
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO … · 2013 FES IZTACALA, UNAM Universidad Nacional...
70
UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO FACULTAD DE ESTUDIOS SUPERIORES IZTACALA
Transcript of UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO … · 2013 FES IZTACALA, UNAM Universidad Nacional...

UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICOFACULTAD DE ESTUDIOS SUPERIORES IZTACALA


del español de México
de frecuenciasdiccionarioLEXMEX:

Dr. José Narro RoblesRector
Dra. Patricia D. Dávila ArandaDirectora
Dr. Ignacio Peñalosa CastroSecretario General Académico
CD Rubén Muñiz ArzateSecretario de Desarrollo y Relaciones Institucionales
Dr. Raymundo Montoya AyalaSecretario de Planeación y Cuerpos Colegiados
CP Reina Isabel Ferrer TrujilloSecretaria Administrativa
MC José Jaime Ávila ValdiviesoCoordinador Editorial

RESPONSABLE DE LA EDICIÓNMC JOSÉ JAIME ÁVILA VALDIVIESO
FES IZTACALA, UNAM2013
Universidad Nacional Autónoma de MéxicoFacultad de Estudios Superiores Iztacala
Juan Silva-Pereyra Psicólogo y maestro en Neurociencias por la fes Iztacala, unam. Doctor en Ciencias Fisiológi-cas por el Instituto de Neurobiología, unam. Estancia posdoctoral en el Institute for Learning & Brain Sciences (I-Labs), Universidad de Washington, Seattle, eua. Profesor Titular “A” tc de la fes Iztacala, unam. Premio Santiago Ramón y Cajal por investigación psicolingüística en la Universidad de La Laguna, Islas Canarias, España. Reconocimiento Distinción Universidad Nacional para Jóvenes Académicos (rdunja), unam. Su línea de investigación se centra en las bases neurobiológicas de procesos psicolingüísticos.
Mario Arturo Rodríguez-Camacho Médico Cirujano y maestro en Neurociencias por la fes Iztacala, unam. Doctor en Ciencias Fisioló-gicas por la uacpyp, unam. Profesor Titular “B”, fes Iztacala, unam. Nivel II del Sistema Nacional de Investigadores (sni). Su línea de investigación se enfoca en las bases neurobiológicas de los procesos cognoscitivos en niños y adultos.
Dulce María Belén Prieto-Corona Psicóloga y maestra en Neurociencias por la fes Iztacala, unam. Doctora en Psicología (Neurocien-cias de la Conducta) por fes Iztacala, unam. Profesor Titular “A”, fes Iztacala, unam. Nivel I del Sistema Nacional de Investigadores (sni). Su línea de investigación se enfoca en las bases neurobio-lógicas de los procesos cognoscitivos en niños con trastornos en el desarrollo.
Eduardo Aubert-Vázquez Licenciado en Ciencias de la Computación por la Universidad de la Habana. Doctor en Ciencias por el Centro Nacional de Investigaciones Científicas de Cuba. Investigador en el Instituto de Neuro-ciencias de La Habana, Cuba. Sus principales líneas de investigación son el desarrollo de software y métodos de procesamiento para el análisis cuantitativo tomográfico del eeg y las neuroimágenes.
Gloria Avecilla RamírezFacultad de Psicología, Universidad Autónoma de QuerétaroThalía Fernández HarmonyInstituto de Neurobiología, unamJorge Guzmán Cortésfes Iztacala, unamLourdes Luviano Vargasfes Iztacala, unam
Vicenta Reynoso Alcántarafes Iztacala, unamHelena Romero Romerofes Iztacala, unamAlejandro Tapia de Jesúsfes Iztacala, unamGuillermina Yáñez Téllezfes Iztacala, unam
Colaboradores

Primera edición: diciembre de 2013
D.R. © 2013 UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICOCiudad Universitaria, Delegación Coyoacán, CP 04510,México, Distrito Federal.
FACULTAD DE ESTUDIOS SUPERIORES IZTACALAAv. de los Barrios N.o 1, Los Reyes Iztacala, Tlalnepantla,CP 54090, Estado de México, México.
ISBN: 000-000-00-0000-0
Prohibida la reproducción total o parcial por cualquier medio sin la autorización escrita del titular de los derechos patrimoniales.
apoyo técnico
MC José Jaime Ávila ValdiviesoCuidado de la edición y corrección de estilo
Lic. Jorge Pérez Martínez Corrección de estilo
PLH Jorge Arturo Ávila GómoraCorrección de estilo
DG Carlos Domínguez MorenoDiseño de portada, diagramación, preliminares y formación editorial
Libro financiado por el Programa de Apoyo a Proyectos de Investigación e Innovación Tecnológica (papiit) de la Dirección General de Asuntos del Personal Académico (dgapa), UNAM, clave IT300112 “Diccionario léxico del español en México y sus frecuencias de uso”.
Impreso y hecho en México

Prefacio I
1 Factores que inf luyen en el reconocimiento de las palabras: El punto de vista de la Psicolingüística 1
Frecuencia de usoVecindad ortográficaVecindad fonológicaReferencias
2 Estudios lexicográficos en español. Características del corpus los diccionarios 15
Referencias
3 Creación del corpus Lexmex. Muestreo 23Extracción automática de las propiedades léxicas. Programa PEAPLTrabajo de inspección/verificaciónReferencias
4 Medidas léxicas disponibles en el Lexmex 35Frecuencia de usoEstructura y vecindad ortográfica de las palabrasEstructura y vecindad fonológica de las palabrasFrecuencia silábicaReferencias
Índice

5 Estadísticas globales del corpus del Lexmex 43Parámetros de frecuenciaNúmero de letras y de sílabasCategoría gramatical de las palabrasTipo de acentuación de las palabrasSílabas y patrones ortográficos de las palabrasReferencias
Anexo Manual del usuario de Lexmex 51Procedimiento para recuperar información léxicaa partir de un listado de palabrasProcedimiento para generar palabras a partir de una variable léxica

Prefacio
L a evaluación de procesos psicológicos complejos, co- mo aquellos relacionados con el lenguaje, el pensamien-to, la lectura y la comprensión, resulta de gran interés
tanto en el plano pedagógico como en el de la salud. Una adecuada evaluación de ellos depende, en gran medida, del diseño apropiado de las tareas experimentales. Esto implica tener en cuenta, para su construcción, las variables críticas que afectan el proceso en análisis.
El uso de material verbal para la evaluación de procesos psicológicos es frecuente en la investigación dentro de las áreas Neurolingüísti-ca, Psicolingüística, Neurociencias cognoscitivas o Neuropsicología, así como en el diagnóstico y la rehabilitación de pacientes en quie-nes dichos procesos, dañados por diferentes causas, exigen el uso de un material verbal adecuado. Por esta razón, se requiere el conoci-miento de las características léxicas de los vocablos del idioma de que se trate, tales como la longitud, la categoría gramatical, el patrón consonante-vocal, la estructura interna y la frecuencia de uso, por

II
Competencias EducativasEl proceso de enseñanza...
citar algunas. En el estudio del lenguaje, estas variables tienen un probado efecto sobre el reconocimiento de las palabras escritas, por lo que es importante tenerlas en cuenta al diseñar una prueba de diagnóstico o, incluso, una tarea en la que se pretende rehabilitar a un paciente.
Una de las características del material verbal, cuyo estudio re-viste la mayor importancia, es la frecuencia de uso de las palabras en cierta población. La investigación en Psicolingüística y Neu- rociencias cognoscitivas ha demostrado ampliamente el papel de-cisivo que la manipulación de la frecuencia juega en los resultados de dichas investigaciones.
Existen múltiples trabajos sobre la frecuencia de uso de las pala- bras en idiomas como el inglés, el alemán, el holandés, francés y el chino. Si bien el español es la lengua materna de más de 300 millo-nes de personas en el mundo, son escasos los estudios de frecuencia para este idioma, y los que existen presentan limitaciones para ser usados en otro país que no sea el de procedencia.
Mención especial requiere el trabajo titulado Investigaciones lingüís-ticas sobre lexicografía (Lara, Ham y García, 1979), que es el más completo que existe para el español de México. Publicado por el Colegio de México, bajo la dirección de Luis Fernando Lara, este diccionario se realizó sobre una muestra de diversos textos de esa época, escritos en México. Debido a que la muestra tomada pa- ra el estudio no es reciente, el resultado es poco representativo de las actuales tendencias de uso, pues muchas palabras han modificado su frecuencia de uso e, incluso, otras se han incorporado al reper- torio común. A lo anterior hay que agregar la dificultad del acceso a la totalidad de la información del diccionario. La obra mencionada presenta sólo las primeras 100 palabras más frecuentes, pero resul- ta complicado el acceso a la información de las cinco mil palabras restantes y sus frecuencias.

Prefacio
III
Aun más escasos resultan los estudios que abordan las características de la estructura interna de las palabras, es decir, de las sílabas y letras que las componen, así como la frecuencia de uso silábica. Algunos autores han encontrado que la frecuencia de la sílaba en el idioma español influye notablemente en el reconocimiento de las palabras.
Los estudios sobre las características y propiedades del léxico de nuestro idioma, realizados por algunos investigadores españoles, presentan diversos problemas que los limitan en cuanto a su repre-sentatividad y, por ende, en su utilidad para otro medio. El más sig-nificativo de los problemas radica en las diferencias lingüísticas que surgen entre la procedencia geográfica de donde se realiza el estudio y el lugar donde se utilizarán sus resultados. Ejemplo de lo anterior son los frecuentes regionalismos del lugar de procedencia que no se usan en el lugar donde se pretende emplear el material verbal y, por el contrario, se dejan de incluir otros de mayor uso para dicha región.
Una solución factible para este problema es la realización in situ de un estudio que incluya un amplio muestreo de las palabras más usa-das en el lenguaje escrito y de sus características léxicas. Para tal labor, se requiere la introducción del uso de Internet y de softwa- re diseñado ex profeso para el análisis de un volumen significativo de información en un tiempo considerablemente reducido, lo cual eli-mina el riesgo de error humano debido a la fatiga; lo cual posibilita la actualización frecuente de la información.
Con base en lo anterior, en Lexmex; Diccionario de frecuencias del espa-ñol de México se colectaron, por medio de Internet, textos de publica-ciones digitales en español propias de México, que fueron procesados mediante un software especializado y a través de un trabajo de inspec-ción y verificación. De esta manera, para cada palabra analizada, se reportan características y propiedades léxicas, la frecuencia de uso, el número de letras y de sílabas, la categoría gramatical y el tipo de acen-tuación de las palabras, la estructura consonante-vocal, o la estructura silábica, entre otras.


1Factores que influyen en el reconocimiento
de las palabras: el punto de vista de la Psicolingüística
Frecuencia de uso
L as bases de datos que existen del léxico, incluyen varios índices de las propiedades lingüísticas de las palabras. Como hemos mencionado, dichos índi-
ces incluyen, entre otros rasgos, la frecuencia de uso, la estructu- ra consonante-vocal y la estructura silábica. Esta información es útil para psicólogos experimentales, psicolingüistas, neuropsicó- logos y neurocientíficos interesados en controlar los estímulos lin-güísticos para sus investigaciones. El uso de estos índices comenzó en el campo de la Psicología educativa aplicada y se extendió hacia la investigación básica en Psicología cognoscitiva.
El papel predominante de la manipulación de la frecuencia de uso de las palabras en los resultados de la investigación psicolingüística ha sido demostrada consistentemente por Balota, Yap y Cortese (2006). A partir de los años 50 del siglo pasado, se han proporcionado evi-dencias sobre el efecto de la frecuencia de uso en el reconocimiento

2
LEXMEX: diccionario de frecuenciasdel español de México
de las palabras (Howes, 1954, 1957). Se ha demostrado, además, que la frecuencia de uso tiene influencia en el tiempo y la preci-sión de la lectura de palabras (Rayner, 2009; ver Hino & Lupker, 2000 para una revisión). En concreto, la investigación ha demos-trado que se responde de manera más rápida y con mayor precisión a palabras de alta frecuencia que a las de baja frecuencia (Balota & Chumbley, 1984; Balota et ál., 2006). Este efecto de frecuen-cia léxica también es evidente en el rendimiento en la lectura de pacientes con déficits cognoscitivos, como los disléxicos (Behr-mann, Plaut & Nelson, 1998) y los pacientes con enfermedad de Alzheimer (Carreiras, Baquero & Rodríguez, 2008).
La frecuencia con la que aparece un término influye en práctica-mente todas las tareas de reconocimiento de palabras. Por ejemplo, los efectos de frecuencia de vocablos se han encontrado en el ren-dimiento durante tareas de decisión léxica (Forster & Chambers, 1973; Monsell, 1991), de nominación (Balota et ál., 1984), de identi- ficación perceptual (Broadbent, 1967) y en la lectura en línea don-de se mide la duración de la fijación de la mirada (Rayner, 2009; Schilling, Rayner & Chumbley, 1998). Lo anterior, por supuesto, no debería sorprender, ya que la frecuencia de uso de una palabra está relacionada con el número de veces que ésta se ha experimentado anteriormente, de manera que dicha experiencia debe influir en la facilidad de la ejecución de estas operaciones lingüísticas.
Modelos de codificación
A pesar de que parece ser evidente el porqué la frecuencia de uso modula el rendimiento en las tareas de reconocimiento de palabras, las interpretaciones teóricas de tales efectos han sido variadas. Por ejemplo, los modelos de activación, basados en gran medida en el clásico modelo de Logogen (Morton, 1969, 1970), asumen que la frecuencia se codifica a través de los umbrales de activación de los dispositivos de reconocimiento de palabras (logogens). Debido a la

