcosque chocan se destruirán. Empero, un mandador siempre puede detectar un choque escuchando al canal.
• Con una LAN el feedback es instantáneamente, pero con un satélite hay un retraso de 270 msegs.• Si hubo un choque el mandador espera un período aleatorio y manda el marco de nuevo. ¿Por qué
aleatorio? Porque si no, los mismos marcos chocarán repetidamente.• Este tipo de sistema donde usuarios múltiples comparten un canal en una manera que puede
producir conflictos se llama un sistema de contienda.• En ALOHA puro un traslapo de solamente un bit entre dos marcos es suficiente para destruir ambos. Dado
que los usuarios pueden transmitir en cualquier instante, una pregunta interesante es cuál es la utilizaciónmáxima del canal.

Softdownload
Página 25
• Asume que hay un número infinito de usuarios que pueden transmitir marcos. Todos los marcostienen el mismo tamaño, y el tiempo para transmitir un marco es t.
• Asume que en un período t el número de intentos de transmisión tiene una distribución Poissoncon una media G. Nota que las transmisiones pueden ser tanto marcos nuevos comoretransmisiones de marcos que chocaron.
• Si la probabilidad que un marco no choque en un período t es P0, la utilización es S = GP0.Podemos ver S como el número de marcos nuevos que los usuarios pueden producir por t para unestado en equilibrio.
• Si queremos transmitir con éxito un marco en tiempo t0+t, necesitamos que no se inicie latransmisión de otro marco entre t0 y t0 + 2t (de otra manera habría un traslapo). Ve el dibujo.
• La probabilidad que se genera 0 marcos en un período t es dada por la distribución Poisson comoe-G. En un período de 2t es e-Ge-G = e-2G. Esto es P0. Por lo tanto, S = Ge -2G.
• La utilización máxima ocurre con G = 0,5, con S = 1/2e, o 0,184. Es decir, la utilización máximadel canal es solamente 18% cuando todos pueden transmitir en cualquier instante.
• ALOHA dividido. Este sistema dobla la capacidad de ALOHA puro. Se divide el tiempo en intervalosdiscretos; cada intervalo corresponde a un marco. Los usuarios están de acuerdo en los límites de losintervalos (por ejemplo, tienen un reloj de maestro). Se pueden transmitir los marcos solamente a losinicios de los intervalos.
• Para evaluar la utilización de este método, podemos usar el mismo análisis como con ALOHApuro.
• Ahora para evitar un traslapo solamente necesitamos que no se inicie la transmisión de otro marcoen el intervalo de t0+t (es decir, en el mismo intervalo en que transmitimos el marco de interés).
• Por lo tanto la probabilidad que se genera ningún marco en el período vulnerable es e-G. EntoncesS = Ge-G. Si G=1, S=0,368. Entonces 37% de los intervalos están vacíos, 37% tienen un marco, y27% son choques.
• Con G mayor tenemos menos intervalos vacíos pero el número de choques crece de maneraexponencial.
Protocolos de acceso múltiple con sentido de portador
• La mejor utilización con ALOHA fue solamente 1/e. Esto quizás no sea sorpresa, cuando consideramos quenadie presta atención a las acciones de otros. En las redes de área local las estaciones pueden detectar quepasa en la media y adaptar su comportamiento de acuerdo con esto. Los protocolos de este tipo se llamanprotocolos con sentido de portador.
• CSMA de persistencia 1. CSMA es Carrier Sense Multiple Access, o acceso múltiple con sentido deportador. Cuando una estación tiene datos para mandar, primer examina si alguien está usando el canal.Espera hasta que el canal esté desocupado y entonces transmite un marco. Si hay un choque, espera unperíodo aleatorio y trata otra vez.
• Persistencia 1 significa que la estación transmite con una probabilidad de 1 cuando encuentra elcanal desocupado.
• El retraso de propagación tiene gran afecto al rendimiento del protocolo. Hay una probabilidadque poco después una estación manda un marco otra estación también trata de mandar un marco.Si la señal de la primera no ha llegado a la segunda, la segunda detectará un canal desocupado,mandará su marco, y producirá un choque. Cuanto más grande el retraso, tanto peor el rendimientodel protocolo.

Softdownload
Página 26
• Aunque todavía hay la probabilidad de choques, este protocolo es mejor que ALOHA porque lasestaciones no transmiten en la mitad de otra transmisión.
• CSMA sin persistencia. Es menos ávido que el protocolo anterior. Antes de mandar prueba el canal ymanda si nadie lo está usando. Si el canal está ocupado, no lo prueba constantemente hasta que estédesocupado, sino espera un período aleatorio y repite el algoritmo. La utilización es mejor pero los retrasospara mandar los marcos son más largos.
• CSMA de persistencia p. Es para los canales con tiempo dividido. Si el canal está desocupado, transmitecon una probabilidad de p. Con una probabilidad de 1-p espera hasta el próximo intervalo y repite elproceso. Se repite el proceso hasta que se mande el marco o haya un choque, en cual caso espera unperíodo aleatorio y empieza de nuevo. Si el canal originalmente está ocupado el protocolo espera hasta elpróximo intervalo y entonces usa el algoritmo.
Protocolos de CSMA con la detección de choques
• Los protocolos de CSMA son un mejoramiento sobre ALOHA porque aseguran que ninguna estacióntransmite cuando detecta que el canal está ocupado. Un segundo mejoramiento es que las estacionesterminan sus transmisiones tan pronto como detectan un choque. Esto ahorra tiempo y ancho de banda. Losprotocolos de esta clase se llaman CSMA/CD (Carrier Sense Multiple Access with Collision Detection, oCSMA con la detección de choques).
• Después de detectar un choque, una estación termina su transmisión, espera un período aleatorio, y trata denuevo.
• Los choques ocurren en el período de contienda. La duración de este período determina el retraso y lautilización del canal. Para asegurar que tiene control del canal, ¿cuánto tiempo debe esperar una estación?Supongamos que el tiempo para una señal propagar entre las dos estaciones más separadas es t.
• Esperar solamente t no es suficiente. ¿Por qué?• Supon que una estación transmite un bit al tiempo t0. Poco antes t0+t, otra estación, que no ha
recibido el bit transmitido, manda su bit propio. Inmediatamente detecta que hay un choque, perola primera estación no detectará el choque hasta t0+2t.
• En un cable coaxial de 1 km, t = 5 microsegundos.
Protocolos libre de choques

Softdownload
Página 27
• Los períodos de contienda son un problema mayor cuando los cables son largos (retraso de propagación esmayor) y los marcos son cortos (el overhead del los periodos de contienda juega un papel mayor). Esto esel caso en las redes de fibra óptica.
• Podemos eliminar completamente la posibilidad de choques en el período de contienda. En estos protocolosasumimos que las N estaciones tienen direcciones únicas de 0 a N-1.
• Protocolo de bit-map. El período de contienda consiste en N intervalos. Si la estación 0 tiene un marcopara mandar, transmite un bit de 1 en el intervalo 0. Ninguna otra estación puede transmitir en esteintervalo. En general, la estación j transmite un bit de 1 en el intervalo j si tiene un marco para mandar.Después de los N intervalos del período de contienda, todas las estaciones saben cuales quieren transmitirmarcos. En este punto transmiten en orden.
• Porque todas están de acuerdo en el orden de transmisiones, nunca habrá choques.• Después de la última transmisión de un marco, un nuevo período de contienda empieza.• El overhead es solamente un bit por marco.
• Protocolo de cuenta atrás binaria. Reduce el overhead usando direcciones binarias para las estaciones. Elperíodo de contienda ahora tiene solamente log2N intervalos, que es la longitud de la dirección de cadaestación (por ejemplo, direcciones son 0000, 0001, etc.). Cada estación que quiere mandar un marcotransmite el bit más alta de su dirección en intervalo 0, el próximo en intervalo 1, etc. Se hacen un OR delos bits en el canal. Cuando una estación ve un 1 en un intervalo en que el bit que transmitió fue 0,abandona el intento de transmitir en este turno. Finalmente solamente la estación con la dirección más altatransmite su marco después del período de contienda.
• Si en el formato de los marcos la dirección del mandador es el primer campo, ¡este protocolo tieneningún overhead!
• Para mantener la justicia del algoritmo se cambia la asignación de las direcciones. Después detransmitir se asigna una estación la dirección 0 y aumentan las otras.
IEEE 802.3 y Ethernet
• IEEE 802.3 es un protocolo de CSMA/CD con persistencia de 1 para las LANs.• Cuando una estación quiere transmitir, escucha al cable.• Si el cable está ocupado, la estación espera hasta que esté desocupado; de otra manera transmite
inmediatamente.• Si hay un choque, las estaciones involucradas esperan por períodos aleatorios.
• Historia:• Después de ALOHA y el desarrollo del sentido de portador, Xerox PARC construyó un sistema de
CSMA/CD de 2,94 Mbps para conectar más de 100 estaciones de trabajo en un cable de 1 km. Sellamaba Ethernet (red de éter).
• Xerox, DEC, y Intel crearon un estándar para un Ethernet de 10 Mbps. Esto fue el baso para 802.3,que describe una familia de protocolos de velocidades de 1 a 10 Mbps sobre algunos medios.
• Cables:• 10Base5 (Ethernet gruesa). Usa un cable coaxial grueso y tiene una velocidad de 10 Mbps. Los
segmentos pueden ser hasta 500 m en longitud con hasta 100 nodos. Se hacen las conexionesusando derivaciones de vampiro: se inserta un polo hasta la mitad del cable. La derivación esdentro un transceiver, que contiene la electrónica para la detección de portadores y choques. Entreel transceiver y el computador es un cable de hasta 50 m. A veces se pueden conectar más de uncomputador a un solo transceiver. En el computador hay un controlador que crea marcos, hacechecksums, etc.
• 10Base2 (Ethernet delgada). Usa un cable coaxial delgado y dobla más fácilmente. Se hacen lasconexiones usando conectores de T, que son más fáciles para instalar y más confiables. Ethernet

Softdownload
Página 28
delgada es más barata y más fácil instalar pero los segmento pueden ser solamente 200 m con 30nodos. En 10Base2 el transceiver está en el computador con el controlador.
• La detección de derivaciones malas, rupturas, y conectores flojos es un gran problema con ambas.Un método que se usa es la medición de la propagación y la reflexión de un pulso en el cable.
• 10Base-T. Simplifica la ubicación de rupturas. Cada estación tiene una conexión con un hub(centro). Los cables normalmente son los pares trenzados. La desventaja es que los cables tienenun límite de solamente 100 m, y también el costo de un hub puede ser alto.
• 10Base-F. Usa la fibra óptica. Es cara pero buena para las conexiones entre edificios (lossegmentos pueden tener una longitud hasta 2000 m).
• Para eliminar el problema con las longitudes máximas de los segmentos, se pueden instalarrepetidores que reciben, amplifican, y retransmiten las señales en ambas direcciones. La únicarestricción es que la distancia entre cualquier par de transceivers no puede ser más de 2,5 km y nopuede haber más de cuarto repetidores entre transceivers.
• Codificación de Manchester. En 802.3 no hay ningún reloj de maestro. Este produce un problema en ladetección de bits distintos (por ejemplo, ¿cómo se detectan dos bits de 0 en vez de tres?). En la codificaciónde Manchester se usan dos señales para cada bit. Se transmite un bit de 1 estableciendo un voltaje alto en elprimer intervalo y un voltaje bajo en el segundo (un bit de 0 es el inverso). Porque cada bit contiene unatransición de voltajes la sincronización es sencilla.
• Marcos:
• El preámbulo es 7 bytes de bits que se alternan. La codificación de Manchester de esto produceuna onda que el recibidor puede usar para sincronizar su reloj con el mandador. Después está elinicio del marco.
• La dirección de destino puede tener un bit alto de 1, que indica la dirección de un grupo. Todas lasestaciones reciben los marcos que tienen este bit encendido, lo que permite el multicast. Unadirección de todos unos es para el broadcast. El próximo bit distingue entre las direcciones localesy las globales, que son únicas en el mundo.
• La longitud no puede ser 0; un marco debe ser por lo menos 64 bytes. Hay dos razones. Simplificala distinción entre marcos válidos y basura producida por choques. Más importante permite que eltiempo para mandar un marco es suficiente para detectar un choque con la estación más lejana.Para una LAN de 10 Mbps con una longitud máxima de 2500 metros y cuatro repetidores, elmarco mínimo debe tomar 51,2 microsegs, que corresponde a 64 bytes. Se rellena si no haysuficientes datos. Nota que con redes más rápidas se necesitan marcos más largo o longitudesmáximas más cortas.
• El checksum es CRC.• Algoritmo de retiro de manera exponencial binaria. Después de un choque se divide el tiempo en
intervalos de 2t, que es 51,2 microsegs. Después del choque i cada estación elige un número aleatorio entre0 y 2i-1 (pero con un máximo de 1023) y espera por un período de este número de intervalos. Después de

Softdownload
Página 29
16 choques el controlador falla. Este algoritmo adapta automáticamente al número de estaciones que estántratando de mandar.
• Con más y más estaciones y tráfico en una LAN de 802.3, se satura la LAN. Una posibilidad para aumentarel rendimiento del sistema sin usar una velocidad más alta es una LAN 802.3 conmutada.
• El conmutador consiste en un backplane en que se insertan 4 a 32 tarjetas que tienen uno a ochopuertas de (por lo general) 10BaseT.
• Cuando un marco llega en la tarjeta, o se reenvía a una estación conectada a la misma tarjeta o sereenvía a otra tarjeta.
• En un diseño cada tarjeta forma su propio dominio de choques. Es decir, cada tarjeta es un LAN, ytodas las tarjetas pueden transmitir paralelamente.
• Otro diseño es que cada puerta forma su propio dominio de choques. La tarjeta guarda los marcosque llegan en RAM y los choques son raros. Este método puede aumentar el rendimiento de la redun orden de magnitud.
• Se pueden conectar un hub a una puerta también.• Además de 802.3, existen 802.4 (bus de token) y 802.5 (anillo de token). La idea es que las estaciones
alternan en el uso del medio (intercambiando un token, que representa el turno). La ventaja es que el tiempomáximo de espera para mandar un marco tiene un límite. En el bus de token se usa un medio de broadcast,mientras que en el anillo de token se usan enlaces de punto-a-punto entre las estaciones.
Bridges
• Los bridges (puentes) son dispositivos que conectan las LANs. Razones para tener LANs múltiples:• Dueños autónomos (por ejemplos, departamentos distintos en una empresa)• Distancia entre grupos• Carga• Distancia entre computadores que debieran estar en la misma LAN• Confiabilidad: por contraste con un repetidor, un bridge puede rechazar basura de un nodo
defectivo• Seguridad (restringir la propagación de marcos confidenciales)
• Se necesitan bridges distintos para conectar cada combinación de 802.x y 802.y. Los protocolos tienenformatos de marco distintos, velocidades distintas, y longitudes máximas de marco distintas.
• Bridge transparente. Este tipo de bridge no requiere ningún cambia a hardware o software. Hay queconectarlo y no más.
• El bridge opera en un modo donde acepta todos los paquetes de la LAN (modo promiscuo). Concada marco el bridge tiene que decidir si reenviarlo o descartarlo. Busca la dirección del destino enuna tabla de hash dentro del bridge para determinar la línea de salida.
• Al principio las tablas de todos los bridges son vacías. Porque no saben dónde están los destinos,los bridges reenvían marcos a todas las LANs.
• Para llenar las tablas se usan un algoritmo de aprender atrás. Porque los bridges aceptan todos losmarcos transmitidos en sus LANs, pueden notar las direcciones de fuente en los marcos. Con estaspueden guardar las LANs de las cuales los marcos originan. Entonces un bridge puede determinara través de qué LAN se puede alcanzar una estación.
• Porque la topología de las LANs puede cambiar, se expiran las entradas en las tablas después dealgunos minutos. Si una máquina no transmite nada por algunos minutos, para mandar un paquetea él se deben inundar la red.
• Para aumentar la confiabilidad del sistema a veces se usan más de un bridge para conectar dosLANs, que puede producir problemas con la inundación de marcos (ciclos son posibles).
• La solución de este problema es que los bridges se comunican para construir un árbol. Los bridgeshacen broadcasts de sus números de serie para elegir la raíz, y entonces pueden construir el árbol.

Softdownload
Página 30
• Bridge de ruteo de fuente. La desventaja con los bridges transparentes es que malgastan ancho de banda(usan solamente un subconjunto de la topología, el árbol). Con el ruteo de fuente, cada fuente sabe elcamino óptimo a cada destino posible.
• Para encontrar las rutas las estaciones mandan un marco descubridor que es reenviado por cadabridge. Las respuestas incluyen el camino tomado por el marco.
• Un problema es que este método puede producir una explosión en el número de marcosdescubridores.
LANs de velocidad alta
• FDDI (Fiber Distributed Data Interface). Es una LAN de anillo de token que corre con una velocidad de100 Mbps sobre distancias hasta 200 km con hasta 1000 estaciones conectadas. Se lo puede usar como unLAN normal pero el uso más común es para conectar LANs de cobre.
• Consiste en dos anillos que transmiten en sentidos contrarios. Si hay una ruptura (por ejemplo,debido a un fuego) se pueden conectar los dos anillos en uno.
• En vez de la codificación de Manchester usa un esquema que se llama 4 de 5: se usan cinco bitspara codificar cada cuatro. Dieciséis combinaciones son datos y otras son para control. Parasincronizar se usa un preámbulo largo y se requiere que los relojes son estables dentro de 0,005%.
• Debido a la longitud potencial del anillo una estación puede generar un nuevo marcoinmediatamente después de transmitir un marco, en vez de esperar su vuelta (como en 802.5).Pueden estar algunos marcos en el anillo a la vez.
• FDDI también tiene un modo síncrono donde cada marco contiene cuatro canales de T1; puedehaber hasta 16 marcos síncronos cada 125 microsegundos.
• Fast Ethernet (Ethernet rápida ). Ya que FDDI no tenía éxito en el mercado de LANs (sino en el mercadode backbones), se desarrolló 802.3u, o Fast Ethernet. La idea es preservar los formatos de paquetes, lasinterfaces, etc., pero reducir el tiempo por bit de 100 nsegs a 10 nsegs (es decir, 100 Mbps).
• Se usan solamente los cables de 10Base-T porque tienen muchas ventajas. El problema es que elpar trenzado de clase 3 (el más común) no puede portar señales de 200 megabaud (100 Mbps conla codificación de Manchester) sobre 100 metros.
• La solución para clase 3 es usar cuatro pares trenzados que tienen una señalización de 25 MHz,solamente 25% más rápida que con 802.3. De los cuatro, uno es siempre al hub, uno es siembredesde el hub, y los dos otros son conmutables. Se eliminan la codificación de Manchester (no esnecesario en este caso con los relojes de hoy y distancias menos de 100 metros) y se usa laseñalización ternaria. Entonces con tres pares se pueden transmitir 27 símbolos, o 4 bits a la vez.
• Con la clase 5 el sistema es más sencillo porque el cable puede manejar 100 Mbps. Es full dúplexy compatible con FDDI. Hay también un estándar para fibra óptica que permite distancias hasta 2km entre la estación y el hub.
• Los hubs normalmente apoyan ambos 10 Mbps y 100 Mbps, que permite las instalacionesmezcladas.
• HPPI (High-Performance Parallel Interface). Fue desarrollado por Los Alamos para conectar lossupercomputadores. Principios de diseño: chips estándares, ninguna opción, y rendimiento.
• Tiene velocidades de 800 Mbps y 1600 Mbps. El primer es suficiente para 30 marcos por segundode 1024×1024 pixels de 24 bits cada uno. Usa un conmutador de crossbar.
• El cable contiene 50 pares trenzados (32 de datos, otros de control), es simplex, y tiene unalongitud máxima de 25 metros. Se transfiere una palabra cada 40 nsegs. Se usan dos cables para lavelocidad más alta.
• Los marcos tienen 256 palabras. Se limita la detección de errores a un bit de paridad por palabra yuna palabra de paridad por marco; otros checksums eran demasiado lentos.

Softdownload
Página 31
• Fibre channel. La idea fue reemplazar los pares trenzados de HPPI con una sola fibra. Por desgracia esmucho más complicado, y por lo tanto más caro y difícil de implementar. Apoya velocidades de 100, 200,400, y 800 Mbps.