Cap. 1 Factores que influyen en el reconocimiento de las palabras...
3
mayor probabilidad de experiencia, las palabras de alta frecuencia ten-drán menores umbrales de activación que las de baja frecuencia. Por tanto, la información para las palabras de alta frecuencia supera con mayor facilidad un umbral de reconocimiento de palabras, activando su respectivo logogen.
Por otra parte, el modelo de doble ruta de Coltheart, Rastle, Perry, Langdon y Ziegler (2001) interpreta de diferente manera el efec- to de la frecuencia de uso de una palabra. Este modelo capta apro-piadamente este efecto a través de los patrones de activación de una ruta a la que llama léxica. Las palabras conocidas o con mayor fre-cuencia podrán reconocerse vía la ruta léxica sin necesidad de frag-mentar la palabra en sílabas y pasar del grafema al fonema como sucedería con las palabras no conocidas o de baja frecuencia. Los modelos de Seidenberg y McClelland (1989) y Plaut, McClelland, Seidenberg y Paterson (1996) por su parte, asumen que la frecuen- cia se codifica en los pesos asociados con las conexiones entre las unidades léxicas. También, existen modelos híbridos (Zorzi, Hough-ton & Butterworth, 1998) que implementan el procesamiento léxico y subléxico utilizando principios conexionistas, y así, en ambos tipos de procesamiento podrían surgir efectos de la frecuencia.
Vecindad ortográficaSi bien las estimaciones varían, es probable que el lector adulto pro-medio tenga cerca de 50 mil palabras en su vocabulario (Cortese & Balota, 2012). Debido a que éstas se basan en un número limitado de letras, debe existir una considerable sobreposición en los patrones ortográficos a través de las diferentes palabras. Es importante tomar en cuenta que las palabras parecen no ser reconocidas en forma ais-lada de otras ortográficamente relacionadas. Otro de los factores que afecta de manera considerable el reconocimiento de las palabras es la vecindad ortográfica, es decir, cómo el sistema lingüístico seleccio na la representación léxica correcta entre el vecindario de términos parecidos ortográficamente.

4
LEXMEX: diccionario de frecuenciasdel español de México
Coltheart, Davelaar, Jonasson y Besner (1977) introdujeron el concepto de vecindario ortográfico o métrica N. El parámetro N se refiere al número de palabras que pueden ser generadas median-te el cambio de una sola letra en cada una de las posiciones dentro de un término. Por ejemplo, los vecinos ortográficos de casa pue-den ser pasa, caza, cava, por mencionar algunos. Pero, ¿qué influen-cia tiene N en el reconocimiento de palabras? En primer lugar, se ha considerado la influencia de la gran cantidad de vecinos orto-gráficos. Al usar una tarea de nominación, los resultados son claros: conforme aumenta el número de vecinos ortográficos, disminuye la latencia de respuesta, y este efecto es mayor para los términos de baja que para los de alta frecuencia (Andrews, 1992; Balota, Cor-tese, Sergent-Marshall et ál., 2004). En contraste, en la ejecución de una tarea de decisión léxica (i.e., tarea en la que se decide si el estímulo presentado es o no una palabra real), el incremento en N aumenta las latencias de respuesta para el caso de las no palabras (i.e., vocablos inventados que conservan las características fono-tácticas de uno real), mientras que para las palabras, los resultados van desde facilitación (Forster & Shen, 1996) hasta ningún efec- to (Coltheart et ál., 1977), y en algunas otras condiciones incluso se producen efectos inhibitorios ( Johnson & Pugh, 1994).
En una excelente revisión de esta literatura, Andrews (1997) argu-mentó que la varianza en los estudios del tamaño de la vecindad ortográfica en la tarea de decisión léxica, al parecer, se debe a la va-riabilidad en los contextos de la lista de estímulos (i.e., el tipo de no palabras). También, es necesario señalar que no existe evidencia de efectos facilitadores de las N de grandes dimensiones en estudios de clasificación semántica (Sears, Hino & Lupker, 1999a). Por últi-mo, se debe mencionar que la evidencia de los patrones de fijación ocular, mientras el sujeto está leyendo, indica que existe un efec- to inhibidor con una N grande. Pollatsek, Perea y Binder (1999) demostraron que, con un mismo conjunto de palabras y usando dos tipos distintos de evaluación, se pueden producir efectos de facilita-ción en la tarea de decisión léxica y efectos de inhibición en la fijación

Cap. 1 Factores que influyen en el reconocimiento de las palabras...
5
ocular. Claramente, los efectos de N ortográficas son dependien- tes en gran medida de las limitaciones de la tarea, y lo más probable es que sean también dependientes de otras variables, como la veloci-dad de procesamiento individual (Balota et ál., 2004).
Otra manera de investigar la influencia de los vecindarios ortográ-ficos es considerar la frecuencia de los vecinos. En la ejecución de la tarea de decisión léxica, hay pruebas de que los estímulos blanco con vecinos de alta frecuencia tienden a producir inhibición en com-paración con las palabras con vecinos de frecuencia más baja (Grain- ger & Jacobs, 1996; Carreiras, Perea & Grainger, 1997; Pollatsek et ál., 1999). Sin embargo, en una serie de experimentos que involu-craban tanto nominación como ejecución en una tarea de decisión léxica, Sears, Hino y Lupker (1995) encontraron facilitación para los estímulos blanco de baja frecuencia con vecindarios grandes y veci-nos de alta frecuencia.
No sorprende que tanto la frecuencia de los vecinos como el tamaño de los vecindarios desempeñen un papel en las tareas de reconoci-miento de palabras. En este sentido, sería útil considerar la media de la frecuencia de los vecinos. Esto se refiere a la probabilidad de identificar una palabra, que es igual a la probabilidad de ésta dividi-da por sí misma, más las probabilidades combinadas de sus vecinos. Por supuesto, es posible que a su vez, los vecindarios de los veci- nos ortográficos puedan desempeñar un papel junto con el grado de sobreposición de los vecinos. En este nivel, destaca que las si-mulaciones de Sears, Hino y Lupker (1999b) han demostrado que tanto el modelo de Plaut et ál. (1996) como el de Seidenberg et ál. (1989) parecen predecir efectos de facilitación en relación con el tamaño de la vecindad: mayores para las palabras de baja y menores para las de alta frecuencia, lo que en general, tiene mayor coheren-cia con los datos en esta área.
Efectos facilitadores locales para las palabras de baja frecuencia pa-recen ser difíciles de acomodar dentro de los modelos que tienen

6
LEXMEX: diccionario de frecuenciasdel español de México
un componente competitivo de activación interactiva; ejemplo de lo anterior es el modelo de Coltheart et ál. (2001) o el de la lectura múltiple MROM de Grainger et ál. (1996). En concreto, entre más grande es el vecindario ortográfico, la competencia para el reconoci-miento debe ser más fuerte.
Por otra parte, los efectos facilitadores de N producen dificulta- des para los modelos de búsqueda en serie, como el modelo clási- co de Forster. Específicamente, mientras más ítems existan en el es-pacio de búsqueda, la latencia de respuesta debe ser más lenta. Esto es opuesto al patrón común reportado en la literatura. Una variación interesante sobre la influencia ortográfica de N es el efecto de tras-posición de letras. Chambers (1979) y Andrews (1996) encontraron que palabras como crea producen latencias de respuesta más lentas en la ejecución de una tarea de decisión léxica, ya que estos ele-mentos tienen un competidor muy similar: cera. Andrews (1996) también encontró este patrón en tareas de nominación. Cabe tener en cuenta que crea no es un vecino ortográfico de cera pero es simi-lar, ya que dos caracteres en posiciones adyacentes se intercambian.
Como Perea y Lupker (2003) han argumentado, la influencia de los estímulos de letras traspuestas es incompatible con la mayor parte de los modelos disponibles de reconocimiento de léxico, pues estos mo-delos típicamente codifican las posiciones dentro de las palabras. Estos resultados son consistentes con los modelos más recientes de codifi-cación de entrada, como solar (Davis, 1999) y SERIOL (Whitney, 2001) que utilizan esquemas espaciales de codificación para la entrada de letras, que no codifican sólo la posición específica (Davis & Bowers, 2004). Es claro que esta es una nueva e importante área de investiga-ción que extiende el trabajo original de los efectos ortográficos N y que tiene ramificaciones importantes acerca de cómo el sistema visual codifica la posición espacial de las letras dentro de las palabras.

Cap. 1 Factores que influyen en el reconocimiento de las palabras...
7
Vecindad fonológicaSi bien la influencia de los vecinos ortográficos ha dominado en el campo del reconocimiento visual de las palabras, es posible que la vecindad fonológica pueda desempeñar un papel significativo. De hecho, el trabajo de Yates, Locker y Simpson (2004) ha demostrado que, durante una tarea de decisión léxica, la ejecución se ve facilita-da por palabras que tienen grandes vecindarios fonológicos (Yates, 2005). Aquí, un vecino fonológico refleja un cambio en un fonema, por ejemplo, pato tiene los vecinos bato, dato, plato, entre otros. Yates et ál. (2004) señalaron que los estudios anteriores sobre el tamaño de la vecindad ortográfica han mezclado, normalmente, los efec- tos de la vecindad y el tamaño del vecindario fonológico con los del ortográfico. Es importante reconocer el papel de la codificación fonológica en los procesos de acceso al léxico y sus implicaciones en el reconocimiento de las palabras (Ziegler & Perry, 1998).
Si la distinción fonológica desempeña un papel funcional en la ruta hacia el reconocimiento de palabras, entonces, se esperaría también un papel funcional para la sílaba. Al respecto, sorprende el conside-rable desacuerdo sobre el papel de la sílaba en dicho reconocimiento. Algunos autores han encontrado que la frecuencia de la sílaba en el idioma español influye de manera notable en el reconocimiento de las palabras (Vega, Carreiras, Gutiérrez-Calvo et ál., 1990; Ca-rreiras, Vergara & Barber, 2005), mientras que Jared y Seidenberg (1990) han cuestionado el papel de la sílaba como unidad sublexical. De hecho, como Seidenberg (1987) ha señalado, incluso hay cier- to desacuerdo en cuanto a la existencia misma de los límites silábi-cos. Varios autores (Carreiras et ál., 2005; Taft et ál., 2007) han re-velado que en el español, la frecuencia de la sílaba ‒que interactúa con la frecuencia de uso de la palabra‒ influye en la lectura de mane- ra notable. Se ha propuesto también que la estructura consonan- te-vocal de las palabras y su frecuencia en el español tiene un efecto importante en el reconocimiento visual (Duñabeitia & Carreiras, 2011; Duñabeitia, Kinoshita, Carreiras & Norris., 2011; Vergara-Martínez et ál., 2011).

8
LEXMEX: diccionario de frecuenciasdel español de México
Otra unidad sublexical que ha recibido considerable atención en la literatura es el morfema. Una de las razones más convincentes de que los morfemas pueden jugar un papel funcional en el reconoci-miento de palabras es la naturaleza generativa del lenguaje. Rapp (1992) presenta un interesante ejemplo con el término chummily, que parece tener la forma morfológica chummy + ly, pero chummy es un adjetivo que significa familiar y no puede llevar la termina-ción ly. Por eso, aunque es posible que no nos encontremos con esta palabra, podremos asumir que significa algo similar a “de una manera amistosa”.
Modelos lingüísticos de representación léxica asumen la existencia de alguna forma de representación base y un conjunto de reglas que se utilizan para construir otras a partir de ese elemento. La pregunta real es si una forma de una palabra como amigable se analiza como amiga + ble, hacia el reconocimiento de la palabra. Al igual que ocurre con las sílabas, no cuestionamos si los morfemas están representados en el sistema de procesamiento; la pregunta es si el análisis morfé-mico juega un papel en los procesos vinculados al reconocimiento visual de palabras. Gran parte de los primeros trabajos teóricos y em-píricos sobre el papel del morfema en dicho reconocimiento fueron desarrollados originalmente por Taft y Forster (1975, 1976) y Taft (1979a, 1979b, 1985, 1987), quienes argumentaron que los lectores primero descomponen los términos en sus morfemas constituyen- tes para luego acceder al léxico.
Además de los factores antes mencionados, cabe preguntarse si exis-te un efecto de derivado de la longitud de la palabra que también influya en el reconocimiento. Es lógico que si la letra juega un papel fundamental, entonces, se deben encontrar efectos consistentes de la longitud de la palabra (i.e., número de letras por palabra). Resulta curioso el que no ha surgido desacuerdo en este tema. Existen claras pruebas de que para la identificación de términos más largos se usa más tiempo (McGinnies, Comer & Lacey, 1952) y que éstos produ-cen mayor duración de la fijación de la mirada en la lectura ( Just &

Cap. 1 Factores que influyen en el reconocimiento de las palabras...
9
Carpenter, 1980). Sin embargo, el efecto de la longitud en las tareas de decisión léxica y de nominación muestran resultados poco con-sistentes (New, Ferrand, Pallier & Brysbaert, 2006).
El papel de la longitud de la palabra en la nominación ha sido el foco de una serie de estudios recientes. Por ejemplo, Gold et ál. (2005), encontraron que los pacientes con una pérdida de la entra-da semántico-léxica producen efectos exagerados de longitud, en comparación con pacientes con demencia de tipo Alzhéimer. Los autores sugieren que estos resultados pueden apoyar una mayor de-pendencia de la ruta sublexical en personas con demencia semánti-ca. De acuerdo con lo anterior, Weekes (1997) encontró efectos de longitud para términos sin significado (pseudopalabras) y ningún efecto para las palabras que sí lo poseen. Coltheart et ál. (2001), por su parte, interpretaron estos resultados como críticas a su modelo de ruta dual, es decir, los efectos pequeños de longitud para las pa-labras se deben a una vía paralela usada en la ruta léxica, mientras que los efectos grandes de longitud para las no palabras reflejan el análisis en serie que demanda la ruta subléxica. En un estudio de ejecución acelerada de nominación de más de 2 400 palabras de una sílaba, Balota et ál. (2004) obtuvieron efectos claros de longi-tud que fueron modulados por la frecuencia de los términos. Más aún, las palabras de baja frecuencia produjeron mayores efectos de longitud que las de uso frecuente.
Existe cierta controversia sobre los efectos de la longitud en la tarea de decisión léxica. Debido a que ésta se ha tomado como la princi-pal tarea en el desarrollo de modelos de reconocimiento, se trata de un hallazgo problemático (Henderson, 1982). Chumbley y Balota (1984) reportaron efectos de longitud relativamente grandes en la tarea de decisión léxica cuando las palabras y no palabras se equi-paraban en longitud y regularidad. Es posible que los resultados in-consistentes de las pasadas investigaciones sobre los efectos de la longitud durante la decisión léxica se deban a la utilización de un rango relativamente pequeño de longitud. En este sentido, el estudio

10
LEXMEX: diccionario de frecuenciasdel español de México
de New et ál. (2006) centró su análisis en los efectos de longitud en un conjunto de datos de latencias durante la decisión léxica de 33 006 palabras tomadas de Balota et ál. (2002). Ellos encontraron una interesante relación cuadrática entre la longitud y el desempeño en la decisión léxica, de manera que intervino un efecto facilitador para palabras de 3 a 5 letras, un efecto nulo de 5 a 8 letras y un claro efecto inhibitorio de 8 a 13 letras. Las palabras largas parecen exigir algún tipo de procesamiento en serie, mientras que las cortas, curio-samente, indican que pueden tener una longitud ideal ‒basada en la longitud media de las palabras‒, y las más cortas, de hecho, pueden producir una disminución en el rendimiento.
Por último, debe señalarse que la frecuencia de uso parece modular el efecto de la longitud tal como lo reportaron Balota et ál. (2004), donde los efectos de longitud eran más grandes en las decisiones lé-xicas para palabras de baja frecuencia que para las de alta, un patrón similar al obtenido en la nominación, que se mencionó en párrafos anteriores. Por tanto, los efectos de la longitud en la ejecución de ta-reas de decisión léxica parecen depender tanto de la frecuencia como de la longitud particular de cada palabra.
ReferenciasAndrews, S. (1992). Frequency and neighborhood effects on lexical access: lexical similar-
ity orthographic redundancy? Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 234-254.
__________. (1996). Lexical retrieval and selection processes: effects of transposed-letter confusability. Journal of Memory and Language, 35, 775-800.
__________. (1997). The effect of orthographic similarity on lexical retrieval: resolving neighborhood conflicts. Psychonomic Bulletin and Review, 4, 439-461.
Balota, D. & Chumbley, J. (1984). Are lexical decision a good measure of lexical access? The role of word frequency in the neglected decision stage. Journal of Experimental Psychology, Human Perception and Performance, 10, 340.
Balota, D., Cortese, M., Hutchison, K., Neely, J., Nelson, D., Simpson, G. & Treiman, R. (2002). The English Lexicon Project: A Web-Based Repository of Descriptive and Be-havioral Measures for 40,481 English Words and Nonwords. Disponible en Washington University Web Site: http://elexicon.wustl.edu. Consultado el 30 de enero de 2004.

Cap. 1 Factores que influyen en el reconocimiento de las palabras...
11
Balota, D., Cortese, M., Sergent-Marshall, S., Spieler, D. & Yap, M. (2004). Visual word recognition of single-syllable words. Journal of Experimental Psychology: General, 133, 283-316.
Balota, D., Yap, M. & Cortese, M. (2006). “Visual Word Recognition: The Journey from Features to Meaning (A Travel Update).” In M. Traxler & M. Gernsbacher, Hand-book of Psycholinguistics (pp. 285-376). uk: Elsevier.
Behrmann, M., Plaut, D. & Nelson, J. (1998). A literature review and new data supporting an interactive account of letter-by letter reading. Cognitive Neuropsychology, 15, 7-51.
Broadbent, D. (1967). Word-frequency effects and response bias. Psychological Review, 74, 1-15.
Carreiras, M., Baquero, S. & Rodríguez, E. (2008). Syllabic processing in visual word recognition in Alzheimer patients, the elderly and young adults. Aphasiology, 22, 1176-1190.
Carreiras, M., Perea, M. & Grainger, J. (1997). Effects of the orthographic neighborhood in visual word recognition: Cross-task comparisons. Journal of Experimental Psycholo- gy: Learning, Memory, and Cognition, 23, 857-871.
Carreiras, M., Vergara, M. & Barber, H. (2005). Early event-related potential effects of syllabic processing during visual word recognition. Journal of Cognitive Neuroscience, 17, 1803-1817.
Chambers, S. (1979). Letter and order information in lexical access. Journal of Verbal Learning and Verbal Behavior, 18, 225-241.
Chumbley, J. & Balota, D. (1984). A word’s meaning affects the decision in lexical deci-sion. Memory and Cognition, 12, 590-606.
Coltheart, M., Davelaar, E., Jonasson, J. & Besner, D. (1977). “Access to the internal lexicon.” In S. Dornic (Ed.). Attention and performance VI (pp. 535-555). Hills-dale, NJ: Erlbaum.
Coltheart, M., Rastle, K., Perry, C., Langdon, R. & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204-256.
Cortese, M. & Balota, D. (2012). “Visual word recognition in skilled adult readers”. In M. Joanisse & K. McRae (Eds.). Cambridge Handbook of Psycholinguistics (pp. 1-62). Washington University.
Davis, C. (1999). The Self-Organizing Lexical Acquisition and Recognition (solar) model of visual word recognition. Doctoral dissertation. University of New South Wales, Sydney, New South Wales, Australia. Dissertation Abstracts International, 62, 594. Disponible en www.maccs.mq.edu.au/~colin/thesis.zip Consultado el 6 de marzo de 2006.
Davis, C. & Bowers, J. (2004). What do letter migration errors reveal about letter position coding in visual word recognition? Journal of Experimental Psychology: Human Percep-tion and Performance, 30, 923-941.

12
LEXMEX: diccionario de frecuenciasdel español de México
Duñabeitia, J. & Carreiras, M. (2011). The relative position priming effect depends on whether letters are vowels or consonants. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37, 1143-1163.
Duñabeitia, J., Kinoshita, S., Carreiras, M. & Norris, D. (2011). Is morpho-ortho-graphic decomposition purely orthographic? Evidence from masked priming in the same-different task. Language and Cognitive Processes, 26, 509-529.
Forster, K. & Chambers, S. (1973). Lexical access and naming time. Journal of Verbal Learning and Verbal Behavior, 12, 627-635.
Forster, K. & Shen, D. (1996). No enemies in the neighborhood: Absence of inhibitory neighborhood effects in lexical decision and semantic categorization. Journal of Ex-perimental Psychology: Learning, Memory and Cognition, 22, 696-713.
Gold, B., Balota, D., Cortese, M., Sergent-Marshall, S., Snyder, A., Salat, D., Fischl, B., Dale, A., Morris, J. & Buckner, R. (2005). Differing neuropsychological and neu-roanatomical correlates of abnormal reading in early-stage semantic dementia and dementia of the Alzheimer type. Neuropsychologia, 43, 833-846.
Grainger, J. & Jacobs, A. (1996). Orthographic processing in visual word recognition: A multipleread-out model. Psychological Review, 103, 518-565.
Henderson, L. (1982). Orthography and word recognition in reading. London: Aca-demic Press.
Hino, Y. & Lupker, S. (2000). The effects of word frequency and spelling-to-sound regu-larity in naming with and without preceding lexical decision. Journal of Experimental Psychology: Human Perception and Performance, 26, 166-183.
Howes, D. (1954). On the interpretation of word frequency as a variable affecting speed of recognition. Journal of Experimental Psychology, 48, 106.
__________. (1957). On the relationship between intelligibility and frequency word occurrence of English words. Journal of Acoustic of Society of America, 29, 296.
Jared, D. & Seidenberg, M. (1990). Naming multisyllabic words. Journal of Experimental Psychology: Human Perception and Performance, 16, 92-105.
Johnson, N. & Pugh, K. (1994). A cohort model of visual word recognition. Cognitive Psychology, 26, 240-346.
Just, M. & Carpenter, P. (1980). A theory of reading: From eye fixations to comprehen-sion. Psychological Review, 87, 329-354.
McGinnies, E., Comer, P. & Lacey, O. (1952). Visual-recognition thresholds as a function of word length and word frequency. Journal of Experimental Psychology, 44, 65-69.
Monsell, S. (1991). “The nature and locus of word frequency effects in reading”. In D. Besner & G. Humphreys (Eds.). Basic processes in reading: Visual word recognition (pp. 148-197). Hillsdale, NJ: Lawrence Erlbaum Associates.
Morton, J. (1969). The interaction of information in word recognition. Psychological Review, 76, 165-178.

Cap. 1 Factores que influyen en el reconocimiento de las palabras...
13
_________. (1970). “A functional model for memory”. In D. Norman (Ed.). Models of human memory (pp. 203-254). New York: Academic Press.
New, B., Ferrand, L., Pallier, C. & Brysbaert, M. (2006). Re-examining word length effects in visual word recognition: New evidence from the English Lexicon Project. Psychonomic Bulletin and Review, 13, 45-52.
Perea, M. & Lupker, S. (2003). “Transposed-letter confusability effects in masked form priming”. In S. Kinoshita & S. Lupker (Eds.). Masked priming: State of the art (pp. 97-120). Hove, uk: Psychology Press.
Plaut, D., McClelland, J., Seidenberg, M. & Patterson, K. (1996). Understanding nor-mal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103, 56-115.
Pollatsek, A., Perea, M. & Binder, K. (1999). The effects of neighborhood size in reading and lexical decision. Journal of Experimental Psychology: Human Perception and Per-formance, 25, 1142-1158.
Rapp, B. C. (1992). The nature of sublexical orthographic organization: The bigram trough hypothesis examined. Journal of Memory & Language, 31, 33-53.
Rayner, K. (2009). Eye movements and attention in reading, scene perception and visual search. The Quarterly Journal of Experimental Psychology, 62, 1457-1506.
Schilling, H., Rayner, K. & Chumbley, J. (1998). Comparing naming, lexical decision, and eye fixation times: Word frequency effects and individual differences. Memory and Cognition, 26, 1270-1281.
Sears, C., Hino, Y. & Lupker, S. (1995). Neighborhood size and neighborhood frequency effects in word recognition. Journal of Experimental Psychology: Human Perception and Performance, 21, 876-900.
__________. (1999a). Orthographic neighborhood effects in perceptual identification and semantic categorization tasks. Perception & Psychophysics, 61, 1537-1554.
__________. (1999b). Orthographic neighborhood effects in parallel distributed pro- cessing models. Canadian Journal Experimental Psychology, 53, 220-229.
Seidenberg, M. (1987). “Sublexical structures in visual word recognition: Access units or orthographic redundancy?” In M. Coltheart (Ed.). Attention and performance XII: The psychology of reading (pp. 245-263). Hillsdale, NJ: Erlbaum.
Seidenberg, M. & McClelland, J. (1989). A distributed developmental model of word recognition and naming. Psychological Review, 96, 523-568.
Taft, M. (1979a). Recognition of affixed words and the word frequency effect. Memory and Cognition, 7, 263-272.
__________. (1979b). Lexical access via an orthographic code: The Basic Orthographic Syllabic Structure (boss). Journal of Verbal Learning and Verbal Behavior, 18, 21-39.
__________. (1985). “The decoding of words in lexical access: A review of the morpho-graphic approach”. In D. Besner, T. Waller & G. MacKinnon (Eds.). Reading research: Advances in theory and practice (Vol. 5, pp. 83-123). Orlando, FL: Academic Press.

14
LEXMEX: diccionario de frecuenciasdel español de México
__________. (1987). “Morphographic processing: The boss Re-emerges”. In M. Coltheart (Ed.). Attention and performance XII: The psychology of reading (pp. 265-279). Hills-dale, NJ: Erlbaum.
Taft, M., Alvarez, C. & Carreiras, M. (2007). Cross-language differences in the use of internal orthographic structure when reading polysyllabic words. The Mental Lexicon, 2, 49-63.
Taft, M. & Forster, K. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal Learning and Verbal Behavior, 14, 638-647.
__________. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. Journal of Verbal Learning and Verbal Behavior, 15, 607-620.
Vega, M., de Carreiras, M., Gutiérrez-Calvo, M. y Alonso-Quecuty, M. (1990). Lectura y comprensión. Una perspectiva cognitiva. Madrid: Alianza Psicología.
Vergara-Martínez, M., Perea, M., Marín, A. & Carreiras, M. (2011).The processing of consonants and vowels during letter identity and letter position assignment in vi-sual-word recognition: An ERP study. Brain and Language, 118, 105-117.
Weekes, B. (1997). Differential effects of number of letters on word and nonword naming latency. Quarterly Journal of Experimental Psychology: Human Experimental Psycholo-gy, 50A, 439-456.
Whitney, C. (2001). How the brain encodes the order of letters in a printed word: The se-riol model and selective literature review. Psychonomic Bulletin and Review, 8, 221-243.
Yates, M. (2005). Phonological neighbors speed visual word processing: Evidence from multipletasks. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 1385-1397.
Yates, M., Locker, L. & Simpson, G. (2004). The influence of phonological neighborhood on visual word perception. Psychonomic Bulletin and Review, 11, 452-457.
Ziegler, J. & Perry, C. (1998). No more problems in Coltheart’s neighborhood: resolving neighborhood conflicts in the lexical decision task. Cognition, 68, 53-62.
Zorzi, M., Houghton, G. & Butterworth, B. (1998). Two routes or one in reading aloud? A connectionist dual-process model. Journal of Experimental Psychology: Human Per-ception and Performance, 24, 1131-1161.