Softdownload
Página 32
El nivel de red• Rutea los paquetes de la fuente al destino final a través de ruteadores intermedios. Tiene que saber la
topología de la subred, evitar la congestión, y manejar los casos cuando la fuente y el destino están en redesdistintas.
• El nivel de red normalmente es la interfaz entre el portador y el cliente. Sus servicios son los servicios de lasubred. Fines:
• Los servicios debieran ser independientes de la tecnología de la subred.• Se debiera resguardar el nivel de transporte de las características de las subredes.• Las direcciones de red disponibles al nivel de transporte debieran usar un sistema uniforme.
• La gran decisión en el nivel de red es si el servicio debiera ser orientado a la conexión o sin conexión.• Sin conexión (Internet). La subred no es confiable; porta bits y no más. Los hosts tienen que
manejar el control de errores. El nivel de red ni garantiza el orden de paquetes ni controla su flujo.Los paquetes tienen que llevar sus direcciones completas de destino.
• Orientado a la conexión (sistema telefónico). Los pares en el nivel de red establecen conexionescon características tal como la calidad, el costo, y el ancho de banda. Se entregan los paquetes enorden y sin errores, la comunicación es dúplex, y el control de flujo es automático.
• El punto central en este debate es donde ubicar la complejidad. En el servicio orientado a la conexión estáen el nivel de red, pero en el servicio sin conexión está en el nivel de transporte. Se representan los dosenfoques en los ejemplos de la Internet y ATM.
Estructura interna de la subred
• Hay dos posibilidades que son independientes del servicio que se ofrece.• Circuitos virtuales. Dentro de la subred normalmente se llama una conexión un circuito virtual. En un
circuito virtual uno evita la necesidad de elegir una ruta nueva para cada paquete. Cuando se inicializa laconexión se determina una ruta de la fuente al destino que es usada por todo el tráfico.
• Cada ruteador tiene que guardar adónde debiera reenviar los paquetes para cada uno de loscircuitos que lo pasan. Los paquetes tienen un campo de número de circuito virtual en susencabezamientos, y los ruteadores usan este campo, la línea de entrada, y sus tablas de ruta parareenviar el paquete en la línea de salida propia.
• Se cobra el tiempo que la conexión existe, que corresponde a la reservación de entradas de tabla,ancho de banda, etc.
• Datagramas. Son paquetes que se rutean independientemente.• Los ruteadores tienen solamente las tablas que indican qué línea de salida usar para cada ruteador
de destino posible. (Se usan estos tablas en los circuitos virtuales también, durante la inicializaciónde un circuito.)
• Cada datagrama tiene la dirección completa del destino (estas pueden ser largas).• El establecimiento de las conexiones en el nivel de red o de transporte no requiere ningún trabajo
especial de los ruteadores.• Balanzas:
• Entre el espacio de memoria en los ruteadores y el ancho de banda. Con paquetes cortos lasdirecciones usan un gran porcentaje del ancho de banda; el espacio de memoria quizás esté másbarato.
• Entre el tiempo de inicialización y el tiempo a analizar las direcciones.• Evitación de congestión. Es más fácil con los circuitos virtuales.

Softdownload
Página 33
• Vulnerabilidad. La falla de un ruteador en un circuito virtual destruye el circuito. Los datagramasestán más robustos.
• Cada combinación de servicio y estructura interna es posible y existe. Ejemplos: UDP sobre IP (sinconexión, datagrama), TCP sobre IP (conexión, datagrama), UDP sobre IP sobre ATM (sin conexión,circuito virtual), ATM AAL1 sobre ATM (conexión, circuito virtual).
Algoritmos de ruteo
• El algoritmo de ruteo decide en qué línea de salida se debiera transmitir un paquete que llega. Propiedadesdeseables:
• Correctitud y sencillez.• Robustez. Una red puede tener que operar por años y experimentará fallas de software y hardware.
El algoritmo de ruteo no debe requerer que se reinicializa la red después de fallas parciales.• Estabilidad. Debiera tener un equilibrio.• Justicia y optimalidad. Están frecuentemente contradictorias. Se necesita una balanza entre la
eficiencia global y la justicia al individual. ¿Qué podemos optimizar? El retraso por paquete o lautilización global de la red son posibilidades. Estos también están contradictorios, porque con100% utilización los retrasos aumentan. Una solución intermedia es minimizar el número desaltos.
• Los algoritmos pueden ser adaptativos o no. Los primeros cambian sus decisiones de ruteo para reflejar latopología y el tráfico en la red. Los últimos son estáticos.
• El principio de optimalidad. Si el ruteador J está en el camino óptimo desde ruteador I a ruteador K,entonces la ruta óptima desde J a K está en la misma ruta. El conjunto de rutas óptimas forma el árbol dehundir (sink tree). El fin de los algoritmos de ruteo es descubrir y usar los árboles de hundir de todos losruteadores. Un problema es que la topología cambia.
Algoritmos estáticos
• Camino más corto. Se calculan los caminos más cortos usando alguna métrica. Posibilidades: el númerode saltos, la distancia física, el retraso de transmisión por un paquete de prueba, el ancho de banda, eltráfico promedio, el costo de comunicación, etc.
• Inundación. Se manda cada paquete que llega sobre todas las otras líneas. Puede generar un númeroinfinito de paquetes, así que se necesita un método para restringir la inundación.
• Se puede usar un contador de saltos en cada paquete que se decrementa después de cada salto.Cuando el contador es cero se descarta el paquete.
• Se pueden guardar números de secuencia agregados por cada ruteador a los paquetes. Losruteadores mantienen listas de los números de secuencia más altos vistos y descartan los paquetesque son duplicados.
• En la inundación selectiva se mandan los paquetes solamente sobre las líneas que salen más omenos en la dirección correcta.
• Ruteo basado en el flujo. Usa la topología y la carga para determinar las rutas óptimas. Si el tráfico entrenodos es conocido, se lo puede analizar usando la teoría de colas. Probando conjuntos distintos de rutas sepuede minimizar el retraso promedio de la red.
• En general las redes modernas usan los algoritmos dinámicos en vez de los estáticos.
Ruteo de vector de distancia

Softdownload
Página 34
• Se llaman estos algoritmos también Bellman-Ford y Ford-Fulkerson. Eran los algoritmos originales deruteo de la ARPANET.
• Cada ruteador mantiene una tabla (un vector) que almacena las mejores distancias conocidas a cada destinoy las líneas a usar para cada destino. Se actualizan las tablas intercambiando información con los vecinos.
• La tabla de un ruteador almacena una entrada para cada uno de los ruteadores en la subred (los ruteadoresson los índices). Las entradas almacenan la línea preferida de salida y una estimación del tiempo o ladistancia al destino. Se pueden usar métricas distintas (saltos, retrasos, etc.).
• Cada ruteador tiene que medir las distancias a sus vecinos. Por ejemplo, si la métrica es el retraso, elruteador la puede medir usando paquetes de eco.
• Cada T msegs los ruteadores intercambian sus tablas con sus vecinos. Un ruteador usa las tablas de susvecinos y sus mediciones de las distancias a sus vecinos para calcular una nueva tabla.
• El ruteo de vector de distancia sufre el problema que incorpora buenas noticias rápidamente pero malasnoticias muy lentamente. Por ejemplo, en la parte (a) del dibujo siguiente el ruteador A acaba de subir. Enesta red lineal la distancia nueva a A (en saltos) se propaga un salto por intercambio. Por contraste, en laparte (b) A acaba de bajar. Aunque B ahora no tiene una ruta a A, cree que hay una ruta a través de C, quecree que hay una ruta a través de B. Los ruteadores no pueden detectar el ciclo, y el número de saltos a Acrece por solamente uno en cada turno. Este problema se llama contar a infinito, y hay que establecer un
valor de infinito suficiente pequeño para detectarlo. Por ejemplo, el valor puede ser la longitud del caminomás largo más uno.
• Hay muchas soluciones a este problema, pero ninguna lo soluciona completamente. Una usadafrecuentemente es la del horizonte partido. En esta variación del algoritmo la única diferencia es quesiempre se reporta una distancia infinita a ruteador X sobre la línea que se usa para rutear a X.
• En nuestro ejemplo esta modificación permite que las malas noticias se propagan un salto porintercambio.

Softdownload
Página 35
• Por desgracia no funciona siempre. En el dibujo siguiente, A y B cuentan a infinito cuando D baja.
Ruteo de estado de enlace
• En 1979 se reemplazó el uso del ruteo de vector de distancia en la ARPANET. Tenía dos problemasprincipales:
• La métrica era la longitud de las colas y no consideraba los anchos de banda de las líneas(originalmente todos eran 56 kpbs).
• El tiempo para converger era demasiado grande.• El nuevo algoritmo que se usa es el ruteo de estado de enlace. Tiene cinco partes. Cada ruteador tiene que
• Descubrir sus vecinos y sus direcciones.• Medir el retraso o costo a cada vecino.• Construir un paquete con la información que ha averiguado.• Mandar este paquete a todo los ruteadores.• Calcular la ruta mínima a cada ruteador.
• Descubrir los vecinos. Cuando se bootea un ruteador, manda paquetes especiales de saludos sobre cadalínea punto-a-punto suya. Los vecinos contestan con sus direcciones únicas. Si más de dos ruteadores estánconectados por la LAN, se modela la LAN como un nodo artificial.
• Medir el costo. El ruteador manda paquetes de eco que los recipientes tienen que contestarinmediatamente. Se divide el tiempo por el viaje de ida y vuelta para determinar el retraso.
• Un punto interesante es si debiera incluir en el retraso la carga de la línea. Esto corresponde ainiciar el reloj del viaje cuando se pone el paquete en la cola o cuando el paquete alcanza la cabezade la cola.
• Si incluimos la carga, se usan las líneas menos cargadas, que mejora el rendimiento.• Empero, en este caso es posible tener oscilaciones grandes en el uso de las líneas.
• Construir el paquete. El paquete consiste en la identidad del mandador, un número de secuencia, la edad,y la lista de vecinos y retrasos. Se pueden construir los paquetes periódicamente o solamente después deeventos especiales.
• Distribuir los paquetes de estado de enlace. Esto es la parte más difícil del algoritmo, porque las rutas enlos ruteadores no cambian juntas. La idea fundamental es usar la inundación.
• Para restringir la inundación se usan los números de secuencia que se incrementan cada vez sereenvía un paquete. Los ruteadores mantienen pares del ruteador de fuente y el número desecuencia que han visto, y descartan los paquetes viejos. Los paquetes nuevos se reenvían sobretodas las líneas salvo la de llegada.
• Para evitar que el número de secuencia se desborda, se usan 32 bits.• Para evitar que los paquetes pueden vivir por siempre, contienen un campo de edad que se
decrementa.

Softdownload
Página 36
• Si un ruteador cae o un número de secuencia se convierte malo, se perderán paquetes. Por lo tantose incluye un campo de edad en cada entrada en la lista. Se decrementa este campo cada segundo yse descarta la información que tiene una edad de cero.
• Calcular las rutas. Se usa el algoritmo de Dijkstra. Un problema es que, debido a errores en losruteadores, puede haber problemas en las rutas.
Ruteo jerárquico
• Las tablas de ruta crecen con la red. Después de algún punto no es práctico mantener toda la informaciónsobre la red en cada ruteador.
• En el ruteo jerárquico se divide la red en regiones. Los ruteadores solamente saben la estructura interna desus regiones.
• Para una subred de N ruteadores el número óptimo de niveles es lnN.
Ruteo de broadcast• Para el broadcast de información hay algunas posibilidades.• La más sencilla es mandar un paquete distinto a cada destino, pero esta malgasta ancho de banda.• Otra posibilidad es la inundación pero genera demasiado paquetes y consume demasiado ancho de banda.• En el ruteo de destinos múltiples, cada paquete almacena la lista de destinos. El ruteador divide el paquete
en nuevos para cada línea de salida. Cada paquete tiene una nueva lista de destinos. Se divide la listaoriginal sobre las líneas de salida.
• Se puede usar el árbol de hundir o cualquier árbol de cobertura para la red, pero esto requiere quelos ruteadores saben el árbol (que no es el caso en el ruteo de vector de distancia).
• En el algoritmo que reenvía usando el camino inverso (reverse path forwarding), se aproxima elcomportamiento del uso de un árbol de cobertura. Cuando un paquete llega, se lo reenvía solamente si llegósobre la línea que se usa para mandar paquetes a su fuente. Es decir, si el paquete llegó sobre esta línea, esprobable que tome la ruta mejor a esta ruteador. Si no, es probable que sea un duplicado.
Algoritmos de control de congestión
• Cuando hay demasiado paquetes en alguna parte de la subred, el rendimiento baja. Esta situación se llamala congestión.
• Razones para la congestión:• Contienda para las líneas.• Memoria insuficiente en los ruteadores. Más memoria puede ayudar hasta un punto, pero aun
cuando los ruteadores tienen memoria infinita, la congestión empeora, ya que los paquetes expiranantes de llegar a la cabeza de la cola.
• Procesadores lentos. Si las CPUs no son suficiente rápidas, las colas pueden aumentar aun cuandohay capacidad en las líneas.
La congestión propaga hacía arriba porque los mandadores tienen que guardar mensajes que no puedenentregar a un ruteador sobrecargado.
• El control de la congestión no es el mismo que el control de flujo. En el último el problema es evitar que elmandador manda más datos que el recibidor puede procesar, mientras que en el control de congestión elproblema es evitar sobrecargar la capacidad de la red.
• Se dividen las soluciones al problema de control de congestión en dos clases:

Softdownload
Página 37
• Loop abierto. Estas intentan evitar el incidente de congestión. Usan algoritmos para decidircuándo aceptar más tráfico, cuándo descartar paquetes, etc. Los algoritmos no utilizan el estadoactual de la red.
• Loop cerrado. Estas monitorean el sistema para la congestión y su ubicación, pasan estainformación a los lugares donde se la pueden utilizar, y ajustan la operación del sistema paracorregir el problema.
Formación del tráfico
• Una razón principal de la congestión es que el tráfico viene frecuentemente en ráfagas. Un método de loopabierto para manejar la congestión es forzar que el tráfico es más predecible. Se lo llama la formación deltráfico.
• La idea en la formación del tráfico es controlar la velocidad promedia de la transmisión de datos y laincidencia de ráfagas.
• Un cliente puede solicitar servicio para tráfico con algún patrón. Entonces el portador tiene que vigilar queel tráfico del cliente tiene este patrón (la vigilancia del tráfico). Esto es más sencillo con los circuitosvirtuales que con los datagramas.
• Algoritmo de cubo agujereado. Cada host es conectado a la red por una interfaz que contiene un cuboagujereado, es decir, una cola interna finita. Si un paquete llega cuando la cola está llena, se lo descarta. Elhost puede poner un paquete en la red en cada intervalo. En esta manera se convierte un flujo ondulado enuno uniforme.
• Con paquetes de tamaños variables se cambia el algoritmo a poner un número fijo de bytes en lared en cada intervalo. Si no quedan suficientes bytes para un paquete, se pierde el residuo y elpaquete tiene que esperar hasta el próximo intervalo.
• Ejemplo: Un computador puede producir 25 MB/seg, que es también la velocidad de la red.Empero los ruteadores solamente pueden manejar esta velocidad por intervalos cortos, y surendimiento mejor es con velocidades de 2 MB/seg. Los datos llegan en ráfagas de 1 MB (40mseg), una cada segundo. Entonces se puede usar un cubo de una capacidad de 1 MB y unavelocidad de salida de 2 MB/seg.
• Algoritmo de cubo de token. El algoritmo de cubo agujereado nunca permite ráfagas en la salida. Paramuchas aplicaciones es deseable que se permitan más variaciones en la velocidad de salida. En el algoritmode cubo de token, el cubo contiene tokens en vez de paquetes.. Se añade un token nuevo cada intervalo alcubo hasta algún máximo. Para transmitir un paquete se necesita sacar un token del cubo.
• No se descartan paquetes cuando el cubo está lleno, sino tokens.• En vez del derecho de mandar un paquete, los tokens pueden significar el derecho de mandar
algún número de bytes.• El algoritmo permite las ráfagas pero hasta alguna longitud limitada S. Si la capacidad del cubo es
C bytes, los tokens llegan con una velocidad de p bytes/seg, y la velocidad de salida máxima es M,tenemos C+pS = MS, o S = C/(M-p ). Si C = 250 KB, M = 25 MB/seg, y p = 2 MB/seg, el tiempode ráfaga máxima es 11 mseg y su tamaño es 272 KB.
• La vigilancia de estos esquemas requiere que la red simula los algoritmos.
Control de congestión en subredes de circuitos virtuales
• Un algoritmo de loop cerrado que se puede usar en las subredes de circuitos virtuales es el control deentrada. Cuando se ha señalizado la congestión, no se establecen más circuitos virtuales.
• Otro enfoque es rutear los circuitos virtuales nuevos alrededor de las áreas con problemas.

Softdownload
Página 38
• También se pueden negociar las características de la conexión durante su establecimiento y reservar elancho de banda necesario. Pero malgasta recursos.
Paquetes de bloqueo
• Cada ruteador puede monitorear las utilizaciones de sus líneas. Puede mantener una variable u para lautilización que se actualiza según
unuevo = auviejo + (1-a)f
donde a es algún constante y f es la utilización del instante.• Cuando u sube sobre algún límite, la línea de salida entra en un estado de aviso. Si la línea de salida de un
paquete nuevo está en un estado de aviso, se manda un paquete de bloqueo a su host de fuente original.Este paquete de bloqueo lleva el destino encontrado en el paquete, que permite que la fuente puedaidentificar el paquete y la ruta que generaron el paquete de bloqueo. Se establece un bit en elencabezamiento del paquete que previene la generación de nuevos paquetes de bloqueo y lo reenvía comonormal.
• Cuando un host recibe el paquete de bloqueo, debe reducir el tráfico al destino especificado por X porciento. Porque ya hay otros paquetes en la ruta que generarán más paquetes de bloqueo, el host los debieraignorar por algún intervalo. Después del intervalo, si hay más paquetes de bloqueo, debe reducir el flujo denuevo.
• Si ningún paquete de bloqueo llega después de algún tiempo, el host puede aumentar el flujo. Normalmentelos decrementos son 0,50, 0,25, etc., de la velocidad original. Los incrementos son más pequeños paraevitar una nueva incidente de congestión.
• Un problema con este algoritmo es que los hosts cambian sus comportamientos voluntariamente. Unavariación entonces es el algoritmo con colas justas. Cada línea de salida en un ruteador tiene un conjuntode colas, una para cada línea de entrada. El ruteador transmite un paquete por cola en turno. Si un hostmanda demasiado paquetes, no afecta a otros.
• Una modificación del algoritmo es tomar en cuenta los tamaños de los paquetes. En esto se elige elpróximo paquete usando un round robin que opera byte-por-byte.
• En el algoritmo con colas justas con pesos, se permiten prioridades distintas para las colas.• Un problema con los paquetes de bloqueo es el tiempo por su propagación. En este tiempo el host puede
mandar muchos paquetes. Una solución es los paquetes de bloque de salto-por-salto. En esta cada ruteadorintermedio tiene que reducir el flujo inmediatamente, que alivia la situación del ruteador más abajo. Esteesquema alivia la congestión antes de que pueda desarrollar, pero al costo de requerir más buffers másarriba en el flujo.
Pérdida de carga
• Cuando todavía hay demasiado paquetes, los ruteadores pueden elegir paquetes a descartar.• En algunas aplicaciones es mejor descartar los paquetes nuevos (por ejemplo, en la transferencia de
archivos). En otras (la multimedia), los nuevos tienen más valor. Se llama la primera política vino y laúltima leche.
• En general se necesita la ayuda de los mandadores. Puede haber dos clases de paquetes con costos distintos(por ejemplo, en ATM esto es el caso).
• Generalmente es mejor que un ruteador empieza con descartar paquetes temprano en vez de tarde.

Softdownload
Página 39
Internets
• La heterogeneidad en las clases de redes no parece que cambie pronto:• La base de redes distintas instaladas está creciendo.• El punto de decisiones de compras de redes se está bajando en las organizaciones.• Las redes distintas tienen tecnología distinta, así que no es una sorpresa que haya software
distinto.• Dispositivos para conectar las redes:
• Repetidores. Amplifican o regeneran las señales para permitir cables más largos.• Bridges. Son dispositivos de guardar-y-reenviar. Operan en el nivel de enlace y pueden cambiar
los campos de los marcos.• Ruteadores de protocolos múltiples. Son como los bridges pero funcionan en el nivel de red.
Pueden conectar redes de protocolos distintos.• Gateways (puertas) de transporte. Conectan las redes a nivel de transporte.• Gateways de aplicación. Conectan dos partes de una aplicación (por ejemplo, correo electrónico)
que usan formatos distintos.• Porque los gateways frecuentemente conectan dos redes que pertenecen a organizaciones distintas, a veces
se divide un gateway en dos partes (gateways medios). Las organizaciones no tienen que estar de acuerdosobre la administración de una máquina ya que cada uno administra su máquina propia. Solamente tienenque estar de acuerdo sobre el protocolo entre los gateways medios.
• Algunas diferencias entre las redes:• Clase de servicio. Orientado a la conexión o sin conexión.• Protocolos. IP, IPX, CLNP, AppleTalk, DECnet, etc.• Direcciones. De un nivel (802) o jerárquicas (IP).• Tamaño de paquete. Cada red tiene su máximo propio.• Control de errores. Entrega confiable y en orden o sin orden.• Control de flujo. Ventana deslizante, control de velocidad, o ningún.• Control de congestión. Cubo agujereado, paquetes de bloqueo, etc.• Seguridad.• Contabilidad. Por tiempo conectado, por paquete, por byte, o ninguna.
• Dos enfoques a la creación de las internets:• Circuitos virtuales concatenados. Se establece una ruta a través de muchos gateways que
convierten los paquetes. No se los pueden implementar si una de las redes es de datagrama.• Internet sin conexión. Los paquetes tienen que encontrar una ruta al destino. Las direcciones
crean problemas. La principal ventaja de las internets basadas en los datagramas es que se laspueden usar sobre redes que no soportan los circuitos virtuales.
• Túneles. Si la fuente y el destino están en la misma clase de red, es sencillo conectarlos a través de algúntipo distinto de red. Se insertan los paquetes de la primera red en paquetes de la red de conexión y seextraen los paquetes de nuevo en la red de destino.
• Fragmentación. Un problema grande en las internets es el tamaño máximo de los paquetes. Si un paquetees demasiado grande para la próxima red que tiene que atravesar, el gateway tiene que partirlo enfragmentos.
• Fragmentación transparente. El gateway parte el paquete. Se mandan todos los fragmentos almismo gateway de salida, donde se los montan de nuevo. El gateway de salida tiene que sabercuando tiene todos los fragmentos. Todos los paquetes tienen que salir a través del mismogateway. Hay que pagar el overhead de partir y montar en cada red de paquetes pequeños.
• Fragmentación no transparente. El host de destino tiene que montar el paquete de nuevo. Haymás overhead porque los fragmentos persisten hasta el fin del viaje. Empero, se pueden usargateways múltiples de salida.
• Una manera para enumerar los fragmentos es que cada encabezamiento tiene el número delpaquete original, el número del primer fragmento elemental en el paquete, y un bit que indica el

Softdownload
Página 40
fragmento final. Los fragmentos consisten en conjuntos de fragmentos elementales que sonsuficientes pequeños para cualquiera red en la internet. Se los dividen cuando sea necesario.
• Firewalls. Con un firewall, todos los paquetes que entran o salen de un dominio son examinados. Consisteen dos filtros de paquete (son ruteadores con alguna funcionalidad extra) y un gateway de aplicación entreellos.
• Se usan dos filtros para asegurar que no hay ningún camino que sale afuera o entra hacia dentrosin pasar el gateway de aplicación.
• Los filtros chequean las puertas de los paquetes de TCP para determinar si dejan pasar un paquete.Porque es difícil determinar los propósitos de los paquetes de UDP, a veces se los prohibencompletamente.
• El gateway de aplicación puede filtrar los paquetes en una manera más sofisticada.
El nivel de red en la Internet
• El protocolo de IP (Internet Protocol) es la base fundamental de la Internet. Porta datagramas de la fuente aldestino. El nivel de transporte parte el flujo de datos en datagramas. Durante su transmisión se puede partirun datagrama en fragmentos que se montan de nuevo en el destino.
• Paquetes de IP:
• Versión. Es 4. Permite las actualizaciones.• IHL. La longitud del encabezamiento en palabras de 32 bits. El valor máximo es 15, o 60 bytes.• Tipo de servicio. Combinaciones varios de la confiabilidad y la velocidad son posibles. No usado.• Longitud total. Hasta un máximo de 65.535 bytes.• Identificación. Para determinar a qué datagrama pertenece un fragmento.• DF (Don't Fragment). El destino no puede montar el datagrama de nuevo.• MF (More Fragments). No establecido en el fragmento último.• Desplazamiento del fragmento. A qué parte del datagrama pertenece este fragmento. El tamaño
del fragmento elemental es 8 bytes.• Tiempo para vivir. Se lo decrementa cada salto.• Protocolo. Protocolo de transporte a que se debiera pasar el datagrama.• Las opciones incluyen el ruteo estricto (se especifica la ruta completa), el ruteo suelto (se
especifican solamente algunos ruteadores en la ruta), y grabación de la ruta.

Softdownload
Página 41
• Las direcciones de IP consisten en 32 bits. Hay 126 redes de 16 millón hosts cada una, 16.382 de 65.536, y2 millón de 254. Los valores de 0 indican esta red y los de -1 la dirección de broadcast. Las direcciones que
empiezan con 127 son para pruebas de loopback.
• Normalmente se dividen una dirección de una clase en subredes. Esto permite que una organización tiene,por ejemplo, una dirección de clase B pero muchas subredes dentro de esto. Se divide la parte de ladirección que es normalmente el host en una dirección de red y una dirección de host.
• Hay una escasez de direcciones. El problema es que la mayoría de las organizaciones eligen direcciones declase B, aunque la mitad de las redes de clase B tienen menos de 50 hosts. Ahora se usa CIDR (ClasslessInterDomain Routing) para asignar las redes de clase C en bloques de tamaños variables. Hay cuatrobloques grandes para Europa, Norteamérica, Sudamérica, y Asia/Pacífico. En cada uno se combinan en losruteadores una dirección y una máscara para determinar a qué organización pertenece una dirección.
Protocolos de control
• La Internet tiene varios protocolos de control al nivel de red.• ICMP (Internet Control Message Protocol). Ejemplos de paquetes: No se puede alcanzar el destino, la
vida de un paquete expiró, valor ilegal en el encabezamiento, paquete de bloqueo (no usado más), paquetede eco o respuesta.
• ARP (Address Resolution Protocol). En una LAN es difícil mantener la correspondencia entre lasdirecciones de IP y las direcciones de LAN (por ejemplo, en una Ethernet hay direcciones de 48 bits). Elprotocolo ARP permite que una máquina haga un broadcast para preguntar qué dirección local pertenece aalguna dirección de IP. En esta manera no se necesita una tabla de configuración, que simplifica laadministración.

Softdownload
Página 42
• RARP (Reverse ARP). Permite que una máquina que acaba de bootear pueda encontrar su dirección de IP.Hay también el protocolo BOOTP, cuyos mensajes son de UDP y se pueden reenviar sobre ruteadores.
IPv6
• Fines:• Soportar miles de millones de hosts, incluso con la asignación ineficiente de direcciones.• Reducir el tamaño de las tablas de ruteo.• Simplificar el protocolo, que permite un procesamiento más rápida.• Proveer más seguridad.• Usar tipos distintos de servicio.• Mejorar el multicasting.• Permitir que un host puede viajar sin cambiar su dirección.• Permitir que el protocolo pueda cambiar en el futuro.• Permitir que los protocolos nuevos y antiguos puedan coexistir.
• Puntos principales del diseño aceptado:• Direcciones de 16 bytes, que implica 7×1023 por metro cuadrado de la tierra.• Un encabezamiento de 7 campos en vez de 13.• Mejor apoyo para las opciones.• Mejor seguridad con la autenticación y la privacidad.• Más tipos de servicio.
• IPv6 no usa la fragmentación. Los ruteadores tienen que manejar paquetes de 576 bytes. Si un paquete esmayor que una red puede manejar, se rechaza el paquete y el host tiene que fragmentarlo.
• Se eliminó el checksum.• Se permiten datagramas de tamaños grandes (jumbograms), que es importante para las aplicaciones de
supercomputador.

Softdownload
Página 43
El nivel de transporte• Utiliza los servicios del nivel de red para proveer un servicio eficiente y confiable a sus clientes, que
normalmente son los procesos en el nivel de aplicación. El hardware y software dentro del nivel detransporte se llaman la entidad de transporte. Puede estar en el kernel, en un proceso de usuario, en unatarjeta, etc.
• Hay los mismos dos tipos de servicio que en el nivel de red: orientado a la conexión o sin conexión. Sonmuy semejantes a los del nivel de red. Las direcciones y el control de flujo son semejantes también.
• Por lo tanto, ¿por qué tenemos un nivel de transporte? ¿Por qué no solamente el nivel de red? La razón esque el nivel de red es una parte de la subred y los usuarios no tienen ningún control sobre ella. El nivel detransporte permite que los usuarios puedan mejorar el servicio del nivel de red (que puede perder paquetes,puede tener ruteadores que bajan a veces, etc.).
• El nivel de transporte permite que tengamos un servicio más confiable que el nivel de red. También, lasprimitivas del nivel de transporte pueden ser independiente de las primitivas del nivel de red. Lasaplicaciones pueden usar estas primitivas y funcionar en cualquier tipo de red.
Primitivas del servicio de transporte
• El servicio de transporte orientado a la conexión es confiable, como los pipes en Unix.• El nivel de transporte puede proveer también un servicio no confiable de datagrama, pero eso no es muy
interesante.• Porque muchos programadores usan las primitivas del servicio de transporte, deben ser convenientes y
fáciles de usar.• Ejemplo: Las entidades de transporte se comunican con TPDUs (Transport Protocol Data Units). Un
conjunto de primitivas:
Primitiva TPDU mandado
LISTEN ninguno
CONNECT CONNECTION REQ
SEND DATA
RECEIVE ninguno
DISCONNECT DISCONNECTION REQ
El cliente hace un CONNECT. Cuando el CONNECTION REQUEST (solicitud de conexión) llega, laentidad de transporte del servidor confirma que el servidor está bloqueado en un LISTEN. Entonces manda
un TPDU de CONNECTION ACCEPTED al cliente. Los partidos pueden comunicarse con SEND yRECEIVE, que son confiables. Para desconectar es posible que solamente un partido tiene que mandar un
DISCONNECT (caso asimétrico) o ambos (caso simétrico).• Primitivas de sockets de Berkeley:
Primitiva Significado
SOCKET Crear nuevo punto de comunicación
BIND Ligar el socket con una dirección local
LISTEN Alocar cola para llamadas
ACCEPT Bloquear hasta que una solicitud llegue
CONNECT Bloquear y establecer la conexión
SEND Mandar datos

Softdownload
Página 44
RECEIVE Recibir datos
CLOSE Cerrar la conexión
BIND permite la asignación de una dirección explicita (por ejemplo, una dirección bien conocida) con unsocket. El servidor llama a las cuatro primeras primitivas en orden. El cliente llama a SOCKET y entonces
CONNECT. La desconexión es simétrico.
Protocolos de transporte
• Los protocolos de transporte se parecen los protocolos de enlace. Ambos manejan el control de errores, elcontrol de flujo, la secuencia de paquetes, etc. Pero hay diferencias:
• En el nivel de transporte, se necesita una manera para especificar la dirección del destino. En elnivel de enlace hay solamente el enlace.
• En el nivel de enlace es fácil establecer la conexión; el host en el otro extremo del enlace estásiempre allí. En el nivel de transporte este proceso es mucho más difícil.
• En el nivel de transporte, se pueden almacenar paquetes dentro de la subred. Los paquetes puedenllegan cuando no son esperados.
• El nivel de transporte requiere otro enfoque para manejar los buffers, ya que hay mucho más queconexiones que en el nivel de enlace.
• Cuando una aplicación quiere establecer una conexión con otra aplicación, necesita dar la dirección. Estadirección es una dirección del nivel de transporte, y se llama un TSAP (Transport Service Access Point).Las direcciones del nivel de red se llaman NSAPs (Network Service Access Points). ¿Cómo sabe unaaplicación la dirección del destino?
• Algunos servicios han existido desde años y tienen direcciones bien conocidos. Para evitar quetodos los servicios tienen que correr todo el tiempo (algunos se usan rara vez), puede ser unservidor de procesos que escucha a muchas direcciones a la vez y crea instancias de servicioscuando sea necesario.
• Para otros servicios se necesitan un servidor de nombres. Esto tiene un TSAP bien conocido ymantiene una lista de nombres (strings) y direcciones. Los servidores tienen que registrarse con elservidor de nombres.
• Dado una dirección TSAP, todavía se necesita una dirección de NSAP. Con una estructura jerárquica paralos TSAPs, la dirección NSAP es una parte de la dirección TSAP. Por ejemplo, en la Internet un TSAP esun par que consiste en la dirección de IP (NSAP) y la puerta.
Establecimiento de una conexión
• El problema principal en el establecimiento de una conexión es que la subred puede perder, almacenar, yduplicar los paquetes. En el caso peor un cliente podría abrir una conexión para una transacción, y despuésla subred podría duplicar todos.
• Para eliminar los paquetes duplicados atrasados, se puede limitar el tiempo de vida máximo de un paqueteen la subred (por ejemplo, usando un contador de saltos). Con un límite de los tiempos de vida de lospaquetes y sus acuses de recibo, podemos usar cualquier protocolo de ventana deslizante para intercambiarpaquetes entre dos hosts y detectar los paquetes duplicados.
• Un problema es que se necesita un método para elegir los números de secuencia que puede tolerar unacaída (es decir, hay que asegurar que dos TPDUs con el mismo número de secuencia pueden existir a lavez). Cada host tiene un reloj; no se necesitan sincronizar los relojes de los hosts distintos. Un reloj es uncontador binario que se incrementa en intervalos uniformes. El número de bits en el contador tiene que serigual a o mayor del número de bits en los números de secuencia. Un reloj continúa corriendo aun cuando suhost se baja.

Softdownload
Página 45
• Un host usa los k bits más bajos del contador como el valor inicial de su número de secuencia. Los númerosde secuencia son suficiente grandes que no pueden repetir dentro de la vida de un paquete.
• Después de una caída, un host no sabe donde está en la secuencia. Puede esperar el tiempo de vida máximode un paquete antes de transmitir otra vez. Porque este tiempo puede ser en general demasiado grande, otrométodo es controlar la taza de TPDUs mandados por tick para garantizar que no se pueden duplicarnúmeros de secuencia. La taza no puede ser demasiado grande (un máximo de uno) ni demasiado pequeña.
• Otro problema es establecer la conexión y intercambiar los valores iniciales de los números de secuencia.Un paquete duplicado atrasado puede causar una falla en este establecimiento. La solución es un three-wayhandshake. Host 1 manda un CONNECT REQUEST con su número de secuencia. Host 2 manda un acusede recibo con el número de 1 y su número propio. Finalmente host 1 manda un acuse de recibo con laelección de host 2.
Desconexión
• La desconexión asimétrica puede perder datos. La desconexión simétrica permite que cada lado puedaliberar una dirección de la conexión a la vez.
• La desconexión simétrica sufre del problema de los dos ejércitos. Hay dos ejércitos pequeños y separadosque quieren atacar un ejército más grande. Si tienen un medio de comunicación mala, ¿cómo puedensincronizar un ataque?
• En general, no es posible tener un protocolo perfecto en este caso. En nuestro caso tenemos hosts quequieren desconectar en vez de atacar, pero el problema es el mismo.
• Se usa el protocolo siguiente: El primer lado manda un DISCONNECT REQUEST (DR) y inicia un reloj.El recipiente entonces manda un DR y inicia un reloj. Cuando lo recibe, el mandador original libera laconexión y manda un ACK. El recipiente lo recibe y libera la conexión también. Si hay un timeout en elrecibidor, libera la conexión. Si hay un timeout en el mandador, manda el DR otra vez (hasta N intentos) yfinalmente libera la conexión. Este protocolo puede fallar si ninguna transmisión del mandador llega.

Softdownload
Página 46
Control de flujo
• Si la subred no es confiable, el mandador tiene que almacenar los TPDUs mandados, como en el nivel deenlace. El recibidor puede decidir cuánto espacio en buffers quiere dedicar a sus conexiones, porque sabe sino acepta un paquete el mandador lo reenviará.
• En el caso de tráfico de bajo ancho de banda y en ráfagas, es mejor que se dedican los buffersdinámicamente. Pero con flujos constantes de alto ancho de banda, es mejor si el recibidor reserva unaventana completa de buffers para permitir la velocidad máxima de datos.
• La asignación dinámica de buffers corresponde al uso de ventanas de tamaños variables. El mandador pidealgún número de buffers, y el recibidor contesta con el número disponible. Durante la conexión el recibidorpuede cambiar este número. Para evitar bloqueos indefinidos debido a acuses de recibo perdidos, los hostsdeben intercambiar a veces paquetes de control con los estados de los buffers.
• El mandador también tiene que controlar el tamaño de la ventana teniendo en cuenta la capacidad de lasubred. Si la subred puede manejar c TPDUs/seg y el tiempo para mandar un paquete y recibir su acuse esr, la ventana debiera tener un tamaño de cr. Con este tamaño la conexión normalmente está llena. Elmandador puede medir y monitorear estos parámetros.
Multiplexación
• A veces el nivel de transporte tiene que multiplexar las conexiones. Por ejemplo, si la subred cobra el usode un circuito virtual por tiempo, puede ser demasiado caro para una organización tener muchos circuitosabiertos a la vez. Por lo tanto se usa la multiplexación hacia arriba, con más de una conexión de transporteen una sola conexión de red.
• Otra razón para usar la multiplexación es si la subred impone un control de ventana deslizante. Si unusuario necesita más capacidad que es disponible con la ventana, se puede dividir la conexión de transporteentre unas conexiones de red. Esto el la multiplexación hacia abajo.
Recuperación de caídas
• Si una parte de la subred se cae durante una conexión, el nivel de transporte puede establecer una conexiónnueva y recuperar de la situación. El problema es más difícil si uno de los dos hosts se cae.
• Por ejemplo, considera un host que está mandando un archivo a otro usando un protocolo de parar-y-esperar. El recibidor se cae y se rebootea rápidamente, pero ha perdido su posición. Le puede informar almandador sobre el problema. El mandador puede estar en dos estados: S1, con un TPDU pendiente sinacuse, o S0, con ningún TPDU pendiente. Tiene que decidir si debiera retransmitir el TPDU más reciente.
• El problema es que el mandador no sabe si el recibidor ha escrito el contenido de la última TPDU. Porejemplo, si el mandador retransmite solamente cuando está en S1, tenemos el siguiente problema: Elrecibidor recibió el paquete, generó un acuse, y se cayó sin escribir. El mandador está en S0 y noretransmitirá el paquete.
• Si usamos una estrategia donde el recibidor escribe antes de generar el acuse, tenemos un problema nuevo.En este caso el recibidor escribe pero se cae antes de generar el acuse. El mandador está en S1 yretransmitirá el paquete, que es un error. Protocolos más complejos no ayudan cuando tenemos eventosdistintos come estos.
• En general se puede recuperar de las caídas solamente si hay suficiente estado preservado.

Softdownload
Página 47
El protocolo de TCP
• El fin de TCP es proveer un flujo de bytes confiable de extremo a extremo sobre una internet no confiable.TCP puede adaptarse dinámicamente a las propiedades de la internet y manejar fallas de muchas clases.
• La entidad de transporte de TCP puede estar en un proceso de usuario o en el kernel. Parte un flujo de bytesen trozos y los mande como datagramas de IP.
• Para obtener servicio de TCP, el mandador y el recibidor tienen que crear los puntos terminales de laconexión (los sockets).
• La dirección de un socket es la dirección de IP del host y un número de 16 bits que es local al host(la puerta).
• Se identifica una conexión con las direcciones de socket de cada extremo; se puede usar un socketpara conexiones múltiples a la vez.
• Los números de puerta bajo 256 son puertas bien conocidas para servicios comunes (como FTP).• Las conexiones de TCP son punto-a-punto y full dúplex. No preservan los límites de mensajes.• Cuando una aplicación manda datos a TCP, TCP puede mandarlos inmediatamente o almacenarlos (para
acumular más). Una aplicación puede solicitar que TCP manda los datos inmediatamente a través del flagde PUSH (empujar).
• TCP también apoya los datos urgentes. TCP manda datos con el flag URGENT inmediatamente. En eldestino TCP interrumpe la aplicación (la manda una señal), que permite que la aplicación pueda encontrarlos datos urgentes.
Implementación del protocolo
• Cada byte en una conexión de TCP tiene su propio número de secuencia de 32 bits.• En TCP se mandan datos en segmentos. Un segmento tiene un encabezamiento de 20 bytes (más opciones)
y datos de cero o más bytes. Hay dos límites en el tamaño de segmentos: el tamaño máximo de un paquetede IP (64K bytes) y la unidad de transferencia máxima (MTU, maximum transfer unit) de cada red.
• Si un segmento es demasiado grande para una red, los ruteadores lo puede dividir en segmentos nuevos(cada segmento nuevo añade un overhead de 40 bytes).
• TCP usa un protocolo de ventana deslizante. Cuando un mandador manda un segmento, inicia un reloj. Eldestino responde con un segmento que contiene un acuse de recibo con un número de acuse igual alpróximo número de secuencia que espera. Si el reloj termina antes de que llegue el acuse, el mandadormanda el segmento de nuevo. Problemas:
• Se puede generar un acuse para un fragmento de un segmento, pero se puede perder el resto.• Los segmentos pueden llegar fuera de orden.• Con fragmentación y retransmisión, es posible que fragmentos de una transmisión y una
retransmisión lleguen a la vez.• La red puede tener congestión.
El encabezamiento de TCP

Softdownload
Página 48
• La puerta de la fuente y del destino identifican la conexión.• El número de secuencia y el número de acuse de recibo son normales. El último especifica el próximo byte
esperado.• La longitud (4 bits) indica el número de palabras de 32 bits en el encabezamiento, ya que el campo de
opciones tiene una longitud variable.• Los flags:
• URG. Indica que el segmento contiene datos urgentes. El puntero urgente punta al desplazamientodel número de secuencia corriente donde están los datos urgentes.
• ACK. Indica que hay un número de acuse en el campo de acuse.• PSH (Push). El recibidor no debiera almacenar los datos antes de entregarlos.• RST (Reset). Hay un problema en la conexión.• SYN. Se usa para establecer las conexiones. Una solicitud de conexión tiene SYN = 1 y ACK = 0,
mientras que la aceptación de una conexión tiene SYN = 1 y ACK = 1.• FIN. Indica que el mandador no tiene más datos a mandar. La desconexión es simétrica.
• TCP usa una ventana de tamaño variable. Este campo indica cuantos bytes se pueden mandar después delbyte de acuse. El valor cero es legal; uno puede dar la permisión transmitir de nuevo con un segmento conel mismo número de acuse y una ventana más de cero.
• El checksum provee más confiabilidad.• Las opciones permiten que los hosts puedan especificar el segmento máximo que están listos para aceptar
(tienen que poder recibir segmentos de 556 bytes), usar una ventana mayor que 64K bytes, y usar repetirselectivamente en vez de repetir n.
Administración de conexiones
• TCP usa el three-way handshake para establecer una conexión. Si un segmento de solicitud de conexiónllega y no hay un proceso esperando, TCP contesta con un paquete con el bit de RST establecido.
• Dos hosts pueden tratar de establecer una conexión entre los mismos sockets simultáneamente. Resulta enuna sola conexión.
• Se usa un reloj para asignar los números iniciales de secuencia. Después de una caída un host tiene queesperar el tiempo de vida máximo de un paquete (120 segs).
• Para desconectar un sentido de la conexión, TCP manda un paquete de FIN y entonces espera un acuse.Para evitar el problema de los dos ejércitos el mandador desconecta después de dos tiempos máximos devida de un paquete.