2Estudios lexicográficos en español.
Características del corpus de los diccionarios
L a frecuencia de uso de las palabras escritas se obtie- ne al colectarlas de un conjunto representativo de tex-tos que, se sabe, son leídos por un determinado gru-
po de lectores. Las bases de datos así obtenidas se presentan como diccionarios de frecuencia. Existen múltiples trabajos que reportan el estudio de la frecuencia de uso de las palabras en idiomas como el inglés (Carroll, Davies & Richman, 1971; Francis & Kucera, 1982; Kucera & Francis, 1967; Thorndike & Lorge, 1944), alemán, holan-dés (Baayen, Piepenbrock & Gulikers, 1995), francés (Imbs, 1971) y chino (Beijing Language College, 1986). Dos de los más citados en la literatura internacional, que contienen el léxico del adulto, son el Computational Analysis of Present-Day American English (Kucera & Francis, 1967) y el Celex lexical database, diccionario de inglés, holan-dés y alemán (Baayen et ál., 1995).
Si bien la lengua española es la lengua materna de más de 300 millo-nes de personas en el mundo, son escasos los estudios de frecuencia

16
LEXMEX: diccionario de frecuenciasdel español de México
para este idioma (Davis & Perea, 2005), y los que existen tienen li-mitaciones para ser usados en otro país que no sea el de origen, como es el caso de los diccionarios creados en España, de donde procede la mayor parte de los estudios. Por ello, tratar de utilizar en México un diccionario de frecuencias del español generado en España es algo que se debe tomar con serias reservas, aunque se trate de la misma lengua. Tal es el caso del Léxico informatizado del español (Lexesp) de Sebastián-Gallés, Martí, Cuetos y Carreiras (2000), realizado en España y que presenta diversas limitaciones en cuanto a su repre-sentatividad y, por ende, en su utilidad para otro medio. Las más importantes son las diferencias lingüísticas entre el lugar donde se realiza el estudio y donde se van a utilizar sus resultados. Ejemplo de lo anterior son los frecuentes regionalismos del lugar de pro-cedencia que no se usan en el lugar donde se pretende emplear el material verbal y, por el contrario, se dejan de incluir otros de mayor uso para dicha región.
Aun cuando el Lexesp está elaborado en español, y en la población mexicana se puedan tener similitudes en la frecuencia de uso de algu-nas palabras, no es aplicable del todo en nuestro país, ya que muchos términos utilizados de manera frecuente por el mexicano hispanoha-blante no aparecen en Lexesp, por el contrario, aparecen otras tantas que no le son conocidas. Pongamos el caso de camellón, en Méxi- co significa la parte central que divide una calle a la mitad por sus dos sentidos de vialidad. En España no se entiende en lo absoluto porque no existe en su léxico. De manera que para esa palabra no se encontra-rá valor de frecuencia de uso, por más que el corpus sea lo suficiente-mente grande como lo es el Lexesp.
Sin embargo, Lexesp es uno de los diccionarios de frecuencias más actualizados, completos y usados del léxico en español. Original-mente, contaba con un total de 166 494 entradas independientes con sus respectivas frecuencias (el corpus es de alrededor de cinco mi-llones de palabras). No obstante, un gran número de entradas son nombres propios (i.e., Martínez), palabras relacionadas con guiones

Cap. 2 Estudios lexicográficos en español. Características del corpus...
17
(i.e., el rey-de-España) o palabras que no pertenecen al idioma es-pañol (i.e., Oosterschelde); otras entradas contienen caracteres no alfabéticos (i.e., ‘frica) y, algunos de ellos, ni siquiera son pronun-ciables (i.e., grrrrrr, zzpldos).
Para filtrar el corpus Lexesp, se cotejaron sus entradas con las léxicas del diccionario de la Real Academia Española (rae; edición elec-trónica; Real Academia de la Lengua, 1995). En primer lugar, se excluyeron las entradas del corpus que no figuraban en el diccionario de la rae. Esto eliminó faltas de ortografía, abreviaturas no léxicas y otras rarezas lingüísticas. En segundo lugar, las entradas léxicas en el diccionario de la rae con una frecuencia de cero también fue-ron eliminadas, lo que incluyó palabras de frecuencia baja que no es probable que estén en la mayor parte de los léxicos internos de las personas (i.e., la palabra mizo). En tercer lugar, dado que la mayor parte de los experimentos en los que se utilizan estímulos verbales emplean palabras que son de tres a 12 letras de longitud, sólo se incluyeron en el diccionario las palabras en este rango. Finalmen- te, el número total de palabras incluidas en el diccionario Lexesp fue de 31 491 entradas. Para cada una, se tiene una serie de índices estadísti-cos objetivos: frecuencia de uso, pronunciación y la posición del acento léxico. De acuerdo con lo anterior, la base de datos actual no incluye la gran variedad de formas conjugadas de cada verbo en español.
B-Pal (Davis et ál., 2005) es un programa computacional que ofrece una serie de índices útiles para la investigación sobre el lenguaje a partir del corpus Lexesp, como son los relativos a la ortografía y los vecinos ortográficos; así como la fonología y los vecinos fonológi- cos. Además, claro, de la información de frecuencia de uso de las palabras del corpus. En lo que se refiere a la ortografía, la mayor par- te de las estadísticas son medidas de la frecuencia del bigrama, que dependen de la posición y la longitud. Pero, ¿qué significa un bi-grama? Ejemplo de lo anterior es el estímulo gato que contiene tres bigramas (ga, at, to). Para el primero de éstos (ga), la frecuencia de

18
LEXMEX: diccionario de frecuenciasdel español de México
bigramas correspondiente se basa en el número (y frecuencia) de palabras de cuatro letras que comienzan con ga; esto es, la frecuen-cia para ga es de 15 (que incluye palabras como gafa, gafe, gala, entre otras), y la frecuencia muestra es la suma de las frecuencias de esas 15 palabras. B-Pal también puede utilizar estas frecuencias de bigrama para calcular una variedad de medidas de resumen. Por último, las medidas ortográficas proveen del número de letras en el estímulo, así como una descripción sencilla de la cadena ortográfica de letras consonante-vocal (i.e., gato tiene una estructura CVCV).
B-Pal también ofrece índices estadísticos de la fonología de las palabras. Se incluye información sobre su pronunciación, su fonema ini cial, sus patrones de estrés, el número de fonemas y sílabas que las componen, y si tienen algún homófono. Si esto último es el caso, la ortografía de este homófono es la salida (i.e., bello para la pala-bra vello, pues las letras b y v se pronuncian como /b/ en español). El programa también ofrece una descripción sencilla de la cadena fonológica de letras consonante-vocal. Por ejemplo, gato tiene una es- tructura CVCV, mientras que hato (/Øa-to/) tiene una estructu- ra VCV. La fonología del programa por defecto es la incluida en el Le-xesp, que es la común a la mayor parte de las regiones de España. Así, la letra z se pronuncia como / / en la mayor parte de España, pero se pronuncia como /s/ en las regiones del sur de España y en las Islas Ca-narias, así como en América Latina; es decir, las palabras caza y casa son homófonos para un hablante de México, pero no para uno de Madrid.
En las combinaciones ce y ci, de igual manera, la letra c se pronuncia como / / en la mayor parte de las regiones de España (y aparecen así en los códigos fonológicos de Lexesp), pero se pronuncia como /s/ en el sur de España, las islas Canarias y Latinoamérica. B-Pal también ofrece estadísticas de frecuencia para bi-fonos, que se calcu- lan de la misma manera que para la frecuencia de bigramas, con la excepción de que se basan en códigos fonológicos.
El libro Frecuencias del español. Diccionario de estudios léxicos y mor-fológicos (Almela, Cantos, Sánchez & Almela, 2005) está basado en

Cap. 2 Estudios lexicográficos en español. Características del corpus...
19
el Corpus Cumbre (propiedad de SGEL sa). Este corpus, basa- do en 20 millones de palabras, recoge fragmentos variados de textos orales y escritos recientes de España e Hispanoamérica. Debido al volumen de textos y palabras que contiene y por sus variadas pro-cedencias, puede ser considerado representativo del español actual. Una desventaja de este diccionario, además de la ya señalada (falta de regionalismos propios de la población de estudio donde se aplicará el diccionario), es que tendría que crearse un programa de cómpu-to especial para obtener las medidas estadísticas que nos ofrece el B-Pal. Esto significa que Frecuencias del español no contiene medidas de la estructura ortográfica o fonológica, ni medidas de vecindad.
La versión más completa y actual de un diccionario de frecuencias de la lengua española, y que permite obtener múltiples índices úti- les en el estudio del reconocimiento de las palabras, es el diccionario llamado Espal de reciente aparición (Duchon et ál., en prensa), que se basa en un conjunto ampliable de fuentes de términos, a partir de una base de datos de 300 millones de palabras escritas y otra de 460 millones de palabras provenientes de subtítulos de películas. Se incluyen propiedades como la frecuencia de ocurrencia de los tér- minos; estructura ortográfica y vecindario; estructura fonológica y vecindario, y calificaciones subjetivas como la imaginabilidad. Ade-más, contiene propiedades de la estructura subléxica en términos de bigramas y trigramas, bifonos y bisílabas. También, se presentan índices de la información del lema con su frecuencia de uso.
Para el acceso a la información del diccionario, se creó un sitio web que permite a los usuarios cargar un conjunto de palabras para re-cibir en respuesta las propiedades léxicas antes mencionadas. En el Espal, el procesamiento de la palabra y de las propiedades subléxi-cas se lleva a cabo mediante un programa de varios pasos ‒escrito en Java‒, los cuales calculan no sólo las propiedades básicas de los términos, como su frecuencia y su estructura, sino también los diversos índices y propiedades sobre vecindad, que se recuperarán si el usuario así lo requiere. Un esfuerzo similar es el Syllabarium

20
LEXMEX: diccionario de frecuenciasdel español de México
(Duñabeitia et ál., 2010), que es una herramienta basada también en la web para acceder a una base de datos que contiene infor mación sobre las frecuencias de palabras y frecuencias de sílabas, así como la posición de éstas.
Por otra parte, un número importante de estudios ha demostrado que, a través de diversas lenguas, las frecuencias de palabras derivadas de corpora provenientes de subtítulos de películas proporcionan una buena imagen de los diversos efectos psicolingüísticos (Brysbaert, New & Keuleers, 2012; Cai, & Brysbaert, 2010; Cuetos-Vega, Gon-zález-Nosti, Barbón-Gutiérrez & Brysbaert, 2011; Dimitropoulou et ál., 2010; Keuleers, Brysbaert & New, 2010; New, Brysbaert, Ve-ronis & Pallier, 2007). Sin embargo, en el pasado reciente ha sido común el uso de las propiedades de los corpora de textos escritos, que hasta el momento han podido predecir algunos fenómenos en psicolingüística, por lo que es muy útil contar con diferentes fuen-tes de información, en función de la investigación o el estudio que se quiera realizar.
Al parecer, el Espal cumple bien con este objetivo, mediante la apli-cación del mismo programa para la extracción de propiedades léxicas a un corpus basado en los subtítulos de películas y otro basado en textos escritos.
El corpus de textos escritos del Espal se deriva de una amplia selec-ción de textos recogidos de la web o en formato digital, en los que se incluyen nueve subgrupos en función de su contenido: academia, cultura, derecho, filosofía, literatura, prensa, política, sociedad y Wi-kipedia en español. La mayor parte de los documentos fueron reco-pilados de sitios web que ofrecen una variedad de estilos lingüísticos, incluyendo el lenguaje formal, coloquial y especializado. En cambio, de un total de 100 659 archivos de subtítulos en español (que se obtuvieron de www.opensubtitles.org), el corpus de subtítulos de pe-lículas suministró una diversa cantidad de información al diccionario Espal. Las películas aportaron el 65.6% de los archivos, el resto fue

Cap. 2 Estudios lexicográficos en español. Características del corpus...
21
de episodios de televisión hablados en inglés y en francés. Agrupadas por género, las palabras provenían en mayor medida de drama, co-media, suspenso, crimen, acción, romance, misterio y aventura.
Por último, para el español de México existe el trabajo Investiga-ciones lingüísticas sobre lexicografía (Lara, Ham y García, 1979), que es el más completo en su tipo en nuestro país. Se realizó sobre una muestra de diversos textos de los años 70 del siglo pasado, escritos en México, y presenta sólo las primeras 100 palabras más frecuen-tes, sin facilitar el acceso a la información de las cinco mil restantes y sus frecuencias. Otras de sus desventajas son que el corpus ya no resulta tan representativo de las actuales tendencias del uso del léxico en México y, sobre todo, que no cuenta con índices valiosos sobre la estructura ortográfica o fonológica, ni medidas de vecin-dad de las palabras, debido a que esta obra no perseguía el objeti- vo de servir de base a estudios de psicolingüística.
ReferenciasAlmela, R., Cantos, P., Sánchez, A., Sarmiento, R. y Almela, M. (2005). Frecuencias del
español. Diccionario de estudios léxicos y morfológicos. Disponible en http://www.um.es/grupos/grupo-lacell/publicaciones/dos.php. Consultado el 15 de febrero de 2012
Baayen, R., Piepenbrock, R. & Gulikers, L. (1995). The Celex lexical database (Release 2) [cd-rom]. Philadelphia: University of Pennsylvania, Linguistic Data Consortium.
Beijing Language College (1986). Modern Chinese Frequency Dictionary. Beijing: Lan-guage College Press.
Brysbaert, M., New, B. & Keuleers, E. (2012). Adding part-of-speech information to the Subtlex-us word frequencies. Behavior Research Methods, 1-7.
Cai, Q. & Brysbaert, M. (2010). Subtlex-ch: Chinese Words and Character Frequencies Based on Film Subtitles. PLoS ONE, 5, e10729.
Carroll, J., Davies, P. & Richman, B. (1971). The American Heritage Word Frequency Book. Boston: Houghton Mifflin.
Cuetos-Vega, F., González-Nosti, M., Barbón-Gutiérrez, A. & Brysbaert, M. (2011). Subtlex-esp: Spanish word frequencies based on film subtitles. Psicológica: Revista de metodología y psicología experimental, 32, 133-143.
Davis, C. & Perea, M. (2005). BuscaPalabras: A program for deriving orthographic and phonological neighborhood statistics and other psycholinguistic indices in Spanish. Behavior Research Methods, 37, 665-671.

22
LEXMEX: diccionario de frecuenciasdel español de México
Dimitropoulou, M., Duñabeitia, J., Avilés, A., Corral, J. & Carreiras, M. (2010). Subtitle based word frequencies as the best estimate of reading behavior: The case of Greek. Frontiers in Psychology, 1 (218), 1-12.
Duchon, A., Perea, M., Sebastián-Gallés, N., Martí, A. & Carreiras, M. (En prensa). Espal: One-stop Shopping for Spanish Word Properties. Behavior Research Methods.
Duñabeitia, J., Cholin, J., Corral, J., Perea, M. & Carreiras, M. (2010). Syllabarium: An online application for deriving complete statistics for Basque and Spanish ortho-graphic syllables. Behavior Research Methods, 42, 118-125.
Francis, W. & Kucera, H. (1982). English Frequency Analysis of English Usage: Lexicon and Grammar, Boston: Houghton Mifflin.
Imbs, P. (1971). Etudes statistiques sur le vocabulaire francais. Dictionnaire des fréquences. Vocabulaire littéraire des XIXe et XXesiecles. Paris: Centre de Recherche pour un Trésor de la Langue Francaise.
Keuleers, E., Brysbaert, M. & New, B. (2010). Subtlex-nl: A new measure for Dutch word frequency based on film subtitles. Behavior Research Methods, 42, 643-650.
Kucera, H. & Francis, W. (1967). Computational Analysis of Present-Day American English. Providence, RI: Brown University Press.
Lara, L., Ham, R. y García, M. (1979). Investigaciones lingüísticas sobre lexicografía. Méxi-co: Colmex.
New, B., Brysbaert, M., Veronis, J. & Pallier, C. (2007). The use of film subtitles to estimate word frequencies. Applied Psycholinguistics, 28, 661.
Real Academia Española de la lengua (2001). Diccionario de la lengua española. Ver-sión electrónica. Real Academia Española de la lengua (22a edición). Disponible en http://rae.es/recursos/diccionarios/drae. Consultada el 20 de abril de 2013.
Sebastián-Gallés, N., Martí, M., Cuetos, F. & Carreiras, M. (2000). Lexesp: Léxico in-formatizado del español [Lexesp: A computerized word-pool in Spanish]. Barcelona: Edicions de la Universitat de Barcelona.
Thorndike, E. L. & Lorge, I. (1944). The Teacher’s Word Book of 30,000 Words. New York: Teachers College Press, Columbia University.

3Creación del corpus Lexmex:
muestreo
P ara la obtención del corpus se muestrearon textos tomados de 32 publicaciones periódicas digitales diferentes durante un periodo de nueve meses (marzo-noviembre de 2012), en este
lapso se obtuvieron más de 2.5 millones de palabras. Las publica-ciones seleccionadas fueron aquéllas con mayor cobertura nacional, tiraje, hábito de consumo y, por supuesto, cuya versión digital per- mitiera la recolección del material a analizar. La tabla 3.1 presenta las distintas publicaciones muestreadas.
Tabla 3.1. Publicaciones empleadas para la creación del corpus de Lexmex
Fuente Página web
Tú http://tuenlinea.esmas.com/
Furia Musical http://www.furiamusical.com/Men´s Health http://www.menshealthlatam.com/
Caras http://www.caras.com.mx/Muy Interesante http://www.muyinteresante.com.mx/
National Geographic en Español http://natgeo.televisa.com/

24
LEXMEX: diccionario de frecuenciasdel español de México
Fuente Página webTVyNovelas http://www.tvynovelas.com/
México Desconocido http://www.mexicodesconocido.com.mx/De 15 a 20 http://www.15a20.com.mx/index.phpFútbol Total http://www.futboltotal.com.mx/
Cancha http://www.cancha.com/Defaultr.htmRécord http://www.record.com.mx/
TVyNotas http://www.tvnotas.com.mx/Fortuna http://revistafortuna.com.mx/contenido/
El Economista http://eleconomista.com.mx/Cosmopolitan http://www.cosmoenespanol.com/
Quién http://www.quien.com/Proceso http://www.proceso.com.mx/Siempre http://www.siempre.com.mx/
El Gráfico http://www.elgrafico.mx/Publimetro http://www.publimetro.com.mx/La Jornada http://www.jornada.unam.mx/ultimas/La Prensa http://www.oem.com.mx/laprensa/
El Universal http://www.eluniversal.com.mx/noticias.htmlMilenio http://www.milenio.com/Reforma http://www.reforma.com/Esquire http://esquire.esmas.com/
La Raza http://www.laraza.com/Unomásuno http://www.unomasuno.com.mx/
Etcétera http://www.etcetera.com.mx/noticias.phpVanidades http://www.vanidades.com/
Revista del Consumidor http://revistadelconsumidor.gob.mx/
De las publicaciones digitales de internet se copiaron manualmente a archivos texto los artículos que, posteriormente, se procesaron con el software al que llamamos Programa de Extracción Automática de las Propiedades Léxicas (peapl) y que se creó ex profeso. El corpus de textos escritos del Diccionario de frecuencias del español de México (Lexmex) se deriva así de una amplia selección de textos recogidos de la web en formato digital, en los que se incluyen ocho subgrupos en

Cap. 3 Creación del corpus Lexmex: Muestreo
25
función de su contenido: Cultura, Prensa, Conocimiento, Negocios, Política, Deportes, Sociedad y Entretenimiento. Estos textos tenían que cumplir con los requisitos de ser de libre disposición y no estar sujetos a derechos de autor. La mayor parte de los documentos fue-ron recopilados de sitios web que ofrecen una variedad de estilos lin-güísticos, incluyendo el lenguaje coloquial y el especializado (sobre todo en términos de política, cultura y conocimiento).
El conjunto de textos de Cultura se compone de noticias sobre even-tos y notas culturales de varios periódicos y revistas como La Jornada, Proceso y Siempre. El rubro de Prensa incluyó noticias correspondien-tes a los periódicos La Jornada, El Economista, El Gráfico, Publimetro, La Prensa, El Universal, Milenio, Reforma, La Raza y Unomásu- no, de marzo a noviembre de 2012. El conjunto de textos especiali-zados sobre Política contiene noticias y reportajes de los periódicos mencionados, así como de las revistas Proceso, Siempre y Etcétera, que primordialmente se refirieron a las elecciones presidenciales de 2012 en México. El campo que se refiere a Sociedad se compone de artí-culos y reportajes acerca de la religión, la Psicología, la salud, cocina y moda, que aparecieron en revistas como Vanidades, Cosmopolitan, Tú, Men’s Health y Esquire; mientras que el conjunto de Entretenimiento se compuso de noticias y comentarios sobre espectáculos y sus pro-tagonistas, en especial, personas famosas nacionales y extranjeras, in-cluidas en las revistas TV y Novelas, TVyNotas, Furia Musical, De 15 a 20, Caras y Quién. El conjunto de textos referentes a Conocimiento se extrajeron de artículos publicados en Muy Interesante, National Geographic en Español, México Desconocido y Revista del Consumidor. En el de Negocios, se utilizaron artículos de la revista Fortuna y notas de los periódicos mencionados. Finalmente, en el tema de Depor- tes se usaron los textos de Futbol Total, Récord, Cancha y La Prensa.
El corpus entero se sometió a un proceso de limpieza para eliminar los metadatos (vínculos a otras fuentes) normalmente presentes en este tipo de textos. Este proceso se realizó tanto automática como manualmente y fue en extremo lento.

26
LEXMEX: diccionario de frecuenciasdel español de México
Extracción automática de las propiedades léxicas.
Programa peapl
El programa peapl está elaborado en lenguaje Borland Pascal e in-cluye una serie de algoritmos basados en la gramática y la ortografía de la lengua española. Peapl permitió extraer, de manera automáti- ca, información lingüística a partir de una entrada de ficheros en formato ascii que contenía los textos escritos en español. En una etapa inicial de procesamiento, este programa realizó una secuen- cia de operaciones sobre el texto para crear una primera versión de la base de datos antes de trabajar con las palabras y sus características; en dicha etapa se eliminaron los caracteres sin validez para el estudio (números, signos de puntuación y caracteres de control del editor de textos que se usó originalmente en el proceso de composición). Se convirtieron las palabras de mayúsculas a minúsculas para garantizar la homogeneidad del material a procesar. Esta operación se realizó de manera automática. Peapl segmenta las palabras a partir de lo es-crito en los textos, para colocarlas en orden alfabético considerando las características del español (incluyendo las letras ll y ch, y toman- do como iguales las vocales con y sin acentuación).
Con el listado de palabras en orden alfabético, obtenido de los archi- vos texto de entrada, se cuenta la cantidad de veces que aparece en éstos cada término, es decir, su frecuencia de uso (ocurrencia); asimismo, se calcula la cantidad de letras que tiene cada una de las palabras (longitud ortográfica). En una siguiente etapa, se llevan a cabo operaciones para extraer la información silábica y fonoló-gica. El español, como una lengua con relativa transparencia en términos de su fonología, puede derivar su estructura fonológica de la ortografía basándose en reglas. Para derivar la estructura si-lábica, se implementaron, con algunos cambios menores, las reglas del Silabeador TIP (Hernández-Figueroa, Rodríguez-Rodríguez y Carreras-Riudavets, 2009). A partir de esta información se extraje-ron las siguientes variables:

Cap. 3 Creación del corpus Lexmex: Muestreo
27
• Cantidaddesílabasdecadaunadelaspalabras• Clasificacióndecadapalabrasegúneltipodeacentuación• Patróndedivisiónsilábicadecadapalabra• Frecuenciasilábicamediaabsolutayfrecuenciasilábicame-
dia posicional de cada palabra (ver adelante)• Asignaciónparacadapalabradelpatrónfonológicovocal-
consonante, es decir, de la secuencia de vocales y consonan-tes que constituyen la palabra.
En este punto del procesamiento, la salida del peapl se almace- nó en la base de datos, donde la información referente a las sílabas procedentes de las palabras constituye una parte del cuerpo del dic-cionario. Para el cálculo de la frecuencia silábica media posicional (Frec_Pos_Media_Sílabas) se consideraron las variables de frecuencia por posición en la palabra, de la posición 1 hasta la 10. Estas colum-nas indican el número de veces que la sílaba aparece en cada posición posible. La frecuencia en la posición 3, por ejemplo, indica cuán-tas veces aparece la sílaba en esa posición, y así sucesivamente. Sólo existen 10 posiciones posibles debido a que el máximo de sílabas es 10 en el diccionario que se compiló. La frecuencia se calculó de la manera siguiente: se tomaron las sílabas que forman la palabra y se sumaron los valores de las columnas de las posiciones donde apa-rece la sílaba en el diccionario de sílabas; después, esto se divide entre el número de sílabas. Por ejemplo, en la palabra abajo (de tres sílabas: a-ba-jo), se toma el valor de frecuencia en la posición 1 de a = 4925, en la posición 2 de ba = 403, en la posición 3 de jo = 78, y se promedia [(4925+403+78)/3 = 1802]. El peapl permitió así extraer la frecuen-cia silábica absoluta, es decir, el número de veces que ocurre la sílaba en las palabras que están en el diccionario, en el apartado de palabras.
La transcripción fonética de cada término se obtuvo mediante la implementación de las normas del proyecto SAGA (Nogueiras y Mariño, 2009), aprovechando, cuando fue necesario, el silabeo des-crito anteriormente. Por ejemplo, la letra t se transcribe fonética-mente como t (como en toro toro), excepto cuando aparece al