Softdownload
Página 49
Política de transmisión
• Cuando la ventana tiene un tamaño de cero, el mandador no puede mandar segmentos, con dosexcepciones. Se pueden mandar los datos urgentes y se pueden mandar un segmento de 1 byte para causarque el recibidor genere un acuse nuevo con la ventana. Este último es para evitar el bloqueo indefinido.
• Los mandadores no tienen que mandar datos inmediatamente y los recibidores no tienen que mandar acusesinmediatamente. Se puede usar esta flexibilidad para mejorar el rendimiento.
• Por ejemplo, considera una conexión de TELNET. Cada carácter tipiado genera un paquete de IP de 41bytes, seguido por un acuse de 40 bytes, seguido por una actualización de la ventana de 40 bytes cuando laaplicación lee el carácter, seguido por 41 bytes cuando la aplicación hace un eco del carácter, y finalmente40 y 40 más.
• Una optimización es demorar los acuses y las actualizaciones de ventana por 500 msegs para usarpiggybacking.
• Una segunda optimización para minimizar los segmentos con solamente un byte de información es elalgoritmo de Nagle. En esto se almacena los datos hasta que llegue el último acuse o haya suficiente datospara llenar la mitad de la ventana o un segmento máximo.
• Otro problema es el síndrome tonto de ventana. En esto la ventana del recibidor está llena. La aplicación enel recibidor lee un byte, que causa que el recibidor manda una actualización del tamaño de ventana almandador. El mandador manda un byte y la ventana está llena otra vez. La solución de Clarke es no mandaruna actualización de ventana hasta que el recibidor pueda manejar el segmento máximo de la conexión o elbuffer esté medio vació, cualquier es menor. También el mandador no manda segmentos pequeños (siposible). Debiera esperar hasta que haya suficiente espacio en la ventana para un segmento completo o elbuffer del recibidor esté medio vacío (según su estimación de su tamaño).
Control de congestión
• TCP trata de manejar la congestión usando la conservación del número de paquetes. La idea es no inyectarun paquete nuevo en la red hasta un paquete antiguo es entregado. TCP trata de hacer esto manipulandodinámicamente el tamaño de la ventana.
• El primer paso es detectar la congestión. Antes era difícil ya que el timeout de un paquete perdido podíahaber causado por ruido en la línea o congestión en un ruteador. Ahora la mayoría de los timeouts sondebidos a la congestión.
• Hay dos problemas distintos que tenemos que solucionar: la capacidad de la red y la capacidad delrecipiente. Para manejar cada uno, el mandador mantiene dos ventanas. Una ventana se negocia con elrecipiente, y su tamaño es basado en el tamaño del buffer del recipiente. La otra ventana es la ventana decongestión. El mandador solamente puede mandar el mínimo de las dos ventanas.
• Cuando se establece una conexión, el mandador inicializa la ventana de congestión al tamaño del segmentomáximo de la conexión. Si puede mandar un segmento máximo sin un timeout, se dobla el tamaño de laventana y se mandan dos segmentos máximos. Este aumento continúa hasta que hay un timeout. Se llama lasalida lenta, pero no es lenta, sino exponencial.
• Para controlar la congestión hay un tercer parámetro, el umbral, que al principio tiene un valor de 64K.Cuando hay un timeout, se establece el valor del umbral a la mitad de la ventana corriente de congestión, yse establece la ventana de congestión a un segmento máximo. Otra vez se usa la salida lenta, pero despuésde llegar al umbral la ventana crece solamente por un segmento máximo a la vez (es decir, linealmente)hasta la ventana del recibidor.

Softdownload
Página 50
Administración de relojes
• TCP usa un reloj de retransmisión para determinar si debiera retransmitir un segmento. ¿Por cuánto tiempodebiera durar el intervalo de timeout?
• El problema en establecer un valor para este timeout es que la varianza en tiempos de ida y vuelta es muchomayor que en el nivel de enlace. El promedio y varianza pueden cambiar rápidamente mientras que lacongestión crece y desparece. Si el timeout es demasiado largo el rendimiento sufre, pero si es demasiadocorto hay retransmisiones innecesarias.
• Se usa un algoritmo debido a Jacobson. TCP mantiene un variable RTT para cada conexión con unaestimación del tiempo de ida y vuelta. Si el próximo segmento toma M segundos, se actualiza RTT segúnRTT = alpha RTT + (1-alpha)M. Un valor típico para alpha es 7/8.
• Dado RTT hay que elegir todavía un timeout de retransmisión. TCP normalmente usa beta RTT, donde betadebiera ser proporcional (más o menos) a la desviación estándar. Se usa la desviación promedia D, donde D= alpha D + (1-alpha)|RTT - M|. alpha puede ser distinta a la previa.
• Finalmente, el timeout normalmente es RTT+4D.• Un problema en la estimación de RTT es lo que pasa cuando se retransmite un segmento. Cuando el acuse
llega, no es claro si refiere al primer segmento mandado o a la retransmisión. El algoritmo de Karn es noactualizar RTT con los acuses de segmentos retransmitidos. En vez de eso, se dobla el timeout con cadatimeout hasta que los segmentos llegan sin timeout.
• TCP mantiene también un reloj de persistencia. El mandador lo usa para prevenir el bloqueo indefinido enel caso donde el mandador cree que la ventana del recibidor es cero y la actualización del recibidor fueperdido.
• Algunas implementaciones usan un reloj de keepalive (mantener vida) para determinar si el otro ladotodavía está allí, y si no, desconectar. Una desventaja es que puede matar una conexión debido a una fallatemporal de la red.
Rendimiento
• En general entender el rendimiento de redes es más arte que ciencia. La teoría no ayuda mucho.• Fuentes de problemas de rendimiento:
• Congestión.• Desequilibrios entre recursos. Por ejemplo, una línea gigabit conectada a un PC.• Sobrecarga síncrona. Un TPDU malo mandado en un broadcast puede producir miles de
mensajes de error (una tormenta de broadcast. UDP sufría de este problema. Otro ejemplo:Después de una falla de electricidad todas las máquinas que están rebooteando pueden sobrecargarel servidor de RARP.
• Ajustamiento malo. Si suficiente memoria no es dedicada a buffers, o el algoritmo deplanificación no da una prioridad suficiente alta al procesamiento de TPDUs, o los timeouts sondemasiado cortos o largos, se pueden perder paquetes.
• Redes gigabit. En estos el producto de ancho de banda por retraso, que es la capacidad del canalentre mandador y recibidor, es muy grande (por ejemplo, 5 megabytes en una conexióntranscontinental). Se necesitan ventanas grandes en los recibidores.
• Jitter. Las aplicaciones de audio y video demandan una varianza muy pequeña en la desviaciónestándar del tiempo de transmisión.
• Medición de rendimiento de redes:• Asegurar que la muestra es suficientemente grande para pruebas estadísticas.

Softdownload
Página 51
• Usar muestras representativas, con horas y días distintos.• Tener cuidado en el uso de un reloj de grano grueso. Con repeticiones de mediciones se puede usar
tal reloj para lograr una precisión más alta.• Evitar condiciones extrañas (por ejemplo, respaldos durante pruebas ). Es mejor usar una red
desocupada y generar la carga tú mismo.• El uso de cachés de archivos o buffers en el nivel de transporte pueden cambiar las mediciones.• Entender exactamente lo que estás midiendo. Por ejemplo, las diferencias en los drivers de red
entre dos máquinas distintas pueden ser la fuente de rendimientos distintos.• Tener cuidado en extrapolar los resultados; no son necesariamente lineales.
Diseño para rendimiento mejor
• La velocidad de CPU es más importante que la de la red. En casi todas las redes el overhead del sistemaoperativo y los protocolos es mayor que el tiempo en el alambre. Ejemplos: En un Ethernet el tiempomínimo para la comunicación de un RPC (llamada a procedimiento remoto) es 102 microsegundos, pero larealidad es más cerca a 1500 microsegundos. En una red gigabit, el problema es la transferencia de datosdel buffer al proceso de cliente.
• Reducir el número de paquetes para reducir el overhead de software. Cada TPDU implica algúnprocesamiento, más el costo de una interrupción. Con paquetes mayores hay una reducción en el número depaquetes.
• Minimizar los cambios de contexto. Como las interrupciones pueden disminuir el rendimientodrásticamente. Podemos tener, por ejemplo, 4 cambios de contexto entre procesos de usuario, el kernel, y eladministrador de red para entregar datos recibidos.
• Minimizar la duplicación. Durante el procesamiento de un paquete en los niveles distintos frecuentementese duplica algunas veces. Por ejemplo, si una máquina de 50 MIPS hace tres copias de cada palabra ynecesita 5 instrucciones por copia, vamos a necesitar 75 nanosegundos por byte. Entonces la máquina nopuede manejar más de 107 Mbps, y probablemente no esto, porque hay otro overhead del protocolo, lasinstrucciones que refieren a la memoria son mucho más lentas, etc.
• Puedes comprar más ancho de banda pero no retraso menor. La velocidad de luz es un límiteinevitable.
• Evitar la congestión es mejor que recuperar de la congestión. Cuando hay congestión en la red sepierden paquetes, se malgasta ancho de banda, se introducen retrasos, etc.
• Evitar los timeouts. Los timeouts implican operaciones duplicadas. Es mejor que los relojes sonconservativos.
Procesamiento rápido de TPDUs
• La clave en el procesamiento rápido de TPDUs es identificar y acelerar el caso normal (transferencia dedatos en un sentido).
• En el caso normal del mandador, los encabezamientos de TPDUs seguidos son casi los mismos. La entidadde transporte mantiene un encabezamiento de prototipo que copia a un buffer. Entonces sobreescribe loscampos que cambian.
• En el recibidor el primer paso es identificar la conexión a que pertenece el TPDU (por ejemplo, usando unatabla de hash y las direcciones de socket). Una optimización aquí es mantener un puntero al último registrousado y probarlo primer; da una taza de ciertos de 90%.
• Si el TPDU es uno normal, se llama un procedimiento de camino rápido. Copia los datos a usuario ycalcula el checksum a la vez (eliminando un pase adicional). En general el esquema de chequear si elencabezamiento es lo que es esperado y tener un procedimiento para manejarlo se llama la predicción de

Softdownload
Página 52
encabezamiento. Con estas y otras optimizaciones es posible que TCP corra con una velocidad de 90% deuna copia local de memoria a memoria.
• Otro área para optimización es la administración de relojes. La mayoría de los relojes nunca expiran. Unaposibilidad es manejar los relojes como una lista; cada entrada contiene un contador que indica cuantosticks después su predecesor expira. Entonces se decrementa la entrada en la cabeza a cero.
• Un esquema más eficiente (sin el costo alto de insertar y eliminar) es usar una rueda de reloj. Hay quesaber el intervalo máximo de un timeout. Se usa un array circular donde cada tick corresponde a unaentrada. Las entradas son punteros a los relojes por el tiempo indicado.

Softdownload
Página 53
El nivel de aplicación
DNS--Domain Name System
• En vez de direcciones binarias de red, los programas normalmente usan strings de ASCII, tal comouas.uasnet.mx. Pero la red entiende solamente las direcciones binarias, así que se necesita una manera paratraducir entre las dos.
• Originalmente en la ARPANET se usaba un archivo hosts.txt con todos los hosts y sus direcciones IP. Cadanoche todos los hosts lo bajaban.
• Claramente este enfoque no puede escalar. Se necesita un sistema que evite conflictos pero no requiera laadministración central. Ahora se usa DNS (sistema de nombres de dominios) para manejar los nombres.Usa una base de datos distribuida y una esquema jerárquico de administración de nombres.
• En principio, DNS funciona en la manera siguiente: Para traducir un nombre a una dirección un programallama a un procedimiento de resolución. Esto manda un paquete de UDP al servidor local de DNS, quebusca la dirección de IP usando el nombre. La vuelve al procedimiento de resolución, que la vuelva alprograma.
Espacio de nombres de DNS
• Como en el correo, se parte la Internet en algunos cientos de dominios de primer nivel (edu, com, cl, de, be,etc.). Se parte cada dominio en subdominios, que se parten, etc. El sistema es un árbol.
• Hay dos tipos de dominios de primer nivel: genérico y países. Los dominios genéricos son com (comercial),edu (educación), gov (gobierno de EE.UU.), mil (fuerzas armadas de EE.UU.), net (proveedores de red), yorg (organizaciones sin fines comerciales).
• Se dividen las partes de un nombre por puntos: uas.uasnet.mx. Los nombres pueden ser absolutos orelativos (por ejemplo, ing). Los últimos se tienen que interpretar en algún contexto.
• Los nombres son insensibles a caja. Los componentes pueden tener hasta 63 caracteres, y los nombrescompletos no pueden exceder 255 caracteres.
• Cada dominio controla la asignación de los dominios baja él. Un dominio puede crear nuevos subdominiossin la autorización de dominios arriba.
• Los nombres son basados en las organizaciones, no en las redes físicas.
Registros de recurso
• Cada dominio puede tener un conjunto asociado de registros de recurso. El procedimiento de resoluciónrealmente recibe registros de recurso del servidor de DNS.
• Un registro de recurso tiene cinco partes: nombre de dominio, tiempo de vida, tipo, clase, y valor.• El nombre de dominio es la clave del registro. Normalmente hay muchos registros por dominio y la base de
datos guarda información sobre dominios múltiples. La orden de registros no importa.• El tiempo de vida (en segundos) indica la estabilidad de la información en el registro. Se usa para controlar
la expiración de copias de la información.

Softdownload
Softdownload-Año 2001
• Tipos y valores:• SOA (Start of Authority). Los parámetros para esta zona.• A (Address). La dirección de IP por el host.• MX (Mail Exchange). La prioridad y el nombre del dominio que puede aceptar correo electrónico
dirigido a esto.• NS (Name Server). El nombre de un servidor de DNS para este dominio.• CNAME (Canonical Name). Un alias para un nombre (por ejemplo, www.uasnet.mx ).• PTR (Pointer). Otro tipo de alias.• HINFO (Host Info). Una descripción de la máquina y su sistema operativo.• TXT (Text). Otra información opcional.
• La clase es siempre IN para información de Internet.• Ejemplo: En nslookup prueba "ls -d uas.uasnet.mx".
Servidores de nombres
• Se divide el espacio de nombres de DNS en zonas. Cada zona tiene alguna parte del árbol y contieneservidores de nombre con la información autoritativa de la zona. Normalmente hay un servidor principalcon su información en un archivo y otros secundarios que reciben su información del primario. Se puedenubicar algunos servidores para una zona fuera de la zona para mejorar la confiabilidad.
• Cuando una pregunta llega en un servidor y el dominio está en la zona del servidor, vuelva el registroautoritativo. Si el dominio es remoto y no hay información disponible en el servidor, le pregunta al servidordel primer nivel del dominio. Esto le pregunta a uno de sus hijos, y la cadena sigue.
• Por fin cuando los resultados llegan se guardan en una caché.• En vez de una solicitud recursiva, es posible recibir el nombre del servidor de probar próximo. En esta
manera el cliente tiene más control sobre la búsqueda.

http://www.softdownload.com.ar
Página 1
FIREWALL ...................................................................................................................................................................................... 2 ¿Qué es una red firewall? ........................................................................................................................................................2 ¿Por qué utilizar una red firewall?....................................................................................................................................... 2 ¿Contra qué puede proteger una red firewall?................................................................................................................. 2 ¿Contra qué no puede proteger una red firewall?........................................................................................................... 3 ¿Qué ocurre con los virus? ..................................................................................................................................................... 3 ¿Cuales son algunas de las decisiones básicas al adquirir una red firewall?............................................................ 3 ¿Cuales son los tipos básicos de redes firewall?................................................................................................................ 4 ¿Qué son los servidores proxy y como trabajan? .............................................................................................................6 ¿Cómo podemos hacer para que trabajen la Web/http con una firewall?................................................................ 6 ¿Cómo podemos hacer para que trabaje FTP a través de una firewall?...................................................................7 ¿Cómo podemos hacer para que trabaje Telnet a través de una firewall?............................................................... 7 ¿Qué ocurre con la denegación del servicio? ..................................................................................................................... 7 Perspectiva de gestión de una firewall................................................................................................................................. 7 ¿Qué preguntas han de realizarse a un vendedor de firewall?..................................................................................... 9 Glosario de términos relacionados con firewall..............................................................................................................10 Bibliografía de interés, acerca de firewall. .......................................................................................................................12
REDES PRIVADAS VIRTUALES ...........................................................................................................................................13 ¿Qué es una Red Privada Virtual (VPN)? ........................................................................................................................13 ¿Cómo trabaja la tecnología de túneles de una Red Privada Virtual? ..................................................................... 13 Redes privadas virtuales dinámicas - Dynamic Virtual Private Networks (DVPN) - Enfoque realizado usando aplicaciones de TradeWade Company................................................................................................................ 14 ¿Cómo trabajan las Redes privadas virtuales dinámicas?. Enfoque realizado usando aplicaciones de TradeWade Company. ...........................................................................................................................................................14 Una equivalencia a las VPN dinámicas: Una identificación de empleado y un sistema de identificación. ..... 16 Extensibilidad y Arquitectura basada en agentes de TradeVPI. ............................................................................... 17 TradeAttachés..........................................................................................................................................................................18
ACCESO REMOTO SEGURO ..................................................................................................................................................19 ¿Cuál es el propósito de los accesos remotos seguros?..................................................................................................19 ¿Qué es una red segura, privada y virtual? ..................................................................................................................... 19 ¿Cómo se consigue una red privada segura a través de un paquete de software como la "Serie InfoCrypt de Isolation Systems"?.......................................................................................................................................19 Cómo la serie InfoCrypt de Isolation Systems puede ser utilizada en conjunto con Firewalls para crear verdaderas redes seguras, privadas y virtuales...............................................................................................................20 Conseguir seguridad en las redes privadas virtuales a través del paquete F-Secure de la compañía Data Fellows. .......................................................................................................................................................................................21