28
LEXMEX: diccionario de frecuenciasdel español de México
final de la sílaba (etnia eDnja). Los códigos se muestran en la tabla 3.2. A partir de esta información, se derivó el número de fonemas.
Tabla 3.2. Transcripción fonética de cada palabra mediante la implemen-tación del proyecto SAGA
Grafema Fonema Ejemplos
<a> a
<b>b c’om-ba: k’om-ba
B l’a-bio: l’aBjo
<c>
T c’e-lo: T’e-lo
G ac-n’e: aG-n’e
kt’ac-to: t’ak-toc’o-ro: k’o-rot’e-cla: t’e-kla
<ch> tS ch’e-lo: tS’e-lo
<d>d c’al-do: c’al-do
D c’o-do: k’o-Do
<e> e
<f> f c’o-fia: k’o-fja
<g>
g c’on-go: k’oN-go
x g’e-nio: x’e-njo
G t’i-gre: t’i-Gre l’a-go: l’a-Go
<h>
jj hi’er-ba: jj’er-Ba
G a-hue-c’ar: a-Gue-c’ar
muda h’a-lo: ‘a-lo

Cap. 3 Creación del corpus Lexmex: Muestreo
29
Grafema Fonema Ejemplos
<i>i t’i-po: t’ipo
j ar-m’a-rio: ar-m’a-rjo
<j> x ja-r’a-na: xa-r’a-na
<k> k ki’os-ko: kj’os-ko
<l> l l’o-te: l’o-te
<ll> L t’a-llo: t’a-Lo
<m> m ar-ma: ‘ar-ma
<n>
m an-fo-ra: ‘am-fo-ra
N an-ca: ‘aN-ka
n c’o-no: k’o-no
<ñ> J u-ña: ‘u-Ja
<o> o
<p> p p’e-rro: p’e-rro
<qu> k qu’e-so: k’e-so
<r>
rr r’a-ma: rr’a-ma
rr h’on-ra: ‘on-rra
r
ar-pa: ‘ar-patr’am-pa: tr’am-pa
p’e-ra: p’e-raa-m’or: a-m’or
<rr> rr c’a-rro: k’a-rro
<s>z r’as-go: rr’az-Go
s c’a-sa: k’a-satr’as-to: tr’as-to

30
LEXMEX: diccionario de frecuenciasdel español de México
Grafema Fonema Ejemplos
<t>D et-nia: ‘eD-nja
t t’o-ro: t’o-ro
<u>
muda qu’e-so: k’e-so
u l’u-jo: l’u-xo
w u ‘o-tro: w ‘o-tro
w ci-güe-ña: Ti-Gw’e-Ja
<v>b con v’e-lo: kom b’e-lo
B c’al-vo: k’al-Bo
<w> B k’i-wi: k’i-Bi
<x>C-s e-x’a-men: eC-s’a-men
s ex-t’er-no: es-t’er-no
<y>
jjy’un-que: jj’un-ke
c’on-yu-ge: k’on-jju-xepl’a-ya: pl’a-jja
j r’a-so y t’ul: rr’a-so j t’ulse-s’en-ta y ‘u-no: se-s’en-tajj u-no
i dos y dos: dos i Dos
j no-r’ay: no-r’aj
<z> T z’ar-za: T’ar-Tat’iz-ne: t’iT-ne
En una tercera etapa, el programa peapl identificó y clasificó, de manera automática, las clases gramaticales de palabras que son regulares con respecto a su morfología (Tabla 3.3). Para ello, se basó

Cap. 3 Creación del corpus Lexmex: Muestreo
31
en varias condiciones y reglas consultadas en el Manual de la Nue-va gramática de la lengua española (Asociación de Academias de la Lengua Española, 2010).
Tabla 3.3. Clases gramaticales de palabras según su morfología
Clases de palabras Morfología
Sustantivos Terminaciones: -ción, -sión, o -miento
Verbos
Terminaciones: -ar, -ando, -ado, -aré, -arás, -ará,-aremos, -arán, -aría, -arías, -aríamos, -arían, -aba,-abas, -abamos, -aban, -é, -aste, -ó, -amos, -aron, -er, -iendo, -ido, -eré, -erás, -erá, -eremos, -erán, -ería,-erías, -eríamos, -erían, -ía, -ías, -íamos, -ían, -ímos,-íeron, -ir, -ido, -iré, -irás, -irá, -iremos, -irán, -iría,-irías, -iríamos, -irían
AdjetivosPrefijos: anti- y contra-Terminaciones: -ísimo, -ísima, -ble, -eño, -ense, -iense, -ante, -ente, -iente, -az, -iz, -oz, -il, -dor, -dora
Adverbios Terminaciones: -mente, -quiera
Asimismo, los artículos, pronombres, conjunciones, preposiciones, in- terjecciones, entre otros, se agruparon como palabras cerradas, las que no pudo clasificar el peapl permanecieron etiquetadas como sin cla-sificar (posteriormente, los investigadores tuvieron oportunidad de reclasificarlas). De igual manera, si la palabra era un anglicismo u otro extranjerismo, se le dejó la etiqueta sin clasificar.
La salida del peapl, posterior a esta etapa, fue un campo de la base de datos a la que se denominó categoría gramatical. La base de datos entera se sometió después a un proceso de inspección/verificación de la clasificación gramatical de las palabras por parte de varios investi-gadores. Aun cuando parte de este proceso fue automático, al mismo tiempo tuvo que ser manual, por lo que resultó lento en extremo. En el siguiente apartado, se describe con más detalle el trabajo manual de inspección/verificación.

32
LEXMEX: diccionario de frecuenciasdel español de México
En la última etapa del proceso y después de haber extraído una gran cantidad de variables léxicas con el peapl, se calcularon los valo-res de medición útiles para la conformación del diccionario Lex-mex. Cada una de las mediciones calculadas se incluyó en un campo o columna de la matriz total, y se exponen de manera detallada en el capítulo siguiente.
Trabajo de inspección/verificaciónLa primera versión de la base de datos contó con 80 mil palabras diferentes, lo cual fue el resultado de la aplicación del peapl para extraer automáticamente las palabras de los archivos texto. Después de calcular la frecuencia de uso de cada término, de hacer la seg-mentación silábica de acuerdo con las reglas de acentuación y de hacer la transcripción fonética respecto al español de México, se eva- luó palabra por palabra con el fin de eliminar aquellas que fueran nombres propios o estuvieran mal escritas.
La clasificación automática por categoría gramatical se hizo con una segunda versión del diccionario que contenía 56 443 palabras. Aquellas palabras mal clasificadas eran destinadas por peapl a un campo de la base de datos creado con el fin de que el investigador pudiera clasificarlas manualmente. Aunque se consideraron las regu- laridades del español para la elaboración de un algoritmo que iden-tificara verbos, sustantivos y adjetivos, la mayor parte de las pala-bras fueron categorizadas por tres investigadores que se apoyaron en la información del Diccionario de la lengua española (rae, 1995) y del Diccionario del español usual de México (Lara, 1996). Se esta-blecieron seis categorías fundamentales: adjetivo, adverbio, cerradas, sin_clasificar, sustantivo y verbo. En el caso de la categoría cerra- das, se incluyeron varios tipos de palabras sin importar la diferencia fundamental entre ellas. Así, se incluyeron pronombres, preposi-ciones, conjunciones, interjecciones, prefijos, sufijos y locuciones. Las categorías gramaticales se asignaron a un campo de la base de datos; no obstante, debe mencionarse que en varios casos las

Cap. 3 Creación del corpus Lexmex: Muestreo
33
palabras tuvieron dobles, triples o cuádruples categorías de clasifi-cación. Por ejemplo, la palabra cerca puede ser clasificada como ad-verbio, sustantivo o verbo, dependiendo del contexto de la oración en la que se presente.
ReferenciasAsociación de Academias de la Lengua Española (2010). Manual de la Nueva gramática de
la lengua española. Madrid: Real Academia Española, Espasa Calpe.Hernández-Figueroa, Z., Rodríguez-Rodríguez, G. y Carreras-Riudavets, F. (2009).
Separador de sílabas del español-Silabeador TIP. Disponible en http://tip.dis.ulpgc.es. Consultado el 5 de junio de 2013.
Lara, L. (1996). Diccionario del español usual de México. México: Colmex, Centro de Estu-dios Lingüísticos y Literarios.
Nogueiras, A. y Mariño, J. (2009). SAGA: Transcriptor fonético de las variedades dialecta-les del español. Disponible en http://www.talp.upc.edu/index.php/technology/tools/signalprocessing-tools/81-saga. Consultado el 20 de junio de 2013.
Real Academia Española de la lengua (1995). Diccionario de la lengua española. Edición electrónica. Real Academia Española de la lengua. Disponible en http://www.rae.es/rae.html. Consultado el 20 de abril de 2013.


4Medidas léxicas disponibles
en el Lexmex
E l propósito del Lexmex es ofrecer algunas de las medi-das e índices con mayor utilidad en la psicolingüística, sin soslayar aquéllas que permiten el estudio de los
efectos de frecuencia y vecindad ortográfica y fonológica, pero sin integrar algunos otros índices de que no se ajustaban al objetivo original de este trabajo. De esta manera, las estadísticas disponibles en el Lexmex son una pequeña cantidad comparadas con las que pueden ofrecer el B-Pal (que toma los datos del Lexesp) (Davis & Perea, 2005) o el Espal (Duchon, Perea, Sebastián-Gallés et ál., en prensa), pero útil para los interesados en controlar estímulos lingüísticos para sus investigaciones.
A grandes rasgos, las propiedades léxicas disponibles en el Lexmex se refieren a: a) la frecuencia de uso, b) la estructura y vecindad ortográfica de las palabras, c) la estructura y vecindad fonológica de las palabras, y d) la frecuencia silábica.

36
LEXMEX: diccionario de frecuenciasdel español de México
Frecuencia de usoEl primer valor asociado con la frecuencia de uso de las palabras que ofrece el Lexmex es el número de ocurrencias en el corpus. Otra medida disponible es el logaritmo (en base 10) de la ocurrencia de una palabra más 1. Se puede obtener también la frecuencia de la pa- labra por millón de palabras, que es una medida estándar indepen-diente del tamaño del corpus, y se define como el número de veces que aparece una palabra, dividido entre el tamaño del corpus Lex- mex (2 530 523), multiplicado por 1 millón. Este índice se lleva a cabo para que coincida con otros diccionarios de frecuencias. Se puede obtener el valor del logaritmo de la frecuencia independien- te del tamaño del corpus. Finalmente, en términos de las medidas de frecuencia que se ofrecen en este diccionario, tenemos al LOG10 [(Frec + 1)/N], donde N es el número de palabras del corpus expresado en millones (Tabla 4.1).
Tabla 4.1. Medidas léxicas relacionadas con la frecuencia de uso
Abreviatura Definición
n_Ocur Número de ocurrencia en el corpus
LOG10_n_Ocur Log10 de la ocurrencia de una palabra más 1
Frec Frecuencia de la palabra por millón de palabras. Es (n_Ocur)/ tamaño del corpus Lexmex (2 530 523) multiplicado por un millón
LOG10[Frec+1] Log10 de la frecuencia independiente del tamaño del corpus
LOG10[(Frec + 1)/N] Medida anterior dividida entre N que es el número de palabras del corpus expresado en millones
Estructura y vecindad ortográfica de las palabras
Si bien el Lexmex no pretendió ser tan ambicioso como para calcular los bigramas y trigramas que aparecen en el Espal y el B-Pal (que to- ma la información del Lexesp), sí se calcularon las medidas de estruc-tura y vecindad ortográfica. Así entonces, Lexmex ofrece el número de