http://www.softdownload.com.ar
Página 2
FIREWALL
¿Qué es una red firewall? Se puede definir de una forma simple una red firewall, como aquel sistema o conjunto combinado de sistemas que crean una barrera segura entre 2 redes. Para ilustrar esta definición podemos observar la figura.
¿Por qué utilizar una red firewall?
El propósito de las redes firewall es mantener a los intrusos fuera del alcance de los trabajos que son propiedad de uno. Frecuentemente, una red firewall puede actuar como una empresa embajadora de Internet. Muchas empresas usan susistema firewall como un lugar donde poder almacenar información pública acerca de los productos de la empresa, ficheros que pueden ser recuperados por personal de la empresa y otra información de interés para los miembros de la misma. Muchos de estos sistemas han llegado a ser partes importantes de la estructura de servicios de Internet (entre los ejemplos encontrados tenemos: UUnet.uu.net, whitehouse.gov, gatekeeper.dec.com).
¿Contra qué puede proteger una red firewall?
Alguna firewall sólamente permiten tráfico de correo a través de ellas, de modo que protegen de cualquier ataque sobre la red distinto de un servicio de correo electrónico. Otras firewall proporcionan menos restricciones y bloquean servicios que son conocidos por sus constantes problemas de intrusión. Generalmente, las firewalls están configuradas para proteger contra "logins" interactivos sin autorización expresa, desde cualquier parte del mundo. Esto, ayuda principalmente, a prevenir actos de vandalismos en máquinas y software de nuestra red. Redes firewalls más elaboradas bloquean el tráfico de fuera a dentro, permitiendo a los usuarios del interior, comunicarse libremente con los usuarios del exterior. Las redes firewall, puede protegernos de cualquier tipo de ataque a la red, siempre y cuando se configuren para ello. Las redes
Firewall Animada

http://www.softdownload.com.ar
Página 3
firewall son también un buen sistema de seguridad a la hora de controlar estadísticas de usuarios que intentaron conectarse y no lo consiguieron, tráfico que atraveso la misma, etc... Esto proporciona un sitema muy comodo de auditar la red.
¿Contra qué no puede proteger una red firewall?
Las redes firewall no pueden protegernos de ataques que se producen por cauces distintos de la red firewall instalada. Muchas organizaciones que están aterradas con las conexiones que se puedan producir a través de Internet no tienen coherencia política a la hora de protegerse de invasiones a través de modems con acceso via teléfono. Es estupido poner una puerta de acero de 6 pulgadas de espesor si se vive en una casa de madera, pero por desgracia, algunas empresas se gastan mucho dinero en comprar redes firewall caras, descuidando después las numerosas aberturas por las que se puede colar un intruso (lo que se llaman "back-doors" o "puertas traseras"). Para que una firewall tenga una efectividad completa, debe ser una parte consistente en la arquitectura de seguridad de la empresa. Por ejemplo, una organización que posea datos clasificados o de alto secreto, no necesita una red firewall: En primer lugar, ellos no deberían engacharse a Internet, o los sistemas con los datos realmente secretos deberían ser aislados del resto de la red corportiva. Otra cosa contra la que las firewalls no pueden luchar, son contra los traidores y estupidos que haya en la propia organización. Es evidente, que de nada sirve que se instale una firewall para proteger nuestra red, si existen personas dentro de la misma que se dedican a traspasar información a través de disquettes (por poner un ejemplo) a empresas espias.
¿Qué ocurre con los virus?
Las redes firewalls no pueden protegernos muy bien contra los virus. Hay demasiados modos de condifcación binaria de ficheros para transmitirlos a través de la red y también son demasiadas las diferentes arquitecturas y virus que intentan introducirse en ellas. En el tema de los virus, la mayor responsaiblidad recae como casi siempre en los usuarios de la red, los cuales deberían tener una gran control sobre los programas que ejecutan y donde se ejecutan.
¿Cuales son algunas de las decisiones básicas al adquirir una red firewall?
Hay una serie de asuntos básicos que hay que tratar en el momento de que una persona toma la responsabilidad (o se la asignan), de diseñar, especificar e implementar o supervisar la instalación de una firewall. El primero y más importante, es reflejar la política con la que la compañía u organización quiere trabajar con el sistema: ¿Se destina la firewall para denegar todos los servicios excepto aquellos críticos para la misión de conectarse a la red? o ¿Se destina la firewall para porporcionar un método de medición y auditoria de los accesos no autorizados a la red? El segundo es: ¿Qué nivel de vigilancia, redundancia y control queremos? Hay que establecer una nivel de riesgo aceptable para resolver el primer asunto tratado, para ellos se pueden establecer una lista de comprobración de los que debería ser vigilado, permitido y denegado. En otras palabras, se empieza buscando una serie de objetivos y entonces se combina un análisis de necesidades con una estimación de riesgos para llegar a una lista en la que se especifique los que realmente se puede implementar. El tercer asunto es financiero. Es importante intentar cuantificar y proponer soluciones en términos de cuanto cuesta comprar o implementar tal cosa o tal otra. Por ejemplo, un producto completo de red firewall puede costar 100.000 dolares. Pero este precio se trata de una firewall de alta resolución final. Si no se busca tanta resolución final, existen otras alternativas mucho más baratas. A veces lo realmente necesario no es gastarse mucho dinero en una firewall muy potente, sino perder tiempo en evaluar las necesidades y encontrar una firewall que se adpate a ellas.

http://www.softdownload.com.ar
Página 4
En cuanto al asunto técnico, se debe tomar la decisión de colocar una máquina desprotegida en el exterior de la red para correr servicios proxy tales como telnet, ftp, news, etc.., o bien colocar un router cribador a modo de filtro, que permita comunicaciones con una o más máquinas internas. Hay sus ventajas e incovenientes en ambas opciones, con una máquina proxy se proporciona un gran nivel de auditoria y seguridad en cambio se incrementan los coste de configuración y se decrementa el nivel de servicio que pueden proporcionar.
¿Cuales son los tipos básicos de redes firewall? Conceptualmente, hay dos tipos de firewalls:
• Nivel de red.
• Nivel de aplicación.
No hay tantas diferencias entre los dos tipos como se podría pensar. Además las últimas tecnologías no aportan claridad para distinguirlas hasta el punto que no está claro cual es mejor y cual es peor. Pero en cualquier caso, se deberá prestar atención y poner mucho cuidado a la hora de instalar la que realmente se necesita en nuestra organización. Las firewalls a nivel de red generalmente, toman las decisiones basándose en la fuente, dirección de destino y puertos, todo ello en paquetes individuales IP. Un simple router es un "tradicional" firewall a nivel de red, particularmente, desde el momento que no puede tomar decisiones sofisticadas en relación con quién está hablando un paquete ahora o desde donde está llegando en este momento. Las modernas firewall a nivel de red se han sofisticado ampliamente, y ahora mantienen información interna sobre el estado de las conexiones que están pasando a través de ellas, los contenidos de algunos datagramas y más cosas. Un aspecto importante que distingue a las firewall a nivel de red es que ellas enrutan el tráfico directamente a través de ellas, de forma que
un usuario cualquiera necesita tener un bloque válido de dirección IP asignado. Las firewalls a nivel de red tienden a ser más veloces y más transparentes a los usuarios.
http://www.softdownload.com.ar
Página 5
Un ejemplo de una firewall a nivel de red se muestra en la figura anterior. En este ejemplo se representa una firewall a nivel de red llamada "Screend Host Firewall". En dicha firewall, se accede a y desde un único host el cual es controlado por un router operando a nivel de red. El host es como un bastión, dado que está muy defendido y es un punto seguro para refugiarse contra los ataques.
Otros ejemplo sobre una firewall a nivel de red es el mostrado en la figura anterior.En este ejemplo se representa una firewall a nivel de red llamada "screened subnet firewall". En dicha firewall se accede a y desde el conjunto de la red, la cual es controlada por un router operando a nivel de red. Es similar al firewall indicada en el ejemplo anterior salvo que esta si que es una red efectiva de hosts protegidos. Las Firewalls a nivel de aplicación son generalmente, hosts que corren bajo servidores proxy, que no permiten tráfico directo entre redes y que realizan logines elaborados y auditan el tráfico que pasa a través de ellas. Las
firewall a nivel de aplicación se puede usar como traductoras de direcciones de red, desde que el tráfico entra por un extremo hasta que sale por el otro. Las primeras firewalls a nivel de aplicación eran poco transparentes a los usuarios finales, pero las modernas firewalls a nivel de aplicación son bastante transparentes. Las firewalls a nivel de aplicación, tienden a proporcionar mayor detalle en los informes auditados e implementan modelos de conservación de la seguridad. Esto las hace diferenciarse de las firewalls a nivel de red.
faq2.gif (4231

http://www.softdownload.com.ar
Página 6
Un ejemplo de una firewall a nivel de aplicación es el mostrado en la figura anterior. En este ejemplo, se representa una firewall a nivel de aplicación llamada "dual homed gateway". Una firewall de este tipo es un host de alta seguridad que corre bajo software proxy. Consta de 2 interfaces de red (uno a cada red) los cuales bloquean todo el tráfico que pasa a traves del host. El futuro de las firewalls se encuentra a medio camino entre las firewalls a nivel de red y las firewalls a nivel de aplicación. El resultado final de los estudios que se hagan será un sistema rápido de protección de paquetes que conecte y audite datos que pasan a través de el. Cada vez más, las firewalls (tanto a nivel de red como de aplicación), incorporan encriptación de modo que, pueden proteger el tráfico que se produce entre ellas e Internet. Las firewalls con encriptación extremo-a-extremo (end-to-end), se puede usar por organizaciones con múltiples puntos de conexión a Internet , para conseguir utilizar Internet como una "central privada" donde no sea necesario preocuparse de que los datos o contraseñas puedan ser capturadas.
¿Qué son los servidores proxy y como trabajan? Un servidor proxy (algunas veces se hace referencia a el con el nombre de "gateway" - puerta de comunicación - o "forwarder" - agente de transporte -), es una aplicacion que media en el tráfico que se produce entre una red protegida e Internet. Los proxies se utilizan a menudo, como sustitutorios de routers controladores de tráfico, para prevenir el tráfico que pasa directamente entre las redes. Muchos proxies contienen logines auxiliares y soportan la autentificación de usuarios. Un proxy debe entender el protocolo de la aplicación que está siendo usada, aunque también pueden implementar protocolos específicos de seguridad (por ejemplo: un proxy FTP puede ser configurado para permitir FTP entrante y bloquear FTP saliente). Los servidores proxy, son aplicaciones específicas. Un conjunto muy conocido de servidores proxy son los TIS Internet Firewall Toolkit "FWTK", que incluyen proxies para Telnet, rlogin, FTP, X-Windows, http/Web, y NNTP/Usenet news. SOCKS es un sistema proxy genéricos que puede ser compilado en una aplicación cliente para hacerla trabajar a través de una firewall.
¿Cómo podemos hacer para que trabajen la Web/http con una firewall?
Hay 3 formas de conseguirlo:
• Permitir establecer conexiones via un router, si se están usando routers protegidos.
• Usar un cliente Web que soporte SOCKS, y correr SOCKS en tu firewall.
• Ejecutar alguna clase de servidor Web proxy en la firewall. El TIS firewall tollkit incluye y proxy llamado http-gw, el cual permite proxy Web, gopher/gopher+ y FTP. Además, muchos clientes Web, tienen servidores proxy construidos directamente en ellos, que soportan: Netspace, Mosaic, Spry, Chamaleon, etc...

http://www.softdownload.com.ar
Página 7
¿Cómo podemos hacer para que trabaje FTP a través de una firewall?
Generalemente, se consigue usando un servidor proxy tal como el "firewall toolkit's ftp-gw" o bien realizando alguna de las dos operaciones siguientes:
• Permitiento conexiones entrantes a la red en un rango de puerto restringido. • Restringiendo las conexiones entrantes usando alguna clase de reglas de protección, preestablecidas.
¿Cómo podemos hacer para que trabaje Telnet a través de una firewall?
Telnet se soporta habitualmente, usando una aplicación proxy tal como "firewall toolkit's tn-gw, o simplemente configurando un router que permita las conexiones salientes usando alguna clase de reglas de protección preestablecidas.
¿Qué ocurre con la denegación del servicio?
La denegación del servicio se produce cuanto alguien decice hacer inútil tu red o firewall por desestabilización, colisión, atasco o colapso en la misma. El problema con la denegación de servicio en Internet es que es imposible prevenirlo. La razón biene, por la distribución natural de la red: cada nodo está conectado via otra red la cual está conectada a otra red, etc... Un administrador de firewall o ISP sólo tiene control sobre unos pocos elementos locales dentro del radio de acción.
Perspectiva de gestión de una firewall.
Nivel de esfuerzo para mantener una firewall típica. Las típicas firewalls, requieren requieren alrededor de 1 hora a la semana de mantenimiento. Esto es, sin contar el tiempo realitvo a Internet que el administrador de una firewall gastará. La conectividad con Internet trae consigo la necesidad de que alguiente actue como administrador de correo electrónico para Email, Webmaster, gestor de FTP y gestor de noticias USENET. Estas tareas requieren tiempo y pueden llegar a ser un trabajo a tiempo completo para una única persona. Construirte tu propia firewall. Hay numerosas herramientas disponibles para construirte tu propia firewall. "Trusted Information Systems", "Inc's Internet Firewall Toolkit", son un ejemplo de implementación de un conjunto de aplicaciones proxies. Si tu estás construyendo tu propio firewall usando un router o una router y su herramienta de desarrollo, tu puedes tener ventajas para la protección del router al construirla. Los libros de Brent Chapman y Elizabeth Zwicky's describen algunos metodos sobre configuración de un router protegido en una firewall. A menos que una persona se ofrezca sin cobrar para construir una firewall, tener contratada a una persona durante una semana en la construcción de una firewall es un conste inutil. Además habría que proporcionar un soporte técnico para el futuro lo cual incrementaría el coste. En años anteriores, había una gran variedad de firewalls comerciales disponibles, y muchas compañías contrataban a consultores para que les construyeran las firewalls. Hoy en dia, no es una buena opción seguir realizando esto, si tenemos en cuenta que el coste de contratar un consultor eventual que nos construya la firewall es superior al de comprar una firewall comercial terminada. Conocimientos de seguridad ¿Cómo sabemos si una firewall es segura? Es muy dificil saberlo, dado que no hay tests formales que puedan ser facilmente aplicados a algo tán flexible como una firewall. Una moraleja dice que cuanto mayor tráfico de entrada y salida permite una firewall, menor será su resistencia contra los ataques externos. La única firewall que es absolutamente segura es aquella que está apagada.

http://www.softdownload.com.ar
Página 8
Si usted está preocupado sobre la calidad de una firewall de un vendedor particular, use el sentido comun y hágale preguntas del tipo siguiente:
• ¿Cuanto tiempo ha estado en los negocios dicho producto? • El tamaño de la instalación base. • ¿Han tenido expertos indepedientes revisando el diseño y la implementación de la aplicación en
cuestión? Un vendedor debería claramente explicarle como se diseñó la firewall en concepto de seguridad. No acepte isinuaciones acerca de que los productos de la competencia son inseguros sin habernos explicado la seguridad de producto en cuestión. Una pregunta tópica: ¿Más caro equivale a más seguro? Un error común en las firewalls es pensar que pagando más en una firewall cara se consigue más seguridad en la misma. Hay que pensar que si el coste de una firewall es 2 veces superior al de otra, el vendedor tendría que ser capaz de explicarnos por qué dichos producto es 2 veces mejor que el otro. ¿Cómo es una típica instalación de firewall? La mayoría de la firewalls solía ser verndida como paquetes de consulta. Cuando una firewall erá vendida, parte de su coste se destinaba a instalación y soporte, generalmente, involucrando a un consultor que proporcionaba el vendedor, para ayudar en la instalación. En los "malos días" muchas de las empresas que estabán conectadas a Internet, no tenían expertos en TCP/IP local, de modo que los instaladores de las firewalls, a menudo tenían que dedicar tiempo a configurar los routers y correo electrónico (tareas que deberían haber sido realizadas por el administrador interno de DNS). Algunos vendedores continuan porporcionando tal nivel de servicios mientras que otros, simplemente proporcionan servicio sobre la instalación de su producto. Tipicamente, cuando se instala una firewall, la conexión a Internet debe estar realizada, pero no tiene que estar conectada a la red protegida. El instalador de la firewall, llega, testea las funciones básicas de la máquina y entonces puede dirigir una reunón en la que se detallen los pasos a seguir en la configuración de la firewall:
• Cual será la política de acceso que se va a poner en práctica. • A donde se va a dirigir el correo electrónico. • Dónde se debería buscar la información de login. • Y otras temas...
Una vez que el instalador tiene una buena base para la configuración de la firewall, entonces se conecta a Internet y testea que las operaciones con la red sean correctas. En ese momento se instalan y chequean las reglas para el control de acceso a la firewall y se conectan a la red protegida. Además de realizan, generalmente, algunas operaciones típicas como acceso a Web, recepción y envío de correo electrónico, etc.. Cuando todos los controles son correcto entonces ya se puede decir que uno está en Internet. ¿Qué vendedores proporcionan servicio de firewall? Muchos vendedores, proporcionan alguna clase de soporte periódico para preguntas básicas relacionadas con las firewalls. Algunos vendedores incluso proporcionan servicio a distintacia mediante la utilización del correo electrónico. Algunas proveedores de servicios Internet ofrecen un soporte de firewall como parte del servicio de conexión a Internet. Para organizaciones que son novatas en el uso de TCP/IP o que tienen prisa, es una opción atractiva, dado que un mismo vendedor proporcionar soporte de red, de alquiler de linea y de firewall. Una cosa importante que proporciona un vendedor con respecto a las firewalls, es un entendimiento de como hacer una política sensata de seguridad. A menos que se sea un vendadero entendido en la materia es mejor dejarse aconsejar antes de lanzarse a la aventura. Cuando un vendedor proporcione soporte de firewall, esté podrá guiarnos a través de la configuración de la firewall para que evitemos ataques externos. ¿Qué vendedores no proporcionan servicio de firewall? Los vendedores, tipicamente, no configuran sistemas de herencia interna para trabajar con la firewall. Por ejemplo, muchas firewalls asumen que hay que hablar a Internet por un lado y a la red TCP/IP por el otro. Generalmente, es reponsabilidad del cliente, tener sistemas TCP/IP aptos para interactuar con firewall. Para Email, la mayoría de las firewalls soportan sólamente SMTP(Simple Mail Transfer Protocol) y es reponsabilidad del cliente tener un simple compatible con SMTP en algún lugar de la red. A menos que se esté comprando una firewall desde un proveedor de servicios Internet, es responsabilidad del cliente tener una clase de direcciónes de red C IP y un nombre de dominio localizado.

http://www.softdownload.com.ar
Página 9
¿Qué preguntas han de realizarse a un vendedor de firewall?
Algunas de las preguntas que se le pueden hacer a un comprador son las siguientes:
Seguridad:
• ¿Cuales son los principales diseños de seguridad de tu firewall?
• ¿Por qué piensas que es segura?
• ¿A qué clase de revisiones y pruebas a sido sometida?
Credenciales corporativas:
• ¿Durante cuanto tiempo ha vendido esta firewall.?
• ¿Qué tamaño ocupa la instalación básica?
• ¿Tiene libro de reclamaciones que podamos consultar?
Soporte e ingeniería:
• ¿Cuantos ingenieros de soporte tienes, con contrato indefinido?
• ¿Durante cuantas horas permanece operativo el servicio de soporte?
• ¿Cuanto cuesta el soporte y mantenimiento técnico?
• ¿Cuál es tu política de actualizaciones?
• ¿Incluye el producto, algun tipo de garantía de hardware o software?
Documentación:
• Solicite una copia de la documentación para revisarla.
• ¿Que clases de informe de auditoria general una firewall? Solicita una copia de todos los informes que genere, para revisarlos.
Funcionamiento:
• ¿La firewall incluye hardware o sólo software?
• ¿Qué clase de interfaces de red soforta la firewall? (¿Necesitaré token ring, routers ethernet, etc...?)
• ¿Es manejable la firewall desde un puesto remoto? ¿Cómo es la seguridad que gestiona la firewall al respecto?

http://www.softdownload.com.ar
Página 10
Glosario de términos relacionados con firewall.
Abuso de privilegio:
Cuando un usuario realiza una acción que no tiene asignada de acuerdo a la política organizativa o a la ley.
Ataque interior:
Un atáque originado desde dentro de la red protegida.
Autentificación:
El proceso para determinar la identidad de un usuario que está intentando acceder a un sistema.
Autorización:
Proceso destinado a determinar que tipos de actividades se permiten. Normalmente, la autorización, está en el contexto de la autentificación: una vez autentificado el usuario en cuestión, se les puede autorizar realizar diferentes tipos de acceso o actividades.
Bastion Host:
Un sistema que ha sido configurado para resistir los ataques y que se encuentra instalado en una red en la que se prevee que habrá ataques. Frecuentemente, los Bastion hosts son componentes de las firewalls, o pueden ser servidores Web "exteriores" o sistemas de acceso público. Normalmente, un bastion hosts está ejecutanto alguna aplicación o sistema operativo de propósito general (por ejemplo: UNIX, VMS, WNT, etc...) más que un sistema operativo de firewall.
Detección de intrusión:
Detección de rupturás o intentos de rupturas bien sea manual o vía sistemas expertos de software que atentan contra las actividades que se producen en la red o contra la información disponible en la misma.
Dual Homed Gateway:
Un "Dual Homed Gateway" es un sistema que tiene 2 o más interfaces de red, cada uno de los cuales está conectado a una red diferente. En las configuraciones firewall, un "dual homed gateway" actua generalmente, como bloqueo o filtrador de parte o del total del tráfico que intenta pasar entre las redes.
Firewall:
Un sistema o combinación de sistemas que implementan una frontera entre 2 o más redes.

http://www.softdownload.com.ar
Página 11
Firewall a nivel de aplicación:
Un sistema firewall en el que el servicio se proporciona por procesos que mantienen estados de conexión completos con TCP y secuenciamiento. Las firewalls a nivel de aplicación, a menudo redirigen el tráfico, de modo que el tráfico saliente, es como si se hubiera originado desde la firewall y no desde el host interno.
Firewall a nivel de red:
Una firewall en la que el tráfico es exáminado a nivel de paquete, en el protocolo de red.
Host-based Security:
La técnica para asegurar de los ataques, a un sistema individual.
Logging:
El proceso de almacenamiento de información sobre eventos que ocurren en la firewall o en la red.
Perimeter-based Security:
La técnica de securización de una red, para controlar los accesos a todos los puntos de entrada y salida de la red.
Política:
Reglas de gobierno a nivel empresarial/organizativo que afectan a los recursos informáticos, prácticas de seguridad y procedimientos operativos.
Proxy:
Un agente software que actua en beneficio de un usuario. Los proxies típicos, aceptan una conexión de un usuario, toman una decisión al respecto de si el usuario o cliente IP es o no un usuario del proxy, quizas realicen procesos de autentificación adicionales y entonces completan una conexión entre el usuario y el destino remoto.
Router - Encaminador -:
Dispositivo destinado a conectar 2 o más redes de area local y que se utiliza para encaminar la información que atraviesa dicho dispositivo.
Screened Host:
Un host - ordenador servidor - en una red, detrás de un router protegido. El grado en que el host puede ser accesible depende de las reglas de protección del router.
Screened Subnet:

http://www.softdownload.com.ar
Página 12
Una subred, detrás de un router protegido. El grado en que la subred puede ser accesible depende de las reglas de protección del router.
Tunneling Router:
Un router o sistema capaz de dirigir el tráfico, encriptándolo y encapsulándolo para transmitirlo a traves de una red y que también es capaz de desencaptular y descifrar lo encriptado.
Bibliografía de interés, acerca de firewall. En cuanto a la bibliografía que recomendamos acerca de firewall, existen 2 ligros interesantes, pero que se encuentran en ingles, son los siguientes:
• "Firewalls and Internet Security: pursuing the wily hacker" por Bill Cheswick y Steve Bellovin, editado por Addison-Wesley.
• "Building Internet Firewalls" por Brent Chapman y Elizabeth Zwicky, editado por O'Rielly and Associates.

http://www.softdownload.com.ar
Página 13
REDES PRIVADAS VIRTUALES
¿Qué es una Red Privada Virtual (VPN)? Las redes privadas virtuales crean un tunel o conducto dedicado de un sitio a otro. Las firewalls o ambos sitios permiten una conexión segura a través de Internet. Las VPNs son una alternativa de coste util, para usar lineas alquiladas que conecten sucursales o para hacer negocios con clientes habituales. Los datos se encriptan y se envian a través de la conexión, protegiendo la información y el password. La tecnología de VPN proporciona un medio para usar el canal público de Internet como una canal apropiado para comunicar los datos privados. Con la tecnología de encriptación y encapsulamiento, una VPN básica, crea un pasillo privada a trabés de Internet. Instalando VPNs, se consigue reducir las responsabilidades de gestión de
un red local.
¿Cómo trabaja la tecnología de túneles de una Red Privada Virtual? Las redes privadas virtuales pueden ser relativamente nuevas, pero la tecnología de tuneles está basada en standares preestablecidos. La tecnología de tuneles -Tunneling- es un modo de transferir datos entre 2 redes similares sobre una red intermedia. También se llama "encapsulación", a la tecnología de tuneles que encierra un tipo de paquete de datos dentro del paquete de otro protocolo, que en este caso sería TCP/IP. La tecnología de tuneles VPN, añade otra dimensión al proceso de tuneles antes nombrado -encapsulación-, ya que los paquetes están encriptados de forma de los datos son ilegibles para los extraños. Los paquetes encapsulados viajan a través de Internet hasta que alcanzan su destino, entonces, los paquetes se separan y vuelven a su formato original. La tecnología de autentificación se emplea para asegurar que el cliente tiene autorización para contactar con el servidor. Los proveedores de varias firewall incluyen redes privadas virtuales como una característica segura en sus productos.
VPN

http://www.softdownload.com.ar
Página 14
Redes privadas virtuales dinámicas - Dynamic Virtual Private Networks (DVPN) - Enfoque realizado usando aplicaciones de
TradeWade Company. Basadas en la tecnología de Internet, las intranets, han llegado a ser una parte esencial de los sistema de información corporativos de hoy en dia. Sin embargo, Internet no fue diseñada, originalmente, para el ámbito de los negocios. Carece de la tecnología necesaria para la seguridad en las transacciones y comunicaciones que se producen en los negocios. Se presenta pues, un tema peliagudo en los negocios: ¿Cómo establecer y mantener la confianza en un entorno el cual fue diseñado desde el comienzo, para permitir un acceso libre a la información? Para decirlo de otro modo: ¿Cómo conseguir seguridad en una intranet sin chocar con los principios básicos de Internet sobre la flexibilidad, interoperatibilidad y facilidad de uso? La compañia TradeWade cree que la respuesta apropiada y satisfactoria a esta disyuntiva, se encuentra en la utilización de VPNs dinámicas basadas en los servicios y aplicaciones TradeVPI de dicha compañía. A diferencia de una VPN tradicional que ofrece seguridad limitida e inflexible, una VPN dinámica proporciona ambos extremos, con altos niveles de seguridad, e igualmente importante es que proporciona la flexibilidad necesaria para acoplarse dinámicamente a la información que necesitan los distintos grupos de usuarios. Las VPNs dinámicas, pueden ofrecer esta flexibilidad ya que están básadas en una única arquitectura así como pueden proporcionar otras ventajas. Una VPN dinámica es una habilitadora de intranet. Habilita que una intranet ofrezca más recursos y servicios que de otra forma imposibilitaria al mundo de los negocios a hacer mayor uso de los recursos de información. Potencial de una Red Privada Virutal Dinámica. TradeVPI es un conjunto de aplicaciones y servicios relacionados. El potencial de esta solución es el siguiente:
• Proporciona una seguridad importante para la empresa. • Se ajusta dinámicamente al colectivo dispar de usuarios. • Permite la posibilidad de intercambio de información en diversos formatos (páginas Web, ficheros,
etc.). • El ajuste que hace para cada usuario lo consigue gracias a los diferentes browsers, aplicaciones,
sistemas operativos, etc... • Permite a los usuarios unirse a distintos grupos, así como a los administradores pueden asigar
identidades en un entorno simple pero controlado. • Mantiene la integridad total, independientemente del volumen administrativo, cambios en la tecnología
o complejidad del sistema de información corporativo. TradeVPI posibilita el uso de Intranet en los negocios. Una VPN dinámica basada en TradeVPI, ofrece a los negocios, la posiblidad de usar intranets y tecnología Internet, con la certeza de que las comunicaciones y transacciones estarán protegidas con la más alta tecnología en seguridad. Al mismo tiempo, una VPN dinámica, permite que los negocios extiendan sus comunicaciones, y que el acceso a la información se produzca en un entorno agradable, versatil y controlado. En vez de estar diseñando engorrosas pantallas de usuario con las consabidas limitaciones y con esquemas de seguridad inflexibles, una VPN dinámica ha sido diseñada para proporciona el más alto nivel de libertad dentro de un entorno seguro, consiguiendo que el mayor número de usuarios pueda realizar gran su trábajo con la mayor cantidad de información posible .
¿Cómo trabajan las Redes privadas virtuales dinámicas?. Enfoque realizado usando aplicaciones de TradeWade Company.
La VPN dinámica de TradeWave consta de una plataforma de seguridad de red y un conjunto de aplicaciones para usar en la plataforma de seguridad. El diagrama de abajo, muestra como se engranan las piezas de esta plataforma para conseguir una solución del tipo VPN dinámica.

http://www.softdownload.com.ar
Página 15
El siguiente ejemplo va pasando a través de las parte de una VPN dinámica suponiendo una comunicación segura HTTP (Web). Sin embargo, TradeVPI no es una aplicación específica, sino que puede trabajar con otras aplicaciones Internet, así como con aplicaciones corporativas específicas.
Figura: Una VPN dinámica
Fusionar la VPN. Anteriormente, al usar una VPN, un usuario o servicio en primer lugar, debe fusionar (join) la VPN, registrandola con el certificado de autenticidad (CA). Un empleado corporativo confiada, llamaba a un agente del Registro Local, el cual confirmaba todos los requisitos del registro. Los fuertes procesos de seguridad, aseguraba que sólamente los usuarios nominados, estaban registrados y recibían la certificación. La CA, aseguraba que los certificados revocados eran enviados por correo y se denegaba el servicio cuando se intentaban usar. Usando VPN de TradeWave. Los usuarios y servicios, reciben continuamente, información dentro de la VPN. Sin embargo, los pasos básicos de cada intercambio son los mismos. Siguiendo los pasos ilustrados en la figura, un usuario realiza una petición de información a un servidor, pulsando con su ratón en un hipervínculo. Los pasos seguidos se pueden describir en los siguientes puntos:
1. Un usuario solicita información usando una aplicación tal como un browser Internet, desde un ordenador de sobremesa.El intercambio de información comienza cuando un usuario envia información a otro usuario o solicita información al servidor. La VPN, puede incorporar aplicaciones propietarias. Sin embargo, también debe ofrecer aplicaciones que se beneficien de Internet, y particularmente, de la WWW. En el supuesto de que un usuario ha accedido a un hipervínculo desde dentro de algun documento Web, dicho hipervínculo es seguro y sólamente puede ser accedido por usuarios autorizados.
2. La aplicación envía y asegura el mensaje.Cuando un cliente y un servidor detectan que se necesita seguridad para transmitir la petición y para ver el nuevo documento, ellos se interconectan en un mutuo protocolo de autentificación. Este paso verifica la identidad de ambas parten, antes de llevar a cabo cualquier acción. Una vez se produce la autentificación, pero ántes de que la aplicación envie la petición, se asegura el mensaje encriptándolo. Adicionalmente, se puede atribuir un certificado o firma electrónica al usuario. Encriptando la información, se protege la confidencialidad y la integridad. Si se envía la firma, se podrá usar para auditorias. Para habilitar la interoperatividad entre múltiples mecanismos de seguridad, las funciones de seguridad se deben basar en standares bien definidos, tal como el standard de Internet GSSAPI (Generic Security Services Application Programming Interface).
3. El mensaje se transmite a través de Internet. Para que la p etición alcance el servidor, debe dejar la LAN y viajar a través de Internet, lo cual le permitirá alcanzar el servidor en algún punto de la misma.
Una VPN

http://www.softdownload.com.ar
Página 16
Durante este viaje, puede darse el caso de que atraviese 1 o más firewalls ántes de alcanzar su objetivo. Una vez atravesada la firewall, la petición circula a lo largo del pasillo Internet hasta alcanzar el destino.
4. El mensaje recibido debe pasar controles de seguridad. Cuando el mensaje alcanza su destino, puede ser que tenga que atravesar otra firewall. Esta firewall protegerá cuidadosamente el tráfico entrante asegurando que se ciñe a la política corporativa, antes de dejarlo atravesar la red interna. El mensaje se transfiere al servidor. Como consecuencia de la autentifiación mutua que se produjo entre el cliente y el servidor, el servidor conoce la identidad del usuario cliente cuando recibe la petición.
5. Durante la petición, se verifican los derechos de acceso de los usuarios. Al igual que en todas las redes corporativas, todos los usuarios no pueden acceder a la totalidad de la información corporativa. En una VPN dinámica, el sistema debe poder restringir que usuarios pueden y no pueden acceder a la misma. El servidor debe determinar si el usuario tiene derechos para realizar la petición de información. Esto lo hace, usando un mecanismos de control , preferiblemente un servidor separado. El servidor de control de acceso, restringe el acceso a la información en niveles de documento. De modo que, si incluso un usuario presenta un certificado válido, puede ser que se le deniege el acceso basándose en otros criterios ( por ejemplo: políticas de información corporativa).
6. La petición de información es devuelta por Internet, previamente asegurada. Si el usuario tiene derechos de acceso a la petición de información, el servidor de información encripta la misma y opcionalmente la certifica. Las claves establecidas durante los pasos de autentificación mútua se usan para encriptar y desencriptar el mensaje. Ahora, un usuario tiene su documento asegurado.
Una equivalencia a las VPN dinámicas: Una identificación de empleado y un sistema de identificación.
Para entender la solución propuesta por TradeWave para las VPN podemos considerar un equivalente consistente en una identificación de empleado corporativo y un sistema de identificación. Del mismo modo que los departamentos de Recursos Humanos o Seguridad pueden verificar la identidad de un empleado y asignar un número de empleado único, una VPN verifica la identidad del usuario y emite un único "nombre distintivo" el cual se usa para todos los accesos y movimientos dentro del sistema. Del mismo modo que una compañía también lleva el control de quienes tienen una clave de seguridad y donde pueden ir con ella, las VPN tienen controlada la gestión y ponen a disposición claves y certificados. Al igual que muchas tarjetas de seguridad pueden ser reutilizadas por una compañía, muchas claves se pueden reconvertir, mediante el Certificado de Autorización. Además, del mismo modo que los accesos a construcciones y areas de seguridad, se controlan por varios niveles de seguridad, las VPN validan las Listas de Control de Acceso contra los nombre de usuario y passwords, para autorizar el acceso a redes y a ciertos documentos y ficheros. Por último, las VPN mantienen una lista de usuarios revocados y deniegan los futuros accesos al sistema a dichos usuarios, al igual que se produce en una empresa cuando un usuario se marcha debe devolver todos los sistemas de identificación de seguridad para no poder volver a entrar en la compañía. La siguiente figura muestra la equivalente constatada en este párrafo.
http://www.softdownload.com.ar
Página 17
Extensibilidad y Arquitectura basada en agentes de TradeVPI. Un aspecto crítico en las VPN de TradeWave es su arquitectura basada en agentes. Los agentes TradeWave son módulos o entidades software que se comunican via protocolos standard. Como consecuencia de ello, TradeWave ha "desacoplado" arquitectónicamente sus agentes de otras aplicaciones, de forma que un negocio puede cambiar o expandir su intranet - incluyendo expansión de plataformas - sin tener que rediseñar su sistema intranet. Más especificamente, esta arquitectura permite que un negocio seleccione y use cualquier browser, cualquier servidor y cualquier aplicación con su VPN dinámica. La siguiente figura muestra la arquitectura basada en agentes.
Los agentes TradeWave puden:
• Ser insertados facilmente, en streams de comunicaciones existentes con un mínimo de alteración en el sistema.
equivalencia a una VPN
arquitectura basada en

http://www.softdownload.com.ar
Página 18
• Contener habilidades que no poseen el sistema existente. • Ser actualizados rápidamente. • Incorporar múltiples protocolos de seguridad.
Además, la arquitectura basada en agentes, proporciona una solución la problema tradicional en los sistemas de información corporativos: el conflicto entre los stándares de empresa por un lado y la adopción local de tecnologías para necesidades específicas en el otro. Una arquitectura basada en agentes permite, por ejemplo, departamentos que usen los browsers que ellos quieran sin perturbar los stándares de seguridad empresaria.
TradeAttachés.
Un beneficio adicional a la arquitectura basada en agentes es la posibilidad de usar una variedad de módulos software llamados TradeAttachés. Estos módulos se pueden añadir al sistema TradeVPI para incrementar su funcionalidad e interoperatibilidad. Por ejemplo, TradeAttachés permite que la VPN se puede extender para incluir diferentes protocolos de seguridad sin perturbar a los browsers o servidores. Con este sistema, están inmediatamente disponibles, las nuevas funciones de seguridad. TradeVPI también puede gestionar simultáneamente, varios TradeAttachés de seguridad, de modo que la VPN puede soportar múltiples plataformas de seguridad al mismo tiempo.

http://www.softdownload.com.ar
Página 19
ACCESO REMOTO SEGURO
¿Cuál es el propósito de los accesos remotos seguros?
Con los accesos remotos seguros, las conexiones via modem telefónico pueden transferir datos seguros via un proveedor de servicios Internet o via una red corporativa. Los datos se encriptan en el cliente antes de que sean transmitidos y se desencriptan en la puerta de la firewall. El software proporcionado, habilita a los usuarios remotos a que se pueden conectar a la red corporativa como si ellos estuvieran detrás de la firewall. La tecnología de VPN proporciona un medio para usar el canal público de Internet como una canal apropiado para comunicar los datos privados. Con la tecnología de encriptación y encapsulamiento, una VPN básica, crea un pasillo privada a trabés de Internet. Instalando VPNs, se consigue reducir las responsabilidades de gestión de un red local.
¿Qué es una red segura, privada y virtual? Una red privada virtual es una red donde todos los usuarios parecen estar en el mismo segmento de LAN, pero en realidad están a varias redes (generalmente públicas) de distancia. Esto se muestra en la Figura 1. Para lograr esta funcionalidad, la tecnología de redes seguras, privadas y virtuales debe completar tres tareas. Primero, deben poder pasar paquetes IP a través de un túnel en la red pública, de manera que dos segmentos de LAN remotos no parezcan estar separados por una red pública. Segundo, la solución debe agregar encripción, tal que el tráfico que cruce por la red pública no pueda ser espiado, interceptado, leído o modificado. Finalmente, la solución tiene que ser capaz de autenticar positivamente cualquier extremo del enlace de comunicación de manera que un adversario no pueda acceder a los recursos del sistema.
¿Cómo se consigue una red privada segura a través de un paquete de software como la "Serie InfoCrypt de Isolation Systems"?