Cap. 4 Medidas Léxicas disponibles en el Lexmex
37
letras en la palabra; la estructura CV, que es una representación de la secuencia de consonantes y vocales en el término, y la separación en sílabas de las palabras (i. e., ga-to).
La medida estándar del tamaño de la vecindad ortográfica N, que es equivalente al número de palabras que se pueden formar mediante la sustitución de una sola letra en cualquiera de las posiciones dentro de un término, se ofrece en Lexmex como Ort_N (Coltheart, Davelaar, Jonasson & Besner, 1977). Con base en este parámetro se pueden generar otras medidas. Se encontró que N está relacionado con las medidas de desempeño en una variedad de tareas de lectura, inclui-das las de decisión léxica, nominación y categorización semántica (Andrews, 1997; Perea & Rosa, 2000).
Lexmex cuenta una palabra como un vecino ortográfico sólo si és- ta se encuentra incluida en su corpus. Junto a Ort_N se presenta una lista de los vecinos ortográficos (lista de palabras) en una co-lumna de la matriz, cada uno separado por un punto y coma. La distribución de los vecinos es diferente para cada una de las posi-ciones de 1 a 4 (para palabras de cuatro letras). Por ejemplo, ga- to tiene seis vecinos en la posición 1 (nato, rato, dato, hato, pato, mato), ninguno en la posición 2, tres en la posición 3 (galo, gajo y gano) y uno en la posición 4 (gata). Lexmex ofrece el parámetro P, que es un recuento del número de posiciones en las que los vecinos pueden formarse (i.e., Ort_P = 3 para la palabra gato).
De los parámetros antes descritos, se obtienen otras medidas que tam- bién son útiles y se ofrecen en el B-Pal y el Espal. Por su parte, Lex-mex ofrece así la frecuencia media de los vecinos de la palabra. Tam-bién, la frecuencia del vecino con más alta frecuencia, que para gato es de 139.1, y la frecuencia del vecino con más baja frecuencia, de 0.79. Final-mente, como se ha sugerido que la frecuencia crítica del vecino es su frecuencia relativa (Grainger, O’Regan, Jacobs & Seguí, 1989), se proporcionan medidas de la frecuencia relativa como el número de vecinos que tienen frecuencias más altas que la palabra y el número de
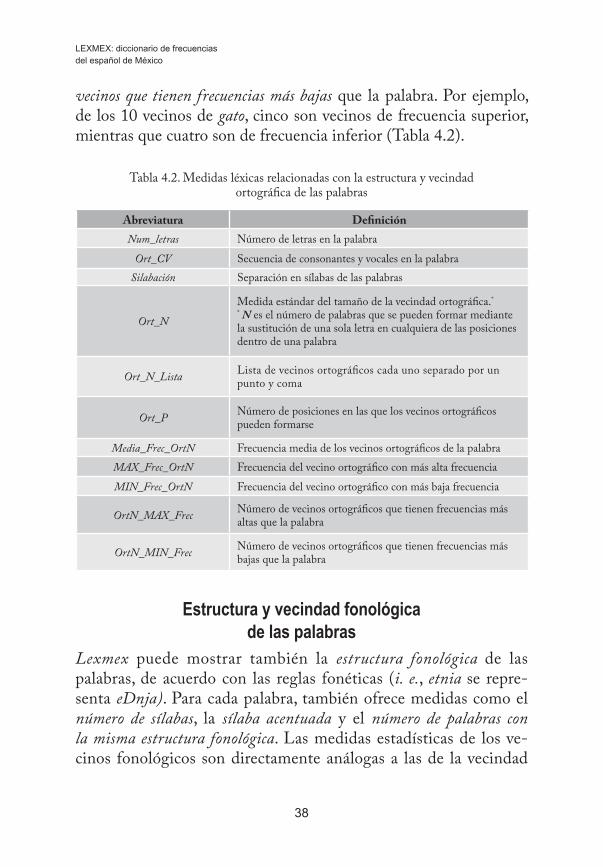
38
LEXMEX: diccionario de frecuenciasdel español de México
vecinos que tienen frecuencias más bajas que la palabra. Por ejemplo, de los 10 vecinos de gato, cinco son vecinos de frecuencia superior, mientras que cuatro son de frecuencia inferior (Tabla 4.2).
Tabla 4.2. Medidas léxicas relacionadas con la estructura y vecindad ortográfica de las palabras
Abreviatura DefiniciónNum_letras Número de letras en la palabra
Ort_CV Secuencia de consonantes y vocales en la palabraSilabación Separación en sílabas de las palabras
Ort_N
Medida estándar del tamaño de la vecindad ortográfica.*
* N es el número de palabras que se pueden formar mediante la sustitución de una sola letra en cualquiera de las posiciones dentro de una palabra
Ort_N_Lista Lista de vecinos ortográficos cada uno separado por un punto y coma
Ort_P Número de posiciones en las que los vecinos ortográficos pueden formarse
Media_Frec_OrtN Frecuencia media de los vecinos ortográficos de la palabraMAX_Frec_OrtN Frecuencia del vecino ortográfico con más alta frecuenciaMIN_Frec_OrtN Frecuencia del vecino ortográfico con más baja frecuencia
OrtN_MAX_Frec Número de vecinos ortográficos que tienen frecuencias más altas que la palabra
OrtN_MIN_Frec Número de vecinos ortográficos que tienen frecuencias más bajas que la palabra
Estructura y vecindad fonológica de las palabras
Lexmex puede mostrar también la estructura fonológica de las palabras, de acuerdo con las reglas fonéticas (i. e., etnia se repre-senta eDnja). Para cada palabra, también ofrece medidas como el número de sílabas, la sílaba acentuada y el número de palabras con la misma estructura fonológica. Las medidas estadísticas de los ve-cinos fonológicos son directamente análogas a las de la vecindad

Cap. 4 Medidas Léxicas disponibles en el Lexmex
39
ortográfica, con la excepción de que N fonológica incluye no sólo a los vecinos de sustitución, sino también a los de eliminación y de adi-ción. Por ejemplo, los vecinos fonológicos de gato (/Ga-to/) incluyen el vecino de eliminación hato (/øa-to/) y los vecinos de adición grato (/Gra-to/) y gasto (/Gas-to/), así como los vecinos de sustitución como gano (/Ga-no/) y gallo (/Ga-Lo/). Los parámetros que se pue-den obtener para la vecindad fonológica se presentan en la tabla 4.3.
Tabla 4.3. Parámetros para obtener la estructura y vecindad fonológica de las palabras
Abreviatura Definición
Fonética Estructura fonológica de una palabra según las reglas fonéticas
n_Sílabas Número de sílabas de una palabra
Acento_Sílaba Sílaba acentuada en una palabra
Homófonas Número de palabras que tienen la misma estructura fonológica
Fon_N N fonológica es el número de palabras que se puede formar sustituyendo, eliminando o adicionando un fonema
Fon_N_Lista Lista de vecinos fonológicos separados por un punto y coma
Fon_P Número de posiciones en las que los vecinos fonológicos pueden formarse
Media_Frec_FonN Frecuencia media de los vecinos fonológicos de la palabra
MAX_Frec_FonN Frecuencia del vecino fonológico con más alta frecuencia
MIN_Frec_FonN Frecuencia del vecino fonológico con más baja frecuencia
FonN_MAX_Frec Número de vecinos fonológicos que tienen frecuencias más altas que la palabra
FonN_MIN_Frec Número de vecinos fonológicos que tienen frecuencias más bajas que la palabra
Frecuencia silábicaEn los últimos años, ha surgido un creciente interés experimen-tal por la utilización de palabras de varias sílabas (Davis & Perea., 2005). Esto es aun más relevante en español, ya que el porcentaje de

40
LEXMEX: diccionario de frecuenciasdel español de México
palabras de varias sílabas es mucho mayor que en inglés (Carreiras & Perea, 2002). En español, la sílaba es la unidad perceptual para el proceso de identificación de la palabra. La investigación sobre el reconocimiento visual de palabras sugiere que los vecinos silábicos se activan durante la identificación de éstas, es posible que a través del nivel de sílaba que media entre el nivel de la letra y el de la palabra (i.e., si se presenta la palabra cabo, se activa parcialmente la palabra de alta frecuencia casa, debido a la sílaba inicial compartida /ka/).
Los vecinos silábicos son las palabras que comparten una sílaba (en especial, la inicial) en aquellas palabras de dos sílabas. Por su na-turaleza, los efectos silábicos se plantean en términos fonológicos (Álvarez, Carreiras & Perea, 2004) y, por tanto, Lexmex calcula la frecuencia silábica sobre la base de los códigos fonológicos y ofrece índices relacionados con la frecuencia de sílabas; calcula el número de vecinos que comparten la primera sílaba, y de la misma can- tidad de sílabas; calcula la frecuencia sumada de vecinos silábicos y muestra la frecuencia máxima del vecino silábico. Lexmex ofrece también las frecuencias de las sílabas en la palabra y la frecuencia media de las sílabas, pero en términos de su posición silábica en la palabra (Tabla 4.4).
Tabla 4.4. Parámetros para obtener las frecuencias de las sílabas y la frecuencia media de las sílabas en la palabra
Abreviatura Definición
N_Silábicos Número de vecinos que comparten la primera sílaba y con de la misma cantidad de sílabas
Frec_Total_N_Silábicos Frecuencia sumada de las palabras que comparten la primera sílaba
Frec_MAX_N_Silábico Frecuencia máxima del vecino silábicoFrec_X_Sílaba Frecuencias de las sílabas en la palabra
Frec_Media_Sílabas Frecuencia media de las sílabas en la palabra
Frec_Pos_Media_Sílabas Frecuencia media de las sílabas en términos de su posición en la palabra

Cap. 4 Medidas Léxicas disponibles en el Lexmex
41
ReferenciasAlvarez, C., Carreiras, M. & Perea, M. (2004). Are syllables phonological units in visual
word recognition? Language and Cognitive Processes, 19, 321-331.Andrews, S. (1997). The effects of orthographic similarity on lexical retrieval: Resolving
neighborhood conflicts. Psychological Bulletin and Review, 4, 439-461.Carreiras, M. & Perea, M. (2002). Masked priming effects with syllabic neighbors in the
lexical decision task. Journal of Experimental Psychology: Human Perception and Per-formance, 28, 1228-1242.
Coltheart, M., Davelaar, E., Jonasson, J. F. & Besner, D. (1977). “Access to the internal lexicon”. In S. Dornic (Ed.). Attention & Performance VI (pp. 535-555). Hillsdale, NJ: Erlbaum.
Davis, C. & Perea, M. (2005). BuscaPalabras: A program for deriving orthographic and phonological neighborhood statistics and other psycholinguistic indices in Spanish. Behavior Research Methods, 37, 665-671.
Duchon, A., Perea, M., Sebastián-Gallés, N., Martí, A. & Carreiras, M. (En prensa) Es-pal: One-stop Shopping for Spanish Word Properties. Behavior Research Methods.
Grainger, J., O’Regan, J. K., Jacobs, A. M. & Seguí, J. (1989). On the role of competing word units in visual word recognition: The neighborhood frequency effect. Perception and Psychophysics, 45, 189-195.
Perea, M. & Rosa, E. (2000). Repetition and form priming interact with neighbor-hood density at a brief stimulus-onset asynchrony. Psychonomic Bulletin and Re-view, 7, 668-677.


5Estadísticas globales
del corpus del Lexmex
E l diccionario de frecuencias de uso del español escrito en México se obtuvo del procesamiento de textos es- cogidos a través de un sistema creado especialmente
para ello; sus características principales se describen a continuación.
La cantidad total de palabras extraídas de los textos fue 2 530 523, de las cuales, 56 443 fueron diferentes. Esta cifra representa el 67.9% de los vocablos aceptados en 1992 por la Real Academia Española, es decir, algo más de las dos terceras partes del total de los mismos, lo que constituye un número considerable, y coloca al presente, como un estudio representativo del idioma español.
En la tabla 5.1, se describe el comportamiento de las variables de frecuencia de uso que aparecen en el Lexmex.
Tabla 5.1. Estadística global de los parámetros del Lexmex
Variables Mínimo Máximo Media Desviación estándar
n_Ocur 1 164 660 41.2 1129.6
n_Letras 1 22 8.9 2.5