http://www.softdownload.com.ar
Página 20
La Serie InfoCrypt de Isolation Systems crea una red privada segura de la siguiente manera. Primero, los paquetes IP que tienen como destino una zona protegida son encapsulados en un nuevo paquete que contiene sólo las direcciones IP de los encriptores origen y destino. Esto le permite a los clientes conectar redes IP sin routear a redes IP routeadas, creando un túnel efectivo a través de la red pública por donde pasar los paquetes. La encripción es lograda usando Triple Pass DES con llaves de doble o triple longitud para encriptar paquetes destinados a redes remotas. Como la encripción es una función matemática que requiere significativos recursos del sistema, los InfoCrypt Enterprise Encrytors de Isolation Systems incorporan un procesador ASIC (Application Specific Integrated Circuit) dedicado exclusivamente a los procesos de encripción y desencripción. Esto provee a los clientes con una performance de red en tiempo de real. Los productos InfoCrypt de Isolation Systems, encriptan el paquete entero, incluyendo el encabezado original, antes de encapsular la información en un nuevo paquete. Además de proteger los datos que se están transmitiendo, esto esconde completamente la topología interna de las dos redes remot as y también protege otra información de encabezado valiosa, tal como el tipo de tráfico (por ejemplo, Mail, tráfico de Web, FTP, etc.), de los ojos curiosos de hackers y adversarios.
Cómo la serie InfoCrypt de Isolation Systems puede ser utilizada en
conjunto con Firewalls para crear verdaderas redes seguras, privadas y virtuales.
Una mejor solución a la hora de buscar un red segura, privada y virtual, consiste en la unión de paquetes de seguridad junto con firewalls, un ejemplo de esta configuración se muestra en la figura 5. La figura, también demuestra como un paquete IP es manipulado mientras se mueve de la computadora cliente de María hasta el site de Web en Boston.
Cuando María necesita el site de Web privado, crea un paquete destinado a la dirección IP del site de Web en Boston. Este paquete es interceptado por el encriptor que se fija en su tabla interna de asociaciones seguras y verifica si María puede, de hecho, acceder al site y determina que algoritmo de encripción debe utilizar cuando encripte el paquete. Asumiendo que María tiene los permisos correctos, el encriptor va a desencriptar el paquete entero incluyendo el encabezado IP original. Como la encripción se realiza con DES o Triple Pass DES, María no tiene que preocuparse de adversarios que quieran interceptar sus paquetes mientras estos viajan a través de la Internet, y luego leer o modificar sus transmisiones. Esta es una ventaja significativa sobre el caso explicado más arriba donde todas las transmisiones a través de la Internet ocurren abiertamente, y por ende, pueden ser fácilmente interceptadas por un hacker. El encriptor en Chicago va a crear un nuevo paquete siendo la dirección origen la dirección IP negra y la dirección destino aquella correspondiente a la firewall en Boston. El paquete tendrá un encabezado UDP con protocolo 2233. El paquete va a pasar a través de la firewall en Chicago que va a usar un proxy de manera tal que el paquete que se va de la firewall tendrá la dirección externa de la firewall de Chicago como su dirección de origen. El paquete tiene ahora un origen routeable y una dirección de destino y por ende, puede ser routeado a través de la Internet a la firewall en Boston. Cuando el paquete es recibido en Boston, la firewall de Boston va

http://www.softdownload.com.ar
Página 21
a examinar el paquete y al encontrar que es UDP protocolo 2233, lo puenteará a la dirección IP negra del encriptor en Boston. Con esta configuración no se abren agujeros en la firewall. Las razones son las siguientes. Primero, el tráfico es sólo puenteado a la interface negra del encriptor que está en Boston. El encriptor en Boston usará certificados digitales X.509 para identificar positivamente que el que envía los paquetes es el encriptor de Chicago y que María tiene permiso para acceder a los recursos especificados antes de pasar el paquete. Si no puede autenticar el otro extremo de la comunicación o si María no tiene permiso para acceder a esos determinados recursos, el paquete será rebotado. Note que los certificados digitales son significativamente mas confiables que usar la dirección IP de María o un password. Es más, un único proxy es creado en la firewall para cualquier tipo de tráfico que María pueda estar enviando, sea este una búsqueda de DNS, acceso al Web, transferencia de archivos, etc. Esto incrementa significativamente la flexibilidad de la solución y reduce el número de agujeros en la firewall. Asumiendo que el encriptor en Boston puede autenticar a María y que ella tiene permiso para acceder a los recursos especificados, el encriptor en Boston va a sacar el encabezado de IP, desencriptar el paquete original de María y routearlo al servidor de Web como fue requerido. Otra ventaja importante es que esta solución va a trabajar tanto si María está detrás del InfoCrypt Enterprise Encryptor en Chicago, o usando el InfoCrypt Solo para llamar al ISP desde otro lugar.
Conseguir seguridad en las redes privadas virtuales a través del paquete F-Secure de la compañía Data Fellows.
F-Secure VPN es una solución flexible y de coste aprovechable para obtener los beneficios de Internet comprometiendose a mantener la seguridad en la misma. Dota a la gestión de la red de tuneles entre los puntos de empresa manteniendo el acceso a puntos externos si se quiere. Es mejor usar este paquete en union a una firewall para conseguir un control total sobre el tráfico de datos de toda la organización. F-Secure VPN es un nuevo producto de la compañía Data Fellows que se encuentra dentro de la linea de productos enfocados a la seguridad de Internet. La compañía Data Fellows Ltd, es la primera vendedora de productos de seguridad. Usa los mecanismos de encriptación disponibles, más sofisticados y además es compatible con las arquitecturas modernas Cliente-Servidor y por supuesto Internet. Introducción al producto F-Secure VPN. El modo tradicional de conectar puntos empresariales próximos es usar servicios tradicionales "Telco" tales como X.25, lineas alquiladas o Frame Relay. Sin embargo, esos servicios tendieron a ser difíciles de obtener o era muy caros, principalmente en el entorno internacional. Como resultado de esto, muchos usuarios están pensando seriamente en usar Internet como su nexo de unión empresarial. Un gran número de analistas creen que pronto Internet reemplazará a la mayoría de las comunicaciones entre puntos empresariales internacionales, y también penetrará en las redes empresariales nacionales. F-Secure VPN es una encaminador -router- de encriptación que te posibilita construir una VPN sobre la red con una seguridad criptográfica similar a la utilizada en el ejercito. Si tu eres un gestor de red corporativa, te ayudará a recortar el coste de las lineas sin perder seguridad. Si eres un proveedor de servicios, te dará la oportunidad de competir y revasar a la competencia, dado que F-Secure VPN te prop orciona nuevos servicios con respecto a la seguridad. Características de F-Secure VPN
Las características principales son las siguientes:
• Fácil de instalar. Requiere muy pocos parámetros de instalación para el administrador, durante la instalación inicial.
• Fácil de configurar. F-Secure VPN 1.1 destaca por un editor de red gráfico que permite configurar la totalidad de la red VPN desde una simple estación de trabajo.

http://www.softdownload.com.ar
Página 22
• Configurable para asegurar las conexiones Extranet. Con el editor de red de F-Secure VPN, se puede definir la seguridad en las conexiones Extranet con tus clientes habituales.
• Rápido. En la actualidad, las redes privadas virtuales pueden aumentar la velocidad en tus conexiones entre puntos empresariales gracias a que comprimen todo el tráfico añadiendoles encriptación.
• Seguro. Usa una extensa variedad de algoritmos de selección de usuarios, incluyendo 3DES, Blowfish, RSA, etc.
• Basado en una tecnología ampliamente testeada y usada. F-Secure VPN está basado en la tecnología F-Secure SSH, el standard de hecho para conexiones entre terminales encriptados usando Internet. De hecho, esta tecnología es usada por la NASA
• Asequible. Una pequeña red privada virtual de 2 puntos puede instalarse por 5000 dolares más el precio de los PC's dedicados.
• Disponible a nivel global, con una fuerte encriptación. Data Fellows puede enviar el software encriptado a todo el mundo, sin ningún compromiso, desde las oficinas situadas en Europa o en US. Como compañía Europea que es, no se encuetra bajo las restricciones de exportación americanas referentes a la encriptación.
Arquitectura de F-Secure VPN F-Secure encripta paquetes TCP/IP en el transcurso de la comunicación sobre Internet o una Intranet. Trabaja con cualquier clase de base de routers y firewalls instalados. También suministra la mayoria de potentes encriptadores disponibles, incluyendo triple DES (Encriptador de Datos Standard) y Blowfish. Además, F-Secure comprime datos, autentifica otros servidores encriptados, realiza gestión de claves distribuidas. Normalmente, F-Secure VPN se situa detrás tanto de la firewall corporativa como del router (aunque también se admite otro tipo de configuraciones). El paquete incluye Unix y la herramienta de encriptación que es facilmente instalable en un Petium PC. Después de un intercambio y autentificación de claves iniciales entre los servidores F-Secure y otros puntos, el gestor de red únicamente desmonta el teclado y la pantalla con lo que la máquina llega a ser un servidor seguro. Entonces, los routers se deben configurar para enviar todos los paquetes TCP/IP procedentes de la encriptación, al servidor F-Secure y el resto de paquetes sin censura, se encaminarán normalmente. Los gestores de red, también tienen que configurar un puerta en su firewall para permitir que el tráfico encriptado alcance el servidor F-Secure sin filtrarlo. Cuando se recibe un paquete, F-Secure VPN comprime y encripta tanto las cabeceras TCP como el resto de datos útiles. Entonces lo encapsula formando un segundo paquete que se envia a través de un "tunel virtual" desde la unidad F-Secure hasta otro punto. El software en el punto destino, desencripta el paquete y lo vuelve a dejar en su estado original antes de enviarlo a través de su LAN. F-Secure VPN usa un protocolo llamada Secure Shell (SSH) que ha surgido como una standard de hecho para las comunicaciones seguras a través de Internet. El protocolo ha sido usado y testeado por organizaciones tales como la NASA (Washington, D.C.), así como por muchos bancos americanos. El standard ha sido desarrollado por el Grupo de Seguridad IP (IPSec) or la IETF(Internet Engineering Task Force) y estará implementado y listo para su aprovación a finales de 1997. SSH permite la gestión de claves distribuidas: en vez de almacenar las claves en una base de datos central lo cual ya es un claro objetivo para los ataques, los servidores F-Secure poseen sus propias claves. Y se pueden configurar para que cambien las claves de sesión cada hora de modo que estén protegidos contra los "hackers". El intercambio de claves se realiza de una forma segura, usando SSH y el

http://www.softdownload.com.ar
Página 23
algoritmo de clave-pública de RSA Data Security Inc. (Redwood City, California). El límite recomendado para una red privada virtual es de 100 puntos seguros, debito al complejo sistema de gestión de claves de sesión. Los beneficios de F-Secure contra los mecanismos de encriptación tradicionales. F-Secure VPN es la única solución si se compara con las alternativas principales de encriptadores hardware standars. A menudo, esos proporcionan sólamente encriptación punto a punto lo cual las hace incómodas y caras para usar en un entorno Internet. Algunas firewall también porporcionan tuneles de encriptación pero esas soluciones son propietarias (atan al usuario a una cierta firewall) y a menudos son más complicadas de configurar y actualizar.
Los beneficios de F-Secure VPN son los siguientes:
• Cualquier PC con los requerimientos mínimos puede correr el software de F-Secure VPN.
• La red VPN es dinámicamente ampliable de modo que nuevas LANs se puede añadir a VPN existente sin demasiada configuración.
• Se pueden usar conexiones a internet de bajo coste para formar la VPN. Tradicionalmente, las redes privadas virtuales seguras han estado construyendose usando lineas alquiladas muy caras.
• Automáticamente se encriptan y protegen contra alteraciones, todas las conexiones F-Secure VPN.
• F-Secure VPN se integra con cualquiera de las firewalls existentes.
• F-Secure VPN soporta conexiones Extranet seguras.

http://www.softdownload.com.ar
Página 1
SWITCHES Y RUTEADORES
• Tecnología de SWITCH • Tecnología de RUTEADOR • Donde usar Switch? • Donde usar un ruteador? • Segmentando con Switches y Ruteadores
o Segmentando LANs con Switch o Segmentando Subredes con Ruteadores o Seleccionando un Switch o un Ruteador para Segmentar
• Diseñando Redes con Switches y Ruteadores • Diseñando Redes para Grupos de Trabajo
o Pequeños Grupos de Trabajo § Opción #1: Solución con Ruteador § Opción #2: Solución con Switch
o Grupos de Trabajo Departamentales § Respecto al tráfico de Broadcast
o Ruteo como Política Segura § Segmentación Física § Segmentación Lógica
• Diseñando para Ambientes de Backbone o Baja Densidad, Alta Velocidad en el Enlace Dentro de la Central de Datos o Alta Densidad, Enlace de Alta Velocidad a la Central de Datos o ATM para el Campus o el Backbone del Edificio o Backbone Redundantes, Garantizan Disponibilidad de la Red
• Diseñando para Acceso a WAN • El Futuro de los Switches
o Soporte Multimedia • Futuro del Ruteo
o Interfaces LAN y WAN • Sumario

http://www.softdownload.com.ar
Página 2
Tecnología de SWITCH
Un switch es un dispositivo de proposito especial diseñado para resolver problemas de rendimiento en la red, debido a anchos de banda pequeños y embotellamientos. El switch puede agregar mayor ancho de banda, acelerar la salida de paquetes, reducir tiempo de espera y bajar el costo por puerto. Opera en la capa 2 del modelo OSI y reenvia los paquetes en base a la dirección MAC.
El switch segmenta económicamente la red dentro de pequeños dominios de colisiones, obteniendo un alto porcentaje de ancho de banda para cada estación final. No estan diseñados con el proposito principal de un control íntimo sobre la red o como la fuente última de seguridad, redundancia o manejo.
Al segmentar la red en pequeños dominios de colisión, reduce o casi elimina que cada estación compita por el medio, dando a cada una de ellas un ancho de banda comparativamente mayor.

http://www.softdownload.com.ar
Página 3
Tecnología de RUTEADOR
Un ruteador es un dispositivo de proposito general diseñado para segmentar la red, con la idea de limitar tráfico de brodcast y proporcionar seguridad, control y redundancia entre dominios individuales de brodcast, también puede dar servicio de firewall y un acceso económico a una WAN.
El ruteador opera en la capa 3 del modelo OSI y tiene más facilidades de software que un switch. Al funcionar en una capa mayor que la del switch, el ruteador distinge entre los diferentes protocolos de red, tales como IP, IPX, AppleTalk o DECnet. Esto le permite hacer una decisión más inteligente que al switch, al momento de reenviar los paquetes.
El ruteador realiza dos funciones basicas:
1. El ruteador es responsable de crear y mantener tablas de ruteo para cada capa de protocolo de red, estas tablas son creadas ya sea estáticamente o dinámicamente. De esta manera el ruteador extrae de la capa de red la dirección destino y realiza una decisión de envio basado sobre el contenido de la especificación del protocolo en la tabla de ruteo.
2. La inteligencia de un ruteador permite seleccionar la mejor ruta, basandose sobre diversos factores, más que por la direccion MAC destino. Estos factores pueden incluir la cuenta de saltos, velocidad de la linea, costo de transmisión, retrazo y condiciones de tráfico. La desventaja es que el proceso adicional de procesado de frames por un ruteador puede incrementar el tiempo de espera o reducir el desempeño del ruteador cuando se compara con una simple arquitectura de switch.

http://www.softdownload.com.ar
Página 4
Donde usar Switch?
Uno de los principales factores que determinan el exito del diseño de una red, es la habilidad de la red para proporcionar una satisfactoria interacción entre cliente/servidor, pues los usuarios juzgan la red por la rápidez de obtener un prompt y la confiabilidad del servicio.
Hay diversos factores que involucran el incremento de ancho de banda en una LAN:
• El elevado incremento de nodos en la red. • El continuo desarrollo de procesadores mas rápidos y poderosos en estaciones de
trabajo y servidores. • La necesidad inmediata de un nuevo tipo de ancho de banda para aplicaciones
intensivas cliente/servidor. • Cultivar la tendencia hacia el desarrollo de granjas centralizadas de servidores para
facilitar la administración y reducir el número total de servidores.
La regla tradicional 80/20 del diseño de redes, donde el 80% del tráfico en una LAN permanece local, se invierte con el uso del switch. Los switches resuelven los problemas de anchos de banda al segmentar un dominio de colisiones de una LAN, en pequeños dominios de colisiones.
En la figura la segmentación casí elimina el concurso por el medio y da a cada estación final más ancho de banda en la LAN.

http://www.softdownload.com.ar
Página 5
Donde usar un ruteador?
Las funciones primarias de un ruteador son:
• Segmentar la red dentro de dominios individuales de brodcast. • Suministrar un envio inteligente de paquetes. Y • Soportar rutas redundantes en la red.
Aislar el tráfico de la red ayuda a diagnosticar problemas, puesto que cada puerto del ruteador es una subred separada, el tráfico de los brodcast no pasaran a través del ruteador.
Otros importantes beneficios del ruteador son:
• Proporcionar seguridad a través de sotisficados filtros de paquetes, en ambiente LAN y WAN.
• Consolidar el legado de las redes de mainframe IBM, con redes basadas en PCs a través del uso de Data Link Switching (DLSw).
• Permitir diseñar redes jerarquicas, que delegen autoridad y puedan forzar el manejo local de regiones separadas de redes internas.
• Integrar diferentes tecnologías de enlace de datos, tales como Ethernet, Fast Ethernet, Token Ring, FDDI y ATM.

http://www.softdownload.com.ar
Página 6
Segmentando con Switches y Ruteadores
Probablemente el área de mayor confusión sobre switch y ruteador, es su habilidad para segmentar la red y operar en diferentes capas del modelo OSI, permitiendo asi, un tipo único de diseño de segmentación.
Segmentando LANs con Switch Podemos definir una LAN como un dominio de colisiones, donde el switch esta diseñado para segmentar estos dominios en dominios más pequeños. Puede ser ventagozo, pues reduce el número de estaciones a competir por el medio.
En la figura cada dominio de colisión representa un ancho de banda de 10 Mbps, mismo que es compartido por todas las estaciones dentro de cada uno de ellos. Aquí el switch incrementa dramáticamente la eficiencia, agregando 60 Mbps de ancho de banda.
Es importante notar que el tráfico originado por el broadcast en un dominio de colisiones, será reenviado a todos los demás dominios, asegurando que todas las estaciones en la red se puedan comunicar entre si.
Segmentando Subredes con Ruteadores Una subred es un puente o un switch compuesto de dominios de broadcast con dominios individuales de colisión. Un ruteador esta diseñado para interconectar y definir los limites de los dominios de broadcast.
La figura muestra un dominio de broadcast que se segmento en dos dominios de colisiones por un switch, aquí el tráfico de broadcast originado en un dominio es reenviado al otro dominio.
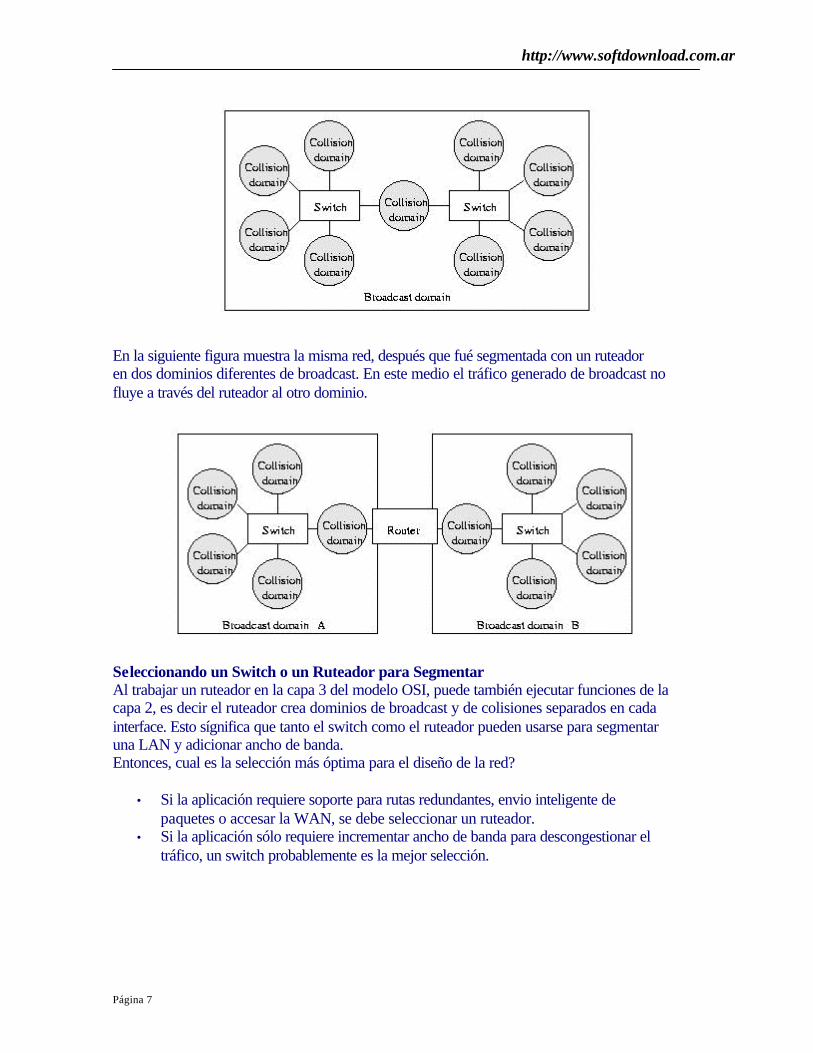
http://www.softdownload.com.ar
Página 7
En la siguiente figura muestra la misma red, después que fué segmentada con un ruteador en dos dominios diferentes de broadcast. En este medio el tráfico generado de broadcast no fluye a través del ruteador al otro dominio.
Seleccionando un Switch o un Ruteador para Segmentar Al trabajar un ruteador en la capa 3 del modelo OSI, puede también ejecutar funciones de la capa 2, es decir el ruteador crea dominios de broadcast y de colisiones separados en cada interface. Esto sígnifica que tanto el switch como el ruteador pueden usarse para segmentar una LAN y adicionar ancho de banda. Entonces, cual es la selección más óptima para el diseño de la red?
• Si la aplicación requiere soporte para rutas redundantes, envio inteligente de paquetes o accesar la WAN, se debe seleccionar un ruteador.
• Si la aplicación sólo requiere incrementar ancho de banda para descongestionar el tráfico, un switch probablemente es la mejor selección.

http://www.softdownload.com.ar
Página 8
Dentro de un ambiente de grupos de trabajo, el costo interviene en la decisión de intalar un switch o un ruteador y como el switch es de proposito general tiene un bajo costo por puerto en comparación con el ruteador. Además el diseño de la red determina cuales son otros requerimientos ( redundancia, seguridad o limitar el tráfico de broadcast) que justifique el gasto extra y la complejidad de instalar un ruteador dentro de dicho ambiente.
Diseñando Redes con Switches y Ruteadores
Cuando se diseña eficientemente una red de comunicación de datos, puede ser la parte central de una organización de negocios. Pero si se diseña mal, la red puede ser un obstáculo para el éxito de la organización.
El diseño abarca todos los aspectos del sistema de comunicación, desde el nivel individual de enlace hasta el manejo global de la red, también un diseño exitoso debe fijarse dentro de los límites presupuestales de la organización.
Se mostrarán diferentes diseños de red con switches y ruteadores, sus beneficios y limitaciones en grupos de trabajo, backbone y ambiente WAN, en ellos se usa la siguiente técnologia:
Estos diseños no deben de ser vistos como una solución, pues cada uno de ellos tiene sus propias prioridades, tópologia y objetivos.

http://www.softdownload.com.ar
Página 9
Diseñando Redes para Grupos de Trabajo
Un grupo de trabajo es una colección de usuarios finales que comparten recursos de cómputo; pueden ser grandes o pequeños, localizados en un edificio o un campus y ser permanente o un proyecto.
Pequeños Grupos de Trabajo En la figura se ve un típico ambiente de grupos de trabajo en una red interna. Tiene dos concentradores y puede crecer hasta 20, con 200 usuarios.
Aquí el administrador quiere máximizar el ancho de banda de los servidores y dividir las PCs en pequeños dominios de colisiones que compartan 10 Mbps y sólo un número límitado de usuarios poderosos requeriran 10 Mbps dedicados para sus aplicaciones.
Opción #1: Solución con Ruteador
El ruteador es configurado con una interface dedicada de alta velocidad al servidor y un número grande de interfaces ethernet, las cuales son asignadas a cada uno de los concentradores y usuarios poderosos. Y para instalarlo, el administrador de red divide los dominios grandes de broadcast y colisiones en dominios pequeños.

http://www.softdownload.com.ar
Página 10
La selección del ruteador no se baso en lo económico o en la tecnología. Desde una perspectiva de costo, el ruteador tiene un alto costo por puerto y un gasto a largo plazo en su manejo, mayor que el de un switch. Desde una perspectiva tecnológica el ruteador proporciona pocos paquetes de salida. Probablemente también los niveles de tráfico de broadcast no justifiquen la complejidad adicional de separarlos.
Opción #2: Solución con Switch
La figura muestra el mismo grupo de trabajo, pero con un switch. En este ambiente el dominio de broadcast se divide en 4 dominios de colisiones, donde los usuarios atados a dichos dominios comparten 10 Mbps. Los accesos dedicados a servidores y usuarios poderosos, eliminan la competencia por accesar el medio y el servidor local tiene una interface de alta velocidad para eliminar posibles cuellos de botella. Además de garantizar que los paquetes no se perderán por la limitación del buffer, cuando el tráfico de varios puertos sea enviado a un sólo puerto destino. Por ejemplo, supongamos un ambiente ethernet, donde cada uno de los 5 puertos del switch es de 10 Mbps, enviando 64 paquetes hacia el servidor en un rango de 4,000 pps, la carga total por puerto sera de 20,000 pps. Este valor sobre pasa al estándar ethernet de 14,880 pps, (límite por frames de 64-octetos). Este problema se elimina con una interface Fast Ethernet, donde su capacidad es hasta 148,800 pps. para frames de 64-octetos.
Si se tiene un dispositivo backbone colapsado en la central de datos de alta velocidad, se puede adicionar un segundo modulo al switch, para acomodarse a esa tecnología e ir emigrando suavemente.
Si únicamente se quiere dar hancho de banda a los grupos de trabajo, el switch es la mejor solución, pues sus ventajas son mayores a las del ruteador para este tipo de aplicaciones dado que:
• El switch ofrece mayor velocidad, al enviar su salida a todos los puertos a la vez. El rendimiento de su salida puede ser crítico, cuando el cliente y el servidor son puestos en segmentos diferentes, pues la información debe pasar por diversos dispositivos de la red interna.

http://www.softdownload.com.ar
Página 11
• El switch da mayor rendimiento por puerto en termino de costos que un ruteador. Un switch ethernet tiene un costo aproximado de $200 DLLS. por puerto, mientras que un ruteador ethernet tiene un costo aproximado de $2,000 DLLS. El costo es un factor importante, pues límita la compra de dispositivos y el poder adicionar segmentos a la red.
• Un switch es más facil de configurar, manejar y reparar que un ruteador. Cuando el número de dispositivos de la red se incrementa, generalmente es más deseable tener unos cuantos dispositivos complejos, que un gran número de dispositivos simples.
Grupos de Trabajo Departamentales Un grupo de trabajo departamental, es un grupo compuesto de varios grupos pequeños de trabajo. La figura ilustra un típico grupo de trabajo departamental, donde los grupos de trabajo individuales son combinados con un switch que proporciona interfaces de alta velocidad -Fast ethernet, FDDI o ATM. Y todos los usuarios tenen acceso a la granja de servidores, vía una interface compartida de alta velocidad al switch departamental.
La eficiencia del switch departamental, debe ser igual a los switches individuales, ofreciendo además un rico conjunto de facilidades, versatilidad modular y una forma de migración a tecnologías de alta velocidad. En general un switch a nivel departamental es la base de los dispositivos del grupo de trabajo. Si los usuarios necesitan más ancho de banda, selectivamente pueden reemplazar la base instalada de concentradores por switches de 10 Mbps de bajo costo.
Respecto al tráfico de Broadcast Dado el alto rendimiento que ofrecen los switches, algunas organizaciones se interezan por los altos niveles de tráfico de broadcast y multicast. Es importante comprender que algunos protocolos como IP, generan una cantidad limitada de tráfico de broadcast, pero otros como IPX, hacen un abundante uso de tráfico de broadcast por requerimientos de RIP, SAP, GetNearestServer y similares.

http://www.softdownload.com.ar
Página 12
Para aliviar la preocupación del consumidor, algunos vendedores de switches tienen implementado un "regulador" de broadcast, para límitar el número de paquetes enviados por el switch y no afectar la eficiencia de algunos dispositivos de la red. El software contabiliza el número de paquetes enviados de broadcast y multicast en un lapso de tiempo específico, una vez que el umbral a sido alcanzado, ningún paquete de este estilo es enviado, hasta el momento de iniciar el siguiente intervalo de tiempo.
Ruteo como Política Segura Cuando el número de usuarios en los grupos de trabajo se incrementa, el crecimiento de los broadcast puede eventualmente causar una legítima preocupación sobre lo siguiente:
• Redimiento en la red. • Problemas de aislamiento. • Los efectos de radiar el broadcast en el rendimiento del CPU de la estación final. • Seguridad en la red.
La desición de instalar un ruteador para prevenir estos problemas potenciales, es a menudo basado en el nivel de confort psicológico de la organización. Generalmente la cantidad de trafico de broadcast en un grupo de trabajo con switches de 100 a 200 usuarios, no es un problema significativo a menos que halla un mal funcionamiento en el equipo o un protocolo se comporte mal. Los factores de riesgo dominantes en grupos de trabajo grandes, es la seguridad y el costo del negocio por una tormenta de broadcast u otro tipo de comportamiento que tire la red.
El ruteador puede proporcionar un bajo costo por usuario en politicas de seguridad en contraste con este tipo de problemas. Hoy día un ruteador Fast Ehternet (100 Mbps), tiene un costo por puerto de aproximadamente $6,000 DLLS. Si se desea mantener el dominio de broadcast de 200 usuarios, un puerto del ruteador proporciona la protección requerida por un costo de sólo $30 DLLS. por usuario. Considerando que el ruteador tiene una vida media de 5 años, esta cantidad se reduce a $6 DLLS usuario/año. Pero además, puede proporcionar dicha seguridad, tanto por la segmentación física como lógica.

http://www.softdownload.com.ar
Página 13
Segmentación Física
La figura ilustra como un ruteador segmenta físicamente la red dentro de dominios de broadcast. En este ejemplo, el administrador de red instala un ruteador como política de seguridad, además para evitar los efectos del broadcast, que alentan la red.
Notar que el ruteador tiene una interface dedicada para cada departamento o switch del grupo de trabajo. Esta disposición da al ruteador un dominio de colisión privado que aisla el tráfico de cada cliente/servidor dentro de cada grupo de trabajo. Si el patron del trafico esta entendido y la red esta propiamente diseñada, los switches haran todo el reenvio entre clientes y servidores. Sólo el tráfico que alcance al ruteador necesitará ir entre dominios individuales de broadcast o a través de una WAN.
Segmentación Lógica
Algunas metas pueden alcanzarse de una manera más flexible al usar ruteadores y switches, para conectar LANs virtuales separadas (VLANs). Una VLAN es una forma sencilla de crear dominios virtuales de broadcast dentro de un ambiente de switches independiente de la estructura física y tiene la habilidad para definir grupos de trabajo basados en grupos lógicos y estaciones de trabajo individuales, más que por la infraestructura física de la red. El tráfico dentro de una VLAN es switcheado por medios rápidos entre los miembros de la VLAN y el tráfico entre diferentes VLANs es reenviado por el ruteador.

http://www.softdownload.com.ar
Página 14
En la figura los puertos de cada switch son configurados como miembros ya sea de la VLAN A o la VLAN B. Si la estación final transmite tráfico de broadcast o multicast, el tráfico es reenviado a todos los puertos miembros. El tráfico que fluye entre las dos VLANs es reenviado por el ruteador, dando así seguridad y manejo del tráfico.

http://www.softdownload.com.ar
Página 15
Diseñando para Ambientes de Backbone
Durante años las organizaciones bienen usando en su central de datos la arquitectura de backbone colapsado, en dicho ambiente una gran cantidad de datos de la empresa se transmite a través de cada dispositivo del backbone. El backbone colapsado de la figura tiene varios beneficios si se compara con la arquitectura tradicional de backbone distribuido.
Un diseño de backbone colapsado centraliza la complejidad, incrementa la funcionalidad, reduce costos y soporta el modelo de granja de servidores. No obstante tiene limitaciones, pues los dispositivo puede ser un potencial cuello de botella y posiblemente un punto simple de falla.
Si la función primaria del backbone es puramente la funcionalidad entonces se selecciona un switch. Si la meta es funcionalidad y seguridad entonces se selecciona un ruteador.
Baja Densidad, Alta Velocidad en el Enlace Dentro de la Central de Datos En la figura los switches de grupo de trabajo son puestos en cada piso. Ellos tienen enlaces dedicados y compartidos de 10 Mbps para los usuarios finales, una interface de alta velocidad para el servidor del grupo de trabajo y un enlace a la central de datos.

http://www.softdownload.com.ar
Página 16
Los servidores en la central de datos son puestos a una sola interface del ruteoador de alta velocidad, compartiendo el ancho de banda. Notar que la funcionalidad de cada servidor en el edificio es optimizada al conectarlo a una interface de alta velocidad, ya sea directa o compartida.
El ruteador proporciona conectividad entre los switches de los grupos de trabajo de cada piso, la granja de servidores, el backbone de campus y la WAN. Algunas de las operaciones de ruteo en la capa de red, dividen los edificios en dominios separados de broadcast en cada una de las interfaces y da la seguridad requerida entre las subredes individuales. En esta configuración, el ruteador es la parte central para la operación de la red, mientras el switch proporciona ancho de banda adicional para el usuario "nervioso".
Alta Densidad, Enlace de Alta Velocidad a la Central de Datos Si la organización esta dispuesta a aceptar un sólo dominio de broadcast para todo el edificio, el siguiente paso en el proceso de migración será la introducción de un switch LAN de alta velocidad en la central de datos, esto es ilustrado en la siguiente figura

http://www.softdownload.com.ar
Página 17
Note que la introducción del switch cambia la tópologia lógica de la red interna y esto impacta en las direcciones del usuario. El switch de alta velocidad permite la conectividad de los pisos e incrementa la funcionalidad, al proporcionar conexiones switcheadas entre los servidores y cada uno de los switches de los grupos de trabajo. Los switch adicionales pueden ser integrados vía concentradores.
Aunque en la figura muestra un switch dedicado de alta velocidad y un solo ruteador, la funcionalidad individual de cada uno de ellos puede ser combinada dentro de una plataforma switch/ruteador. No obstante al integrar los dispositivos, no ofrecera el sopórte completo, ni las facilidades de un ruteador dedicado, en terminos de las capas de protocolos de red (IP, IPX, AppleTalk, DECnet, VINES, etc.) y protocolos de ruteo (RIP, OSPF, MOSPF, NLSP, BGP-4 y otros). Además un switch/ruteador generalmente no dispone de acceso WAN.
Si la organización no acepta un sólo dominio de broadcast para el edificio, se necesitará instalar una interface multiple de ruteo de alta velocidad para soportar un switch en la central de datos, para cada dominio de broadcast. Mientras esta configuración permite conectar más pisos, no provee la misma funcionalidad hacia arriba, porque no hay conexión directa entre la granja de servidores y cada uno de los switch de los grupos de trabajo. Esto se muestra en la siguiente figura:

http://www.softdownload.com.ar
Página 18
ATM para el Campus o el Backbone del Edificio Si tanto el backbone del campus como los edificios comienzan a experimentar congestionamiento, se puede reemplazar el backbone de alta velocidad con un switch ATM.
La figura muestra como un modulo ATM apropiado se integra a la central de datos, notar que los switches de los grupos de trabajo permanecen sin cambios y el acceso a la granja de servidores es via una interface ATM directa al switch de campus.

http://www.softdownload.com.ar
Página 19
Backbone Redundantes, Garantizan Disponibilidad de la Red En cada uno de los ejemplos previos, los switches y ruteadores trabajan conjuntamente en el diseño del backbone. A menudo se pasa por alto, la habilidad del ruteador para soportar rutas redundantes. Los backbone son parte esencial de la infraestructura de comunicación que debe de protegerse de fallas. La figura ilustra como los ruteadores permiten la construcción de backbones redundantes, garantizando la confiabilidad de la operación, disponibilidad y mantenimiento en días criticos de la red. Un buen diseño de red es tal que si, el backbone primario falla, un backbone secundario esta disponible como un inmediato y automático respaldo.

http://www.softdownload.com.ar
Página 20

http://www.softdownload.com.ar
Página 21
Diseñando para Acceso a WAN
Si la organización tiene oficinas localizadas en diferentes áreas geográficas, el soporte a la red metropolitana o de área amplia será un requerimiento clave, donde el ruteador da esa solución.
La figura muestra como los ruteadores dan acceso a las oficinas regionales.
Cuando se compara el ancho de banda de la LAN con una WAN, se vera que es un recurso escaso y debe ser cuidadosamente manejado. La tecnología de ruteo elimina tráfico de broadcast sobre la WAN, de lo contrario, si un dominio de broadcast consiste de 60 usuarios y cada uno de ellos genera 2 paquetes de broadcast por segundo, la capacidad de una WAN de 64 Kbps sera consumida. Por ello el ruteador soporta diversas facilidades adicionales:
• El sotisficado filtreo de paquetes permite al ruteador la construcción de un firewall en la red interna y dar seguridad y control de acceso a la organización. Los accesos no autorizados pueden ser perdidas para el negocio, fuga de secretos, datos corruptos y baja productividad de los empleados, además reduce potenciales responsabilidades legales y otros costos asociados con encubrir la actividad del hacker.
• El ruteador ofrece diversas opciones para conectar oficinas en diferentes áreas geográficas, tomando en cuenta la tecnología exitente en el mercado (X.25, FrameRelay, SMDS, ATM, POTS, ISDN) y los costos de uso, lo que permite a cada organización seleccionar la mejor en valor económico.
• El ruteador permite consolidar la red tradicional terminal-host, con su propio crecimiento de red interna LAN-a-LAN, soporte para DLSw, encapsular tablas

http://www.softdownload.com.ar
Página 22
ruteables y tráfico NetBIOS en paquetes IP. En suma, el soporte APPN manejando ruteo de aplicación SNA LU 6.2-base.
• Los ruteadores soportan compresión de paquetes a nivel enlace, lo cual reduce el tamaño del encabezado y los datos, permitiendo lineas seriales para acarreo de 2 a 4 veces más tráfico con respecto a las líneas sin descomprimir, sin un gasto adicional.
Un ruteador reconoce cada protocolo, permitiendo priorizar tráfico y soporte para protocolos sensibles al tiempo para enlaces lentos en la WAN.
El Futuro de los Switches
El precio de la tecnología del switch continua desendiendo, como resultado del desarrollo ASIC unido con la eficiencia de la manufactura y técnicas de distribución. Como el costo por puerto del switch se aproxima al de los hubs, muchos usuarios eligen el switch. La extensa disponibilidad de la tecnología de switch de bajo costo tiene implicaciones para las redes de los edificios y el backbone de campus. Habra una demanda creciente para switches de backbone de alta densidad, con un número grande de puertos de alta velocidad, para enlazar grupos de trabajo individuales. Eventualmente el equipo de escritorio sera dedicado a enlaces de 10 Mbps, la mayoria de los servidores estaran conectados a los switch de alta velocidad y ATM se usara en enlaces internos del edificios y al backbone de campus.
Soporte Multimedia Nadie puede saber con certeza el futuro de las aplicaciones multimedia, como serán o como se explotarán. En un medio LAN un enlace privado de 10 Mbps provee bastante ancho de banda para soportar video comprimido para videoconferencias. Pero el ancho de banda no es bastante. Tienen pensado poner alta prioridad al tráfico de multimedia, tal que el tráfico tradicional de datos en un camino de datos multimedia no tenga un tiempo sensitivo. En resumen, hay más preguntas concernientes a la habilidad de distribuir aplicaciones multimedia a través de la WAN. Un buen despliege de aplicaciones multimedia requiere que la red tenga altos niveles de funcionalidad y calidad fija en el servicio. Hay diversas inovaciones que se integran dentro de la tecnología del switch para realzar el soporte de futuras aplicaciones multimedia:
• Sobre segmentos privados ethernet 40% o 50% del ancho de banda utilizado, es considerado funcionalmente excelente, debido a los tiempos muertos de colisiones, lagunas de interframe y otros. Sobre una interface LAN privada, una tecnología tal como PACE, asegura un acceso imparcial al ancho de banda, mantiene funcionalidad fluida y crea multiples niveles de servicio. PACE permite tiempo real, multimedia y las aplicaciones de datos tradicionales pueden co-existir. Con esta tecnología, la utilización del ancho de banda puede incrementarse hasta un 90%.
• El IGMP es un estándar IETF que permite a un host participar en un grupo de IP multicast. Ahora los switches son requeridos para enviar tráfico IP multicast sobre todas las interfaces, despojando el ancho de banda sobre esas interfaces que no

http://www.softdownload.com.ar
Página 23
tienen miembros del grupo multicast. Switches pequeños pueden curiosear sobre mensajes IGMP para crear dinámicamente filtros para limitar el flujo de multicast en la red de switches.
Futuro del Ruteo
El ruteo es la llave para desarrollar redes internas. El desafio es integrar el switch con ruteo para que el sistema aproveche el diseño de la red. Cada uno de los grandes vendedores de ruteadores tiene investigando más de 300 millones de dolares en hora/hombre, desarrollando lineas de código para sus productos. Cada liberación de software representa un tremendo esfuerzo de ingenieria, para asegurar que el ruteador soporte la última tecnología y dirección de diseño en redes internas.
Inicialmente los switches estarán en todas las organizaciones que requieran incrementar el ancho de banda y obtener la funcionalidad que necesitan. No obstante al incrementar la complejidad de la red, los administradores necesitarán controlar el ambiente de switch, usando segmentación, redundancia, firewall y seguridad. En este punto, la disponibilidad de ruteo sotisficado esencialmente crecerá y la red se escalará en grandes redes de switches. El usuario demandará que los vendedores de ruteadores hagan sus productos faciles de instalar y configurar.
Interfaces LAN y WAN En general el ruteo dentro de los edificios se esta moviendo hacia un pequeño número de interfaces de alta funcionalidad para conectar switches de alta densidad en los ruteadores. Este es el verdadero modelo costo-efectividad, especialmente cuando un gran número de interfaces LAN van de velocidades baja a media.
Como el número de interfaces LAN decrementa, la venta para interfaces WAN sobre la oficina central de ruteadores es movida a dos diferentes direcciones. Algunos usuarios requeriran un incremento en el número de interfaces WAN de baja velocidad para conectar sus sitios remotos con arrendamiento de lineas y conexiones telefónicas. Otros usuarios requeriran unas cuantas interfaces físicas como FrameRelay y ISDN, proporcionando la funcionalidad de lineas dedicadas arrendadas por fracción de costo.

http://www.softdownload.com.ar
Página 24
Sumario
Antes de seleccionar entre switch y ruteador, los diseñadores de red deben comprender como combinar estas tecnologías para construir eficientes redes escalables. Un administrador de red será extremadamente escéptico de cualquier vendedor que sugiera una solución de alta funcionalidad que pueda ser construida usando sólo tecnología de switch o de ruteador.
Los switches y ruteadores son tecnologías complemetarias que permiten a las redes escalar a tamaños mucho más allá de lo que se puede lograr usando sólo alguna de estas tecnologías. El ruteo proporciona un número de llaves de capacidad que no ofrece un switch, tal como control de broadcast, redundancia, control de protocolos y acceso a WAN. El switch proporciona manejo de la red con un costo efectivo de migración que elimina anchos de banda pequeños. Los switches pueden ser integrados facilmente dentro de redes de ruteadores como reemplazo de la base instalada de repetidores, hubs y puentes. Cuando ATM es eventualmente implementado en el backbone, el ruteo será un requerimiento tecnológico para comunicarse entre VLANs.