44
LEXMEX: diccionario de frecuenciasdel español de México
Variables Mínimo Máximo Media Desviación estándar
n_sílabas 1 10 3.7 1.1
Log10 (n_Ocur+1) .30 5.2 .76 .55Frec .395 65069.6 16.3 446.4
Log10 (Frec+1) .145 4.81 .50 .476
Log10 ([Frec+1]/N) -.259 4.41 .098 .476
Parámetros de frecuenciaEl rango de frecuencias de uso o número de ocurrencias encontra-do oscila entre 1 y 164 660 sobre el total de palabras analizadas, lo que representa una frecuencia entre .395 y 65 069.6 por millón. Para una mejor representación de los datos sobre la composición de frecuencias del diccionario, así como por ser frecuente su empleo en la literatura, se muestra un histograma de las frecuencias por 1 con exponente .5. Así en la figura 5.1, en el eje de las x está repre-sentado el Log10 del número de ocurrencias de las palabras, mien-tras que el eje de las y representa la cantidad de palabras que hay. En la figura 5.2, se muestra también un histograma, pero en el eje de las x se muestran los valores del Log10 de la frecuencia.
Figura 5.1. Histograma de frecuencia de la variable de ocurrencia de las palabras del Lexmex. Se usa una escala en las ordenadas x 1.5.
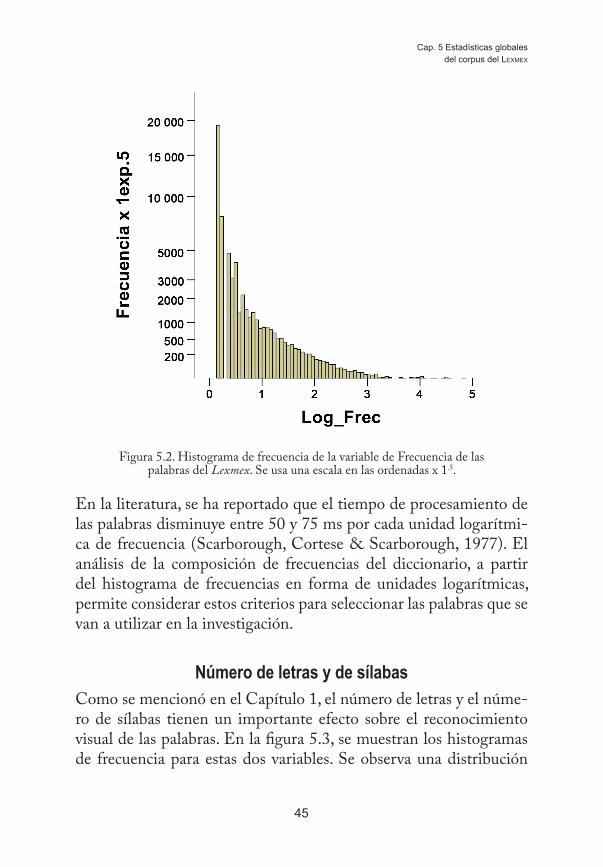
Cap. 5 Estadísticas globales del corpus del Lexmex
45
Figura 5.2. Histograma de frecuencia de la variable de Frecuencia de las palabras del Lexmex. Se usa una escala en las ordenadas x 1.5.
En la literatura, se ha reportado que el tiempo de procesamiento de las palabras disminuye entre 50 y 75 ms por cada unidad logarítmi-ca de frecuencia (Scarborough, Cortese & Scarborough, 1977). El análisis de la composición de frecuencias del diccionario, a partir del histograma de frecuencias en forma de unidades logarítmicas, permite considerar estos criterios para seleccionar las palabras que se van a utilizar en la investigación.
Número de letras y de sílabasComo se mencionó en el Capítulo 1, el número de letras y el núme-ro de sílabas tienen un importante efecto sobre el reconocimiento visual de las palabras. En la figura 5.3, se muestran los histogramas de frecuencia para estas dos variables. Se observa una distribución
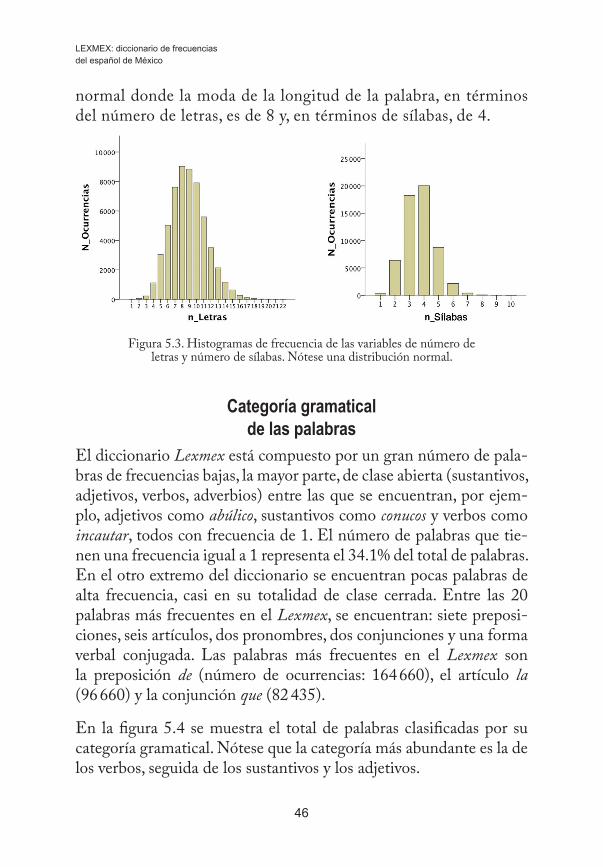
46
LEXMEX: diccionario de frecuenciasdel español de México
normal donde la moda de la longitud de la palabra, en términos del número de letras, es de 8 y, en términos de sílabas, de 4.
Figura 5.3. Histogramas de frecuencia de las variables de número de letras y número de sílabas. Nótese una distribución normal.
Categoría gramatical de las palabras
El diccionario Lexmex está compuesto por un gran número de pala-bras de frecuencias bajas, la mayor parte, de clase abierta (sustantivos, adjetivos, verbos, adverbios) entre las que se encuentran, por ejem- plo, adjetivos como abúlico, sustantivos como conucos y verbos como incautar, todos con frecuencia de 1. El número de palabras que tie-nen una frecuencia igual a 1 representa el 34.1% del total de palabras. En el otro extremo del diccionario se encuentran pocas palabras de alta frecuencia, casi en su totalidad de clase cerrada. Entre las 20 palabras más frecuentes en el Lexmex, se encuentran: siete preposi-ciones, seis artículos, dos pronombres, dos conjunciones y una forma verbal conjugada. Las palabras más frecuentes en el Lexmex son la preposición de (número de ocurrencias: 164 660), el artículo la (96 660) y la conjunción que (82 435).
En la figura 5.4 se muestra el total de palabras clasificadas por su categoría gramatical. Nótese que la categoría más abundante es la de los verbos, seguida de los sustantivos y los adjetivos.
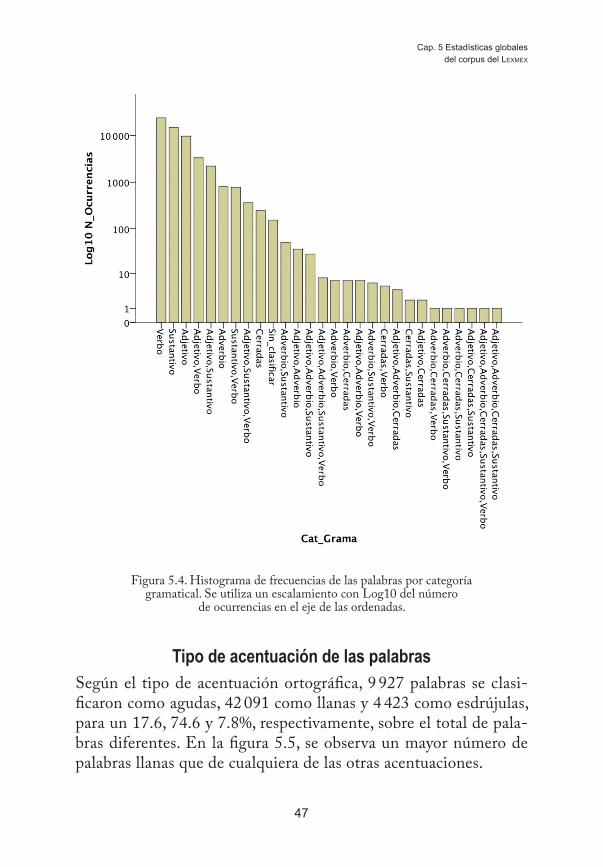
Cap. 5 Estadísticas globales del corpus del Lexmex
47
Figura 5.4. Histograma de frecuencias de las palabras por categoría gramatical. Se utiliza un escalamiento con Log10 del número
de ocurrencias en el eje de las ordenadas.
Tipo de acentuación de las palabrasSegún el tipo de acentuación ortográfica, 9 927 palabras se clasi-ficaron como agudas, 42 091 como llanas y 4 423 como esdrújulas, para un 17.6, 74.6 y 7.8%, respectivamente, sobre el total de pala-bras diferentes. En la figura 5.5, se observa un mayor número de palabras llanas que de cualquiera de las otras acentuaciones.
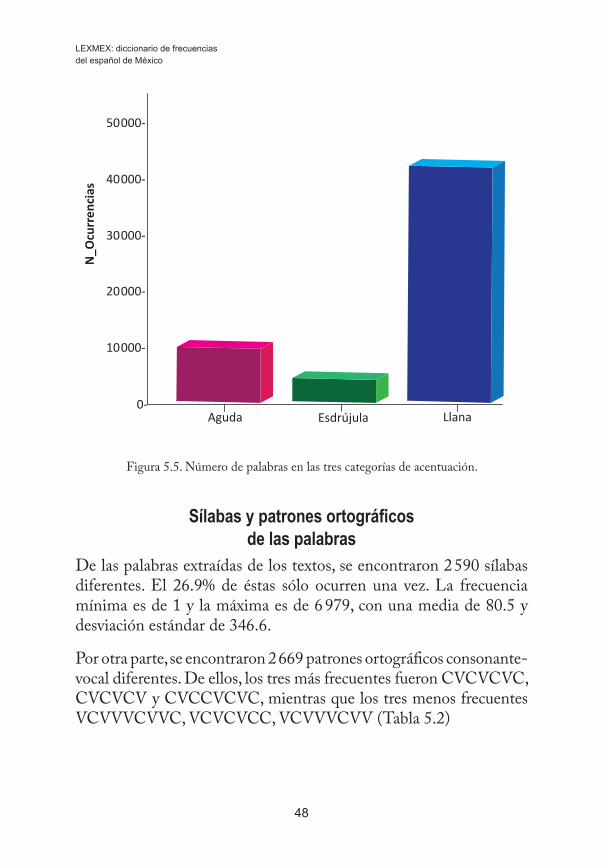
48
LEXMEX: diccionario de frecuenciasdel español de México
50 000-
40 000-
30 000-
20 000-
10 000-
0-Aguda Esdrújula Llana
N_O
curr
enci
as
Figura 5.5. Número de palabras en las tres categorías de acentuación.
Sílabas y patrones ortográficos de las palabras
De las palabras extraídas de los textos, se encontraron 2 590 sílabas diferentes. El 26.9% de éstas sólo ocurren una vez. La frecuencia mínima es de 1 y la máxima es de 6 979, con una media de 80.5 y desviación estándar de 346.6.
Por otra parte, se encontraron 2 669 patrones ortográficos consonante-vocal diferentes. De ellos, los tres más frecuentes fueron CVCVCVC, CVCVCV y CVCCVCVC, mientras que los tres menos frecuentes VCVVVCVVC, VCVCVCC, VCVVVCVV (Tabla 5.2)

Cap. 5 Estadísticas globales del corpus del Lexmex
49
Tabla 5.2. Los 16 patrones ortográficos CV más frecuentes del español de México (de entre 2 669 diferentes)
Patrón ortográfico Frecuencia Porcentaje
CVCVCVC 1 622 2.9
CVCVCV 1 456 2.6
CVCCVCVC 1 332 2.4
CVCCVCV 1 240 2.2
CVCVCVCVC 1 132 2.0
CVCVCVCV 1 064 1.9
CVCVC 940 1.7
CVCCVC 812 1.4
CVCVCCV 812 1.4
CVCCVCVCVC 795 1.4
CVCCV 751 1.3
CVCCVCVCV 728 1.3
CVCV 728 1.3
CVCCVCCV 606 1.1
VCCVCVCVC 551 1.0
VCCVCVCV 541 1.0
ReferenciasScarborough, D., Cortese, C. & Scarborough, H. (1977). Frequency and repetition
effects in lexical memory. Journal of Experimental Psychology: Human Perception and Performance, 3, 1.


ANEXO
Manual del usuario de Lexmex
L exmex contiene dos archivos: uno ejecutable en siste-ma Windows y otro con la base de datos.

52
LEXMEX: diccionario de frecuenciasdel español de México
Al ejecutar el archivo lexmex.exe, el sistema despliega un menú ge-neral de dos opciones, una de ellas permite la recuperación de la información léxica de un listado de palabras que el usuario debe in-troducir como archivo texto.
Procedimiento para recuperar información léxica a partir de un listado de palabras
En cualquier procesador de textos se crea un archivo con las pala-bras en forma de lista, todas ellas escritas en minúsculas. No hay número máximo de palabras a enlistarse. Se debe guardar el ar-chivo en formato texto. Una vez creado tal archivo, se carga en la ventana Archivo con palabras, vía el ícono señalizado que permite su búsqueda en las carpetas del sistema.

Anexo Manual del usuario de Lexmex
53
Una vez añadida la ruta del archivo, se presiona Recuperar con botón izquierdo del ratón.
Al cargar el archivo texto con el listado de palabras, se despliega un menú con todas las características y variables léxicas que pueden obtenerse. Se seleccionan las que se quieran. En este ejemplo, se seleccionaron con el botón izquierdo del ratón el número de letras de las palabras (N_letras), el patrón consonante-vocal (Ortografía CV), la frecuencia de uso quitando el efecto del tamaño del corpus (Frecuencia), el número de vecinos ortográficos (N_Ortográfico), la codificación fonética (Fonética) y el número de vecinos fonoló-gicos (N_Fonológico).

54
LEXMEX: diccionario de frecuenciasdel español de México
El visor de salida es una tabla donde las columnas son las varia-bles seleccionadas en el menú de las características léxicas. Cada renglón es cada una de las palabras enlistadas del archivo texto. El visor permite guardar la tabla en un archivo texto con separación Tab entre columnas.
Procedimiento para generar palabras a partir de una variable léxica
En el menú inicial del Lexmex, se oprime el botón izquierdo del ratón sobre Generar.

Anexo Manual del usuario de Lexmex
55
Se despliega un nuevo menú con las opciones para generar un listado de palabras. Las opciones de la columna izquierda del menú son los cri- terios seleccionables, pero sólo es factible seleccionar uno de ellos.
A la derecha, aparece un submenú que muestra las opciones deriva-das de la columna izquierda.
Al oprimir Aceptar en cualquiera de las opciones, se despliega nueva-mente el menú de las características léxicas. Se seleccionan las que se necesiten y se oprime Aceptar otra vez.

56
LEXMEX: diccionario de frecuenciasdel español de México
El resultado también se muestra en un visor donde las colum- nas son las variables seleccionadas del último menú, y los renglones, las palabras que cumplen con el criterio seleccionado en la genera-ción. En este ejemplo, se generaron palabras de acuerdo con el cri-terio de 10 vecinos ortográficos (N_Ortográfico). Se generaron 137 palabras que muestran las características seleccionadas.


Es una obra editada y publicada por la Universidad Nacio-nal Autónoma de México en la Coordinación Editorial de la Facultad de Estudios Superiores Iztacala, Avenida de los Barrios N.o 1, Los Reyes Iztacala, CP 54090, Tlalnepantla, Es-tado de México. Se concluyeron los trabajos de impresión y encuadernación el 00 de febrero de 2013, en las instalaciones de Master Copy SA de CV, Av. Coyoacán 1450 bis, Del Valle, CP 03220, México, DF. Se tiraron 000 ejemplares sobre pa-pel bond de 75 g/m2 para interiores y papel couché de 250 g/m2 para la portada. Se utilizaron en la composición tipográfica las familias Adobe Caslon Pro 8:9, 8.6:10, 9:10, 9.6:12, 11:9, 11.5:12, 13.5:15, 17.6:21, Arial 6.6:9, 9:11, 12.3:14, 12.6:15, 13:17, 41:49, Zeferino Two12.6:15 puntos. Impresión tipo
digital a 1x1 tintas en interiores y 4x0 tintas en portada.
El cuidado de la edición estuvo a cargo deJosé Jaime Ávila Valdivieso
Pedidos:Librería FES Iztacala: 5623-1194
Coordinación Editorial: 5623-1203Correo-e: [email protected]
Los Reyes Iztacala, 2013


















